
A Reinforcement Learning-Based Traffic Engineering Algorithm for Enterprise Network Backbone Links


Abstract
1. Introduction
2. The CFRW-RL Model
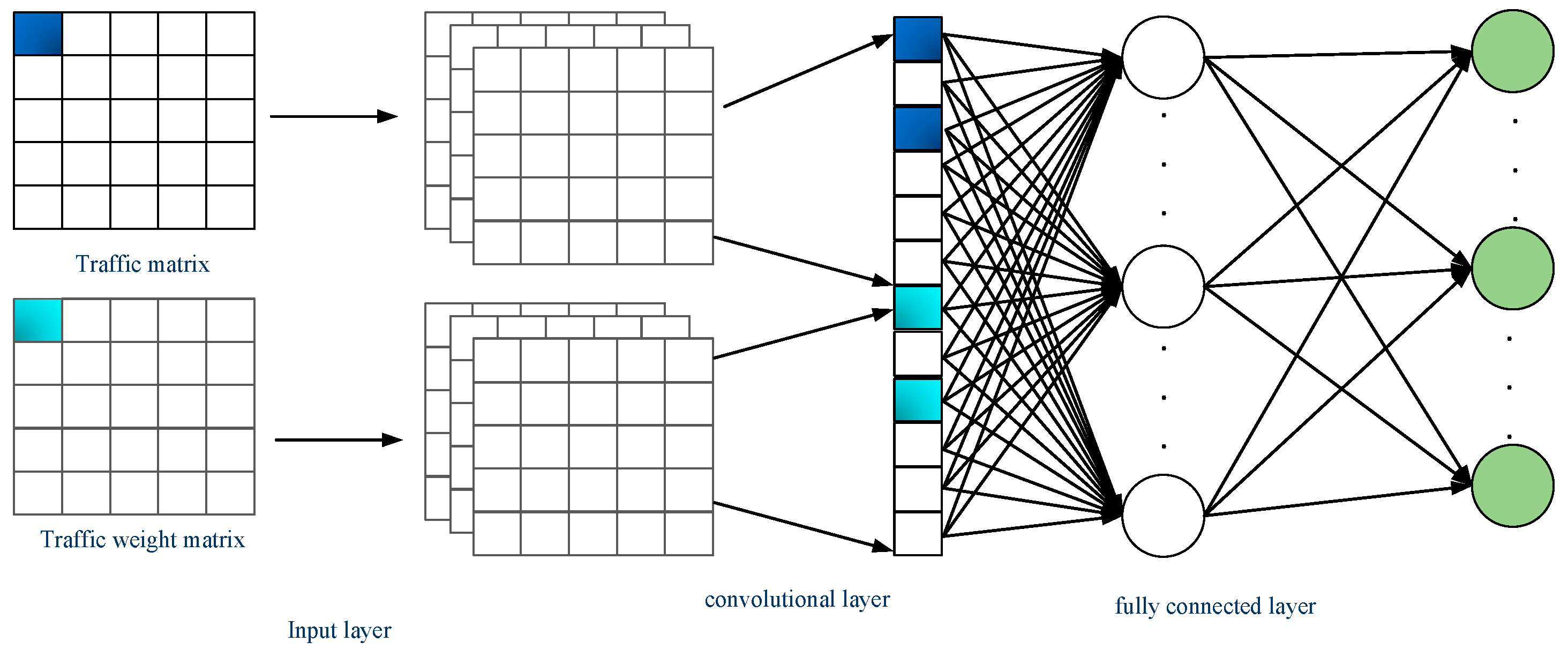
2.1. Model Overview
2.2. State and Action Space
- 1.
- Input/State Space
- 2.
- Action Space
2.3. Reward Function
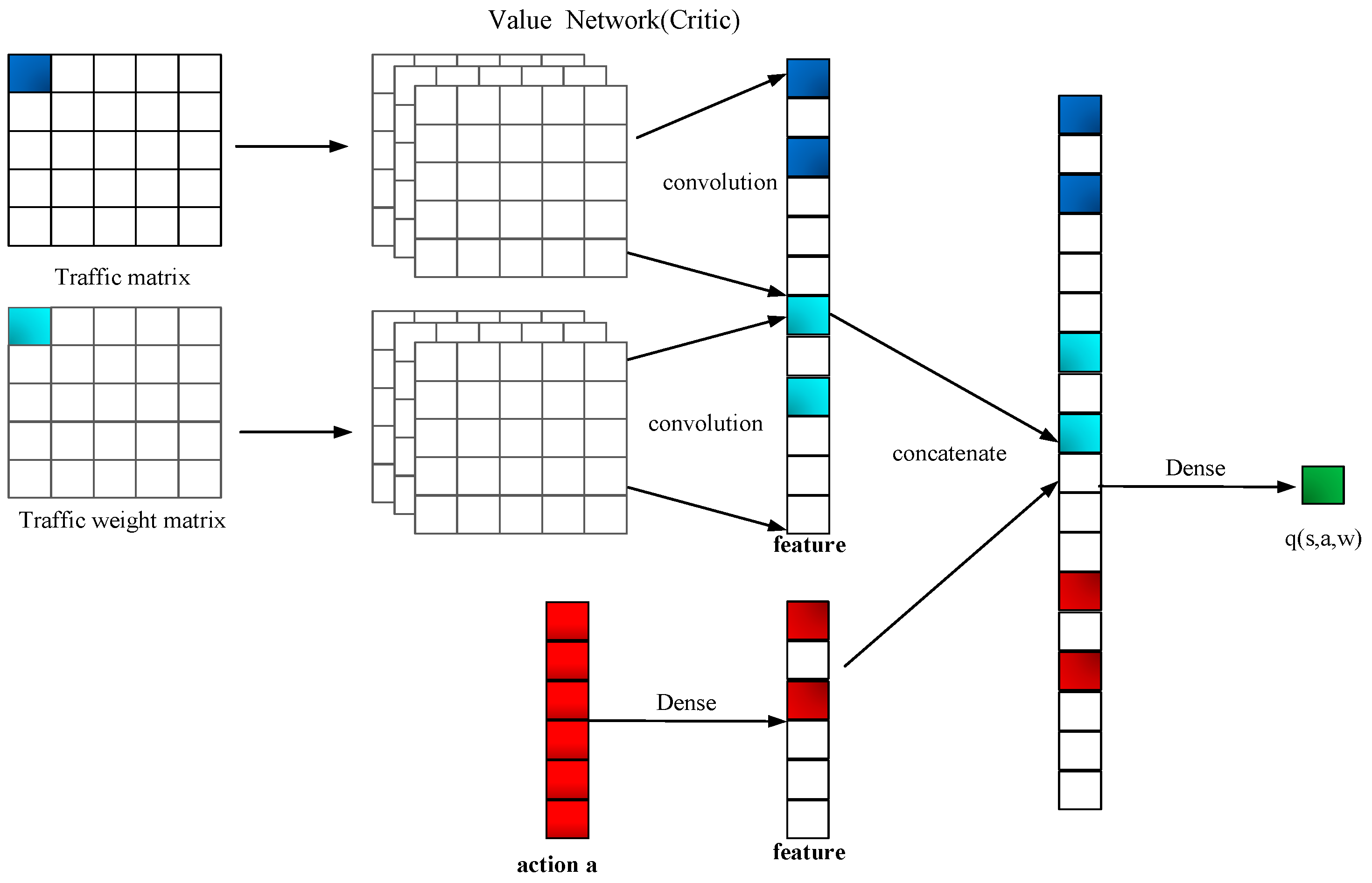
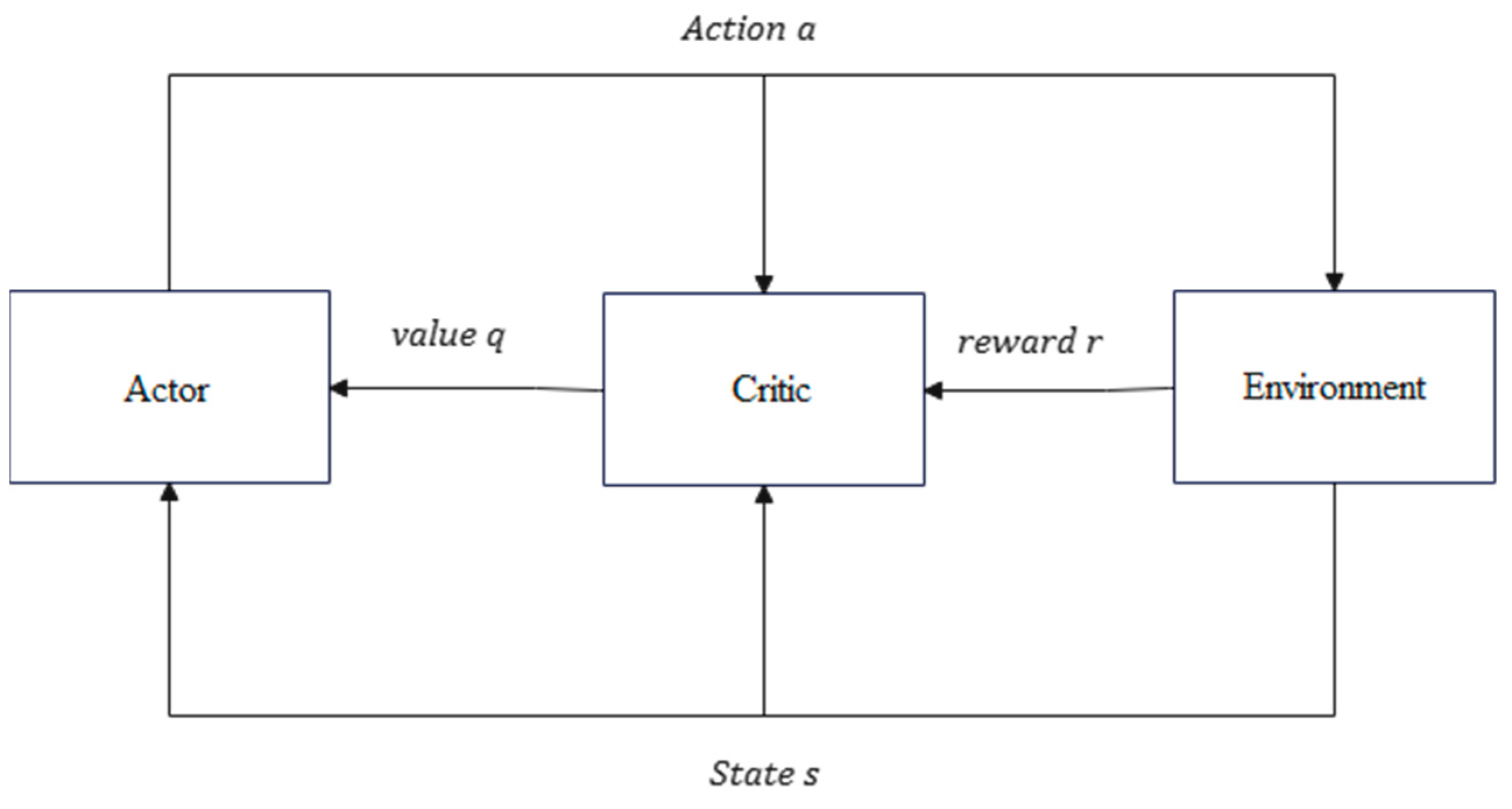
2.4. Actor Network and Critic Network
- : this is the value function for state , where represents the parameters of the policy network (Actor) and represents the parameters of the value function network (Critic);
- : this denotes the summation over all possible actions , indicating the summation over the action space;
- : this is the State-action Value Function (Q-value Function) generated by the value function network, representing the expected value of taking action in state ;
- : this is the action probability generated by the policy network, representing the probability of taking action. This is the action probability generated by the policy network, representing the probability of taking action in state .
3. The CFRW-RL Algorithm
3.1. Critical Flow Identification
- Observe the current state of the environment at time step t, use it as input, and calculate the probability distribution with the policy network. Randomly sample an action based on the computed probabilities.
- The intelligent agent executes the action , the environment transitions to a new state , and a reward is given.
- Use the new stat as input and calculate the probability distribution with the policy network. Randomly sample an action (note that this action is for computing the Q-value and is not actually executed).
- Evaluate the value network using Equations (7) and (8).
- Calculate the Temporal Difference (TD) error using Equation (9).
- Derive the value network using Equation (10).
- Update the value network using Equation (11). This involves gradient descent to make the predicted value closer to the TD target.
- Derive the policy network using Equation (12).
- Update the policy network using Equation (13). This involves gradient ascent to increase the score of the Actor’s action.
| Algorithm 1: pseudocode for the critical flow selection algorithm | |
| 1 | Initialize actor network parameters θ_actor, critic network parameters θ_critic |
| 2 | Initialize actor optimizer optimizer_actor and critic optimizer optimizer_critic |
| 3 | for each training iteration do: |
| 4 | Collect a batch of inputs, actions, rewards (and possibly next states) from the environment |
| 5 | with tf.GradientTape(tape1) as tape1: |
| 6 | Compute critic model’s value predictions values from inputs |
| 7 | Calculate value loss and advantages using value_loss_fn with rewards and values |
| 8 | Compute gradients for the critic network with tape1 |
| 9 | Update critic network parameters using optimizer_critic and critic_gradients |
| 10 | with tf.GradientTape(tape2) as tape2: |
| 11 | Compute actor model’s policy logits from inputs |
| 12 | Calculate policy loss and entropy using policy_loss_fn with logits, actions, advantages, and entropy_weight |
| 13 | Compute gradients for the actor network with tape2 |
| 14 | Update actor network parameters using optimizer_actor and actor_gradients |
| 15 | End for |
- ‘θ_actor’ and ‘θ_critic’ represent the parameters of the Actor network and Critic network, respectively.
- ‘optimizer_actor’ and ‘optimizer_critic’ are the optimizers used to update the network parameters.
- During each training iteration, a batch of inputs, actions, and rewards (and possibly next states) is first collected from the environment.
- ‘tf.GradientTape’ is used to track the gradients of the Critic network, and to calculate the value loss and advantage values.
- The gradients computed are used to update the parameters of the Critic network.
- ‘tf.GradientTape’ is used again to track the gradients of the Actor network, and to calculate the policy loss and entropy.
- The gradients computed are used to update the parameters of the Actor network.
3.2. Critical Flow Rerouting Strategy
4. Simulation and Results Analysis
4.1. Experimental Setup
4.1.1. Dataset
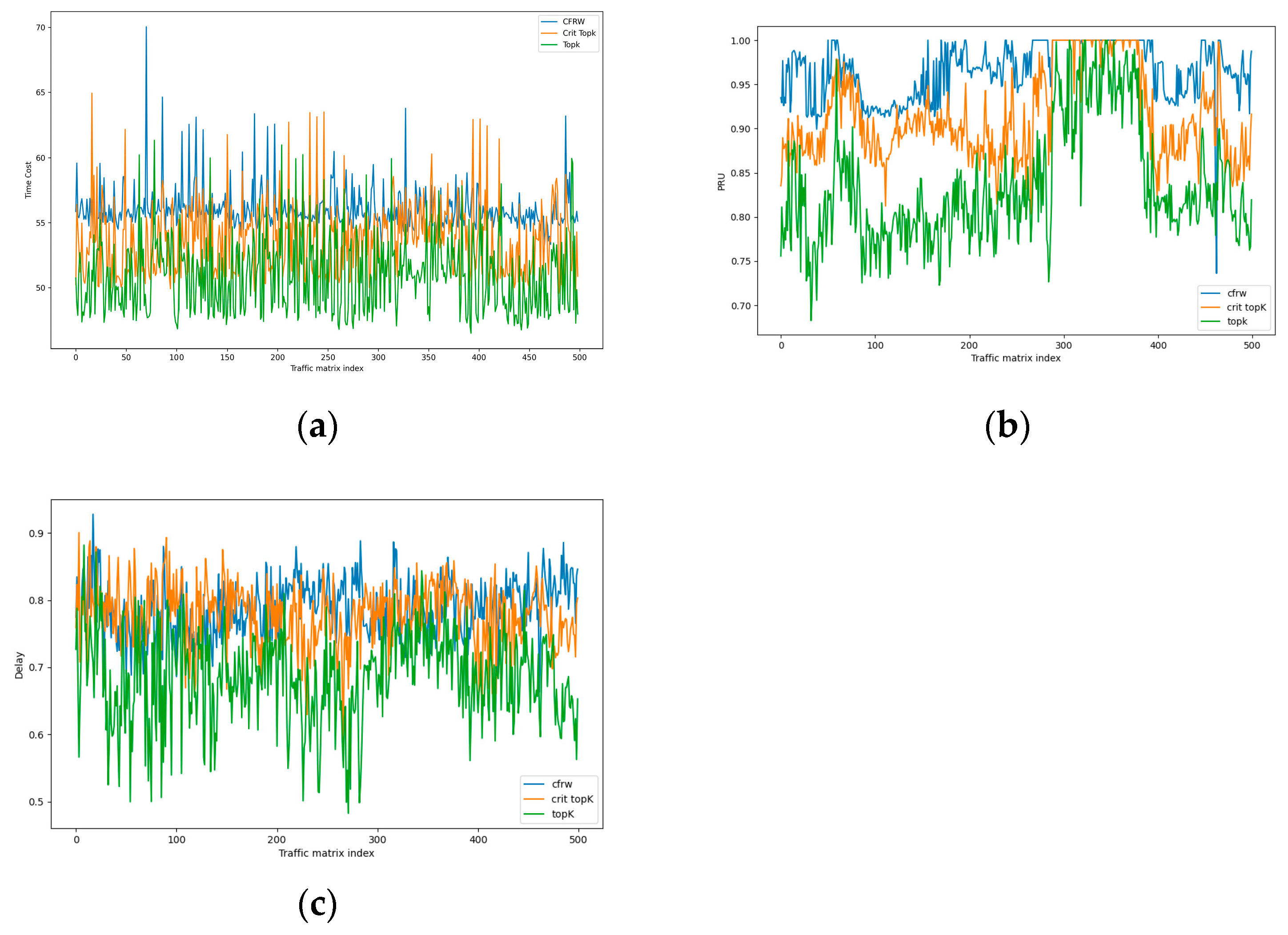
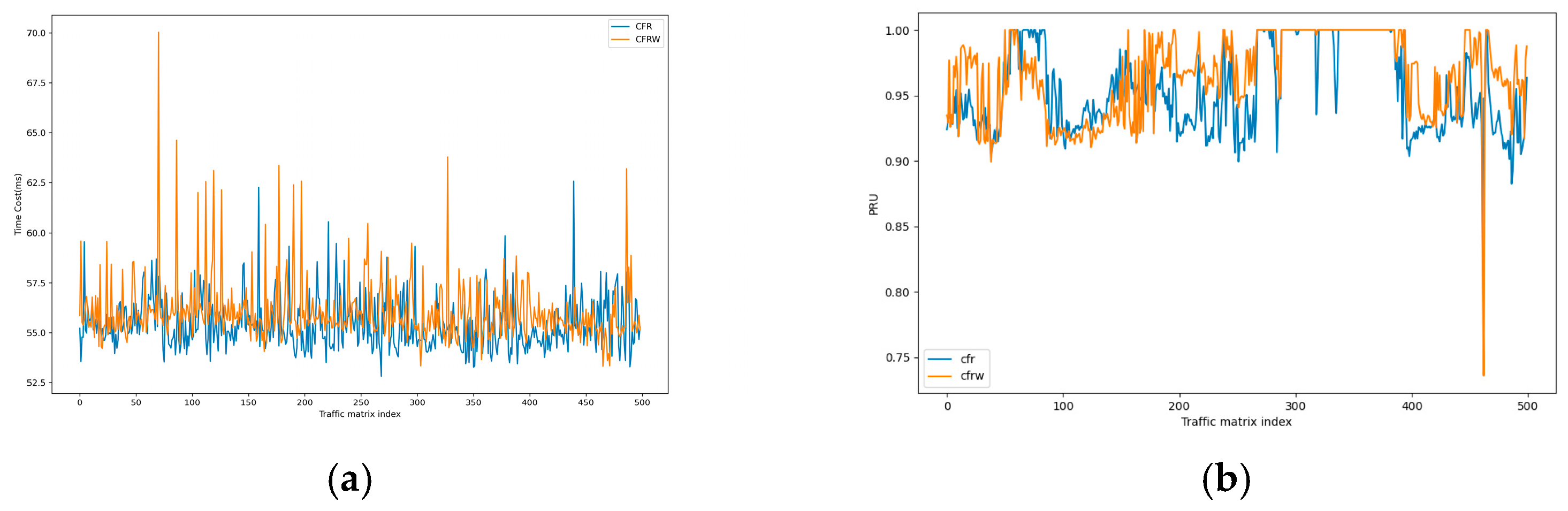
4.1.2. Evaluation Metrics
- 1.
- Load-balancing Performance Ratio
- 2.
- Rerouting Disruption (RD)
- 3.
- Comparison Algorithms
- (1)
- Top-K Algorithm
- (2)
- Top-K Critical Algorithm
- (3)
- CFR-RL Algorithm
4.2. Experiments and Results Analysis
4.2.1. Generation of Data-Flow Weight Values
- 1.
- Data Fitting
- 2.
- Generating Weights Based on Probability Distribution and Normalization
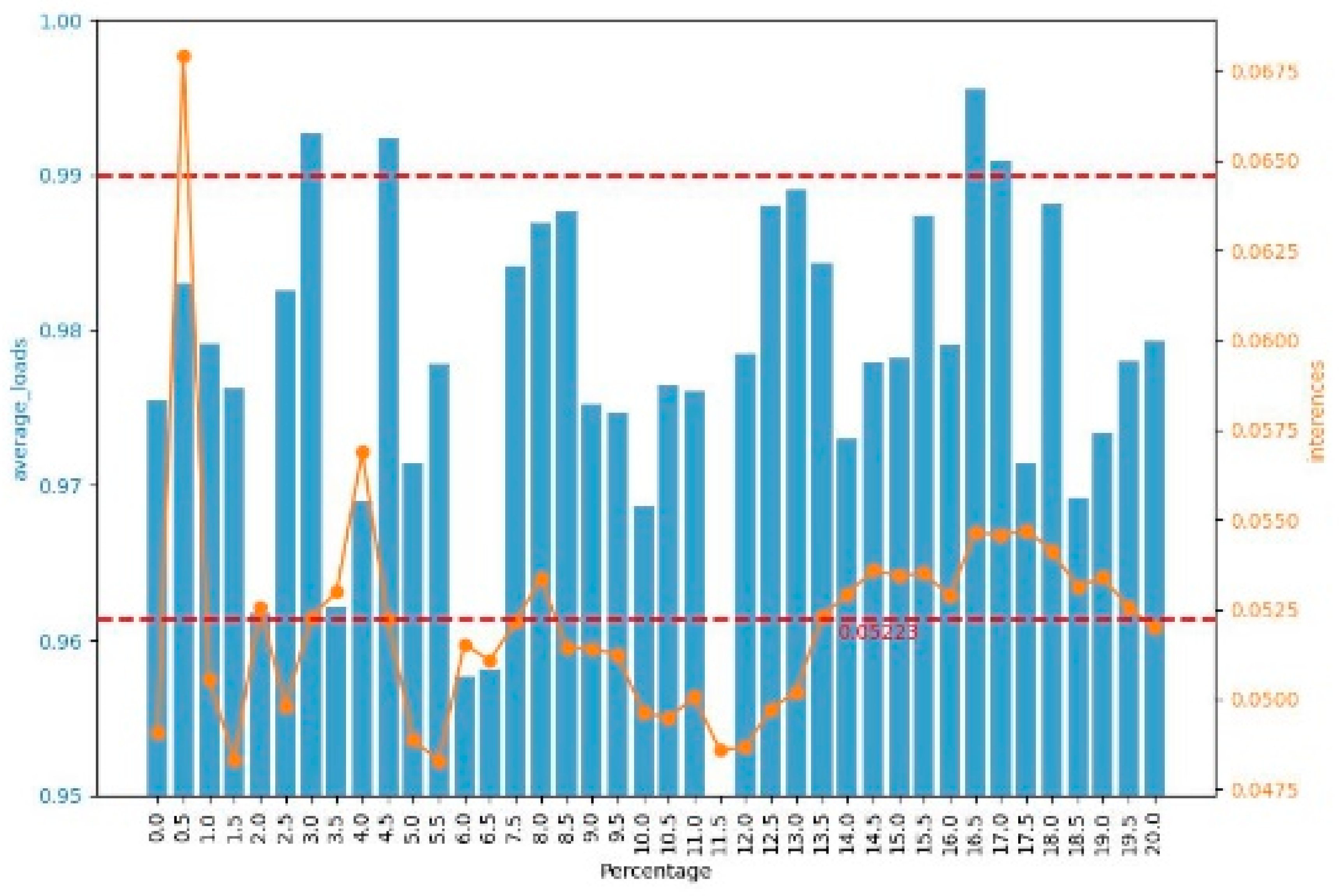
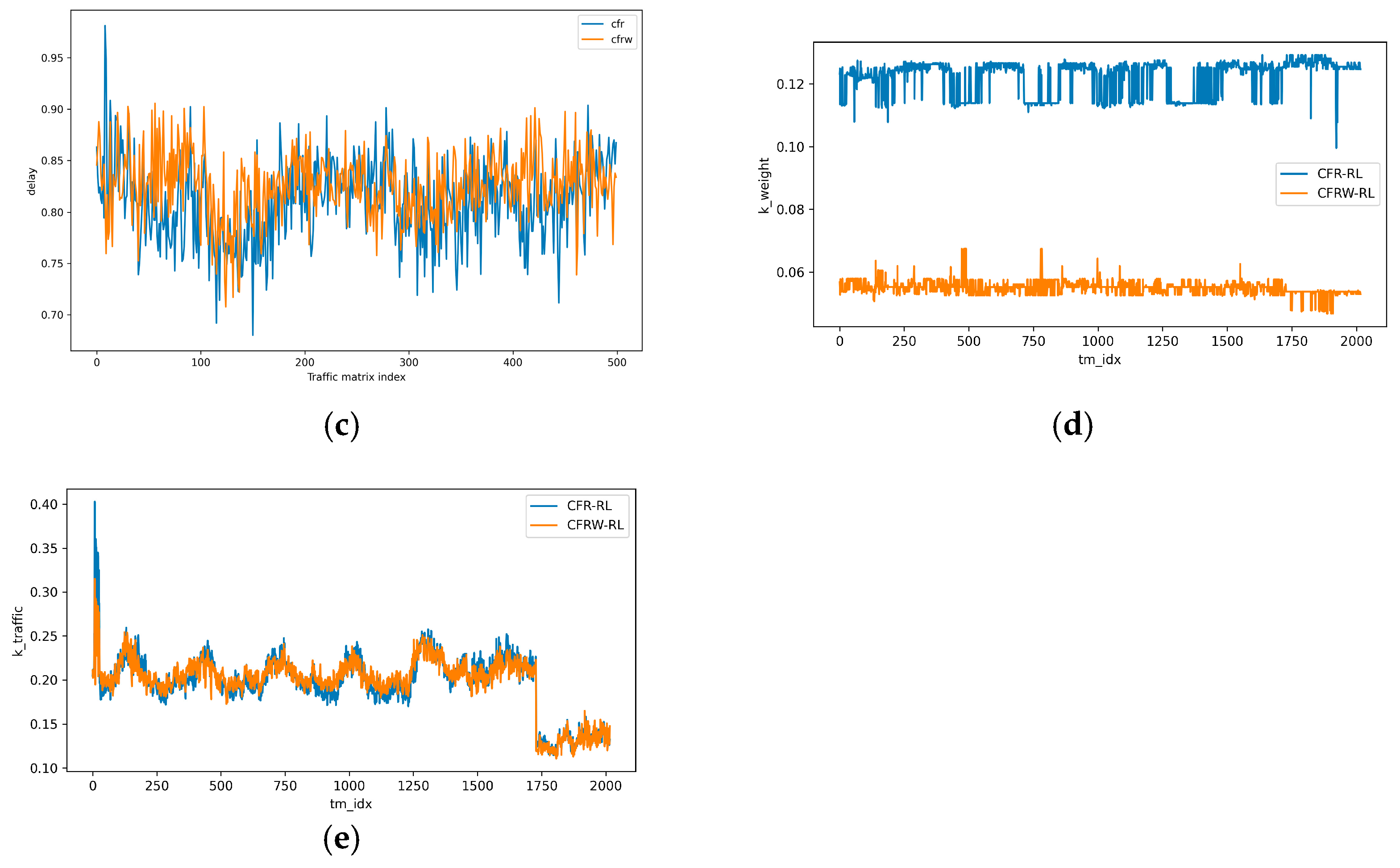
4.2.2. Impact of Key Flow Setting Ratio on CFRW-RL Algorithm
4.2.3. Effect of Weight Proportion ε on CFRW-RL Algorithm
4.2.4. Validation of the Effectiveness of a Reinforcement Learning Network Structure
4.2.5. Performance Comparison between CFRW-RL Algorithm and Heuristic Algorithms
4.2.6. Performance Comparison between the CFRW-RL Algorithm and CFR-RL Algorithm
5. Conclusions
- Adaptive Weight Adjustment Mechanism: We will research and develop a mechanism that can dynamically adjust the weights of data flows based on real-time network conditions and business requirements. This will help achieve more refined and effective traffic management in changing network environments.
- Algorithmic Scalability: We will investigate the scalability of the algorithm for large enterprise networks, particularly in the face of complex network topologies and high volumes of traffic, to ensure the effectiveness and efficiency of the algorithm.
- Real-World Deployment and Testing: We plan to deploy and test the CFRW-RL algorithm in real enterprise network environments to verify its practical applicability and to further optimize the algorithm’s performance based on actual data.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Garani, S.S.; Zhang, T.; Motwani, R.H.; Pozidis, H.; Vasic, B. Guest Editorial Channel Modeling, Coding and Signal Processing for Novel Physical Memory Devices and Systems. IEEE J. Sel. Areas Commun. 2016, 34, 2289–2293. [Google Scholar] [CrossRef]
- Chang, H.; Kodialam, M.; Lakshman, T.V.; Mukherjee, S.; Van der Merwe, J.K.; Zaheer, Z. MAGNet: Machine Learning Guided Application-Aware Networking for Data Centers. IEEE Trans. Cloud Comput. 2023, 11, 291–307. [Google Scholar] [CrossRef]
- Garcia-Dorado, J.L.; Rao, S.G. Cost-aware Multi Data-Center Bulk Transfers in the Cloud from a Customer-Side Perspective. IEEE Trans. Cloud Comput. 2019, 7, 34–47. [Google Scholar] [CrossRef]
- Zhu, J.; Jiang, X.; Yu, Y.; Jin, G.; Chen, H.; Li, X.; Qu, L. An efficient priority-driven congestion control algorithm for data center networks. China Commun. 2020, 17, 37–50. [Google Scholar] [CrossRef]
- Islam, S.U.; Javaid, N.; Pierson, J.M. A novel utilisation-aware energy consumption model for content distribution networks. Int. J. Web Grid Serv. 2017, 13, 290. [Google Scholar] [CrossRef]
- Guo, Y.; Ma, Y.; Luo, H.; Wu, J. Traffic Engineering in a Shared Inter-DC WAN via Deep Reinforcement Learning. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2870–2881. [Google Scholar] [CrossRef]
- Xu, Z.; Tang, J.; Meng, J.; Zhang, W.; Wang, Y.; Liu, C.H.; Yang, D. Experience-driven Networking: A Deep Reinforcement Learning based Approach. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1871–1879. [Google Scholar]
- Guo, Y.; Wang, W.; Zhang, H.; Guo, W.; Wang, Z.; Tian, Y.; Yin, X.; Wu, J. Traffic Engineering in Hybrid Software Defined Network via Reinforcement Learning. J. Netw. Comput. Appl. 2021, 189, 103116. [Google Scholar] [CrossRef]
- Sun, P.; Hu, Y.; Lan, J.; Tian, L.; Chen, M. TIDE: Time-relevant deep reinforcement learning for routing optimization. Future Gener. Comput. Syst. 2019, 99, 401–409. [Google Scholar] [CrossRef]
- Sun, P.; Guo, Z.; Lan, J.; Li, J.; Hu, Y.; Baker, T. ScaleDRL: A Scalable Deep Reinforcement Learning Approach for Traffic Engineering in SDN with Pinning Control. Comput. Netw. 2021, 190, 107891. [Google Scholar] [CrossRef]
- Rischke, J.; Sossalla, P.; Salah, H.; Fitzek, F.H.P.; Reisslein, M. QR-SDN: Towards Reinforcement Learning States, Actions, and Rewards for Direct Flow Routing in Software-Defined Networks. IEEE Access 2020, 8, 174773–174791. [Google Scholar] [CrossRef]
- Wu, T.; Zhou, P.; Wang, B.; Li, A.; Tang, X.; Xu, Z.; Chen, K.; Ding, X. Joint traffic control and multichannel reassignment for core backbone network in SDN-IoT: A multi-agent deep reinforcement learning approach. IEEE Trans. Netw. Sci. Eng. 2020, 8, 231–245. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, J.; Bai, W.; Chen, K.; Chowdhury, M. Resilient datacenter load balancing in the wild. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 253–266. [Google Scholar]
- Zhang, J.; Ye, M.; Guo, Z.; Yen, C.-Y.; Chao, H.J. CFR-RL: Traffic Engineering with Reinforcement Learning in SDN. IEEE J. Sel. Areas Commun. 2020, 38, 2249–2259. [Google Scholar] [CrossRef]
- Wu, X.; Huang, C.; Tang, M.; Sang, Y.; Zhou, W.; Wang, T.; He, Y.; Cai, D.; Wang, H.; Zhang, M. NetO: Alibaba’s WAN Orchestra-tor[EB/OL]. 2017. Available online: http://conferences.sigcomm.org/sigcomm/2017/files/program-industrial-demos/sigcomm17industrialdemos-paper1.pdf (accessed on 26 October 2017).
- Wang, R.; Zhang, Y.; Wang, W.; Xu, K.; Cui, L. Algorithm of Mixed Traffic Scheduling Among Data Centers Based on Prediction. J. Comput. Res. Dev. 2021, 58, 1307–1317. [Google Scholar] [CrossRef]
- Kandula, S.; Menache, I.; Schwartz, R.; Babbula, S.R. Calendaring for wide area networks. In Proceedings of the 2014 ACM conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; pp. 515–526. [Google Scholar]
- Mao, H.; Alizadeh, M.; Menache, I.; Kandula, S. Resource management with deep reinforcement learning. In Proceedings of the 15th ACM Workshop on Hot Topics in Networks, Atlanta, GA, USA, 9–10 November 2016; pp. 50–56. [Google Scholar]
- Zhang, Y. Abilene Network Traffic Data[EB/OL]. 2023. Available online: https://www.cs.utexas.edu/~yzhang/research/AbileneTM (accessed on 26 October 2017).
- Benson, T.; Akella, A.; Maltz, D.A. Network traffic characteristics of data centers in the wild. In Proceedings of the 10th ACM SIGCOMM Conference on Internet measurement, Melbourne, Australia, 1–3 November 2010; pp. 267–280. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| The physical bandwidth of link . | |
| The total load of link , . | |
| The initial load of link . | |
| The set of K critical flows identified by the CFRW-RL algorithm. | |
| The residual flows excluding . | |
| The bandwidth requirement for the data flow from source node s to destination node d, . | |
| The probability of the data flow from source node s to destination node d traversing link , . | |
| U | The maximum bandwidth utilization across various links in the network. |
| The traffic demand employing the ECMP algorithm. | |
| The traffic demand of critical flow . | |
| The in-degree of node i | |
| The out-degree of node i. | |
| The traffic load of critical flow allocated to link . |
| Probability Distribution | EXPONWEIB | WEIBULL_MIN | Gamma | Gamma | Other |
|---|---|---|---|---|---|
| Percentage | 43.95% | 20.19% | 17.7% | 12.81% | 5.35% |
| Algorithm | Time Consumption (ms) | Load-Balancing Ratio | Delay (ms) | The Average Traffic | The Average Weight |
|---|---|---|---|---|---|
| CFRW-RL | 56.04 | 95.7% | 0.8075 | 0.1972 | 0.0550 |
| CFR-RL | 55.44 | 95.6% | 0.8068 | 0.1965 | 0.1673 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, H.; Luo, Y.; Zhang, L.; Liao, Z. A Reinforcement Learning-Based Traffic Engineering Algorithm for Enterprise Network Backbone Links. Electronics 2024, 13, 1441. https://doi.org/10.3390/electronics13081441
Cheng H, Luo Y, Zhang L, Liao Z. A Reinforcement Learning-Based Traffic Engineering Algorithm for Enterprise Network Backbone Links. Electronics. 2024; 13(8):1441. https://doi.org/10.3390/electronics13081441
Chicago/Turabian StyleCheng, Haixiu, Yingxin Luo, Ling Zhang, and Zhiwen Liao. 2024. "A Reinforcement Learning-Based Traffic Engineering Algorithm for Enterprise Network Backbone Links" Electronics 13, no. 8: 1441. https://doi.org/10.3390/electronics13081441
APA StyleCheng, H., Luo, Y., Zhang, L., & Liao, Z. (2024). A Reinforcement Learning-Based Traffic Engineering Algorithm for Enterprise Network Backbone Links. Electronics, 13(8), 1441. https://doi.org/10.3390/electronics13081441