
Efficient X-ray Security Images for Dangerous Goods Detection Based on Improved YOLOv7



Abstract
1. Introduction
- (1)
- Background complexity: Due to the different transmittance of X-rays through different objects, objects with different materials and thicknesses exhibit different colors under X-rays. Objects with similar thicknesses to hazardous materials can interfere with the model’s learning of hazardous material feature information;
- (2)
- Serious overlap phenomenon: The overlapping stacking of items can obscure the edges of objects, reducing the characteristic of dangerous goods and increasing the difficulty of dangerous goods detection;
- (3)
- Multi-scale dangerous goods: In X-ray images, dangerous goods, such as knives and liquid containers, have multiple categories, shapes, and scales. Different types of dangerous goods have different sizes, and there are also differences in the size and shape of the same category of dangerous goods. Dangerous goods have intra-class and inter-class differences. Therefore, complex backgrounds, overlapping occlusion of hazardous materials, and multiple scales are the main problems faced by current X-ray security image hazardous material detection tasks.
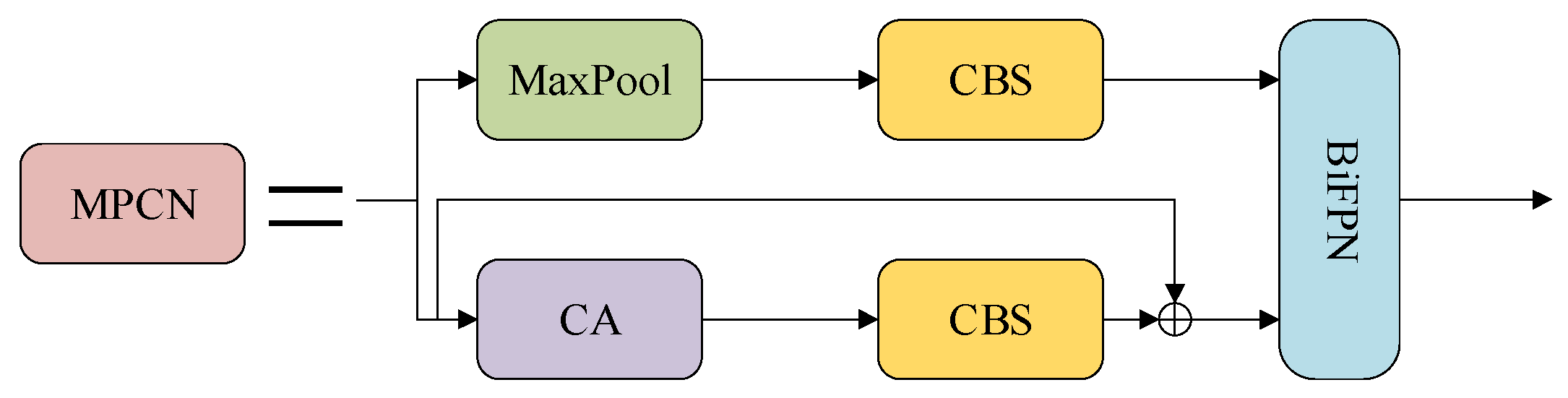
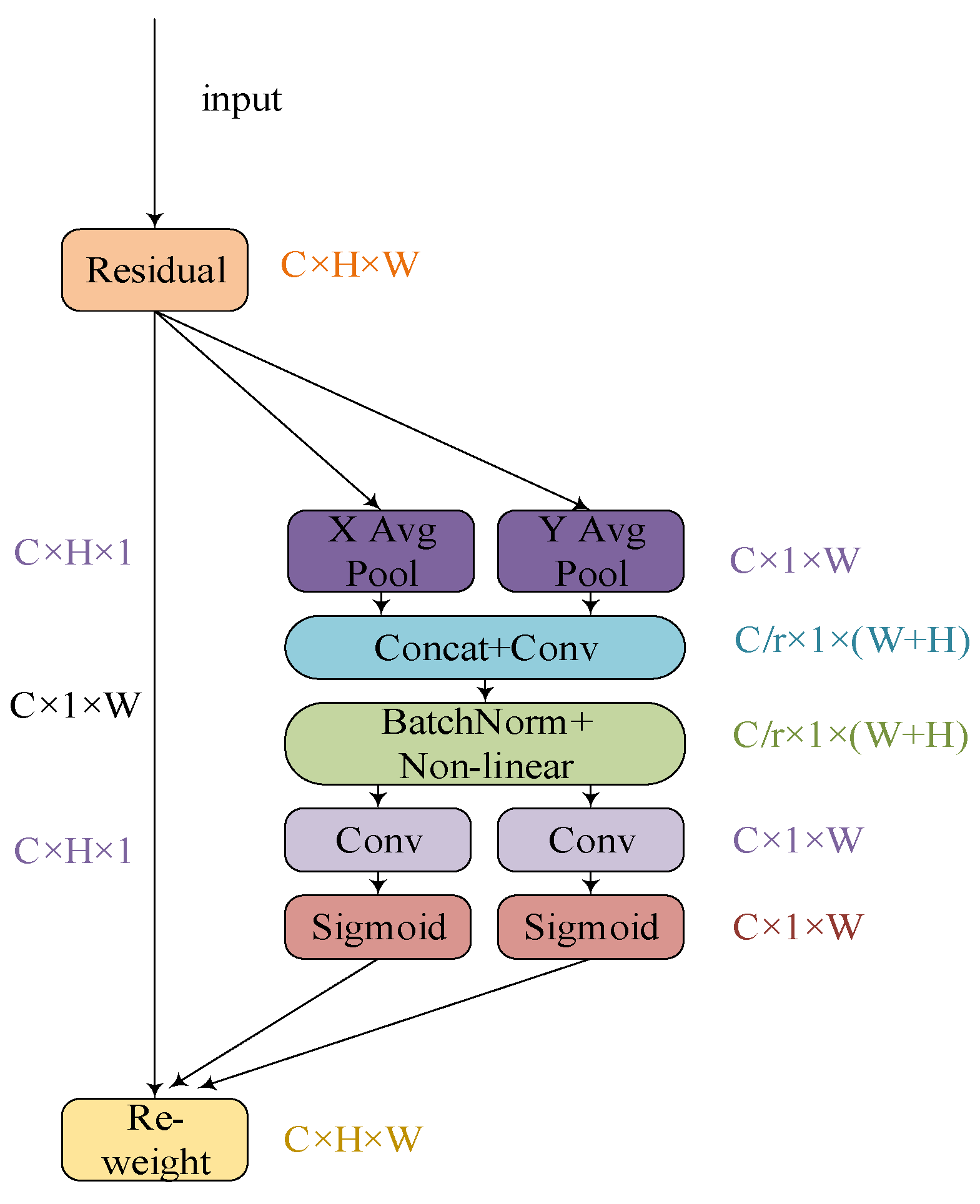
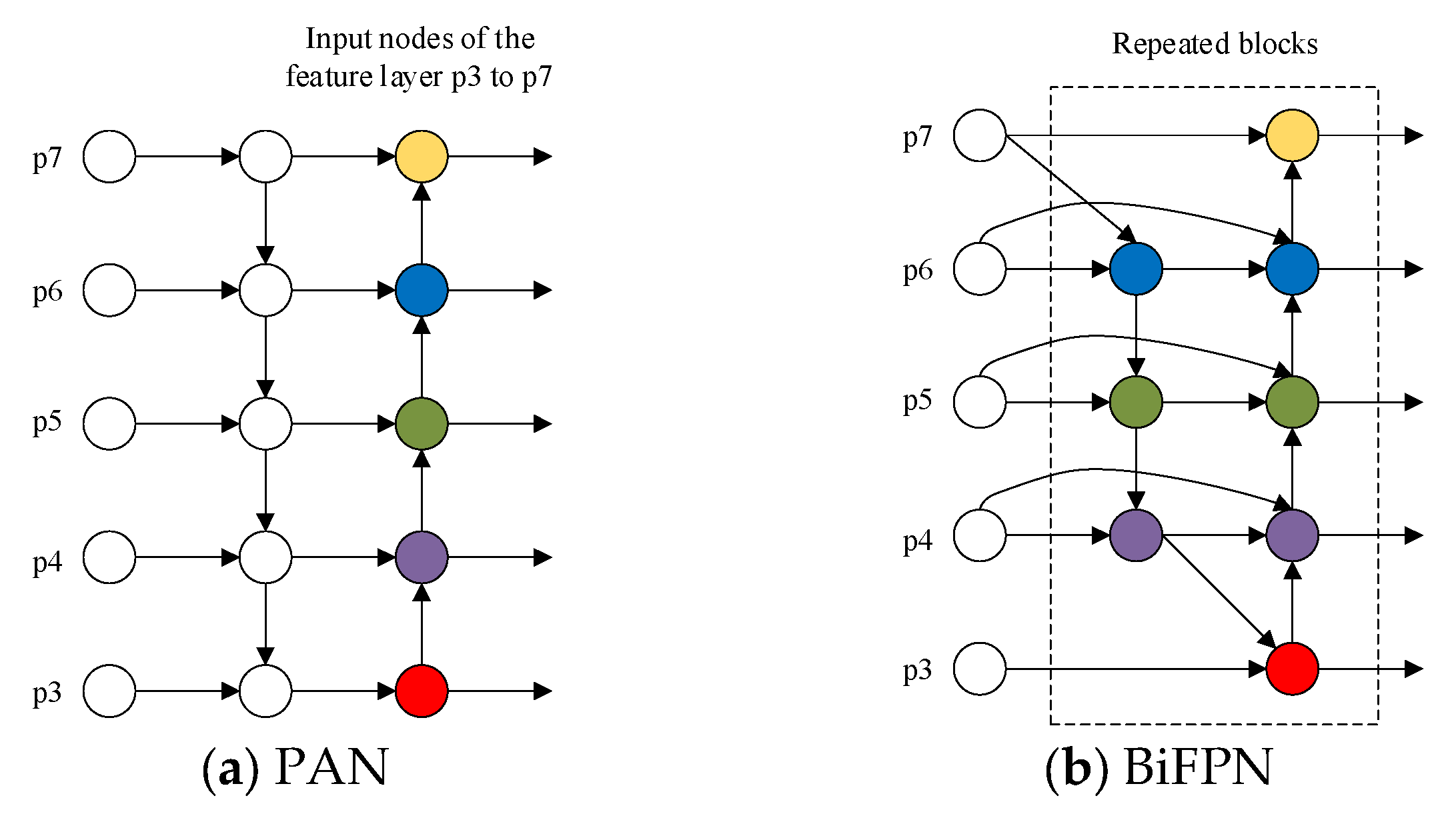
- In the downsampling part of the backbone network, coordinate attention is combined to focus on the spatial position information of the input image, making the deep convolutions in the network more sensitive to the position information of the feature map and effectively improving the detection ability of the model. In addition, BiFPN (Bidirectional Feature Pyramid Network) is used as a feature fusion structure to simplify the network and enhance its feature fusion capability.
- In the downsampling part of the neck network, dynamic snake-shaped convolution is combined as a cross-scale embedding layer for feature extraction at different scales to enhance the robustness of the detection model to changes in the shape and position of dangerous goods, and multi-scale feature information is considered to improve the localization and recognition ability of dangerous goods in complex backgrounds.
- To design a multi-scale grouped convolution module, a multi-convolution transformer (MCT) block based on Conv2Former was used to simplify the self-attention mechanism in the vision transformer and further refine the key feature layers to prevent the loss of feature information at different scales. This effectively reduces computational costs while processing high-resolution images and enhancing the network’s ability to extract local feature information of hazardous material.
2. Methods
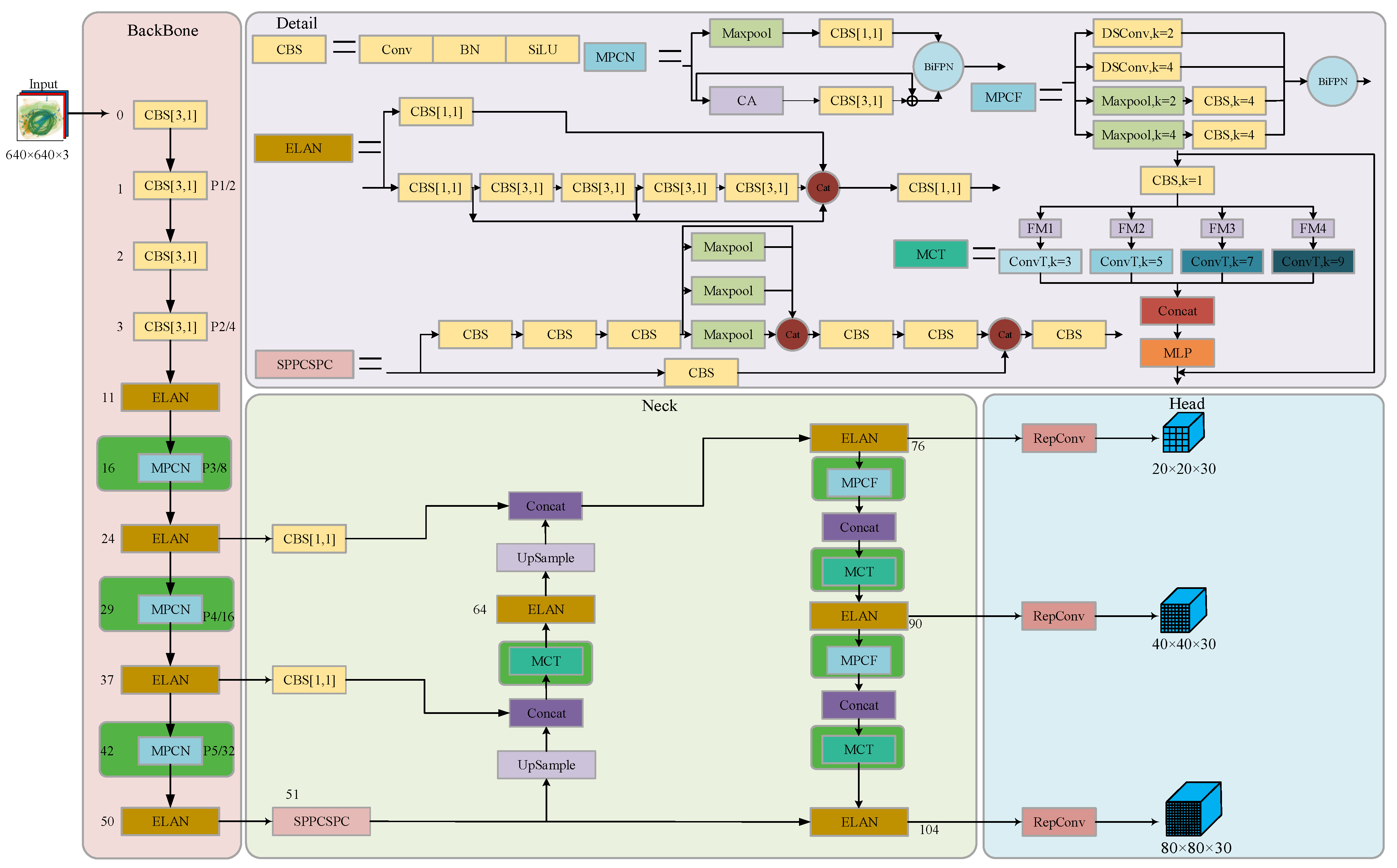
2.1. Overview
2.2. Improvement of MPConv Module in Backbone Network
2.2.1. Coordinate Attention Mechanism
2.2.2. Weighted Bidirectional Feature Pyramid Network
2.3. Improvement of MPConv Module in Neck Network
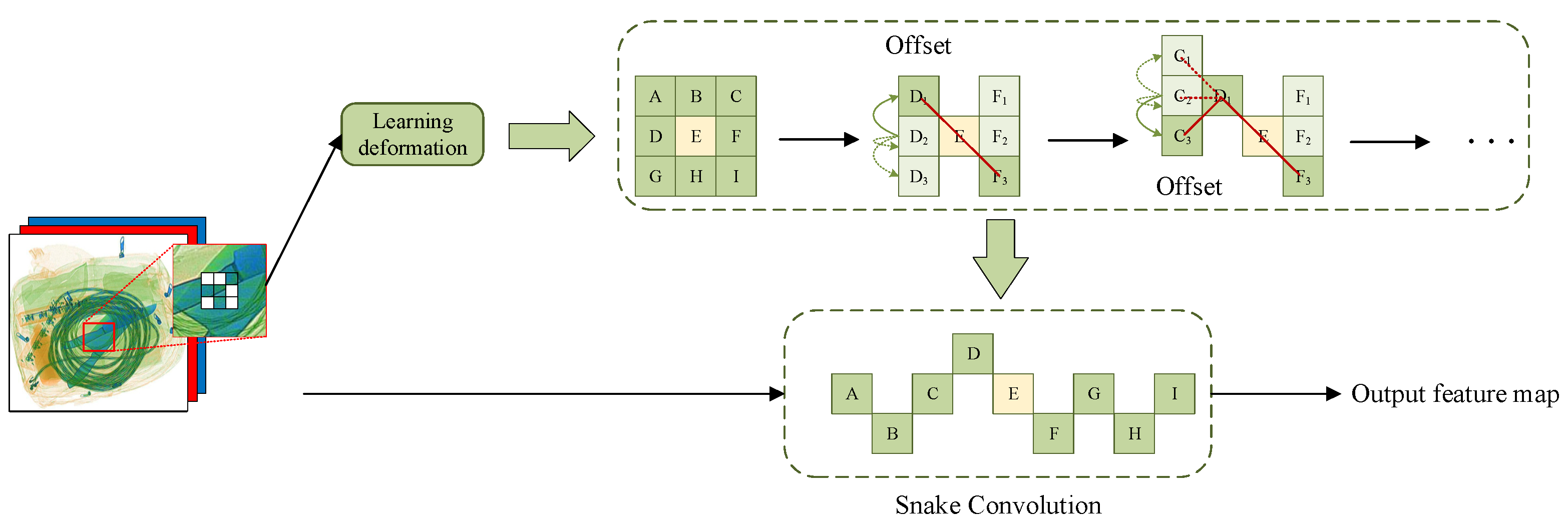
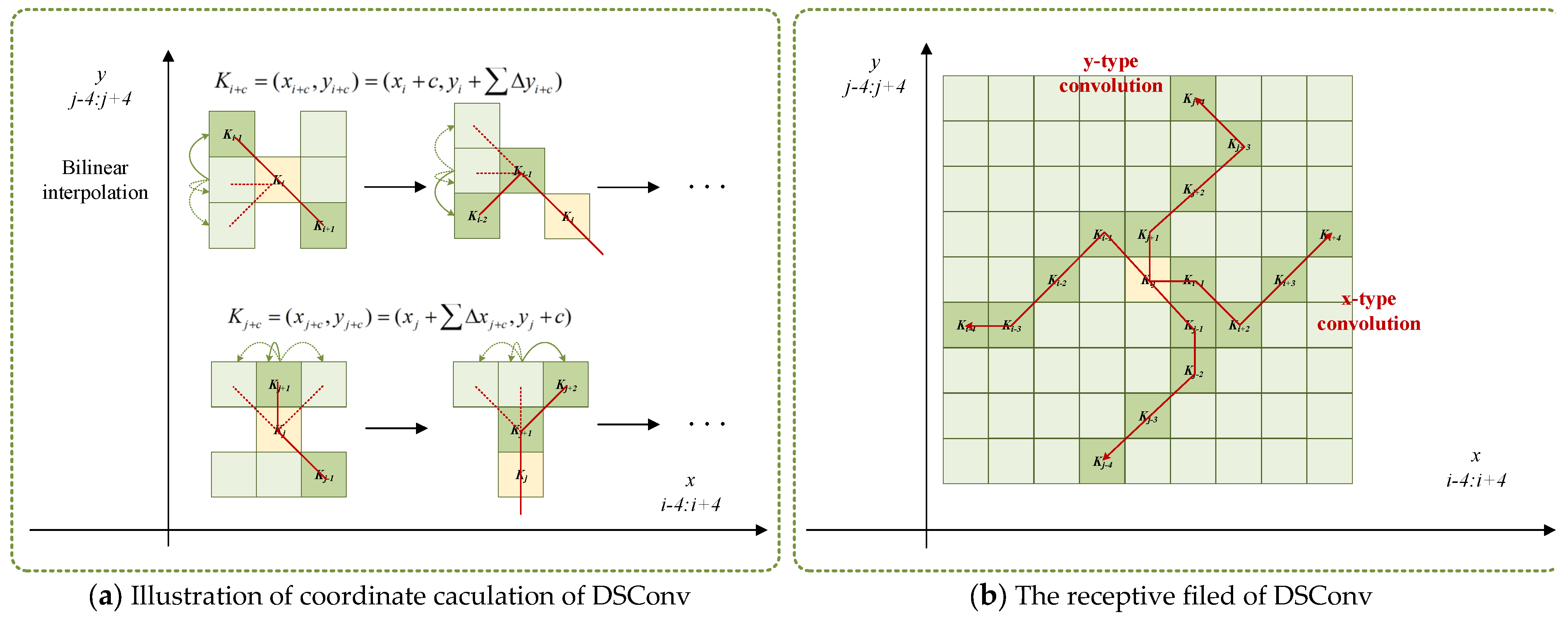
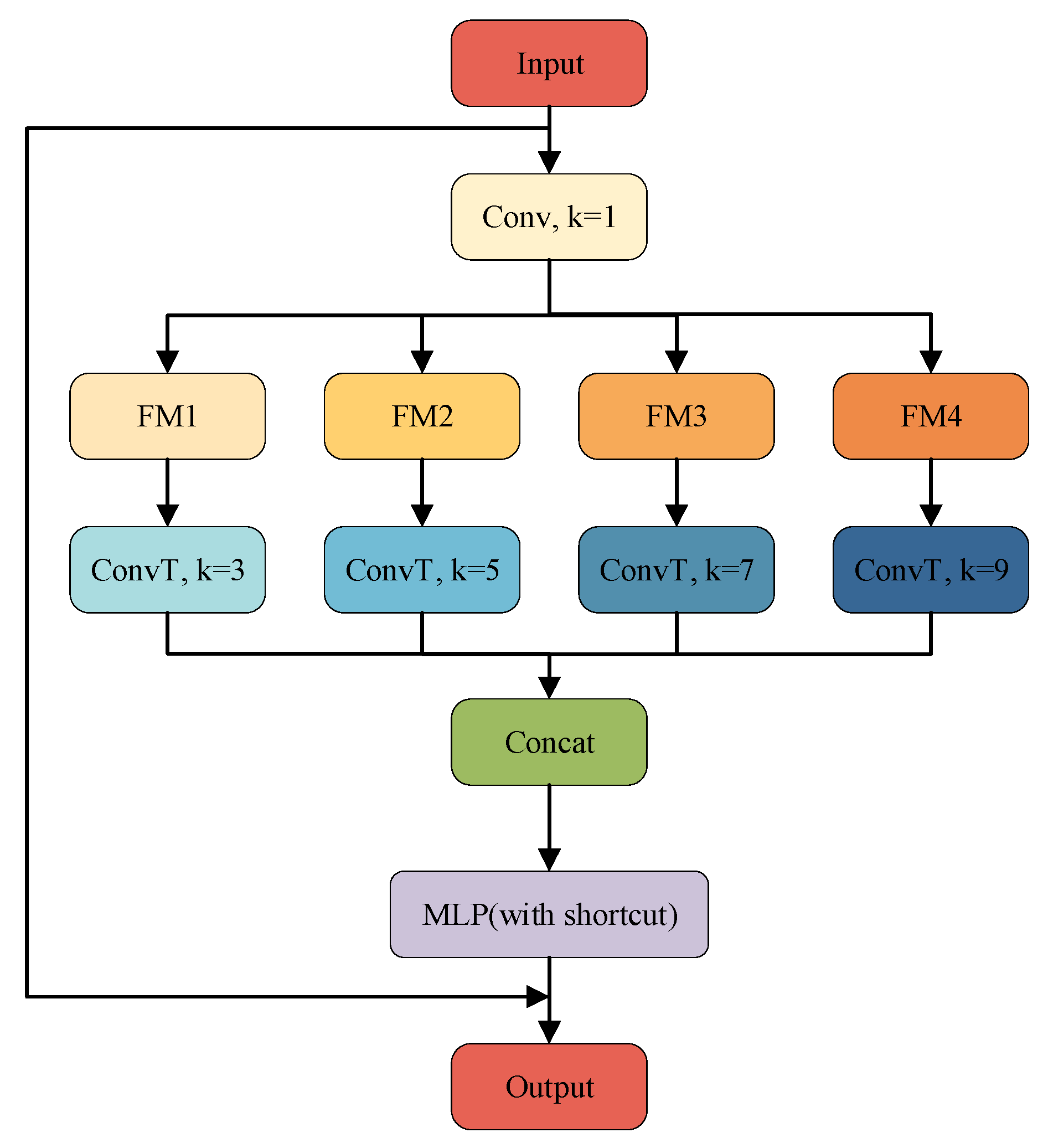
2.3.1. Dynamic Snake Convolution
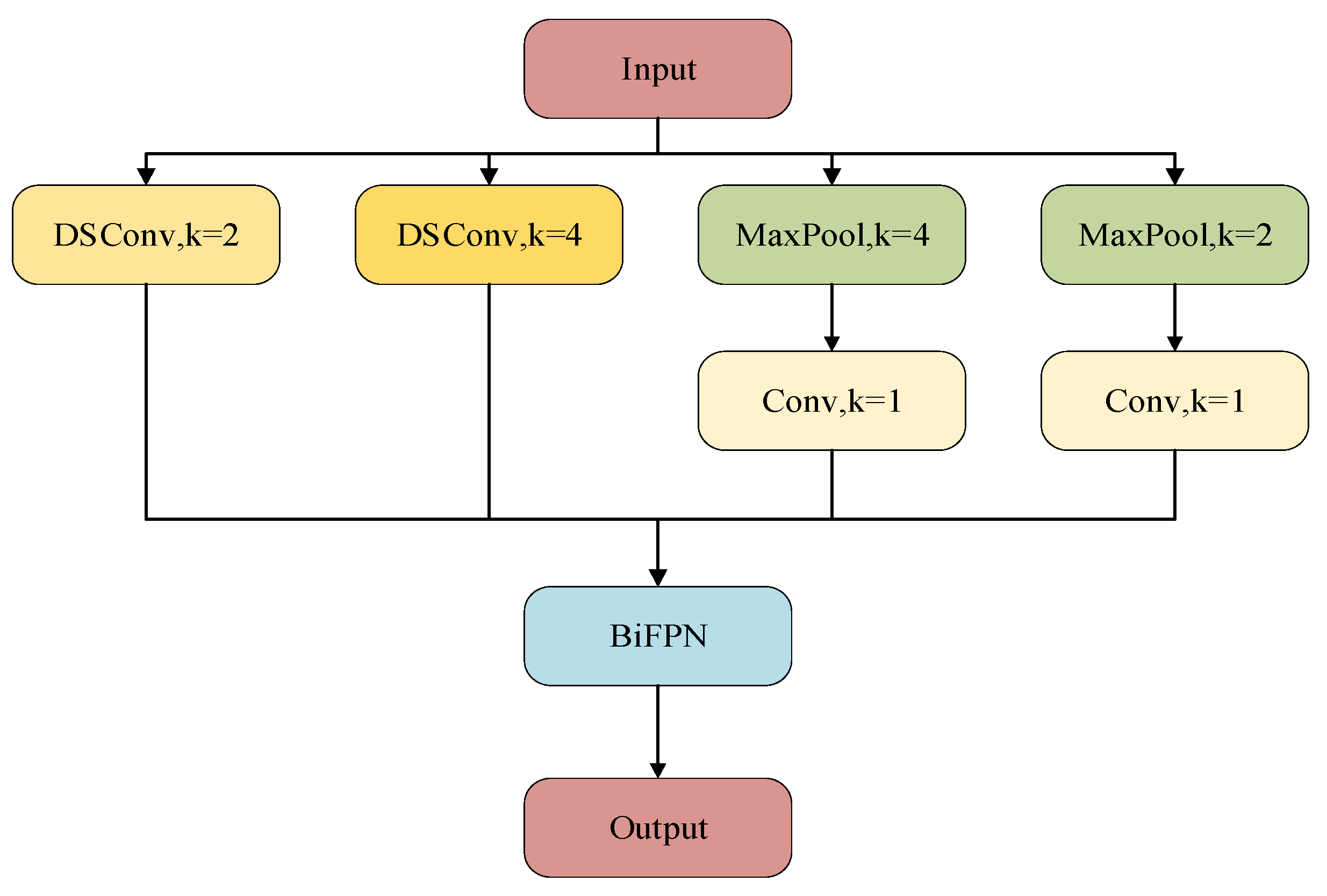
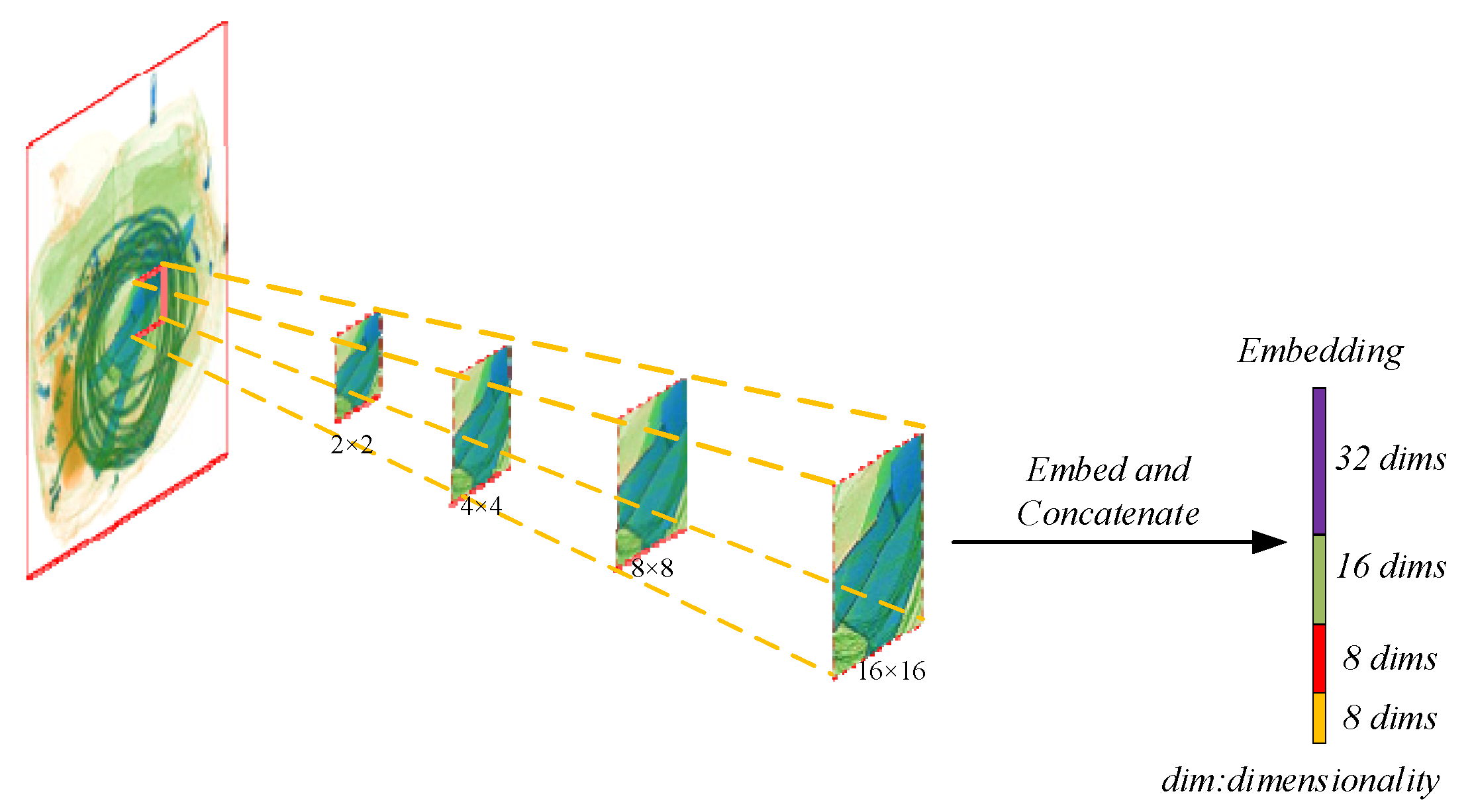
2.3.2. Cross-Scale Embedding Layer
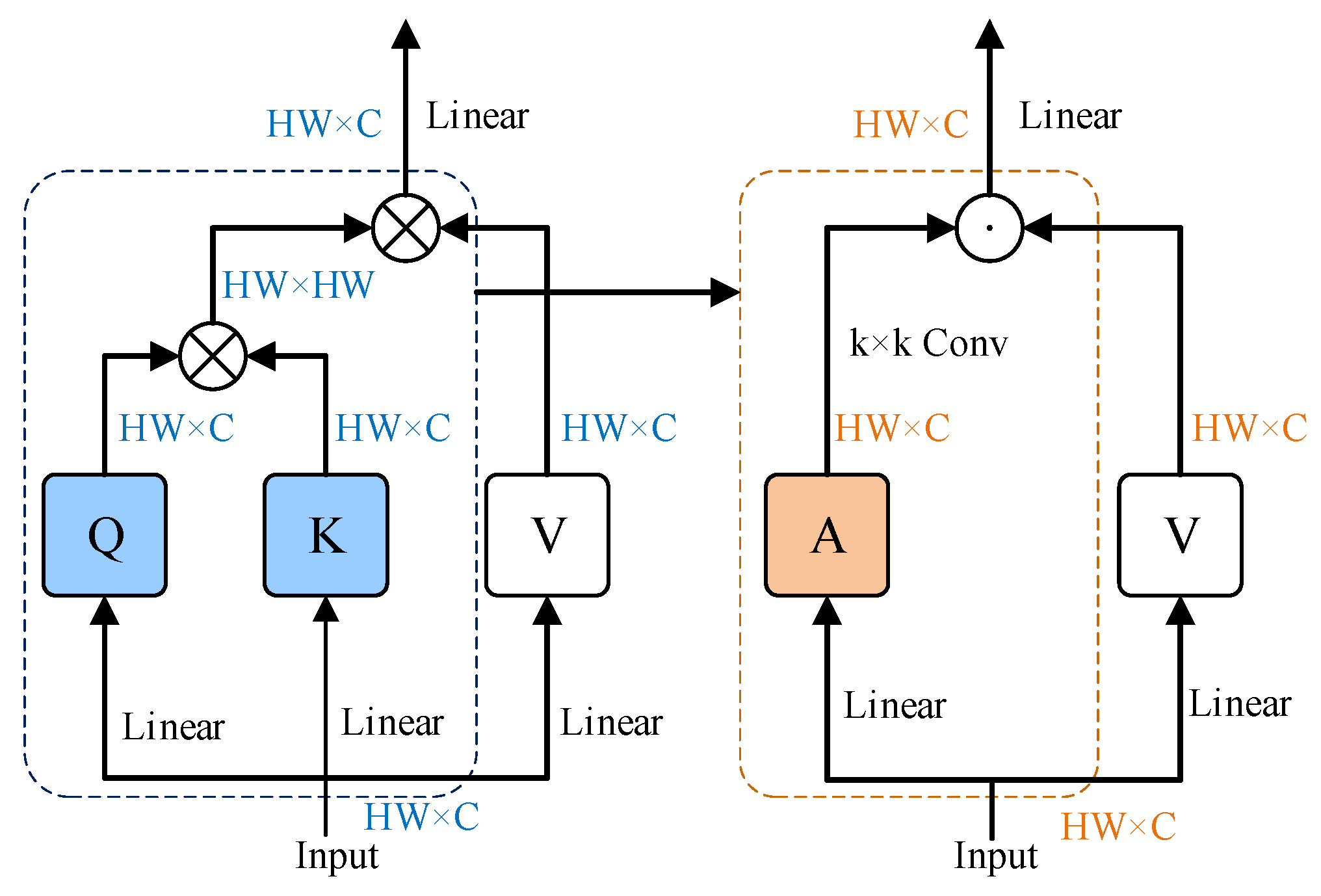
2.4. MCT Module Combined with Conv2Former
2.4.1. Conv2Former
2.4.2. MCT Module
3. Results
3.1. Dataset Description and Experimental Environment Settings
- SIXray: The SIXray dataset [17] was released by the Pattern Recognition and Intelligent System Development Laboratory of the University of the Chinese Academy of Sciences and contains 1,059,231 X-ray screening images obtained from personal baggage scanning, of which 8929 X-ray screening images contain guns, knives, wrenches, pliers, or scissors—five kinds of contraband.
- CLCXray: The CLCXray dataset [34] is a public dataset jointly released by the University of the Chinese Academy of Sciences, Tongji University, and Beijing University of Posts and Telecommunications. The dataset contains 9565 X-ray security images. There are 12 categories of contraband in the dataset, including five kinds of knives and seven kinds of liquid containers. The knives are specifically blades, daggers, knives, scissors, and Swiss army knives. The liquid containers are specifically cans, carton drinks, glass bottles, plastic bottles, vacuum bottles, spray cans, and tin cans.
- PIDray: The PIDray dataset [35] is a large-scale X-ray security image dataset released in 2021, which was collected by Wang et al. using three different brands of security machines and contains 47,677 X-ray security images. There are a total of 12 categories of prohibited items in the dataset, namely batons, pliers, handcuffs, hammers, wrenches, lighters, scissors, knives, guns, powerbanks, sprayers, and bullets. The training set consists of 76,913 images, and the test set is divided into three small test sets classified as easy, hard, and hidden, corresponding to single-target, multiple-target, and intentionally hidden situations, respectively. The number of images is 24,758, 9746, and 13,069, respectively. This paper uses the easy test set to test the performance of the model.
3.2. The Evaluating Indicators
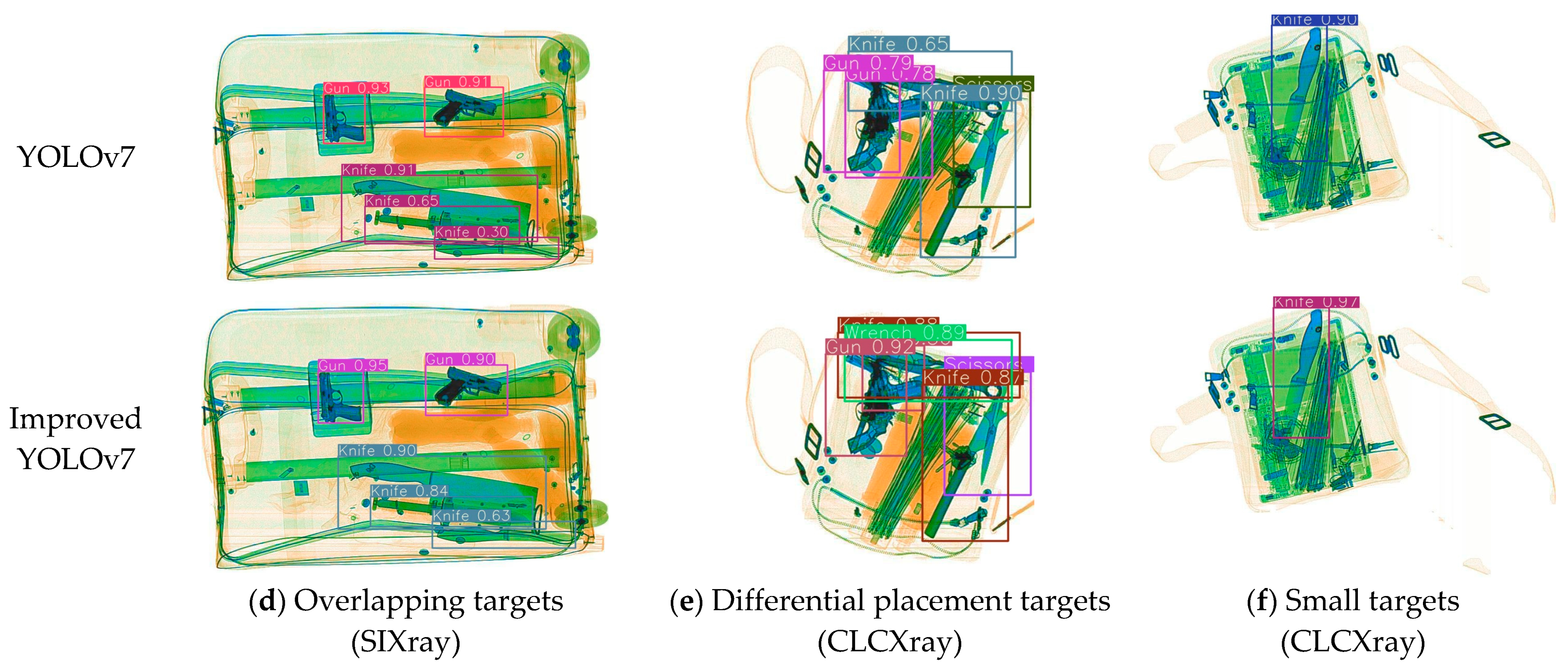
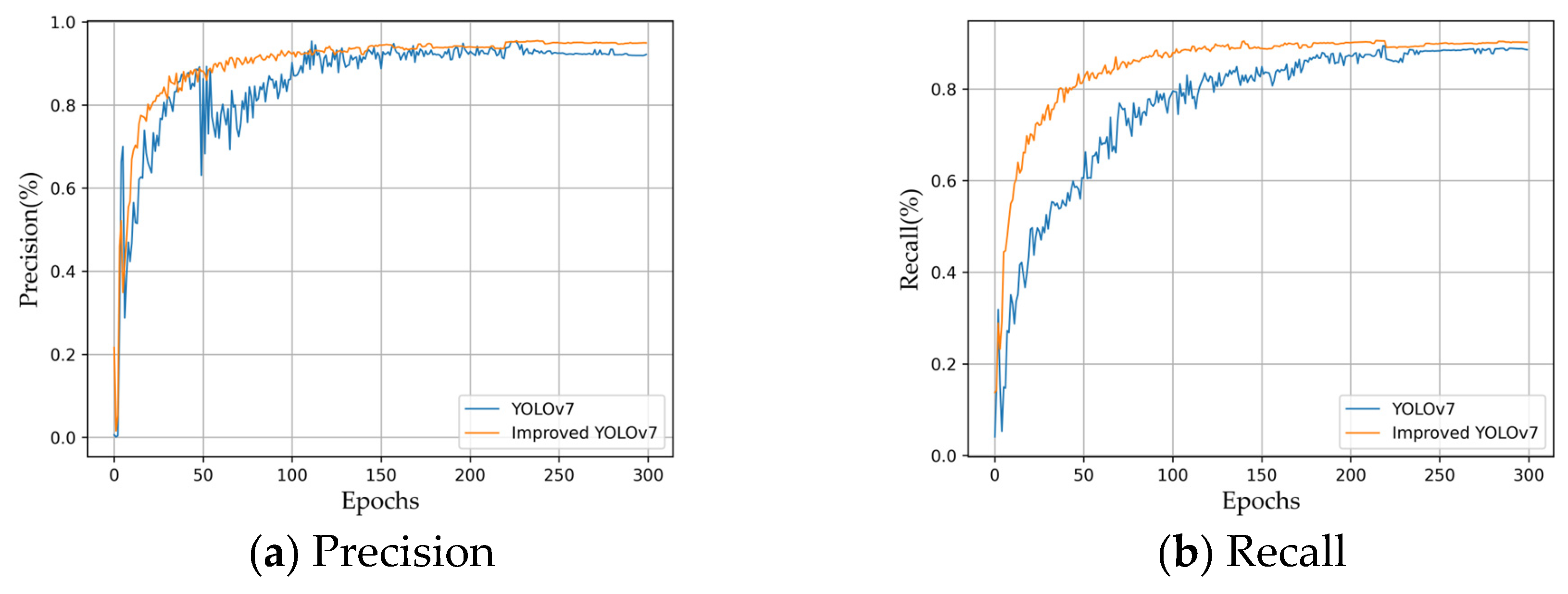
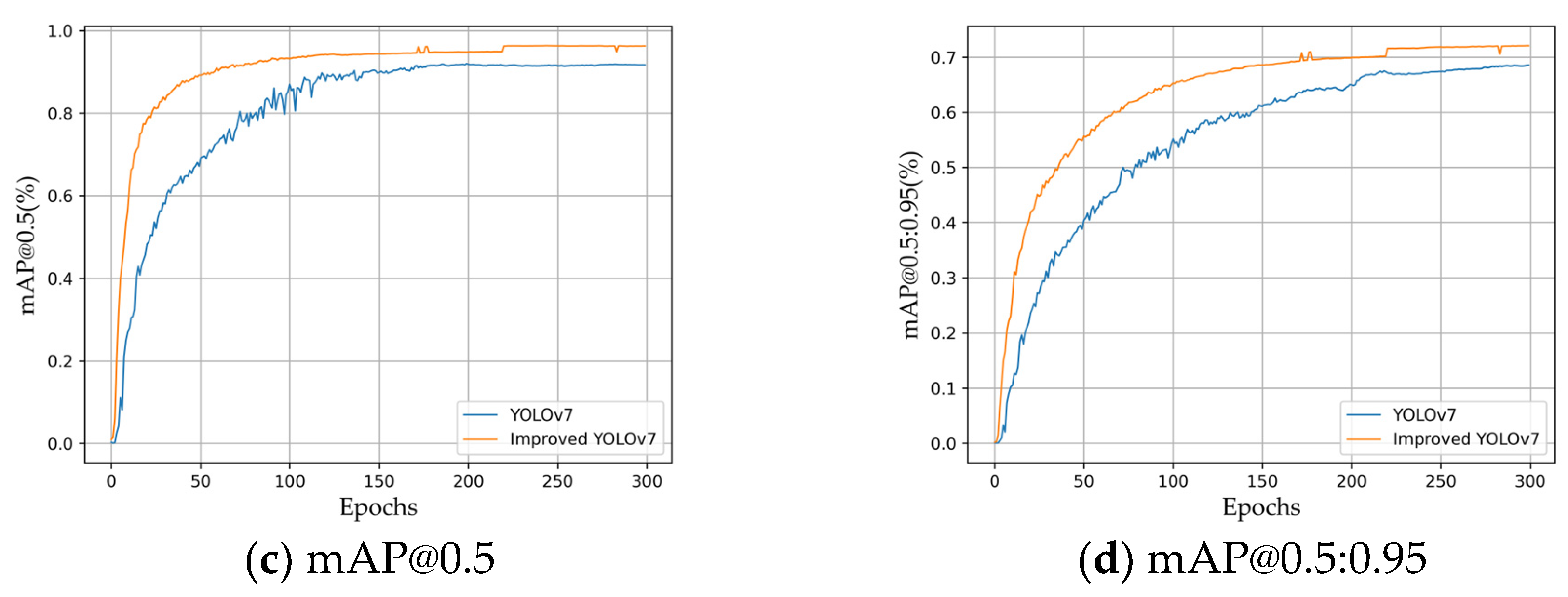
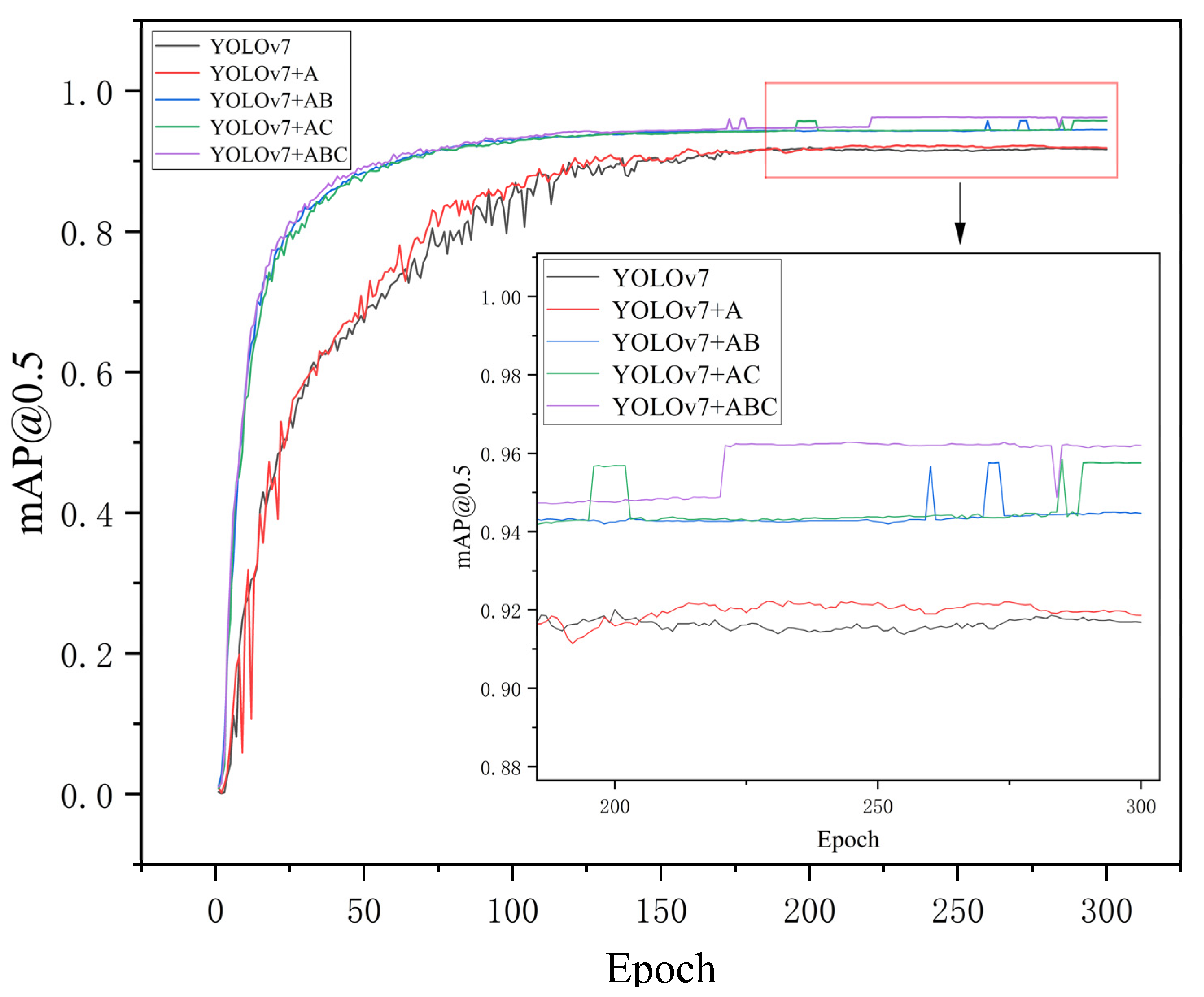
3.3. Experimental Results and Analysis
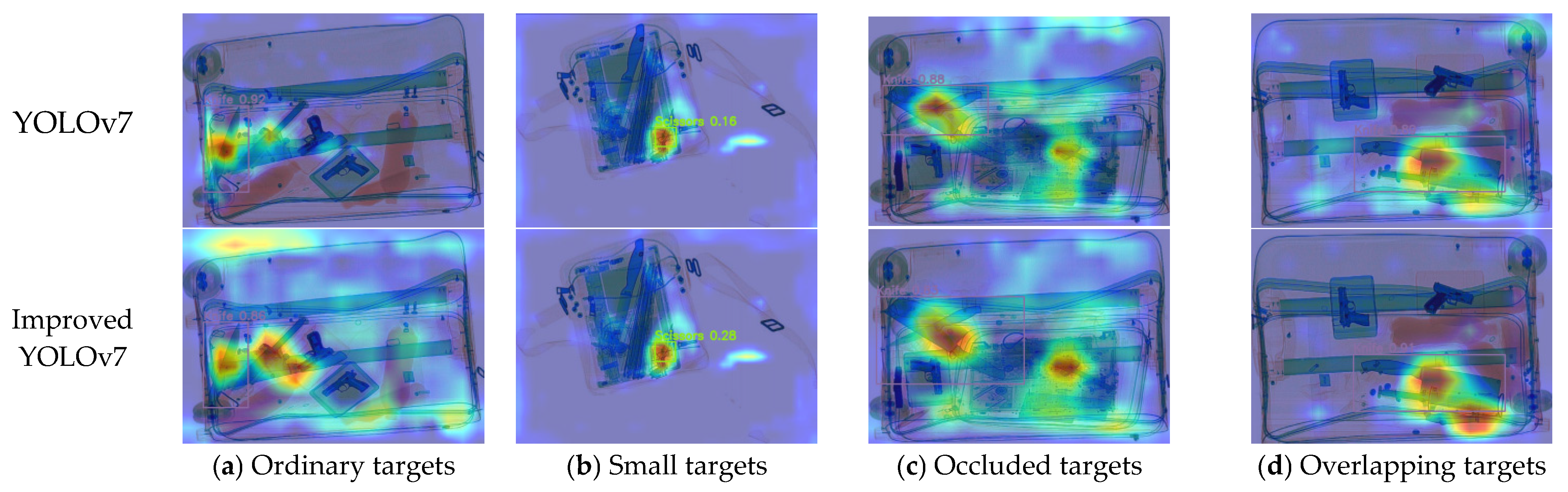
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Y.-L. Security Inspection Image Detection and Application Based on Deep Learning. Mod. Inf. Technol. 2021, 5, 82–85. [Google Scholar]
- Han, B.-M.; Xi, Z.; Sun, Y.-J. Summary of 2022 World Urban Rail Transit Operation Statistics and Analysis; Urban Rapid Rail Transit: Beijing, China, 2022. [Google Scholar]
- Bastan, M.; Yousefi, M.R.; Breuel, T.M. Visual words on baggage X-ray images. In Proceedings of the 2011 International Conference on Computer Analysis of Images and Patterns, Seville, Spain, 29–31 August 2011; pp. 360–368. [Google Scholar]
- Turcsany, D.; Mouton, A.; Breckon, T.P. Improving feature-based object recognition for X-ray baggage security screening using primed visualwords. In Proceedings of the 2013 International Conference on Industrial Technology, Cape Town, South Africa, 25–28 February 2013; pp. 1140–1145. [Google Scholar]
- Flitton, G.; Mouton, A.; Breckon, T.P. Object Classification in 3D Baggage Security Computed Tomography Imagery Using Visual Codebooks; Elsevier Science Inc.: Amsterdam, The Netherlands, 2015. [Google Scholar]
- Mery, D.; Katsaggelos, A.K. A Logarithmic X-ray Imaging Model for Baggage Inspection: Simulation and Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 251–259. [Google Scholar]
- Xing, X.-L.; Hu, H.; Xu, Y.-F. Security Inspection Image Interpretation and FPGA Implementation Method of Gray Scale Projection Algorithm. Microcontroll. Embed. Syst. 2018, 18, 42–44. [Google Scholar]
- Russo, A.U.; Deb, K.; Tista, S.C.; Islam, A. Smoke Detection Method Based on LBP and SVM from Surveillance Camera. In Proceedings of the 2018 International Conference on Computer, Communication, Chemical, Material and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 8–9 February 2018; pp. 1–4. [Google Scholar]
- Lyu, S.; Tu, X.; Lu, Y. X-ray image classification for parcel inspection in high-speed sorting line. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018. [Google Scholar]
- Akcay, S.; Breckon, T.P. An Evaluation of Region Based Object Detection Strategies within X-ray Baggage Security Imagery. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1337–1341. [Google Scholar]
- Mery, D.; Svec, E.; Arias, M.; Riffo, V.; Saavedra, J.M.; Banerjee, S. Modern Computer Vision Techniques for X-ray Testing in Baggage Inspection. IEEE Access 2017, 47, 682–692. [Google Scholar] [CrossRef]
- Singh, B.; Li, H.; Sharma, A.; Davis, L.S. R-FCN-3000 at 30 fps: Decoupling Detection and Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1081–1090. [Google Scholar]
- Gu, L. Research and implementation of automatic cutlery recognition method based on X-ray security inspection image. In Proceedings of the 2020 3rd World Conference on Mechanical Engineering and Intelligent Manufacturing (WCMEIM), Shanghai, China, 4–6 December 2020; pp. 12–17. [Google Scholar]
- Gaus, Y.F.A.; Bhowmik, N.; Akçay, S.; Guillén-Garcia, P.M.; Barker, J.W.; Breckon, T.P. Evaluation of a Dual Convolutional Neural Network Architecture for Object-wise Anomaly Detection in Cluttered X-ray Security Imagery. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Li, D.; Hu, X.; Zhang, H.G.; Yang, J.F. A GAN based method for multiple prohibited items synthesis of X-ray security image. Optoelectron. Lett. 2021, 17, 112–117. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, L. Dangerous goods detection based on multi-scale feature fusion in security images. Laser Optoelect-Tronics Progress 2021, 58, 152–159. [Google Scholar]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. SIXray: Alarge-scale security inspection X-ray benchmark for prohibited item discovery in overlapping images. In Proceedings of the IEEE, CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: New York, NY, USA, 2019; pp. 2119–2128. [Google Scholar]
- Tang, H.; Wang, Y.; Zhang, X. Dangerous goods detection algorithm by X-ray machine based on feature pyramid. J. Xi’an Univ. Postand Telecommun. 2020, 25, 58–63. [Google Scholar]
- Zhang, Y.-K.; Su, Z.-G.; Zhang, H.-G. Multi scale detection of prohibited items in X-ray security inspection images. J. Signal Process. 2020, 36, 1096–1106. [Google Scholar]
- Wei, Y.L.; Tao, R.S.; Wu, Z.J.; Ma, Y.; Zhang, L.; Liu, X. Occluded prohibited items detection: An X-ray security inspection benchmark and de-occlusion attention module. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 138–146. [Google Scholar]
- Yang, F.; Jiang, R.; Yan, Y.; Xue, J.H.; Wang, B.; Wang, H. Dual-Mode Learning for Multi-Dataset X-ray Security Image Detection. IEEE Trans. Inf. Forensics Secur. 2024. [Google Scholar] [CrossRef]
- Lu, G.-Y.; Gu, Z.-H. Improved YOLOv3 security inspection algorithm for detecting dangerous goods in packages. Comput. Appl. Softw. 2021, 38, 197–204. [Google Scholar]
- Wu, H.-B.; Wei, X.-Y.; Liu, M.-H. Combining dilated convolution and transfer learning to improve YOLOv4’s X-ray security dangerous goods detection. Chin. Opt. 2021, 14, 1417–1425. [Google Scholar]
- Dong, Y.-S.; Li, Z.-X.; Guo, J.-Y. An improved X-ray prohibited item detection model for YOLOv5. Laser Optoelectron. Prog. 2023, 60, 359–366. [Google Scholar]
- Xianning, H.; Zhang, Y. ScanGuard-YOLO: Enhancing X-ray Prohibited Item Detection with Significant Performance Gains. Sensors 2023, 24, 102. [Google Scholar] [CrossRef] [PubMed]
- Han, L.; Ma, C.; Liu, Y.; Jia, J.; Sun, J. SC-YOLOv8: A Security Check Model for the Inspection of Prohibited Items in X-ray Images. Electronics 2023, 12, 4208. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, B.-Y.; Gao, Y. X-ray security inspection recognition based on improved self attention neural network. Laser J. 2023, 44, 47–55. [Google Scholar]
- Yang, P.; Yang, H.; Fang, C. Regional enhancement and multi feature fusion for identifying prohibited items in X-ray images. J. Image Graph. 2023, 28, 430–440. [Google Scholar]
- Cheng, L.; Jing, C. X-ray image rotation target detection based on improved YOLOv7. J. Graph. 2023, 44, 324–334. [Google Scholar]
- de Zarzà, I.; de Curtò, J.; Roig, G.; Calafate, C.T. LLM Multimodal Traffic Accident Forecasting. Sensors 2023, 23, 9225. [Google Scholar] [CrossRef]
- Mukherjee, P.; Hou, B.; Lanfredi, R.B.; Summers, R.M. Feasibility of using the privacy-preserving large language model Vicuna for labeling radiology reports. Radiology 2023, 309, e231147. [Google Scholar] [CrossRef] [PubMed]
- Cheng, T.; Song, L.; Ge, Y.; Liu, W.; Wang, X.; Shan, Y. YOLO-World: Real-Time Open-Vocabulary Object Detection. arXiv 2024, arXiv:2401.17270. [Google Scholar]
- Minderer, M.; Gritsenko, A.; Houlsby, N. Scaling Open-Vocabulary Object Detection. arXiv 2023, arXiv:2306.09683. [Google Scholar]
- Zhao, C.; Zhu, L.; Dou, S.; Deng, W.; Wang, L. Detecting Overlapped Objects in X-Ray Security Imagery by a Label-Aware Mechanism. IEEE Trans. Inform. Forensics Secur. 2022, 17, 998–1009. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, L.; Wen, L.; Liu, X.; Wu, Y. Towars Real-World Prohibited Item Detection: A Large-Scale X-Ray Benchmark. In Proceedings of the IEEE/CVF Internatianal Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5412–5421. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Zhu, B.-Y.; Liu, Z.; Zhang, J.-X. A COVID-19 detection algorithm combining Grad CAM and convolutional neural networks. J. Front. Comput. Sci. Technol. 2022, 16, 2108–2120. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label ID | Dataset | |||||
|---|---|---|---|---|---|---|
| SIXray | CLCXray | PIDray | ||||
| Name | Number | Name | Number | Name | Number | |
| 1 | Gun | 3131 | Blade | 3539 | Baton | 2399 |
| 2 | Knife | 1943 | Dagger | 988 | Pliers | 6814 |
| 3 | Wrench | 2199 | Knife | 700 | Hammer | 6229 |
| 4 | Pliers | 3961 | Scissors | 2496 | Powerbank | 8116 |
| 5 | Scissors | 983 | Swiss Army Knife | 1041 | Scissors | 7060 |
| 6 | Cans | 789 | Wrench | 6437 | ||
| 7 | Carton Drinks | 1926 | Gun | 3757 | ||
| 8 | Glass Bottle | 540 | Bullet | 2957 | ||
| 9 | Plastic Bottle | 5998 | Sprayer | 4227 | ||
| 10 | Vacuum Cup | 2166 | HandCuffs | 3388 | ||
| 11 | Spray Cans | 1077 | Knife | 5549 | ||
| 12 | Tin | 856 | Lighter | 6157 | ||
| Methods | AP (%) | mAP_0.5(%) | ||||
|---|---|---|---|---|---|---|
| Gun | Knife | Wrench | Pliers | Scissors | ||
| Faster R-CNN | 90.10 | 81.10 | 79.40 | 88.30 | 88.30 | 85.40 |
| M2Det | 95.49 | 75.70 | 70.17 | 83.00 | 82.96 | 81.47 |
| SSD | 94.91 | 77.87 | 74.82 | 84.51 | 82.69 | 82.96 |
| YOLOv4 | 94.40 | 81.69 | 77.38 | 84.50 | 77.55 | 83.11 |
| YOLOv5s | 98.40 | 86.70 | 88.40 | 92.70 | 79.20 | 89.10 |
| YOLOv7 | 98.60 | 90.00 | 92.40 | 93.80 | 83.30 | 91.60 |
| YOLOv8n | 98.47 | 88.90 | 93.74 | 94.22 | 84.50 | 91.96 |
| Ours | 100.00 | 92.50 | 94.60 | 97.30 | 96.80 | 96.30 |
| Categories | AP (%) | Precision (%) | Recall (%) | F1 Measure |
|---|---|---|---|---|
| Gun | 100.0 | 96.7 | 97.4 | 97.1 |
| Knife | 92.5 | 94.0 | 85.4 | 89.5 |
| Wrench | 94.6 | 91.8 | 89.3 | 90.5 |
| Pliers | 97.3 | 95.8 | 91.4 | 93.6 |
| Scissors | 96.8 | 94.4 | 88.0 | 91.1 |
| Models | mAP@0.5[%] | FPS (SIXray) | ||
|---|---|---|---|---|
| SIXray | CLCXray | PIDray | ||
| Faster R-CNN | 86.4 | 68.5 | 55.7 | 11 |
| M2Det | 84.2 | 66.7 | 58.6 | 44 |
| SSD | 83.9 | 64.6 | 57.8 | 38 |
| YOLOv4 | 84.9 | 73.1 | 78.9 | 51 |
| YOLOv5s | 89.6 | 75.5 | 80.3 | 57 |
| YOLOv7 | 91.6 | 76.6 | 81.6 | 69 |
| YOLOv8n | 92.0 | 77.2 | 82.5 | 74 |
| Ours | 96.3 | 79.3 | 84.7 | 65 |
| Models | AP[%] | mAP@0.5 (%) | mAP@0.5:0.95 (%) | ||||
|---|---|---|---|---|---|---|---|
| Gun | Knife | Wrench | Pliers | Scissors | |||
| YOLOv7 | 98.6 | 90.0 | 92.4 | 93.8 | 83.3 | 91.6 | 68.6 |
| YOLOv7 + A | 98.3 | 90.5 | 94.0 | 93.9 | 85.5 | 92.5 | 69.4 |
| YOLOv7 + AB | 99.9 | 92.3 | 94.4 | 97.2 | 95.6 | 95.9 | 71.0 |
| YOLOv7 + AC | 100.0 | 92.3 | 94.8 | 96.9 | 97.2 | 96.2 | 71.7 |
| YOLOv7 + ABC | 100.0 | 92.5 | 94.6 | 97.3 | 96.8 | 96.3 | 72.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, E.; Yu, X.; Wang, A. Efficient X-ray Security Images for Dangerous Goods Detection Based on Improved YOLOv7. Electronics 2024, 13, 1530. https://doi.org/10.3390/electronics13081530
Liu Y, Zhang E, Yu X, Wang A. Efficient X-ray Security Images for Dangerous Goods Detection Based on Improved YOLOv7. Electronics. 2024; 13(8):1530. https://doi.org/10.3390/electronics13081530
Chicago/Turabian StyleLiu, Yan, Enyan Zhang, Xiaoyu Yu, and Aili Wang. 2024. "Efficient X-ray Security Images for Dangerous Goods Detection Based on Improved YOLOv7" Electronics 13, no. 8: 1530. https://doi.org/10.3390/electronics13081530
APA StyleLiu, Y., Zhang, E., Yu, X., & Wang, A. (2024). Efficient X-ray Security Images for Dangerous Goods Detection Based on Improved YOLOv7. Electronics, 13(8), 1530. https://doi.org/10.3390/electronics13081530