
Cosine Distance Loss for Open-Set Image Recognition


Abstract
1. Introduction
2. Related Work
3. Open-Set Image Classification by Incorporating CDLoss
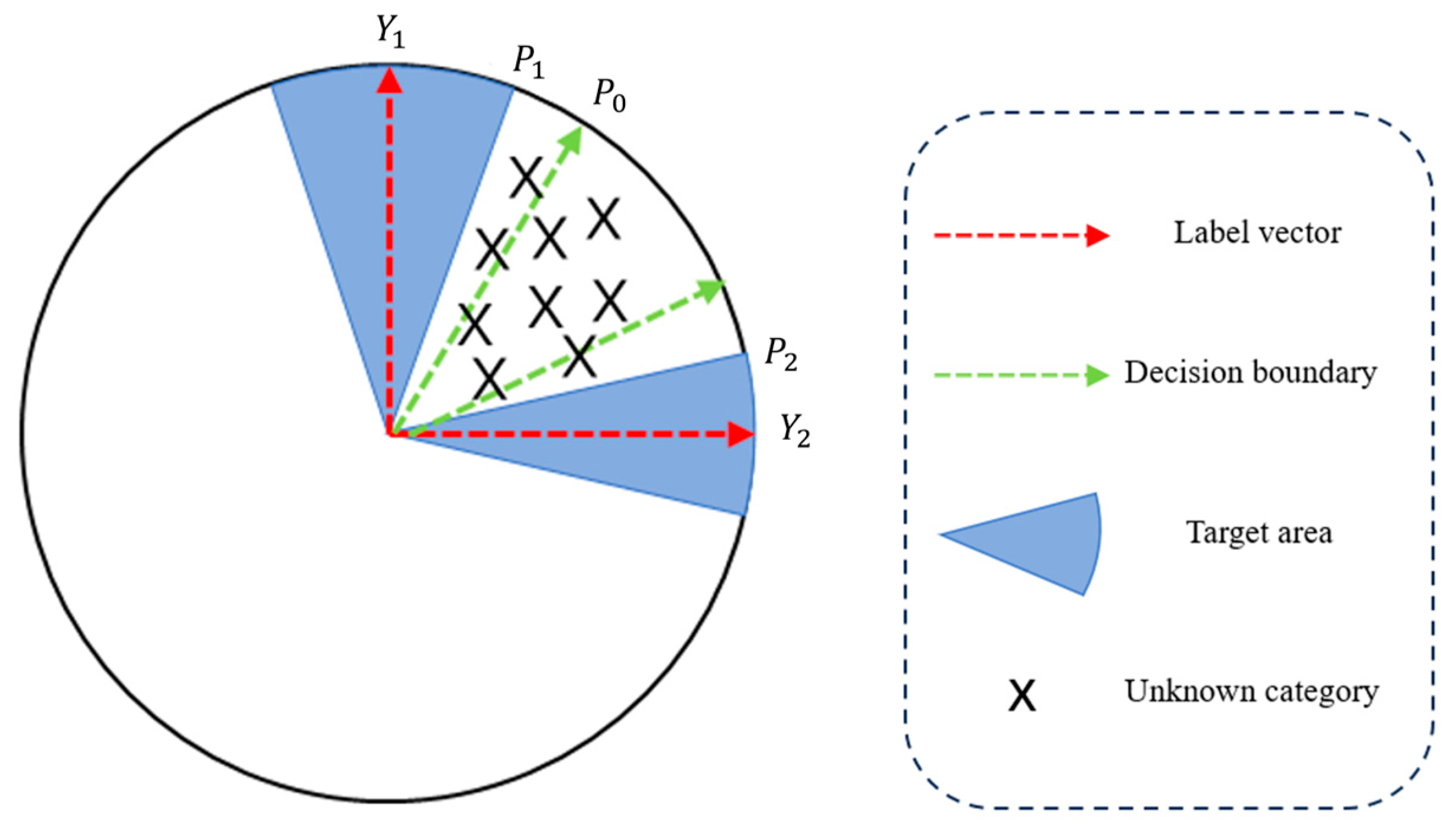
3.1. Motivation for Incorporation of CDLoss
3.2. Proposed Framework
3.3. CDLoss and Its Spatial Characteristics
3.4. Loss Function for Model
3.5. Unknown Class Detection
4. Experimental Platform and Settings
4.1. Experimental Platform
4.2. Parameter Settings
4.3. Dataset Partitioning
- MNIST, SVHN, CIFAR10. These datasets consist of a total of 10 categories, 6 of which are selected as the KCs and the remaining 4 categories are the UCs, i.e., |K| = 6, |U| = 4.
- CIFAR+50. Derived from CIFAR10 and CIFAR100, 4 classes are taken from CIFAR10 as the KCs and 50 classes are taken from CIFAR100 as the UCs, i.e., |K| = 4 and |U| = 50.
- TinyImagenet. The dataset has a total of 200 classes, 20 of which are selected as the KCs and the remaining180 as the UCs, i.e., |K| = 20, |U| = 180.
4.4. Evaluation Metrics
5. Results and Analyses
5.1. Performance Comparison
5.2. The Influence of Different Weights of Loss on Performance
5.3. Visualization of the Impact of CDLoss on Feature Response
5.4. Stability Analysis of the Proposed Method
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Maurício, J.; Domingues, I.; Bernardino, J. Comparing vision transformers and convolutional neural networks for image classification: A literature review. Appl. Sci. 2023, 13, 5521. [Google Scholar] [CrossRef]
- Scheirer, W.J.; de Rezende Rocha, A.; Sapkota, A.; Boult, T.E. Toward open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1757–1772. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Tian, J.; Han, W.; Qin, Z.; Fan, Y.; Shao, J. Learning multiple Gaussian prototypes for open-set recognition. Inf. Sci. 2023, 626, 738–753. [Google Scholar] [CrossRef]
- Hein, M.; Andriushchenko, M.; Bitterwolf, J. Why ReLU networks yield high-confidence predictions far away from the training data and how to mitigate the problem. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 41–50. [Google Scholar]
- Bendale, A.; Boult, T.E. Towards open set deep networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1563–1572. [Google Scholar]
- Ge, Z.; Demyanov, S.; Chen, Z.; Garnavi, R. Generative OpenMax for multi-class open set classification. arXiv 2017, arXiv:1707.07418. [Google Scholar]
- Neal, L.; Olson, M.; Fern, X.; Wong, W.-K.; Li, F. Open set learning with counterfactual images. In Proceedings of the Computer Vision-ECCV 2018, 15th European Conference, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Liu, C.L. Robust classification with convolutional prototype learning. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3474–3482. [Google Scholar]
- Chen, G.; Qiao, L.; Shi, Y.; Peng, P.; Li, J.; Huang, T.; Pu, S.; Tian, Y. Learning open set network with discriminative reciprocal points. In Proceedings of the Computer Vision–ECCV 2020, 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Chen, G.; Peng, P.; Wang, X.; Tian, Y. Adversarial reciprocal points learning for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8065–8081. [Google Scholar] [CrossRef]
- Xia, Z.; Wang, P.; Dong, G.; Liu, H. Spatial location constraint prototype loss for open set recognition. Comput. Vis. Image Underst. 2023, 229, 103651. [Google Scholar] [CrossRef]
- Scheirer, W.J.; Jain, L.P.; Boult, T.E. Probability models for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2317–2324. [Google Scholar] [CrossRef]
- Jain, L.P.; Scheirer, W.J.; Boult, T.E. Multi-class open set recognition using probability of inclusion. In Proceedings of the Computer Vision–ECCV 2014, 13th European Conference, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Rudd, E.M.; Jain, L.P.; Scheirer, W.J.; Boult, T.E. The extreme value machine. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 762–768. [Google Scholar] [CrossRef]
- Mendes Júnior, P.R.; De Souza, R.M.; Werneck, R.D.O.; Stein, B.V.; Pazinato, D.V.; De Almeida, W.R.; Penatti, O.A.B.; Rocha, A. Nearest neighbors distance ratio open-set classifier. Mach. Learn. 2017, 106, 359–386. [Google Scholar] [CrossRef]
- Zhang, H.; Patel, V.M. Sparse representation-based open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1690–1696. [Google Scholar] [CrossRef]
- Shah, A.; Azam, N.; Ali, B.; Khan, M.T.; Yao, J. A three-way clustering approach for novelty detection. Inf. Sci. 2021, 569, 650–668. [Google Scholar] [CrossRef]
- Shu, L.; Xu, H.; Liu, B. Doc: Deep open classification of text documents. arXiv 2017, arXiv:1709.08716. [Google Scholar]
- Yoshihashi, R.; Shao, W.; Kawakami, R.; You, S.; Iida, M.; Naemura, T. Classification-reconstruction learning for open-set recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4016–4025. [Google Scholar]
- Jang, J.; Kim, C.O. Collective decision of one-vs-rest networks for open-set recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 2327–2338. [Google Scholar] [CrossRef] [PubMed]
- Chen, M.; Xia, J.Y.; Liu, T.; Liu, L.; Liu, Y. Open Set Recognition and Category Discovery Framework for SAR Target Classification Based on K-Contrast Loss and Deep Clustering. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 3489–3501. [Google Scholar] [CrossRef]
- Vareto, R.H.; Linghu, Y.; Boult, T.E.; Schwartz, W.R.; Günther, M. Open-set face recognition with maximal entropy and Objectosphere loss. Image Vision Comput. 2024, 141, 104862. [Google Scholar] [CrossRef]
- Wang, G.; Gao, Y. Open-Set Jamming Pattern Recognition via Generated Unknown Jamming Data. IEEE Signal Process. Lett. 2024, 31, 1079–1083. [Google Scholar] [CrossRef]
- Guo, Y.; Camporese, G.; Yang, W.; Sperduti, A.; Ballan, L. Conditional variational capsule network for open set recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 103–111. [Google Scholar]
- Cao, A.; Luo, Y.; Klabjan, D. Open-set recognition with gaussian mixture variational autoencoders. In Proceedings of the 2021 AAAI Conference on Artificial Intelligence, Vancouver Convention Centre, Vancouver, BC, Canada, 2–9 February 2021; pp. 6877–6884. [Google Scholar]
- Sun, J.; Wang, H.; Dong, Q. MoEP-AE: Autoencoding mixtures of exponential power distributions for open-set recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 312–325. [Google Scholar] [CrossRef]
- Yang, H.M.; Zhang, X.Y.; Yin, F.; Yang, Q.; Liu, C.L. Convolutional prototype network for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2358–2370. [Google Scholar] [CrossRef]
- Huang, H.; Wang, Y.; Hu, Q.; Cheng, M.M. Class-specific semantic reconstruction for open set recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4214–4228. [Google Scholar] [CrossRef]
- Menon, A.K.; Jayasumana, S.; Rawat, A.S.; Jain, H.; Veit, A.; Kumar, S. Long-tail learning via logit adjustment. arXiv 2020, arXiv:2007.07314. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the Computer Vision–ECCV 2016, 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Perera, P.; Morariu, V.I.; Jain, R.; Manjunatha, V.; Wigington, C.; Ordonez, V.; Patel, V.M. Generative-discriminative feature representations for open-set recognition. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11814–11823. [Google Scholar]
- Davis, J.; Goadrich, M. The relationship between Precision-Recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 28–29 June 2006; pp. 233–240. [Google Scholar]
- Yang, S.; Zhang, W.; Tang, R.; Zhang, M.; Huang, Z. Approximate inferring with confidence predicting based on uncertain knowledge graph embedding. Inf. Sci. 2022, 609, 679–690. [Google Scholar] [CrossRef]
- Dhamija, A.R.; Günther, M.; Boult, T. Reducing network agnostophobia. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Vaze, S.; Han, K.; Vedaldi, A.; Zisserman, A. Open-set recognition: A good closed-set classifier is all you need? arXiv 2021, arXiv:2110.06207. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MNIST | SVHN | CIFAR10 | CIFAR+50 | TinyImagenet |
|---|---|---|---|---|---|
| MSP [28] | 99.42 | 94.46 | 86.08 | 90.04 | 74.02 |
| MSP + CDLoss | 99.58 | 95.18 | 86.96 | 91.31 | 74.70 |
| GCPL [7] | 99.40 | 94.71 | 84.29 | 88.40 | 69.89 |
| GCPL + CDLoss | 99.48 | 94.88 | 85.57 | 89.57 | 73.23 |
| RPL [8] | 99.46 | 94.69 | 85.6 | 88.97 | 68.82 |
| RPL + CDLoss | 99.52 | 94.87 | 85.96 | 89.30 | 72.79 |
| ARPL [9] | 99.57 | 95.68 | 89.39 | 93.91 | 75.77 |
| ARPL + CDLoss | 99.62 | 95.77 | 89.67 | 93.86 | 76.11 |
| SLCPL [10] | 99.40 | 94.86 | 85.11 | 88.22 | 70.15 |
| SLCPL + CDLoss | 99.42 | 95.10 | 85.65 | 89.04 | 74.08 |
| Method | MNIST | SVHN | CIFAR10 | CIFAR+50 | TinyImagenet |
|---|---|---|---|---|---|
| MSP | 99.24 | 92.63 | 83.75 | 88.21 | 60.50 |
| MSP + CDLoss | 99.41 | 93.45 | 84.62 | 89.49 | 61.36 |
| GCPL | 99.24 | 93.05 | 81.69 | 86.47 | 48.83 |
| GCPL + CDLoss | 99.30 | 93.33 | 83.14 | 87.73 | 55.70 |
| RPL | 99.31 | 93.18 | 83.29 | 87.51 | 48.92 |
| RPL + CDLoss | 99.37 | 93.41 | 83.78 | 87.86 | 56.50 |
| ARPL | 99.36 | 93.51 | 86.04 | 91.36 | 61.87 |
| ARPL + CDLoss | 99.39 | 93.85 | 86.46 | 91.48 | 62.39 |
| SLCPL | 99.23 | 93.24 | 82.51 | 86.33 | 50.69 |
| SLCPL + CDLoss | 99.27 | 93.53 | 83.10 | 87.37 | 57.12 |
| Method | MNIST | SVHN | CIFAR10 | CIFAR+50 | TinyImagenet |
|---|---|---|---|---|---|
| MSP | 99.74 | 96.59 | 94.31 | 96.10 | 73.66 |
| MSP + CDLoss | 99.78 | 96.89 | 94.49 | 96.34 | 74.06 |
| GCPL | 99.80 | 97.00 | 93.90 | 95.91 | 60.50 |
| GCPL + CDLoss | 99.80 | 97.15 | 94.50 | 96.31 | 67.68 |
| RPL | 99.76 | 97.05 | 94.35 | 96.48 | 61.56 |
| RPL + CDLoss | 99.79 | 93.15 | 94.63 | 96.53 | 68.98 |
| ARPL | 99.73 | 93.61 | 94.41 | 96.29 | 74.98 |
| ARPL + CDLoss | 99.70 | 93.91 | 94.61 | 96.47 | 75.36 |
| SLCPL | 99.79 | 97.06 | 94.22 | 96.09 | 63.30 |
| SLCPL + CDLoss | 99.82 | 97.20 | 94.45 | 96.44 | 69.06 |
| ARPL | CDLoss | AUROC | OSCR | Accuracy |
|---|---|---|---|---|
| 1 | 1 | 76.11 | 62.39 | 75.36 |
| 2 | 1 | 75.82 | 61.99 | 74.72 |
| 1 | 2 | 76.57 | 62.53 | 78.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Chen, B.; Li, J.; Chen, S.; Huang, S. Cosine Distance Loss for Open-Set Image Recognition. Electronics 2025, 14, 180. https://doi.org/10.3390/electronics14010180
Li X, Chen B, Li J, Chen S, Huang S. Cosine Distance Loss for Open-Set Image Recognition. Electronics. 2025; 14(1):180. https://doi.org/10.3390/electronics14010180
Chicago/Turabian StyleLi, Xiaolin, Binbin Chen, Jianxiang Li, Shuwu Chen, and Shiguo Huang. 2025. "Cosine Distance Loss for Open-Set Image Recognition" Electronics 14, no. 1: 180. https://doi.org/10.3390/electronics14010180
APA StyleLi, X., Chen, B., Li, J., Chen, S., & Huang, S. (2025). Cosine Distance Loss for Open-Set Image Recognition. Electronics, 14(1), 180. https://doi.org/10.3390/electronics14010180