
Stock Price Prediction Using Candlestick Patterns and Sparrow Search Algorithm
Abstract
:1. Introduction
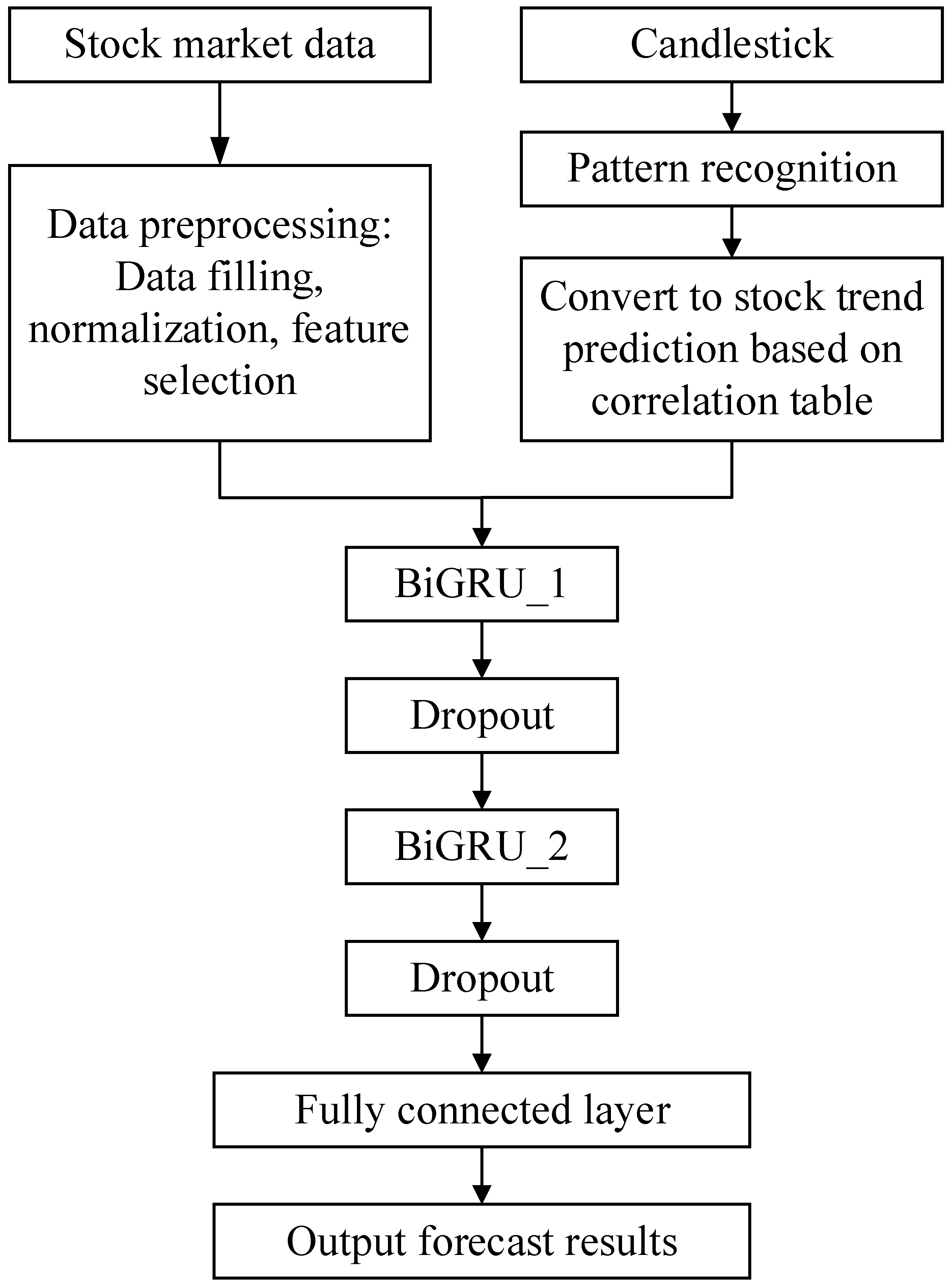
- Currently, the primary information utilized for predicting stock prices is basic market data, which lacks structural relationships and exhibits limited expression capacity for the overall system state. This model ingeniously integrates candlestick patterns with stock market data, serving as input for the stock price prediction model, imbuing the input data with structural characteristics and time series relationships. Furthermore, this paper uses a Bidirectional Gated Recurrent Unit (BiGRU) network to extract deeper feature relationships, thereby enhancing the learning ability of the network;
- This paper applies a sparrow search algorithm (SSA) [14] to stock price forecasting, addressing the challenge of high randomness and difficulty in hyperparameter selection of the CPBiGRU network. Simultaneously, it enhances the accuracy of stock price forecasting;
- Current research typically utilizes data from the same time window for forecasting. However, in actual trading decisions, investors often refer to stock price information from multiple trading days. Therefore, this paper explores the impact of extracting stock data from different time windows on prediction results.
2. Related Work
2.1. Candlestick Patterns Analysis
2.2. Deeping Learning Approaches in Stock Prediction
3. Methodology
3.1. BiGRU Network
3.2. A Dual Port BiGRU Network Integrating Candlestick Patterns
3.3. Principle of Sparrow Search Algorithm
- Initialization: We take the learning rate, iteration times and the number of units in two hidden layers of the CPBiGRU network as the hyperparameter objectives to be optimized by the SSA. The position information of the population and related parameters are randomly initialized after setting the value range of the optimized hyperparameter, the population size of sparrows, optimization iteration times, and initial safety threshold value;
- Fitness value: We use the RMSE between the predicted value of the network model and the real value as the fitness function for SSA and the loss function for CPBiGRU, to determine the fitness values of each sparrow;
- Update: We update the sparrow position by Equations (8)–(10) and obtain the fitness value of the sparrow population. Simultaneously, we record the optimal individual position and global optimal position value in the population;
- Iteration: We ascertain if the maximum value of the number of update iterations has been attained. In such a case, conclude the loop and yield the optimal individual solution, signifying the determination of the optimal parameters for the network structure. Otherwise, return to step (3);
- Optimization results output: The optimal hyperparameter values output by the SSA algorithm are employed as the learning rate, iteration number, and number of units in two hidden layers of the CPBiGRU network. Afterwards, the network is reconstructed and we proceed with subsequent procedures such as inverse normalization and evaluation analysis.
4. Experiments and Discussions
4.1. Experimental Environment
4.2. Datasets
4.3. Data Preprocessing
4.3.1. Missing Value Processing
4.3.2. Data Standardization
4.4. Evaluation Criteria
4.5. Comparing the Prediction Accuracy
4.5.1. Experimentation and Analysis of Stock Price Prediction Model
4.5.2. Experimentation and Analysis of the Effect of Trading Day on Stock Price Prediction
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chung, H.; Shin, K.S. Genetic algorithm-optimized multi-channel convolutional neural network for stock market prediction. Neural Comput. Appl. 2020, 32, 7897–7914. [Google Scholar] [CrossRef]
- Pang, X.W.; Zhou, Y.Q.; Wang, P.; Lin, W.W.; Chang, V. An innovative neural network approach for stock market prediction. J. Supercomput. 2020, 76, 2098–2118. [Google Scholar] [CrossRef]
- Rounaghi, M.M.; Zadeh, F.N. Investigation of market efficiency and Financial Stability between S&P 500 and London Stock Exchange: Monthly and yearly Forecasting of Time Series Stock Returns using ARMA model. Phys. A Stat. Mech. Its Appl. 2016, 456, 10–21. [Google Scholar] [CrossRef]
- Jarrett, J.E.; Kyper, E. ARIMA Modeling with Intervention to Forecast and Analyze Chinese Stock Prices. Int. J. Eng. Bus. Manag. 2011, 3, 17. [Google Scholar] [CrossRef]
- Dempere, J.M.; Modugu, K.P. The impact of the Dubai International Airport’s activity volume on the Emirati stock market. Int. J. Bus. Perform. Manag. 2022, 23, 118–134. [Google Scholar] [CrossRef]
- Lin, A.J.; Shang, P.J.; Zhou, H.C. Cross-correlations and structures of stock markets based on multiscale MF-DXA and PCA. Nonlinear Dyn. 2014, 78, 485–494. [Google Scholar] [CrossRef]
- Patel, J.; Shah, S.; Thakkar, P.; Kotecha, K. Predicting stock and stock price index movement using Trend Deterministic Data Preparation and machine learning techniques. Expert Syst. Appl. 2015, 42, 259–268. [Google Scholar] [CrossRef]
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A. Random Forest Based Feature Selection of Macroeconomic Variables for Stock Market Prediction. Am. J. Appl. Sci. 2019, 16, 200–212. [Google Scholar] [CrossRef]
- Fu, S.B.; Li, Y.W.; Sun, S.L.; Li, H.T. Evolutionary support vector machine for RMB exchange rate forecasting. Phys. A-Stat. Mech. Its Appl. 2019, 521, 692–704. [Google Scholar] [CrossRef]
- Xu, Y.; Yan, C.J.; Peng, S.L.; Nojima, Y. A hybrid two-stage financial stock forecasting algorithm based on clustering and ensemble learning. Appl. Intell. 2020, 50, 3852–3867. [Google Scholar] [CrossRef]
- Zhang, G.P. Time series forecasting using a hybrid ARIMA and neural network model. Neurocomputing 2003, 50, 159–175. [Google Scholar] [CrossRef]
- Yu, Z.X.; Qin, L.; Chen, Y.J.; Parmar, M.D. Stock price forecasting based on LLE-BP neural network model. Phys. A-Stat. Mech. Its Appl. 2020, 553, 124197. [Google Scholar] [CrossRef]
- Udagawa, Y. Predicting Stock Price Trend Using Candlestick Chart Blending Technique. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 4709–4715. [Google Scholar]
- Xue, J. Research and Application of A Novel Swarm Intelligence Optimization Technique: Sparrow Search Algorithm. Master’s Thesis, Donghua University, Shanghai, China, 2020. [Google Scholar]
- Tao, L.; Hao, Y.T.; Hao, Y.J.; Shen, C.F. K-Line Patterns’ Predictive Power Analysis Using the Methods of Similarity Match and Clustering. Math. Probl. Eng. 2017, 2017, 3096917. [Google Scholar] [CrossRef]
- Li, H.B.; Liang, M.X.; He, T. Optimizing the Composition of a Resource Service Chain With Interorganizational Collaboration. IEEE Trans. Ind. Inform. 2017, 13, 1152–1161. [Google Scholar] [CrossRef]
- Iqbal, M.; Pao, H.-K. Mining non-redundant distinguishing subsequence for trip destination forecasting. Knowl. -Based Syst. 2021, 211, 106519. [Google Scholar] [CrossRef]
- Li, H.; Li, Z.; Peng, S.; Li, J.; Tungom, C.E. Mining the frequency of time-constrained serial episodes over massive data sequences and streams. Future Gener. Comput. Syst. 2020, 110, 849–863. [Google Scholar] [CrossRef]
- Wang, W.; Tian, J.; Lv, F.; Xin, G.; Ma, Y.; Wang, B. Mining frequent pyramid patterns from time series transaction data with custom constraints. Comput. Secur. 2021, 100, 102088. [Google Scholar] [CrossRef]
- Birogul, S.; Temür, G.; Kose, U. YOLO Object Recognition Algorithm and “Buy-Sell Decision” Model Over 2D Candlestick Charts. IEEE Access 2020, 8, 91894–91915. [Google Scholar] [CrossRef]
- Guo, S.J.; Hung, C.C.; Hsu, F.C.; IEEE. Deep Candlestick Predictor: A Framework Toward Forecasting the Price Movement from Candlestick Charts. In Proceedings of the 9th International Conference on Parallel Architectures, Algorithms and Programming (PAAP), Natl Taiwan Univ Sci & Technol, Taipei, Taiwan, 26–28 December 2018; pp. 219–226. [Google Scholar]
- Chen, J.H.; Tsai, Y.C. Encoding candlesticks as images for pattern classification using convolutional neural networks. Financ. Innov. 2020, 6, 26. [Google Scholar] [CrossRef]
- Fengqian, D.; Chao, L. An Adaptive Financial Trading System Using Deep Reinforcement Learning with Candlestick Decomposing Features. IEEE Access 2020, 8, 63666–63678. [Google Scholar] [CrossRef]
- Wang, M.J.; Wang, Y.J. Evaluating the Effectiveness of Candlestick Analysis in Forecasting US Stock Market. In Proceedings of the 3rd International Conference on Compute and Data Analysis (ICCDA), Univ Hawaii Maui Coll, Kahului, HI, USA, 14–17 March 2019; pp. 98–101. [Google Scholar]
- Madbouly, M.M.; Elkholy, M.; Gharib, Y.M.; Darwish, S.M. Predicting Stock Market Trends for Japanese Candlestick Using Cloud Model. In Proceedings of the International Conference on Artificial Intelligence and Computer Vision (AICV2020), Cairo, Egypt, 8–10 April 2020; pp. 628–645. [Google Scholar]
- Wang, J.; Li, X.H.; Jia, H.D.; Peng, T.; Tan, J.H. Predicting Stock Market Volatility from Candlestick Charts: A Multiple Attention Mechanism Graph Neural Network Approach. Math. Probl. Eng. 2022, 2022, 4743643. [Google Scholar] [CrossRef]
- Rather, A.M.; Agarvval, A.; Sastry, V.N. Recurrent neural network and a hybrid model for prediction of stock returns. Expert Syst. Appl. 2015, 42, 3234–3241. [Google Scholar] [CrossRef]
- Minami, S. Predicting Equity Price with Corporate Action Events Using LSTM-RNN. J. Math. Financ. 2018, 08, 58–63. [Google Scholar] [CrossRef]
- Gupta, U.; Bhattacharjee, V.; Bishnu, P.S. StockNet-GRU based stock index prediction. Expert Syst. Appl. 2022, 207, 117986. [Google Scholar] [CrossRef]
- Kumar Chandar, S.; Sumathi, M.; Sivanandam, S.N. Prediction of Stock Market Price using Hybrid of Wavelet Transform and Artificial Neural Network. Indian J. Sci. Technol. 2016, 9, 1–5. [Google Scholar] [CrossRef]
- Cai, S.; Feng, X.; Deng, Z.; Ming, Z.; Shan, Z. Financial News Quantization and Stock Market Forecast Research Based on CNN and LSTM. In Smart Computing and Communication; Springer: Cham, Switzerland, 2018; pp. 366–375. [Google Scholar]
- Ho, T.T.; Huang, Y.N. Stock Price Movement Prediction Using Sentiment Analysis and CandleStick Chart Representation. Sensors 2021, 21, 7957. [Google Scholar] [CrossRef]
- Hu, Y. Reserach on Stock Trend Forecasting Method Based on Multi Technical Indicators and Deep Learning Mode. Master’s Thesis, Jiangxi University of Finance and Economics, Nanchang, China, 2021; pp. 1–64. [Google Scholar] [CrossRef]
- Hinchey, M.G.; Sterritt, R.; Rouff, C. Swarms and Swarm Intelligence. Computer 2007, 40, 111–113. [Google Scholar] [CrossRef]
- Bonabeau, E.; Meyer, C. Swarm intelligence—A whole new way to think about business. Harv. Bus. Rev. 2001, 79, 106. [Google Scholar]
- Song, G.; Zhang, Y.; Bao, F.; Qin, C. Stock prediction model based on particle swarm optimization LSTM. J. Beijing Univ. Aeronaut. Astronaut. 2019, 45, 2533–2542. [Google Scholar]
- Li, Y.; Wang, S.; Chen, Q.; Wang, X. Comparative study of several new swarm intelligence optimization algorithms. Comput. Eng. Appl. 2020, 56, 1–12. [Google Scholar] [CrossRef]
- Liao, G.C. Fusion of Improved Sparrow Search Algorithm and Long Short-Term Memory Neural Network Application in Load Forecasting. Energies 2022, 15, 130. [Google Scholar] [CrossRef]
- Cho, K.; Van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Li, W.Y.; Wu, H.; Zhu, N.Y.; Jiang, Y.N.; Tan, J.L.; Guo, Y. Prediction of dissolved oxygen in a fishery pond based on gated recurrent unit (GRU). Inf. Process. Agric. 2021, 8, 185–193. [Google Scholar] [CrossRef]
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger Causality and Transfer Entropy Are Equivalent for Gaussian Variables. Phys. Rev. Lett. 2009, 103, 238701. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Candlestick Patterns | Return Value | Predictive Trending | Candlestick Patterns | Return Value | Predictive Trending |
|---|---|---|---|---|---|
| Two Crows | 100 | −1 | Identical Three Crows | 100 | −1 |
| −100 | 1 | −100 | −1 | ||
| Three Black Crows | 100 | −1 | In-Neck Pattern | 100 | 1 |
| −100 | 1 | −100 | −1 | ||
| Three Inside Up/Down | 100 | 1 | Inverted Hammer | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Three Line Strike | 100 | 1 | Kicking | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Three Outside Up/Down | 100 | 1 | Kicking-bull/bear determined by the longer marubozu | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Three Stars In The South | 100 | 1 | Ladder Bottom | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Three Advancing White Soldiers | 100 | 1 | Long Legged Doji | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Abandoned Baby | 100 | 1 | Long Line Candle | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Advance Block | 100 | 1 | Marubozu | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Belt-hold | 100 | 1 | Matching Low | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Breakaway | 100 | 1 | Mat Hold | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Closing Marubozu | 100 | 1 | Morning Doji Star | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Concealing Baby Swallow | 100 | 1 | Morning Star | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Counterattack | 100 | 1 | On-Neck Pattern | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Dark Cloud Cover | 100 | −1 | Piercing Pattern | 100 | 1 |
| −100 | 1 | −100 | −1 | ||
| Doji | 100 | 1 | Rickshaw Man | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Doji Star | 100 | 1 | Rising/Falling Three Methods | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Dragonfly Doji | 100 | 1 | Separating Lines | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Engulfing Pattern | 100 | 1 | Shooting Star | 100 | −1 |
| −100 | −1 | −100 | 1 | ||
| Evening Doji Star | 100 | 1 | Short Line Candle | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Evening Star | 100 | 1 | Spinning Top | 100 | −1 |
| −100 | −1 | −100 | 1 | ||
| Up/Down-gap side-by-side white lines | 100 | 1 | Stalled Pattern | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Gravestone Doji | 100 | 1 | Stick Sandwich | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Hammer | 100 | 1 | Takuri | 100 | −1 |
| −100 | −1 | −100 | 1 | ||
| Hanging Man | 100 | 1 | Tasuki Gap | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Harami Pattern | 100 | 1 | Thrusting Pattern | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Harami Cross Pattern | 100 | 1 | Tristar Pattern | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| High-Wave Candle | 100 | −1 | Unique 3 River | 100 | 1 |
| −100 | 1 | −100 | −1 | ||
| Hikkake Pattern | 100 | 1 | Upside Gap Two Crows | 100 | −1 |
| −100 | −1 | −100 | 1 | ||
| Modified Hikkake Pattern | 100 | 1 | Upside/Downside Gap Three Methods | 100 | 1 |
| −100 | −1 | −100 | −1 | ||
| Homing Pigeon | 100 | 1 | |||
| −100 | −1 |
| Hyperparameter | Value |
|---|---|
| Batch size | 128 |
| Optimizer | Adam |
| Number of hidden layer units | 2 |
| SSA population size | 10 |
| SSA iterations | 20 |
| SSA discoverer ratio | 0.2 |
| Stock | Plate | Sector |
|---|---|---|
| SH.600000 | Main Board of the Shanghai Stock Exchange | Bank |
| SH.603589 | Main Board of the Shanghai Stock Exchange | Liquor |
| SH.600104 | Main Board of the Shanghai Stock Exchange | Automobile |
| SZ.300294 | Shenzhen Stock Exchange GEM | Medicine |
| SZ.002415 | Shenzhen Stock Exchange SME | Computer |
| SZ.000725 | Main Board of the Shenzhen Stock Exchange | Electron |
| Model | Stock | MAPE | RMSE | MAE | |
|---|---|---|---|---|---|
| LSTM | SH.600000 | 0.0137 | 0.1489 | 0.1178 | 0.9756 |
| SH.603589 | 0.0277 | 2.3260 | 1.7570 | 0.9264 | |
| SH.600104 | 0.0168 | 0.4178 | 0.3157 | 0.9392 | |
| SZ.300294 | 0.0337 | 1.6722 | 1.2259 | 0.9088 | |
| SZ.002415 | 0.0311 | 2.1352 | 1.6488 | 0.9538 | |
| SZ.000725 | 0.0332 | 0.1845 | 0.1650 | 0.9649 | |
| GRU | SH.600000 | 0.0120 | 0.1313 | 0.1080 | 0.9810 |
| SH.603589 | 0.0262 | 2.2027 | 1.6451 | 0.9340 | |
| SH.600104 | 0.0142 | 0.3813 | 0.2714 | 0.9493 | |
| SZ.300294 | 0.0325 | 1.6306 | 1.1828 | 0.9132 | |
| SZ.002415 | 0.0295 | 2.0208 | 1.5643 | 0.9585 | |
| SZ.000725 | 0.0316 | 0.1802 | 0.1594 | 0.9665 | |
| BiGRU | SH.600000 | 0.0102 | 0.1152 | 0.0906 | 0.9854 |
| SH.603589 | 0.0249 | 2.1920 | 1.5678 | 0.9347 | |
| SH.600104 | 0.0139 | 0.3720 | 0.2688 | 0.9518 | |
| SZ.300294 | 0.0319 | 1.6146 | 1.1758 | 0.9149 | |
| SZ.002415 | 0.0232 | 1.5993 | 1.2063 | 0.9741 | |
| SZ.000725 | 0.0235 | 0.1421 | 0.1205 | 0.9792 | |
| CPBiGRU | SH.600000 | 0.0094 | 0.1079 | 0.0834 | 0.9871 |
| SH.603589 | 0.0245 | 2.1829 | 1.5543 | 0.9352 | |
| SH.600104 | 0.0137 | 0.3657 | 0.2641 | 0.9536 | |
| SZ.300294 | 0.0304 | 1.6077 | 1.1262 | 0.9157 | |
| SZ.002415 | 0.0216 | 1.4820 | 1.1078 | 0.9777 | |
| SZ.000725 | 0.0191 | 0.1248 | 0.0990 | 0.9839 | |
| SSA-BiGRU | SH.600000 | 0.0086 | 0.1066 | 0.0768 | 0.9875 |
| SH.603589 | 0.0241 | 2.0366 | 1.4912 | 0.9433 | |
| SH.600104 | 0.0136 | 0.3639 | 0.2619 | 0.9539 | |
| SZ.300294 | 0.0293 | 1.4882 | 1.0839 | 0.9277 | |
| SZ.002415 | 0.0209 | 1.4449 | 1.0710 | 0.9788 | |
| SZ.000725 | 0.0177 | 0.1160 | 0.0918 | 0.9861 | |
| SSA-CPBiGRU | SH.600000 | 0.0077 | 0.0989 | 0.0689 | 0.9892 |
| SH.603589 | 0.0235 | 2.0330 | 1.4685 | 0.9439 | |
| SH.600104 | 0.0134 | 0.3639 | 0.2601 | 0.9542 | |
| SZ.300294 | 0.0282 | 1.4572 | 1.0290 | 0.9307 | |
| SZ.002415 | 0.0193 | 1.3275 | 0.9654 | 0.9821 | |
| SZ.000725 | 0.0155 | 0.1112 | 0.0834 | 0.9872 |
| Model | Stock | MAPE | RMSE | MAE | |
|---|---|---|---|---|---|
| SSA-CPBiGRU (1) | SH.600000 | 0.0095 | 0.1149 | 0.0835 | 0.9854 |
| SH.603589 | 0.0235 | 2.0330 | 1.4685 | 0.9439 | |
| SH.600104 | 0.0134 | 0.3639 | 0.2601 | 0.9542 | |
| SZ.300294 | 0.0282 | 1.4572 | 1.0290 | 0.9307 | |
| SZ.002415 | 0.0237 | 1.6354 | 1.2313 | 0.9728 | |
| SZ.000725 | 0.0278 | 0.1597 | 0.1395 | 0.9737 | |
| SSA-CPBiGRU (2) | SH.600000 | 0.0079 | 0.0996 | 0.0710 | 0.9892 |
| SH.603589 | 0.0253 | 2.2558 | 1.6093 | 0.9308 | |
| SH.600104 | 0.0139 | 0.3626 | 0.2662 | 0.9539 | |
| SZ.300294 | 0.0303 | 1.5543 | 1.1087 | 0.9212 | |
| SZ.002415 | 0.0222 | 1.4902 | 1.1234 | 0.9774 | |
| SZ.000725 | 0.0261 | 0.1521 | 0.1294 | 0.9761 | |
| SSA-CPBiGRU (3) | SH.600000 | 0.0087 | 0.1071 | 0.0770 | 0.9873 |
| SH.603589 | 0.0255 | 2.2630 | 1.6195 | 0.9304 | |
| SH.600104 | 0.0140 | 0.3739 | 0.2711 | 0.9513 | |
| SZ.300294 | 0.0300 | 1.6116 | 1.1171 | 0.9145 | |
| SZ.002415 | 0.0219 | 1.5373 | 1.1346 | 0.9759 | |
| SZ.000725 | 0.0176 | 0.1212 | 0.0941 | 0.9849 | |
| SSA-CPBiGRU (5) | SH.600000 | 0.0098 | 0.1180 | 0.0868 | 0.9845 |
| SH.603589 | 0.0288 | 2.5816 | 1.8620 | 0.9095 | |
| SH.600104 | 0.0142 | 0.3702 | 0.2725 | 0.9523 | |
| SZ.300294 | 0.0346 | 1.9086 | 1.3105 | 0.8811 | |
| SZ.002415 | 0.0212 | 1.3392 | 1.0357 | 0.9818 | |
| SZ.000725 | 0.0155 | 0.1112 | 0.0834 | 0.9872 | |
| SSA-CPBiGRU (10) | SH.600000 | 0.0107 | 0.1277 | 0.0939 | 0.9816 |
| SH.603589 | 0.0276 | 2.4660 | 1.7691 | 0.9176 | |
| SH.600104 | 0.0154 | 0.3934 | 0.2932 | 0.9463 | |
| SZ.300294 | 0.0354 | 1.7844 | 1.3038 | 0.8944 | |
| SZ.002415 | 0.0193 | 1.3275 | 0.9654 | 0.9821 | |
| SZ.000725 | 0.0277 | 0.1609 | 0.1401 | 0.9733 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Hu, W.; Xue, L. Stock Price Prediction Using Candlestick Patterns and Sparrow Search Algorithm. Electronics 2024, 13, 771. https://doi.org/10.3390/electronics13040771
Chen X, Hu W, Xue L. Stock Price Prediction Using Candlestick Patterns and Sparrow Search Algorithm. Electronics. 2024; 13(4):771. https://doi.org/10.3390/electronics13040771
Chicago/Turabian StyleChen, Xiaozhou, Wenping Hu, and Lei Xue. 2024. "Stock Price Prediction Using Candlestick Patterns and Sparrow Search Algorithm" Electronics 13, no. 4: 771. https://doi.org/10.3390/electronics13040771