

Robust Distributed Containment Control with Adaptive Performance and Collision Avoidance for Multi-Agent Systems

Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
- We propose a novel distributed estimation algorithm for a reference trajectory that converges within the convex hull of the leaders with the prescribed transient and steady-state performance, even though the leaders may be dynamic. To the best of the authors’ knowledge, this is the first time that a distributed dynamic average consensus algorithm is adopted to calculate a reference trajectory that enters the convex hull of the leaders and remains there, despite the state evolution of the leaders, thus yielding a rather robust trajectory estimation scheme.
- We enforce robust trajectory tracking with adaptive performance despite the presence of bounded, piece-wise continuous but unmodeled disturbances. Notice that since the control action of each follower is rendered local, owing to the distributed estimation of a reference trajectory that lies within the convex hull of the leaders, the application of the adaptive performance tracking control technique reinforces the robustness against model uncertainties.
- Imminent collisions among the agents are avoided by adopting a novel adaptation of the performance specifications when agents approach each other. As collision avoidance among the agents and the trajectory tracking of a common trajectory become eventually conflicting, we introduce, for the first time, a relaxation of the performance envelope based on the distances of closely related agents.
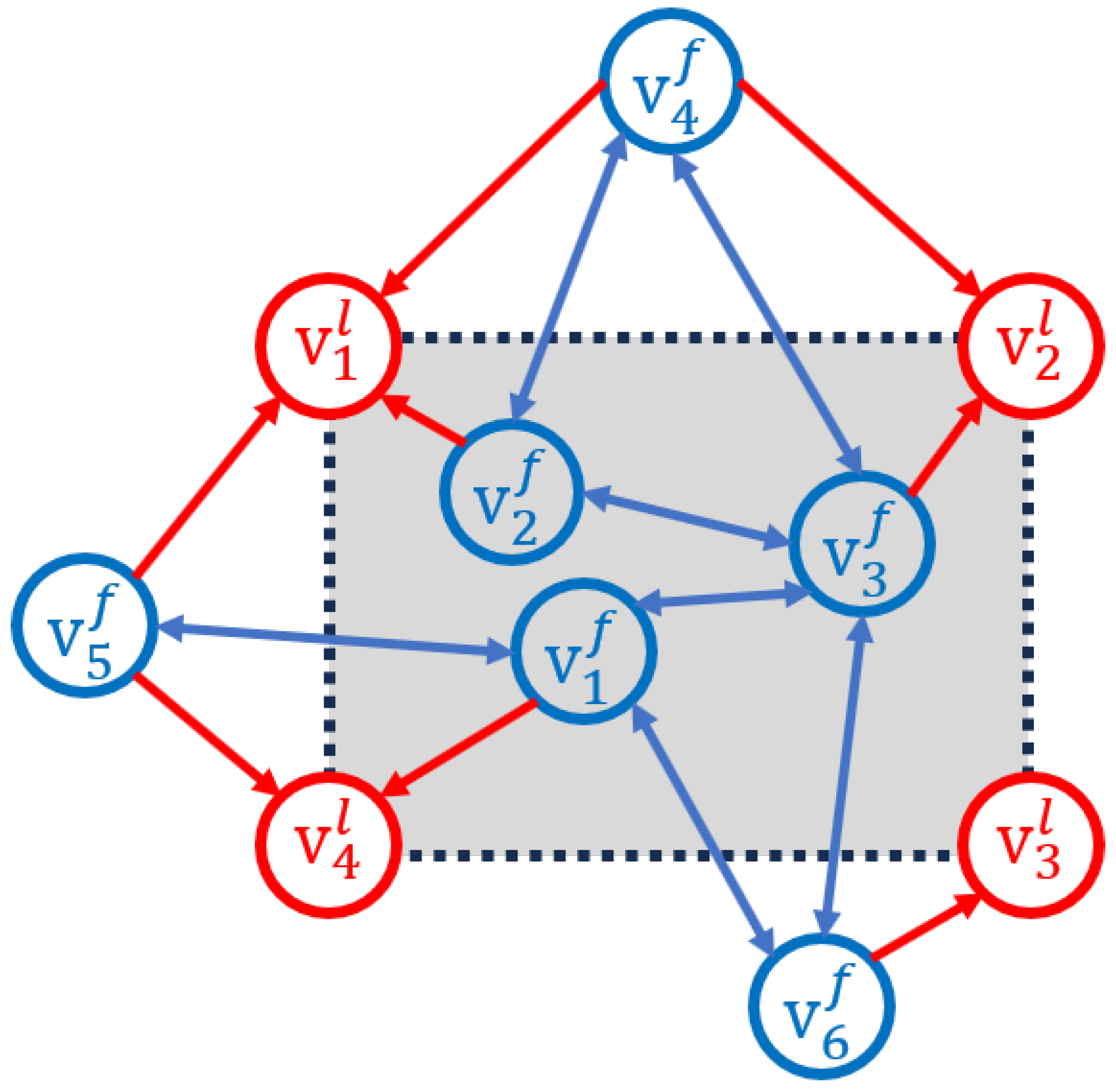
2. Problem Formulation
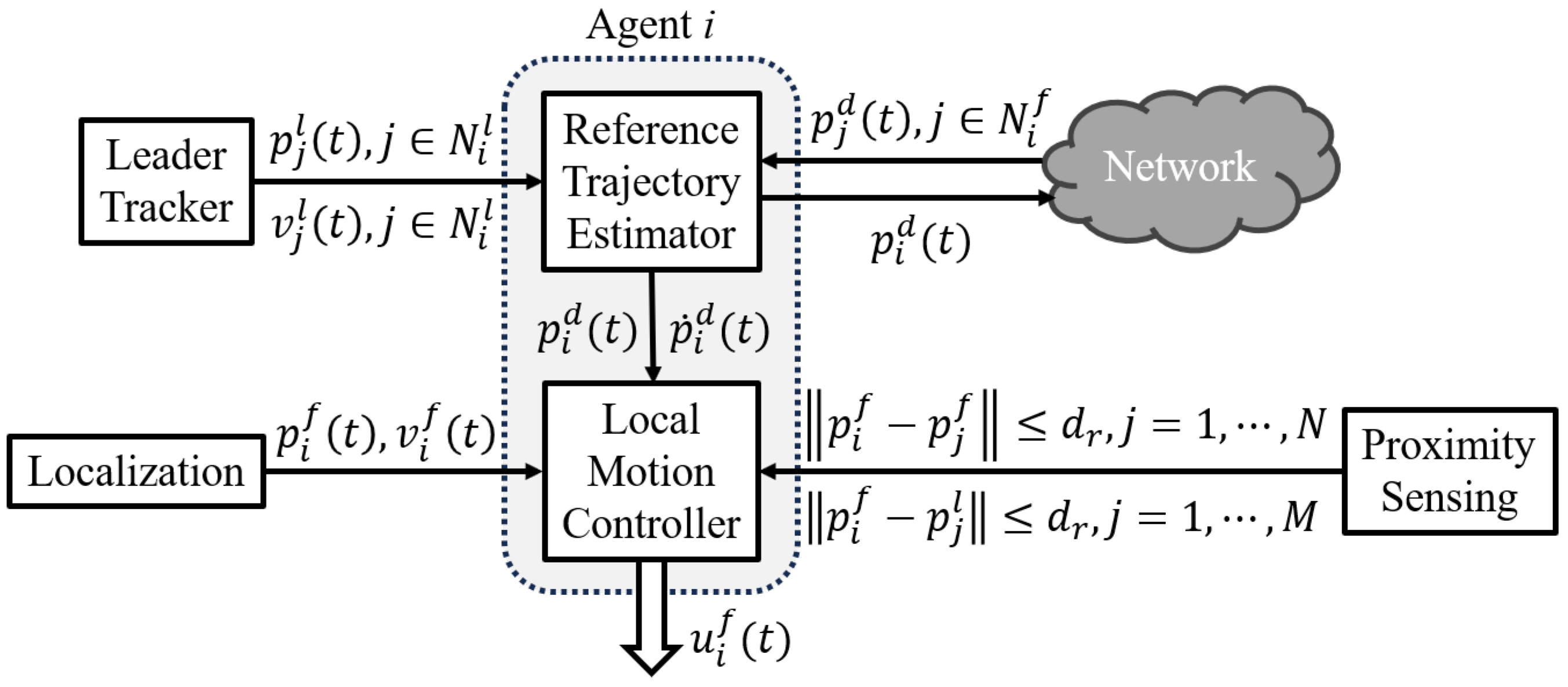
3. Control Design
3.1. Distributed Reference Trajectory Estimation
3.2. Local Motion Control
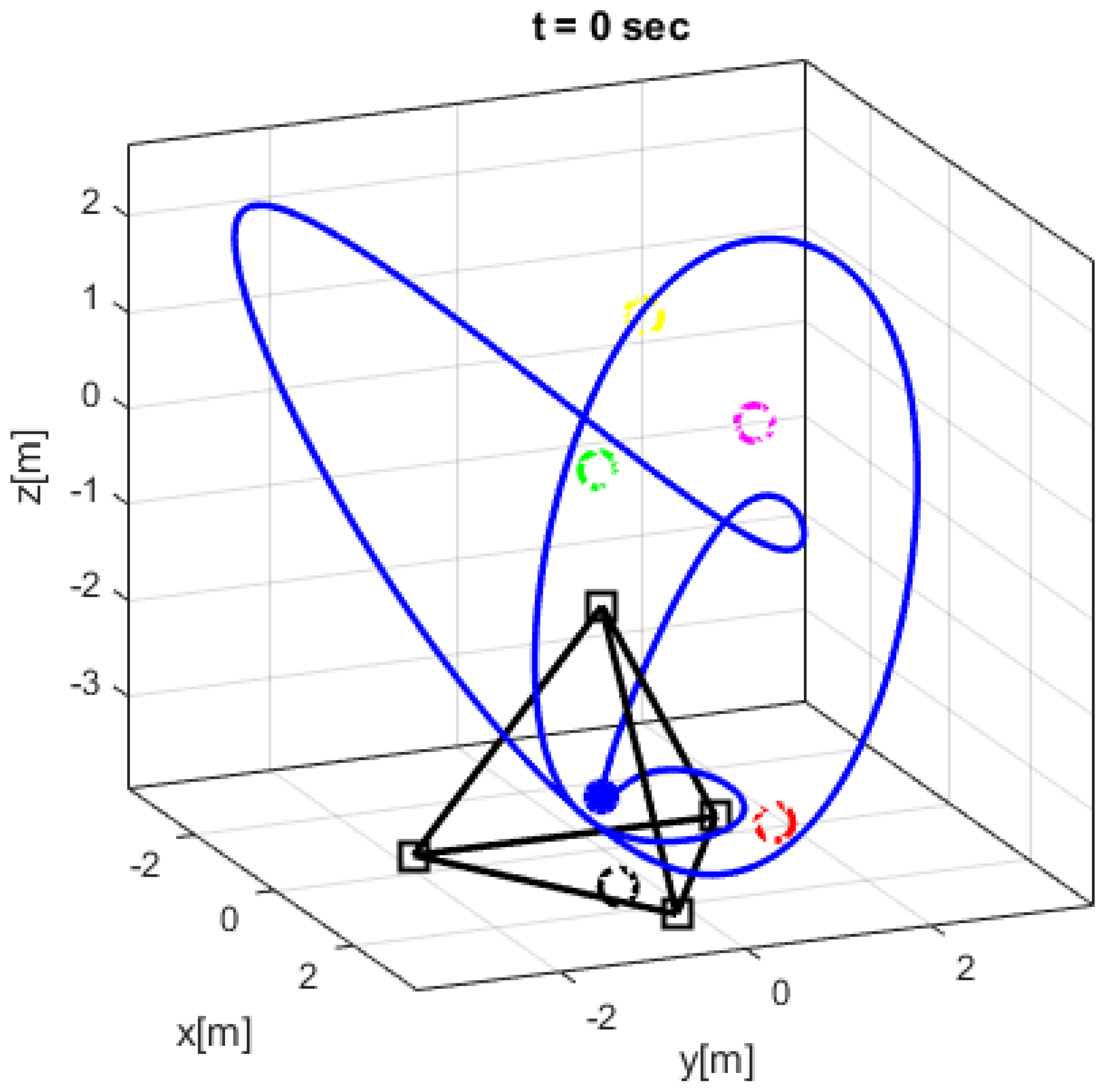
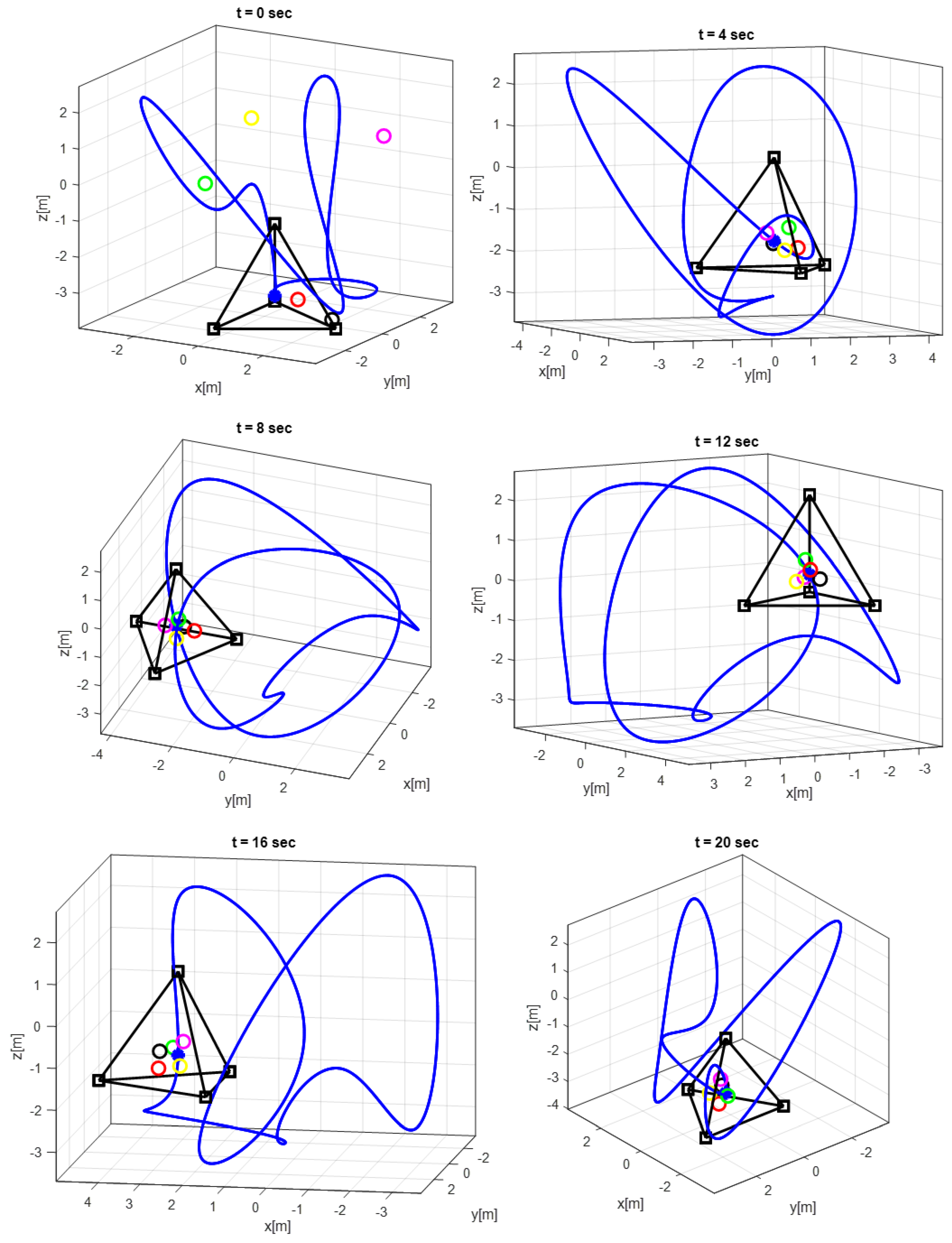
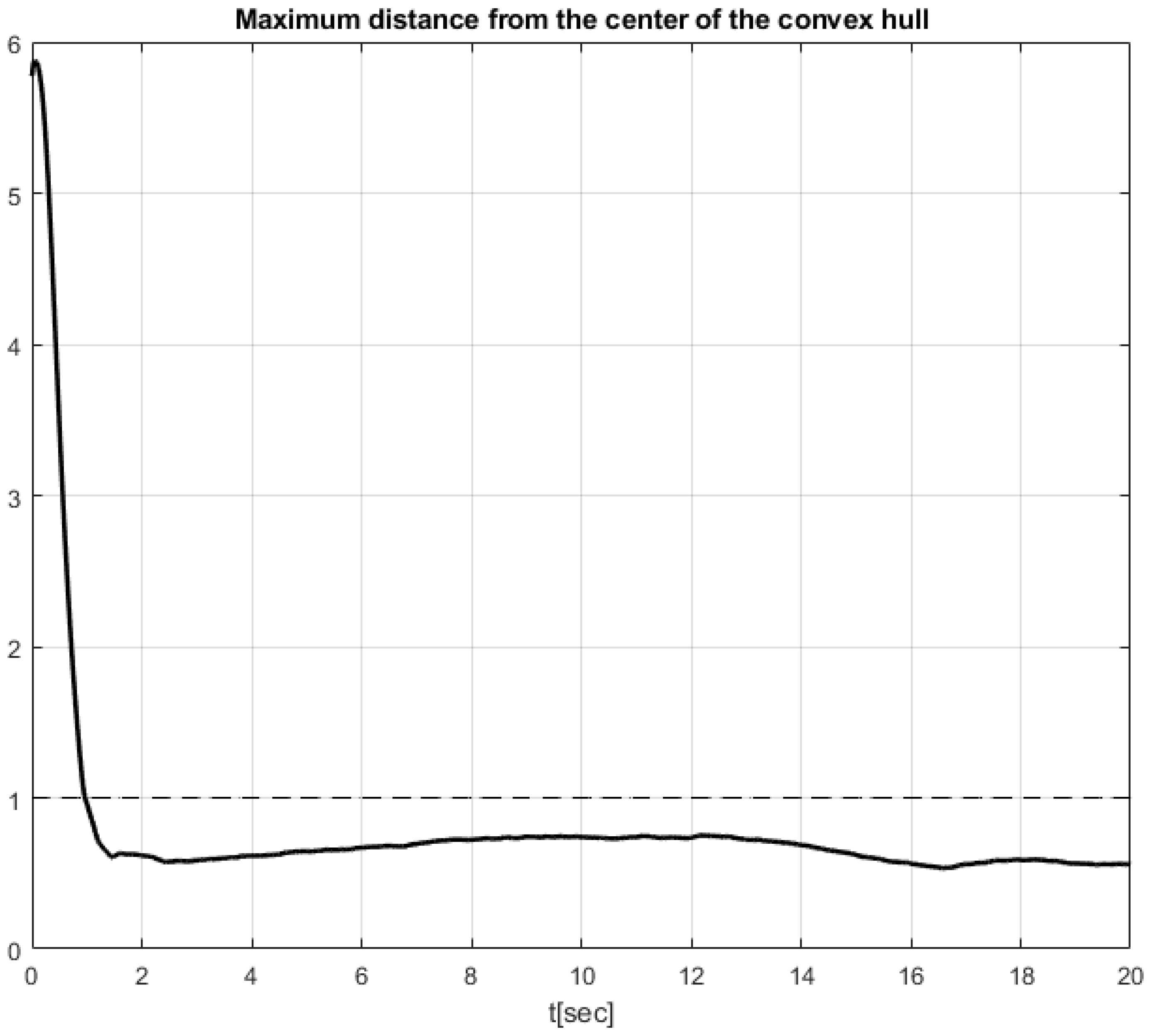
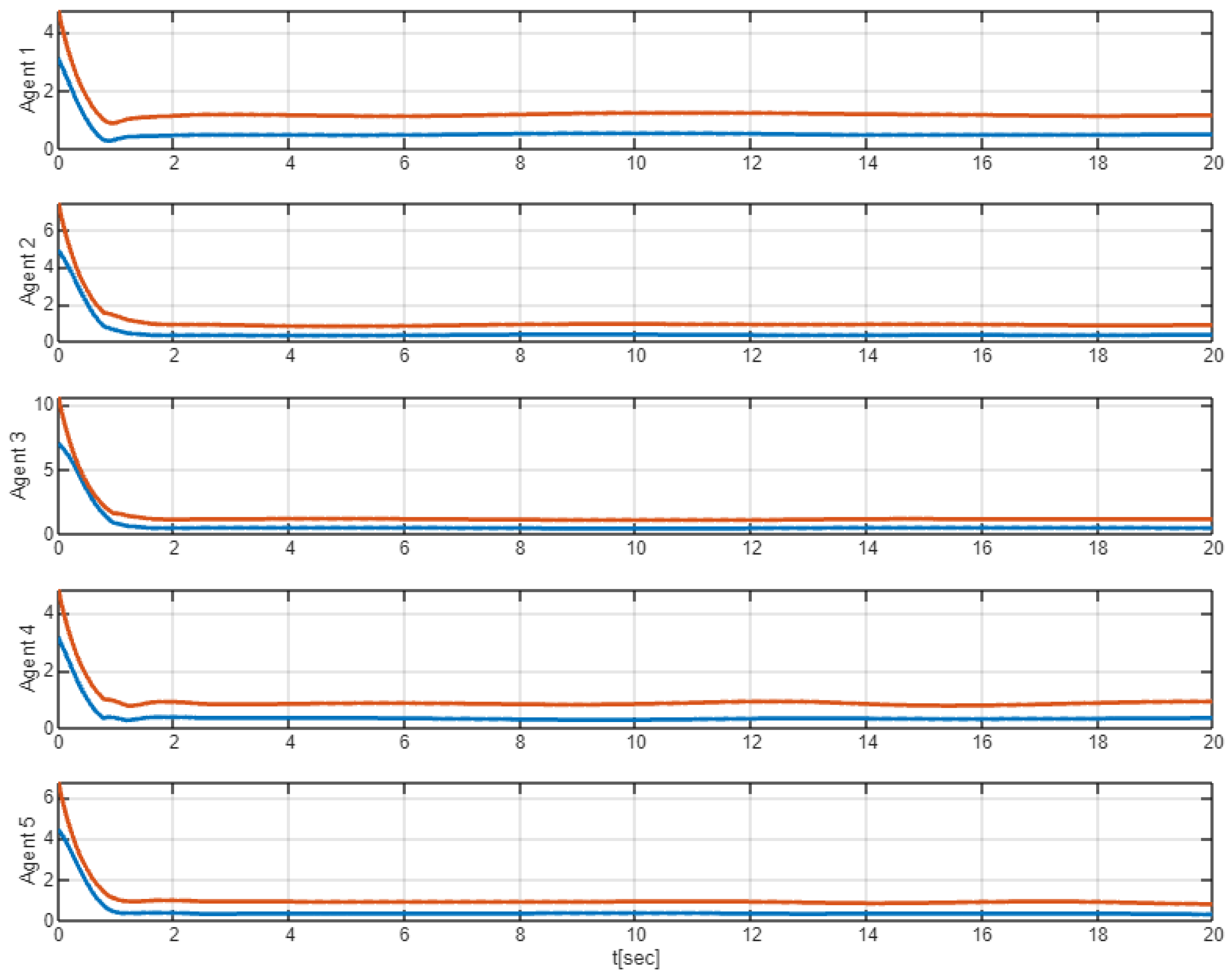
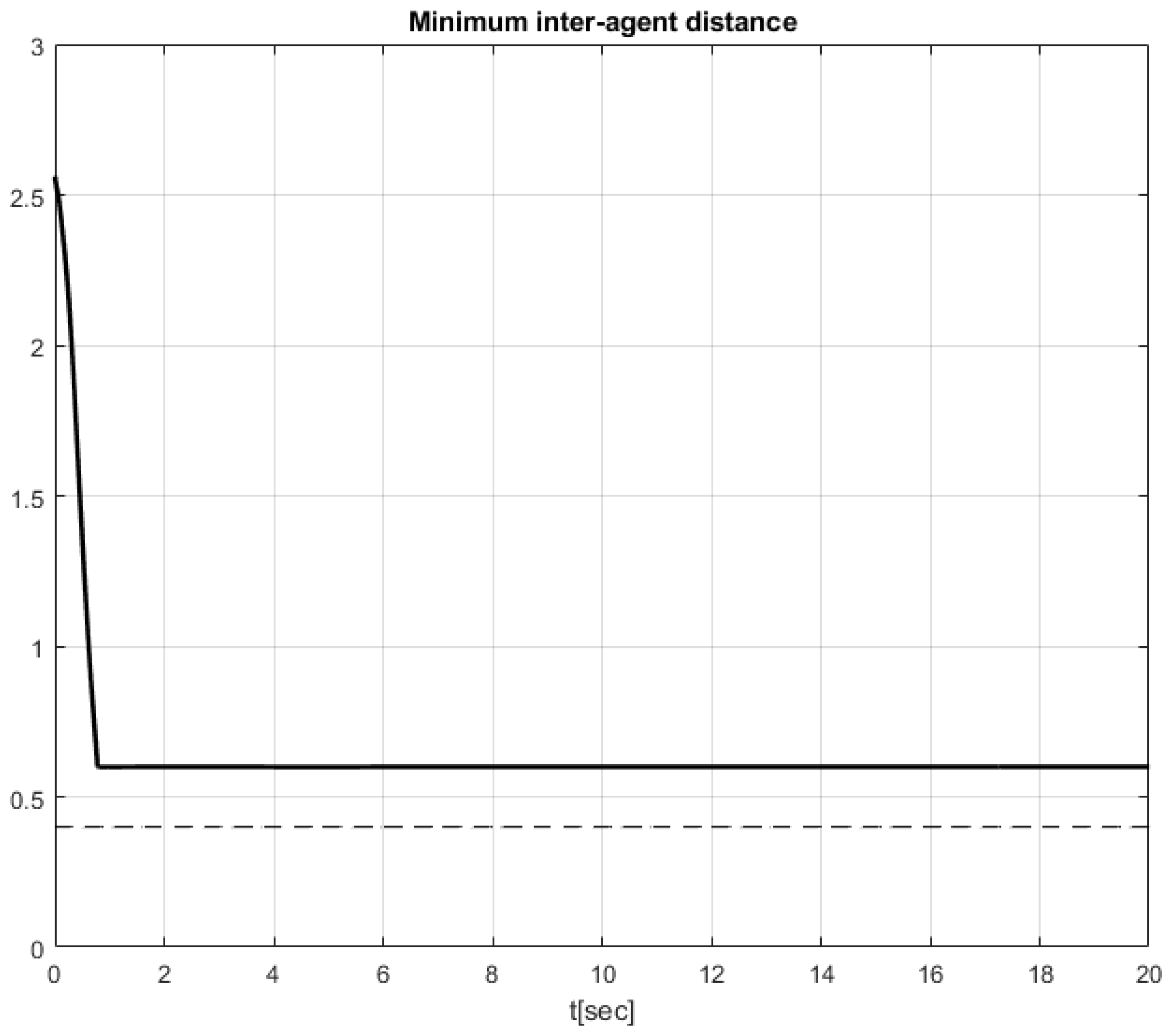
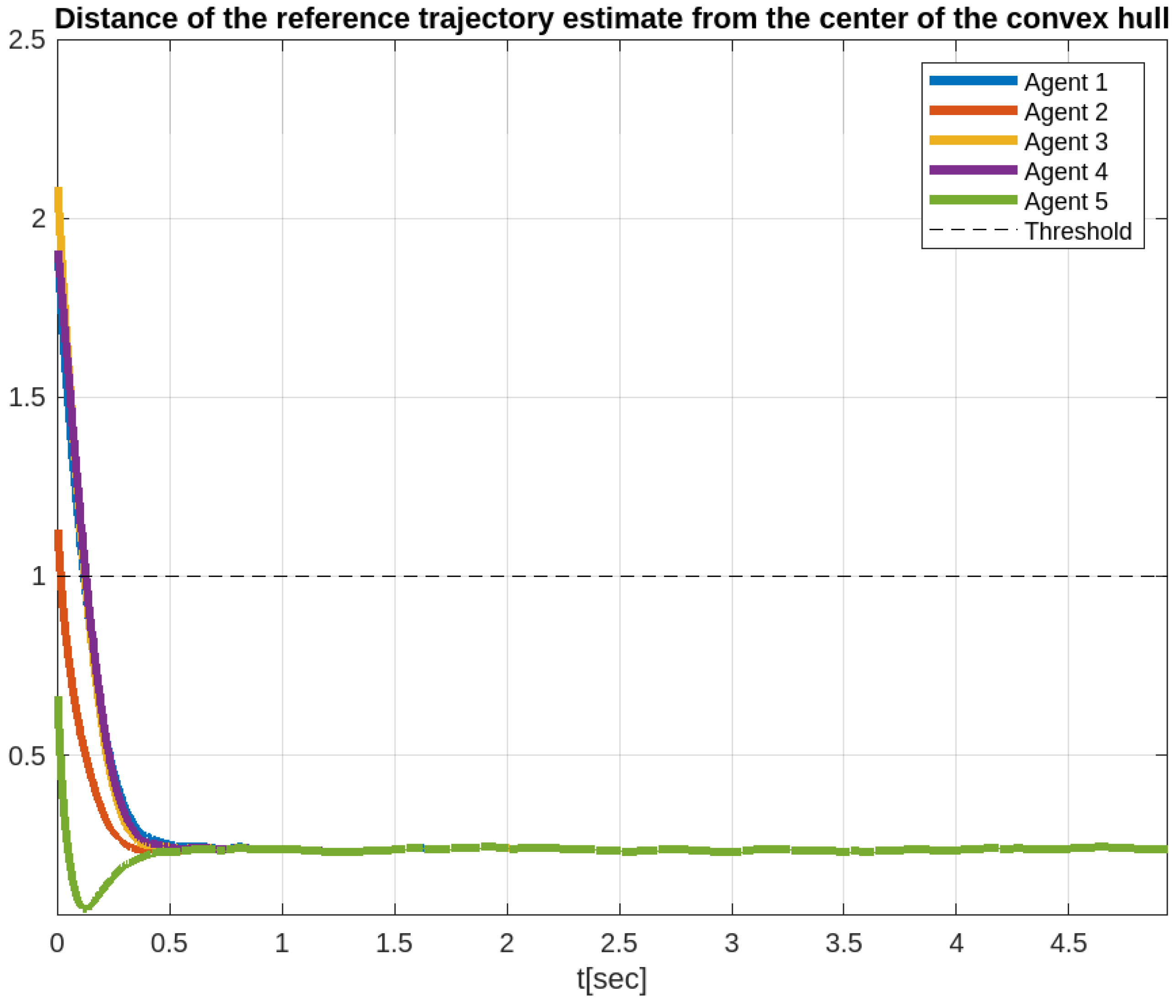
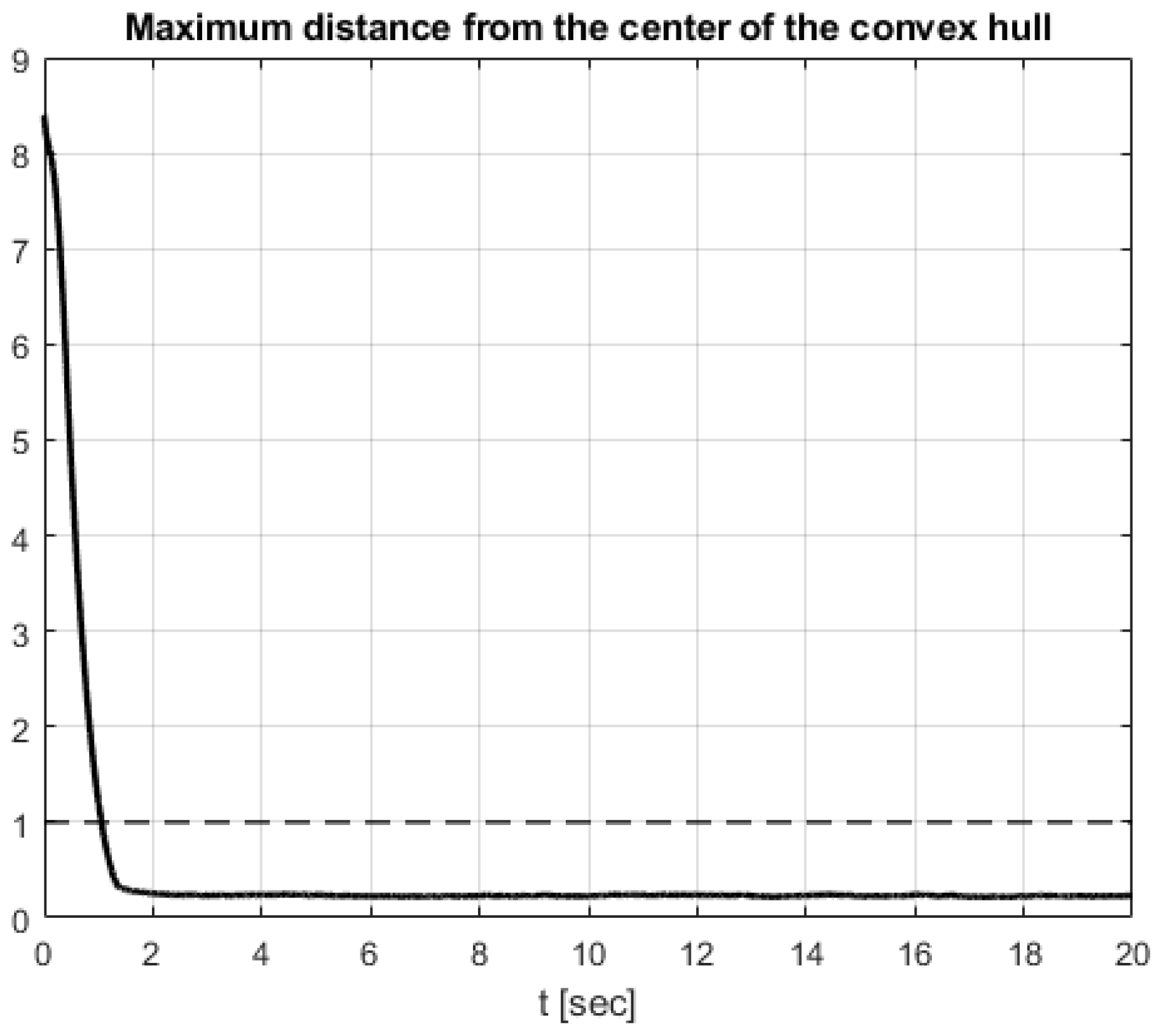
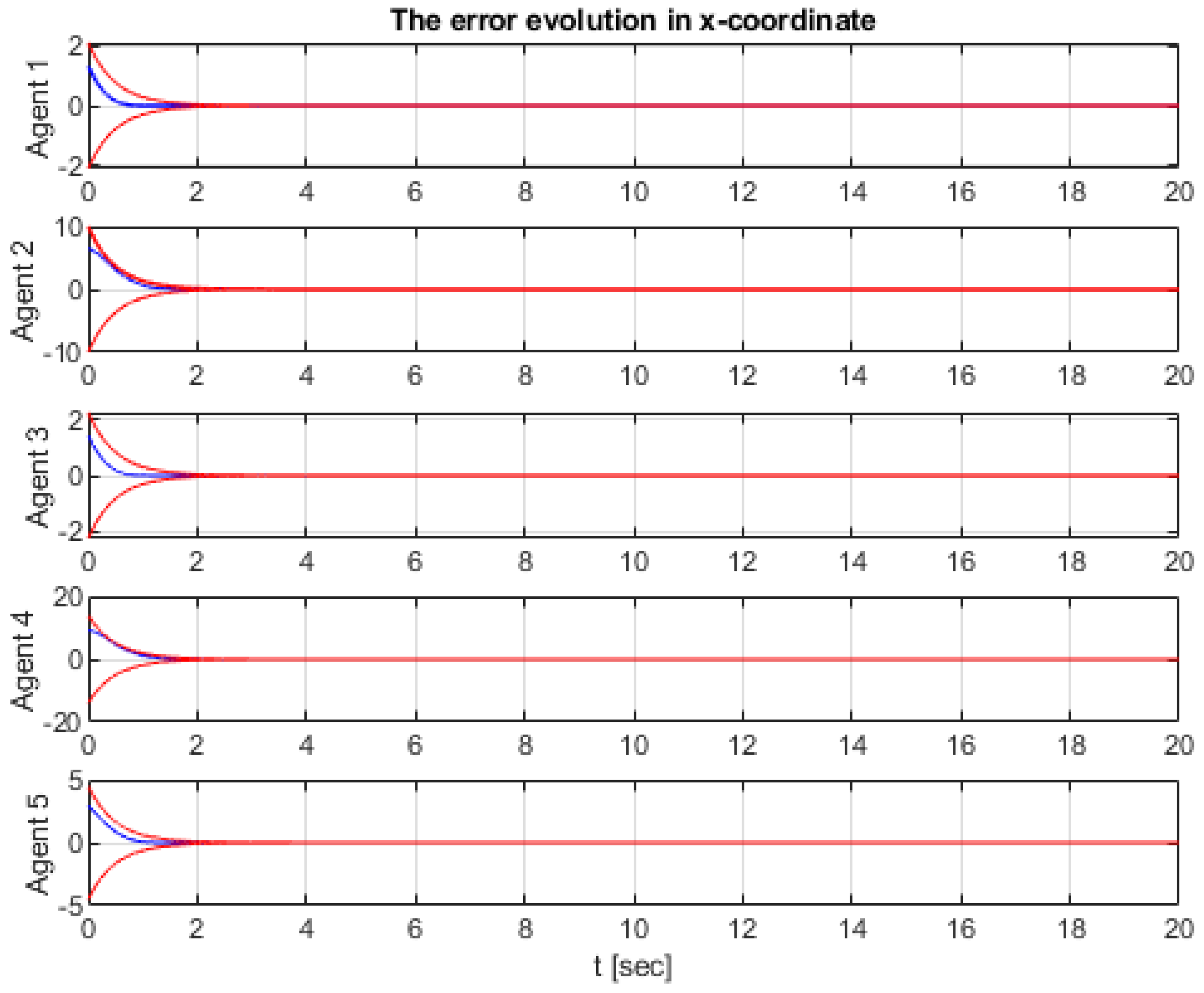
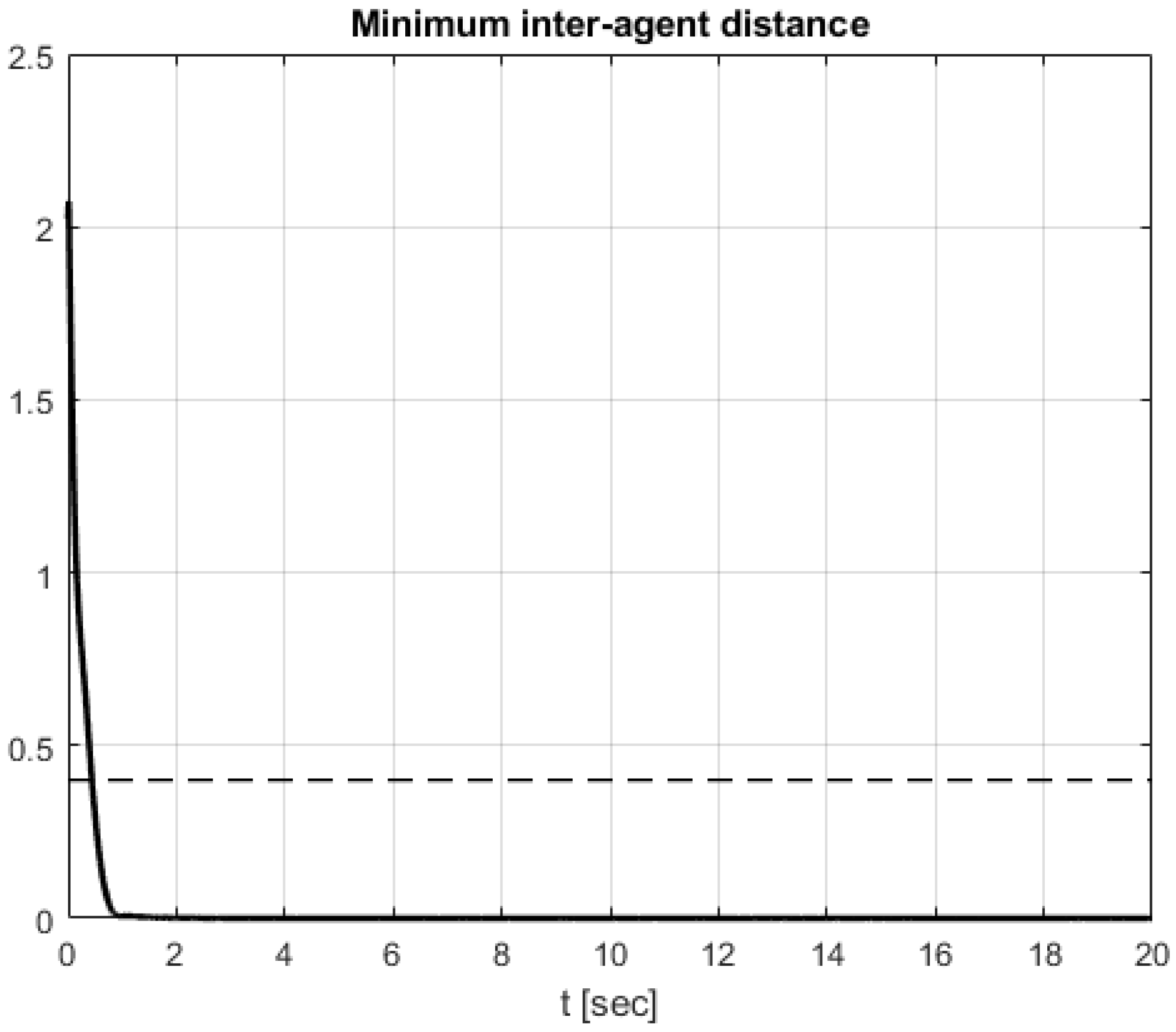
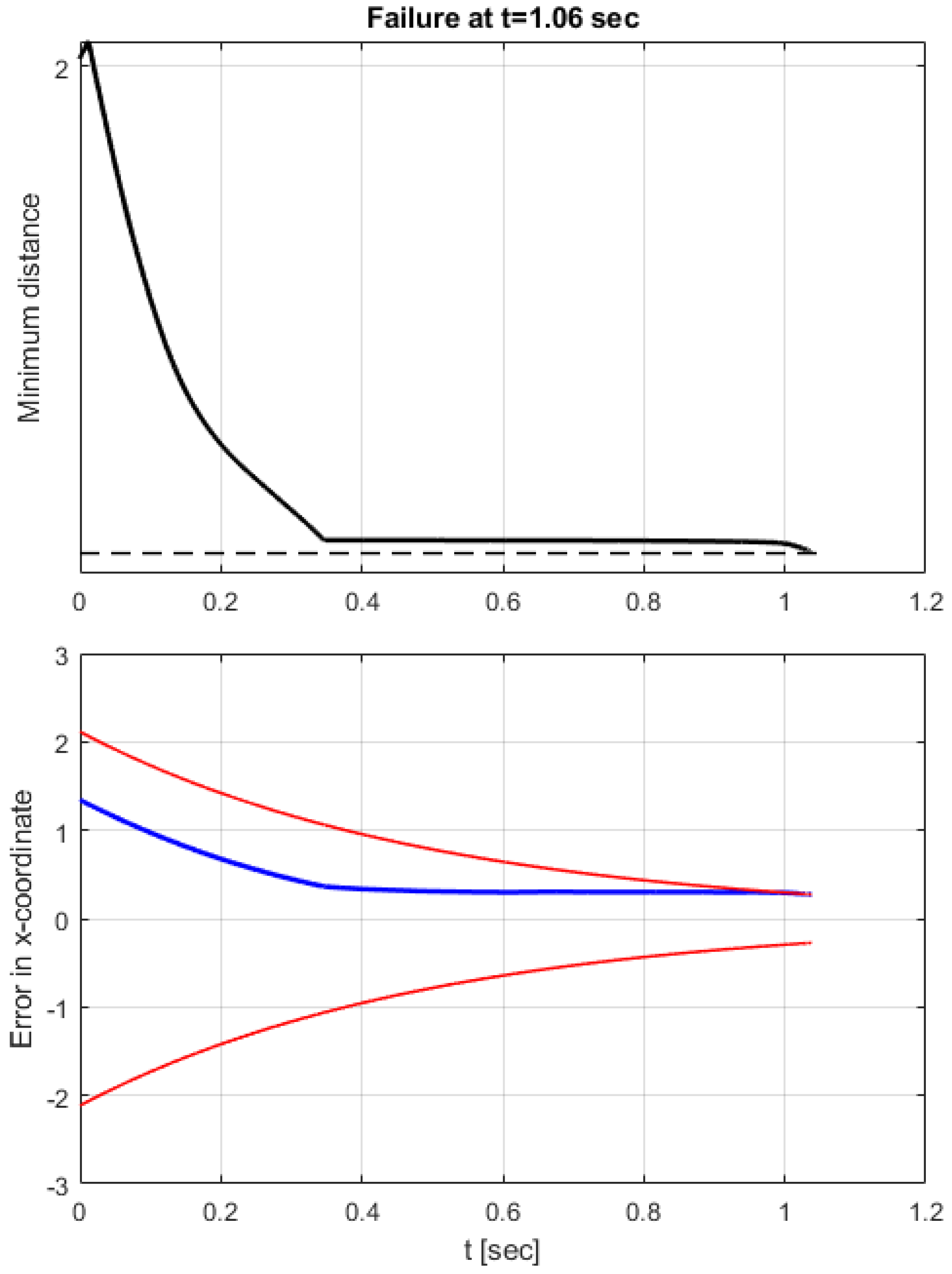
4. Simulation Results
Comparative Simulation Study
5. Conclusions and Future Directions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cohen, A.P.; Shaheen, S.A.; Farrar, E.M. Urban Air Mobility: History, Ecosystem, Market Potential, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 6074–6087. [Google Scholar] [CrossRef]
- Wurman, P.R.; D’Andrea, R.; Mountz, M. Coordinating hundreds of cooperative, autonomous vehicles in warehouses. AI Mag. 2008, 29, 9–19. [Google Scholar]
- Zhou, X.; Wang, Z.; Ye, H.; Xu, C.; Gao, F. EGO-Planner: An ESDF-Free Gradient-Based Local Planner for Quadrotors. IEEE Robot. Autom. Lett. 2021, 6, 478–485. [Google Scholar] [CrossRef]
- Zhou, X.; Wen, X.; Wang, Z.; Gao, Y.; Li, H.; Wang, Q.; Yang, T.; Lu, H.; Cao, Y.; Xu, C.; et al. Swarm of micro flying robots in the wild. Sci. Robot. 2022, 7, eabm595. [Google Scholar] [CrossRef]
- Quan, L.; Han, L.; Zhou, B.; Shen, S.; Gao, F. Survey of UAV motion planning. IET Cyber-Syst. Robot. 2020, 2, 14–21. [Google Scholar] [CrossRef]
- Mueller, M.W.; Lee, S.J.; D’Andrea, R. Design and Control of Drones. Annu. Rev. Control. Robot. Auton. Syst. 2022, 5, 161–177. [Google Scholar] [CrossRef]
- Thummalapeta, M.; Liu, Y.C. Survey of containment control in multi-agent systems: Concepts, communication, dynamics, and controller design. Int. J. Syst. Sci. 2023, 54, 2809–2835. [Google Scholar] [CrossRef]
- Chen, C.; Han, Y.; Zhu, S.; Zeng, Z. Distributed Fixed-Time Tracking and Containment Control for Second-Order Multi-Agent Systems: A Nonsingular Sliding-Mode Control Approach. IEEE Trans. Netw. Sci. Eng. 2023, 10, 687–697. [Google Scholar] [CrossRef]
- Chen, C.; Han, Y.; Zhu, S.; Zeng, Z. Neural Network-Based Fixed-Time Tracking and Containment Control of Second-Order Heterogeneous Nonlinear Multiagent Systems. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–15. [Google Scholar] [CrossRef]
- Zhao, G.; Liu, Q.; Hua, C. Prescribed-time containment control of high-order nonlinear multi-agent systems based on distributed observer. J. Frankl. Inst. 2023, 360, 6736–6756. [Google Scholar] [CrossRef]
- Chang, S.; Wang, Y.; Zuo, Z.; Yang, H.; Luo, X. Robust prescribed-time containment control for high-order uncertain multi-agent systems with extended state observer. Neurocomputing 2023, 559, 126782. [Google Scholar] [CrossRef]
- Yi, J.; Li, J. Distributed Containment Control with Prescribed Accuracy for Nonstrict-Feedback Switched Nonlinear Multiagent Systems. IEEE Syst. J. 2023, 17, 5671–5682. [Google Scholar] [CrossRef]
- Sui, J.; Liu, C.; Niu, B.; Zhao, X.; Wang, D.; Yan, B. Prescribed Performance Adaptive Containment Control for Full-State Constrained Nonlinear Multiagent Systems: A Disturbance Observer-Based Design Strategy. IEEE Trans. Autom. Sci. Eng. 2024, 1–12. [Google Scholar] [CrossRef]
- Lin, Q.; Zhou, Y.; Jiang, G.P.; Ge, S.; Ye, S. Prescribed-time containment control based on distributed observer for multi-agent systems. Neurocomputing 2021, 431, 69–77. [Google Scholar] [CrossRef]
- Wang, Y.; Song, Y.; Hill, D.J.; Krstic, M. Prescribed-time consensus and containment control of networked multiagent systems. IEEE Trans. Cybern. 2019, 49, 1138–1147. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Liu, Z.; Chen, C.P.; Zhang, Y. Prescribed-time containment control with prescribed performance for uncertain nonlinear multi-agent systems. J. Frankl. Inst. 2021, 358, 1782–1811. [Google Scholar] [CrossRef]
- Wang, W.; Liang, H.; Pan, Y.; Li, T. Prescribed Performance Adaptive Fuzzy Containment Control for Nonlinear Multiagent Systems Using Disturbance Observer. IEEE Trans. Cybern. 2020, 50, 3879–3891. [Google Scholar] [CrossRef] [PubMed]
- Liu, D.; Liu, Z.; Chen, C.L.P.; Zhang, Y. Distributed adaptive fuzzy control approach for prescribed-time containment of uncertain nonlinear multi-agent systems with unknown hysteresis. Nonlinear Dyn. 2021, 105, 257–275. [Google Scholar] [CrossRef]
- Yang, T.; Dong, J. Funnel-Based Predefined-Time Containment Control of Heterogeneous Multiagent Systems With Sensor and Actuator Faults. IEEE Trans. Syst. Man Cybern. Syst. 2023, 54, 1903–1913. [Google Scholar] [CrossRef]
- Luo, A.; Xiao, W.; Li, X.M.; Yao, D.; Zhou, Q. Performance-guaranteed containment control for pure-feedback multi agent systems via reinforcement learning algorithm. Int. J. Robust Nonlinear Control. 2022, 32, 10180–10200. [Google Scholar] [CrossRef]
- Biao, T.; Xingling, S.; Wei, Y.; Wendong, Z. Fixed time output feedback containment for uncertain nonlinear multiagent systems with switching communication topologies. ISA Trans. 2021, 111, 82–95. [Google Scholar] [CrossRef] [PubMed]
- Santiaguillo-Salinas, J.; Aranda-Bricaire, E. Containment problem with time-varying formation and collision avoidance for multiagent systems. Int. J. Adv. Robot. Syst. 2017, 14, 1–13. [Google Scholar] [CrossRef]
- Gong, J.; Jiang, B.; Ma, Y.; Mao, Z. Distributed Adaptive Fault-Tolerant Formation-Containment Control With Prescribed Performance for Heterogeneous Multiagent Systems. IEEE Trans. Cybern. 2023, 53, 7787–7799. [Google Scholar] [CrossRef]
- Bi, C.; Xu, X.; Liu, L.; Feng, G. Formation-Containment Tracking for Heterogeneous Linear Multiagent Systems under Unbounded Distributed Transmission Delays. IEEE Trans. Control. Netw. Syst. 2023, 10, 822–833. [Google Scholar] [CrossRef]
- Xu, R.; Wang, X.; Zhou, Y. Observer-based event-triggered adaptive containment control for multiagent systems with prescribed performance. Nonlinear Dyn. 2022, 107, 2345–2362. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, X.; Niu, B.; Wang, H.; Liu, X. Event-triggered adaptive tracking containment control of nonlinear multiagent systems with unmodeled dynamics and prescribed performance. Int. J. Robust Nonlinear Control. 2023, 33, 2629–2650. [Google Scholar] [CrossRef]
- Xia, M.D.; Liu, C.L.; Liu, F. Formation-Containment Control of Second-Order Multiagent Systems via Intermittent Communication. Complexity 2018, 2018, 2501427. [Google Scholar] [CrossRef]
- Atrianfar, H.; Karimi, A. Robust H∞ containment control of heterogeneous multi-agent systems with structured uncertainty and external disturbances. Int. J. Robust Nonlinear Control. 2022, 32, 698–714. [Google Scholar] [CrossRef]
- Dong, X.; Yu, B.; Shi, Z.; Zhong, Y. Time-varying formation control for unmanned aerial vehicles: Theories and applications. IEEE Trans. Control. Syst. Technol. 2015, 23, 340–348. [Google Scholar] [CrossRef]
- Guo, B.Z.; Zhao, Z.L. On convergence of tracking differentiator. Int. J. Control. 2011, 84, 693–701. [Google Scholar] [CrossRef]
- Khatib, O. Real-Time Obstacle Avoidance for Manipulators and Mobile Robots. Int. J. Robot. Res. 1986, 5, 90–98. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| k | ||||||
|---|---|---|---|---|---|---|
| 4 | 2 | 4 | 1 | 2 | 4 | |
| 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bechlioulis, C.P. Robust Distributed Containment Control with Adaptive Performance and Collision Avoidance for Multi-Agent Systems. Electronics 2024, 13, 1439. https://doi.org/10.3390/electronics13081439
Bechlioulis CP. Robust Distributed Containment Control with Adaptive Performance and Collision Avoidance for Multi-Agent Systems. Electronics. 2024; 13(8):1439. https://doi.org/10.3390/electronics13081439
Chicago/Turabian StyleBechlioulis, Charalampos P. 2024. "Robust Distributed Containment Control with Adaptive Performance and Collision Avoidance for Multi-Agent Systems" Electronics 13, no. 8: 1439. https://doi.org/10.3390/electronics13081439