
Active Visual Perception Enhancement Method Based on Deep Reinforcement Learning


Abstract
1. Introduction
- We successfully applied reinforcement learning to PTZ camera control, designing and implementing a comprehensive reinforcement learning framework. This framework enables PTZ cameras to autonomously adopt control strategies through interactive learning with their environment, significantly enhancing their intelligent perception capabilities.
- We introduce the Comprehensive Object Perception Reward Function (COMPRF), a novel approach that significantly improves the intelligence of PTZ cameras in terms of object detection performance.
- A simulation environment, based on the Unity3D engine, is proposed for simulating PTZ cameras. This simulation environment is fully compatible with the OpenAI Gym [5] interface, accurately simulating camera control tasks in real-world scenarios. It seamlessly receives action commands and returns images along with the object detection results observed by the camera.
2. Related Work
3. Methods
3.1. Reinforcement Learning
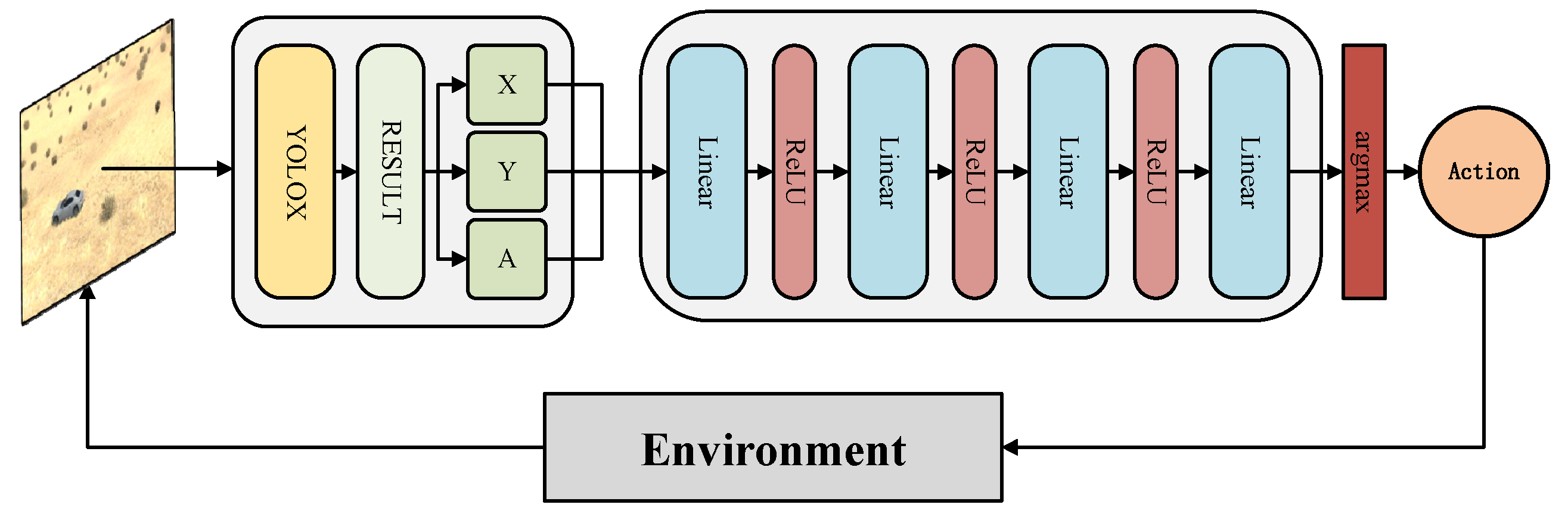
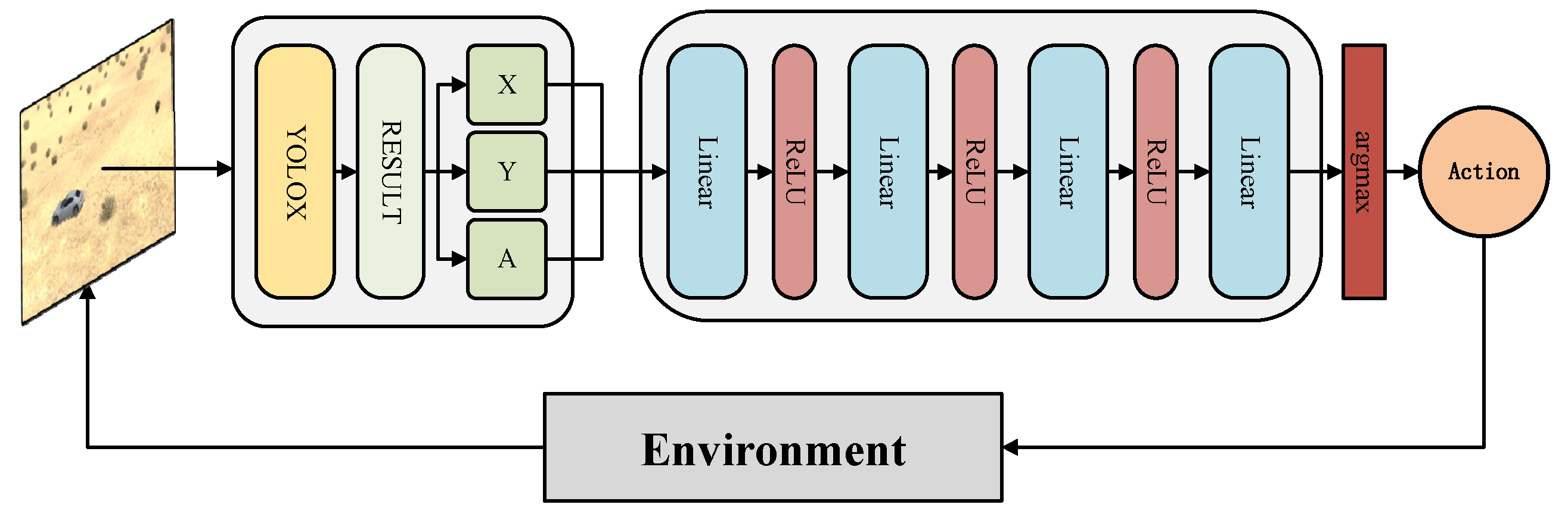
3.2. Network Structure
3.3. Intelligent Perception Enhancement Method Based on Deep Reinforcement Learning
3.3.1. Action Space
3.3.2. State Space
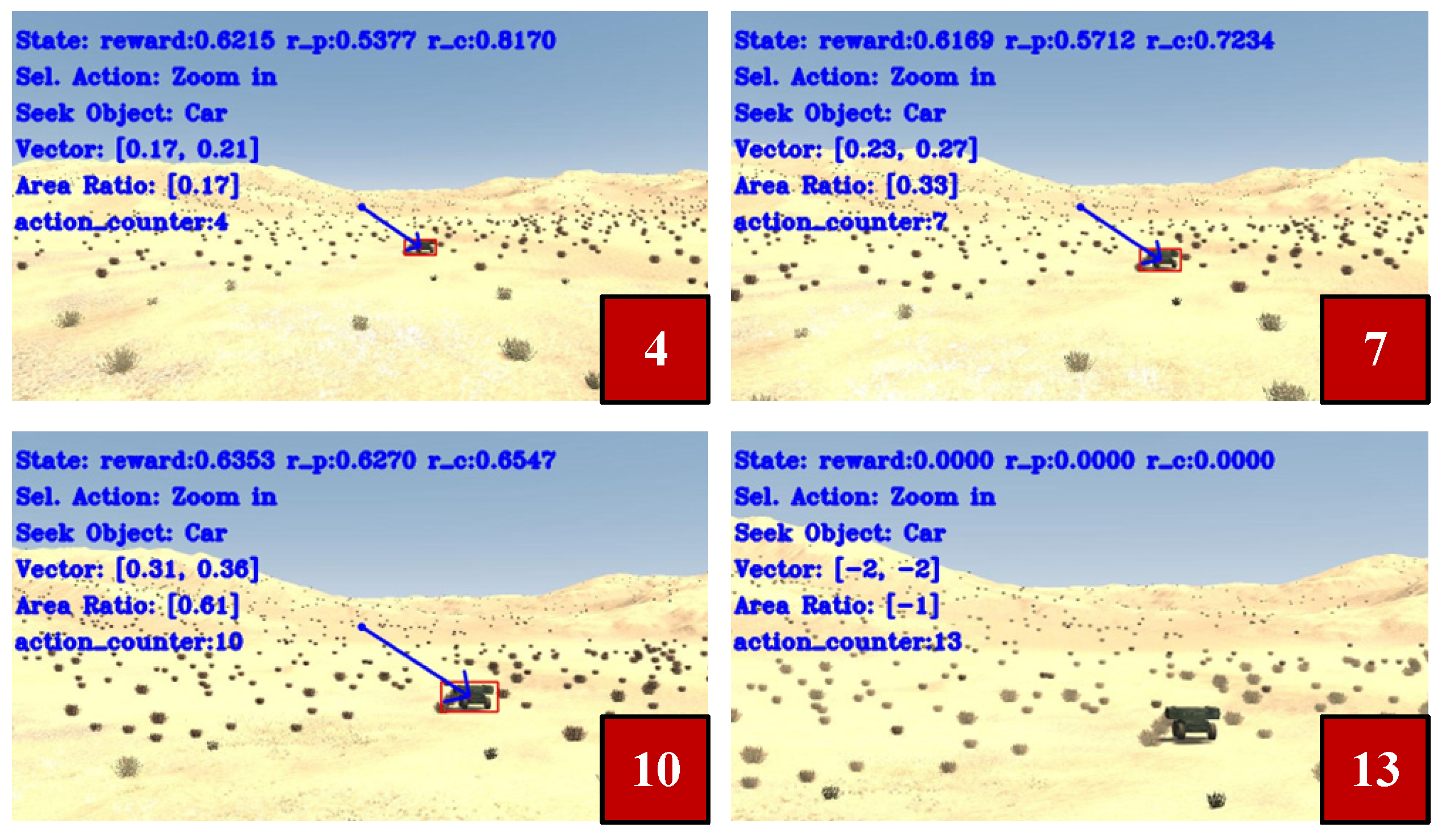
3.3.3. Reward Function
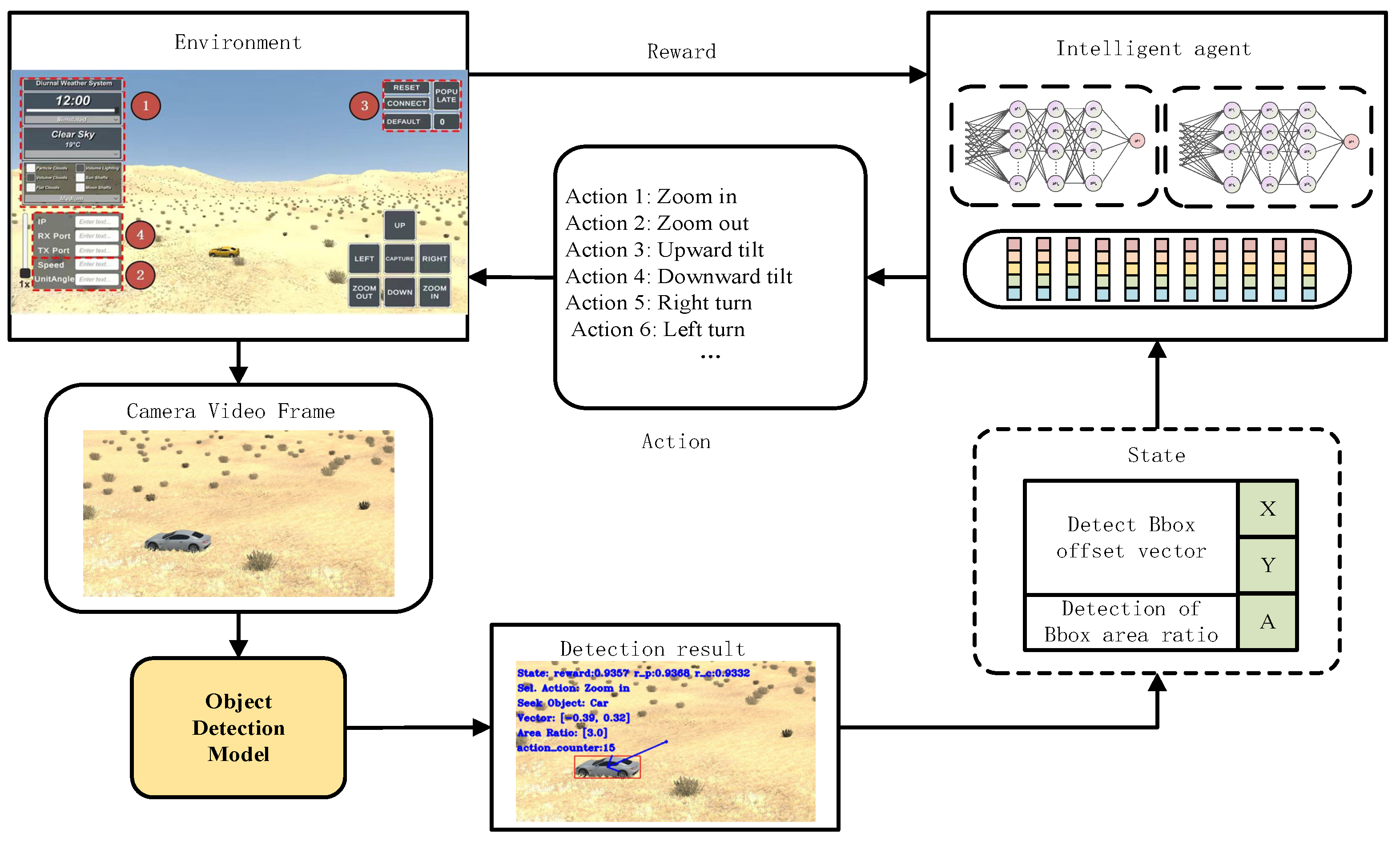
3.4. Simulation Environment
- Day, night, and weather adjustments: The simulation environment faithfully replicates changing conditions throughout the day, including shifts in time and random weather patterns. These changes can be modulated by adjusting the simulation environment’s time flow rate, which operates at a faster pace compared to real-world conditions. This accelerated pace enables a comprehensive evaluation of reinforcement learning algorithms’ performance across diverse temporal and atmospheric scenarios.
- Camera parameter customization: Users can tailor the rotation angle and speed of simulated PTZ cameras based on their specific hardware capabilities. This customization ensures that the simulation accurately reflects the observation capabilities and response speeds of various PTZ cameras in real-world settings, thereby enhancing the precision of reinforcement learning algorithm evaluation and training.
- Experimental object and trajectory generation: The simulation environment incorporates seven distinct car object types. Users can select specific car types or opt for random generation to cater to their experimental or training needs. Additionally, the simulation environment provides preset trajectories and speed profiles, allowing users to combine them freely to create diverse scenarios tailored for evaluating and training reinforcement learning algorithms.
- UDP communication support: The simulation environment boasts a robust UDP communication function that facilitates the use of customized IP addresses and ports. This functionality enables seamless contact with external systems for data transmission, environmental status detection, control operations, and various other tasks.
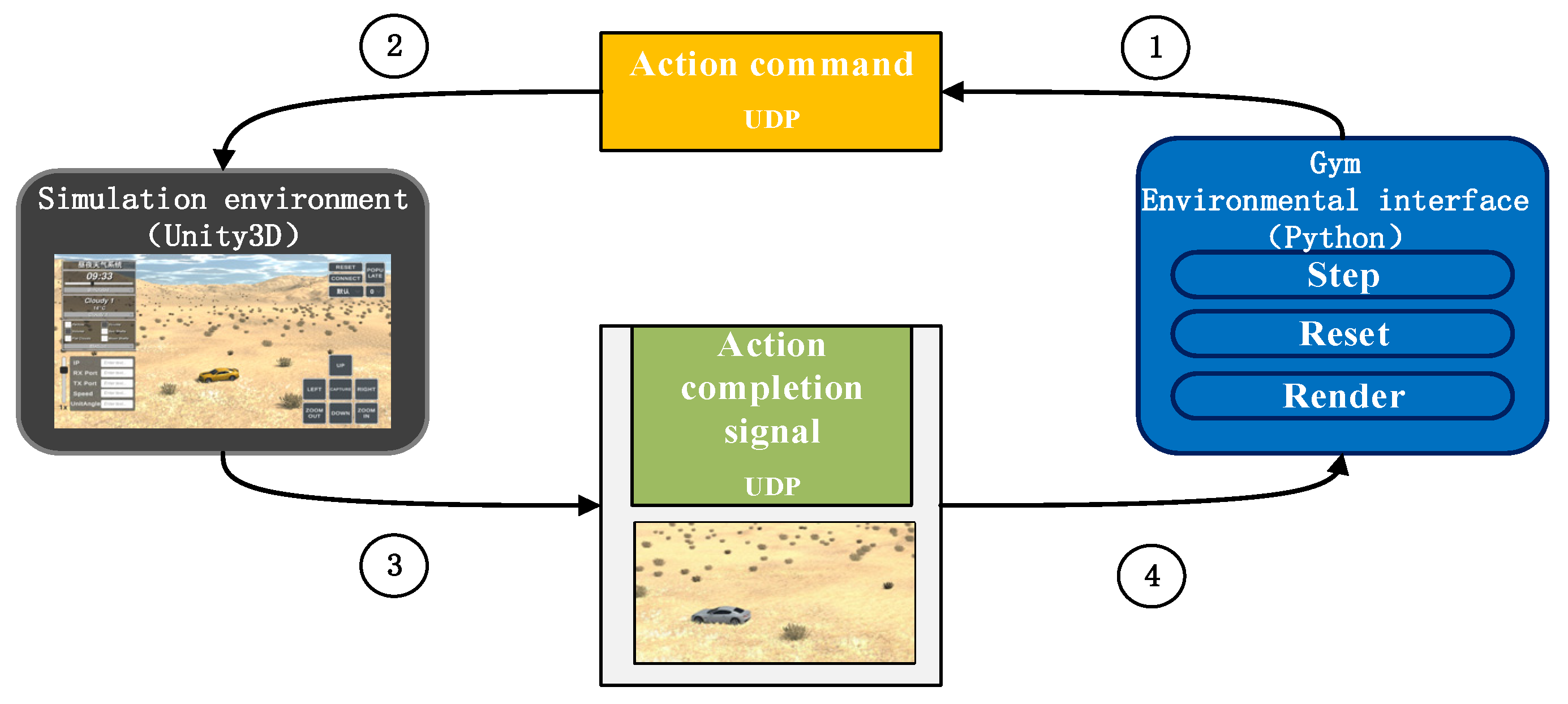
- The intelligent agent transmits action commands to the simulation environment via the Gym interface. Based on its current strategy, the agent selects appropriate actions and sends these commands to the simulation environment using UDP. These commands specify the control actions for the PTZ camera. Once the instruction is dispatched, the agent transitions to a waiting state, suspending further actions until it receives a completion signal from the simulation environment.
- Execution of actions within the simulation environment: Upon receiving the action instructions from the agent, the simulation environment interprets them and directs the PTZ camera in the scene to perform the corresponding actions.
- Completion signal from the simulated environment: Once the PTZ camera has executed the designated action, the simulated environment transmits a completion signal to the agent, indicating that it can proceed with subsequent operations. Concurrently, the simulation environment captures the current video frame image and forwards it to the agent.
- Agents receive observation data: Upon receiving the action signal, the agent exits the waiting state and proceeds with subsequent operations. Simultaneously, the video frame images are processed using the YOLOX model interface, enabling further elaboration to extract state space information and reward values.
4. Experimental Results and Analysis
4.1. Experimental Setup
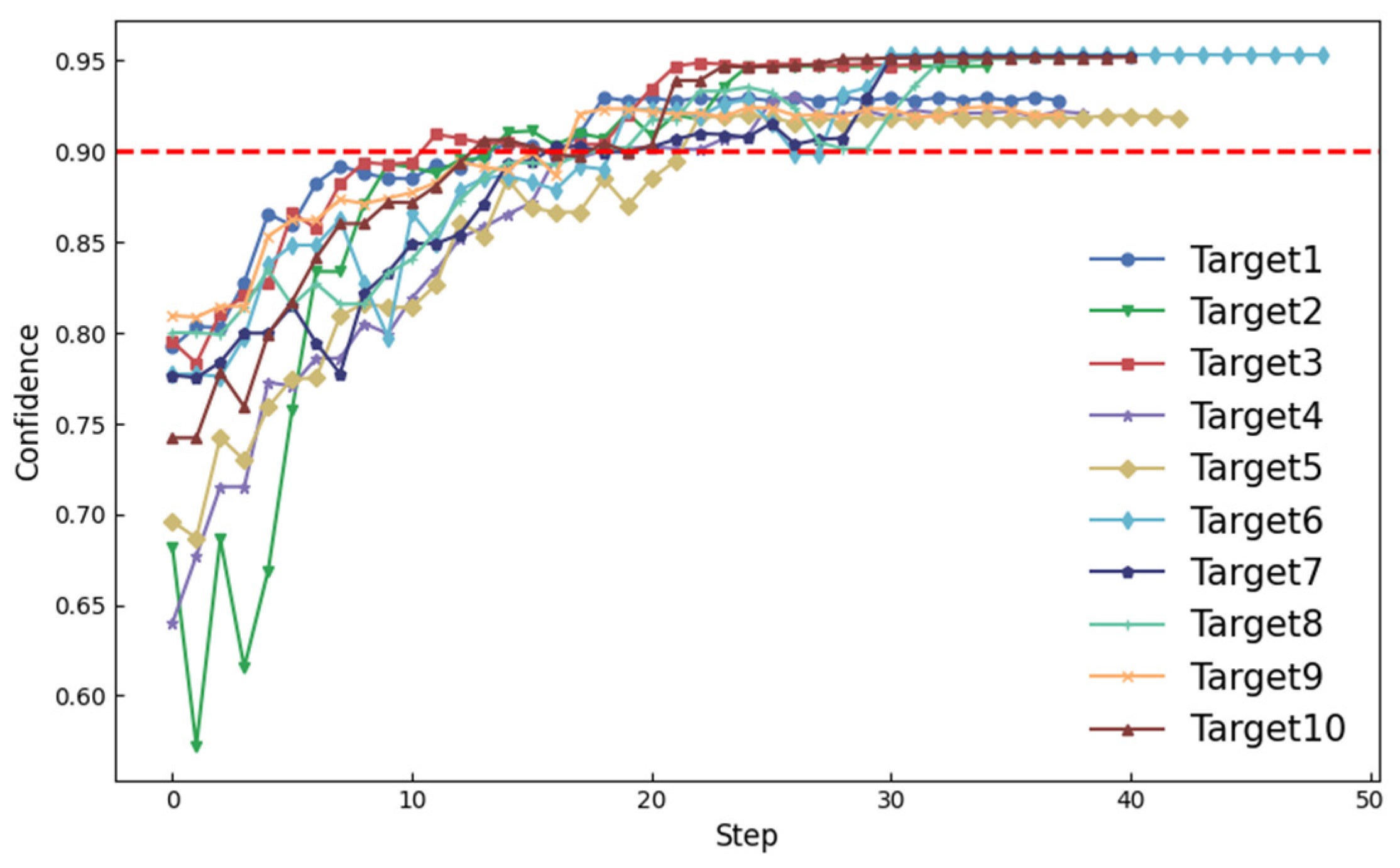
4.2. Confidence Experiment
4.3. Scene Generalization Experiment
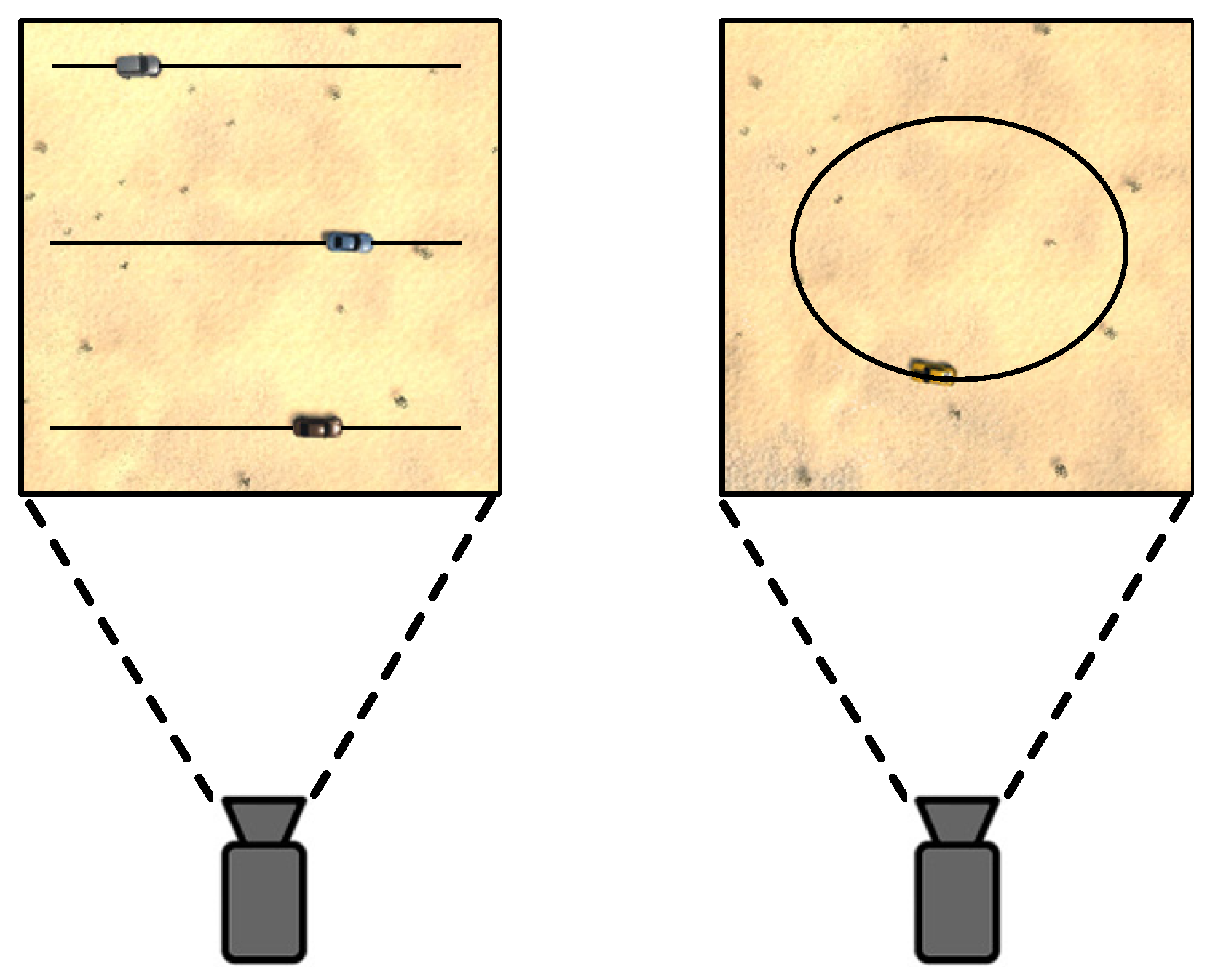
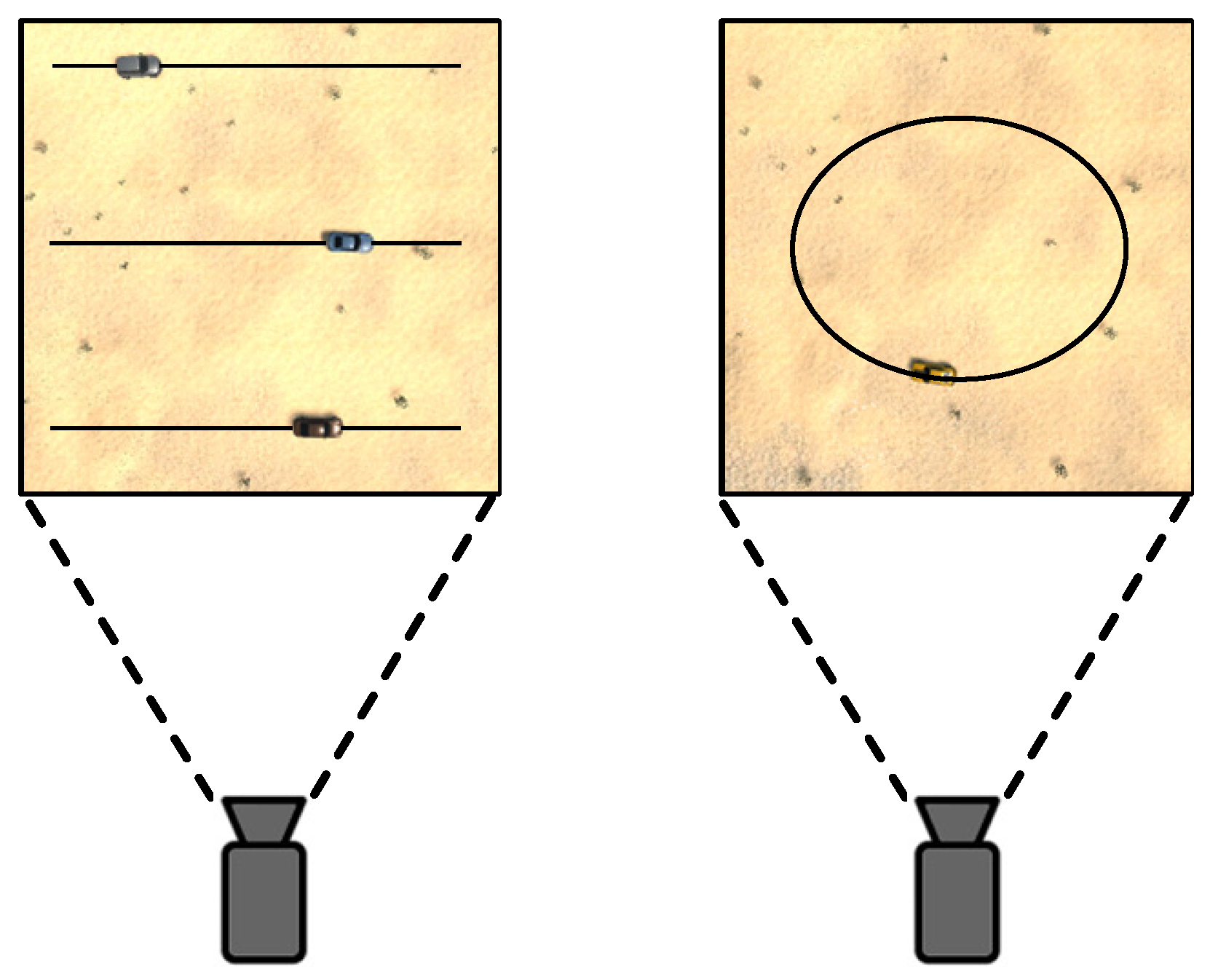
- Distance scene: involves three driving routes for the vehicle, each corresponding to a different distance level: far, middle, and near, while assuming a zero vehicle target speed.
- Sports scene: involves a designated car driving route where the route is divided into seven distinct speed levels.
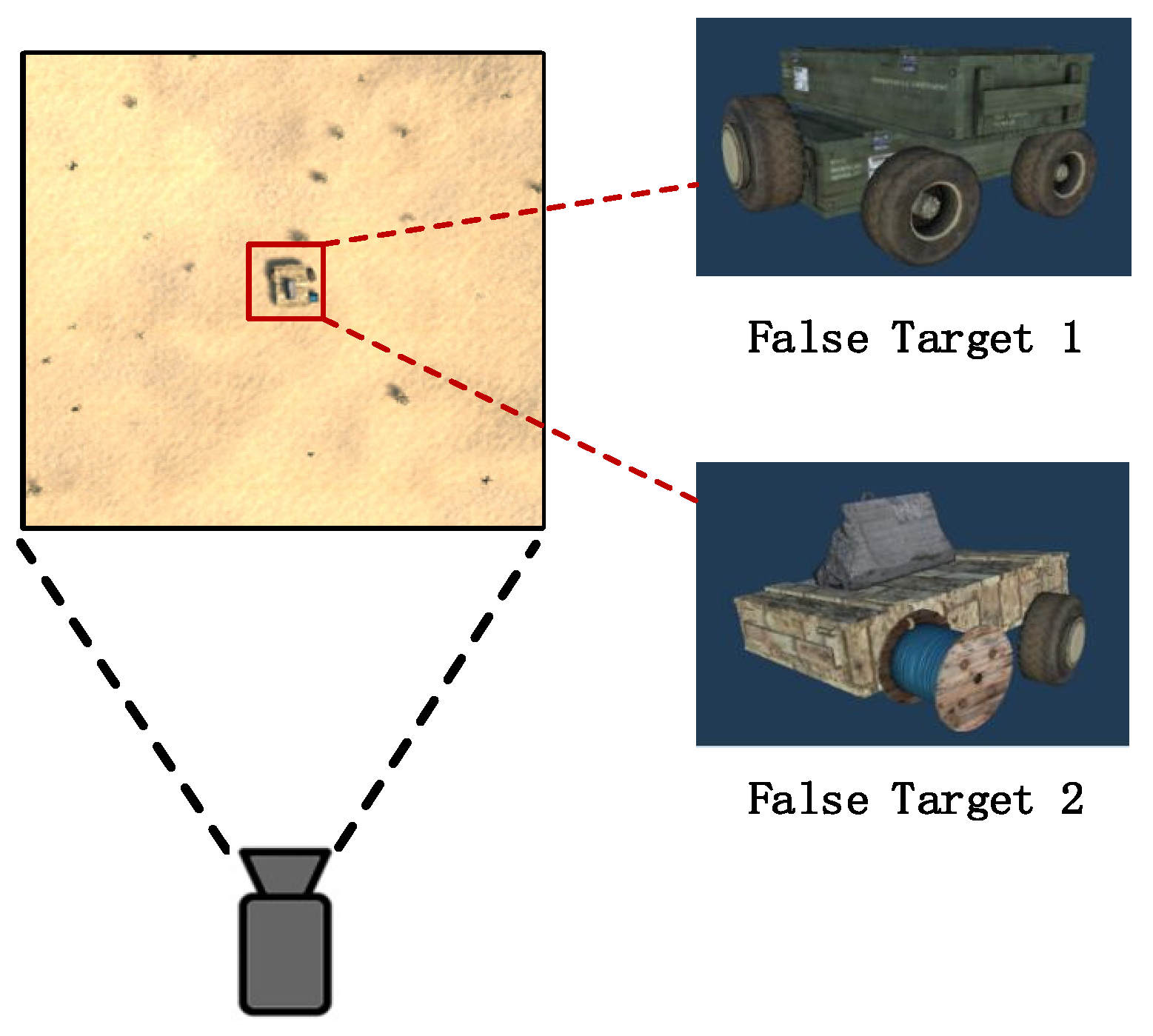
4.4. False Target Experiment
4.5. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

References
- Tsakanikas, V.; Dagiuklas, T. Video Surveillance Systems-Current Status and Future Trends. Comput. Electr. Eng. 2018, 70, 736–753. [Google Scholar] [CrossRef]
- Zhang, J.; Meng, Y.; Chen, Z. A Small Target Detection Method Based on Deep Learning with Considerate Feature and Effectively Expanded Sample Size. IEEE Access 2021, 9, 96559–96572. [Google Scholar] [CrossRef]
- Wang, S.; Tian, Y.; Xu, Y. Automatic Control of PTZ Camera Based on Object Detection and Scene Partition. In Proceedings of the 2015 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Ningbo, China, 19–22 September 2015; pp. 1–6. [Google Scholar]
- Wang, X.; Van De Weem, J.; Jonker, P. An Advanced Active Vision System Imitating Human Eye Movements. In Proceedings of the 2013 16th International Conference on Advanced Robotics (ICAR), Montevideo, Uruguay, 25–29 November 2013; pp. 1–6. [Google Scholar]
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym 2016. arXiv 2016, arXiv:1606.01540. [Google Scholar] [CrossRef]
- Xu, Z.; Wang, S.; Xu, G.; Liu, Y.; Yu, M.; Zhang, H.; Lukasiewicz, T.; Gu, J. Automatic Data Augmentation for Medical Image Segmentation Using Adaptive Sequence-Length Based Deep Reinforcement Learning. Comput. Biol. Med. 2024, 169, 107877. [Google Scholar] [CrossRef]
- López Diez, P.; Sundgaard, J.V.; Margeta, J.; Diab, K.; Patou, F.; Paulsen, R.R. Deep Reinforcement Learning and Convolutional Autoencoders for Anomaly Detection of Congenital Inner Ear Malformations in Clinical CT Images. Comput. Med. Imaging Graph. 2024, 113, 102343. [Google Scholar] [CrossRef] [PubMed]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.P.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous Methods for Deep Reinforcement Learning. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Sandha, S.S.; Balaji, B.; Garcia, L.; Srivastava, M. Eagle: End-to-End Deep Reinforcement Learning Based Autonomous Control of PTZ Cameras. In Proceedings of the 8th ACM/IEEE Conference on Internet of Things Design and Implementation, San Antonio, TX, USA, 9 May 2023; pp. 144–157. [Google Scholar]
- Passalis, N.; Tefas, A. Deep Reinforcement Learning for Controlling Frontal Person Close-up Shooting. Neurocomputing 2019, 335, 37–47. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-Level Feature. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13034–13043. [Google Scholar]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Wang, Y.; Chen, Z.; Sun, M.; Sun, Q. Enhancing Active Disturbance Rejection Design via Deep Reinforcement Learning and Its Application to Autonomous Vehicle. Expert Syst. Appl. 2024, 239, 122433. [Google Scholar] [CrossRef]
- Zhang, H.; Chang, H.; Ma, B.; Wang, N.; Chen, X. Dynamic R-CNN: Towards High Quality Object Detection via Dynamic Training. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Kim, D.; Yang, C.M. Reinforcement Learning-Based Multiple Camera Collaboration Control Scheme. In Proceedings of the 2022 Thirteenth International Conference on Ubiquitous and Future Networks (ICUFN), Barcelona, Spain, 5 July 2022; pp. 414–416. [Google Scholar]
- Kim, D.; Kim, K.; Park, S. Automatic PTZ Camera Control Based on Deep-Q Network in Video Surveillance System. In Proceedings of the 2019 International Conference on Electronics, Information, and Communication (ICEIC), Auckland, New Zealand, 22–25 January 2019; pp. 1–3. [Google Scholar]
- Fahim, A.; Papalexakis, E.; Krishnamurthy, S.V.; Roy Chowdhury, A.K.; Kaplan, L.; Abdelzaher, T. AcTrak: Controlling a Steerable Surveillance Camera Using Reinforcement Learning. ACM Trans. Cyber-Phys. Syst. 2023, 7, 1–27. [Google Scholar] [CrossRef]
- Wang, H.; Sun, S.; Chang, L.; Li, H.; Zhang, W.; Frery, A.C.; Ren, P. INSPIRATION: A Reinforcement Learning-Based Human Visual Perception-Driven Image Enhancement Paradigm for Underwater Scenes. Eng. Appl. Artif. Intell. 2024, 133, 108411. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Confidence | Method + Ours | Confidence |
|---|---|---|---|
| YOLOX | 0.723 ± 0.121 | YOLOX + Ours | 0.940 ± 0.013 |
| YOLOv8 | 0.833 ± 0.161 | YOLOv8 + Ours | 0.985 ± 0.019 |
| SSD | 0.718 ± 0.190 | SSD + Ours | 0.996 ± 0.017 |
| Cascade RCNN | 0.652 ± 0.138 | Cascade RCNN + Ours | 0.957 ± 0.028 |
| Scene | Scene Subdivision | Bonus Value |
|---|---|---|
| Distance scene | Far | 291.056 ± 1.516 |
| Medium | 291.552 ± 1.425 | |
| Near | 293.531 ± 1.268 | |
| Speed scene | Speed rating 1 | 289.187 ± 3.371 |
| Speed rating 2 | 290.744 ± 3.291 | |
| Speed rating 3 | 286.934 ± 4.344 | |
| Speed rating 4 | 286.928 ± 4.810 | |
| Speed rating 5 | 282.227 ± 9.795 | |
| Speed rating 6 | 260.014 ± 27.862 | |
| Speed rating 7 | 242.048 ± 28.010 |
| False Target | The False Target, Whether Can Judge |
|---|---|
| False target 1 | Yes |
| False target 2 | Yes |
| Scene | Rt | rp | rc | The Success Rate |
|---|---|---|---|---|
| Near | √ | √ | √ | 100% |
| √ | √ | 100% | ||
| √ | √ | 10% | ||
| √ | √ | 80% | ||
| Medium | √ | √ | √ | 100% |
| √ | √ | 60% | ||
| √ | √ | 0% | ||
| √ | √ | 70% | ||
| Far | √ | √ | √ | 100% |
| √ | √ | 70% | ||
| √ | √ | 0% | ||
| √ | √ | 80% | ||
| move | √ | √ | √ | 100% |
| √ | √ | 0% | ||
| √ | √ | 30% | ||
| √ | √ | 30% | ||
| Target lost | √ | √ | √ | 100% |
| √ | √ | 0% | ||
| √ | √ | 0% | ||
| √ | √ | 60% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, Z.; Fang, H.; Liu, H.; Li, J.; Jiang, Y.; Zhu, M. Active Visual Perception Enhancement Method Based on Deep Reinforcement Learning. Electronics 2024, 13, 1654. https://doi.org/10.3390/electronics13091654
Yang Z, Fang H, Liu H, Li J, Jiang Y, Zhu M. Active Visual Perception Enhancement Method Based on Deep Reinforcement Learning. Electronics. 2024; 13(9):1654. https://doi.org/10.3390/electronics13091654
Chicago/Turabian StyleYang, Zhonglin, Hao Fang, Huanyu Liu, Junbao Li, Yutong Jiang, and Mengqi Zhu. 2024. "Active Visual Perception Enhancement Method Based on Deep Reinforcement Learning" Electronics 13, no. 9: 1654. https://doi.org/10.3390/electronics13091654
APA StyleYang, Z., Fang, H., Liu, H., Li, J., Jiang, Y., & Zhu, M. (2024). Active Visual Perception Enhancement Method Based on Deep Reinforcement Learning. Electronics, 13(9), 1654. https://doi.org/10.3390/electronics13091654