Abstract
Vision–language pre-training (VLP) faces challenges in aligning hierarchical textual semantics (words/phrases/sentences) with multi-scale visual features (objects/relations/global context). We propose a hierarchical VLP model (HieVLP) that addresses such challenges through semantic decomposition and progressive alignment. Textually, a semantic parser deconstructs captions into word-, phrase-, and sentence-level components, which are encoded via hierarchical BERT layers. Visually, a Swin Transformer extracts object- (local), relation- (mid-scale), and global-level features through shifted window hierarchies. During pre-training, a freezing strategy sequentially activates text layers (sentence→phrase→word), aligning each with the corresponding visual scales via contrastive and language modeling losses. The experimental evaluations demonstrate that HieVLP outperforms hierarchical baselines across various tasks, with the performance improvements ranging from approximately 3.2% to 11.2%. In the image captioning task, HieVLP exhibits an average CIDEr improvement of around 7.2% and a 2.1% improvement in the SPICE metric. For image–text retrieval, it achieves recall increases of 4.7–6.8%. In reasoning tasks, HieVLP boosts accuracy by 2.96–5.8%. These results validate that explicit multi-level alignment enables contextually coherent caption generation and precise cross-modal reasoning.
1. Introduction
In recent years, aligning the semantics between vision and language within a spectrum of image–text tasks has become more common, encompassing image–text retrieval [1,2], visual question answering [3,4], natural language for visual reasoning [5], visual entailment [6], and image captioning [7]. Notably, the research of semantic alignment technology has experienced significant success in vision–language pre-training (VLP). VLP entails pre-training models on large datasets of image–text pairs collected from the internet, which can then be fine-tuned for improved performance on various downstream tasks [8,9,10,11].
The prevalent VLP methodologies commonly adopt sequence modeling techniques rooted in the bidirectional encoder representations from transformers (BERT) framework [12]. Such methods generate multi-modal sequences that stem from image–text pairs. Conversely, visual contents are tokenized by utilizing objects identified by commercially available detectors [13] or by encoding patches that employ vision transformers (ViTs) [14]. Establishing cross-modal interaction and alignment hinges on the acquisition of associations between the textual tokens and their corresponding object or patch tokens. Essentially, VLP is tasked with comprehending intricate visual and textual tokens and ascertaining the alignment between the textual content and the visual semantics, as illustrated in Figure 1. Existing vision–language alignment methods have been categorized into the following two primary types: object–word alignment and global–sentence alignment. Object–word alignment involves the utilization of off-the-shelf object detectors (ODs) [15,16,17,18] to extract all the potential objects (bounding boxes in Figure 1) within an image. The objects are subsequently aligned with individual words in an accompanying sentence, such as “man”, “air”, and “skateboard”. Conversely, global–sentence alignment employs ViT-based methods [19,20,21] to extract patch tokens from an image, which are then aligned with an accompanying sentence, typically containing the main content conveyed by the overall image.
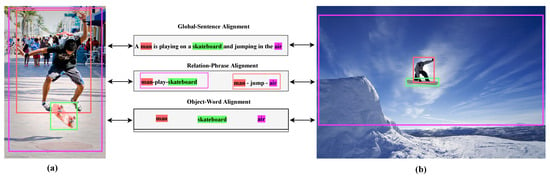
Figure 1.
Multi-level semantic alignment visualization: Object–word correspondences (purple), relation–phrase interactions (green), and global–sentence contexts (red). Subfigures (a,b) are detected under a standard textual description, with their individual targets exhibiting notable scale variations.
Two images are observed alongside their identically associated textual descriptions in Figure 1. Firstly, recognizing the inherent encapsulation of the aligned multi-level semantic information by image–text pairs is essential. The object–word alignment information contains individual elements such as “man”, “air”, and “skateboard”. The global–sentence alignment information conveys the primary content encapsulated by an overall image, while the relation–phrase alignment information reflects the associations including “man–play–skateboard” and “man–jump–air”. Effectively conducting multi-level semantic alignments across the “global–sentence”, “relation–phrase”, and “object–word” aspects between the images and the text is fundamental in generating precise and contextually rich image descriptions. The correspondence between such elements is visually indicated using the colored bounding boxes. Secondly, the differently colored bounding boxes in Figure 1a,b are detected under a standard textual description, signified by the terms “man”, “air”, and “skateboard”. Evidently, the individual targets in Figure 1a,b exhibit notable variations in scale. Essentially, while the textual elements are processed at a fixed scale, the visual components grapple with the intricate challenge of accommodating objects that manifest diverse scales within the framework of a multi-level perspective. The comprehension of textual descriptions alongside images necessitates multi-scale and multi-level perspectives.
- Multi-Level Perspective [16,18,22,23]: Comprehending textual descriptions alongside images necessitates a multi-level perspective. On the visual side, an image comprises sub-images or bounding boxes that inherently contain multi-level semantics, as the bounding boxes encompass one or more objects, implying the presence of visual relationships. On the textual side, words form fundamental linguistic units, with structurally interconnected words forming phrases and multiple phrases amalgamating to constitute a sentence. Therefore, semantic alignment at multiple levels, beyond the object–word and global–sentence alignments, is imperative. Existing methods overlook the alignment relations of phrases and objects (relation–phrase alignment), such as “man–play–skateboard” and “man–jump–air”. Conducting “global–sentence”, “relation–phrase”, and “object–word” multi-level semantic alignment between images and texts is essential for generating precise image descriptions.
- Multi-Scale Perspective [21,24,25,26]. Within the context of multi-level perception, emphasizing the choice of object-detector-based object–word alignment or vision-transformer-based global–sentence alignment is important because a noteworthy disparity arises when considering scale. Unlike word tokens that serve as the foundational units for processing in VLP, visual objects (as exemplified by the bounding boxes in Figure 1a,b) exhibit significant variability in scale. As a standard practice, existing VLP models tend to process textual elements (words, phrases, and sentences) at a fixed scale. Simultaneously, the visual components face the intricate challenge of accommodating objects that manifest diverse scales within the context of a multi-level perspective. Such incongruity in the processing scale between textual and visual aspects of the VLP framework underscores the need for innovative strategies to effectively address multi-scaling issues.
In this paper, we propose a hierarchical vision–language pre-training (HieVLP) model [27] that supports multi-scale processing on the visual side and incorporates a freezing strategy to achieve multi-level semantic alignment between images and their textual descriptions (image–text pairs). Specifically, we utilize a Swin Transformer [21] on the visual side as the backbone for hierarchical multi-scale (objects, relation, and global) image encoding. On the textual side, we employ a semantic parser to deconstruct semantic structures at three levels (words, phrases, and sentences) within a given caption by utilizing BERT [12] as the underlying framework for hierarchical encoding. Further, we customize the pre-training objective [28,29,30] to ensure the alignment of all textual levels with the corresponding image scale. Notably, we introduce a freezing strategy [31,32] to mitigate potential overfitting and model performance compromise during hierarchical pre-training.
Effectively harnessing multi-scale and multi-level information for vision–language semantic alignment is vital to enhance the performance of VLP and attain a more detailed and precise understanding of multi-modal information. We assess the performance of the HieVLP model across various downstream tasks, including visual question answering, natural language for visual reasoning, visual entailment, image–text retrieval, and image captioning. Our comprehensive experimental evaluations provide compelling evidence of the advancements provided by the proposed HieVLP model.
Our main contributions are summarized as follows:
(1) We propose a novel VLP model that leverages a hierarchical structure to achieve a multi-scale perception of image information and employs a freezing strategy to understand and align multi-level semantic content in images and text. Our approach enhances the alignment between images and textual descriptions during vision–language pre-training and customizes the pre-training objectives for each level of alignment.
(2) We introduce a freezing strategy during pre-training to enable the model to learn from multi-level inputs without interference and achieve meaningful multi-level semantic alignment. Our strategy ensures a controlled pre-training process for each layer of the text encoder, allowing for the gradual incorporation of semantics from different levels and preventing chaotic interactions and overfitting.
(3) We establish a unified evaluation protocol for hierarchical VLP, spanning five vision–language tasks with distinct granularities (word level to global level), and demonstrate that our freezing strategy achieves consistent improvements across all tasks.
2. Related Work
Vision and Language Pre-Training: Most VLP approaches utilize single- or dual-stream architectures [8,9,10] based on transformer models [33] to facilitate interaction and alignment between the image and text data. A single-stream architecture employs a transformer encoder to model image and text representations, which are then unified into a shared semantic space and aligned using the multi-head self-attention mechanism of the transformer [15,16,19]. Conversely, a dual-stream architecture encodes image and text features separately and then aligns them using decoupled encoders or decoders [17,34,35], thereby allowing for independent image and text data processing before aligning them within the VLP model. Research within this domain is categorized into three main groups based on the transformation mechanism of the visual inputs into sequences.
The first category involves OD-based region feature utilization that relies on off-the-shelf ODs such as faster region-based convolution neural networks (Fast-RCNNs) [13] to identify and encode objects within an image. Examples of single-stream VLP architectures that rely on ODs include OSCAR [16], UNITER [15], VinVL [18], Unicoder-VL [36], and VILLA [37]. Such models encode text and visual tokens at the input level, enabling comprehensive alignment at both the object and word levels. Notably, ViLBERT [17] and LXMERT [34] are examples of dual-stream VLP models that employ ODs, where image and text features are independently encoded by two distinct transformers, while multi-modal integration is achieved through a third transformer, thereby aligning and fusing both modalities effectively. Assuming the pre-training objectives include generative tasks, VLP models add a decoder after the encoder to convert multi-modal fusion features into corresponding outputs, as exemplified by UVLP [38] and VL-BART/T5 [39]. However, OD-based approaches offer some limitations because they do not provide a comprehensive global understanding of an image, can be time-consuming, and depend on OD performance.
Therefore, the second category is designed to explore the use of visual grid features obtained from convolutional neural networks (CNNs) including ResNets [40]. While grid features offer several benefits, deep CNNs still pose computational challenges and consume a significant portion of computational resources. SOHO [41] is an example of a method that first discretizes grid features using a learned vision dictionary and then feeds them into a cross-modal module.
The emergence of ViT [14] has introduced a third category in VLP, where the direct extraction of global features from images is focused. Images are segmented into patches and treated as individual visual tokens, representing a departure from the previous methods that are predominantly based on grid or ODs. Single-stream VLP architectures such as VILT [19] and ALBEF [20] use a ViT-based image encoder to address the limitations of heavy reliance on region supervision and convolutions for image feature extraction. Based on the ViT architecture, the Swin Transformer [21] has recently made notable advancements in addressing the issues associated with scale variations and high image pixel resolutions. Various VIT-based image encoder performances within the VLP model have been assessed using METER [10], and the METER-Swin [10] model based on the Swin Transformer is known to exhibit superior performance under similar conditions. Thus, our model is built on global features and draws inspiration from the Swin Transformer to explore multi-scale and multi-level semantic alignments in VLP.
Multi-Stage Semantic Alignment: In our proposed model, we aim to address the semantic gap challenges between image and text by introducing specific-scale and specific-level semantic alignments, which guide our model as a multi-stage approach, thereby leveraging the concept of multi-scale and multi-level features extracted from different stages to enhance VLP. Previous studies have highlighted the effectiveness of leveraging global and local features [42] for semantic alignment by employing techniques such as contrastive learning [43] or mutual information maximization [44] across diverse scales and levels. Indeed, examples including CLIP [45] and ALIGN [46] have achieved significant advancements by focusing on global image–text alignment. Self-supervised contrastive learning [8,28] is utilized to align images and text and optimize a global similarity measure between output embeddings. However, local image–text alignment is equally essential as it provides accurate and detailed supervision signals across various granularities, which ultimately lead to a significant improvement in performance. Methods like OSCAR [16], VinVL [18], MVPTR [22], X-VLM [24], and ViCHA [23] construct multi-level semantic concepts for local image–text alignment. OSCAR [16] introduces multi-level semantics by capturing object region features and the corresponding tags with a pre-trained OD. They are then concatenated with text for joint representations. VinVL [18] improves upon OSCAR by pre-training a more robust object-attributed detector. MVPTR [22] achieves multi-level semantic alignment through the explicit alignment of local and global features. Additionally, it models the nested structure of languages by learning phrase-level semantics. X-VLM [24] learns multi-level alignments by positioning vision concepts using given texts and establishing alignments between these components. ViCHA [23] introduces a hierarchical cross-modal alignment loss, effectively utilizing image-level annotations to enhance model performance, especially in scenarios with limited pre-training data.
However, the current methods often focus on local feature correspondence between the word and image regions, thereby missing the high-level phrase and relation semantic components and neglecting the multi-scale image characteristics. Our proposed model bridges these gaps by integrating a multi-scale framework with different-level alignments thus surpassing the local–global feature alignment dichotomy. The Swin Transformer is leveraged to capture multi-scale image information and explicitly handle global–sentence, object–word, and relation–phrase semantic alignments, thereby enriching the alignments and interactions across scales and levels for a holistic understanding of multi-modal content.
3. The Proposed Method
As shown in Figure 2, the entire architecture of the proposed HieVLP model includes an encoder–decoder framework that aims to facilitate a more nuanced and precise alignment between the images and textual descriptions during vision–language pre-training. The HieVLP model employs a hierarchical structure alongside a fixed strategy to bolster the alignment process. The proposed strategy facilitates a multi-level amalgamation of semantic information from both the visual and textual domains, thereby enhancing the pre-training performance. Augmentation equips the model with a capability to effectively traverse an array of downstream tasks.
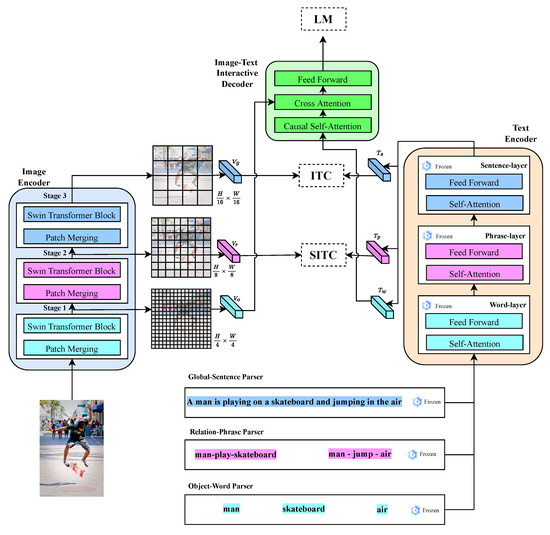
Figure 2.
Overall architecture of the proposed model. The HieVLP model employs a hierarchical structure alongside a fixed strategy to bolster the alignment process. The proposed strategy facilitates a multi-level amalgamation of semantic information from both visual and textual domains, thereby enhancing the pre-training performance.
3.1. Hierarchical Multi-Scale Image Feature Encoding
The proposed HieVLP model leverages the Swin Transformer Swin-B backbone [21] for hierarchical multi-scale image feature encoding, which is pre-trained on ImageNet-1K [47]. The Swin-B backbone is employed to encode an image into three different scales, yielding the following three distinct feature layers: global, relation, and object features, denoted as , , and , respectively. Each of these feature layers serve a unique purpose in capturing the different aspects of contents in an image. The features encapsulate holistic context and overall information in an image and provide a broad understanding of the entire scene, while capturing high-level visual cues and context. Contrarily, the features focus on encoding the relationships or interactions between the various elements or entities within an image. The features play a crucial role in capturing spatial arrangements, object interactions, and other contextual dependencies that exist between the different components within a scene. The features are designed to capture teh individual objects or entities present within an image by delving into the finer details of the image, isolating and encoding the characteristics of specific objects, enabling the model to discern different object attributes. The resulting feature representations, namely , , and , are crucial inputs that are subsequently utilized within the HieVLP framework to facilitate multi-scale processing on the visual side and provide effective vision–language alignment and comprehension. Further, the image feature hierarchical multi-scale processing pipeline of the HieVLP model involves the following steps:
(1) Patch Tokenization: The input image is partitioned into non-overlapping patches, which are treated as individual tokens. These patch tokens are then directed to the initial stage of the Swin Transformer architecture.
(2) Stage 1 Processing: At this stage, the patch tokens undergo both patch merging (PM) and Swin Transformer block (STB) operations. The resultant output features of Stage 1 maintain a token count of , where H and W signify the height and width of the image, respectively. Further, the features are served as input and processed in the subsequent stages.
(3) Stage 2 Processing: In Stage 2, the PM and STB operations are applied to the features. The output features from this stage maintain a token count of . The final output features , , and from the image encoder are subsequently fed into the image–text interactive decoder. Refer to Section 3.3 for a detailed exposition of the decoder functionality.
3.2. Hierarchical Multi-Level Text Feature Encoding
The proposed HieVLP model adopts the pre-trained BERT-based backbone [12,20] from Hugging Face [48] to encode the input text into three distinct layers of features including the sentence, phrase, and word features—, , and , respectively. The features capture the context of entire sentences within the text captions; the features capture the relationship or interaction phrases within the text captions; and the features capture the individual words within the text captions. As shown in Figure 2, the text feature hierarchical multi-level processing pipeline of the HieVLP model involves the following steps.
To illustrate, the example caption presented in Figure 1, “A man is playing on a skateboard and jumping in the air’’ is analyzed.
(1) Semantic Parser: When processing a given caption associated with an image–text pair, the textual semantics associated with the layered features of the image is correspondingly parsed by identifying three categories of semantic parser (https://github.com/vacancy/SceneGraphParser, accessed on 15 October 2024), including the global–sentence, relation–phrase, and object–word parsers. These parsing categories are aligned with specific aspects of the textual description and implemented based on a semantic parsing methodology adopted by Wu et al. [49]. The semantic parser effectively dissects the given caption by adhering to pre-defined rules in order to reveal its underlying hierarchical semantic structure. The object–word parser extracts single-word adjectives that serve as attributes for the object entities mentioned within the caption (for example, man, air, and skateboard). These adjectives contribute to object characterizations in the image. The relation–phrase parser focuses on extracting subject–predicate phrases from the caption by denoting the relationships or interactions between different object entities in the image (for example, man–play–skateboard and man–jump–air). The global–sentence parser is responsible for extracting the contextual information conveyed by the caption by encapsulating the complete meaning of the sentence. It facilitates a comprehensive understanding of the contents in an image–text pair and forms a basis for subsequent encoding and alignment processes in the proposed model.
(2) Semantic Encoding: The results produced by the parsers undergo tokenization, after which they are incorporated into the text encoder. The tokenized outcomes are sequentially fed into the following three layers: word, phrase, and sentence layers. Each of these layers incorporate the self-attention (SA) and feed-forward (FF) modules inherent to the transformer network, as proposed by Vaswani et al. [33]. Specifically, the word layer processes the tokenized outcomes and the SA module captures contextual relationships and dependencies among the individual tokens. Further, the FF module enables feature extraction and transformation. Thereafter, the tokenized results are propagated into the phrase layer from the word layer. The phrase layer encompasses slightly larger semantic units such as phrases. Similar to the word layer, the SA module of the phrase layer processes the input and captures contextual nuances among larger linguistic units. Subsequently, its FF module refines all representations. The final layer is the sentence layer that operates on the tokenized outcomes at the sentence level. The SA module of the sentence layer ensures the effective modeling of the overall context and inter-dependencies of a sentence. Its FF module rounds out the process and refines the sentence-level features.
The aforementioned configuration allows the proposed model to progressively capture intricate contextual information and hierarchical relationships among tokens at varying linguistic levels, thereby contributing to a comprehensive understanding of textual semantics by the model. However, concatenating the layers of a text encoder and processing the same textual content repeatedly is undesirable. Hence, to fully harness the value embedded within the diverse strata of textual semantics, the design of the text encoder is imbued with a strategic freezing strategy, as detailed in Section 3.4. By incorporating the freezing strategy, the text encoder can effectively manage the integration of different semantic content layers. The culmination of such a process results in the generation of textual semantic features, denoted as , , and , each representing different levels of textual semantics. The resulting , , and features generated by the text encoder serve as the textual counterparts to the layered features of images. These features encapsulate distinct aspects of the semantics in the captions at varying levels of granularity. Subsequently, the final output features , , and from the text encoder are fed to the image–text interactive decoder. Refer to Section 3.3 for a detailed exposition of the decoder functionality.
3.3. Image–Text Interactive Decoding
In the final stage, a dynamic interaction unfolds between the output features , , and generated by the text encoder and the image features , , and produced by the image encoder. The interaction is orchestrated within the framework of the image–text interactive decoder, which effectively amalgamates and aligns these multi-level features to foster a comprehensive understanding of the image–text relationship. Thus, the text features , , and serve as inputs to the image–text interactive decoder, which in turn seamlessly incorporates the visual features , , and by inserting an additional cross-attention (CA) module between the SA and FF modules within each transformer block of the text encoder. This strategic modification facilitates the integration of both textual and visual information at various stages of processing. Furthermore, the conventional SA module is replaced with a causal self-attention (CSA) module, a concept introduced by Li et al. [20], to enhance the capabilities of the image-text interactive decoder. The CSA modules enable the decoder to employ a predictive mechanism, wherein the decoder anticipates the upcoming tokens in the sequence.
3.4. Pre-Training Objectives and Frozen Strategy
The freezing strategy is designed to address the following two fundamental challenges in hierarchical alignment: (1) semantic confusion caused by the simultaneous learning of multi-level representations, and (2) overfitting risks from excessive parameter co-adaptation across the different semantic levels. Unlike conventional regularization methods that act on parameter magnitudes (e.g., weight decay) or activation patterns (e.g., dropout), our approach achieves structural regularization through phased parameter freezing, as evidenced in Section 4.5.
The implementation proceeds as follows: During global–sentence alignment (S-L), the phrase and word layers remain frozen to establish stable anchor points. When progressing to relation–phrase alignment (P-L), the now-fixed sentence layer provides consistent contextual constraints while the word layer remains inactive. Finally, object–word alignment (W-L) operates with fixed upper layers, allowing localized fine-tuning without distorting higher-level semantics. This creates an implicit curriculum where global semantics constrain local adjustments, contrasting with the layer-wise pre-training that isolates hierarchical information.
Sentence Layer Pre-Training: Pre-training is initiated by focusing on the sentence layer (S-L), utilizing the image–text contrastive (ITC) loss [20,45,50]. The global–sentence parser is active during this stage, while the relation–phrase and object–word parser remain frozen. Following this pre-training, the weights of the sentence layer are frozen, thereby ensuring consistency in subsequent stages. The ITC loss employs a mechanism akin to MoCo [51] in order to establish the global–sentence alignment between the global features () of the image and the sentence features () of the text for the image–text pair in the dataset D. The goal of ITC loss, formulated analogously to InfoNCE [52], is to achieve alignment between the global visual and sentence levels of captions. Practically, the normalized vision-to-language () and language-to-vision () similarity values are computed.
Here, is a learnable scaling parameter that sharpens the similarity distribution for robust alignment. It is initialized to 0.06 [20]. The function sim(·) conducts the dot product to measure the similarity scores.
For the image–text pair ITC loss, we used and to denote the ground-truth one-hot similarities. The corresponding one-hot label vectors of the ground-truth, with a positive pair denoted by 1 and a negative one by 0, are used as targets to calculate cross-entropy as follows:
Phrase Layer Pre-Training: After the frozen sentence layer, the phrase layer (P-L) is pre-trained using softened image–text contrastive (SITC) loss [49]. In this stage, the relation–phrase parser is active, while the global–sentence and object–word parsers remain frozen. After pre-training, the phrase and sentence layer weights are frozen to preserve the learned information. Practically, paired or unpaired images and text often exhibit varying degrees of local similarity. For instance, certain local (relation) regions in an image can correspond to specific words or phrases in other textual descriptions. Thus, label smoothing is introduced to soften the hard targets associated with the SITC loss to address the complexities of image–text similarities within larger batch sizes. The essence of the SITC loss lies in establishing a relationship between the relation features () of the image and the phrase features () of the text for the image–text pair within D. The SITC loss aims to create cohesion between the visual local (relation) level and the corresponding phrase levels of the caption. By incorporating label smoothing, the resulting vision-to-language () and language-to-vision () similarity scores are softened and normalized. The calculation of these scores follows a methodology similar to that adopted while considering the ITC loss (Equations (1) and (2)), with the integration of label smoothing techniques. The approach enhances the robustness and subtlety of the alignment process during the pre-training stage. To soften the hard targets in the SITC loss, we redefine the vision-to-language and language-to-vision similarity scores through the following convex combinations:
where denotes the smoothing hyper-parameter that is set to 0.3 in our experiments. For the image–text pair SITC loss, the corresponding softened targets and for the pair is formulated as follows:
where denotes the smoothing hyper-parameter that is set to 0.25 in our experiments. Following Equation (3) of , the SITC loss is calculated as follows:
Word Layer Pre-Training: In the final phase of the pre-training process, the word layer (W-L) is analyzed. The W-L layer undergoes pre-training using unidirectional language modeling (LM) loss [53,54]. During this stage, the object–word parser is activated, while the global–sentence and relation–phrase parsers remain inactive and frozen. Given that the parameters of the sentence and phrase layers are frozen, the primary objective is to pre-train only the weights (parameters) associated with the W-L layer using the LM loss. The LM loss initiates an engagement of the image–text interactive decoder, whose primary function is to generate the textual captions corresponding to a given image. Assuming that the length of the textual caption in the image–text pair is M, with the token in the generated text description denoted as y, the image–text interactive decoder iteratively attends to the previously generated tokens from the text encoder outputs of the word feature (via the CSA module). Furthermore, the image encoder outputs of the object feature (via the CA module) are addressed, and the prediction of the future text token probabilities is facilitated. To pre-train our model parameters , the approach outlined by Raffel et al. [53] and Lewis et al. [54] was adopted. Specifically, the negative log-likelihood of label caption y tokens is minimized for the given input text and the image features as follows:
By adopting the aforementioned approach, the effectiveness of the word layer in learning to generate coherent and contextually appropriate text tokens is enhanced, thereby improving the alignment between vision and language.
In summary, the freezing strategy ensures a controlled and meaningful pre-training process for each layer of the text encoder and allows for the incremental incorporation of semantics from different linguistic levels, preventing chaotic interactions and overfitting. The usage of specific loss functions (ITC, SITC, and LM) tailored to the objectives of each layer further refines the alignment capabilities of the model between vision and language. The proposed comprehensive approach equips the HieVLP model with the ability to effectively capture multi-layered semantics and align them coherently.
4. Experiments
To ascertain the efficacy of the proposed HieVLP model, a rigorous validation process encompassing both quantitative and qualitative analyses was performed. In our quantitative assessment, the results from a range of downstream understanding and generation tasks mentioned in Section 4.3 were analyzed. Furthermore, ablation experiments were conducted to dissect the contributions of different components or strategies used in the proposed model. Subsequently, visualization experiments to investigate the quantitative superiority of the model in multiple aspects were performed.
4.1. Pre-Training Datasets
For this study, previous research [15,19,20,55] was followed to construct the pre-training dataset. Our pre-training dataset included two web datasets: Conceptual Captions [56] and SBU Captions [57], along with manually curated COCO [1] and Visual Genome (VG) [58] datasets. The COCO dataset focused on providing image captioning for data. Contrarily, the VG dataset contained comprehensive information about each image, encompassing region descriptions, objects, attributes, relationships, region maps, and scene maps.
Notably, the Karpathy’s training split [59] from the COCO dataset, excluding all validation and test images that appeared in the downstream tasks, was used to ensure fairness and impartiality in the model training and the subsequent testing of its performance. Furthermore, any coincidental visual content overlap with the Flickr30K dataset [60] was eliminated through uniform resource locator (URL) comparisons because both the COCO and Flickr30K datasets were sourced from the Flickr website, which raised the possibility of shared content between them. Further, the VG dataset was rigorously maintained based on the same rules to ensure data fairness. Thus, the developed dataset was a large group of approximately 4 million pictures, all captioned to explain their content.
4.2. Implementation Details
The model was pre-trained for 30 epochs with three distinct phases corresponding to the freezing strategy. The first 10 epochs consisted of training sentence layers with a learning rate of 1 × (Sentence Alignment). The middle 10 epochs consisted of training phrase layers (lr = 8 × ) while keeping the sentence layer frozen (Phrase Alignment). The final 10 epochs consisted of training word layers (lr = 5 × ) with the upper layers fixed. Layer freezing was implemented through parameter group masking in AdamW optimizer, where the frozen parameters maintained zero gradient entries. Batch size remained consistent at 512 across phases to isolate freezing effects. The warm-up ratio was adjusted per phase (10%/5%/3%) to accommodate the decreasing parameter mobility. Notably, the image encoder’s Swin-B backbone remained fully trainable throughout all the phases to preserve visual feature adaptability, while text encoder layers were selectively frozen as per the strategy in Section 3.4. This configuration consumed 23.7 GB GPU memory on average, with phase transitions adding <1% overhead due to parameter masking.
4.3. Downstream Tasks and Evaluation Metrics
We conducted a comprehensive evaluation of both the HieVLP model and baseline models across widely studied vision–language downstream tasks, which included image–text retrieval, image captioning, visual question answering, and natural language for visual reasoning that serve as common benchmarks to assess the performance of the proposed model. An overview of each task and the proposed fine-tuning strategy are outlined as follows:
Image–Text Retrieval denotes the task of discerning an image or caption from a given set of candidates based on the description of its content, encompassing both the image-to-text retrieval (TR) and text-to-image retrieval (IR) approaches. We meticulously assess the efficacy of our model across downstream retrieval tasks, analyzing its performance in zero-shot and fine-tuning contexts. Karpathy’s split [59] for both the COCO [1] and Flickr30k [60] datasets was adopted. Karpathy’s split divided the data into training, validation, and test sets. For COCO, approximately 113.2 k/5 k/5 k images for the train/val/test splits, respectively, were available. Similarly, for the Flickr30k dataset, 29.8 k/1 k/1 k images for the train/val/test splits, respectively, were available. Meticulous fine-tuning procedures were followed to leverage the training samples from each dataset. Additionally, the evaluation for zero-shot retrieval in the Flickr30K dataset involved deploying a model fine-tuned on the COCO dataset.
The fine-tuning process applied to the COCO dataset jointly optimized the ITC and LM losses. During the fine-tuning process, TR and IR were reinterpreted as open-ended retrieval–answer generation tasks, initiated by the prompt “the image–text pair is”. Specifically, in the case of the aligned image–text pairs, ITC fostered the acquisition of a scoring function predicated on feature similarity by utilizing the image and text encoders of the model. Subsequently, the image–text interactive decoder generated an aligned response “the image–text pair is aligned” by employing the LM loss. Conversely, the contrastive negative examples outlined by Wu et al. [49] were utilized, wherein ITC loss was calculated by including negative image–text pairs. This approach spanned a spectrum of semantic levels including word-level, phrase-level, and sentence-level contrastive negative samples. By incorporating such diverse and contextualized negative samples, the ITC mechanism effectively enhanced the ability of the model to differentiate and align relevant image–text pairs, further contributing to the precision of the retrieval process.
During the inference phase, we adhered to the approach outlined by Li et al. [20], wherein the pairwise similarities for all combinations of the image–text pairs within the dataset were calculated. An initial subset of top K candidates was identified based on their pairwise ITC scores, utilizing the image and text encoders of the model. Subsequently, the image–text interactive decoder engaged in a re-ranking procedure predicated on their pairwise LM scores. This comprehensive strategy ensured an enhanced ranking of candidates, ultimately augmenting the precision of the retrieval process.
Model performance quantification was conducted using Recall@K (R@K) scores, which ascertained the proportion of correct matches among the top K outcomes predicted by the model. Common choices for K included 1, 5, and 10, offering a multi-faceted perspective on the model performance. Typically, R@K scores for various K values were presented collectively by comprehensively evaluating the effectiveness of the model across different retrieval scenarios.
Image Captioning (IC) refers to the generation of a descriptive sentence that encapsulates the contents of an image. Our rigorous evaluation of model effectiveness encompassed various downstream generation tasks including meticulous scrutiny of its performance within fine-tuning scenarios. The partitioning approach proposed by Karpathy [59] for both the COCO [1] and NoCaps [61] datasets was adopted. The fine-tuning process was conducted meticulously, employing training samples from each dataset.
The fine-tuning process was conducted on the COCO dataset using the LM loss. The procedure entailed translating visual information into natural language text. During fine-tuning, a subtle but effective modification was introduced, where the input captions were enhanced with the prompt “a picture of” at the outset [62]. The aforementioned simple augmentation contributed to marginally improved results.
The auto-regressive image–text interactive decoder assumed a pivotal role in image captioning inference, as it leveraged CA modules to integrate image features and CSA module to incorporate text features. The decoder began decoding with a start-of-sequence token ([CLS]), which continued until an end-of-sequence token ([SEP]) was appended to the generated outputs, signifying the completion of the caption generation process. The design ensured the coherence and meaningfulness of the generated captions, aligning them closely with the content of the corresponding images.
The evaluation of model performance in tasks such as image captioning relied on assessing both the quality of the generated captions and their similarity to human-authored captions. Several established language metrics were employed to quantify the degree of resemblance between generated and referenced captions. The following metrics served as vital benchmarks for evaluating the model effectiveness: BLEU@4 [63] (BLEU@4 is a metric that measures the overlap of n-grams between the generated and referenced captions); METEOR [64] (METEOR is another metric that computes the alignment of words and phrases between the generated and referenced captions); CIDEr [65] (CIDEr measures the consensus among multiple referenced captions for a given image, and it considers the precision of n-grams, long-term structure, and rewards diversity in the generated captions.); and SPICE [66] (SPICE is a metric that evaluates captions based on semantic propositions, assessing the generation of accurate, relevant, and specific content in the captions).
Visual question answering (VQA) required the model to answer questions based on an image. The efficacy of the model was meticulously assessed across downstream understanding tasks to analyze its performance in fine-tuning contexts. For our experiments in VQA, we relied on the VQAv2 dataset [4], which comprised a substantial collection of 1.1 million questions related to COCO images. Each question in this dataset was associated with multiple ground-truth answers. The dataset was thoughtfully divided into training, validation, and testing splits, featuring 83,000/41,000/81,000 images, respectively.
In the fine-tuning process for VQA, our model was trained using the LM loss on both the training and validation splits of the VQAv2 dataset. VQA was framed as an open-ended answer generation task [39], where the LM loss allowed the model to generate accurate answers to a wide array of questions about images by encoding both the image and the question into their respective image and text features. Subsequently, the model employed an auto-regressive decoding approach using the image–text interactive decoder to generate answers.
During the inference phase of VQA, the image–text interactive decoder was initialized with [CLS]. As the decoding process progressed, a sequence of tokens was generated, and the conclusion of caption generation was marked by appending [SEP] to the generated outputs.
To evaluate the model performance in VQA, accuracy was evaluated as the primary metric. The accuracy of the model-predicted answers was compared to that of the ground-truth answers on both the test-dev and test-std splits of the VQAv2 dataset. The test-dev subset served as an initial evaluation, providing insights into the model performance during development. Conversely, the test-std subset represented a more extensive evaluation, assessing the model capacity to generalize to a broader range of complex and diverse questions, thereby offering a robust measure of its VQA capabilities.
Natural language for visual reasoning (NLVR2) is a specialized task designed to assess the ability of a model to reason visual information through natural language comprehension. In this task, the proposed model was presented with a natural language statement describing a scene with objects arranged in a specific configuration. The model had to determine whether another image matched the description provided.
Our evaluation of the model performance encompassed a range of downstream understanding tasks, with particular focus on its effectiveness within fine-tuning scenarios. To conduct the experiments, we adhered to the official NLVR2 split methodology and dataset [67], which was thoughtfully divided into the training, development (dev), and public test (test-P) sets.
During fine-tuning, the reasoning capabilities of the proposed model was enhanced across multiple images by incorporating an additional image encoder. The two encoders within each layer were initialized with the same pre-trained weights, and the output vectors of both encoders were merged before being processed by the CA module. Our model was trained on both the training and dev splits of the NLVR2 dataset using the LM loss. NLVR2 was considered an open-ended answer generation task [39], and the LM loss enabled the image–text interactive decoder to generate “True” or “False” based on the corresponding image and text features.
In the inference phase, the image–text interactive decoder was initialized with [CLS]; as the decoding process unfolded, it generated a sequence of tokens. The conclusion of caption generation was marked by appending [SEP] to the generated outputs.
To evaluate the model performance on the NLVR2 task, accuracy was evaluated as the primary metric. Accuracy measured the ability of the model to accurately determine the compatibility of textual descriptions and visual scenes, providing valuable insights into its proficiency in nuanced cross-modal reasoning. The evaluation was conducted on both the dev and test-P subsets of the dataset. For initial model development and performance assessment, dev was used. The test-P set served as an independent evaluation set to test the generalization ability of the model on novel examples that were not encountered during training.
Visual Entailment (VE) is a task focused on determining whether the visual content of an image supports or implies a given textual statement. VE involves assessing the relationship between the visual and textual information to determine the alignment of the visual content with the information conveyed in the text. Essentially, the objective is to confirm whether the visual evidence in an image logically implies or aligns with the content of a provided text. Our thorough evaluation of the model performance encompassed various downstream understanding tasks, with a particular focus on its performance in fine-tuning contexts.
For our experiments, the official SNLI-VE dataset [6], constructed using data from the Stanford Natural Language Inference (SNLI) [68] and Flickr30K datasets, was adopted. This dataset was thoughtfully partitioned into training, validation, and testing splits, consisting of 29.8 K/1 K/1 K —training/validation/testing images—respectively. While fine-tuning for SNLI-VE, our model was trained using the LM loss on the training splits of the SNLI-VE dataset.
SNLI-VE was essentially a three-way classification problem [15] that categorized instances into entailment (where the hypothesis was true given the image), contradiction (where the hypothesis was false given the image), and neutral (instances where the hypothesis could not be determined from the image). To ensure accurate class-probability predictions, we incorporated an MLP classifier into the output of the image–text interactive decoder.
The evaluation of model performance on SNLI-VE primarily involved the accuracy metric, assessed on both the validation (val) and test subsets. During the inference phase of SNLI-VE, we reported the model performance on these splits, leveraging the accuracy metric to gauge its effectiveness in determining the relationship the between visual and textual information. The comprehensive evaluation provided valuable insights into the fine-grained visual reasoning capabilities of the model.
4.4. Comparison with State-of-the-Art Approaches
4.4.1. Evaluation on Image–Text Retrieval
Table 1 presents the comparative analysis results of the proposed methodology against state-of-the-art approaches to studying the task performance for TR and IR on the Flickr30k and COCO datasets. Experimentations were conducted using the fine-tuning configuration, resulting in a noteworthy performance enhancement observed in the HieVLP model. Notably, the pre-training data that comprised approximately 4 million pre-training images were equivalent in scale to that of ViLT, UNITER, and OSCAR. For the Flickr30k dataset, the performance of the TR@1 and TR@1 approaches closely approximated the current state-of-the-art ALBEF model. Conversely, on the COCO dataset, the HieVLP model significantly outperformed ALBEF, with TR@1 and IR@1 demonstrating improvements of 2.4% and 1.3%, respectively. Interestingly, the proposed model surpassed the VinVL approaches trained on larger datasets. Particularly, our model possessed superiority over the hierarchical-based ViCHA model [23] in terms of balanced performance across both datasets. Furthermore, the proposed model outperformed the Swin-Transformer-based METER-Swin model, with TR@1 and IR@1 exhibiting improvements of 1.6% and 3%, respectively, on the Flickr30k dataset. Additionally, TR@1 increased by 2.5%, while IR@1 improved by 4% on the COCO dataset. Therefore, when the proposed approach was compared to ViCHA and METER-Swin, our methodology was evidently superior among image-based and text-based hierarchical methods in the context of retrieval tasks.

Table 1.
Comparison with state-of-the-art methods on Flickr30k and COCO text retrieval and image retrieval tasks in the fine-tuning setting.
Table 2 presents the comparative analysis results for the proposed methodology and state-of-the-art approaches in the context of TR and IR tasks on the Flickr30k dataset conducted in the zero-shot configuration. The analytical results were achieved by using an equivalent scale to ViLT, UNITER, and ALBEF, for approximately 4 million pre-training images. In this configuration, the TR@1 and IR@1 performances of the HieVLP model on the Flickr30k dataset matched or slightly surpassed the current state-of-the-art ALBEF models. Notably, our model demonstrated superior performance compared to the hierarchical-based ViCHA model [23], with TR@1 exhibiting a 4.6% increase and IR@1 improving by 4.3%. Furthermore, our model outperformed the Swin-Transformer-based METER-Swin model, with TR@1 indicating a 5.3% increase and IR@1 improving by 5.2%.
Table 2.
Comparison with state-of-the-art methods on Flickr30k text retrieval and image retrieval tasks in the zero-shot setting.
4.4.2. Evaluation on VQA, NLVR2, and VE
Table 3 presents the comprehensive comparative analysis results of the proposed methodology and state-of-the-art approaches across the various tasks, including VQA, NLVR2, and VE. Our pre-training data were consistent with the size of the datasets used in widely adopted methods such as ViLT, UNITER, and OSCAR, consisting of approximately 4 million pre-trained images. The HieVLP model showcased remarkable performance across all the tasks. Notably, in comparison to ALBEF, the HieVLP model achieved the following signficant improvements: 1.96% enhancement on the VQA test-std, 2.39% boost on NLVR2 test-P, and 0.67% improvement on the SNLI-VE test. Interestingly, our model performance closely rivaled that of the VinVL model, which utilized a significantly larger dataset size. Typically, larger dataset sizes were expected to lead to superior performance. Notably, our model surpassed the hierarchical-based ViCHA model [23], demonstrating significant performance gains. Specifically, in the VQA test-std, our model exhibited a 2.95% improvement, while NLVR2 test-P showcased a remarkable increase of 5.81%. Additionally, the SNLI-VE test demonstrated a notable enhancement of 2.75%. Moreover, our model outperformed the Swin-Transformer-based METER-Swin model, with a slight but still notable 0.07% increase in VQA test-std, 0.42% boost in NLVR2 test-P, and 0.52% improvement in the SNLI-VE test. Thus, upon comparing our approach to ViCHA and METER-Swin, our methodology was evidently superior among image-based and text-based hierarchical methods in the context of understanding tasks.
Table 3.
Comparison with state-of-the-art methods on VQA, NLVR2, and VE tasks.
4.4.3. Evaluation on Image Captioning
Table 4 presents the comprehensive comparative analysis results of the proposed methodology and state-of-the-art approaches focusing on IC task performance, evaluated on both the COCO and NoCaps datasets. In image caption generation, the HieVLP model outperformed other established models such as OSCAR, UVLP, and METER when trained on the pre-training dataset of approximately 4 million images. Specifically, regarding Karpathy’s test split of the COCO captioning, the HieVLP model surpassed the METEOR and CIDEr metrics compared to the current state-of-the-art METER model. Furthermore, this superior performance extended to the NoCaps benchmark. Notably, in the case of CIDEr metric, our model outperformed the VinVL model, which employed a larger dataset of 5.6 million images. This substantial improvement in the CIDEr metric signified that the HieVLP model excelled at generating content with long-term structural coherence and offered more diverse textual descriptions. Table 4 highlights the effectiveness of the HieVLP model in the CIDEr metric of IC, showcasing its capability to generate contextually long-term and diverse captions, surpassing the performance of the leading models in the field.
Table 4.
Comparison with state-of-the-art methods for COCO (Karpathy’s test split) and NoCaps (validation split) on image captioning task. the effectiveness of HieVLP in the CIDEr metric of image captioning, showcasing its capability to generate contextually long-term and diverse captions, surpassing the performance of leading models in the field.
4.5. Ablation Study
A series of ablation experiments were conducted across various downstream understanding and generation tasks.
Components Analysis: In the image processing component of the HieVLP model, one critical ablation experiment removed the hierarchical structure, replacing the Swin Transformer-based (ST-B) [21] hierarchical encoder with standard ViT-based (ViT-B) [14] processing. For this purpose, a pre-trained ViT-B/16 model that underwent pre-training on ImageNet [47] was employed as the image encoder, extracting patch features.
During text encoding processing of the HieVLP model, the role of the freezing strategy and the significance of the individual layers (the word, phrase, or sentence layers) in the text encoder were explored. Various configurations were tested, including the removal of one or two layers from the text decoder while maintaining the freezing strategy intact, as well as removing one or two layers without employing the freezing process.
The results of the ablation experiments are presented in Table 5. Based on the results presented in rows 7 and 9 of Table 5, where the freezing strategy was omitted in both image and text components, the model’s downstream task performance was found to have significantly deteriorated. This outcome validated the argument presented in Section 3.4, thereby emphasizing the importance of strategic intervention to prevent chaos, overfitting, and the potential degradation of model performance. Furthermore, the absence of freezing strategy could lead to the loss of meaningful layered text parsing.
Table 5.
Ablation study on IC, VQA, and retrieval tasks to assess the significance of individual components and the efficacy of the hierarchical and freezing strategies within the HieVLP model. ViT-B: ViT-based image-encoding component. ST-B: a Swin Transformer-based [21] image-encoding component. S-L, P-L, and W-L denote the sentence, phrase, and word layers in the hierarchical text encoder, respectively.
Conversely, when the freezing strategy was incorporated, the results presented in rows 8 and 10 of Table 5, the Swin-Transformer-based image encoder proved to be better suited for processing layered information within the image compared to the global ViT-based image encoder. This improvement was reflected across downstream generation, comprehension, and retrieval tasks.
Regarding the text encoding component, when only one of the three layers was used (rows 1, 2, and 3) compared to the full HieVLP model (row 10), a decrease in performance was evident. However, each layer exhibited a distinct performance contribution. Furthermore, employing any two of the three layers (rows 4, 5, and 6) resulted in a performance decrease compared to the full HieVLP model (row 10). Nevertheless, the model outperformed using a single layer alone. Consequently, increasing the text encoder layers enhanced the ability of the model to capture detailed multi-modal information by aligning image and text at each layer. Thus, the model gained a more accurate understanding of the relationship between image and text, generating more detailed image descriptions.
In summary, the ablation experiments underscored the critical role played by the freezing strategy and the advantages of the layering approach within the HieVLP model. These findings highlighted the ability of the model in leveraging its hierarchical architecture and frozen design to achieve superior performance in various multi-modal tasks.
Freezing Strategy Effectiveness Analysis: To assess the effectiveness of the freezing strategy, we examine its regularization dynamics through three experimental approaches. First, the evolution of gradient norms reveals that the frozen stages reduce parameter oscillations, as shown in the left panel of Figure 3 (Freezing Strategy). During training, the gradient of the sentence layer (Sentence) becomes zero, while the phrase layer (Phrase) and word layer (Word) are activated sequentially, with the gradient decreasing progressively, indicating controllable parameter updates. In contrast, the right panel of Figure 3 (No Freezing) shows that gradients at all layers continue to oscillate, with the gradient of the sentence layer (dashed line) still fluctuating significantly in the later stages of training, suggesting parameter conflicts between the layers. Therefore, the freezing strategy reduces gradient conflicts by isolating parameters in stages.
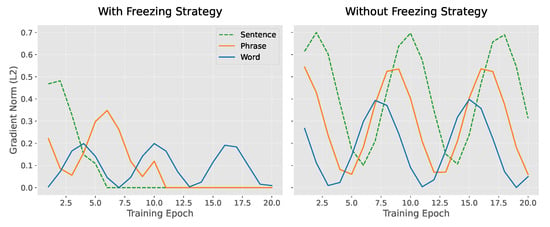
Figure 3.
Comparison of Gradient Norm Evolution with and without Freezing Strategy.
Second, as shown in Figure 4, the validation loss curves demonstrate that the freezing strategy helps to prevent overfitting. The validation loss (dashed line) for the freezing strategy (blue) consistently remains lower than that of the non-freezing strategy (orange), with a final gap of 0.15, representing a 20% relative reduction. This stable decrease in validation loss indicates that the freezing strategy effectively controls model complexity.
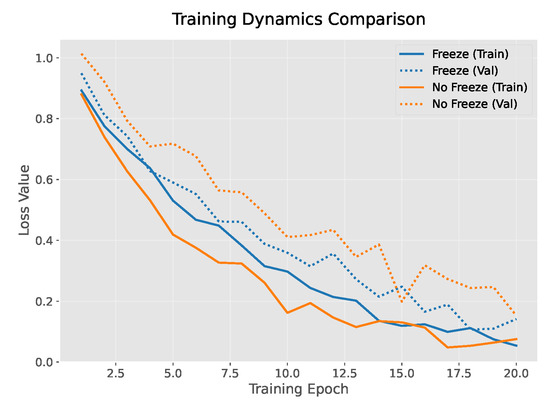
Figure 4.
Comparison of Validation Loss with and without Freezing Strategy.
Third, as illustrated in Figure 5, the ablation studies quantify the performance gap compared to alternative regularization methods. The freezing strategy outperforms dropout by 4.2 CIDEr points (blue bar) and weight decay by 2.8 VQA accuracy points (orange bar), while requiring 23% fewer training iterations to converge. In comparison, the NO Regularization (No Reg) method performs the worst, highlighting the necessity of regularization in the model. Overall, the freezing strategy demonstrates significant improvements in both generation and comprehension tasks relative to traditional regularization methods.
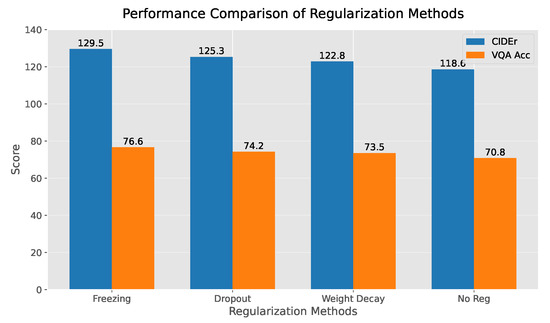
Figure 5.
Performance Comparison between Freezing Strategy and Other Regularization Methods.
Ablation Studies on Image Encoder Resolutions: To validate the design choice of hierarchical resolutions (H/4 × W/4, H/8 × W/8, H/16 × W/16), we conducted extensive ablation experiments, as presented in Table 6. This table showcases several key metrics, including CIDEr (COCO), VQA test - std, IR@1 (Flickr30K), parameter quantity (M), and GPU memory occupancy (GB), for different image resolution configurations. The following three settings were tested: “H/2 × W/2, H/4 × W/4, H/8 × W/8”, “H/4 × W/4, H/8 × W/8, H/16 × W/16”, and “H/8 × W/8 → H/16 × W/16 → H/32 × W/32”. The experimental results demonstrate the superiority of our selected multi-scale setup compared to alternative configurations.
Table 6.
Performance comparison of different image resolution configurations. Values in parentheses denote standard deviations over 5 runs.
The middle configuration (H/4 × W/4, H/8 × W/8, H/16 × W/16) achieves superior performance across all the semantic alignment metrics, as follows: 129.5 CIDEr on COCO captioning (+8.2 improvement over H/2 configuration), 76.5 VQA accuracy (+2.4), and 82.0 IR@1 on Flickr30K (+5.8), with marginally reduced parameters (215M vs. 220M) and moderate GPU memory consumption (16.2GB). This balanced configuration effectively preserves fine-grained visual semantics while avoiding redundancy, as evidenced by ±1.1 CIDEr variance, demonstrating stable learning across five independent trials.
Higher-resolution inputs (H/2 × W/2, H/4 × W/4, H/8 × W/8) exhibit performance degradation (121.3 CIDEr, 74.1 VQA) with 14.7% greater memory demand (18.6 GB), suggesting that over-resolution introduces redundant visual details that complicate cross-modal alignment. Conversely, the coarsest configuration (H/8 × W/8 → H/16 × W/16 → H/32 × W/32) suffers significant semantic loss (68.3 IR@1, −13.7 from optimal), confirming that excessive downsampling eliminates crucial visual relationships despite achieving the lowest resource requirements (210M parameters, 13.8 GB memory).
These quantitative results validate our multi-scale design philosophy—moderate intermediate resolutions optimally balance computational efficiency and semantic retention, enabling the hierarchical alignment of object–word, relation–phrase, and global–sentence features without information redundancy or loss. The standard deviations (0.3–1.1 across metrics) further confirm the robustness of the selected configuration in diverse training scenarios.
Impact of Text–Image Layer Mismatch. We tested flexible layer configurations to assess whether matching text and image layers (three vs. three) were strictly necessary. As shown in Table 7, the experimental results demonstrate that hierarchical alignment between the text and image layers is critical for maintaining cross-modal semantic coherence. When expanding the visual encoder to four layers while retaining three textual layers, performance degradation occurs regardless of the redundancy-handling strategies. The random discarding of redundant image layers reduces CIDEr by 2.7% (126.8 vs. 129.5) and VQA accuracy by 2.1% (74.4 vs. 76.5), while the average pooling of excess visual features only partially mitigates these losses (CIDEr: 127.1, −2.4%; VQA: 74.9, −1.6%). This performance gap highlights the structural incompatibility between unmatched hierarchies, where surplus visual features introduce noise rather than complementary information. By contrast, the strictly aligned (three vs. three) layer configuration achieves optimal parameter efficiency (215M vs. 230M in mismatched models) through isomorphic semantic mapping; global image features align with sentence-level text, mid-scale visual relations correspond to phrases, and object-centric details match word-level semantics. The findings validate that forced hierarchical symmetry outperforms post hoc fusion methods, emphasizing the necessity of architectural parity in multi-scale vision–language integration.
Table 7.
Impact of text–image layer mismatch. “Avg. pooling” denotes merging extra image layers via average pooling.
4.6. Visualization of Qualitative Analysis
Visualization of qualitative examples for the COCO dataset is shown in Figure 6. The first column indicates images from the COCO validation set. The second column shows the five human-annotated ground-truth captions. The third column indicates captions generated by our pre-trained HieVLP and baseline model and the corresponding CIDEr scores (CIDEr scores are in parentheses in the third column). The baseline model was the one with the highest CIDEr score for generating descriptions under the current image, selected from all the compared models in Section 4.4.3. We extracted the hierarchical information of our model-generated descriptions using the word, phrase, and sentence parsers. Instinctively, the following observation emerged from the presented sample images in Figure 6: There exists a discernible disparity in the number of target entities within the first and second rows as compared to the third and fourth rows. This discrepancy is pivotal in elucidating the relative ease or difficulty in articulating the relationships between these target entities. Consequently, both our model and the baseline model exhibit comparatively elevated CIDEr scores for the initial scores, reflective of the more straightforward nature of the task.

Figure 6.
Visualization of qualitative examples on the COCO dataset. The first column indicates images from the COCO validation set. The second column shows the five human-annotated ground-truth captions. The third column indicates captions generated by our pre-trained HieVLP and baseline models and the corresponding CIDEr scores (CIDEr scores are in parentheses in the third column). The baseline model is the one with the highest CIDEr score for generating descriptions under the current image, selected from all the compared models in Section 4.4.3. We extract the hierarchical information of the generated descriptions using the word parser, phrase parser, and sentence parser, respectively. Intuitively, our model descriptions compare the ground-truth and baseline models that contain more multi-layered information, higher CIDEr scores, more long-term structure, and more accurate and detailed descriptions.
Conversely, the third and fourth rows of the sample images manifest a greater profusion of target entities, rendering the task of delineating inter-entity relationships considerably more intricate. This complexity is underscored by the discernible decrement in CIDEr scores associated with the baseline model. Contrarily, our model demonstrates remarkable resilience, maintaining consistently high CIDEr scores even in the face of augmented target entity densities. This resilience is particularly salient in the final row of samples, where the number of target entities in our generated descriptions escalates to seven, resulting in the discernible emergence of a multi-layered hierarchical categorization involving six reliable tiers. Consequently, the CIDEr scores attributed to the final image description of our model attain an impressive value of 131.
In comparison with both the ground-truth descriptions and those generated by the baseline model, our descriptions unravel more direct hierarchical relationships among the target entities. Furthermore, our model generates lengthier sentences infused with a greater abundance of meticulously articulated details.
5. Conclusions
In this paper, we introduce a novel HieVLP model and a freezing strategy for learning the multi-level and multi-scale semantic alignment for image–text pairs. Specifically, our approach employs a semantic parser to deconstruct the semantic components of a given text at the following three levels: words, phrases, and sentences. We extract semantic features at each level through hierarchical text encoding. Concurrently, we hierarchically encode the corresponding images, extracting multi-scale semantic features in the object, relation, and global contexts. We customize the pre-training objective to ensure alignment between all the textual levels and the corresponding scale in the images. Additionally, we implement a freezing strategy to mitigate potential overfitting and model performance compromises during hierarchical pre-training. The proposed HieVLP model achieves state-of-the-art performance across the various vision–language understanding and generation tasks. HieVLP exhibits promising capabilities in generating contextually long-term dependencies and diverse captions, surpassing leading models in the field.
However, our work has limitations. First, challenges in hierarchical alignment for complex scenes. The model may struggle with phrase-level alignment in scenarios involving multi-object interactions (e.g., occlusions or reflective surfaces), primarily due to insufficient multi-scale feature fusion in the visual encoder (see Figure 6). Second, data-driven semantic bias. Generalization to long-tailed categories (e.g., rare objects like blue poison dart frogs) remains limited, as training data biases toward common concepts. Addressing this requires integrating external knowledge bases or few-shot learning strategies. Third, trade-offs in the freezing strategy. While the freezing strategy stabilizes hierarchical training, it may restrict fine-grained semantic adaptation in lower-level parameters. Future work will explore dynamic freezing mechanisms to balance stability and flexibility.
For the convenience of readers, all abbreviations used in this paper are summarized as shown in Abbreviations.
Author Contributions
Conceptualization, Y.Q. and H.X.; Methodology, Y.Q.; Software, Y.Q. and H.X.; Formal analysis, Y.Q.; Investigation, H.X.; Resources, Y.Q.; Data curation, Y.Q.; Writing—original draft, Y.Q.; Writing—review & editing, Y.Q., H.X. and S.D.; Visualization, Y.Q.; Supervision, S.D.; Project administration, S.D.; Funding acquisition, S.D. and H.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under Grant No. 62076077, the Science and Technology Major Project of Guangxi under Grant No. AA22068057, the School Foundation of Guilin University of Aerospace Technology under Grant No. XJ21KT32, and the Higher Education Undergraduate Teaching Reform Project of Guangxi under Grant No. 2023JGB408.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
| VLP | Vision–language Pre-training |
| BERT | Bidirectional Encoder Representations from Transformers |
| ViT | Vision Transformers |
| ODs | Object Detectors |
| Fast-RCNN | Faster Region-Based Convolution Neural Networks |
| OSCAR | Object Semantic-Aligned Pre-Training for Vision–Language Tasks |
| UNITER | Universal image–text representation learning |
| VinVL | Revisiting Visual Representations in Vision–Language Models |
| Unicoder-VL | A Universal Encoder for Vision and Language by Cross-Modal Pre-Training |
| VILLA | Vision-and-Language Learning via Association |
| ViLBERT | Pretraining Task-Agnostic Visiolinguistic Representations for |
| Vision-and-Language Tasks | |
| LXMERT | Learning Cross-Modality Encoder Representations from Transformers |
| UVLP | Unified Vision–Language Pre-Training for Image Captioning and VQA |
| VL-BART/T5 | Unifying Vision-and-Language Tasks via Text Generation |
| CNNs | Convolutional Neural Networks |
| ResNets | Residual Networks |
| SOHO | Self-Supervised Hierarchical Object-Oriented Representation Learning |
| CLIP | Learning Transferable Visual Models from Natural Language Supervision |
| ALIGN | Scaling Up Visual and Vision–Language Representation Learning |
| With Noisy Text Supervision | |
| HieVLP | Hierarchical Vision–Language Pre-training |
| Swin-B | Swin Transformer Base |
| ITC | Image–Text Contrastive |
| SITC | Softened Image–Text Contrastive |
| LM | Language Modeling |
| CSA | Causal Self-Attention |
| CA | Cross-Attention |
| SA | Self-Attention |
| FF | Feed-Forward |
| TR | Text Retrieval |
| IR | Image Retrieval |
| IC | Image Captioning |
| VQA | Visual Question Answering |
| NLVR2 | Natural Language for Visual Reasoning 2 |
| VE | Visual Entailment |
| SNLI-VE | Stanford Natural Language Inference - Visual Entailment |
| MLP | Multi-Layer Perceptron |
| BLEU@4 | BiLingual Evaluation Understudy at 4-gram |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering |
| CIDEr | Consensus-Based Image Description Evaluation |
| SPICE | Semantic Propositional Image Caption Evaluation |
| ViT-B | Vision Transformer-Based |
| ST-B | Swin Transformer-Based |
| S-L | Sentence Layer |
| P-L | Phrase Layer |
| W-L | Word Layer |
| PM | Patch Merging |
| STB | Swin Transformer Blocks |
| MoCo | Momentum Contrast |
| InfoNCE | Information Noise-Contrastive Estimation |
| VQAv2 | Visual Question Answering version 2 |
| VG | Visual Genome |
| COCO | Common Objects in Context |
| Flickr30K | Flickr30,000 Entities |
| AdamW | A variant of the Adam optimizer with weight decay |
| ViCHA | Efficient Vision–Language Pretraining with Visual Concepts |
| and Hierarchical Alignment | |
| METER | An Empirical Study of Training End-to-End Vision-and-Language Transformers |
| NoCaps | Novel Object Captioning at Scale |
| CLS | Classification Token |
| SEP | Separator Token |
References
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From Image Descriptions to Visual Denotations: New Similarity Metrics for Semantic Inference over Event Descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual Question Answering. In Proceedings of the 2015 IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar] [CrossRef]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the v in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6904–6913. [Google Scholar]
- Suhr, A.; Lewis, M.; Yeh, J.; Artzi, Y. A Corpus of Natural Language for Visual Reasoning. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 2, pp. 217–223. [Google Scholar] [CrossRef]
- Thomas, C.; Zhang, Y.; Chang, S.F. Fine-Grained Visual Entailment. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 398–416. [Google Scholar] [CrossRef]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6077–6086. [Google Scholar] [CrossRef]
- Agrawal, A.; Teney, D.; Nematzadeh, A. Vision-Language Pretraining: Current Trends and the Future. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), Dublin, Ireland, 22–27 May 2022; pp. 38–43. [Google Scholar] [CrossRef]
- Baltrusaitis, T.; Ahuja, C.; Morency, L.P. Multimodal Machine Learning: A Survey and Taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Dou, Z.Y.; Xu, Y.; Gan, Z.; Wang, J.; Wang, S.; Wang, L.; Zhu, C.; Zhang, P.; Yuan, L.; Peng, N.; et al. An Empirical Study of Training End-to-End Vision-and-Language Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18166–18176. [Google Scholar]
- Uppal, S.; Bhagat, S.; Hazarika, D.; Majumder, N.; Poria, S.; Zimmermann, R.; Zadeh, A. Multimodal Research in Vision and Language: A Review of Current and Emerging Trends. Inf. Fusion 2022, 77, 149–171. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Advances in the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Chen, Y.C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. UNITER: Universal image-text representation learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 104–120. [Google Scholar]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F. Oscar: Object-Semantics Aligned Pre-Training for Vision-Language Tasks. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 121–137. [Google Scholar]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 13–23. [Google Scholar]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. VinVL: Revisiting Visual Representations in Vision-Language Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 5579–5588. [Google Scholar]
- Kim, W.; Son, B.; Kim, I. VILT: Vision-and-Language Transformer without Convolution or Region Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5583–5594. [Google Scholar]
- Li, J.; Selvaraju, R.; Gotmare, A.; Joty, S.; Xiong, C.; Hoi, S.C.H. Align before Fuse: Vision and Language Representation Learning with Momentum Distillation. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 9694–9705. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- Li, Z.; Fan, Z.; Tou, H.; Chen, J.; Wei, Z.; Huang, X. MVPTR: Multi-Level Semantic Alignment for Vision-Language Pre-Training via Multi-Stage Learning. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022. [Google Scholar] [CrossRef]
- Shukor, M.; Ai, M. Efficient Vision-Language Pretraining with Visual Concepts and Hierarchical Alignment. In Proceedings of the 33rd British Machine Vision Conference (BMVC), London, UK, 21–24 November 2022. [Google Scholar]
- Zeng, Y.; Zhang, X.; Li, H. Multi-Grained Vision Language Pre-Training: Aligning Texts with Visual Concepts. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 25994–26009. [Google Scholar]
- Li, W.; Wang, Y.; Su, Y.; Li, X.; Liu, A.A.; Zhang, Y. Multi-Scale Fine-Grained Alignments for Image and Sentence Matching. IEEE Trans. Multimed. 2023, 25, 543–556. [Google Scholar] [CrossRef]
- Gao, Y.; Liu, J.; Xu, Z.; Zhang, J.; Li, K.; Ji, R.; Shen, C. PyramidCLIP: Hierarchical Feature Alignment for Vision-Language Model Pretraining. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 35959–35970. [Google Scholar]
- Qin, Y.; Xie, H.; Ding, S.; Tan, B.; Li, Y.; Zhao, B.; Ye, M. Bar Transformer: A Hierarchical Model for Learning Long-Term Structure and Generating Impressive Pop Music. Appl. Intell. 2023, 53, 10130–10148. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-Supervised Visual Feature Learning With Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Zhou, P.; Yan, S. Towards Understanding Why Mask Reconstruction Pretraining Helps in Downstream Tasks. In Proceedings of the International Conference on Learning Representations, Virtual, 25 April 2022. [Google Scholar]
- Yamaguchi, A.; Ozaki, H.; Morishita, T.; Morio, G.; Sogawa, Y. How Does the Task Complexity of Masked Pretraining Objectives Affect Downstream Performance? In Proceedings of the Findings of the Association for Computational Linguistics (ACL), Toronto, ON, Canada, 9–14 July 2023; pp. 10527–10537. [Google Scholar] [CrossRef]
- Li, J.; Li, D.; Savarese, S.; Hoi, S. BLIP-2: Bootstrapping Language-Image Pre-Training with Frozen Image Encoders and Large Language Models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 19730–19742. [Google Scholar]
- Tsimpoukelli, M.; Menick, J.L.; Cabi, S.; Eslami, S.M.A.; Vinyals, O.; Hill, F. Multimodal Few-Shot Learning with Frozen Language Models. In Proceedings of the Advances in Neural Information Processing, Online, 6–14 December 2021; Volume 34, pp. 200–212. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Tan, H.; Bansal, M. LXMERT: Learning Cross-Modality Encoder Representations from Transformers. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5100–5111. [Google Scholar]
- Yu, F.; Tang, J.; Yin, W.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. ERNIE-ViL: Knowledge Enhanced Vision-Language Representations through Scene Graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, pp. 3208–3216. [Google Scholar]
- Li, G.; Duan, N.; Fang, Y.; Gong, M.; Jiang, D. Unicoder-vl: A Universal Encoder for Vision and Language by Cross-Modal Pre-Training. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11336–11344. [Google Scholar]
- Gan, Z.; Chen, Y.C.; Li, L.; Zhu, C.; Cheng, Y.; Liu, J. Large-Scale Adversarial Training for Vision-and-Language Representation Learning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 6616–6628. [Google Scholar]
- Zhou, L.; Palangi, H.; Zhang, L.; Hu, H.; Corso, J.; Gao, J. Unified Vision-Language Pre-Training for Image Captioning and VQA. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13041–13049. [Google Scholar] [CrossRef]
- Cho, J.; Lei, J.; Tan, H.; Bansal, M. Unifying Vision-and-Language Tasks via Text Generation. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 1931–1942. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, Z.; Zeng, Z.; Huang, Y.; Liu, B.; Fu, D.; Fu, J. Seeing Out of the Box: End-to-End Pre-Training for Vision-Language Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12976–12985. [Google Scholar]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning Deep Representations by Mutual Information Estimation and Maximization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Pissas, T.; Ravasio, C.S.; Cruz, L.D.; Bergeles, C. Multi-Scale and Cross-Scale Contrastive Learning for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 413–429. [Google Scholar] [CrossRef]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning Representations by Maximizing Mutual Information Across Views. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning Transferable Visual Models from Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Jia, C.; Yang, Y.; Xia, Y.; Chen, Y.T.; Parekh, Z.; Pham, H.; Le, Q.; Sung, Y.H.; Li, Z.; Duerig, T. Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 4904–4916. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jegou, H. Training Data-Efficient Image Transformers & Distillation through Attention. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Wu, H.; Mao, J.; Zhang, Y.; Jiang, Y.; Li, L.; Sun, W.; Ma, W.Y. Unified Visual-Semantic Embeddings: Bridging Vision and Language with Structured Meaning Representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Tian, Y.; Sun, C.; Poole, B.; Krishnan, D.; Schmid, C.; Isola, P. What Makes for Good Views for Contrastive Learning? In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 6827–6839. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum Contrast for Unsupervised Visual Representation Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Liu, Y.; Ma, J.; Xie, Y.; Yang, X.; Tao, X.; Peng, L.; Gao, W. Contrastive predictive coding with transformer for video representationlearning. Neurocomputing 2022, 482, 154–162. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. BLIP: Bootstrapping Language-Image Pre-Training for Unified Vision-Language Understanding and Generation. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. [Google Scholar]
- Sharma, P.; Ding, N.; Goodman, S.; Soricut, R. Conceptual Captions: A Cleaned, Hypernymed, Image Alt-Text Dataset For Automatic Image Captioning. In Proceedings of the Association for Computational Linguistics, Melbourne, BC, Australia, 15–20 July 2018; pp. 2556–2565. [Google Scholar] [CrossRef]
- Ordonez, V.; Kulkarni, G.; Berg, T. Im2Text: Describing Images Using 1 Million Captioned Photographs. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; Volume 24. [Google Scholar]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.J.; Shamma, D.A.; et al. Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Karpathy, A.; Fei-Fei, L. Deep Visual-Semantic Alignments for Generating Image Descriptions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Plummer, B.A.; Wang, L.; Cervantes, C.M.; Caicedo, J.C.; Hockenmaier, J.; Lazebnik, S. Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models. In Proceedings of the 2015 IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2641–2649. [Google Scholar]
- Agrawal, H.; Desai, K.; Wang, Y.; Chen, X.; Jain, R.; Johnson, M.; Batra, D.; Parikh, D.; Lee, S.; Anderson, P. Nocaps: Novel Object Captioning at Scale. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Repiblic of Korea, 27 October–2 November 2019; pp. 8947–8956. [Google Scholar] [CrossRef]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-Based Image Description Evaluation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar] [CrossRef]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. SPICE: Semantic Propositional Image Caption Evaluation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 382–398. [Google Scholar] [CrossRef]
- Suhr, A.; Zhou, S.; Zhang, A.; Zhang, I.; Bai, H.; Artzi, Y. A Corpus for Reasoning about Natural Language Grounded in Photographs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6418–6428. [Google Scholar] [CrossRef]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A Large Annotated Corpus for Learning Natural Language Inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 632–642. [Google Scholar] [CrossRef]
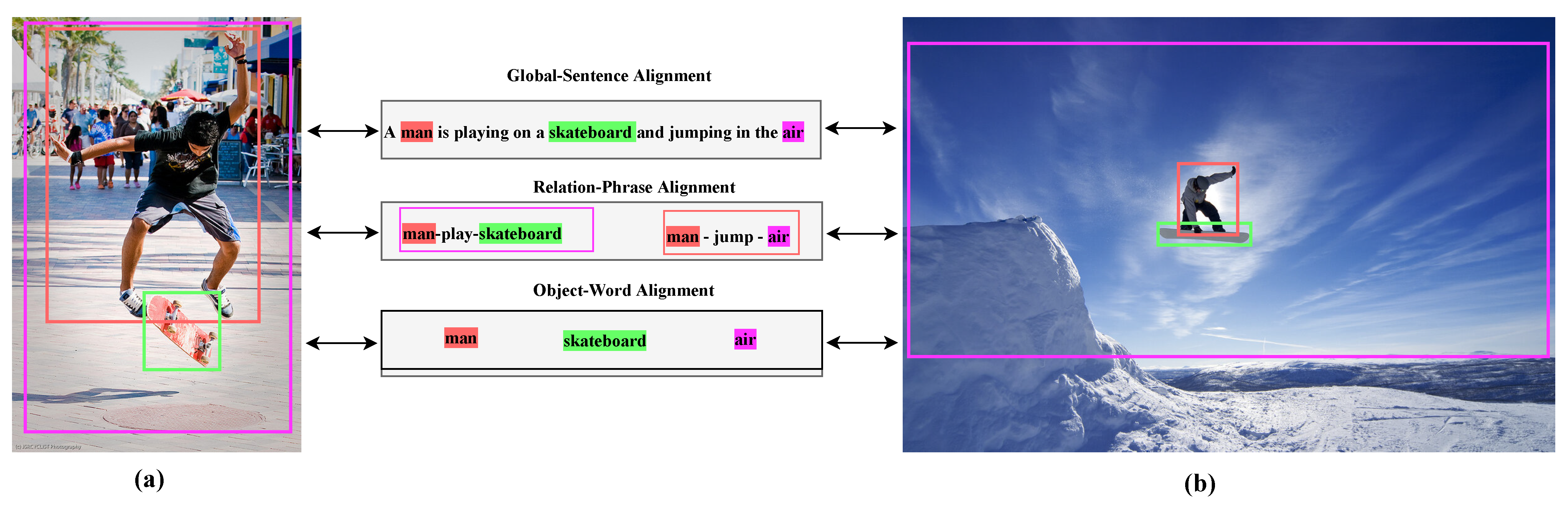
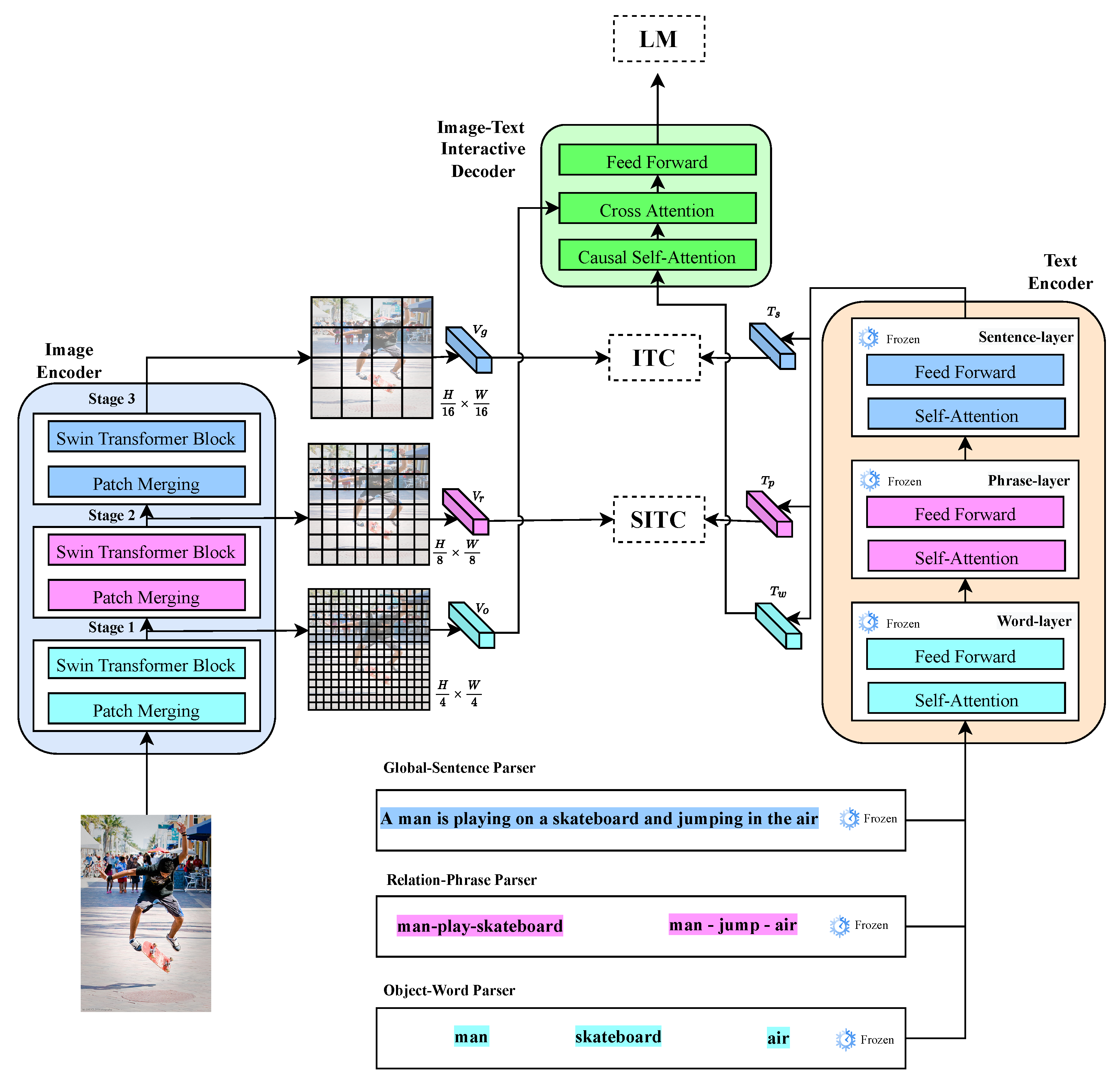
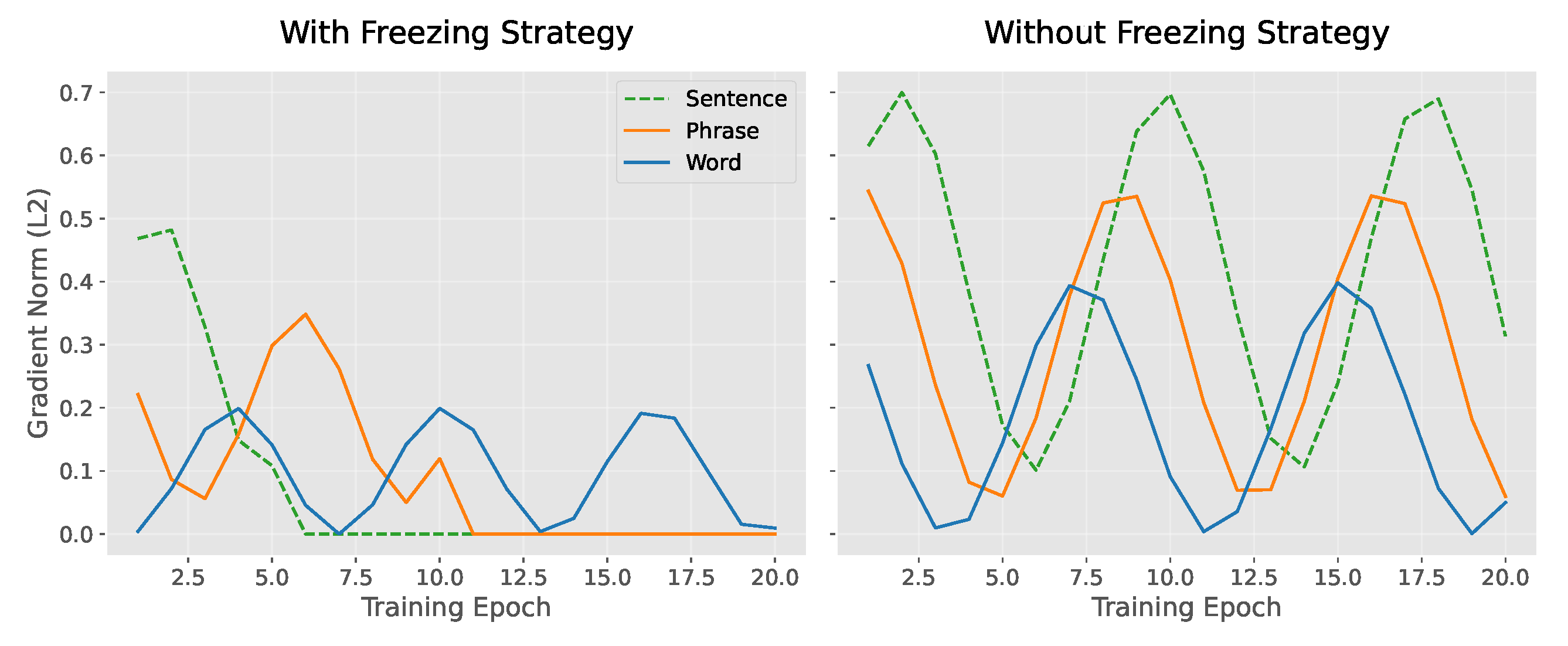
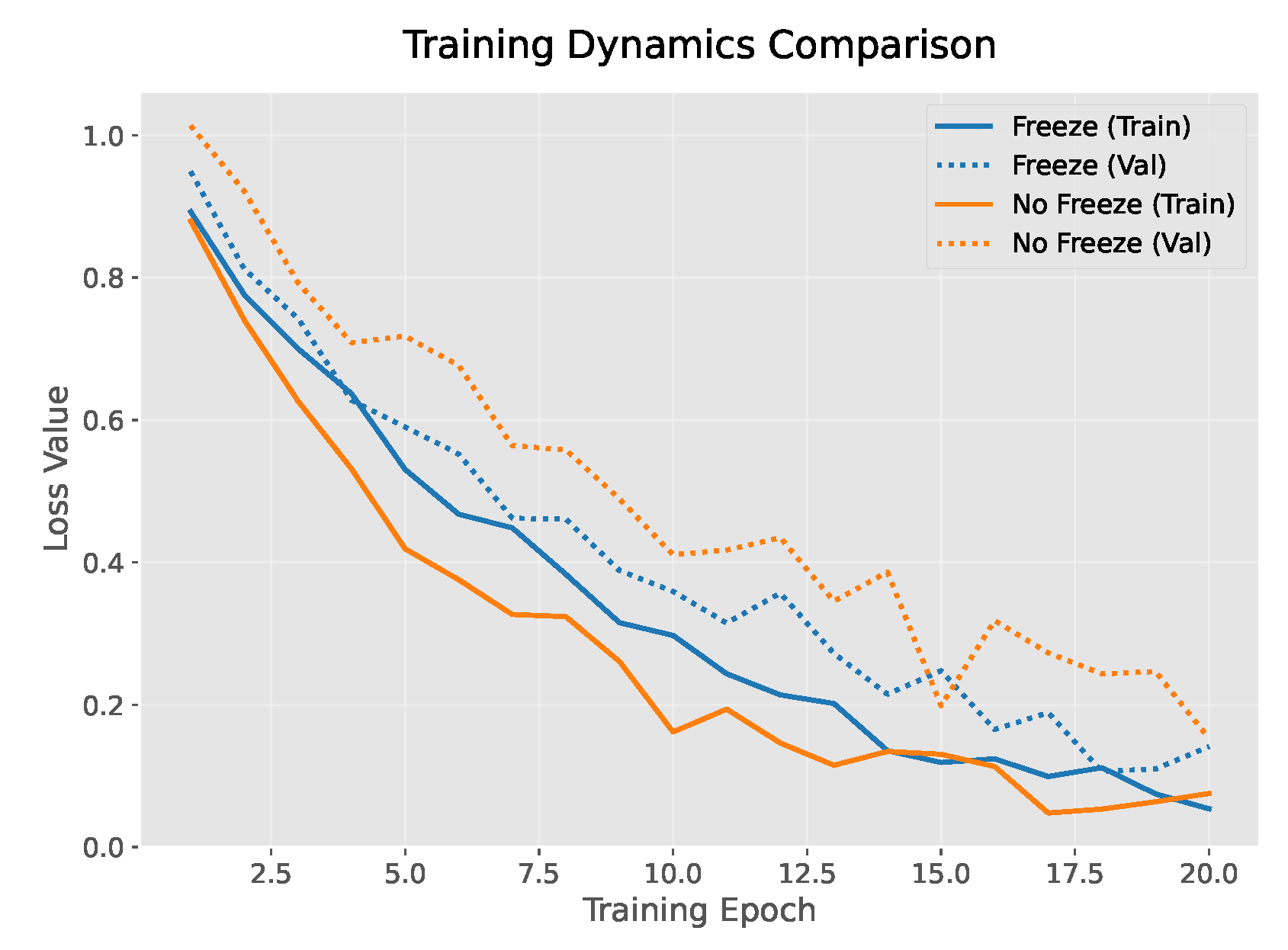
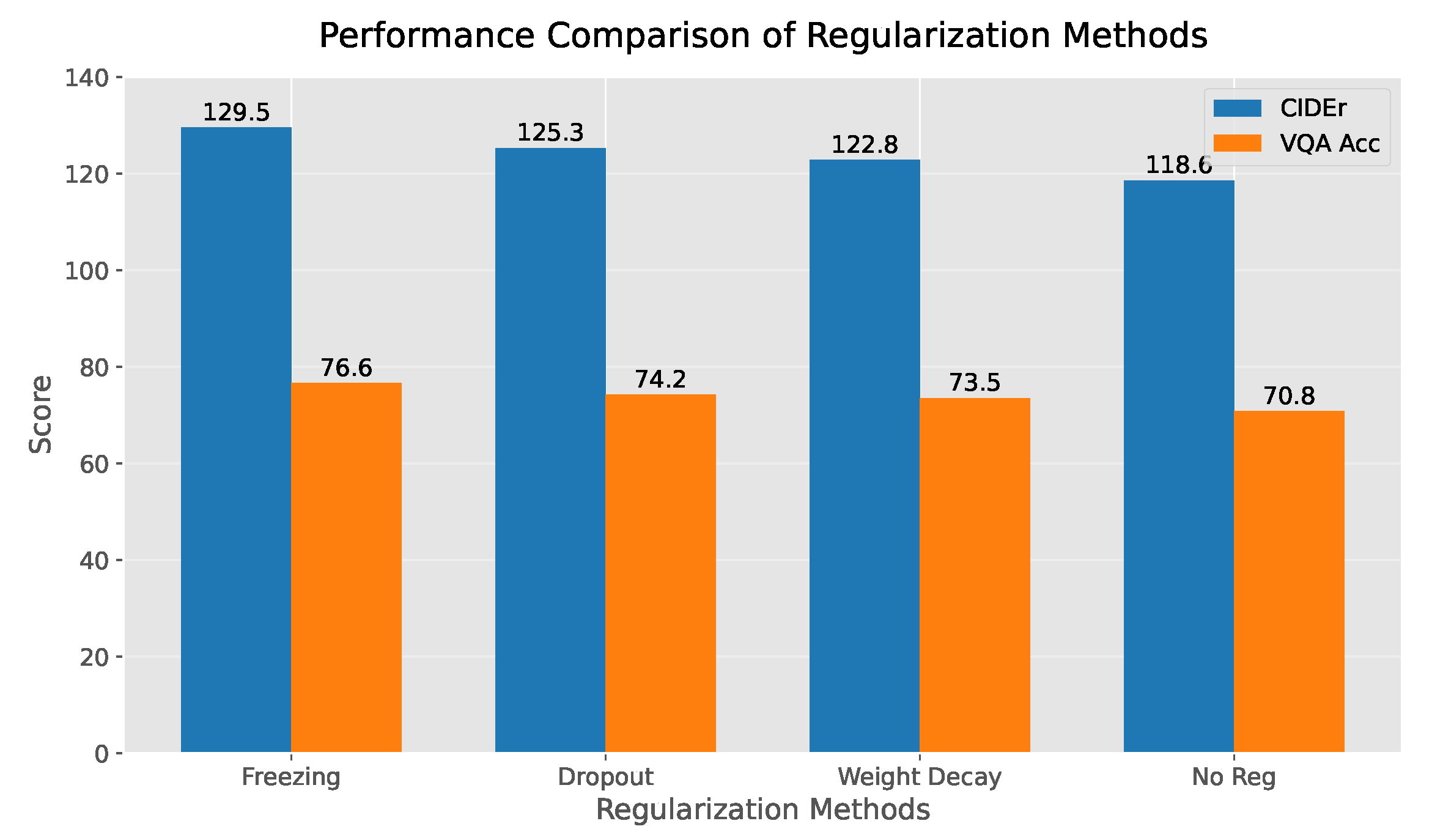
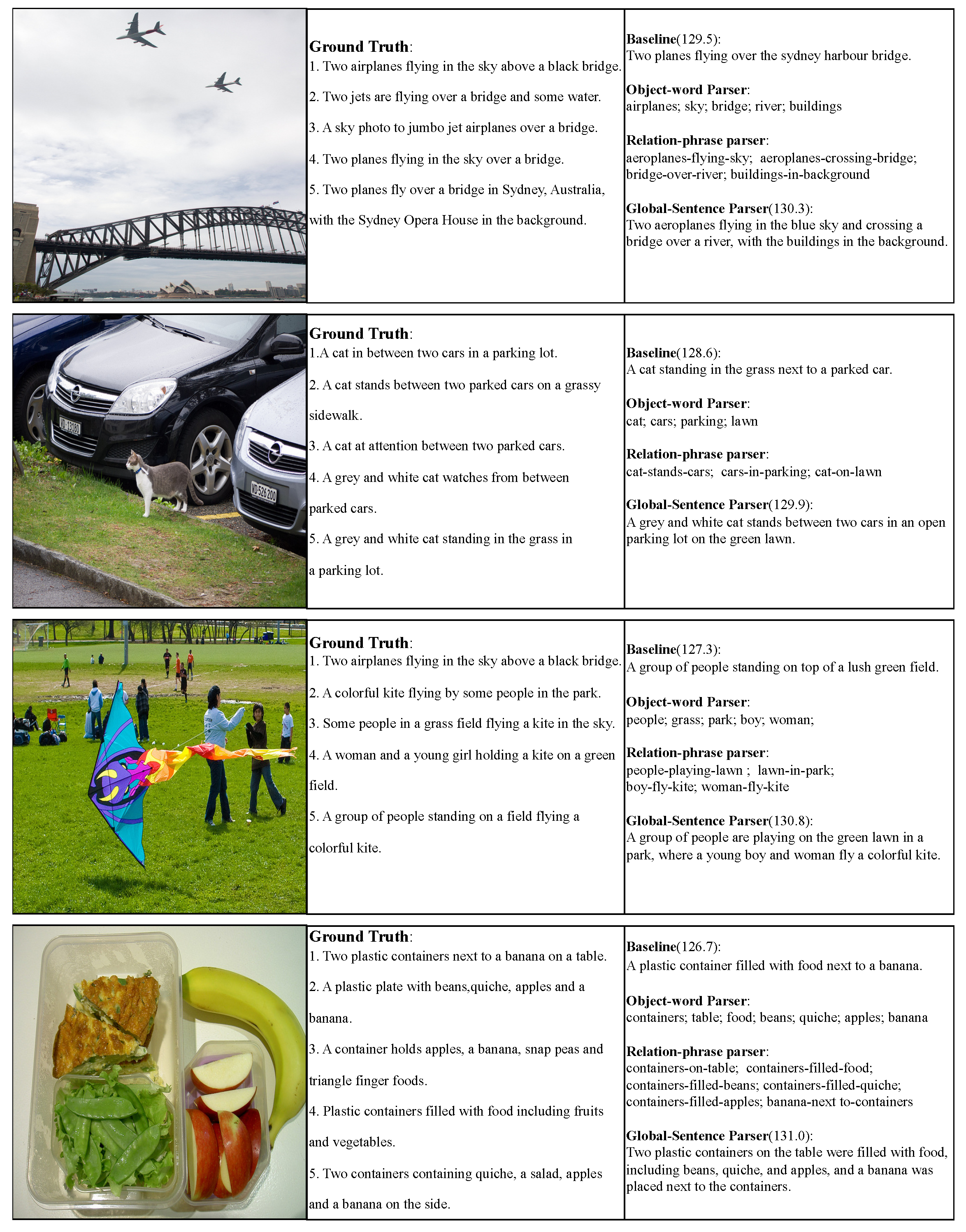
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).