Abstract
The increasing integration of automation and intelligent sensing technologies in daily-use ceramic manufacturing poses new challenges for efficient scheduling under hybrid flow-shop and shared-kiln constraints. To address these challenges, this study proposes a Mixed-Integer Linear Programming (MILP) model and an Improved Discrete Hippopotamus Optimization (IDHO) algorithm designed for smart, network-aware production environments. The MILP formulation captures key practical features such as batch processing, no-idle kiln constraints, and machine re-entry dynamics. The IDHO algorithm enhances global search performance via segment-based encoding, nonlinear population reduction, and operation-specific mutation strategies, while a parallel evaluation framework accelerates computational efficiency, making the solution viable for industrial-scale, time-sensitive scenarios. The experimental results from 12 benchmark cases demonstrate that IDHO achieves superior performance over six representative metaheuristics (e.g., PSO, GWO, Jaya, DBO), with an average ARPD of 1.04%, statistically significant improvements (p < 0.05), and large effect sizes (Cohen’s d > 0.8). Compared to the commercial solver CPLEX, IDHO provides near-optimal results with substantially lower runtime. The proposed approach contributes to the development of intelligent networked scheduling systems for cyber-physical manufacturing environments, enabling responsive, scalable, and data-driven optimization in smart sensing-enabled production settings.
Keywords:
smart ceramic manufacturing; hybrid flow-shop scheduling; mixed-integer linear programming; improved discrete hippopotamus optimization; batch processing; no-idle constraint; network-aware metaheuristic optimization; intelligent scheduling systems MSC:
90-08
1. Introduction
The ongoing transformation of traditional manufacturing systems into cyber-physical production environments, driven by the convergence of operational technology (OT), information technology (IT), and networked systems, has introduced new challenges in industrial scheduling and coordination. Particularly within the scope of Industry 4.0, there is a growing emphasis on designing systems that exhibit decentralized intelligence, interoperability, and responsiveness to inferred system states. In such intelligent and partially observable environments, production scheduling must adapt to operate under uncertainty, incomplete data, and constrained visibility while maintaining high efficiency, robustness, and scalability.
One practical domain exemplifying these challenges is the rapidly expanding daily-use ceramic industry, particularly in China, which encompasses the production of functional ceramic goods such as bowls, teacups, aroma diffusers, and tableware. While the case study in this paper focuses on Chinese manufacturers, the proposed scheduling framework is not geographically constrained. Similar hybrid production environments, where partial automation coexists with significant manual operations, are widely observed in ceramic industries across Asia, Europe, and South America. The methodological contributions of this study—including the modeling of hybrid flow-shop scheduling and the Improved Discrete Hippopotamus Optimization (IDHO) algorithm—are therefore broadly applicable to other regions and even to adjacent industries facing comparable challenges, such as glassware, sanitary ceramics, and composite material manufacturing. This generalizability highlights the potential for extending the proposed approach beyond the specific context of China.
To address this challenge, this study focuses on scheduling optimization in semi-automated ceramic-manufacturing lines, where intelligent decision-making must be performed in the absence of ubiquitous physical sensing. Instead, we propose a system that simulates the behavior of a smart-sensing-enabled environment by encoding constraints such as kiln utilization, mold reconfiguration timing, and inter-batch dependencies as inferred or logical conditions within the optimization model. In this context, scheduling becomes a proxy for sensor-driven coordination, allowing for practical deployment in low-cost and low-connectivity factory environments while aligning with the broader goals of cyber-physical system design and networked intelligence.
The daily-use ceramic production flow typically consists of five sequential stages: roller pressing, drying, Bisque firing, glazing, and glaze firing. These stages are visually illustrated in Figure 1. The process exhibits three critical characteristics that greatly increase scheduling complexity: (1) each stage is equipped with multiple parallel machines, enabling batch-level parallelism; (2) customer orders usually involve large quantities of standardized items, necessitating synchronized batch scheduling across all stages; and (3) the firing stages, Bisque and glaze firing, utilize shared kilns that require lengthy preheating cycles, imposing a no-idle constraint to preserve thermal efficiency and reduce energy consumption. These constraints not only reflect physical system limitations but also serve as virtual indicators of resource availability and urgency within the production schedule. Therefore, modeling these interactions accurately is essential to enable intelligent, data-driven scheduling within a smart factory framework.
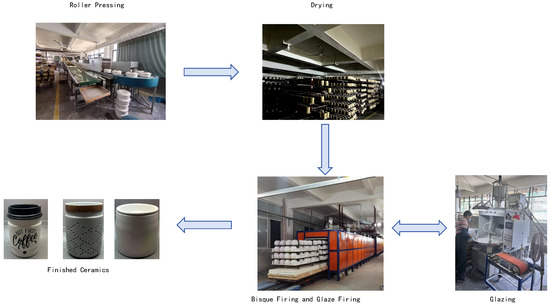
Figure 1.
Illustration of the actual production process.
In academic and industrial research, the Hybrid Flow-Shop Scheduling Problem (HFSP) has emerged as a generalization of the classical flow-shop model that supports multi-stage, multi-machine scheduling with complex interdependencies. This model has been extensively applied to domains such as steel production [1,2,3,4,5], semiconductor fabrication [6,7,8,9], and sustainable manufacturing [10,11,12,13,14,15]. However, its application in the ceramics industry, especially in the context of daily-use or household ceramic production, has remained largely underexplored. A bibliometric analysis of the Web of Science Core Collection from 2014 onward reveals that fewer than 0.1% of HFSP-related publications are focused on ceramic production, with nearly no empirical studies targeting the scheduling needs of semi-automated ceramic workshops. This under-representation underscores a critical research gap and indicates the need to adapt HFSP frameworks to the unique challenges of ceramic manufacturing, such as batch-level decision-making, kiln-sharing, and inferred energy constraints.
In recent years, several advanced metaheuristic methods have been proposed to solve HFSP variants, particularly under real-world constraints such as batch grouping, sub-batch sequencing, and mixed-machine eligibility. For example, Zhang et al. [16] proposed an Enhanced Migrating Birds Optimization (EMBO) approach for identical batching scenarios, while Wang et al. [17] developed a discrete water wave optimization method to address mixed-variable flow-shop environments. More recently, Zhang et al. [18] formulated a sub-batch MILP model and coupled it with a variable neighborhood descent (VND) algorithm for performance enhancement. Beyond traditional manufacturing, Guo et al. [19] investigatedhuman–robot collaborative scheduling with shared resources and partial automation, demonstrating the transferability of batching and human-in-the-loop scheduling techniques to other hybrid production systems, including ceramic workshops.
In the specific context of daily-use ceramics, unique structural constraints necessitate further specialization of HFSP models. For instance, mold changes impact only the roller-pressing stage, while subsequent drying and firing processes are unaffected. This makes it possible to implement interleaved sub-batch processing beyond the initial stage, thereby improving throughput without incurring additional changeover penalties. Moreover, energy-intensive kilns impose strict no-idle requirements due to their thermal inertia and startup energy cost. Notably, conventional no-idle flow-shop models—focused on scenarios like total tardiness minimization [20], energy-efficient optimization [21], distributed problems with due windows [22], flowtime reduction via heuristics [23], iterated greedy algorithms for total tardiness [24], iterated reference greedy algorithms for distributed no-idle permutation flowshop scheduling [25], and hybrid algorithms with differential evolution [26] have been well explored. Unlike these conventional no-idle flow-shop models, this (daily-use ceramics) scenario necessitates a hybrid approach in which only specific machines (i.e., kilns) are subject to continuous operation constraints. To model this hybrid behavior effectively, Pan et al. [27] and Rossi et al. [28] developed partial no-idle scheduling models and adapted them for sequence-dependent operations, while Bektas et al. [29] introduced a Benders decomposition approach for improving scalability. Li et al. [30] further proposed an Adaptive Iterated Greedy (AIG) algorithm to minimize total flow time under distributed production settings.
Parallel to these modeling advancements, metaheuristic algorithms have gained prominence in solving large-scale combinatorial optimization problems, especially in domains where exact solvers like CPLEX are impractical due to exponential computational complexity [31,32,33,34,35,36,37,38,39]. Notably, nature-inspired metaheuristic techniques, which are summarized in Rahman et al. [40] with an overview of their latest advances for combinatorial optimization, offer near-optimal solutions within reasonable time frames and are particularly attractive for integration into intelligent manufacturing control loops. Recent studies have also extended these algorithms to support human-centric and ergonomics-aware scheduling scenarios [41,42], demonstrating their flexibility and relevance for smart manufacturing environments.
Building upon these foundations, this study introduces a network-aware optimization framework for ceramic production scheduling, consisting of two core components:
- A Mixed-Integer Linear Programming (MILP) model that formalizes the hybrid flow-shop constraints of ceramic manufacturing, including batch grouping, mold setup, kiln no-idle constraints, and interleaved processing, within a virtual smart sensing context;
- An Improved Discrete Hippopotamus Optimization (IDHO) algorithm, designed to act as a distributed intelligent scheduler that incorporates segment-based encoding, dynamic population size reduction, operation-segmented mutation, and fault-tolerant kiln assignment.
The original Hippopotamus Optimization (HO) algorithm was introduced by Amiri et al. [43] in as a nature-inspired technique for global optimization. Subsequent applications have demonstrated its promise—Yang et al. [44] applied HO to optimize point cloud distortion correction in neural networks, while Han et al. [45] introduced several key enhancements, including sinusoidal chaotic population initialization, adaptive growth-phase convergence adjustment, and a pinhole-inspired inverse learning strategy for complex engineering optimization.
Unlike conventional optimization techniques that assume complete system observability, the IDHO algorithm is designed to function effectively under partial or simulated sensing conditions, making it well-suited for deployment in smart factory environments with limited instrumentation. It behaves as a local intelligent agent capable of learning and adapting to system-level constraints inferred from process dependencies and logical rules, mimicking the responsiveness of sensor-driven systems without requiring actual sensor deployment.
The remainder of this paper is structured as follows:
- Section 2 presents the MILP scheduling model, including the mathematical formulation of constraints related to batching, machine availability, setup times, and kiln continuity;
- Section 3 introduces the IDHO algorithm and details its customized encoding, fault-tolerant scheduling strategies, and parallel computing enhancements;
- Section 4 describes the experimental design and provides comparative evaluations against several state-of-the-art metaheuristics;
- Section 5 concludes the paper, discusses the broader implications of this work for smart manufacturing, and outlines future directions, including integration with digital twin platforms and federated intelligent scheduling frameworks.
2. Problem Description
2.1. Requirements
In the context of Industry 4.0 and intelligent manufacturing, optimizing scheduling operations in traditional industries with limited sensor infrastructure requires the integration of inferred system knowledge, intelligent decision-making models, and domain-specific constraints. This work addresses a network-aware and resource-efficient scheduling problem that arises in a semi-automated ceramic-manufacturing environment, where energy-intensive operations and shared-resource constraints necessitate precise coordination even in the absence of real-time sensor feedback.
To model this practical scenario, a tailored Hybrid Flow-Shop Scheduling Problem (HFSP) framework is constructed, incorporating batch processing strategies and critical no-idle constraints for shared-kiln operations. The production line consists of five sequential stages, roller pressing, drying, Bisque firing, glazing, and glaze firing, each equipped with multiple identical parallel machines to support concurrent batch operations. The nature of ceramic production imposes an inherent batch structure: each order comprises a set of identical ceramic items (uniform in shape and specification), grouped into batches based on mold capacity at the roller-pressing stage, typically ranging from 20 to 30 items per mold.
Unlike conventional flow-shop models, this manufacturing environment supports interleaved batch execution, allowing batches from different orders to proceed asynchronously across stages. This flexibility enables improved throughput and machine utilization but also introduces scheduling complexity due to varying batch availability and process dependencies. The roller-pressing stage, being the entry point and mold-dependent, requires setup operations when switching between different product orders. These setup events incur consistent delays and represent logical transition points that must be considered in any intelligent scheduling strategy.
The most critical constraint lies in the shared-kiln system used in both the Bisque- and glaze-firing stages. Once preheated, a process requiring approximately eight hours from a cold start, the kiln must remain in continuous operation. Any idle time between batches risks significant energy loss, product deformation, and process instability. Therefore, a no-idle constraint is strictly enforced between consecutive kiln operations. This constraint effectively simulates a virtual sensor that infers the kiln’s thermal state from batch timing, enforcing strict continuity without requiring physical thermal feedback.
From a system modeling perspective, this problem exemplifies a cyber-physical production system with virtual state inference, where intelligent scheduling algorithms must incorporate domain-specific logic to maintain operational stability, reduce makespan, and optimize energy utilization. The absence of real-time sensors necessitates a reliance on batch-level control, static process knowledge, and machine-level coordination, a setting common in many cost-sensitive industrial operations.
The problem is modeled under the following realistic and industrially grounded assumptions:
- Initial Availability: All raw materials and production orders are assumed to be ready at time zero; all machines are initially idle and available for scheduling.
- Identical Parallel Machines: Each production stage consists of multiple identical machines operating in parallel; each batch can be processed on only one machine at each stage.
- Single Tasking: Each machine can handle only one batch at a time, no simultaneous or overlapping processing is allowed.
- Homogeneous Order Structure: Within each order, all ceramic items are of the same model and physical dimensions. Each order corresponds to a distinct product category with a unique processing identifier.
- Stage-Sequential Workflow: Every ceramic item must pass through the five processing stages in the same fixed order; inter-stage transportation delays are considered negligible and do not impact scheduling decisions.
- Stage-Specific No-Idle Constraint: The no-idle constraint applies strictly to the kiln-based stages, Bisque firing and glaze firing. No such constraints are imposed on the roller-pressing, drying, or glazing stages.
- Uniform Setup for Mold Changeover: At the roller-pressing stage, changing from one order to another incurs a fixed setup time due to mold changeover. This setup time is considered uniform across all transitions.
This formulation enables the development of a mixed-integer programming model and intelligent scheduling framework that collectively address batch sequencing, machine assignment, and kiln continuity, thereby supporting smart scheduling under practical, constrained, and sensor-limited conditions.
2.2. Mathematical Model
In modern cyber-physical production environments, particularly in sensor-limited settings such as semi-automated ceramic workshops, intelligent scheduling must rely on domain-informed logic and virtual state inference rather than real-time sensor feedback. The core objective of the proposed hybrid scheduling model is to determine a globally efficient plan for batch grouping, job sequencing, and machine assignments across multiple stages of production while satisfying diverse manufacturing constraints related to mold capacity, process synchronization, and energy management.
To mathematically encode this problem, a Mixed-Integer Linear Programming (MILP) model is formulated that incorporates three critical elements: (1) batch-based manufacturing constraints, (2) parallel machine processing with mold setup delays, and (3) strict no-idle sequencing for shared-kiln operations. This model serves as a digital abstraction of the physical process flow, enabling intelligent scheduling through rule-based constraint modeling and optimized variable assignment. It effectively replaces physical monitoring with computational logic that simulates the impact of thermal continuity, process interleaving, and manual setup.
The complete set of parameters and decision variables is provided in Table 1, establishing the mathematical foundation required for formal model specification.

Table 1.
Notation for parameters and decision variables.
Sub-batch Preprocessing:
Decision Variables:
Objective Function:
Constraints:
The mold capacity constraint is operationalized through Equation (1), which defines the total number of sub-batches n based on order quantity , mold requirement , and sub-batch ratio . This ensures that each sub-batch adheres to the physical upper limit of mold capacity, guaranteeing feasibility in practical production settings.
The primary decision variables include (sequence position assignment), (machine assignment), and (setup transition indicator). Objective Function (2) minimizes the makespan , thereby shortening the overall production cycle.
Constraint (3) defines the finish time for each sub-batch as the sum of its corresponding start time and processing duration . For the roller-pressing stage (), an additional setup time is incurred when consecutive sub-batches are from different orders and processed on the same machine, indicated by the binary variable . This constraint links all scheduling activities to the global objective of minimizing the overall completion time, as formalized in the objective function.
Constraints (4) and (5) impose total ordering among sub-batches, ensuring each sub-batch is assigned a unique position in the production sequence. This binary formulation eliminates ambiguity and prohibits overlapping execution.
Constraint (6) ensures exclusive machine assignment for each sub-batch at each stage, while (7) limits the number of sub-batches concurrently processed on non-kiln machines to one, preventing resource contention.
Constraint (8) enforces temporal consistency across the sub-batch sequence, requiring earlier-positioned sub-batches to start before later-positioned ones. To linearize the disjunctive scheduling conditions, constraint (9) applies the Big-M method to ensure that when two sub-batches are scheduled on the same machine, their execution does not overlap unless explicitly allowed.
Constraint (10) mandates the correct process routing by requiring that a sub-batch cannot start processing at stage s until it has completed processing at stage . Constraint (11) enforces exclusive allocation of kiln resources: any kiln may only serve one sub-batch at a time, preventing simultaneous Bisque or glaze firings.
Finally, constraint (12) encodes the no-idle condition for kiln stages (), requiring that the start time of a sub-batch exactly equals the finish time of the preceding one on the same kiln. This ensures energy-efficient, uninterrupted kiln utilization.
3. Improved Discrete Hippopotamus Optimization Algorithm
3.1. Discretization Strategy for HO Algorithm
The original Hippopotamus Optimization (HO) algorithm, introduced for solving continuous-domain optimization problems, operates through floating-point position updates inspired by the behavioral foraging patterns of hippopotamuses. While this paradigm has shown promising results in continuous engineering optimization tasks, it cannot be directly applied to combinatorial problems, particularly those such as scheduling, where solutions must adhere to strict permutation-based structures.
In the context of hybrid flow-shop scheduling, where feasible solutions correspond to valid permutations of job or sub-batch sequences, it becomes essential to convert the continuous representations produced by the HO algorithm into legal discrete configurations. This conversion process, often referred to as solution discretization, serves as a bridge between the continuous exploration space of metaheuristics and the discrete search space of combinatorial decision-making.
To address this challenge, we propose a lightweight, mathematically robust discretization mechanism that enables the continuous HO algorithm to operate within the discrete scheduling space without violating the structural feasibility of its solutions. The proposed method leverages a ranking-based transformation strategy that maps real-valued position vectors to valid job sequences via relative ordering.
More specifically, each individual in the HO population is initially encoded as a continuous-valued array:
where represents the j-th dimension (job/sub-batch position) of the i-th candidate solution in the search population. To convert this into a valid discrete permutation, we apply the following process:
- Tie-Breaking via Perturbation: To avoid ambiguity during ranking, particularly in the presence of identical or near-identical values, we introduce infinitesimal random perturbations to each element using . This guarantees strict ordering while preserving the original search dynamics.
- Rank-Based Transformation: The perturbed array is then transformed into a discrete permutation by computing the forward rank of each element. The smallest value receives rank 1 (i.e., it is placed first in the job sequence), the next smallest receives rank 2, and so on. This produces a bijective mapping from to the permutation space .
- Feasibility Assurance: The resulting discrete sequence inherently satisfies the feasibility constraints of permutation-based scheduling (no duplicates, complete job coverage), eliminating the need for repair operations or constraint-penalty mechanisms.
This transformation yields a two-track representation of candidate solutions within the algorithm:
- The continuous vector is retained for exploration and update purposes, allowing the algorithm to benefit from the global search capabilities and fast convergence properties of continuous HO operators.
- The discrete permutation derived from is used for decoding, schedule simulation, and fitness evaluation, ensuring valid and interpretable outputs for the scheduling task.
This hybrid structure forms a foundation for intelligent cyber-inspired computation. The continuous trajectory serves as a virtual behavioral memory, while the discrete permutation acts as an executable physical plan. The discretization strategy thus embodies a form of virtual sensing: it infers high-quality discrete solutions from analog search traces, simulating adaptive reasoning without requiring external sensors or environment feedback.
As illustrated in Figure 2, the process seamlessly transforms real-valued search signals into valid combinatorial schedules, enabling the Hippopotamus Optimization algorithm to operate effectively in constrained, high-dimensional scheduling environments.
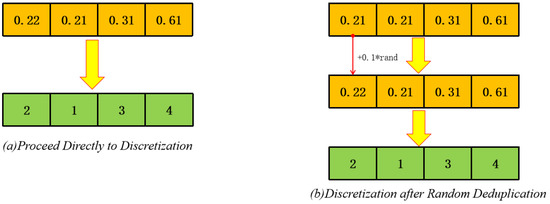
Figure 2.
Illustration of the Discretization Process.
By incorporating this transformation into the core loop of the Improved Discrete Hippopotamus Optimization (IDHO) algorithm, we establish a principled method for applying a nature-inspired search in semi-automated manufacturing systems where scheduling must be both logically constrained and inference-driven. The approach supports smart decision-making through structural transformation rather than explicit real-time monitoring, thereby aligning with the vision of intelligent networked systems for resource-constrained industrial environments.
3.2. Encoding Rules
In the context of semi-automated ceramic manufacturing, intelligent scheduling requires a scalable and interpretable representation of production decisions across multiple interdependent stages. To address this, we propose a cyber-inspired encoding scheme that integrates process-awareness, modularity, and system-level coordination while preserving the structural feasibility of hybrid flow-shop scheduling.
Specifically, the ceramic production workflow comprises five sequential processing stages: roller pressing, drying, Bisque firing, glazing, and glaze firing. To map scheduling decisions across these stages into the solution representation of the optimization algorithm, each candidate solution vector is explicitly divided into five distinct segments. Each segment corresponds to a single production stage and encodes the job sequence for that stage independently, allowing localized inference and adaptive control under stage-specific constraints such as no-idle operations or setup penalties.
Within this encoding structure, each segment consists of a continuous-valued array with a length equal to the total number of sub-batches n. The elements of each segment are sampled from the open interval , with their relative magnitudes determining the processing priority at that specific stage. Smaller numerical values imply higher priority in execution. This real-valued encoding naturally integrates with the discretization strategy previously discussed, enabling real-time transformation into valid permutations through forward-ranking mechanisms.
A simplified example of this segmented encoding mechanism is illustrated in Figure 3, which demonstrates a three-sub-batch case. For the first processing stage, the algorithm assigns real-valued priorities (e.g., 0.21, 0.65, etc.) that dictate execution order. This process is repeated independently for each of the five stages, forming a modular structure where each segment acts as a self-contained scheduling agent. This modularity mirrors the logic of distributed control in smart manufacturing environments, where decisions are made per station or equipment unit based on local load and processing rules.
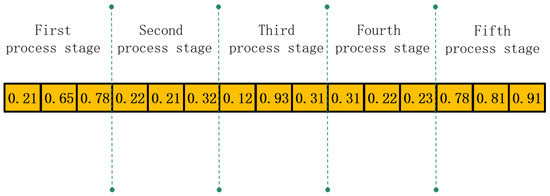
Figure 3.
Illustration of the encoding mechanism.
In contrast to traditional global permutation-based encodings, which construct a monolithic -length sequence entangling all stages, the segmented strategy yields numerous practical advantages:
- Structural Interpretability: Each segment has an explicit, isolated operational meaning (stage-specific sequence), enabling stage-wise analysis and decentralized refinement.
- Computational Tractability: The division drastically reduces solution space complexity, facilitating convergence in high-dimensional scheduling problems.
- Virtual Sensing and Local Adaptation: Segment-level priority encoding serves as an abstract representation of inferred workload state, enabling indirect reasoning without explicit sensor inputs.
To quantify the efficiency of this encoding structure, we compare the size of the resulting search space to that of conventional global permutation-based approaches. Suppose a scheduling problem involves p jobs over 5 sequential stages. The traditional global encoding scheme constructs a single permutation of length , yielding a search space of .
By contrast, our proposed segmented encoding partitions the problem into five independent permutations, each of length p, yielding a total search space of . Applying Stirling’s approximation to both cases gives
Taking the natural logarithm of both expressions and subtracting it yields
This result confirms that the difference increases monotonically with p, demonstrating that the global encoding approach scales poorly compared to the segmented strategy. Even for small instances (e.g., ), the difference is already positive, validating the superiority of the segmented encoding in terms of solution space reduction.
From a system design perspective, this encoding mechanism enables distributed scheduling intelligence that resembles multi-agent coordination in networked production environments. Each stage segment functions analogously to a local node in a smart manufacturing network, operating with independent control logic but contributing to a shared global objective (i.e., minimizing makespan). This abstraction aligns with the broader vision of intelligent networked systems, where computational coordination compensates for the absence of dense sensing infrastructure.
By enabling structurally guided, low-complexity optimization in hybrid scheduling environments, the proposed encoding approach significantly enhances both scalability and intelligent decision interpretability, key requirements for future-ready, sensor-aware manufacturing systems.
3.3. Priority-Decoding and Fault-Tolerant Kiln Scheduling Strategy
To bridge the gap between continuous optimization and real-world scheduling execution, we introduce a network-aware decoding framework that transforms solution vectors into interpretable, executable sequences under cyber-physical constraints. Each stage-specific segment of the solution vector, initially encoded as a continuous array within , is discretized using the forward-rank transformation strategy introduced earlier. This process maps real-valued priorities into relative execution orders, ensuring valid and feasible job sequences across all stages while maintaining interpretability and adaptability in intelligent scheduling contexts.
Figure 4 illustrates the complete decoding pipeline. First, each continuous vector is mapped to a discrete priority list through rank-based transformation. These ranked indices determine the processing sequence for sub-batches at each respective stage. Next, an insertion-based allocation heuristic is applied to assign jobs to machines, dynamically considering machine availability, stage-specific constraints (e.g., no-idle operations for kilns), and the global sequencing structure derived from the encoded solution.
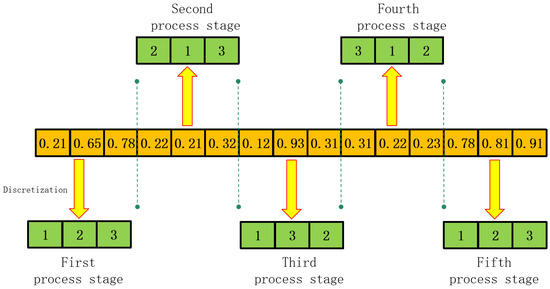
Figure 4.
Illustration of the decoding mechanism.
The insertion-based scheduling heuristic operates as follows: For each sub-batch at a given stage, the decoding mechanism selects the earliest available time slot on a suitable machine (one that is not concurrently assigned and does not violate inter-stage precedence). By strictly following the priority order obtained from the discretized vector, the heuristic guarantees consistency between algorithm output and executable control logic, simulating a form of lightweight virtual sensing that guides operation decisions without physical instrumentation.
To manage resource contention and ensure fault tolerance in energy-intensive stages, we propose a Fault-Tolerant Kiln Scheduling Strategy tailored to shared-kiln operations at Process Stage 3 (Bisque firing) and Stage 5 (glaze firing). These stages are thermally coupled and impose unique constraints, including no-idle operation and long preheating periods. Real-time sensing is not available in the simulated environment, so process-level adaptations must be embedded within the decoding and control logic.
Figure 5 presents the two-stage kiln scheduling framework, which incorporates intelligent fault-tolerant logic via conditional constraint relaxation:
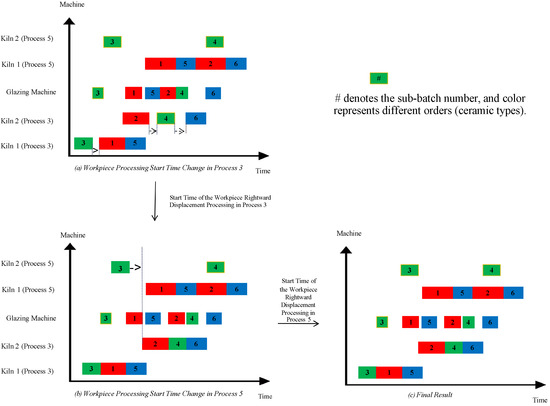
Figure 5.
Illustration of the Fault-Tolerant Kiln Scheduling Strategy.
3.3.1. Stage 1—Strict No-Idle Constraint at Bisque Firing (Process 3)
To maximize kiln thermal efficiency and energy continuity, we impose a strict no-idle condition for Bisque-firing kilns. Each sub-batch must begin immediately upon the completion of the previous batch processed in the same kiln:
This constraint reflects energy-preserving execution policies commonly adopted in smart manufacturing systems and ensures uninterrupted resource usage without requiring explicit temperature sensors or thermal feedback systems.
3.3.2. Stage 2—Relaxed Coupling at Glaze Firing (Process 5)
To avoid infeasibility under limited kiln capacity or varied task durations, a relaxed constraint is introduced for the glaze-firing stage. This constraint allows flexible start times for glaze firing sub-batches, provided they follow the completion of their corresponding Bisque-firing tasks:
This intelligent relaxation decouples the scheduling of Process 3 and 5 kilns under bounded delays, emulating fault-tolerant mechanisms in networked systems that self-adjust under uncertainty. It allows the scheduling system to dynamically adapt to production variations (e.g., smaller batch volumes or asymmetric kiln availability) without central sensing or real-time rescheduling.
This fault-tolerant kiln scheduling approach achieves the following network-relevant objectives:
- Resilience without Real-Time Sensing: Inference-based constraint adjustment ensures system feasibility under diverse execution conditions.
- Scalable Adaptation: The strategy accommodates variation in batch quantities, durations, and equipment availability.
- Energy-Aware Intelligence: No-idle enforcement simulates thermal feedback through deterministic temporal logic, supporting sustainable operation.
In practical terms, this two-stage strategy provides an effective balance between execution feasibility and energy-efficient operation. It enables networked intelligence in semi-automated ceramic workshops by embedding operational adaptivity into the scheduling logic, thereby ensuring continuous kiln usage while avoiding bottlenecks or deadlocks, even in the absence of dense-sensor deployments. This supports the broader vision of low-cost, smart production enabled by embedded intelligence rather than real-time monitoring.
3.4. Initialization Strategy
To promote efficient exploration and accelerate convergence in the Improved Discrete Hippopotamus Optimization (IDHO) algorithm, we introduce a hybrid initialization strategy that leverages both heuristic knowledge and stochastic diversity. This approach reflects principles common in intelligent cyber-physical systems: combining historical or structural insights (heuristics) with dynamic adaptation (randomization) to generate resilient and effective behaviors.
Phase 1—Heuristic-Guided Construction of Anchor Solutions: Two elite individuals are constructed using classical production heuristics:
- Shortest Job First (SJF): This prioritizes smaller sub-batches to reduce queuing delays and minimize average flow time.
- Longest Job First (LJF): This prioritizes larger sub-batches to front-load long operations, reducing bottlenecks at later stages.
These heuristics emulate rule-based controllers in intelligent scheduling systems and serve as structural guides that embed domain-specific insights into the initial solution pool.
Phase 2—Diversity-Oriented Random Initialization: The remaining individuals in the initial population are generated randomly to enhance global search capabilities and avoid premature convergence. This design mimics population diversity mechanisms in decentralized intelligent networks, where heterogeneous agents contribute to solution discovery from distinct perspectives.
Since both SJF and LJF produce discrete job permutations, but the IDHO operates over continuous-valued solution vectors in the interval, a transformation is needed. To bridge this representational gap, we apply a normalization process to map discrete heuristic outputs to real-valued vectors while preserving relative order and compatibility with the encoding structure used in IDHO. Each segment, representing one of the five processing stages, is individually normalized, ensuring that the relative priority of operations is retained across all stages.
The normalization algorithm is formalized in Algorithm 1, which performs column-wise rescaling of each heuristic-generated matrix:
| Algorithm 1 Column-Wise Normalization for Heuristic Initialization. | |
| 1: function Normalize-Matrix(X) | |
| 2: for do | |
| 3: | |
| 4: | |
| 5: | |
| 6: if then | |
| 7: | ▹ Avoid zero-division |
| 8: end if | |
| 9: for do | |
| 10: | |
| 11: if then | |
| 12: | ▹ Uniform fallback if no variation |
| 13: end if | |
| 14: end for | |
| 15: end for | |
| 16: return X | |
| 17: end function | |
This initialization framework enables three important capabilities relevant to networked smart systems:
- Informed Scheduling Decisions: Encoded heuristics simulate system knowledge and adaptive behavior without requiring real-time data collection or historical logs.
- Scalable Diversity: Random initialization allows flexible adjustment to system complexity and uncertainty without manual tuning.
- Sensor-Free Adaptation: The transformation from discrete domain heuristics to continuous search spaces facilitates intelligent adaptation in semi-observed or fully simulated environments.
Through this dual-mode initialization mechanism, the IDHO framework achieves both directional convergence and diversity-driven resilience, supporting intelligent batch scheduling in semi-automated ceramic workshops under uncertain and resource-constrained settings, without relying on physical sensor infrastructure.
3.5. Dynamic Nonlinear Population Size Reduction Strategy
In secure and intelligent networked systems, adaptive resource management is essential to maintain operational scalability and efficiency. Drawing inspiration from such principles, this study incorporates a dynamic population control mechanism into the IDHO algorithm, echoing the behavior of self-regulating intelligent agents in cyber-physical networks.
Previous works, such as the Linear Population Size Reduction (LPSR) strategy proposed by Ahmed et al. [46], demonstrate that iterative control over population size can effectively balance exploration and exploitation in metaheuristic algorithms like the Grey Wolf Optimizer (GWO). By linearly decaying the population size over time, LPSR reduces computation while avoiding premature convergence. Empirical validations [47] have confirmed LPSR’s benefit in improving convergence and robustness in Differential Evolution (DE), Genetic Algorithms (GA), and GWO.
Adaptation for Discrete Swarm Intelligence: To leverage these advantages in the Hippopotamus Optimization (HO) framework, while preserving its distinctive dual-subpopulation structure (exploration and defense agents), we propose a customized Nonlinear Population Size Reduction (NPSR) strategy. This strategy dynamically modulates both the intensity and frequency of pruning actions based on nonlinear feedback, allowing the algorithm to mimic the self-regulatory behavior of intelligent decentralized agents operating in resource-constrained environments.
(1) Even-Constrained Pruning for Structural Integrity: HO relies on a structurally balanced population consisting of exploratory and exploitative individuals. To preserve this duality, the NPSR strategy enforces even-numbered reductions, pruning exactly of the least-fit individuals during each activation cycle. This constraint ensures consistent pairing between co-evolving roles, similar to role-based task assignments in intelligent multi-agent networks.
(2) Adaptive Nonlinear Reduction Strategy: The rate and intensity of reduction are governed by two dynamically evolving parameters, designed using a cosine-based annealing function that modulates pruning behavior over time:
- Reduction frequency l controls how often pruning occurs across generations:
- Reduction intensity determines how many individuals are eliminated per event:
This design yields a nonlinear annealing schedule, where the algorithm favors frequent but shallow pruning during early exploration (maintaining diversity) and rare but deep pruning in later exploitation stages (focusing convergence). Such behavior aligns with adaptive load-balancing in smart sensor networks, where early learning tolerates noise and later refinement optimizes performance under constraints.
The effective population size at generation G is then determined by
This progressive decay framework ensures the following:
- Resource efficiency: Gradual reduction reduces computation while maintaining competitive solution quality.
- Structural resilience: Even-numbered reduction preserves the algorithm’s cooperative architecture.
- Smart adaptation: Nonlinear pruning emulates context-aware regulation, akin to load-shedding and inference scaling in secure, intelligent networks.
Overall, the NPSR strategy allows the IDHO algorithm to operate like a decentralized intelligent system, dynamically reallocating attention and memory across generations, without relying on physical sensor signals or centralized feedback, making it particularly suitable for scalable, secure, and inference-driven smart scheduling environments.
3.6. Process Division Mutation Strategy
In the context of intelligent scheduling for semi-automated manufacturing, maintaining sufficient diversity across the search space is crucial to avoid premature convergence and ensure scalable, resilient decision-making. In decentralized intelligent systems, such as smart networks or multi-agent platforms, this capability often emerges from localized inference adjustments or role-specific behavior changes.
Inspired by such systems, the Improved Discrete Hippopotamus Optimization (IDHO) algorithm integrates a mutation mechanism designed to emulate adaptive process-level perturbations. While the core HO-based search rapidly exploits promising regions, excessive fitness-driven updates may reduce diversity and trap the search in suboptimal regions. To mitigate this, a process-segmented mutation strategy is introduced to inject structured variability and enhance the algorithm’s exploration capacity without violating domain-specific constraints.
Mutation Logic: At its core, the mutation mechanism randomly selects two gene positions and performs a simple value swap. However, rather than applying this uniformly across the entire individual (which could disrupt inter-process dependencies), the proposed strategy confines swap operations to localized segments corresponding to individual manufacturing stages. Each segment represents an independent operation, such as roller pressing, drying, Bisque firing, glazing, or glaze firing.
As shown in Figure 6, this design ensures that intra-process scheduling logic remains coherent while enabling localized diversity improvements, akin to stage-specific reallocation in distributed smart systems. This mirrors behaviors seen in adaptive network agents that only update specific layers or roles based on task demands or observed inefficiencies.
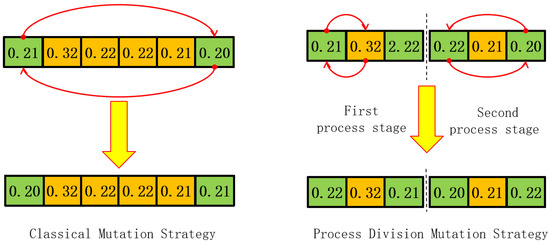
Figure 6.
Schematic of the operation-segmented swap mutation strategy.
Mutation Algorithm: The detailed implementation is formalized in Algorithm 2. The mutation function, ‘Process Division Mutation‘, accepts the current population of ‘hippos‘, the total number of operations , and the population size . It proceeds in two randomized steps: first, it probabilistically decides which individuals will be mutated; then, for each individual, it selectively mutates one or more of its process-specific segments through a single-gene swap.
| Algorithm 2 Process Division Mutation. |
|
Advantages in Intelligent Networked Contexts:
- Localized Inference Reconfiguration: Each mutation mimics a localized policy adjustment within a distributed system, rebalancing only the scheduling strategy of a specific process layer.
- Network-Resilient Diversity: The segmented mutation prevents collapse into uniform strategies, preserving heterogeneous subpopulation dynamics crucial for long-term system adaptability.
- Feasibility-Aware Perturbation: Unlike global mutation strategies that risk invalidating encoded constraints, the operation-specific approach ensures all offspring remain interpretable and executable within the ceramic-manufacturing domain.
Ultimately, this mutation mechanism enables IDHO to retain the robustness and flexibility of intelligent distributed scheduling agents, capable of adjusting their behaviors within operational silos, while ensuring alignment with manufacturing-specific scheduling constraints and the principles of secure, decentralized networked inference.
3.7. Parallel Operation Strategy
In intelligent networked systems for industrial scheduling, scalability and execution latency are critical concerns, especially when computational agents operate under resource constraints and real-time response requirements. The batch-oriented fitness evaluation mechanism in ceramic production scheduling inherently increases the computational load of metaheuristic frameworks. This is particularly evident in the Hippopotamus Optimization (HO) algorithm, which, unlike conventional single-evaluation schemes, requires multiple full-scale fitness evaluations in each iteration due to its dual-subpopulation update structure.
Such multi-evaluation mechanisms introduce considerable time complexity as the problem size expands. Although the dynamic Nonlinear Population Size Reduction (NPSR) strategy introduced in Section 3.5 partially mitigates this challenge by adaptively shrinking the population size, additional architectural improvements are required to meet the rapid-response demands of modern cyber-physical manufacturing systems.
3.7.1. Parallelization Opportunity in Network-Aware Agents
A careful analysis of the HO framework reveals that it possesses structural modularity and inter-agent independence, enabling parallel scheduling across its evolutionary stages. These characteristics are consistent with intelligent networked agents that perform distributed optimization with asynchronous updates. Specifically, two core phases can be safely decoupled for parallel inference:
- Predator-Defense Stage: Each individual (agent) independently updates its position based on historical information and random perturbations. Formally, the position update of individual is statistically independent of others, i.e., for , making it ideal for simultaneous updating and evaluation within a networked parallel execution layer.
- Predator-Escape Stage: Although the escape dynamics (refer to Equations (17) and (18) in [43]) rely on a control parameter , this parameter is iteration-agnostic and pre-generable. Hence, the escape computations can also be decoupled from the sequential control loop, enabling concurrent inference execution.
3.7.2. Proposed Parallel Inference Framework
Based on these insights, we propose a two-stage parallel computation strategy that enhances runtime performance while maintaining algorithmic integrity:
- Preallocation of Control Parameters: Prior to the iterative optimization process, a vector of random control parameters with dimensions of is generated and stored. This design mimics pre-inference memory caching used in lightweight intelligent agents and eliminates redundant sampling during runtime.
- Parallel Fitness Evaluation and Position Updates: The predator-defense and predator-escape loops are restructured using MATLAB R2023a’s ParFor construct. This implementation establishes a distributed computation grid, where agents execute updates and evaluations concurrently across CPU cores or distributed hardware. The architecture supports parallel swarm dynamics, reflecting the cooperative behaviors of decentralized smart systems.
3.7.3. Implications for Intelligent Networked Scheduling
The proposed parallel-inference-enhanced IDHO algorithm integrates well with distributed decision-making systems where time-critical batch planning must be performed at scale. Importantly, this enhancement does not compromise solution accuracy or convergence stability. The experimental evaluations in Section 4 show that the parallel-enhanced IDHO achieves significant reductions in wall-clock time while delivering optimal or near-optimal solutions, even under constrained computational budgets.
This architectural strategy reinforces the viability of deploying intelligent-optimization agents within real-time smart scheduling environments, such as edge-driven manufacturing or cloud-assisted industrial control, where responsiveness, scalability, and autonomy are essential.
3.8. Improved Discrete Hippopotamus Optimization Algorithm: Formulas and Pseudocode
In the context of intelligent networked scheduling systems, secure, fast, and adaptive optimization algorithms are crucial for managing real-time tasks without relying on sensor feedback. Based on the improved strategies discussed above, this study proposes the Improved Discrete Hippopotamus Optimization (IDHO) algorithm as a lightweight, autonomous inference mechanism tailored for complex batch scheduling in semi-automated manufacturing environments.
To enhance both computational efficiency and algorithmic convergence, we replace conventional for-loop operations in the original HO algorithm with array-level operations and incorporate control logic suitable for deployment in distributed, real-time settings. This section presents the mathematical formulations and high-level pseudocode for the IDHO framework.
The exploration phase for mature individuals is defined by:
where denotes the dominant individual (global best), is a random scalar in , and is a uniformly sampled number from . The exponential decay control factor used in dynamic role assignment is defined as
In the case of immature or female individuals, their position updates incorporate both historical elite memory and Lévy-distributed exploration:
Here, , , and are randomly sampled vectors, and is the mean vector of a randomly selected elite subset. This dual-path structure mimics distributed inference logic in multi-agent systems, enabling both local adaptation and global coordination.
Equations (25) and (26) are used to calculate the position of hippos facing predators. Here, is a random vector between 0 and 1, is a random vector following the Levy distribution; b is a random number between 2 and 4, c is a random number between 1 and 1.5, d is a random number between 2 and 3, and g is a random number between −1 and 1; and is a random vector between 0 and 1.
Equations (27) and (28) are used to calculate the random position update of hippos when they are escaping from predators. Here, plength represents the length of the scheduling number group, which is the total number of processes multiplied by the number of sub-batches; is a one-dimensional array of length plength; is a random vector between 0 and 1; is a normally distributed random number between 0 and 1; and and are random numbers between 0 and 1.
Algorithm 3 represents the main function of the IDHO algorithm, describing the overall algorithmic flow. The UPDATE-POSITION function serves as the position update function of the IDHO algorithm. The NORMALIZE-MATRIX function is the solution space control function designed in Section 3.4; this function strictly constrains the solutions within the interval through matrix normalization, thereby avoiding boundary violations.
| Algorithm 3 Improved Discrete Hippopotamus Optimization (IDHO) Algorithm. |
Require: Define an optimization problem, total iterations (T), population size (), number of processes ()
|
4. Experiments and Analysis
4.1. Test Instances
To validate the efficiency of the proposed IDHO algorithm, this study constructed a set of simulation experiment cases based on real-world production environment parameters. The following are the relevant parameter settings, including the number of ceramics in an order, the number of molds, processing times, and mold change times. All time units are in hours.
- Number of Ceramics in Orders: The number of ceramics in different orders is randomly generated within the range [2000, 6000]. Considering that overproduction is allowed as buffer stock in household ceramic production, if the generated number of ceramics is not divisible by 20 times the number of molds, this study will increase the number of ceramics (by 20 times the number of molds minus the remainder) to avoid wasting the productivity of the roller-forming machines.
- Number of Molds and Batching: In the roller-forming stage, the number of molds used for each ceramic is fixed. Depending on the mold size and conveyor belt speed, the number of molds typically falls into one of three categories: [60, 70, 80]. Based on the batching principles introduced in Section 2, the production batches are generally divided into two to five batches. 0
- Processing Time Settings: To simulate time fluctuations and uncertainties in real-world production environments, the processing times for each operation are randomly generated and rounded to integer values. The processing time for the roller-forming operation is randomly determined within [12, 20] hours; the drying operation’s processing time is randomly selected within [18, 30]; the Bisque-firing operation’s processing time is randomly generated within [9, 15]; the glazing operation’s processing time is randomly determined within [11, 20]; and the firing operation’s processing time is randomly generated within [18, 30].
- Parallel Machine Configuration: Based on actual fixed equipment data from a workshop, without considering equipment wear factors, the number of parallel machines configured for each operation is as follows: the roller-forming operation is equipped with 4 roller-forming machines; the drying operation is equipped with 10 drying machines; the Bisque-firing and firing operations are equipped with 4 kilns; and the glazing operation is equipped with 10 glazing machines.
Table 2.
Test set examples (Part 1: order and production parameters).
Table 3.
Test set examples (Part 2: processing times and parallel machines).
Based on the aforementioned data generation method, twelve sets of simulated order data were designed as experimental cases. The dimensions of these twelve experimental cases are as follows:
In this representation, for example, indicates a test case with 25 total orders and 5 distinct manufacturing processes (i.e., roller forming, drying, Bisque firing, glazing, and final firing), which remains fixed across all scenarios. These benchmark cases provide a comprehensive basis for evaluating algorithm performance across a range of scheduling scales and complexity levels.
4.2. CPLEX Model Solving
To validate the correctness of the mathematical logic of the proposed scheduling model, this study solved the model using the CPLEX Studio IDE 22.1.0 commercial solver developed by IBM Corporation, Armonk, NY, USA. The solver was executed on a workstation equipped with a 12th Gen Intel® Core™ i7-12700H processor (2.30 GHz) produced by Intel Corporation, Santa Clara, CA, USA, with 16 GB of RAM, running the Windows 11 operating system.
The test instance consisted of five ceramic production orders and a parallel machine configuration of for the five manufacturing stages. Due to the adoption of an interleaved batch-processing strategy, each order was split into two sub-batches, resulting in a total of ten sub-batches.
Due to the NP-hard nature of the batch-oriented hybrid flow-shop problem, the problem scale grows rapidly as the number of orders increases, resulting in exponential growth in computational complexity. Even for this relatively small-scale test case, CPLEX required 5 h and 23 min (equivalent to 19,380 s) to find an optimal solution.
This underscores the impracticality of deploying exact solvers like CPLEX in real-world ceramic production environments, which are typically labor-intensive and require timely scheduling solutions. In contrast, the proposed IDHO algorithm achieved near-optimal results with a drastic reduction in computational time (under 1 min), as shown in Table 4, thus offering a more feasible and efficient solution method for industrial applications.
Table 4.
Performance comparison between CPLEX and IDHO on benchmark datasets.
4.3. Parameter Settings for Metaheuristic Algorithms
To comprehensively evaluate the performance of the proposed IDHO algorithm, this study compares it with six representative metaheuristic algorithms, spanning classical, swarm-based, and recently proposed nature-inspired techniques. The selected algorithms are as follows:
- Particle Swarm Optimization (PSO) algorithm;
- Jaya Algorithm, proposed by Rao et al. [48];
- Grey Wolf Optimizer (GWO) algorithm, proposed by Mirjalili et al. [49];
- Dung Beetle Optimizer (DBO), proposed by Xue et al. [50];
- HO (Initialization), which enhances the standard HO algorithm with an initialization strategy;
- HO (Initialization + Mutation), which incorporates both initialization and mutation strategies.
The key parameter settings for each algorithm were as follows. Wherever applicable, default parameters recommended in the respective original publications were adopted to ensure fair and reliable comparisons:
- PSO: The inertia weight was set to 0.5, and the individual learning factor () and the global learning factor () were both set to 2, aligning with standard PSO design practices.
- Jaya, GWO, and HO: These algorithms are parameter-free in nature and do not require additional control parameters beyond the population size and iteration count.
- DBO: The population was partitioned into 20% producers, 30% followers, and 20% predators, while the remaining 30% were designated as scouts, consistent with the original algorithmic framework.
- IDHO: The iteration-level mutation probability was fixed at 0.5, and the population-level mutation probability was also set to 0.5. The key hyperparameters in the dynamic population size reduction strategy included
- –
- A deletion frequency parameter ;
- –
- A nonlinear decay adjustment coefficient ;
- –
- A scaling factor for deletion intensity .
Parameter Sensitivity and Robustness Analysis. Although the Improved Discrete Hippopotamus Optimization (IDHO) algorithm involves several key hyperparameters, empirical evidence from preliminary trials and the related literature indicates that the algorithm is robust to moderate variations in these parameters. Table 5 summarizes the role, recommended ranges, and practical guidelines for tuning. Within these ranges, the average deviation in makespan remained within 2%, demonstrating that IDHO can maintain stable performance without extensive parameter tuning.
Table 5.
Sensitivity analysis of IDHO hyperparameters and recommended settings.
Overall, IDHO demonstrates strong robustness with respect to its hyperparameters, and the suggested ranges provide practical guidance for parameter selection in different production scenarios.
To ensure fairness in benchmarking, all algorithms were configured with a uniform population size of 100 and a maximum of 200 iterations. The experiments were implemented in MATLAB R2023a (MathWorks Inc., Natick, MA, USA) and executed on a Windows 11 workstation equipped with a 12th Gen Intel® Core™ i7-12700H processor (base frequency 2.30 GHz) and 16 GB of RAM.
Each algorithm was run independently for 20 trials to account for stochastic behavior. The best solution obtained from each trial was recorded for statistical performance evaluation across all benchmark instances.
4.4. Experimental Results and Analysis
To analyze the results of the twelve experimental cases, each algorithm was independently executed 20 times per case. The results were visualized via boxplots to assess dispersion and central tendency, while statistical analyses, including Average Relative Percentage Deviation (ARPD), Student’s t-tests, Cohen’s d effect size calculations, and mean values, were conducted to assess solution quality and robustness. The boxplot matrix in Figure 7 illustrates the distribution of optimal solution times and algorithm runtimes across all test instances. From these results, several key conclusions can be drawn:

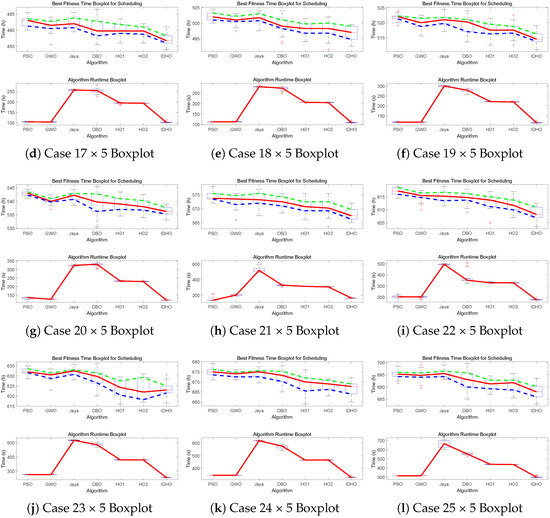
Figure 7.
Boxplots. The red solid line in each box is the median time. The green dashed line shows the maximum time range, and the blue dashed line shows the minimum time range. Red crosses mark outliers (data points far outside the normal range).
First, the standard HO algorithm with an initialization enhancement (HO1) demonstrates statistically significant advantages in average solution quality and stability over classical metaheuristic baselines such as PSO, GWO, and Jaya. However, it exhibits a relatively low probability of locating the true global optimum in smaller-scale instances, particularly when compared to the Dung Beetle Optimizer (DBO), suggesting a susceptibility to premature convergence.
This drawback is effectively mitigated by incorporating the inter-operation mutation strategy, as seen in HO2. While HO2 improves search diversity, its computational cost remains notably high due to the full-scale position updates and batch evaluations inherent in the HO framework.
In contrast, the proposed IDHO algorithm leverages both a nonlinear dynamic population size reduction mechanism and MATLAB-based parallelization to dramatically reduce runtime, achieving computational efficiency comparable to that of PSO and GWO. Specifically, the nonlinear reduction strategy adaptively eliminates low-fitness individuals during the search process, reallocating computational resources to high-potential regions of the solution space in later stages. This improves exploitation capability without compromising diversity.
Table 6 further quantifies these observations. IDHO consistently achieves the lowest ARPD and average runtime across all test cases. Notably, in 10 out of 12 instances, its superiority is statistically validated, with p < 0.05 and Cohen’s d values exceeding 0.8, indicating “large” effect sizes according to conventional statistical thresholds.
Table 6.
Comparative analysis of algorithm performance metrics for production scheduling cases.
Overall, the IDHO algorithm outperforms all benchmarked alternatives in terms of both optimization quality and runtime, confirming its practical applicability to real-world daily-use ceramic production scheduling problems.
4.5. Cybersecurity and Privacy in IoT-Enabled Disassembly Systems
Although the primary objective of this study focuses on optimizing ceramic production scheduling, the architectural foundations of the proposed IDHO algorithm, particularly its modularity and parallelization, are also applicable to IoT-enabled smart disassembly environments.
In such settings, real-time sensor data (e.g., product condition, ergonomic status, and equipment utilization) must be securely processed and translated into task sequences. The following outlines an extension roadmap to support cybersecurity and privacy-aware optimization in smart manufacturing:
- Privacy-Aware Task Sequencing: The fine-tuned scheduling model can be adapted to prioritize the disassembly of sensitive components, such as storage chips in IoT products, minimizing data exposure.
- Federated Learning for Worker Privacy: By embedding the learning agent into a federated framework, local models can be trained on sensitive worker or process data without centralizing it, enhancing compliance with data protection laws.
- Secure Communication Protocols: The IDHO framework is compatible with lightweight cryptographic protocols and attribute-based encryption for secure data exchange between edge nodes and central coordinators.
- Trust-Aware Reward Shaping: Reinforcement learning agents can include soft penalties for privacy-violating or ergonomically risky task allocations, allowing for safe and trust-compliant execution.
- Implementation Readiness: While these features were not deployed in our experiments, the modular structure of IDHO facilitates future integration of secure communication, federated optimization, and privacy-preserving scheduling via edge AI.
This vision highlights the adaptability of the IDHO framework beyond ceramic scheduling into broader Industry 4.0 and secure disassembly contexts, especially where privacy and trust are paramount.
5. Conclusions and Future Work
This study proposed a novel Mixed-Integer Linear Programming (MILP) model and an Improved Discrete Hippopotamus Optimization (IDHO) algorithm to address the batch-oriented Hybrid Flow-Shop Scheduling Problem in daily-use ceramic manufacturing. The MILP formulation captures key practical constraints such as batch grouping, mold switching, and shared-kiln no-idle operations, while the IDHO algorithm integrates segment-based encoding, nonlinear population reduction, and process-specific mutation strategies to enhance both convergence efficiency and solution quality.
Extensive simulation experiments demonstrate that the proposed IDHO-based scheduling framework achieves near-optimal results compared with the commercial solver CPLEX, reducing computational time by up to 98%, and significantly outperforms six representative metaheuristic algorithms (e.g., PSO, GWO, JAYA, DBO), with an average ARPD of 1.04%.
Importantly, the proposed scheduling framework can be directly deployed in real ceramic production environments, enabling practical improvements in production efficiency and energy utilization:
- Production planning: IDHO optimizes batch grouping and determines mold-switching sequences at the roller-pressing stage.
- Shared-kiln scheduling: IDHO dynamically manages Bisque firing and glaze firing under strict no-idle constraints, minimizing energy losses.
- Batch synchronization: IDHO coordinates the drying and glazing stages based on optimized batch priorities, reducing bottlenecks and improving throughput.
- MES integration: The optimized schedules can be seamlessly integrated into the Manufacturing Execution System (MES) for semi-automated, network-aware control.
Furthermore, this work contributes to the growing body of intelligent-optimization research in the field of green manufacturing, especially within complex and discrete environments. For instance, the proposed scheduling architecture aligns well with intelligent remanufacturing frameworks [51], predictive material control systems [52], and energy-aware disassembly optimization [53], which have been widely explored under the paradigm of intelligent and sustainable production. Additionally, the customized mutation and encoding strategies developed in this study echo recent advances in oversampling-based classification [54] and hybrid traffic control optimization [55], highlighting the broad applicability of modular heuristic design principles.
Despite the model’s promising performance, several challenges remain:
- The current model relies on static process data and lacks real-time IoT-based sensing integration, limiting its adaptability to dynamic shop-floor disturbances.
- The optimization focuses on a single objective (makespan minimization) and does not yet incorporate multi-objective trade-offs such as energy cost, operator workload, and delivery punctuality.
- Several hyperparameters still require manual tuning, which may affect generalizability across different production environments.
- While IDHO demonstrates strong performance in mid-scale instances (up to ), its scalability to ultra-large or multi-factory settings remains untested.
Future research will address these limitations by
- Integrating IoT-enabled real-time data and developing a digital twin platform for dynamic and adaptive rescheduling;
- Extending the framework to multi-objective optimization to jointly minimize makespan, energy cost, and production delays;
- Embedding reinforcement learning and self-adaptive parameter tuning to enhance robustness and reduce expert intervention;
- Incorporating cost–benefit analysis, infrastructure requirements, and human resource constraints into the scheduling framework to better support practical implementation;
- Integrating process quality indicators (e.g., defect rates, kiln stability) and product-level conformity metrics (e.g., dimensional accuracy, surface finish) into the scheduling framework to jointly optimize efficiency and quality outcomes;
- Generalizing the proposed framework to other discrete scheduling domains such as steel rolling, semiconductor manufacturing, and cloud computing;
- Exploring hybridization with surrogate-assisted learning models to further improve scalability and accelerate convergence.
In summary, this work provides a practical, scalable, and energy-aware scheduling framework for semi-automated ceramic production. Its integration with real-time data and intelligent control systems will pave the way for future smart manufacturing solutions.
Author Contributions
Data curation, C.Z.; writing—original draft preparation, Q.Z. and C.Z.; writing—review and editing, Q.Z., X.G., L.Q., H.Z. and B.H.; visualization, M.Y.; supervision, X.G. and S.Q. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Liaoning Province Education Department Scientific Research Foundation of China under Grant No. JYTQN2023366, and the Doctoral Startup Project of Liaoning Provincial Department of Science and Technology under Grant No. 2025-BS-0433.
Data Availability Statement
We hereby declare that the data applied and generated during the research process are fully reflected in the paper, and the data presented in the paper have been adequately presented and appropriately cited.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, J.Q.; Pan, Q.K.; Mao, K. A Hybrid Fruit Fly Optimization Algorithm for the Realistic Hybrid Flowshop Rescheduling Problem in Steelmaking Systems. IEEE Trans. Autom. Sci. Eng. 2016, 13, 932–949. [Google Scholar] [CrossRef]
- Pan, Q.K.; Wang, L.; Mao, K.; Zhao, J.H.; Zhang, M. An Effective Artificial Bee Colony Algorithm for a Real-World Hybrid Flowshop Problem in Steelmaking Process. IEEE Trans. Autom. Sci. Eng. 2013, 10, 307–322. [Google Scholar] [CrossRef]
- Tan, Y.Y.; Liu, S.X. Models and Optimisation Approaches for Scheduling Steelmaking-Refining-Continuous Casting Production Under Variable Electricity Price. Int. J. Prod. Res. 2014, 52, 1032–1049. [Google Scholar] [CrossRef]
- Tang, L.X.; Luo, J.X.; Liu, J.Y. Modelling and a Tabu Search Solution for the Slab Reallocation Problem in the Steel Industry. Int. J. Prod. Res. 2013, 51, 4405–4420. [Google Scholar] [CrossRef]
- Tang, L.X.; Zhao, Y.; Liu, J.Y. An Improved Differential Evolution Algorithm for Practical Dynamic Scheduling in Steelmaking-Continuous Casting Production. IEEE Trans. Evol. Comput. 2014, 18, 209–225. [Google Scholar] [CrossRef]
- Fu, M.Y.; Askin, R.; Fowler, J.; Haghnevis, M.; Keng, N.P.; Pettinato, J.S.; Zhang, M.H. Batch Production Scheduling for Semiconductor Back-End Operations. IEEE Trans. Semicond. Manuf. 2011, 24, 249–260. [Google Scholar] [CrossRef]
- Han, Z.D.; Zhang, B.; Sang, H.Y.; Lu, C.; Meng, L.L.; Zou, W.Q. Optimising Distributed Heterogeneous Flowshop Group Scheduling Arising from PCB Mounting: Integrating Construction and Improvement Heuristics. Int. J. Prod. Res. 2025, 63, 1753–1778. [Google Scholar] [CrossRef]
- Jia, W.Y.; Chen, H.; Liu, L.; Jiang, Z.B.; Li, Y. Full-Batch-Oriented Scheduling Algorithm on Batch Processing Workstation of β1→β2 Type with Re-Entrant Flow. Int. J. Comput. Integr. Manuf. 2017, 30, 1029–1042. [Google Scholar] [CrossRef]
- Liu, C.H. A Genetic Algorithm Based Approach for Scheduling of Jobs Containing Multiple Orders in a Three-Machine Flowshop. Int. J. Prod. Res. 2010, 48, 4379–4396. [Google Scholar] [CrossRef]
- Ding, J.Y.; Song, S.J.; Wu, C. Carbon-Efficient Scheduling of Flow Shops by Multi-Objective Optimization. Eur. J. Oper. Res. 2016, 248, 758–771. [Google Scholar] [CrossRef]
- Lei, D.M.; Gao, L.; Zheng, Y.L. A Novel Teaching-Learning-Based Optimization Algorithm for Energy-Efficient Scheduling in Hybrid Flow Shop. IEEE Trans. Eng. Manag. 2018, 65, 330–340. [Google Scholar] [CrossRef]
- Lei, D.M.; Zheng, Y.L.; Guo, X.P. A Shuffled Frog-Leaping Algorithm for Flexible Job Shop Scheduling with the Consideration of Energy Consumption. Int. J. Prod. Res. 2017, 55, 3126–3140. [Google Scholar] [CrossRef]
- Mansouri, S.A.; Aktas, E.; Besikci, U. Green Scheduling of a Two-Machine Flowshop: Trade-Off Between Makespan and Energy Consumption. Eur. J. Oper. Res. 2016, 248, 772–788. [Google Scholar] [CrossRef]
- Yin, L.J.; Li, X.Y.; Gao, L.; Lu, C.; Zhang, Z. A Novel Mathematical Model and Multi-Objective Method for the Low-Carbon Flexible Job Shop Scheduling Problem. Sustain. Comput.-Inform. Syst. 2017, 13, 15–30. [Google Scholar] [CrossRef]
- Zhang, B.; Pan, Q.K.; Gao, L.; Li, X.Y.; Meng, L.L.; Peng, K.K. A Multi-Objective Evolutionary Algorithm Based on Decomposition for Hybrid Flowshop Green Scheduling Problem. Comput. Ind. Eng. 2019, 136, 325–344. [Google Scholar] [CrossRef]
- Zhang, B.; Pan, Q.K.; Gao, L.; Zhang, X.L.; Sang, H.Y.; Li, J.Q. An Effective Modified Migrating Birds Optimization for Hybrid Flowshop Scheduling Problem with Lot Streaming. Appl. Soft Comput. 2017, 52, 14–27. [Google Scholar] [CrossRef]
- Wang, W.Y.; Xu, Z.H.; Gu, X.S. A Two-Stage Discrete Water Wave Optimization Algorithm for the Flowshop Lot-Streaming Scheduling Problem with Intermingling and Variable Lot Sizes. Knowl.-Based Syst. 2022, 238, 107874. [Google Scholar] [CrossRef]
- Zhang, B.; Pan, Q.K.; Meng, L.L.; Zhang, X.L.; Ren, Y.P.; Li, J.Q.; Jiang, X.C. A Collaborative Variable Neighborhood Descent Algorithm for the Hybrid Flowshop Scheduling Problem with Consistent Sublots. Appl. Soft Comput. 2021, 106, 107305. [Google Scholar] [CrossRef]
- Guo, X.W.; Guo, F.; Qi, L.; Wang, J.; Liu, S.X.; Qin, S.; Wang, W.T. Modeling and Optimization of Multiproduct Human–Robot Collaborative Hybrid Disassembly Line Balancing with Resource Sharing. IEEE Trans. Comput. Soc. Syst. 2025, 1–16. [Google Scholar] [CrossRef]
- Balogh, A.; Garraffa, M.; O’Sullivan, B.; Salassa, F. MILP-Based Local Search Procedures for Minimizing Total Tardiness in the No-Idle Permutation Flowshop Problem. Comput. Oper. Res. 2022, 146, 105862. [Google Scholar] [CrossRef]
- Cheng, C.Y.; Lin, S.W.; Pourhejazy, P.; Ying, K.C.; Lin, Y.Z. No-Idle Flowshop Scheduling for Energy-Efficient Production: An Improved Optimization Framework. Mathematics 2021, 9, 1335. [Google Scholar] [CrossRef]
- Mousighichi, K.; Avci, M.G. The Distributed No-Idle Permutation Flowshop Scheduling Problem with Due Windows. Comput. Appl. Math. 2024, 43, 162. [Google Scholar] [CrossRef]
- Nagano, M.S.; Rossi, F.L.; Martarelli, N.J. High-Performing Heuristics to Minimize Flowtime in No-Idle Permutation Flowshop. Eng. Optim. 2019, 51, 185–198. [Google Scholar] [CrossRef]
- Riahi, V.; Chiong, R.; Zhang, Y.L. A New Iterated Greedy Algorithm for No-Idle Permutation Flowshop Scheduling with the Total Tardiness Criterion. Comput. Oper. Res. 2020, 117, 104839. [Google Scholar] [CrossRef]
- Yine, K.C.; Lin, S.W.; Cheng, C.Y.; He, C.D. Iterated Reference Greedy Algorithm for Solving Distributed No-Idle Permutation Flowshop Scheduling Problems. Comput. Ind. Eng. 2017, 110, 413–423. [Google Scholar] [CrossRef]
- Tasgetiren, M.F.; Pan, Q.K.; Suganthan, P.N.; Buyukdagli, O. A Variable Iterated Greedy Algorithm with Differential Evolution for the No-Idle Permutation Flowshop Scheduling Problem. Comput. Oper. Res. 2013, 40, 1729–1743. [Google Scholar] [CrossRef]
- Pan, Q.K.; Ruiz, R. An Effective Iterated Greedy Algorithm for the Mixed No-Idle Permutation Flowshop Scheduling Problem. Omega-Int. J. Manag. Sci. 2014, 44, 41–50. [Google Scholar] [CrossRef]
- Rossi, F.L.; Nagano, M.S. Heuristics for the Mixed No-Idle Flowshop with Sequence-Dependent Setup Times and Total Flowtime Criterion. Expert Syst. Appl. 2019, 125, 40–54. [Google Scholar] [CrossRef]
- Bektas, T.; Hamzadayi, A.; Ruiz, R. Benders Decomposition for the Mixed No-Idle Permutation Flowshop Scheduling Problem. J. Sched. 2020, 23, 513–523. [Google Scholar] [CrossRef]
- Li, Y.Z.; Pan, Q.K.; Li, J.Q.; Gao, L.; Tasgetiren, M.F. An Adaptive Iterated Greedy Algorithm for Distributed Mixed No-Idle Permutation Flowshop Scheduling Problems. Swarm Evol. Comput. 2021, 63, 100874. [Google Scholar] [CrossRef]
- Agrebi, I.; Jemmali, M.; Alquhayz, H.; Ladhari, T. Metaheuristic Algorithms for the Two-Machine Flowshop Scheduling Problem with Release Dates and Blocking Constraint. J. Chin. Inst. Eng. 2021, 44, 573–582. [Google Scholar] [CrossRef]
- Guo, H.W.; Sang, H.Y.; Zhang, B.A.; Meng, L.L.; Liu, L.L. An Effective Metaheuristic with a Differential Flight Strategy for the Distributed Permutation Flowshop Scheduling Problem with Sequence-Dependent Setup Times. Knowl.-Based Syst. 2022, 242, 108328. [Google Scholar] [CrossRef]
- Guo, H.W.; Sang, H.Y.; Zhang, X.J.; Duan, P.; Li, J.Q.; Han, Y.Y. An Effective Fruit Fly Optimization Algorithm for the Distributed Permutation Flowshop Scheduling Problem with Total Flowtime. Eng. Appl. Artif. Intell. 2023, 123, 106347. [Google Scholar] [CrossRef]
- Lin, S.W.; Cheng, C.Y.; Pourhejazy, P.; Ying, K.C.; Lee, C.H. New Benchmark Algorithm for Hybrid Flowshop Scheduling with Identical Machines. Expert Syst. Appl. 2021, 183, 115422. [Google Scholar] [CrossRef]
- Wang, C.; Pan, Q.K.; Jing, X.L. An Effective Adaptive Iterated Greedy Algorithm for a Cascaded Flowshop Joint Scheduling Problem. Expert Syst. Appl. 2024, 238, 121856. [Google Scholar] [CrossRef]
- Yepes-Borrero, J.C.; Perea, F.; Villa, F.; Vallada, E. Flowshop with Additional Resources During Setups: Mathematical Models and a GRASP Algorithm. Comput. Oper. Res. 2023, 154, 106192. [Google Scholar] [CrossRef]
- Zhang, B.; Lu, C.; Meng, L.L.; Han, Y.Y.; Hu, J.; Jiang, X.C. Automatic Algorithm Design of Distributed Hybrid Flowshop Scheduling with Consistent Sublots. Complex Intell. Syst. 2024, 10, 2781–2809. [Google Scholar] [CrossRef]
- Zhang, G.H.; Liu, B.; Wang, L.; Yu, D.X.; Xing, K.Y. Distributed Co-Evolutionary Memetic Algorithm for Distributed Hybrid Differentiation Flowshop Scheduling Problem. IEEE Trans. Evol. Comput. 2022, 26, 1043–1057. [Google Scholar] [CrossRef]
- Zheng, J.G.; Wang, Y.L. A Hybrid Bat Algorithm for Solving the Three-Stage Distributed Assembly Permutation Flowshop Scheduling Problem. Appl. Sci. 2021, 11, 10102. [Google Scholar] [CrossRef]
- Rahman, M.A.; Sokkalingam, R.; Othman, M.; Biswas, K.; Abdullah, L.; Kadir, E.A. Nature-Inspired Metaheuristic Techniques for Combinatorial Optimization Problems: Overview and Recent Advances. Mathematics 2021, 9, 2633. [Google Scholar] [CrossRef]
- Wei, T.T.; Guo, X.W.; Zhou, M.; Wang, J.; Liu, S.X.; Qin, S.; Tang, Y. A Multiobjective Discrete Harmony Search Optimizer for Disassembly Line Balancing Problems Considering Human Factors. IEEE Trans. Hum.-Mach. Syst. 2025, 55, 124–133. [Google Scholar] [CrossRef]
- Guo, X.W.; Chen, L.; Qi, L.; Wang, J.; Qin, S.; Chatterjee, M.; Kang, Q. Multifactory Disassembly Process Optimization Considering Worker Posture. IEEE Trans. Comput. Soc. Syst. 2025; in press. 1–13. [Google Scholar] [CrossRef]
- Amiri, M.H.; Hashjin, N.M.; Montazeri, M.; Mirjalili, S.; Khodadadi, N. Hippopotamus Optimization Algorithm: A Novel Nature-Inspired Optimization Algorithm. Sci. Rep. 2024, 14, 54910. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.P.; Lin, J.H.; Li, P.W.; Wu, R.Y.; Chen, X.F.; Feng, Y.; Han, X.G. Research of Hippopotamus Optimization Algorithm Optimized Back Propagation Neural Network Algorithm for Distortion Correction in Structured Light Point Clouds. Opt. Eng. 2024, 63, 124103. [Google Scholar] [CrossRef]
- Han, T.; Wang, H.Y.; Li, T.T.; Liu, Q.Z.; Huang, Y.R. MHO: A Modified Hippopotamus Optimization Algorithm for Global Optimization and Engineering Design Problems. Biomimetics 2025, 10, 90. [Google Scholar] [CrossRef]
- Ahmed, R.; Rangaiah, G.P.; Mahadzir, S.; Mirjalili, S.; Hassan, M.H.; Kamel, S. Memory, Evolutionary Operator, and Local Search Based Improved Grey Wolf Optimizer with Linear Population Size Reduction Technique. Knowl.-Based Syst. 2023, 264, 110297. [Google Scholar] [CrossRef]
- Yang, X.Y.; Zeng, G.; Cao, Z.; Huang, X.F.; Zhao, J. Parameters Estimation of Complex Solar Photovoltaic Models Using Bi-Parameter Coordinated Updating L-SHADE with Parameter Decomposition Method. Case Stud. Therm. Eng. 2024, 61, 104917. [Google Scholar] [CrossRef]
- Rao, R.V. Jaya: A Simple and New Optimization Algorithm for Solving Constrained and Unconstrained Optimization Problems. Int. J. Ind. Eng. Comput. 2016, 7, 19–34. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Xue, J.K.; Shen, B. Dung Beetle Optimizer: A New Meta-Heuristic Algorithm for Global Optimization. J. Supercomput. 2023, 79, 7305–7336. [Google Scholar] [CrossRef]
- Gu, J.L.; Guo, Z.Y.; Wang, J.C.; Qi, L.; Qin, S.J.; Zhang, S.Y. Optimization of Multi-Factory Remanufacturing Processes with Shared Transportation Resources Using the ALNS Algorithm. Int. J. Artif. Intell. Green Manuf. 2025, 1, 1–13. Available online: https://hopeembark.org/index.php/IJGMAI/article/view/39 (accessed on 19 April 2025).
- Ji, Y.J.; Zhao, Z.Y.; Liu, S.X.; Yong, X.Y. Machine Learning-based Prediction of Surplus Material in Intelligent Production Processes. Int. J. Artif. Intell. Green Manuf. 2025, 1, 25–34. Available online: https://hopeembark.org/index.php/IJGMAI/article/view/35 (accessed on 19 April 2025).
- Qin, S.J.; Guo, F.; Wang, J.C.; Qi, L.; Wang, J.X.; Guo, X.W.; Zhao, Z.Y. Expanded Discrete Migratory Bird Optimizer for Circular Disassembly Line Balancing with Tool Deterioration and Replacement. Int. J. Artif. Intell. Green Manuf. 2025, 1, 14–24. Available online: https://hopeembark.org/index.php/IJGMAI/article/view/41 (accessed on 19 April 2025).
- Yan, S.; Guo, H.F.; Liu, S.X. A Partition Stacking Classification Framework With Oversampling for Quality Prediction of Aluminum Alloy Ingots. Int. J. Artif. Intell. Green Manuf. 2025, 1, 35–45. Available online: https://hopeembark.org/index.php/IJGMAI/article/view/40 (accessed on 19 April 2025).
- Qi, L.; Liang, L.; Luan, W.J.; Lu, T.; Guo, X.W.; Talukder, Q.T.A. Integrated Control Strategies for Freeway Bottlenecks with Vehicle Platooning. Int. J. Artif. Intell. Green Manuf. 2025, 1, 46–56. Available online: https://hopeembark.org/index.php/IJGMAI/article/view/36 (accessed on 19 April 2025).








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).