
VConMC: Enabling Consistency Verification for Distributed Systems Using Implementation-Level Model Checkers and Consistency Oracles


Abstract
:1. Introduction
Contributions
- Making the key observation that there is a client API exposing internal partial-order information;
- Building the consistency invariant checker by leveraging the aforementioned client API and consistency oracles;
- Integrating an implementation-level model checker with the consistency invariant checker above;
- Demonstrating the effectiveness of the proposed methodology by applying it to find real-world consistency bugs in a well-known distributed key-value store.
2. Consistency Models
3. Materials and Methods
3.1. Problem Statement
- It must be able to reliably explore state space of the system-under-test;
- It must be able to systematically and exhaustively explore the state space;
- It must be able to check for various consistency models;
- It must be able to mitigate state explosion problem during invariant checking.
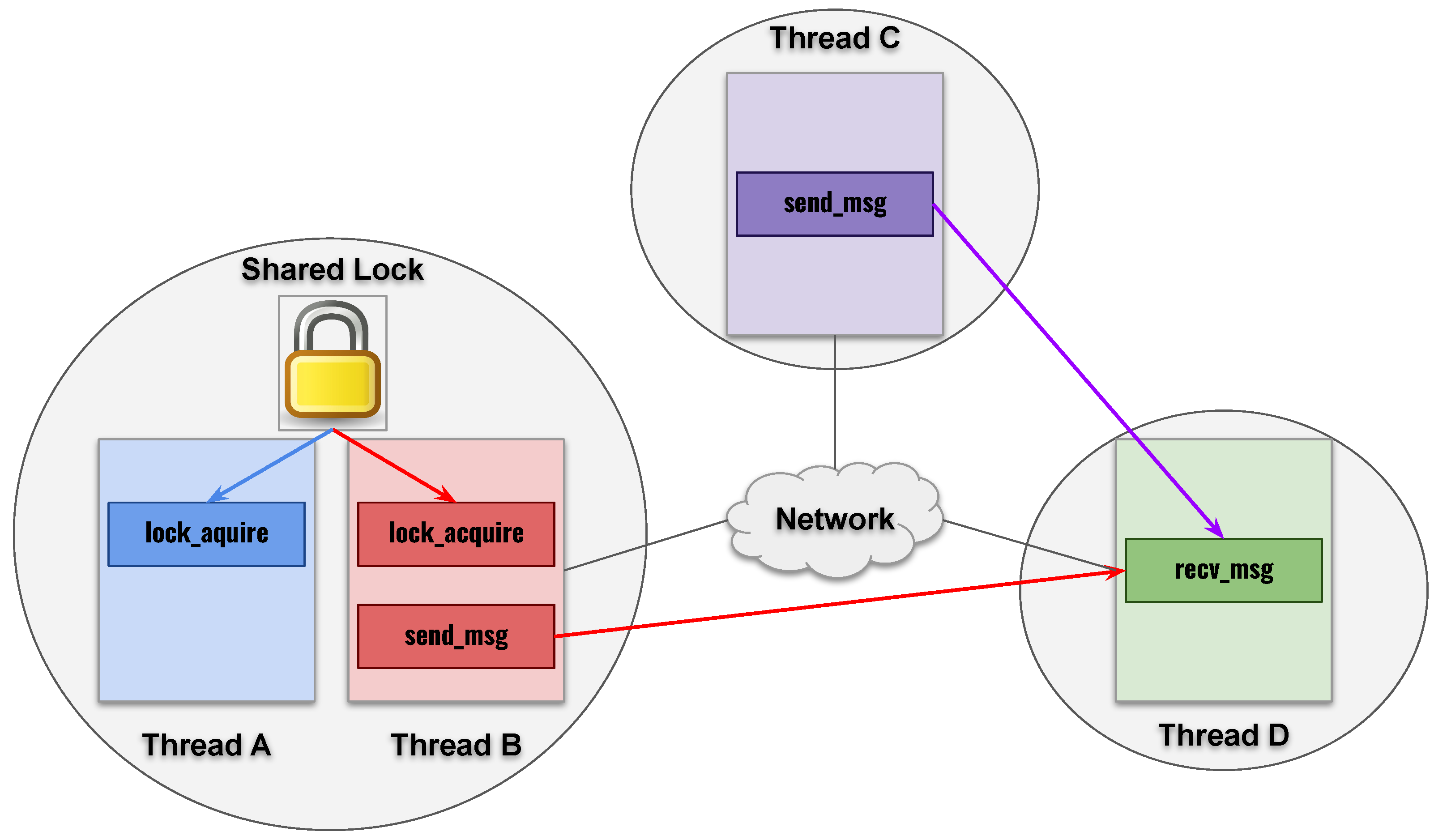
3.2. Architecture Overview
3.3. Controlled Environment
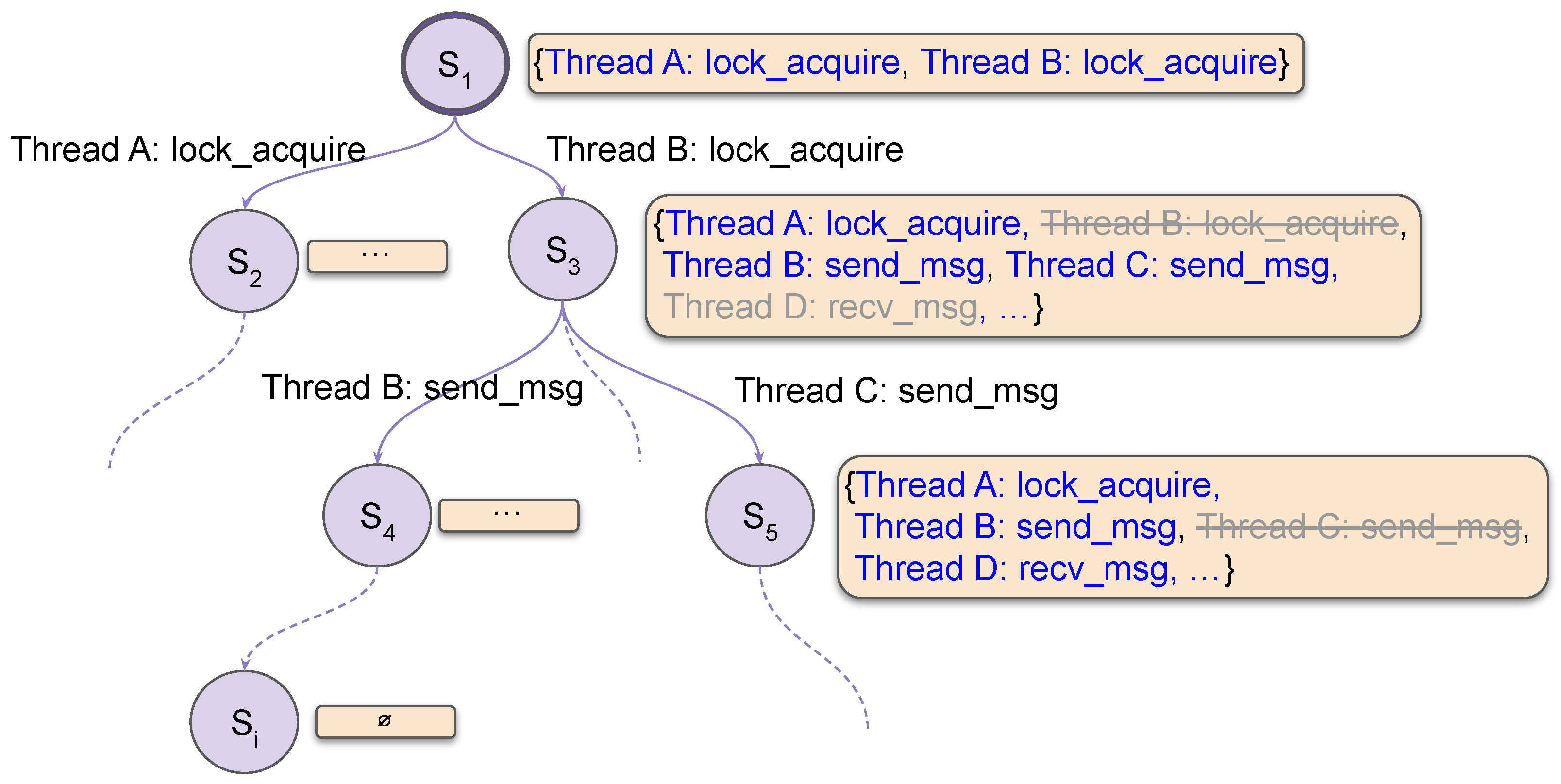
3.4. Model Checkers
| Algorithm 1 VConMC’s Stateless State Space Exploration Algorithm |
|
| Algorithm 2 VConMC’s Consistency Invariant Checking using Consistency Oracles |
|
3.5. Consistency Oracles
3.6. Consistency Invariant Checking
3.7. Implementation
4. Results
- Initially, three nodes start and one becomes leader while the other two become followers. Also, all three nodes have the same two key-value pairs after executing create(“k1”, “k1v0”) and create(“k2”, “k2v0”).
- Crash Node B
- Crash Node C
- Client invokes an API call setData(“k1”, “k1v1”)
- Node A executes the setData(“k1”, “k1v1”)
- Crash Node A
- Start Node A
- Start Node B
- Start Node C
- Node A executes takeSnapshot()
- Crash Node B
- Crash Node C
- Crash Node A
- Start Node B
- Start Node C
- Node B executes takeSnapshot()
- Node C executes syncWithLeader()
- Client invokes an API call setData(“k2”, “k2v1”)
- Node B executes commit()
- Node C executes commit()
- Start Node A
- Node A syncWithLeader()
Discussion
5. Related Work
5.1. Distributed Systems Model Checking
5.2. Distributed Systems Testing
5.3. Consistency Checking
5.4. Blockchain Databases
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hunt, P.; Konar, M.; Junqueira, F.P.; Reed, B. ZooKeeper: Wait-free Coordination for Internet-scale Systems. In Proceedings of the 2010 USENIX Conference on USENIX Annual Technical Conference, Berkeley, CA, USA, 23–25 June 2010; p. 11. [Google Scholar]
- MongoDB. Available online: https://www.mongodb.com/ (accessed on 13 October 2023).
- Lakshman, A.; Malik, P. Cassandra: A Decentralized Structured Storage System. SIGOPS Oper. Syst. Rev. 2010, 44, 35–40. [Google Scholar] [CrossRef]
- Apache HBase. Available online: https://hbase.apache.org (accessed on 10 October 2023).
- Gunawi, H.S.; Hao, M.; Leesatapornwongsa, T.; Patana-anake, T.; Do, T.; Adityatama, J.; Eliazar, K.J.; Laksono, A.; Lukman, J.F.; Martin, V.; et al. What Bugs Live in the Cloud? A Study of 3000+ Issues in Cloud Systems. In Proceedings of the 5th ACM Symposium on Cloud Computing (SoCC), Seattle, WA, USA, 3–5 November 2014. [Google Scholar]
- Kim, B.H.; Kim, T.; Lie, D. Modulo: Finding Convergence Failure Bugs in Distributed Systems with Divergence Resync Models. In Proceedings of the 2022 USENIX Annual Technical Conference, USENIX ATC 2022, Carlsbad, CA, USA, 11–13 July 2022; Schindler, J., Zilberman, N., Eds.; USENIX Association: Berkeley, CA, USA, 2022; pp. 383–398. [Google Scholar]
- Lloyd, W.; Freedman, M.J.; Kaminsky, M.; Andersen, D.G. Stronger semantics for low-latency geo-replicated storage. In Proceedings of the 10th USENIX Conference on Networked Systems Design and Implementation, Berkeley, CA, USA, 2–5 April 2013; pp. 313–328. [Google Scholar]
- Kingsbury, K. Distributed Systems Safety Research. Available online: https://jepsen.io/ (accessed on 13 October 2023).
- Liu, Z.; Xia, S.; Liang, Y.; Song, L.; Hu, H. Who Goes First? Detecting Go Concurrency Bugs via Message Reordering. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, New York, NY, USA, 28 February–4 March 2022; pp. 888–902. [Google Scholar] [CrossRef]
- Ba, J.; Böhme, M.; Mirzamomen, Z.; Roychoudhury, A. Stateful Greybox Fuzzing. In Proceedings of the 31st USENIX Security Symposium, USENIX Security 2022, Boston, MA, USA, 10–12 August 2022; pp. 3255–3272. [Google Scholar]
- Jeong, D.R.; Lee, B.; Shin, I.; Kwon, Y. SEGFUZZ: Segmentizing Thread Interleaving to Discover Kernel Concurrency Bugs through Fuzzing. In Proceedings of the 2023 IEEE Symposium on Security and Privacy (SP), Los Alamitos, CA, USA, 22–24 May 2023; pp. 2104–2121. [Google Scholar]
- Andronidis, A.; Cadar, C. SnapFuzz: High-Throughput Fuzzing of Network Applications. In Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, Online, 18–22 July 2022; pp. 340–351. [Google Scholar] [CrossRef]
- Jiang, Z.; Bai, J.; Lu, K.; Hu, S. Context-Sensitive and Directional Concurrency Fuzzing for Data-Race Detection. In Proceedings of the 29th Annual Network and Distributed System Security Symposium, NDSS 2022, San Diego, CA, USA, 24–28 April 2022. [Google Scholar]
- Wilcox, J.R.; Woos, D.; Panchekha, P.; Tatlock, Z.; Wang, X.; Ernst, M.D.; Anderson, T. Verdi: A framework for implementing and formally verifying distributed systems. SIGPLAN Not. 2015, 50, 357–368. [Google Scholar] [CrossRef]
- Hawblitzel, C.; Howell, J.; Kapritsos, M.; Lorch, J.; Parno, B.; Roberts, M.L.; Setty, S.; Zill, B. IronFleet: Proving Practical Distributed Systems Correct. In Proceedings of the ACM Symposium on Operating Systems Principles (SOSP). ACM—Association for Computing Machinery, Monterey, CA, USA, 4–7 October 2015. [Google Scholar]
- Hackett, F.; Hosseini, S.; Costa, R.; Do, M.; Beschastnikh, I. Compiling Distributed System Models with PGo. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2023), Vancouver, BC, USA, 25–29 March 2023; Volume 2, pp. 159–175. [Google Scholar] [CrossRef]
- Godefroid, P. Model Checking for Programming Languages Using VeriSoft. In Proceedings of the 24th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, Paris, France, 15–17 January 1997; pp. 174–186. [Google Scholar] [CrossRef]
- Guo, H.; Wu, M.; Zhou, L.; Hu, G.; Yang, J.; Zhang, L. Practical software model checking via dynamic interface reduction. In Proceedings of the Twenty-Third ACM Symposium on Operating Systems Principles, Cascais, Portugal, 23–26 October 2011; pp. 265–278. [Google Scholar]
- Guerraoui, R.; Yabandeh, M. Model checking a networked system without the network. In Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 30 March–1 April 2011; p. 225. [Google Scholar]
- Lin, H.; Yang, M.; Long, F.; Zhang, L.; Zhou, L. MODIST: Transparent model checking of unmodified distributed systems. In Proceedings of the 6th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 22–24 April 2009. [Google Scholar]
- Killian, C.; Anderson, J.W.; Jhala, R.; Vahdat, A. Life, death, and the critical transition: Finding liveness bugs in systems code. In Proceedings of the 4th USENIX Symposium on Networked Systems Design and Implementation, Cambridge, MA, USA, 11–13 April 2007. [Google Scholar]
- Musuvathi, M.; Park, D.Y.W.; Chou, A.; Engler, D.R.; Dill, D.L. CMC: A pragmatic approach to model checking real code. ACM SIGOPS Oper. Syst. Rev. 2002, 36, 75–88. [Google Scholar] [CrossRef]
- Simsa, J.; Bryant, R.; Gibson, G. dBug: Systematic Evaluation of Distributed Systems. In Proceedings of the 5th International Conference on Systems Software Verification, Vancouver, BC, Canada, 6–7 October 2010; p. 3. [Google Scholar]
- Leesatapornwongsa, T.; Hao, M.; Joshi, P.; Lukman, J.F.; Gunawi, H.S. SAMC: Semantic-aware model checking for fast discovery of deep bugs in cloud systems. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI 14), Broomfield, CO, USA, 6–8 October 2014; pp. 399–414. [Google Scholar]
- Lukman, J.F.; Ke, H.; Stuardo, C.A.; Suminto, R.O.; Kurniawan, D.H.; Simon, D.; Priambada, S.; Tian, C.; Ye, F.; Leesatapornwongsa, T.; et al. FlyMC: Highly Scalable Testing of Complex Interleavings in Distributed Systems. In Proceedings of the Fourteenth EuroSys Conference 2019, Dresden, Germany, 25–28 March 2019; pp. 20:1–20:16. [Google Scholar] [CrossRef]
- Gorjiara, H.; Xu, G.H.; Demsky, B. Jaaru: Efficiently Model Checking Persistent Memory Programs. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Online, 19–23 April 2021; pp. 415–428. [Google Scholar] [CrossRef]
- Kim, B.H.; Oh, S.; Lie, D. Consistency Oracles: Towards an Interactive and Flexible Consistency Model Specification. In Proceedings of the 16th Workshop on Hot Topics in Operating Systems, Whistler, BC, Canada, 7–10 May 2017; pp. 82–87. [Google Scholar] [CrossRef]
- Brewer, E. CAP twelve years later: How the “rules” have changed. Computer 2012, 45, 23–29. [Google Scholar] [CrossRef]
- Abadi, D. Consistency Tradeoffs in Modern Distributed Database System Design: CAP is Only Part of the Story. Computer 2012, 45, 37–42. [Google Scholar] [CrossRef]
- Terry, D. Replicated Data Consistency Explained Through Baseball. Commun. ACM 2013, 56, 82–89. [Google Scholar] [CrossRef]
- Higham, L.; Kawash, J.; Verwaal, N. Defining and comparing memory consistency models. In Proceedings of the 10th International Conference on Parallel and Distributed Computing Systems, New Orleans, LO, USA, 1–3 October 1997. [Google Scholar]
- Herlihy, M.P.; Wing, J.M. Linearizability: A correctness condition for concurrent objects. ACM Trans. Program. Lang. Syst. 1990, 12, 463–492. [Google Scholar] [CrossRef]
- Robinson, H. Consensus Protocols: Two-Phase Commit. 2011. Available online: https://www.the-paper-trail.org/post/2008-11-27-consensus-protocols-two-phase-commit/ (accessed on 3 March 2024).
- Vogels, W. Eventually Consistent. Commun. ACM 2008, 52, 40–44. [Google Scholar] [CrossRef]
- Lamport, L. The Part-Time Parliament. ACM Trans. Comput. Syst. 1998, 16, 133–169. [Google Scholar] [CrossRef]
- Burrows, M. The Chubby Lock Service for Loosely-Coupled Distributed Systems. In Proceedings of the 7th Symposium on Operating Systems Design and Implementation (OSDI ’06), Seattle, WA, USA, 6–8 November 2006; Bershad, B.N., Mogul, J.C., Eds.; USENIX Association: Berkeley, CA, USA, 2006; pp. 335–350. [Google Scholar]
- Corbett, J.C.; Dean, J.; Epstein, M.; Fikes, A.; Frost, C.; Furman, J.J.; Ghemawat, S.; Gubarev, A.; Heiser, C.; Hochschild, P.; et al. Spanner: Google’s Globally-Distributed Database. In Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2012, Hollywood, CA, USA, 8–10 October 2012; Thekkath, C., Vahdat, A., Eds.; USENIX Association: Berkeley, CA, USA, 2012; pp. 251–264. [Google Scholar]
- Reed, B.C.; Junqueira, F.P. A simple totally ordered broadcast protocol. In Proceedings of the 2nd Workshop on Large-Scale Distributed Systems and Middleware, LADIS’08, Yorktown Heights, NY, USA, 15–17 September 2008; Dekel, E., Chockler, G.V., Eds.; ACM: New York, NY, USA, 2008; pp. 2:1–2:6. [Google Scholar] [CrossRef]
- Ongaro, D.; Ousterhout, J.K. In Search of an Understandable Consensus Algorithm. In Proceedings of the 2014 USENIX Annual Technical Conference, USENIX ATC’14, Philadelphia, PA, USA, 19–20 June 2014; Gibson, G., Zeldovich, N., Eds.; USENIX Association: Berkeley, CA, USA, 2014; pp. 305–319. [Google Scholar]
- Zhou, S.; Mu, S. Fault-Tolerant Replication with Pull-Based Consensus in MongoDB. In Proceedings of the 18th USENIX Symposium on Networked Systems Design and Implementation, NSDI 2021, Boston, MA, USA, 2–4 April 2021; Mickens, J., Teixeira, R., Eds.; USENIX Association: Berkeley, CA, USA, 2021; pp. 687–703. [Google Scholar]
- Lamport, L. Time, clocks, and the ordering of events in a distributed system. In Concurrency: The Works of Leslie Lamport; Association for Computing Machinery: New York, NY, USA, 2019; pp. 179–196. [Google Scholar]
- Liskov, B.; Ladin, R. Highly available distributed services and fault-tolerant distributed garbage collection. In Proceedings of the 5th Annual ACM Symposium on Principles of Distributed Computing, Calgary, AB, Canada, 11–13 August 1986; pp. 29–39. [Google Scholar]
- Fidge, C.J. A limitation of vector timestamps for reconstructing distributed computations. Inf. Process. Lett. 1998, 68, 87–91. [Google Scholar] [CrossRef]
- Mattern, F. Efficient algorithms for distributed snapshots and global virtual time approximation. J. Parallel Distrib. Comput. 1993, 18, 423–434. [Google Scholar] [CrossRef]
- Yabandeh, M.; Knezevic, N.; Kostic, D.; Kuncak, V. CrystalBall: Predicting and Preventing Inconsistencies in Deployed Distributed Systems. In Proceedings of the NSDI 2009, Boston, MA, USA, 22–24 April 2009; Volume 9, pp. 229–244. [Google Scholar]
- Nelson, L.; Bornholt, J.; Gu, R.; Baumann, A.; Torlak, E.; Wang, X. Scaling Symbolic Evaluation for Automated Verification of Systems Code with Serval. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, Huntsville, ON, Canada, 27–30 October 2019; pp. 225–242. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, D.; Dai, Q.; Dou, W.; Wei, J. Common Data Guided Crash Injection for Cloud Systems. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings, Pittsburgh, PA, USA, 25–27 May 2022; pp. 36–40. [Google Scholar] [CrossRef]
- Chen, H.; Dou, W.; Wang, D.; Qin, F. CoFI: Consistency-Guided Fault Injection for Cloud Systems. In Proceedings of the 35th IEEE/ACM International Conference on Automated Software Engineering, Melbourne, Australia, 21–25 September 2021; pp. 536–547. [Google Scholar] [CrossRef]
- Lu, J.; Liu, C.; Li, L.; Feng, X.; Tan, F.; Yang, J.; You, L. CrashTuner: Detecting Crash-Recovery Bugs in Cloud Systems via Meta-Info Analysis. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP’19), Huntsville, ON, Canada, 27–30 October 2019; pp. 114–130. [Google Scholar] [CrossRef]
- Leesatapornwongsa, T.; Ren, X.; Nath, S. FlakeRepro: Automated and Efficient Reproduction of Concurrency-Related Flaky Tests. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Singapore, 14–16 November 2022; pp. 1509–1520. [Google Scholar] [CrossRef]
- Sun, X.; Luo, W.; Gu, J.T.; Ganesan, A.; Alagappan, R.; Gasch, M.; Suresh, L.; Xu, T. Automatic Reliability Testing For Cluster Management Controllers. In Proceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), Carlsbad, CA, USA, 11–13 July 2022; pp. 143–159. [Google Scholar]
- Yuan, X.; Yang, J. Effective Concurrency Testing for Distributed Systems. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 1141–1156. [Google Scholar] [CrossRef]
- Golab, W.; Rahman, M.; Auyoung, A.; Keeton, K.; Gupta, I. Client-Centric Benchmarking of Eventual Consistency for Cloud Storage Systems. In Proceedings of the 34th International Conference on Distributed Computing Systems (ICDCS), Madrid, Spain, 30 June–3 July 2014. [Google Scholar]
- Golab, W.; Li, X.S.; López-Ortiz, A.; Nishimura, N. Computing Weak Consistency in Polynomial Time: [Extended Abstract]. In Proceedings of the 2015 ACM Symposium on Principles of Distributed Computing, San Sebastian, Spain, 21–23 July 2015; pp. 395–404. [Google Scholar] [CrossRef]
- Golab, W.; Li, X.; Shah, M.A. Analyzing Consistency Properties for Fun and Profit. In Proceedings of the 30th Annual ACM SIGACT-SIGOPS Symposium on Principles of Distributed Computing, San Jose, CA, USA, 6–8 June 2011; pp. 197–206. [Google Scholar] [CrossRef]
- Rahman, M.R.; Golab, W.; AuYoung, A.; Keeton, K.; Wylie, J.J. Toward a Principled Framework for Benchmarking Consistency. In Proceedings of the 8th USENIX Conference on Hot Topics in System Dependability (HotDep), Hollywood, CA, USA, 7 October 2012. [Google Scholar]
- Bailis, P.; Venkataraman, S.; Franklin, M.J.; Hellerstein, J.M.; Stoica, I. Probabilistically Bounded Staleness for Practical Partial Quorums. VLDB Endow. 2012, 5, 776–787. [Google Scholar] [CrossRef]
- Bermbach, D.; Tai, S. Eventual Consistency: How Soon Is Eventual? An Evaluation of Amazon S3’s Consistency Behavior. In Proceedings of the 6th Workshop on Middleware for Service Oriented Computing (MW4SOC), Lisbon, Portugal, 12 December 2011. [Google Scholar]
- Anderson, E.; Li, X.; Shah, M.A.; Tucek, J.; Wylie, J.J. What Consistency Does Your Key-Value Store Actually Provide? In Proceedings of the 6th International Conference on Hot Topics in System Dependability (HotDep), Vancouver, BC, Canada, 3 October 2010. [Google Scholar]
- Wada, H.; Fekete, A.; Zhao, L.; Lee, K.; Liu, A. Data Consistency Properties and the Tradeoffs in Commercial Cloud Storages: The Consumers’ Perspective. In Proceedings of the 5th Biennial Conference on Innovative Data Systems Research (CIDR), Asilomar, CA, USA, 9–12 January 2011. [Google Scholar]
- Bermbach, D.; Sakr, S.; Zhao, L. Towards Comprehensive Measurement of Consistency Guarantees for Cloud-Hosted Data Storage Services. In Proceedings of the 5th TPC Technology Conference on Performance Evaluation & Benchmarking (TPCTC 2013), Trento, Italy, 26 August 2013. [Google Scholar]
- Li, J.; Krohn, M.; Mazières, D.; Shasha, D. Secure Untrusted Data Repository (SUNDR). In Proceedings of the 6th USENIX Symposium on Operating Systems Design and Implementation (OSDI), San Francisco, CA, USA, 6–8 December 2004. [Google Scholar]
- Feldman, A.J.; Zeller, W.P.; Freedman, M.J.; Felten, E.W. SPORC: Group Collaboration using Untrusted Cloud Resources. In Proceedings of the The 9th USENIX Symposium on Operating Systems Design and Implementation (OSDI), Vancouver, BC, Canada, 4–6 October 2010. [Google Scholar]
- Kim, B.H.; Lie, D. Caelus: Verifying the Consistency of Cloud Services with Battery-Powered Devices. In Proceedings of the 2015 IEEE Symposium on Security and Privacy, Washington, DC, USA, 21 May 2015; pp. 880–896. [Google Scholar] [CrossRef]
- Zhou, J.; Xu, M.; Shraer, A.; Namasivayam, B.; Miller, A.; Tschannen, E.; Atherton, S.; Beamon, A.J.; Sears, R.; Leach, J.; et al. FoundationDB: A Distributed Unbundled Transactional Key Value Store. In Proceedings of the 2021 International Conference on Management of Data, Online, 20–25 June 2021; pp. 2653–2666. [Google Scholar] [CrossRef]
- Xia, Y.; Yu, X.; Butrovich, M.; Pavlo, A.; Devadas, S. Litmus: Towards a Practical Database Management System with Verifiable ACID Properties and Transaction Correctness. In Proceedings of the 2022 International Conference on Management of Data, Philadelphia, PA, USA, 12–17 June 2022; pp. 1478–1492. [Google Scholar] [CrossRef]
- Cui, Z.; Dou, W.; Dai, Q.; Song, J.; Wang, W.; Wei, J.; Ye, D. Differentially Testing Database Transactions for Fun and Profit. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022; Association for Computing Machinery: New York, NY, USA, 2023. [Google Scholar]
- Tan, C.; Zhao, C.; Mu, S.; Walfish, M. Cobra: Making Transactional Key-Value Stores Verifiably Serializable. In Proceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), Online, 4–6 November 2020; USENIX Association: Berkley, CA, USA, 2020; pp. 63–80. [Google Scholar]
- Gürsoy, G.; Brannon, C.; Gerstein, M. Using Ethereum blockchain to store and query pharmacogenomics data via smart contracts. BMC Med. Genom. 2020, 13, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Fekete, D.L.; Kiss, A. A Survey of Ledger Technology-Based Databases. Future Internet 2021, 13, 197. [Google Scholar] [CrossRef]
- Loghin, D. The Anatomy of Blockchain Database Systems. IEEE Data Eng. Bull. 2022, 45, 48–58. [Google Scholar]
- Sharma, A.; Schuhknecht, F.M.; Agrawal, D.; Dittrich, J. Blurring the Lines between Blockchains and Database Systems: The Case of Hyperledger Fabric. In Proceedings of the 2019 International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2019; pp. 105–122. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bug ID | Severity | Duration | Symptoms | Root Cause |
|---|---|---|---|---|
| 1154 | Blocker | 21 days | Data Loss | Resync Errors |
| 1319 | Blocker | 3 days | Data Loss | Replication Errors |
| 1549 | Major | Unresolved | Corrupted Data | Truncation Errors |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, B.-H. VConMC: Enabling Consistency Verification for Distributed Systems Using Implementation-Level Model Checkers and Consistency Oracles. Electronics 2024, 13, 1153. https://doi.org/10.3390/electronics13061153
Kim B-H. VConMC: Enabling Consistency Verification for Distributed Systems Using Implementation-Level Model Checkers and Consistency Oracles. Electronics. 2024; 13(6):1153. https://doi.org/10.3390/electronics13061153
Chicago/Turabian StyleKim, Beom-Heyn. 2024. "VConMC: Enabling Consistency Verification for Distributed Systems Using Implementation-Level Model Checkers and Consistency Oracles" Electronics 13, no. 6: 1153. https://doi.org/10.3390/electronics13061153
APA StyleKim, B.-H. (2024). VConMC: Enabling Consistency Verification for Distributed Systems Using Implementation-Level Model Checkers and Consistency Oracles. Electronics, 13(6), 1153. https://doi.org/10.3390/electronics13061153