
Large Language Model Inference Acceleration Based on Hybrid Model Branch Prediction


Abstract
:1. Introduction
- Firstly, we propose a hybrid model acceleration inference method based on branch prediction. By using branch prediction, the validation time during hybrid model inference would be reduced, which significantly reduces the inference time.
- Secondly, we construct a branch-prediction function based on the binomial distribution assumption to fit the empirical distribution, further accelerating the inference speed.
- Lastly, through experiments, it is demonstrated that the proposed algorithm achieves better acceleration effects in tasks of generating combinations of models of different scales.
2. Related Work
3. Prior Knowledge
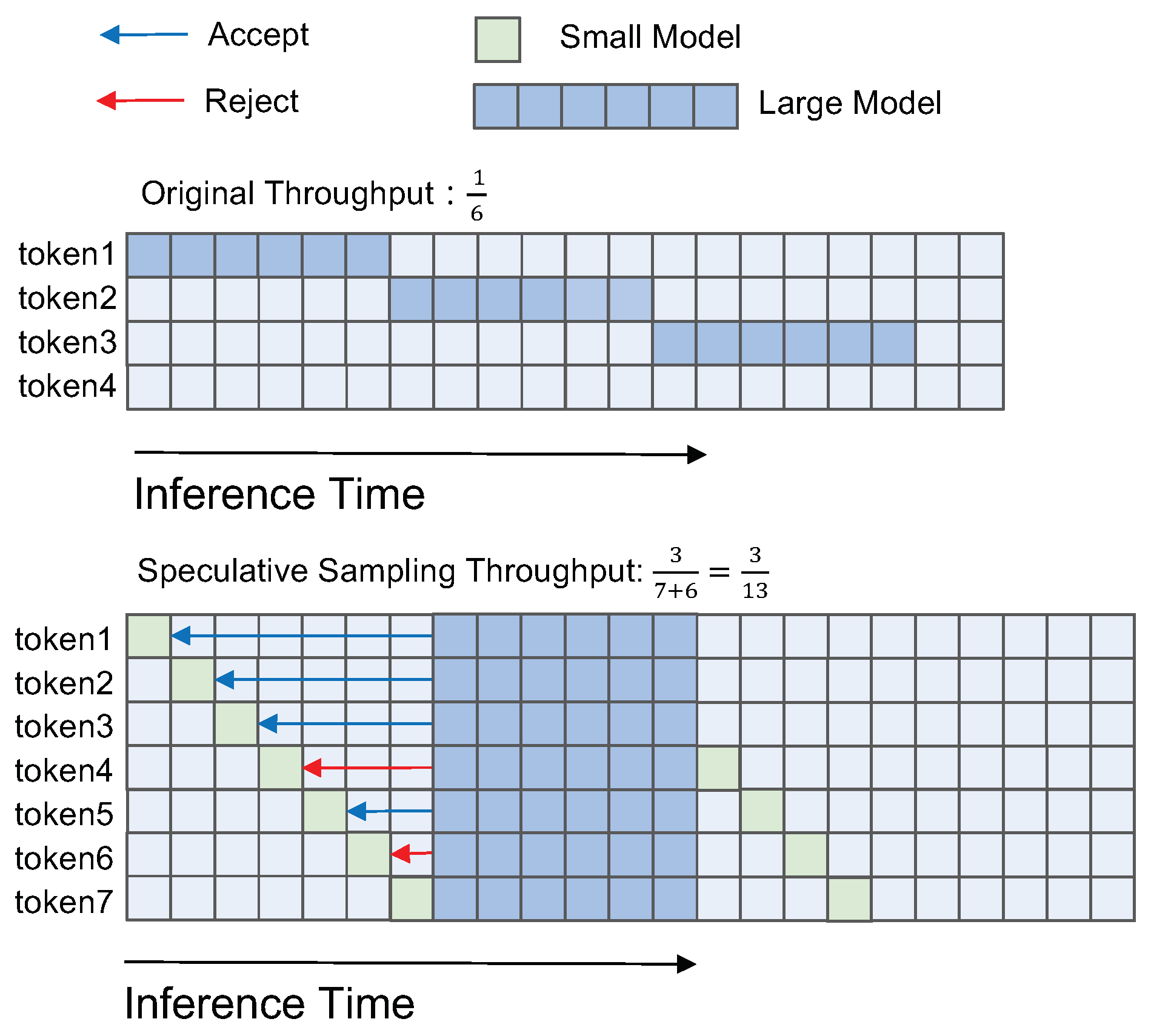
3.1. Speculative Sampling
- The smaller model is used to quickly generate a series of inference output drafts characters (tokens) .
- These drafts are then verified and, if necessary, corrected by the original large model. In detail, the number of accepted drafts is defined aswhere .
- After validation, adjust the result:where is defined to ensure the final output is just like the sample from the large model :
3.2. Branch Prediction
- Static prediction typically relies on simple rules, such as always predicting that a branch will go in a specific direction (for example, always predicting that a loop will continue).
- Dynamic prediction, on the other hand, depends on information collected at runtime, predicting future branch decisions based on historical branch behavior. This category includes a range of complex algorithms, such as Two-Level Adaptive Training and History Table-Based Prediction.
4. Methods
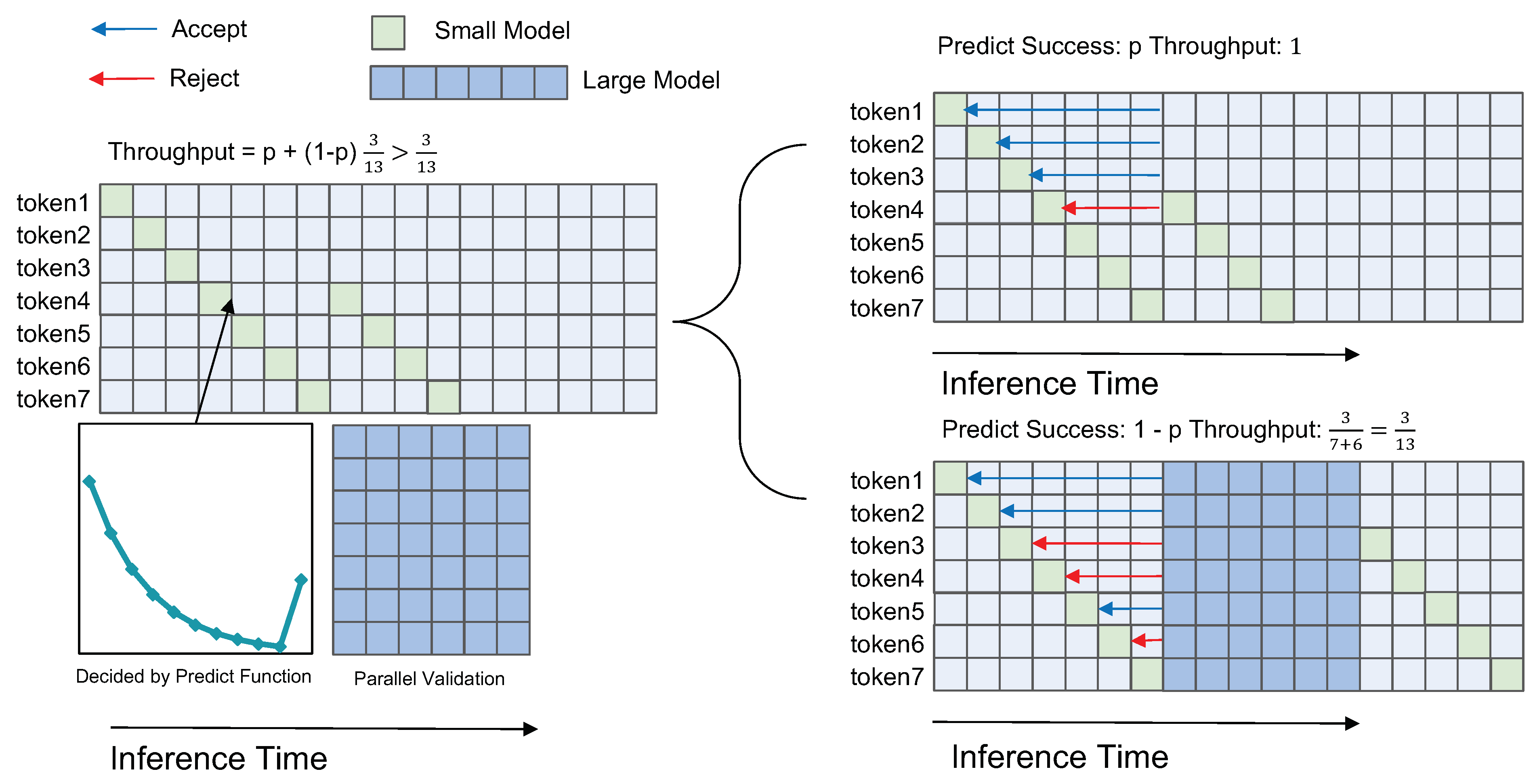
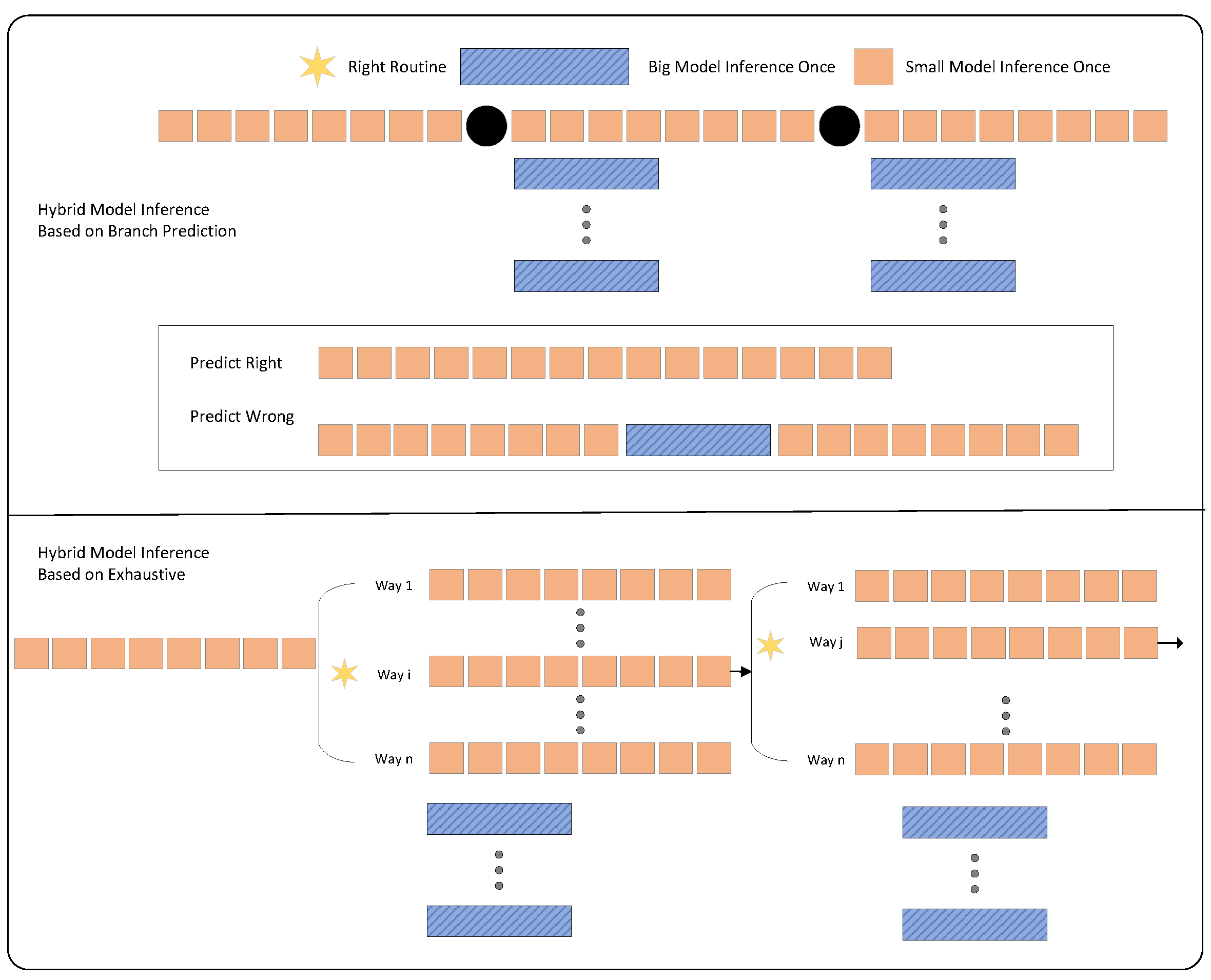
4.1. Hybrid Model Inference Acceleration Algorithm Based on Branch Prediction
- Small Model Draft Generation: Initially, the small model generates drafts of tokens , which could be the potential generation output after the validation of the large model. The objective of this phase is to swiftly produce preliminary inference outcomes using the small model. These initial results then enable the large model to overcome sequence limitations by utilizing these drafts as a foundation.
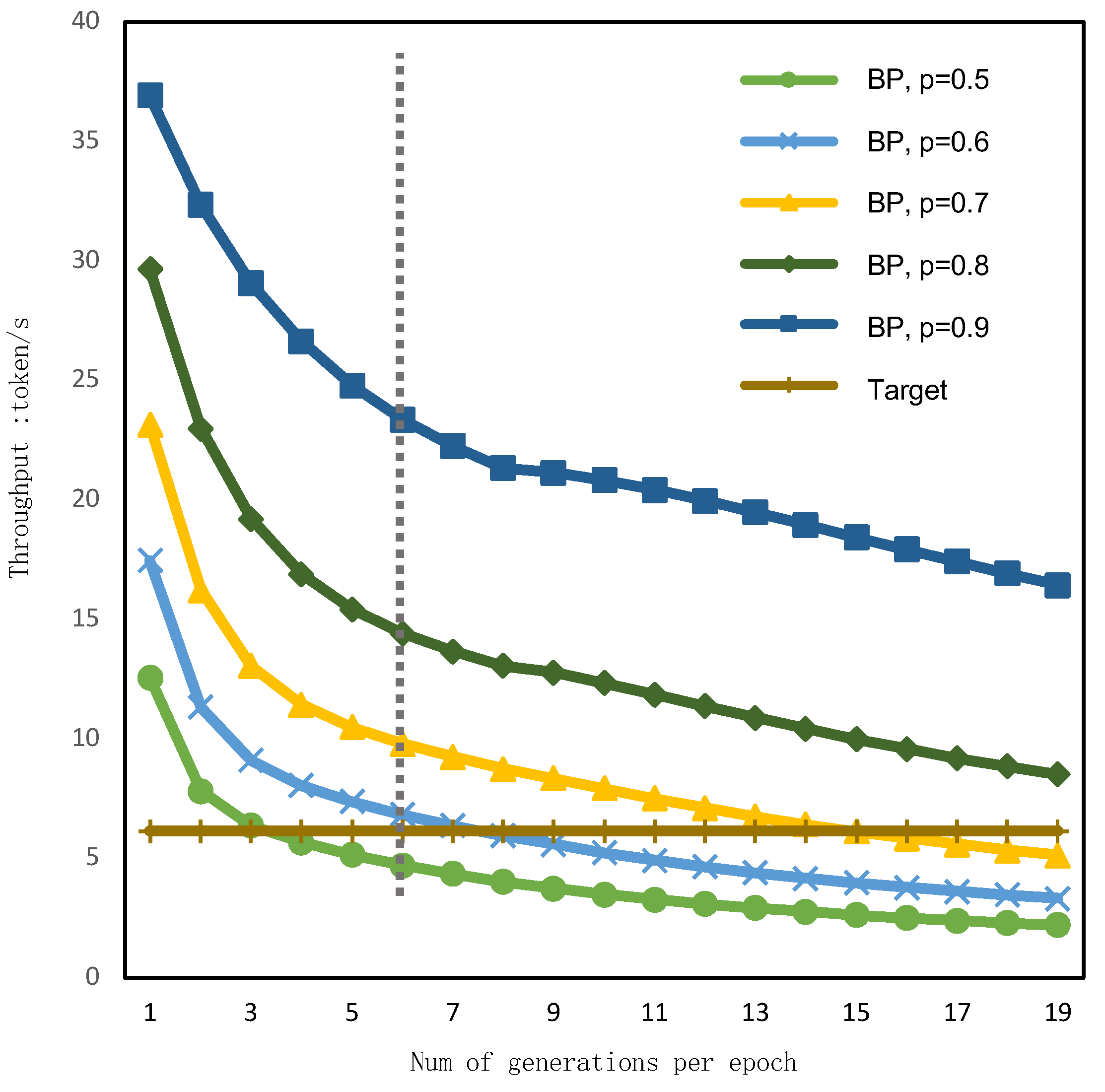
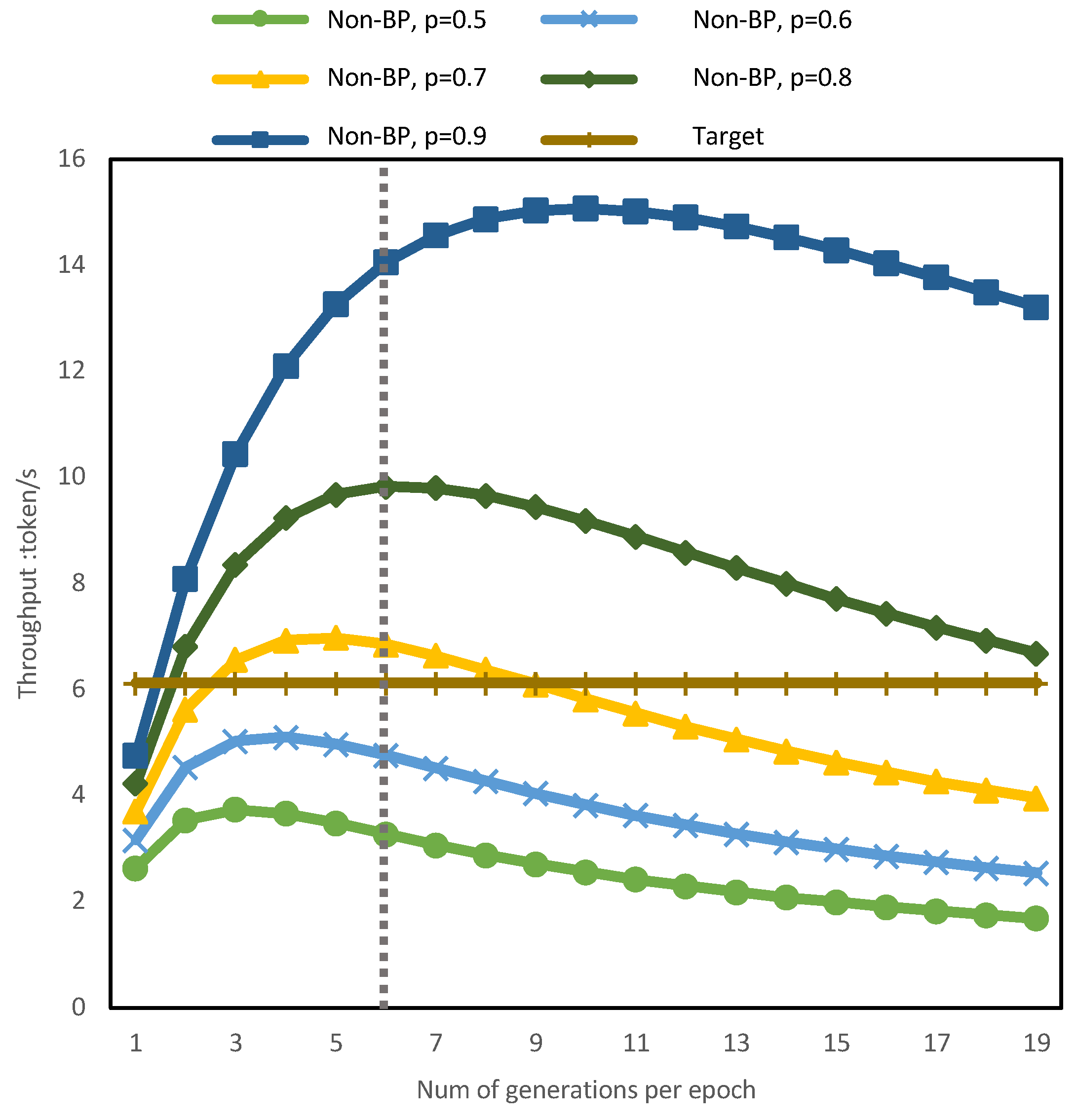
- Branch Prediction: The prediction function is employed to predict the number of acceptable drafts . The first tokens are accepted, and is set as the starting point for the next round of small model inference, followed by the commencement of the next round generation. By introducing branch prediction, we optimized the scheduling of the entire inference process. In the subsequent steps, we will observe that the total inference time is reduced when predictions are accurate.
- Large Model Validation: Concurrently with the generation of the next round of drafts by the small model, the large model parallelly evaluates all draft tokens from of this round and their respective probabilities to determine the actual number of accepted . If , it signifies that the output result of the target model at this position is consistent with that of the approximate model, accepting the token generated by the approximate model at the ith position of this round; otherwise, it is considered a failure in draft generation by the approximate model at this position. The longest consecutive number of accepted tokens starting from the initial position is counted as the real number of accepted for this round:The validation step will determine the actual acceptable draft length, similar to speculative sampling. The retained tokens will ensure consistency with the results directly sampled from the large model.
- Branch-Prediction Result Check: After the validation by the large model is completed, the prediction for this round is checked:If , the prediction is deemed successful, and the small model proceeds to the next round of draft generation. Otherwise, in the event of prediction failure, the process reverts to the verification point and restarts the generation process. The determination of whether a prediction is successful is based on the comparison between the predicted values and the actual values. Whether the prediction is successful or not also decides if the inference process can be accelerated.
4.2. Design of Prediction Function for Acceleration
5. Analysis
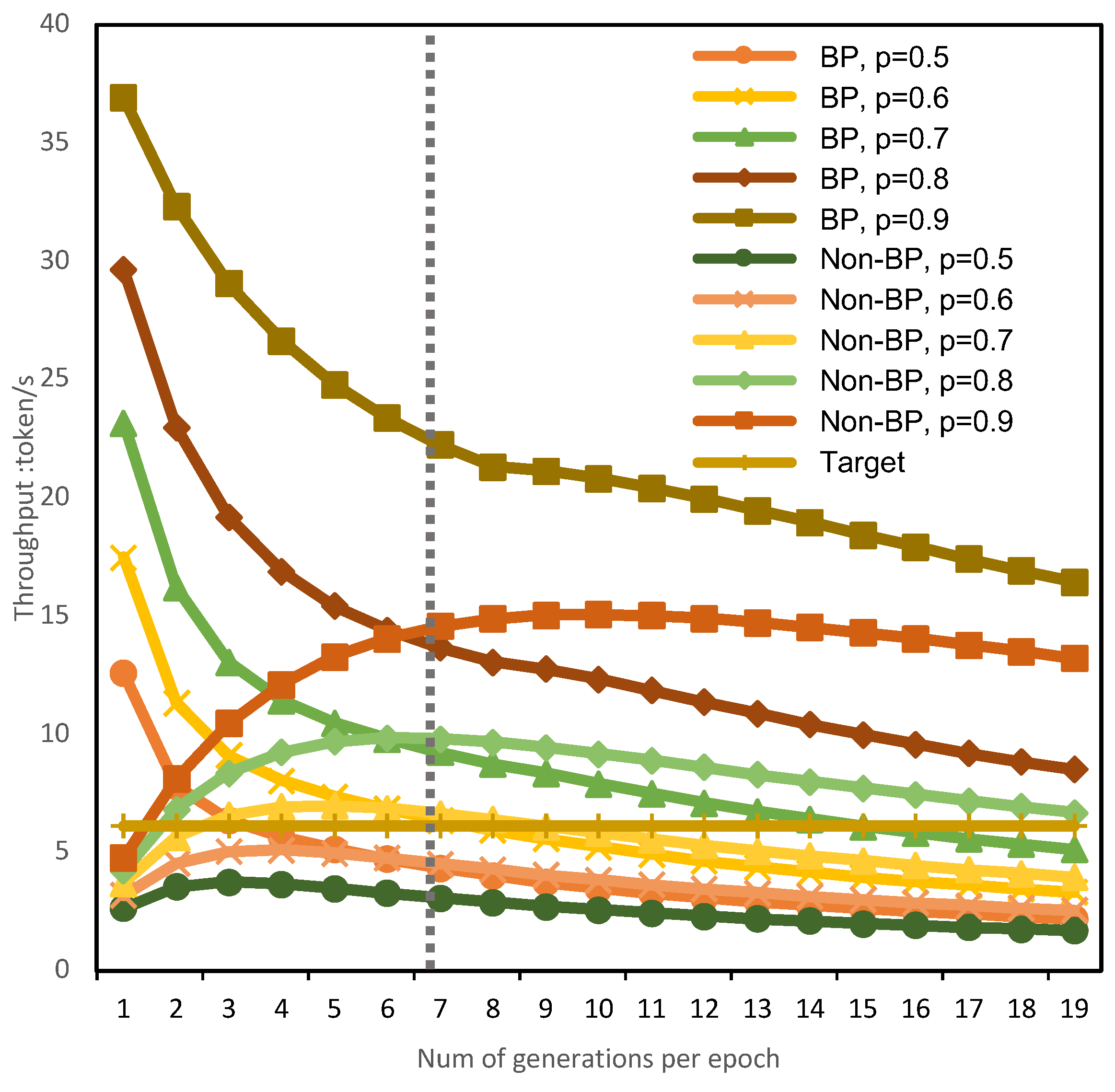
5.1. Impact of Branch-Prediction Strategy on Throughput
5.2. Prediction Function Optimization
5.2.1. Prediction Function Based on Independent and Identically Distributed (IID) Theory Analysis
- The probability density distribution function is a monotonically decreasing convex function.
- There is a significant increase in probability at n compared to the adjacent probability before it. The probability at n should be the sum of all probabilities greater than or equal to n; that is:
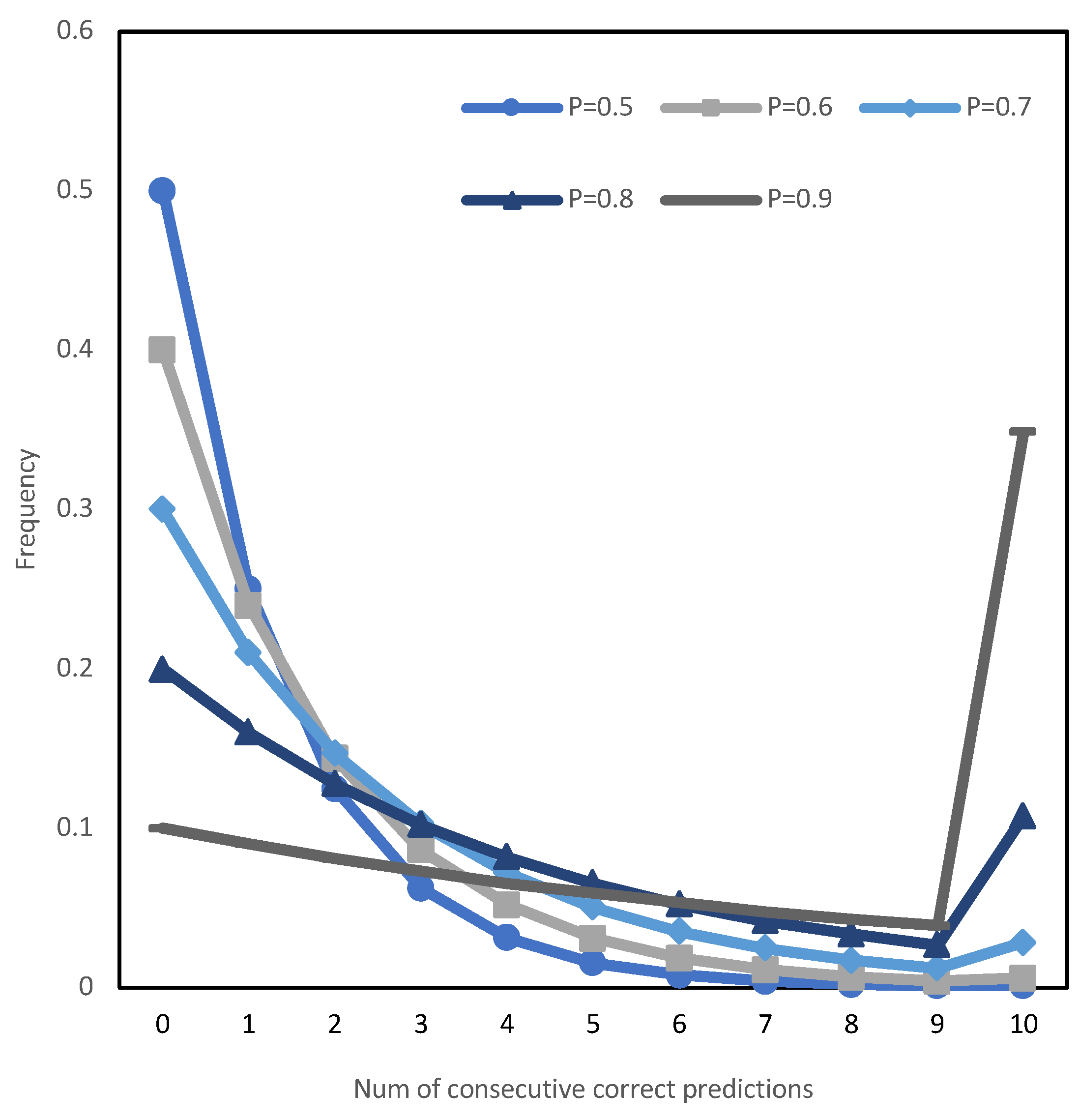
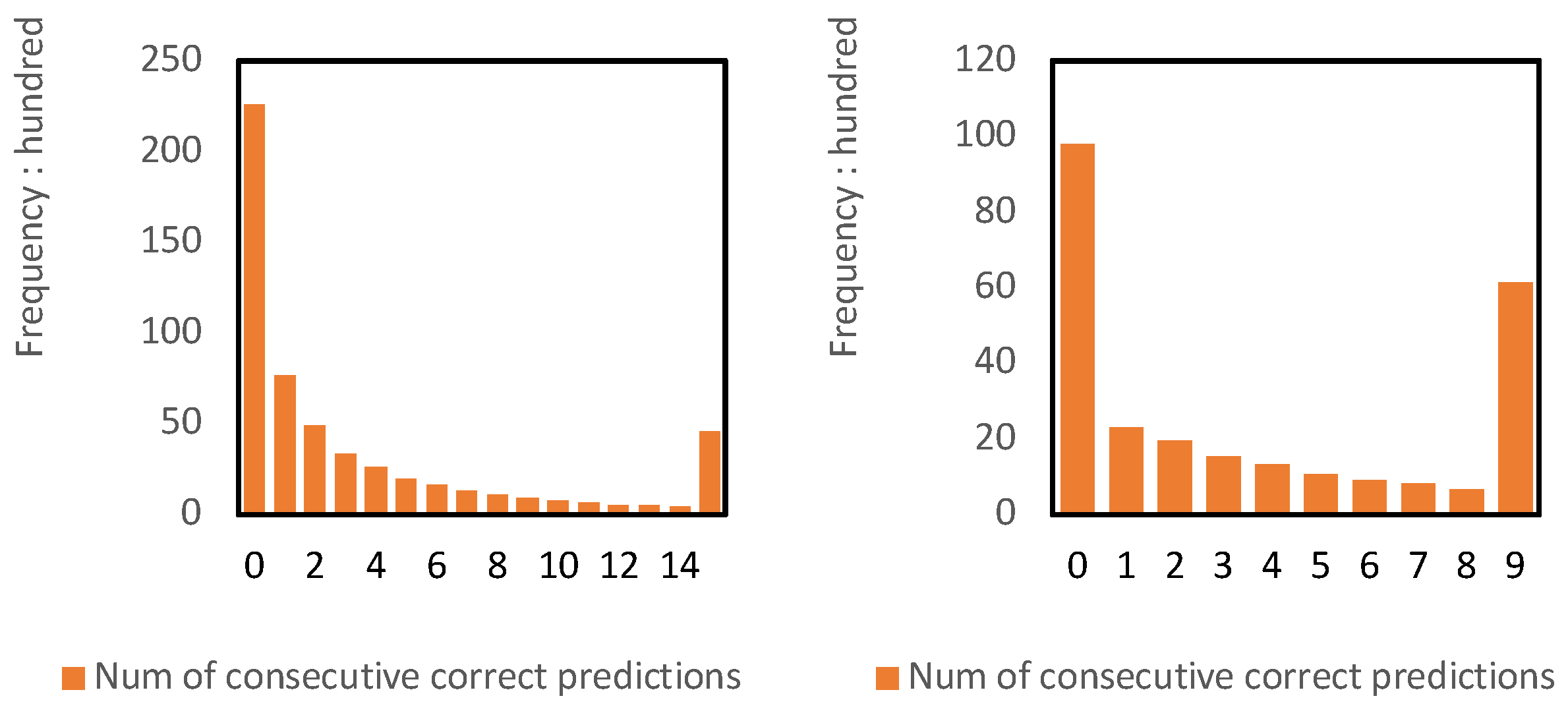
5.2.2. Prediction Function Based on Empirical Distribution Experimental Analysis
- The continuous approximation function of the frequency distribution is a monotonically decreasing convex function.
- There is a significant abnormal increase in the frequency distribution at the end n compared to the adjacent frequency data before it.
5.2.3. Determination of the Prediction Function
6. Experiments
6.1. Experiments Setup
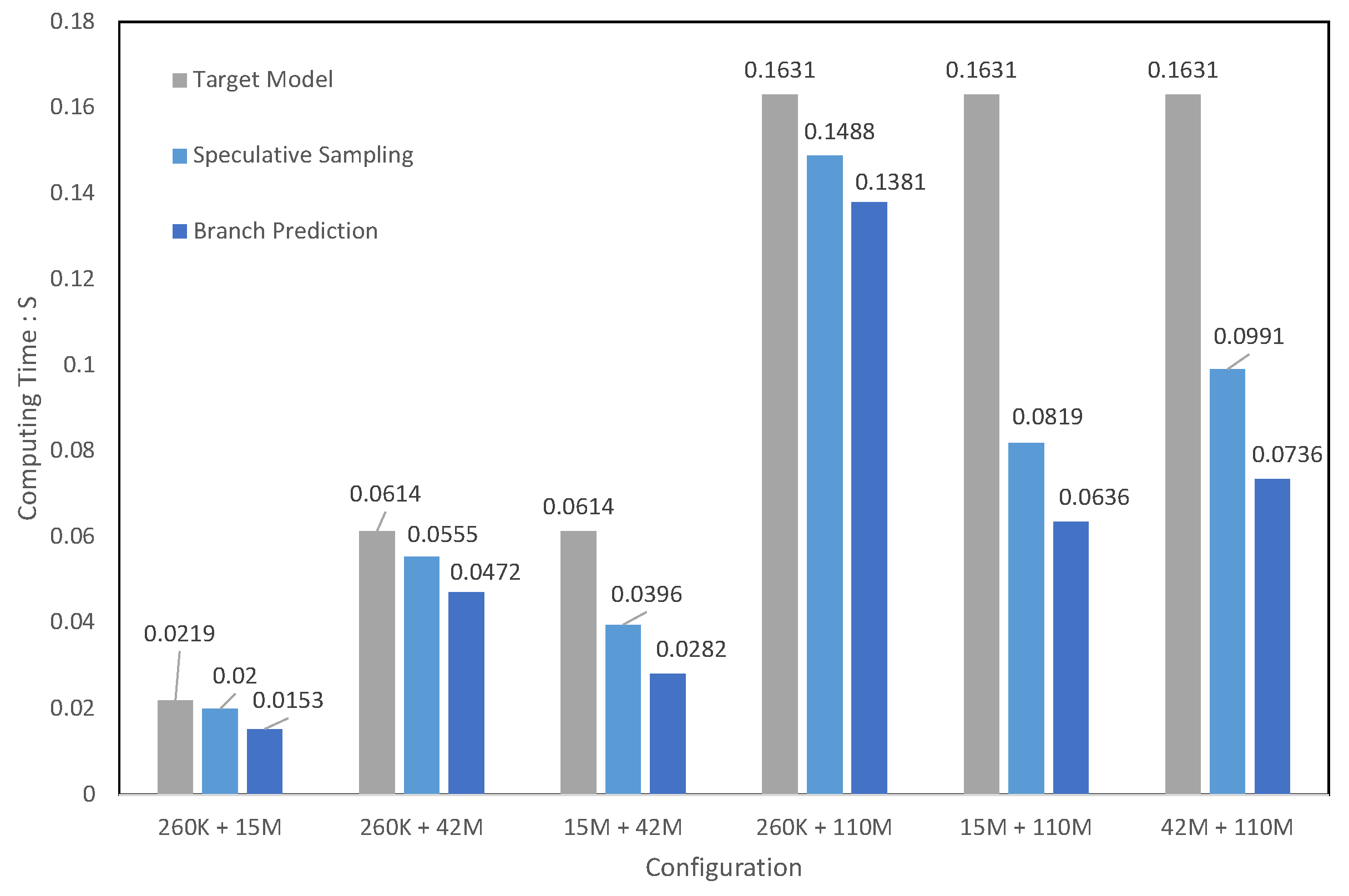
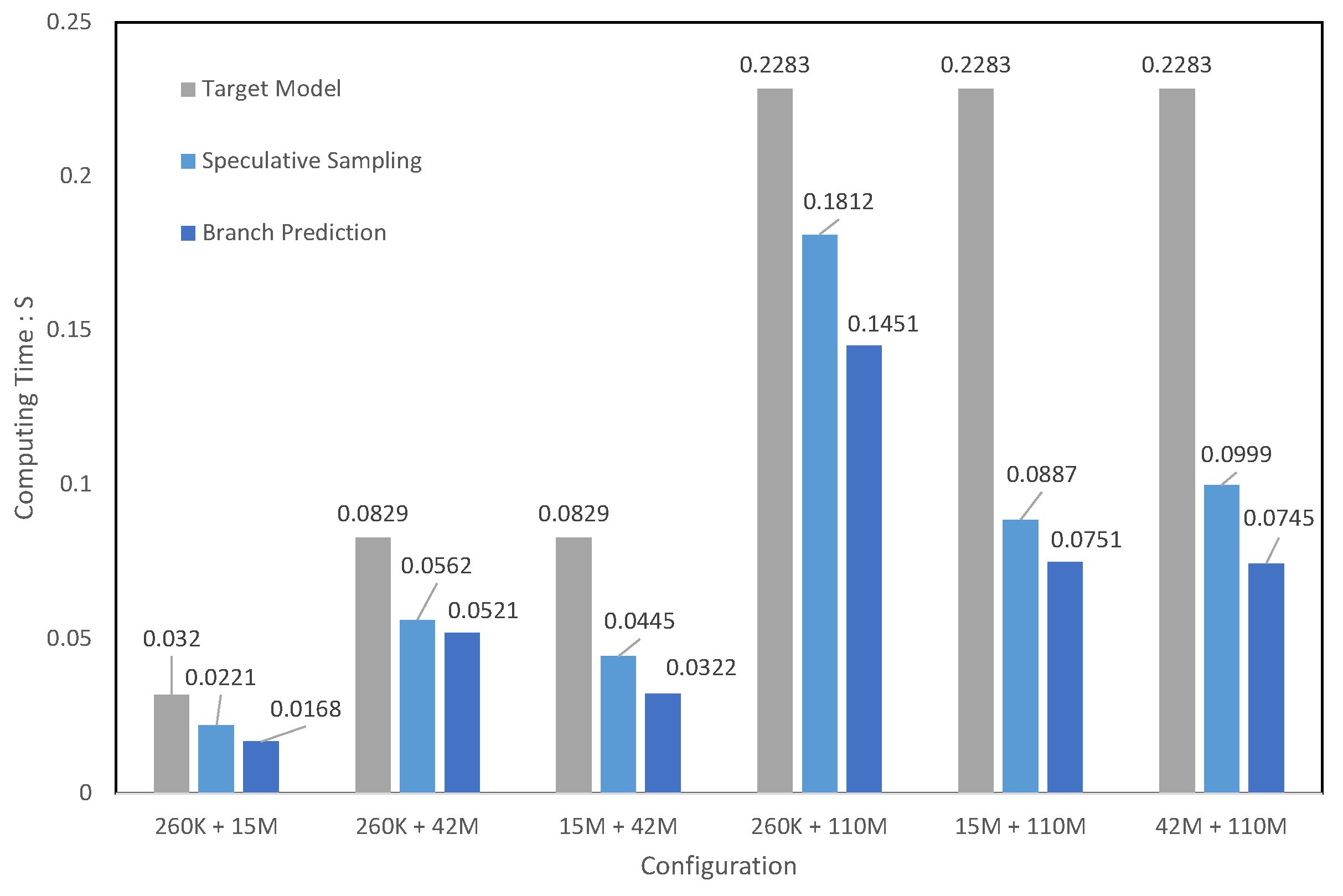
6.2. The Impact of Branch-Prediction Algorithm across Diverse Model Scales
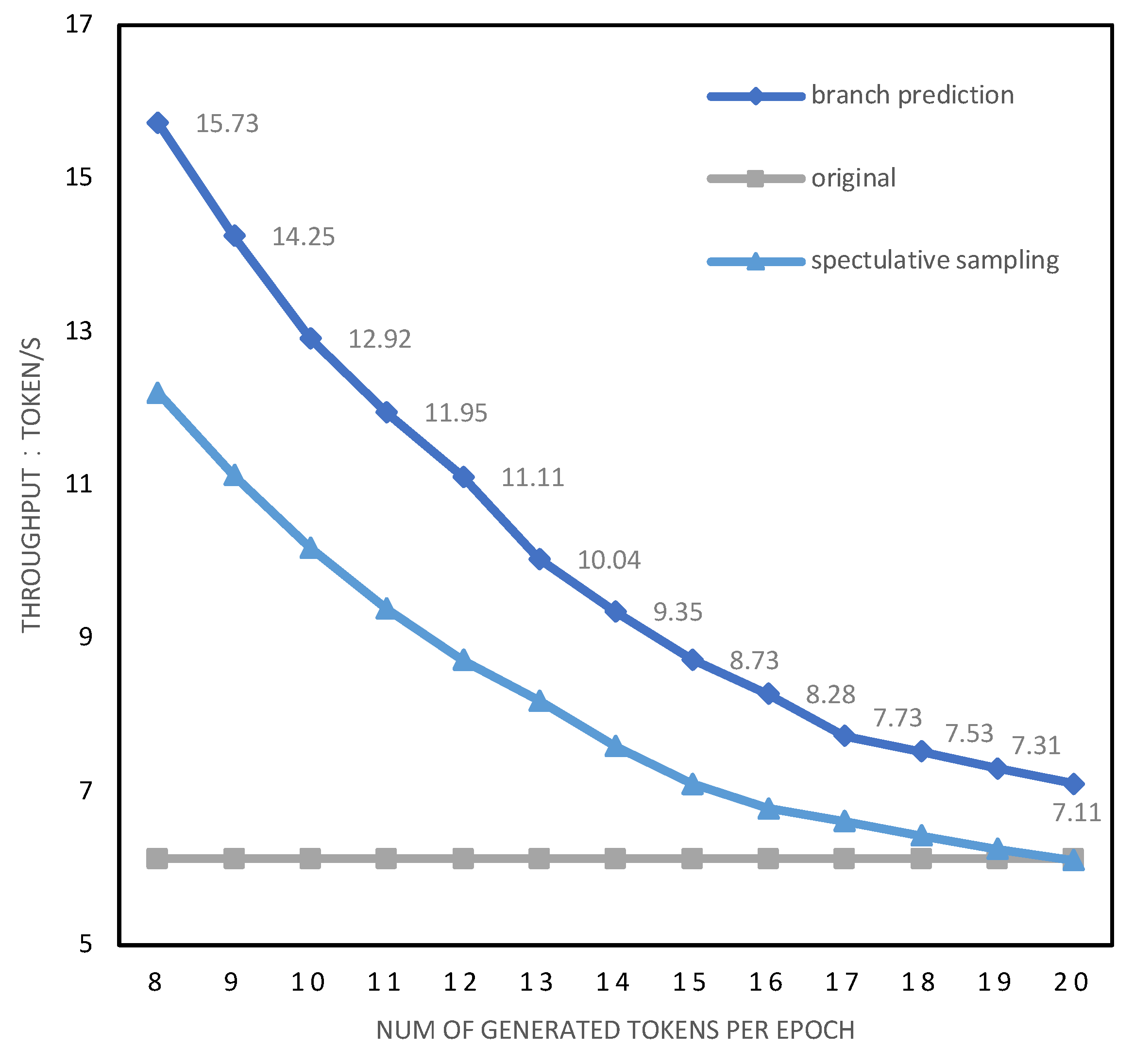
6.3. Ablation Experiment on the Impact of Single-Round Token Generation Quantity on Acceleration Effect
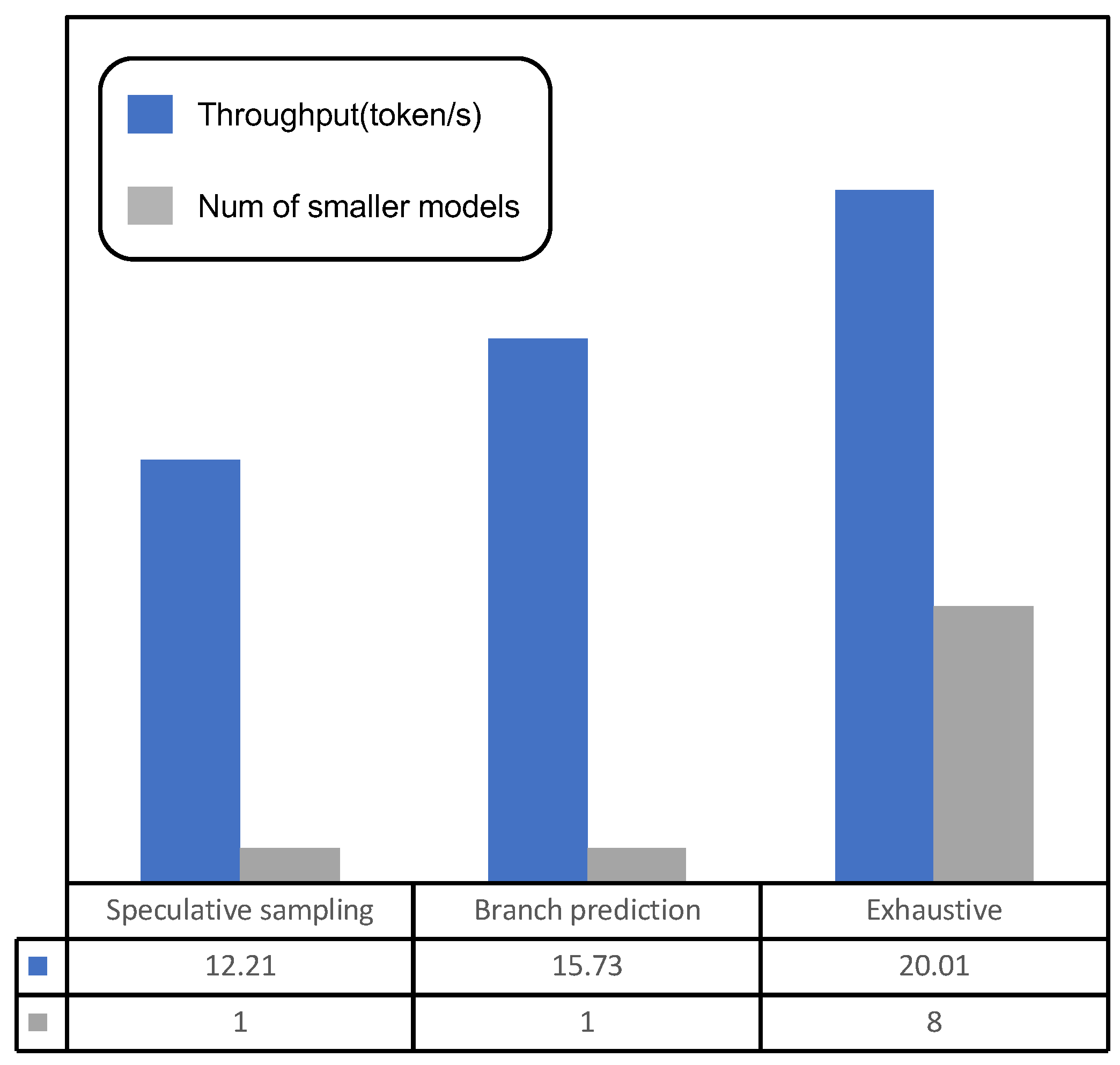
6.4. Extreme Trade-Off Strategy: Exploring Exhaustive Methods
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the naacL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Liu, Y.; Pan, D.; Zhang, H.; Zhong, K. Degradation-Trend-Aware Deep Neural Network with Attention Mechanism for Bearing Remaining Useful Life Prediction. IEEE Trans. Artif. Intell. 2023, 1–15. [Google Scholar] [CrossRef]
- Kitaev, N.; Kaiser, Ł.; Levskaya, A. Reformer: The efficient transformer. arXiv 2020, arXiv:2001.04451. [Google Scholar]
- Ghimire, D.; Kil, D.; Kim, S.h. A survey on efficient convolutional neural networks and hardware acceleration. Electronics 2022, 11, 945. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhu, Y.; He, C.; Wang, Y.; Yan, S.; Tian, Y.; Yuan, L. Spikformer: When spiking neural network meets transformer. arXiv 2022, arXiv:2209.15425. [Google Scholar]
- Leviathan, Y.; Kalman, M.; Matias, Y. Fast inference from transformers via speculative decoding. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 21–17 July 2023; pp. 19274–19286. [Google Scholar]
- Dehghani, M.; Arnab, A.; Beyer, L.; Vaswani, A.; Tay, Y. The efficiency misnomer. arXiv 2021, arXiv:2110.12894. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12104–12113. [Google Scholar]
- Qiu, J.; Ma, H.; Levy, O.; Yih, S.W.t.; Wang, S.; Tang, J. Blockwise self-attention for long document understanding. arXiv 2019, arXiv:1911.02972. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The long-document transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Schwartz, R.; Stanovsky, G.; Swayamdipta, S.; Dodge, J.; Smith, N.A. The right tool for the job: Matching model and instance complexities. arXiv 2020, arXiv:2004.07453. [Google Scholar]
- Han, Y.; Huang, G.; Song, S.; Yang, L.; Wang, H.; Wang, Y. Dynamic neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 7436–7456. [Google Scholar] [CrossRef] [PubMed]
- Schuster, T.; Fisch, A.; Jaakkola, T.; Barzilay, R. Consistent accelerated inference via confident adaptive transformers. arXiv 2021, arXiv:2104.08803. [Google Scholar]
- Shazeer, N. Fast transformer decoding: One write-head is all you need. arXiv 2019, arXiv:1911.02150. [Google Scholar]
- Zhang, R.; Han, J.; Zhou, A.; Hu, X.; Yan, S.; Lu, P.; Li, H.; Gao, P.; Qiao, Y. Llama-adapter: Efficient fine-tuning of language models with zero-init attention. arXiv 2023, arXiv:2303.16199. [Google Scholar]
- Eldan, R.; Li, Y. TinyStories: How Small Can Language Models Be and Still Speak Coherent English? arXiv 2023, arXiv:2305.07759. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Improving neural machine translation models with monolingual data. arXiv 2015, arXiv:1511.06709. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acceleration Algorithms | Acceleration Type | Need Retrain | Align Original Output |
|---|---|---|---|
| distillation [11] | single-round decoder | Yes | No |
| sparsification [12] | Yes | No | |
| quantization [13] | Yes | No | |
| architectural modifications [14] | Yes | No | |
| confident adaptive transformers [17] | entire inference process | Yes | No |
| fast transformer decoding [18] | Yes | No | |
| speculative sampling [8] | No | Yes |
| Model | Dimension | Number of Attention Heads | Layers | Parameters |
|---|---|---|---|---|
| 260 K | 64 | 8 | 5 | 260 K |
| 15 M | 288 | 6 | 6 | 15 M |
| 42 M | 512 | 8 | 8 | 42 M |
| 110 M | 768 | 12 | 12 | 110 M |
| Hybrid Model Configuration | Small Model Throughput (tokens/s) | Target Model Throughput (tokens/s) | Speculative Sampling Throughput (tokens/s) | Branch-Prediction Throughput (tokens/s) |
|---|---|---|---|---|
| 260 K + 15 M | 2400 | 45.59 | 50.12 | 65.33 (1.4×) |
| 260 K + 42 M | 2400 | 16.29 | 18.02 | 21.18 (1.3×) |
| 15 M + 42 M | 45.59 | 16.29 | 25.23 | 35.51 (2.2×) |
| 260 K + 110 M | 2400 | 6.13 | 6.72 | 7.24 (1.2×) |
| 15 M + 110 M | 45.59 | 6.13 | 12.21 | 15.73 (2.6×) |
| 42 M + 110 M | 16.29 | 6.13 | 10.09 | 13.58 (2.2×) |
| Hybrid Model Configuration | Small Model Throughput (tokens/s) | Target Model Throughput (tokens/s) | Speculative Sampling Throughput (tokens/s) | Branch-Prediction Throughput (tokens/s) |
|---|---|---|---|---|
| 260 K + 15 M | 1852 | 31.29 | 45.33 | 59.53 (1.9×) |
| 260 K + 42 M | 1852 | 12.06 | 17.79 | 19.21 (1.6×) |
| 15 M + 42 M | 31.29 | 12.06 | 22.48 | 31.01 (2.6×) |
| 260 K + 110 M | 1852 | 4.38 | 5.52 | 6.89 (1.6×) |
| 15 M + 110 M | 31.29 | 4.38 | 11.28 | 13.31 (3.2×) |
| 42 M + 110 M | 12.06 | 4.38 | 10.01 | 13.42 (3.4×) |
| Method | Origin (110 M) | Speculative Sampling (110M + 42 M) | Our Work (110 M + 42 M) |
| Content | One day, Lily met a Shoggoth. He was very shy, but was also very generous. Lily said “Hello Shoggy! Can I be your friend?” Shoggy was happy to have a friend and said “Yes, let’s explore the universe together!” So they set off on a journey to explore the universe. As they travelled, Shoggy was happy to explain to Lily about all the wonderful things in the universe. At the end of the day, Lily and Shoggy had gathered lots of wonderful things from the universe, and they both felt very proud. They promised to explore the universe as one big pair and to never stop being generous to each other. | One day, Lily met a Shoggoth. He was very shy, but was also very generous. Lily said “Hello Shoggy! Can I be your friend?” Shoggy was happy to have a friend and said “Yes, let’s explore the universe together!” So they set off on a journey to explore the universe. As they travelled, Shoggy was happy to explain to Lily about all the wonderful things in the universe. At the end of the day, Lily and Shoggy had gathered lots of wonderful things from the universe, and they both felt very proud. They promised to explore the universe as one big pair and to never stop being generous to each other. | One day, Lily met a Shoggoth. He was very shy, but was also very generous. Lily said “Hello Shoggy! Can I be your friend?” Shoggy was happy to have a friend and said “Yes, let’s explore the universe together!” So they set off on a journey to explore the universe. As they travelled, Shoggy was happy to explain to Lily about all the wonderful things in the universe. At the end of the day, Lily and Shoggy had gathered lots of wonderful things from the universe, and they both felt very proud. They promised to explore the universe as one big pair and to never stop being generous to each other. |
| Total Computing Time: s | 18.10 | 10.99 | 8.10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, G.; Chen, J.; Zhou, Y.; Zheng, X.; Zhu, Y. Large Language Model Inference Acceleration Based on Hybrid Model Branch Prediction. Electronics 2024, 13, 1376. https://doi.org/10.3390/electronics13071376
Duan G, Chen J, Zhou Y, Zheng X, Zhu Y. Large Language Model Inference Acceleration Based on Hybrid Model Branch Prediction. Electronics. 2024; 13(7):1376. https://doi.org/10.3390/electronics13071376
Chicago/Turabian StyleDuan, Gaoxiang, Jiajie Chen, Yueying Zhou, Xiaoying Zheng, and Yongxin Zhu. 2024. "Large Language Model Inference Acceleration Based on Hybrid Model Branch Prediction" Electronics 13, no. 7: 1376. https://doi.org/10.3390/electronics13071376