1. Introduction
Traditional Chinese Medicine (TCM) embodies the unique wisdom of the Chinese nation regarding life, health, and medical treatment [
1]. With rich theoretical knowledge and clinical expertise, TCM holds significant academic and practical value. As an integral part of Traditional Chinese Medicine, TCM has accumulated centuries of abundant experience and knowledge. However, challenges persist in the modernization and intelligent application of TCM, hindering the effective utilization of knowledge and information within the field [
2].
With the development of computer technology and related theories, the reorganization and utilization of TCM knowledge information through advanced modern technology have gained recognition, leading to notable achievements in relevant research. The integration of advanced ontological theories and techniques from the field of computer science into the study of TCM knowledge organization, constructing a Chinese medicine ontology, and achieving the knowledge–based restructuring of Chinese medicine information can provide a foundational data structure for data mining and knowledge discovery in the field of TCM [
3].
In the era of big data, Knowledge Graphs (KGs) serve as crucial data resources for knowledge management and applications, playing a key role in various fields such as semantic retrieval, knowledge inference, decision–making, question–answering, and system recommendations. In 2012, Google introduced the concept of the KG and applied it to search engines [
4]. Since then, the KG has been widely employed in various domains. A Chinese Medicine KG is a structured knowledge base modeling and representing concepts, entities, and relationships in the field of TCM. It aids doctors, researchers, and patients in better understanding and utilizing knowledge in TCM.
The traditional process of constructing knowledge graphs often relies on extensive manual operations and expert knowledge, which can lead to inefficiency and errors when dealing with massive data and complex relationships [
5]. Knowledge graph construction typically involves various methods such as manual construction, automatic construction, and semi–automatic construction. Manual construction involves domain experts manually inputting entities, attributes, and relationships, but this method is time–consuming and labor–intensive, with limited applicability. Automatic construction utilizes information extraction techniques to extract knowledge from structured and unstructured data, but may face challenges in terms of accuracy and completeness. Semi–automatic construction combines manual and automatic approaches, guiding experts through construction using assisting tools or algorithms and achieving certain effectiveness.
Currently, with the development of large language models (LLMs), their application in knowledge graph construction has gradually become a research hotspot. LLMs possess outstanding representation learning capabilities, extracting rich semantic information from text through learning from extensive corpora. Introducing LLMs into the knowledge graph construction process allows for the automated extraction of entities, attributes, and relationships from text, significantly reducing the manual annotation workload, improving construction efficiency, and ensuring accuracy [
6]. Furthermore, LLMs can handle multimodal data, such as text and images, providing support for the richness and diversity of knowledge graphs.
The current developmental status indicates that LLMs are emerging as powerful tools for knowledge graph construction. This is attributed not only to their capability to handle and analyze extensive unstructured textual data but also to their adaptability to specific domains through pre–training and fine–tuning [
7]. This adaptability ensures both the quality of construction and a significant enhancement in the automation and efficiency of the construction process.
The objective of constructing a knowledge graph for TCM is to structurally represent and link entities, relationships, and attributes related to TCM, forming a comprehensive and accurate network of TCM knowledge. Such a knowledge graph can assist healthcare professionals in disease differentiation and treatment, support clinical decision–making, and provide rich data for TCM research. Furthermore, a TCM knowledge graph facilitates the integration of TCM with modern medicine, opening new possibilities for interdisciplinary medical research and applications.
Despite several studies focusing on the construction of TCM knowledge graphs, the field still faces numerous challenges. The primary challenges include the complexity, diversity, and ambiguity of TCM knowledge, which increase the difficulty of accurately characterizing and correlating various types of knowledge. Additionally, given the vast and decentralized nature of the TCM knowledge system, effectively collecting, integrating, and storing relevant knowledge poses a challenging task. Furthermore, ensuring the timeliness and updateability of the knowledge graph is crucial as TCM knowledge continues to evolve and develop [
8].
The literature [
9,
10,
11,
12] commonly employs natural language processing and machine learning techniques for the automated construction of knowledge graphs. However, these studies still face challenges in accurately identifying entities, extracting relationships, and achieving comprehensive coverage of domain knowledge. They heavily rely on significant manual intervention to rectify errors and enhance data quality, leading to an increase in human resource costs. Addressing these limitations, this study aims to enhance the accuracy of the automated extraction process and reduce the dependency on human resources by adopting advanced LLMs and fine–tuning them with domain expert knowledge. This approach is expected to automatically extract high–quality knowledge structures from extensive Chinese medicine text data and effectively transform them into a format suitable for knowledge graph construction, thereby promoting the automation and intelligence of TCM knowledge graph development.
The main contributions of this paper include the following:
- (1)
Adopting LLMs for named entity recognition, utilizing few–shot learning techniques to achieve high accuracy in identification, significantly reducing the cost of manual annotation, and laying a solid foundation for the construction of an accurate Chinese medicine knowledge graph.
- (2)
Constructing a knowledge graph of TCM, which not only contributes to the preservation and dissemination of TCM knowledge but also facilitates the integration of traditional knowledge with modern technology, opening up new possibilities for the innovation and development of TCM.
- (3)
In the experimental evaluation phase, this study systematically validates and assesses the proposed named entity recognition method using real–world Chinese medicine domain text data. Experimental results demonstrate a significant improvement in the efficiency and accuracy of the knowledge extraction process.
2. Related Work
2.1. Construction of Traditional Chinese Medicine Knowledge Graph
A knowledge graph is a semantic network that maps the real world onto the data world, composed of nodes and edges. It can be understood as a semantic network consisting of numerous knowledge points and their interconnecting relationships. Alternatively, it can be simplified as a “multi–relational graph,” encompassing various types of nodes and edges. In a knowledge graph, entities, representing real–world entities, are used to denote nodes, and relationships are employed to express edges, indicating certain connections between different entities. Entities and relationships typically possess their respective attributes.
In 2012, Google first introduced the concept of the knowledge graph and applied it to its search engine. Since the inception of the knowledge graph concept, numerous researchers have undertaken substantial efforts to construct large–scale, high–quality knowledge graphs. Knowledge graphs can be broadly categorized into general knowledge graphs and domain–specific knowledge graphs. In the realm of research, there exist various general knowledge graphs and extensive public knowledge repositories. This paper focuses on a domain–specific knowledge graph, specifically addressing TCM knowledge.
In the field of TCM knowledge, numerous researchers have already constructed relevant knowledge graphs. Cheng et al. developed a medical knowledge graph for stroke [
4]; Wang et al. designed a knowledge graph–based monitoring system for Traditional Chinese Medicine prescriptions [
10]; Yang et al. built a TCM knowledge graph based on Chinese classical texts [
11]; Zheng et al. created a deep learning–based TCM knowledge graph platform, TCMKG [
12]. While these knowledge graphs have significantly contributed to applied research in this domain, most of them are manually constructed by domain experts or rely heavily on unstructured data during integration, resulting in lower accuracy. The data sources for the knowledge graph constructed in this paper come from various online sources, including structured, semi–structured, and unstructured data. Compared to existing knowledge repositories, our graph has a simpler structure, facilitating easier extraction and achieving higher accuracy. Given the limited availability of TCM data for training, which can lead to reduced accuracy, this paper utilizes few–shot LLMs to construct the database, reducing the annotation workload significantly and minimizing human labor.
2.2. Named Entity Recognition
Named entity recognition (NER) refers to the identification and extraction of entities with specific meanings from a given text, typically involving the tasks of determining entity boundaries and determining entity categories or attributes [
13].
In the field of NER, there are mainly four approaches: rule–based methods, statistical–model–based methods, neural network–based methods, and pre–trained–model–based methods.
Rule–based methods utilize predefined rules and patterns to identify entities. For instance, regular expressions can be employed to match strings with specific patterns as entities. The advantage of this approach lies in its simplicity and intuitiveness, but it requires manual rule crafting and may be challenging to cover all possible cases.
Statistical–model–based methods employ machine learning algorithms such as Conditional Random Fields (CRFs) [
14] and Hidden Markov Models (HMMs) [
15] for named entity recognition. Statistical models identify entities by learning the mapping relationship from input text to output labels (entity categories). This approach takes into account contextual information and relationships between features but necessitates a substantial amount of annotated data for model training.
With the rise of deep learning, neural network–based methods have made significant advancements in NER. Models based on Recurrent Neural Networks (RNNs) and Long Short–Term Memory (LSTM) [
16] networks are widely applied. These models can capture context information and sequence relationships, thereby enhancing the accuracy of named entity recognition.
2.3. Large Language Models
Recently, the emergence of pre–trained language models has further advanced the development of NER. Through pre–training on large–scale text corpora, these models can learn rich language representations, including entity information. By fine–tuning specific tasks, pre–trained models can achieve outstanding NER performance. One widely used pre–trained language model based on the Transformer architecture is BERT (Bidirectional Encoder Representations from Transformers) [
17]. Building upon BERT, several pre–trained models tailored for the biomedical domain have been developed to perform NER tasks. For instance, BioBERT is based on BERT and further pre–trained on biomedical data, followed by fine–tuning medical text data for NER [
18]. ClinicalBERT is another model pre–trained on clinical medical text data and fine–tuned for tasks like medical entity recognition [
19]. MedBERT, a domain–specific pre–trained model for the medical field, is based on the Transformer architecture and pre–trained on medical literature and clinical data. MedBERT demonstrates strong performance in medical entity recognition tasks, identifying entities such as diseases, drugs, and treatment methods [
20]. These models have found extensive applications in building knowledge graphs in the medical domain.
GPT (Generative Pre–trained Transformer), as a pre–trained language model, can be fine–tuned or applied to specific domains or tasks to obtain large language models (LLMs) that better understand and generate text in those domains, providing more accurate predictions and generation results. GPT has demonstrated impressive performance in various NLP tasks [
21]. In November 2022, OpenAI introduced ChatGPT [
22] as an extension of GPT–3, one of the state–of–the–art NLP models at that time. ChatGPT has exhibited excellent performance across various NLP tasks.
With the growing interest in ChatGPT among the general public, experts from various fields are exploring its application in their respective domains, aiming to reduce human labor consumption, and the field of medicine is no exception. According to surveys, ChatGPT achieved an accuracy rate of approximately 60% in the United States Medical Licensing Examination [
20]. Ni et al. [
23] investigated the ability of LLMs to comprehend instructions and perform text–structured tasks. They proposed adding a prefix and suffix instruction before inputting text into the LLM to indicate the required information extraction (IE) task. Through testing on different datasets, it was demonstrated that a simple instruction could enable the LLM to perform comparably to other state–of–the–art methods on the dataset. However, despite the promising performance of LLMs on various natural language processing tasks, their performance on named entity recognition (NER) remains lower than supervised baselines. Even with the addition of instructions, the accuracy of the task cannot be guaranteed. This is due to the nature of NER as a sequence labeling task, while LLM is primarily a text generation model. In this study, we address this gap by transforming the sequence labeling task into a generative task that LLMs can easily adapt to [
24]. Specifically, through few–shot prompts, we guide LLMs to annotate relevant entities related to TCM in sentences using the special symbol “【】”.
For large–scale knowledge extraction tasks, it is necessary to rely on the API (Application Programming Interface) of LLMs. The iFLYTEK Spark Cognitive Large Model is a Chinese natural language processing full–stack platform introduced by iFLYTEK, a Chinese tech giant. It is currently the largest Chinese pre–trained language model in the world, with over 1000 billion parameters, covering more than 1000 billion characters of Chinese text data. It possesses powerful general language representation capabilities, performing better than or close to human level on multiple public datasets; it has a rich Chinese knowledge base, significantly outperforming other models on Chinese–question–answering datasets; it has flexible generation capabilities, able to generate various types and styles of Chinese texts according to user needs and preferences, scoring higher than other models on Chinese generation datasets; it also has an open platform and interface.
In the field of Chinese natural language processing, the iFLYTEK Spark Cognitive Large Model has demonstrated superior performance compared to ChatGPT. Specifically, according to the experimental results in
Section 4, this model has shown better application performance in the field of TCM, surpassing the effects of ChatGPT. Moreover, unlike ChatGPT, which requires a fee to access its API, the iFLYTEK Spark Cognitive Large Model offers a free API service, significantly reducing the financial burden of research tasks. In view of the above factors, this study ultimately decided to employ the iFLYTEK Spark Cognitive Large Model to carry out various research tasks.
2.4. Few–Shot Prompting
The burgeoning paradigm of few–shot prompting has increasingly been recognized as a viable strategy to circumvent the dependence on voluminous task–specific training datasets. Distinguishing itself from conventional few–shot learning techniques, which necessitate the fine–tuning of models with scarce supervision [
25,
26], few–shot prompting is a technique applied to support the model through input and output examples. The technique does not require large amounts of training data and the model uses pre–given training to give the desired answer when prompted for output.
Comprehensive studies have corroborated the adeptness of few–shot prompting across a spectrum of disciplines. Notably, within the ambit of natural language processing (NLP), empirical findings have substantiated that the incorporation of elementary yet task–pertinent prompts within input sequences significantly augments the performance of pre–trained language models on designated tasks, obviating the need for additional fine–tuning [
21]. This approach has demonstrated its superiority particularly in scenarios where the procurement of numerous annotated examples is infeasible.
In essence, few–shot prompting presents an innovative and pragmatic solution to the data intensiveness traditionally associated with the training of machine learning models. As research in this area progresses, the potential applications of few–shot prompting are being extended, holding promise for enhanced efficiency and adaptability in a multitude of NLP tasks and beyond.
3. Algorithm Implementation
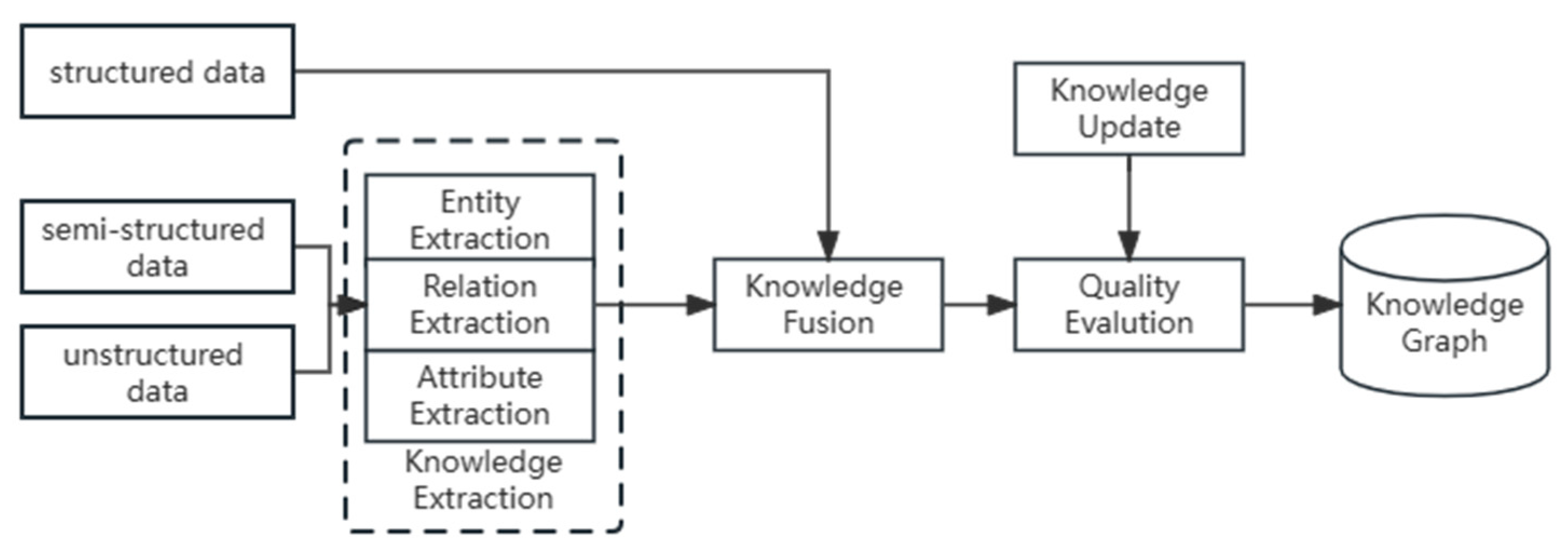
In this section, we introduce the construction process of the TCM knowledge graph, which is illustrated in
Figure 1. The process consists of knowledge acquisition, knowledge extraction, knowledge fusion, and data storage.
3.1. Data Collection and Data Cleaning
Data resources can be categorized into three types based on their structural characteristics: structured data, referring to data conforming to a fixed format and commonly stored in relational databases; semi–structured data, such as tables and lists in web pages, which possess a certain structure but lack standardization; unstructured data, like web page text, which lacks predefined organizational formats.
In the process of constructing the TCM knowledge graph, the main data sources include semi–structured and unstructured data. Specifically, semi–structured data are primarily obtained from Baidu Baike (Baidu Baike_Global Leading Chinese Encyclopedia (
www.baidu.com (16 April 2023))) and Zhongyi Baodian ([Zhongyi Baodian] Complete Collection of Famous Traditional Chinese Medicine Books, Online Reading of Traditional Chinese Medicine Books, Online Learning of Traditional Chinese Medicine (
www.zhongyibaodian.com (16 April 2023))); unstructured data are mainly sourced from web pages related to TCM and TCM on the internet, such as Zhongyi Zhongyao Wang (TCM Online_Traditional Chinese Medicine Network (
www.zhzyw.com (16 April 2023))). We utilize thematic web crawling techniques to obtain TCM–related text data from specified websites and save them in .txt format.
The extraction process for semi–structured data is as follows: The crawler technology crawls the semi–structured data in the information box (InfoBox) in the Baidu Encyclopedia.
Figure 2 shows the InfoBox in Baidu Encyclopedia using “Gardenia” as an example. Starting with the initial page provided, we crawl clickable web pages in a manner similar to breadth–first search. We save the obtained page information as an HTML (Hyper Text Markup Language) file in web format. Subsequently, use the Xpath selector to extract the contents of the InfoBox in the saved web page. We organize the data, including the basicInfo–item name and basicInfo–item value, into an Excel file according to their correspondence. These semi–structured data will be stored in the database as attributes of the entity and together with the entity form a property triplet, such as
.
For unstructured textual data, we view the web page format and use generalized web crawling techniques to access data information of all pages after that by using the breadth–first search strategy, starting from a preset URL (Uniform Resource Locator) and continuously extracting new URLs from the URL queue. This information is then saved as a text file for subsequent knowledge extraction operations.
To ensure that the data obtained met high quality standards, a meticulous data cleaning process was conducted. In this study, data cleaning was carried out according to a series of strict filtering criteria, which mainly consisted of identifying and removing outliers. Outliers in this context mainly refer to possible HTML tags, URL links, special characters, garbled or inconsistently encoded data, and recurring data. The purpose of this data cleaning process is to provide carefully filtered input data for the subsequent knowledge extraction phase, thereby improving the overall data quality.
3.2. Prompt Construction
In this study, we adopt the methodology of few–shot prompting to perform knowledge extraction tasks. The task is divided into three coherent stages: (1) task description: this stage involves the precise articulation and definition of the knowledge to be extracted, informing large language models (LLMs) of the nature of the task at hand; (2) few–shot demonstration: in this phase, by presenting a limited number of examples as guidance, the model is directed to understand the expected output structure and content, with different examples provided according to the task’s specificity; (3) input sentence: the final stage requires the model to generate a structured knowledge output based on the provided input sentences, utilizing the information and framework acquired in the previous two stages. Through this staged approach, we aim to utilize few–shot prompting techniques to achieve effective knowledge extraction using LLMs.
3.2.1. Named Entity Recognition
The prompt structure for named entity recognition comprises three integral components, as delineated below. An exemplification of prompt instances is provided in
Figure 3.
- (1)
Task description.
“Your task is to use brackets “【】” to select the [entity type] entities in the given sentences. Here are some examples:”
In the task of entity recognition, LLMs are required to identify and bracket the entities specified by [entity type] from the provided statements. The [entity type] in this instruction indicates the description of the desired information category. This study involves multiple types of entities, implying that the extraction task needs to be completed through multiple iterations. This process essentially transforms a multi–class classification problem into several binary classification problems.
- (2)
Few–shot demonstration.
To ensure uniformity in the output format of the Large Language Model (LLM) and facilitate subsequent processing, three examples are provided to standardize the input and output forms. The three examples cover three scenarios: (a) the sentence does not contain any specific type of entity; (b) the sentence contains only one specific type of entity; (c) the sentence contains multiple specific types of entities. Each example consists of an input sequence X and the corresponding output sequence Y.
Regarding the output format, if the input sequence X does not contain the target entity, the output sequence Y should directly copy the input sequence X. Conversely, if the input sequence X contains one or more target entities, the special brackets “【” and “】” should be used to annotate the entities.
- (3)
Input sentence.
3.2.2. Matching Prompts Based on Text Similarity
During the NER phase, multiple samples were designed for each prompt category to enhance relevance to the textual content. To achieve effective extraction for seven different entity types, thirty prompt samples were devised for each entity type. Specifically, each set of prompt samples for a given entity type included three different coverage scenarios, with ten samples under each scenario, ensuring a comprehensive evaluation of the model’s performance in various contexts.
In the sample selection process, the Sentence–BERT model [
27] was employed to compute the semantic similarity between the target text and candidate samples in the sample set, determining the most suitable prompt. The Sentence–BERT model utilizes a Siamese network structure to generate fixed–length sentence embeddings rich in semantic information. Subsequently, it employs cosine distance, Manhattan distance, or Euclidean distance measurement methods to calculate text similarity. The model exhibits significant advantages in computational efficiency compared to other models.
3.2.3. Self–Validation
Self–validation is mainly used to verify whether the entity extracted from a given sentence belongs to a particular entity type. An example of a self–validation prompt is shown in
Figure 4.
- (1)
Task description.
“Your task is to verify whether the entity in the given sentence, which is framed with “【】”, belongs to the [entity type]. Here are some examples:” Here, [entity type] refers to the category of the target entity to be determined, such as disease entities in this case.
- (2)
Few–shot demonstrations.
To standardize the output format of LLMs and facilitate the parsing of subsequent data, two example inputs and their expected outputs are provided for each verification. The demonstrations include two scenarios: (a) the provided sentence contains entities that do not belong to the specified entity type; (b) the provided sentence contains entities belonging to the specified entity type. Each demonstration consists of an input sequence X and an expected output sequence Y. Regarding the output format, it is specified as follows: if the entities contained in the input sequence X match the specified [entity type], the output is “Yes”; otherwise, if they do not match, the output is “No”.
- (3)
Input sentence.
The given sentence, entities, and entity types.
3.2.4. Entity Relationship Extraction
Figure 5 exemplifies the process of entity relationship extraction. Specifically, the entity relationship extraction task involves relationship judgment prompts that contain the following components:
- (1)
Task description.
“Your task is to verify whether the given relationship is extracted from the given sentence for the [relation type]. Here are some examples:” The relationship extraction task in this study aims to validate the presence of a specific relationship type in the given sentence. Here, the term “relation type” refers to the specific type of relationship to be verified.
- (2)
Few–shot demonstrations.
To guide the output format of the LLM and facilitate subsequent parsing, we provide two input–output examples. The examples cover two scenarios: (1) instances where two specified entities in the given sentence do not conform to the established relationship type, and (2) instances where two specified entities in the given sentence satisfy the established relationship type. Each example consists of an input sequence X and an expected output sequence Y. In defining the output format, if the input sequence X indicates the existence of the relationship type r between entities e1 and e2, the expected output sequence Y should respond with “Yes”; otherwise, it should output “No”.
- (3)
Input sentence.
The given sentence, entities, and relationship.
3.3. Knowledge Extraction
In the process of constructing a knowledge graph, knowledge extraction is a critical phase aimed at distilling structured information from a vast amount of data, encompassing core elements such as named entities, entity attributes, and entity relationships. The realization of this phase relies not only on cutting–edge natural language processing techniques but also integrates innovative approaches from the fields of deep learning and information extraction to ensure the efficient transformation and processing of unstructured data.
In this study, relevant entities within the field of TCM were successfully identified through named entity recognition techniques. Subsequently, entity relationship extraction methods were employed to reveal the unique relationships among these entities in TCM. Ultimately, by processing semi–structured data, the extraction of relevant attributes associated with the identified entities was achieved, laying a solid foundation for the construction of a knowledge graph rich in domain–specific knowledge.
3.3.1. Entity Normalization
Due to the data collected from various websites, the use of the same entity may have different terminologies. Therefore, entity standardization is needed to map original terms to standard terms and further create entities through the inheritance of standard terms.
This paper focuses on the field of TCM. By consulting the literature, we have established entity types and identifiers within the entity relationship recognition model, totaling seven categories, disease, symptom, drug, prescription, diet, treatment methods, and etiology and pathogenesis, as shown in
Table 1.
3.3.2. Named Entity Recognition
Named entity recognition (NER) refers to the identification of named entities from text and serves as the foundation for information extraction. The results of NER directly impact the outcomes of entity relationship extraction and attribute extraction. In this study, we conducted named entity extraction on the acquired data using few–shot prompts. The specific implementation is shown in
Section 3.2.1.
Figure 3 illustrates the prompt instances used for performing named entity recognition, consisting of three parts.
Table A1 in
Appendix A illustrates instances of errors in NER.
3.3.3. Self–Validation
Due to the challenges posed by hallucination or overprediction issues in LLMs, there is a notable tendency in LLMs for named entity recognition (NER) tasks. Specifically, even when provided with demonstrations, LLMs tend to excessively and overconfidently label empty data as entities [
23,
28,
29]. To mitigate the impact on the results, we designed a self–validation cue to verify that the entity extracted from a given sentence belongs to a specific entity type; the composition of the cue is described in
Section 3.2.3.
Figure 4 shows an example of an extracted disease entity.
3.3.4. Entity Relationship Extraction
Entity relation extraction, as an essential task in information extraction, refers to the extraction of predefined entity relationships from unstructured text, based on entity recognition. The relationships between entity pairs can be formalized as relationship triplets
, where e1 and e2 are entities, and r belongs to the target relationship set
. The task of relation extraction is to extract relationship triplets
from natural language text, thereby extracting textual information [
30]. For the entity relation extraction part, the LLM is used to obtain entity relationships through a question–and–answer format.
This paper involves seven types of relationships between entities, manifestation, category, treatment, administration, composition, dietary therapy, and induction, as shown in
Table 2. The determination of the subject and object of entities in this paper is based on their order of appearance in the text, where the entity that appears first is considered the subject, and the one that appears later is the object.
In the context of entity relationships, this paper adopts an inquiry–based approach. For the entities extracted during the previous step of named entity recognition, for any two entities, e1 and e2, we determine the potential relationship r between these two entities based on their types and the types of subject and object in the eight relationship types.
If r does not exist, no inquiry is made; otherwise, we ascertain whether represents a relationship extracted from the text in the form of a question.
Section 3.2.4 describes in detail the composition and roles of the various parts of the few–shot prompt, and
Figure 5 shows an example used for entity relationship extraction, using relationship judgment as an example.
Table A2 in
Appendix A illustrates instances of errors in entity relationship extraction.
3.3.5. Attribute Extraction
Attribute extraction refers to the task of extracting relevant attributes or features of entities from text. The attribute extraction in this paper primarily derives from semi–structured data found on Baidu Baike and the Chinese Traditional Medicine and Medicinal Herbs website. As shown in
Figure 6, the left side represents the extracted data, while the right side displays the processed results. The format used is as follows:
.
3.4. Knowledge Fusion
After the knowledge extraction process, entity attributes are extracted from structured data, while entities, relationships between entities, and some entity attributes are extracted from semi–structured and unstructured data. Subsequently, entity fusion is performed to eliminate duplicate information and correct any erroneous data that may have occurred during the extraction process. To achieve this, we extract Chinese medicine synonyms pairs from “Classification and Codes of Traditional Chinese Medicine Diseases” and “Clinical Terminology of Traditional Chinese Medicine” to construct a thesaurus. For any two named entities, a search is conducted in the thesaurus, and if matching synonym pairs are found, the two named entities are considered similar. Afterward, the same entity is used to represent these two similar entities.
3.5. Data Storage
In this paper, the processed data are stored in the form of triplets. In the context of constructing a knowledge graph, the ontology and representation of the knowledge graph can be formalized using standardized languages such as the Resource Description Framework (RDF) and Web Ontology Language (OWL). These languages provide a standardized semantic foundation aimed at facilitating knowledge sharing and reuse across applications and platforms. Specifically, the RDF provides a flexible and scalable data model for encoding information, expressing associations between entities and their properties in the form of triplets. The OWL further enhances the expressive power of the RDF, introducing richer modeling primitives and logical constructs to precisely define complex knowledge systems and support automated reasoning.
However, despite the significant advantages of RDF and OWL in terms of semantic interoperability and machine understandability, they may face performance bottlenecks when dealing with large–scale datasets. In contrast, graph databases optimize access efficiency for large amounts of graph–structured data, with a design focus on achieving efficient data storage, indexing, and querying performance. Graph databases represent entities and their relationships through nodes and edges, similar to the data model of RDF, but typically provide more direct methods to support real–time analysis and management of large datasets.
Given the requirements for data processing and retrieval efficiency in practical applications of knowledge graphs, we choose to adopt graph databases as the solution for data storage. Graph databases not only effectively store and manage vast amounts of entity and relationship data but also support complex queries, thereby meeting the demand for high–performance data access in the later stages of knowledge graph applications. Additionally, the selection of graph databases also facilitates future analysis and mining of graph–structured data that may be involved.
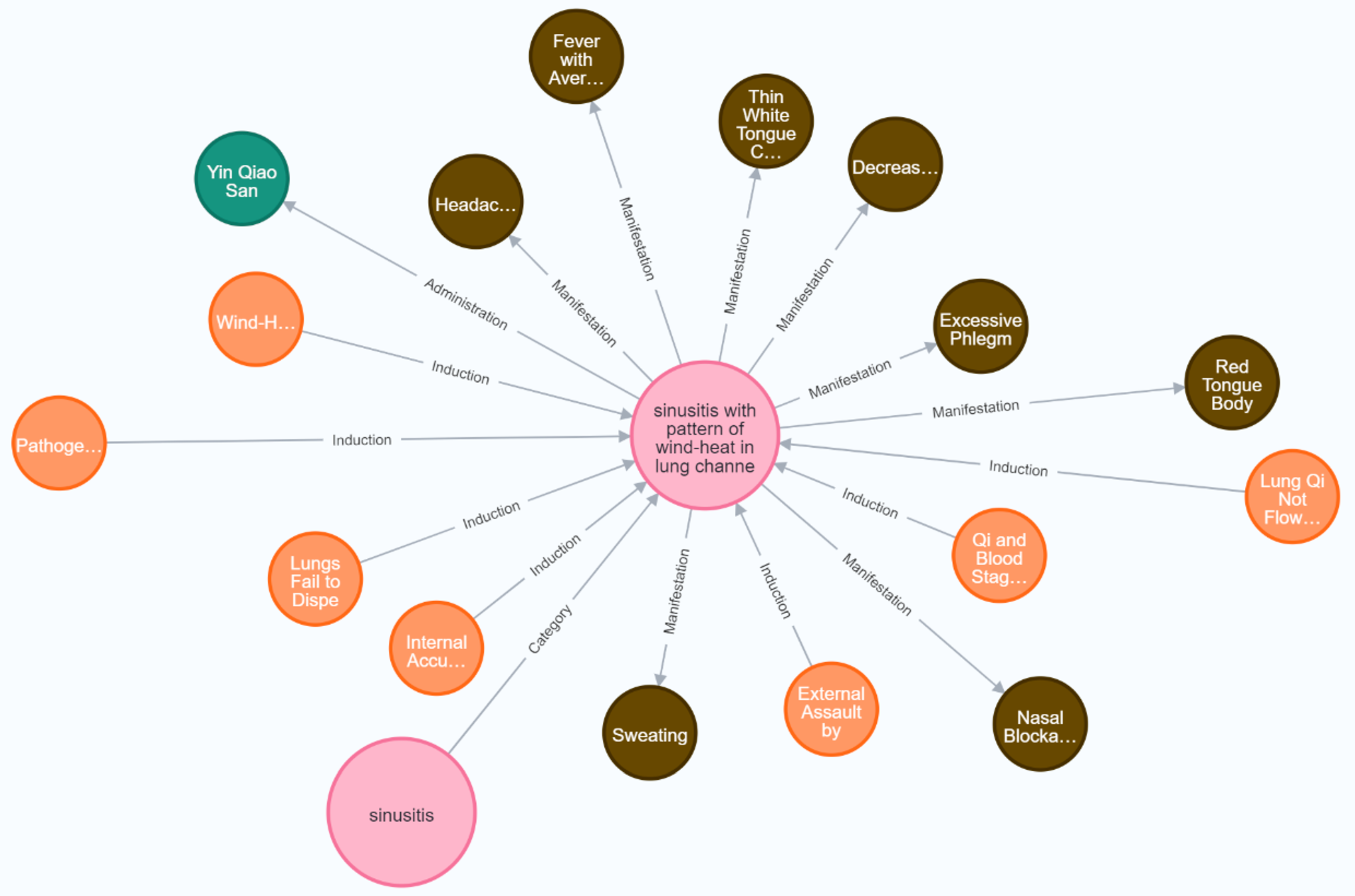
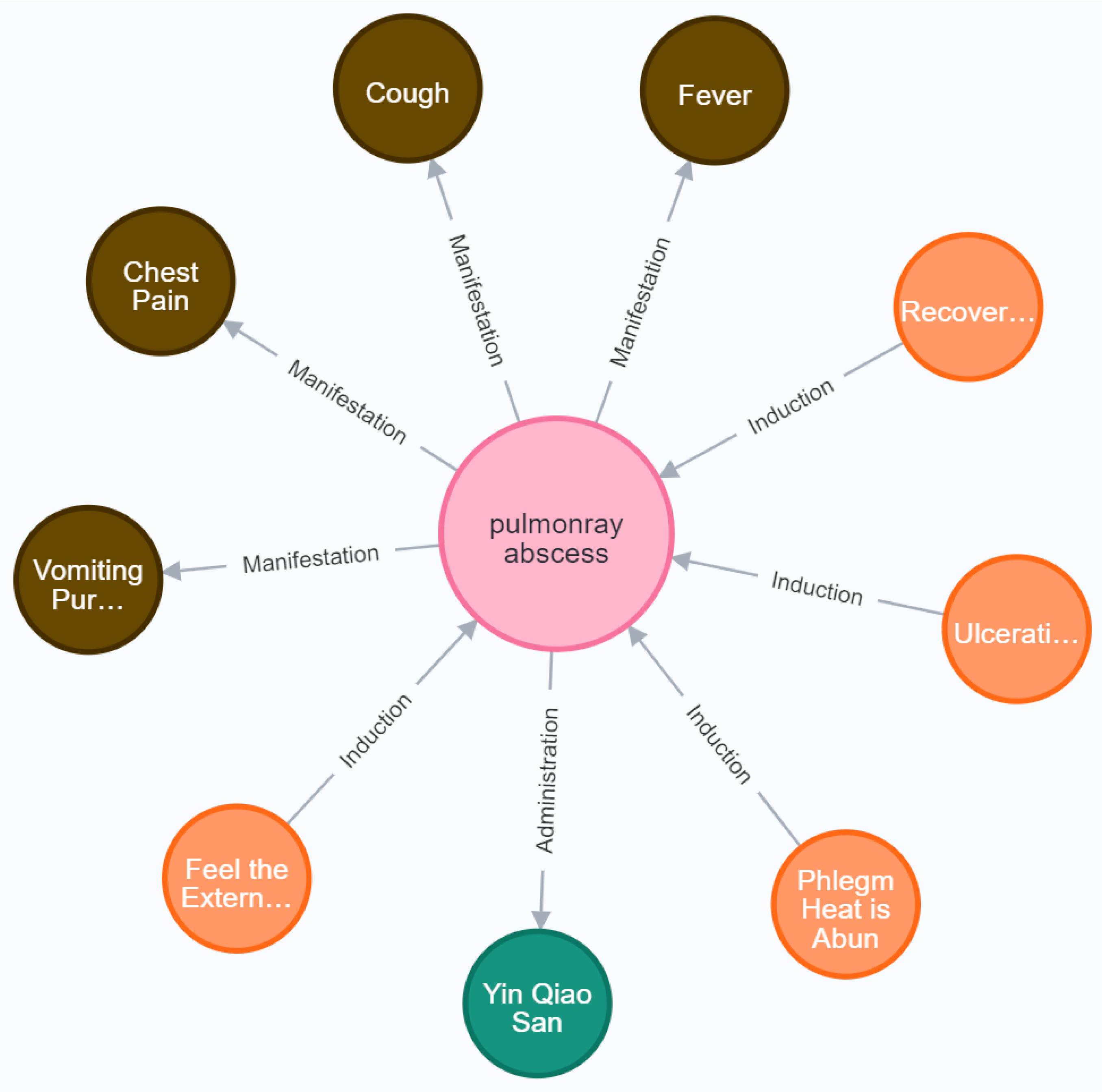
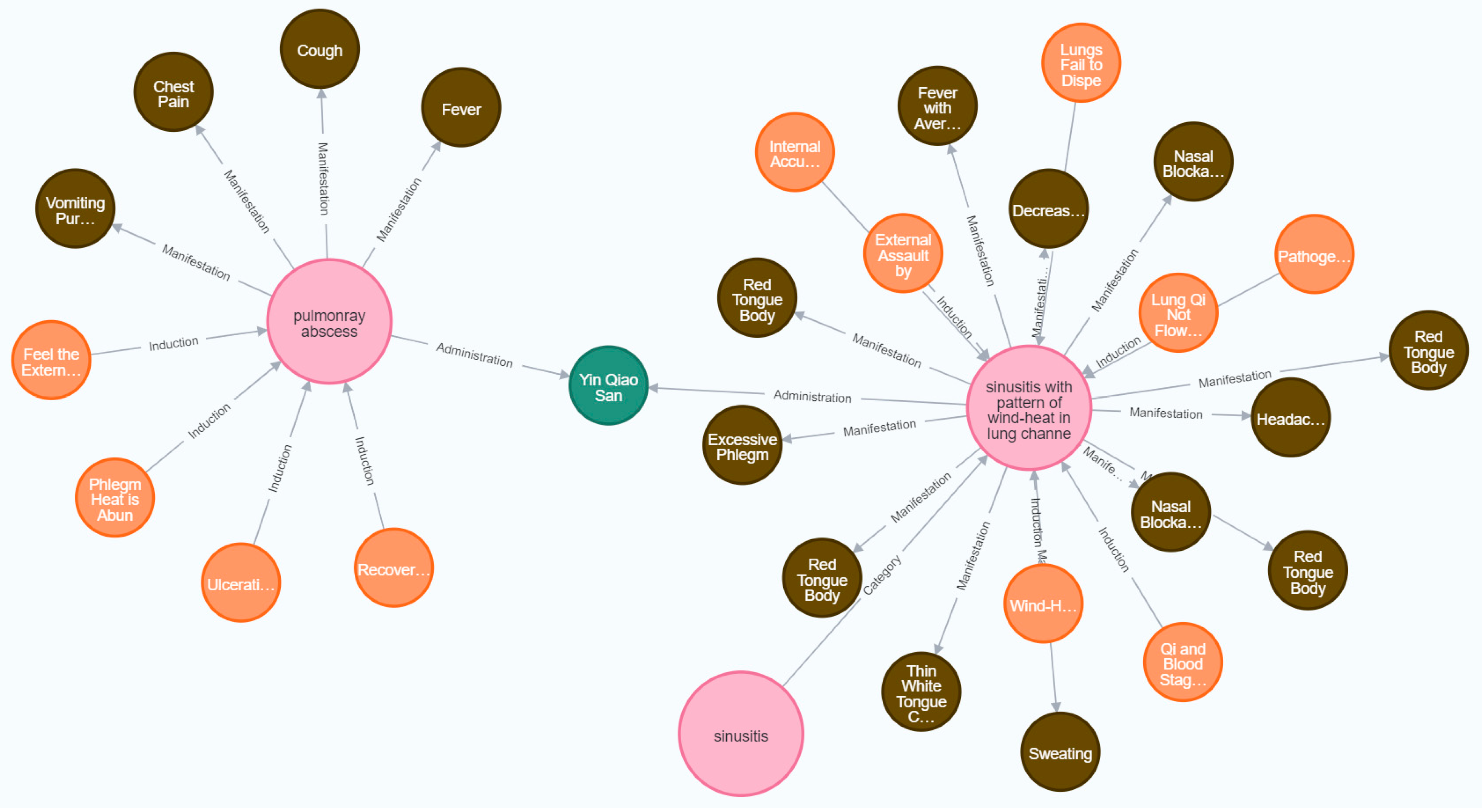
We have chosen the Neo4j graph database for data storage. In the graph, nodes represent entities related to TCM and traditional Chinese herbs. Relationships in the triplets are represented as edges in the graph, indicating some form of relationship between two nodes by pointing from one node to another. These edges point from the subject to the object. Attribute triplets are stored in the graph database in the format .
5. Conclusions and Future Work
The present research proposes a novel approach for constructing a TCM knowledge graph based on the few–shot learning paradigm of LLMs. Initially, this study comprehensively outlines the data crawling process, with a specific emphasis on the strategies employed for acquiring TCM–related textual datasets using web crawling techniques. Subsequently, it provides a detailed exposition of the methods for extracting entities and their relational information from the acquired data. It highlights the key steps in information extraction by integrating large language models and few–shot learning strategies, with a thorough analysis of the advantages of LLMs. In the experimental process, this research utilizes the iFLYTEK Spark Cognitive Large Model, evaluating its performance based on various metrics. Ultimately, this study adopts the Neo4j graph database as the data storage solution, storing extracted entities, attributes, and relationships in triplet form for effective data management and querying. Additionally, the structural aspects of the TCM knowledge graph are visually presented through data visualization methods.
Based on an in–depth analysis of entity relation extraction results, this study observes that across datasets with significant structural characteristics, various classification methods tend to exhibit consistent performance. This phenomenon suggests that traditional classification accuracy, as an evaluation metric, may not fully reveal performance differences among these methods within such specific datasets. Hence, for a more effective assessment and comparison of the efficiency and effectiveness of different classification methods in handling datasets with similar structural properties, future research efforts need to explore and develop more sensitive evaluation criteria.
In light of this, we plan to continuously optimize the knowledge extraction process in our future work, aiming to enhance the accuracy of data extraction. Additionally, we will strive to continually update and improve the database, gradually expanding its scale to provide a more comprehensive and diverse data resource for entity relation extraction.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








