
RadiantVisions: Illuminating Low-Light Imagery with a Multi-Scale Branch Network


Abstract
:1. Introduction
- We integrate multi-scale feature extraction into MSBN. This integration enables the model to enhance images with non-uniform lighting conditions, preserving the original uneven illumination and retaining details across different scales after enhancement.
- We introduce a custom denoising loss function tailored specifically for low-light conditions. This feature effectively alleviates the noise issues introduced in low-light images after enhancement, ensuring the clarity of the images.
- Our model combines inter-branch correlations, employing weighted feature fusion to enhance the extraction and integration of prominent features. It strengthens the correlation between color, brightness, and the image itself, resulting in a more realistic effect in the enhanced images.
2. Related Work
2.1. Image Signal Processor
2.2. Multi-Scale Feature Extraction
2.3. Image Denoising
3. Methodology
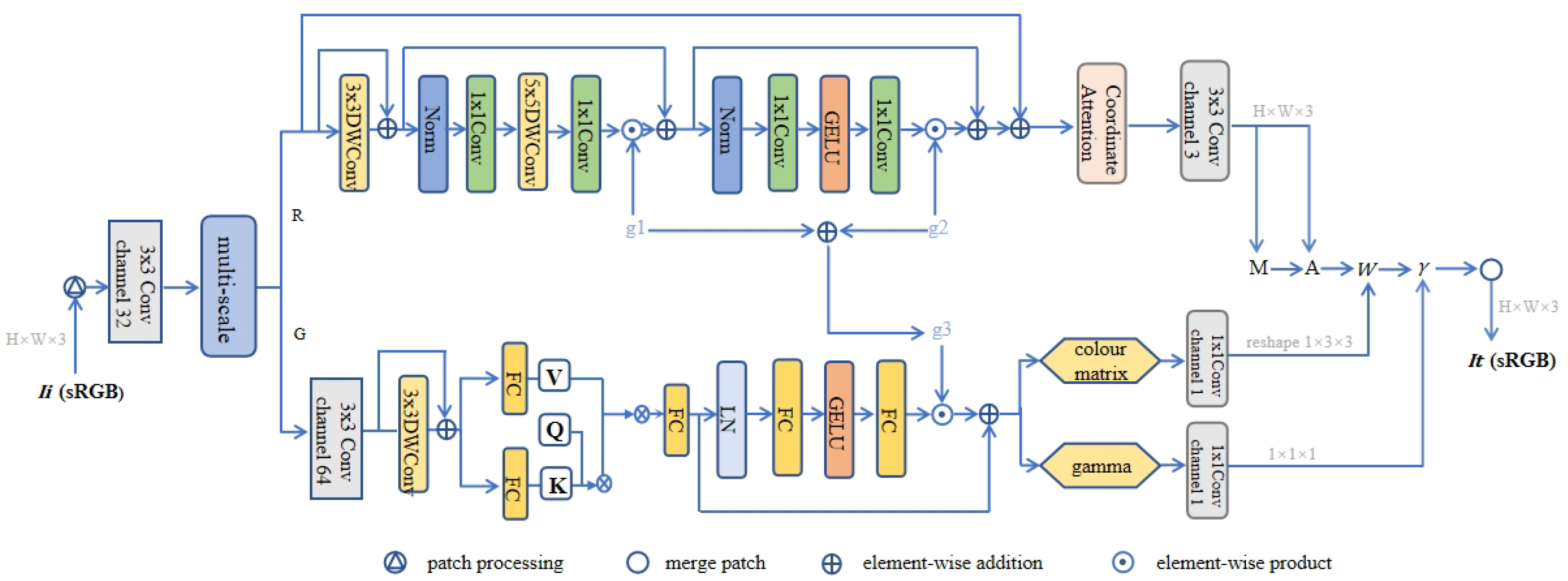
3.1. Model Structure
- Multi-scale module
- 2.
- Branch correlation module
3.2. Loss Function
4. Experimental Results
4.1. Experimental Settings
4.2. Visual and Perceptual Comparisons
4.3. Hyperparameter Details
4.4. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hu, C.; Zhang, C.; Lei, D.; Wu, T.; Liu, X.; Zhu, L. Achieving Privacy-Preserving and Verifiable Support Vector Machine Training in the Cloud. IEEE Trans. Inf. Forensics Secur. 2023, 18, 3476–4291. [Google Scholar] [CrossRef]
- Zhang, C.; Hu, C.; Wu, T.; Zhu, L.; Liu, X. Achieving Efficient and Privacy-Preserving Neural Network Training and Prediction in Cloud Environments. IEEE Trans. Dependable Secur. Comput. 2023, 20, 4245–4257. [Google Scholar] [CrossRef]
- Zhang, C.; Luo, X.; Liang, J.; Liu, X.; Zhu, L.; Guo, S. POTA: Privacy-Preserving Online Multi-Task Assignment with Path Planning. IEEE Trans. Mob. Comput. 2023; in press. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, M.; Liang, J.; Fan, Q.; Zhu, L.; Guo, S. NANO: Cryptographic Enforcement of Readability and Editability Governance in Blockchain Database. IEEE Trans. Dependable Secur. Comput. 2023; in press. [Google Scholar] [CrossRef]
- Ai, S.; Kwon, J. Extreme low-light image enhancement for surveillance cameras using attention U-Net. Sensors 2020, 20, 495. [Google Scholar] [CrossRef] [PubMed]
- Panwar, M.; Gaur, S.B. Inception-based CNN for low-light image enhancement. In Computational Vision and Bio-Inspired Computing, Proceedings of the 5th International Conference on Computational Vision and Bio Inspired Computing (ICCVBIC 2021), Coimbatore, India, 25–26 November 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 533–545. [Google Scholar]
- Wang, T.; Zhang, K.; Shen, T.; Luo, W.; Stenger, B.; Lu, T. Ultra-high-definition low-light image enhancement: A benchmark and transformer-based method. In Proceedings of the 37th AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2654–2662. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the British Machine Vision Conference (BMVC 2018), Newcastle, UK, 3–6 September 2018; Volume 220, p. 4. [Google Scholar]
- Zeng, H.; Cai, J.; Li, L.; Cao, Z.; Zhang, L. Learning Image-adaptive 3D Lookup Tables for High Performance Photo Enhancement in Real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 2058–2073. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Li, K.; Gu, L.; Su, S.; Gao, P.; Jiang, Z.; Qiao, Y.; Harada, T. You Only Need 90K Parameters to Adapt Light: A Light Weight Transformer for Image Enhancement and Exposure Correction. In Proceedings of the 33rd British Machine Vision Conference (BMVC 2022), London, UK, 21–24 November 2022; p. 238. [Google Scholar]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef] [PubMed]
- Liang, L.; Zharkov, I.; Amjadi, F.; Joze, H.R.V.; Pradeep, V. Guidance network with staged learning for image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 836–845. [Google Scholar]
- Park, K.; Chae, M.; Cho, J.H. Image pre-processing method of machine learning for edge detection with image signal processor enhancement. Micromachines 2021, 12, 73. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Xu, K.; Lau, R.W. Local color distributions prior for image enhancement. In Proceedings of the European Conference on Computer Vision (ECCV 2022), Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 343–359. [Google Scholar]
- Wang, Y.; Song, X.; Gong, G.; Li, N. A multi-scale feature extraction-based normalized attention neural network for image denoising. Electronics 2021, 10, 319. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Jiang, J.; Liu, R.; Luo, Z. Learning a deep multi-scale feature ensemble and an edge-attention guidance for image fusion. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 105–119. [Google Scholar] [CrossRef]
- Qi, Q.; Li, K.; Zheng, H.; Gao, X.; Hou, G.; Sun, K. SGUIE-Net: Semantic attention guided underwater image enhancement with multi-scale perception. IEEE Trans. Image Process. 2022, 31, 6816–6830. [Google Scholar] [CrossRef] [PubMed]
- Yahya, A.A.; Tan, J.; Su, B.; Hu, M.; Wang, Y.; Liu, K.; Hadi, A.N. BM3D image denoising algorithm based on an adaptive filtering. Multimed. Tools Appl. 2020, 79, 20391–20427. [Google Scholar] [CrossRef]
- Ou, Y.; He, B.; Luo, J.; Li, B. Improving the denoising of WNNM-based imagery: Three different strategies. Remote Sens. Lett. 2021, 12, 307–314. [Google Scholar] [CrossRef]
- Murali, V.; Sudeep, P. Image denoising using DnCNN: An exploration study. In Advances in Communication Systems and Networks; Springer: Singapore, 2020; pp. 847–859. [Google Scholar]
- Bled, C.; Pitie, F. Assessing Advances in Real Noise Image Denoisers. In Proceedings of the 19th ACM SIGGRAPH European Conference on Visual Media Production, Austin, TX, USA, 2–4 October 2022; pp. 1–9. [Google Scholar]
- Brooks, T.; Mildenhall, B.; Xue, T.; Chen, J.; Sharlet, D.; Barron, J.T. Unprocessing Images for Learned Raw Denoising. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Afifi, M.; Brown, M.S. Deep white-balance editing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1397–1406. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Wu, D.; Wang, Y.; Xia, S.T.; Bailey, J.; Ma, X. Skip connections matter: On the transferability of adversarial examples generated with resnets. arXiv 2020, arXiv:2002.05990. [Google Scholar]
- Touvron, H.; Cord, M.; Sablayrolles, A.; Synnaeve, G.; Jégou, H. Going deeper with image transformers. In Proceedings of the EEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 19–25 June 2021; pp. 32–42. [Google Scholar]
- Gao, S.H.; Cheng, M.M.; Zhao, K.; Zhang, X.Y.; Yang, M.H.; Torr, P. Res2Net: A New Multi-scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision (ECCV 2016): 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Mansour, Y.; Heckel, R. Zero-Shot Noise2Noise: Efficient Image Denoising without any Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14018–14027. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From Fidelity to Perceptual Quality: A Semi-Supervised Approach for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Cun, X.; Bao, J.; Zhou, W.; Liu, J.; Li, H. Uformer: A general u-shaped transformer for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 17683–17693. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MAE ↓ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | Params (M) ↓ |
|---|---|---|---|---|---|
| LIME | 0.155 | 0.397 | 15.481 | 0.480 | - |
| Zero-DCE | 0.149 | 0.412 | 14.893 | 0.517 | 0.08 |
| RetiNexNet | 0.115 | 0.196 | 18.554 | 0.733 | 0.84 |
| MBLLEN | 0.122 | 0.271 | 18.115 | 0.717 | 20.47 |
| 3D-LUT | 0.130 | 0.276 | 17.653 | 0.719 | 0.6 |
| UFormer | 0.114 | 0.144 | 18.764 | 0.774 | 5.29 |
| KIND | 0.098 | 0.121 | 19.621 | 0.770 | 8.16 |
| IAT | 0.065 | 0.097 | 23.487 | 0.828 | 0.09 |
| MSBN | 0.062 | 0.088 | 23.742 | 0.851 | 0.16 |
| Hyperparameter | Search Space | Optimal Configuration |
|---|---|---|
| Batch size | 4–32 | 8 |
| Display iteration | 5–20 | 10 |
| Learning rate | – | |
| Number of epochs | 50–300 | 250 |
| Weight decay | – |
| MAE ↓ | LPIPS ↓ | PSNR ↑ | SSIM ↑ | |
|---|---|---|---|---|
| O | 0.088 | 0.112 | 21.951 | 0.815 |
| O + A | 0.075 | 0.103 | 23.173 | 0.833 |
| O + B | 0.081 | 0.117 | 22.941 | 0.828 |
| O + C | 0.094 | 0.105 | 22.031 | 0.819 |
| O + A + B + C | 0.062 | 0.088 | 23.742 | 0.851 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Jiang, S.; Tang, X. RadiantVisions: Illuminating Low-Light Imagery with a Multi-Scale Branch Network. Electronics 2024, 13, 788. https://doi.org/10.3390/electronics13040788
Zhang Y, Jiang S, Tang X. RadiantVisions: Illuminating Low-Light Imagery with a Multi-Scale Branch Network. Electronics. 2024; 13(4):788. https://doi.org/10.3390/electronics13040788
Chicago/Turabian StyleZhang, Yu, Shan Jiang, and Xiangyun Tang. 2024. "RadiantVisions: Illuminating Low-Light Imagery with a Multi-Scale Branch Network" Electronics 13, no. 4: 788. https://doi.org/10.3390/electronics13040788
APA StyleZhang, Y., Jiang, S., & Tang, X. (2024). RadiantVisions: Illuminating Low-Light Imagery with a Multi-Scale Branch Network. Electronics, 13(4), 788. https://doi.org/10.3390/electronics13040788