1. Introduction
The smart grid is an innovative power grid that integrates information technology, communication technology, computer technology, and existing transmission and distribution power infrastructure. It offers various advantages, such as enhanced energy efficiency, reduced environmental impact, improved power supply safety and reliability, and minimized transmission power losses [
1]. Intelligence operations within the context of a smart grid are primarily manifested through observability, controllability, real-time analysis, adaptability, and self-healing capabilities [
2].
The power communication network is a specialized communication network that provides communication service to the smart grid [
3]. It supports essential operations such as protection, automatic control, precision control, automation, scheduling data transfer, dispatching telephone services, and so on [
4]. As a vital infrastructure for data transmission in power scheduling and production, the power communication network constitutes a critical component of the secondary system within the smart grid. The reliable operation of secondary systems, including protection and automatic control, is crucial for the stable functioning of the smart grid [
5]. Such reliability is heavily dependent on the robust support provided by the power communication network, leading to strong interconnections and interdependent relationships between two networks.
As information and communication technologies rapidly evolve, there exists a profound interconnection between the power system and the power communication network. The monitoring and scheduling operations between two networks exhibit a high degree of interdependence, necessitating a natural fusion of these domains. Due to the high integration of smart grid and power communication network, faults occurring during operation may trigger a cascade effect, expanding the scope and severity of accidents leading to major system failures such as grid collapse and widespread power outages. Therefore, timely FD and ensuring prompt resolution are of utmost importance [
6,
7,
8].
The smart grid has established data collection systems and fault information systems, which can provide event information and waveform data during faults, laying the data foundation for the application of artificial intelligence algorithms [
9]. In addition, when faults occur in the power communication network, dispatch centers issue alarms, which serve as the basis for fault localization and diagnosis [
10]. In various operating conditions of the actual system, there are often limited fault samples, leading to poor diagnostic performance with traditional deep learning methods. For both networks, it is a critical issue to quickly locate and diagnose system faults with stable and safe methods. However, some conventional system FD schemes usually depend on manpower, leading to low efficient operations. Moreover, the system fault information is not enough, that is, only a small amount of practical data can be used to diagnose system faults. Therefore, a new and efficient FD scheme should be studied with inadequate fault information.
This paper introduces a data fusion model with the primary objective of enhancing system reliability and robustness, expanding the spatiotemporal scope of observations, and augmenting the system’s resolution capabilities. Furthermore, the inherent complexity of the system can introduce potential risks, posing threats to the normal operations of both the smart grid and power communication network. Motivated by the practical issues in smart grid and power communication networks, this paper designs a newfangled FD scheme with tensor computing and meta-learning, in order to provide an efficient diagnosis scheme with a small amount of system information.
The contributions of this paper can be summarized as follows:
An innovative fault diagnosis (FD) scheme with tensor computing and meta-learning is proposed for smart grid and power communication networks. The tensor data model is used to compact multi-dimensional and heterogeneous data from both networks. The meta-learning method is used to detect and locate system faults for both networks.
Tensor computing is used to deal with the data fusion (DF) problem for smart grid and power communication networks. Employing a tensor completion approach aids in filling in missing data to augment sparse tensor big data sets, while tensor decomposition facilitates the data fusion process.
The meta-learning scheme is used to diagnose system faults with a small quantity of fused data. The fused data from both networks can be analyzed by the meta-learning scheme in order to conquer the limitations of inadequate fault information.
The suggested FD scheme can attain superior detection accuracy using a modest dataset, offering an effective diagnostic approach for future smart grid maintenance and ensuring stable power provision.
The paper continues with the following sections.
Section 3 presents the whole system model and discusses the DF and FD issues.
Section 4 introduces tensor computing and proposes an efficient DF scheme utilizing tensors.
Section 5 outlines the FD scheme with meta-learning and introduces the model-agnostic meta-learning algorithm for designing an optimal FD policy. Simulation outcomes are furnished to showcase the efficacy of the FD scheme in
Section 6. In
Section 7, the paper is concluded.
Notations: Constants, vectors, matrices and tensors are denoted by lowercase letters, bold lowercase letters, bold uppercase letters and Euler script letters, respectively. The superscript denotes the transpose. , and denote the element of , the i th row of , and the submatrix of from the ith to the jth rows. denotes the tensor of order N with dimension for each order, and denotes the n-mode product.
4. Data Fusion Based on Tensor Computing
Tensor computing is a feasible way to realize the DF, which is based on tensor to solve the problem shown in (
1). The big data of the smart grid and power communication network is mapped into matrices,
and
. For generating the fused data, a tensor is used as a transition state to associate two big data matrices, tensor completion realizes the completion of missing data in the original data, and tensor decomposition compresses the data from the perspective of feature extraction to combine the tensor, which contains two data matrices, into a fusion matrix
.
4.1. Preliminary
The notion of tensor is defined as a higher-order multi-dimensional array, which is regarded as a term in mathematics. The tensor is the general case of the vector or the matrix, where the first-order tensor is the vector and the second-order tensor is the matrix. Arrays of order three or more are higher-order tensors, called
Nth-order or
N-way tensors. The definitions of tensor-related concepts in this paper are based on [
14].
4.1.1. Rank-1 Tensor
An
Nth-order tensor
is rank-1 when it can be expressed by the outer product of N vectors, i.e.,
where “∘” denotes the operation of the outer product, and
denotes a vector, of which length is
. In other words, each element of
is the product of corresponding vector elements
4.1.2. Cubical Tensor
An Nth-order tensor is cubical when , that is, the dimensions of the tensor are equal. The notion is used to represent that the tensor is an mth-order n-dimension tensor, where .
4.1.3. Diagonal Tensor
An
Nth-order tensor
is diagonal, if
only when
. If a tensor satisfies the conditions of both a cubical tensor and a diagonal tensor, the tensor is super-diagonal. On this basis, the tensor
is an identity tensor if and only if
is super-diagonal and
for all
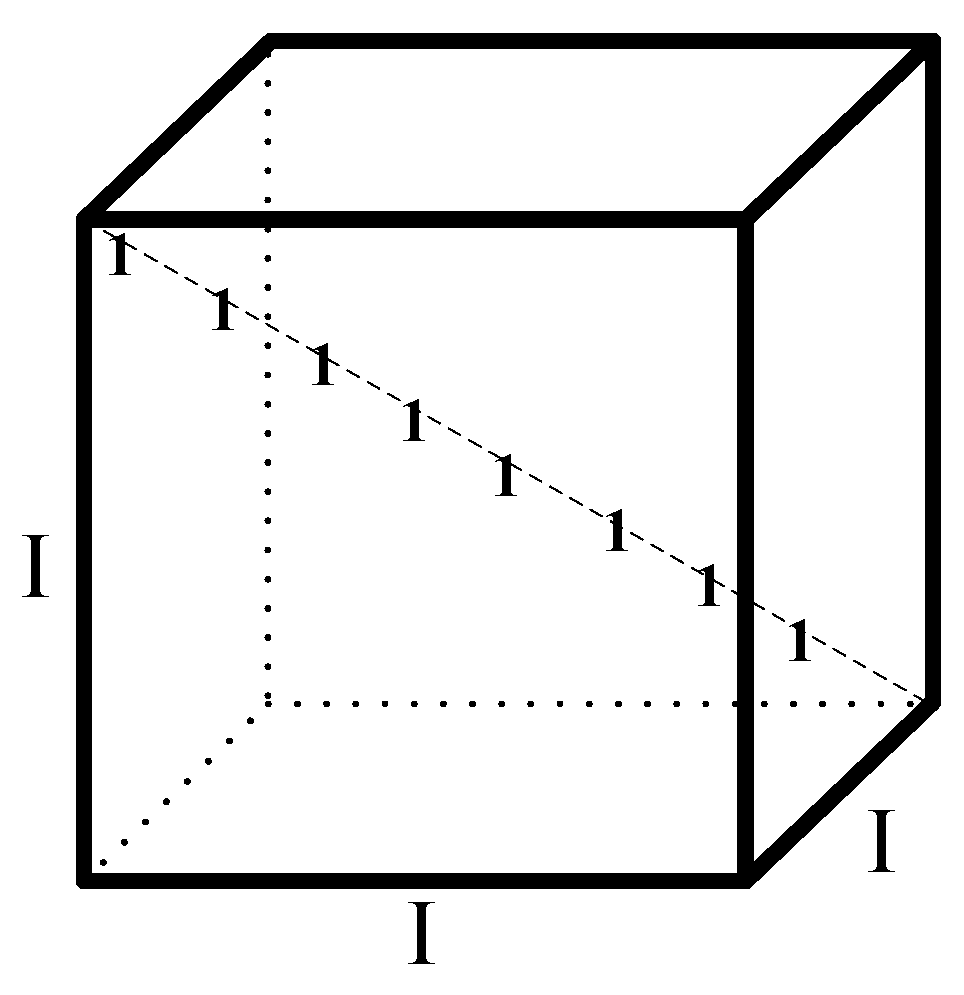
. The 3rd-order identity tensor is shown in
Figure 3.
4.1.4. n-Mode Product
The n-mode product of
with a matrix
is denoted by
, and the size of the result is
Elementswise, we have
4.2. Tensor Decomposition
Tensor decomposition can realize dimensionality reduction to solve the problem of dimensionality disaster in various tensor calculations and to dig the implicit relations in tensors. Two typical decomposition schemes in tensor decomposition are the CP Decomposition (CPD) and the Tucker decomposition.
4.2.1. CP Decomposition
The CPD is to transform tensors into sums of rank-1 tensors. Set a third-order tensor
, and the CPD of
can be written as
where
R is the tensor CP-rank,
. The process of CPD is illustrated in
Figure 4.
The matrix composed of vectors that form rank-1 tensors is referred to as the factor matrix of CPD, such as
, and the factor matrices
and
are defined the same. Based on the factor matrix, CPD can be more simply expressed as follows
4.2.2. Tucker Decomposition
Tucker decomposition can be expressed as
where
denotes the core tensor, and
are three-factor matrices from three dimensions, as shown in
Figure 5.
The scalar form is expressed as
When the core tensor
is a super-diagonal tensor, Tucker decomposition degenerates into CPD.
4.3. Tensor Completion
Considering the actual emergencies such as sensor failure, there is often some data loss in the data matrix, named missing values. Completion is to fulfill these missing values completely, and completion in the tensor is called tensor completion. The central issue in completion revolves around uncovering the association between missing values and observed values.
In order to introduce tensor completion, we take a classic tensor completion algorithm for the third-order tensors as an example, which is called high-accuracy low-rank tensor completion (HaLrTC), where the algorithm associates missing values with observed values through low rank based on the data sparsity hypothesis [
35]. Given a sparse tensor
of size
, the index set of the observed values is set to
. Let the index tensor
with the same size of
satisfy
The objective function of tensor completion is formulated as follows
where
denotes the estimation of the original tensor
, the size of tensors
,
,
are
, the matrix
with the size of
represents the mode-1 unfolding of tensor
under mode-1 unfolding, and the meaning of matrix
and the matrix
is uniform as the former. In the objective function, the symbol
is the norm for trace, which is the sum of the matrix singular values.
The optimization model is subject to two constraints, as illustrated in Equation (
11). The initial constraint ensures equality between the elements of estimated tensor
and original tensor
within
. The secondary constraint sets the intermediate variables
,
, and
equal to the estimated tensors, serving as an optimization termination condition. The constraints are formulated as follows
where the notation * represents the dot product, which means that the same index elements are directly multiplied.
The HaLrTC algorithm [
35] is indicated in the Algorithm 1, in which
is the inverse process of tensor unfolding, that is, folding the matrix into the tensor in the order of unfolding.
| Algorithm 1 HaLrTC algorithm |
- 1:
Input index tensor , adaptively changing , residual threshold and maximum iteration number K. - 2:
Initialize estimated tensor that and the iteration number . - 3:
set zero transitional tensor . - 4:
Update : , where . - 5:
Update : . - 6:
Update : . - 7:
If , stop and output estimated tensor . - 8:
If , return to step 4. If not, stop and output estimated tensor . - 9:
End.
|
4.4. Algorithm for Data Fusion
Data fusion, as a means of data processing, aims to transform two multi-dimensional heterogeneous mapping data matrices into a unified fusion matrix by tensor computing. Compared with the traditional data fusion scheme of direct splicing, the new data fusion scheme completely retains the original data information without matrix clipping. In the following meta-learning algorithm, the data information of the smart grid and power communication network can be obtained simultaneously by using the fusion data matrix.
The data of the smart grid and power communication network in
Figure 1 can be mapped into the smart grid data matrix
and the power communication network data matrix
. Here, we assume that
and
. Then, the work to be completed is to combine these two data matrices into a fusion matrix while preserving the validity and structural relationship of the two data, that is, the fusion matrix can lossless restore two original data matrices after DF is complete. To complete the above work and achieve
in (
1), the algorithm is designed as follows.
After completing DF, the size of the fused data matrix is . In order to obtain a larger compression ratio, the columns of the matrix are completed to during the second step of the algorithm. However, this change will cause the fused matrix to lack a block of size . Without changing the fusion matrix arrangement, there is no difference between the two schemes in actual storage.
The third step reverses the Tucker decomposition. The identity matrix is used in the third-order direction to ensure the sparsity of the fusion tensor
without changing the value so as to facilitate the subsequent tensor completion operation, which is based on the sparsity of tensors. As mentioned in the Tucker decomposition above, Tucker decomposition degenerates to CP decomposition when the core tensor is hyper-diagonal. The core tensor
in the algorithm is an identity tensor that satisfies the condition, and the resulting fusion tensor
can be reduced to the original matrices
and
by CP decomposition. Due to the uniqueness of CP decomposition, it is provable that the whole fusion algorithm is reversible. The specific algorithm is shown in Algorithm 2.
| Algorithm 2 Data fusion algorithm based on tensor computing |
- 1:
Input the smart grid data matrix and the communication network data matrix , adaptively changing , fit index and maximum iteration number K. - 2:
Initialize identity tensor , where , set the number of iterations , and fulfill and with zero row vectors and zero column vectors to get and . - 3:
Compute , where is a identity matrix. - 4:
Use Algorithm 1 to generate . - 5:
Set CP-rank , , , and . - 6:
Compute three sets of equations in sequence , ; , ; , . - 7:
Compute and . - 8:
If , stop and output fused data matrix . - 9:
If , return to step 6. If not, stop and output fused data matrix . - 10:
End.
|
5. Fault Diagnosis Based on Meta Learning
5.1. Meta Learning
Meta-learning introduces a range of concepts, including support set, query set, and N-way K-shot problems. The dataset of meta-learning can be divided into meta-training sets and meta-testing sets which, respectively, contain support sets and query sets used to support the training and testing of tasks.
When assessing the effectiveness of meta-learning models, the results of N-way K-shot problems are commonly used. Here, N signifies the number of classes, while K denotes the number of samples per class. Assuming there are classes in the meta-training set, with each class containing samples, and classes in the meta-testing set, with each class containing samples. N typically refers to the number of categories taken from the support set in the meta-testing set, while K represents the number of samples per class, where and . To maintain consistency between the meta-training and meta-testing stages, the model is trained on the meta-training set with the same number of categories and samples.
The Model-Agnostic Meta-Learning (MAML) algorithm is an outstanding algorithm in the field of meta-learning [
36], continually optimizing the model’s generalization ability on new tasks by guiding the initialization parameters of the base learners. MAML is versatile, working well with various neural networks and different types of loss functions. It is similar to a learn skill that trains the initialization parameters of the model to achieve rapid convergence with limited sample data.
We assume that the MAML algorithm is applied to an image classification task. It is usually handled by the CNN model, so we use this model as the base-learner to process image classification problems. Then MAML learns the parameters in the model training process as meta-knowledge and adjusts the initialization parameters on the new image classification task. Finally, we obtain the model that is adapted to the new task.
The base-learner
can be represented as a function
with parameter
. When the learner fits the new task
, the parameters become
. Based on the training samples in task
, the base-learner
performs one or several gradient update iterations to update parameter
. Assuming that one gradient update is required [
36]
where
is the hyperparameter learning rate and
is the loss function. The model parameter
is updated by training the test samples from
to optimize the performance of
. Its objective function is
The MAML aims to update the model parameters to produce the most efficient behavior. The model parameters
are updated as
where
represents the meta-update step size.
In practical applications, MAML demonstrates strong scalability across different datasets, but it also has some limitations. There needs to be a certain degree of similarity between the training and testing datasets; otherwise, it may lead to a decrease in generalization performance. Additionally, the multiple gradient updates performed in each iteration can result in longer training times and substantial computational resource consumption. Despite these limitations, MAML remains a highly effective meta-learning approach, particularly in terms of sample efficiency and generalization capabilities.
5.2. Fault Diagnosis in Power Communication Network and Smart Grid
5.2.1. Power Communication Network
When malfunctions occur within the power communication network, a substantial number of alarms are generated. These alarm notifications provide detailed information, including alarm device, alarm type, alarm level, alarm cause, and more. The alarm data primarily comprise three distinct categories: communication alarms, device-related alarms, and security alarms. Moreover, the alarm source and alarm name designate the unique identifier for the originating alarm and the nomenclature of the associated network element. These attributes constitute pivotal criteria for activities such as fault localization and fault classification.
To prepare the alarm information for subsequent utilization in feature vector extraction and training neural networks, a preprocessing stage is imperative. Initially, from the original alarm information database, relevant alarm information fields that exhibit substantial relevance to FD are meticulously selected. Furthermore, any redundant fields present within the original alarm database are systematically eliminated. Following this, standardization procedures are applied to ensure uniformity and consistency. Subsequently, the processed alarm dataset is subjected to a temporal and spatial synchronization procedure, employing a time window mechanism. Distinct alarms exert varying influence upon the ultimate determination of faults, signifying that these alarms possess disparate weights. These weights are utilized to establish a hierarchical order of priority, with higher weights signifying augmented precedence. Each distinct type of alarm is then subjected to a Boolean encoding process.
To depict the intricate topological interconnections existing between various sites within the power communication network, a graph theoretical approach involving an adjacency matrix is employed. Let
G represent a graph encompassing
m vertices (corresponding to sites),
represents the set of vertices within
G, and
signifies the set of edges. The adjacency matrix for
G is denoted as
When a malfunction occurs, the alarm transaction encodings of each site form a matrix
, where
represents the alarm transaction encoding of the site
. The mathematical expression for the fault state encoding matrix
is
After encoding the fault state matrix , the matrix is transformed into grayscale images and annotated with corresponding root cause fault labels. Finally, the fault state images from all instances of faults are compiled to form the training dataset. In the context of FD for the power communication network, the objective involves achieving fault localization and fault classification. As a result, for each fault state matrix, the corresponding root cause fault label is two-dimensional. This necessitates defining and encoding fault type labels and fault site labels.
Taking the power communication network of some cities in Shandong Province of China as an example, which is shown in
Figure 6, there are a total of 30 network element sites. We select 12 sites among them and define fault site labels. The set of defined fault site labels is
. As shown in
Table 1, the simulated fault types in this study encompass five categories, and the set of defined fault type labels is
. Train separately on the fault site label set and fault type label set to ultimately achieve the goal of fault localization and fault classification.
5.2.2. Smart Grid
We build a small current grounding fault simulation model within the Matlab Simulink module, utilizing the fault module to define various types of circuit faults, including single line-to-ground faults, double line faults, double line-to-ground faults and three-phase faults, comprising a total of 10 fault types. In which, single line-to-ground faults include Line A to Ground (AG), Line B to Ground (BG) and Line C to Ground (CG). Double line faults include Lines A and B (AB), Line B and C (BC) and Line A and C (AC). Double line-to-ground faults include Line A, B and Ground (ABG), Lines B, C and Ground(BCG), and Line A, C and Ground(ACG). Three phase faults include Lines A, B, C (ABC).
When the faults occur, fluctuations are observed in the voltage and current at both ends of the line. Thus, different fault types can be distinguished by observing changes in the magnitude and nature of these electrical parameters. We collect three-phase currents and voltages at both ends of the faulty line, denoted as
, and configure various system parameters to generate a dataset through batch simulations. The parameters for the fault samples are defined in
Table 2.
The sampler is configured with a frequency of 1 kHz, a sampling time of 0.3 s, a fault initiation time of 0.1 s, and a fault clearing time of 0.15 s. Within a single sampling period, each sample contains 1800 data points. We extract 50 data points each from the six electrical parameters before and after the fault occurrence. The acquired data are then subjected to grayscale transformation according to Equation (
18), resulting in the formation of grayscale images
where
represents the sequentially acquired electrical parameters, and
denotes the data after grayscale transformation. By altering parameters such as frequency and voltage, we obtain distinct fault grayscale images corresponding to different fault occurrences. These images collectively constitute the training dataset. The fault labels (AG, AB, etc.) are encoded, and the classification can be achieved using a meta-learning model.
6. Simulation Results and Theoretical Analysis
6.1. Evaluation Metrics and Model Parameters
The experimental setup includes a PC with Windows 10 operating system, an Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz, two RTX 3080 (10 GB) GPUs, a development environment with Python 3.9.16, and a learning framework with PyTorch 1.11.0. For a 5-way 1-shot task, it requires GPU resources of at least 3 GB.
The experiment evaluates the performance of the model using accuracy (
), which is calculated as the ratio of correctly predicted samples to the total number of samples, as depicted in the following formula,
where
signifies true positive samples predicted by the model,
signifies true negative samples predicted by the model,
signifies false positive samples predicted as positive by the model, and
signifies false negative samples predicted by the model.
Before conducting the experiment, it is essential to fine-tune the parameters of the model. While keeping other parameters constant, optimization is performed on the number of epochs, learning rate, and the minimum batch size. An epoch represents the process of training all training samples once. The model tends to stabilize after 30 epochs, so the number of epochs is set to 35. Fine-tuning the accuracy from 0.001 to 0.1 reveals that its impact on accuracy is minimal; thus, a learning rate of 0.001, which yields the optimal model performance, is selected. Additionally, adjusting the minimum batch size produces the results shown in
Figure 7. The trends of both curves show an initial increase followed by a decrease, with both reaching their peak when the minimum batch size is set to 64. At this point, the model performs optimally, and thus, this parameter is chosen for subsequent experiments.
6.2. Performance of MAML Algorithm
In this section, the performance of meta-learning is evaluated by comparing it with CNN. The results of model training are depicted in
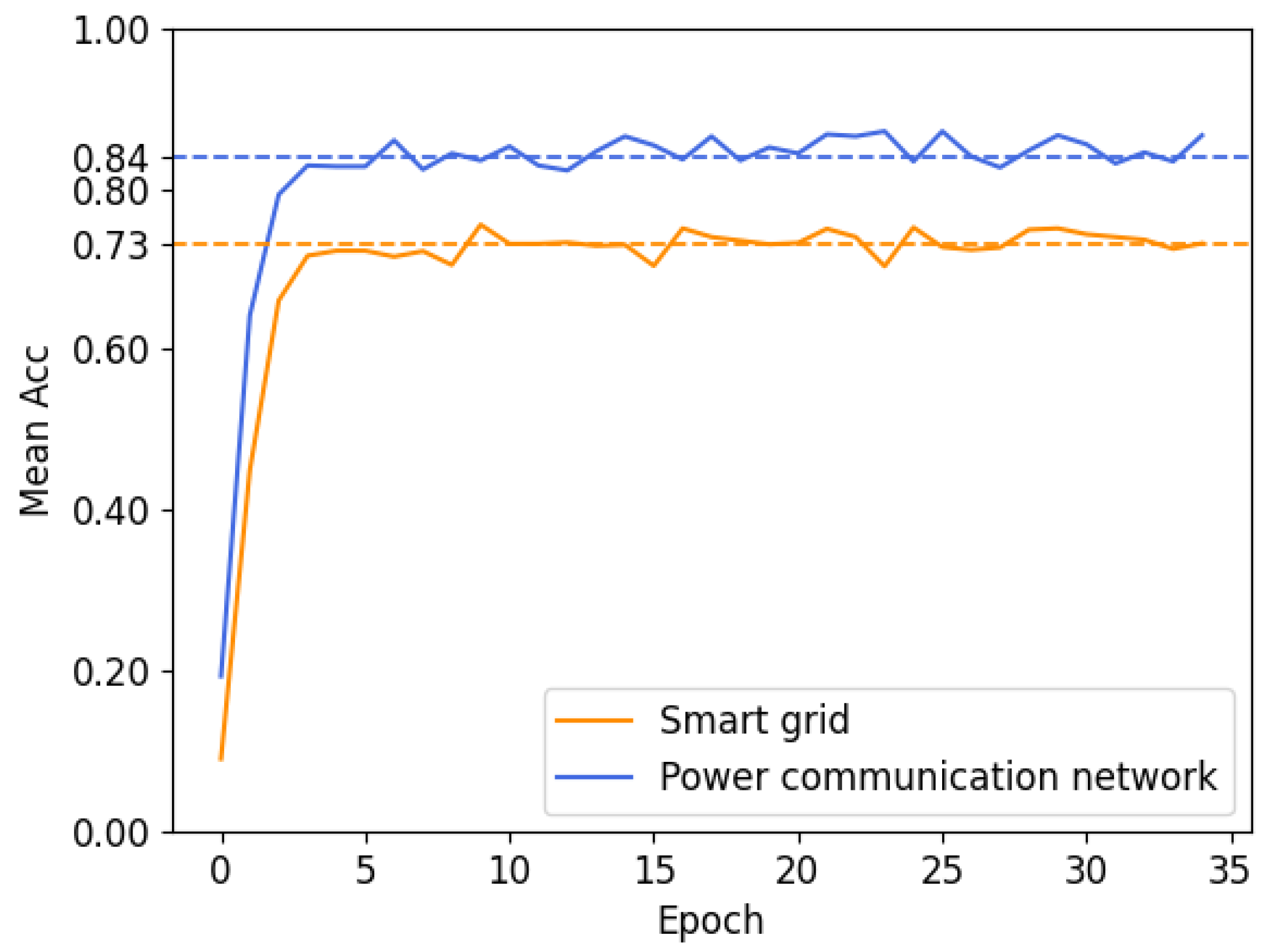
Figure 8. As shown in
Figure 8, the blue line represents the power communication network, and the yellow line represents smart grid.
As the number of epochs increases, the model quickly converges, with the diagnosis accuracy reaching its peak as early as the fourth iteration. Due to differences in the number of fault types in the smart grid and the power communication network, the difficulty of fault diagnosis varies. As a result, the diagnosis accuracy for the power communication network is higher, fluctuating around 84%. In contrast, the diagnosis accuracy for the smart grid converges to 73%.
The performance of the MAML algorithm was assessed through a comparative analysis with a CNN model that was not equipped with MAML. The training results are depicted in
Figure 9. It is clear that both smart grid and power communication networks experienced varying degrees of reduced diagnosis accuracy. The diagnosis accuracy of the smart grid decreased from the original 73% to 68%, and that of the power communication network dropped from the initial 84% to 66%.
In the simulation experiments for the smart grid, we sampled electrical quantities at different fault occurrences, processed them into grayscale samples, and modified system parameters such as frequencies and voltages to simulate the source and target domains. The dataset for the power communication network includes fault state matrices containing topological relationships and fault information. The disparities in topological relationships between the source and target domains necessitate the model to possess superior transferability. As a result, in the comparison between CNN and MAML, the diagnosis accuracy improvement for the power communication network was more pronounced than that of the smart grid.
6.3. Contribution of Data Fusion
The data processed by the DF model is a form of multi-modal heterogeneous data, comprising 10 fault types for the smart grid and five fault types for the power communication network. If converted into one-dimensional labels, the number of fault categories would increase to 50, which could adversely affect the model’s classification performance. Therefore, we chose to independently train networks for these two label categories. This approach allows for a more comprehensive utilization of the dataset and yields superior classification results. However, it is worth noting that training the same dataset twice requires more time.
After processing the feature-layer data with the DF model, we trained the fused data, which is based on Algorithm 2, and obtained model accuracy results based on various DF strategies. As shown in
Figure 10 and
Figure 11, both fusion approaches have improved diagnosis accuracy, but the extent of improvement varies. For the smart grid, using the CP decomposition scheme resulted in an increase of approximately 3% in accuracy, while the DF tensor scheme led to an improvement of around 6%. In the case of the power communication network, the CP decomposition approach raised accuracy by about 3%, while the DF tensor approach boosted it by approximately 8%. This demonstrates that, whether for the smart grid or the power communication network, the DF tensor scheme is superior.
Fused multi-modal data provide the model with additional information for decision-making, consequently enhancing diagnosis accuracy. CP decomposition addresses redundancy issues in the input space by reducing dimensions but can result in information loss. In contrast, the DF tensor retains all the original data’s information and exhibits superior diagnosis accuracy.















{kind=link}
{kind=link}
{kind=link}
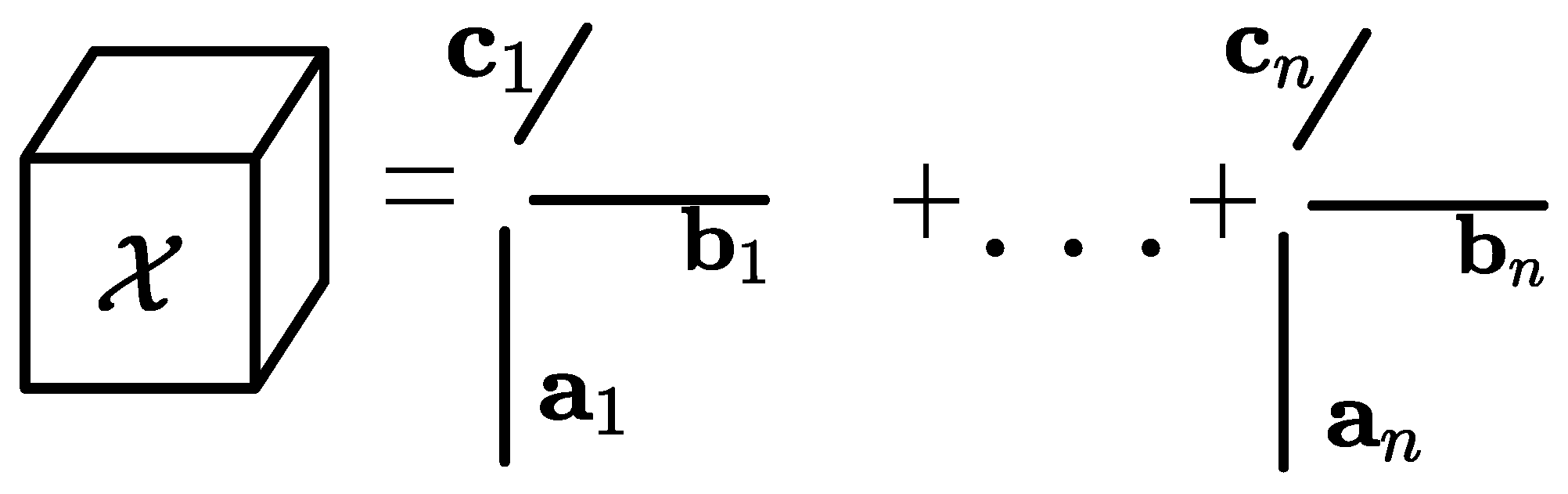{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}