In this section, evaluation indicator results for battery RUL estimation based on the Transformer model with a stacked noise-reducing self-encoder are given and its performance is compared with other state-of-the-art neural network methods such as MLP, LSTM, and Transformers.
4.1. Model Online Validation
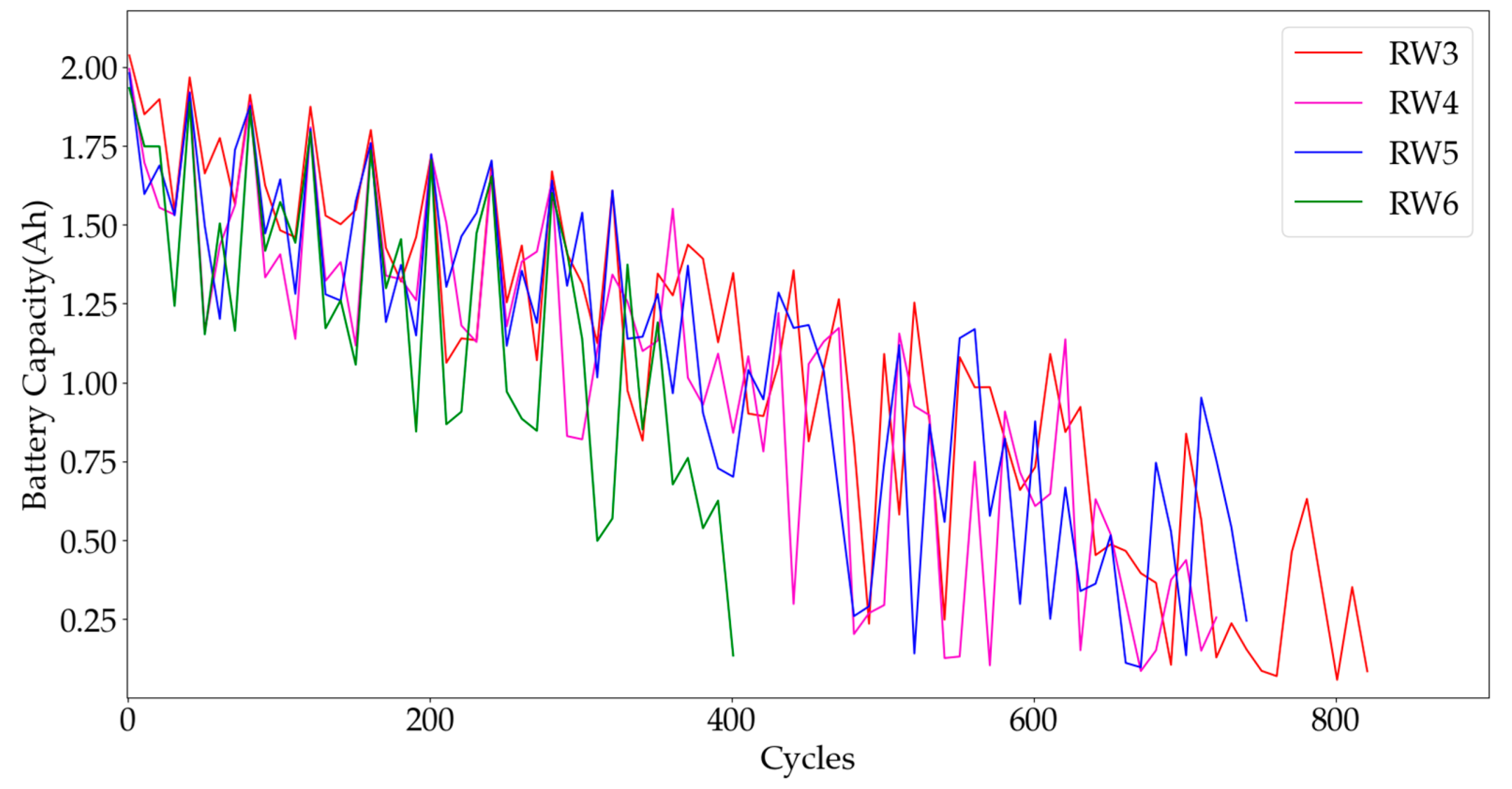
We first validate the overall prediction performance of different batteries with different health factors. We selected a subset of batteries from the datasets and used a cross-validation method to randomly select one battery for testing, while the rest were used for training, and finally predicted the RUL of the batteries. For example, in the first experiment, we used batteries RW4, RW5, and RW6 as training batteries and RW3 as the test battery. The results of the final evaluation metrics (
,
and
) for these four sets of experiments are shown in
Table 4.
According to
Table 4, we can calculate the mean values of the three evaluation indicators of the three health factors:
is 0.170,
is 0.202, and
is 19.611%. The results show that the SDAE-Transformer model has high prediction accuracy and can accurately reflect the actual value. The values of
,
and
are close to each other, indicating that the prediction error of the model is relatively stable with no obvious deviation. As shown in
Table 4, we observed that our model exhibited substantial accuracy and stability across different individual batteries. Our model consistently and accurately predicted their performance. This indicates the strong generalization capability of our model, enabling it to adapt to diverse individual batteries. Furthermore, we observed minimal discrepancies between the model’s predictions and the actual data. This implies the model’s adeptness at capturing the performance characteristics and variation trends of the batteries, thus facilitating accurate predictions.
In battery prediction experiments based on different health factors, our optimization model similarly made equally accurate predictions for each battery. The results show that the SDAE-Transformer model is proficient in extracting key features from different health factors and effectively integrating these features to comprehensively analyze the RUL status of the battery. The SDAE-Transformer model effectively captures the nonlinear relationship between battery capacity and various health factors. In addition, it extracts valuable temporal information from the capacity sequences for accurate prediction.
By comparing and analyzing the predictive evaluation metrics of the three health factors in
Table 4, we can draw the following conclusions: (1) The values of all evaluation metrics for H
2 are higher than those for H
1, possibly due to H
2 being extracted based on random discharge, which more accurately reflects the battery’s health status under random discharge conditions. This also demonstrates that our model is more suitable for predicting battery remaining life in random states and can provide higher prediction accuracy. (2) Among the three health factors, H
3 has the best predictive performance with the smallest values of
,
, and
. This indicates that H
3 possesses the superior capability to accurately predict the battery’s health status. When a singular set of feature sequences is presented to the network, the model may encounter challenges in accommodating the diverse fluctuations within these sequences, consequently constraining its predictive capability. In order to enhance precision, we integrate supplementary feature sequences to capture the battery’s dynamic changes. This allows us to establish global dependencies between different positions, successfully achieving the interaction of global information.
4.3. Comparison with Other Advanced Methods
In order to validate the efficacy of the proposed SDAE–Transformer model, it was extensively compared with other data-driven approaches such as LSTM, MLP, and the Transformer.
MLP [
32]: It is a feedforward neural network with simpler connectivity. With multiple fully connected layers, it is used to learn the dynamic and nonlinear degradation trends of the battery.
LSTM [
33]: It is a temporal recurrent neural network that solves the long-term dependency problem present in general RNNs for learning degradation trends from input sequences.
Transformer [
17]: It is a deep learning model based on the attention mechanism, which utilizes the self-attention mechanism to capture the dependencies between the positions in the input sequence, thus enabling the modeling and processing of sequence data.
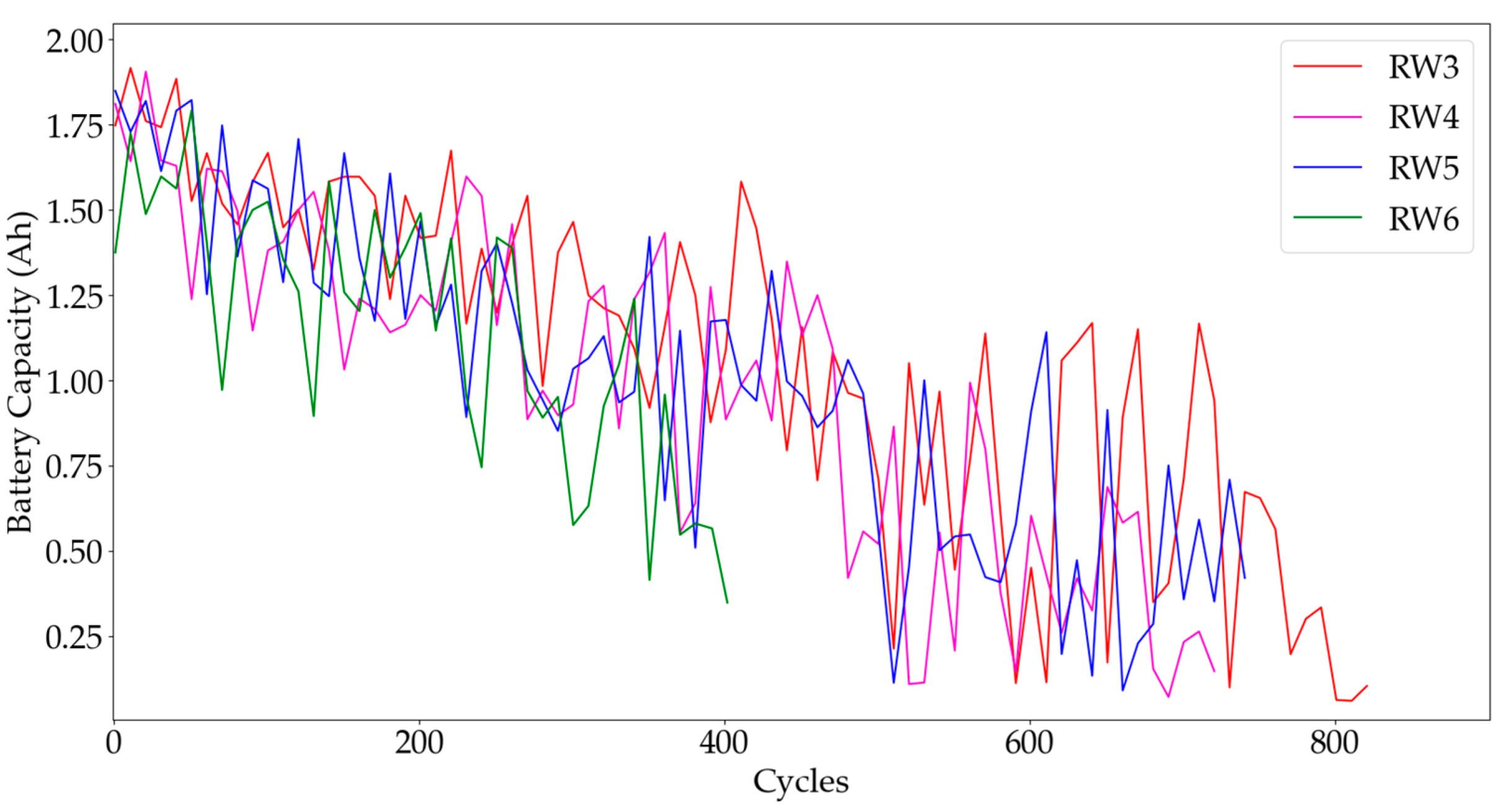
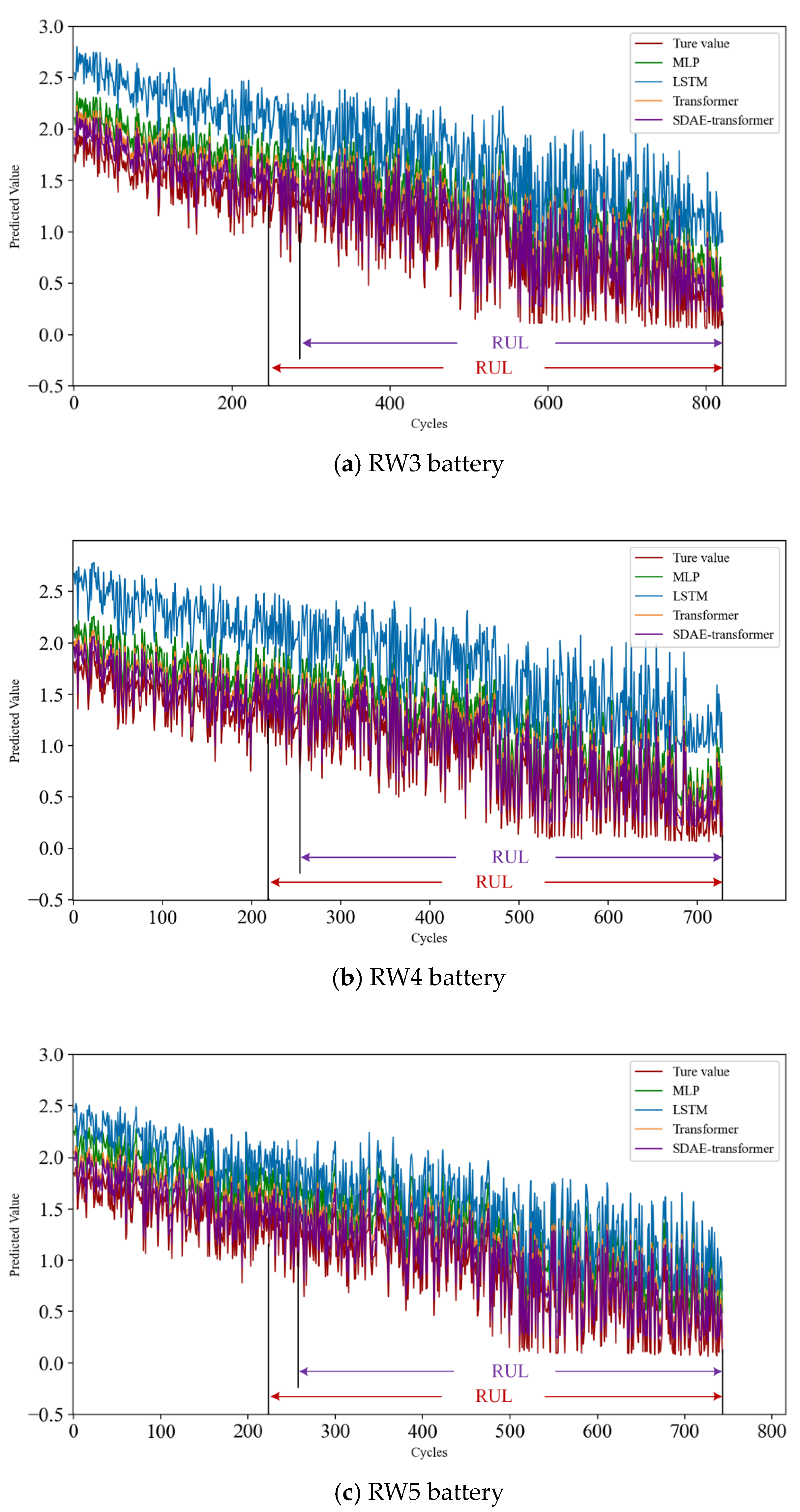
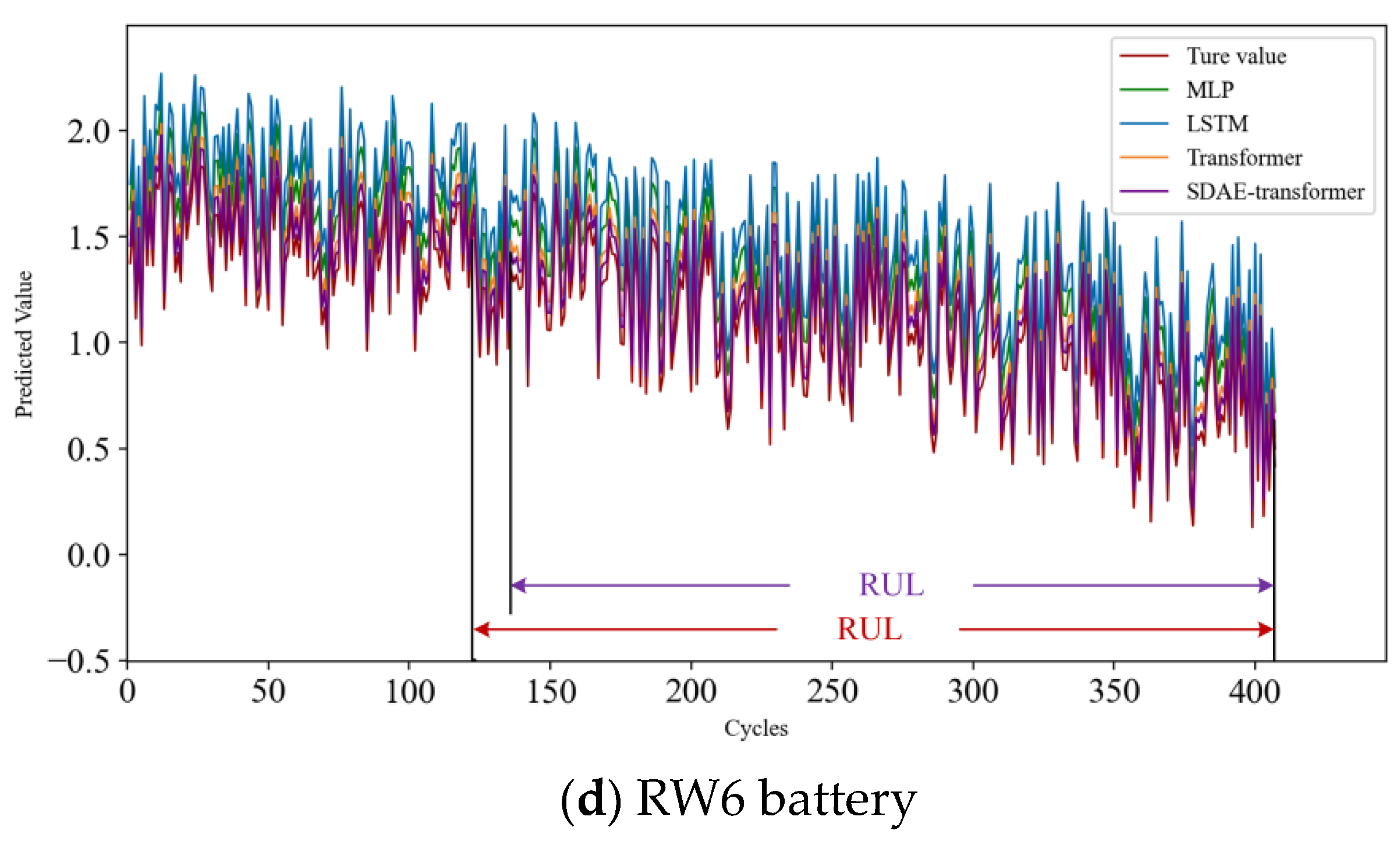
Figure 9 illustrates the predicted values versus H
3 health factor curves for the four models.
Figure 9 shows that comparing the predicted and H
3 curves, the SDAE-transformer model has the best performance and is closest to the actual values. This is attributed to its combination of SDAE and Transformer characteristics, enabling better learning and feature extraction of the battery RUL, thereby improving predictive accuracy. On the other hand, LSTM had the largest error. This may be due to the large datasets and high noise, making it difficult for LSTM to effectively capture complex long-term dependencies, resulting in significant prediction errors. The Transformer-based models exhibited reduced prediction errors as a result of the self-attention mechanism’s capacity to capture long-range dependencies within the sequence data. This enhancement contributed to improved predictive accuracy for RUL. In general, the models we proposed have shown superior predictive capabilities and greater precision in handling battery datasets that contain a substantial amount of noise and outliers. These findings highlight the effectiveness of our models in dealing with challenging data scenarios.
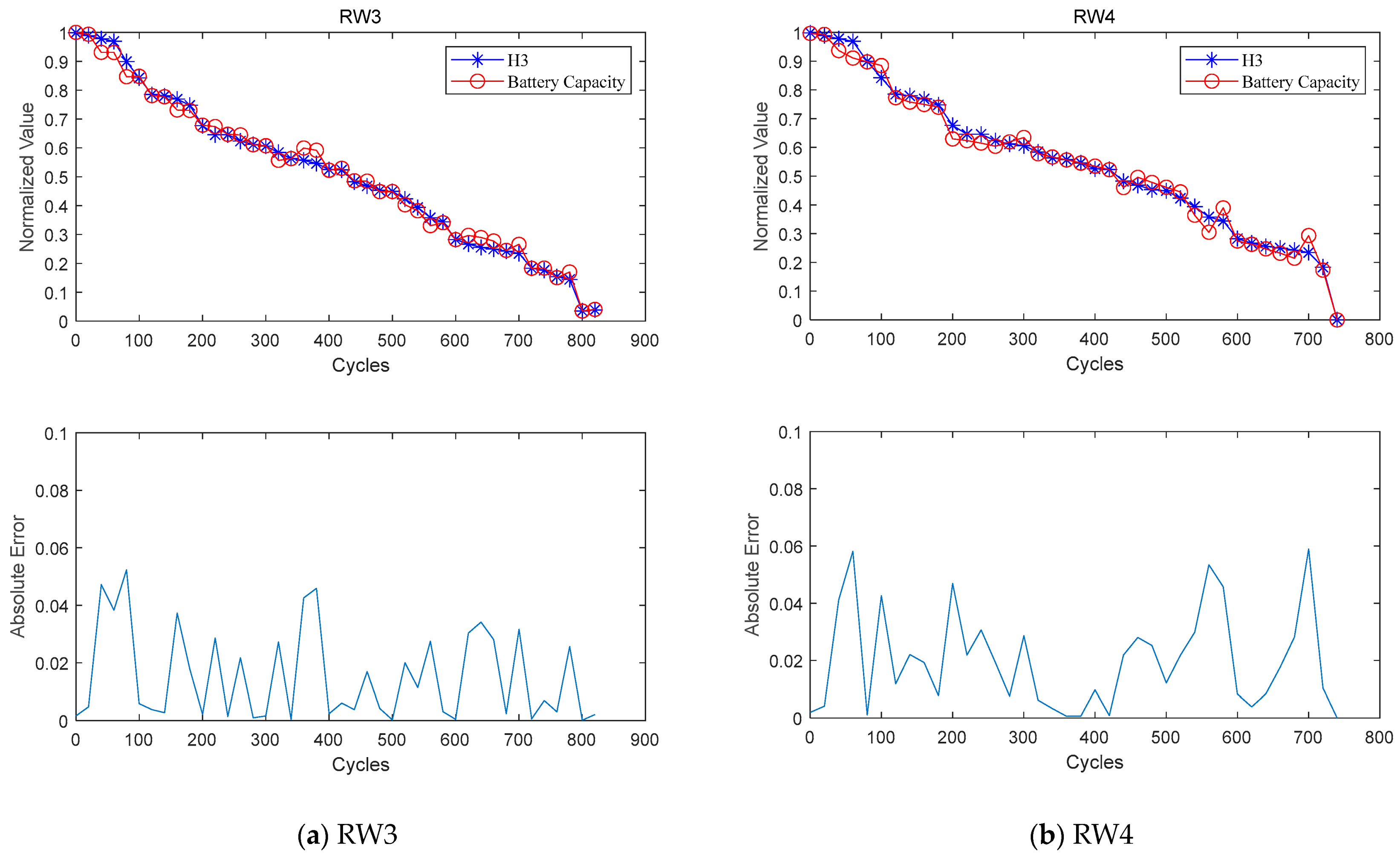
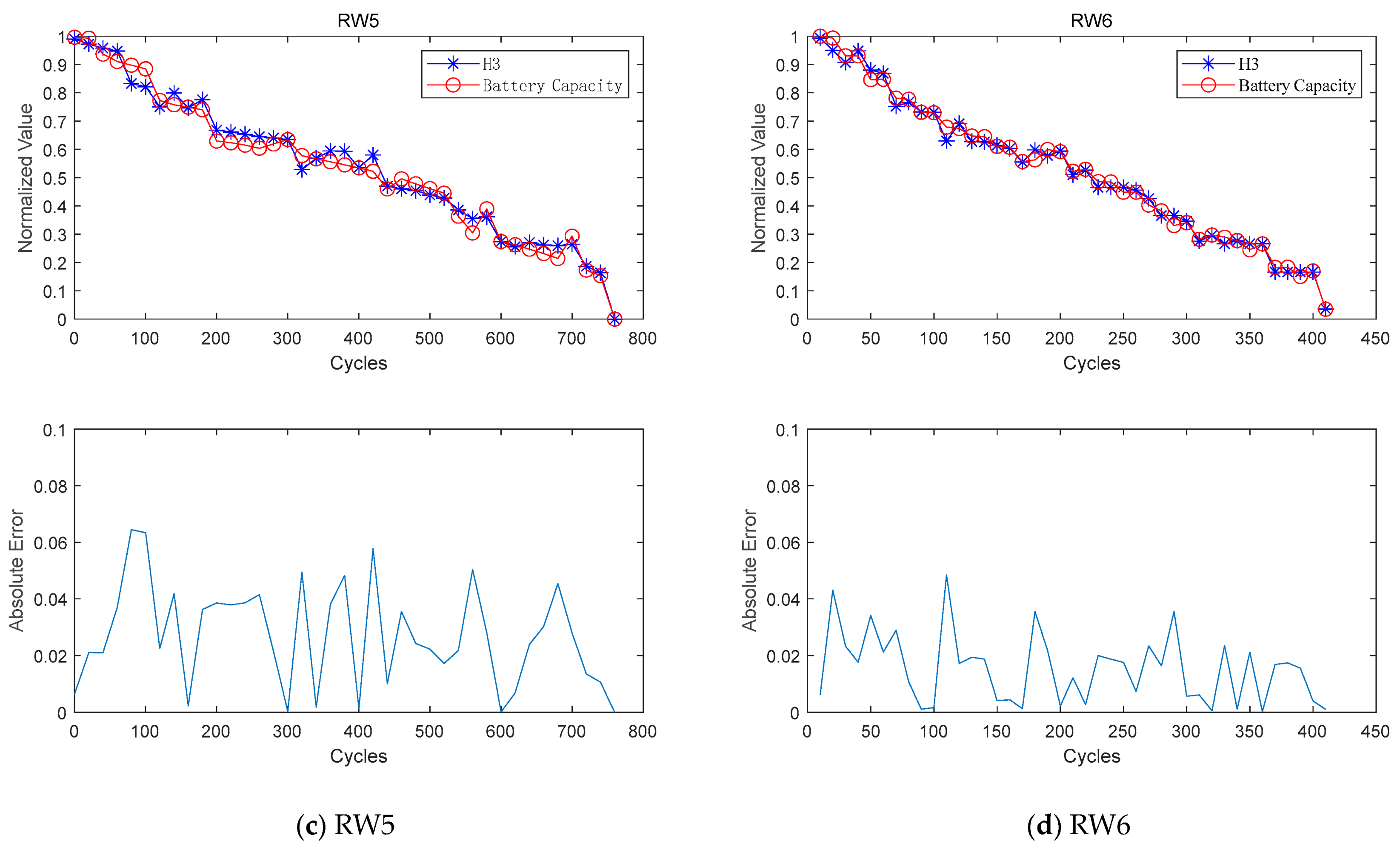
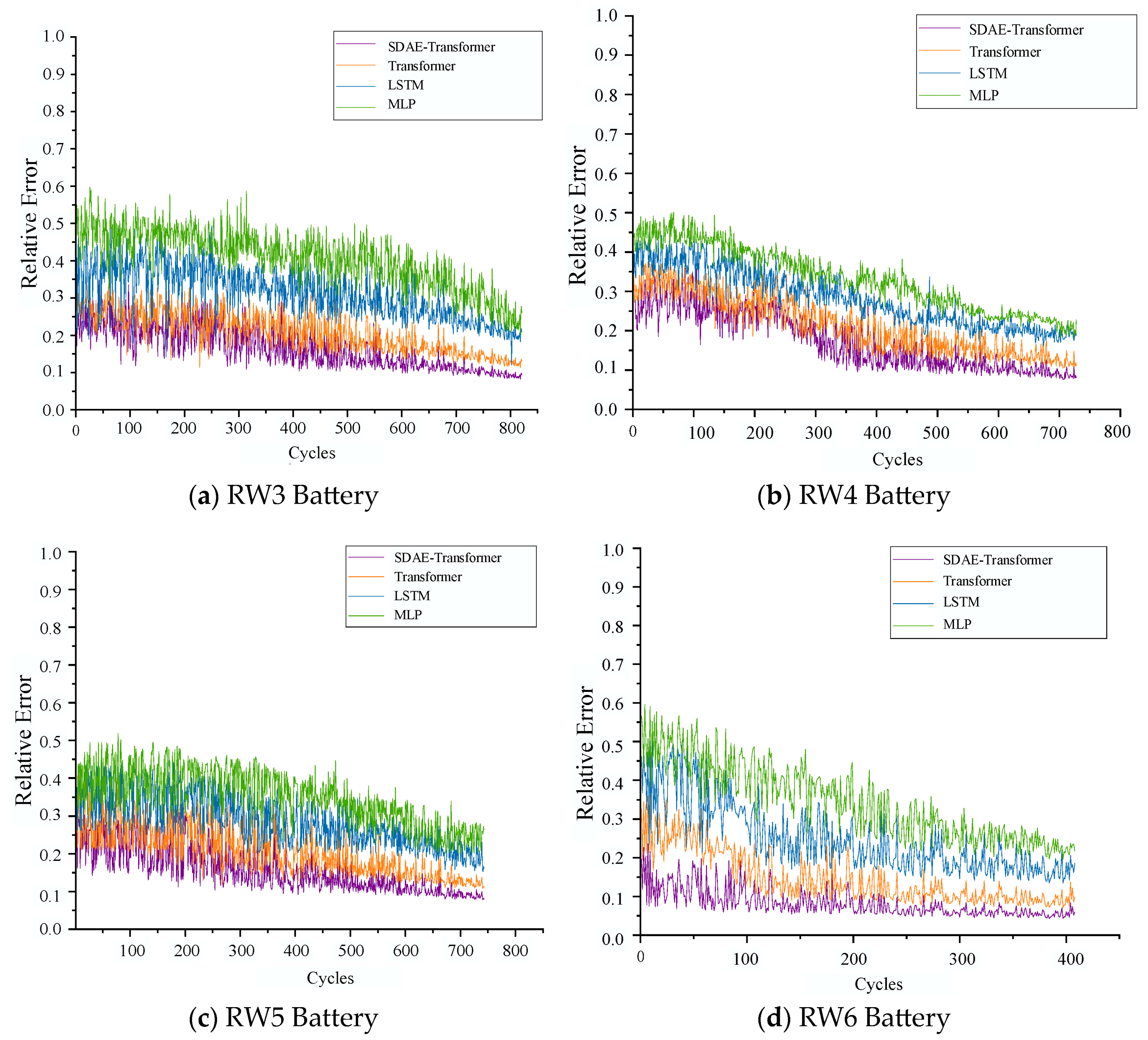
Figure 10 shows the RE results for the four batteries with the four different methods. The curves shows that the improved model achieves the lowest RE value in the predictive experiments for all four batteries, while the MLP model exhibits the highest RE value. Notably, the RE prediction curves during the early stages of the experiments exhibit varying degrees of fluctuation. This observation can be attributed to the limited historical data available and the insufficient understanding of the intricate and nonlinear degradation patterns exhibited by lithium-ion batteries in the initial phases of their lifespan. These factors can introduce inaccuracies in the predictions and result in noticeable fluctuations in the curves. Additionally, the collection of data under random discharge conditions can introduce noise and uncertainty, influencing capacitance measurements and data recording. As the model accumulates more data and gains experience, its understanding deepens, leading to improved prediction accuracy and stability. Consequently, the fluctuation in the prediction curves diminishes over time, and the model approaches a more stable performance.
Figure 10 illustrates that the Transformer model demonstrates a lower degree of fluctuation in contrast to the MLP and LSTM models. This can be attributed to the inclusion of the self-attention mechanism. It enables comprehensive interactivity to model the interconnections between each position and other positions. As a result, this diminishes fluctuations in the curve. Furthermore, the Transformer model utilizes positional encoding to encapsulate positional information within the sequence. This facilitates a nuanced understanding of sequential relationships.
Furthermore, it is noteworthy that
Figure 10 shows significant differences in the curves of the SDAE–Transformer model and the Transformer model, whereas the evaluation metrics in
Table 6 may not exhibit such pronounced distinctions. Several factors contribute to this observation: (1) The sensitivity of evaluation metrics: RE is highly influenced by extreme values or outliers, while
and
are relatively less sensitive. Consequently, even if there exists a disparity in the performance of the models, the differences in the metric values may not be readily apparent. (2) Variances in data preprocessing: The SDAE–Transformer may employ an autoencoder for data dimensionality reduction or feature extraction, whereas a Transformer may utilize raw data directly. The characteristics and parameter settings of the autoencoder impact feature extraction and representation. This discrepancy may result in divergent understandings and processing of the data by the two models, ultimately affecting the performance of the results. (3) Disparities in model training: The SDAE–Transformer and Transformer may be subjected to distinct parameter settings and optimization strategies, such as the learning rate, regularization parameter, and optimizer selection. These dissimilarities can give rise to performance disparities in the obtained results. To further evaluate the models,
was also considered.
Table 6 presents the values of all evaluation metrics for the four models approaches across different health factors and every battery. From
Table 6, the following conclusions can be drawn: (1) Our model excels across all evaluation metrics among the four models. This achievement demonstrates its ability to effectively extract valuable information from the modeled capacity sequences. (2) Both our model and the RNN-based model exhibit better predictive accuracy than the MLP, indicating the importance of incorporating sequence information for accurate RUL prediction. The attention network of the Transformer captures global trends by simulating the correlations between historical capacity features. Consequently, our model can effectively simulate the influence of historical capacities on the sequential state. (3) The optimized SDAE–Transformer demonstrates superior accuracy in various scenarios compared to the traditional Transformer model. SDAE can assist the Transformer model in learning feature representations from the data more effectively and capturing critical information. Introducing a certain degree of noise during the training process helps the model to better resist overfitting, thereby enhancing its generalization ability. SDAE also provides greater nonlinear expressive power, enabling the Transformer model to better adapt to complex data distributions and improve its robustness.
Meanwhile, we delve into the computational cost of various prediction models in the experiments, as shown in
Table 6. The experimental results show that the computational time of MLP and LSTM models is shorter compared to the other models. The LSTM model is a variant of RNN that solves the problem of vanishing and exploding RNN gradients. However, it requires training the weight matrix and bias vector at each time step. This increases the number of parameters and lengthens the runtime. Considering the large number of data sequences and intricate data dependencies in the dataset, the LSTM model may require a longer run time. However, experimental predictions for sequential data are not as good, resulting in poor accuracy. The most notable feature of Transformers is the self-attention mechanism, which speeds up computation by allowing parallel computation for each position without sequential computation. Compared with traditional RNN-based models, Transformers directly utilize the self-attention mechanism to compute all positions, which reduces the number of parameters, decreases computational complexity, and shortens runtime.
A comparison of the runtimes for SDAE–Transformer and Transformer shows that they exhibit different efficiencies under different health factor input conditions. Under the H1 input condition, the runtime of the Transformer model is relatively short due to fewer outliers and noise in the dataset. In contrast, SDAE–Transformer learns a more compact data representation through the self-encoder, which reduces the input dimensions of the Transformer model and produces a more optimized combination of parameters, and thus it is more efficient and has a shorter runtime than the traditional Transformer model under the H2 health factor input condition. In the H3 condition, the difference in running time between the two is not significant, but it is clear that the SDAE-Transformer has a shorter running time.
The improved SDAE–Transformer shows significant advantages in extracting health factors, especially in terms of shorter run times for H2 and H3 health factors. This is valuable for practical applications, especially in random application scenarios such as the daily use of lithium-ion batteries. The improved model can quickly and accurately predict battery life, providing timely failure warnings and maintenance guidance to avoid depletion and potential safety risks. In addition, the model can better adapt to the complex dependencies of the data and learn a more compact data representation through SDAE, reducing the number of input dimensions and parameters to further improve computational efficiency.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}