
Optimizing CNN Hardware Acceleration with Configurable Vector Units and Feature Layout Strategies


Abstract
1. Introduction
- In order to address the issue of the low utilization efficiency of the computation units when processing large images and small channels, a configurable vector computation unit is proposed. This unit allows for the dynamic adjustment of the hardware structure based on specific task requirements, thereby improving flexibility.
- To solve the problem of mismatch between feature loading order and feature usage order, a novel off-chip layout strategy based on feature data width grouping is proposed. This strategy effectively improves the burst access efficiency of the feature data and on-chip feature cache hit rate, enabling the more efficient utilization of hardware resources.
- An adjustable feature block computation scheduling strategy is proposed, which not only serves as a means to adjust weight reuse and feature write-back pressure, but also has great potential in the parallel processing of computational tasks.
2. Related Work
3. The Proposed Methods
3.1. Overview of Optimization Strategies
3.1.1. Mapping of Computation with Feature Group Constraints
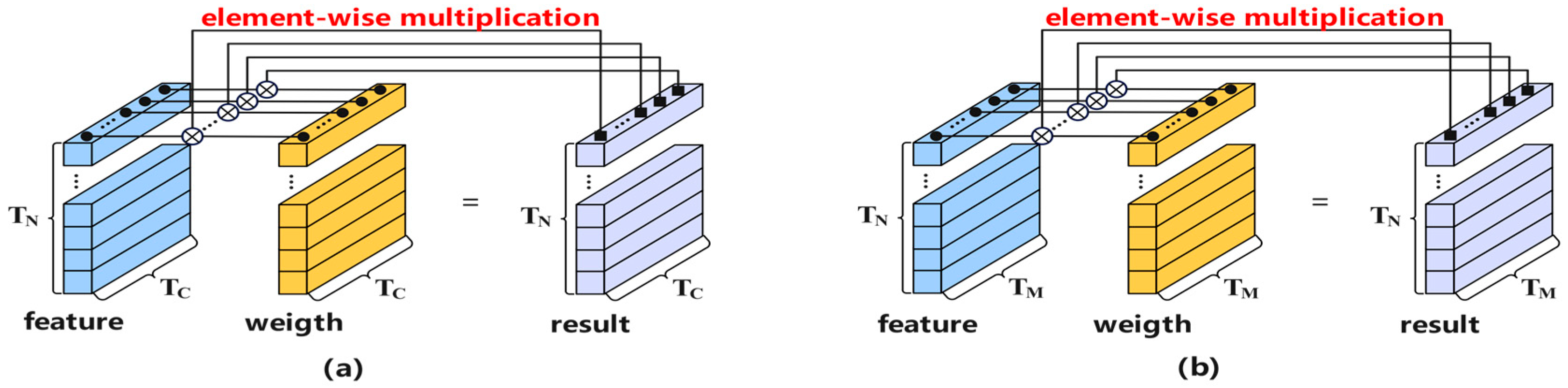
3.1.2. Configurable Vector Unit
3.2. Feature Organization
- First, organizing off-chip features into a format that matches the configurable vector units based on the computation mapping strategies;
- Second, designing on-chip feature caches to support various feature format organizations, thereby improving the efficiency of feature selection and concatenation during feature distribution;
- Third, achieving complete alignment between the feature distribution format and the configurable vector units through flexible on-chip addressing for on-chip feature selection and concatenation.
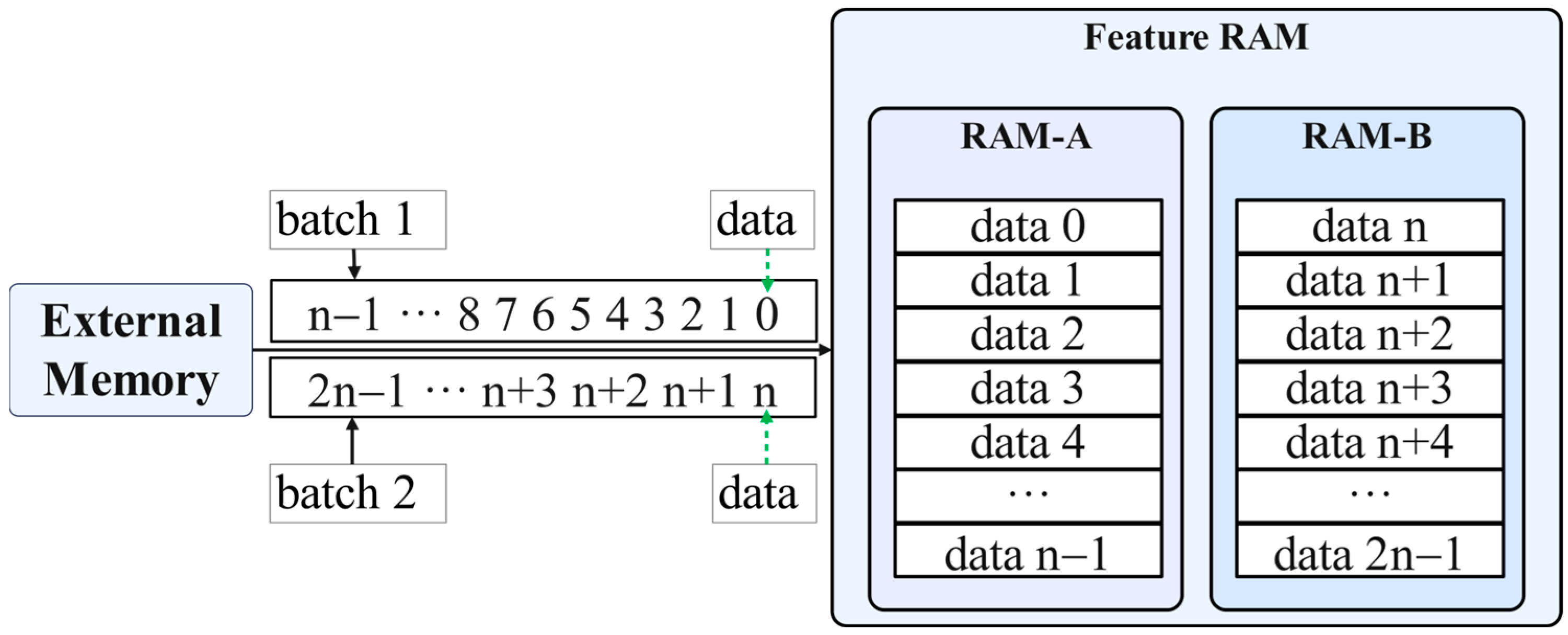
3.2.1. Off-Chip Feature Organization
3.2.2. Feature Cache Array Design
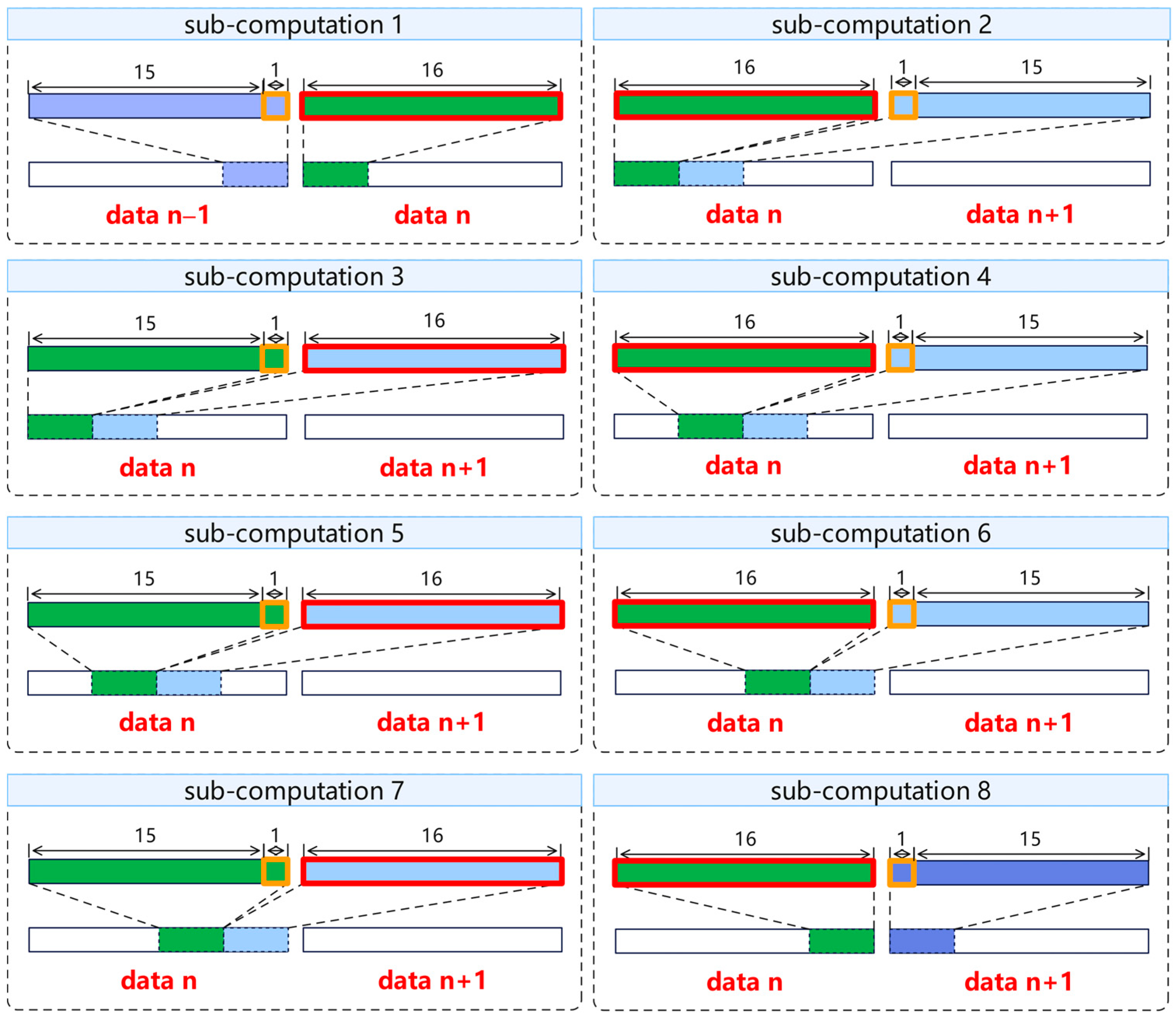
- Assuming that the output feature points calculated in the current calculation chunk contain the first feature point of a row, the real padding points can be used instead of 1 input feature point;
- Assuming that the output feature points calculated in the current calculation chunk do not contain the first and last feature points of a row, the real padding points cannot be utilized at this time, and the cached data points are used instead of 1 input feature point;
- Assuming that the output feature points calculated by the current calculation chunk contain the last feature point of a row, the real padding points can be used instead of 1 input feature point.
- When utilizing data from real padding points and cached data points, the effective input feature width is expressed as Equation (2).
3.2.3. On-Chip Feature Organization
3.3. Feature Chunk Scheduling and Distribution
3.3.1. Format
3.3.2. Format
3.4. Feature Computation
3.5. Proposed Hardware Architecture
4. Experiments
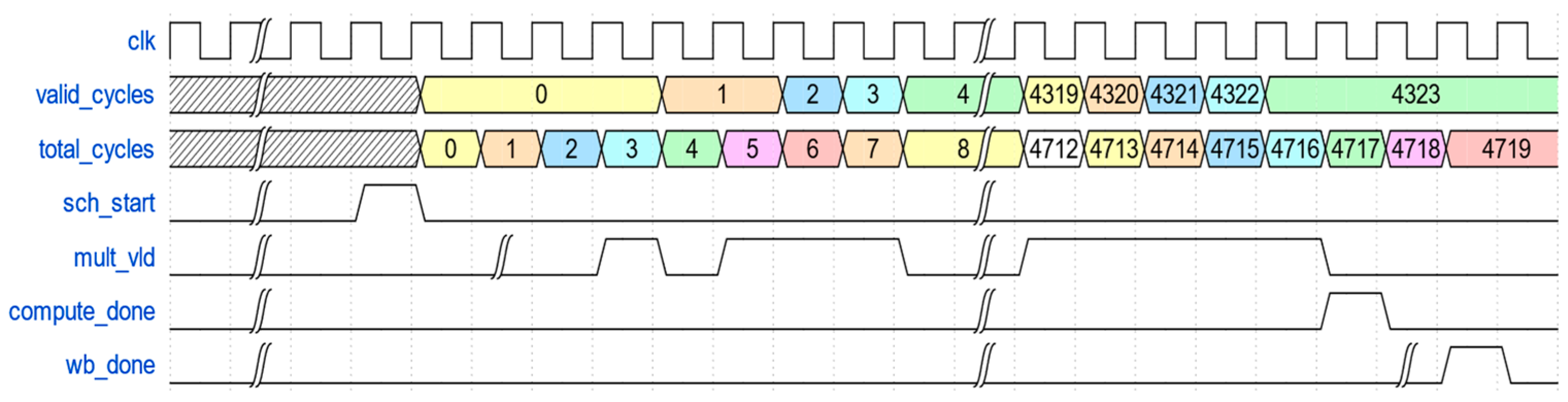
4.1. Experimental Design
4.2. Results and Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation tech report. In Proceedings of the IEEE 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Bontar, J.; Lecun, Y. Stereo matching by training a convolutional neural network to compare image patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and <0.5 mb model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Liang, S.; Yin, S.; Liu, L.; Luk, W.; Wei, S. FP-BNN: Binarized neural network on FPGA. Neurocomputing 2018, 275, 1072–1086. [Google Scholar] [CrossRef]
- Shen, Y.; Ferdman, M.; Milder, P. Overcoming resource underutilization in spatial CNN accelerators. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Liang, Y.; Lu, L.; Xiao, Q.; Yan, S. Evaluating fast algorithms for convolutional neural networks on FPGAs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2019, 39, 857–870. [Google Scholar] [CrossRef]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.-S. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.-S. Optimizing the Convolution Operation to Accelerate Deep Neural Networks on FPGA. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]
- Venieris, S.I.; Bouganis, C.S. Latency-driven design for FPGA-based convolutional neural networks. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
- Shen, Y.; Ferdman, M.; Milder, P. Maximizing CNN Accelerator Efficiency Through Resource Partitioning. ACM SIGARCH Comput. Arch. News 2017, 45, 535–547. [Google Scholar] [CrossRef]
- Zhang, C.; Sun, G.; Fang, Z.; Zhou, P.; Cong, J. Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks. In Proceedings of the ACM Turing Award Celebration Conference, Wuhan, China, 28–30 July 2023; pp. 47–48. [Google Scholar]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H.-J. A high-throughput and power-efficient FPGA implementation of YOLO CNN for object detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Zhu, H.; Wang, Y.; Shi, C.-J.R. Tanji: A General-purpose Neural Network Accelerator with Unified Crossbar Architecture. IEEE Des. Test 2019, 37, 56–63. [Google Scholar] [CrossRef]
- Qiao, R.; Gang, C.; Gong, G.; Chen, G. High performance reconfigurable accelerator for deep convolutional neural networks. J. Xidian Univ. 2019, 3, 136–145. [Google Scholar]
- Shen, Y.; Ferdman, M.; Milder, P. Escher: A CNN Accelerator with Flexible Buffering to Minimize Off-Chip Transfer. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Alawad, M.; Lin, M. Scalable FPGA accelerator for deep convolutional neural networks with stochastic streaming. IEEE Trans. Multi Scale Comput. Syst. 2018, 4, 888–899. [Google Scholar] [CrossRef]
- Xia, M.; Huang, Z.; Tian, L.; Wang, H.; Chang, V.; Zhu, Y.; Feng, S. Sparknoc: An energy-efficiency FPGA-based accelerator using optimized lightweight CNN for edge computing. J. Syst. Archit. 2021, 115, 101991. [Google Scholar] [CrossRef]
- Basalama, S.; Sohrabizadeh, A.; Wang, J.; Guo, L.; Cong, J. FlexCNN: An end-to-end framework for composing CNN accelerators on FPGA. ACM Trans. Reconfigurable Technol. Syst. 2023, 2, 16. [Google Scholar] [CrossRef]
- Huang, W.; Wu, H.; Chen, Q.; Luo, C.; Zeng, S.; Li, T.; Huang, Y. FPGA-Based High-Throughput CNN Hardware Accelerator with High Computing Resource Utilization Ratio. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 4069–4083. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Fan, X.; Jiao, L.; Cao, W.; Zhou, X.; Wang, L. A high performance FPGA-based accelerator for large-scale convolutional neural networks. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 29 August–2 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–9. [Google Scholar]
- Shan, J.; Lazarescu, M.T.; Cortadella, J.; Lavagno, L.; Casu, M.R. CNN-on-AWS: Efficient Allocation of Multikernel Applications on Multi-FPGA Platforms. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2020, 40, 301–314. [Google Scholar] [CrossRef]
- Yin, S.; Tang, S.; Lin, X.; Ouyang, P.; Tu, F.; Liu, L.; Wei, S. A High Throughput Acceleration for Hybrid Neural Networks with Efficient Resource Management on FPGA. IEEE Trans. Comput. Des. Integr. Circuits Syst. 2018, 38, 678–691. [Google Scholar] [CrossRef]
- Sze, V.; Chen, Y.-H.; Yang, T.-J.; Emer, J. Efficient processing of deep neural networks: A tutorial survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Liu, Z.; Dou, Y.; Jiang, J.; Wang, Q.; Chow, P. An FPGA-based processor for training convolutional neural networks. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, Australia, 11–13 December 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y. DianNao: A small-footprint high-throughput accelerator for ubiquitous machine-learning. ACM SIGPLAN Not. 2014, 49, 269–284. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, C. A Multi-Scale Neural Network for Traffic Sign Detection Based on Pyramid Feature Maps. In Proceedings of the 2019 IEEE 21st International Conference on High Performance Computing and Communications, Zhangjiajie, China, 10–12 August 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Putra, R.V.W.; Hanif, M.A.; Shafique, M. ROMANet: Fine-Grained Reuse-Driven Off-Chip Memory Access Management and Data Organization for Deep Neural Network Accelerators. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2021, 29, 702–715. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Jia, H.; Ren, D.; Zou, X. An FPGA-based accelerator for deep neural network with novel reconfigurable architecture. IEICE Electron. Express 2021, 18, 20210012. [Google Scholar] [CrossRef]
- Zeng, S.; Huang, Y. A Hybrid-Pipelined Architecture for FPGA-based Binary Weight DenseNet with High Performance-Efficiency. In Proceedings of the 2020 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 22–24 September 2020. [Google Scholar]
- Yu, Y.; Wu, C.; Zhao, T.; Wang, K.; He, L. OPU: An FPGA-Based Overlay Processor for Convolutional Neural Networks. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2020, 28, 35–47. [Google Scholar] [CrossRef]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Total Cycles | Valid Cycles | UCA |
|---|---|---|---|
| fc1 | 262,144 | 2,461,446 | 10.65 |
| fc2 | 32,768 | 309,132 | 10.60 |
| fc3 | 8192 | 77,944 | 10.51 |
| Layer | Shape | Total Cycles | Valid Cycles | UCA |
|---|---|---|---|---|
| conv1 | (3, 64, 3, 1) | 222,251 | 221,184 | 99.52 |
| conv2 | (64, 64, 3, 1) | 4,726,215 | 4,718,592 | 99.84 |
| conv2-pool | (64, 64, 3, 1) | 4,726,227 | 4,718,592 | 99.84 |
| conv3 | (64, 128, 3, 1) | 2,361,615 | 2,359,296 | 99.90 |
| conv4 | (128, 128, 3, 1) | 4,721,061 | 4,718,592 | 99.95 |
| conv4-pool | (128, 128, 3, 1) | 4,720,986 | 4,718,592 | 99.95 |
| conv5 | (128, 256, 3, 1) | 2,360,549 | 2,359,296 | 99.95 |
| conv6 | (256, 256, 3, 1) | 4,720,149 | 4,718,592 | 99.97 |
| conv7 | (256, 256, 3, 1) | 4,720,149 | 4,718,592 | 99.97 |
| conv7-pool | (256, 256, 3, 1) | 4,719,994 | 4,718,592 | 99.97 |
| conv8 | (512, 512, 3, 1) | 2,360,778 | 2,359,296 | 99.94 |
| conv9 | (512, 512, 3, 1) | 4,720,708 | 4,718,592 | 99.96 |
| conv10 | (512, 512, 3, 1) | 4,720,681 | 4,718,592 | 99.96 |
| conv10-pool | (512, 512, 3, 1) | 4,719,754 | 4,718,592 | 99.98 |
| conv11 | (512, 512, 3, 1) | 1,181,589 | 1,179,648 | 99.84 |
| conv12 | (512, 512, 3, 1) | 1,181,624 | 1,179,648 | 99.83 |
| conv13 | (512, 512, 3, 1) | 1,181,587 | 1,179,648 | 99.84 |
| conv13-pool | (512, 512, 3, 1) | 1,180,726 | 1,179,648 | 99.91 |
| Layer | Shape | Total Cycles | Valid Cycles | UCA |
|---|---|---|---|---|
| conv1 | (3, 64, 3, 1) | 222,251 | 221,184 | 99.52 |
| conv2 | (64, 64, 3, 1) | 4,722,888 | 4,718,592 | 99.91 |
| conv2-pool | (64, 64, 3, 1) | 4,722,826 | 4,718,592 | 99.91 |
| conv3 | (64, 128, 3, 1) | 2,361,037 | 2,359,296 | 99.93 |
| conv4 | (128, 128, 3, 1) | 4,720,611 | 4,718,592 | 99.96 |
| conv4-pool | (128, 128, 3, 1) | 4,720,474 | 4,718,592 | 99.96 |
| conv5 | (128, 256, 3, 1) | 2,360,905 | 2,359,296 | 99.93 |
| conv6 | (256, 256, 3, 1) | 4,720,795 | 4,718,592 | 99.95 |
| conv7 | (256, 256, 3, 1) | 4,720,795 | 4,718,592 | 99.95 |
| conv7-pool | (256, 256, 3, 1) | 4,720,472 | 4,718,592 | 99.96 |
| conv8 | (512, 512, 3, 1) | 2,361,786 | 2,359,296 | 99.89 |
| conv9 | (512, 512, 3, 1) | 4,721,052 | 4,718,592 | 99.95 |
| conv10 | (512, 512, 3, 1) | 4,722,172 | 4,718,592 | 99.92 |
| conv10-pool | (512, 512, 3, 1) | 4,720,534 | 4,718,592 | 99.96 |
| conv11 | (512, 512, 3, 1) | 1,182,004 | 1,179,648 | 99.80 |
| conv12 | (512, 512, 3, 1) | 1,182,004 | 1,179,648 | 99.80 |
| conv13 | (512, 512, 3, 1) | 1,182,040 | 1,179,648 | 99.80 |
| conv13-pool | (512, 512, 3, 1) | 1,181,484 | 1,179,648 | 99.84 |
| Layer | Shape | Total Cycles | Valid Cycles | UCA |
|---|---|---|---|---|
| conv1 | (3, 64, 3, 1) | 222,250 | 221,184 | 99.52 |
| conv2 | (64, 64, 3, 1) | 4,721,633 | 4,718,592 | 99.94 |
| conv2-pool | (64, 64, 3, 1) | 4,721,481 | 4,718,592 | 99.94 |
| conv3 | (64, 128, 3, 1) | 2,361,235 | 2,359,296 | 99.92 |
| conv4 | (128, 128, 3, 1) | 4,721,063 | 4,718,592 | 99.95 |
| conv4-pool | (128, 128, 3, 1) | 4,720,794 | 4,718,592 | 99.95 |
| conv5 | (128, 256, 3, 1) | 2,361,380 | 2,359,296 | 99.91 |
| conv6 | (256, 256, 3, 1) | 4,722,307 | 4,718,592 | 99.92 |
| conv7 | (256, 256, 3, 1) | 4,722,292 | 4,718,592 | 99.92 |
| conv7-pool | (256, 256, 3, 1) | 4,721,803 | 4,718,592 | 99.93 |
| conv8 | (512, 512, 3, 1) | 2,362,834 | 2,359,296 | 99.85 |
| conv9 | (512, 512, 3, 1) | 4,723,154 | 4,718,592 | 99.90 |
| conv10 | (512, 512, 3, 1) | 4,723,152 | 4,718,592 | 99.90 |
| conv10-pool | (512, 512, 3, 1) | 4,724,228 | 4,718,592 | 99.88 |
| conv11 | (512, 512, 3, 1) | - | - | - |
| conv12 | (512, 512, 3, 1) | - | - | - |
| conv13 | (512, 512, 3, 1) | - | - | - |
| conv13-pool | (512, 512, 3, 1) | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Zhang, M.; Xu, J.; Yu, L.; Li, W. Optimizing CNN Hardware Acceleration with Configurable Vector Units and Feature Layout Strategies. Electronics 2024, 13, 1050. https://doi.org/10.3390/electronics13061050
He J, Zhang M, Xu J, Yu L, Li W. Optimizing CNN Hardware Acceleration with Configurable Vector Units and Feature Layout Strategies. Electronics. 2024; 13(6):1050. https://doi.org/10.3390/electronics13061050
Chicago/Turabian StyleHe, Jinzhong, Ming Zhang, Jian Xu, Lina Yu, and Weijun Li. 2024. "Optimizing CNN Hardware Acceleration with Configurable Vector Units and Feature Layout Strategies" Electronics 13, no. 6: 1050. https://doi.org/10.3390/electronics13061050
APA StyleHe, J., Zhang, M., Xu, J., Yu, L., & Li, W. (2024). Optimizing CNN Hardware Acceleration with Configurable Vector Units and Feature Layout Strategies. Electronics, 13(6), 1050. https://doi.org/10.3390/electronics13061050