Abstract
Precise segmentation of cell nuclei in pathological images is the foundation of cancer diagnosis and quantitative analysis, but blurred boundaries, scale variability, and staining differences have long constrained its reliability. To address this, this paper proposes AL-Net—an adaptive learning network that breaks through these bottlenecks through three innovative mechanisms: First, it integrates dilated convolutions with attention-guided skip connections to dynamically integrate multi-scale contextual information, adapting to variations in cell nucleus morphology and size. Second, it employs self-scheduling loss optimization: during the initial training phase, it focuses on region segmentation (Dice loss) and later switches to a boundary refinement stage, introducing gradient manifold constraints to sharpen edge localization. Finally, it designs an adaptive optimizer strategy, leveraging symbolic exploration (Lion) to accelerate convergence, and switches to gradient fine-tuning after reaching a dynamic threshold to stabilize parameters. On the 2018 Data Science Bowl dataset, AL-Net achieved state-of-the-art performance (Dice coefficient 92.96%, IoU 86.86%), reducing boundary error by 15% compared to U-Net/DeepLab; in cross-domain testing (ETIS/ColonDB polyp segmentation), it demonstrated over 80% improvement in generalization performance. AL-Net establishes a new adaptive learning paradigm for computational pathology, significantly enhancing diagnostic reliability.
1. Introduction
Medical image segmentation constitutes a pivotal facet of biomedical image processing, entailing the precise demarcation and localization of specific structures or regions within medical images [1]. This function assumes paramount importance across a spectrum of clinical applications, encompassing lesion detection and quantification, anatomical structure scrutiny, surgical strategizing and navigation, among others. Recent advances in deep learning have propelled automated segmentation techniques across modalities: in brain MRI analysis, Zhang et al. [2] developed a Modified Recurrent Residual Attention U-Net achieving a 94.3% Dice score for tumor segmentation through spatial-channel attention fusion, while Li et al. [3] proposed a hybrid transformer–CNN architecture for pancreatic CT segmentation with 89.2% vessel boundary accuracy. These breakthroughs demonstrate how adaptive feature fusion and hybrid architectures can address modality-specific challenges.
Notably, cell nucleus segmentation presents unique technical demands distinct from organ-level segmentation. While Caicedo et al. [4] have contributed extensively to stained nucleus segmentation through their 2018 Data Science Bowl dataset with enhanced edge contrast, Uka et al. [5] explored techniques for unstained brightfield images in microfluidic chambers. This dichotomy mirrors the modality adaptation challenges seen in cross-organ segmentation [3] but with added complexity: nuclear boundaries exhibit <1 μm transitional zones compared to >5 mm tumor margins [2], and stain-induced domain shifts exceed typical cross-modality variations [6].
The nucleus, a cell’s central component, serves as the repository of genetic information and regulatory mechanisms, endowing it with profound significance in deciphering cellular structure and function as well as probing the mechanisms underlying diseases. Through the accurate segmentation and quantitative analysis of cell nuclei, clinicians and researchers can access crucial data pertaining to the contours, quantities, locations, and distributions of these nuclei. This, in turn, empowers them to render precise judgments in the domains of cancer treatment, genetic disease diagnosis, cytological investigations, and decision-making processes. Nevertheless, the task of accurate cell nucleus segmentation remains a formidable challenge due to the intricate and noise-laden nature of medical images. These images typically exhibit low contrast, indistinct boundaries (~2–5 pixel transitional zones), and intricate tissue architectures, all of which compound the complexities of cell nucleus segmentation. Moreover, variations in nuclei shape (polymorphism index up to 0.38 [7]), size (5–50 μm diameter range), and hue (stain color deviation ΔE > 15 in CIELAB space [6]) across diverse tissues and pathological conditions further augment the intricacies of this segmentation endeavor. Hence, the development of efficient and precise cell nucleus segmentation methodologies assumes pivotal significance within the ambit of medical image analysis and diagnosis.
In recent years, a plethora of deep learning-based image segmentation models have emerged, yielding significant successes across various vision-related tasks. The fully convolutional neural network (FCN) stands as a distinctive neural network architecture, primarily tailored for image segmentation purposes [2,3,4,5,6]. Diverging from conventional convolutional neural networks, FCN comprises solely convolutional and pooling layers, eschewing fully connected layers, thereby facilitating the production of a segmentation output of the same dimensions as the input image. To augment its performance, FCN also incorporates an upsampling operation to restore feature maps to the original input image dimensions. This design allows FCN to classify individual pixels within the input image, thereby achieving pixel-level image segmentation. U-Net, a seminal image segmentation model, was introduced by Ronneberger et al. in 2015 [7]. A pivotal component of U-Net is the skip connection, which links corresponding layers between the encoder and decoder, facilitating the transmission of low-level details to the decoder. Through these skip connections, U-Net effectively harnesses both low-level detailed information and high-level semantic knowledge for segmentation, thereby preserving rich details and contextual information across multiple scales. This proves particularly advantageous in addressing multi-scale objects and boundary delineation. However, U-Net does exhibit certain limitations. Firstly, its reliance on fixed-scale pooling and upsampling operations constrains its adaptability to objects of varying scales. Secondly, U-Net may grapple with memory and computational resource limitations when processing large-scale images. Additionally, the symmetrical encoding–decoding structure of U-Net may result in suboptimal performance when handling fine-grained boundaries and small objects. DeepLab [8], another pivotal image segmentation model, was originally proposed by Chen et al. in 2016. DeepLab leverages dilated convolutions to expand the receptive field. By introducing varying dilation rates within the convolution layers, DeepLab achieves multi-scale information fusion, a technique widely employed across the DeepLab series with commendable results. Nonetheless, the fixed dilation rate of dilated convolution may not always cater to the requirements of diverse scale objects, thereby imposing constraints on fine-grained segmentation tasks. In addition to conventional CNN architectures, models rooted in the transformer architecture [9,10,11,12] have gained prominence. The transformer model, renowned for its ability to model global dependencies through self-attention mechanisms, has also made inroads into the domain of medical image segmentation. FCBFormer [13], a hybrid model merging transformer and CNN, represents a novel architecture for polyp segmentation in colonoscopy images. In this design, the upsampling branch employs deconvolution layers to upsample low-resolution feature maps to match the input image dimensions, thus preserving spatial information. Meanwhile, the downsampling branch employs convolutional layers to downsample high-resolution feature maps to match the dimensions of the upsampling branch, thereby curtailing computational and memory demands. Additionally, skip connections interconnect the two sub-branches, amalgamating and harmonizing feature maps across different scales. This configuration empowers the FCB branch to adeptly process images of varying scales and yield high-quality, dense predictions. This paper amalgamates the structural attributes of DeepLab and FCBFormer to tackle the challenge of multi-scale feature fusion.
Chen et al. [14] have proposed an innovative perspective wherein algorithm discovery is construed as a program search, skillfully applied to unearth optimally tailored algorithms for deep neural network training. Employing efficient search techniques, the authors traverse the boundless and sparse program space, supplementing their quest with program selection and simplification strategies to bridge the considerable chasm in generalization between the agent and target tasks. This endeavor has led to the discovery of a succinct yet highly effective optimization algorithm known as Lion (Evolved SignMomentum) [14]. The Lion optimizer utilizes the sign symbol to compute updates of equal magnitude; the employment of this sign operation stems from its ability to convert gradients, be they positive or negative, into +1 or −1, thus streamlining the computation process. This uniform treatment of each component by the sign operation enables the model to fully harness the potential of all components, thereby enhancing its generalization capabilities. Nonetheless, once the model reaches convergence, each component has exploited its potential, necessitating a shift towards a gradient-based update strategy. In this paper, we introduce the Lion optimizer to the domain of medical image segmentation, amalgamating the attributes of both gradient-based and symbol-based updates. Early-stage training adopts the symbol-based update to fully explore the model’s potential, while once stability is achieved, the gradient-based method takes precedence.
The loss function assumes a pivotal role in the realm of deep learning, serving as a means to gauge the disparity between model predictions and actual labels. In tandem with the burgeoning progress of deep learning, an ever-expanding array of loss functions has surfaced, finding application across diverse tasks. For instance, the cross-entropy loss function enjoys widespread utility in classification tasks, whereas Dice loss [15] finds its niche in segmentation endeavors. Nonetheless, extant loss functions exhibit certain limitations. Notably, in boundary detection tasks, commonly employed loss functions like BCE Loss or Dice loss fall short in duly penalizing boundary misalignment. Addressing this limitation, Bokhovkin and Burnaev introduced a boundary loss function [16] capable of more effectively penalizing boundary misalignment, thus ameliorating segmentation quality. This paper introduces the boundary loss function into the domain of medical image segmentation. During the initial stages of training, the conventional loss function is harnessed to cultivate fundamental area segmentation proficiency. Subsequently, it is complemented by the boundary loss function, imparting a more nuanced correction capability to the boundary region, consequently enhancing the precision of boundary extraction within the image and, by extension, the accuracy of medical image segmentation.
The subsequent sections of this paper are structured as follows: Section 2 delves into related work, while Section 3 expounds upon the principal methods and intricacies of the segmentation model. Moving forward to Section 4, we elucidate implementation particulars and present experimental outcomes. Section 5 encapsulates the study’s limitations and its concluding remarks.
2. Related Work
Within the domain of medical image segmentation, numerous researchers have dedicated their efforts to enhancing algorithms and methodologies for cell nucleus segmentation. This section offers a comprehensive review of pertinent work, encompassing cell nucleus segmentation techniques, the integration of deep learning into medical image segmentation, and the ongoing developments in loss functions and optimizers.
2.1. Application of Deep Learning in Medical Image Segmentation
Historically, early cell nucleus segmentation methodologies relied heavily on traditional image processing techniques, including threshold segmentation, edge detection, and mathematical morphology. Nonetheless, these approaches tend to exhibit heightened sensitivity to image noise and intricate backgrounds, rendering them less adept at handling deformed, overlapping, or partially obscured nuclei. With the development of deep learning, methods rooted in convolutional neural networks (CNNs) have gained ascendancy. Among these, the U-Net model stands out as a classic fully convolutional neural network [17]. It preserves feature information across varying scales through its encoder–decoder architecture and the judicious use of skip connections, thereby yielding superior results in cell nucleus segmentation. Subsequently, a cadre of refined network architectures emerged, including UNet+ [18], SegNet [19], and DeepLabv3+ [20], among others, each further elevating performance standards in the realm of medical image segmentation.
2.2. Research Progress of Loss Function
The significance of the loss function in medical image segmentation cannot be overstated. It serves as a pivotal metric for quantifying the dissimilarity between the predicted segmentation outcome and the ground truth label, thereby guiding the optimal model training process. Over recent years, researchers have introduced an array of novel loss functions to elevate the efficacy of medical image segmentation. Conventional loss functions encompass the cross-entropy loss function and Dice loss, among others. Dice loss can provide a more stable gradient signal when gradient descent occurs, as it focuses on the global matching between prediction and true annotation, while cross-entropy loss may lead to gradient vanishing or exploding problems when categories are extremely imbalanced [21]. To circumvent this issue, Dice loss has emerged as a prominent choice in medical image segmentation, notably excelling in quantifying the degree of overlap between segmentation outcomes. In addition to these conventional counterparts, a suite of refined loss functions has emerged. For instance, Focal Loss [22] directs attention towards challenging-to-segment samples by introducing a dynamic weighting term, thereby enhancing the segmentation accuracy of boundary pixels. Boundary loss, on the other hand, zeroes in on optimizing the boundary segment of the segmentation result, enhancing boundary segmentation precision through judicious weight allocation.
2.3. Research Progress of Optimizer
The optimizer plays a pivotal role in the training of deep learning models, responsible for fine-tuning model parameters to minimize the loss function. In the realm of medical image segmentation, considerable strides have also been made in optimizers. Traditional optimizers encompass Stochastic Gradient Descent (SGD) and momentum-based optimizers, such as Momentum and Nesterov Momentum [23].
Nevertheless, these optimizers can encounter issues of sluggish convergence and susceptibility to local optima during deep learning model training. To surmount these challenges, an array of enhanced optimizers has been introduced. The Adam optimizer [24], for instance, amalgamates the strengths of Adagrad [25] and Momentum, dynamically adjusting learning rates and accommodating varying rates for distinct parameters. Furthermore, optimizers like AdaBound [26] and RAdam [27] have addressed learning rate challenges during the optimization process, delivering commendable results. Additionally, adaptive optimizers widely adopted in medical image segmentation, such as RMSProp [28] and Adadelta [29], enhance training efficiency and performance by automatically adapting learning rates to different parameter update scenarios during model training. The Lion optimizer, on the other hand, is crafted through a search algorithm, automatically pruning redundant statements from the original program to derive the final algorithm. It stands out as a straightforward, memory-efficient, and potent optimizer, leveraging the sign operation for update computation and ensuring equal treatment of all parameters during initial training phases, facilitating superior adaptation to data and optimization objectives, a trait previously explored in earlier optimizers [30,31]. Among these, signSGD [30] bears the closest resemblance to Lion, employing the sign operation for update computation, albeit featuring distinct momentum update rules. Conversely, NAdam [32] combines the first-order moment and gradient for update computation, whereas Lion disentangles momentum tracking and its application to updates via β2.
From the review of related work elucidated above, it becomes evident that nucleus segmentation remains a formidable challenge, especially when confronted with intricate backgrounds, irregular shapes, and indistinct boundaries. This study seeks to address some of the extant challenges in nucleus segmentation and proffers a novel methodology to enhance segmentation accuracy and robustness. The ensuing section will expound upon our method’s design and furnish detailed insights into our experimental outcomes.
3. Materials and Methods
This study utilized the 2018 Data Science Bowl dataset, sourced from Kaggle, and publicly accessible to all. In the preceding section, we discussed the relevant work pertaining to cell nucleus segmentation within medical image analysis. In this section, we will delve into our proposed methodology, which involved the fusion of the Hollow Convolution Branch (HCB) and the full convolution branch (FCB), as well as delineate our approach to loss function design and optimizer fusion. The following paragraphs will elucidate these methods systematically, focusing on key components.
3.1. The AL-Net Architecture
The architecture of the cell nucleus segmentation model presented in this paper is visualized in Figure 1. The model comprised a Hollow Convolution Branch (HCB) and a full convolution branch (FCB), as depicted in the figure. To address the challenge of suboptimal cell nucleus segmentation across multiple scales, we introduced a Full Convolution Branch (FCB) [13]. This module adeptly captured cell nucleus information at varying scales by amalgamating feature maps of diverse dimensions. Simultaneously, we incorporated the DeepLabV3+ module, wherein dilated convolutions extended the convolution kernel’s receptive field, facilitating the acquisition of broader contextual information. Through the strategic application of dilated convolutions with distinct hole sizes at different levels, we attained multi-scale information fusion, thereby enhancing our ability to handle image features of varying scales.
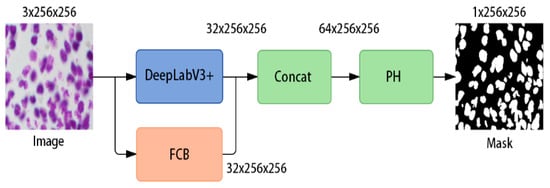
Figure 1.
The structure of the AL-Net model.
To extract more comprehensive feature information, we augmented the output of the DeepLabV3+ module to 32 layers, relocating the sigmoid operation to the Post-Processing (PH) module. Specifically, the initial input image underwent preprocessing, resulting in a 3 × 256 × 256 image, which was subsequently processed through both the DeepLabV3+ module and the FCB module. Since the raw output of DeepLabV3+ has a lower spatial resolution, it was first upsampled to 256 × 256 to match the resolution of the FCB output. This yielded two 32 × 256 × 256 feature maps, subsequently concatenated to produce a single 64 × 256 × 256 feature map. The PH module was employed to fine-tune the number of feature map layers, culminating in the ultimate output result.
3.2. Fully Convolutional Branch
The configuration of the FCB (fully convolutional branch) module, as illustrated in Figure 2, shares similarities with the UNet architecture yet incorporates several advanced modules and methodologies. The foundational downsampling module utilized a convolution operation with a stride of 2. This strategic choice served to curtail information loss. Conversely, the upsampling module leveraged the nearest neighbor interpolation algorithm, referred to as ‘nearest’. Operating with inputs of dimensions 3 × 256 × 256, this module generated three sets of outputs, each measuring 32 × 256 × 256. Furthermore, the Post-Processing (PH) component, inherited from FCBFormer, played a crucial role in fine-tuning the layer count and overseeing information fusion within the final feature map. It encompassed two RB modules and, in the final stages, adjusted the layer count via a 1 × 1 convolution operation. Ultimately, the final output was obtained through the sigmoid activation function.
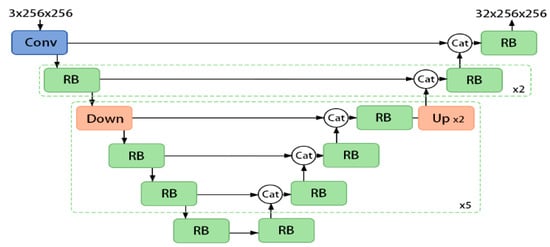
Figure 2.
FCB module structure.
3.3. Loss Function
In the context of nucleus segmentation, the judicious selection of an appropriate loss function assumes paramount significance in the model’s training and performance. To holistically address both nucleus segmentation and boundary delineation, we adopted a weighted loss function. This function seamlessly integrated the Dice loss function and the boundary loss function, thereby augmenting the model’s capacity for precise nucleus segmentation.
3.3.1. Dice Loss Function
The Dice loss function is a widely employed loss function for segmentation tasks, quantifying the similarity between predicted and actual segmentation outcomes. This similarity is gauged by computing the ratio of the intersection between predicted and true segmentation results to their union. The Dice loss function was utilized to assess the overall accuracy of nucleus segmentation and incentivize the model to more effectively glean shape and positional information of the nucleus. It is mathematically expressed as follows in Equation (1):
The symbol denotes the intersection between sets X and Y and represent the respective cardinalities of sets and . Notably, the numerator includes a coefficient of 2 due to the common element shared by X and Y in the denominator. The Dice loss function’s output spans the range of 0 to 1, wherein values closer to 1 indicate a higher degree of overlap between the segmentation result and the ground truth label, signifying enhanced accuracy.
3.3.2. Boundary Loss Function
In pursuit of heightened accuracy in nucleus boundary segmentation, we introduced a boundary loss function. This loss function primarily evaluated the consistency between the predicted boundary and the actual boundary. Our adoption of the boundary loss function, as proposed by Bokhovkin et al., served to effectively guide the model in learning the nuanced features of nucleus boundaries. Initially, precision and recall for boundary prediction are defined as per Equation (2):
Among these variables, where c represents categories, Bpdc and Bgtc denote the boundaries of the prediction map and the label map, respectively. The variable d signifies the Euclidean distance measured in pixels, serving as a predefined threshold upon which the boundary score of the category and the corresponding boundary loss function are contingent, as delineated in Equation (3):
This score epitomizes the harmonic mean of precision and recall, and the overarching purpose of this margin loss function is to optimize the alignment between precision and recall, thereby enhancing the congruence of predicted boundaries with the actual boundaries. Such optimization aids the model in acquiring more precise boundary features, ultimately elevating the quality of segmentation results.
3.3.3. Loss Function Fusion Method
The loss function fusion method represents a strategy that amalgamates distinct loss functions to harness their individual strengths. In the context of nucleus segmentation, we propose a loss function fusion method tailored to select appropriate loss functions corresponding to diverse task objectives during distinct phases of training. Refer to Equation (4) for the formal definition:
Among these variables, the weight coefficients, denoted as α and β, assume a pivotal role in regulating the relative significance of the two distinct loss functions. Through careful adjustment of these parameters, we gained the capacity to finely calibrate the emphasis placed on overall nucleus segmentation versus boundary segmentation, aligning them with the specific requirements of our tasks. The parameter ‘threshold’ constitutes a hyperparameter, with its value signifying the epoch at which the model attains convergence during the initial training stage. Specifically, for training epochs falling below the threshold, we employed the Dice loss function, facilitating the model in acquiring the nuances of nucleus shape and positional information. Conversely, once the training epoch surpassed the threshold, we transitioned to the weighted fusion of the Dice loss function and the boundary loss function. This transition enabled us to steer the model more effectively towards acquiring the intricacies of nucleus boundary features. By judiciously balancing the importance attributed to shape, position information, and boundary features and capitalizing on the strengths of diverse loss functions, we facilitated the model’s progressive acquisition of more precise segmentation outcomes across various training phases.
3.4. Optimizer
In the realm of deep learning, the selection of an appropriate optimizer bears utmost significance in shaping the model’s training and subsequent performance. Conventional optimizers encompass the traditional Stochastic Gradient Descent (SGD), alongside adaptive optimizers such as Adam, Adagrad, and RMSprop. Notably, a recent addition to the optimizer repertoire, the Lion optimizer, was introduced in a Google publication. This section serves to elucidate the Lion optimizer and explore avenues for its enhancement.
3.4.1. Lion Optimizer
The Lion optimizer operates on the principle of the sign function, transforming the gradient’s positivity or negativity into +1 or −1, respectively. It then incorporates this information by multiplying it with the learning rate and weight decay coefficient to derive the direction and magnitude of updates. Distinguished from conventional optimization algorithms, the Lion optimizer introduces a novel update rule that attains a superior equilibrium between weight decay and learning rate. In certain scenarios, it exhibits enhanced performance. The Lion optimizer, through its use of the sign operation, confers equitable treatment to each parameter component, thereby enabling the model to harness the full potential of each constituent part, ultimately augmenting generalization capabilities. When operating with large batch sizes, the Lion optimizer attains expedited convergence and superior generalization performance. Its robustness is evident in its adaptability to varying hyperparameter values. On select tasks, the Lion optimizer demonstrates the ability to achieve heightened accuracy and stability. Formula (5) outlines the formal definition of the Lion optimizer:
where is the gradient of the loss function and is the sign function, which controls the trade-off between gradient and momentum. It is an exponential moving average factor used to calculate momentum. Larger values give more consideration to historical gradients, while smaller values pay more attention to current gradients. is used to calculate the moving average of gradients, which controls the decay rate of the second moment of the gradient. is the factor used to control the weight decay. By introducing weight decay, the model can be prevented from overfitting. indicates the learning rate, which is used to control the step size of each parameter update. represents the parameter values of the model, while represents the value of the momentum. The corresponding pseudocode is shown in Algorithm 1 (Pseudocode of Lion optimizer):
| Algorithm 1 Lion Optimizer | |
| 1: | |
| 2: | |
| 3: | not converged do |
| 4: | |
| 5: | update model parameters |
| 6: | |
| 7: | |
| 8: | |
| 9: | |
| 10: | end while |
| 11: | |
3.4.2. Improvement Method
A distinctive attribute of the Lion optimizer, founded on the sign operation, lies in its capacity to fully exploit the potential of each constituent element. However, once the model attains convergence, the latent capacity of these elements becomes depleted. At this juncture, it becomes imperative to revert to the conventional gradient-based update strategy, executed with greater precision to accommodate custom-tailored training requirements. The disparity between the gradient-based update strategy and the sign operation-based update strategy is elucidated in Figure 3. In the gradient method, the update magnitude is directly proportionate to the gradient’s magnitude, whereas the sign-based method’s update magnitude hinges solely upon the gradient’s direction.
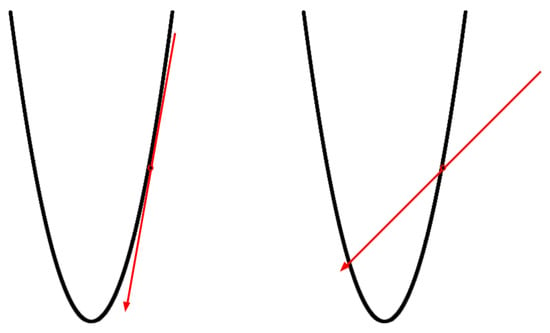
Figure 3.
Gradient-based update strategy (left) and sign-based update strategy (right).
In this paper, we introduced an enhanced optimizer building upon the Lion optimizer. Specifically, during the initial training phase, we employed the Lion optimizer and utilized the sign symbol for parameter updates. This approach allowed us to fully exploit the Lion optimizer’s characteristics, delve into the role of each parameter component, and provide a more extensive optimization space. As training progresses and the model converges, we removed the sign operation and transition to the Lion optimizer without employing the sign symbol for training. Such a strategy maximized the advantages of the Lion optimizer in the early training stages and further enhanced performance and effectiveness once the model converges. Refer to Algorithm 2 (Pseudocode of improved method based on Lion optimizer) for the pseudocode:
| Algorithm 2 Lion Optimizer (Updated) | |
| 1: | |
| 2: | |
| 3: | not converged do |
| 4: | |
| 5: | update model parameters |
| 6: | |
| 7: | if epoch < threshold then |
| 8: | |
| 9: | else |
| 10: | |
| 11: | end if |
| 12: | |
| 13: | |
| 14: | end while |
| 15: | |
In the provided pseudocode, we introduced a new hyperparameter called “threshold,” which signified the epoch at which the Lion optimizer was employed for convergence and governed the timing of the sign symbol’s usage.
This section combined the sign-based operation with the gradient-based update strategy. This enhanced approach built upon the Lion optimizer maximized the benefits of the sign symbol throughout the training process, expediting model convergence, and seamlessly transitioning to the gradient-based update method to ensure model stability and generalization capability. It is worth noting that specific hyperparameter configurations and implementation details may require fine-tuning based on particular problem contexts and experimental outcomes to achieve optimal training results. In the subsequent sections, we will provide a comprehensive account of our experimental setup and a detailed analysis of the result.
4. Results
4.1. Experiment Settings
This study employed three publicly available datasets: the 2018 Data Science Bowl dataset [33], ColonDB [34], and ETIS-LaribPolypDB [35]. The 2018 Data Science Bowl dataset, obtained from Kaggle, consists of 670 images depicting nuclei with varying shapes, distinct cell types, multiple magnifications, and different imaging modalities (brightfield and fluorescence). Following the dataset division protocol described in [36], we performed uniform preprocessing across all three datasets.
Segmentation masks were annotated as binary labels and strictly aligned with their corresponding images during preprocessing to ensure spatial consistency. All images and their associated masks were resampled to a resolution of 256 × 256 pixels and then randomly partitioned into training, validation, and test sets using an 8:1:1 ratio. To guarantee reproducibility, a fixed random seed was applied during dataset splitting.
In the training phase, data augmentation strategies included random cropping and horizontal flipping. For the validation and testing phases, only resizing operations were applied, without additional augmentations. Furthermore, the input channel order was converted from H × W × C to C × H × W, while pixel intensity values were preserved within their original range.
4.2. Experimental Results
4.2.1. Ablation Study
This article is grounded in the DeepLabv3+ model, employing the Dice loss function and the AdamW optimizer as the reference methods. Additionally, the FCB module, BD module, and Lion module are each incorporated. The results demonstrate that every method has led to improved accuracy, with the most significant enhancement occurring when they are used in combination. This implies that all the modules have yielded enhancements, as depicted in Table 1:

Table 1.
Ablation analysis of different modules on the test set.
4.2.2. Comparison of the Results of Other Models
The performance of the method outlined in this paper, alongside other techniques, was evaluated not only on the 2018 Data Science Bowl nucleus segmentation dataset but also on the ColonDB and ETIS-LaribPolypDB datasets, with results presented, respectively, in Table 2, Table 3 and Table 4. The data from Table 2, Table 3 and Table 4 reveal that our approach achieved the best outcomes in terms of Dice coefficient and recall evaluation metrics, while showing relatively lower results in IoU (Intersection over Union) and precision. Particularly on the ETIS-LaribPolypDB [35] and ColonDB [36] datasets, our method demonstrated superior performance. A comprehensive quantitative comparative analysis underscores that the overall segmentation performance of the method proposed in this paper surpasses that of other comparative algorithms, showcasing strong competitiveness in both nucleus segmentation and polyp detection and segmentation tasks.
Table 2.
Performance comparison of other models on the test set.
Table 3.
Performance comparison of other models on the ETIS.
Table 4.
Performance comparison of other models on the ColonDB.
To more rigorously evaluate the performance advantages of the proposed AL-Net over existing state-of-the-art models in segmentation tasks, we conducted systematic experiments on the 2018 Data Science Bowl dataset, using the Dice similarity coefficient (DSC) as the primary evaluation metric. Specifically, paired t-tests were performed between AL-Net and several representative baseline models to verify whether the observed improvements were statistically significant. The experimental results are presented in Table 5.
Table 5.
Statistical significance analysis/paired t-test.
As shown in Table 5, all p-values are well below the significance threshold of α = 0.05, indicating that the observed improvements are statistically significant and unlikely to be caused by random fluctuations. Specifically, AL-Net achieves a notable improvement of +1.98% compared to U-Net and a meaningful gain of +0.42% over the high-performance competitive model SSFormer-S.
This consistent performance advantage stems from the effective integration of the adaptive hole fusion module, self-scheduling loss optimization mechanism, and enhanced Lion optimizer. The synergy of these components enables the model to better capture multi-scale contextual information, optimize the training process, and improve convergence stability, thereby ensuring both high accuracy and consistent segmentation performance.
4.2.3. Visualize Segmentation Results
We selected some representative original images from the test set for visual analysis, which contain different size and density features, as shown in Figure 4. The green line represents the predicted value of the model, and the red line represents the label value. It can be seen that the predicted value basically overlaps with the label, and the model has achieved good prediction results. For further comparative evaluation of segmentation performance, Figure 5 presents a systematic visualization of polyp segmentation results across multiple state-of-the-art models (Unet, Unet++, SFA, PraNet) and our proposed method on challenging cases from both CVC-ColonDB and ETIS datasets. The ground-truth masks and model outputs are displayed in binary format, where our method demonstrates superior boundary adherence and completeness in capturing polyp morphology compared to baseline approaches, particularly for small and low-contrast lesions.

Figure 4.
The green line represents the predicted value of the model, and the red line represents the label value.
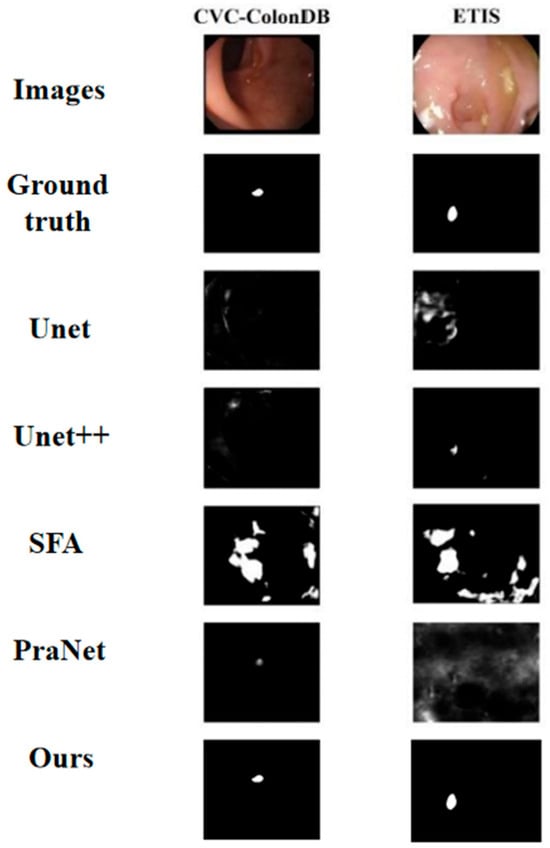
Figure 5.
Polyp segmentation results.
5. Discussion
AL-Net presents a deep learning-based solution for cell nucleus segmentation in medical image analysis. The framework introduces a more powerful multi-scale module, utilizes DeepLabV3+’s dilated convolutional architecture, and employs the Lion optimizer with boundary loss function, demonstrating significant advantages in nucleus segmentation accuracy and boundary precision. Experimental validation on the 2018 Data Science Bowl dataset—encompassing diverse cell types, magnifications, and imaging techniques—shows that AL-Net consistently delivers outstanding results, underscoring its effectiveness and generalization capacity across varied conditions. By improving segmentation accuracy and robustness, AL-Net’s precision enhancements can yield substantial clinical impact, particularly in cancer diagnosis, where precise nuclear identification informs tumor aggressiveness assessment and treatment planning.
Nonetheless, limitations in the AL-Net framework require acknowledgment. The current threshold-based strategy for loss–optimizer fusion may prove suboptimal in complex scenarios. Future work will develop advanced adaptive fusion algorithms to enhance segmentation resilience. Additionally, AL-Net’s validation on stained images constrains its applicability; future research will extend the framework to more complex unstained and multi-modal nucleus segmentation tasks.
6. Conclusions
AL-Net is a novel model for cell nucleus segmentation that advances both accuracy and boundary precision through its multi-scale module, dilated convolutions, and the combined use of the Lion optimizer with a boundary loss function. Extensive experiments demonstrate its superior performance and strong generalization across cell types, imaging modalities, and magnifications. These results highlight AL-Net’s potential as a robust tool for medical image analysis, particularly in clinical applications requiring precise nucleus delineation. Future work will extend its evaluation to more complex and multimodal datasets and explore adaptive optimization strategies, aiming to establish AL-Net as a versatile framework for reliable medical image segmentation.
Author Contributions
Investigation and methodology, Z.C. and S.-L.P.; formal analysis, R.Y.; validation and writing—original draft preparation, M.Z. and C.Z.; writing—review and editing, Z.C. and S.-L.P.; supervision, Z.C. All authors have read and agreed to the published version of the manuscript.
Funding
This study was funded by the Wuxi University Research Start-up Fund for High-level Talents (grant number 2025r023) and the China University Industry-University-Research Innovation Fund–Innovation Project of New-generation Information Technology 2023 (grant number 2023IT072). The APC was funded by Wuxi University.
Data Availability Statement
The data used in this study are publicly available.
Acknowledgments
During the preparation of this manuscript, the authors used ChatGPT-4o for non-substantive language editing, including grammar correction, sentence structure optimization, and phrasing adjustments. The authors have reviewed and revised the output and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Srivastava, A.; Jha, D.; Chanda, S.; Pal, U.; Johansen, H.D.; Johansen, D.; Riegler, M.A.; Ali, S.; Halvorsen, P. Msrf-net: A multi-scale residual fusion network for biomedical image segmentation. IEEE J. Biomed. Health Inform. 2021, 26, 2252–2263. [Google Scholar] [CrossRef]
- Yadav, A.C.; Kolekar, M.H.; Zope, M.K. Modified Recurrent Residual Attention U-Net model for MRI-based brain tumor segmentation. Biomed. Signal Process. Control 2025, 102, 107220. [Google Scholar] [CrossRef]
- Lee, J.; Nishikawa, R.M. Cross-organ, cross-modality transfer learning: Feasibility study for segmentation and classification. IEEE Access 2020, 8, 210194–210205. [Google Scholar] [CrossRef]
- Ali, S.; Dmitrieva, M.; Ghatwary, N.; Bano, S.; Polat, G.; Temizel, A.; Krenzer, A.; Hekalo, A.; Guo, Y.B.; Matuszewski, B.; et al. Deep learning for detection and segmentation of artefact and disease instances in gastrointestinal endoscopy. Med. Image Anal. 2021, 70, 102002. [Google Scholar] [CrossRef] [PubMed]
- Jha, D.; Riegler, M.A.; Johansen, D.; Halvorsen, P.; Johansen, H.D. Doubleu-net: A deep convolutional neural network for medical image segmentation. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 558–564. [Google Scholar]
- Tellez, D.; Balkenhol, M.; Otte-Höller, I.; Van De Loo, R.; Vogels, R.; Bult, P.; Wauters, C.; Vreuls, W.; Mol, S.; Karssemeijer, N.; et al. Whole-slide mitosis detection in H&E breast histology using PHH3 as a reference to train distilled stain-invariant convolutional networks. IEEE Trans. Med. Imaging 2018, 37, 2126–2136. [Google Scholar] [PubMed]
- Kumar, N.; Verma, R.; Sharma, S.; Bhargava, S.; Vahadane, A.; Sethi, A. A dataset and a technique for generalized nuclear segmentation for computational pathology. IEEE Trans. Med. Imaging 2017, 36, 1550–1560. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision transformers for dense prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2021; pp. 12179–12188. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Wang, J.; Huang, Q.; Tang, F.; Meng, J.; Su, J.; Song, S. Stepwise feature fusion: Local guides global. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2022, Proceedings of the 25th International Conference, Singapore, 18–22 September 2022; Proceedings, Part III; Springer: Cham, Switzerland, 2022; pp. 110–120. [Google Scholar]
- Sanderson, E.; Matuszewski, B.J. FCN-transformer feature fusion for polyp segmentation. In Medical Image Understanding and Analysis, Proceedings of the 26th Annual Conference, MIUA 2022, Cambridge, UK, 27–29 July 2022; Springer: Cham, Switzerland, 2022; pp. 892–907. [Google Scholar]
- Chen, X.; Liang, C.; Huang, D.; Real, E.; Wang, K.; Liu, Y.; Pham, H.; Dong, X.; Luong, T.; Hsieh, C. Symbolic discovery of optimization algorithms. arXiv 2023, arXiv:2302.06675. [Google Scholar] [CrossRef]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar]
- Bokhovkin, A.; Burnaev, E. Boundary loss for remote sensing imagery semantic segmentation. In Advances in Neural Networks–ISNN 2019, Proceedings of the 16th International Symposium on Neural Networks, ISNN 2019, Moscow, Russia, 10–12 July 2019; Proceedings, Part II; Springer: Cham, Switzerland, 2019; pp. 388–401. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 1139–1147. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive gradient methods with dynamic bound of learning rate. arXiv 2019, arXiv:1902.09843. [Google Scholar] [CrossRef]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar] [CrossRef]
- Bernstein, J.; Wang, Y.; Azizzadenesheli, K.; Anandkumar, A. signSGD: Compressed optimisation for non-convex problems. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 560–569. [Google Scholar]
- Riedmiller, M.; Braun, H. A direct adaptive method for faster backpropagation learning: The RPROP algorithm. In Proceedings of the IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; pp. 586–591. [Google Scholar]
- Dozat, T. Incorporating nesterov momentum into adam. In Proceedings of the 4th International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Caicedo, J.C.; Goodman, A.; Karhohs, K.W.; Cimini, B.A.; Ackerman, J.; Haghighi, M.; Heng, C.; Becker, T.; Doan, M.; McQuin, C.; et al. Nucleus segmentation across imaging experiments: The 2018 Data Science Bowl. Nat. Methods 2019, 16, 1247–1253. [Google Scholar] [CrossRef]
- Tajbakhsh, N.; Gurudu, S.R.; Liang, J. Automated polyp detection in colonoscopy videos using shape and context information. IEEE Trans. Med. Imaging 2015, 35, 630–644. [Google Scholar] [CrossRef]
- Silva, J.; Histace, A.; Romain, O.; Dray, X.; Granado, B. Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer. Int. J. Comput. Assist. Radiol. Surg. 2014, 9, 283–293. [Google Scholar] [CrossRef]
- Uka, A.; Halili, A.N.; Polisi, X.; Topal, A.O.; Imeraj, G.; Vrana, N.E. Basis of image analysis for evaluating cell biomaterial interaction using brightfield microscopy. Cells Tissues Organs 2021, 210, 77–104. [Google Scholar] [CrossRef]
- Lou, A.; Guan, S.; Ko, H.; Loew, M.H. CaraNet: Context axial reverse attention network for segmentation of small medical objects. In Proceedings of the Medical Imaging 2022: Image Processing, San Diego, CA, USA, 20–24 February 2022; pp. 81–92. [Google Scholar]
- Wang, H.; Cao, P.; Wang, J.; Zaiane, O.R. Uctransnet: Rethinking the skip connections in u-net from a channel-wise perspective with transformer. Proc. Conf. AAAI Artif. Intell. 2022, 36, 2441–2449. [Google Scholar] [CrossRef]
- Fan, D.; Ji, G.; Zhou, T.; Chen, G.; Fu, H.; Shen, J.; Shao, L. Pranet: Parallel reverse attention network for polyp segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020, Proceedings of the 23rd International Conference, Lima, Peru, 4–8 October 2020; Proceedings, Part VI; Springer: Cham, Switzerland, 2020; pp. 263–273. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers make strong encoders for medical image segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, H.; Hu, Q. Transfuse: Fusing transformers and cnns for medical image segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2021, Proceeding of the 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part I 24; Springer: Cham, Switzerland, 2021; pp. 14–24. [Google Scholar]
- Dong, B.; Wang, W.; Fan, D.; Li, J.; Fu, H.; Shao, L. Polyp-pvt: Polyp segmentation with pyramid vision transformers. arXiv 2021, arXiv:2108.06932. [Google Scholar] [CrossRef]
- Tomar, N.K.; Jha, D.; Riegler, M.A.; Johansen, H.D.; Johansen, D.; Rittscher, J.; Halvorsen, P.; Ali, S. Fanet: A feedback attention network for improved biomedical image segmentation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9375–9388. [Google Scholar] [CrossRef]
- Tang, F.; Xu, Z.; Huang, Q.; Wang, J.; Hou, X.; Su, J.; Liu, J. DuAT: Dual-Aggregation Transformer Network for Medical Image Segmentation. arXiv 2022, arXiv:2212.11677. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).