
CrptAC: Find the Attack Chain with Multiple Encrypted System Logs
Abstract
:1. Introduction
- We propose a novel SSE scheme that supports fuzzy multi-keyword search and result ranking, offering a solution for handling keyword imprecision. This enhances the system’s ability to recognize various attack patterns, particularly when dealing with ambiguous or fluctuating keywords. (Section 3.1);
- We enhance the accuracy of tracing the cause of attacks by integrating and correlating logs from multiple sources within the system, rather than relying on a singular perspective. This multi-faceted approach allows for a more comprehensive analysis, leading to more precise identification of attack origins. (Section 3.2);
- Our framework employs the LCS matching algorithm for tracing regular steps and constructing attack chains, enabling the identification of systematic attack patterns even in the absence of explicit alerts from security system logs. This approach thus provides a powerful mechanism for early threat detection and prevention. (Section 3.4);
- Our approach can identify syslog sequences to proactively defend against attacks to avoid device or network paralysis. (Section 4).
2. Related Work
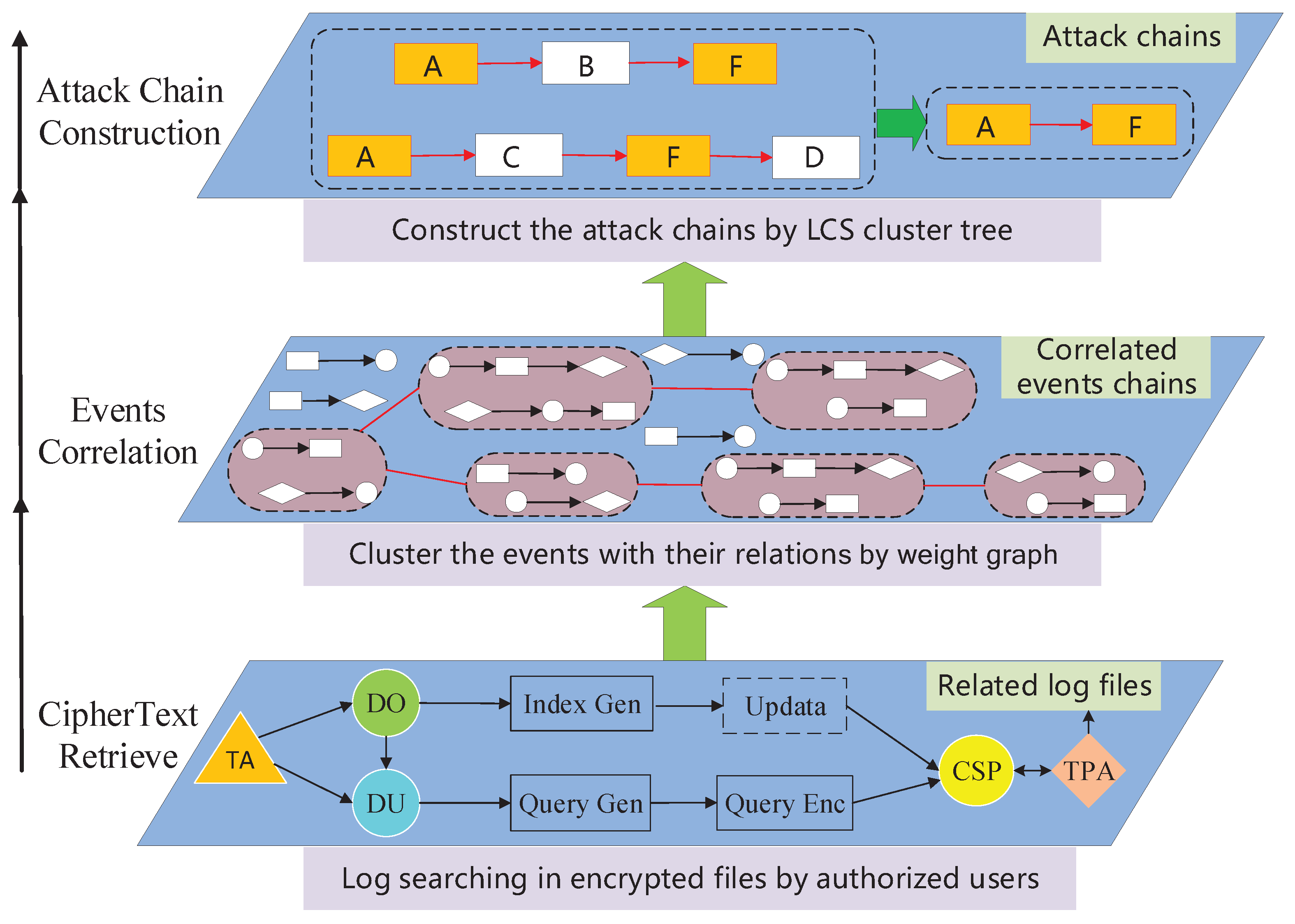
3. System Model
- (1)
- Cipher text retrieve. Initially, we query encrypted logs for keywords related to the attack, verifying the integrity of the logs found. This step ensures that we focus only on relevant data;
- (2)
- Events correlation. Using a weighted graph, we assess how different events relate to one another, removing logs that do not contribute to understanding the attack. This analysis helps to streamline the pool of data under consideration;
- (3)
- Attack chain construction. In this part, we aim to establish a logical sequence of events leading up to the attack. After decrypting the relevant logs, we standardize data from varied sources like DNS, CPU usage, and firewalls for preprocessing. Then, employing the LCS algorithm, we convert the identification of attack steps into a search for the longest common sequence of conditions. Finally, by matching syslogs with identical timestamps to these conditions, we pinpoint specific events and analyze syslog templates and parameters to uncover attackers’ tactics.
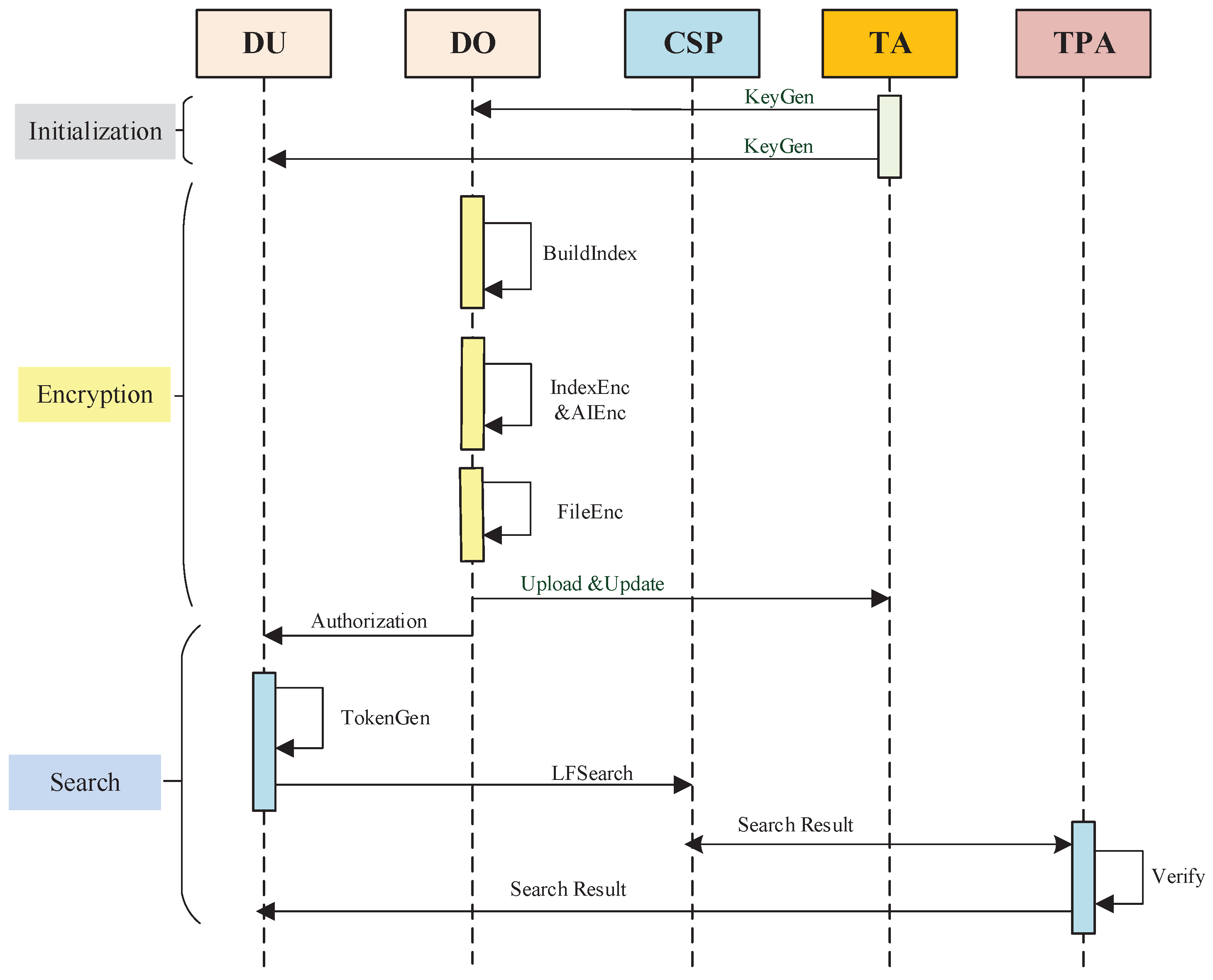
3.1. Fuzzy Multi-Keyword Symmetric Searchable Encryption
3.1.1. Notations and Preliminaries
3.1.2. Search+ Model
3.1.3. Threat Model
3.1.4. Design Goals
- (1)
- Dynamic rank fuzzy multi-keyword search: The proposal should support top-k search result ranking and the dynamic updating feature;
- (2)
- Privacy guarantee: The CSP should be prevented from containing additional information from encrypted logs, secure index, search result, and newly added logs;
- (3)
- Token unlinkability: The CSP should have no ability to infer the relationship between tokens to determine whether they are from the same query, which requires randomized algorithms in tokens and queries;
- (4)
- Multi-user support: The unauthorized DU should not have the same ability as the authorized ones;
- (5)
- Efficiency and accuracy: The efficiency should be at least equivalent to that of the original scheme while achieving improved high ranking accuracy in search results.
3.1.5. Construction
| Algorithm 1 Index Construction |
| Require: D, F, Ensure: 1: for each in F do do 2: 3: for each in do do 4: 5: end for 6: 7: 8: 9: end for |
| Algorithm 2 Index Encryption |
| Require:, Ensure: 1: Divide the index into two parts (, ) with the random vector S of using the following steps. 2: for each in do do 3: if = 1 where S then 4: = = 5: else 6: = + r (r is a random number) 7: = −r 8: end if 9: end for |
3.1.6. Security Analysis
- (1)
- Data Confidentiality: The log files stored in the CSP are encrypted with symmetric key encryption algorithm. Meanwhile, the symmetric key is unknown to the CSP and unauthorized users, which ensures the confidentiality of the log files;
- (2)
- Index and token security: In our proposal, the indexes and tokens are all encrypted with secret key sk, which is kept concealed from the attacker as shown in and . Obviously, it is difficult for attackers to infer additional information from secure indexes and tokens;
- (3)
- Token unlinkability: The token in our proposal is encrypted as in with non-deterministic encryption algorithms. Hence, the CSP cannot obtain for and obtain extra information about permuted by pseudo-random functions. As a result, it is infeasible for the CSP to establish the relationship between two tokens;
- (4)
- Forward Privacy: The CSP cannot obtain more information from encrypted log files or the secure indexes, which means that the CSP has no ability to link the keyword in the newly added log files to any stored encrypted keyword. Moreover, as the CSP cannot obtain search results and establish the relationship between tokens. It also cannot learn whether the newly log files contains any stored encrypted keywords or not;
- (5)
- Multi-user search ability: In our proposal, we use the group key to protect data users’ token and make sure that only authorized data users can generate valid search tokens. Unauthorized data users cannot obtain the group key shared by the data owner and thus have no capacity to generate a satisfactory token. (Assuming that the CSP is not allowed to collude with the data users)
3.2. Plaintext Data Preprocessing
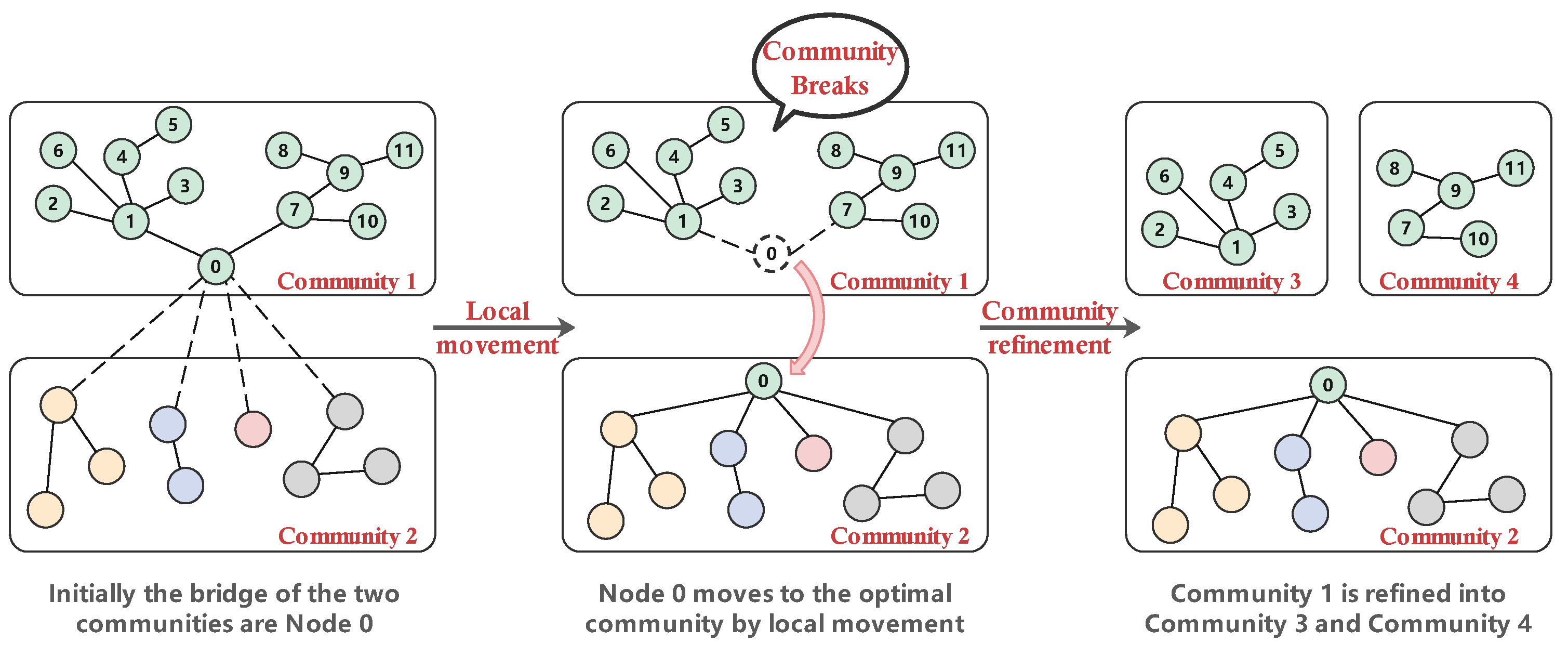
3.3. Log Correlation Analysis
- Neighboring nodes of the node i that are not in its new communities B that have the potential to increase the modularity of the original community A;
- Neighboring nodes of the node i that are in in the new community B. Their removal has the potential to decrease the modularity of the new community;
- Neighboring nodes of community A that have no links to the node i;
- Nodes in community B that have no links to node i.
| Algorithm 3 Local Optimization |
| Require: Ensure: P←INITIAL; L←Queue; while isNotEmpty(L) do ; ; ; for each neighboring node j of i do Cj = community of j; if ∧ then ; ; ; end if end for ; for each neighboring nodes j of i do if j isNotIn C then ; end if end for end while return P |
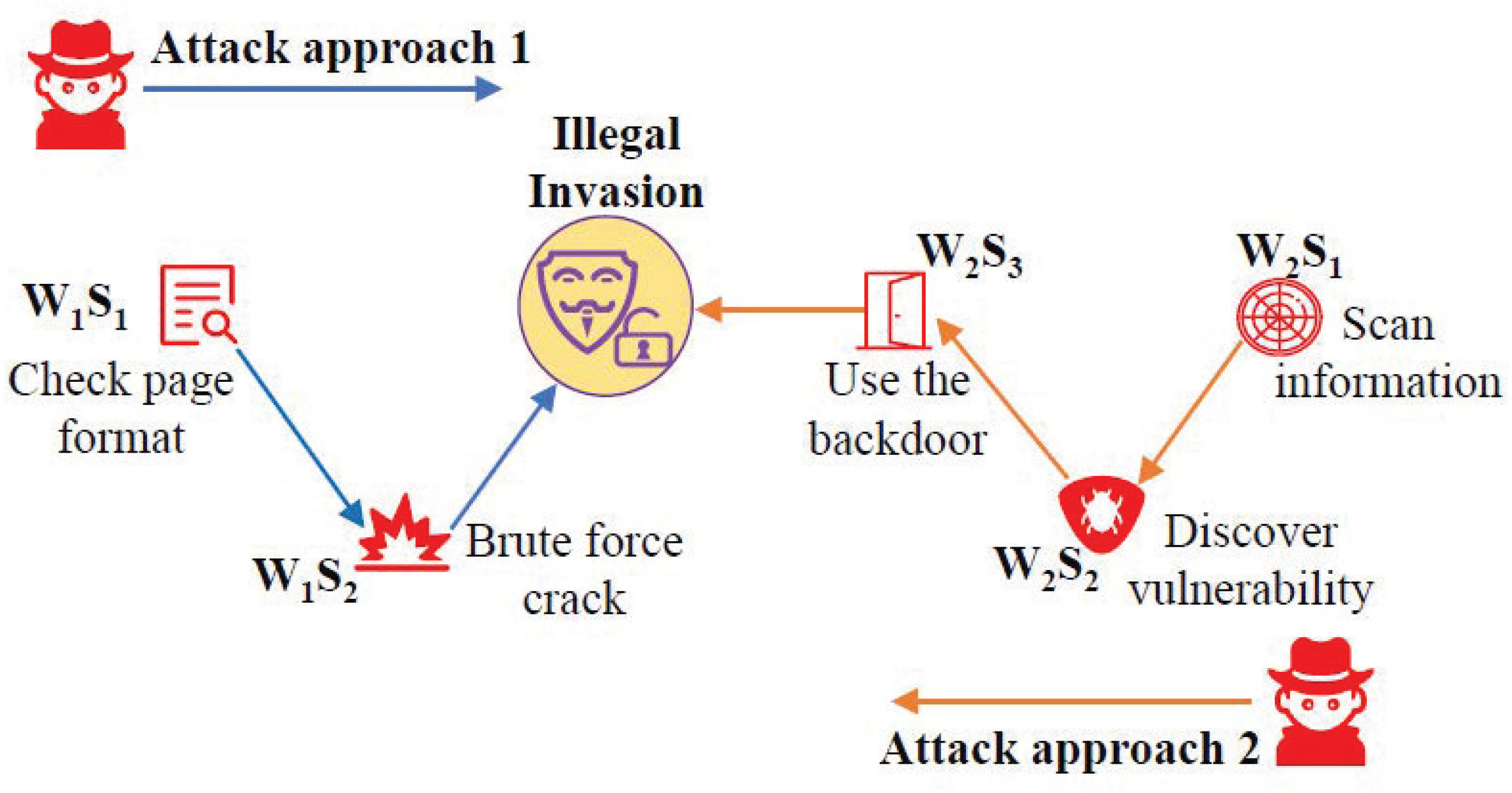
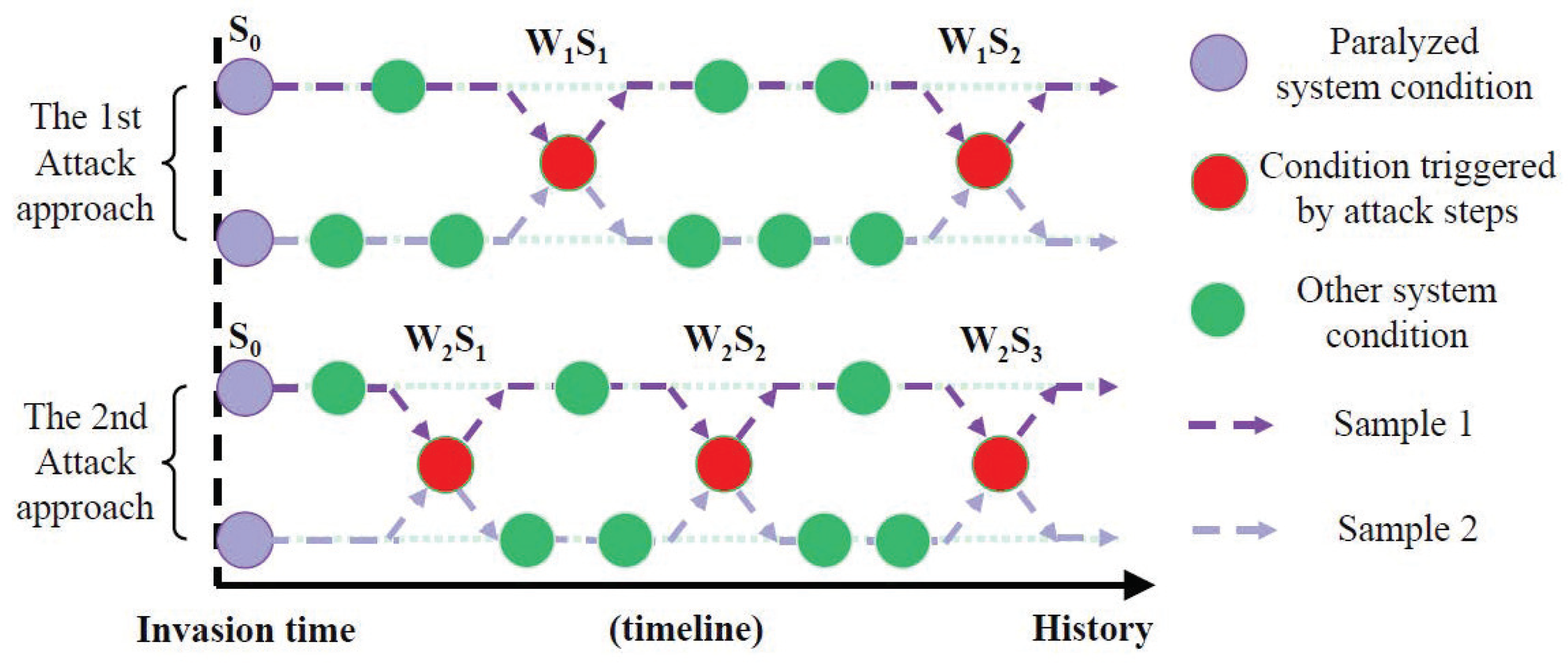
3.4. Attack Chain Construction
3.5. Event Analysis
4. Performance Evaluation
4.1. Performance of Search+
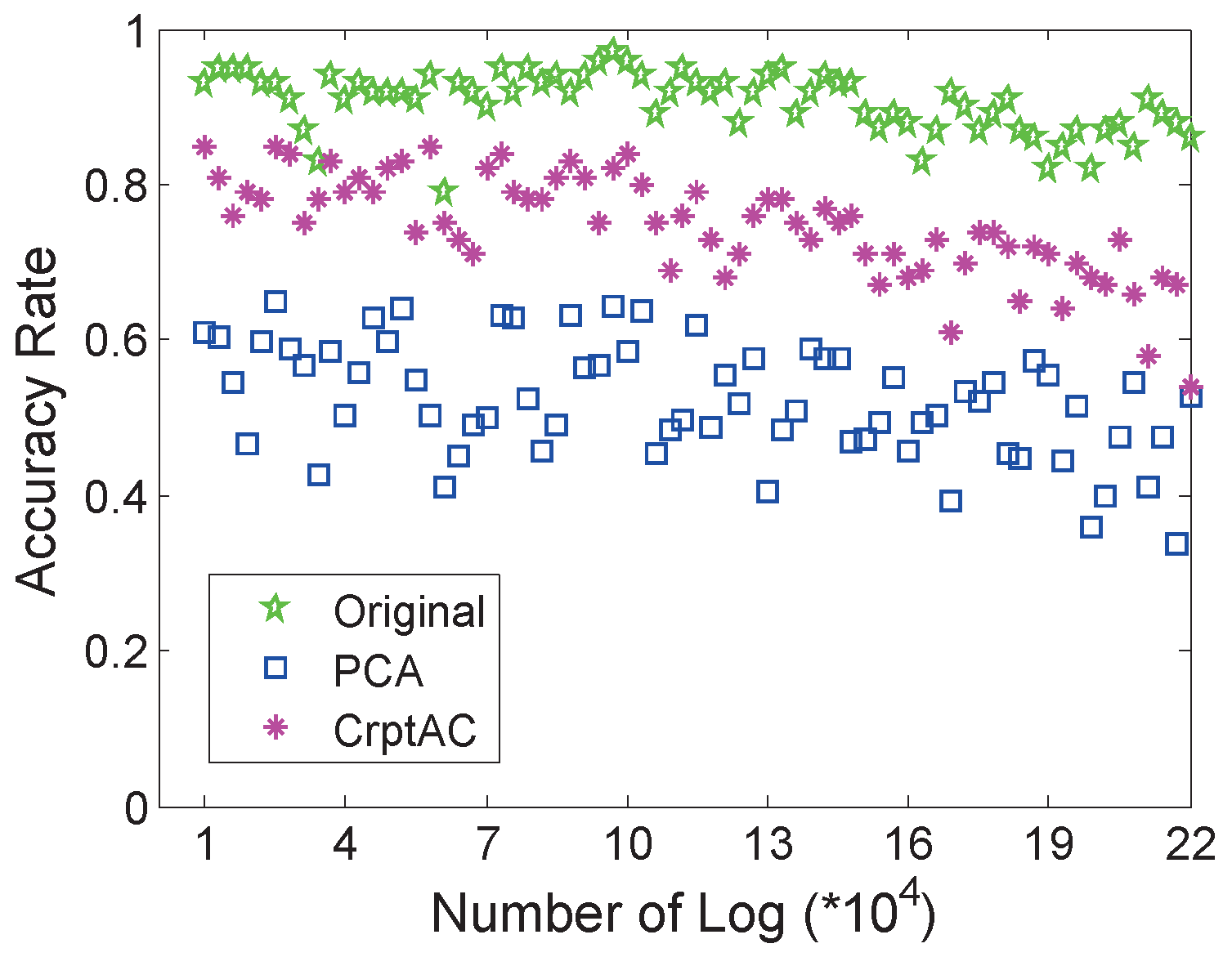
4.2. Performance of Log Correlation Analysis
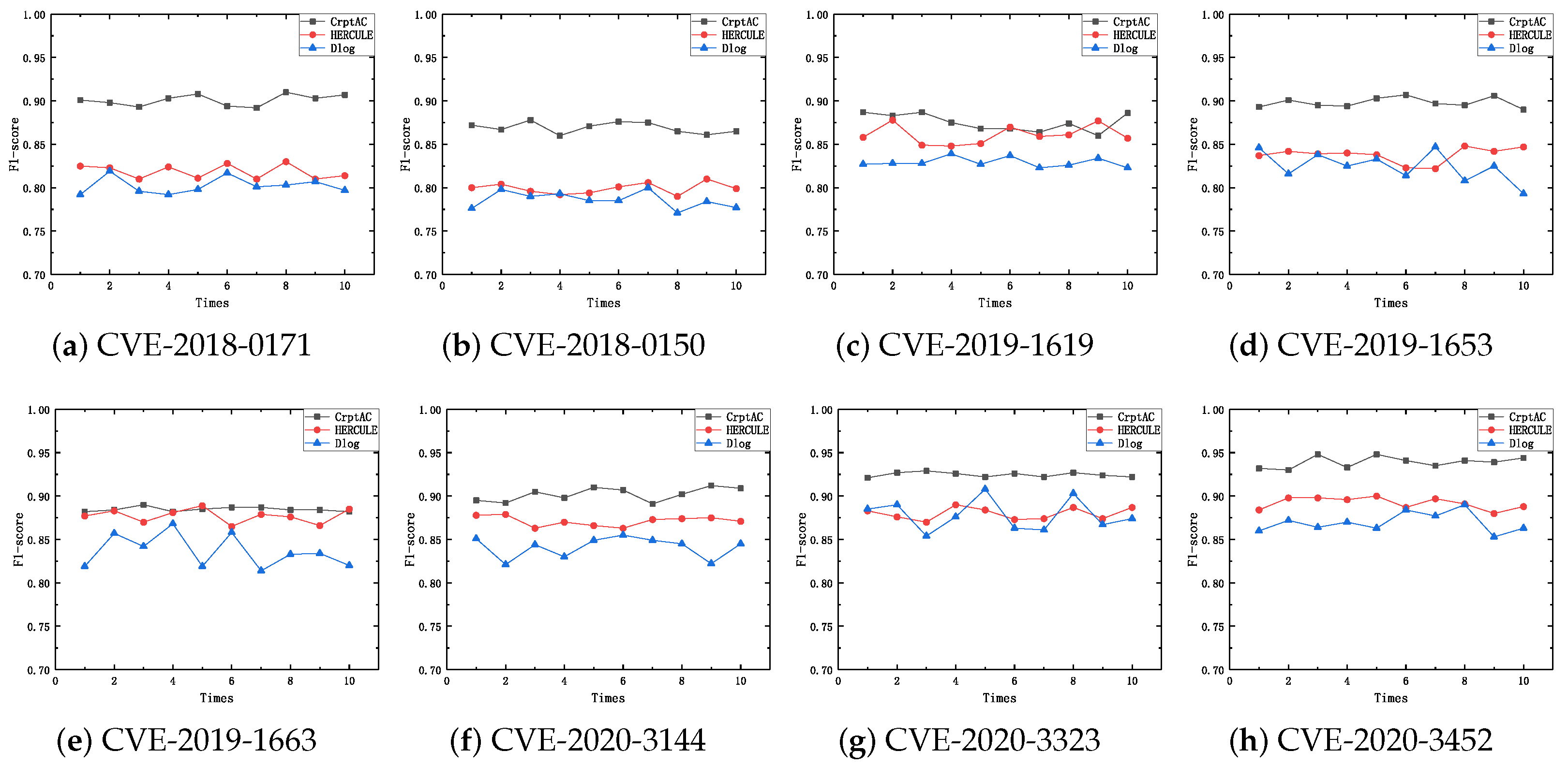
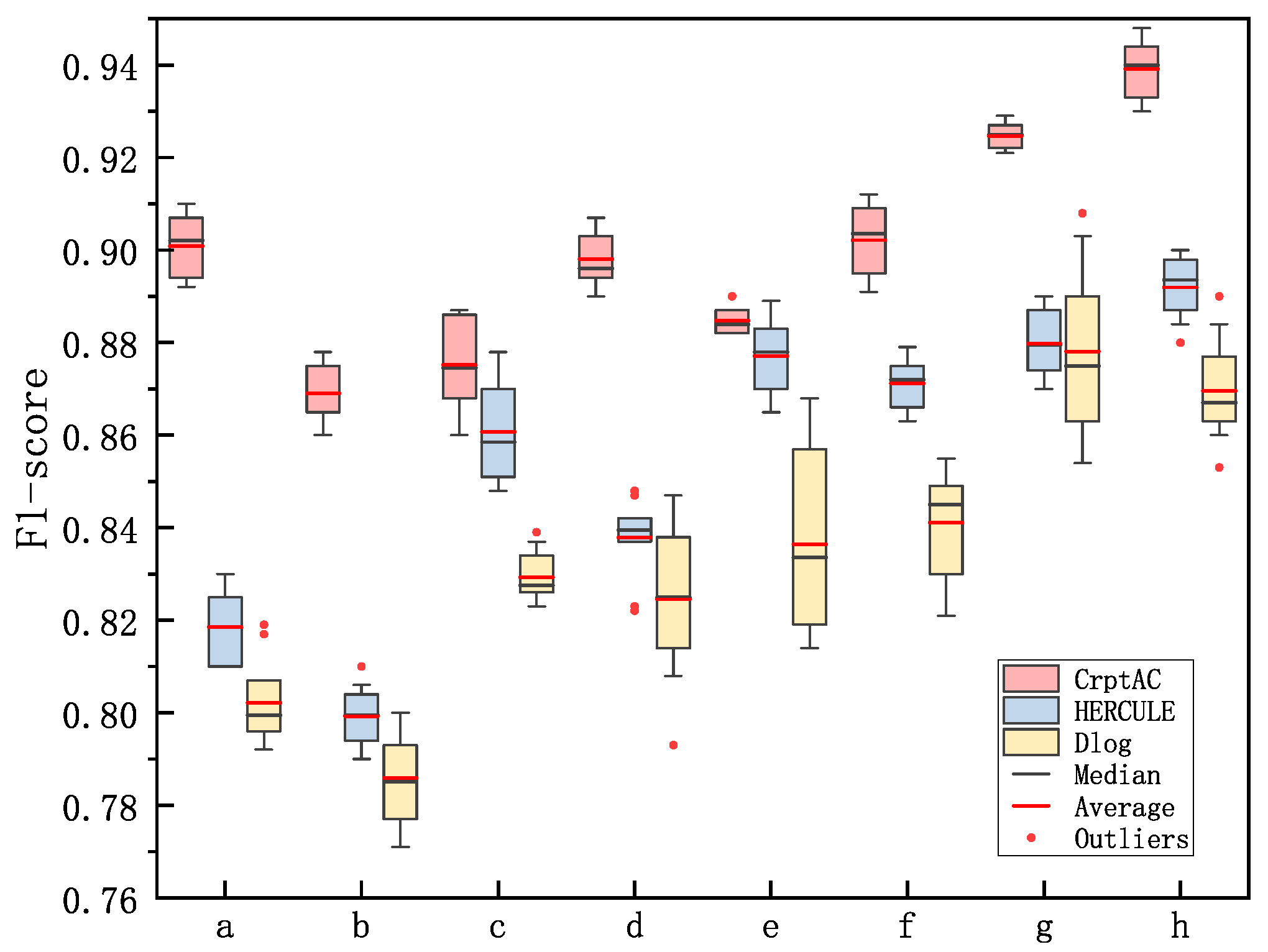
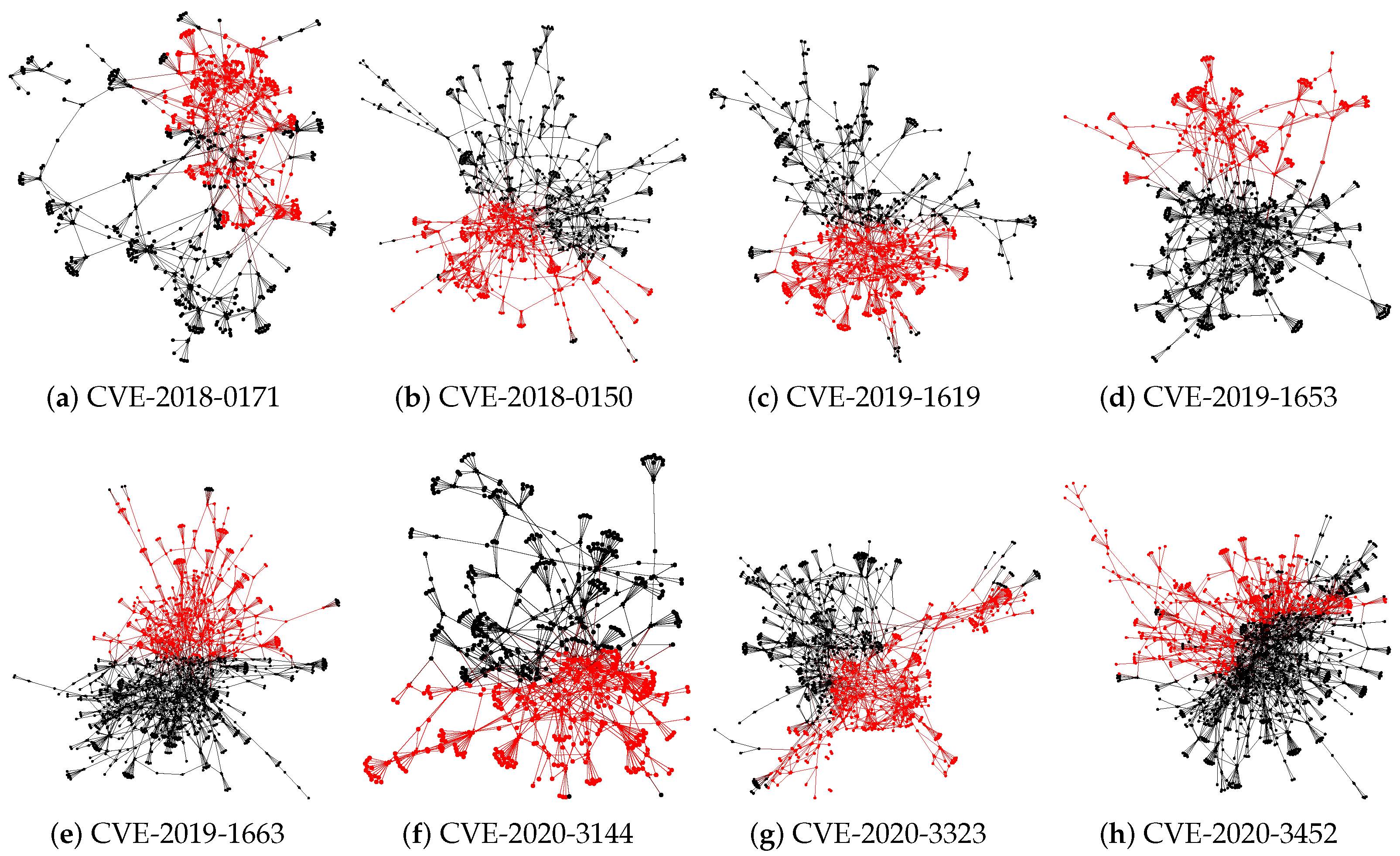
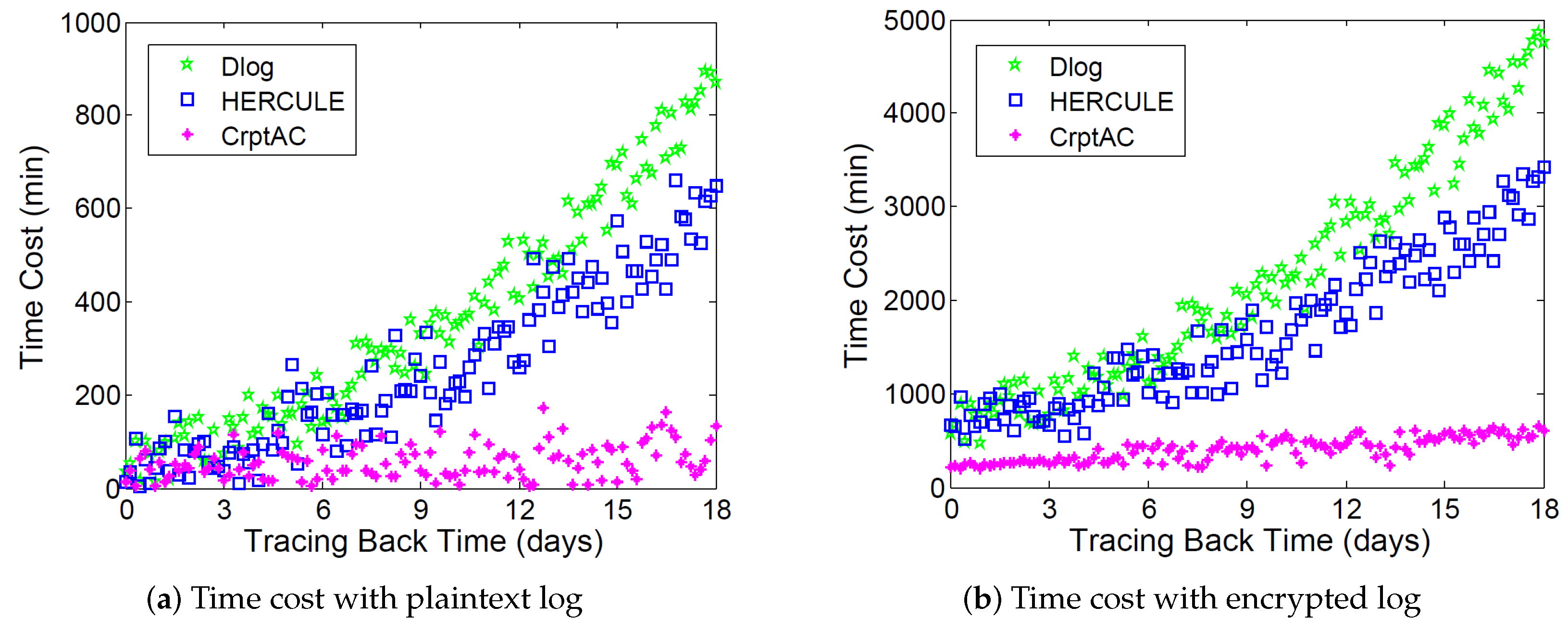
4.3. Performance with Respect to Finding the Attack Chain
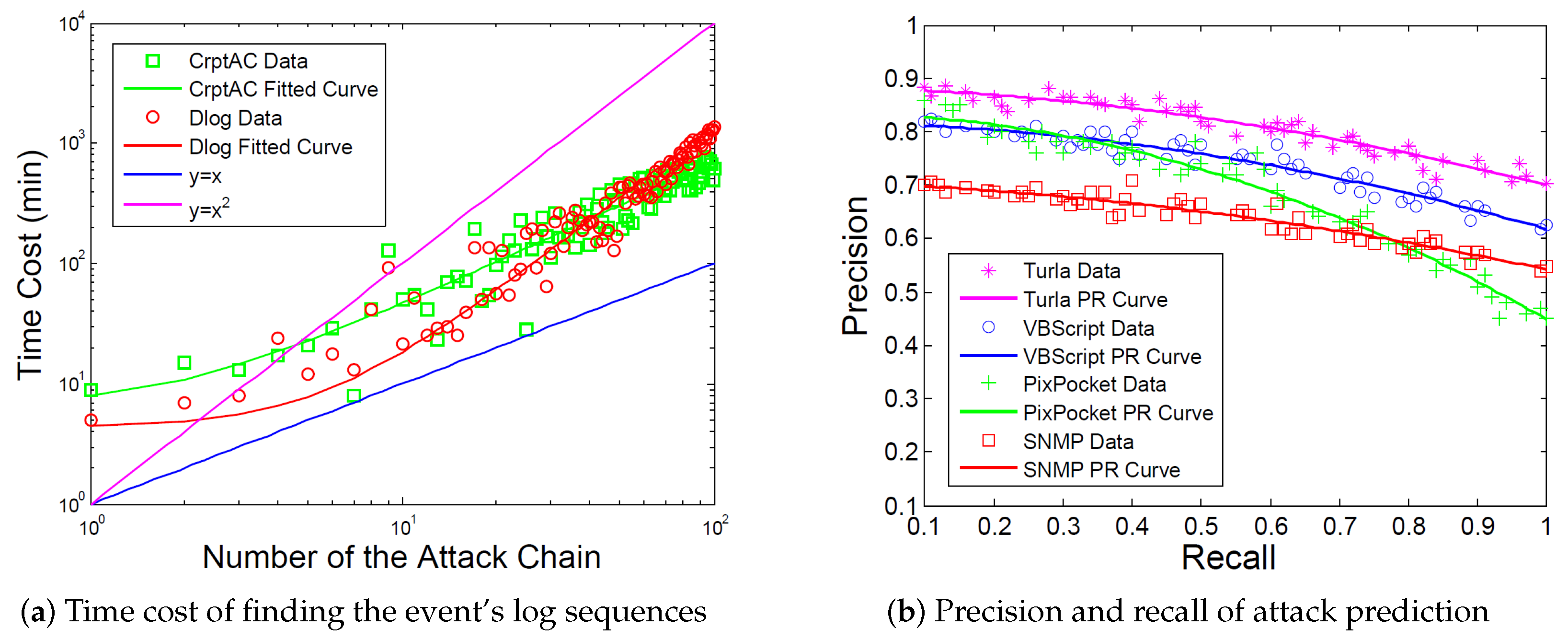
4.4. Performance with Respect to Extracting the Event’s Log Sequences
4.5. Performance with Respect to Predicting the Attack
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, K.; Shi, Y.; Karnouskos, S.; Sauter, T.; Fang, H.; Colombo, A.W. Advancements in industrial cyber-physical systems: An overview and perspectives. IEEE Trans. Ind. Inform. 2022, 19, 716–729. [Google Scholar] [CrossRef]
- Rahman, Z.; Yi, X.; Khalil, I. Blockchain based AI-enabled Industry 4.0 CPS Protection against Advanced Persistent Threat. IEEE Internet Things J. 2022, 10, 6769–6778. [Google Scholar] [CrossRef]
- Xiong, C.; Zhu, T.; Dong, W.; Ruan, L.; Yang, R.; Chen, Y.; Cheng, Y.; Cheng, S.; Chen, X. CONAN: A Practical Real-time APT Detection System with High Accuracy and Efficiency. IEEE Trans. Dependable Secur. Comput. 2020, 19, 551–565. [Google Scholar] [CrossRef]
- Hassan, W.U.; Bates, A.; Marino, D. Tactical Provenance Analysis for Endpoint Detection and Response Systems. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020. [Google Scholar]
- Wang, J.; Yin, X.; Ning, J.; Xu, S.; Xu, G.; Huang, X. Secure Updatable Storage Access Control System for EHRs in the Cloud. IEEE Trans. Serv. Comput. 2022, 16, 2939–2953. [Google Scholar] [CrossRef]
- Yu, L.; Ma, S.; Zhang, Z.; Tao, G.; Zhang, X.; Xu, D.; Urias, V.E.; Lin, H.W.; Ciocarlie, G.; Yegneswaran, V.; et al. ALchemist: Fusing Application and Audit Logs for Precise Attack Provenance without Instrumentation. In Proceedings of the 2021 Network and Distributed System Security Symposium, Virtually, 21–25 February 2021. [Google Scholar]
- Li, T.; Ma, J.; Shen, Y.; Pei, Q. Anomalies Detection and Proactive Defence of Routers Based on Multiple Information Learning. Entropy 2019, 21, 734. [Google Scholar] [CrossRef]
- Hassan, W.U.; Noureddine, M.A.; Datta, P.; Bates, A. Omega-Log: High-Fidelity Attack Investigation via Transparent Multi-Layer Log Analysis; NDSS: San Diego, CA, USA, 2020. [Google Scholar]
- Pei, K.; Gu, Z.; Saltaformaggio, B.; Ma, S.; Wang, F.; Zhang, Z.; Si, L.; Zhang, X.; Xu, D. Hercule: Attack story reconstruction via community discovery on correlated log graph. In Proceedings of the Computer Security Applications, Los Angeles, CA, USA, 5–8 December 2016; pp. 583–595. [Google Scholar]
- Kwon, Y.; Wang, F.; Wang, W.; Lee, K.H.; Lee, W.C.; Ma, S.; Zhang, X.; Xu, D.; Jha, S.; Ciocarlie, G.; et al. Mci: Modeling-based causality inference in audit logging for attack investigation. In Proceedings of the NDSS, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Irshad, H.; Ciocarlie, G.; Gehani, A.; Yegneswaran, V.; Lee, K.H.; Patel, J.; Jha, S.; Kwon, Y.; Xu, D.; Zhang, X. TRACE: Enterprise-Wide Provenance Tracking for Real-Time APT Detection. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4363–4376. [Google Scholar] [CrossRef]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the 2000 IEEE Symposium on Security and Privacy, S&P 2000, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Wang, B.; Yu, S.; Lou, W.; Hou, Y.T. Privacy-preserving multi-keyword fuzzy search over encrypted data in the cloud. In Proceedings of the INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 2112–2120. [Google Scholar]
- Zengy, J.; Wang, X.; Liu, J.; Chen, Y.; Liang, Z.; Chua, T.S.; Chua, Z.L. Shadewatcher: Recommendation-guided cyber threat analysis using system audit records. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; pp. 489–506. [Google Scholar]
- Li, Z.; Chen, Q.A.; Yang, R.; Chen, Y.; Ruan, W. Threat detection and investigation with system-level provenance graphs: A survey. Comput. Secur. 2021, 106, 102282. [Google Scholar] [CrossRef]
- Kimura, T.; Ishibashi, K.; Mori, T.; Sawada, H.; Toyono, T.; Nishimatsu, K.; Watanabe, A.; Shimoda, A.; Shiomoto, K. Spatio-temporal factorization of log data for understanding network events. In Proceedings of the INFOCOM, Toronto, ON, Canada, 27 April–2 May 2014; pp. 610–618. [Google Scholar]
- Kavousi, M.; Yang, R.; Ma, S.; Chen, Y. SemFlow: Accurate Semantic Identification from Low-Level System Data. In Proceedings of the Security and Privacy in Communication Networks; Garcia-Alfaro, J., Li, S., Poovendran, R., Debar, H., Yung, M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning. In Proceedings of the CCS, Dallas, TX, USA, 30 October–3 November 2017; pp. 1285–1298. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. When edge meets learning: Adaptive control for resource-constrained distributed machine learning. In Proceedings of the INFOCOM, Honolulu, HI, USA, 16–19 April 2018; pp. 63–71. [Google Scholar]
- Li, T.; Ma, J.; Sun, C. Dlog: Diagnosing router events with syslogs for anomaly detection. J. Supercomput. 2018, 74, 845–867. [Google Scholar] [CrossRef]
- Li, T.; Ma, J.; Pei, Q.; Shen, Y.; Lin, C.; Ma, S.; Obaidat, M.S. AClog: Attack Chain Construction Based on Log Correlation. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December2019; pp. 1–6. [Google Scholar]
- Hassan, W.U.; Lemay, M.; Aguse, N.; Bates, A.; Moyer, T. Towards Scalable Cluster Auditing through Grammatical Inference over Provenance Graphs. In Proceedings of the NDSS; Internet Society: San Diego, CA, USA, 2018. [Google Scholar]
- Zhu, T.; Wang, J.; Ruan, L.; Xiong, C.; Yu, J.; Li, Y.; Chen, Y.; Lv, M.; Chen, T. General, Efficient, and Real-Time Data Compaction Strategy for APT Forensic Analysis. IEEE Trans. Inf. Forensics Secur. 2021, 16, 3312–3325. [Google Scholar] [CrossRef]
- Zou, Q.; Singhal, A.; Sun, X.; Liu, P. Automatic Recognition of Advanced Persistent Threat Tactics for Enterprise Security. In Proceedings of the Sixth International Workshop on Security and Privacy Analytics, New Orleans, LA, USA, 18 March 2020. [Google Scholar]
- Yang, J.; Zhang, Q.; Jiang, X.; Chen, S.; Yang, F. Poirot: Causal Correlation Aided Semantic Analysis for Advanced Persistent Threat Detection. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3546–3563. [Google Scholar] [CrossRef]
- Gui, J.; Li, D.; Chen, Z.; Rhee, J.; Xiao, X.; Zhang, M.; Jee, K.; Li, Z.; Chen, H. APTrace: A Responsive System for Agile Enterprise Level Causality Analysis. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020. [Google Scholar]
- Fukuda, K. On the use of weighted syslog time series for anomaly detection. In Proceedings of the 12th IFIP/IEEE International Symposium on Integrated Network Management (IM 2011) and Workshops, Dublin, Ireland, 23–27 May 2011; pp. 393–398. [Google Scholar]
- Hu, E.; Fu, A.; Zhang, Z.; Zhang, L.; Guo, Y.; Liu, Y. ACTracker: A Fast and Efficient Attack Investigation Method Based on Event Causality. In Proceedings of the IEEE INFOCOM 2021-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Vancouver, BC, Canada, 10–13 May 2021. [Google Scholar]
- Chuah, E.; Kuo, S.h.; Hiew, P.; Tjhi, W.C.; Lee, G.; Hammond, J.; Michalewicz, M.T.; Hung, T.; Browne, J.C. Diagnosing the root-causes of failures from cluster log files. In Proceedings of the 2010 International Conference on High Performance Computing, Goa, India, 19–22 December 2010; pp. 1–10. [Google Scholar]
- Barre, M.; Gehani, A.; Yegneswaran, V. Mining data provenance to detect advanced persistent threats. In Proceedings of the 11th International Workshop on Theory and Practice of Provenance (TaPP 2019), Philadelphia, PA, USA, 3 June 2019. [Google Scholar]
- Li, Z.; Cheng, X.; Sun, L.; Zhang, J.; Chen, B. A Hierarchical Approach for Advanced Persistent Threat Detection with Attention-Based Graph Neural Networks. Secur. Commun. Netw. 2021, 2021, 9961342. [Google Scholar] [CrossRef]
- Kamara, S.; Papamanthou, C.; Roeder, T. Dynamic searchable symmetric encryption. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh North, CA, USA, 16–18 October 2012; pp. 965–976. [Google Scholar]
- Kim, K.S.; Kim, M.; Lee, D.; Park, J.H.; Kim, W.H. Forward secure dynamic searchable symmetric encryption with efficient updates. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1449–1463. [Google Scholar]
- Bost, R.; Minaud, B.; Ohrimenko, O. Forward and backward private searchable encryption from constrained cryptographic primitives. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1465–1482. [Google Scholar]
- Wang, C.; Cao, N.; Ren, K.; Lou, W. Enabling secure and efficient ranked keyword search over outsourced cloud data. IEEE Trans. Parallel Distrib. Syst. 2011, 23, 1467–1479. [Google Scholar] [CrossRef]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-preserving multi-keyword ranked search over encrypted cloud data. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 222–233. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Yuan, J.; Tian, Y. Practical privacy-preserving mapreduce based k-means clustering over large-scale dataset. IEEE Trans. Cloud Comput. 2017, 7, 568–579. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 10008. [Google Scholar] [CrossRef]
- Ozaki, N.; Tezuka, H.; Inaba, M. A simple acceleration method for the Louvain algorithm. J. Comput. Electr. Eng. 2016, 8, 207. [Google Scholar] [CrossRef]
- Traag, V.A.; Waltman, L.; Van Eck, N.J. From Louvain to Leiden: Guaranteeing well-connected communities. Sci. Rep. 2019, 9, 5233. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yu, X.; Zhao, M. Privacy-preserving ranked multi-keyword fuzzy search on cloud encrypted data supporting range query. Arab. J. Sci. Eng. 2015, 40, 2375–2388. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | [9] | [10] | [18] | [16] | [20] | CrptAC |
|---|---|---|---|---|---|---|
| Ciphertext Search | ✓ | |||||
| Correlation | ✓ | ✓ | ✓ | ✓ | ||
| Provenance | ✓ | ✓ | ✓ | |||
| Training set | ✓ | ✓ | ✓ |
| Notations | Descriptions |
|---|---|
| The file set of all log files | |
| The dictionary of all keywords in F | |
| The encrypted log file stored in CSP | |
| The keyword set in with number s | |
| The file set with keyword | |
| The query with each keyword |
| D | Meaning | Calculation |
|---|---|---|
| The value of cpu utilization | Get from log directly | |
| Rate of increase of cpu utilization | ||
| cpu utilization rank rate | ||
| cpu utilization deviation |
| Attack Name | CVE | Initial Tactics | Post Exploitation |
|---|---|---|---|
| “Cisco IOS Input Validation Error” | 2018-0171 | Buffer stack overflow | Remotely execute system commands |
| “Cisco IOS XE Static Credential” | 2018-0150 | Default account vulnerability | Unauthorized remote access |
| “Cisco DCNM Authentication Bypass” | 2019-1619 | Authentication Bypass | Unauthorized access |
| “Cisco RV320 Access Control” | 2019-1653 | Unauthorized access control | Retrieve sensitive information |
| “Cisco RV110W Buffer Error” | 2019-1663 | Buffer stack overflow | Arbitrary code execution |
| “Cisco RV110W Authentication Bypass” | 2020-3144 | Bypass authentication | Unauthorized access control |
| “Cisco RV110W Remote command execution” | 2020-3323 | Send a specially crafted HTTP request | Arbitrary code execution |
| “Cisco ASA Remote Arbitrary File Reading” | 2020-3452 | Unauthorized directory traversal | Read sensitive files |
| Eigenvalues | Contribution Rate | Cumulative |
|---|---|---|
| 2.73 | 15.4% | 15.4% |
| 2.55 | 14.8% | 30.2% |
| 2.26 | 13.2% | 43.4% |
| 1.94 | 10.6% | 54.0% |
| 1.52 | 9.8% | 63.8% |
| 1.27 | 8.5% | 72.3% |
| 1.01 | 7.9% | 80.2% |
| 0.83 | 7.4% | 87.6% |
| 0.75 | 5.1% | 92.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, W.; Ma, J.; Li, T.; Ye, H.; Zhang, J.; Xiao, Y. CrptAC: Find the Attack Chain with Multiple Encrypted System Logs. Electronics 2024, 13, 1378. https://doi.org/10.3390/electronics13071378
Lin W, Ma J, Li T, Ye H, Zhang J, Xiao Y. CrptAC: Find the Attack Chain with Multiple Encrypted System Logs. Electronics. 2024; 13(7):1378. https://doi.org/10.3390/electronics13071378
Chicago/Turabian StyleLin, Weiguo, Jianfeng Ma, Teng Li, Haoyu Ye, Jiawei Zhang, and Yongcai Xiao. 2024. "CrptAC: Find the Attack Chain with Multiple Encrypted System Logs" Electronics 13, no. 7: 1378. https://doi.org/10.3390/electronics13071378