

MHDNet: A Multi-Scale Hybrid Deep Learning Model for Person Re-Identification

Abstract
:1. Introduction
2. Related Work
2.1. Transformer in Person Re-ID
2.2. Multi-Scale Feature Method
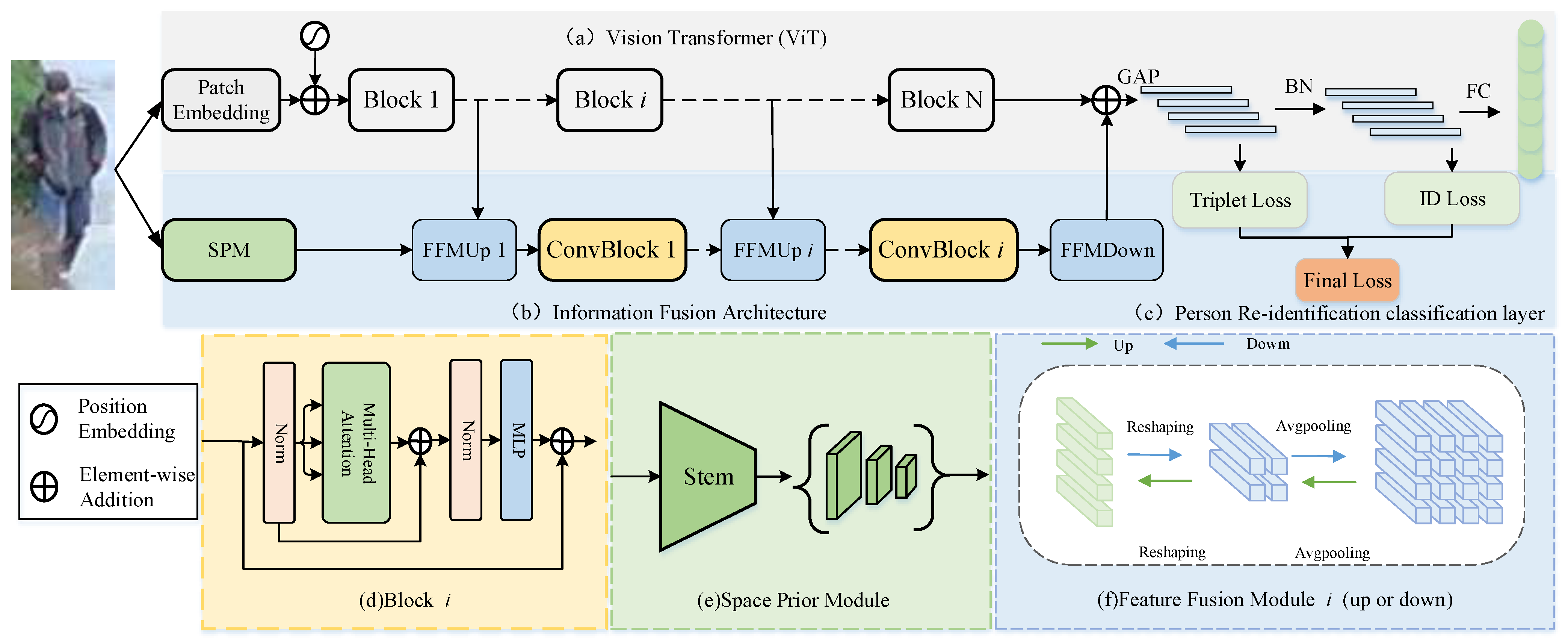
3. The Proposed Method
3.1. Framework Overview
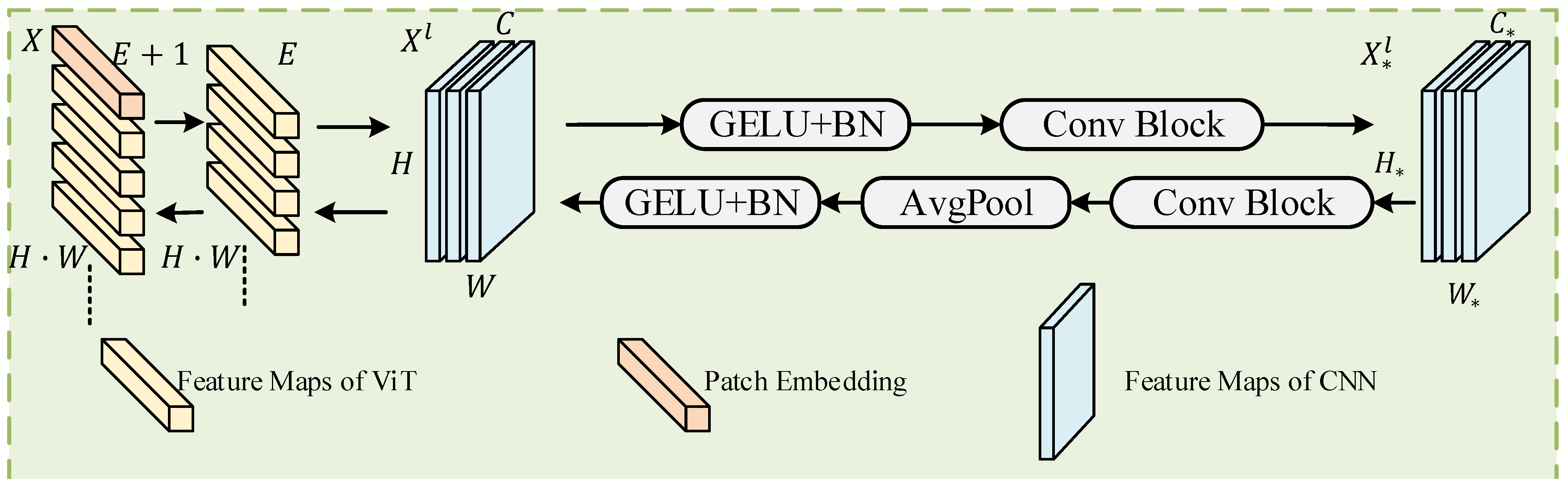
3.2. Space Prior Module
3.3. Feature Fusion Module
3.4. Loss Function
3.4.1. Cross-Entropy Loss
3.4.2. Triplet Loss
3.4.3. Circle Loss
4. Experiment
4.1. Datasets
4.2. Implementation Details
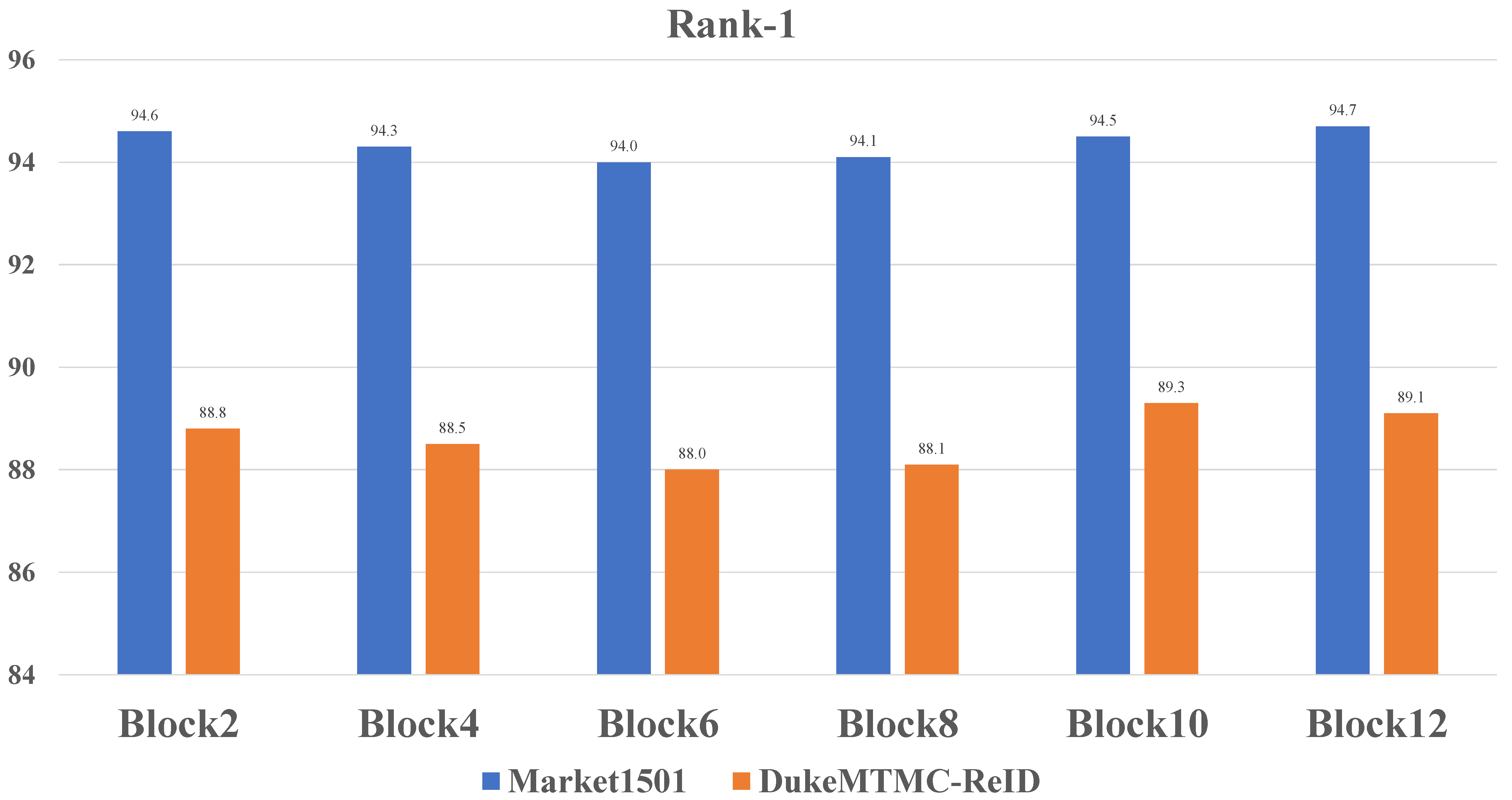
4.3. Ablation Study
4.4. Effectiveness of Different Loss Functions
4.5. Comparison with the State-of-the-Art Methods in Single-Domain Person Re-Identification
4.6. Comparison with the State-of-the-Art Methods in Cross-Domain Person Re-Identification
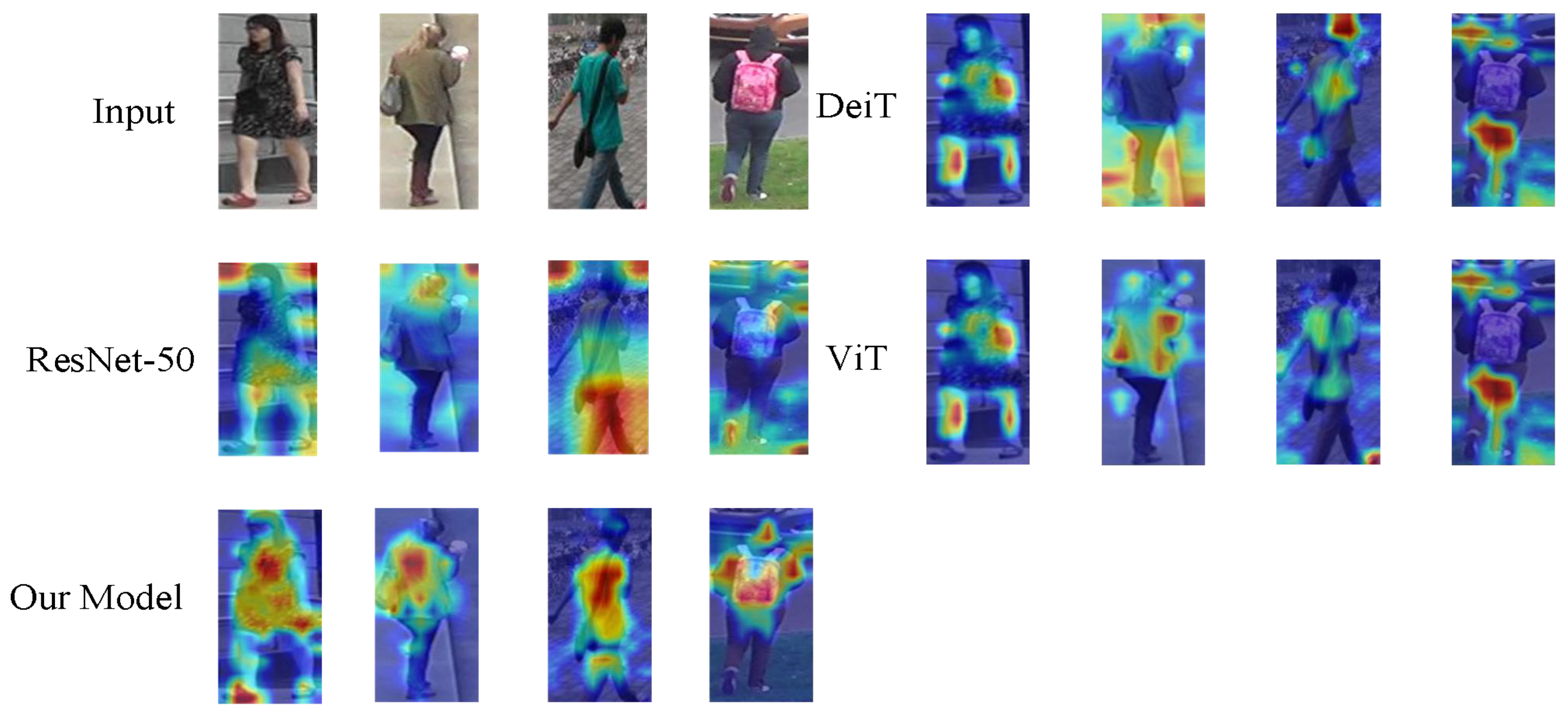
4.7. Visualized Attention Maps of the MHDNet
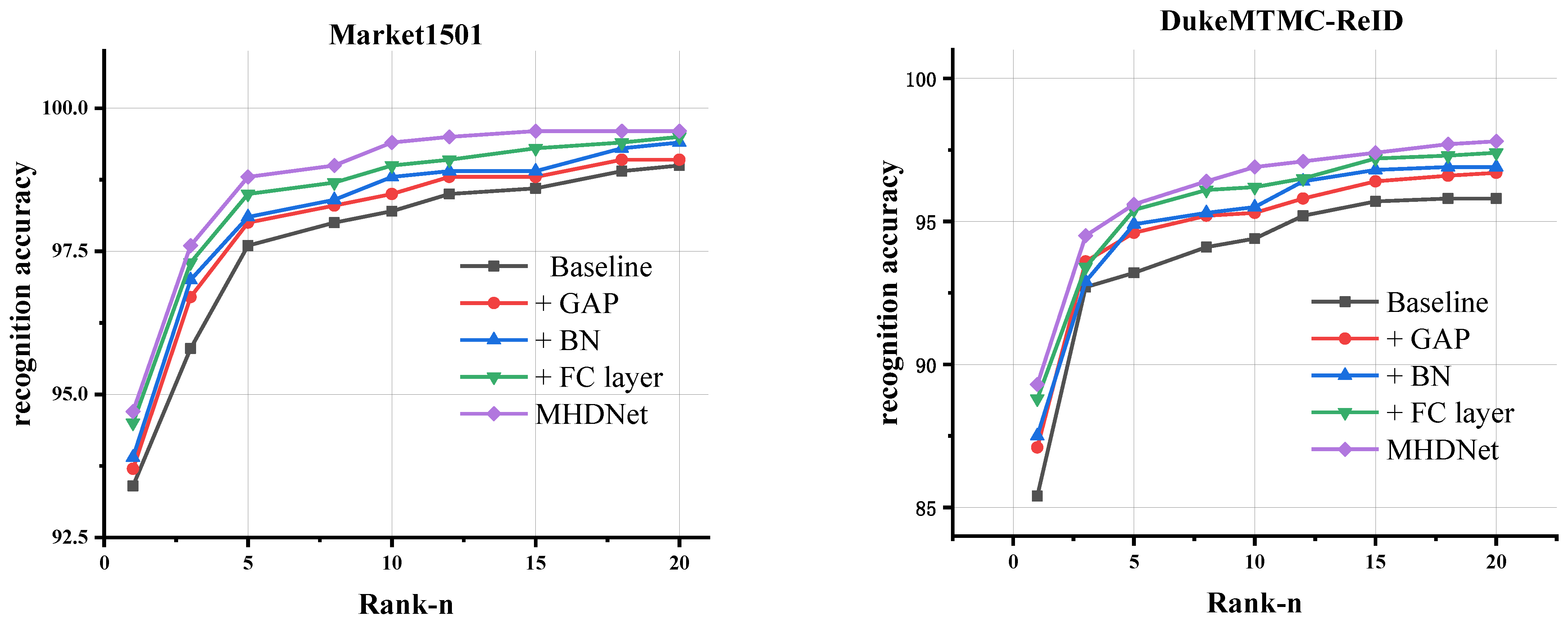
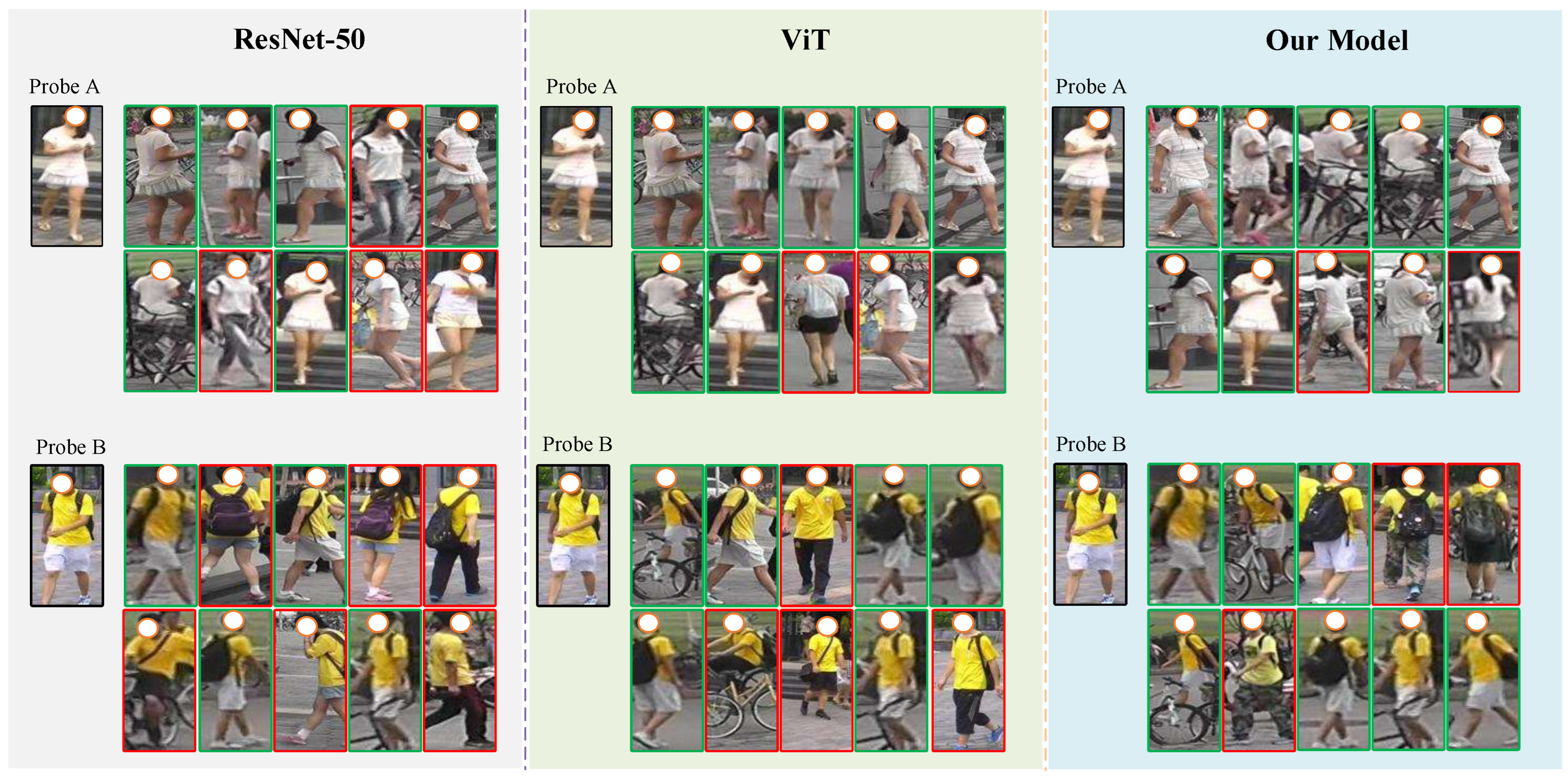
4.8. Rank-List Visualization Analysis
5. Conclusions
6. Privacy and Ethical Considerations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Almasawa, M.O.; Elrefaei, L.A.; Moria, K. A Survey on Deep Learning-Based Person Re-Identification Systems. IEEE Access 2019, 7, 175228–175247. [Google Scholar] [CrossRef]
- Zahra, A.; Perwaiz, N.; Shahzad, M.; Fraz, M.M. Person re-identification: A retrospective on domain specific open challenges and future trends. Pattern Recognit. 2023, 142, 109669. [Google Scholar] [CrossRef]
- Huang, H.; Li, D.; Zhang, Z.; Chen, X.; Huang, K. Adversarially Occluded Samples for Person Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5098–5107. [Google Scholar] [CrossRef]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. VRSTC: Occlusion-Free Video Person Re-Identification. arXiv 2019, arXiv:1907.08427. [Google Scholar] [CrossRef]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle Net: Person Re-identification with Human Body Region Guided Feature Decomposition and Fusion. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 907–915. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-Guided Contrastive Attention Model for Person Re-identification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar] [CrossRef]
- Xiong, F.; Gou, M.; Camps, O.; Sznaier, M. Person Re-Identification Using Kernel-Based Metric Learning Methods. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Zhao, R.; Ouyang, W.; Wang, X. Person Re-identification by Salience Matching. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2528–2535. [Google Scholar] [CrossRef]
- Guillaumin, M.; Verbeek, J.; Schmid, C. Is that you? Metric learning approaches for face identification. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 498–505. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, Z.; Wang, Y. Relevance Metric Learning for Person Re-identification by Exploiting Global Similarities. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1657–1662. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling (and A Strong Convolutional Baseline). In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of Tricks and a Strong Baseline for Deep Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 1487–1495. [Google Scholar] [CrossRef]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3183–3192. [Google Scholar] [CrossRef]
- Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Ren, Z.; Wang, Z. ABD-Net: Attentive but Diverse Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8350–8360. [Google Scholar] [CrossRef]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018. [Google Scholar]
- Yang, W.; Huang, H.; Zhang, Z.; Chen, X.; Huang, K.; Zhang, S. Towards Rich Feature Discovery With Class Activation Maps Augmentation for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1389–1398. [Google Scholar] [CrossRef]
- Zheng, F.; Deng, C.; Sun, X.; Jiang, X.; Guo, X.; Yu, Z.; Huang, F.; Ji, R. Pyramidal Person Re-IDentification via Multi-Loss Dynamic Training. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8506–8514. [Google Scholar] [CrossRef]
- Wang, P.; Zhao, Z.; Su, F.; Zu, X.; Boulgouris, N.V. HOReID: Deep High-Order Mapping Enhances Pose Alignment for Person Re-Identification. IEEE Trans. Image Process. 2021, 30, 2908–2922. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Jiang, Y.; Chang, S.; Wang, Z. TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up. In Proceedings of the Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Li, X.; Hou, Y.; Wang, P.; Gao, Z.; Xu, M.; Li, W. Trear: Transformer-Based RGB-D Egocentric Action Recognition. IEEE Trans. Cogn. Dev. Syst. 2022, 14, 246–252. [Google Scholar] [CrossRef]
- Zhang, Q.L.; Yang, Y. ResT: An Efficient Transformer for Visual Recognition. arXiv 2021, arXiv:2105.13677. [Google Scholar]
- Zheng, L.; Yang, Y.; Hauptmann, A. Person Re-identification: Past, Present and Future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Wang, G.; Yang, S.; Liu, H.; Wang, Z.; Yang, Y.; Wang, S.; Yu, G.; Zhou, E.; Sun, J. High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 6448–6457. [Google Scholar] [CrossRef]
- Wu, D.; Wang, C.; Wu, Y.; Wang, Q.C.; Huang, D.S. Attention Deep Model With Multi-Scale Deep Supervision for Person Re-Identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]
- Jiao, S.; Pan, Z.; Hu, G.; Shen, Q.; Du, L.; Chen, Y.; Wang, J. Multi-scale and multi-branch feature representation for person re-identification. Neurocomputing 2020, 414, 120–130. [Google Scholar] [CrossRef]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. TransReID: Transformer-based Object Re-Identification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 14993–15002. [Google Scholar]
- Chen, X.; Xu, J.; Xu, J.; Gao, S. OH-Former: Omni-Relational High-Order Transformer for Person Re-Identification. arXiv 2021, arXiv:2109.11159. [Google Scholar]
- Chen, Y.; Xia, S.; Zhao, J.; Zhou, Y.; Niu, Q.; Yao, R.; Zhu, D.; Liu, D. ResT-ReID: Transformer block-based residual learning for person re-identification. Pattern Recognit. Lett. 2022, 157, 90–96. [Google Scholar] [CrossRef]
- Lai, S.; Chai, Z.; Wei, X. Transformer Meets Part Model: Adaptive Part Division for Person Re-Identification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 4133–4140. [Google Scholar] [CrossRef]
- Cai, H.; Wang, Z.; Cheng, J. Multi-Scale Body-Part Mask Guided Attention for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 15–20 June 2019; pp. 1555–1564. [Google Scholar]
- Wang, C.; Song, L.; Wang, G.; Zhang, Q.; Wang, X. Multi-scale multi-patch person re-identification with exclusivity regularized softmax. Neurocomputing 2020, 382, 64–70. [Google Scholar] [CrossRef]
- Liu, X.; Tan, H.; Tong, X.; Cao, J.; Zhou, J. Feature preserving GAN and multi-scale feature enhancement for domain adaption person Re-identification. Neurocomputing 2019, 364, 108–118. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-Scale Feature Learning for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Long Beach, CA, USA, 15–20 June 2019; pp. 3701–3711. [Google Scholar]
- Zhang, H.; Tian, L.; Wang, Z.; Xu, Y.; Cheng, P.; Bai, K.; Chen, B. Multiscale Visual-Attribute Co-Attention for Zero-Shot Image Recognition. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 6003–6014. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, M. Multiscale Emotion Representation Learning for Affective Image Recognition. IEEE Trans. Multimed. 2023, 25, 2203–2212. [Google Scholar] [CrossRef]
- Zhou, W.; Chen, Z. Deep Multi-Scale Features Learning for Distorted Image Quality Assessment. In Proceedings of the 2021 IEEE International Symposium on Circuits and Systems (ISCAS), Daegu, Republic of Korea, 22–28 May 2021; pp. 1–5. [Google Scholar]
- Chen, Z.; Li, J.; Liu, H.; Wang, X.; Wang, H.; Zheng, Q. Learning multi-scale features for speech emotion recognition with connection attention mechanism. Expert Syst. Appl. 2023, 214, 118943. [Google Scholar] [CrossRef]
- Hu, J.; Tu, B.; Ren, Q.; Liao, X.; Cao, Z.; Plaza, A. Hyperspectral Image Classification via Multiscale Multiangle Attention Network. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–18. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.S.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-target, Multi-camera Tracking. In Proceedings of the ECCV Workshops, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Wang, Y.; Wang, L.; You, Y.; Zou, X.; Chen, V.; Li, S.; Huang, G.; Hariharan, B.; Weinberger, K.Q. Resource Aware Person Re-identification Across Multiple Resolutions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8042–8051. [Google Scholar] [CrossRef]
- Chen, B.; Deng, W.; Hu, J. Mixed High-Order Attention Network for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 371–381. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling. In Proceedings of the European Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, A.; Gao, Y.; Niu, Y.; Liu, W.; Zhou, Y. Coarse-to-Fine Person Re-Identification with Auxiliary-Domain Classification and Second-Order Information Bottleneck. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 598–608. [Google Scholar] [CrossRef]
- Xu, Y.; Zhao, L.; Qin, F. Dual attention-based method for occluded person re-identification. Knowl.-Based Syst. 2021, 212, 106554. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Learning Generalisable Omni-Scale Representations for Person Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5056–5069. [Google Scholar] [CrossRef]
- Jin, H.; Lai, S.; Qian, X. Occlusion-Sensitive Person Re-Identification via Attribute-Based Shift Attention. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 2170–2185. [Google Scholar] [CrossRef]
- Li, H.; Wu, G.; Zheng, W. Combined Depth Space based Architecture Search For Person Re-identification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 6725–6734. [Google Scholar]
- Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; Wu, F. Diverse Part Discovery: Occluded Person Re-identification with Part-Aware Transformer. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 2897–2906. [Google Scholar] [CrossRef]
- Chen, J.; Jiang, X.; Wang, F.; Zhang, J.; Zheng, F.; Sun, X.; Zheng, W.S. Learning 3D Shape Feature for Texture-insensitive Person Re-identification. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 8142–8151. [Google Scholar] [CrossRef]
- Huang, J.; Yu, X.; An, D.; Wei, Y.; Bai, X.; Zheng, J.; Wang, C.; Zhou, J. Learning consistent region features for lifelong person re-identification. Pattern Recognit. 2023, 144, 109837. [Google Scholar] [CrossRef]
- Zhu, H.; Ke, W.; Li, D.; Liu, J.; Tian, L.; Shan, Y. Dual Cross-Attention Learning for Fine-Grained Visual Categorization and Object Re-Identification. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4682–4692. [Google Scholar]
- Mamedov, T.; Kuplyakov, D.; Konushin, A. Approaches to Improve the Quality of Person Re-Identification for Practical Use. Sensors 2023, 23, 7382. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Liu, P.; Cao, X.; Liu, C. Dynamic Weighting Network for Person Re-Identification. Sensors 2023, 23, 5579. [Google Scholar] [CrossRef]
- Wang, M.; Ma, H.; Huang, Y. Information complementary attention-based multidimension feature learning for person re-identification. Eng. Appl. Artif. Intell. 2023, 123, 106348. [Google Scholar] [CrossRef]
- Chang, X.; Yang, Y.; Xiang, T.; Hospedales, T.M. Disjoint Label Space Transfer Learning with Common Factorised Space. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Qi, L.; Wang, L.; Huo, J.; Zhou, L.; Shi, Y.; Gao, Y. A Novel Unsupervised Camera-Aware Domain Adaptation Framework for Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8079–8088. [Google Scholar]
- Li, M.; Zhu, X.; Gong, S. Unsupervised Tracklet Person Re-Identification. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1770–1782. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Luo, Z.; Li, S.; Yang, Y. Invariance Matters: Exemplar Memory for Domain Adaptive Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 598–607. [Google Scholar]
- Li, Y.J.; Lin, C.S.; Lin, Y.B.; Wang, Y. Cross-Dataset Person Re-Identification via Unsupervised Pose Disentanglement and Adaptation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7918–7928. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Instance-Guided Context Rendering for Cross-Domain Person Re-Identification. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 232–242. [Google Scholar] [CrossRef]
- Mekhazni, D.; Bhuiyan, A.; Ekladious, G.S.E.; Granger, E. Unsupervised Domain Adaptation in the Dissimilarity Space for Person Re-identification. arXiv 2020, arXiv:2007.13890. [Google Scholar]
- Zhai, Y.; Lu, S.; Ye, Q.; Shan, X.; Chen, J.; Ji, R.; Tian, Y. AD-Cluster: Augmented Discriminative Clustering for Domain Adaptive Person Re-Identification. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9018–9027. [Google Scholar]
- Tang, Y.; Yang, X.; Wang, N.; Song, B.; Gao, X. CGAN-TM: A Novel Domain-to-Domain Transferring Method for Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 5641–5651. [Google Scholar] [CrossRef]
- Verma, A.; Subramanyam, A.; Wang, Z.; Satoh, S.; Shah, R.R. Unsupervised Domain Adaptation for Person Re-Identification Via Individual-Preserving and Environmental-Switching Cyclic Generation. IEEE Trans. Multimed. 2023, 25, 364–377. [Google Scholar] [CrossRef]
- Zhang, H.; Cao, H.; Yang, X.; Deng, C.; Tao, D. Self-Training With Progressive Representation Enhancement for Unsupervised Cross-Domain Person Re-Identification. IEEE Trans. Image Process. 2021, 30, 5287–5298. [Google Scholar] [CrossRef]
- Li, H.; Pang, J.; Tao, D.; Yu, Z. Cross adversarial consistency self-prediction learning for unsupervised domain adaptation person re-identification. Inform. Sci. 2021, 559, 46–60. [Google Scholar] [CrossRef]
- Khatun, A.; Denman, S.; Sridharan, S.; Fookes, C. End-to-End Domain Adaptive Attention Network for Cross-Domain Person Re-Identification. IEEE Trans. Inform. Forensics Secur. 2021, 16, 3803–3813. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Y.; Zhuang, Z.; Xie, L.; Tian, Q. 3D-GAT: 3D-Guided adversarial transform network for person re-identification in unseen domains. Pattern Recognit. 2021, 112, 107799. [Google Scholar] [CrossRef]
- Chong, Y.; Peng, C.; Zhang, J.; Pan, S. Style transfer for unsupervised domain-adaptive person re-identification. Neurocomputing 2021, 422, 314–321. [Google Scholar] [CrossRef]
- Tang, G.; Gao, X.; Chen, Z.; Zhong, H. Unsupervised adversarial domain adaptation with similarity diffusion for person re-identification. Neurocomputing 2021, 442, 337–347. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Cameras | TrainIDs | TrainImgs | TestIDs | QueryImgs | GalleryImgs |
|---|---|---|---|---|---|---|
| Market-1501 [46] | 6 | 751 | 12,396 | 750 | 3368 | 19,732 |
| DukeMTMC-reID [36] | 8 | 702 | 16,522 | 702 | 2228 | 17,661 |
| Methods | Inference Time | Market1501 | DukeMTMC-reID | ||||
|---|---|---|---|---|---|---|---|
| mAP | Rank 1 | Rank 5 | mAP | Rank 1 | Rank 5 | ||
| ResNet-18 | 5 ms | 77.5 | 91.2 | 95.5 | 68.5 | 82.2 | 92.8 |
| ResNet-34 | 11 ms | 82.4 | 92.5 | 96.2 | 73.4 | 84.7 | 93.4 |
| ResNet-50 | 16 ms | 85.7 | 94.2 | 97.6 | 75.9 | 86.2 | 94.7 |
| ResNet-101 | 24 ms | 86.8 | 94.4 | 98.3 | 77.2 | 87.3 | 95.2 |
| ViT-B | 40 ms | 86.8 | 94.5 | 98.1 | 79.3 | 88.8 | 95.4 |
| Deit-B | 36 ms | 86.6 | 94.4 | 97.8 | 78.9 | 88.3 | 95.1 |
| MHDNet (Our) | 38 ms | 87.7 | 94.6 | 98.6 | 79.7 | 89.1 | 95.6 |
| Methods | Market1501 | DukeMTMC-reID | ||||||
|---|---|---|---|---|---|---|---|---|
| mAP | Rank 1 | Rank 5 | Rank 10 | mAP | Rank 1 | Rank 5 | Rank 10 | |
| Baseline | 84.0 | 92.4 | 95.4 | 96.6 | 76.4 | 85.4 | 93.2 | 94.4 |
| + GAP | 85.1 | 93.7 | 97.2 | 98.0 | 77.8 | 87.1 | 94.6 | 95.3 |
| + BN | 85.2 | 93.9 | 97.5 | 98.1 | 78.1 | 87.5 | 94.9 | 95.5 |
| + FC Layer | 86.8 | 94.5 | 98.1 | 98.9 | 79.3 | 88.8 | 95.4 | 96.2 |
| MHDNet (Our) | 87.7 | 94.6 | 98.6 | 99.3 | 79.7 | 89.1 | 95.6 | 96.6 |
| Loss Function | mAP | Rank 1 | Rank 5 | Rank 10 |
|---|---|---|---|---|
| ID | 81.8 | 93.1 | 97.2 | 98.5 |
| Triplet | 80.3 | 91.8 | 96.2 | 98.1 |
| ID + Spere | 78.5 | 90.9 | 97.1 | 98.2 |
| ID + Contrast | 82.6 | 93.0 | 97.9 | 98.7 |
| ID + Cricle | 83.4 | 93.7 | 98.1 | 98.9 |
| ID + Instance | 82.2 | 92.9 | 97.7 | 98.6 |
| ID + Triplet | 87.7 | 94.6 | 98.6 | 99.3 |
| ID + Triplet + Cricle | 84.1 | 93.6 | 98.3 | 98.8 |
| ID + Triplet + Instance | 83.8 | 93.4 | 97.5 | 98.9 |
| Loss Function | mAP | Rank 1 | Rank 5 | Rank 10 |
|---|---|---|---|---|
| ID | 75.3 | 86.4 | 94.5 | 96.2 |
| Triplet | 74.2 | 85.8 | 93.7 | 96.1 |
| ID + Spere | 71.8 | 81.6 | 94.1 | 95.9 |
| ID + Contrast | 76.9 | 87.8 | 95.2 | 96.3 |
| ID + Cricle | 77.6 | 88.1 | 95.4 | 96.5 |
| ID + Instance | 76.2 | 87.6 | 95.1 | 96.0 |
| ID + Triplet | 79.7 | 89.1 | 95.6 | 96.6 |
| ID + Triplet + Cricle | 78.5 | 88.7 | 95.5 | 96.6 |
| ID + Triplet + Instance | 77.4 | 87.9 | 95.0 | 96.4 |
| Method | Venue | Market1501 | DukeMTMC-reID | ||
|---|---|---|---|---|---|
| mAP | Rank 1 | mAP | Rank 1 | ||
| PCB [47] | ECCV 2018 | 81.6 | 93.8 | 69.2 | 83.3 |
| BoT [14] | CVPR 2019 | 85.9 | 94.5 | 76.4 | 86.4 |
| HOReID [26] | CVPR 2020 | 84.9 | 94.2 | 75.6 | 86.9 |
| M-DEFNet | MTA 2020 | 82.7 | 94.8 | 73.1 | 84.7 |
| ADC-2OIB [48] | CVPR 2021 | 87.7 | 94.8 | 74.9 | 87.4 |
| DAReID [49] | KBS 2021 | 87.0 | 94.6 | 78.4 | 88.9 |
| OSNet [50] | TPAMI 2021 | 86.7 | 94.8 | 76.3 | 88.7 |
| ASAN [51] | TCSVT 2021 | 85.3 | 94.6 | 76.3 | 88.7 |
| CDNet [52] | CVPR 2021 | 86.0 | 95.1 | 76.8 | 88.6 |
| PAT [53] | CVPR 2021 | 86.6 | 95.4 | 78.2 | 88.8 |
| L3DS [54] | CVPR 2021 | 87.3 | 95.0 | 76.1 | 88.2 |
| TransReID [29] | ICCV 2021 | 86.8 | 94.6 | 79.3 | 88.8 |
| ConRFL [55] | PR 2022 | 81.4 | 92.8 | 68.4 | 80.5 |
| CAL | CVPR 2022 | 87.5 | 94.7 | 74.1 | 86.2 |
| AOPS [51] | TCSVT 2022 | 84.1 | 93.4 | 74.1 | 86.2 |
| DeiT-Small + DCAL [56] | CVPR 2022 | 85.3 | 94.0 | 77.4 | 87.9 |
| IIANet | MTA 2023 | 84.9 | 94.2 | - | - |
| With Res2Net50 [57] | Sensors 2023 | 87.1 | 95.0 | 77.6 | 88.1 |
| DWNet-R [58] | Sensors 2023 | 87.5 | 94.9 | 79.1 | 88.4 |
| UV-ReID-ABLM | MVA 2023 | 75.0 | 89.9 | 61.8 | 81.4 |
| ICAM [59] | EAAI 2023 | 82.3 | 93.3 | 71.6 | 85.6 |
| MHDNet (Ours) | 87.7 | 94.6 | 79.7 | 89.1 | |
| Method | DukeMTMC-reID→Market1501 | Market1501→DukeMTMC-reID | ||||||
|---|---|---|---|---|---|---|---|---|
| mAP | Rank 1 | Rank 5 | Rank 10 | mAP | Rank 1 | Rank 5 | Rank 10 | |
| CFSM [60] | 28.3 | 61.2 | - | - | 27.3 | 49.8 | - | - |
| UCDA-CCE [61] | 30.9 | 60.4 | - | - | 31.0 | 47.7 | - | - |
| UTAL [62] | 46.2 | 69.2 | - | - | 44.6 | 62.3 | - | - |
| ECN [63] | 43.0 | 75.6 | 87.5 | 91.6 | 40.4 | 63.3 | 75.8 | 80.4 |
| PDA-Net [64] | 47.6 | 75.2 | 86.3 | 90.2 | 45.1 | 63.2 | 77.0 | 82.5 |
| CR-CAN+ [65] | 54.0 | 77.7 | 89.7 | 92.7 | 48.6 | 68.9 | 80.2 | 84.7 |
| D-MMD [66] | 48.8 | 70.6 | 87.0 | 91.5 | 46.0 | 63.5 | 78.8 | 83.9 |
| AD-Cluster [67] | 68.3 | 86.7 | 94.4 | 96.5 | 54.1 | 72.6 | 82.5 | 85.5 |
| CGAN-TM [68] | 35.2 | 57.3 | - | - | 36.2 | 65.3 | - | - |
| Soft-mask [69] | 69.5 | 86.9 | - | - | 61.3 | 76.9 | - | - |
| PREST [70] | 62.4 | 82.5 | 92.1 | 94.9 | 56.1 | 74.4 | 83.7 | 85.9 |
| CAC–CSP [71] | 36.9 | 69.4 | 82.8 | - | 37.0 | 57.5 | 71.2 | - |
| EDAAN [72] | 35.4 | 64.5 | 83.0 | - | 39.6 | 57.8 | 72.2 | - |
| 3D-GAT [73] | 28.6 | 59.4 | 75.2 | - | 26.1 | 45.1 | 59.3 | - |
| STReID [74] | 31.6 | 62.3 | 79.1 | - | 29.2 | 52.3 | 65.9 | - |
| UADA-SD [75] | 30.2 | 57.4 | 72.4 | 30.3 | 45.3 | 57.8 | - | |
| MHDNet (Ours) | 63.8 | 81.8 | 88.8 | 91.5 | 58.8 | 70.9 | 80.8 | 83.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wang, J. MHDNet: A Multi-Scale Hybrid Deep Learning Model for Person Re-Identification. Electronics 2024, 13, 1435. https://doi.org/10.3390/electronics13081435
Wang J, Wang J. MHDNet: A Multi-Scale Hybrid Deep Learning Model for Person Re-Identification. Electronics. 2024; 13(8):1435. https://doi.org/10.3390/electronics13081435
Chicago/Turabian StyleWang, Jinghui, and Jun Wang. 2024. "MHDNet: A Multi-Scale Hybrid Deep Learning Model for Person Re-Identification" Electronics 13, no. 8: 1435. https://doi.org/10.3390/electronics13081435
APA StyleWang, J., & Wang, J. (2024). MHDNet: A Multi-Scale Hybrid Deep Learning Model for Person Re-Identification. Electronics, 13(8), 1435. https://doi.org/10.3390/electronics13081435