

Design of an Assisted Driving System for Obstacle Avoidance Based on Reinforcement Learning Applied to Electrified Wheelchairs

Abstract
:1. Introduction
1.1. Motivation
1.2. Related Works
1.3. Author Contributions
- Formulated a cooperative system that prioritizes adhering to the user’s input while ensuring safety conditions and providing a way to escape from dangerous situations;
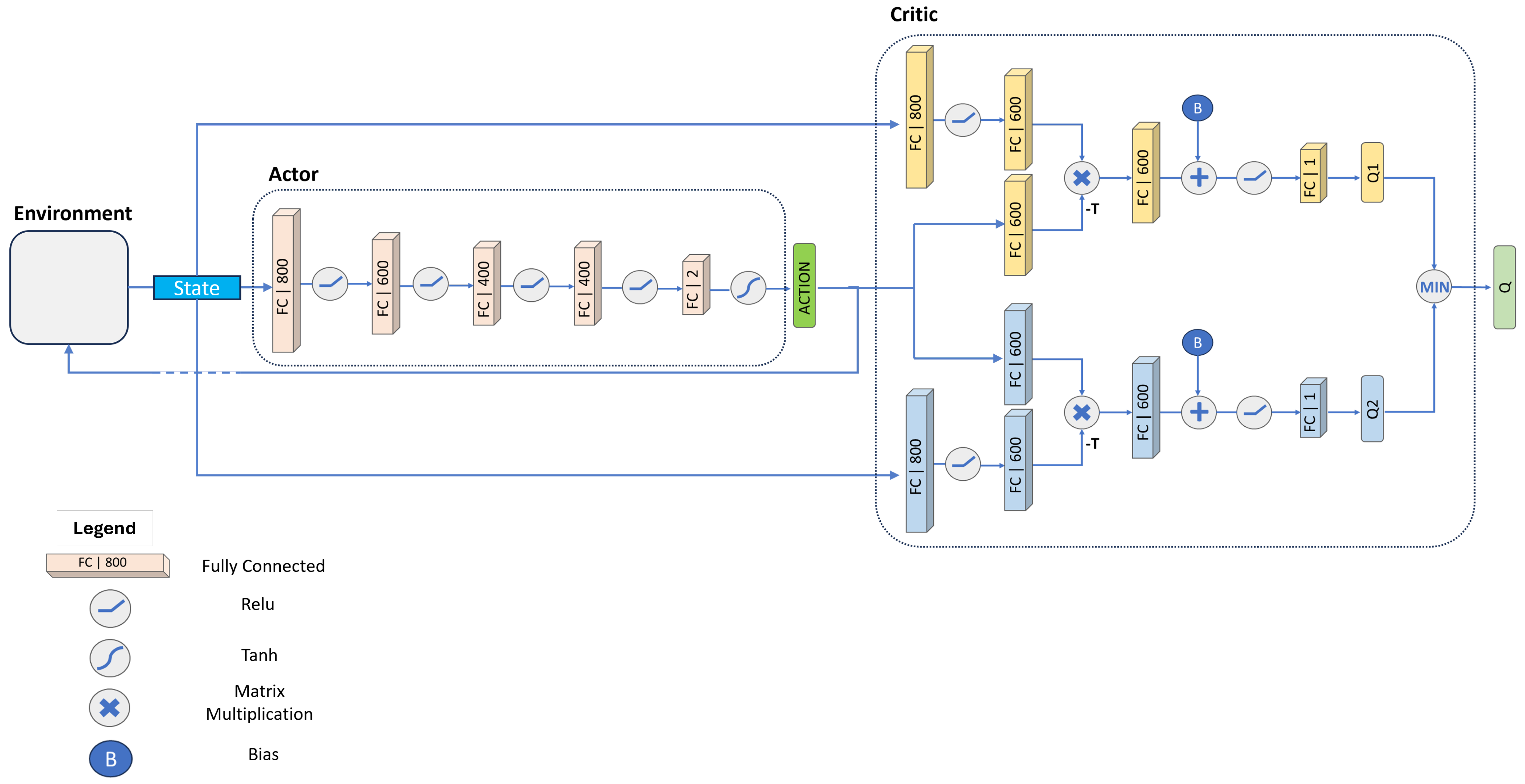
- Developed a neural network architecture based on the twin delayed deep deterministic policy gradient (TD3) for wheelchair navigation in a continuous action space;
- Established an infrastructure for hyper-parameter optimization and parallel agent training in deep reinforcement learning based on the Robotic Operating System (ROS) and Gazebo.
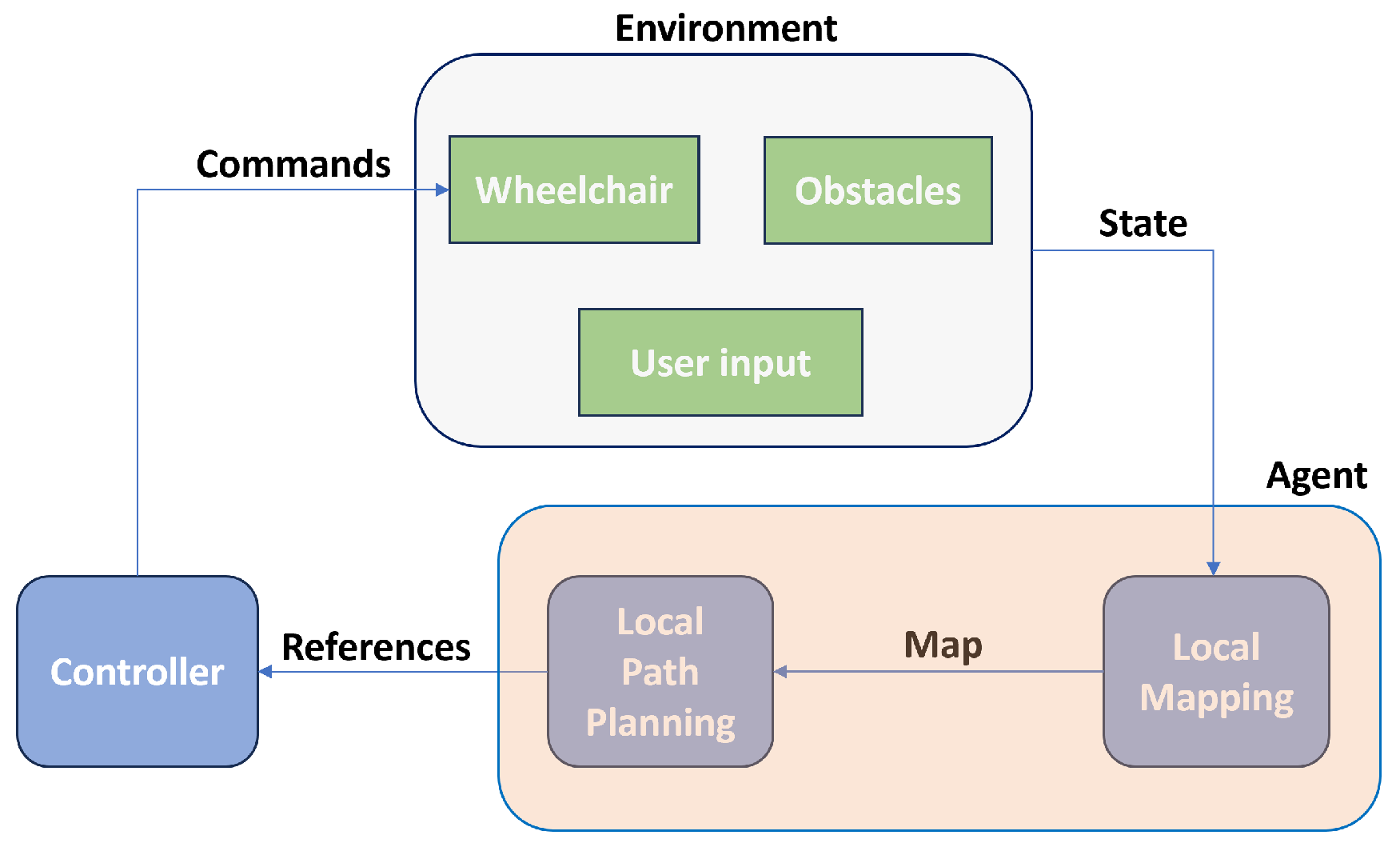
2. Simulation Environment and Setup
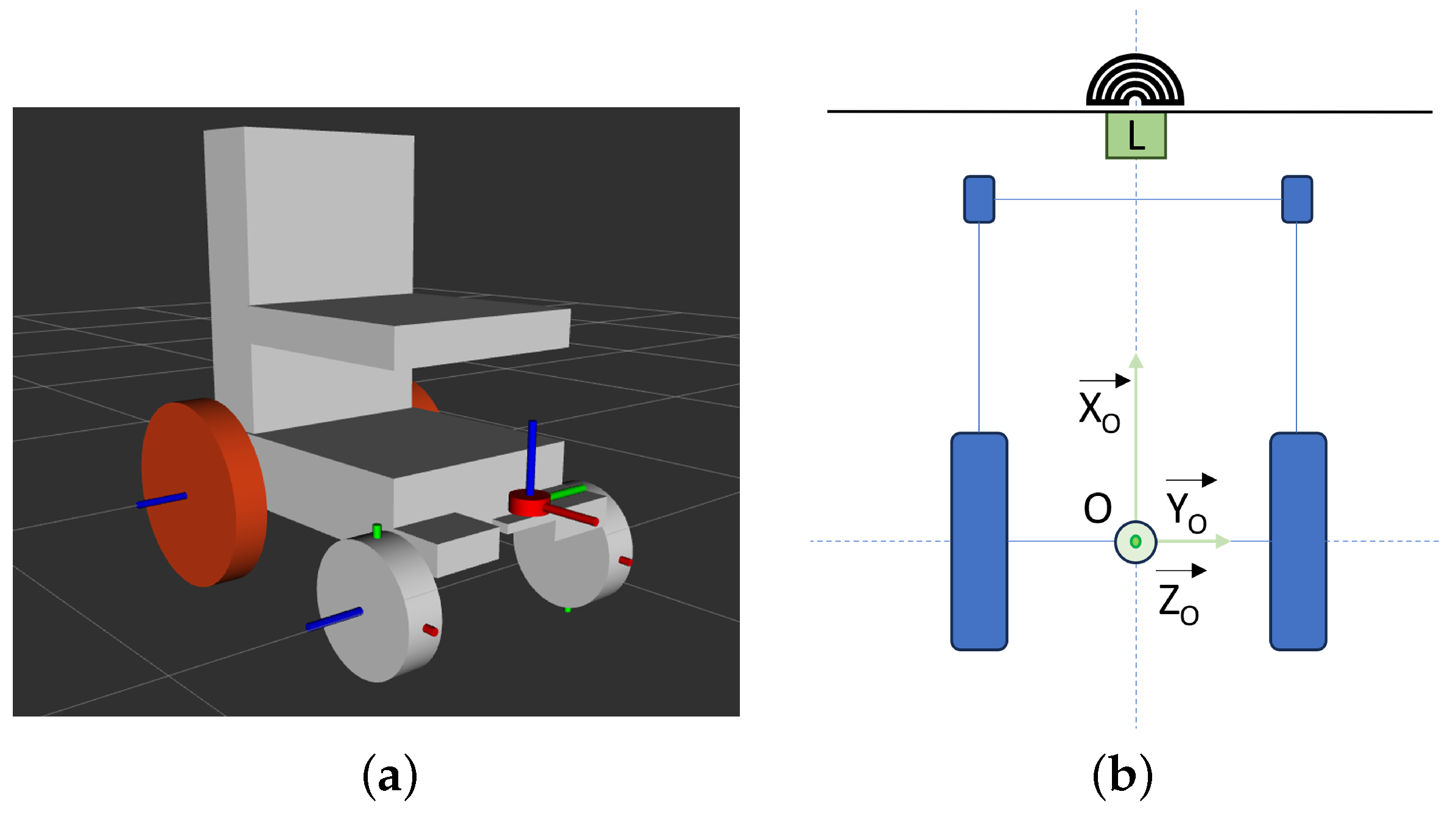
2.1. Wheelchair
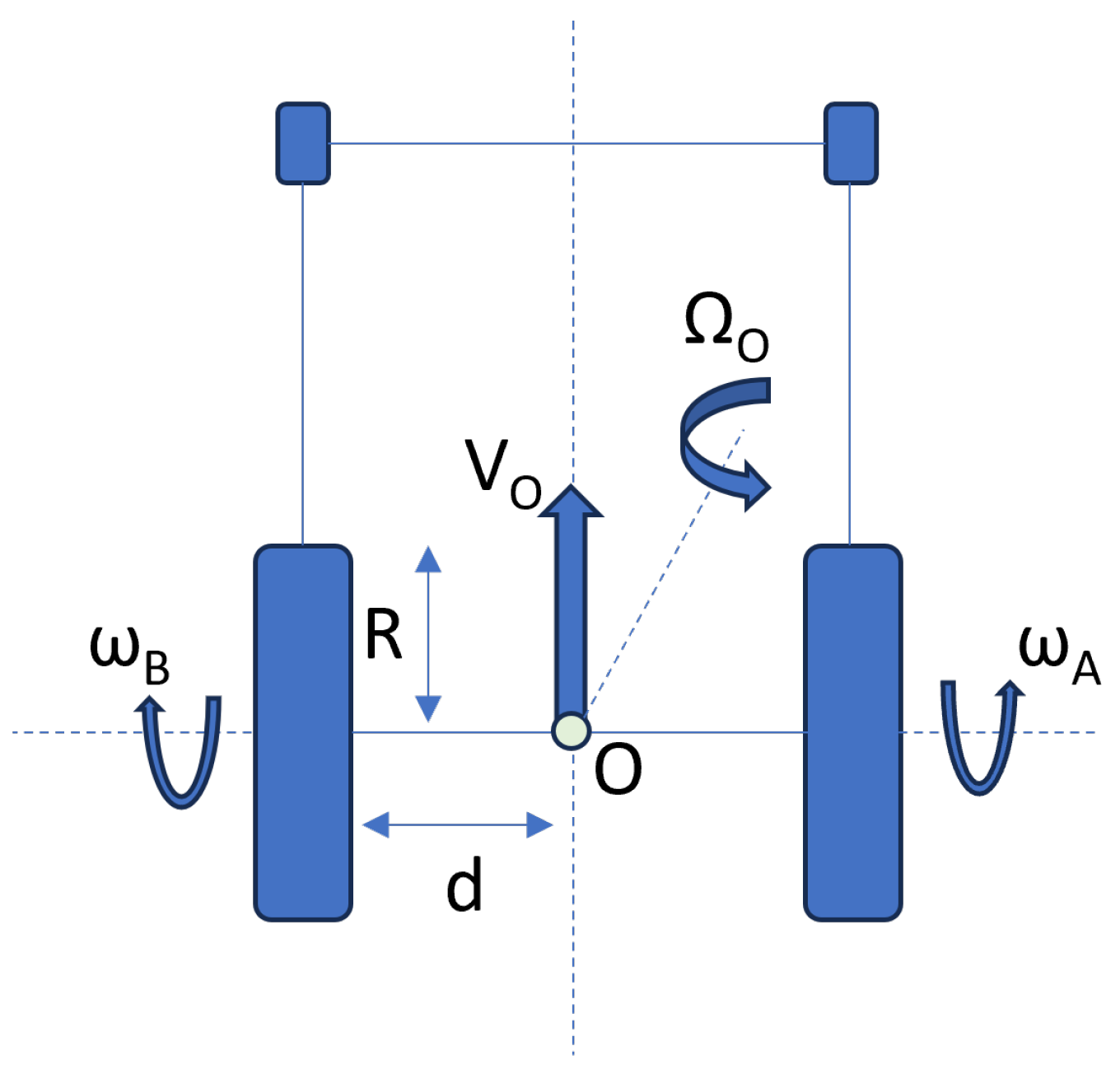
2.2. System Definition
2.3. Setup
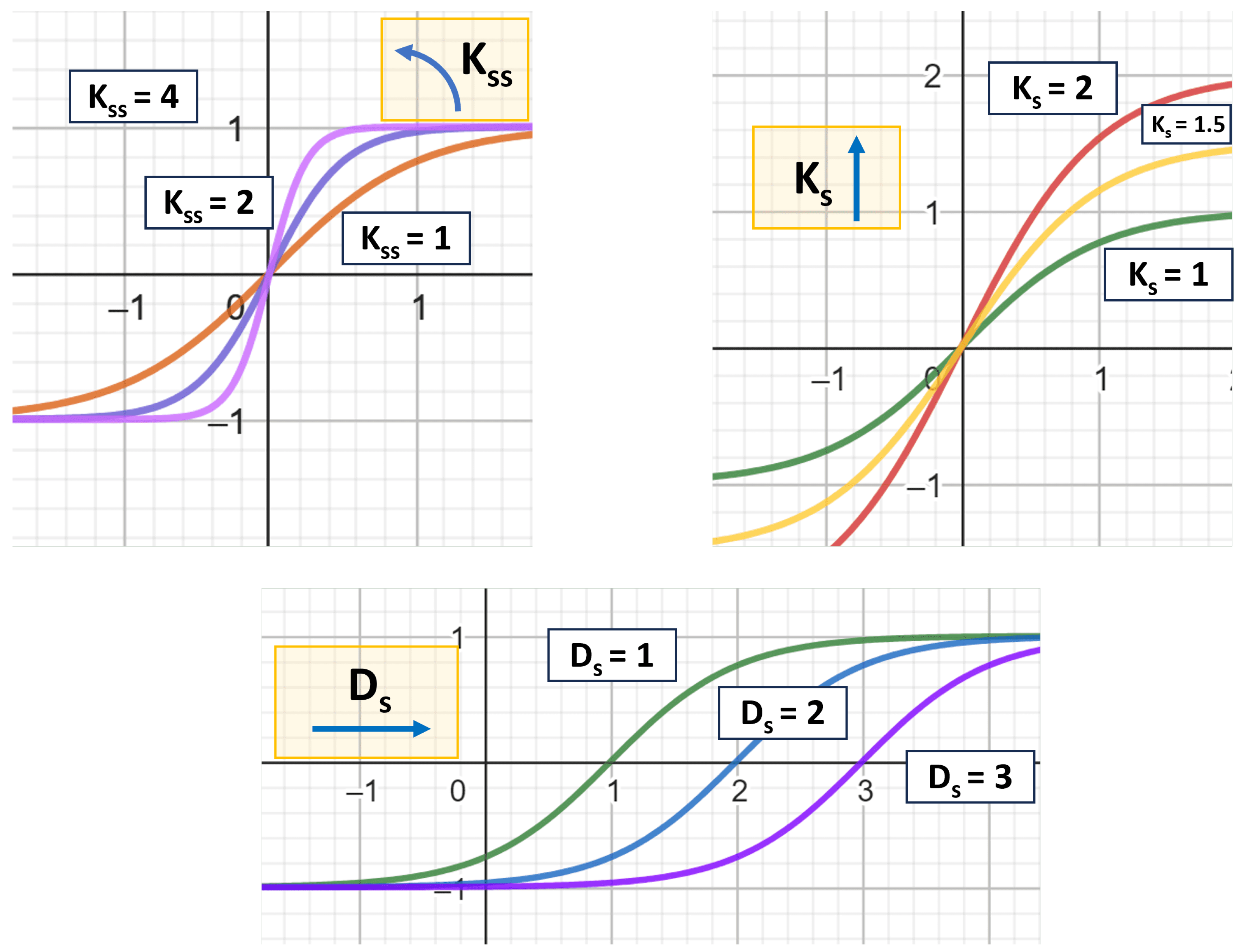
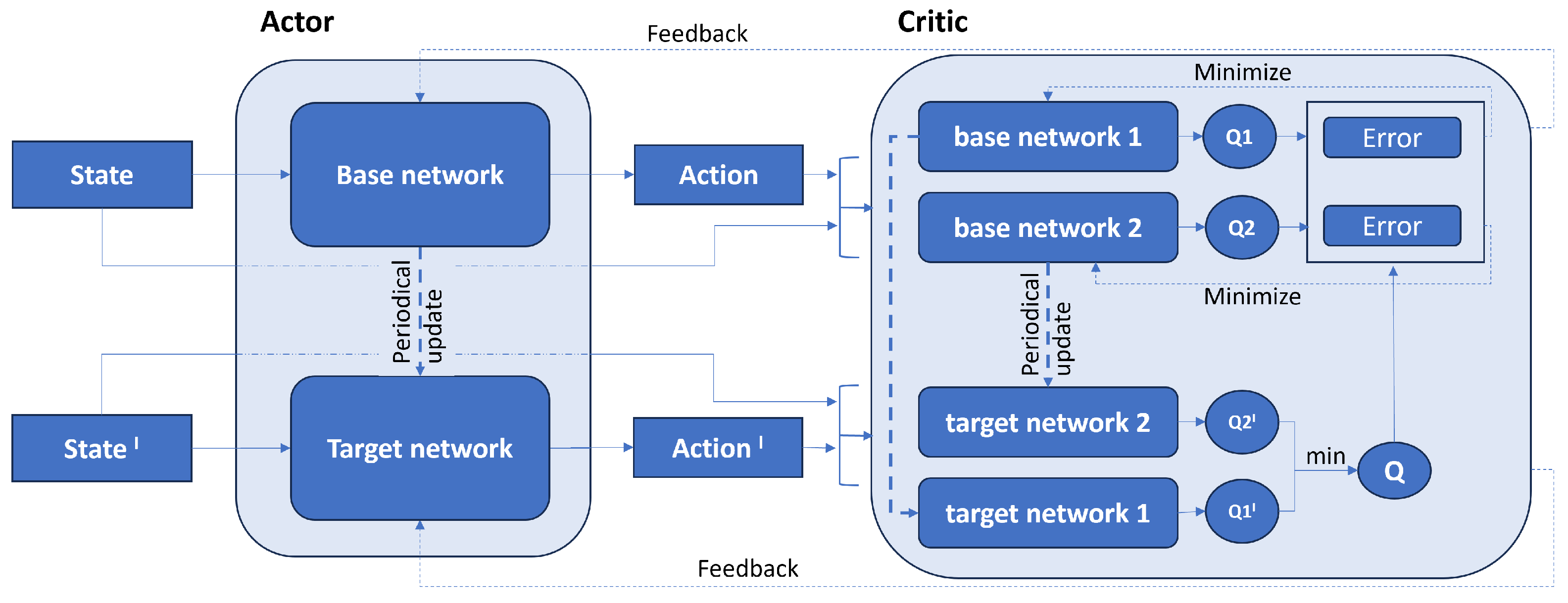
3. Reinforcement Learning Algorithm Architecture
Software Infrastructure
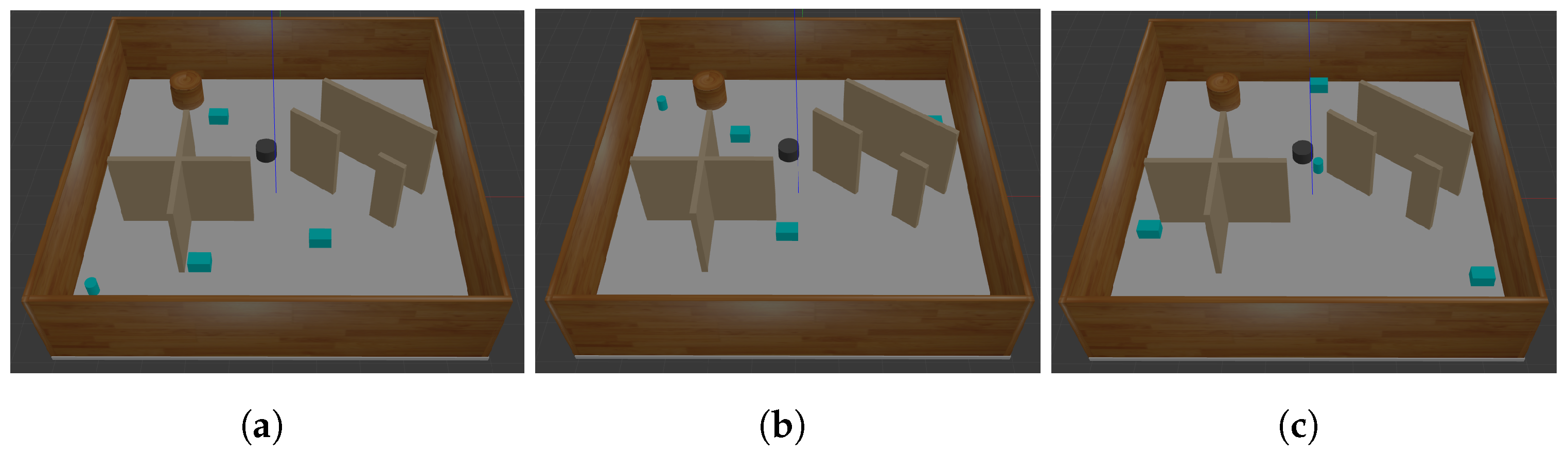
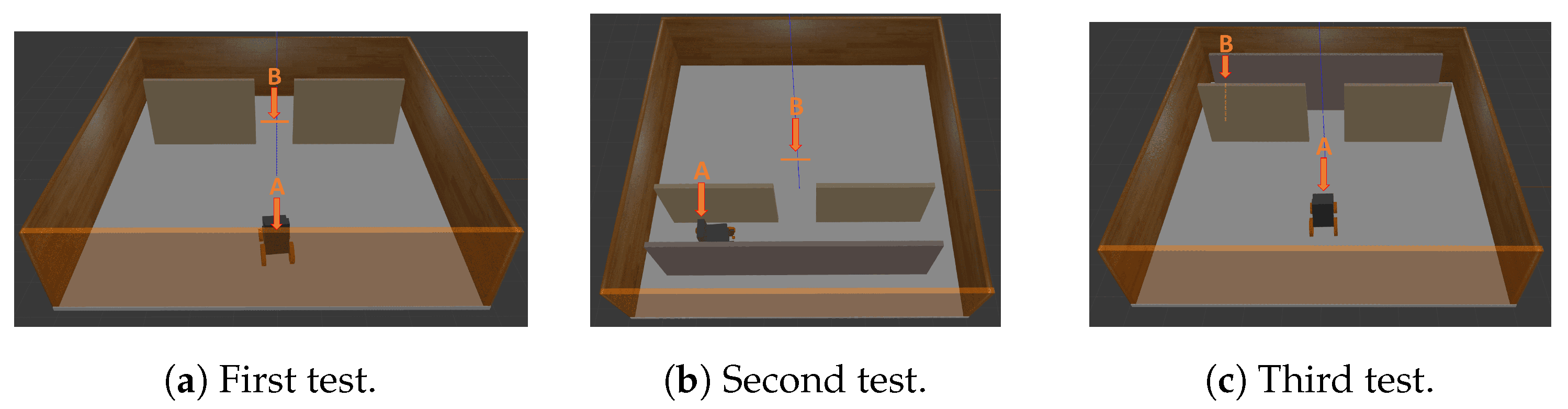
4. Simulations
- Average forward speed.
- Jerkiness, which measures how “smooth” the wheelchair handling is, as represented by the mean and standard deviation value of the gradient generated by subsequent motor command variations (the lower, the better).
- Collision risk, which is the number of occurred collisions.
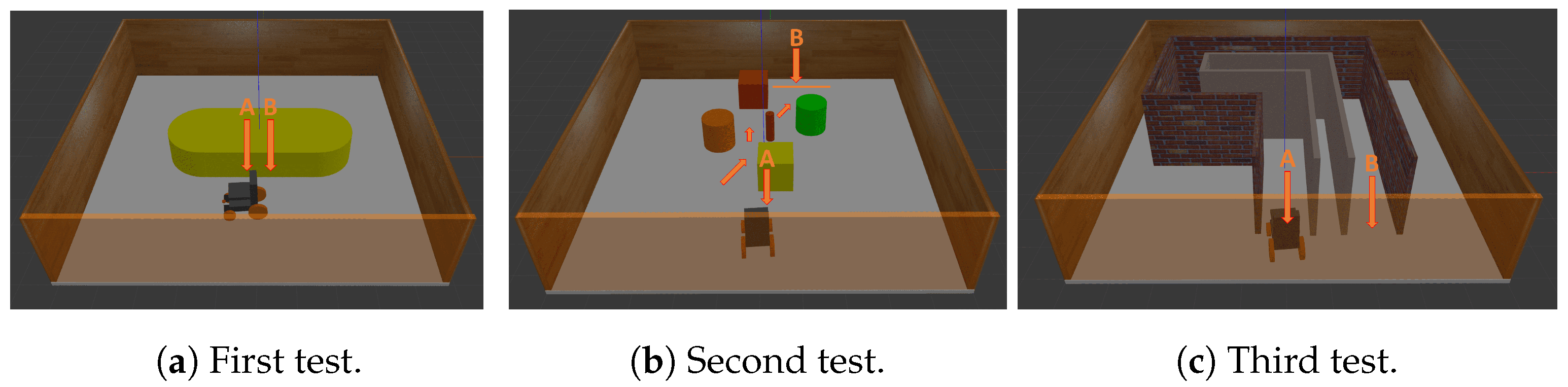
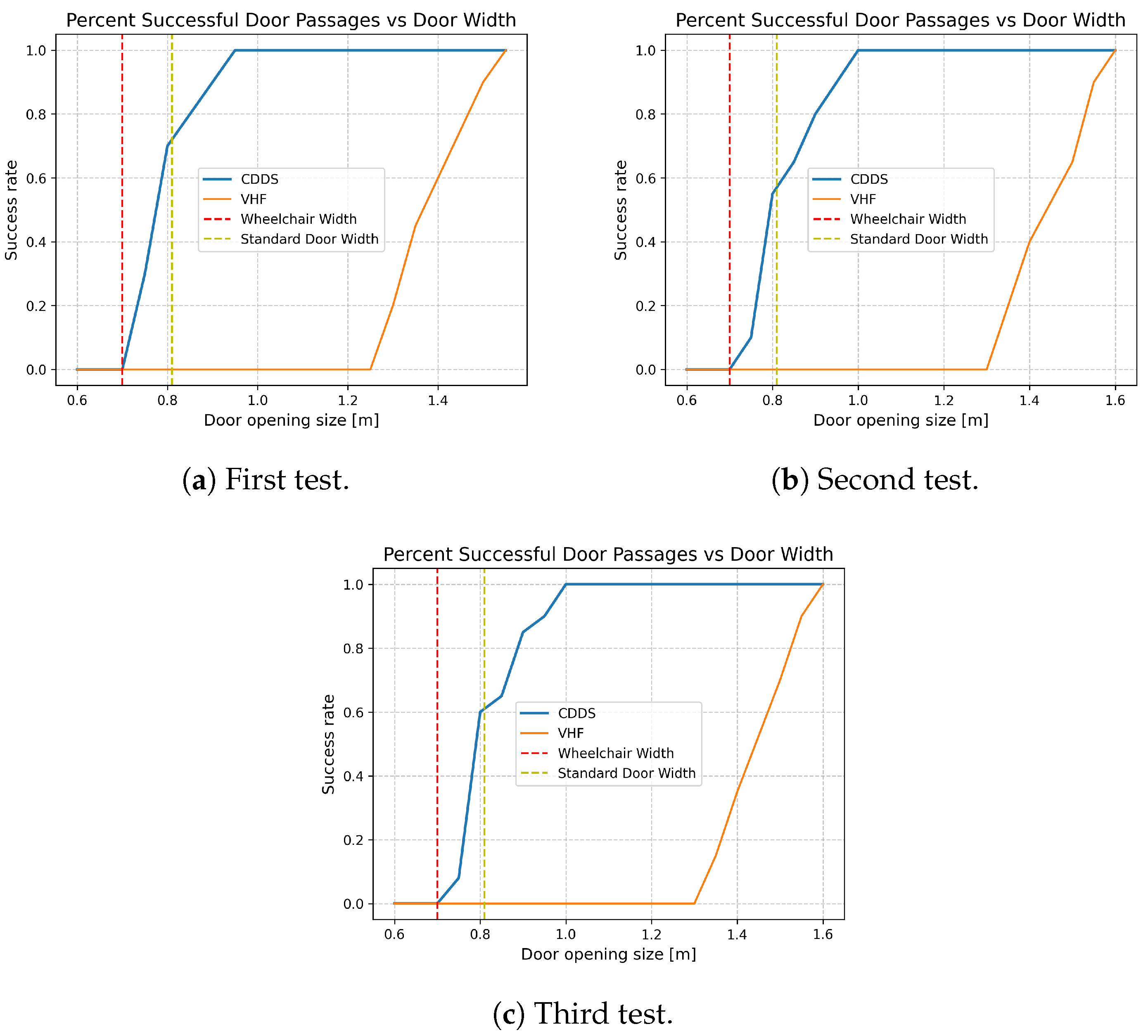
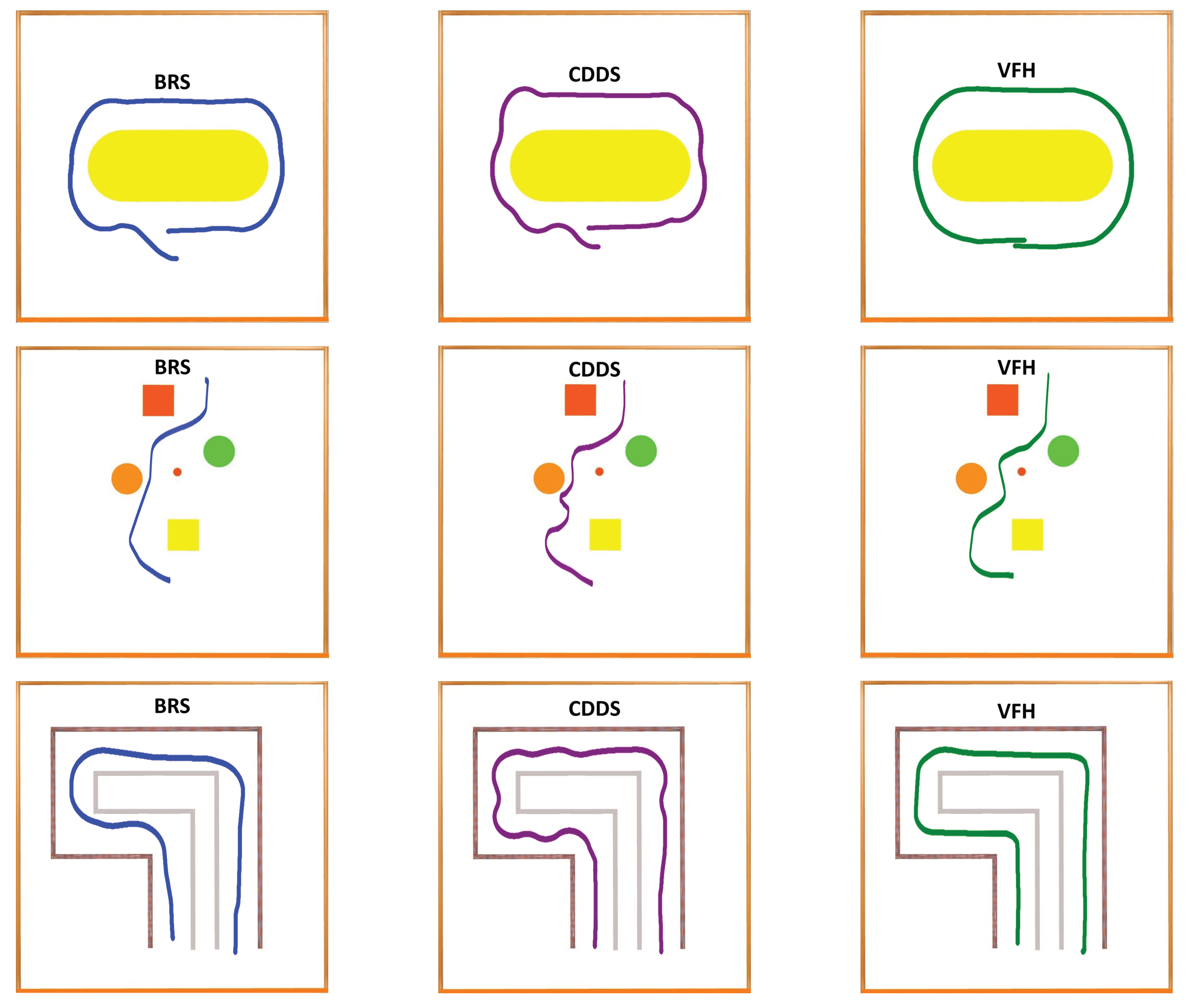
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value | |
|---|---|---|
| Actor | Layer 1 | 25 × 800 |
| | | Activation 1 | Relu |
| | | Layer 2 | 800 × 600 |
| | | Activation | Relu |
| | | Layer 3 | 600 × 400 |
| | | Activation | Relu |
| | | Layer 4 | 400 × 400 |
| | | Activation | Relu |
| | | Layer 5 | 400 × 2 |
| | | Activation | Tanh |
| Layer 1 | 25 × 800 | |
| | | Activation 1 | Relu |
| | | Layer 2 | 600 × 600, 600 × 600 |
| | | Activation | Matrix Mul |
| | | Layer 3 | 600 × 600 |
| | | Activation | Relu |
| | | Layer 5 | 600 × 1 |
| Layer 1 | 25 × 800 | |
| | | Activation 1 | Relu |
| | | Layer 2 | 600 × 600, 600 × 600 |
| | | Activation | Matrix Mul |
| | | Layer 3 | 600 × 600 |
| | | Activation | Relu |
| | | Layer 5 | 600 × 1 |
| Critic | Activation | min |
| - | State | [, …, ,, , , ] |
| - | Action | [, ] |
| - | (safety distance) * | 0.1 m |
| Parameters | Value | |
|---|---|---|
| Wheelchair | Footprint radius | 0.61 m |
| | | Safety distance | 0.1 m |
| | | Minimum turning radius | 0.61 m |
| Cost function | Target direction weight | 5 |
| | | Current direction weight | 2 |
| | | Previous direction weight | 2 |
| Histogram | Number of angular sectors | 180 |
| | | Range distance limits | [0.05 m, 6 m] |
| | | Histogram thresholds | [3, 10] |
Appendix B

References
- World Health Organization; World Bank. World Report on Disability 2011; World Health Organization: Geneva, Switzerland, 2011. [Google Scholar]
- UN General Assembly, Convention on the Rights of People with Disabilities, 24 January 2007, A/RES/61/106. Available online: https://www.un.org/development/desa/disabilities/resources/general-assembly/convention-on-the-rights-of-persons-with-disabilities-ares61106.html (accessed on 12 November 2023).
- Mars, L.; Arroyo, R.; Ruiz, T. Mobility and wellbeing during the covid-19 lockdown. Evidence from Spain. Transp. Res. Part A Policy Pract. 2022, 161, 107–129. [Google Scholar] [CrossRef] [PubMed]
- Landry, B.W.; Driscoll, S.W. Physical activity in children and adolescents. PM&R 2012, 4, 826–832. [Google Scholar]
- Freedman, V.A.; Carr, D.; Cornman, J.C.; Lucas, R.E. Aging, mobility impairments and subjective wellbeing. Disabil. Health J. 2017, 10, 525–531. [Google Scholar] [CrossRef] [PubMed]
- Arroyo, R.; Mars, L.; Ruiz, T. Activity Participation and wellbeing during the covid-19 lockdown in Spain. Int. J. Urban Sci. 2021, 25, 386–415. [Google Scholar] [CrossRef]
- Mussone, L.; Changizi, F. The relationship between subjective well-being and individual characteristics, personality traits, and choice of transport mode during the first lock-down in Milan, Italy. J. Transp. Health 2023, 30, 101600. [Google Scholar] [CrossRef] [PubMed]
- Checa, J.; Martín, J.; López, J.; Nel-Lo, O. Those Who Cannot Stay at Home: Urban Mobility and Social Vulnerability in Barcelona during the COVID-19 Pandemic; Asociacion Espanola de Geografia: Madrid, Spain, 2020. [Google Scholar]
- Sánchez-Rodríguez, E.; Ferreira-Valente, A.; Pimenta, F.; Ciaramella, A.; Miró, J. Mental, physical and socio-economic status of adults living in Spain during the late stages of the state of emergency caused by COVID-19. Int. J. Environ. Res. Public Health 2022, 19, 854. [Google Scholar] [CrossRef] [PubMed]
- Tsouros, I.; Tsirimpa, A.; Pagoni, I.; Polydoropoulou, A. Activities, time-use and mental health during the first COVID-19 pandemic wave: Insight from Greece. Transp. Res. Interdiscip. Perspect. 2021, 11, 100442. [Google Scholar] [CrossRef] [PubMed]
- Politis, I.; Georgiadis, G.; Nikolaidou, A.; Kopsacheilis, A.; Fyrogenis, I.; Sdoukopoulos, A.; Verani, E.; Papadopoulos, E. Mapping travel behavior changes during the COVID-19 lock-down: A socioeconomic analysis in Greece. Eur. Transp. Res. Rev. 2021, 13, 21. [Google Scholar] [CrossRef]
- Mussone, L.; Changizi, F. A study on the factors that influenced the choice of transport mode before, during, and after the first lockdown in Milan, Italy. Cities 2023, 136, 104251. [Google Scholar] [CrossRef]
- Politis, I.; Georgiadis, G.; Papadopoulos, E.; Fyrogenis, I.; Nikolaidou, A.; Kopsacheilis, A.; Sdoukopoulos, A.; Verani, E. COVID-19 lockdown measures and travel behavior: The case of Thessaloniki, Greece. Transp. Res. Interdiscip. Perspect. 2021, 10, 100345. [Google Scholar] [CrossRef]
- Chen, W.Y.; Jang, Y.; Wang, J.D.; Huang, W.N.; Chang, C.C.; Mao, H.F.; Wang, Y.H. Wheelchair-Related Accidents: Relationship With Wheelchair-Using Behavior in Active Community Wheelchair Users. Arch. Phys. Med. Rehabil. 2011, 92, 892–898. [Google Scholar] [CrossRef] [PubMed]
- Worobey, L.; Oyster, M.; Pearlman, J.; Gebrosky, B.; Boninger, M.L. Differences between manufacturers in reported power wheelchair repairs and adverse consequences among people with spinal cord injury. Arch. Phys. Med. Rehabil. 2014, 95, 597–603. [Google Scholar] [CrossRef] [PubMed]
- Abou, L.; Rice, L.A. Risk factors associated with falls and fall-related injuries among wheelchair users with spinal cord injury. Arch. Rehabil. Res. Clin. Transl. 2022, 4, 100195. [Google Scholar] [CrossRef] [PubMed]
- McClure, L.A.; Boninger, M.L.; Oyster, M.L.; Williams, S.; Houlihan, B.; Lieberman, J.A.; Cooper, R.A. Wheelchair repairs, breakdown, and adverse consequences for people with traumatic spinal cord injury. Arch. Phys. Med. Rehabil. 2009, 90, 2034–2038. [Google Scholar] [CrossRef] [PubMed]
- Worobey, L.A.; Heinemann, A.W.; Anderson, K.D.; Fyffe, D.; Dyson-Hudson, T.A.; Berner, T.; Boninger, M.L. Factors influencing incidence of wheelchair repairs and consequences among individuals with spinal cord injury. Arch. Phys. Med. Rehabil. 2022, 103, 779–789. [Google Scholar] [CrossRef] [PubMed]
- Toro, M.L.; Worobey, L.; Boninger, M.L.; Cooper, R.A.; Pearlman, J. Type and frequency of reported wheelchair repairs and related adverse consequences among people with spinal cord injury. Arch. Phys. Med. Rehabil. 2016, 97, 1753–1760. [Google Scholar] [CrossRef] [PubMed]
- Hogaboom, N.S.; Worobey, L.A.; Houlihan, B.V.; Heinemann, A.W.; Boninger, M.L. Wheelchair breakdowns are associated with pain, pressure injuries, rehospitalization, and self-perceived health in full-time wheelchair users with spinal cord injury. Arch. Phys. Med. Rehabil. 2018, 99, 1949–1956. [Google Scholar] [CrossRef] [PubMed]
- Seki, H.; Tanohata, N. Fuzzy control for electric power-assisted wheelchair driving on disturbance roads. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2012, 42, 1624–1632. [Google Scholar] [CrossRef]
- Seki, H.; Kiso, A. Disturbance road adaptive driving control of power-assisted wheelchair using fuzzy inference. In Proceedings of the 2011 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 1594–1599. [Google Scholar] [CrossRef]
- Sankardoss, V.; Geethanjali, P. Design and low-cost implementation of an electric wheelchair control. IETE J. Res. 2021, 67, 657–666. [Google Scholar] [CrossRef]
- Callejas-Cuervo, M.; González-Cely, A.X.; Bastos-Filho, T. Design and implementation of a position, speed and orientation fuzzy controller using a motion capture system to operate a wheelchair prototype. Sensors 2021, 21, 4344. [Google Scholar] [CrossRef]
- Seki, H.; Kuramoto, T. Fuzzy Inference-Based Driving Control System for Pushrim-Activated Power-Assisted Wheelchairs Considering User Characteristics. IEEE Trans. Hum.-Mach. Syst. 2022, 52, 1049–1059. [Google Scholar] [CrossRef]
- Sier, H.; Yu, X.; Catalano, I.; Queralta, J.P.; Zou, Z.; Westerlund, T. UAV Tracking with Lidar as a Camera Sensor in GNSS-Denied Environments. In Proceedings of the 2023 International Conference on Localization and GNSS (ICL-GNSS), Castellon, Spain, 6–8 June 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Antonopoulos, A.; Lagoudakis, M.G.; Partsinevelos, P. A ROS multi-tier UAV localization module based on GNSS, inertial and visual-depth data. Drones 2022, 6, 135. [Google Scholar] [CrossRef]
- Ito, S.; Hiratsuka, S.; Ohta, M.; Matsubara, H.; Ogawa, M. Small imaging depth LIDAR and DCNN-based localization for automated guided vehicle. Sensors 2018, 18, 177. [Google Scholar] [CrossRef]
- Deng, C.; Wang, S.; Wang, J.; Xu, Y.; Chen, Z. LiDAR Depth Cluster Active Detection and Localization for a UAV with Partial Information Loss in GNSS. In Unmanned Systems; World Scientific: Singapore, 2024. [Google Scholar]
- Biao, J.; Xiangwen, Z.; Yangxiong, W.; Wenchao, H. Regenerative braking control strategy of electric vehicles based on braking stability requirements. Int. J. Automot. Technol. 2021, 22, 465–473. [Google Scholar] [CrossRef]
- Zhang, J.; Yang, Y.; Qin, D.; Fu, C.; Cong, Z. Regenerative Braking Control Method Based on Predictive Optimization for Four-Wheel Drive Pure Electric Vehicle. IEEE Access 2021, 9, 1394–1406. [Google Scholar] [CrossRef]
- Heerwan, P.; Shahrom, M.; Ishak, M.; Kato, H.; Narita, T. Investigation of the Performance of Plugging Braking System as a Hill Descent Control (HDC) for Electric-Powered Wheelchair. Int. J. Automot. Mech. Eng. 2023, 20, 10906–10916. [Google Scholar] [CrossRef]
- Seki, H.; Ishihara, K.; Tadakuma, S. Novel Regenerative Braking Control of Electric Power-Assisted Wheelchair for Safety Downhill Road Driving. IEEE Trans. Ind. Electron. 2009, 56, 1393–1400. [Google Scholar] [CrossRef]
- Baek, S.J.; Kim, A.; Kim, J.W. Implementation of Wheelchair Robot Applying SLAM and Global Path Planning Methods Suitable for Indoor Autonomous Driving. IEMEK J. Embed. Syst. Appl. 2021, 16, 293–297. [Google Scholar]
- Somwanshi, D.; Bundele, M. Obstacle detection approach for robotic wheelchair navigation. In Proceedings of the International Conference on Artificial Intelligence: Advances and Applications 2019: Proceedings of ICAIAA 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 261–268. [Google Scholar]
- Wahid, A.B.; Siraj, U.; Affan, M.; Ahmed, H.; Islam, F.; Ansari, U.; Naveed, M.; Ayaz, Y. Development of modular framework for the semi-autonomous RISE wheelchair with multiple user interfaces using robot operating system (ROS). Int. J. Mech. Eng. Robot. Res. 2018, 7, 515–520. [Google Scholar] [CrossRef]
- Jung, Y.; Kim, Y.; Lee, W.H.; Bang, M.S.; Kim, Y.; Kim, S. Path Planning Algorithm for an Autonomous Electric Wheelchair in Hospitals. IEEE Access 2020, 8, 208199–208213. [Google Scholar] [CrossRef]
- Green, J.; Clounie, J.; Galarza, R.; Anderson, S.; Campell-Smith, J.; Voicu, R.C. Optimization of an Intelligent Wheelchair: LiDAR and Camera Vision for Obstacle Avoidance. In Proceedings of the 2022 22nd International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 27–30 November 2022; pp. 313–318. [Google Scholar] [CrossRef]
- de Paiva, F.P.; Cardozo, E.; Rohmer, E. A Path Tracking Control Algorithm for Smart Wheelchairs. In Proceedings of the 2020 International Symposium on Medical Robotics (ISMR), Atlanta, GA, USA, 18–20 November 2020; pp. 76–82. [Google Scholar] [CrossRef]
- Maciel, G.M.; Pinto, M.F.; Júnior, I.C.d.S.; Marcato, A.L. Methodology for autonomous crossing narrow passages applied on assistive mobile robots. J. Control Autom. Electr. Syst. 2019, 30, 943–953. [Google Scholar] [CrossRef]
- Levine, S.P.; Bell, D.A.; Jaros, L.A.; Simpson, R.C.; Koren, Y.; Borenstein, J. The NavChair assistive wheelchair navigation system. IEEE Trans. Rehabil. Eng. 1999, 7, 443–451. [Google Scholar] [CrossRef] [PubMed]
- Messaoudi, M.D.; Menelas, B.A.J.; Mcheick, H. Review of navigation assistive tools and technologies for the visually impaired. Sensors 2022, 22, 7888. [Google Scholar] [CrossRef] [PubMed]
- Callejas-Cuervo, M.; González-Cely, A.X.; Bastos-Filho, T. Control systems and electronic instrumentation applied to autonomy in wheelchair mobility: The state of the art. Sensors 2020, 20, 6326. [Google Scholar] [CrossRef] [PubMed]
- Kim, E.Y. Wheelchair navigation system for disabled and elderly people. Sensors 2016, 16, 1806. [Google Scholar] [CrossRef] [PubMed]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef]
- Wieczorek, B.; Kukla, M.; Rybarczyk, D.; Warguła, Ł. Evaluation of the biomechanical parameters of human-wheelchair systems during ramp climbing with the use of a manual wheelchair with anti-rollback devices. Appl. Sci. 2020, 10, 8757. [Google Scholar] [CrossRef]
- Abdulghani, M.M.; Al-Aubidy, K.M.; Ali, M.M.; Hamarsheh, Q.J. Wheelchair neuro fuzzy control and tracking system based on voice recognition. Sensors 2020, 20, 2872. [Google Scholar] [CrossRef] [PubMed]
- Gao, J.; Ye, W.; Guo, J.; Li, Z. Deep reinforcement learning for indoor mobile robot path planning. Sensors 2020, 20, 5493. [Google Scholar] [CrossRef]
- Wang, Z.; Liang, Y.; Gong, C.; Zhou, Y.; Zeng, C.; Zhu, S. Improved dynamic window approach for Unmanned Surface Vehicles’ local path planning considering the impact of environmental factors. Sensors 2022, 22, 5181. [Google Scholar] [CrossRef]
- Molinos, E.J.; Llamazares, A.; Ocaña, M. Dynamic window based approaches for avoiding obstacles in moving. Robot. Auton. Syst. 2019, 118, 112–130. [Google Scholar] [CrossRef]
- Zhang, B.; Holloway, C.; Carlson, T. A hierarchical design for shared-control wheelchair navigation in dynamic environments. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 4439–4446. [Google Scholar]
- Demeester, E.; Nuttin, M.; Vanhooydonck, D.; Vanacker, G.; Van Brussel, H. Global dynamic window approach for holonomic and non-holonomic mobile robots with arbitrary cross-section. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 2357–2362. [Google Scholar]
- Devigne, L.; Narayanan, V.K.; Pasteau, F.; Babel, M. Low complex sensor-based shared control for power wheelchair navigation. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 5434–5439. [Google Scholar]
- Zhang, B.; Barbareschi, G.; Ramirez Herrera, R.; Carlson, T.; Holloway, C. Understanding interactions for smart wheelchair navigation in crowds. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, Orleans, LA, USA, 29 April–5 May 2022; pp. 1–16. [Google Scholar]
- Chiang, H.H.; You, W.T.; Lee, J.S. Shared driving assistance design considering human error protection for intelligent electric wheelchairs. Energies 2023, 16, 2583. [Google Scholar] [CrossRef]
- Xi, L.; Shino, M. Shared control of an electric wheelchair considering physical functions and driving motivation. Int. J. Environ. Res. Public Health 2020, 17, 5502. [Google Scholar] [CrossRef]
- Deng, X.; Yu, Z.L.; Lin, C.; Gu, Z.; Li, Y. Self-adaptive shared control with brain state evaluation network for human-wheelchair cooperation. J. Neural Eng. 2020, 17, 045005. [Google Scholar] [CrossRef]
- Deng, X.; Yu, Z.L.; Lin, C.; Gu, Z.; Li, Y. A Bayesian Shared Control Approach for Wheelchair Robot With Brain Machine Interface. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 328–338. [Google Scholar] [CrossRef]
- Koren, Y.; Borenstein, J. Analys of Control Methods for Mobile Robot Obstacle Avoidance. In Proceedings of the IEEE International Workshop on Intelligent Motion Control, Istanbul, Turkey, 20–22 August 1990; Volume 2, pp. 457–461. [Google Scholar]
- Koren, Y.; Borenstein, J. Potential field methods and their inherent limitations for mobile robot navigation. In Proceedings of the Icra, Sacramento, CA, USA, 9–11 April 1991; Volume 2, pp. 1398–1404. [Google Scholar]
- Chen, W.; Chen, S.K.; Liu, Y.H.; Chen, Y.J.; Chen, C.S. An electric wheelchair manipulating system using SSVEP-based BCI system. Biosensors 2022, 12, 772. [Google Scholar] [CrossRef]
- Matsuura, H.; Nonaka, K.; Sekiguchi, K. Model Predictive Obstacle Avoidance Control for an Electric Wheelchair in Indoor Environments Using Artificial Potential Field Method. In Proceedings of the 2022 IEEE/SICE International Symposium on System Integration (SII), Virtual, 9–12 January 2022; pp. 19–24. [Google Scholar] [CrossRef]
- Sollehudin, I.; Heerwan, P.; Ishak, M.; Zakaria, M. Electric Powered Wheelchair Trajectory Planning on Artificial Potential Field Method. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Sanya, China, 12–14 November 2021; Volume 1068, p. 012012. [Google Scholar]
- Borenstein, J.; Koren, Y. The vector field histogram-fast obstacle avoidance for mobile robots. IEEE Trans. Robot. Autom. 1991, 7, 278–288. [Google Scholar] [CrossRef]
- Gallo, V.; Shallari, I.; Carratù, M.; Laino, V.; Liguori, C. Design and Characterization of a Powered Wheelchair Autonomous Guidance System. Sensors 2024, 24, 1581. [Google Scholar] [CrossRef]
- Adámek, R.; Bugeja, M.K.; Fabri, S.G.; Grepl, R. Enhancing the Obstacle Avoidance Capabilities of a Smart Wheelchair. In Proceedings of the 2022 20th International Conference on Mechatronics—Mechatronika (ME), Pilsen, Czech Republic, 7–9 December 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Li, K.; Ramkumar, S.; Thimmiaraja, J.; Diwakaran, S. Optimized artificial neural network based performance analysis of wheelchair movement for ALS patients. Artif. Intell. Med. 2020, 102, 101754. [Google Scholar] [CrossRef]
- Bolbhat, S.; Bhosale, A.; Sakthivel, G.; Saravanakumar, D.; Sivakumar, R.; Lakshmipathi, J. Intelligent obstacle avoiding agv using vector field histogram and supervisory control. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1716, p. 012030. [Google Scholar]
- Zhang, G.; Zhang, Y.; Xu, J.; Chen, T.; Zhang, W.; Xing, W. Intelligent vector field histogram based collision avoidance method for auv. Ocean. Eng. 2022, 264, 112525. [Google Scholar] [CrossRef]
- Kumar, J.S.; Kaleeswari, R. Implementation of Vector Field Histogram based obstacle avoidance wheeled robot. In Proceedings of the 2016 Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 19 November 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Sary, I.P.; Nugraha, Y.P.; Megayanti, M.; Hidayat, E.; Trilaksono, B.R. Design of Obstacle Avoidance System on Hexacopter Using Vector Field Histogram-Plus. In Proceedings of the 2018 IEEE 8th International Conference on System Engineering and Technology (ICSET), Bandung, Indonesia, 15–16 October 2018; pp. 18–23. [Google Scholar] [CrossRef]
- Bell, D.A.; Borenstein, J.; Levine, S.P.; Koren, Y.; Jaros, J. An assistive navigation system for wheelchairs based upon mobile robot obstacle avoidance. In Proceedings of the 1994 IEEE International Conference on Robotics and Automation, San Diego, CA, USA, 8–13 May 1994; pp. 2018–2022. [Google Scholar]
- Fearn, T.; Labrosse, F.; Shaw, P. Wheelchair Navigation: Automatically Adapting to Evolving Environments. In Proceedings of the Towards Autonomous Robotic Systems: 20th Annual Conference, TAROS 2019, London, UK, 3–5 July 2019; Proceedings, Part II 20. Springer: Berlin/Heidelberg, Germany, 2019; pp. 496–500. [Google Scholar]
- Sahoo, S.K.; Choudhury, B.B. AI advances in wheelchair navigation and control: A comprehensive review. J. Process. Manag. New Technol. 2023, 11, 115–132. [Google Scholar] [CrossRef]
- Sahoo, S.K.; Choudhury, B.B. A review on smart robotic wheelchairs with advancing mobility and independence for individuals with disabilities. J. Decis. Anal. Intell. Comput. 2023, 3, 221–242. [Google Scholar] [CrossRef]
- Sahoo, S.K.; Choudhury, B.B. Autonomous navigation and obstacle avoidance in smart robotic wheelchairs. J. Decis. Anal. Intell. Comput. 2024, 4, 47–66. [Google Scholar] [CrossRef]
- Grewal, H.S.; Jayaprakash, N.T.; Matthews, A.; Shrivastav, C.; George, K. Autonomous wheelchair navigation in unmapped indoor environments. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Dai, X.; Mao, Y.; Huang, T.; Qin, N.; Huang, D.; Li, Y. Automatic obstacle avoidance of quadrotor UAV via CNN-based learning. Neurocomputing 2020, 402, 346–358. [Google Scholar] [CrossRef]
- Zhou, C.; Li, F.; Cao, W.; Wang, C.; Wu, Y. Design and implementation of a novel obstacle avoidance scheme based on combination of CNN-based deep learning method and liDAR-based image processing approach. J. Intell. Fuzzy Syst. 2018, 35, 1695–1705. [Google Scholar] [CrossRef]
- Chakravarty, P.; Kelchtermans, K.; Roussel, T.; Wellens, S.; Tuytelaars, T.; Van Eycken, L. CNN-based single image obstacle avoidance on a quadrotor. In Proceedings of the 2017 IEEE international conference on robotics and automation (ICRA), Singapore, 29 May–3 June 2017; pp. 6369–6374. [Google Scholar]
- Yoon, H.Y.; Kim, J.H.; Jeong, J.W. Classification of the sidewalk condition using self-supervised transfer learning for wheelchair safety driving. Sensors 2022, 22, 380. [Google Scholar] [CrossRef]
- Bakouri, M.; Alsehaimi, M.; Ismail, H.F.; Alshareef, K.; Ganoun, A.; Alqahtani, A.; Alharbi, Y. Steering a robotic wheelchair based on voice recognition system using convolutional neural networks. Electronics 2022, 11, 168. [Google Scholar] [CrossRef]
- Zhang, Z.; Mao, S.; Chen, K.; Xiao, L.; Liao, B.; Li, C.; Zhang, P. CNN and PCA Based Visual System of A Wheelchair Manipulator Robot for Automatic Drinking. In Proceedings of the 2018 IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1280–1286. [Google Scholar] [CrossRef]
- Sutikno; Anam, K.; Saleh, A. Voice Controlled Wheelchair for Disabled Patients based on CNN and LSTM. In Proceedings of the 2020 4th International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 10–11 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Tawil, Y.; Hafez, A.A. Deep Learning Obstacle Detection and Avoidance for Powered Wheelchair. In Proceedings of the 2022 Innovations in Intelligent Systems and Applications Conference (ASYU), Antalya, Turkey, 7–9 September 2022; pp. 1–6. [Google Scholar]
- Ali, S.; Al Mamun, S.; Fukuda, H.; Lam, A.; Kobayashi, Y.; Kuno, Y. Smart robotic wheelchair for bus boarding using CNN combined with hough transforms. In Proceedings of the Intelligent Computing Methodologies: 14th International Conference, ICIC 2018, Wuhan, China, 15–18 August 2018; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2018; pp. 163–172. [Google Scholar]
- Xu, Z.; Zhou, X.; Wu, H.; Li, X.; Li, S. Motion planning of manipulators for simultaneous obstacle avoidance and target tracking: An RNN approach with guaranteed performance. IEEE Trans. Ind. Electron. 2021, 69, 3887–3897. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, H.; Lin, C.; Liu, D.; Yu, D. A novel GRU-RNN network model for dynamic path planning of mobile robot. IEEE Access 2019, 7, 15140–15151. [Google Scholar] [CrossRef]
- Savage, J.; Munoz, S.; Matamoros, M.; Osorio, R. Obstacle avoidance behaviors for mobile robots using genetic algorithms and recurrent neural networks. IFAC Proc. Vol. 2013, 46, 141–146. [Google Scholar] [CrossRef]
- Haddad, M.J.; Sanders, D.A. Deep Learning architecture to assist with steering a powered wheelchair. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 2987–2994. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Palumbo, A.; Gramigna, V.; Calabrese, B.; Ielpo, N. Motor-imagery EEG-based BCIs in wheelchair movement and control: A systematic literature review. Sensors 2021, 21, 6285. [Google Scholar] [CrossRef]
- Shamseldin, M.A.; Khaled, E.; Youssef, A.; Mohamed, D.; Ahmed, S.; Hesham, A.; Elkodama, A.; Badran, M. A new design identification and control based on GA optimization for an autonomous wheelchair. Robotics 2022, 11, 101. [Google Scholar] [CrossRef]
- Kocejko, T.; Matuszkiewicz, N.; Durawa, P.; Madajczak, A.; Kwiatkowski, J. How Integration of a Brain-Machine Interface and Obstacle Detection System Can Improve Wheelchair Control via Movement Imagery. Sensors 2024, 24, 918. [Google Scholar] [CrossRef]
- Xue, X.; Li, Z.; Zhang, D.; Yan, Y. A deep reinforcement learning method for mobile robot collision avoidance based on double dqn. In Proceedings of the 2019 IEEE 28th International Symposium on Industrial Electronics (ISIE), Vancouver, BC, Canada, 12–14 June 2019; pp. 2131–2136. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar]
- Cimurs, R.; Suh, I.H.; Lee, J.H. Goal-driven autonomous exploration through deep reinforcement learning. IEEE Robot. Autom. Lett. 2021, 7, 730–737. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International conference on machine learning. PMLR, New York City, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to train your robot with deep reinforcement learning: Lessons we have learned. Int. J. Robot. Res. 2021, 40, 698–721. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Shi, H.; Shi, L.; Xu, M.; Hwang, K.S. End-to-end navigation strategy with deep reinforcement learning for mobile robots. IEEE Trans. Ind. Inform. 2019, 16, 2393–2402. [Google Scholar] [CrossRef]
- Zhang, J.; Springenberg, J.T.; Boedecker, J.; Burgard, W. Deep reinforcement learning with successor features for navigation across similar environments. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 2371–2378. [Google Scholar]
- Dini, P.; Saponara, S. Cogging torque reduction in brushless motors by a nonlinear control technique. Energies 2019, 12, 2224. [Google Scholar] [CrossRef]
- Pierpaolo, D.; Saponara, S. Control system design for cogging torque reduction based on sensor-less architecture. In Proceedings of the Applications in Electronics Pervading Industry, Environment and Society: APPLEPIES 2019 7, Pisa, Italy, 12–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 309–321. [Google Scholar]
- Bernardeschi, C.; Dini, P.; Domenici, A.; Saponara, S. Co-simulation and verification of a non-linear control system for cogging torque reduction in brushless motors. In Proceedings of the Software Engineering and Formal Methods: SEFM 2019 Collocated Workshops: CoSim-CPS, ASYDE, CIFMA, and FOCLASA, Oslo, Norway, 16–20 September 2019; Revised Selected Papers 17. Springer: Berlin/Heidelberg, Germany, 2020; pp. 3–19. [Google Scholar]
- Dini, P.; Saponara, S. Design of an observer-based architecture and non-linear control algorithm for cogging torque reduction in synchronous motors. Energies 2020, 13, 2077. [Google Scholar] [CrossRef]
- Bernardeschi, C.; Dini, P.; Domenici, A.; Palmieri, M.; Saponara, S. Formal verification and co-simulation in the design of a synchronous motor control algorithm. Energies 2020, 13, 4057. [Google Scholar] [CrossRef]
- Cosimi, F.; Dini, P.; Giannetti, S.; Petrelli, M.; Saponara, S. Analysis and design of a non-linear MPC algorithm for vehicle trajectory tracking and obstacle avoidance. In Applications in Electronics Pervading Industry, Environment and Society. ApplePies 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 229–234. [Google Scholar]
- Dini, P.; Saponara, S. Model-based design of an improved electric drive controller for high-precision applications based on feedback linearization technique. Electronics 2021, 10, 2954. [Google Scholar] [CrossRef]
- Bernardeschi, C.; Dini, P.; Domenici, A.; Mouhagir, A.; Palmieri, M.; Saponara, S.; Sassolas, T.; Zaourar, L. Co-simulation of a model predictive control system for automotive applications. In Proceedings of the International Conference on Software Engineering and Formal Methods, Virtual Event, 6–10 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 204–220. [Google Scholar]
- Dini, P.; Saponara, S. Processor-in-the-Loop Validation of a Gradient Descent-Based Model Predictive Control for Assisted Driving and Obstacles Avoidance Applications. IEEE Access 2022, 10, 67958–67975. [Google Scholar] [CrossRef]
- Pacini, F.; Di Matteo, S.; Dini, P.; Fanucci, L.; Bucchi, F. Innovative Plug-and-Play System for Electrification of Wheel-Chairs. IEEE Access 2023, 11, 89038–89051. [Google Scholar] [CrossRef]
- Pacini, F.; Dini, P.; Fanucci, L. Cooperative Driver Assistance for Electric Wheelchair. In Proceedings of the International Conference on Applications in Electronics Pervading Industry, Environment and Society, Genova, Italy, 28–29 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 109–116. [Google Scholar]
- Dini, P.; Ariaudo, G.; Botto, G.; Greca, F.L.; Saponara, S. Real-time electro-thermal modelling and predictive control design of resonant power converter in full electric vehicle applications. IET Power Electron. 2023, 16, 2045–2064. [Google Scholar] [CrossRef]
- Dini, P.; Basso, G.; Saponara, S.; Romano, C. Real-time monitoring and ageing detection algorithm design with application on SiC-based automotive power drive system. IET Power Electron. 2024. [Google Scholar] [CrossRef]
- Fujimoto, S.; Hoof, H.; Meger, D. Addressing function approximation error in actor-critic methods. In Proceedings of the International conference on machine learning. PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 1587–1596. [Google Scholar]
- Nvidia Container Toolkit. Available online: https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/sample-workload.html (accessed on 3 December 2023).
- Americans with Disabilities Act of 1990. Public Law 101–336. 1990. 104 Stat. 327, July 26, 1990; U.S. Government Printing Office: Washington, DC, USA, 1990.
- NVIDIA. Jetson Nano 2GB Developer Kit; NVIDIA: Santa Clara, CA, USA, 2020. [Google Scholar]










| Parameter | Value |
|---|---|
| Width | 0.7 m |
| Length | 1.1 m |
| Drive wheel radius | 0.27 m |
| Drive wheel width | 0.05 m |
| Castor wheel radius | 0.17 m |
| CDDS | VFH | BRS | ||
|---|---|---|---|---|
| First test | Average forward speed [m/s] | 0.59 | 0.35 | 0.64 |
| Jerkiness | 8.3 ± 58.8 | 3.6 ± 21.2 | 6.5 ± 57.4 | |
| Max collisions | 0 | 0 | 0 | |
| Second test | Average forward speed [m/s] | 0.29 | 0.14 | 0.37 |
| Jerkiness | 13.8 ± 71.1 | 4.9 ± 24.7 | 10.6 ± 69.2 | |
| Max collisions | 0 | 0 | 1 | |
| Third test | Average forward speed [m/s] | 0.39 | 0.31 | 0.42 |
| Jerkiness | 12.1 ± 83.4 | 5.7 ± 29.6 | 11.8 ± 85.9 | |
| Max collisions | 0 | 0 | 2 |
| Platform | Execution Time |
|---|---|
| PC (only CPU) | 0.098 ± 0.038 ms |
| Jetson Nano | 1.22 ± 0.73 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pacini, F.; Dini, P.; Fanucci, L. Design of an Assisted Driving System for Obstacle Avoidance Based on Reinforcement Learning Applied to Electrified Wheelchairs. Electronics 2024, 13, 1507. https://doi.org/10.3390/electronics13081507
Pacini F, Dini P, Fanucci L. Design of an Assisted Driving System for Obstacle Avoidance Based on Reinforcement Learning Applied to Electrified Wheelchairs. Electronics. 2024; 13(8):1507. https://doi.org/10.3390/electronics13081507
Chicago/Turabian StylePacini, Federico, Pierpaolo Dini, and Luca Fanucci. 2024. "Design of an Assisted Driving System for Obstacle Avoidance Based on Reinforcement Learning Applied to Electrified Wheelchairs" Electronics 13, no. 8: 1507. https://doi.org/10.3390/electronics13081507