1. Introduction
The rapid expansion of the Internet over the past two decades has ushered in a transformative era in Bangladesh, with the Bangladesh Telecommunication Regulatory Commission (BTRC) reporting a quickly growing user base exceeding 125 million as of November 2022 [
1]. This surge highlights the country’s remarkable digital trajectory, which has been further bolstered by initiatives like Digital Bangladesh [
2], which has significantly expanded Internet access, especially in Chittagong [
3], the nation’s second-largest city. In Chittagong, Internet adoption has become synonymous with active participation in social media platforms, thus propelling Bangladesh’s online presence, particularly on platforms like Facebook [
4]. Within this digital landscape, linguistic diversity thrives, with Chittagonian and Bangla languages emerging as primary modes of communication [
5,
6].
Chittagonian, spoken by approximately 13 million people, adds to Bangladesh’s rich linguistic tapestry [
5]. The widespread use of Unicode across communication devices has enabled individuals, including Chittagonian speakers, to freely express themselves in their native tongues [
7,
8]. Social media platforms like Facebook, imo, WhatsApp, or various blog services have been embraced by the people of Chittagong, thereby fostering an environment conducive to uninhibited self-expression [
9,
10,
11].
However, this digital revolution is not devoid of challenges. The allure of social media, particularly among youth, has led to excessive usage, potentially bordering on addiction [
12]. Such behavior can weaken social interactions and family ties, thereby adversely impacting overall well-being [
13]. Moreover, there has been a concerning rise in online abuse, cyberbullying, and the dissemination of hateful content, thereby contributing to a distressing increase in physical violence [
14].
In response to these pressing issues, this paper aims to create a multilingual classification model specifically tailored to combat cyberbullying in Bangla and Chittagonian texts. The overarching goal is to leverage technology to foster a safe and respectful online environment for both languages, thus drawing upon Bangladesh’s unique linguistic and cultural context for the betterment of society as a whole.
The research framework we applied to achieve this goal encompasses a comprehensive exploration of various machine learning and deep learning techniques [
15,
16,
17,
18]. The array of ML techniques includes Logistic Regression, Support Vector Machines, Multinomial Naive Bayes, Decision Trees, Random Forest, K-Nearest Neighbors, as well as ensemble methods like Bagging, Boosting, and Voting. Especially, deep learning has played a pivotal role in advancing many important problems in signal processing [
19,
20,
21], image processing [
22,
23,
24], and medical diagnosis [
25,
26,
27]. The deep learning methods applied in this study include Multilayer Perceptron, Simple Recurrent Neural Networks, Long Short-Term Memory, Bidirectional Long Short-Term Memory, Gated Recurrent Unit, Convolutional Neural Networks, as well as hybrid models DL such as BiLSTM+GRU, CNN+LSTM, CNN+BiLSTM, CNN+GRU, and (CNN+LSTM)+BiLSTM, along with Transformer-based models like BERT, Bangla BERT, Bangla ELECTRA [
28], Multilingual BERT, and XLM-Roberta.
The subsequent sections elaborate in detail on the process and outcomes of this study, thus offering insights that could bolster strategies for addressing cyberbullying in the Bangla and Chittagonian linguistic domains.
The research objectives of this study were as follows:
To curate a comprehensive dataset comprising at minimum five thousand manually collected samples from both Bangla and Chittagonian languages, thereby ensuring balanced representation.
To ensure the production of high-quality ground truth data through meticulous manual labeling by human annotators validated using Krippendorff’s alpha [
29] and Cohen’s kappa [
30] scores.
To conduct an exhaustive analysis starting with baseline methods based on traditional machine learning (ML) models, including Support Vector Machine (SVM), Bagging, Boosting, and Voting, to determine their effectiveness in cyberbullying detection.
To explore deep learning (DL) models, particularly Convolutional Neural Network (CNN) architectures, and assess their performance compared to traditional ML approaches.
To propose and evaluate hybrid network-based models, such as BiLSTM+GRU, CNN+LSTM, CNN+BiLSTM, and CNN+GRU for cyberbullying detection.
To investigate Transformer-based models, including BERT, Bangla BERT, Bangla ELECTRA, Multilingual BERT, and XLM-Roberta, and estimate their impact on enhancing the accuracy levels in cyberbullying detection.
The paper follows a structured approach beginning with a review of the literature on multilingual cyberbullying detection, which is presented in
Section 2.
Section 3 details the proposed methodology, thereby encompassing dataset acquisition, annotation, and preprocessing, with a specific focus on Chittagonian and Bangla nuances and the application of NLP, ML, and DL techniques. In
Section 4, the experimental results and evaluation procedures are detailed, thus offering insights into the effectiveness of the proposed methodologies. Ethical considerations pertinent to the study are deliberated upon in
Section 4.9. Finally, the paper concludes in
Section 5, where the contributions are summarized, and avenues for future research are suggested.
2. Related Work
Cyberbullying detection has gained considerable attention in recent years owing to the widespread use of social media platforms and online communication channels [
7]. Researchers have explored various techniques and methodologies to identify and address cyberbullying among various languages and cultures [
7,
8,
31,
32,
33,
34,
35]. However, while numerous research efforts have introduced solutions to detect cyberbullying in high-resource languages such as English or Japanese, there is a limited number of studies that have extensively addressed cyberbullying detection in the low-resource languages, such as the Bangla language. Furthermore, to date, there has been no research specifically targeting both Bangla and its dialects and similar languages simultaneously. This section reviews the pertinent literature on cyberbullying detection, multilingual text analysis, and studies specifically focusing on low-resource languages like Arabic [
16], Hindi [
15,
28], Marathi [
15], Indonesian [
18], and Turkish [
36].
Pawar et al. [
15] suggested developing a multilingual system to identify cyberbullying in Hindi, Marathi, and English. It used lexicon-based and machine learning classification techniques to determine whether or not the input data represented cyberbullying. They experimented with several prototypes (standalone, collaborative, and cloud-based) to detect cyberbullying in a variety of datasets and languages. The results of their tests demonstrated that the machine learning model outperformed the lexicon-based model in all languages. Furthermore, the outcomes demonstrated that cooperation strategies could raise a system node’s accuracy that is not performing at its peak. Ultimately, they discovered that the cloud-based configurations outperformed the local configurations, covering Marathi, Hindi, and English in obtaining high levels of accuracy (0.8106 for the lexicon-based approach and 0.9024 for the LR-based classifier).
Haidar et al. [
16] presented a multilingual model for Arabic and English cyberbullying detection with notable SVM F1 scores of 0.927 and NB scores of 0.905. Mahajan et al. [
18] investigated the use of deep learning methods to improve the accuracy of detection. There have been positive improvements in the overall performance observed in models that use Bidirectional Long Short-Term Memory (BiLSTM), the Bidirectional Gated Recurrent Unit (Bi-GRU), Convolutional Neural Networks (CNNs), and Long Short-Term Memory (LSTM). Furthermore, the use of Global vectors for word Representation (GloVe) embeddings made it easier to translate words into vector representations, which sped up the processing of multilingual data streams. Novel methods have surfaced to augment detection efficacy, including hybrid ensemble techniques. By combining several effective models, like CNN-LSTM, these techniques optimize weights and increase model accuracy through the use of bagging ensemble methods and stacking approaches. Moreover, they outperformed alternatives with at least a 4.44% increase in F1 score.
Michele et al. [
37] proposed neural architecture that functioned reasonably well in a number of languages, including Italian, German, and English. A detailed examination of the experimental findings in all three languages was carried out in order to better understand the contributions made by the various system components, such as long short-term memory, gated recurrent units, and bidirectional long short-term memory. In addition, word embeddings, emotion expressions, n grams, social network-specific features, and emojis were among the features chosen for the system. To conduct such a thorough analysis, they used three publicly available datasets for the identification of hate speech on social media in the languages of English, Italian, and German.
Shukrity et al. [
38] dealt with English, Hindi, and Hindi–English (mixed code) datasets. They used features like word vectors and manually assembled dictionaries for aggressive words, sentiment scores, parts of speech, and emojis for the classification task. They discovered that the Gradient Boosting Classifier (GBM), XGBoost Classifier, and Support Vector Machine (SVM) were the best models for the task after experimenting with a variety of machine learning and deep learning models. Therefore, majority voting was done using the output of the three classifiers, which produced F1 scores of 68.13, 54.82, and 55.31 for the English, Hindi, and mixed code datasets, respectively.
Sayar Ghosh et al. [
39] examined how challenging it is to identify offensive or hateful content on Twitter. Three categories of harmful content were identified: profane (PRFN), offensive (OFFN), and hate speech (HATE). They first used a Transformer-based text encoder that was multilingual and pretrained it to identify and classify hate speech in a range of languages. When they performed hate speech detection on the provided testing corpora, they received macro F1 scores of 60.70, 53.28, and 49.74 for fine-grained classification and 90.29, 81.87, and 75.40 for English, German, and Hindi, respectively.
El-Alami et al. [
40] applied a model based on Bidirectional Encoder Representations from Transformers (BERTs), which is helpful in extracting semantic and contextual information from texts. Their system consisted of three stages: preprocessing, text representation with BERT models, and classification into offensive and nonoffensive categories. To address multilingualism, they looked into a number of techniques, including translation-based and joint multilingual approaches. Whereas all texts were translated into a single universal language prior to classification in the latter scenario, a single classification system was developed in the former scenario for multiple languages. For several tests, they applied a bilingual dataset from the Semisupervised Offensive Language Identification Dataset (SOLID). The translation-based approach combined with Arabic BERT (AraBERT) produced an accuracy and an F1 score of over 91% and 93%, respectively, based on the experimental results.
To detect hate speech on various social media platforms, including Facebook, Instagram, WhatsApp, Twitter, and Facebook, Arijit et al. [
41] suggested a Transformer-based model. Datasets with contents in Bengali, English, Italian, and German were used for testing. In the evaluation, based on prepared gold standard datasets, the accuracy rates for the Bengali dataset were 89%, while the English, German, and Italian datasets obtained accuracy rates of 91%, 91%, and 77%, respectively. Their proposed model was able to identify hate speech with greater accuracy than both baseline and state-of-the-art models.
For the purpose of identifying cyberbullying in texts with mixed Hindi–English (Hinglish) and English codes, Malte et al. [
28] proposed a deep learning generative method. Bidirectional transformer-based BERT architecture was used in this technique. The proposed architecture yielded state-of-the-art results on the mixed code Hindi dataset and satisfying results on the English task leaderboard in the TRAC-1 standard aggression identification task. The results showed an improved alternative to the existing approaches because they could be obtained without requiring multiple models or ensemble-based methods. Deep learning-based models that performed well on multilingual text were considered to be crucial to addressing the problem of cyberbullying because they could handle a wider range of inputs.
Through transfer learning and crosslingual contextual word embeddings, Ranasinghe et al. [
36] produced predictions in low-resource languages using English data at their disposal. They reported results of a 0.8415 F1 macro for Bengali, a 0.8568 F1 macro for Hindi, and a 0.7513 F1 macro for Spanish after projecting predictions onto comparable data in those three languages. Lastly, they showed that their method outperformed the top systems that had been submitted in recently shared tasks on these three languages, thus proving the usefulness of transfer learning and crosslingual contextual embeddings for similar tasks.
3. Data and Methods
3.1. Data Collection
The data collection for this study was conducted manually from April to June 2022. A total of 5120 Bangla and 5146 Chittagonian samples were obtained from a diverse set of online platforms, including social media sites, forums, and comment sections of various websites.
Figure 1 shows the steps that encompassed the comprehensive process involved in both obtaining and managing the data to ensure their effectiveness and accessibility for further investigation. These datasets comprise text samples in both Chittagonian and Bangla languages, thus encompassing various types of content such as posts and comments (refer to
Figure 2).
Figure 3 illustrates a selection of data samples.
To ensure a comprehensive representation, we systematically gathered political, religious, and COVID-19-related content, as these topics often provoke intense debates and potential cyberbullying incidents. Furthermore, a wide variety of sources comprise the majority of the dataset, including blogs, YouTube channels, news platforms, Facebook pages, and various Facebook groups like Chatgaiya Express [
42] and Chatgaiya Tourist Gang [
43].
The dataset encompasses a range of cyberbullying instances, thus facilitating the training and testing of deep multilingual models. Our objective was to establish a robust foundation for evaluating the effectiveness of cyberbullying detection methods in both languages through this extensive data collection process.
The collected data served as the cornerstone of our comparative analysis, thus enabling a deeper understanding of cyberbullying trends and the performance of the developed detection models. For a summary of both Bangla and Chittagonian datasets, please refer to
Table 1.
3.2. Data Annotation
3.2.1. Annotator Selection
To ensure optimal data quality, the effectiveness of any cyberbullying detection system hinges not only on the quantity but primarily on the quality of annotated data. To achieve this, we meticulously designed a systematic data annotation process.
We leveraged the expertise and fluency of three native speakers proficient in both Chittagonian and Bangla. These annotators, consisting of two females and one male, possess advanced degrees in linguistics and demonstrate a deep understanding of the intricacies of both languages. The inclusion of gender diversity among annotators was deliberate, thereby aiming to capture a diverse range of linguistic nuances that may vary between male and female speakers.
3.2.2. Data Annotation Guidelines
In the data annotation guidelines of this study, annotators were instructed to categorize instances of cyberbullying within Bangla and Chittagonian texts based on predefined criteria. Annotations primarily focused on identifying various forms of cyberbullying, including but not limited to offensive language, harassment, threats, and derogatory remarks. Annotators were encouraged to consider cultural nuances and language-specific expressions prevalent in Bangla and Chittagonian texts while evaluating the severity and context of cyberbullying instances. Additionally, guidelines emphasized the importance of consistency and accuracy in annotation practices to ensure the reliability and validity of the annotated dataset for training and evaluating transformer models aimed at multilingual cyberbullying detection.
The data annotation guidelines applied in this study were structured as follows:
- a.
Furnish annotators with explicit definitions and examples for clarity.
- b.
Label each post as either ‘bullying’ or ‘not-bullying’ in accordance with predetermined definitions.
- c.
Take cultural nuances into account during the labeling process.
- d.
Conduct regular meetings with annotators to ensure consensus.
- e.
Address language variations and slang to maintain accuracy in annotations.
3.2.3. Data Annotation Results
The data annotation methods employed in the study on multilingual cyberbullying detection in Bangla and Chittagonian languages, depicted in
Figure 4, yielded a dataset with the following distribution:
In Bangla, the dataset comprised 2545 instances labeled as bullying, 2555 instances labeled as not bullying, 11 instances of conflicts (after discussions with annotators, these were excluded and discarded from the final dataset), and 9 instances marked as ignored.
Conversely, in the Chittagonian language, the distribution included 2610 instances of bullying, 2490 instances of not bullying, 25 instances of conflicts, and 21 instances labeled as ignored (refer to
Figure 5).
These annotations established a robust foundation for training and evaluating multilingual cyberbullying detection models, thus providing insights into the prevalence of various content categories in online interactions across both languages.
3.2.4. Quality Evaluation of Data and Annotation
We rigorously assessed the quality of data and annotations through inter-rater reliability measures. Specifically, for the Chittagonian language, the annotations achieved high Krippendorff’s alpha (See
Box 1) [
29] values ranging from 0.9342 to 0.9641 and Cohen’s kappa (See
Box 2) [
30] values ranging from 0.9281 to 0.9484 among annotator pairs, thereby indicating a commendable level of agreement in labeling cyberbullying instances (refer to
Figure 6). This consistency in annotations underscores the dataset’s high reliability and suitability for training cyberbullying detection models, thereby enhancing the credibility and effectiveness of the research presented.
Box 1. Krippendorff’s alpha calculation.
The formula for calculating Krippendorff’s alpha involves four steps:
Compute Observed Agreement (Po): Tally agreements and disagreements between annotator pairs. It is calculated by
Compute Expected Agreement (Pe): Calculate the proportion of expected agreement under the assumption of random labeling.
Calculate Disagreement Matrix (Do): This matrix captures the differences between annotator responses for each item in the dataset.
Calculate Alpha Value: Use observed and expected agreement to compute Krippendorff’s alpha using the following formula:
(where is the mean of the squared differences between observed and expected disagreement, and is the sum of squared differences between expected agreement and the product of observed agreement and its complement.)
Similarly, for the Bangla language, Krippendorff’s alpha and Cohen’s kappa values consistently surpassed 0.8 for all annotator pairs, thereby indicating substantial to near-perfect agreement among annotators (refer to
Figure 7). These metrics reflect a meticulous annotation process, clear guidelines, and a strong foundation for data reliability. The high inter-rater reliability underscores the accuracy and consistency of the data annotations, thereby substantiating their efficacy for training and evaluating deep learning models targeting cyberbullying detection in both Bangla and Chittagonian languages.
Box 2. Cohen’s kappa calculation.
The formula for calculating Cohen’s kappa involves four steps:
3.3. Data Preprocessing
The data preprocessing procedure for the multilingual cyberbullying detection in Bangla and Chittagonian languages encompassed a series of sequential steps as shown in
Figure 8. Python’s NLTK library [
44,
45] was used for the elimination of stop words, while Matplotlib and Seaborn were utilized for data visualization. Additionally, the Pandas library facilitated the preparation of the data for the subsequent stages of analysis.
3.3.1. Removing Punctuations
In this study, the applied text data comprises various punctuation and special characters, which serve diverse grammatical functions such as denoting pauses, emphasis, and other structural aspects in written language. These characters encompass periods, commas, question marks, exclamation marks, hyphens, parentheses, quotation marks, and other nonalphanumeric symbols. While some punctuation may not significantly alter the meaning of a sentence, their presence can impact text classification tasks, including automatic cyberbullying detection, as demonstrated by Mahmud et al. [
7] in previous research. Their findings suggest that removing punctuation can enhance text classification accuracy, particularly when employing traditional machine learning algorithms. Hence, we adopted a similar approach and removed all punctuation from the text during the analysis. The list of punctuation considered for removal included characters such as periods, commas, quotation marks, exclamation marks, hashtags, parentheses, and various other symbols commonly found in written text found on the Internet.
3.3.2. Removing Emoji and Emoticons
In written communication, emoticons and emojis serve as graphical representations of emotions, expressions, or symbols, thus offering users a means to convey feelings and reactions in online interactions. These elements play a significant role in adding context and enhancing the emotional tone of text-based conversations. When handling such information in text analysis, two approaches are commonly adopted: either removing emoticons and emojis entirely from the text or substituting them with corresponding textual representations.
While research has demonstrated that both emoticons [
46] and emojis [
47] can contribute to text classification tasks in certain scenarios [
47], we chose not to consider emojis and emoticons during the classification process. As a result, we opted to exclude them from our analysis to maintain a focus on textual content without graphical representations of emotions and expressions.
3.3.3. Removing English Characters
In multilingual text analysis, ensuring the purity and integrity of language data is paramount for the precise performance of models developed specifically for the specific linguistic context. Therefore, removing English characters from Bangla and Chittagonian text becomes imperative. Bangla and Chittagonian, as distinct languages, possess their unique scripts and character sets, which contribute to their linguistic identity. Mixing English characters with Bangla or Chittagonian text introduces noise and inconsistencies, thereby potentially impeding the effectiveness of the multilingual models trained on these datasets. Standardizing preprocessing procedures by eliminating extraneous characters aids in maintaining data integrity and ensuring that models learn the specific linguistic patterns and nuances inherent to Bangla and Chittagonian. This preprocessing step not only enhances model robustness but also fosters language consistency, thereby enabling the model to focus solely on the linguistic characteristics of the target languages. By avoiding confusion during training and inference, the models can more accurately process and classify text, thereby advancing the effectiveness of multilingual text analysis throughout a variety of language corpora.
3.3.4. Removing English Digits
After closely examining the samples in the dataset, we found that some of them contained digits and numbers with no apparent semantic meaning. Phone numbers, currencies, and percentages are examples of numerical entities that are commonly identified and categorized using Named Entity Recognition (NER) tools [
48]. However, there is currently no NER tool available for Chittagonian text. Therefore, we decided to eliminate the digits and numbers from the dataset in order to get around this restriction and streamline our initial experiment. Nevertheless, we acknowledge that precise manipulation of numerical entities is necessary for subsequent investigations. For this reason, we plan to create a Chittagonian-only NER tool in the future.
3.3.5. Removing Stopwords
Words that are frequently used in a language but typically do not significantly change the meaning of a sentence are known as stopwords. When processing text data for tasks involving natural language processing, stopwords are often omitted. In the Chittagonian language, such words include, for example,
![Electronics 13 01677 i001]()
etc. In many natural language processing tasks, like text classification, they are frequently eliminated in order to decrease the dataset dimensionality [
34]. We thus decided to eliminate stopwords from the dataset in order to reduce the dimensionality of the text data and boost the efficacy and efficiency of the subsequent analyses.
3.3.6. Tokenization
In preparation for cyberbullying detection analysis in Bangla and Chittagonian languages, we conducted tokenization, which involves dividing the text into tokens or individual words. This process enables the segmentation of text into meaningful linguistic units, such as words or subwords, thereby facilitating further analysis. Our approach to tokenization aligns with previous research on the Chittagonian language, which also emphasized the importance of breaking down text into linguistic units [
7].
3.4. Feature Extraction
In this study, for feature extraction, we utilized Term Frequency–Inverse Document Frequency (TF-IDF) [
49,
50,
51] for classic machine learning and Word2Vec embeddings [
52,
53] for deep learning algorithms. TF-IDF functions as a conventional feature extraction method for ML, thus capturing the significance of words in numerical vectors. Conversely, DL employs Word2Vec embeddings to represent semantic meaning and encapsulate word relationships in vector space. This strategy extracted language nuances specific to Bangla and Chittagonian languages, thereby enhancing the efficacy of cyberbullying detection.
3.4.1. TF-IDF
The TF-IDF method transforms text data into numerical vectors by calculating the importance of terms based on their frequency in each document and rarity across the entire dataset [
49,
54]. Each document is represented as a vector, where each element corresponds to the TF-IDF score of a term. This vectorization process enables the use of machine learning algorithms for tasks such as classification and clustering. By capturing the unique linguistic characteristics of Bangla and Chittagonian languages, the TF-IDF method facilitates the development of effective multilingual models for tasks like cyberbullying detection. Through the integration of TF-IDF, ML models can recognize patterns and extract relevant word features from text data, which allows them to achieve high accuracy with competitive applicability in a variety of linguistic circumstances [
31,
32].
3.4.2. Word2Vec
In multilingual models tailored for Bangla and Chittagonian languages, Word2Vec embeddings serve as crucial components for encoding semantic information and capturing intricate linguistic relationships [
53,
55]. These embeddings transform words into dense vector representations, where each word’s position in the vector space reflects its semantic context and proximity to other words. By leveraging Word2Vec embeddings, multilingual models can effectively discern subtle nuances specific to Bangla and Chittagonian, thus facilitating more accurate and contextually relevant cyberbullying detection [
34].
3.5. Classification Algorithms
In this section, we present a diverse array of methods aimed at addressing the challenge of multilingual cyberbullying detection in the Bangla and Chittagonian languages. Our investigation begins with traditional machine learning algorithms, including Support Vector Machine, Logistic Regression, Decision Tree, Random Forest, and K-Nearest Neighbors. These algorithms serve as foundational techniques in our exploration.
Furthermore, we employ ensemble models such as Bagging, Boosting, and Voting classifiers to enhance the robustness and accuracy of our detection framework. These ensemble methods leverage the collective decision making of multiple composing models to improve overall classification performance.
Transitioning to deep learning architectures, we further apply the efficacy of various neural networks, such as Multilayer Perceptron, Recurrent Neural Networks encompassing SimpleRNN and Long Short-Term Memory, Gated Recurrent Units, and Convolutional Neural Networks. Each architecture offers unique advantages in capturing complex patterns and features present in cyberbullying text data.
Moreover, we evaluate the performance of hybrid architectures, namely BiLSTM+GRU, CNN+LSTM, CNN+GRU, CNN+BiLSTM, and (CNN+LSTM)+BiLSTM. These hybrid models combine the strengths of multiple architectures, thus harnessing the complementary nature of different neural network components to improve classification accuracy and generalization.
In addition to exploring neural network architectures, we employ Transformer-based models including XLM-Roberta, Bangla BERT, Multilingual BERT, BERT, and Bangla ELECTRA. These state-of-the-art models leverage pretrained representations to capture contextual information and semantic relationships, thereby enhancing the detection accuracy across multilingual text data.
Overall, our classification framework integrates a comprehensive range of methods, which we test on the nuances of Bangla and Chittagonian languages. Through rigorous evaluation and comparison, we aim to discern the most effective approaches for multilingual cyberbullying detection, thereby providing insights into the advancement of cyberbullying detection technology.
3.5.1. Classic Machine Learning Algorithms
Logistic Regression
In our multilingual model for Bangla and Chittagonian languages, Logistic Regression (LR) serves as a fundamental baseline classification algorithm [
51]. LR leverages probabilistic estimation to categorize input text into cyberbullying or noncyberbullying categories. Its simplicity and efficiency make it an attractive choice for multilingual text classification tasks. By analyzing the linguistic characteristics specific to Bangla and Chittagonian, LR effectively learns discriminative patterns to differentiate between cyberbullying and noncyberbullying content. Through comprehensive evaluation and fine-tuning, LR contributes to the robustness and accuracy of our multilingual cyberbullying detection framework.
Support Vector Machine
Support Vector Machine (SVM) serves as a strong baseline method for constructing a multilingual cyberbullying detection model [
16]. SVM is adept at separating data points into different classes by finding the optimal hyperplane that maximizes the margin between classes. In our study, SVM is applied to the multilingual dataset comprising both Bangla and Chittagonian text samples. By leveraging SVM, we aim to discern distinctive patterns and features indicative of cyberbullying behavior in a variety of linguistic settings. The versatility of SVM allows it to handle high-dimensional data efficiently, thus making it suitable for processing text data with varying complexities. Thorough assessment, we assess the effectiveness of SVM in classifying instances as cyberbullying, thereby contributing to the advancement of multilingual cyberbullying detection methodology.
Multinomial Naive Bayes
In our multilingual model for cyberbullying detection, we also leverage Multinomial Naive Bayes (MNB), a versatile algorithm known for its simplicity and effectiveness in text classification tasks. MNB operates based on the assumption of independence between features, thereby making it particularly suitable for processing text data. By calculating the likelihood of each class given a set of input features, MNB efficiently assigns probabilities to different categories, thus facilitating accurate classification. Despite its simplicity, MNB has demonstrated robust performance in various natural language processing applications, including sentiment analysis [
16] and spam detection [
56,
57].
Decision Trees
Decision Trees (DTs) serve as another baseline for our multilingual cyberbullying detection study. Decision Trees recursively partition the feature space based on attribute values, thereby enabling the classification of text data into distinct categories [
58]. In our study, DTs offer an interpretable and transparent approach to extracting linguistic patterns indicative of cyberbullying across Bangla and Chittagonian texts. By recursively splitting the dataset into homogeneous subsets, DTs effectively capture the discriminatory power of various features present in the text. We carefully evaluate DTs’ performance in comparison to other classification techniques in order to determine how effective it is at detecting multilingual cyberbullying.
K-Nearest Neighbors
K-Nearest Neighbors (kNNs) is an instance-based machine learning algorithm popularly used as a baseline, which has also been used in previous studies on multilingual cyberbullying detection [
59]. It operates based on the principle of similarity, where instances are classified by the majority class of their K-Nearest Neighbors. The simplicity of KNNs and its intuitive approach make it an attractive choice for classifying text data in linguistic contexts. However, its performance heavily depends on the choice of distance metric and the value of k, which may require careful tuning. Despite its straightforward implementation, kNNs may face challenges in high-dimensional spaces and with large datasets, thereby potentially affecting their computational efficiency and classification accuracy. Nonetheless, when appropriately applied and optimized, kNNs can serve as a valuable tool in the multilingual cyberbullying detection pipeline.
3.5.2. Ensemble Methods
Random Forest
Random Forest (RF) is an ensemble learning technique utilized in our multilingual offensive text detection model [
60]. It operates by constructing multiple decision trees during training and outputs the mode of the classes as the prediction of individual trees. RF is well-suited for handling complex data and is particularly effective in capturing nonlinear relationships between features. In our study, RF serves as one of the traditional machine learning algorithms employed alongside other methods to enhance classification accuracy. Through assessment, we assess the performance of RF in discerning cyberbullying content across Bangla and Chittagonian texts, thereby contributing valuable insights to the field of multilingual cyberbullying detection.
Bagging
In our study on multilingual cyberbullying detection, we employed Ensemble Bagging with Random Forest (RF) as a robust classification technique. Bagging, or Bootstrap Aggregating, is a powerful ensemble method [
61] that combines multiple base learners to improve overall model performance. By training multiple RF classifiers on different subsets of the dataset and aggregating their predictions, Ensemble Bagging reduces variance and enhances model stability. This approach allows us to mitigate overfitting and capture diverse patterns present in cyberbullying text data.
Boosting
In the Boosting approach for cyberbullying detection, we utilize three powerful classifiers: AdaBoost Classifier, XGB Classifier, and Gradient Boosting Classifier. These classifiers are renowned for their ability to leverage the collective strength of multiple weak learners to improve overall prediction accuracy [
62]. AdaBoost Classifier adapts by focusing more on misclassified instances, while XGB Classifier implements gradient boosting to optimize performance iteratively. Similarly, Gradient Boosting Classifier constructs a sequence of decision trees to progressively correct errors, thus resulting in enhanced classification performance. By combining the capabilities of these classifiers, our ensemble boosting method aims to achieve satisfactory cyberbullying detection accuracy across Bangla and Chittagonian texts.
Voting Approach
In our ensemble voting approach, we combine the predictive power of Random Forest, Support Vector Machine, and Gradient Boosting Machine to create a robust and diverse classification ensemble. Each base model, RF, SVM, and GBM, brings its unique strengths in handling complex patterns and relationships within the multilingual cyberbullying detection task. The ensemble voting mechanism aggregates the individual predictions from these models, thereby allowing them to collectively contribute to the final decision-making process [
63]. By leveraging the complementary nature of these diverse algorithms, our ensemble voting strategy aims to enhance overall accuracy and robustness, providing a more reliable and effective solution for multilingual cyberbullying detection in Bangla and Chittagonian texts.
3.5.3. Neural Network-Based Methods
Multilayer Perceptron
Multilayer Perceptron (MLP) is a fundamental neural network architecture widely used in machine learning tasks [
64]. It consists of multiple layers of nodes, including an input layer, one or more hidden layers, and an output layer. MLP is characterized by its ability to learn complex patterns and nonlinear relationships within data. By employing activation functions and backpropagation algorithms, MLP can effectively model intricate structures in cyberbullying text data. Its versatility and scalability make MLP a popular choice for various classification tasks, including cyberbullying detection in multilingual contexts.
Simple Recurrent Neural Network
The SimpleRNN, or Simple Recurrent Neural Network, is a basic form of recurrent neural network architecture designed to process sequential data by maintaining a hidden state. It operates by taking input at each time step and producing an output while retaining information from previous time steps [
65]. Despite its simplicity, SimpleRNNs suffer from the vanishing gradient problem, thereby limiting their ability to capture long-range dependencies in sequences. Consequently, they are less effective in handling long-term dependencies compared to more advanced recurrent architectures like LSTM and GRU. However, SimpleRNNs remain valuable for tasks requiring short-term memory and basic sequence processing.
Long Short-Term Memory Network
Long Short-Term Memory (LSTM) is a type of recurrent neural network architecture known for its ability to capture long-term dependencies in sequential data [
66]. It achieves this by utilizing a memory cell that can maintain information over extended time periods. The architecture consists of input, output, and forget gates, which regulate the flow of information within the network. LSTM networks are particularly effective for tasks involving sequential data processing, such as natural language processing and time series prediction. Due to its unique architecture, LSTM has been widely adopted in various applications, including language modeling, sentiment analysis, and speech recognition [
67]. Its ability to mitigate the vanishing gradient problem makes it well suited for modeling long sequences and handling complex temporal relationships in data.
Bidirectional Long Short-Term Memory Network
Bidirectional Long Short-Term Memory (BiLSTM) is a type of recurrent neural network architecture that is adept at capturing long-range dependencies in sequential data [
68]. It consists of two LSTM layers, with each processing input sequences in forward and backward directions simultaneously. By leveraging both past and future context, BiLSTM effectively captures contextual information and semantic dependencies in text data. This architecture is particularly well suited for tasks involving natural language processing, including sentiment analysis, named entity recognition [
69], and sequence labeling. BiLSTM has gained popularity due to its ability to model complex temporal relationships and achieve high accuracy in various sequence-based tasks. In the context of cyberbullying detection, BiLSTM offers a promising approach for capturing linguistic nuances and identifying subtle patterns indicative of cyberbullying behavior.
Gated Recurrent Units
Gated Recurrent Units (GRUs) are a type of recurrent neural network architecture widely used in natural language processing tasks [
70]. GRU models are adept at capturing long-term dependencies in sequential data while mitigating the vanishing gradient problem encountered in traditional RNNs. Unlike traditional RNNs, GRUs employ gating mechanisms to regulate the flow of information within the network, thereby allowing for more efficient information propagation across time steps. This gating mechanism enables GRUs to retain relevant information while discarding irrelevant information, thus enhancing their ability to model sequential data effectively. GRUs have demonstrated promising performance in various text-related tasks, including sentiment analysis, machine translation, and sequence labeling, thus making them a valuable component in deep learning architectures for cyberbullying detection.
Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are powerful deep learning architectures commonly used for various tasks including image recognition and natural language processing [
34,
71,
72]. In the context of text classification, CNNs excel at capturing local patterns and features within sequential data such as sentences or documents. They utilize convolutional layers to apply filters over input text, thereby extracting relevant features at different levels of abstraction. CNNs are particularly effective for cyberbullying detection tasks, as they can automatically learn hierarchical representations of textual data, thereby discerning important linguistic patterns associated with cyberbullying behavior. By leveraging the inherent parallelism and parameter sharing of convolutional operations, CNNs can efficiently process large volumes of text data, thus making them suitable for real-time cyberbullying detection systems.
3.5.4. Hybrid Netowrk Models
BiLSTM+GRU
The hybrid architecture of BiLSTM+GRU represents a framework for multilingual cyberbullying detection. By combining Bidirectional Long Short-Term Memory and the Gated Recurrent Unit, this model effectively captures both forward and backward contextual information within sequences of text data. The BiLSTM component facilitates bidirectional processing, thereby enabling the model to learn intricate patterns and dependencies in the input text. Meanwhile, the GRU module introduces gating mechanisms that enhance the model’s ability to retain relevant information and mitigate vanishing gradient problems. Together, the BiLSTM+GRU architecture offers a robust solution for multilingual cyberbullying detection, thus leveraging the strengths of both LSTM and GRU networks to achieve high classification accuracy in various linguistic contexts.
CNN+LSTM
The hybrid CNN+LSTM architecture combines the strengths of Convolutional Neural Networks and Long Short-Term Memory networks for multilingual cyberbullying detection. CNNs excel at extracting spatial features and patterns from textual data, while LSTMs are proficient at capturing sequential dependencies and long-term context. By integrating CNNs and LSTMs, the model can effectively capture both local and global contextual information in multilingual text, thereby enhancing its ability to detect cyberbullying throughout various linguistic contexts. This hybrid architecture offers a promising approach to multilingual cyberbullying detection by leveraging the complementary strengths of CNNs and LSTMs in text analysis.
CNN+GRU
The hybrid CNN+GRU architecture offers a powerful approach to multilingual cyberbullying detection. By combining the convolutional layers of CNN with the recurrent memory units of the GRU, the model can effectively capture both spatial features and temporal dependencies within the text data. This integration enables the network to learn intricate patterns and nuances present in Bangla and Chittagonian languages, thereby enhancing its ability to discern cyberbullying content accurately.
CNN+BiLSTM
The hybrid architecture of CNN+BiLSTM combines the strengths of Convolutional Neural Networks and Bidirectional Long Short-Term Memory networks, thus offering a robust solution for multilingual cyberbullying detection. CNNs excel at capturing local patterns and features from text data through convolutional filters, while BiLSTMs effectively model long-range dependencies and sequential information. By integrating these two architectures, the hybrid model leverages both local and global contextual information, thereby enabling it to capture diverse linguistic nuances present in Bangla and Chittagonian languages. Through its synergistic combination of CNN and BiLSTM layers, the hybrid model enhances the accuracy and robustness of multilingual cyberbullying detection systems.
(CNN+LSTM)+BiLSTM
The hybrid architecture (CNN+LSTM)+BiLSTM is a powerful model designed for multilingual cyberbullying detection. By combining the convolutional neural network for feature extraction with the long short-term memory and bidirectional LSTM layers for sequence modeling, this hybrid approach enables the model to effectively learn complex patterns and relationships present in cyberbullying content. Through its innovative design, the (CNN+LSTM)+BiLSTM architecture offers enhanced performance and robustness in multilingual cyberbullying detection tasks.
3.5.5. Transformer Models
BERT
Natural language processing tasks have been recently transformed by potent Transformer-based language models. One of the first of such models was BERT, or Bidirectional Encoder Representations from Transformers [
73]. BERT is capable of capturing contextual information and semantic relationships within sentences because of its extensive pretraining on text data. Because it is also bidirectional, it can encode each word in a sentence by taking into account both words before and after, thus producing rich contextual embeddings. By fine-tuning BERT for particular downstream tasks [
74], like cyberbullying detection, it can achieve high performance by adapting its learned representations to the specifics of the target domain.
Bangla BERT
Specialized for the Bangla language, Bangla BERT is a version of the BERT model [
75]. It makes use of Transformer-based architecture to extract semantic subtleties and contextual information from Bangla text. Bangla BERT is capable of efficiently processing intricate linguistic patterns in Bangla thanks to pretraining on sizable corpora of text data and fine-tuning on datasets tailored to particular tasks. Promising results have been obtained from its deployment in natural language processing tasks, such as cyberbullying detection, thereby indicating its usefulness in a range of Bangla text analysis applications.
Bangla ELECTRA
Bangla ELECTRA is a cutting-edge Transformer-based model created especially for tasks involving the natural language processing of Bangla [
76]. It utilizes a pretraining approach that focuses on substituting probable alternatives for input tokens and training a discriminator model to discern between authentic and substituted tokens, thus making use of the ELECTRA architecture. This method improves model performance and efficiency by capturing semantic subtleties and contextual information found in Bangla text data. The creation of language models specifically suited for Bangla-specific natural language processing applications has advanced significantly with the release of Bangla ELECTRA.
Multilingual BERT
A Transformer-based model called Multilingual BERT (or mBERT) was created to efficiently handle tasks involving multilingual text processing. It uses contextual embeddings that have already been trained to capture semantic information from multiple languages at once [
77]. Through exposure to a variety of linguistic data, Multilingual BERT has the ability to process and convey the subtleties of various languages, including Bangla. Because of its strong architecture, it can handle a wide range of natural language processing tasks, such as the detection of cyberbullying [
35], which makes it an invaluable tool for multilingual text analysis.
XLM-Roberta
For multilingual natural language processing tasks, XLM-Roberta is a state-of-the-art Transformer-based model [
78]. It applies RoBERTa, or a Robustly Optimized BERT Pretraining Approach [
79], while also extending its robust architecture to multiple languages. XLM-Roberta improves mBERT’s ability to manage multilingual text data efficiently. Through the utilization of pretrained representations in various languages, XLM-Roberta is able to accurately grasp complex linguistic subtleties and semantic relationships. The model’s sophisticated attention mechanisms allow it to produce high-quality embeddings and contextualize input text, which makes it an effective tool for multilingual cyberbullying detection tasks [
35].
3.6. Evaluation Metrics
Analyzing a model’s performance using test data is known as model evaluation. The following assessment metrics were applied in this study [
16,
18,
80]:
Precision,
Recall,
F1 Score, and
Accuracy. These metrics are computed based on the counts of
True Positives (TPs),
False Positives (FPs),
True Negatives (TNs), and
False Negatives (FNs). The equations for these metrics are given in Equations (
1)–(
4).
Accuracy: Accuracy is a measure of the proportion of correctly classified instances out of the total number of instances in a dataset.
Precision: Precision measures how many out of a total number of predicted positive observations were correct. It reveals how well the model can avoid the positive labeling of negative instances.
Recall: Recall is calculated by dividing the number of positive observations predicted by the model by the total number of positive observations in the training set. It shows how fully the model captures the positive class.
F1 Score: By combining recall and precision, we obtain the F1 Score. When there is an imbalance in the class distribution, it strikes a good balance between recall and precision.
In the context of these equations, we utilize the following:
TruePositives represent the count of positive instances correctly identified as positive. FalsePositives denote the count of instances predicted as positive when their actual label is negative. TrueNegatives stand for the count of observations accurately classified as negative. FalseNegatives refer to the count of observations inaccurately classified as negative when they actually belong to the positive class.
4. Results and Discussion
4.1. Experimental Setup
In this work, we tackled the problem of multilingual cyberbullying detection in Bangla and Chittagonian texts by thoroughly examining a range of Machine Learning (ML), Ensemble, Deep Learning (DL), and Transformer models. Making use of the processing power offered by Google Colab’s T4 GPU, we carried out exhaustive tests to assess these models’ ability to identify cyberbullying in a variety of language contexts. Each model category’s specific training and parameter tuning procedures were included in the experimental setup to provide a methodical and comprehensive evaluation of the models’ performance in this crucial task.
4.1.1. Model Parameters for Classic Machine Learning
Logistic Regression: Maximum Iterations (max_iter): 1000
Random State: 42
Support Vector Machine:
Kernel: “linear”
Regularization Parameter (C): 1
Random State: 42
Multinomial Naive Bayes:
Alpha (Smoothing Parameter): The alpha parameter was set to 1.0.
Random State: 42
Decision Tree:
Criterion: “Gini”
Splitter: “Best”
Random State: 42
Random Forest:
Number of Estimators (n_estimators): 100
Random State: 42
K-Nearest Neighbors:
Number of Neighbors (n_neighbors): 5
Random State: 42
4.1.2. Parameter Settings for Ensemble Learning
Bagging:
Base Estimator: RandomForestClassifier with random_state = 42
Number of Estimators (n_estimators): 209
Random State: 42
Boosting:
Estimators: AdaBoostClassifier with random_state = 42
XGBClassifier with various hyperparameters set to None and random_state = 42
GradientBoostingClassifier with random_state = 42
Voting:
Estimators: RandomForestClassifier with random_state = 42
SVC (Support Vector Classifier) with probability = True and random_state = 42
GradientBoostingClassifier with random_state = 42
4.1.3. Hyperparameter Settings for Deep Learning
Batch Size:
This was set to 64 for all models except for the hybrid network, where it was reduced to 32.
Epochs: This was set to 5 for most models and extended to 10 for the hybrid network.
Learning Rate: This was set to 0.01, which was chosen to balance stability and efficiency.
Optimizer: Adam optimizer.
Evaluation Metric: Accuracy.
Loss Function: Binary crossentropy.
4.1.4. Hyperparameter Settings for Transformer Model
Hardware: Google Colab’s T4 GPU
Transformer Models: XLM-RoBERTa, BERT, Bangla BERT, mBERT, Bangla ELECTRA
Common Parameters: The same hyperparameters were used for all
transformer models except BERT and Bangla ELECTRA, which were trained for 10 epochs.
Data Splitting:
Test Size: 0.2 (20% of the data reserved for testing)
Random State: 42 (for reproducibility)
Tokenizer Settings:
Model: XLM-RoBERTa, BERT, Bangla BERT, mBERT, Bangla ELECTRA
Padding: True
Truncation: True
Return Tensors: ‘tf’ (TensorFlow tensors)
Training:
Optimizer: Adam
Learning Rate: 1 ×
Loss Function: Sparse Categorical Crossentropy
Metrics: Sparse Categorical Accuracy
Batch Size: 64
Epochs: 5
4.2. Classic Machine Learning for Multilingual Cyberbullying Detection
In our investigation, we conducted a thorough analysis of various machine learning algorithms applied to multilingual cyberbullying detection in Bangla and Chittagonian languages, thus employing an 80%:20% training–testing ratio. We meticulously evaluated algorithm performance using diverse evaluation metrics [
16,
18], with accuracy as our primary focus, which was supported by the F1 score. Support Vector Machine (SVM) emerged as the most effective model, thus showcasing balanced precision, recall, and F1 scores for both bullying and nonbullying instances, with an accuracy of 0.711. Multinomial Naive Bayes (MNB) closely followed SVM, thus demonstrating similar precision and recall rates across both classes, with an accuracy of 0.71. Logistic Regression (LR) also exhibited moderately satisfying performance, thus achieving an accuracy of 0.69. Decision Trees (DT) and Random Forests (RF) performed reasonably well, with accuracies of 0.66 and 0.70, respectively. However, K-Nearest Neighbors (KNNs) lagged behind in performance metrics, particularly in recall for nonbullying instances, thus resulting in an accuracy of 0.63 (refer to
Table 2).
4.3. Ensemble Learning Multilingual Cyberbullying Detection
In evaluating the performance of the Bagging, Boosting, and Voting ensembles for multilingual cyberbullying detection in Bangla and Chittagonian texts, distinct patterns emerged across various metrics.
The Bagging ensemble model demonstrated a commendable balance between precision, recall, F1 score, and accuracy. Notably, its precision for identifying instances labeled as “Not Bullying” was 0.67, with a corresponding recall of 0.74, thus resulting in an F1 score of 0.70. Similarly, Bagging achieved a precision of 0.73 and a recall of 0.65 for identifying instances of “Bullying”, thus resulting in an F1 score of 0.69. Overall, Bagging attained an accuracy of 0.70 for “Not Bullying” and 0.69 for “Bullying” instances (refer to
Table 3).
The Boosting ensemble method exhibited similar trends to Bagging, albeit with slightly higher recall rates for the “Not Bullying” class. It achieved a precision of 0.65 and a recall of 0.78 for “Not Bullying”, thus leading to an F1 score of 0.71 and an accuracy of 0.69. For “Bullying” instances, Boosting achieved a precision of 0.75 and a recall of 0.60, thus resulting in an F1 score of 0.67 and an accuracy of 0.67.
In contrast, the Voting ensemble consistently outperformed Bagging and Boosting across all evaluation metrics. With precision, recall, F1 score, and accuracy of 0.69, 0.73, 0.71, and 0.72, respectively, for “Not Bullying” instances and 0.74, 0.70, 0.72, and 0.72, respectively, for “Bullying” instances, the Voting ensemble demonstrated superior performance. These findings highlight how well the Voting ensemble performs when a variety of classifiers are combined, which makes it the best option for precise cyberbullying detection in multilingual environments.
4.4. Deep Learning for Multilingual Cyberbullying Detection
In this experiment, where we utilized a 70%:10%:20% training–validation–testing ratio, distinct performance trends emerged among various deep learning models. Based on the specified hyperparameters—Adam optimizer, a learning rate of 0.01, dropout set to 0.1, 5 epochs, and a batch size of 64—the assessment of model performance for detecting cyberbullying across Bangla and Chittagonian texts offered intriguing insights.
The Multilayer Perceptron (MLP) demonstrated moderate effectiveness, thus achieving a precision of 0.67 for nonbullying instances and 0.70 for bullying instances, with corresponding recall values of 0.68 and 0.69, respectively. However, its F1 scores and overall accuracy remained relatively modest at 0.68 and 0.69, respectively.
Moving to Recurrent Neural Network (RNN) architectures, the SimpleRNN, LSTM, and BiLSTM models exhibited notable enhancements in performance. Particularly, the LSTM model excelled with remarkable precision, recall, and F1 score values for both bullying and nonbullying instances, thus improving the highest accuracy among RNNs and showcasing its adeptness in capturing intricate linguistic patterns in cyberbullying detection tasks.
Similarly, the Gated Recurrent Unit (GRU) architecture delivered competitive results, with well-balanced precision, recall, and F1 score values for both bullying and nonbullying classes, thus mirroring its efficacy in classifying cyberbullying texts.
The Convolutional Neural Network (CNN) emerged as the most effective architecture, demonstrating high precision, recall, and F1 score values for both bullying and nonbullying instances. With precision scores of 0.79 and 0.83 for nonbullying and bullying instances, respectively, along with a recall of 0.82 for nonbullying and 0.80 for bullying instances, the CNN model showcased superior classification capabilities. Its F1 score of 0.80 for nonbullying and 0.81 for bullying instances further underscores its efficacy in cyberbullying detection tasks, as suggested in previous research [
71]. Moreover, the CNN model achieved the highest overall accuracy of 0.811, thereby affirming its robustness in identifying cyberbullying content across Bangla and Chittagonian texts (refer to
Table 4).
In conclusion, all DL models demonstrated potential in detecting cyberbullying; however, the LSTM, BiLSTM, GRU, and CNN architectures outperformed the others, with the CNN model being especially effective at capturing the nuances of cyberbullying in many languages.
4.5. Hybrid Deep Learning for Multilingual Cyberbullying Detection
In this experiment, we rigorously assessed our proposed models, thereby maintaining a consistent data splitting ratio of 70% for training, 10% for validation, and 20% for testing. Hybrid models, configured with an epoch setting of five and a batch size of 64, demonstrated compelling performance metrics. In the exploration of hybrid models for multilingual cyberbullying detection in Bangla and Chittagonian texts, we conducted a thorough analysis of various model architectures and evaluated their performance using precision, recall, F1 score, and accuracy metrics.
In the results, with an overall accuracy of 0.799, the BiLSTM+GRU model demonstrated balanced precision, recall, and F1 scores for both bullying and nonbullying classes. This implies that the model (see
Table 5) successfully captures minor linguistic patterns suggestive of cyberbullying behavior across a variety of textual data.
In contrast, the CNN+LSTM model demonstrated high precision for nonbullying instances but lower recall, thus resulting in a balanced F1 score of 0.78. However, its ability to identify bullying instances with a recall of 0.87 contributed to an overall accuracy of 0.801, thus indicating proficient detection capabilities.
The CNN+GRU model showcased balanced performance metrics, similar to the BiLSTM+GRU model, with an accuracy of 0.804. This suggests robust discrimination between cyberbullying and nonbullying content, thereby underscoring its potential for effective multilingual cyberbullying detection.
On the other hand, the CNN+BiLSTM model demonstrated higher precision for bullying instances but lower recall for nonbullying instances, thus resulting in an accuracy of 0.78. This indicates a need for further refinement to ensure balanced performance across both classes.
Lastly, the (CNN+LSTM)+BiLSTM hybrid model achieved balanced precision, recall, and F1 scores for both classes, culminating in an accuracy of 0.82. This highlights the model’s potential for strong detection capabilities by demonstrating its ability to capture the subtleties of cyberbullying behavior in Bangla and Chittagonian texts.
4.6. Transformer-Based Models for Multilingual Cyberbullying Detection
The results presented in this section showcase the performance of various transformer models in the multilingual cyberbullying detection task for Bangla and Chittagonian texts. Across the evaluated models, XLM-Roberta demonstrated notable precision and recall metrics for identifying instances of cyberbullying. With a precision of 0.78 and a recall of 0.91 for bullying instances, the XLM-Roberta model exhibited a strong capability to accurately classify instances of cyberbullying, thus achieving an overall accuracy of 0.841 (See
Table 6 and
Figure 9). This indicates that the model is a promising candidate for cyberbullying detection tasks, since it successfully detects instances of cyberbullying while maintaining a comparatively low False Positive rate.
Figure 10 shows the confusion matrix of XLM-Roberta model.
In contrast, the Bangla BERT and Multilingual BERT models exhibited consistent and balanced performance across both bullying and nonbullying classes, with the precision, recall, F1 score, and accuracy all reaching 0.82 ( See
Figure 11). This consistency implies that these models maintained a stable performance across different evaluation metrics, thereby indicating robustness in their cyberbullying detection capabilities.
Figure 12 shows the confusion matrix of the Bangla BERT model.
Figure 13 shows the performance curve of Multilingual BERT based on the confusion matrix (see
Figure 14). The BERT model also demonstrated balanced performance, with precision, recall, F1 score, and accuracy all at 0.82 for both bullying and nonbullying instances (See
Figure 15) based on the confusion matrix (See
Figure 16).
However, the Bangla ELECTRA model showed a trade-off between precision and recall, particularly in identifying instances of cyberbullying. While achieving a high recall of 0.89 for bullying instances, the model’s precision was comparatively lower at 0.74, thus resulting in a lower F1 score of 0.81 and an accuracy of 0.785 (See
Figure 17). This shows that although the model successfully captured a sizable percentage of cyberbullying incidents, it at the same time incorrectly categorized a sizable portion of nonbullying incidents, which lowered the overall performance.
Figure 18 shows the confusion matrix of Bangla ELECTRA model.
In general, the assessment highlights the effectiveness of transformer models in multilingual cyberbullying detection tasks in Bangla and Chittagonian texts, especially for XLM-Roberta, Bangla BERT, and Multilingual BERT. Among efficient cyberbullying detection techniques, these models exhibit strong performance metrics across a range of evaluation criteria, thereby indicating their potential to improve online safety and promote healthier digital communities.
4.7. Comparative Analysis
The comparative analysis of machine learning and deep learning models for multilingual cyberbullying detection in Bangla and Chittagonian texts revealed distinctive performance trends across various algorithms and architectures. With balanced datasets of over 5000 samples each in Chittagonian and Bangla, covering cyberbullying and noncyberbullying instances, our study provides a robust evaluation framework.
In terms of machine learning algorithms, Support Vector Machine (SVM) emerged as the most effective classic ML model, thus achieving an accuracy of 0.711. Multinomial Naive Bayes (MNB) closely followed SVM with an accuracy of 0.71. Logistic Regression (LR) and Random Forest (RF) demonstrated moderate performance, while Decision Trees (DTs) and K-Nearest Neighbors (KNNs) performed slightly lower, with an accuracy of 0.63 as shown in
Table 2.
The ensemble methods, including Bagging, Boosting, and Voting, showcased a commendable balance between precision, recall, F1 score, and accuracy. Bagging and Boosting exhibited similar trends, while Voting consistently outperformed both, thus achieving superior performance across all metrics as shown in
Table 3.
Transitioning to deep learning architectures, the Long Short-Term Memory (LSTM), Bidirectional LSTM (BiLSTM), and Convolutional Neural Network (CNN) models emerged as top performers. The CNN model achieved the highest accuracy of 0.811, thus highlighting its proficiency in extracting valuable features from textual data shown in
Table 4. Other models like BiLSTM+GRU, CNN+LSTM, CNN+GRU, CNN+BiLSTM, and (CNN+LSTM)+BiLSTM demonstrated balanced performance metrics, albeit with slight variations in precision, recall, and F1 score values, as shown in
Table 5.
Some minor differences in the results between single-type networks and hybrid networks could come from two causes, namely, model architecture and hardware limitations. Regarding the first possible cause, namely the difference in architecture and how the networks are filtering out the features along the way, since CNNs and RNNs (including BiLSTMs), filter out features that are considered not important during their processing and use in classifications only those features that are considered important during the whole training run, the main difficulty in applying classic NNs has been in specifying the optimal architecture, such as the number of layers, types of layers, etc. Too many layers of a certain type could cause some useful features to be discarded along the way. Thus, a combined CNN+BiLSTM network could end up having lower results than the CNN-only network. Regarding the second possible cause, namely, hardware limitations, due to the limitations of the environment we were able to use for this research (Google Colaboratory free version), we needed to use different training parameters for single-type and hybrid networks (see
Section 4.1), which could have also slightly influenced the results. However, since the overall differences in the results, especially the top-scoring networks, are not that large, it is not expected that the end result would be much different in a more robust environment (e.g., Google Colaboratory paid version).
Among Transformer-based models, XLM-Roberta demonstrated strong precision and recall metrics for cyberbullying detection, thus achieving an accuracy of 0.841, as shown in
Table 6. The Bangla BERT, Multilingual BERT, and BERT models exhibited consistent and balanced performance across different evaluation metrics. However, Bangla ELECTRA showed a trade-off between precision and recall, thus indicating the need for further refinement.
As a whole, the comparative analysis shows how well different Transformer-based models, deep learning architectures, and machine learning algorithms identify cyberbullying samples in multilingual contexts. The research provides significant insights into the performance attributes of various models, thereby facilitating the identification of suitable approaches for cyberbullying detection tasks in Bangla and Chittagonian texts.
In fact, the datasets used in our study for Bangla and Chittagonian were balanced, with roughly equal numbers of texts falling into the categories of “bullying” and “not bullying”. In the Bangla dataset, 2545 instances were classified as bullying and 2555 instances were classified as nonbullying. Similarly, there were 2610 bullying instances and 2490 nonbullying instances in the Chittagonian dataset (See
Figure 5). During training, the classifiers were exposed to an equal number of instances from each class, thus allowing them to learn effectively from both bullying and nonbullying examples.
We made sure that every class—bullying and nonbullying—had an equal representation during classifier training because of the datasets’ balanced nature. This strategy aids in avoiding problems with class imbalance, which may result in biased model performance.
4.8. Comparison with Previous Studies
As far as we are aware, this study is the first to detect cyberbullying using multilingual models in Bangla and Chittagonian languages. One previous study by Mahmud et al. [
54] also focused on Bangla and Chittagonian languages for cyberbullying detection. Below, we list the key distinctions and conclusions from the earlier research with reference to the present study:
Our creation of a dataset comprising over 5000 samples for both Bangla and Chittagonian languages, alongside the thorough validation, presents a unique contribution to linguistic research due to the absence of such datasets previously or prior investigations into the distinctions between the two languages [
28,
36,
38,
39,
40,
41].
Our study encompasses the Chittagonian and Bangla language domains, whereas previous research [
81,
82,
83,
84] was limited to the Bengali/Bangla language. Managing a multilingual model presented a number of challenges, including problems with data collection, annotation, processing, validation, and model construction. Despite these challenges, we overcame them to complete the study.
The study was implemented using five different sets of methods. Firstly, we evaluated the efficacy of traditional machine learning. We then investigated ensemble learning and deep learning methods. We also looked at hybrid deep learning techniques, and lastly, Transformer-based models. This all-encompassing strategy that incorporated different approaches represents the most extensive and exhaustive study so far when compared to all earlier research [
15,
16,
18,
37,
38,
39,
40,
41].
Upon building a variety of learning models and performing comparative analyses using various techniques, we observed that our models produced better results than those described in earlier studies [
15,
38,
39].
Finally, we also paid much attention to the data annotation methodology (see
Section 3.2) and ethical issues (see
Section 4.9) regarding data collection, which previous studies did not account for [
15,
16,
18,
37,
38,
39,
40,
41].
4.9. Ethical Considerations
In conducting this study, which revolved around the human population, particularly social media users and the unethical use of language online, an ethical approach to the research process was important—starting with data collection [
85]. Data collection for this study involved exclusively public user posts and comments. Facebook and other social media venues’ open access policy permits the collection of data from public posts. Given that we gathered solely public comments/posts, they no longer retained their status as private, hence obviating the need for any special agreement for data collection and research implementation [
86]. Furthermore, we adhered to stringent ethical standards during the collection of data from social media platforms, which included the following measures:
Data collection was limited to open SNS forums where users had previously consented to data collection for analytical purposes.
All identifying private information was removed from the collected data to ensure anonymity.
Data storage was conducted securely and exclusively for research purposes.
Materials that could potentially harm specific groups was avoided during the study.
Annotators were tasked with labeling the data conscientiously, considering gender and religious aspects of the data composition, with clear guidelines provided to mitigate bias during annotation.
5. Conclusions and Future Work
5.1. Conclusions
In this paper, we conducted a comprehensive investigation into multilingual cyberbullying detection focusing on Bangla and Chittagonian texts. Our study has yielded several noteworthy findings and implications for future research.
Firstly, through meticulous data collection and annotation processes, we curated a robust dataset comprising over 5000 samples from both Bangla and Chittagonian languages, thereby ensuring balanced representation. The high-quality ground truth data, validated using Krippendorff’s alpha and Cohen’s kappa scores, forms a solid foundation for cyberbullying detection research in these linguistic contexts.
Our analysis encompassed a wide range of methods, beginning with traditional machine learning and deep learning models. While traditional ML models, such as Support Vector Machine and ensemble methods showed promising results, DL models, particularly Convolutional Neural Networks, exhibited superior performance in the cyberbullying detection task.
Furthermore, we proposed and evaluated hybrid network-based models, thus demonstrating the effectiveness of combining different architectures for enhanced accuracy. Transformer-based models, including XLM-Roberta, Bangla BERT, and Multilingual BERT, also showed significant improvements in cyberbullying detection accuracy.
5.2. Contributions of this Study
The primary contributions of this study are as follows:
The dataset was meticulously compiled, thus containing manually gathered samples from both Bangla and Chittagonian languages. Each language contributed over 5000 samples, thus ensuring a balanced representation in the dataset.
Thorough manual labeling by human annotators guaranteed the production of quality ground truth data for both model training and evaluation. This quality was further verified through the rigorous assessment of Krippendorff’s alpha and Cohen’s kappa scores.
We conducted an extensive comparison of the performance of traditional machine learning (ML) models, with Support Vector Machine (SVM) emerging as the top performer, thus achieving an accuracy of 0.711.
We evaluated ensemble models including Bagging (0.70 accuracy), Boosting (0.69 accuracy), and Voting (0.72 accuracy), thus demonstrating promising results.
We explored Deep Learning (DL) models, particularly Convolutional Neural Network (CNN), which outperformed traditional ML approaches with accuracies ranging from 0.69 to 0.811.
We proposed a series of hybrid network-based models, such as BiLSTM+GRU, CNN+LSTM, CNN+BiLSTM, and CNN+GRU, thus achieving accuracies ranging from 0.78 to 0.804.
We investigated Transformer-based models, including XLM-Roberta, Bangla BERT, Multilingual BERT, BERT, and Bangla ELECTRA, which significantly enhanced accuracy levels.
5.3. Future Work
Future studies will concentrate on improving and enhancing current models; we intend to investigate various approaches to address the problem of data scarcity, such as data augmentation methods, transfer learning from similar tasks or languages, and active learning methods to iteratively obtain labeled data. Additionally, we will carry out thorough analyses to spot any biases in our datasets and create mitigation plans to enhance the generalization of our models in a variety of linguistic and cultural contexts.
Enhancing the efficacy of cyberbullying detection systems can also be accomplished through the creation of specialized tools and resources, such as NER tools for Chittagonian. Additionally, investigating explainable AI (XAI) techniques will enhance model interpretability, thus fostering safer online environments.





 etc. In many natural language processing tasks, like text classification, they are frequently eliminated in order to decrease the dataset dimensionality [34]. We thus decided to eliminate stopwords from the dataset in order to reduce the dimensionality of the text data and boost the efficacy and efficiency of the subsequent analyses.
etc. In many natural language processing tasks, like text classification, they are frequently eliminated in order to decrease the dataset dimensionality [34]. We thus decided to eliminate stopwords from the dataset in order to reduce the dimensionality of the text data and boost the efficacy and efficiency of the subsequent analyses.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
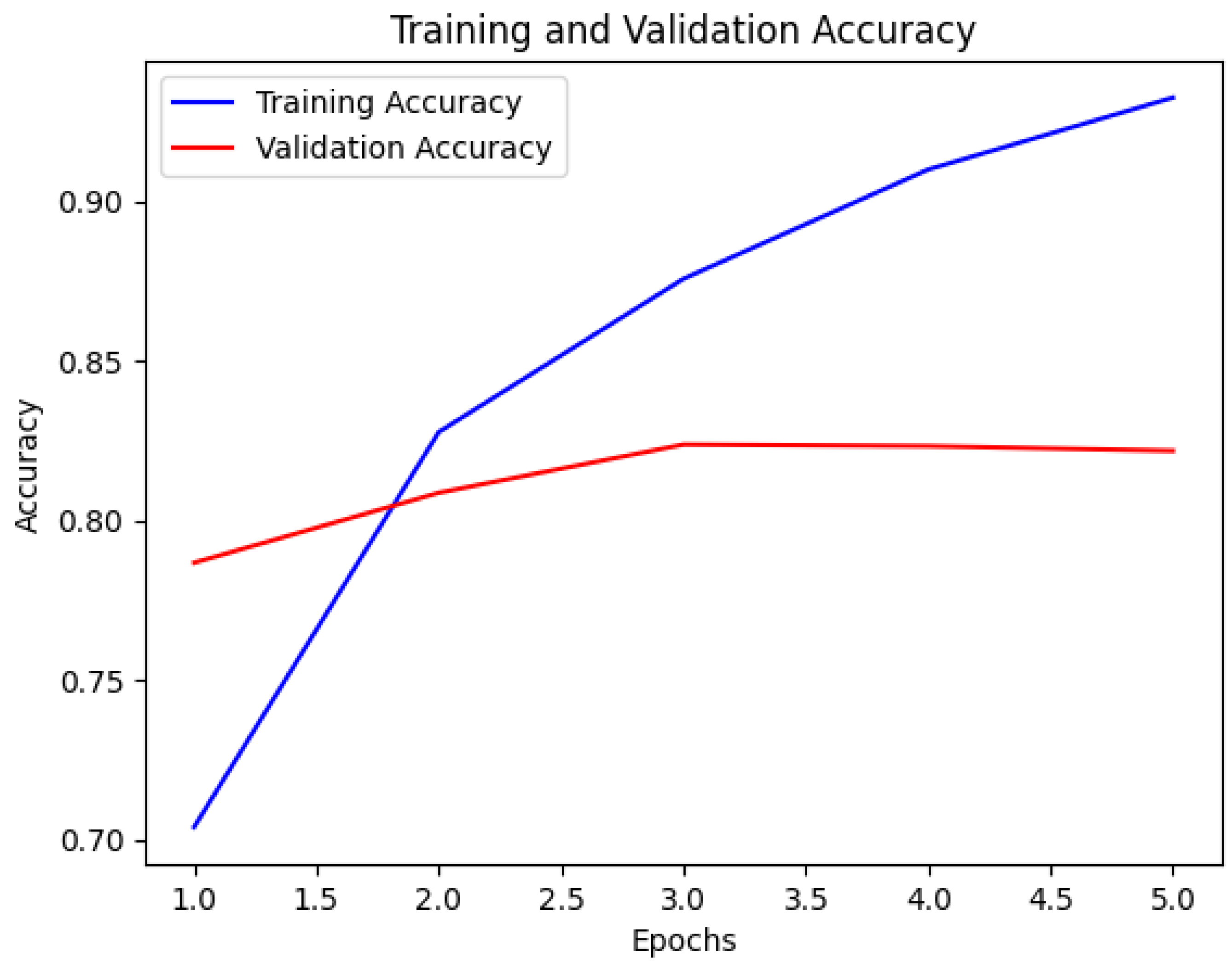{kind=link}
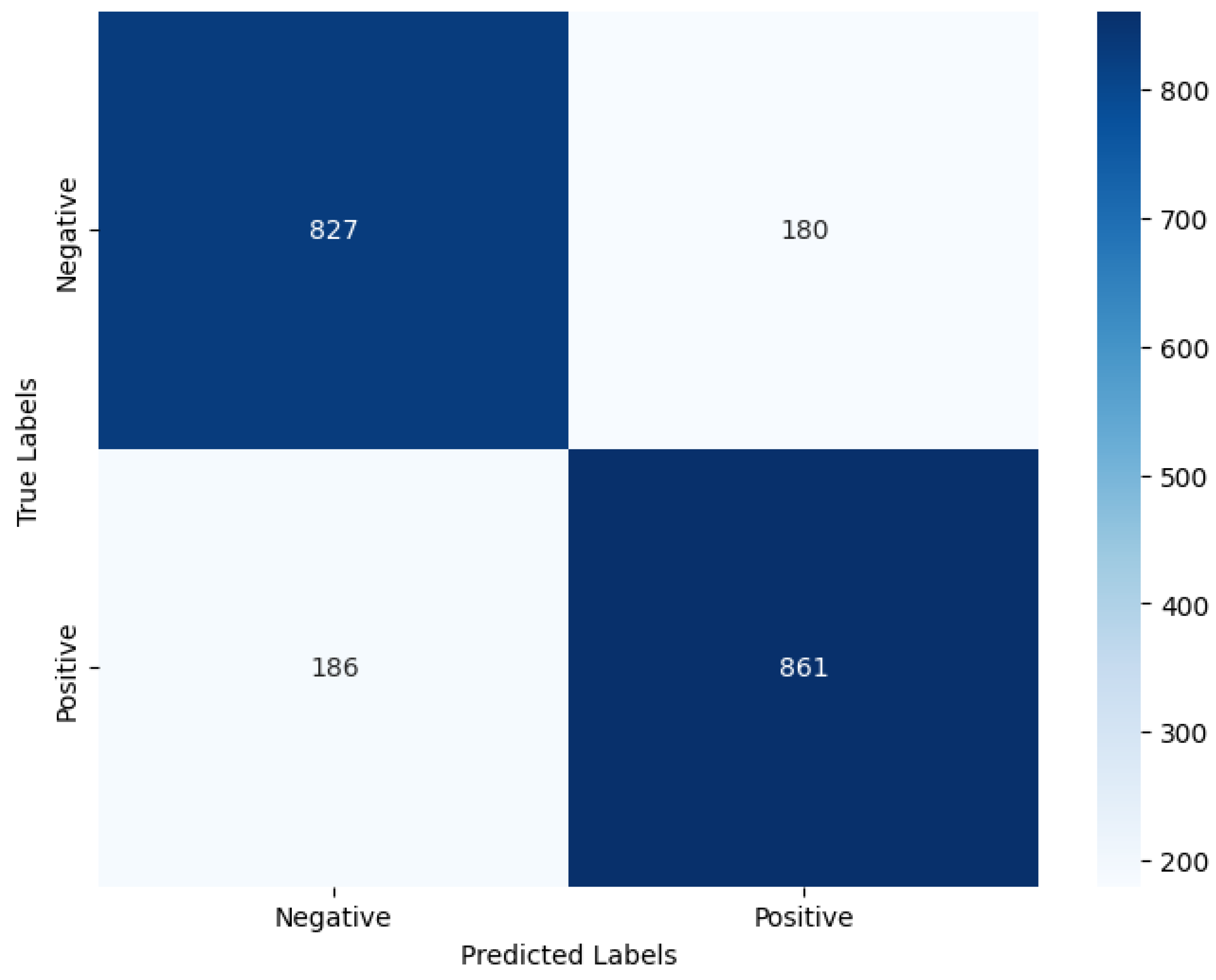{kind=link}
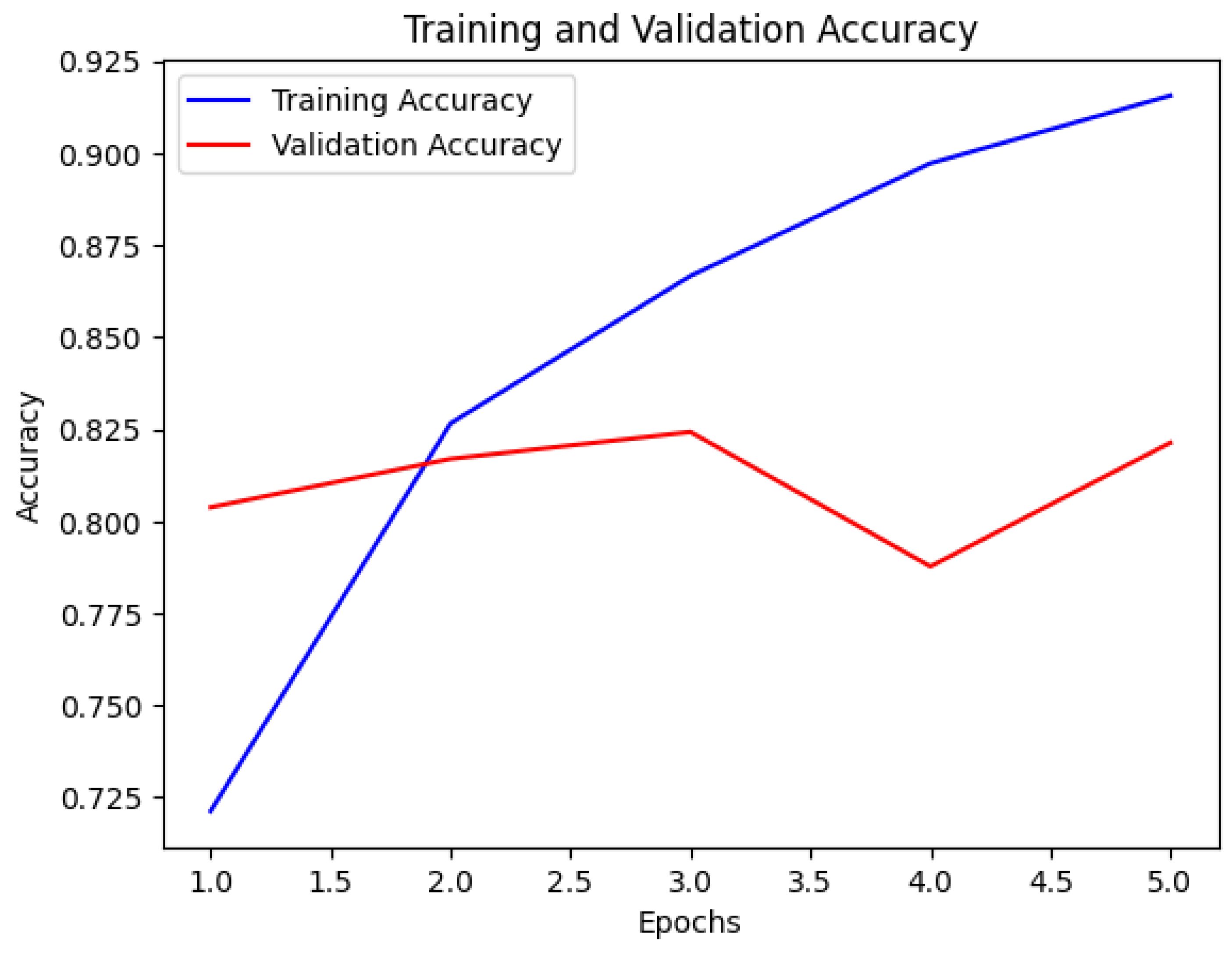{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}