Abstract
Background: Large Language Models (LLMs) are emerging as promising tools in hardware design and verification, with recent advancements suggesting they could fundamentally reshape conventional practices. Objective: This study examines the significance of LLMs in shaping the future of hardware design and verification. It offers an extensive literature review, addresses key challenges, and highlights open research questions in this field. Design: in this scoping review, we survey over 360 papers most of the published between 2022 and 2024, including 71 directly relevant ones to the topic, to evaluate the current role of LLMs in advancing automation, optimization, and innovation in hardware design and verification workflows. Results: Our review highlights LLM applications across synthesis, simulation, and formal verification, emphasizing their potential to streamline development processes while upholding high standards of accuracy and performance. We identify critical challenges, such as scalability, model interpretability, and the alignment of LLMs with domain-specific languages and methodologies. Furthermore, we discuss open issues, including the necessity for tailored model fine-tuning, integration with existing Electronic Design Automation (EDA) tools, and effective handling of complex data structures typical of hardware projects. Conclusions: this survey not only consolidates existing knowledge but also outlines prospective research directions, underscoring the transformative role LLMs could play in the future of hardware design and verification.
1. Introduction
LLMs such as OpenAI’s GPT-4 (https://chatgpt.com, accessed on 29 December 2024), Google’s Gemini (https://gemini.google.com/app, accessed on 29 December 2024), Google’s Bidirectional Encoder Representations from transformers (BERT) (https://github.com/google-research/bert, accessed on 29 December 2024), and Denoising Autoencoder from transformer (BART) (https://huggingface.co/docs/transformers/model_doc/bart, accessed on 29 December 2024), which is a transformer-based model introduced by Facebook, are at the forefront of Artificial Intelligence (AI) research, revolutionizing how machines understand and generate human language. These models process extensive datasets covering a wide spectrum of human discourse, enabling them to perform complex tasks including translation, summarization, conversation, and creative content generation [1,2,3,4,5]. Recent advancements in this field, driven by innovative model architectures, refined training methodologies, and expanded data processing capabilities, have significantly enhanced the ability of these models to deliver nuanced and contextually relevant outputs. This evolution reflects a growing sophistication in AI’s approach to Natural Language Processing (NLP), positioning LLMs as crucial tools in both academic research and practical applications, transforming interactions between humans and machines [5,6,7].
This evolution can be traced back to early statistical language models like n-gram models, which simply predicted word sequences based on the frequencies of previous sequences observed in a dataset. Although these models provided a foundational approach for text prediction, their limited ability to perceive broader contextual cues restricted their application to basic tasks [8,9,10,11,12]. The advent of neural network-based models, especially Recurrent Neural Networks (RNN), represented a significant advancement, offering the ability to retain information over longer text sequences and thus, managing more complex dialogues and text structures [13,14,15]. Although RNNs made advancements, they continued to struggle with scalability and long-term dependency issues, leading to the creation of transformer models. These models introduced an innovative self-attention mechanism, allowing simultaneous processing of different sentence segments to enhance relevance and contextuality in text interpretation. This breakthrough underpins modern LLMs, which are pre-trained in extensive web-text data and subsequently fine-tuned for specific tasks, enabling them to generate nuanced, stylistically diverse, and seemingly authentic human text [16,17,18,19,20,21].
Moreover, with the advent of highly sophisticated models, LLMs have become an indispensable domain for both academic research and practical applications. These models necessitate thorough evaluations to fully understand their potential risks and impacts, both at task-specific and societal levels. In recent years, significant efforts have been invested in assessing LLMs from multiple perspectives, enhancing their applicability and effectiveness. The adaptability and deep comprehension abilities of LLMs have led to their extensive deployment across numerous AI domains. They are utilized not only in fundamental NLP tasks but also in complex scenarios involving autonomous agents and multimodal systems that integrate textual data with other data forms [22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39]. The utility of LLMs spans several domains, including healthcare [40,41,42,43,44,45], education [46,47,48,49,50], law [51,52,53,54,55,56,57,58], finance [59,60,61,62,63], and sciences [64,65,66,67,68,69], where they substantially improve data analysis and decision-making processes. This wide-ranging application underscores the transformative impact of LLMs on both technological innovation and societal functions.
In particular, within domains like hardware design and verification, LLMs enhance productivity and innovation by automating and optimizing various stages of the design process. These models can assist engineers in generating design specifications, suggesting improvements, and even creating initial design drafts. By leveraging vast amounts of data and advanced algorithms, LLMs can identify patterns and propose design optimizations that might not be immediately apparent to human designers. This capability helps in reducing time-to-market and ensuring that hardware designs are both efficient and innovative [70].
In hardware design, verification is a critical step in the lifecycle of hardware development. Verification ensures that the hardware performs as intended and meets all specified requirements before going into production. Traditionally, this process has been time-consuming and prone to human error. LLMs can automate much of the verification process by generating test cases, simulating hardware behavior, and identifying potential faults or discrepancies. They can analyze a large amount of verification data to predict potential issues and provide solutions, thus enhancing the reliability and accuracy of the hardware verification process. This not only speeds up the verification process but also ensures a higher quality of the final product [71].
In addition to automation, LLMs facilitate better communication and collaboration among hardware design and verification teams. By providing a common platform where designers, engineers, and verification experts can interact with the model, LLMs help in bridging the gap between different teams. This collaborative approach ensures that all aspects of the hardware design and verification are aligned and that any issues are identified and addressed early in the process. Furthermore, LLMs can serve as knowledge repositories, offering solutions based on previous designs and verifications, thus ensuring that best practices are followed and past mistakes are not repeated [72].
Another significant benefit of LLMs in hardware design and verification is their ability to handle complex and high-dimensional data. Modern hardware designs are increasingly complex with numerous components and interdependencies. LLMs can manage this complexity by analyzing and processing large datasets to extract meaningful insights. They can model intricate relationships between different hardware components and predict how changes in one part of the design could impact the overall system. This holistic understanding is crucial for creating robust and reliable hardware systems [73].
In conclusion, the integration of LLMs in hardware design and verification not only fosters innovation but also ensures the development of cutting-edge hardware technologies [74,75]. This survey aims to explore the transformative role of LLMs in this domain, highlighting key contributions, addressing challenges, and discussing open issues that continue to shape this dynamic landscape. The goal is to provide a comprehensive overview that not only informs but also inspires continued research and application of LLMs to improve hardware design and verification processes. We hope that this study will contribute to a better understanding and use of LLMs. This scoping review aims to systematically map the research conducted in this area and identify gaps in existing knowledge. In summary, the contributions of this paper can be summarized as follows:
- Identification of core applications: we detail the fundamental ways in which LLMs are currently applied in hardware design, debugging, and verification, providing a solid foundation to understand their impact.
- Analysis of challenges: this paper presents a critical analysis of the inherent challenges in applying LLMs to hardware design, such as data scarcity, the need for specialized training, and integration with existing tools.
- Future directions and open issues: we outline potential future applications of LLMs in hardware design and verification and discuss methodological improvements to bridge the identified gaps.
Figure 1 outlines the structure of the review paper, which is organized into five main sections. Section 1 serves as an introduction, offering an overview of LLMs, their historical development, related survey papers, and their role in facilitating hardware design and verification. Section 2 illustrates the methodology Preferred Reporting Items for Systematic Reviews and Meta-Analyses Extension for Scoping Reviews (PRISMA-ScR), which is followed by Section 3 discussing the main results of the methodology applied in this survey paper. Section 4 provides a detailed literature review, discussing the application of LLMs in hardware design, categorizing different hardware design and verification methods, and highlighting significant use cases and success stories. Section 5 focuses on the challenges associated with applying LLMs in this field, such as training difficulties, adapting to hardware-specific terminology, ensuring explainability and interpretability, and integrating these models with existing design tools. Section 6 explores open issues, including unexplored applications, research gaps, and the need for methodological improvements. Finally, Section 7 concludes the paper with a summary of the findings and offers implications and recommendations for future research. This structured framework ensures a comprehensive exploration of the role of LLMs in hardware design and verification while addressing critical challenges and opportunities.
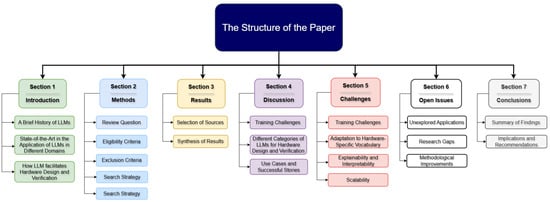
Figure 1.
Section organization of the paper.
1.1. A Brief History of LLMs
The evolution of LLMs represents a crucial aspect of the broader development in AI. This progression begins with the earliest models and extends through to the sophisticated systems that today significantly influence computational linguistics and AI applications. A very brief history of LLMs is shown by Figure 2.

Figure 2.
Brief history of language models [5].
Initially, LLMs operated on rule-based systems established in the mid-20th century, which were limited by strict linguistic rules and struggled to adapt to the variability of natural language. These systems, while foundational, offered limited utility for complex language tasks due to their inability to capture nuanced linguistic patterns [76]. The transition to statistical models like n-grams and Hidden Markov Models (HMMs) [77] in the late 20th century marked a pivotal enhancement. These models introduced a statistical approach to language processing, utilizing probabilities derived from large text corpora to predict language patterns. This shift allowed better handling of larger datasets, significantly improving real-world language processing capabilities. Despite these advancements, these models continued to struggle with deep contextual and semantic understanding, which later developments in algorithmic technology aimed to address [8,9,10,11,12].
By the early 2000s, the integration of advanced neural networks, specifically RNN [13,14,15] and Long Short-Term Memory (LSTM) networks [78], brought about substantial improvements in modeling sequential data. Additionally, the emergence of word embedding technologies like Word2Vec and GloVe advanced LLM capabilities by mapping words into dense vector spaces, capturing complex semantic and syntactic relationships more effectively. Despite these innovations, the increasing complexity of neural networks raised new challenges, particularly in model interpretability and the computational resources required [14,79,80].
The mid-2010s marked another significant advancement with the introduction of deep learning-based neural language models, notably the Recurrent Neural Network Language Model (RNNLM) in 2010, designed to effectively capture textual dependencies [81,82]. This development improved the generation of text that was more natural and contextually informed. However, these models also faced limitations such as restricted memory capacity and extensive training demands [83]. In 2015, Google’s breakthrough with the Neural Machine Translation (GNMT) model utilized deep learning to significantly enhance machine translation, moving away from traditional rule-based and statistical techniques towards a more robust neural approach. This development not only improved translation accuracy but also addressed complex NLP challenges with greater efficacy [84,85].
A major breakthrough occurred in 2017 with the development of the transformer model, which abandoned the sequential processing limitations of previous models in favor of self-attention mechanisms [16,17,86]. This innovation allowed for the parallel processing of words, drastically increasing efficiency and enhancing the model’s ability to manage long-range dependencies. The transformer architecture facilitated the creation of more sophisticated models such as BERT, which utilized bidirectional processing to achieve a deep understanding of text context, greatly improving performance across a multitude of NLP tasks [18,19,87]. Following BERT, models such as RoBERTa, T5, and DistilBERT have been tailored to meet the diverse requirements of various domains, illustrating the adaptability and expansiveness of LLM applications [88].
Subsequently, the introduction of OpenAI’s GPT series further pushed the boundaries of what LLMs could achieve. Starting with GPT-1 and evolving through GPT-3, these models demonstrated exceptional capabilities in generating coherent and contextually relevant text across various applications. GPT-3, in particular, with its wide array of parameters, showcased the potential of LLMs to perform complex language tasks such as translation, question–answering, and creative writing with minimal specific tuning. The advent of GPT-4 further broadened these capabilities by incorporating multimodal applications that process both text and images, thus significantly expanding the scope of LLMs. Recent developments, including enhancements in GPT-4 and the introduction of innovative models such as DALL-E 3, have continued this trend, emphasizing efficiency in fine-tuning and enhancing capabilities in creative AI fields, demonstrating the versatility and depth of current models [19,21,87,89,90,91,92].
This progression from statistical models to today’s advanced, multimodal, and domain-specific systems illustrates the dynamic and ongoing nature of LLMs development. These continual innovations not only advance the technology but also significantly impact the fields of AI and computational linguistics. Innovations such as sparse attention mechanisms, more efficient training algorithms, and the use of specialized hardware like Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) have enabled researchers to build increasingly larger and more powerful models. Moreover, efforts to improve model interpretability, reduce bias, and ensure ethical use are increasingly becoming central to the field.
In summary, the history of LLMs is a story of rapid progress driven by breakthroughs in Machine Learning (ML) and neural network architectures. From early statistical models to the transformative impact of the transformer architecture and the rise of models like GPT-4, LLMs have evolved dramatically, reshaping our understanding of language and AI. As research continues, LLMs are poised to become even more integral to technological innovation and human–computer interaction in the years to come.
1.2. State-of-the-Art in the Application of LLMs in Different Domains
Due to the success of LLMs on various tasks and their increasing integration into AI research, examining the extensive literature survey on these models is essential. A significant number of surveys [5,93,94,95,96,97,98,99,100,101,102,103] provide detailed insights into the application of LLMs across different fields, demonstrating their advancements and wide-ranging uses. By analyzing research papers, primarily published in 2022 and 2024, our aim is to gain a deeper understanding of LLMs’ applications and evaluate their potential impact across various sectors.
In this context, the work by Huang et al. [93] presented a comprehensive survey of reasoning in LLMs, focusing on the current methodologies and techniques to enhance and evaluate reasoning capabilities in these models. The authors provided an in-depth review of various reasoning types, including deductive, inductive, and abductive reasoning, and discussed how these reasoning forms can be applied in LLMs. They also explored key methods used to elicit reasoning, such as fully supervised fine-tuning, prompting, and techniques like “chain of thought” prompting, which encourages models to generate reasoning steps explicitly. The authors reviewed benchmarks and evaluation methods to assess reasoning abilities and analyze recent findings in this rapidly evolving field. Despite the advancements in reasoning with LLMs, the authors pointed out the limitations of current models, emphasizing that it remains unclear whether LLMs truly possess reasoning abilities or are merely following heuristics. Huang et al. concluded by offering insights into future directions, suggesting that better benchmarks and more robust reasoning techniques are needed to push the boundaries of LLMs’ reasoning capabilities. The research conducted by the authors served as an essential resource for researchers looking to understand the nuances of reasoning in LLMs and guide future research in this critical area.
In this study by Xi et al. [94], the authors comprehensively surveyed the rise and potential of LLM-based agents. The authors traced the evolution of AI agents, with a particular focus on LLMs as foundational components. They explored the conceptual framework of LLM-based agents, which consists of three main parts: brain, perception, and action. This survey discussed how LLMs, particularly transformer models, have been leveraged to enhance various agent capabilities, such as knowledge processing, reasoning, and decision-making, allowing them to interact effectively with their environments. Furthermore, the study delved into the real-world applications of LLM-based agents across different sectors, including single-agent and multi-agent systems, as well as human-agent cooperation scenarios. It also highlighted how LLM-based agents can exhibit behaviors akin to social phenomena when placed in societies of multiple agents. In addition, the authors examined the ethical, security, and trustworthiness challenges posed by these agents, stressing the need for robust evaluation frameworks to ensure their responsible deployment. Finally, they presented future research directions, particularly around scaling LLM-based agents, improving their capabilities in real-world settings, and addressing open problems related to their generalization and adaptability.
In [95], the authors presented a detailed review of LLMs’ evolution, applications, and challenges. The authors highlighted the architecture and training methods of LLMs, particularly focusing on transformer-based models, and emphasized their significant contributions across a range of sectors, including medicine, education, finance, and engineering. They also explored both the potential and limitations of LLMs, addressing ethical concerns such as biases, the need for vast computational resources, and issues of model interpretability. Furthermore, the survey delved into emerging trends, including efforts to improve model robustness and fairness, while anticipating future directions for research and development in the field. This comprehensive analysis served as a valuable resource for researchers and practitioners, offering insights into the current state and future prospects of LLM technologies.
Naveed et al. [96] provided a comprehensive overview of LLMs, focusing on their architectural design, training methodologies, and diverse applications across various domains. The authors delved deeply into transformer models and their role in advancing NLP tasks. They also highlighted the challenges associated with LLM deployment, including ethical concerns, computational resource demands, and the complexity of training these models. Additionally, the survey explored the impact of LLMs on different sectors such as healthcare, engineering, and social sciences and identified potential research directions for the future. This review served as a key resource for researchers and practitioners looking to understand the current landscape of LLM development and deployment.
Fan et al. [97] presented a comprehensive bibliometric analysis of over 5000 publications on LLMs spanning from 2017 to 2023. The authors aimed to provide a detailed map of the progression and trends in LLM research, offering valuable insights for researchers, practitioners, and policymakers. The analysis delved into key developments in LLM algorithms and explored their applications across a wide range of fields, including NLP, medicine, engineering, and the social sciences. Additionally, the authors revealed the dynamic and fast-paced evolution of LLM research, highlighting the core algorithms that have driven advancements and examining how LLMs have been applied in diverse domains. By tracing these developments, the study underscored the substantial impact LLMs have had on both scientific research and technological innovation and provided a roadmap for future research in the field.
The study by Zhao et al. [5] offered an extensive survey of the evolution and impact of LLMs within AI and NLP. The authors traced the development from early statistical and neural language models to modern pre-trained language models (PLMs) with vast parameter sets. They highlighted the unique capabilities that emerge as LLMs scale, such as in-context learning and instruction-following, which distinguish them from smaller models. A significant portion of the survey was dedicated to the contributions of LLMs, including their role in advancing AI applications like ChatGPT. Organized around four key areas—pre-training, adaptation tuning, utilization, and capacity evaluation—the study provided a comprehensive analysis of current evaluation techniques and benchmarks while also identifying future research directions for enhancing LLMs and exploring their full potential.
In the study by Raiaan et al. [98], the authors conducted a comprehensive review of LLMs, focusing on their architecture, particularly transformer-based models, and their role in advancing NLP tasks such as text generation, translation, and question answering. The authors explored the historical development of LLMs, beginning with early neural network-based models, and examined the evolution of architectures like transformers, which have significantly enhanced the capabilities of LLMs. They discussed key aspects such as training methods, datasets, and the implementation of LLMs across various domains, including healthcare, education, and business.
In another study, Minaee et al. [99] survey on LLMs illustrated an insightful analysis of the rise and development of LLMs, focusing on key models like GPT, LLaMA, and PaLM. The authors offered a comprehensive analysis of their architectures, training methodologies, and the scaling laws that underpin their performance in natural language tasks. Additionally, the survey examined key advancements in LLM development techniques, evaluated commonly used training datasets, and compared the effectiveness of different models through benchmark testing. Importantly, the study explored the emergent abilities of LLMs—such as in-context learning and multi-step reasoning—that differentiate them from smaller models while also addressing real-world applications, current limitations, and potential future research directions.
In [100], the authors provided an in-depth analysis of the methodologies and technological advancements in the training and inference phases of LLMs. The authors explored various aspects of LLM development, including data preprocessing, model architecture, pre-training tasks, and fine-tuning strategies. Additionally, they covered the deployment of LLMs, with a particular emphasis on cost-efficient training, model compression, and the optimization of computational resources. The review concluded by discussing future trends and potential developments in LLM technology, making it a valuable resource for understanding the current and future landscape of LLM research and deployment.
Cui et al. [101] presented a comprehensive survey on the role of Multimodal Large Language Models (MLLMs) in advancing autonomous driving technologies. The authors systematically explored the evolution and integration of LLMs with vision foundation models, focusing on their potential to enhance perception, decision-making, and control in autonomous vehicles. They reviewed current methodologies and real-world applications of MLLMs in the context of autonomous driving, including insights from the 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD). The study highlighted emerging research trends, key challenges, and innovative approaches to improving autonomous driving systems through MLLM technology, emphasizing the importance of multimodal learning for the future of autonomous vehicles. Additionally, the authors stressed the need for further research to address critical issues like safety, data processing, and real-time decision-making in the deployment of these models.
Chang et al. [102] thoroughly explored the essential practices for assessing the performance and applicability of LLMs. The authors systematically reviewed evaluation methodologies focusing on what aspects of LLMs to evaluate, where these evaluations should occur, and the best practices on how to conduct them. They explored evaluations across various domains, including NLP, reasoning, medical applications, ethics, and education, among others. The study highlighted successful and unsuccessful case studies in LLM applications, providing critical insight into future challenges that might arise in LLM evaluation and stressing the need for a discipline-specific approach to effectively support the ongoing development of these models.
Kachris [103] provided a comprehensive analysis of the various hardware solutions designed to optimize the performance and efficiency of LLMs. The author explored a wide variety of accelerators, including GPUs, FPGAs, and Application-Specific Integrated Circuits (ASICs), providing a detailed discussion of their architectures, performance, and energy efficiency metrics. They focused on the significant computational demands of LLMs, particularly in both training and inference, and evaluated how these accelerators help meet these demands. The survey also highlighted the trade-offs in performance and energy consumption, making it a valuable resource for those seeking to optimize hardware solutions for LLM deployment in data centers and edge computing.
Table 1 provides a comparison between various review papers, categorizing them based on critical features such as LLM models, Application Programming Interfaces (APIs), datasets, domain-specific LLMs, ML-based comparisons, taxonomies, architectures, performance, hardware specifications for testing and training, and configurations.

Table 1.
Comparison of LLM review papers.
1.3. How LLM Facilitates Hardware Design and Verification?
By automating repetitive tasks, providing intelligent suggestions, and facilitating better communication and documentation, LLMs significantly improve the efficiency and effectiveness of hardware design and verification processes. They enable engineers to focus on higher-level problem-solving and innovation, thereby accelerating the development cycle and improving the quality of hardware products. A comprehensive series of these tasks is listed in Table 2.
Table 2.
Tasks in hardware design and verification that can be done by LLMs.
Before diving into the literature survey, we explore the potential of advanced LLMs such as GPT-4 and GPT-4o in addressing the current limitations of HDL design and verification. As one of the latest advancements in large-scale language models, GPT-4o introduces several enhancements over its predecessors, which can effectively tackle key challenges in hardware design and verification tasks [104,105].
- Improved Context Handling: GPT-4o can process significantly larger input contexts (e.g., up to 32k tokens) compared with GPT-3.5. This capability is critical for analyzing complex, multi-file HDL projects, where maintaining contextual relationships between modules, signals, and timing constraints is essential.
- Higher Code Accuracy and Reliability: GPT-4o demonstrates superior accuracy in generating and debugging HDL code. Its advanced reasoning capabilities reduce syntax errors and hallucinations, which are common issues in earlier models. In internal benchmarks (e.g., OpenAI Codex (https://openai.com/index/openai-codex/, accessed on 29 December 2024) vs. GPT-4o), GPT-4o achieved higher pass rates for code generation tasks across diverse programming languages, including Verilog and VHDL.
- Integration with Multi-Modal Systems: GPT-4o’s multi-modal capabilities allow it to process text and visual information simultaneously. In hardware verification, this means it can analyze waveforms, simulation results, and timing diagrams alongside textual descriptions, enhancing its ability to detect errors or inconsistencies.
- Applications in Code Verification: GPT-4o can enhance formal verification processes by assisting with property generation for assertions and test cases. For example, GPT-4o can translate specifications into formal properties expressed in System-Verilog Assertions (SVA)s.
2. Methods
The reporting process followed the PRISMA-ScR checklist (Supplementary Materials) to maintain transparency and completeness [106].
2.1. Review Question
The research question guiding this review is as follows: What does the literature reveal about the role of LLMs in the future of hardware design and verification, what are the primary challenges, and what open issues warrant further investigation?
2.2. Eligibility Criteria
Research articles, conference papers, related books, and arXiv papers that explicitly address the use of LLMs in hardware design, verification, or related domains were considered. Only works published in peer-reviewed journals or presented at reputable conferences were included. Furthermore, studies had to clearly articulate their methodologies and applications, focusing on at least one of the following areas: hardware design, hardware/software codesign, hardware accelerators, hardware security, hardware debugging, or hardware verification. The timeline for inclusion spanned publications from 2018 to the present, reflecting the rapid evolution of LLMs in the last five years.
2.3. Exclusion Criteria
Studies were excluded if they did not directly relate to the application of LLMs in hardware-related domains. General discussions on artificial intelligence without hardware-specific contexts, theoretical works without practical implications, and duplicate publications were omitted. Additionally, non-peer-reviewed content, such as blog posts and opinion articles, as well as works lacking sufficient technical detail, were excluded. Papers written in languages other than English were also excluded unless an accurate translation was available to ensure consistent comprehension and analysis.
2.4. Search Strategy
A comprehensive search strategy was implemented to identify relevant literature. We searched multiple academic databases, including Google Scholar, IEEE Xplore, ACM Digital Library, Scopus, and Web of Science, using a combination of keywords and Boolean operators (“AND”, “OR”). Keywords included “Large Language Models”, “Hardware Design”, “Hardware-Software Codesign”, “Hardware Verification”, “Hardware Accelerators”, and “Hardware Debugging”, among others. Supplementary searches were conducted on arXiv (https://arxiv.org/, accessed on 29 December 2024) and preprint servers to capture emerging trends. We manually screened the reference lists of included studies to identify additional relevant works. Search results were imported into the Mendeley reference management tool (https://www.mendeley.com/, accessed on 29 December 2024) for deduplication and systematic screening.
2.5. Data Extraction and Data Synthesis
Data extraction was performed using a standardized template to capture relevant information, including publication year, authorship, research objectives, methodologies, key findings, and implications. A thematic synthesis approach was used to organize the data into predefined categories aligned with the study focus areas: hardware design, hardware/software codesign, hardware accelerators, hardware security, hardware debugging, and hardware verification. The synthesis aimed to identify patterns, highlight challenges, and map open issues within these domains. Visual representations, such as tables and diagrams, were employed to summarize findings and facilitate comparative analysis across studies.
3. Results
3.1. Selection of Sources
The literature review involved analyzing the titles and abstracts of studies to identify matches with the searched keywords. A total of 3570 studies were initially identified based on these keywords. After eliminating duplicates and excluding articles with unrelated content, the remaining full-text studies were selected, screened, and evaluated for inclusion in the systematic review. The flow chart of PRISMA method is shown in Figure 3.
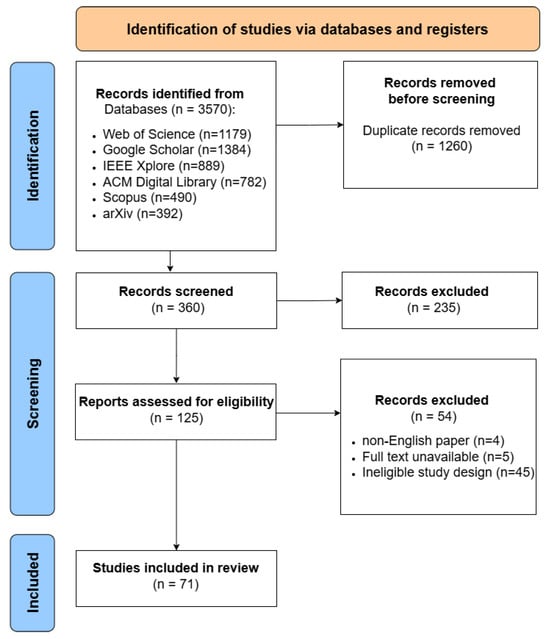
Figure 3.
PRISMA flow chart.
Initially, we reviewed 360 articles, and after the first and second rounds of evaluation, we excluded those deemed irrelevant to the topic, non-English papers, and unavailable full-text papers, selecting 71 articles for our survey. As stated in Section 1.2, we also reviewed several survey articles with various LLM applications outside the scope of hardware design and verification. As follows, some statistical analysis will be discussed for better clarity.
3.2. Synthesis of Results
Figure 4 provides a comprehensive breakdown of the reviewed publications. In terms of research focus (Figure 4a), the majority (37%) addressed hardware design, with significant attention also given to hardware security (16%) and verification (13%), showcasing the wide applicability of LLMs across hardware domains. The distribution of publishers (Figure 4b) highlights that arXiv and IEEE Journals dominate with 37%, followed by ACM Journals (12%), reflecting a mix of preprints and peer-reviewed dissemination. These trends illustrate both the growing engagement with LLMs in hardware domains and the diversity of publication forums. The publication timeline (Figure 4c) indicates a rapid increase in interest, with 91% of studies published in 2023–2024. Finally, the authorship data (Figure 4d) reveal that 49% of the works were authored by 2–5 contributors, showing a collaborative trend, while 7% had solo authorship and 11% involved large teams of 10 or more.
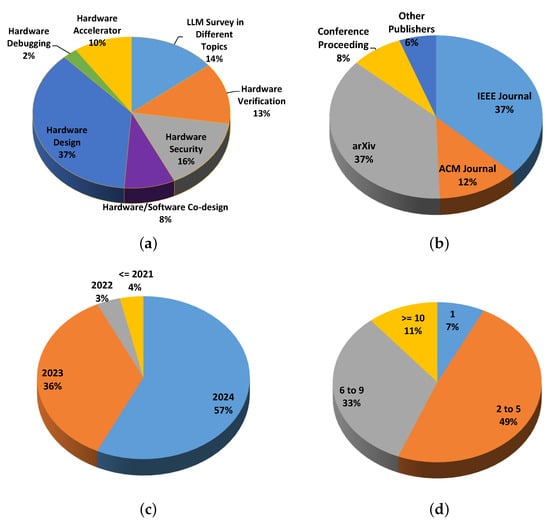
Figure 4.
Statistics analysis for reviewed papers in this survey. (a) Category; (b) publisher; (c) publishing year; (d) number of authors.
4. Discussion
4.1. Overview of LLMs in Hardware Design
LLMs have become a transformative tool in the field of hardware design and verification, bringing significant advancements in efficiency and accuracy. These models, powered by sophisticated AI and NLP capabilities, can analyze and interpret vast amounts of documentation, code, and design specifications, which accelerates the initial phases of hardware design. Using LLMs, engineers can automate the generation of design documents, ensuring consistency and reducing human error. This automation not only speeds up the design process but also enables the exploration of more complex and innovative designs, as the model can provide insights and suggestions based on a wide array of previous designs and industry standards.
In the realm of hardware verification, LLMs play a crucial role in improving the robustness and reliability of hardware systems. Verification is a critical step that ensures that the designed hardware functions correctly under all specified conditions. LLMs can help generate comprehensive test cases, identifying potential edge cases that could be overlooked by human designers. In addition, they can analyze the results of these tests more efficiently, highlighting discrepancies and providing detailed diagnostics that can pinpoint the root causes of failures. This capability significantly reduces the time and resources required for verification, allowing quicker iterations and more reliable hardware products. As a result, the integration of LLMs into hardware design and verification workflows is increasingly essential to maintain a competitive advantage in the fast-paced tech industry.
This survey [107] examines the applications, challenges, and potential of LLMs in hardware design, focusing on Verilog code generation and hardware security enhancement. It reviews existing techniques for automating HDL generation and highlights the need for robust LLM solutions to address verification, debugging, and security challenges in increasingly complex hardware. The paper identifies gaps in current research, such as limitations in dataset quality and the challenges of ensuring generated code correctness. Future directions include developing tailored benchmarks and datasets, enhancing interpretability, and improving LLM performance for domain-specific tasks.
These studies collectively illustrate the transformative potential of LLMs in hardware design and verification, offering new methodologies that enhance efficiency, accuracy, and innovation in the field. As technology continues to evolve, further research and development will likely uncover even more applications and benefits, solidifying the role of LLMs as a crucial tool in modern hardware engineering.
4.2. Different Categories of LLMs for Hardware Design and Verification
To the best of our knowledge, all articles in the literature can be categorized into six categories, as depicted in Figure 5. It should be noted that, although some papers could belong to two or more categories due to their approaches, we have decided to assign them to the category that most closely aligns with the majority of their content. In the following sections, each category will be discussed in detail together with all surveyed papers.
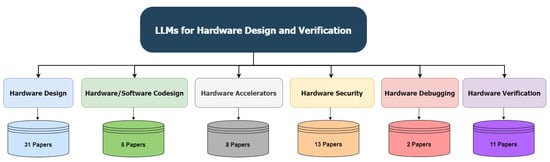
Figure 5.
Different Categories of LLMs for hardware design and verification.
4.2.1. Hardware Design
Hardware design using HDLs is evolving with the integration of LLMs such as OpenAI’s ChatGPT, Google Gemini, and Microsoft Copilot. These LLMs assist in modifying and generating HDL code by accepting design specifications as input prompts, streamlining the development process. In Figure 6, we demonstrate an HDL design for a shift register, where the input prompt describes the desired behavior and adjustments. The results of this input prompt processed by different LLMs are presented in Figure 7, Figure 8 and Figure 9, showing the outputs of ChatGPT 4o, Gemini, and Copilot, respectively. These figures illustrate the varying approaches taken by each model to interpret and modify the HDL design.

Figure 6.
Input prompt for an HDL design.

Figure 7.
ChatGPT output for the input prompt of the HDL design.

Figure 8.
Gemini output for the input prompt of the HDL design. Gemini uses various colors to distinguish between HDL keywords (purple), constants (red), variables and names (black).

Figure 9.
Copilot output for the input prompt of the HDL design. Copilot uses various colors to distinguish between HDL keywords (red), constants (blue), variables and names (black).
For more clarity, the main differences of these responses are mentioned in Table 3. The comparison highlights that ChatGPT’s design stands out for its comprehensive handling of both functionality and edge cases, including explicit checks for the critical scenario where WIDTH == 1, ensuring robustness against potential errors. Its code structure is clear, well-commented, and adheres strictly to the given specifications, making it highly reliable for implementation. While Copilot provides a parameterized design with basic functionality, it lacks the detailed error handling for edge cases, such as WIDTH == 1, which may lead to out-of-bounds indexing issues. Gemini’s implementation, though concise and readable, similarly misses critical edge-case handling and flexibility, focusing more on the general functionality without addressing all potential pitfalls. This comparison underscores the importance of comprehensive error handling and clarity in code when designing robust parameterized hardware modules.
Table 3.
Comparing different LLM responses to the same design input prompt.
The authors in [108] present a comprehensive framework for evaluating the performance of hardware setups used in the inference of LLMs. Their research aims to measure critical performance metrics such as latency, throughput, energy efficiency, and resource utilization to provide a detailed assessment of hardware capabilities. By standardizing these measurements, the framework facilitates consistent and comparable evaluations across different hardware platforms, enabling researchers and engineers to identify the most efficient configurations for LLM inference. The authors’ proposed framework addresses the growing complexity and computational demands of LLMs by offering a robust tool for hardware benchmarking. It integrates various testing scenarios to capture the diverse workloads LLMs handle during inference. This allows for a nuanced understanding of how different hardware components contribute to overall performance. Ultimately, the framework aims to guide the development of more efficient hardware solutions tailored to the specific needs of LLMs, promoting advancements in both hardware design and LLM deployment strategies.
In [109], the authors investigate the application of LLMs in optimizing and designing VHDL (VHSIC Hardware Description Language (HDL)) code, a critical aspect of digital circuit design. Their research explores how LLMs can automate the generation of efficient VHDL code, potentially reducing the time and effort required in the design process. Through a series of experiments, the authors demonstrate the capability of LLMs to provide high-quality code suggestions and optimizations, which can enhance the performance and reliability of digital circuits. The research also addresses the challenges associated with integrating LLMs into the VHDL design workflow. It highlights issues such as the need for domain-specific training data and the importance of understanding the context and constraints of hardware design. By addressing these challenges, the study provides insights into how LLMs can be effectively utilized to support and streamline VHDL code development, paving the way for more automated and intelligent design processes in digital electronics.
The authors of AutoChip [110] introduce a novel method to automate the generation of HDL code by using feedback from LLMs. Their research involves an iterative process where LLMs provide suggestions and improvements on initial HDL code drafts, leading to refined and optimized final versions. This method significantly reduces the need for manual intervention, making the design process more efficient and accessible, especially for complex hardware projects. The authors outline the technical details of implementing AutoChip, including training LLMs on domain-specific datasets and the integration of feedback loops into the design workflow. Their case studies demonstrate the effectiveness of AutoChip in producing high-quality HDL code with minimal human oversight. By automating routine and complex coding tasks, AutoChip has the potential to revolutionize the field of hardware design, enabling faster prototyping and more innovative solutions in hardware development.
The authors in [111] focus on benchmarking various LLMs to evaluate their performance in generating Verilog Register Transfer Level (RTL) code. Their research compares the accuracy, efficiency, and complexity handling capabilities of different models, providing a comprehensive assessment of their suitability for automated hardware design tasks. By establishing standardized benchmarks, the research offers valuable insight into the strengths and limitations of each model in the context of the generation of Verilog code RTL. The findings highlight significant differences in model performance, emphasizing the importance of selecting the right LLM for specific hardware design tasks. The authors also discuss the potential for further improving LLMs by incorporating more specialized training data and refining model architectures. Through detailed comparisons and practical examples, their study contributes to the ongoing effort to enhance the role of LLMs in automating and optimizing the hardware design process.
The authors in Chip-Chat [112] explore the emerging field of using conversational glsai, particularly LLMs, in hardware design. Their research discusses the potential benefits of natural language interfaces, such as increased accessibility and collaboration, by enabling designers to interact with design tools through simple conversational commands. This approach could democratize hardware design, making it more accessible to non-experts and fostering innovation through diverse contributions. However, the authors highlight significant challenges in this domain, including the current limitations of LLMs in understanding complex hardware design concepts and the need for precise and unambiguous communication in technical contexts. They propose potential solutions, such as improving model training with domain-specific data and developing more sophisticated interaction protocols. By addressing these challenges, their study aims to pave the way for more effective integration of conversational AI in hardware design, potentially transforming how engineers and designers approach complex projects.
The authors in ChipGPT [113] examine the current state of using LLMs for natural language-based hardware design, assessing their capabilities and identifying existing gaps. Their research evaluates various LLMs in terms of their ability to understand and generate hardware design code from natural language descriptions. The authors highlight the potential of these models to streamline the design process by enabling more intuitive and accessible interactions between designers and design tools. Despite the promising potential, the authors identify several challenges that need to be addressed to achieve seamless natural language hardware design. These include improving the models’ understanding of technical jargon and design constraints, enhancing the accuracy and efficiency of code generation, and ensuring robust handling of complex design scenarios. By outlining these challenges and suggesting areas for future research, their study provides a roadmap for advancing the integration of NLP in hardware design workflows.
Martínez et al. [114] explore the application of LLMs to detect code segments that can benefit from hardware acceleration. Their research presents techniques for identifying computation-intensive parts of code that, when offloaded to specialized hardware, can significantly improve overall system performance. The authors demonstrate the effectiveness of LLMs in pinpointing these critical segments and providing recommendations for hardware acceleration. The research also discusses the practical implementation of this approach, discussing how LLMs can be integrated into existing development workflows to automatically suggest and optimize code for hardware acceleration. The authors highlight the potential performance gains and efficiency improvements achievable through this method, making a strong case for the use of LLMs to optimize software for better hardware utilization. By leveraging LLMs for this purpose, developers can achieve more efficient and powerful computing solutions.
The authors in CreativEval [115] introduce a novel approach to evaluating the creativity of hardware design code generated by LLMs. The authors propose specific metrics and benchmarks to assess the originality, efficiency, and practicality of the generated code, emphasizing the importance of creativity in hardware design. By focusing on these aspects, their research aims to determine how well LLMs can innovate within the constraints of hardware development. The findings from the study suggest that while LLMs are capable of producing creative solutions, there are limitations to their ability to fully replicate human ingenuity in hardware design. The authors discuss the potential for improving LLMs through more diverse and comprehensive training data, as well as refining the evaluation metrics to better capture the nuances of creative design. Through this evaluation framework, CreativEval contributes to the understanding of LLM capabilities in generating novel and effective hardware design solutions.
The authors in Designing Silicon Brains using LLM [116] explore the use of ChatGPT, a type of LLM, for designing a spiking neuron array, which is a type of neuromorphic hardware that mimics the behavior of biological neurons. They demonstrate how ChatGPT can generate detailed and accurate descriptions of the neuron array, including its architecture and functionality, thereby aiding in the design process. This approach leverages the model’s ability to understand and articulate complex technical concepts in natural language. The authors showcase the potential of using LLMs for designing advanced neuromorphic systems, highlighting the benefits of automated description and specification generation. By providing a structured and comprehensive design output, ChatGPT can significantly streamline the development process of spiking neuron arrays. The study also discusses the challenges and future directions for integrating LLMs into neuromorphic hardware design, emphasizing the need for further refinement and domain-specific training to enhance the accuracy and utility of the generated descriptions.
The authors in Digital Application-Specific Integrated Circuit (ASIC) Design with Ongoing LLMs [117] explore the application of ongoing LLMs in the design of ASICs. They provide an overview of current methodologies and strategies for incorporating LLMs into various stages of the ASIC design process, from initial specification to final implementation. The authors highlight the potential of LLMs to automate routine tasks, enhance design accuracy, and reduce development time. They also discuss the prospects and challenges of using LLMs in digital ASIC design, including the need for specialized training data, the integration of LLMs into existing design workflows, and the importance of maintaining design integrity and performance. By addressing these issues, their study offers valuable insights into the future of ASIC design, suggesting that LLMs could play a significant role in advancing the field through increased automation and intelligent design support.
In [118], the authors review recent advancements in the development of efficient algorithms and hardware architectures specifically tailored for NLP tasks. They discuss various techniques for optimizing NLP algorithms to improve performance and reduce computational requirements. These optimizations are crucial for handling large-scale data and complex models typical of modern NLP applications, including LLMs. Their study also explores the design of specialized hardware that can support efficient NLP. This includes discussing hardware accelerators, such as GPUs and TPUs, and their role in enhancing the performance of NLP tasks. By combining algorithmic improvements with hardware advancements, the authors outline a comprehensive approach to achieving high efficiency and scalability in NLP applications. This integrated approach is essential for meeting the growing demands of NLP and leveraging the full potential of LLMs.
The authors in GPT4AIGChip [119] investigate the use of LLMs to automate the design of AI accelerators. They present methodologies for leveraging LLMs to generate design specifications and optimize the architecture of AI accelerators. By automating these processes, their study aims to streamline the development of specialized hardware for AI tasks, reducing both the time and costs associated with traditional design methods. The authors provide detailed case studies demonstrating the effectiveness of LLMs in producing high-quality design outputs for AI accelerators. They highlight the potential for LLMs to not only accelerate the design process but also to innovate and improve upon existing architectures. Their research discusses future directions, including the integration of more advanced LLMs and the development of more sophisticated automation tools. By advancing the use of LLMs in hardware design, GPT4AIGChip contributes to the ongoing evolution of AI hardware development.
The authors in Hardware Phi-1.5B [120] introduce an LLM trained specifically on hardware-related data, demonstrating its capability to encode domain-specific knowledge. In their research, the authors discuss the model’s architecture and training process, emphasizing the importance of specialized datasets for achieving high performance in hardware design tasks. The authors showcase various applications of Hardware Phi-1.5B, including code generation, optimization, and troubleshooting in hardware development. The study highlights the advantages of using domain-specific LLMs over general-purpose models, particularly in terms of the accuracy and relevance of the generated content. By tailoring the model to the hardware domain, Hardware Phi-1.5B is able to provide more precise and contextually appropriate outputs, which can significantly enhance the efficiency and effectiveness of hardware design processes. The authors conclude with a discussion of future research directions and potential improvements to further leverage domain-specific LLMs in hardware engineering.
The authors in Hardware-Aware Transformers (HAT) [121] introduce a novel approach to designing LLMs that consider hardware constraints during model training and inference. Their research details the development of transformers that are optimized for specific hardware configurations, aiming to improve performance and reduce resource consumption. This hardware-aware design is particularly important for deploying NLP tasks on various platforms, including edge devices and specialized accelerators. The study presents experimental results demonstrating the efficiency gains achieved by HAT models compared with traditional transformers. The authors highlight significant reductions in latency and energy usage, making these models more suitable for real-world applications where resource constraints are a critical factor. By focusing on the co-design of hardware and software, HAT offers a promising solution for enhancing the performance and scalability of NLP tasks in diverse deployment environments.
In the study by Chang et al. [122], the authors propose a post-processing technique to improve the quality of hardware design code generated by LLMs. Their approach involves applying search algorithms to refine and optimize the initial outputs from LLMs, ensuring higher quality and more reliable code generation. The authors detail the implementation of this technique and provide experimental results demonstrating its effectiveness in enhancing code quality. The study highlights the limitations of current LLM-generated code, such as inaccuracies and inefficiencies, and shows how post-LLM search can address these issues. By iteratively refining the code, the proposed method can significantly improve the final output, making it more suitable for practical hardware design applications. This approach underscores the potential for combining LLM capabilities with additional optimization techniques to achieve superior results in automated code generation.
The authors in OliVe [123] introduce a quantization technique designed to accelerate LLMs by focusing on hardware-friendly implementations. The concept of outlier–victim pair quantization is presented as a method to reduce the computational load and improve inference speed on hardware platforms. This technique targets specific outliers in the data, which typically require more resources, and optimizes their representation to enhance overall model efficiency. The authors provide a detailed analysis of the quantization process and its impact on model performance. Experimental results demonstrate significant improvements in inference speed and resource utilization without compromising the accuracy of the LLMs. By making LLMs more hardware-friendly, OliVe offers a practical solution for deploying these models in environments with limited computational resources, such as mobile devices and edge computing platforms.
The authors in RTLCoder [124] present a specialized model designed to outperform GPT-3.5 in generating RTL code. They highlight the use of an open-source dataset and a lightweight model architecture to achieve superior results in RTL code generation tasks. The authors provide a comprehensive comparison of RTLCoder’s performance against GPT-3.5, demonstrating significant improvements in accuracy, efficiency, and code quality. Their study also discusses the advantages of using a focused dataset and a streamlined model for specific applications, such as hardware design. By tailoring the model to the unique requirements of RTL code generation, RTLCoder can provide more relevant and high-quality outputs, reducing the need for extensive manual corrections. This approach underscores the potential for developing specialized models that can outperform general-purpose LLMs in targeted tasks.
The authors in RTLLM [125] introduced an open-source benchmark specifically designed to evaluate the performance of LLMs in generating RTL code. Their benchmark provides a standardized set of tasks and metrics to facilitate consistent and comprehensive assessments of LLM capabilities in RTL generation. By offering a common evaluation framework, RTLLM aims to drive improvements and innovation in the use of LLMs for hardware design. The authors detail the creation of the benchmark, including the selection of tasks, the development of evaluation criteria, and the compilation of relevant datasets. They present initial results from using RTLLM to evaluate various LLMs, highlighting strengths and areas for improvement. By providing an open-source tool for benchmarking, RTLLM encourages collaboration and transparency in the development and assessment of LLMs for RTL code generation, fostering advancements in this emerging field.
In this study by Pandelea et al. [126], the authors discuss the co-design approach to selecting features for language models and balancing software and hardware requirements to achieve optimal performance. They highlight the importance of considering both aspects in the development of LLMs, as hardware constraints can significantly impact model efficiency and scalability. By integrating software and hardware design, their study aims to create more efficient and effective LLMs. The authors present case studies and experimental results demonstrating the benefits of the co-design approach. These examples show how tailored features can enhance model performance on specific hardware platforms, reducing latency and resource consumption. They argue that this integrated approach is essential for developing LLMs that can meet the growing demands of real-world applications, offering a path forward for more sustainable and scalable NLP solutions.
The authors in SlowLLM [127] investigate the feasibility and performance of running LLMs on consumer-grade hardware. They address the challenges and limitations of deploying LLMs on less powerful devices, such as personal computers and smartphones, which often lack the computational resources of specialized hardware. The authors propose solutions to enhance performance, such as model compression and optimization techniques tailored for consumer hardware. Their study provides experimental results showcasing the performance of various LLMs on consumer devices, highlighting both successes and areas for improvement. The findings demonstrate that, while there are significant challenges, it is possible to achieve acceptable performance levels with appropriate optimizations. By exploring these possibilities, SlowLLM contributes to making advanced NLP capabilities more accessible to a broader audience, potentially expanding the applications and impact of LLMs in everyday technology use.
The authors in SpecLLM [128] investigate the use of LLMs for generating and reviewing Very-Large Scale Integration (VLSI) design specifications. They evaluate the ability of LLMs to produce accurate and comprehensive specifications, which are crucial for the development of complex integrated circuits. The authors present methods for training LLMs on domain-specific data to enhance their understanding and performance in VLSI design tasks. Their study provides experimental results demonstrating the effectiveness of LLMs in generating VLSI design specifications, highlighting their potential to streamline the design process and reduce errors. The authors discuss the challenges and future directions for improving the integration of LLMs in VLSI design, including the need for more sophisticated training techniques and better handling of technical jargon. By exploring these possibilities, SpecLLM contributes to the ongoing efforts to enhance the role of LLMs in the field of hardware design.
The authors in ZipLM [129] introduce a structured pruning technique designed to improve the inference efficiency of LLMs. They detail the development of pruning methods that selectively remove less important components of the model, reducing its size and computational requirements without significantly impacting performance. This inference-aware approach ensures that the pruned models remain effective for their intended tasks while benefiting from enhanced efficiency. Their study presents experimental results demonstrating the effectiveness of ZipLM in reducing model size and improving inference speed. The authors highlight the potential applications of this technique in environments with limited computational resources, such as edge devices and mobile platforms. By focusing on structured pruning, ZipLM offers a practical solution for deploying LLMs more efficiently, enabling broader accessibility and application of these powerful models in various real-world scenarios.
This study by Thorat et al. [130] explores the application of advanced language models (ALMs), such as GPT-3.5 and GPT-4, in the realm of electronic hardware design, particularly focusing on Verilog programming. Verilog is an HDL used for designing and modeling digital systems. The authors introduce the VeriPPA framework, which utilizes ALMs to generate and refine Verilog code. This framework incorporates a two-stage refinement process to enhance both the syntactic and functional correctness of the generated code and to align it with key performance metrics: power, performance, and area (PPA). This iterative approach involves leveraging diagnostic feedback from simulators to identify and correct errors systematically, akin to human problem-solving techniques. The methodology begins with ALMs generating initial Verilog code, which is then refined through the VeriRectify process. This process uses error diagnostics from simulators to guide the correction of syntactic and functional issues, ensuring the generated code meets specific correctness criteria. Following this, the code undergoes a PPA optimization stage where its power consumption, performance, and area efficiency are evaluated and further refined if necessary. This dual-stage approach significantly improves the quality of Verilog code, achieving an 81.37% linguistic accuracy and a 62.0% operational efficacy in programming synthesis, surpassing existing techniques. The study highlights the potential of ALMs in automating and improving the hardware design process, making it more accessible and efficient for those with limited expertise in chip design.
This study by Huang et al. [131] reviews and proposes various strategies to accelerate and optimize LLM, addressing the computational and memory challenges associated with their deployment. The authors cover algorithmic improvements, including early exiting and parallel decoding, and introduce hardware-specific optimizations through LLM-hardware co-design. They present frameworks like Medusa for parallel decoding, achieving speedups up to 2.8x, and SnapKV for memory efficiency improvements. Their research also explores High-Level Synthesis (HLS) applications with frameworks like ScaleHLS and HIDA, which convert LLM architectures into hardware accelerators. These advances improve LLM performance in real-time applications, such as NLP and EDA, while reducing energy consumption and improving efficiency.
From English to ASIC [132] explores the application of LLMs in automating hardware design using HDLs like Verilog for ASICs. The authors focus on improving the precision of LLM-generated HDL code by fine-tuning Mistral 7B and addressing challenges such as syntax errors and the scarcity of quality training datasets. By creating a labeled Verilog dataset and applying advanced optimization techniques such as LoRA and DeepSpeed ZeRO, their study demonstrates significant improvements in code generation accuracy, with up to a 20% increase in pass@1 metrics. The contributions of their research include optimizing memory usage and inference speed, making LLMs more practical for EDA in hardware development.
The authors in this paper introduce LLMCompass [133], a hardware evaluation framework specifically designed for optimizing hardware used in LLM inference. Addressing the high computational and memory demands of LLMs, LLMCompass provides an efficient, versatile tool for evaluating hardware designs. They incorporate a comprehensive performance and cost model that enables architects to assess trade-offs in hardware configuration. Validated against commercial hardware such as NVIDIA A100 and Google TPUv3, LLMCompass achieves low error rates (4.1% for LLM inference) while offering fast simulation times. By exploring architectural implications, such as memory bandwidth and compute capabilities, LLMCompass guides the development of cost-effective hardware designs, enabling the democratization of LLM deployment. For example, proposed modifications to existing architectures yielded up to a 3.41× improvement in performance/cost. This tool is positioned as a critical enabler for optimizing next-generation hardware for large-scale AI applications.
Addressing the scarcity of high-quality Verilog data for LLM fine-tuning, the authors in this paper [134] introduce a design-data augmentation framework to automate dataset generation for chip design tasks. The framework aligns Verilog files with natural language descriptions, error feedback, and EDA scripts to create comprehensive datasets. Fine-tuning Llama2 models on these datasets resulted in a substantial improvement in Verilog code generation accuracy, surpassing state-of-the-art benchmarks. The authors argue that such automated augmentation methods are critical for developing domain-specific LLMs capable of agile and accurate chip design, paving the way for scalable hardware development.
The authors in this paper [135] introduce a hierarchical prompting approach to improve the generation of HDL designs using LLMs. The authors highlight the limitations of standard “flat” prompting methods, especially for complex modules like finite-state machines or multi-component processors. They propose an eight-stage pipeline, Recurrent Optimization via Machine Editing (ROME), which automates the hierarchical design process by dividing designs into smaller submodules. Evaluations of benchmarks and case studies, including a 32-bit Reduced Instruction Set Computer (RISC)-V processor, demonstrate that hierarchical prompting improves both the quality of HDL generation and its scalability to complex designs. The study also depicts that smaller, fine-tuned open-source models can effectively compete with larger proprietary LLMs when using hierarchical commands.
The authors in this paper [136] explore the feasibility of using LLMs for designing a RISC processor, focusing on generating VHDL code for components such as the ALU, control unit, and memory modules. LLM-generated code was verified through simulation and implementation on an FPGA. The results reveal significant limitations, including frequent errors in generated code and a reliance on human intervention for debugging and refinement. While LLMs show potential for automating initial design steps, the authors in this study conclude that they currently serve better as complements to human designers rather than standalone tools.
The authors of this paper [137] present MG-Verilog, a dataset designed to improve LLM performance in Verilog generation tasks. The dataset includes multi-grained descriptions and diverse code samples, enabling fine-tuning for better generalization across hardware design tasks. The authors also propose a balanced fine-tuning scheme to leverage the dataset’s diversity effectively. Extensive evaluations demonstrate that MG-Verilog significantly enhances LLM-generated Verilog quality, promoting its use for inference and training in hardware design workflows. Table 4 provides an overview of all the papers discussed in the hardware design subsection for comparison.
Table 4.
Comparison of papers focusing on hardware design with LLMs.
4.2.2. Hardware/Software Codesign
This study by Mudigere et al. [138] explores co-design strategies to improve training speed and scalability of deep learning recommendation models. The authors emphasize the integration of software and hardware design to achieve significant performance gains, addressing the computational intensity and resource demands of training large models. They present various techniques for optimizing algorithms and hardware architectures, ensuring efficient utilization of resources. Their study showcases experimental results demonstrating the effectiveness of co-design strategies in accelerating model training. These results highlight improvements in training times and scalability, making it feasible to handle larger datasets and more complex models. By focusing on the co-design approach, their study provides valuable insights into achieving faster and more scalable training processes, which are essential for the ongoing advancement of deep learning recommendation systems.
This study by Wan et al. [139] explores the integration of software and hardware design principles to optimize the performance of LLMs. The authors focus on the co-design approach, which synchronizes the development of software algorithms and hardware architecture to achieve efficient processing and better utilization of resources. This synergy is essential in managing the computational demands of LLMs, which require significant processing power and memory bandwidth. They discuss various strategies for optimizing both hardware (such as specialized accelerators and memory hierarchies) and software (such as algorithmic improvements and efficient coding practices) to enhance the performance and efficiency of LLMs. Their research further delves into the application of this co-design methodology in design verification processes. Design verification, a critical phase in the development of digital systems, benefits from the enhanced capabilities of co-designed LLMs. By leveraging optimized LLMs, verification tools can process complex datasets and simulations more effectively, leading to more accurate and faster verification results. The integration of co-designed LLMs into verification workflows helps in identifying design flaws early, reducing the time and cost associated with the design and development of hardware systems. Their study presents case studies and experimental results that demonstrate the practical benefits and improvements achieved through the software/hardware co-design approach in real-world verification scenarios.
This study by Yan et al. [140] investigates the potential of leveraging LLMs in the co-design process of software and hardware, specifically for designing Compute-in-Memory (CiM) Deep Neural Network (DNN) accelerators. The authors explore how LLMs can be utilized to enhance the co-design process by providing advanced capabilities in generating design solutions and optimizing both software and hardware components concurrently. They emphasize the importance of LLMs in automating and improving the design workflow, leading to more efficient and effective development of CiM DNN accelerators. Their study presents a detailed case study demonstrating the application of LLMs in the co-design of CiM DNN accelerators. Through this case study, the authors illustrate how LLMs can aid in identifying optimal design configurations and addressing complex design challenges. The study shows that LLMs can significantly reduce the time and effort required for design iterations and verification, thereby accelerating the overall development process. The findings suggest that integrating LLMs into the co-design framework can result in substantial performance gains and resource savings, highlighting the viability and benefits of using LLMs in the co-design of advanced hardware accelerators.
The authors of C2HLSC [141] investigate the ability of LLMs to assist in refactoring software code into formats compatible with HLS tools. The authors showcase case studies where an LLM transforms C code, including the QuickSort algorithm and AES-128 encryption, into HLS-synthesizable code. By iteratively modifying software constructs such as dynamic memory allocation and recursion, the LLM produces hardware-compatible code that adheres to HLS constraints. This approach significantly reduces manual effort and errors, traditionally required in preparing software for hardware synthesis. The findings highlight the transformative potential of LLMs in bridging the software-to-hardware design gap, enabling more seamless hardware development processes.
The authors in this paper [142] evaluate LLMs for both hardware design and testing by examining their ability to generate functional Verilog modules and testbenches from plain language specifications. Benchmarks show that LLMs can automate significant portions of the design process, including functional verification. Successful tapeouts based on generated designs demonstrate the feasibility of using LLMs for end-to-end hardware workflows. The findings highlight the potential of LLMs to reduce manual effort and accelerate the development pipeline for digital hardware.
PyHDL-Eval [143] is a framework for evaluating LLMs on specification-to-RTL tasks using Python-embedded DSLs. The framework includes 168 problems across 19 RTL design categories and supports testing on DSLs like PyMTL3, MyHDL, and Migen. Experiments with multiple LLMs show better performance on Verilog than Python-embedded DSLs, underscoring challenges in leveraging LLMs for high-level languages. PyHDL-Eval serves as a valuable tool for advancing research in Python-embedded DSLs and their intersection with LLM capabilities.
4.2.3. Hardware Accelerators
Nazzal et al. [144] present a comprehensive dataset specifically designed to facilitate the generation of AI accelerators driven by LLMs. The dataset includes a diverse range of hardware design benchmarks, synthesis results, and performance metrics. The goal is to provide a robust foundation for training LLMs to understand and optimize hardware accelerators effectively. By offering detailed annotations and a variety of design scenarios, their dataset aims to enhance the ability of LLMs to generate efficient and optimized hardware designs. The authors detail the structure of the dataset, which covers various aspects of hardware accelerator design, including computational kernels, memory hierarchies, and interconnect architectures. They also discuss the potential applications of the dataset in training LLMs for tasks such as design space exploration, performance prediction, and design optimization. Their study demonstrates the utility of the dataset through several case studies, showing how LLMs can leverage the provided data to generate and optimize hardware accelerators with significant improvements in performance and efficiency.
The work by Martínez et al. [114] explores the use of LLMs to detect and optimize code for hardware acceleration. The authors propose a methodology where LLMs analyze software codebases to identify sections that can benefit from hardware acceleration. The LLMs are trained to recognize patterns and structures within the code that are amenable to acceleration, such as loops and parallelizable tasks. Their study presents an evaluation of this methodology using several open-source projects, demonstrating that LLMs can effectively identify and suggest optimizations for hardware acceleration. The authors also highlight the potential for integrating this approach into existing development workflows, allowing for seamless detection and acceleration of critical code sections. The study concludes by discussing the challenges and future directions for improving the accuracy and applicability of LLM-driven code detection for hardware acceleration.
The authors in Gen-acceleration [145] focus on the pioneering efforts to use LLMs for the automatic generation of hardware accelerators. They outline a novel framework where LLMs are employed to translate high-level design specifications directly into hardware accelerator designs. The approach leverages the NLP capabilities of LLMs to understand and interpret complex design requirements and convert them into efficient hardware architectures. The authors provide a detailed analysis of the framework, including its architecture, training process, and performance evaluation. They demonstrate the effectiveness of the approach through multiple case studies, showing that LLMs can generate hardware accelerators that meet or exceed the performance of manually designed counterparts. They also discuss the potential for this technology to revolutionize the hardware design process, making it more accessible and efficient.
The authors in NeuPIMs [146] introduce a heterogeneous acceleration framework that combines Neural Processing Units (NPUs) with Processing-In-Memory (PIM) technologies to enhance the performance of batched LLM inferencing. They discuss the architectural innovations that enable this combination, focusing on how NPUs and PIM can work together to overcome the memory bandwidth limitations and computational bottlenecks typically associated with LLM inferencing. The authors provide a comprehensive evaluation of the NeuPIMs framework, highlighting its performance benefits across various LLM benchmarks. They demonstrate significant improvements in throughput and energy efficiency compared with traditional GPU-based solutions. They also delve into the technical details of the NPU-PIM integration, including the data flow, memory management, and synchronization mechanisms that enable efficient batched inferencing.
The study by Lai et al. [147] presents the LCM (LLM-focused Hybrid Scratch-Pad Memory (SPM)-cache) architecture designed for multi-core AI accelerators to address the growing computational demands of LLMs. By integrating a hybrid system combining SPM and a shared cache, this architecture provides shorter compilation times and better memory management, particularly for LLMs using mixed-precision quantization. The proposed system utilizes a Tensor Management Unit (TMU) for efficient cache handling and employs innovative hardware prefetching and dead block prediction strategies to mitigate memory access issues. The system outperforms conventional SPM-based architectures, showing up to 50.5% performance improvements in specific scenarios.
The FLAG framework [148] integrates LLMs with formula-based representations to automate baseband hardware design, such as polar encoders. By combining traditional template-based methods with LLMs, FLAG achieves high-quality Verilog HDL generation while reducing design complexity and time. The framework is the first to demonstrate large-scale baseband hardware generation using LLMs, offering a promising direction for future research in signal processing hardware design.
The authors of this paper propose Parallel Prompt Decoding (PPD) [149], a memory-efficient approach for accelerating LLM inference. By leveraging hardware-aware optimizations and dynamic sparse trees, PPD significantly reduces runtime memory overhead while improving inference speed. It achieves up to a 2.49× speedup across various benchmarks with minimal training requirements, demonstrating its applicability for deploying LLMs in memory-constrained environments. Table 5 provides an overview of all the papers discussed in the hardware accelerators subsection for comparison.
Table 5.
Comparison of papers focuses on hardware accelerators with LLMs.
4.2.4. Hardware Security
The authors in DIVAS (Distributed Intelligence for Verification and Security) [150] introduce a comprehensive framework utilizing LLMs to improve the security of System on Chip (SoC) designs. DIVAS integrates multiple security analysis tools and LLMs to provide an end-to-end solution for detecting vulnerabilities and enforcing security policies in SoC designs. The framework automates the identification of security threats and applies policy-based protection mechanisms, with the aim of streamlining and fortifying the security analysis process. DIVAS employs LLMs for various tasks such as vulnerability assessment, anomaly detection, and generating mitigation strategies. The authors detail the system architecture, including its integration with existing SoC design tools and the use of LLMs to interpret and analyze complex security data. The experimental results demonstrate the effectiveness of DIVAS in identifying security vulnerabilities and implementing policies, leading to a significant improvement in SoC security. The study concludes with a discussion of potential improvements, such as the incorporation of real-time monitoring and refinement of LLMs to handle a wider range of security scenarios.
This study by Srikumar et al. [151] addresses the potential pitfalls of relying on LLMs for hardware specification, particularly in the context of security. The authors argue that, while LLMs can accelerate the specification process, they often generate specifications that are syntactically correct but semantically flawed, leading to security vulnerabilities. Their work presents case studies where LLM-generated specifications resulted in security issues, emphasizing the need for formal methods to verify these specifications. The authors propose a hybrid approach that combines LLMs with formal verification techniques to ensure the correctness and security of hardware specifications. They present a framework that uses LLMs to generate initial specifications, followed by formal verification tools to validate and correct these specifications. Experimental results show that this approach significantly reduces the incidence of security flaws compared with using LLMs alone. The paper concludes with a discussion on the limitations of current LLMs in understanding complex security requirements and the importance of integrating formal methods to achieve reliable and secure hardware designs.
This study by Ahmad et al. [152] also explores the use of LLMs to identify and fix security bugs in hardware designs. The authors describe a system where LLMs analyze hardware code to detect potential security vulnerabilities and suggest fixes. This approach aims to automate the bug-fixing process, reducing the time and expertise required to secure hardware designs. Their work details the methodology for training LLMs on hardware security datasets, the types of bugs the system can identify, and the accuracy of the suggested fixes. Experimental results indicate that LLMs can effectively identify and propose solutions for a wide range of security bugs, though their effectiveness varies with the complexity of the bugs. The authors discuss the limitations of LLMs in understanding intricate hardware interactions and suggest future work to improve the robustness of the models and expand their applicability to more complex security scenarios.
This study by Kokolakis et al. [153] examines the potential misuse of general-purpose LLMs in designing hardware Trojans, malicious circuits embedded in hardware designs. The authors demonstrate how LLMs, typically used for benign purposes, can be repurposed to create sophisticated Trojans that are difficult to detect. Their work presents a series of experiments where LLMs are used to generate Trojan designs and assesses their effectiveness and stealthiness. The authors highlight the risks posed by the accessibility of powerful LLMs and the need for robust detection mechanisms. They propose countermeasures, including enhanced verification processes and the development of specialized LLMs trained to recognize and flag suspicious patterns in hardware designs. The paper concludes by discussing the ethical implications of LLMs in hardware design and the importance of proactive measures to prevent their misuse in creating security threats.
The authors in LLM for SoC Security [154] explore the transformative impact of LLMs on the security of SoC designs. They argue that LLMs represent a significant advancement in the ability to analyze and secure SoC architectures. The authors describe various applications of LLMs in SoC security, including vulnerability detection, threat modeling, and automated patch generation. Their work provides detailed case studies demonstrating the effectiveness of LLMs in enhancing SoC security. Experimental results show that LLMs can identify vulnerabilities more efficiently and accurately than traditional methods. The authors discuss the challenges in integrating LLMs with existing security workflows and propose solutions to address these challenges. The study concludes by highlighting the potential for LLMs to redefine SoC security practices and the need for continued research to fully realize their potential.
This study by Wang et al. [155] discusses the dual role of LLMs in chip design: as tools for improving design efficiency and as potential sources of security risks. The authors examine the capabilities of LLMs in automating various aspects of chip design, including specification, verification, and optimization. They also highlight the security risks associated with LLM-generated designs, such as the inadvertent introduction of vulnerabilities and the potential for malicious use. The authors propose a framework for building trust in LLM-generated designs by incorporating rigorous security checks and validation processes. They present case studies where LLMs successfully aided in chip design and instances where they introduced security risks. The paper concludes with recommendations for developing secure LLM workflows, including enhanced training protocols and collaboration between LLM developers and security experts to mitigate risks and ensure the reliability of LLM-assisted chip designs.
This study by Ahmad et al. [156] investigates the use of LLMs to assist in fixing security bugs in hardware code. The authors present a system where developers can interactively prompt LLMs to identify and correct security vulnerabilities in hardware designs. The approach aims to leverage the language understanding capabilities of LLMs to enhance the efficiency and accuracy of bug fixing. Their work details the interactive prompting system, the types of security bugs it can address, and the effectiveness of the LLM-generated fixes. Experimental results show that the system can significantly reduce the time required to identify and fix security bugs, though the success rate varies with the complexity of the bugs. The authors discuss the limitations of current LLMs in handling complex hardware security scenarios and suggest future research directions to improve the system’s robustness and expand its capabilities.
This study by Kande et al. [157] explores the use of LLMs to generate security assertions for hardware designs. Security assertions are critical for verifying that hardware operates as intended without vulnerabilities. The authors propose a framework where LLMs are trained to understand the hardware specifications and automatically generate the corresponding security assertions. Their work demonstrates the effectiveness of this approach through multiple case studies, showing that LLM-generated assertions can identify security issues early in the design process. The authors also discuss the challenges of training LLMs to understand complex hardware specifications and the need for continuous improvement in the training datasets. The study concludes that LLMs have a significant potential to enhance the security verification process by providing accurate and automated security assertions.
This study by Paria et al. [158] explores how LLMs can be leveraged to enhance SoC security by automating the HDL generation process, bug fixing, and security verification. The authors highlight the potential of LLMs such as GPT, ChatGPT, and BERT to assist in SoC security through NLP and contextual reasoning. They emphasize the role of LLMs in automating the detection of security vulnerabilities across the complex design process of SoCs, offering automated fixes and providing a framework for generating secure HDL code. Their work focuses on the importance of policies and asserts that LLMs can not only identify vulnerabilities but also automatically generate assertions and security policies to mitigate these risks. The paper illustrates several use cases, such as detecting vulnerabilities from HDL documentation and using LLMs to map security weaknesses to known vulnerabilities like Common Weakness Enumerations (CWEs). It also outlines the challenges of applying LLMs to hardware design, such as token limitations and incomplete context processing. The study concludes by identifying current limitations and suggesting directions for improving LLM integration in SoC security.
The authors in SoCureLLM [159] introduce an innovative LLM-based framework that addresses the limitations of contemporary hardware security verification techniques, especially their adaptability and scalability for large-scale SoC designs. The framework leverages LLMs’ advanced reasoning and pattern recognition abilities to detect vulnerabilities in large SoC designs and generate comprehensive security policies. Unlike previous methods that focus on smaller designs, SoCureLLM overcomes challenges related to token limitations and memory constraints, effectively partitioning designs into smaller code snippets and analyzing them contextually. In evaluations, SoCureLLM successfully detected 76.47% of security bugs on vulnerable RISC-V SoCs and formulated 84 novel security policies. The framework introduces automation in both the detection and the generation of security policies based on threat models, significantly reducing manual effort. The authors emphasize the importance of automated security policy databases to address SoC vulnerabilities and enhance presilicon verification. The paper concludes by highlighting the scalability and effectiveness of SoCureLLM in verifying large designs while proposing potential refinements for future iterations.
The authors in this paper [160] evaluate the dual impact of LLMs in hardware security. On one hand, LLMs have shown potential in automating security testing processes, such as generating test cases and assertion rules to identify vulnerabilities in hardware designs. On the other hand, they present risks by potentially enabling attackers to exploit hardware systems more effectively. The authors provide an extensive analysis of the role of LLMs in addressing supply chain vulnerabilities, hardware Trojans, and fault injection attacks while acknowledging their limitations in scaling to large, complex designs. Additionally, the paper explores future threats enabled by LLMs, such as the automated generation of malicious code for hardware attacks. It concludes with a call for robust mitigation strategies to counterbalance the risks introduced by these advanced AI tools.
The authors of this paper present SecRT-LLM [161], a framework for creating a database of 10,000 vulnerable RTL designs with 16 distinct security weaknesses. Leveraging LLMs for vulnerability insertion and detection, the framework combines in-context learning and fidelity checks to ensure precision. The resulting database supports AI-based hardware security solutions by providing a robust benchmark for vulnerability analysis and mitigation. This research demonstrates the potential of LLMs to address the pressing need for scalable, security-aware databases in the hardware domain.
The authors in this paper propose Self-HWDebug [162], a framework leveraging LLMs to automatically generate debugging instructions for hardware security verification. The framework uses existing vulnerable and secure RTL code pairs to guide LLMs in generating instructions for addressing security vulnerabilities. These instructions are applied to debug unseen designs within the same vulnerability category, reducing human effort and improving scalability. Comprehensive testing indicates the framework’s ability to adapt to new vulnerabilities efficiently while improving debugging quality. The authors argue that Self-HWDebug significantly enhances the applicability of LLMs for secure hardware design. Table 6 compares all the paper discussed in this subsection.
Table 6.
Comparison of papers focusing on hardware security with LLMs.
4.2.5. Hardware Debugging
In Figure 10, we demonstrate HDL debugging for a shift register, where the input prompt describes the desired behavior and adjustments. The results of this input prompt processed by different LLMs are presented in Figure 11, Figure 12 and Figure 13, showcasing the outputs from ChatGPT 4o, Gemini, and Copilot, respectively. These figures illustrate the varying approaches taken by each model to interpret and modify the HDL design.

Figure 10.
Input prompt for a HDL debugging.

Figure 11.
ChatGPT output for the input prompt of the HDL debugging.
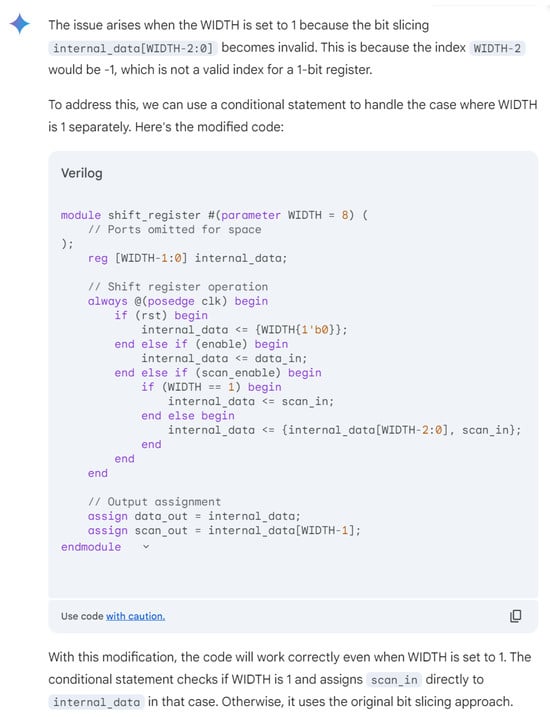
Figure 12.
Gemini output for the input prompt of the HDL debugging. Gemini uses various colors to distinguish between HDL keywords (purple), constants (red), variables and names (black).

Figure 13.
Copilot output for the input prompt of the HDL debugging. Copilot uses various colors to distinguish between HDL keywords (red), constants (blue), variables and names (black).
Table 7 highlights that ChatGPT’s response excels in identifying and addressing the critical issue of handling WIDTH == 1, providing a clear and robust solution with detailed reasoning. It explicitly points out the root cause (negative indexing) and offers a flexible, well-structured, and commented solution adaptable to various scenarios. In contrast, Copilot identifies the problem but offers a less detailed explanation and solution, missing clarity and robustness in handling edge cases like WIDTH == 1. Gemini, while concise and readable, lacks technical depth and sufficient detail for edge case handling, limiting its flexibility and adherence to the problem requirements. Overall, ChatGPT’s response stands out for its thoroughness, flexibility, and adherence to best practices.
Table 7.
Comparing different LLM responses to the same HDL debugging input prompt.
The authors in HDLdebugger [163] present a novel approach to debugging HDL code using LLMs. The authors introduce a system that leverages the capabilities of LLMs to automate and streamline the debugging process for HDL, which includes languages like Verilog and VHDL. The system is designed to identify syntax and semantic errors, suggest corrections, and provide explanations for detected issues, thereby reducing the manual effort and expertise required in traditional debugging methods. Their work details the architecture of HDL debugger, which includes modules for parsing HDL code, generating debugging suggestions, and integrating user feedback to refine its outputs. The authors provide experimental results showing that HDL debugger can effectively identify and correct a wide range of common errors in HDL code, significantly improving debugging efficiency. The study concludes by discussing potential enhancements, such as expanding the system’s knowledge base and incorporating more advanced ML techniques to handle more complex debugging scenarios.
The authors in LLM4SecHW [164] explore the use of a domain-specific LLM for hardware debugging, particularly focusing on security-related issues. They introduce a specialized LLM trained on hardware design and security datasets to assist in identifying and fixing security vulnerabilities in hardware designs. The system aims to enhance the debugging process by providing targeted suggestions and fixes for security bugs, which are often more challenging to detect and resolve than general errors. The authors describe the development of LLM4SecHW, including the data collection, training process, and the integration of the model into existing hardware debugging workflows. Experimental results demonstrate that LLM4SecHW is effective in detecting and resolving a variety of security-related issues in hardware designs, outperforming general-purpose LLMs in both accuracy and relevance. The study concludes with a discussion on the limitations of the current model and future directions for improving its performance, such as expanding the training dataset and refining the model’s understanding of complex security scenarios. Table 8 compares the papers discussed in this subsection.
Table 8.
Comparison of papers focusing on hardware debugging with LLMs.
4.2.6. Hardware Verification
In Figure 14, we demonstrate an HDL verification for a shift register, where the input prompt describes the desired behavior and adjustments. The results of this input prompt processed by different LLMs are presented in Figure 15, Figure 16 and Figure 17, showcasing the outputs from ChatGPT 4o, Gemini, and Copilot, respectively. These figures illustrate the varying approaches taken by each model to interpret and modify the HDL design.

Figure 14.
Input prompt for HDL verification.

Figure 15.
ChatGPT output for the input prompt of the HDL verification. Subfigure 1 outlines all the necessary steps for UVM verification. Subfigures 2 through 6 further elaborate on these steps. Subfigures 7 to 9 detail the required interface, the top testbench module, and the test class, respectively. Subfigure 10 illustrates how to execute the entire code.
Figure 16.
Gemini output for the input prompt of the HDL verification. Subfigures 1 and 2 present the first and second sections of the UVM verification code along with their respective descriptions. Gemini uses various colors to distinguish between HDL keywords (purple), constants (red), variables and names (black).

Figure 17.
Copilot output for the input prompt of the HDL verification. Subfigures 1 and 2 present the first and second sections of the UVM verification code.
The comparison Table 9 highlights ChatGPT’s superior performance in providing a comprehensive Universal Verification Methodology (UVM) environment for the verification of the shift register design. It includes all necessary components, such as the driver, monitor, scoreboard, sequencer, and testbench, with clear and well-structured code that is highly reusable and scalable. ChatGPT also offers a detailed explanation of the UVM flow, ensuring clarity for users implementing the environment. Additionally, it covers a wide range of test cases, including critical edge cases like WIDTH == 1, and provides excellent error handling and debugging assistance. In contrast, Copilot delivers a basic UVM setup, with moderate scalability and readability, but lacks depth in component implementation and edge case handling. Gemini provides a brief overview but misses key details and components, limiting its scalability and effectiveness. Overall, ChatGPT stands out for its thoroughness, clarity, and adaptability in verifying the design.
Table 9.
Comparing different LLM responses to the same HDL verification input prompt.
The authors in AssertLLM [165] focus on utilizing multiple LLMs to generate and evaluate hardware verification assertions directly from the design specifications. They present a novel approach where various LLMs are used to understand the design specifications and subsequently generate appropriate verification assertions that ensure the correctness of hardware designs. This methodology aims to streamline the process of hardware verification by automating the generation of assertions, which traditionally requires significant manual effort and expertise. The authors detail the framework architecture, which includes parsing design specifications, employing multiple LLMs for assertion generation, and using evaluation metrics to assess the quality and accuracy of the generated assertions. The paper showcases experimental results indicating that the multi-LLM approach produces assertions that are both accurate and relevant, reducing the overall time and effort required for hardware verification. The study concludes by discussing potential improvements and future directions, such as refining LLM training datasets and integrating the framework with existing verification tools.
This study by Orenes et al. [166] explores the application of LLMs to assist in the formal verification of RTL designs. The authors introduce methods for leveraging LLMs to automatically generate properties and invariants that are crucial for formal verification processes. The goal is to improve the efficiency and accuracy of formal verification by reducing the dependency on manual property generation, which can be time consuming and error-prone. The authors present a detailed workflow where LLMs are used to interpret the RTL code and produce formal properties that can be verified using formal methods. They provide experimental results that demonstrate LLM-generated properties can significantly augment the formal verification process, catching more design errors and reducing verification time. The study also discusses the limitations of current LLMs in understanding complex RTL semantics and suggests future research directions to improve LLM capabilities in formal verification tasks.
This study by Varambally et al. [167] addresses the optimization of design verification processes using ML techniques, presenting an open-source solution for the hardware design community. The authors outline a framework that integrates ML algorithms to predict verification outcomes, identify potential design issues early, and prioritize verification tasks. This approach aims to enhance the efficiency and effectiveness of the design verification process by leveraging data-driven insights. The framework’s implementation is discussed in detail, including the selection of ML models, training datasets, and integration with existing verification workflows. Experimental results are provided to demonstrate the improvements in verification coverage and reduction in verification time achieved by the ML-enhanced framework. The study concludes with a discussion on the open-source nature of the solution, encouraging community collaboration and further development, as well as outlining potential future enhancements such as incorporating more sophisticated ML models and expanding the dataset.
The authors in VerilogEval [168] focus on assessing the performance of LLMs in generating Verilog code, which is critical for hardware design. They provide a comprehensive evaluation framework to benchmark various LLMs’ ability to generate accurate and efficient Verilog code from high-level descriptions. The authors detail the criteria used for the evaluation, including code accuracy, readability, and resource efficiency. The study presents extensive experimental results comparing different LLMs on a series of Verilog code generation tasks. These results highlight the strengths and weaknesses of each model, providing insights into how well they can support hardware designers in automating code generation. The study concludes by discussing the implications of these findings for future research and development, suggesting ways to improve LLM training for better performance in hardware design applications, such as using more domain-specific datasets and refining model architectures.
This study by Sun et al. [169] proposes a method for enhancing verification productivity by translating natural language descriptions into System Verilog assertions with a circuit-aware approach. The authors introduce a system that leverages NLP techniques to interpret design specifications and automatically generate corresponding verification assertions. This approach aims to bridge the gap between high-level design intents and low-level verification tasks, making the verification process more intuitive and efficient. The system’s architecture is described in detail, including the use of NLP models to understand natural language inputs and generate accurate System Verilog assertions that are contextually aware of the circuit design. Experimental results are presented to demonstrate the effectiveness of the proposed method, showing significant improvements in the speed and accuracy of assertion generation compared with manual methods. The study concludes with discussions on the potential impact of this approach on the verification industry and future research directions to further refine the translation process.
The authors in ChipNeMo [170] explore the adaptation of LLMs specifically for the domain of chip design. They present techniques for fine-tuning LLMs on chip design-related datasets to enhance their performance in tasks such as code generation, optimization, and verification. The goal is to create domain-adapted models that can understand and generate chip design content more effectively than general-purpose LLMs. The authors describe the process of collecting and curating domain-specific datasets, the fine-tuning methodology, and the evaluation metrics used to assess the performance of the adapted models. Experimental results show that ChipNeMo outperforms general-purpose LLMs in various chip design tasks, demonstrating the benefits of domain adaptation. The study concludes with a discussion on the broader implications of domain-adapted LLMs for the chip design industry and potential future research directions, including the integration of these models into existing design workflows and further refinement of adaptation techniques.
The authors in LLM4DV [171] investigate the use of LLMs to generate test stimuli for hardware verification. They present methods for training LLMs to understand hardware design specifications and produce relevant test cases that can be used to verify the correctness and performance of hardware designs. This approach aims to automate the test generation process, reducing the time and effort required for comprehensive hardware verification. The authors provide a detailed description of the training process, including the selection of training data, model architecture, and the generation of test stimuli. Experimental results demonstrate that LLM4DV-generated test cases are effective in identifying design issues and achieving high coverage in verification tasks. The authors discuss the potential for further enhancing test generation capabilities by incorporating more sophisticated LLMs and integrating the approach with existing verification frameworks. It concludes by highlighting the benefits of using LLMs in hardware verification, such as increased efficiency and reduced manual effort.
This study by Kande et al. [172] explores the use of LLMs to assist in generating hardware assertions, which are critical for verifying the correct behavior of hardware designs. The authors present a framework that uses LLMs to interpret design documentation and automatically produce assertions that can be used in formal verification processes. The goal is to streamline the assertion generation process and ensure comprehensive coverage of design specifications. The framework architecture is described, including the use of LLMs to parse design documents and generate assertions and evaluation methods to assess the quality and precision of these assertions. Experimental results indicate that the LLM-assisted approach produces high-quality assertions that can significantly improve verification efficiency. The study concludes with a discussion on the limitations of current LLMs in understanding complex hardware designs and potential future research directions to improve the capabilities of LLMs in generating assertions, such as incorporating more detailed training data and refining model architectures. Table 10 compares all the papers discussed in this subsection.
Table 10.
Comparison of papers focusing on hardware verification with LLMs.
The authors of this paper [173] present a novel methodology for leveraging LLMs in incremental proof generation for hardware verification. The proposed approach systematically breaks down the DUV into smaller, manageable modules and uses LLMs to generate invariants and integration properties for these modules. The verification process begins by defining unit properties for basic modules, verified with tools like the Z3 solver, and progressively integrates more complex modules while ensuring interface compatibility. This incremental process ensures both scalability and reliability, addressing the challenges posed by the complexity of modern hardware designs. The methodology is demonstrated through case studies on a Ripple Carry Adder and a Dadda Tree Multiplier, showcasing its ability to reduce manual effort and increase efficiency in formal verification. The authors highlight the transformative potential of LLMs in simplifying property generation, improving accuracy, and mitigating human errors in the verification workflow.
The increasing complexity of hardware, especially domain-specific architectures like neuromorphic processors, poses significant challenges for functional verification. The authors in this paper [174] explore the integration of LLMs in the verification process, focusing on test generation, simulation, and analysis. A structured LLM-based workflow is proposed, where the LLM generates test cases in C and assembly for a traditional RISC-V core and a custom neuromorphic processor. The generated tests cover a wide range of functional conditions, achieving high code coverage (89% for the RISC-V and 91% for the neuromorphic processor) while reducing manual effort. The study highlights the potential of LLMs to enhance existing verification tools by generating diverse and effective stimuli, automating the verification pipeline, and addressing gaps in traditional approaches. While promising, the paper also discusses limitations, including the dependency on prompt quality and the need for human oversight during result interpretation.
The authors in VerilogReader [175] integrate LLMs into Coverage-Directed Test Generation (CDG) for hardware verification. Acting as a “Verilog Reader”, the LLM analyzes hardware designs to identify unexplored code branches and generates targeted test stimuli. By enhancing the test generation process with prompt engineering techniques, the framework achieves better code coverage compared with random testing. Experiments using a benchmark suite of Verilog designs demonstrate the method’s effectiveness in reducing manual effort while improving verification quality for small- to medium-complexity designs.
4.3. Use Cases and Successful Stories
LLMs have seen promising applications in real-world hardware design projects, particularly in areas such as Design for Manufacturing (DfM) and embedded system development. LLMs have been integrated into DfM processes to help generate, optimize, and modify designs based on manufacturing constraints. For example, in a study, an LLM was used to modify a parametric design of parts like LEGO bricks and CNC machined components, offering improvements in manufacturability and efficiency. LLM could even suggest optimal manufacturing techniques and improve design geometry to streamline production [176].
In the realm of hardware design, LLMs have also been employed to generate HDL code such as Verilog. For example, LLMs can be used to write, annotate, and debug hardware code, potentially improving design efficiency and reducing errors. While still in experimental stages, these systems show potential in automating parts of the hardware development process [177]. LLMs like GPT-4 and Codex have demonstrated their ability to generate RTL code from natural language descriptions. For instance, recent research has shown that LLMs can automatically generate Verilog or VHDL modules for basic circuits, such as ALUs or FSMs. In practical settings, an engineer provides a description like, “Create a 4-bit ALU with add, subtract, and AND operations”, and the LLM generates functional Verilog code. Such tools can drastically reduce the time and manual effort required in early hardware prototyping and enable faster design exploration.
LLMs have shown promise in generating code for embedded systems, particularly in automating the development of C/C++ code for hardware platforms. While their use is still evolving in this field, LLMs offer the potential to make hardware programming more approachable and help debugging and improving low-level code [178].
LLMs, such as GPT-3.5 and GPT-4, have been applied to generate and refine Verilog code used in hardware design. A process called “VeriRectify” allows the LLM to take error diagnostics from simulators (e.g., iverilog) and iteratively refine the generated Verilog code, significantly improving its correctness and performance. This approach has led to successful code generation for complex hardware designs like multipliers, incorporating both error correction and Power, Performance, and Area (PPA) checks, ensuring optimal designs [130,168].
LLMs can also enhance verification workflows by assisting in detecting errors in HDL code. Verification tasks, which involve writing testbenches and identifying corner cases, are resource-intensive and time-consuming. LLMs can automate parts of this process by analyzing HDL code and flagging potential errors, such as missing signals or incorrect timing constraints. In a case study conducted using ChatGPT-4, the model analyzed HDL snippets and successfully detected common bugs, such as combinational loops, missing always blocks, or improper signal assignments. While the LLM did not replace formal verification tools, it acted as an efficient pre-verification assistant to flag basic issues. Integrating LLMs into verification pipelines can complement formal verification tools, reducing the bug discovery phase and enabling quicker iterations.
LLMs are also being explored for validating system configurations. The “Ciri” framework leverages models like GPT-4 to detect misconfigurations in large-scale systems (e.g., HBase, ZooKeeper). Ciri uses prompt engineering and few-shot learning to improve accuracy, achieving promising F1 scores in identifying configuration errors. While it excels at catching certain types of misconfigurations, challenges remain, such as handling dependency violations [179].
LLMs can generate user documentation, functional specifications, and even testbenches for verification. This is especially useful in hardware/software co-design processes, where clear documentation is critical for collaboration. Recent tools like OpenAI Codex have been explored to automatically generate Verilog testbenches based on existing RTL code and English descriptions. For example, given a Verilog module for a FIFO buffer, the LLM generated a corresponding testbench with input stimulus, assertions, and coverage checks. Automating testbench generation reduces manual overhead, improves verification efficiency, and ensures that testbenches are aligned with the design intent.
5. Challenges
The most important challenges of LLMs in hardware design and verification are shown in Figure 18.
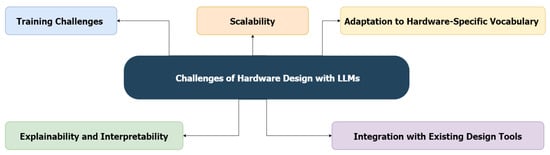
Figure 18.
The most notable challenges of hardware design with LLMs.
5.1. Training Challenges
Training LLMs for hardware design and verification faces substantial challenges primarily due to the nature of the data and the computational demands involved. Hardware design and verification data are highly specialized, often proprietary, and not readily available in public repositories. This scarcity of high-quality, annotated data makes it difficult to train effective models. Moreover, the data’s heterogeneity, encompassing HDL code, schematic diagrams, and natural language documentation, complicates the integration into a cohesive training set. Additionally, the technical expertise required for labeling such data further complicates and prolongs the preparation process. The resource-intensive nature of training LLMs, which demands powerful GPUs or TPUs, significant memory, and extensive storage, is another major hurdle. The energy consumption associated with training these models is also considerable, raising sustainability concerns.
The domain-specific nature of hardware design and verification adds another layer of complexity. LLMs must understand and accurately interpret the intricate language and concepts specific to this field, ensuring that generated outputs are both syntactically correct and semantically meaningful. Errors in generated code can lead to significant functional issues, necessitating robust verification and validation processes. The black-box nature of LLMs presents interpretability challenges, making it difficult to trace and understand their decision-making processes. This lack of transparency can hinder trust and acceptance among hardware engineers, who require clear explanations for the model’s outputs. Integrating LLMs into existing workflows without causing disruptions, ensuring compatibility with various industry tools, and providing adequate training and support for users are critical for successful implementation. Addressing these challenges requires a multidisciplinary approach, continuous collaboration, and advances in both ML and hardware design methodologies.
To overcome data scarcity and quality issues, collaboration between academia, industry, and research institutions is crucial. Establishing partnerships can facilitate the sharing of proprietary data under strict confidentiality agreements, expanding the pool of available training data. Additionally, crowdsourcing initiatives and competitions can be organized to gather more annotated data. Developing advanced data augmentation techniques can help generate synthetic data that closely mimics real-world hardware design scenarios, enhancing the diversity and richness of the training datasets. Implementing semi-supervised or self-supervised learning methods can also leverage unlabeled data to improve model performance [180,181].
5.2. Adaptation to Hardware-Specific Vocabulary
Adapting LLMs to hardware-specific vocabulary for hardware design and verification involves enhancing the models’ ability to understand and generate text that accurately reflects the specialized terminology and concepts used in this field. This process begins with the careful curation of domain-specific corpora, which include HDLs like VHDL and Verilog, technical documentation, research papers, and industry standards. These corpora provide the foundational data that the models need to learn the syntax, semantics, and context of hardware-related terms. Fine-tuning pre-trained LLMs on these specialized datasets enables the models to grasp the nuances of hardware design language, ensuring that they can generate syntactically correct and semantically meaningful code. Additionally, incorporating glossaries and thesauri specific to hardware design during the training phase can help models better understand and use technical terms accurately [182].
Furthermore, integrating feedback loops with domain experts during the training and evaluation phases is crucial for refining the models’ understanding of hardware-specific vocabulary. Experts can review and provide insights on the models’ outputs, identifying areas where the terminology might be used incorrectly or where the context may be misunderstood. This feedback can be used to iteratively improve the models, making them more adept at handling the intricate and precise language of hardware design. Leveraging transfer learning techniques, where models trained on general data are subsequently fine-tuned on hardware-specific data, also enhances their adaptability. This approach allows the models to retain their broad language understanding while becoming proficient in the specialized vocabulary of hardware design and verification. By continuously refining the training process and incorporating expert feedback, LLMs can become powerful tools for assisting in hardware design and verification tasks, offering precise and reliable language understanding tailored to the domain [120].
5.3. Explainability and Interpretability
Explainability and interpretability are critical issues when applying LLMs to hardware design and verification, given the need for transparency, traceability, and trust in the model’s outputs. In hardware design, even minor errors can lead to significant functional flaws, making it essential for engineers to understand how and why an LLM arrived at a particular decision or generated specific code. The black-box nature of LLMs, where the internal workings are opaque and difficult to interpret, poses a significant challenge. This lack of transparency can hinder engineers’ ability to trust the model’s outputs, as they cannot easily verify the correctness or understand the rationale behind specific decisions. Moreover, in the highly specialized field of hardware design, the contextual nuances and technical details are crucial, and any misinterpretation can have far-reaching consequences [183].
To address these issues, several strategies can be employed to enhance the explainability and interpretability of LLMs in hardware design and verification. One approach is the use of attention mechanisms and visualization tools that highlight which parts of the input data the model focused on when generating its outputs. This can provide engineers with insights into the model’s decision-making process and help them understand how specific terms and concepts were interpreted. Another strategy is incorporating explainable AI (XAI) techniques, which aim to make the outputs of ML models more transparent and interpretable. For instance, generating intermediate representations or step-by-step explanations can help bridge the gap between the model’s complex computations and the human engineer’s understanding. Additionally, involving domain experts in the training and validation process can ensure that the model’s explanations align with the technical realities of hardware design. By continuously refining the model based on expert feedback and focusing on transparency, LLMs can become more reliable and trustworthy tools in the hardware design and verification process [184].
5.4. Integration with Existing Design Tools
Integrating LLMs with existing design tools in hardware design and verification presents several challenges due to the specialized and complex nature of these tools. Hardware design workflows rely heavily on sophisticated software such as EDA tools, simulation environments, and formal verification systems. These tools have been optimized over years to handle specific tasks efficiently, and introducing LLMs into this ecosystem requires ensuring seamless interoperability. One significant issue is compatibility: the LLMs must be able to interact with various file formats, data structures, and APIs used by these tools. This necessitates the development of robust interfaces and integration layers that can bridge the gap between the general-purpose nature of LLMs and the specialized requirements of hardware design tools [107].
Additionally, the integration process must ensure that the introduction of LLMs does not disrupt existing workflows. Hardware engineers are accustomed to certain processes and toolchains that have been fine-tuned for productivity and reliability. Introducing LLMs should enhance these workflows by providing added value, such as automating repetitive tasks, offering code suggestions, and assisting in error detection, without requiring significant changes to established practices. This requires careful design of user interfaces and interaction models, ensuring that the outputs from LLMs are presented in a way that is intuitive and easily actionable for engineers. Furthermore, extensive testing and validation are needed to ensure that the LLMs’ outputs are reliable and accurate, thereby gaining the trust of the engineers. Training sessions and comprehensive documentation will also be necessary to help users understand and effectively utilize the new capabilities brought by LLMs. By addressing these integration challenges thoughtfully, LLMs can be successfully incorporated into the hardware design and verification ecosystem, enhancing efficiency and innovation [185].
5.5. Scalability
Scaling large LLMs like GPT-3 or GPT-4 for hardware tasks requires significant memory and compute resources. Model optimization techniques such as pruning, quantization, and Low-Rank Adaptation (LoRA) can reduce the size and computational cost of LLMs while maintaining their performance. Hu et al. [186] demonstrated that LoRA reduces model size by over 90% while preserving fine-tuning accuracy, making it ideal for domain-specific tasks like HDL code generation. Applying these techniques allows LLMs to run efficiently on resource-constrained environments such as edge computing devices used in real-time verification tasks.
Fine-tuning smaller, domain-specific models rather than using general-purpose LLMs can improve scalability. For hardware verification, models trained specifically on HDL code (e.g., Verilog, VHDL) and verification tasks perform better while requiring fewer resources. CodeGen [187] and PolyCoder [188] are examples of smaller models fine-tuned on programming languages. Extending this approach to HDL-specific datasets can improve accuracy and reduce computational load.
Combining LLMs with traditional hardware verification methods (e.g., formal verification, simulation) can address scalability concerns. In such frameworks, the LLM handles simpler tasks like syntax checking or generating testbenches, while the heavy lifting (e.g., formal proofs) is performed by specialized tools [189]. In hybrid systems, LLMs act as assistants that offload simpler tasks, ensuring that large-scale verification processes remain efficient.
6. Open Issues
6.1. Unexplored Applications
LLMs have the potential to significantly improve a variety of sub-domains by automating and optimizing complex tasks. LLMs can streamline the High Level Synthesis (HLS) process by converting high-level code into RTL code and optimizing for performance, area, and power. Similarly, in HDL Generation, LLMs can automate the generation of Verilog, VHDL, or SystemVerilog based on functional specifications.
Moreover, LLMs can enhance component integration by automating the management of hardware module interactions, while in design optimization, they can suggest optimal configurations that balance performance and power trade-offs. In areas like Finite State Machines (FSM) design and Design Space Exploration (DSE), LLMs can assist in optimizing state transitions, identifying unreachable states, and exploring multiple design alternatives for better performance.
LLMs are also helpful in power-conscious tasks like power-aware design, providing suggestions for power-saving techniques, and in timing analysis and optimization, where they assist in meeting timing constraints through clock tree and propagation optimizations. Other physical design tasks, such as floor planning and physical layout, benefit from the ability of LLMs to optimize component placement and routing for improved performance and reduced congestion.
The role of LLMs extends to low-power design techniques, hardware accelerators, and clock tree synthesis (CTS), where they help designers balance power with performance, create architectures for AI accelerators, and optimize clock distribution networks. LLMs can also influence chip architecture design by proposing architectural suggestions and improving data flow.
In advanced design areas such as ASIC design, fault-tolerant design, and verification plan generation, LLMs provide automated support for optimizing integrated circuits, generating redundancy schemes, and creating comprehensive verification plans. For detailed tasks and applications of LLMs in each sub-domain, refer to Table 11, which offers a structured overview of how LLMs contribute to enhancing various aspects of hardware design.
Table 11.
Open issues in terms of main domains, tasks, and LLM usage for future research.
6.2. Research Gaps
The current research landscape for LLMs in hardware design reveals several significant gaps that limit their application in critical areas such as formal verification, design optimization, and security. Despite the potential of LLMs, their integration with formal methods remains largely absent, posing risks to safety-critical systems. Moreover, the lack of contextual understanding in optimizing complex design trade-offs between PPA hampers multi-objective optimization efforts. Security vulnerabilities specific to hardware designs are also underexplored, leaving hardware systems at risk. The shortage of specialized datasets further compounds the challenge, limiting LLMs’ effectiveness in hardware-specific tasks like circuit design and verification. As hardware designs scale in complexity, managing large systems like SoCs becomes increasingly challenging for LLMs, and areas such as analog/mixed-signal design, hardware/software codesign, and post-silicon validation remain underdeveloped.Table 12 provided details on the specific gaps in each of these areas and their respective impacts, offering a clearer picture of the current limitations and opportunities for further research. The most significant sub-domains for each domain can be mentioned as follows:
Table 12.
Gaps and impacts of LLMs in hardware design.
- HLS
- -
- Behavioral synthesis: converting behavioral descriptions directly into RTL [190,191].
- -
- Scheduling: managing operation timing to meet performance and resource constraints [192,193].
- -
- Resource allocation: assigning operations to hardware resources such as registers or functional units [194,195].
- -
- Loop unrolling and pipelining: enhance parallelism by optimizing loop handling [196,197].
- -
- Bit-width optimization: minimizing the width of variables without sacrificing accuracy [198].
- -
- Control flow management: managing control flow statements (if-else, switch-case) for hardware synthesis [199].
- -
- Memory access optimization: efficiently handling memory access patterns to reduce latency [200,201].
- -
- Interface generation: creating interfaces for communication between blocks during synthesis [202].
- HDL Generation
- -
- Synthesis-ready HDL code generation: automatically generating Verilog or VHDL that is ready for synthesis [203].
- -
- Parameterized HDL code: creating reusable code with configurable parameters [204].
- -
- State machine code generation: creating FSMs based on behavioral specifications [205,206].
- -
- HDL code translation: translating high-level or behavioral code into synthesizable HDL [207,208].
- -
- Testbench generation: automatically generating testbenches for HDL verification [209,210,211].
- -
- Hierarchical module design: automatically generating modular and hierarchical HDL blocks [212].
- -
- Assertions and constraints: generating assertion-based HDL for formal verification [165,213].
- -
- Code formatting and cleanup: ensuring HDL code is clean, well-formatted, and error-free (https://www.einfochips.com, accessed on 29 December 2024, https://blogs.sw.siemens.com, accessed on 29 December 2024).
- Component Integration
- -
- Interface synthesis: automatically generating interfaces (e.g., Advanced eXtensible Interface (AXI), Advanced Microcontroller Bus Architecture specification (AMBA)) between hardware modules [214].
- -
- Signal mapping: automating the signal connection and mapping between modules [215].
- -
- Inter-module communication: managing and optimizing data and control flow between different hardware blocks [216].
- -
- Bus arbitration: design of efficient bus systems for shared resources [217].
- -
- Protocol handling: automating protocol management for communication between modules (https://www.mhtechin.com, accessed on 29 December 2024).
- -
- System berification: automatically generating testbenches to verify integrated systems [205,218].
- -
- Hierarchical integration: building hierarchical hardware designs by integrating reusable IP blocks [219,220].
- Design Optimization
- -
- Timing optimization: optimizing designs to meet timing constraints [221,222].
- -
- Power optimization: minimizing power consumption through design improvements [223,224,225].
- -
- Area optimization: reducing the overall silicon area used by the hardware [226,227].
- -
- Pipelining and parallelization: introducing pipelining and parallelization to improve performance [228,229].
- -
- Data path optimization: optimizing the data path for reduced latency and better resource utilization [230].
- -
- Power–performance trade-offs: balancing between performance gains and power savings [231,232,233].
- -
- Critical path reduction: shortening the critical path to improve clock frequency [234,235].
- FSM Design
- -
- State minimization: reducing the number of states to optimize hardware usage [236,237,238].
- -
- Hierarchical FSM design: creating complex FSMs using a hierarchical approach [239].
- -
- Error detection FSMs: design of FSMs with built-in error detection mechanisms [240,241].
- -
- Power-aware FSM design: creating FSMs optimized for low power consumption [242].
- -
- State encoding optimization: optimizing state encodings (e.g., one-hot, binary) for efficiency [243].
- -
- Timing-aware FSM design: ensure that FSMs meet timing constraints [244].
- DSE
- -
- Pareto-optimal design space exploration: exploring the design space to identify Pareto-optimal trade-offs between power, area, and performance [245].
- -
- Multi-objective optimization: optimizing designs for multiple conflicting objectives (e.g., power vs. performance) [246].
- -
- Parametric design exploration: exploring various parameter configurations to achieve optimal results [247].
- -
- Constraint-driven design: ensure that all design options meet predefined constraints [248].
- -
- ML-assisted DSE: using ML models to predict design performance and help in exploration [249,250,251].
- -
- Scenario-based DSE: exploring designs based on different use-case scenarios (e.g., high-performance vs. low-power modes) [252].
- Power-Aware Design
- -
- Dynamic power management: real-time power adjustments based on workload [231,232,253,254].
- -
- Clock gating: reducing power consumption by turning off clocks in idle modules [223,255].
- -
- Voltage scaling: dynamically adjust the voltage supply to minimize power usage [256].
- -
- Multi-VDD design: design of hardware that operates at multiple voltage levels for different modules [257].
- -
- Leakage power reduction: techniques to reduce leakage power in idle states [258].
- -
- Low-power memory design: optimizing memory access and design to minimize power [259,260].
- -
- Thermal-aware power optimization: ensuring power optimizations also consider thermal constraints [261,262,263].
- Timing Analysis and Optimization
- -
- Static Timing Analysis (STA): automatically analyzing and optimizing timing paths [264].
- -
- Critical path analysis: identifying and optimizing the critical path to ensure timing closure [265].
- -
- Clock skew minimization: optimizing the clock distribution to minimize the skew in the design [266].
- -
- Multi-clock domain design: managing and optimizing designs with multiple clock domains [267,268].
- -
- Hold and setup time optimization: ensure that all paths meet the hold and setup time constraints [269].
- -
- Path delay optimization: shortening the longest paths in the design to improve performance [270].
- Floorplanning and Physical Design
- -
- Component placement optimization: place components to minimize delays and area usage [271].
- -
- Power grid design: design of power distribution networks to ensure reliable power delivery [272].
- -
- Routing congestion management: optimize placement to avoid routing congestion and improve performance [273].
- -
- Thermal-aware floorplanning: ensure that heat-generating components are placed efficiently for heat dissipation [274,275].
- -
- Timing-aware floorplanning: ensure that critical timing paths are optimized in the placement process [276].
- Low-Power Design Techniques
- -
- Multi-threshold design: using multiple threshold voltages to optimize power [277,278].
- -
- Adaptive Voltage Scaling (AVS): dynamically adjust voltage levels for power savings [279,280].
- -
- Dynamic power gating: turn off parts of the circuit during inactivity to save power [281,282].
- -
- Energy-efficient logic synthesis: design circuits with low power consumption from the ground up [283].
- -
- Sleep mode design: implement deep sleep modes for minimal power consumption during idle periods [284].
- Hardware Accelerators
- -
- AI/ML accelerators: design of hardware specialized for AI/ML tasks (for example, matrix multiplication, deep learning) [285,286].
- -
- DSP accelerators: optimizing hardware for DSP tasks such as filtering and transforms [287,288].
- -
- Parallel computing accelerators: designing hardware for parallel task execution, such as multi-core GPUs or FPGAs [289,290].
- -
- Memory bandwidth optimization: ensure that memory subsystems can handle the data bandwidth required for high-throughput hardware accelerators [291,292].
- -
- Reconfigurable accelerators: design flexible hardware accelerators, such as FPGAs, that can be adapted to different tasks [293,294].
- -
- Low-power accelerators: optimizing accelerators to be power efficient, especially for mobile and embedded systems [295,296].
- -
- AI hardware/software co-optimization: co-design of AI software and hardware to maximize hardware utilization and performance [297,298].
- CTS
- -
- Clock skew minimization: ensure that clock signals arrive at all components simultaneously to minimize skew [299].
- -
- Power-aware CTS: design of clock trees to minimize power consumption [300].
- -
- Multi-domain clock tree design: managing multiple clock domains to ensure efficient clock distribution [301].
- -
- Clock buffer insertion: strategic placement of buffers to reduce clock delay and skew [302].
- -
- Gated clock design: reduction in power by turning off the clock in inactive areas of the design [303,304].
- -
- CTS for low-power designs: techniques to reduce clock power consumption, like multi-threshold designs or clock gating [305].
- Chip Architecture Design
- -
- Multi-core architecture design: defining architectures with multiple cores for parallelism and performance improvements [306,307].
- -
- Memory hierarchy design: design of the memory subsystem, including caches, RAM, and register files, to optimize data access speeds [308,309].
- -
- Dataflow architecture: optimizing the flow of data between processing units to maximize throughput [310,311].
- -
- Instruction Set Architecture (ISA): defining and optimizing the instruction set used by processors [312,313].
- -
- On-chip communication networks: design of networks for communication between cores and other processing units [314,315,316,317,318,319,320].
- -
- Performance bottleneck identification: analyze architectural designs to find and eliminate performance bottlenecks [321,322].
- -
- Scalability optimization: ensure that the chip architecture scales well with increasing system complexity (e.g., more cores or memory) [323,324].
- Physical Layout and Routing
- -
- Component placement optimization: identifying the optimal placement of components to reduce routing length and delay [271,325].
- -
- Wire routing: definition of the path of signal wires to minimize delay, power consumption, and congestion [326,327].
- -
- Congestion management: preventing over-congested regions in the design by optimizing component placement and routing [328,329].
- -
- Thermal-aware layout: ensure that heat-generating components are placed strategically for heat dissipation [330,331].
- -
- Signal Integrity optimization: preventing issues such as crosstalk and electromagnetic interference in wire routing [332,333].
- -
- Area optimization: minimizing the total area occupied by the physical layout of the components [334].
- ASIC Design
- -
- Standard cell library selection: choosing the right standard cell libraries for performance, power, and area trade-offs [335].
- -
- Custom cell design: design of custom logic cells optimized for specific performance and area requirements [336].
- -
- Power grid optimization: design of efficient power distribution networks across ASICs [337].
- -
- Design-for-Test (DFT): embedding testability features into the design to ensure that the ASIC is testable after fabrication [338,339].
- -
- ASIC synthesis: translating high-level designs into a netlist using synthesis tools [340,341].
- -
- Timing closure for ASICs: ensure that the final design meets the timing constraints before manufacturing [342,343].
- -
- Packaging and I/O design: optimizing external interfaces and packaging for the ASIC [344].
- Fault-Tolerant Design
- -
- Error Detection and Correction (EDAC): design hardware with the ability to detect and correct errors (e.g., Error Correction Code (ECC)) [345,346].
- -
- Redundancy techniques: implementing redundancy at various levels (e.g., triple modular redundancy, hot spares) [192,347,348].
- -
- Built-in Self-test (BIST): design self-test circuits that can detect faults during run-time [349,350].
- -
- Fault-tolerant FSMs: design of finite-state machines that can recover from faulty states [351,352].
- -
- Radiation hardening: designing hardware that is resilient to radiation effects, particularly for aerospace applications [353,354].
- -
- Soft error mitigation: techniques for preventing or recovering transient errors caused by cosmic rays or other environmental factors [355,356].
- -
- Failure mode analysis: analyze hardware to predict and mitigate potential failure modes [357,358].
- Verification Plan Generation
- -
- Testbench automation: automatically generating testbenches for verifying different parts of the hardware design [211,218].
- -
- Random test generation: creating random test sequences to stress the design and catch edge cases [359].
- -
- Constraint-based verification: defining constraints for test generation to ensure valid input/output scenarios [360].
- -
- Formal verification: using mathematical techniques to prove that a design meets its specifications [361,362].
- -
- Assertion-based Verification (ABV): embedding assertions in the design to ensure it behaves as expected under all conditions [363,364].
- -
- Equivalence checking: ensure that two versions of a design (e.g., RTL vs. synthesized) are functionally equivalent [365,366].
- -
- UVM and SystemVerilog: implement advanced verification techniques using UVM and SystemVerilog [367].
6.3. Methodological Improvements
With making significant improvements in hardware design and verification, several aspects of LLMs need to be reinforced. These enhancements would target specific challenges in hardware engineering and leverage LLMs to their full potential in assisting designers and verification teams. The key aspects that should be reinforced are as follows:
- (1)
- Domain-specific understanding and contextual knowledge: LLMs need a deeper and more precise understanding of hardware design languages, methodologies, and tools. While LLMs excel at NLP, they often lack in-depth knowledge of domain-specific languages like Verilog, VHDL, SystemVerilog, and UVM. To truly aid hardware designers, LLMs must be fine-tuned on vast datasets of HDLs, verification code, design documentation, and real-world projects. Additionally, understanding the context of a design, such as the specific requirements of a given project (e.g., low-power design, high performance, etc.), will enable LLMs to make more relevant suggestions during both the design and verification processes.
- (2)
- Enhanced formal reasoning capabilities: LLMs need to improve their formal reasoning abilities, especially for tasks such as formal verification, model checking, and constraint satisfaction, which are essential to hardware verification. Hardware design often involves proving that a design meets certain formal specifications, such as safety or liveness properties. Currently, LLMs struggle with formal logic and mathematical rigor. Enhancing their capability to handle formal methods—like understanding temporal logic, SVA, and finite state machines—would significantly improve their utility in verification tasks. This would allow LLMs to automatically generate and validate formal properties from natural language specifications, ensuring that hardware designs conform to their intended behavior.
- (3)
- Code generation for synthesis-ready HDL: While LLMs can generate HDL code from behavioral descriptions, they must become more adept at creating synthesis-ready code. This requires not only understanding how to describe hardware behavior but also generating optimized code that meets the constraints of modern hardware synthesis tools. To achieve this, LLMs need reinforcement in optimizing generated code for real-world constraints such as timing, power, and area. Incorporating feedback from synthesis and place-and-route tools into the LLM’s training data can improve its ability to generate resource-efficient, high-performance HDL designs.
- (4)
- Design space exploration and optimization: One of the critical tasks in hardware design is balancing multiple design constraints—performance, power, area, and cost—through DSE. LLMs should be reinforced with advanced optimization techniques and predictive modeling capabilities to help guide the exploration of various design parameters. Reinforcement learning approaches combined with LLMs can enable them to predict the impact of parameter choices on design metrics and suggest optimal configurations based on trade-offs. By enhancing LLMs’ ability to navigate complex design spaces, designers could receive better support in exploring Pareto-optimal designs that balance competing objectives.
- (5)
- Error detection and debugging: LLMs can play a crucial role in identifying bugs and design flaws, but their error detection capabilities must be reinforced to be more effective in the hardware domain. This includes being able to recognize subtle errors in HDL, such as incorrect state machine transitions, misaligned clock domain crossings, or resource contention. LLMs need to be trained on common hardware design errors and verification failures, improving their ability to offer precise feedback on potential issues. Additionally, LLMs should be reinforced with an understanding of simulation and synthesis reports, enabling them to trace errors back to their root causes and provide actionable debugging suggestions.
- (6)
- Verification automation and coverage analysis: Verification is one of the most time-consuming aspects of hardware development. To improve LLMs’ contributions in this domain, they should be reinforced with better tools for generating comprehensive testbenches, performing functional coverage analysis, and creating directed random tests. Specifically, LLMs should be enhanced to recognize coverage gaps in verification plans and generate appropriate tests to fill those gaps, ensuring that designs are thoroughly tested. Furthermore, improving the LLM’s ability to integrate with simulation tools, extract meaningful insights from waveform data, and recommend additional verification steps will reduce the manual burden on verification teams.
- (7)
- Learning from hardware development iterations: LLMs should be able to learn from previous iterations of a hardware design to assist in continuous improvement. By analyzing successive versions of a design, LLMs can identify what changes led to better performance, lower power consumption, or reduced area. Reinforcing this ability would enable LLMs to provide context-specific recommendations based on past design choices, helping hardware designers optimize their designs more effectively across multiple development cycles. This capability could also be extended to learning from community-wide datasets of hardware designs to suggest best practices and design patterns that are tailored to specific project goals.
- (8)
- Interaction with EDA tools and integration into workflows: For LLMs to be more effective in hardware design, they need tighter integration with EDA tools and workflows. LLMs should be able to interface with common hardware design tools (such as simulation, synthesis, and formal verification tools), extract relevant data, and act on that information in real time. By integrating LLMs with these tools, designers can receive real-time feedback on design choices, simulation results, or synthesis reports. LLMs should also be capable of automating repetitive tasks within the EDA workflow, such as setting up project configurations, running simulations, and analyzing results, reducing the overall design time.
- (9)
- Memory and state tracking for large-scale projects: Hardware design projects can span months or years and involve numerous changes over time. LLMs should be reinforced with better long-term memory and state-tracking capabilities so that they can keep track of ongoing changes across large projects. This would allow LLMs to assist designers by recalling relevant design decisions, tracking the evolution of specific modules or components, and ensuring consistency across the entire design. This state-tracking ability is crucial for handling complex projects with multiple designers, where coordination and memory of past decisions are key to success.
- (10)
- Security and safety in hardware design: LLMs should be enhanced to understand and enforce security and safety requirements during the design process. With the growing need for hardware security, LLMs must be able to detect potential vulnerabilities, such as insecure communication protocols or improper handling of sensitive data. Similarly, in safety-critical designs, such as automotive or aerospace systems, LLMs need reinforcement to ensure compliance with safety standards and protocols. By improving LLMs’ capabilities in these areas, designers can be alerted to potential security risks and safety violations early in the design phase.
7. Conclusions
This survey has explored the emerging role of LLMs in hardware design and verification, presenting an overview of the current state of the literature, key challenges, and open issues. The integration of LLMs into this domain offers significant potential to revolutionize traditional workflows, enhancing productivity and enabling more automated and intelligent design processes. From facilitating high-level hardware description generation to improving verification through natural language interfaces, LLMs provide promising avenues to reduce complexity, improve accuracy, and accelerate time-to-market in hardware development cycles. However, despite the promising advancements, several challenges remain. The specialized nature of hardware design and verification demands precise and domain-specific capabilities from LLMs, which are not always easy to align with the general-purpose nature of current models. Additionally, issues like explainability, the handling of large-scale designs, the ability to generate verifiably correct hardware descriptions, and integration into existing workflows highlight the limitations of current LLM-based approaches. Moreover, concerns around model reliability, data privacy, and security in industrial settings require further attention before widespread adoption.
7.1. Summary of Findings
This paper discusses the transformative role of LLMs in hardware design and verification. It highlights several key areas where LLMs are improving efficiency and accuracy in hardware design by automating repetitive tasks, generating code, and facilitating better communication among engineers. The paper emphasizes the following contributions:
- (1)
- Core applications:LLMs are applied to various tasks, including generating HDL code, optimizing design parameters, and automating verification processes like test case generation and bug detection. They can also enhance documentation and project management.
- (2)
- Challenges:Despite the advancements, challenges such as data scarcity, the need for specialized training, and integration with existing tools remain. The complexity of hardware design requires fine-tuning LLMs for specific tasks.
- (3)
- Future directions:the paper suggests potential areas for future research, including improving LLM integration in hardware design workflows, refining LLM-generated outputs, and addressing open issues such as handling high-dimensional data and design complexity.
In summary, LLMs hold significant potential to transform hardware design and verification by automating complex tasks, enhancing productivity, and ensuring higher quality designs. However, there are still challenges related to training, data availability, and tool integration that need to be addressed to fully realize this potential.
7.2. Implications and Recommendations
There are several key areas where future research can focus to advance the application of LLMs in hardware design and verification:
- (1)
- Domain-specific LLMs:Developing LLMs tailored to the specific needs of hardware design and verification could enhance their effectiveness. This includes models trained on HDL, circuit layouts, and specialized verification protocols.
- (2)
- Improving verification capabilities: expanding the capacity of LLMs to automatically verify hardware designs through formal methods and simulation could reduce the burden of manual verification and lead to more robust, error-free hardware.
- (3)
- Hybrid systems: combining LLMs with other AI and traditional formal verification techniques could result in hybrid systems that leverage the strengths of both approaches, improving the accuracy and reliability of hardware designs.
- (4)
- Explainability and interpretability: Ensuring that LLM-generated hardware descriptions are transparent and interpretable by engineers is critical. Future research could focus on developing methods to make the reasoning behind LLM outputs more understandable and trustworthy.
- (5)
- Real-world applications: More real-world case studies are needed to evaluate the practical utility of LLMs in large-scale hardware projects. This will provide insights into the models’ performance in complex, industrial settings and help identify further areas of improvement.
- (6)
- Data privacy and security: addressing concerns around the secure use of LLMs in proprietary hardware design environments, including techniques for ensuring that sensitive data remains protected during model training and deployment, will be crucial for industrial adoption.
Supplementary Materials
The following supporting information can be downloaded at www.mdpi.com/article/10.3390/electronics14010120/s1, Table S1: PRISMA-ScR checklist.
Author Contributions
Conceptualization, M.A.; methodology, M.A. and S.F.Y.; software, M.A., S.F.Y. and M.B.; validation, M.A., S.F.Y. and M.B.; formal analysis, M.A. and S.F.Y.; investigation, M.A. and S.F.Y.; resources, M.A. and S.F.Y.; data curation, M.A. and S.F.Y.; writing—original draft preparation, M.A., S.F.Y. and M.B.; writing—review and editing, M.A., S.F.Y., M.B. and A.B.; visualization, M.A. and S.F.Y.; supervision, M.A.; project administration, M.A.; funding acquisition, A.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pinker, S. The Language Instinct: How the Mind Creates Language; Penguin uK: New York, NY, USA, 2003. [Google Scholar]
- Hauser, M.D.; Chomsky, N.; Fitch, W.T. The faculty of language: What is it, who has it, and how did it evolve? Science 2002, 298, 1569–1579. [Google Scholar] [CrossRef] [PubMed]
- Turing, A.M. Computing Machinery and Intelligence; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Chernyavskiy, A.; Ilvovsky, D.; Nakov, P. Transformers: “the end of history” for natural language processing? In Proceedings of the Machine Learning and Knowledge Discovery in Databases. Research Track: European Conference, ECML PKDD 2021, Bilbao, Spain, 13–17 September 2021; Proceedings, Part III 21. Springer: Berlin/Heidelberg, Germany, 2021; pp. 677–693. [Google Scholar]
- Zhao, W.X.; Zhou, K.; Li, J.; Tang, T.; Wang, X.; Hou, Y.; Min, Y.; Zhang, B.; Zhang, J.; Dong, Z.; et al. A survey of large language models. arXiv 2023, arXiv:2303.18223. [Google Scholar]
- Bommasani, R.; Hudson, D.A.; Adeli, E.; Altman, R.; Arora, S.; von Arx, S.; Bernstein, M.S.; Bohg, J.; Bosselut, A.; Brunskill, E.; et al. On the opportunities and risks of foundation models. arXiv 2021, arXiv:2108.07258. [Google Scholar]
- Wei, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent abilities of large language models. arXiv 2022, arXiv:2206.07682. [Google Scholar]
- Bahl, L.R.; Brown, P.F.; De Souza, P.V.; Mercer, R.L. A tree-based statistical language model for natural language speech recognition. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 1001–1008. [Google Scholar] [CrossRef]
- Frederick, J. Statistical Methods for Speech Recognition; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Gao, J.; Lin, C.Y. Introduction to the special issue on statistical language modeling. ACM Trans. Asian Lang. Inf. Process. 2004, 3, 87–93. [Google Scholar] [CrossRef]
- Bellegarda, J.R. Statistical language model adaptation: Review and perspectives. Speech Commun. 2004, 42, 93–108. [Google Scholar] [CrossRef]
- Zhai, C. Statistical language models for information retrieval a critical review. Found. Trends Inf. Retr. 2008, 2, 137–213. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. Adv. Neural Inf. Process. Syst. 2000, 13, 1137–1155. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech, Makuhari, Chiba, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Kombrink, S.; Mikolov, T.; Karafiát, M.; Burget, L. Recurrent Neural Network Based Language Modeling in Meeting Recognition. In Proceedings of the Interspeech, Florence, Italy, 27–31 August 2011; Volume 11, pp. 2877–2880. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ghojogh, B.; Ghodsi, A. Attention Mechanism, Transformers, BERT, and GPT: Tutorial and Survey; OSF Preprints: Charlottesville, VA, USA, 2020. [Google Scholar]
- Liu, Q.; Kusner, M.J.; Blunsom, P. A survey on contextual embeddings. arXiv 2020, arXiv:2003.07278. [Google Scholar]
- Ge, Y.; Hua, W.; Mei, K.; Tan, J.; Xu, S.; Li, Z.; Zhang, Y. Openagi: When llm meets domain experts. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Alex, N.; Lifland, E.; Tunstall, L.; Thakur, A.; Maham, P.; Riedel, C.J.; Hine, E.; Ashurst, C.; Sedille, P.; Carlier, A.; et al. RAFT: A real-world few-shot text classification benchmark. arXiv 2021, arXiv:2109.14076. [Google Scholar]
- Qin, C.; Zhang, A.; Zhang, Z.; Chen, J.; Yasunaga, M.; Yang, D. Is ChatGPT a general-purpose natural language processing task solver? arXiv 2023, arXiv:2302.06476. [Google Scholar]
- Gao, J.; Zhao, H.; Yu, C.; Xu, R. Exploring the feasibility of chatgpt for event extraction. arXiv 2023, arXiv:2303.03836. [Google Scholar]
- Ma, Y.; Cao, Y.; Hong, Y.; Sun, A. Large language model is not a good few-shot information extractor, but a good reranker for hard samples! arXiv 2023, arXiv:2303.08559. [Google Scholar]
- Cheng, D.; Huang, S.; Bi, J.; Zhan, Y.; Liu, J.; Wang, Y.; Sun, H.; Wei, F.; Deng, D.; Zhang, Q. Uprise: Universal prompt retrieval for improving zero-shot evaluation. arXiv 2023, arXiv:2303.08518. [Google Scholar]
- Ren, R.; Qu, Y.; Liu, J.; Zhao, W.X.; She, Q.; Wu, H.; Wang, H.; Wen, J.R. Rocketqav2: A joint training method for dense passage retrieval and passage re-ranking. arXiv 2021, arXiv:2110.07367. [Google Scholar]
- Sun, W.; Yan, L.; Ma, X.; Wang, S.; Ren, P.; Chen, Z.; Yin, D.; Ren, Z. Is ChatGPT good at search? investigating large language models as re-ranking agents. arXiv 2023, arXiv:2304.09542. [Google Scholar]
- Ziems, N.; Yu, W.; Zhang, Z.; Jiang, M. Large language models are built-in autoregressive search engines. arXiv 2023, arXiv:2305.09612. [Google Scholar]
- Tay, Y.; Tran, V.; Dehghani, M.; Ni, J.; Bahri, D.; Mehta, H.; Qin, Z.; Hui, K.; Zhao, Z.; Gupta, J.; et al. Transformer memory as a differentiable search index. Adv. Neural Inf. Process. Syst. 2022, 35, 21831–21843. [Google Scholar]
- Dai, S.; Shao, N.; Zhao, H.; Yu, W.; Si, Z.; Xu, C.; Sun, Z.; Zhang, X.; Xu, J. Uncovering chatgpt’s capabilities in recommender systems. In Proceedings of the 17th ACM Conference on Recommender Systems, Singapore, 18–22 September 2023; pp. 1126–1132. [Google Scholar]
- Zheng, B.; Hou, Y.; Lu, H.; Chen, Y.; Zhao, W.X.; Wen, J.R. Adapting large language models by integrating collaborative semantics for recommendation. arXiv 2023, arXiv:2311.09049. [Google Scholar]
- Wang, L.; Ma, C.; Feng, X.; Zhang, Z.; Yang, H.; Zhang, J.; Chen, Z.; Tang, J.; Chen, X.; Lin, Y.; et al. A survey on large language model based autonomous agents. Front. Comput. Sci. 2024, 18, 186345. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, J.; Chen, X.; Lin, Y.; Song, R.; Zhao, W.X.; Wen, J.R. Recagent: A novel simulation paradigm for recommender systems. arXiv 2023, arXiv:2306.02552. [Google Scholar]
- Du, Y.; Liu, Z.; Li, J.; Zhao, W.X. A survey of vision-language pre-trained models. arXiv 2022, arXiv:2202.10936. [Google Scholar]
- Gan, Z.; Li, L.; Li, C.; Wang, L.; Liu, Z.; Gao, J. Vision-language pre-training: Basics, recent advances, and future trends. Found. Trends Comput. Graph. Vis. 2022, 14, 163–352. [Google Scholar] [CrossRef]
- Chen, W.; Su, Y.; Yan, X.; Wang, W.Y. KGPT: Knowledge-grounded pre-training for data-to-text generation. arXiv 2020, arXiv:2010.02307. [Google Scholar]
- Wang, X.; Wang, Z.; Liu, J.; Chen, Y.; Yuan, L.; Peng, H.; Ji, H. Mint: Evaluating llms in multi-turn interaction with tools and language feedback. arXiv 2023, arXiv:2309.10691. [Google Scholar]
- Zhang, X.; Yu, B.; Yu, H.; Lv, Y.; Liu, T.; Huang, F.; Xu, H.; Li, Y. Wider and deeper llm networks are fairer llm evaluators. arXiv 2023, arXiv:2308.01862. [Google Scholar]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef] [PubMed]
- Jeblick, K.; Schachtner, B.; Dexl, J.; Mittermeier, A.; Stüber, A.T.; Topalis, J.; Weber, T.; Wesp, P.; Sabel, B.O.; Ricke, J.; et al. ChatGPT makes medicine easy to swallow: An exploratory case study on simplified radiology reports. Eur. Radiol. 2024, 34, 2817–2825. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Kann, B.H.; Foote, M.B.; Aerts, H.J.; Savova, G.K.; Mak, R.H.; Bitterman, D.S. The utility of chatgpt for cancer treatment information. medRxiv 2023, 16. [Google Scholar] [CrossRef]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Hou, L.; Clark, K.; Pfohl, S.; Cole-Lewis, H.; Neal, D.; et al. Towards expert-level medical question answering with large language models. arXiv 2023, arXiv:2305.09617. [Google Scholar]
- Yang, K.; Ji, S.; Zhang, T.; Xie, Q.; Ananiadou, S. On the evaluations of chatgpt and emotion-enhanced prompting for mental health analysis. arXiv 2023, arXiv:2304.03347. [Google Scholar]
- Tang, R.; Han, X.; Jiang, X.; Hu, X. Does synthetic data generation of llms help clinical text mining? arXiv 2023, arXiv:2303.04360. [Google Scholar]
- Rane, N.L.; Tawde, A.; Choudhary, S.P.; Rane, J. Contribution and performance of ChatGPT and other Large Language Models (LLM) for scientific and research advancements: A double-edged sword. Int. Res. J. Mod. Eng. Technol. Sci. 2023, 5, 875–899. [Google Scholar]
- Dai, W.; Lin, J.; Jin, H.; Li, T.; Tsai, Y.S.; Gašević, D.; Chen, G. Can large language models provide feedback to students? A case study on ChatGPT. In Proceedings of the 2023 IEEE International Conference on Advanced Learning Technologies (ICALT), Orem, UT, USA, 10–13 July 2023; pp. 323–325. [Google Scholar]
- Young, J.C.; Shishido, M. Investigating OpenAI’s ChatGPT potentials in generating Chatbot’s dialogue for English as a foreign language learning. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- Susnjak, T.; McIntosh, T.R. ChatGPT: The end of online exam integrity? Educ. Sci. 2024, 14, 656. [Google Scholar] [CrossRef]
- Tamkin, A.; Brundage, M.; Clark, J.; Ganguli, D. Understanding the capabilities, limitations, and societal impact of large language models. arXiv 2021, arXiv:2102.02503. [Google Scholar]
- Nay, J.J. Law informs code: A legal informatics approach to aligning artificial intelligence with humans. Nw. J. Tech. Intell. Prop. 2022, 20, 309. [Google Scholar] [CrossRef]
- Yu, F.; Quartey, L.; Schilder, F. Legal prompting: Teaching a language model to think like a lawyer. arXiv 2022, arXiv:2212.01326. [Google Scholar]
- Trautmann, D.; Petrova, A.; Schilder, F. Legal prompt engineering for multilingual legal judgement prediction. arXiv 2022, arXiv:2212.02199. [Google Scholar]
- Sun, Z. A short survey of viewing large language models in legal aspect. arXiv 2023, arXiv:2303.09136. [Google Scholar]
- Savelka, J.; Ashley, K.D.; Gray, M.A.; Westermann, H.; Xu, H. Explaining legal concepts with augmented large language models (gpt-4). arXiv 2023, arXiv:2306.09525. [Google Scholar]
- Cui, J.; Li, Z.; Yan, Y.; Chen, B.; Yuan, L. Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv 2023, arXiv:2306.16092. [Google Scholar]
- Guha, N.; Nyarko, J.; Ho, D.; Ré, C.; Chilton, A.; Chohlas-Wood, A.; Peters, A.; Waldon, B.; Rockmore, D.; Zambrano, D.; et al. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. Adv. Neural Inf. Process. Syst. 2024, 36. [Google Scholar] [CrossRef]
- Araci, D. Finbert: Financial sentiment analysis with pre-trained language models. arXiv 2019, arXiv:1908.10063. [Google Scholar]
- Li, Y.; Wang, S.; Ding, H.; Chen, H. Large language models in finance: A survey. In Proceedings of the Fourth ACM International Conference on AI in Finance, Brooklyn, NY, USA, 27–29 November 2023; pp. 374–382. [Google Scholar]
- Yang, H.; Liu, X.Y.; Wang, C.D. Fingpt: Open-source financial large language models. arXiv 2023, arXiv:2306.06031. [Google Scholar] [CrossRef]
- Son, G.; Jung, H.; Hahm, M.; Na, K.; Jin, S. Beyond classification: Financial reasoning in state-of-the-art language models. arXiv 2023, arXiv:2305.01505. [Google Scholar]
- Shah, A.; Chava, S. Zero is not hero yet: Benchmarking zero-shot performance of llms for financial tasks. arXiv 2023, arXiv:2305.16633. [Google Scholar] [CrossRef]
- Jin, Q.; Dhingra, B.; Liu, Z.; Cohen, W.W.; Lu, X. Pubmedqa: A dataset for biomedical research question answering. arXiv 2019, arXiv:1909.06146. [Google Scholar]
- Mahadi Hassan, M.; Knipper, A.; Kanti Karmaker Santu, S. ChatGPT as your Personal Data Scientist. arXiv 2023, arXiv:2305.13657. [Google Scholar]
- Irons, J.; Mason, C.; Cooper, P.; Sidra, S.; Reeson, A.; Paris, C. Exploring the Impacts of ChatGPT on Future Scientific Work 2023; SocArXiv Papers: Eveleigh, Australia, 2023. [Google Scholar]
- Altmäe, S.; Sola-Leyva, A.; Salumets, A. Artificial intelligence in scientific writing: A friend or a foe? Reprod. Biomed. Online 2023, 47, 3–9. [Google Scholar] [CrossRef]
- Zheng, Y.; Koh, H.Y.; Ju, J.; Nguyen, A.T.; May, L.T.; Webb, G.I.; Pan, S. Large language models for scientific synthesis, inference and explanation. arXiv 2023, arXiv:2310.07984. [Google Scholar]
- Aczel, B.; Wagenmakers, E.J. Transparency Guidance for ChatGPT Usage in Scientific Writing; PsyArXiv 2023 Preprint: Charlottesville, VA, USA.
- Jin, H.; Huang, L.; Cai, H.; Yan, J.; Li, B.; Chen, H. From llms to llm-based agents for software engineering: A survey of current, challenges and future. arXiv 2024, arXiv:2408.02479. [Google Scholar]
- Kimura, A.; Scholl, J.; Schaffranek, J.; Sutter, M.; Elliott, A.; Strizich, M.; Via, G.D. A decomposition workflow for integrated circuit verification and validation. J. Hardw. Syst. Secur. 2020, 4, 34–43. [Google Scholar] [CrossRef]
- Roy, D.; Zhang, X.; Bhave, R.; Bansal, C.; Las-Casas, P.; Fonseca, R.; Rajmohan, S. Exploring llm-based agents for root cause analysis. In Proceedings of the Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering, Porto de Galinhas, Brazil, 15–19 July 2024; pp. 208–219. [Google Scholar]
- Guo, C.; Cheng, F.; Du, Z.; Kiessling, J.; Ku, J.; Li, S.; Li, Z.; Ma, M.; Molom-Ochir, T.; Morris, B.; et al. A Survey: Collaborative Hardware and Software Design in the Era of Large Language Models. arXiv 2024, arXiv:2410.07265. [Google Scholar]
- Xu, N.; Zhang, Z.; Qi, L.; Wang, W.; Zhang, C.; Ren, Z.; Zhang, H.; Cheng, X.; Zhang, Y.; Liu, Z.; et al. ChipExpert: The Open-Source Integrated-Circuit-Design-Specific Large Language Model. arXiv 2024, arXiv:2408.00804. [Google Scholar]
- Zheng, Y.; Chen, Y.; Qian, B.; Shi, X.; Shu, Y.; Chen, J. A Review on Edge Large Language Models: Design, Execution, and Applications. arXiv 2024, arXiv:2410.11845. [Google Scholar]
- Hirschberg, J.; Ballard, B.W.; Hindle, D. Natural language processing. AT&T Tech. J. 1988, 67, 41–57. [Google Scholar]
- Petrushin, V.A. Hidden markov models: Fundamentals and applications. In Proceedings of the Online Symposium for Electronics Engineer, Rapallo, Italy, 25–27 July 2000. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative study of CNN and RNN for natural language processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Hihi, S.; Bengio, Y. Hierarchical recurrent neural networks for long-term dependencies. Adv. Neural Inf. Process. Syst. 1995, 8, 493–499. [Google Scholar]
- Hochreiter, S. Recurrent neural net learning and vanishing gradient. Int. J. Uncertainity Fuzziness-Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Azunre, P. Transfer Learning for Natural Language Processing; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Shi, Y.; Larson, M.; Jonker, C.M. Recurrent neural network language model adaptation with curriculum learning. Comput. Speech Lang. 2015, 33, 136–154. [Google Scholar] [CrossRef]
- Kovačević, A.; Kečo, D. Bidirectional LSTM networks for abstractive text summarization. In Proceedings of the Advanced Technologies, Systems, and Applications VI: Proceedings of the International Symposium on Innovative and Interdisciplinary Applications of Advanced Technologies (IAT), Bosnia and Herzegovina, 17 November 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 281–293. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Yadav, R.K.; Harwani, S.; Maurya, S.K.; Kumar, S. Intelligent Chatbot Using GNMT, SEQ-2-SEQ Techniques. In Proceedings of the 2021 International Conference on Intelligent Technologies (CONIT), Hubli, India, 25–27 June 2021; pp. 1–5. [Google Scholar]
- Luitse, D.; Denkena, W. The great transformer: Examining the role of large language models in the political economy of AI. Big Data Soc. 2021, 8, 20539517211047734. [Google Scholar] [CrossRef]
- Topal, M.O.; Bas, A.; van Heerden, I. Exploring transformers in natural language generation: Gpt, bert, and xlnet. arXiv 2021, arXiv:2102.08036. [Google Scholar]
- Bird, J.J.; Ekárt, A.; Faria, D.R. Chatbot Interaction with Artificial Intelligence: Human data augmentation with T5 and language transformer ensemble for text classification. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 3129–3144. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Radford, A.; Wu, J.; Amodei, D.; Amodei, D.; Clark, J.; Brundage, M.; Sutskever, I. Better language models and their implications. OpenAI Blog. 14 February 2019. blog 1, no 2. Available online: https://openai.com/index/better-language-models/ (accessed on 19 December 2024).
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Huang, J.; Chang, K.C.C. Towards reasoning in large language models: A survey. arXiv 2022, arXiv:2212.10403. [Google Scholar]
- Xi, Z.; Chen, W.; Guo, X.; He, W.; Ding, Y.; Hong, B.; Zhang, M.; Wang, J.; Jin, S.; Zhou, E.; et al. The rise and potential of large language model based agents: A survey. arXiv 2023, arXiv:2309.07864. [Google Scholar]
- Hadi, M.U.; Al Tashi, Q.; Shah, A.; Qureshi, R.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; et al. Large language models: A comprehensive survey of its applications, challenges, limitations, and future prospects. Authorea Preprints. 12 August 2024. Available online: https://www.techrxiv.org/doi/full/10.36227/techrxiv.23589741.v6 (accessed on 19 December 2024).
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2023, arXiv:2307.06435. [Google Scholar]
- Fan, L.; Li, L.; Ma, Z.; Lee, S.; Yu, H.; Hemphill, L. A bibliometric review of large language models research from 2017 to 2023. arXiv 2023, arXiv:2304.02020. [Google Scholar] [CrossRef]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large Language Models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Minaee, S.; Mikolov, T.; Nikzad, N.; Chenaghlu, M.; Socher, R.; Amatriain, X.; Gao, J. Large language models: A survey. arXiv 2024, arXiv:2402.06196. [Google Scholar]
- Liu, Y.; He, H.; Han, T.; Zhang, X.; Liu, M.; Tian, J.; Zhang, Y.; Wang, J.; Gao, X.; Zhong, T.; et al. Understanding llms: A comprehensive overview from training to inference. arXiv 2024, arXiv:2401.02038. [Google Scholar] [CrossRef]
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Zhou, Y.; Liang, K.; Chen, J.; Lu, J.; Yang, Z.; Liao, K.D.; et al. A survey on multimodal large language models for autonomous driving. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 958–979. [Google Scholar]
- Chang, Y.; Wang, X.; Wang, J.; Wu, Y.; Yang, L.; Zhu, K.; Chen, H.; Yi, X.; Wang, C.; Wang, Y.; et al. A survey on evaluation of large language models. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–45. [Google Scholar] [CrossRef]
- Kachris, C. A survey on hardware accelerators for large language models. arXiv 2024, arXiv:2401.09890. [Google Scholar]
- Islam, R.; Moushi, O.M.; Gpt-4o: The cutting-edge advancement in multimodal llm. Authorea Prepr, 2 July 2024. Available online: https://easychair.org/publications/preprint/z4TJ/open (accessed on 19 December 2024).
- Šimsová, J. Examining Cognitive Abilities and Multilingual Performance of Large Language Models: A Comparative Analysis of GPT-3 and GPT-4; Univerzita Karlova, Filozofická Fakulta: Prague, Czech Republic, 2024. [Google Scholar]
- Tricco, A.C.; Lillie, E.; Zarin, W.; O’Brien, K.K.; Colquhoun, H.; Levac, D.; Moher, D.; Peters, M.D.; Horsley, T.; Weeks, L.; et al. PRISMA extension for scoping reviews (PRISMA-ScR): Checklist and explanation. Ann. Intern. Med. 2018, 169, 467–473. [Google Scholar] [CrossRef]
- Alsaqer, S.; Alajmi, S.; Ahmad, I.; Alfailakawi, M. The potential of llms in hardware design. J. Eng. Res. 2024, in press. [CrossRef]
- Zhang, H.; Ning, A.; Prabhakar, R.; Wentzlaff, D. A Hardware Evaluation Framework for Large Language Model Inference. arXiv 2023, arXiv:2312.03134. [Google Scholar]
- Korvala, A. Analysis of LLM-Models in Optimizing and Designing VHDL Code. Master’s Thesis, Modern SW and Computing Technolgies, Oulu University of Applied Sciences, Oulu, Finland, 2023. [Google Scholar]
- Thakur, S.; Blocklove, J.; Pearce, H.; Tan, B.; Garg, S.; Karri, R. Autochip: Automating hdl generation using llm feedback. arXiv 2023, arXiv:2311.04887. [Google Scholar]
- Thakur, S.; Ahmad, B.; Fan, Z.; Pearce, H.; Tan, B.; Karri, R.; Dolan-Gavitt, B.; Garg, S. Benchmarking large language models for automated verilog rtl code generation. In Proceedings of the 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 17–19 April 2023. [Google Scholar]
- Blocklove, J.; Garg, S.; Karri, R.; Pearce, H. Chip-chat: Challenges and opportunities in conversational hardware design. In Proceedings of the 2023 ACM/IEEE 5th Workshop on Machine Learning for CAD (MLCAD), Snowbird, UT, USA, 10–13 September 2023; pp. 1–6. [Google Scholar]
- Chang, K.; Wang, Y.; Ren, H.; Wang, M.; Liang, S.; Han, Y.; Li, H.; Li, X. Chipgpt: How far are we from natural language hardware design. arXiv 2023, arXiv:2305.14019. [Google Scholar]
- Martínez, P.A.; Bernabé, G.; García, J.M. Code Detection for Hardware Acceleration Using Large Language Models. IEEE Access 2024, 12, 35271–35281. [Google Scholar] [CrossRef]
- DeLorenzo, M.; Gohil, V.; Rajendran, J. CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation. arXiv 2024, arXiv:2404.08806. [Google Scholar]
- Tomlinson, M.; Li, J.; Andreou, A. Designing Silicon Brains using LLM: Leveraging ChatGPT for Automated Description of a Spiking Neuron Array. arXiv 2024, arXiv:2402.10920. [Google Scholar]
- Xiang, M.; Goh, E.; Teo, T.H. Digital ASIC Design with Ongoing LLMs: Strategies and Prospects. arXiv 2024, arXiv:2405.02329. [Google Scholar]
- Wang, H. Efficient Algorithms and Hardware for Natural Language Processing. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2020. [Google Scholar]
- Fu, Y.; Zhang, Y.; Yu, Z.; Li, S.; Ye, Z.; Li, C.; Wan, C.; Lin, Y.C. Gpt4aigchip: Towards next-generation ai accelerator design automation via large language models. In Proceedings of the 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Francisco, CA, USA, 28 October–2 November 2023; pp. 1–9. [Google Scholar]
- Fu, W.; Li, S.; Zhao, Y.; Ma, H.; Dutta, R.; Zhang, X.; Yang, K.; Jin, Y.; Guo, X. Hardware Phi-1.5 B: A Large Language Model Encodes Hardware Domain Specific Knowledge. arXiv 2024, arXiv:2402.01728. [Google Scholar]
- Wang, H.; Wu, Z.; Liu, Z.; Cai, H.; Zhu, L.; Gan, C.; Han, S. Hat: Hardware-aware transformers for efficient natural language processing. arXiv 2020, arXiv:2005.14187. [Google Scholar]
- Chang, K.; Ren, H.; Wang, M.; Liang, S.; Han, Y.; Li, H.; Li, X.; Wang, Y. Improving Large Language Model Hardware Generating Quality through Post-LLM Search. In Proceedings of the Machine Learning for Systems 2023, Zhuhai, China, 17–20 February 2023. [Google Scholar]
- Guo, C.; Tang, J.; Hu, W.; Leng, J.; Zhang, C.; Yang, F.; Liu, Y.; Guo, M.; Zhu, Y. Olive: Accelerating large language models via hardware-friendly outlier-victim pair quantization. In Proceedings of the 50th Annual International Symposium on Computer Architecture, Orlando, FL, USA, 17–21 June 2023; pp. 1–15. [Google Scholar]
- Liu, S.; Fang, W.; Lu, Y.; Zhang, Q.; Zhang, H.; Xie, Z. Rtlcoder: Outperforming gpt-3.5 in design rtl generation with our open-source dataset and lightweight solution. arXiv 2023, arXiv:2312.08617. [Google Scholar]
- Lu, Y.; Liu, S.; Zhang, Q.; Xie, Z. Rtllm: An open-source benchmark for design rtl generation with large language model. In Proceedings of the 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), Incheon, Republic of Korea, 22–25 January 2024; pp. 722–727. [Google Scholar]
- Pandelea, V.; Ragusa, E.; Gastaldo, P.; Cambria, E. Selecting Language Models Features VIA Software-Hardware Co-Design. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Cerisara, C. SlowLLM: Large Language Models on Consumer Hardware. Ph.D. Thesis, CNRS, Paris, France, 2023. [Google Scholar]
- Li, M.; Fang, W.; Zhang, Q.; Xie, Z. Specllm: Exploring generation and review of vlsi design specification with large language model. arXiv 2024, arXiv:2401.13266. [Google Scholar]
- Kurtić, E.; Frantar, E.; Alistarh, D. ZipLM: Inference-Aware Structured Pruning of Language Models. Adv. Neural Inf. Process. Syst. 2024, 36. Available online: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ced46a50befedcb884ccf0cbe8c3ad23-Abstract-Conference.html (accessed on 19 December 2024).
- Thorat, K.; Zhao, J.; Liu, Y.; Peng, H.; Xie, X.; Lei, B.; Zhang, J.; Ding, C. Advanced language model-driven verilog development: Enhancing power, performance, and area optimization in code synthesis. arXiv 2023, arXiv:2312.01022. [Google Scholar]
- Huang, Y.; Wan, L.J.; Ye, H.; Jha, M.; Wang, J.; Li, Y.; Zhang, X.; Chen, D. New Solutions on LLM Acceleration, Optimization, and Application. arXiv 2024, arXiv:2406.10903. [Google Scholar]
- Goh, E.; Xiang, M.; Wey, I.; Teo, T.H. From English to ASIC: Hardware Implementation with Large Language Model. arXiv 2024, arXiv:2403.07039. [Google Scholar]
- Zhang, H.; Ning, A.; Prabhakar, R.B.; Wentzlaff, D. Llmcompass: Enabling efficient hardware design for large language model inference. In Proceedings of the 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), Buenos Aires, Argentina, 29 June–3 July 2024; pp. 1080–1096. [Google Scholar]
- Chang, K.; Wang, K.; Yang, N.; Wang, Y.; Jin, D.; Zhu, W.; Chen, Z.; Li, C.; Yan, H.; Zhou, Y.; et al. Data is all you need: Finetuning llms for chip design via an automated design-data augmentation framework. In Proceedings of the 61st ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 23–27 June 2024; pp. 1–6. [Google Scholar]
- Nakkab, A.; Zhang, S.Q.; Karri, R.; Garg, S. Rome was Not Built in a Single Step: Hierarchical Prompting for LLM-based Chip Design. In Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, Salt Lake City, UT, USA, 9–11 September 2024; pp. 1–11. [Google Scholar]
- Hossain, S.; Gohil, A.; Wang, Y. Using LLM such as ChatGPT for Designing and Implementing a RISC Processor: Execution, Challenges and Limitations. arXiv 2024, arXiv:2401.10364. [Google Scholar]
- Zhang, Y.; Yu, Z.; Fu, Y.; Wan, C.; Lin, Y.C. Mg-verilog: Multi-grained dataset towards enhanced llm-assisted verilog generation. In Proceedings of the 2024 IEEE LLM Aided Design Workshop (LAD), San Jose, CA, USA, 28 June 2024; pp. 1–5. [Google Scholar]
- Mudigere, D.; Hao, Y.; Huang, J.; Jia, Z.; Tulloch, A.; Sridharan, S.; Liu, X.; Ozdal, M.; Nie, J.; Park, J.; et al. Software-hardware co-design for fast and scalable training of deep learning recommendation models. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; pp. 993–1011. [Google Scholar]
- Wan, L.J.; Huang, Y.; Li, Y.; Ye, H.; Wang, J.; Zhang, X.; Chen, D. Software/Hardware Co-design for LLM and Its Application for Design Verification. In Proceedings of the 2024 29th Asia and South Pacific Design Automation Conference (ASP-DAC), Incheon, Republic of Korea, 22–25 January 2024; pp. 435–441. [Google Scholar]
- Yan, Z.; Qin, Y.; Hu, X.S.; Shi, Y. On the viability of using llms for sw/hw co-design: An example in designing cim dnn accelerators. In Proceedings of the 2023 IEEE 36th International System-on-Chip Conference (SOCC), Santa Clara, CA, USA, 5–8 September 2023; pp. 1–6. [Google Scholar]
- Collini, L.; Garg, S.; Karri, R. C2HLSC: Can LLMs Bridge the Software-to-Hardware Design Gap? arXiv 2024, arXiv:2406.09233. [Google Scholar]
- Blocklove, J.; Garg, S.; Karri, R.; Pearce, H. Evaluating LLMs for Hardware Design and Test. arXiv 2024, arXiv:2405.02326. [Google Scholar]
- Batten, C.; Pinckney, N.; Liu, M.; Ren, H.; Khailany, B. PyHDL-Eval: An LLM Evaluation Framework for Hardware Design Using Python-Embedded DSLs. In Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, Salt Lake City, UT, USA, 9–11 September 2024; pp. 1–17. [Google Scholar]
- Nazzal, M.; Vungarala, D.; Morsali, M.; Zhang, C.; Ghosh, A.; Khreishah, A.; Angizi, S. A Dataset for Large Language Model-Driven AI Accelerator Generation. arXiv 2024, arXiv:2404.10875. [Google Scholar]
- Vungarala, D.L.V.D. Gen-Acceleration: Pioneering Work for Hardware Accelerator Generation Using Large Language Models. Master’s Thesis, Electrical and Computer Engineering, New Jersey Institute of Technology, Newark, NJ, USA, 2023. [Google Scholar]
- Heo, G.; Lee, S.; Cho, J.; Choi, H.; Lee, S.; Ham, H.; Kim, G.; Mahajan, D.; Park, J. NeuPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, La Jolla CA USA, 27 April 2024; Volume 3, pp. 722–737. [Google Scholar]
- Lai, C.; Zhou, Z.; Poptani, A.; Zhang, W. LCM: LLM-focused Hybrid SPM-cache Architecture with Cache Management for Multi-Core AI Accelerators. In Proceedings of the 38th ACM International Conference on Supercomputing, Kyoto, Japan, 4–7 June 2024; pp. 62–73. [Google Scholar]
- Mao, Y.; You, Y.; Tan, X.; Huang, Y.; You, X.; Zhang, C. FLAG: Formula-LLM-Based Auto-Generator for Baseband Hardware. In Proceedings of the 2024 IEEE International Symposium on Circuits and Systems (ISCAS), New Delhi, India, 18–19 October 2024; pp. 1–5. [Google Scholar]
- Chen, H.M.; Luk, W.; Yiu, K.F.C.; Li, R.; Mishchenko, K.; Venieris, S.I.; Fan, H. Hardware-aware parallel prompt decoding for memory-efficient acceleration of llm inference. arXiv 2024, arXiv:2405.18628. [Google Scholar]
- Paria, S.; Dasgupta, A.; Bhunia, S. Divas: An llm-based end-to-end framework for soc security analysis and policy-based protection. arXiv 2023, arXiv:2308.06932. [Google Scholar]
- Srikumar, P. Fast and wrong: The case for formally specifying hardware with LLMS. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), La Jolla, CA, USA, 27 April 2023; ACM Press: New York, NY, USA, 2023. [Google Scholar]
- Ahmad, B.; Thakur, S.; Tan, B.; Karri, R.; Pearce, H. Fixing hardware security bugs with large language models. arXiv 2023, arXiv:2302.01215. [Google Scholar]
- Kokolakis, G.; Moschos, A.; Keromytis, A.D. Harnessing the power of general-purpose llms in hardware trojan design. In Proceedings of the 5th Workshop on Artificial Intelligence in Hardware Security, in Conjunction with ACNS, Abu Dhabi, United Arab Emirates, 5 March 2024; Volume 14. [Google Scholar]
- Saha, D.; Tarek, S.; Yahyaei, K.; Saha, S.K.; Zhou, J.; Tehranipoor, M.; Farahmandi, F. Llm for soc security: A paradigm shift. arXiv 2023, arXiv:2310.06046. [Google Scholar] [CrossRef]
- Wang, Z.; Alrahis, L.; Mankali, L.; Knechtel, J.; Sinanoglu, O. LLMs and the Future of Chip Design: Unveiling Security Risks and Building Trust. arXiv 2024, arXiv:2405.07061. [Google Scholar]
- Ahmad, B.; Thakur, S.; Tan, B.; Karri, R.; Pearce, H. On hardware security bug code fixes by prompting large language models. IEEE Trans. Inf. Forensics Secur. 2024, 19, 4043–4057. [Google Scholar] [CrossRef]
- Kande, R.; Pearce, H.; Tan, B.; Dolan-Gavitt, B.; Thakur, S.; Karri, R.; Rajendran, J. (Security) Assertions by Large Language Models. IEEE Trans. Inf. Forensics Secur. 2024, 19, 4374–4389. [Google Scholar] [CrossRef]
- Paria, S.; Dasgupta, A.; Bhunia, S. Navigating SoC Security Landscape on LLM-Guided Paths. In Proceedings of the Great Lakes Symposium on VLSI 2024, Clearwater, FL, USA, 12–14 June 2024; pp. 252–257. [Google Scholar]
- Tarek, S.; Saha, D.; Saha, S.K.; Tehranipoor, M.; Farahmandi, F. SoCureLLM: An LLM-driven Approach for Large-Scale System-on-Chip Security Verification and Policy Generation. Cryptol. ePrint Arch. 2024. Available online: https://eprint.iacr.org/2024/983 (accessed on 19 December 2024).
- Kande, R.; Gohil, V.; DeLorenzo, M.; Chen, C.; Rajendran, J. LLMs for Hardware Security: Boon or Bane? In Proceedings of the 2024 IEEE 42nd VLSI Test Symposium (VTS), Tempe, AZ, USA, 22–24 April 2024; pp. 1–4. [Google Scholar]
- Saha, D.; Yahyaei, K.; Saha, S.K.; Tehranipoor, M.; Farahmandi, F. Empowering Hardware Security with LLM: The Development of a Vulnerable Hardware Database. In Proceedings of the 2024 IEEE International Symposium on Hardware Oriented Security and Trust (HOST), Tysons Corner, VA, USA, 6–9 May 2024; pp. 233–243. [Google Scholar]
- Akyash, M.; Kamali, H.M. Self-HWDebug: Automation of LLM Self-Instructing for Hardware Security Verification. arXiv 2024, arXiv:2405.12347. [Google Scholar]
- Yao, X.; Li, H.; Chan, T.H.; Xiao, W.; Yuan, M.; Huang, Y.; Chen, L.; Yu, B. Hdldebugger: Streamlining hdl debugging with large language models. arXiv 2024, arXiv:2403.11671. [Google Scholar]
- Fu, W.; Yang, K.; Dutta, R.G.; Guo, X.; Qu, G. LLM4SecHW: Leveraging domain-specific large language model for hardware debugging. In Proceedings of the 2023 Asian Hardware Oriented Security and Trust Symposium (AsianHOST), Tianjin, China, 13–15 December 2023; pp. 1–6. [Google Scholar]
- Fang, W.; Li, M.; Li, M.; Yan, Z.; Liu, S.; Zhang, H.; Xie, Z. AssertLLM: Generating and Evaluating Hardware Verification Assertions from Design Specifications via Multi-LLMs. arXiv 2024, arXiv:2402.00386. [Google Scholar]
- Orenes-Vera, M.; Martonosi, M.; Wentzlaff, D. Using llms to facilitate formal verification of rtl. arXiv 2023, arXiv:2309.09437. [Google Scholar]
- Varambally, B.S.; Sehgal, N. Optimising design verification using machine learning: An open source solution. arXiv 2020, arXiv:2012.02453. [Google Scholar]
- Liu, M.; Pinckney, N.; Khailany, B.; Ren, H. Verilogeval: Evaluating large language models for verilog code generation. In Proceedings of the 2023 IEEE/ACM International Conference on Computer Aided Design (ICCAD), San Francisco, CA, USA, 28 October–2 November 2023; pp. 1–8. [Google Scholar]
- Sun, C.; Hahn, C.; Trippel, C. Towards improving verification productivity with circuit-aware translation of natural language to systemverilog assertions. In Proceedings of the First International Workshop on Deep Learning-Aided Verification, Paris, France, 18 July 2023. [Google Scholar]
- Liu, M.; Ene, T.D.; Kirby, R.; Cheng, C.; Pinckney, N.; Liang, R.; Alben, J.; Anand, H.; Banerjee, S.; Bayraktaroglu, I.; et al. Chipnemo: Domain-adapted llms for chip design. arXiv 2023, arXiv:2311.00176. [Google Scholar]
- Zhang, Z.; Chadwick, G.; McNally, H.; Zhao, Y.; Mullins, R. Llm4dv: Using large language models for hardware test stimuli generation. arXiv 2023, arXiv:2310.04535. [Google Scholar]
- Kande, R.; Pearce, H.; Tan, B.; Dolan-Gavitt, B.; Thakur, S.; Karri, R.; Rajendran, J. Llm-assisted generation of hardware assertions. arXiv 2023, arXiv:2306.14027. [Google Scholar]
- Qayyum, K.; Hassan, M.; Ahmadi-Pour, S.; Jha, C.K.; Drechsler, R. Late breaking results: LLM-assisted automated incremental proof generation for hardware verification. In Proceedings of the 61st ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 23–27 June 2024; pp. 1–2. [Google Scholar]
- Xiao, C.; Deng, Y.; Yang, Z.; Chen, R.; Wang, H.; Zhao, J.; Dai, H.; Wang, L.; Tang, Y.; Xu, W. LLM-Based Processor Verification: A Case Study for Neuronnorphic Processor. In Proceedings of the 2024 Design, Automation & Test in Europe Conference & Exhibition (DATE), Valencia, Spain, 25–27 March 2024; pp. 1–6. [Google Scholar]
- Ma, R.; Yang, Y.; Liu, Z.; Zhang, J.; Li, M.; Huang, J.; Luo, G. VerilogReader: LLM-Aided Hardware Test Generation. arXiv 2024, arXiv:2406.04373. [Google Scholar]
- Makatura, L.; Foshey, M.; Wang, B.; Hähnlein, F.; Ma, P.; Deng, B.; Tjandrasuwita, M.; Spielberg, A.; Owens, C.E.; Chen, P.Y.; et al. Large Language Models for Design and Manufacturing. MIT Explor. Gener. AI. Available online: https://mit-genai.pubpub.org/pub/nmypmnhs (accessed on 19 December 2024).
- Du, Y.; Deng, H.; Liew, S.C.; Chen, K.; Shao, Y.; Chen, H. The Power of Large Language Models for Wireless Communication System Development: A Case Study on FPGA Platforms. arXiv 2024, arXiv:2307.07319. [Google Scholar]
- Englhardt, Z.; Li, R.; Nissanka, D.; Zhang, Z.; Narayanswamy, G.; Breda, J.; Liu, X.; Patel, S.; Iyer, V. Exploring and Characterizing Large Language Models For Embedded System Development and Debugging. arXiv 2023, arXiv:2307.03817. [Google Scholar]
- Lian, X.; Chen, Y.; Cheng, R.; Huang, J.; Thakkar, P.; Zhang, M.; Xu, T. Configuration Validation with Large Language Models. arXiv 2024, arXiv:2310.09690. [Google Scholar]
- Patil, R.; Gudivada, V. A review of current trends, techniques, and challenges in large language models (llms). Appl. Sci. 2024, 14, 2074. [Google Scholar] [CrossRef]
- Kumar, P. Large language models (LLMs): Survey, technical frameworks, and future challenges. Artif. Intell. Rev. 2024, 57, 260. [Google Scholar] [CrossRef]
- Li, R.; Fu, D.; Shi, C.; Huang, Z.; Lu, G. Efficient LLMs Training and Inference: An Introduction. IEEE Access 2024. [Google Scholar] [CrossRef]
- Luz, A. Enhancing the Interpretability and Explainability of AI-Driven Risk Models Using LLM Capabilities; Technical Report; EasyChair: Stockport, UK, 2024. [Google Scholar]
- Fujiwara, K.; Sasaki, M.; Nakamura, A.; Watanabe, N. Measuring the Interpretability and Explainability of Model Decisions of Five Large Language Models; Open Science Framework: Charlottesville, VA, USA, 2024. [Google Scholar]
- Weber, I. Large Language Models as Software Components: A Taxonomy for LLM-Integrated Applications. arXiv 2024, arXiv:2406.10300. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Nijkamp, E.; Pang, B.; Hayashi, H.; Tu, L.; Wang, H.; Zhou, Y.; Savarese, S.; Xiong, C. Codegen: An open large language model for code with multi-turn program synthesis. arXiv 2022, arXiv:2203.13474. [Google Scholar]
- Xu, F.F.; Alon, U.; Neubig, G.; Hellendoorn, V.J. A systematic evaluation of large language models of code. In Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, San Diego, CA, USA, 13 June 2022; pp. 1–10. [Google Scholar]
- Tihanyi, N.; Jain, R.; Charalambous, Y.; Ferrag, M.A.; Sun, Y.; Cordeiro, L.C. A new era in software security: Towards self-healing software via large language models and formal verification. arXiv 2023, arXiv:2305.14752. [Google Scholar]
- Sandal, S.; Akturk, I. Zero-Shot RTL Code Generation with Attention Sink Augmented Large Language Models. arXiv 2024, arXiv:2401.08683. [Google Scholar]
- Parchamdar, B.; Schafer, B.C. Finding Bugs in RTL Descriptions: High-Level Synthesis to the Rescue. In Proceedings of the 61st Design Automation Conference (DAC), Francisco, CA, USA, 23–27 June 2024. [Google Scholar]
- Tavana, M.K.; Teimouri, N.; Abdollahi, M.; Goudarzi, M. Simultaneous hardware and time redundancy with online task scheduling for low energy highly reliable standby-sparing system. ACM Trans. Embed. Comput. Syst. 2014, 13, 1–13. [Google Scholar] [CrossRef]
- Luo, Q.; Hu, S.; Li, C.; Li, G.; Shi, W. Resource scheduling in edge computing: A survey. IEEE Commun. Surv. Tutor. 2021, 23, 2131–2165. [Google Scholar] [CrossRef]
- Kumar, S.; Singh, S.K.; Aggarwal, N.; Gupta, B.B.; Alhalabi, W.; Band, S.S. An efficient hardware supported and parallelization architecture for intelligent systems to overcome speculative overheads. Int. J. Intell. Syst. 2022, 37, 11764–11790. [Google Scholar] [CrossRef]
- Kao, S.C.; Jeong, G.; Krishna, T. Confuciux: Autonomous hardware resource assignment for dnn accelerators using reinforcement learning. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 622–636. [Google Scholar]
- Alwan, E.H.; Ketran, R.M.; Hussein, I.A. A Comprehensive Survey on Loop Unrolling Technique In Code Optimization. J. Univ. Babylon Pure Appl. Sci. 2024, 32, 108–117. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, Y.; Zhang, B.; Liu, L.; Wang, J.; Tang, S. Improving the computational efficiency and flexibility of FPGA-based CNN accelerator through loop optimization. Microelectron. J. 2024, 147, 106197. [Google Scholar] [CrossRef]
- Hasan, B.M.S.; Abdulazeez, A.M. A review of principal component analysis algorithm for dimensionality reduction. J. Soft Comput. Data Min. 2021, 2, 20–30. [Google Scholar]
- Wang, Q.; Li, X.; Yue, C.; He, Y. A Survey of Control Flow Graph Recovery for Binary Code. In Proceedings of the CCF National Conference of Computer Applications, Suzhou, China, 16–20 July 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 225–244. [Google Scholar]
- Talati, N.; May, K.; Behroozi, A.; Yang, Y.; Kaszyk, K.; Vasiladiotis, C.; Verma, T.; Li, L.; Nguyen, B.; Sun, J.; et al. Prodigy: Improving the memory latency of data-indirect irregular workloads using hardware-software co-design. In Proceedings of the 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Republic of Korea, 27 February–3 March 2021; pp. 654–667. [Google Scholar]
- Ayers, G.; Litz, H.; Kozyrakis, C.; Ranganathan, P. Classifying memory access patterns for prefetching. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 513–526. [Google Scholar]
- Kastner, R.; Gong, W.; Hao, X.; Brewer, F.; Kaplan, A.; Brisk, P.; Sarrafzadeh, M. Physically Aware Data Communication Optimization for Hardware Synthesis. Available online: https://cseweb.ucsd.edu/~kastner/papers/iwls05-phy_aware_data_comm.pdf (accessed on 19 December 2024).
- Fan, Z. Automatically Generating Verilog RTL Code with Large Language Models. Master’s Thesis, New York University Tandon School of Engineering, New York, NY, USA, 2023. [Google Scholar]
- Lekidis, A. Automated Code Generation for Industrial Applications Based on Configurable Programming Models. Preprints 2023. [Google Scholar] [CrossRef]
- Bhandari, J.; Knechtel, J.; Narayanaswamy, R.; Garg, S.; Karri, R. LLM-Aided Testbench Generation and Bug Detection for Finite-State Machines. arXiv 2024, arXiv:2406.17132. [Google Scholar]
- Kibria, R.; Farahmandi, F.; Tehranipoor, M. FSMx-Ultra: Finite State Machine Extraction from Gate-Level Netlist for Security Assessment. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 3613–3627. [Google Scholar] [CrossRef]
- Gauthier, L.; Ishikawa, Y. HDLRuby: A Ruby Extension for Hardware Description and its Translation to Synthesizable Verilog HDL. ACM Trans. Embed. Comput. Syst. 2024, 23, 1–26. [Google Scholar] [CrossRef]
- Rashid, M.I.; Schaefer, B.C. VeriPy: A Python-Powered Framework for Parsing Verilog HDL and High-Level Behavioral Analysis of Hardware. In Proceedings of the 2024 IEEE 17th Dallas Circuits and Systems Conference (DCAS), Richardson, TX, USA, 19–21 April 2024; pp. 1–6. [Google Scholar]
- Morgan, F.; Byrne, J.P.; Bupathi, A.; George, R.; Elahi, A.; Callaly, F.; Kelly, S.; O’Loughlin, D. HDLGen-ChatGPT Case Study: RISC-V Processor VHDL and Verilog Model-Testbench and EDA Project Generation. In Proceedings of the 34th International Workshop on Rapid System Prototyping, Hamburg, Germany, 21 September 2023; pp. 1–7. [Google Scholar]
- Kumar, B.; Nanda, S.; Parthasarathy, G.; Patil, P.; Tsai, A.; Choudhary, P. HDL-GPT: High-Quality HDL is All You Need. arXiv 2024, arXiv:2407.18423. [Google Scholar]
- Qiu, R.; Zhang, G.L.; Drechsler, R.; Schlichtmann, U.; Li, B. AutoBench: Automatic Testbench Generation and Evaluation Using LLMs for HDL Design. In Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, Salt Lake City, UT, USA, 9–11 September 2024; pp. 1–10. [Google Scholar]
- Wenzel, J.; Hochberger, C. Automatically Restructuring HDL Modules for Improved Reusability in Rapid Synthesis. In Proceedings of the 2022 IEEE International Workshop on Rapid System Prototyping (RSP), Shanghai, China, 13 October 2022; pp. 43–49. [Google Scholar]
- Witharana, H.; Lyu, Y.; Charles, S.; Mishra, P. A survey on assertion-based hardware verification. ACM Comput. Surv. CSUR 2022, 54, 1–33. [Google Scholar] [CrossRef]
- Agostini, N.B.; Haris, J.; Gibson, P.; Jayaweera, M.; Rubin, N.; Tumeo, A.; Abellán, J.L.; Cano, J.; Kaeli, D. AXI4MLIR: User-Driven Automatic Host Code Generation for Custom AXI-Based Accelerators. In Proceedings of the 2024 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Edinburgh, UK, 2–6 March 2024; pp. 143–157. [Google Scholar]
- Vivekananda, A.A.; Enoiu, E. Automated test case generation for digital system designs: A mapping study on vhdl, verilog, and systemverilog description languages. Designs 2020, 4, 31. [Google Scholar] [CrossRef]
- Nuocheng, W. HDL Synthesis, Inference and Technology Mapping Algorithms for FPGA Configuration. Int. J. Eng. Technol. 2024, 16, 32–38. [Google Scholar]
- Cardona Nadal, J. Practical Strategies to Monitor and Control Contention in Shared Resources of Critical Real-Time Embedded Systems. Ph.D. Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2023. [Google Scholar]
- Jayasena, A.; Mishra, P. Directed test generation for hardware validation: A survey. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Srivastava, A.; Mukherjee, R.; Marschner, E.; Seeley, C.; Dobre, S. Low Power SoC Verification: IP Reuse and Hierarchical Composition using UPF. DVCon Proc. San Jose, CA, USA. 2012. Available online: https://dvcon-proceedings.org/document/low-power-soc-verification-ip-reuse-and-hierarchical-composition-using-upf/ (accessed on 19 December 2024).
- Mullane, B.; MacNamee, C. Developing a reusable IP platform within a System-on-Chip design framework targeted towards an academic R&D environment. Design and Reuse 2008. Available online: https://www.design-reuse.com/articles/16039/developing-a-reusable-ip-platform-within-a-system-on-chip-design-framework-targeted-towards-an-academic-r-d-environment.html (accessed on 19 December 2024).
- Leipnitz, M.T.; Nazar, G.L. High-level synthesis of approximate designs under real-time constraints. ACM Trans. Embed. Comput. Syst. TECS 2019, 18, 1–21. [Google Scholar] [CrossRef]
- Gangadharan, S.; Churiwala, S. Constraining Designs for Synthesis and Timing Analysis; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Namazi, A.; Abdollahi, M. PCG: Partially clock-gating approach to reduce the power consumption of fault-tolerant register files. In Proceedings of the 2017 Euromicro Conference on Digital System Design (DSD), Vienna, Austria, 30 August–1 September 2017; pp. 323–328. [Google Scholar]
- Namazi, A.; Abdollahi, M.; Safari, S.; Mohammadi, S. LORAP: Low-overhead power and reliability-aware task mapping based on instruction footprint for real-time applications. In Proceedings of the 2017 Euromicro Conference on Digital System Design (DSD), Vienna, Austria, 30 August–1 September 2017; pp. 364–367. [Google Scholar]
- Alireza, N.; Meisam, A. LPVM: Low-Power Variation-Mitigant Adder Architecture Using Carry Expedition. In Proceedings of the Workshop on Early Reliability Modeling for Aging and Variability in Silicon Systems, Dresden, Germany, 18 March 2016; pp. 41–44. [Google Scholar]
- Chandra, A.; Chattopadhyay, S. Design of hardware efficient FIR filter: A review of the state-of-the-art approaches. Eng. Sci. Technol. Int. J. 2016, 19, 212–226. [Google Scholar] [CrossRef]
- Chegini, M.; Abdollahi, M.; Baniasadi, A.; Patooghy, A. Tiny-RFNet: Enabling Modulation Classification of Radio Signals on Edge Systems. In Proceedings of the 2024 5th CPSSI International Symposium on Cyber-Physical Systems (Applications and Theory) (CPSAT), Tehran, Iran, 16–17 October 2024; pp. 1–8. [Google Scholar]
- Narayanan, D.; Harlap, A.; Phanishayee, A.; Seshadri, V.; Devanur, N.R.; Ganger, G.R.; Gibbons, P.B.; Zaharia, M. PipeDream: Generalized pipeline parallelism for DNN training. In Proceedings of the 27th ACM Symposium on Operating Systems Principles, Huntsville, ON, Canada, 27–30 October 2019; pp. 1–15. [Google Scholar]
- Osawa, K.; Li, S.; Hoefler, T. PipeFisher: Efficient training of large language models using pipelining and Fisher information matrices. Proc. Mach. Learn. Syst. 2023, 5, 708–727. [Google Scholar]
- Shibo, C.; Zhang, H.; Todd, A. Zipper: Latency-Tolerant Optimizations for High-Performance Buses. In Proceedings of the To Appear in The Asia and South Pacific Design Automation Conference, Tokyo, Japan, 20–23 January 2025. [Google Scholar]
- Shammasi, M.; Baharloo, M.; Abdollahi, M.; Baniasadi, A. Turn-aware application mapping using reinforcement learning in power gating-enabled network on chip. In Proceedings of the 2022 IEEE 15th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), Penang, Malaysia, 19–22 December 2022; pp. 345–352. [Google Scholar]
- Aligholipour, R.; Baharloo, M.; Farzaneh, B.; Abdollahi, M.; Khonsari, A. TAMA: Turn-aware mapping and architecture–a power-efficient network-on-chip approach. ACM Trans. Embed. Comput. Syst. TECS 2021, 20, 1–24. [Google Scholar] [CrossRef]
- Abdollahi, M.; Namazi, A.; Mohammadi, S. Clustering effects on the design of opto-electrical network-on-chip. In Proceedings of the 2016 24th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing (PDP), Heraklion, Greece, 17–19 February 2016; pp. 427–430. [Google Scholar]
- Jayakrishnan, M.; Chang, A.; Kim, T.T.H. Power and area efficient clock stretching and critical path reshaping for error resilience. J. Low Power Electron. Appl. 2019, 9, 5. [Google Scholar] [CrossRef]
- Smith, F.; Van den Berg, A.E. Hardware genetic algorithm optimisation by critical path analysis using a custom VLSI architecture. S. Afr. Comput. J. 2015, 56, 120–135. [Google Scholar]
- Barkalov, A.; Titarenko, L.; Mielcarek, K.; Mazurkiewicz, M. Hardware reduction for FSMs with extended state codes. IEEE Access 2024, 12, 42369–42384. [Google Scholar] [CrossRef]
- Barkalov, A.; Titarenko, L.; Chmielewski, S. Hardware reduction in CPLD-based Moore FSM. J. Circuits Syst. Comput. 2014, 23, 1450086. [Google Scholar] [CrossRef]
- Barkalov, A.; Titarenko, L.; Malcheva, R.; Soldatov, K. Hardware reduction in FPGA-based Moore FSM. J. Circuits Syst. Comput. 2013, 22, 1350006. [Google Scholar] [CrossRef]
- Fummi, F.; Sciuto, D. A complete testing strategy based on interacting and hierarchical FSMs. Integration 1997, 23, 75–93. [Google Scholar] [CrossRef]
- Farahmandi, F.; Rahman, M.S.; Rajendran, S.R.; Tehranipoor, M. CAD for Fault Injection Detection. In CAD for Hardware Security; Springer: Berlin/Heidelberg, Germany, 2023; pp. 149–168. [Google Scholar]
- Minns, P.D. Digital System Design Using FSMs: A Practical Learning Approach; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Barkalov, A.; Titarenko, L.; Bieganowski, J.; Krzywicki, K. Basic Approaches for Reducing Power Consumption in Finite State Machine Circuits—A Review. Appl. Sci. 2024, 14, 2693. [Google Scholar] [CrossRef]
- Okada, S.; Ohzeki, M.; Taguchi, S. Efficient partition of integer optimization problems with one-hot encoding. Sci. Rep. 2019, 9, 13036. [Google Scholar] [CrossRef]
- Uyar, M.Ü.; Fecko, M.A.; Sethi, A.S.; Amer, P.D. Testing protocols modeled as FSMs with timing parameters. Comput. Netw. 1999, 31, 1967–1988. [Google Scholar] [CrossRef]
- Amir, M.; Givargis, T. Pareto optimal design space exploration of cyber-physical systems. Internet Things 2020, 12, 100308. [Google Scholar] [CrossRef]
- Tian, Y.; Si, L.; Zhang, X.; Cheng, R.; He, C.; Tan, K.C.; Jin, Y. Evolutionary large-scale multi-objective optimization: A survey. ACM Comput. Surv. CSUR 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Balasubramaniam, D.; Jefferson, C.; Kotthoff, L.; Miguel, I.; Nightingale, P. An automated approach to generating efficient constraint solvers. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 661–671. [Google Scholar]
- Abdollahi, M.; Mashhadi, S.; Sabzalizadeh, R.; Mirzaei, A.; Elahi, M.; Baharloo, M.; Baniasadi, A. IODnet: Indoor/Outdoor Telecommunication Signal Detection through Deep Neural Network. In Proceedings of the 2023 IEEE 16th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC), Singapore, 18–21 December 2023; pp. 134–141. [Google Scholar]
- Mashhadi, S.; Diyanat, A.; Abdollahi, M.; Baniasadi, A. DSP: A Deep Neural Network Approach for Serving Cell Positioning in Mobile Networks. In Proceedings of the 2023 10th International Conference on Wireless Networks and Mobile Communications (WINCOM), Istanbul, Turkey, 26–28 October 2023; pp. 1–6. [Google Scholar]
- Abdollahi, M.; Sabzalizadeh, R.; Javadinia, S.; Mashhadi, S.; Mehrizi, S.S.; Baniasadi, A. Automatic Modulation Classification for NLOS 5G Signals with Deep Learning Approaches. In Proceedings of the 2023 10th International Conference on Wireless Networks and Mobile Communications (WINCOM), Istanbul, Turkey, 26–28 October 2023; pp. 1–6. [Google Scholar]
- Yoo, H.J.; Lee, K.; Kim, J.K. Low-Power Noc for High-Performance Soc Design; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Baharloo, M.; Aligholipour, R.; Abdollahi, M.; Khonsari, A. ChangeSUB: A power efficient multiple network-on-chip architecture. Comput. Electr. Eng. 2020, 83, 106578. [Google Scholar] [CrossRef]
- Yenugula, M. Data Center Power Management Using Neural Network. Int. J. Adv. Acad. Stud. 2021, 3, 320–325. [Google Scholar] [CrossRef]
- Kose, N.A.; Jinad, R.; Rasheed, A.; Shashidhar, N.; Baza, M.; Alshahrani, H. Detection of Malicious Threats Exploiting Clock-Gating Hardware Using Machine Learning. Sensors 2024, 24, 983. [Google Scholar] [CrossRef]
- Wang, Y.; Sheng, M.; Wang, X.; Wang, L.; Li, J. Mobile-edge computing: Partial computation offloading using dynamic voltage scaling. IEEE Trans. Commun. 2016, 64, 4268–4282. [Google Scholar] [CrossRef]
- Joshi, S.; Li, D.; Ogrenci-Memik, S.; Deptuch, G.; Hoff, J.; Jindariani, S.; Liu, T.; Olsen, J.; Tran, N. Multi-Vdd design for content addressable memories (CAM): A power-delay optimization analysis. J. Low Power Electron. Appl. 2018, 8, 25. [Google Scholar] [CrossRef]
- Tiwari, A.; Bisht, M.R. Leakage Power Reduction in CMOS VLSI Circuits using Advance Leakage Reduction Method. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 962–966. [Google Scholar] [CrossRef]
- Pathak, A.; Sachan, D.; Peta, H.; Goswami, M. A modified SRAM based low power memory design. In Proceedings of the 2016 29th International Conference on VLSI Design and 2016 15th International Conference on Embedded Systems (VLSID), Kolkata, India, 4–8 January 2016; pp. 122–127. [Google Scholar]
- Birla, S.; Singh, N.; Shukla, N. Low-power memory design for IoT-enabled systems: Part 2. In Electrical and Electronic Devices, Circuits and Materials; CRC Press: Boca Raton, FL, USA, 2021; pp. 63–80. [Google Scholar]
- Cao, R.; Yang, Y.; Gu, H.; Huang, L. A thermal-aware power allocation method for optical network-on-chip. IEEE Access 2018, 6, 61176–61183. [Google Scholar] [CrossRef]
- Dehghani, F.; Mohammadi, S.; Barekatain, B.; Abdollahi, M. Power loss analysis in thermally-tuned nanophotonic switch for on-chip interconnect. Nano Commun. Netw. 2020, 26, 100323. [Google Scholar] [CrossRef]
- Abdollahi, M.; Chegini, M.; Hesar, M.H.; Javadinia, S.; Patooghy, A.; Baniasadi, A. NoCSNet: Network-on-Chip Security Assessment Under Thermal Attacks Using Deep Neural Network. In Proceedings of the 2024 17th IEEE/ACM International Workshop on Network on Chip Architectures (NoCArc), Austin, TX, USA, 3 November 2024; pp. 1–6. [Google Scholar]
- Bhasker, J.; Chadha, R. Static Timing Analysis for Nanometer Designs: A Practical Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Willis, R. Critical path analysis and resource constrained project scheduling—theory and practice. Eur. J. Oper. Res. 1985, 21, 149–155. [Google Scholar] [CrossRef]
- Kao, C.C. Clock skew minimization in multiple dynamic supply voltage with adjustable delay buffers restriction. J. Signal Process. Syst. 2015, 79, 99–104. [Google Scholar] [CrossRef]
- Hatture, S.; Dhage, S. Multi-clock domain synchronizers. In Proceedings of the 2015 International Conference on Computation of Power, Energy, Information and Communication (ICCPEIC), Melmaruvathur, India, 22–23 April 2015; pp. 403–408. [Google Scholar]
- Saboori, E.; Abdi, S. Rapid design space exploration of multi-clock domain MPSoCs with Hybrid Prototyping. In Proceedings of the 2016 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Vancouver, Canada, 15–18 May 2016; pp. 1–6. [Google Scholar]
- Chentouf, M.; Ismaili, Z.E.A.A. A PUS based nets weighting mechanism for power, hold, and setup timing optimization. Integration 2022, 84, 122–130. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Mirhoseini, A.; Goldie, A.; Yazgan, M.; Jiang, J.W.; Songhori, E.; Wang, S.; Lee, Y.J.; Johnson, E.; Pathak, O.; Nazi, A.; et al. A graph placement methodology for fast chip design. Nature 2021, 594, 207–212. [Google Scholar] [CrossRef] [PubMed]
- Dey, S.; Nandi, S.; Trivedi, G. PowerPlanningDL: Reliability-aware framework for on-chip power grid design using deep learning. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; pp. 1520–1525. [Google Scholar]
- Szentimrey, H.; Al-Hyari, A.; Foxcroft, J.; Martin, T.; Noel, D.; Grewal, G.; Areibi, S. Machine learning for congestion management and routability prediction within FPGA placement. ACM Trans. Des. Autom. Electron. Syst. TODAES 2020, 25, 1–25. [Google Scholar] [CrossRef]
- Lin, J.M.; Chang, W.Y.; Hsieh, H.Y.; Shyu, Y.T.; Chang, Y.J.; Lu, J.M. Thermal-aware floorplanning and TSV-planning for mixed-type modules in a fixed-outline 3-D IC. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2021, 29, 1652–1664. [Google Scholar] [CrossRef]
- Guan, W.; Tang, X.; Lu, H.; Zhang, Y.; Zhang, Y. Thermal-Aware Fixed-Outline 3-D IC Floorplanning: An End-to-End Learning-Based Approach. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2023, 12, 1882–1895. [Google Scholar] [CrossRef]
- Kim, D.; Kim, M.; Hur, J.; Lee, J.; Cho, J.; Kang, S. TA3D: Timing-Aware 3D IC Partitioning and Placement by Optimizing the Critical Path. In Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, Salt Lake City, UT, USA, 9–11 September 2024; pp. 1–7. [Google Scholar]
- Xu, Q.; Rocha, R.T.; Algoos, Y.; Feron, E.; Younis, M.I. Design, simulation, and testing of a tunable MEMS multi-threshold inertial switch. Microsyst. Nanoeng. 2024, 10, 31. [Google Scholar] [CrossRef]
- Hosseini, S.A.; Roosta, E. A novel technique to produce logic ‘1’in multi-threshold ternary circuits design. Circuits Syst. Signal Process. 2021, 40, 1152–1165. [Google Scholar] [CrossRef]
- Haj-Yahya, J.; Alser, M.; Kim, J.; Yağlıkçı, A.G.; Vijaykumar, N.; Rotem, E.; Mutlu, O. SysScale: Exploiting multi-domain dynamic voltage and frequency scaling for energy efficient mobile processors. In Proceedings of the 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 30 May–3 June 2020; pp. 227–240. [Google Scholar]
- Tsou, W.J.; Yang, W.H.; Lin, J.H.; Chen, H.; Chen, K.H.; Wey, C.L.; Lin, Y.H.; Lin, S.R.; Tsai, T.Y. 20.2 digital low-dropout regulator with anti PVT-variation technique for dynamic voltage scaling and adaptive voltage scaling multicore processor. In Proceedings of the 2017 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 5–9 February 2017; pp. 338–339. [Google Scholar]
- Lungu, A.; Bose, P.; Buyuktosunoglu, A.; Sorin, D.J. Dynamic power gating with quality guarantees. In Proceedings of the 2009 ACM/IEEE International Symposium on Low Power Electronics and Design, San Francisco, CA, USA, 19–21 August 2009; pp. 377–382. [Google Scholar]
- Jahanirad, H. Dynamic power-gating for leakage power reduction in FPGAs. Front. Inf. Technol. Electron. Eng. 2023, 24, 582–598. [Google Scholar] [CrossRef]
- Scarabottolo, I.; Ansaloni, G.; Constantinides, G.A.; Pozzi, L.; Reda, S. Approximate logic synthesis: A survey. Proc. IEEE 2020, 108, 2195–2213. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, Y.; Zukerman, M.; Yung, E.K.N. Energy-efficient base-stations sleep-mode techniques in green cellular networks: A survey. IEEE Commun. Surv. Tutor. 2015, 17, 803–826. [Google Scholar] [CrossRef]
- Ning, S.; Zhu, H.; Feng, C.; Gu, J.; Jiang, Z.; Ying, Z.; Midkiff, J.; Jain, S.; Hlaing, M.H.; Pan, D.Z.; et al. Photonic-Electronic Integrated Circuits for High-Performance Computing and AI Accelerators. J. Light. Technol. 2024. [Google Scholar] [CrossRef]
- Park, H.; Kim, S. Hardware accelerator systems for artificial intelligence and machine learning. In Advances in Computers; Elsevier: Amsterdam, The Netherlands, 2021; Volume 122, pp. 51–95. [Google Scholar]
- Hu, X.; Li, X.; Huang, H.; Zheng, X.; Xiong, X. Tinna: A tiny accelerator for neural networks with efficient dsp optimization. IEEE Trans. Circuits Syst. II Express Briefs 2022, 69, 2301–2305. [Google Scholar] [CrossRef]
- Liu, S.; Cao, Y.; Sun, S. Mapping and optimization method of SpMV on Multi-DSP accelerator. Electronics 2022, 11, 3699. [Google Scholar] [CrossRef]
- Dai, K.; Xie, Z.; Liu, S. DCP-CNN: Efficient Acceleration of CNNs With Dynamic Computing Parallelism on FPGA. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2024. [Google Scholar] [CrossRef]
- Zacharopoulos, G.; Ejjeh, A.; Jing, Y.; Yang, E.Y.; Jia, T.; Brumar, I.; Intan, J.; Huzaifa, M.; Adve, S.; Adve, V.; et al. Trireme: Exploration of hierarchical multi-level parallelism for hardware acceleration. ACM Trans. Embed. Comput. Syst. 2023, 22, 1–23. [Google Scholar] [CrossRef]
- Jamilan, S.; Abdollahi, M.; Mohammadi, S. Cache energy management through dynamic reconfiguration approach in opto-electrical noc. In Proceedings of the 2017 25th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), St. Petersburg, Russia, 6–8 March 2017; pp. 576–583. [Google Scholar]
- Sanca, V.; Ailamaki, A. Post-Moore’s Law Fusion: High-Bandwidth Memory, Accelerators, and Native Half-Precision Processing for CPU-Local Analytics. In Proceedings of the Joint Workshops at 49th International Conference on Very Large Data Bases (VLDBW’23), Vancouver, BC, Canada, 28 August–1 September 2023. [Google Scholar]
- Hur, S.; Na, S.; Kwon, D.; Kim, J.; Boutros, A.; Nurvitadhi, E.; Kim, J. A fast and flexible FPGA-based accelerator for natural language processing neural networks. ACM Trans. Archit. Code Optim. 2023, 20, 1–24. [Google Scholar] [CrossRef]
- Kabir, E.; Kabir, M.A.; Downey, A.R.; Bakos, J.D.; Andrews, D.; Huang, M. FAMOUS: Flexible Accelerator for the Attention Mechanism of Transformer on UltraScale+ FPGAs. arXiv 2024, arXiv:2409.14023. [Google Scholar]
- Lee, H.; Lee, J.; Kang, S. A Robust Test Architecture for Low-Power AI Accelerators. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2024. [Google Scholar] [CrossRef]
- Lee, S.; Park, J.; Park, S.; Kim, H.; Kang, S. A New Zero-Overhead Test Method for Low-Power AI Accelerators. IEEE Trans. Circuits Syst. II Express Briefs 2023, 71, 2649–2653. [Google Scholar] [CrossRef]
- Shah, N.; Meert, W.; Verhelst, M. Efficient Execution of Irregular Dataflow Graphs: Hardware/Software Co-Optimization for Probabilistic AI and Sparse Linear Algebra; Springer Nature: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Rashidi, B.; Gao, C.; Lu, S.; Wang, Z.; Zhou, C.; Niu, D.; Sun, F. UNICO: Unified Hardware Software Co-Optimization for Robust Neural Network Acceleration. In Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, Toronto, ON, Canada, 28 October–1 November 2023; pp. 77–90. [Google Scholar]
- Arman, G. New Approach of IO Cell Placement Addressing Minimized Data and Clock Skews in Top Level. In Proceedings of the 2023 IEEE East-West Design & Test Symposium (EWDTS), Batumi, Georgia, 22–25 September 2023; pp. 1–5. [Google Scholar]
- Deng, C.; Cai, Y.C.; Zhou, Q. Register clustering methodology for low power clock tree synthesis. J. Comput. Sci. Technol. 2015, 30, 391–403. [Google Scholar] [CrossRef]
- Kyriakakis, E.; Tange, K.; Reusch, N.; Zaballa, E.O.; Fafoutis, X.; Schoeberl, M.; Dragoni, N. Fault-tolerant clock synchronization using precise time protocol multi-domain aggregation. In Proceedings of the 2021 IEEE 24th International Symposium on Real-Time Distributed Computing (ISORC), Daegu, Republic of Korea, 1–3 June 2021; pp. 114–122. [Google Scholar]
- Han, K.; Kahng, A.B.; Li, J. Optimal generalized H-tree topology and buffering for high-performance and low-power clock distribution. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2018, 39, 478–491. [Google Scholar] [CrossRef]
- Rahman, M.S.; Guo, R.; Kamali, H.M.; Rahman, F.; Farahmandi, F.; Abdel-Moneum, M.; Tehranipoor, M. O’clock: Lock the clock via clock-gating for soc ip protection. In Proceedings of the 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; pp. 775–780. [Google Scholar]
- Hu, K.; Hou, X.; Lin, Z. Advancements In Low-Power Technologies: Clock-Gated Circuits and Beyond. Highlights Sci. Eng. Technol. 2024, 81, 218–225. [Google Scholar] [CrossRef]
- Erra, R.; Stine, J.E. Power Reduction of Montgomery Multiplication Architectures Using Clock Gating. In Proceedings of the 2024 IEEE 67th International Midwest Symposium on Circuits and Systems (MWSCAS), Springfield, MA, USA, 11–14 August 2024; pp. 474–478. [Google Scholar]
- Namazi, A.; Safari, S.; Mohammadi, S.; Abdollahi, M. SORT: Semi online reliable task mapping for embedded multi-core systems. ACM Trans. Model. Perform. Eval. Comput. Syst. TOMPECS 2019, 4, 1–25. [Google Scholar] [CrossRef]
- Namazi, A.; Abdollahi, M.; Safari, S.; Mohammadi, S.; Daneshtalab, M. Lrtm: Life-time and reliability-aware task mapping approach for heterogeneous multi-core systems. In Proceedings of the 2018 11th International Workshop on Network on Chip Architectures (NoCArc), Fukuoka, Japan, 20 October 2018; pp. 1–6. [Google Scholar]
- Abumwais, A.; Obaid, M. Shared Cache Based on Content Addressable Memory in a Multi-Core Architecture. Comput. Mater. Contin. 2023, 74. [Google Scholar] [CrossRef]
- Bahn, H.; Cho, K. Implications of NVM based storage on memory subsystem management. Appl. Sci. 2020, 10, 999. [Google Scholar] [CrossRef]
- Sarkar, R.; Abi-Karam, S.; He, Y.; Sathidevi, L.; Hao, C. FlowGNN: A dataflow architecture for real-time workload-agnostic graph neural network inference. In Proceedings of the 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Montreal, QC, Canada, 25 February–1 March 2023; pp. 1099–1112. [Google Scholar]
- Kenter, T.; Shambhu, A.; Faghih-Naini, S.; Aizinger, V. Algorithm-hardware co-design of a discontinuous Galerkin shallow-water model for a dataflow architecture on FPGA. In Proceedings of the Platform for Advanced Scientific Computing Conference, Geneva, Switzerland, 5–9 July 2021; pp. 1–11. [Google Scholar]
- Besta, M.; Kanakagiri, R.; Kwasniewski, G.; Ausavarungnirun, R.; Beránek, J.; Kanellopoulos, K.; Janda, K.; Vonarburg-Shmaria, Z.; Gianinazzi, L.; Stefan, I.; et al. Sisa: Set-centric instruction set architecture for graph mining on processing-in-memory systems. In Proceedings of the MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, Athens, Greece, 18–22 October 2021; pp. 282–297. [Google Scholar]
- Sahabandu, D.; Mertoguno, J.S.; Poovendran, R. A natural language processing approach for instruction set architecture identification. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4086–4099. [Google Scholar] [CrossRef]
- Baharloo, M.; Abdollahi, M.; Baniasadi, A. System-level reliability assessment of optical network on chip. Microprocess. Microsystems 2023, 99, 104843. [Google Scholar] [CrossRef]
- Abdollahi, M.; Baharloo, M.; Shokouhinia, F.; Ebrahimi, M. RAP-NOC: Reliability assessment of photonic network-on-chips, a simulator. In Proceedings of the Eight Annual ACM International Conference on Nanoscale Computing and Communication, Virtual, 7–9 September 2021; pp. 1–7. [Google Scholar]
- Hasanzadeh, M.; Abdollahi, M.; Baniasadi, A.; Patooghy, A. Thermo-Attack Resiliency: Addressing a New Vulnerability in Opto-Electrical Network-on-Chips. In Proceedings of the 2024 25th International Symposium on Quality Electronic Design (ISQED), San Francisco, CA, USA, 3–5 April 2024; pp. 1–9. [Google Scholar]
- Anuradha, P.; Majumder, P.; Sivaraman, K.; Vignesh, N.A.; Jayakar, A.; Anthonirj, S.; Mallik, S.; Al-Rasheed, A.; Abbas, M.; Soufiene, B.O. Enhancing High-Speed Data Communications: Optimization of Route Controlling Network on Chip Implementation. IEEE Access 2024, 12, 123514–123528. [Google Scholar] [CrossRef]
- Nisa, U.U.; Bashir, J. Towards efficient on-chip communication: A survey on silicon nanophotonics and optical networks-on-chip. J. Syst. Archit. 2024, 152, 103171. [Google Scholar] [CrossRef]
- Abdollahi, M.; Firouzabadi, Y.; Dehghani, F.; Mohammadi, S. THAMON: Thermal-aware High-performance Application Mapping onto Opto-electrical network-on-chip. J. Syst. Archit. 2021, 121, 102315. [Google Scholar] [CrossRef]
- Abdollahi, M.; Tavana, M.K.; Koohi, S.; Hessabi, S. ONC3: All-optical NoC based on cube-connected cycles with quasi-DOR algorithm. In Proceedings of the 2012 15th Euromicro Conference on Digital System Design, Izmir, Turkey, 5–8 September 2012; pp. 296–303. [Google Scholar]
- Bai, C.; Huang, J.; Wei, X.; Ma, Y.; Li, S.; Zheng, H.; Yu, B.; Xie, Y. ArchExplorer: Microarchitecture exploration via bottleneck analysis. In Proceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, Toronto, ON, Canada, 28 October–1 November 2023; pp. 268–282. [Google Scholar]
- Dave, S.; Nowatzki, T.; Shrivastava, A. Explainable-DSE: An Agile and Explainable Exploration of Efficient HW/SW Codesigns of Deep Learning Accelerators Using Bottleneck Analysis. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; Volume 4, pp. 87–107. [Google Scholar]
- Bernstein, L.; Sludds, A.; Hamerly, R.; Sze, V.; Emer, J.; Englund, D. Freely scalable and reconfigurable optical hardware for deep learning. Sci. Rep. 2021, 11, 3144. [Google Scholar] [CrossRef]
- Jia, H.; Ozatay, M.; Tang, Y.; Valavi, H.; Pathak, R.; Lee, J.; Verma, N. 15.1 a programmable neural-network inference accelerator based on scalable in-memory computing. In Proceedings of the 2021 IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021; Volume 64, pp. 236–238. [Google Scholar]
- Lakshmanna, K.; Shaik, F.; Gunjan, V.K.; Singh, N.; Kumar, G.; Shafi, R.M. Perimeter degree technique for the reduction of routing congestion during placement in physical design of VLSI circuits. Complexity 2022, 2022, 8658770. [Google Scholar] [CrossRef]
- Chen, X.; Liu, G.; Xiong, N.; Su, Y.; Chen, G. A survey of swarm intelligence techniques in VLSI routing problems. IEEE Access 2020, 8, 26266–26292. [Google Scholar] [CrossRef]
- Karimullah, S.; Vishnuvardhan, D. Experimental analysis of optimization techniques for placement and routing in Asic design. In Proceedings of the ICDSMLA 2019: Proceedings of the 1st International Conference on Data Science, Machine Learning and Applications, Hyderabad, India, 29–30 March 2019; Springer: Berlin/Heidelberg, Germany, 2020; pp. 908–917. [Google Scholar]
- Ramesh, S.; Manna, K.; Gogineni, V.C.; Chattopadhyay, S.; Mahapatra, S. Congestion-Aware Vertical Link Placement and Application Mapping Onto Three-Dimensional Network-On-Chip Architectures. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 2249–2262. [Google Scholar] [CrossRef]
- Rocher-Gonzalez, J.; Escudero-Sahuquillo, J.; Garcia, P.J.; Quiles, F.J. Congestion management in high-performance interconnection networks using adaptive routing notifications. J. Supercomput. 2023, 79, 7804–7834. [Google Scholar] [CrossRef]
- Cho, Y.; Kim, H.; Lee, K.; Jo, H.; Lee, H.; Kim, M.; Im, Y. Fast and Real-Time Thermal-Aware Floorplan Methodology for SoC. IEEE Trans. Components Packag. Manuf. Technol. 2024, 14, 1568–1576. [Google Scholar] [CrossRef]
- Cho, Y.; Kim, H.; Lee, K.; Im, Y.; Lee, H.; Kim, M. Thermal Aware Floorplan Optimization of SoC in Mobile Phone. In Proceedings of the 2023 22nd IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm), Orlando, FL, USA, 30 May–2 June 2023; pp. 1–7. [Google Scholar]
- Dehghani, F.; Mohammadi, S.; Barekatain, B.; Abdollahi, M. ICES: An innovative crosstalk-efficient 2 × 2 photonic-crystal switch. Opt. Quantum Electron. 2021, 53, 1–15. [Google Scholar] [CrossRef]
- Kaur, M.; Singh, G.; Kumar, Y. RF and Crosstalk Characterization of Chip Interconnects Using Finite Element Method. Indian J. Eng. Mater. Sci. IJEMS 2023, 30, 132–137. [Google Scholar]
- Kashif, M.; Cicek, I. Field-programmable gate array (FPGA) hardware design and implementation ofa new area efficient elliptic curve crypto-processor. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 2127–2139. [Google Scholar] [CrossRef]
- Bardon, M.G.; Sherazi, Y.; Jang, D.; Yakimets, D.; Schuddinck, P.; Baert, R.; Mertens, H.; Mattii, L.; Parvais, B.; Mocuta, A.; et al. Power-performance trade-offs for lateral nanosheets on ultra-scaled standard cells. In Proceedings of the 2018 IEEE Symposium on VLSI Technology, Honolulu, HI, USA, 18–22 June 2018; pp. 143–144. [Google Scholar]
- Gao, X.; Qiao, Q.; Wang, M.; Niu, M.; Liu, H.; Maezawa, M.; Ren, J.; Wang, Z. Design and verification of SFQ cell library for superconducting LSI digital circuits. IEEE Trans. Appl. Supercond. 2021, 31, 1–5. [Google Scholar] [CrossRef]
- Dannan, B.; Grumman, N.; Kuszewski, J.; Vincent, R.; Wu, S.; McCaffrey, W.; Park, A. Improved methodology to accurately perform system level power integrity analysis including an ASIC die; Presented at DesignCon: Santa Clara, CA, USA, 2022; pp. 5–7. [Google Scholar]
- Meixner, A.; Gullo, L.J. Design for Test and Testability. Des. Maintainab. 2021, 245–264. [Google Scholar] [CrossRef]
- Huhn, S.; Drechsler, R. Design for Testability, Debug and Reliability; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Deshpande, N.; Sowmya, K. A review on ASIC synthesis flow employing two industry standard tools. Int. J. Eng. Res. Technol. 2020, 8. [Google Scholar] [CrossRef]
- Taraate, V. ASIC Design and Synthesis; Springer Nature: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Golshan, K. The Art of Timing Closure; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Sariki, A.; Sai, G.M.V.; Khosla, M.; Raj, B. ASIC Design using Post Route ECO Methodologies for Timing Closure and Power Optimization. Int. J. Microsystems IoT 2023, 1, 195–204. [Google Scholar]
- Lau, J.H. Recent advances and trends in advanced packaging. IEEE Trans. Components, Packag. Manuf. Technol. 2022, 12, 228–252. [Google Scholar] [CrossRef]
- Abdollahi, M.; Mohammadi, S. Vulnerability assessment of fault-tolerant optical network-on-chips. J. Parallel Distrib. Comput. 2020, 145, 140–159. [Google Scholar] [CrossRef]
- Hiller, M.; Kürzinger, L.; Sigl, G. Review of error correction for PUFs and evaluation on state-of-the-art FPGAs. J. Cryptogr. Eng. 2020, 10, 229–247. [Google Scholar] [CrossRef]
- Djambazova, E.; Andreev, R. Redundancy Management in Dependable Distributed Real-Time Systems. Probl. Eng. Cybern. Robot. 2023, 79, 37–54. [Google Scholar] [CrossRef]
- Oszczypała, M.; Ziółkowski, J.; Małachowski, J. Redundancy allocation problem in repairable k-out-of-n systems with cold, warm, and hot standby: A genetic algorithm for availability optimization. Appl. Soft Comput. 2024, 165, 112041. [Google Scholar] [CrossRef]
- Hantos, G.; Flynn, D.; Desmulliez, M.P. Built-in self-test (BIST) methods for MEMS: A review. Micromachines 2020, 12, 40. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Lin, Y.; Gupta, S. Built in self test (BIST) for RSFQ circuits. In Proceedings of the 2024 IEEE 42nd VLSI Test Symposium (VTS), Tempe, AZ, USA, 22–24 April 2024; pp. 1–7. [Google Scholar]
- Verducci, O.; Oliveira, D.L.; Batista, G. Fault-tolerant finite state machine quasi delay insensitive in commercial FPGA devices. In Proceedings of the 2022 IEEE 13th Latin America Symposium on Circuits and System (LASCAS), Santiago, Chile, 1–4 March 2022; pp. 1–4. [Google Scholar]
- Salauyou, V. Fault Detection of Moore Finite State Machines by Structural Models. In Proceedings of the International Conference on Computer Information Systems and Industrial Management, Tokyo, Japan, 22–24 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 394–409. [Google Scholar]
- Pavan Kumar, M.; Lorenzo, R. A review on radiation-hardened memory cells for space and terrestrial applications. Int. J. Circuit Theory Appl. 2023, 51, 475–499. [Google Scholar] [CrossRef]
- Lee, M.; Cho, S.; Lee, N.; Kim, J. New radiation-hardened design of a cmos instrumentation amplifier and its tolerant characteristic analysis. Electronics 2020, 9, 388. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, L.; Wang, S.; Zhou, J.; Tian, C.; Feng, H. AIP-SEM: An Efficient ML-Boost In-Place Soft Error Mitigation Method for SRAM-Based FPGA. In Proceedings of the 2024 2nd International Symposium of Electronics Design Automation (ISEDA), Xi’an, China, 10–13 May 2024; pp. 351–354. [Google Scholar]
- Xie, Y.; Qiao, T.; Xie, Y.; Chen, H. Soft error mitigation and recovery of SRAM-based FPGAs using brain-inspired hybrid-grained scrubbing mechanism. Front. Comput. Neurosci. 2023, 17, 1268374. [Google Scholar] [CrossRef]
- Xu, F.; Ding, N.; Li, N.; Liu, L.; Hou, N.; Xu, N.; Guo, W.; Tian, L.; Xu, H.; Wu, C.M.L.; et al. A review of bearing failure Modes, mechanisms and causes. Eng. Fail. Anal. 2023, 152, 107518. [Google Scholar] [CrossRef]
- Huang, J.; You, J.X.; Liu, H.C.; Song, M.S. Failure mode and effect analysis improvement: A systematic literature review and future research agenda. Reliab. Eng. Syst. Saf. 2020, 199, 106885. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, F.; Nguyen, A.; Zan, D.; Lin, Z.; Lou, J.G.; Chen, W. Codet: Code generation with generated tests. arXiv 2022, arXiv:2207.10397. [Google Scholar]
- Unno, H.; Terauchi, T.; Koskinen, E. Constraint-based relational verification. In Proceedings of the International Conference on Computer Aided Verification, Los Angeles, CA, USA, 18–24 July 2021; Springer: Berlin/Heidelberg, Germany; pp. 742–766. [Google Scholar]
- Jha, C.K.; Qayyum, K.; Coşkun, K.Ç.; Singh, S.; Hassan, M.; Leupers, R.; Merchant, F.; Drechsler, R. veriSIMPLER: An Automated Formal Verification Methodology for SIMPLER MAGIC Design Style Based In-Memory Computing. IEEE Trans. Circuits Syst. Regul. Pap. 2024, 71, 4169–4179. [Google Scholar] [CrossRef]
- Coudert, S.; Apvrille, L.; Sultan, B.; Hotescu, O.; de Saqui-Sannes, P. Incremental and Formal Verification of SysML Models. SN Comput. Sci. 2024, 5, 714. [Google Scholar] [CrossRef]
- Ayalasomayajula, A.; Farzana, N.; Tehranipoor, M.; Farahmandi, F. Automatic Asset Identification for Assertion-Based SoC Security Verification. IEEE Trans.-Comput.-Aided Des. Integr. Circuits Syst. 2024, 43, 3264–3277. [Google Scholar] [CrossRef]
- Rostami, H.; Hosseini, M.; Azarpeyvand, A.; Iman, M.R.H.; Ghasempouri, T. Automatic High Functional Coverage Stimuli Generation for Assertion-based Verification. In Proceedings of the 2024 IEEE 30th International Symposium on On-Line Testing and Robust System Design (IOLTS), Brittany, France, 3–5 July 2024; pp. 1–7. [Google Scholar]
- Tian, K.; Mitchell, E.; Yao, H.; Manning, C.D.; Finn, C. Fine-tuning language models for factuality. arXiv 2023, arXiv:2311.08401. [Google Scholar]
- Yang, Z. Scalable Equivalence Checking for Behavioral Synthesis. Ph.D. Thesis, Computer Science Department, Portland State University, Portland, OR, USA, 2015. [Google Scholar]
- Aboudeif, R.A.H. Design and Implementation of UVM-Based Verification Framework for Deep Learning Accelerators. Master’s Thesis, School of Sciences and Engineering, The American University in Cairo, New Cairo, Egypt, 2024. [Google Scholar]
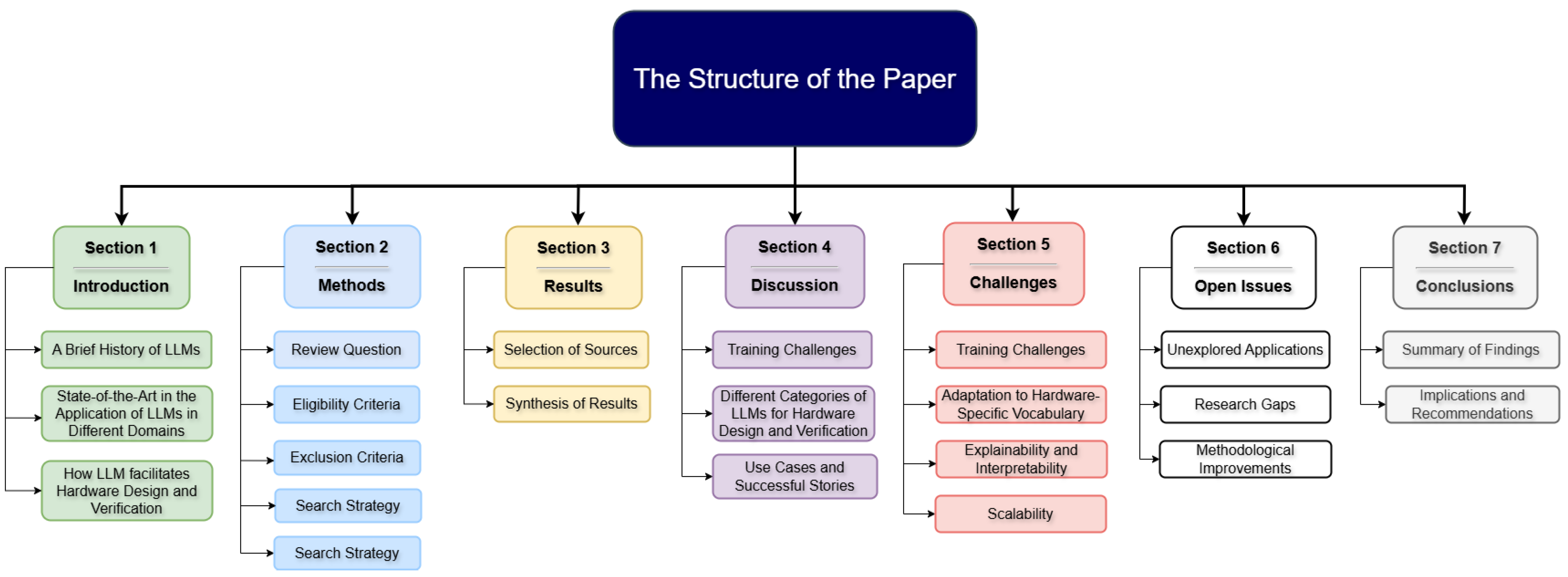

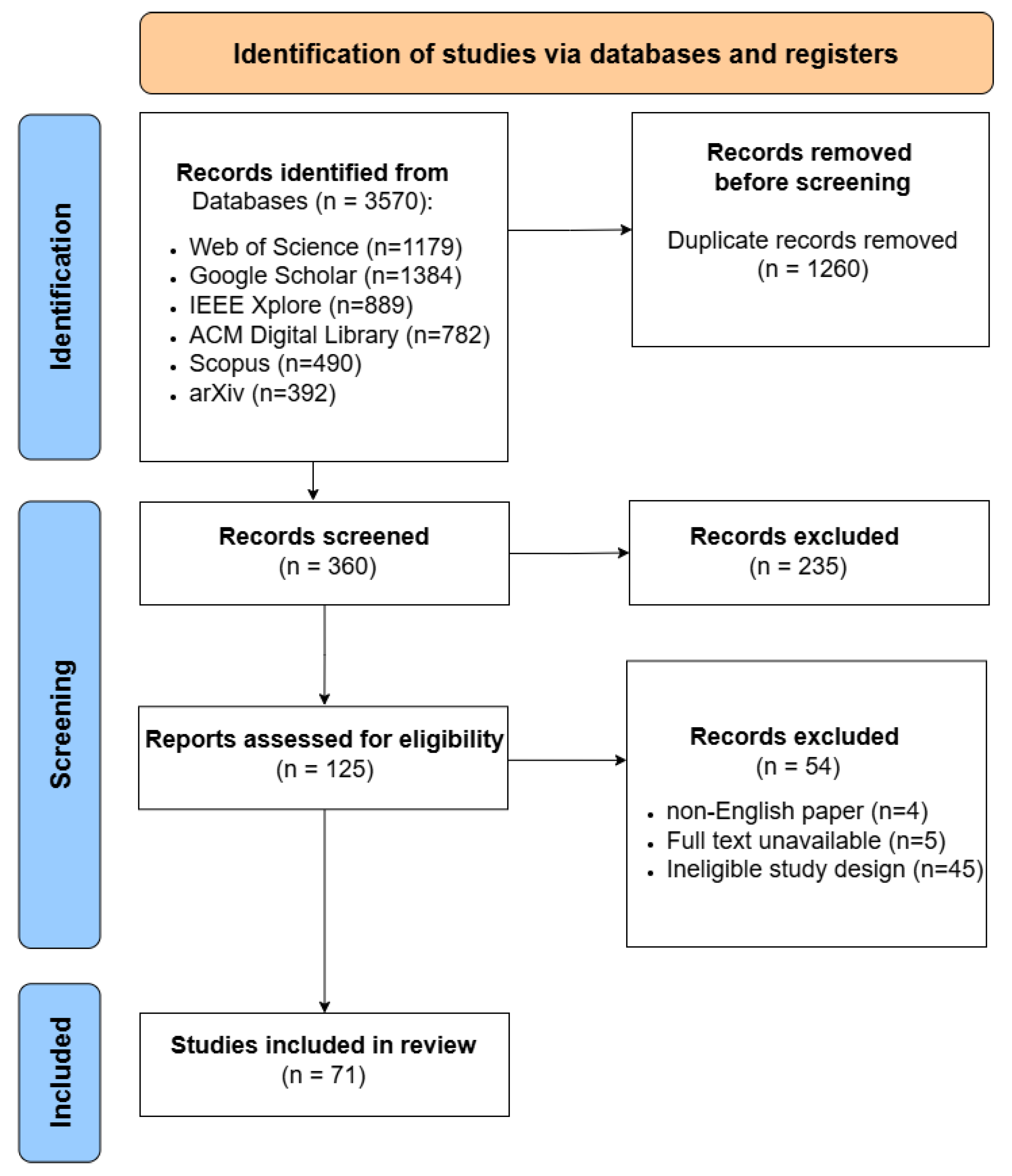
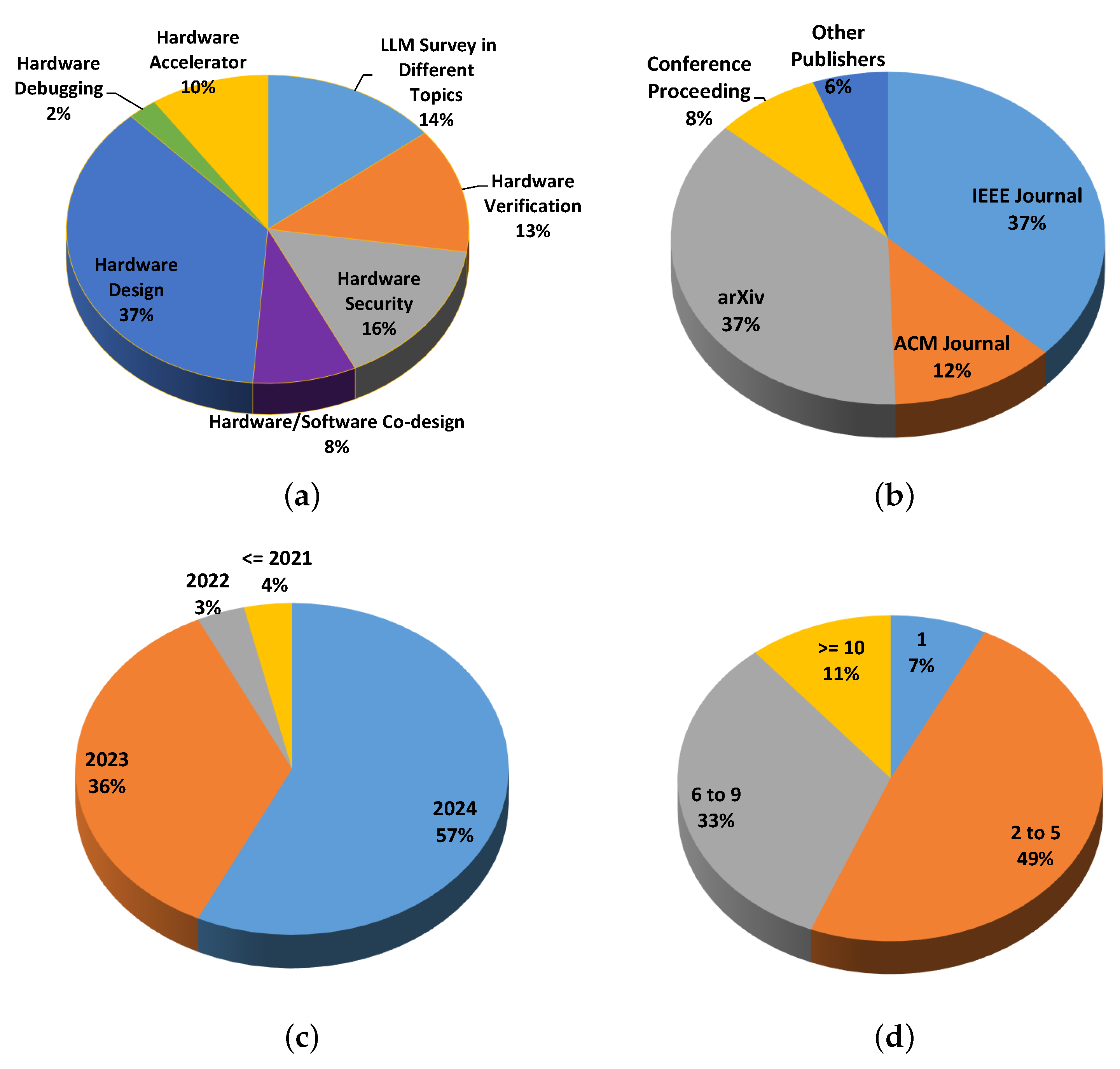
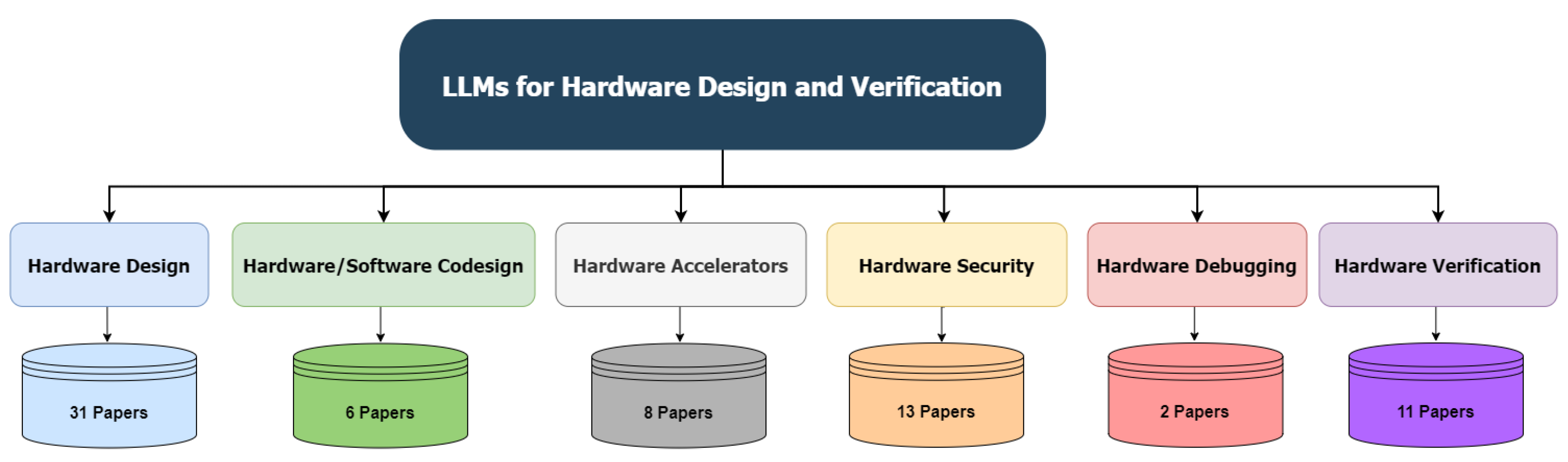






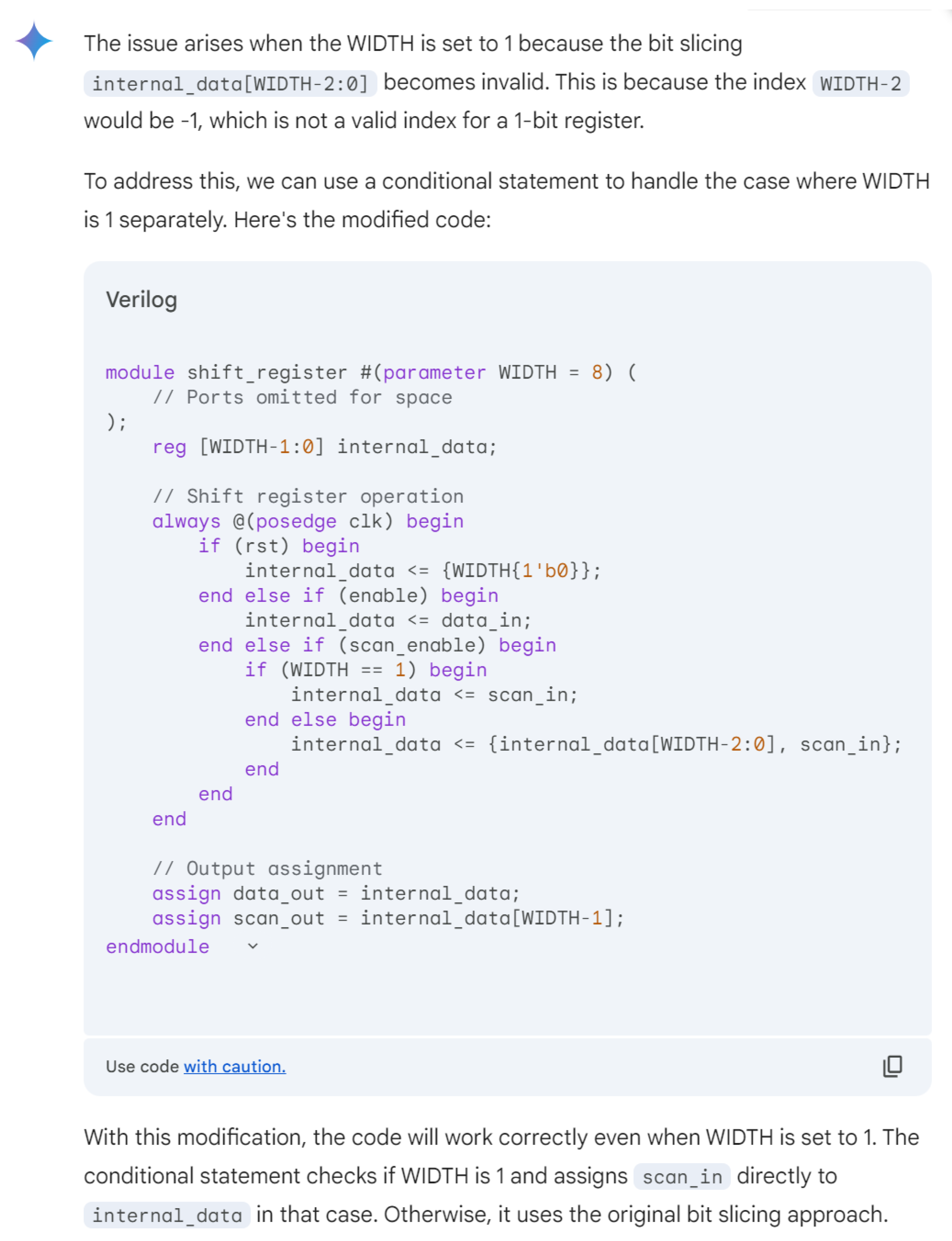



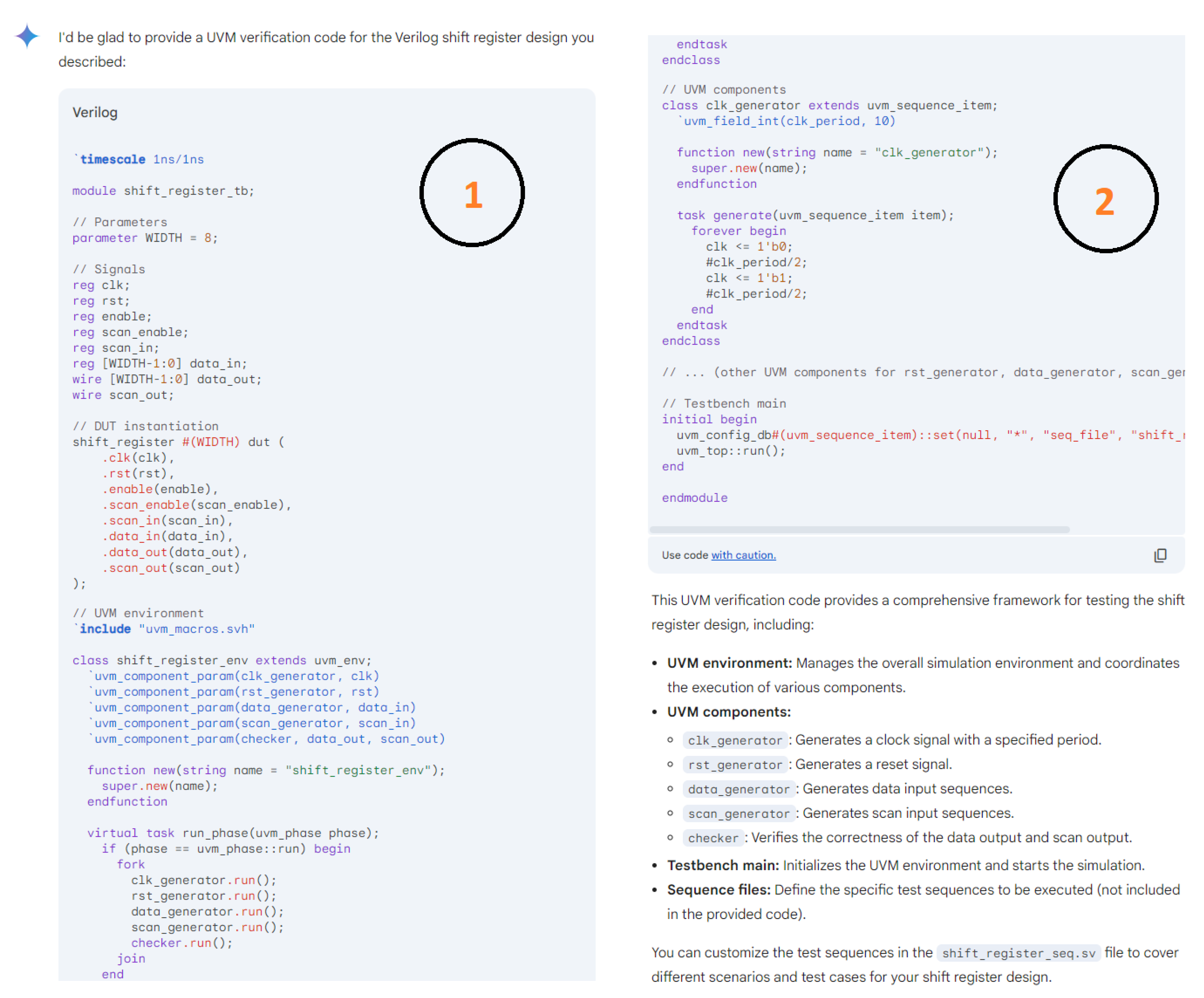

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).