
Prompt-Enhanced Generation for Multimodal Open Question Answering


Abstract
:1. Introduction
- We propose a prompt-enhanced generation model, PEG, for multimodal open question answering. By employing prompt learning to generate supplementary descriptions for images, ample material is provided for semantic alignment of vision and language. Subsequently, vision–language joint encoding is utilized for fine-grained alignment of visual and linguistic semantics, thereby enhancing encoding and retrieval performance.
- We employ prefix-tuning to mine the knowledge within pre-trained model parameters, generating background knowledge related to the question. This provides an additional input for answer generation, thereby reducing the model’s dependency on retrieval results. Thus, the model can generate answers to the question, even if it retrieves irrelevant information.
- The experimental results for two datasets demonstrate that our model, utilizing prompt learning, can enhance encoding and retrieval capabilities, generating more accurate answers.
2. Related work
2.1. Multimodal Question Answering
2.2. Retrieval Augmented Generation
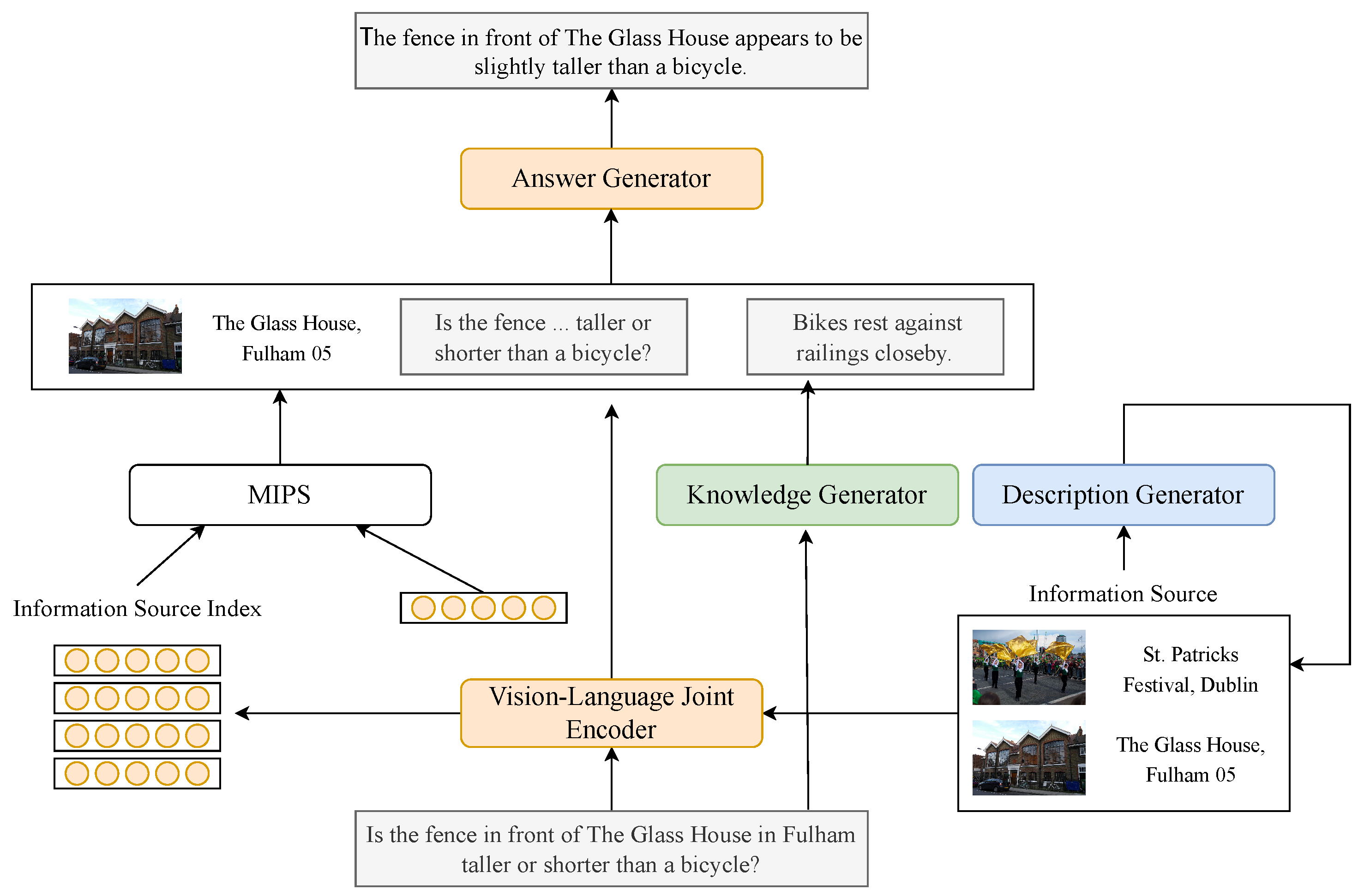
3. Method
3.1. Task Formulation
3.2. Model Overview
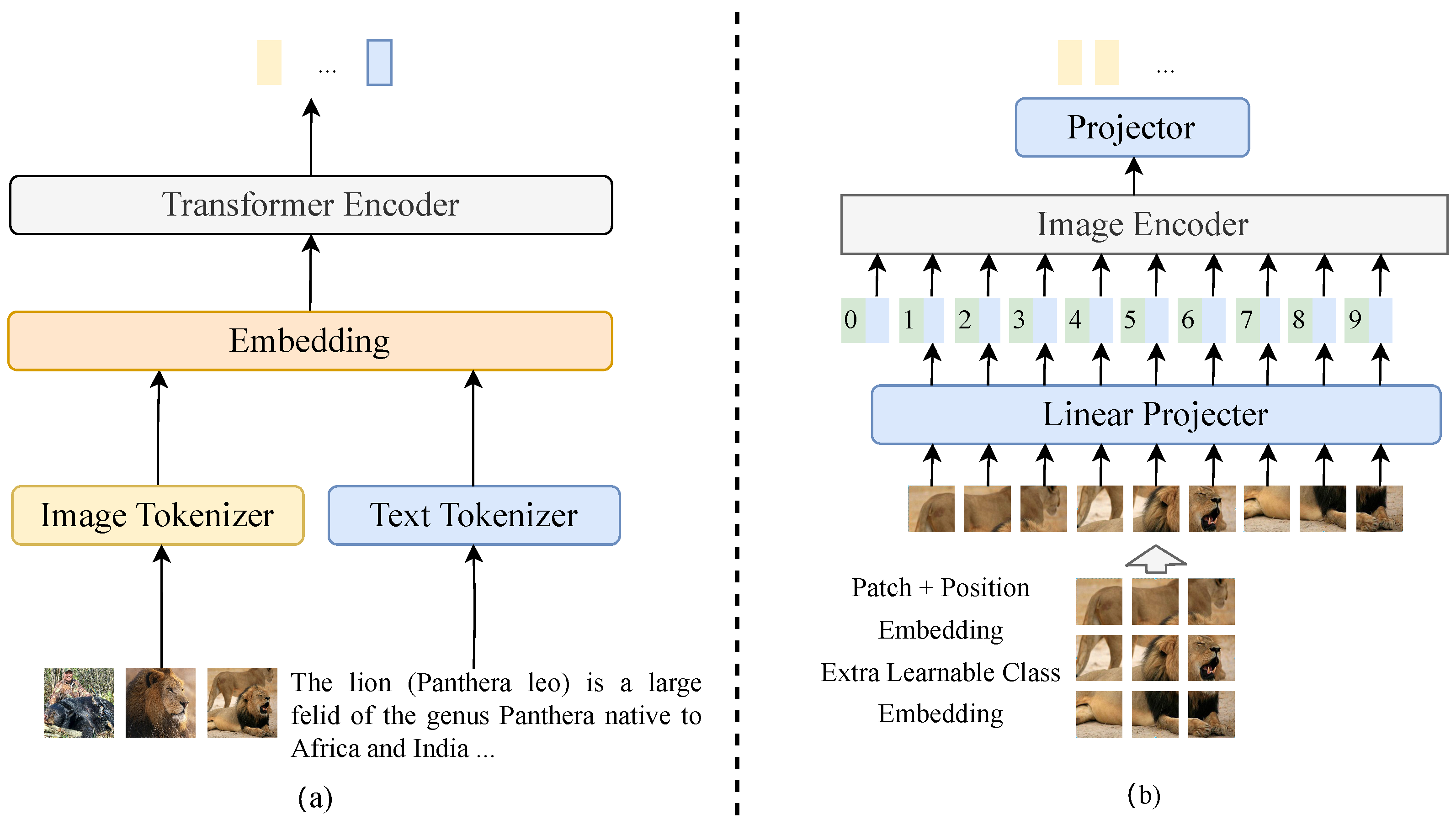
3.3. Prompt-Based Image Supplementary Description Generation
3.4. Vision–Language Joint Representation
3.5. Information Source Retrieval
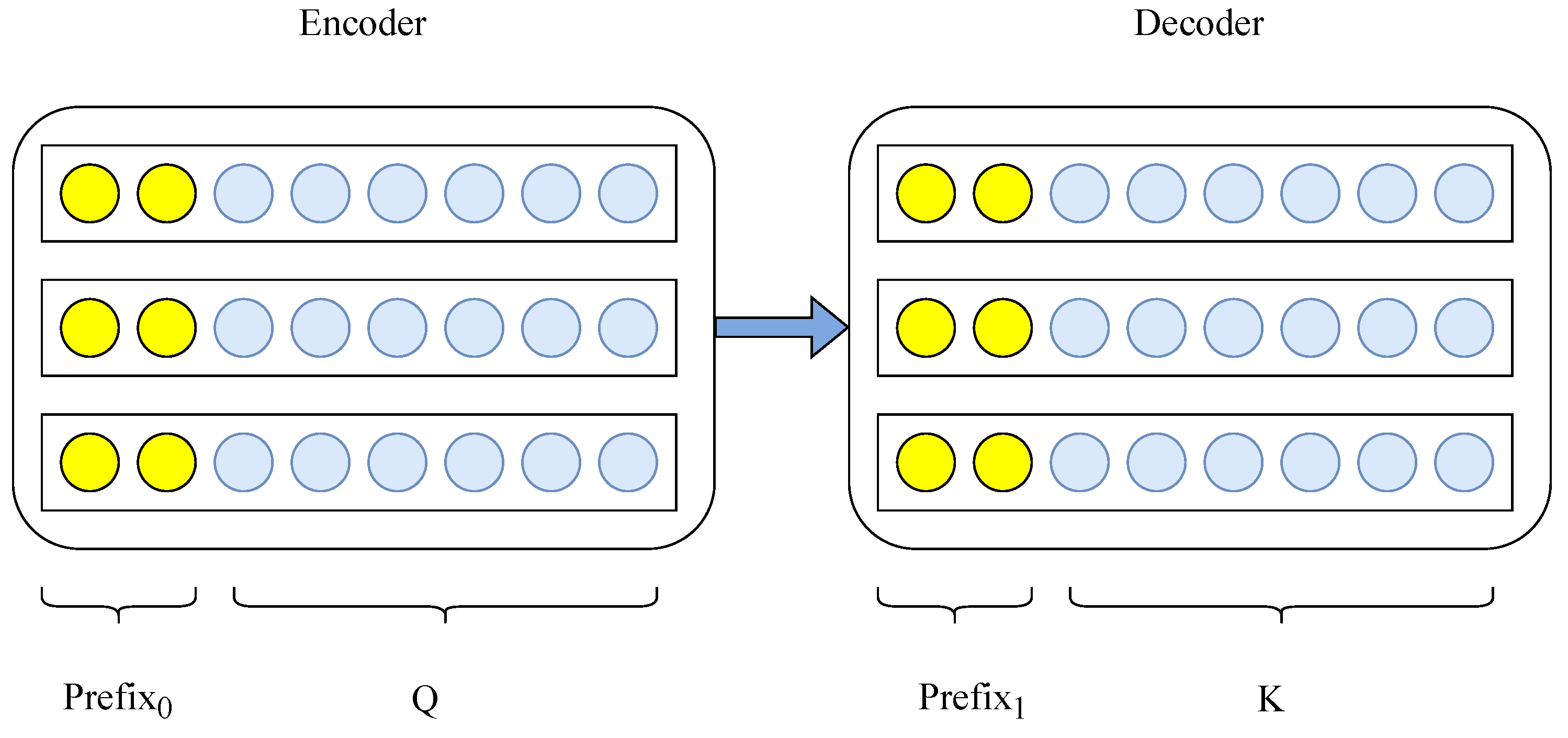
3.6. Prefix-Tuning for Background Knowledge Generation
3.7. Answer Generation
4. Experiments
4.1. Datasets
- WebQA is a multimodal, multi-hop reasoning dataset where all questions require the retrieval of one to two images or text segments as knowledge for answering. Each question in the dataset is associated with a set of visual and textual distractors, necessitating the retrieval of relevant visual and textual sources as knowledge input. The answers in this dataset are typically complete sentences, facilitating a better evaluation of the model’s generative capabilities.
- MultimodalQA contains multimodal question-answer pairs in text, image, and table formats. This dataset features 16 types of questions, most of which require multimodal retrieval and reasoning. Unlike WebQA, the answers in MultimodalQA are in the form of text fragments or phrases. The dataset initially generates questions through templates, then asks crowd workers to filter and interpret the generated questions. Each question is also associated with a set of visual and textual distractors. Following MuRAG [6], we have only considered text and image questions.
4.2. Implementation Details
4.3. Baselines
- Question-Only: This method does not search for information sources related to the question but directly inputs the question into the BART model to generate an answer.
- VLP [5]: Models such as Oscar [29] and VinVL [30] are typically used as standard baseline models. These models are based on transformer encoder–decoder architectures. They concatenate the question and information sources and evaluate the probability of information sources being selected. The question and the selected information sources are concatenated and inputted into the model to generate answers to the question.
- AutoRouting [4]: This method initially employs a question-type classifier to identify the modality (image or text) that may contain the answer. Subsequently, the question and input sources are allocated to different unimodal sub-models to generate answers, transforming multimodal question answering into several unimodal question answering tasks. This approach uses the RoBERTa [31] model to answer text questions, VilBERT [32] to answer image questions, and FasterRCNN [33] to extract image features.
- CLIP [34]: This model is used to encode questions and image–text input sources separately. It employs Approximated Nearest Neighbor Search (ANN) to find k candidate input sources. Then, through re-ranking, one to two sources are selected and input into the question-answering model to generate answers.
- ImplicitDec [4]: Similar to AutoRouting, this model calls different sub-models for different information source modalities but generates answers to multi-hop questions in a stepwise manner. It uses a question-type classifier to determine the modality of the question-related information sources, the order of the modalities, and the logical operations required to be called. During each hop, the corresponding sub-model generates an answer based on the question, the information source of the current modality, and the answers generated in previous hops. The sub-models applied for each modality are similar to those used in AutoRouting.
- MuRAG [6]: This model is pre-trained on a large-scale corpus of image–text pairs and pure text. It retrieves the top-k nearest neighbors from the memory of image–text pairs based on the question. The retrieved results and the question are concatenated and input into an encoder–decoder to generate an answer. The model uses ViT to encode images and T5 [35] to encode text and generate answers.
4.4. Evaluation Metrics
4.5. Results
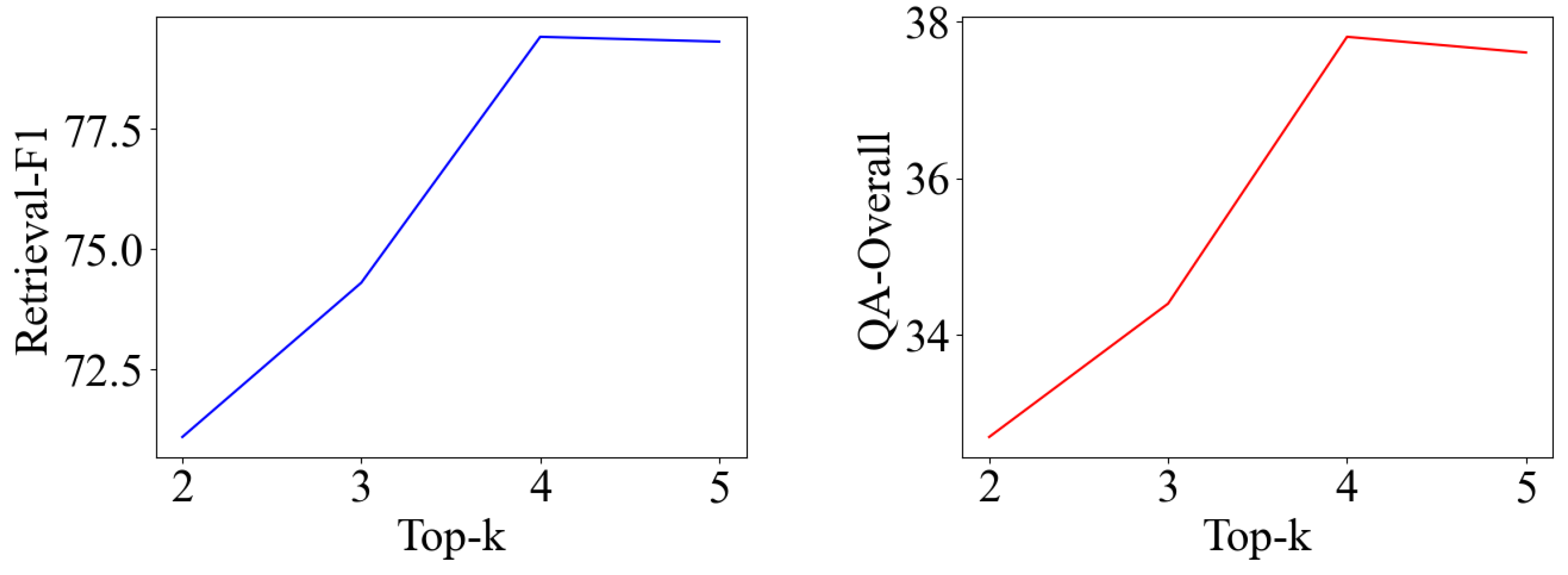
4.6. Ablation Study
4.7. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hannan, D.; Jain, A.; Bansal, M. Manymodalqa: Modality disambiguation and qa over diverse inputs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 7879–7886. [Google Scholar]
- Reddy, R.G.; Rui, X.; Li, M.; Lin, X.; Wen, H.; Cho, J.; Huang, L.; Bansal, M.; Sil, A.; Chang, S.F.; et al. Mumuqa: Multimedia multi-hop news question answering via cross-media knowledge extraction and grounding. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; pp. 11200–11208. [Google Scholar]
- Chang, Y.; Narang, M.; Suzuki, H.; Cao, G.; Gao, J.; Bisk, Y. WebQA: Multihop and Multimodal QA. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 16495–16504. [Google Scholar]
- Talmor, A.; Yoran, O.; Catav, A.; Lahav, D.; Wang, Y.; Asai, A.; Ilharco, G.; Hajishirzi, H.; Berant, J. MultiModalQA: Complex question answering over text, tables and images. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.; Gao, J. Unified Vision-Language Pre-Training for Image Captioning and VQA. Proc. Aaai Conf. Artif. Intell. 2020, 34, 13041–13049. [Google Scholar] [CrossRef]
- Chen, W.; Hu, H.; Chen, X.; Verga, P.; Cohen, W. MuRAG: Multimodal Retrieval-Augmented Generator for Open Question Answering over Images and Text. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Goldberg, Y., Kozareva, Z., Zhang, Y., Eds.; Association for Computational Linguistics: Abu Dhabi, United Arab Emirates, 2022; pp. 5558–5570. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. Openai Blog 2019, 1, 9. [Google Scholar]
- Wang, C.; Liu, P.; Zhang, Y. Can Generative Pre-trained Language Models Serve As Knowledge Bases for Closed-book QA? In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; pp. 3241–3251. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Mahabadi, R.K.; Zettlemoyer, L.; Henderson, J.; Mathias, L.; Saeidi, M.; Stoyanov, V.; Yazdani, M. Prompt-free and Efficient Few-shot Learning with Language Models. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 3638–3652. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. Vqa: Visual question answering. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Marino, K.; Rastegari, M.; Farhadi, A.; Mottaghi, R. Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3195–3204. [Google Scholar]
- Singh, H.; Nasery, A.; Mehta, D.; Agarwal, A.; Lamba, J.; Srinivasan, B.V. Mimoqa: Multimodal input multimodal output question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 5317–5332. [Google Scholar]
- Lin, W.; Byrne, B. Retrieval Augmented Visual Question Answering with Outside Knowledge. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 11238–11254. [Google Scholar]
- Yang, Z.; Gan, Z.; Wang, J.; Hu, X.; Lu, Y.; Liu, Z.; Wang, L. An empirical study of gpt-3 for few-shot knowledge-based vqa. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 22 February–1 March 2022; Volume 36, pp. 3081–3089. [Google Scholar]
- Yu, B.; Fu, C.; Yu, H.; Huang, F.; Li, Y. Unified Language Representation for Question Answering over Text, Tables, and Images. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 4756–4765. [Google Scholar]
- Shi, Q.; Cui, H.; Wang, H.; Zhu, Q.; Che, W.; Liu, T. Exploring Hybrid Question Answering via Program-based Prompting. arXiv 2024, arXiv:2402.10812. [Google Scholar]
- Karpukhin, V.; Oguz, B.; Min, S.; Lewis, P.; Wu, L.; Edunov, S.; Chen, D.; Yih, W.T. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 6–20 November 2020; pp. 6769–6781. [Google Scholar]
- Guu, K.; Lee, K.; Tung, Z.; Pasupat, P.; Chang, M. Retrieval augmented language model pre-training. In Proceedings of the International conference on machine learning. PMLR, Virtual Event, 13–18 July 2020; pp. 3929–3938. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Izacard, G.; Grave, É. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 874–880. [Google Scholar]
- Wang, P.; Yang, A.; Men, R.; Lin, J.; Bai, S.; Li, Z.; Ma, J.; Zhou, C.; Zhou, J.; Yang, H. OFA: Unifying Architectures, Tasks, and Modalities Through a Simple Sequence-to-Sequence Learning Framework. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S., Eds.; PMLR (Proceedings of Machine Learning Research): Baltimore, ML, USA, 2022; Volume 162, pp. 23318–23340. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
- Guo, R.; Sun, P.; Lindgren, E.; Geng, Q.; Simcha, D.; Chern, F.; Kumar, S. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; III, H.D., Singh, A., Eds.; PMLR (Proceedings of Machine Learning Research): Baltimore, ML, USA, 2020; Volume 119, pp. 3887–3896. [Google Scholar]
- Roberts, A.; Raffel, C.; Shazeer, N. How Much Knowledge Can You Pack Into the Parameters of a Language Model? In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 5418–5426. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; pp. 4582–4597. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the ACL 2020, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F.; et al. Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 121–137. [Google Scholar]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. VinVL: Revisiting Visual Representations in Vision-Language Models. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019. Available online: https://arxiv.org/abs/1907.11692 (accessed on 9 April 2024).
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. Neural Inf. Process. Syst. Inf. Process. Syst. 2019, 32, 13–23. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual Event, 18–24 July 2021; Meila, M., Zhang, T., Eds.; PMLR (Proceedings of Machine Learning Research): Baltimore, ML, USA, 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Yuan, W.; Neubig, G.; Liu, P. BARTScore: Evaluating Generated Text as Text Generation. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Curran Associates, Inc.: Virtual, 2021; Volume 34, pp. 27263–27277. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT Understands, Too. arXiv 2021, arXiv:2103.10385. [Google Scholar] [CrossRef]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; Tang, J. P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 61–68. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Retrieval-F1 | QA-FL | QA-Acc | QA-Overall |
|---|---|---|---|---|
| Question-Only | - | 34.9 | 22.2 | 13.4 |
| VLP (Oscar) | 68.9 | 42.6 | 36.7 | 22.6 |
| VLP + ResNeXt | 69.0 | 43.0 | 37.0 | 23.0 |
| VLP + VinVL | 70.9 | 44.2 | 38.9 | 24.1 |
| MuRAG | 74.6 | 55.7 | 54.6 | 36.1 |
| PEG | 79.4 | 56.1 | 56.7 | 37.8 |
| Model | Text | Image | All | ||
|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | |
| Question-Only | 15.4 | 18.4 | 11.0 | 15.6 | 13.8 |
| AutoRouting | 49.5 | 56.9 | 37.8 | 37.8 | 46.6 |
| MuRAG | 60.8 | 67.5 | 58.2 | 58.2 | 60.2 |
| PEG | 64.7 | 70.5 | 60.3 | 60.3 | 63.8 |
| Model | Retrieval-F1 | QA-FL | QA-Acc | QA-Overall |
|---|---|---|---|---|
| PEG | 79.4 | 56.1 | 56.7 | 37.8 |
| PEG w/o IC | 76.0 | 55.7 | 55.3 | 36.3 |
| PEG w/o CON | 73.1 | 54.9 | 54.1 | 35.4 |
| PEG w/o BK | 78.8 | 55.9 | 55.8 | 36.8 |
| Model | Text | Image | All | ||
|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | |
| PEG | 64.7 | 70.5 | 60.3 | 60.3 | 63.8 |
| PEG w/o IC | 62.4 | 68.9 | 59.5 | 59.5 | 61.7 |
| PEG w/o CON | 60.2 | 67.0 | 58.1 | 58.1 | 60.1 |
| PEG w/o BK | 63.3 | 69.6 | 59.8 | 59.8 | 62.5 |
| Model | Retrieval-F1 | QA-FL | QA-Acc | QA-Overall |
|---|---|---|---|---|
| PEG | 79.4 | 56.1 | 56.7 | 37.8 |
| PEG w/o BK | 78.8 | 55.9 | 55.8 | 36.8 |
| PEG with P-tuning | 79.1 | 56.0 | 56.2 | 37.1 |
| PEG with P-tuning v2 | 79.8 | 56.4 | 57.1 | 38.1 |
| Model | Text | Image | All | ||
|---|---|---|---|---|---|
| EM | F1 | EM | F1 | EM | |
| PEG | 64.7 | 70.5 | 60.3 | 60.3 | 63.8 |
| PEG w/o BK | 63.3 | 69.6 | 59.8 | 59.8 | 62.5 |
| PEG with P-tuning | 63.7 | 70.0 | 59.9 | 59.9 | 63.0 |
| PEG with P-tuning v2 | 65.2 | 70.9 | 60.5 | 60.5 | 64.2 |
| Question: | What Body of Water Is Both Trinidad and the Petites Antilles in? |
|---|---|
| Relatex text 1: | Major bodies of water on Trinidad include the Hollis Reservoir, Navet Reservoir, Caroni Reservoir. Trinidad is made up of a variety of soil types, the majority being fine sands and heavy clays. |
| Relatex text 2: | The Lesser Antilles (Spanish: Pequeas Antillas; French: Petites Antilles; Papiamento: Antias Menor; Dutch: Kleine Antillen) is a group of islands in the Caribbean Sea. Most form a long, partly volcanic island arc between the Greater Antilles to the north-west and the continent of South America. |
| Background knowledge: | Trinidad is situated in the Caribbean Sea, which is a part of the western Atlantic Ocean. |
| Genarated answer: | Both Trinidad and the Petites Antilles are in the Caribbean Sea. |
| Ground truth: | The Caribbean. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, C.; Li, Z. Prompt-Enhanced Generation for Multimodal Open Question Answering. Electronics 2024, 13, 1434. https://doi.org/10.3390/electronics13081434
Cui C, Li Z. Prompt-Enhanced Generation for Multimodal Open Question Answering. Electronics. 2024; 13(8):1434. https://doi.org/10.3390/electronics13081434
Chicago/Turabian StyleCui, Chenhao, and Zhoujun Li. 2024. "Prompt-Enhanced Generation for Multimodal Open Question Answering" Electronics 13, no. 8: 1434. https://doi.org/10.3390/electronics13081434