
Spatial–Temporal Fusion Gated Transformer Network (STFGTN) for Traffic Flow Prediction


Abstract
:1. Introduction
- We introduce a novel spatial–temporal dependency fusion model (STFGTN) for traffic flow prediction, leveraging an attention mechanism. This model effectively captures spatial–temporal correlations, aggregates relevant information, and notably enhances traffic flow prediction accuracy.
- A novel dynamic graph convolutional neural network (DGCN) is employed to capture evolving spatial dependencies among traffic flow data nodes, complemented by an attention mechanism. This network adeptly mines spatial data correlations by dynamically adjusting node correlation coefficients and aggregating high-node-correlation information.
- Two gating mechanisms are incorporated to integrate various components within our model. Firstly, we fuse local spatial features from DGCNs with global spatial features from spatial multi-attention. Secondly, we introduce a gating nonlinearity to fuse previously integrated spatial features with temporal features obtained through temporal multi-head attention.
2. Relation Work
2.1. Deep Learning for Traffic Prediction
2.2. Graph Convolution Networks
2.3. Transformer
3. Problem Definition
Problem Formalization
4. Methods
4.1. Data Embedding Layer
4.2. Spatial–Temporal Block Layer
4.3. Temporal Transformer
4.4. Spatial Transformer
4.5. Dynamic Spatial Graph Convolution
4.6. Gate Mechanism for Feature Fusion
4.6.1. Spatial Gate Mechanism
4.6.2. Spatial–Temporal Bilinear Gate Mechanism
4.7. Output Layer
5. Experiments
5.1. Datasets
5.2. Baseline
5.3. Experimental Settings
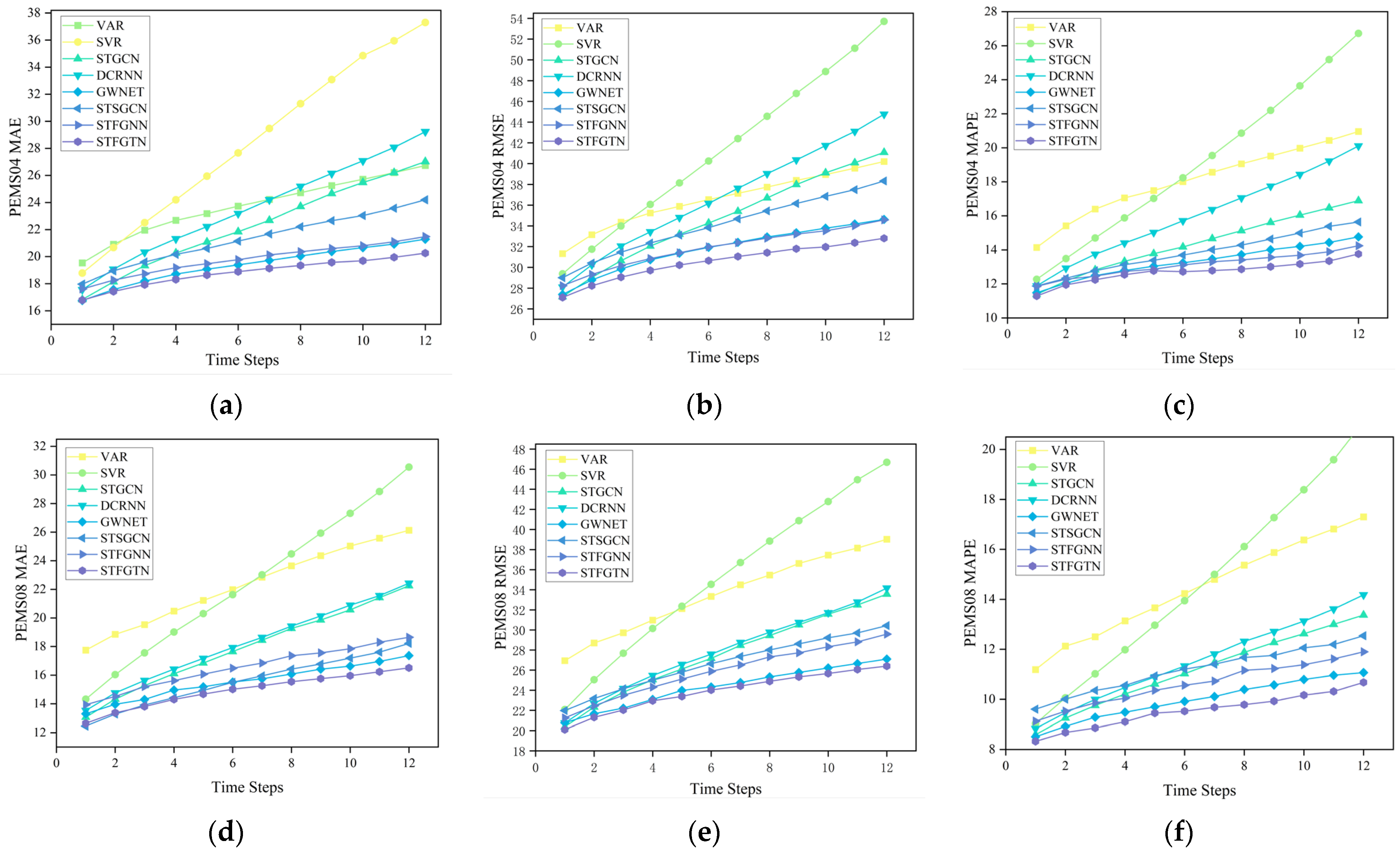
5.4. Experimental Results
5.5. Ablation Study
- w/o s_gate: this variant removes the spatial fusion gating and simply splices the GCN with the output of spatial attention.
- w/o st_fusion_gate: this variant removes the spatial–temporal fusion gating mechanism and splices the output of fused spatial features with temporal attention.
- w/o Ttrans: this variant removes the time transformer.
- w/o Strans: this variant removes the spatial transformer.
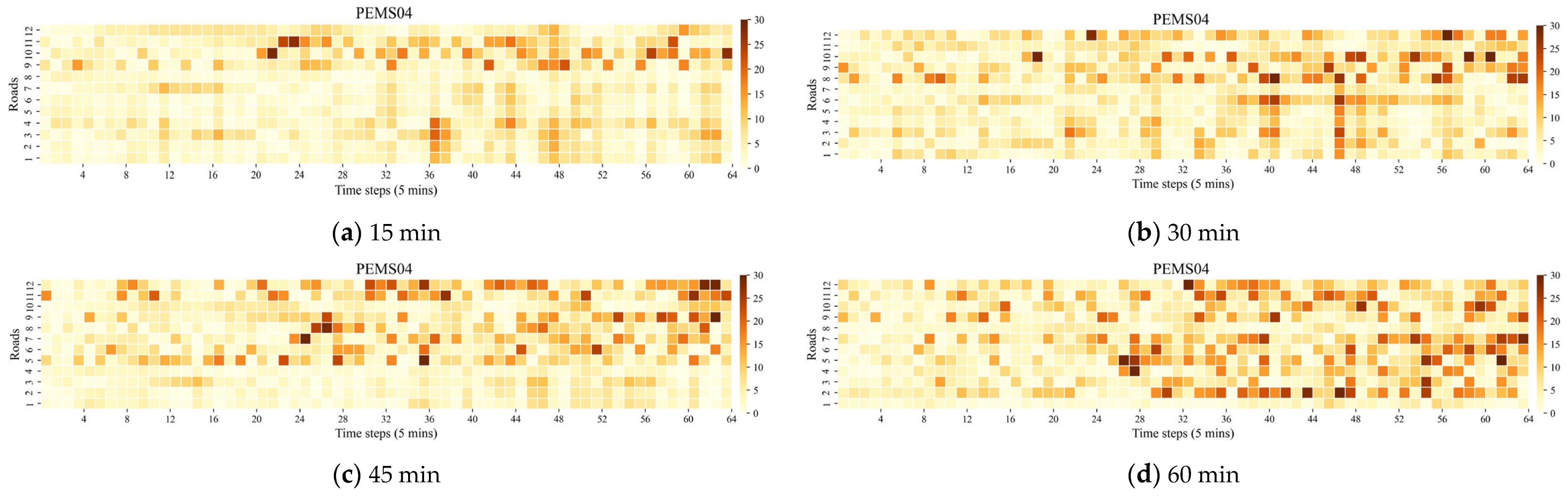
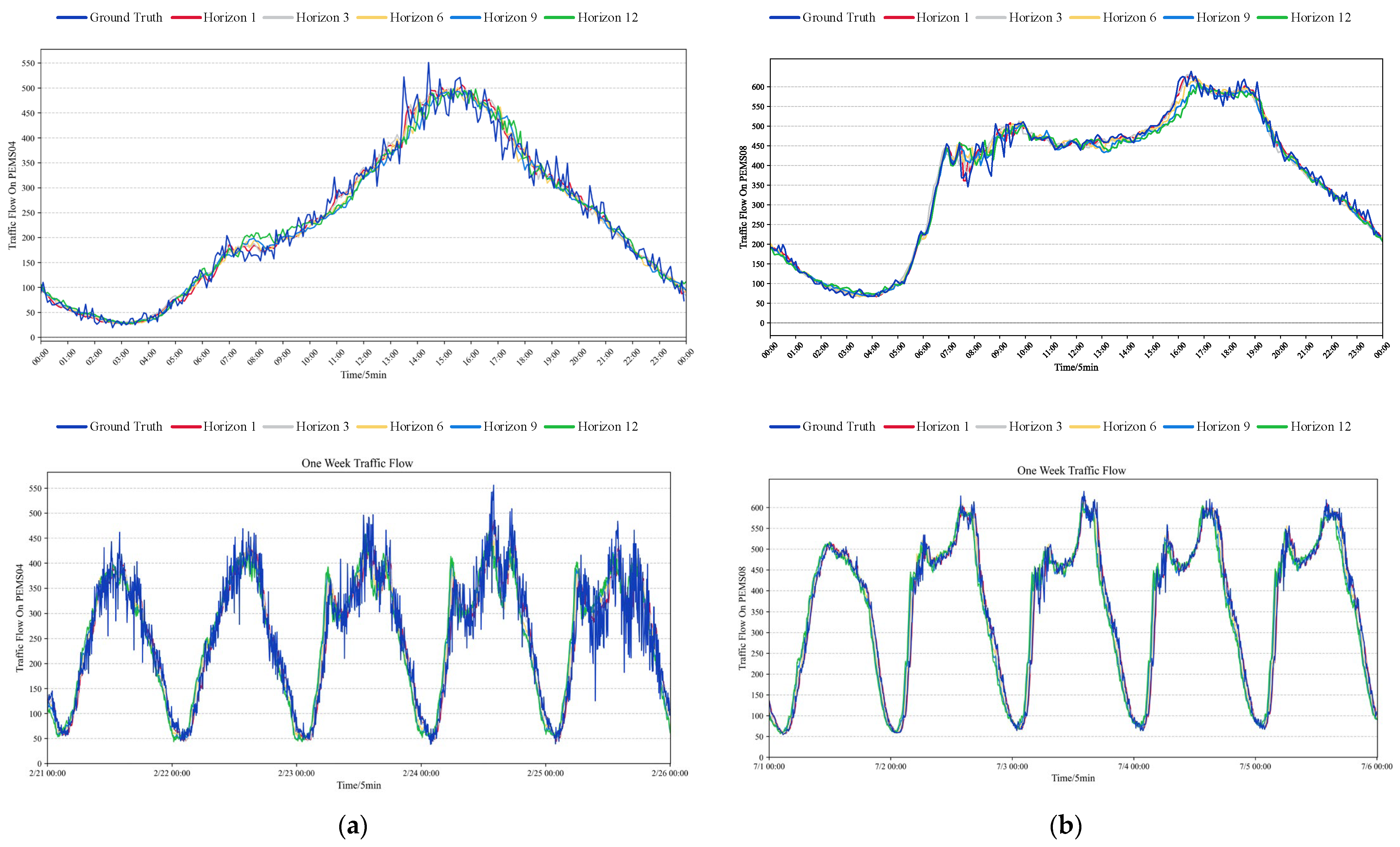
5.6. Visualization
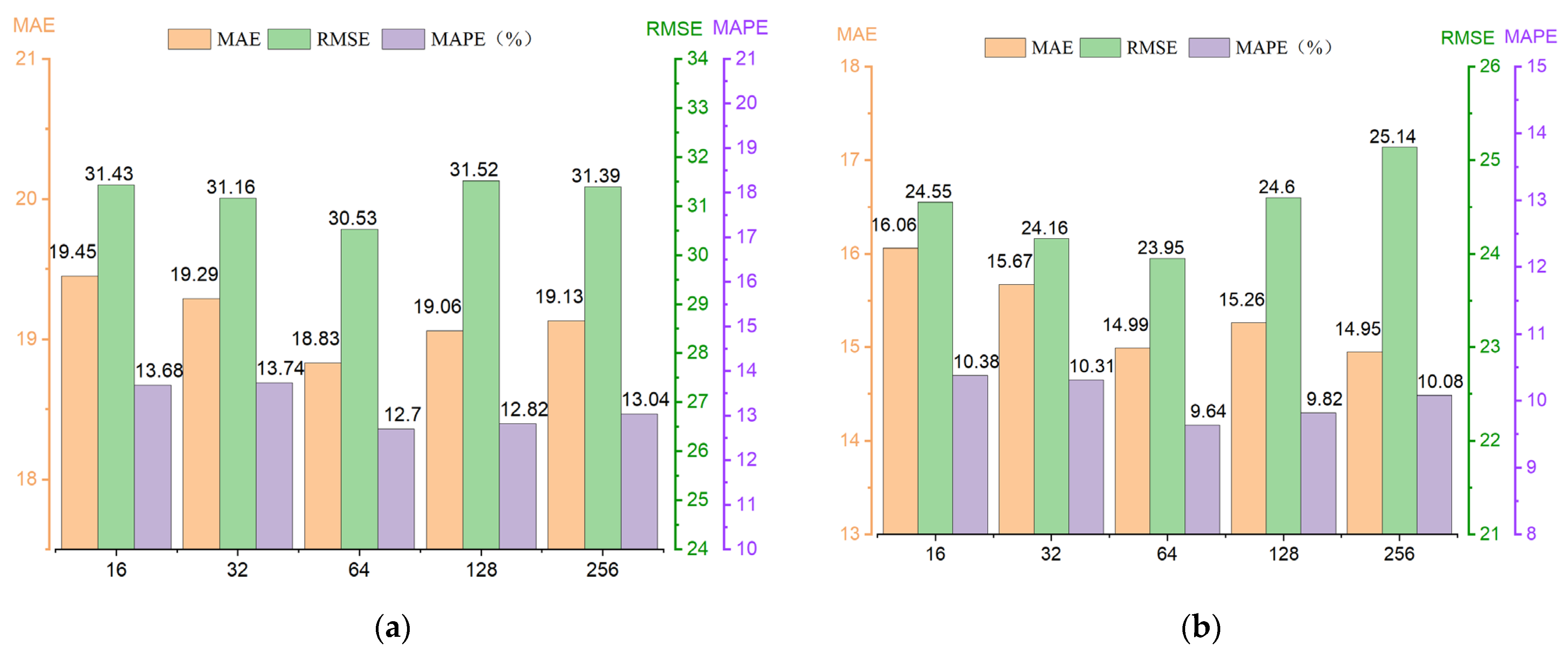
5.7. Effect of Hyperparameters
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Yin, C.; Xiong, Z.; Chen, H.; Wang, J.; Cooper, D.; David, B. A literature survey on smart cities. Sci. China Inf. Sci. 2015, 58, 1–18. [Google Scholar] [CrossRef]
- Tedjopurnomo, D.A.; Bao, Z.; Zheng, B.; Choudhury, F.M.; Qin, A.K. A Survey on Modern Deep Neural Network for Traffic Prediction: Trends, Methods and Challenges. IEEE Trans. Knowl. Data Eng. 2022, 34, 1544–1561. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, J.; Jiang, W.; Li, C.; Zhao, W.X. LibCity: An Open Library for Traffic Prediction. In Proceedings of the 29th International Conference on Advances in Geographic Information Systems, Beijing, China, 2–5 November 2021; pp. 145–148. [Google Scholar]
- Petrlik, J.; Fucik, O.; Sekanina, L. Multi objective selection of input sensors for SVR applied to road traffic prediction. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Ljubljana, Slovenia, 13–17 September 2014; Springer: Cham, Switzerland, 2014; Volume 8672, pp. 79–90. [Google Scholar]
- Westgate, B.S.; Woodard, D.B.; Matteson, D.S.; Henderson, S.G. Travel time estimation for ambulances using Bayesian data augmentation. Ann. Appl. Stat. 2013, 7, 1139–1161. [Google Scholar] [CrossRef]
- Paliwal, C.; Bhatt, U.; Biyani, P.; Rajawat, K. Traffic estimation and prediction via online variational Bayesian subspace filtering. IEEE Trans. Intell. Transp. Syst. 2021, 1, 1–11. [Google Scholar] [CrossRef]
- Zivot, E.; Wang, J. Vector Autoregressive Models for Multivariate Time Series; Springer: New York, NY, USA, 2003; pp. 385–427. [Google Scholar]
- Zhang, J.; Zheng, Y.; Qi, D. Deep spatio-temporal residual networks for citywide crowd flows prediction. Proc. AAAI Conf. Artif. Intell. 2017, 31, 1655–1661. [Google Scholar] [CrossRef]
- Yao, H.; Tang, X.; Wei, H.; Zheng, G.; Li, Z. Deep STN+: Context-aware spatial-temporal neural network for crowd flow prediction in metropolis. Proc. AAAI Conf. Artif. Intell. 2019, 33, 1020–1027. [Google Scholar]
- Yao, H.; Wu, F.; Ke, J.; Tang, X.; Jia, Y.; Lu, S.; Gong, P.; Ye, J.; Li, Z. Deep multi-view spatial-temporal network for taxi demand prediction. Proc. AAAI Conf. Artif. Intell. 2019, 32, 2588–2595. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.-K.; Woo, W.-C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Proc. NeurIPS. 2015, 28, 802–810. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. Predrnn: Recurrent neural networks for predictive learning using spatio-temporal lstms. Proc. NeurIPS. 2017, 30, 879–888. [Google Scholar]
- Geng, X.; Li, Y.; Wang, L.; Zhang, L.; Yang, Q.; Ye, J.; Liu, Y. Spatiotemporal multi-graph convolution network for ride-hailing demand forecasting. Proc. AAAI Conf. Artif. Intell. 2019, 33, 3656–3663. [Google Scholar] [CrossRef]
- Li, M.; Zhu, Z. Spatial-temporal fusion graph neural networks for traffic flow forecasting. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4189–4196. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for Deep Spatial-Temporal Graph Modeling. In Proceedings of the International Joint Conference on Artificial Intelligence 2020, Virtual, 7–15 January 2021; pp. 1907–1913. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the KDD 2‘0: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. Proc. AAAI Conf. Artif. Intell. 2019, 33, 922–929. [Google Scholar] [CrossRef]
- Wen, T.; Chen, E.; Chen, Y. Tensor-view Topological Graph Neural Network. arXiv 2024, arXiv:2401.12007. [Google Scholar]
- Subramonian, A.; Kang, J.; Sun, Y. Theoretical and Empirical Insights into the Origins of Degree Bias in Graph Neural Networks. arXiv 2024, arXiv:2404.03139. [Google Scholar]
- Subram Zhao, J.; Zhou, Z.; Guan, Z.; Zhao, W.; Ning, W.; Qiu, G.; He, X. IntentGC: A scalable graph convolution framework fusing heterogeneous information for recommendation. In Proceedings of the KDD 1‘9: The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2347–2357. [Google Scholar]
- Bai, L.; Yao, L.; Li, C.; Wang, X.; Wang, C. Adaptive Graph Convolutional Recurrent Network for Traffic Forecasting. Proc. NeurIPS Conf. 2020, 33, 17804–17815. [Google Scholar]
- Zhang, J.; Zheng, Y. Traffic Flow Forecasting with Spatial-Temporal Graph Diffusion Network. Proc. AAAI Conf. Artif. Intell. 2021, 35, 15008–15015. [Google Scholar] [CrossRef]
- Ye, J.; Sun, L.; Du, B.; Fu, Y.; Xiong, H. Coupled Layer-wise Graph Convolution for Transportation Demand Prediction. Proc. AAAI Conf. Artif. Intell. 2021, 35, 4617–4625. [Google Scholar] [CrossRef]
- Liu, D.; Wang, J.; Shang, S.; Han, P. MSDR: Multi-Step Dependency Relation Networks for Spatial Temporal Forecasting. In Proceedings of the KDD 2‘2: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 1042–1050. [Google Scholar]
- Mao, X.; Wan, H. GMDNet: A graph-based mixture density network for estimating packages’ multimodal travel time distribution. Proc. AAAI Conf. Artif. Intell. 2023, 37, 4561–4568. [Google Scholar] [CrossRef]
- Zheng, C.; Fan, X.; Wang, C.; Qi, J. GMAN: A Graph Multi-Attention Network for Traffic Prediction. Proc. AAAI Conf. Artif. Intell. 2020, 34, 1234–1241. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Wan, H.; Li, X.; Cong, G. Learning Dynamics and Heterogeneity of Spatial-Temporal Graph Data for Traffic Forecasting. IEEE Trans. Knowl. Data Eng. 2021, 34, 5415–5428. [Google Scholar] [CrossRef]
- Lan, S.; Ma, Y. DSTAGNN: Dynamic Spatial-Temporal Aware Graph Neural Network for Traffic Flow Forecasting. Proc. 39th Int. Conf. Mach. Learn. 2022, 162, 11906–11917. [Google Scholar]
- Jin, D.; Shi, J. Trafformer: Unify Time and Space in Traffic Prediction. Proc. AAAI Conf. Artif. Intell. 2023, 37, 8114–8122. [Google Scholar] [CrossRef]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Proc. NeurIPS Conf. 2016, 29, 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Xing, Z.; Huang, M.; Li, W. Spatial linear transformer and temporal convolution network for traffic flow prediction. Sci. Rep. 2024, 14, 4040. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Jiang, J.; Han, C.; Zhao, W.X.; Wang, J. PDFormer: Propagation Delay-aware Dynamic Long-range Transformer for Traffic Flow Prediction. Proc. AAAI Conf. Artif. Intell. 2023, 37, 4365–4373. [Google Scholar] [CrossRef]
- Yan, H.; Ma, X. Learning dynamic and hierarchical traffic spatiotemporal features with Transformer. arXiv 2021, arXiv:2104.05163. [Google Scholar] [CrossRef]
- Cai, L.; Janowicz, K.; Mai, G.; Yan, B.; Zhu, R. Traffic transformer: Capturing the continuity and periodicity of time series for traffic forecasting. Trans. GIS 2020, 24, 736–755. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-temporal graph convolutional networks: A deep learning framework for traffic forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Song, C.; Lin, Y.; Guo, S.; Wan, H. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. Proc. AAAI Conf. Artif. Intell. 2020, 34, 914–921. [Google Scholar] [CrossRef]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Fang, Z.; Long, Q.; Song, G.; Xie, K. Spatial Temporal Graph ODE Networks for Traffic Flow Forecasting. In Proceedings of the KDD 2‘1: The 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual, 14–18 August 2021; pp. 364–373. [Google Scholar]
- Choi, J.; Choi, H.; Hwang, J.; Park, N. Graph Neural Controlled Differential Equations for Traffic Forecasting. Proc. AAAI Conf. Artif. Intell. 2022, 36, 6367–6374. [Google Scholar] [CrossRef]
- Han, L.; Ma, X.; Sun, L.; Du, B.; Fu, Y.; Lv, W.; Xiong, H. Continuous-Time and Multi-Level Graph Representation Learning for Origin-Destination Demand Prediction. In Proceedings of the KDD 2‘2: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 145–148. [Google Scholar]
- Yu, Q.; Ding, W.; Sun, M.; Huang, J. An Evolving Transformer Network Based on Hybrid Dilated Convolution for Traffic Flow Prediction. Collab. Com. 2024, 563, 329–343. [Google Scholar]
- Yun, I.; Shin, C.; Lee, H.; Lee, H.-J.; Rhee, C.E. EGformer: Equirectangular Geometry-biased Transformer for 360 Depth Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6101–6112. [Google Scholar]
- Alshehri, A.; Owais, M.; Gyani, J.; Aljarbou, M.H.; Alsulamy, S. Residual Neural Networks for Origin–Destination Trip Matrix Estimation from Traffic Sensor Information. Sustainability 2024, 15, 9881. [Google Scholar] [CrossRef]
- Owais, M. Deep Learning for Integrated Origin–Destination Estimation and Traffic Sensor Location Problems. IEEE Trans. 2024, 1–13. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Nodes | Timesteps | Time Range |
|---|---|---|---|
| PEMS04 | 307 | 16,992 | 1/1/2018–2/28/2018 |
| PEMS07 | 883 | 28,224 | 5/1/2017–8/31/2017 |
| PEMS08 | 170 | 17,856 | 7/1/2016–8/31/2016 |
| PEMS-BAY | 325 | 52,116 | 1/1/2017–5/1/2017 |
| Model | PEMS04 | PEMS07 | PEMS08 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | |
| VAR | 23.750 | 18.090 | 36.660 | 101.200 | 39.690 | 155.140 | 22.320 | 14.470 | 33.830 |
| SVR | 28.660 | 19.150 | 44.590 | 32.970 | 15.430 | 50.150 | 23.250 | 14.710 | 36.150 |
| DCRNN | 22.737 | 14.751 | 36.575 | 23.634 | 12.281 | 36.514 | 18.185 | 11.235 | 28.176 |
| STGCN | 21.758 | 13.874 | 34.769 | 22.898 | 11.983 | 35.440 | 17.838 | 11.235 | 27.122 |
| GWNET | 19.358 | 13.301 | 31.719 | 21.221 | 9.075 | 34.117 | 15.063 | 11.211 | 24.855 |
| MTGNN | 19.076 | 12.964 | 31.564 | 20.824 | 9.032 | 34.087 | 15.396 | 9.514 | 24.934 |
| STSGCN | 21.185 | 13.882 | 33.649 | 24.264 | 10.204 | 39.034 | 17.133 | 10.170 | 36.785 |
| STFGNN | 19.830 | 13.021 | 31.870 | 22.072 | 9.212 | 35.805 | 16.636 | 10.961 | 26.206 |
| STGODE | 20.849 | 13.781 | 32.825 | 22.976 | 10.142 | 36.190 | 16.819 | 10.547 | 26.240 |
| STGNCDE | 19.211 | 12.772 | 31.088 | 20.620 | 8.864 | 34.036 | 15.455 | 10.623 | 24.813 |
| GMAN | 19.139 | 13.192 | 31.601 | 20.967 | 9.052 | 34.097 | 16.819 | 10.134 | 24.915 |
| TFormer | 18.916 | 12.711 | 31.349 | 20.754 | 8.972 | 34.062 | 15.455 | 9.925 | 24.883 |
| STFGTN | 18.829 | 12.703 | 30.532 | 20.549 | 8.673 | 33.802 | 14.987 | 9.638 | 23.950 |
| Datasets | Metric | DCRNN | STGCN | MTGNN | GMAN | STFGTN | |
|---|---|---|---|---|---|---|---|
| PEMS-BAY | Horizon 3 (15 min) | MAE | 1.38 | 1.36 | 1.33 | 1.35 | 1.33 |
| RMSE | 2.95 | 2.96 | 2.80 | 2.90 | 2.85 | ||
| MAPE | 2.90% | 2.90% | 2.81% | 2.87% | 2.83% | ||
| Horizon 6 (30 min) | MAE | 1.74 | 1.81 | 1.66 | 1.65 | 1.63 | |
| RMSE | 3.97 | 4.27 | 3.77 | 3.82 | 3.70 | ||
| MAPE | 3.90% | 4.17% | 3.75% | 3.74% | 3.63% | ||
| Horizon 9 (60 min) | MAE | 2.07 | 2.49 | 1.95 | 1.92 | 1.90 | |
| RMSE | 4.74 | 5.69 | 4.50 | 4.49 | 4.38 | ||
| MAPE | 4.90% | 5.79% | 4.62% | 4.52% | 4.44% |
| Model | PEMS04 | PEMS08 | ||||
|---|---|---|---|---|---|---|
| MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | |
| GMAN | 19.139 | 13.192 | 31.601 | 16.819 | 10.134 | 24.915 |
| TFormer | 18.916 | 12.711 | 31.349 | 15.455 | 9.925 | 24.883 |
| DSTAGNN | 19.304 | 12.700 | 31.460 | 15.671 | 9.943 | 24.772 |
| HDCFormer | 32.806 | 16.154 | 43.602 | 15.715 | 10.612 | 20.543 |
| EGFormer | 29.796 | 14.792 | 40.822 | 31.523 | 11.386 | 44.104 |
| STFGTN | 18.829 | 12.703 | 30.532 | 14.987 | 9.638 | 23.950 |
| Datasets | Metrics | Classical GCN | DGCN |
|---|---|---|---|
| PEMS04 | MAE | 19.263 | 18.829 |
| MAPE(%) | 13.038 | 12.703 | |
| RMSE | 31.074 | 30.532 | |
| PEMS08 | MAE | 15.597 | 14.987 |
| MAPE(%) | 10.058 | 9.638 | |
| RMSE | 24.614 | 23.950 |
| PEMS04 | |||
|---|---|---|---|
| Model | MAE | MAPE (%) | RMSE |
| STFGTN (2, 3) * | 18.829 | 12.703 | 30.532 |
| STFGTN (1, 3) | 19.111 | 12.886 | 31.561 |
| STFGTN (4, 3) | 18.962 | 12.679 | 31.086 |
| STFGTN (8, 3) | 18.962 | 12.795 | 31.122 |
| STFGTN (2, 1) | 20.076 | 13.571 | 32.520 |
| STFGTN (2, 2) | 19.164 | 13.329 | 31.024 |
| STFGTN (2, 4) | 19.195 | 12.760 | 31.362 |
| PEMS08 | |||
|---|---|---|---|
| Model | MAE | MAPE (%) | RMSE |
| STFGTN (2, 3) * | 14.987 | 9.638 | 23.950 |
| STFGTN (1, 3) | 15.511 | 10.014 | 24.619 |
| STFGTN (4, 3) | 15.097 | 9.965 | 23.992 |
| STFGTN (8, 3) | 15.203 | 10.045 | 24.152 |
| STFGTN (2, 1) | 16.033 | 10.260 | 24.330 |
| STFGTN (2, 2) | 15.337 | 9.981 | 31.024 |
| STFGTN (2, 4) | 15.097 | 9.651 | 23.992 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, H.; Fan, X.; Qi, K.; Wu, D.; Ren, C. Spatial–Temporal Fusion Gated Transformer Network (STFGTN) for Traffic Flow Prediction. Electronics 2024, 13, 1594. https://doi.org/10.3390/electronics13081594
Xie H, Fan X, Qi K, Wu D, Ren C. Spatial–Temporal Fusion Gated Transformer Network (STFGTN) for Traffic Flow Prediction. Electronics. 2024; 13(8):1594. https://doi.org/10.3390/electronics13081594
Chicago/Turabian StyleXie, Haonan, Xuanxuan Fan, Kaiyuan Qi, Dong Wu, and Chongguang Ren. 2024. "Spatial–Temporal Fusion Gated Transformer Network (STFGTN) for Traffic Flow Prediction" Electronics 13, no. 8: 1594. https://doi.org/10.3390/electronics13081594
APA StyleXie, H., Fan, X., Qi, K., Wu, D., & Ren, C. (2024). Spatial–Temporal Fusion Gated Transformer Network (STFGTN) for Traffic Flow Prediction. Electronics, 13(8), 1594. https://doi.org/10.3390/electronics13081594