Abstract
Parameter tuning based adapter methods have achieved notable success in vision-language models (VLMs). However, they face challenges in scenarios with insufficient training samples or limited resources. While leveraging image modality caching and retrieval techniques can reduce resource requirements, these approaches often overlook the significance of textual modality and cross-modal cues in VLMs. To address this, we propose a Conditional Cross-Modal learning model, which is abbreviated as CoCM. CoCM builds separate cache models for both the text and image modalities and embedding textual knowledge conditioned on image information. It dynamically adjusts the cross-modal fusion affinity ratio and disentangles similarity measures across different modalities. Additionally, CoCM incorporates intra-batch image similarity loss as a regularization term to identify hard samples and enhance fine-grained classification performance. CoCM surpasses existing methods in terms of accuracy, generalization ability, and efficiency, achieving a 0.28% accuracy improvement over XMAdapter across 11 datasets and demonstrating 44.79% generalization performance on four cross-domain datasets.
1. Introduction
Common vision-language models (VLMs) like CLIP [1], ALIGAN [2], and BLIP [3] have achieved impressive results across tasks such as image recognition, image classification, and domain generalization. Traditional approaches often rely on auxiliary loss to fine-tune models for downstream tasks. However, when the model size is large, full-parameter fine tuning requires substantial time and memory resources, which can lead to overfitting, especially in resource-constrained environments. Efficient Transfer Learning (ETL) focuses on fine tuning only a small subset of parameters to extract the knowledge embedded in vision-language models (VLMs) and transfer it to downstream tasks. In scenarios where large models assist with unfamiliar or novel tasks—such as object recognition in open environments or automated robotic vision—establishing a robust baseline classifier using only a limited number of collected samples is crucial. ETL offers an effective solution for addressing challenges in few-shot scenarios, meeting high accuracy demands, and leveraging large model assistance for complex tasks.
The classic ETL methods include prompt [4], adapter [5], and LoRA [6]. Prompt [4,7] uses prompt-based learning to guide the model in generating knowledge. Adapters [5] are lightweight neural modules introduced into pretrained models to facilitate task-specific fine tuning or adaptation while maintaining computational efficiency and reducing memory overhead. LoRA [6] uses low-rank matrix decomposition to update the model, but its performance can suffer when the model has relatively few parameters. COOP [8] transforms fixed prompts in CLIP [1] into learnable prompts to improve the generalization of the model. However, this approach is sensitive to parameter settings, making the model challenging to train effectively.
Parameter tuning based adapter techniques have shown impressive performance in VLM. In Figure 1a, CLIP [1] uses frozen parameters of the visual encoder () and the textual encoder () to directly access the pretrained model parameters, outputting image categories in zero-shot inference. CLIP-Adapter [9] introduces adapters on both and to capture information from the image and text domains. These adapters are connected to the original features through residual connections, ultimately enabling effective image classification. In Figure 1b, CLIP-Adapter [9] achieves impressive results by freezing the parameters of the visual encoder () and the textual encoder (). Adapters are then added separately to and to extract information from the image and text domains. The features extracted by the model are connected to the original features through residual connections, leading to outstanding performance in image classification and recognition tasks.
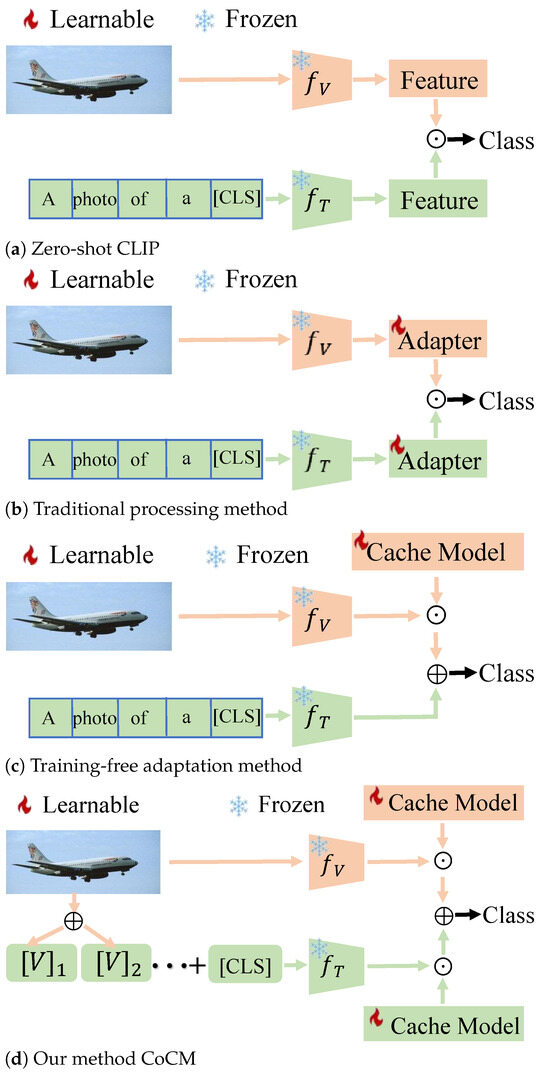
Figure 1.
Illustration comparing CoCM with CLIP [1], CLIP-Adapter [9] and Tip-Adapter [10].
In Figure 1c, Tip-Adapter [10] stores image labels and features as a cache model at the beginning of training. During inference, it calculates cosine similarity between the image features and the cached features; then, it combines with the original model features to enhance performance. Tip-Adapter [10] still relies on manually designed prompts, which fail to fully utilize the knowledge of the TextEncoder [1]. Prompt-Adapter employs learnable text prompts but does not effectively integrate textual and visual modality information. These adapters operate independently on either the image or text side with no merging or interaction of information between the two parts. Maximizing the fusion of image and text information has thus become a key focus within the community.
To address this issue, we propose a CoCM model that integrates textual and image information, as illustrated in Figure 1d. The model establishes key-value pairs for both the image and text domains, embedding textual knowledge into the image domain, thereby creating a cross-modal cache model. To further enhance model performance, we adjust the fusion ratio between the image cache and text cache, disentangling the similarity measurement methods for different modalities. This approach overcomes the challenges associated with using image-only or text-only classification. By leveraging modality-specific affinity differences, the model identifies hard samples and dynamically adjusts the learning intensity for these samples, thereby improving classification effectiveness.
During the inference stage, the model first calculates the similarity between the features of the test data and the key-value pairs in the cache model. It then combines the model’s predictions with the original model predictions through residual connections. This enables the model to effectively learn from both the cache model and the original model’s knowledge. While CoCM’s architecture increases the system’s tunable parameters, training time, and inference time, it significantly enhances overall generalization performance. To validate the performance of our model, we conducted tests on 15 commonly used datasets. CoCM achieved state-of-the-art (SOTA) results with only a few epochs of training. Our key innovations are summarized as follows:
- We propose a novel cross-modal CoCM model that builds separate cache models for the image and text domains while integrating image features into text-based prompt learning. This approach constructs a cross-modal cache model, enabling multimodal metric classification and significantly improving the accuracy of model predictions.
- The model extracts inference cues by integrating vision-language bimodal information, dynamically adjusts the cross-modal fusion affinity ratio, and disentangles the similarity measures of different modalities. It further enhances model performance by adaptively adjusting the learning intensity for these samples. Additionally, the model incorporates similarity loss among images within a batch as a constraint, improving fine-grained classification performance.
- CoCM exhibits exceptional representation learning capabilities, achieving outstanding performance on 11 classification and recognition datasets. Additionally, its strong generalization ability has been demonstrated across four benchmark datasets.
2. Related Work
2.1. Vision-Language Model
Influenced by the tremendous success of pretrained models in computer vision and natural language processing, the community has begun applying pretraining techniques to vision and language models. Classic VLMs typically consist of a vision encoder, a language encoder, a fusion encoder, and a loss function. In the early stages, models like BAN [11], MCAN [12], and Intra-Inter [13] dominated the scene. Influenced by the BERT [14] philosophy, models like LXMERT [15], ViLBERT [16], and UNITER [17] have achieved remarkable success in the VLM domain. Recently, models such as CLIP [1], DeCLIP [18], BLIP [3], and ALIGN [2] have demonstrated that contrastive learning based on visual and language inputs can generate transferable features. They achieve good performance on downstream tasks without the need for fine tuning. CoOp [8] transformed the fixed prompts in CLIP into learnable prompts, further enhancing the model’s performance. CoCoOp [19], by incorporating the characteristics of input images, improved the model’s generalization by introducing inductive biases through image augmentation. TaskRes [20] proposed the establishment of a text-based classifier that decouples the prior knowledge of the pretrained model from the new knowledge of the target task, thereby improving the model’s performance. XMAdapter [21] established cache models for both text and image modalities but did not embed image features into the text modality, limiting its ability to achieve deep fusion between modalities. GraphAdapter [22] proposes constructing images and text as separate subgraphs to improve model performance. LLaVA [23] utilized machine instructions to fine-tune large language models (LLMs) for instruction-following tasks. It connected a visual encoder with an LLM, enabling it to handle general vision and language understanding tasks. Qwen-VL [24] used images, text, and detection boxes as model inputs with text and detection boxes as outputs. It has achieved impressive results in Chinese open-domain localization and fine-grained image recognition and understanding tasks. Our CoCM explores the model’s potential by adaptively adjusting the fusion ratio between images and text, achieving good performance in downstream tasks such as image classification and image recognition.
2.2. Parameter-Efficient Transfer Learning
Prompt learning is widely used in model tuning, especially for large language models. P-tuning [25] proposed to make the prompt into a token and use BiLSTM [26] for learning. P-tuning v2 [27] combined the advantages of P-tuning and prefix tuning to make the model suitable for small models and complex natural language understanding tasks by removing repetitive parameters and enabling multi-task learning. Inspired by prompts in the natural language processing field, VPT [28] introduced a small number of trainable parameters as image prompts and achieves good results in downstream tasks. To improve the efficiency of prompt design, NOAH [29] used an evolutionary search technique to find the optimal design of vision prompts, adapters, and LoRA as parameter-efficient tuning modules in each layer of the vision transformer. DP [30] proposed a method to dynamically adjust the prompt’s position and length according to the instance’s different tasks. UPT [31] and MAPLE [32] proposed adding learnable contextual markers in the language and visual branches, respectively, and mapping language prompts to visual prompts through aggregation functions.
2.3. Cache Model
The cache model is a collection of key-value pairs storing training data and labels. It is established during the model’s training phase and, during inference, aggregates information from the cache model by treating the test samples as query conditions and utilizing similarity retrieval. This approach does not require updating model parameters and can improve the system’s inference speed. It has been widely applied in Unbounded Cache [33], Matching Networks [34], Prototypical Networks [35], and MAML [36]. Unbounded Cache [33] expanded the scale of a continuous cache through approximate nearest neighbor search and quantization algorithms. Matching Network [34] adapted to new class types by establishing a small labeled support set and mapping an unlabeled example to its label. Prototypical Networks [35] achieved classification by learning the mean of the samples for each class in the embedding space. MAML [36] proposed a meta-learning method designed to quickly adapt to new tasks using only a small number of training samples. The methods mentioned above have achieved good results, and they are all based on single-image or text features without extensively exploring the correlation between images and text. The CoCM proposed in this paper fully integrates features from both images and text, disentangling the similarity measurement methods of different modalities. This enables the mutual utilization of knowledge between the two modalities, achieving good performance in downstream tasks.
2.4. Hard Samples Mining
Hard sample mining refers to the process of identifying and focusing on challenging samples that the model struggles to classify correctly. By emphasizing these hard-to-classify examples, the model can better learn complex patterns and improve its robustness, ultimately enhancing generalization to new data. HCL [37] proposed an unsupervised method for selecting hard negative samples, aiming to achieve tight clustering within each class and pushing samples of different classes as far apart as possible. This method encourages the model to learn more distinct representations by focusing on challenging, misclassified, or borderline examples that lie close to the decision boundary. DiscrimLoss [38] proposed adding a new loss function on top of the existing ones to automatically estimate the importance of easily confused and hard samples in the early stages of model training, aiming to improve model accuracy. PSNR [39] proposed using two identical neural networks to construct triplets and applies contrastive learning to find hard negative samples. Wang [40] introduced local and global hard sample mining to address data imbalance in the task. For local hard sample mining, weighted loss is applied to increase the weight of hard samples within each batch, compensating for these samples. Global hard sample mining and resampling are then performed to increase the proportion of hard samples in the training set. DM [41] proposed a hybrid objective function with a disentangled regularizer that adaptively leverages these hard mixed samples to mine discriminative features without losing the smoothness of the original mixture. This approach achieves performance comparable to, or even surpassing, dynamic methods without any additional computational cost. These methods lack well-established application scenarios in the vision-language model domain.
3. Methodology
3.1. Preliminaries
Unlike traditional pretrained models, VLMs are pretrained on a large number of text–image pairs. The labels in VLMs are discrete, making it challenging to precisely describe image attributes or capture relationships between different categories. A typical VLM consists of an ImageEncoder [1] and a TextEncoder [1] . The ImageEncoder , often implemented using ResNet or ViT, transforms images into visual embedding vectors . The TextEncoder , typically based on BERT [14], converts text prompts into text embeddings . During the inference phase, K prompts are input into to obtain text embeddings representing K categories. Each image category can be expressed as follows:
where c, , and denote the class, cosine similarity, and the temperature of VLM.
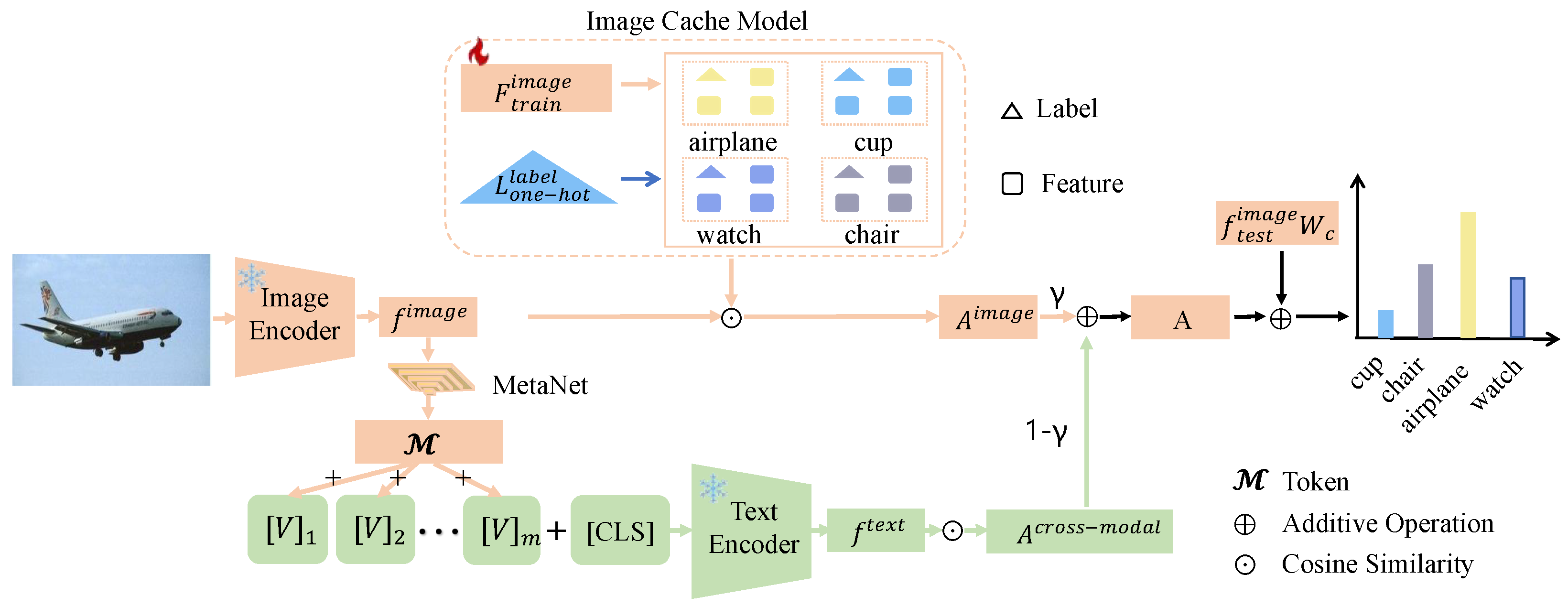
The detailed process of building the CoCM model is shown in Figure 2. In the first step, a small set of labeled training samples is passed through the ImageEncoder to generate , which serves as the keys for the cache model. The sample labels are encoded using one-hot encoding to produce , which serves as the values for the cache model, forming the image cache model. For test images, their features are generated using the ImageEncoder. Cosine similarity is then computed between and , resulting in the image affinity matrix . In the second step, we transform the fixed text prompts in CoOp into learnable text prompts. The values are processed through MetaNet to extract features, which are then used to enhance the original text prompt features. These enhanced features, passed through the TextEncoder, are combined with the test image features to compute the cosine similarity, resulting in the cross-modal affinity matrix . This process allows the model to dynamically adapt text prompts based on image-specific features, enabling more accurate alignment between textual and visual modalities, and improving the model’s ability to handle challenging samples.
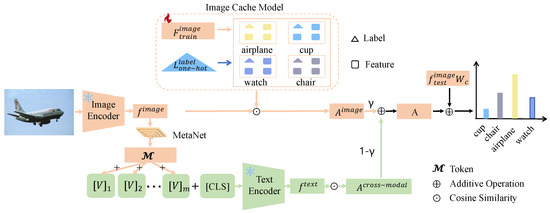
Figure 2.
Illustration of the proposed CoCM. The (reddish orange) line depicts the flow of image features, while the (pea green) line represents the flow of text features. The model first constructs a key-value cache model and then builds a cross-modal cache by integrating image and text features. It uses similarity loss among images to identify hard samples. Finally, the model combines the knowledge from the original VLM to enhance the accuracy of its predictions.
In the third step, based on the affinity values between the images and text within each batch, we adaptively adjust the ratio between and affinities to generate the corresponding A. This adaptive weighting mechanism dynamically balances the contributions of image-specific and cross-modal affinities, ensuring that the final affinity matrix A accurately reflects the relationships within the batch. In the fourth step, to further enhance the model’s ability to mine hard samples, we adjust the loss function according to the classification principle of maximizing inter-class distances and minimizing intra-class distances. This adjustment ensures the model learns more discriminative features. By leveraging the knowledge learned from the cache model along with the prior knowledge embedded in the original CLIP [1] model, the predictions for each image are refined. The sample’s label is then determined by taking the class corresponding to the highest predicted probability as the output.
3.2. Image Cache Model Construction
To fully leverage the knowledge embedded in the data, we designed a key-value cache model that acts as a feature adapter to extract meaningful data representations. Specifically, the process is as follows: for each training image, a vision encoder is used to extract a C-dimensional -normalized feature vector. The corresponding ground truth label is then transformed into an N-dimensional one-hot vector, which is represented as .
For a K-shot N-class training set , containing a total of samples (with K labeled images per class), we represent the visual features and label encodings as and , respectively, and use them as the cache model’s key and value. This key-value pair captures the newly extracted knowledge from the small training set. Finally, the affinities of can be described as follows:
where ImageEncoder serves as the vision encoder of the model, and OneHot represents the operation that converts into a one-hot encoding. The feature is obtained by passing the image through the ImageEncoder, and calculates the cosine similarity between two feature vectors.
3.3. Cross-Modal Cache Model Construction
To fully exploit the hard samples in the test data, we need to conduct divergence inconsistency estimation at the sample level. By utilizing the information across different modalities, we construct a cross-modal caching model. The specific approach involves using a lightweight neural network, referred to as Meta-Net, to extract features from the image side. For each image, we generate an input condition token, which is then linearly added to the text vector to create a set of learnable text prompts. This ensures that each sample has unique image and text features, facilitating the model’s ability to extract characteristics of hard samples. Finally, the affinities of the cross_modal side, denoted as , can be described as follows:
where MetaNet represents a linear neural network.
3.4. Adaptive Scaling
We calculate image-side similarity and text-side similarity separately. Based on the contributions of different modalities to the model’s classification results, we propose a dynamic adjustment method for balancing the proportions of and . This approach disentangles the similarity measurement methods of different modalities. The adjustment process is outlined as follows:
where represents the adaptive adjustment coefficient.
3.5. Building Logits
The model’s logits are composed of two parts. One part is derived from the cache model built using a small number of labeled samples, which are obtained as the product of the affinities matrix A and . The other part comes from the prior knowledge of the original model’s classifier . These two terms are balanced by the weight , and the construction process of the overall logits can be described as follows:
where controls the fusion ratio, and controls the sharpness of the affinities matrix. To further improve the model’s performance and finely capture distinctions between modalities, we calculate the similarity between the image affinity matrix and the text . By leveraging the differences in inter-modal affinity, we adaptively adjust the learning weights of the model. The specific operations can be described as follows:
where denotes the absolute value of two numbers, is a sample in the affinities matrix, N represents the number of samples in the cache model, and sigmoid is the threshold function with values ranging between [0, 1].
3.6. Loss Function
During the training phase, the model first computes the cross-entropy loss between the logits and the labels of the training samples. To further enhance the model’s performance and ensure it follows the classification principle of maximizing inter-class distances while minimizing intra-class distances, we introduce an additional similarity loss into the original loss function. This similarity loss encourages high similarity between input images and their corresponding categories while minimizing the similarity between different categories within the same batch. It is treated as a constraint for fine-grained classification. Finally, the average value of is used for adjustment, resulting in the final loss function. The process can be described as follows:
where K is the number of classes, y represents the label of the sample, B is the total number of samples in a batch, and b represents a sample in the batch. When , it indicates that the samples in the cache belong to the same class. When , it indicates that the samples in the cache belong to different classes.
3.7. Algorithm Description
This section uses pseudocode to describe the pipline of CoCM, as shown in Algorithm 1. First, the model constructs an image cache model based on the input images and sample labels, integrating image features into text-prompt learning to build a cross-modal cache model. Next, it adaptively adjusts the proportions of the two cache models to obtain the final modality affinity matrix. By analyzing affinity differences, the model identifies hard samples and adjusts their learning weights. Following the classification principle of maximizing inter-class distance and minimizing intra-class distance, a regularization term is introduced to constrain hard samples. Finally, the learning weights for these hard samples are adjusted, resulting in the final loss function for the model.
| Algorithm 1 CoCM Algorithm Description |
|
4. Experiments
4.1. Experimental Setups
According to the comparative methods proposed by previous researchers [9,10], we validate our CoCM on 11 few-shot classification tasks, including ImageNet [42], Caltech101 [43], OxfordPets [44], StandfordCars [45], Flowers102 [46], Food101 [47], FGVCAircraft [48], SUN397 [49], DTD [50], EuroSAT [51], and UCF101 [52]. Among them, OxfordPets, StanfordCars, Flowers102, FGVCAircraft, and Food101 belong to fine-grained classification tasks, DTD is the dataset of texture classification and EuroSAT is for remote sensing classification. To investigate the generalization capability of our CoCM, we conduct experiments on ImageNet-V2 [53], ImageNet-Sketch [54], ImageNet-A [55] and ImageNet-R [56].
This paper adopts CLIP as the backbone model. By default, ResNet-50 [57] is used as the visual encoder, and it is paired with a 12-layer transformer as the textual encoder. To assess the adaptability of our approach, we conducted a fair comparison with GraphAdapter [22] and XMAdapter [21]. CoCM also incorporates alternative CLIP visual encoders, including ResNet-101 [57], ViT-B/32 [58], and ViT-B/16 [58]. All experiments are conducted with a batch size of 32 across datasets, running for 20 epochs while optimizing the model using 1, 2, 4, 8, and 16 shots. The Adam optimizer is employed with an initial learning rate of , which follows a cosine decay schedule. For text initialization in CoOp, parameters are randomly sampled from a Gaussian distribution with a standard deviation of 0.02, and the context length is set to 16. The data augmentation strategy is minimal, consisting only of “random resizing crop” and “random flipping”. To ensure experimental reliability, a fixed random seed is used, and each experiment is repeated three times. The average accuracy is reported as the evaluation metric with the best results highlighted in bold.
4.2. Cross Label Generalization
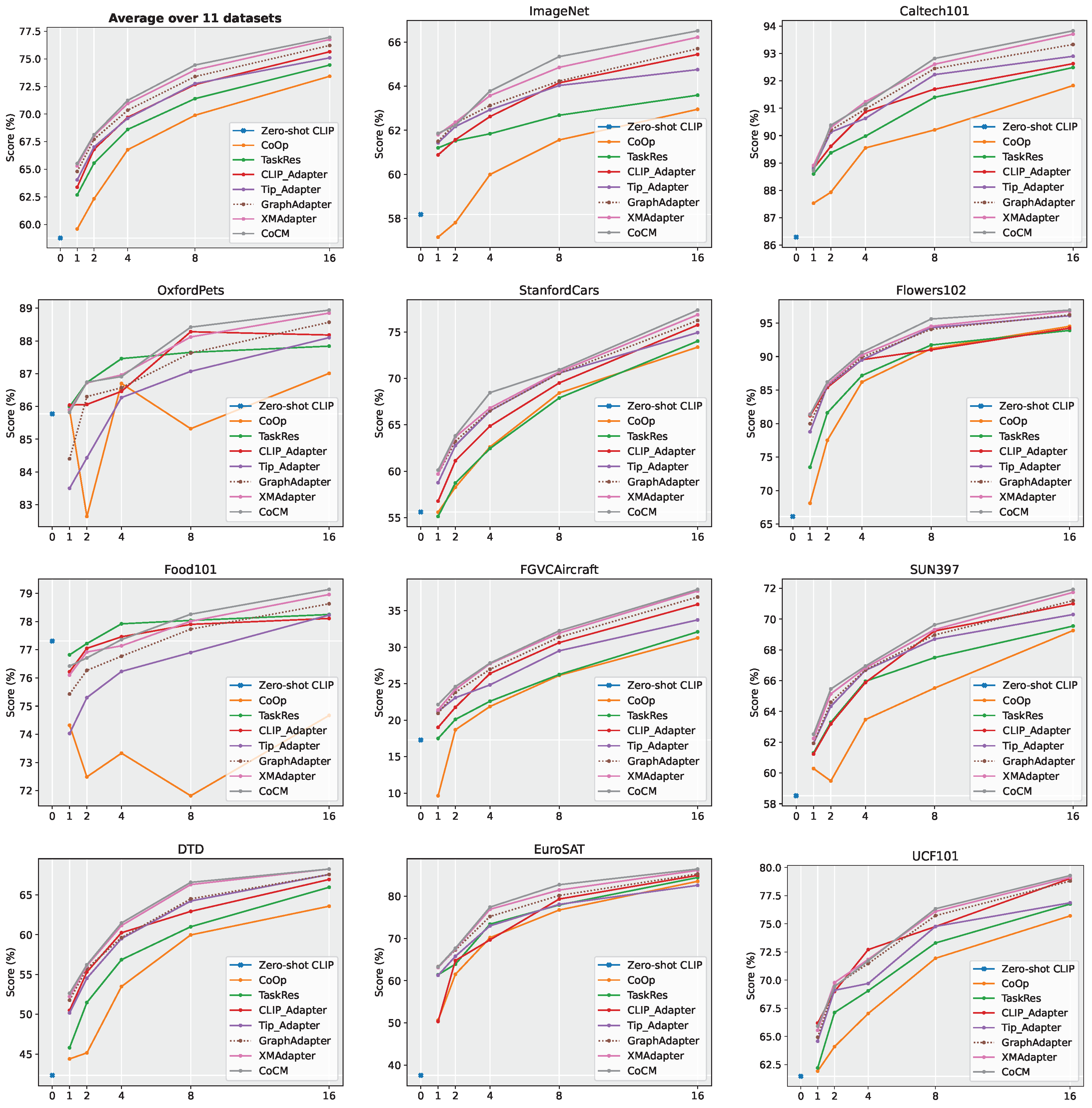
We compared the performance of CoCM with Zero-shot CLIP [1], CoOp [8], TaskRes [20], CLIP-Adapter [9], Tip-Adapter [10], GraphAdapter [22] and XMAdapter [21] on 11 datasets, as illustrated in Figure 3. CoCM consistently delivered strong results across 1-/2-/4-/8-/16-shot settings. Notably, at 16 shots, CoCM achieved an average accuracy of 77.03% across the 11 datasets, outperforming XMAdapter’s 76.75% by a margin of 0.28%. On the challenging fine-grained classification dataset FGVCAircraft, CoCM surpassed all seven compared methods in the 1-/2-/4-/8-/16-shot settings. This highlights the effectiveness of CoCM’s cross-modal adapter design, which seamlessly integrates image and text information, making it particularly well suited for downstream tasks.
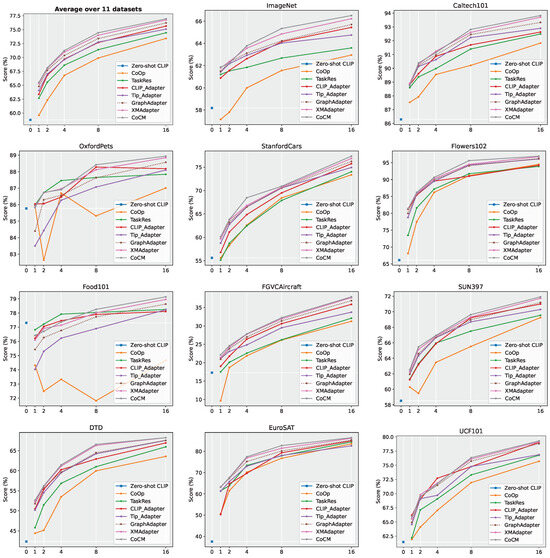
Figure 3.
The performance comparison of our CoCM with the SOTA method on cross label generalization, including 1-/2-/4-/8-/16-shots on 11 benchmark datasets.
4.3. Domain Generalization
We further evaluated the generalization capability of CoCM, and the experimental results are presented in Table 1, with the best results highlighted in the bold. Using 16-shot training samples and ImageNet [42] as the training set, we tested the model on ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R, which share the same categories as ImageNet but differ in background, texture, and semantics. When ResNet-50 is used as the backbone, CoCM achieves a performance of 66.51% on ImageNet, surpassing XMAdapter by 0.29%. The average performance on ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R reaches 44.79%, exceeding XMAdapter by 0.23%, indicating that the model’s performance is relatively stable. When ResNet-101 is used as the backbone, CoCM achieves a source domain accuracy of 69.23%, outperforming all current methods. The accuracy on the four target domains reaches 50.33%, surpassing XMAdapter by 0.2%. This shows that the feature extraction ability improves as the backbone network progresses from ResNet-50 to ResNet-101, leading to a steady improvement in model performance. When ViT-B/32 is used as the backbone, CoCM achieves a performance of 69.72% on ImageNet, surpassing comparison methods like XMAdapter and GraphAdapter. The average accuracy on the four target domains reaches 51.10%. The model’s performance on the ImageNet-Sketch dataset (a black-and-white sketch variant of ImageNet) is slightly lower than XMAdapter, suggesting there is room for improvement in object contour recognition. When ViT-B/16 is used as the backbone, CoCM achieves a performance of 74.58% on ImageNet, surpassing all comparison methods. On the target domain ImageNet-R, it is slightly lower than XMAdapter, but the average accuracy on the four target domains reaches 61.10%, achieving the current SoTA value. Thus, it can be observed that as the backbone’s feature extraction capability improves, the model’s performance steadily increases. The performance gains are more pronounced on the source domain (ImageNet), while the generalization performance on the target domains remains stable. These results highlight that CoCM achieves strong performance across different backbone networks, demonstrating its robustness and generalizability.

Table 1.
The performance comparison regarding generalization capability on four visual backbones. The ETL methods are optimized with the ImageNet dataset on a 16-shot setting and tested on cross-domain datasets, including ImageNet-V2, ImageNet-Sketch, ImageNet-A, and ImageNet-R.
4.4. Model Complexity
We compared CoCM with existing efficient transfer learning methods from six perspectives: tunable parameters, GFlops, training time, inference time, GPU memory, and performance, under the 16-shot setting on the ImageNet [42] dataset. The experimental results are presented in Table 2, with the best results highlighted in bold. The results show that CoCM has slightly higher tunable parameters compared to Tip-Adapter due to the added complexity of constructing a multimodal cache model compared to a conventional cache model. The GFlops are comparable to those of Tip-Adapter [10], TaskRes [20], and GraphAdapter [22]. CoCM’s training time is lower than that of CoOp [8], TaskRes [20], and GraphAdapter [22]. Its inference time and GPU memory usage are positioned mid-range among the compared methods. Although the tunable parameters of CoCM are slightly higher than those of Tip-Adapter [10], its significantly reduced training time makes it highly suitable for time-sensitive applications. The results indicate that compared to Tip-Adapter [10], CoCM requires slightly more tunable parameters due to the need to construct multimodal cache models. In terms of GFlops, CoCM is comparable to Tip-Adapter [10], TaskRes [20], and GraphAdapter [22] while remaining significantly lower than CLIP-Adapter. CoCM’s training time is slightly higher than Tip-Adapter and XMAdapter but significantly lower than CoOp and CLIP-Adapter. This is due to the neural network processing on the image-side features. However, the notable reduction in training time ensures that CoCM is well suited for time-sensitive application scenarios. Regarding inference time and GPU memory usage, CoCM performs at an intermediate level compared to the other baseline methods. In terms of performance, CoCM outperforms CoOp [8] by 3.56% and XMAdapter [22] by 0.29%. These results indicate that CoCM meets the requirements of parameter-efficient transfer learning in terms of resource consumption and operational efficiency while also delivering impressive experimental results.
Table 2.
Comparison between our CoCM and existing methods on time and model complexity.
4.5. Ablation Studies
4.5.1. Different BackBones
We used ResNet-50 [57], ResNet-101 [57], ViT-B/32 [58], and ViT-B/16 [58] as backbones to conduct comparative experiments on the 16-shot ImageNet [42] dataset. As shown in Table 3, the best results are highlighted in bold. Using ResNet-50 as the backbone, CoCM achieved an accuracy of 66.51%, surpassing XMAdapter by 0.29%. Using ResNet-101, CoCM surpassed Tip-Adapter by +0.61%. With ViT-B/32, CoCM outperformed XMAdapter by +0.17%. When employing ViT-B/16, CoCM achieved an accuracy of 74.58%, exceeding Tip-Adapter by +0.92%. Under the same settings, when the backbone has a stronger ability to extract image features, the text-side backbone remains unchanged, so the performance gap between CoCM and models like XMAdapter and GraphAdapter is relatively small. As the backbone network improves from ResNet-50 to ViT-B/16, the feature extraction ability of the network increases, and the model performance improves. This further validates Equation (4), where improves as the backbone becomes larger, leading to better model performance. These results demonstrate that CoCM achieves strong performance across various backbone networks, showcasing its robustness and generalizability.
Table 3.
Classification accuracy (%) of different visual encoders on 16-shot ImageNet.
4.5.2. Different Hyper-Parameters
In Equation (4), adjusts the fusion ratio between and . To determine the optimal value of , we conducted experiments on the 16-shot ImageNet dataset. The results are presented in Table 4, with the best outcomes highlighted in bold. when is set to 0, only is utilized, making the model similar to the CoOp [8] setting, achieving a performance of 62.95%. When is set to 1, the model resembles the Tip-Adapter [10] setting with a performance of 65.44%. When is set to 0.7, the model achieves the best performance of 66.51%, confirming the effectiveness of CoCM in integrating image and text features. These results further validate the rationality of CoCM’s approach to fusing image and text features, optimizing the balance for improved performance.
Table 4.
Comparing the effect of the on 16-shot ImageNet.
4.5.3. Different Coefficient and
As shown in Equation (5), controls the ratio at which the cache model’s predictions are combined with the few-shot training set. To assess the impact of different values on model performance, we conducted experiments on the 16-shot ImageNet dataset, assuming ranges from 0 to 4.0. The results are summarized in Table 5, with the best outcomes highlighted in bold. When is set to 0, CoCM relies solely on pretrained knowledge and ignores the cache model’s content. This is equivalent to the Zero-shot CLIP, where the model does not retrieve knowledge from the training dataset, resulting in a performance of 58.18%. When is set to 1.2, the model achieves its best performance of 66.51%. However, as increases further, model performance begins to degrade. At , performance declines, indicating an overreliance on the cache model. These results emphasize that the knowledge stored in the cache model is as crucial as the pretrained model’s knowledge for optimal performance. Additionally, as described in Equation (5), controls the sharpness of the affinities, determining the influence of similar samples in the test images on model predictions. As shown in Table 5, the model achieves its best performance when is set to 3.5. When is large, the model focuses on training samples that are most similar to the embedding space of the test image, which significantly affects the model’s predictions. Conversely, when is small, the influence of these samples is reduced. We observed that changes in have a limited impact on model performance.
Table 5.
The ablation studies for two coefficients and .
4.5.4. Analysis of Hard Example Mining
The model identifies hard samples based on the differences in modality affinity and validates its performance on five datasets: ImageNet, StanfordCars, FGVCAircraft, DTD, and EuroSTA. These datasets contain many images with complex backgrounds, unique visual characteristics, and significant occlusions. For each dataset, 16 samples per class are selected. The “w/o hard sample mining” indicates the model’s performance without using hard sample mining. The experimental results are shown in Table 6, with the best outcomes highlighted in bold. The average accuracy of XMAdapter [21] on the five datasets is 67.02%. Without using hard sample mining techniques, CoCM achieves a performance of 66.84%. When the model utilizes hard sample mining, there are varying degrees of performance improvement across all five datasets. CoCM achieves a performance of 67.36%, particularly in the more complex datasets such as FGVCAircraft, DTD, and EuroSTA.
Table 6.
The performance of hard example mining on different datasets.
4.5.5. Analysis of Similarity Loss
Equation (7) defines the composition of CoCM’s loss function. To further analyze the relationship between the cross-entropy loss and the similarity loss, we conducted ablation experiments on five fine-grained classification datasets: Flowers102, StanfordCars, FGVC Aircraft, OxfordPets, and Food101. As shown in Table 7, the best results are highlighted in bold. CoCM achieves state-of-the-art (SoTA) performance across all five datasets, with an average accuracy of 76.14%, surpassing the accuracy of the model using only the cross-entropy loss.
Table 7.
The performance of similarity loss on different datasets.
5. Discussion
Different modalities of data (e.g., images and text) often contain complementary semantic information. Capturing the relationships between modalities is a key to improving model accuracy. This can be achieved either by explicitly querying the model’s built-in knowledge through textual prompts or by transferring knowledge to lightweight models via knowledge distillation. Evaluating the model’s performance across multiple related tasks under a unified training framework can help fully exploit the knowledge embedded in multimodal models. Furthermore, cross-modal learning requires designing sophisticated architectures to fuse information from different modalities, addressing challenges such as maximizing modality alignment, leveraging cross-modal attention mechanisms, and optimizing fusion mechanisms with dynamic strategies. Solving these challenges can enhance domain transferability, model interpretability, and cross-modal relationship modeling, advancing the application of multimodal learning in real-world tasks.
6. Conclusions
We propose a novel CoCM model that builds cross-modal caches, dynamically adjusts the fusion ratio between modalities, and minimizes intra-class distance while maximizing inter-class distance to mine hard samples. The model demonstrates excellent generalization performance across 15 benchmark datasets. Future research on cross-modal learning in vision-language models (VLMs) can be explored in four directions: (1) Unified Modal Representation. Developing shared network architectures to encode all modalities or using a unified feature space enables efficient interaction between different modalities within the same semantic space. (2) Dynamic Adaptation to Task Requirements. Automatically adjusting the fusion methods between modalities improves performance across different tasks. (3) Efficient Cross-Modal Training Methods. Exploring unsupervised learning, knowledge distillation and multi-task joint learning enables conducting efficient training. (4) Efficient Cross-Modal Inference. Developing low-computation, high-accuracy cross-modal inference methods requires model compression, knowledge distillation, and lightweight design.
However, challenges such as the heterogeneity between modalities make feature alignment and unified representation difficult. Modality absence is also a significant challenge in cross-modal learning. Additionally, increased training time and inference costs can make models unsuitable for real-time tasks, and the scarcity of labeled data may lead to underfitting. Furthermore, VLMs are complex black-box systems with limited transparency and interpretability, which may result in user distrust in the model’s decisions, especially in high-risk domains like medical diagnosis and autonomous driving. Current techniques face limitations in fusion mechanisms between modalities, the trade-off between model generalization and task specificity, and insufficient fine-grained modeling within and between modalities. These challenges require further exploration and research from the community and researchers.
Author Contributions
Conceptualization, J.Y. and S.X.; methodology, Z.C.; software, S.X.; formal analysis, S.L.; writing—original draft preparation, Y.L.; writing—review and editing, W.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China No. 62172310, the Science and Technology Tackling in Henan Province No. 242102210072, and the Hubei Natural Science Foundation No. 2022CFB309.
Data Availability Statement
The original contributions presented in the study are included in the article; further inquiries can be directed to the authors.
Conflicts of Interest
Author Shuai Xie was employed by JD Explore Academy and author Yijia Li was employed by Dropbox.inc. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR. pp. 8748–8762. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling up visual and vision-language representation learning with noisy text supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR. pp. 4904–4916. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; PMLR. pp. 12888–12900. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event/Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics. pp. 3045–3059. [Google Scholar]
- Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter-efficient transfer learning for NLP. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; PMLR. pp. 2790–2799. [Google Scholar]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]
- Gao, P.; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. Clip-adapter: Better vision-language models with feature adapters. Int. J. Comput. Vis. 2023, 132, 581–595. [Google Scholar] [CrossRef]
- Zhang, R.; Zhang, W.; Fang, R.; Gao, P.; Li, K.; Dai, J.; Qiao, Y.; Li, H. Tip-adapter: Training-free adaption of clip for few-shot classification. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 493–510. [Google Scholar]
- Kim, J.H.; Jun, J.; Zhang, B.T. Bilinear attention networks. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6281–6290. [Google Scholar]
- Gao, P.; Jiang, Z.; You, H.; Lu, P.; Hoi, S.C.; Wang, X.; Li, H. Dynamic fusion with intra-and inter-modality attention flow for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6639–6648. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4171–4186. [Google Scholar]
- Tan, H.; Bansal, M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 5099–5110. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Chen, Y.; Li, L.; Yu, L.; Kholy, A.E.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: Learning UNiversal Image-TExt Representations. arXiv 2019, arXiv:1909.11740. [Google Scholar]
- Li, Y.; Liang, F.; Zhao, L.; Cui, Y.; Ouyang, W.; Shao, J.; Yu, F.; Yan, J. Supervision Exists Everywhere: A Data Efficient Contrastive Language-Image Pre-training Paradigm. In Proceedings of the The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, 25–29 April 2022. [Google Scholar]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Conditional prompt learning for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16816–16825. [Google Scholar]
- Yu, T.; Lu, Z.; Jin, X.; Chen, Z.; Wang, X. Task residual for tuning vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10899–10909. [Google Scholar]
- Yang, J.; Li, Z.; Xie, S.; Zhu, W.; Yu, W.; Li, S. Cross-Modal Adapter: Parameter-Efficient Transfer Learning Approach for Vision-Language Models. In Proceedings of the IEEE International Conference on Multimedia and Expo, ICME 2024, Niagara Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar]
- Li, X.; Lian, D.; Lu, Z.; Bai, J.; Chen, Z.; Wang, X. Graphadapter: Tuning vision-language models with dual knowledge graph. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual instruction tuning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024; Volume 36. [Google Scholar]
- Bai, J.; Bai, S.; Yang, S.; Wang, S.; Tan, S.; Wang, P.; Lin, J.; Zhou, C.; Zhou, J. Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv 2023, arXiv:2308.12966. [Google Scholar]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; Tang, J. P-tuning: Prompt tuning can be comparable to fine-tuning across scales and tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 61–68. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.L.; Du, Z.; Yang, Z.; Tang, J. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv 2021, arXiv:2110.07602. [Google Scholar]
- Jia, M.; Tang, L.; Chen, B.C.; Cardie, C.; Belongie, S.; Hariharan, B.; Lim, S.N. Visual prompt tuning. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXXIII. Springer: Berlin/Heidelberg, Germany, 2022; pp. 709–727. [Google Scholar]
- Zhang, Y.; Zhou, K.; Liu, Z. Neural prompt search. arXiv 2022, arXiv:2206.04673. [Google Scholar] [CrossRef]
- Yang, X.; Cheng, W.; Zhao, X.; Petzold, L.; Chen, H. Dynamic Prompting: A Unified Framework for Prompt Tuning. arXiv 2023, arXiv:2303.02909. [Google Scholar]
- Zang, Y.; Li, W.; Zhou, K.; Huang, C.; Loy, C.C. Unified vision and language prompt learning. arXiv 2022, arXiv:2210.07225. [Google Scholar]
- Khattak, M.U.; Rasheed, H.; Maaz, M.; Khan, S.; Khan, F.S. Maple: Multi-modal prompt learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19113–19122. [Google Scholar]
- Grave, E.; Cisse, M.M.; Joulin, A. Unbounded cache model for online language modeling with open vocabulary. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; PMLR. pp. 1126–1135. [Google Scholar]
- Robinson, J.D.; Chuang, C.; Sra, S.; Jegelka, S. Contrastive Learning with Hard Negative Samples. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Wu, T.; Ding, X.; Zhang, H.; Gao, J.; Tang, M.; Du, L.; Qin, B.; Liu, T. Discrimloss: A universal loss for hard samples and incorrect samples discrimination. IEEE Trans. Multimed. 2023, 26, 1957–1968. [Google Scholar] [CrossRef]
- Song, S.; Bae, H. Hard-negative Sampling with Cascaded Fine-Tuning Network to Boost Flare Removal Performance in the Nighttime Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2843–2852. [Google Scholar]
- Wang, K.; Peng, Y.; Huang, H.; Hu, Y.; Li, S. Mining hard samples locally and globally for improved speech separation. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; pp. 6037–6041. [Google Scholar]
- Liu, Z.; Li, S.; Wang, G.; Wu, L.; Tan, C.; Li, S.Z. Harnessing hard mixed samples with decoupled regularizer. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 10–15 December 2024; Volume 36. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Fei-Fei, L.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 178. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C. Cats and dogs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 July 2012; pp. 3498–3505. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101–mining discriminative components with random forests. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VI 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 446–461. [Google Scholar]
- Maji, S.; Rahtu, E.; Kannala, J.; Blaschko, M.; Vedaldi, A. Fine-grained visual classification of aircraft. arXiv 2013, arXiv:1306.5151. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Sun database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing textures in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3606–3613. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2217–2226. [Google Scholar] [CrossRef]
- Soomro, K.; Zamir, A.R.; Shah, M. A dataset of 101 human action classes from videos in the wild. Cent. Res. Comput. Vis. 2012, 2, 1–7. [Google Scholar]
- Recht, B.; Roelofs, R.; Schmidt, L.; Shankar, V. Do imagenet classifiers generalize to imagenet? In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR. pp. 5389–5400. [Google Scholar]
- Wang, H.; Ge, S.; Lipton, Z.; Xing, E.P. Learning robust global representations by penalizing local predictive power. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Hendrycks, D.; Zhao, K.; Basart, S.; Steinhardt, J.; Song, D. Natural adversarial examples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15262–15271. [Google Scholar]
- Hendrycks, D.; Basart, S.; Mu, N.; Kadavath, S.; Wang, F.; Dorundo, E.; Desai, R.; Zhu, T.; Parajuli, S.; Guo, M.; et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 8340–8349. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Heigold, G.; Gelly, S.; Uszkoreit, J.; Houlsby, N. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Machine Learning, Virtual, 3–7 May 2021. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).