Abstract
In the domain of natural language processing (NLP), a primary challenge pertains to the process of Chinese tokenization, which remains challenging due to the lack of explicit word boundaries in written Chinese. The existing tokenization methods often treat each Chinese character as an indivisible unit, neglecting the finer semantic features embedded in the characters, such as radicals. To tackle this issue, we propose a novel token representation method that integrates radical-based features into the process. The proposed method extends the vocabulary to include both radicals and original character tokens, enabling a more granular understanding of Chinese text. We also conduct experiments on seven datasets covering multiple Chinese natural language processing tasks. The results show that our method significantly improves model performance on downstream tasks. Specifically, the accuracy of BERT on the BQ Croups dataset was enhanced to 86.95%, showing an improvement of 1.65% over the baseline. Additionally, the BERT-wwm performance demonstrated a 1.28% enhancement, suggesting that the incorporation of fine-grained radical features offers a more efficacious solution for Chinese tokenization and paves the way for future research in Chinese text processing.
1. Introduction
The field of Chinese natural language processing has recently seen a surge in interest, largely due to the unique characteristics of the Chinese language. In contrast to alphabetic languages [1], Chinese is a logographic language [2], where each character typically encodes substantial semantic information. This distinction makes traditional subword-based tokenization methods [3,4], which break text into smaller units such as words or subwords, less effective for Chinese text processing. This underscores the necessity for the development of effective tokenization methods for Chinese, representing a critical challenge in natural language processing (NLP).
Subword tokenization is a prevalent approach in modern natural language processing (NLP), having found success in alphabetic languages such as English [5]. In alphabetic languages, words can often be broken down into smaller subword units [6], as in the case of “boys” being split into “boy” and “s”. However, this approach is not as effective for Chinese. The challenge in Chinese tokenization arises not from the lack of word boundaries but from the fact that Chinese characters, being logograms, carry rich semantic information that cannot be fully captured by a simple subword-based approach [7]. Each Chinese character may contain radicals, which are semantic building blocks that help to convey meaning at a finer granularity.
Figure 1 illustrates the process of extracting the radical component “鬼” from the Chinese characters “魑魅魍魉”. These four characters form a common Chinese idiom referring to ghosts, water spirits, or demons, often used to describe evil individuals or sinister forces. Despite their complex shapes, they share the same radical “鬼”, which carries a common semantic feature related to “ghosts” or “evil”. In Chinese character formation, radicals play a crucial role in guiding semantic categories. For instance, the “鬼” radical unifies the semantic scope of these four characters, all of which are associated with themes of the supernatural. It also provides a crucial clue in the process of meaning reasoning, aiding in the differentiation of words related to the theme of ghosts.

Figure 1.
Radical extraction example: extracting the “鬼” radical from the characters “魑魅魍魉”.
This distinction highlights a key limitation in the current Chinese NLP methods. Despite the success of subword tokenization in morphologically rich languages, it frequently fails to capture the nuanced structural and semantic characteristics inherent in Chinese characters, such as radicals and strokes [8,9]. For this reason, the traditional tokenization methods fail to fully capture the intricate relationships between characters in Chinese, often leaving semantic subtleties [7].
To tackle the above-mentioned issue, deep-learning-based models have been developed to enhance Chinese NLP tasks. These models, such as BERT [10], leverage large corpora to pre-train deep representations [11,12,13,14,15], which helps in understanding language. Despite their noteworthy performance across a variety of tasks, these models frequently underperform in terms of capturing the fine-grained structural information inherent in Chinese characters [16]. In general, Chinese characters consist of radicals and components, which contribute valuable semantic cues. However, the existing models typically overlook this information, particularly when dealing with complexities like polysemy, homophones, and domain-specific terminology. Relying solely on the contextual information at the character level may not fully uncover the intricate semantic relationships embedded in the text [17].
To address these challenges, we propose a novel method that integrates radical-based information into Chinese pre-trained language models. Unlike the existing methods that incorporate radical-based information, our approach introduces the following key innovations:
- Higher Efficiency, Lower Cost: Unlike many radical-based methods (e.g., SubChar Tokenization), our approach extends the vocabulary and adds a radical embedding layer without requiring re-training of the pre-trained model, maintaining efficiency.
- Independent Radical Representation: We use a separate radical embedding layer, combining it with character embeddings through a weighted fusion mechanism, ensuring that radical information remains independent and complementary.
- Flexible Radical Extraction: We propose a dynamic method for extracting radicals, with a strategy for handling characters that cannot be classified, making the approach widely applicable.
Our method aims to enhance the semantic representation of Chinese characters by introducing radical embeddings, which capture both structural and semantic nuances at the character level. Specifically, we improve performance in tasks such as text classification and named entity recognition by leveraging radical-aware tokenization. The contributions of this paper are as follows:
- We develop a radical-aware tokenization method that enhances character-level representations by integrating structural information from radicals.
- We enhance pre-trained Chinese models by integrating radical features into their vocabulary and architecture, improving semantic understanding without re-training.
- We conduct extensive experiments on different datasets of multiple NLP tasks to verify the effectiveness of our method.
The rest of this paper is structured as follows: Section 2 discusses the related work. Section 3 describes the proposed methodology. Section 4 outlines the experimental setup. Section 5 presents the results and analysis. Finally, Section 6 concludes this paper and presents some future research directions.
2. Related Work
In this section, we re-examine the fundamental domains associated with this study, encompassing the background of tokenization and text processing, as well as the implementation of fine-grained features in Chinese deep learning. The aim is to provide a theoretical foundation and technical support for the subsequent research.
2.1. Tokenization
Tokenization is a fundamental step in natural language processing (NLP) [18,19], aimed at breaking text into smaller units, such as characters, subwords, or other tokens [20]. In Chinese NLP, due to the lack of explicit word boundaries, tokenization is not only a word segmentation problem but also involves efficiently representing the structural information of each Chinese character and its components [21,22].
The traditional Chinese tokenization methods often rely on character-level tokenization, such as CharTokenizer [23], which treats each Chinese character as an independent token. While this approach is straightforward, it ignores the morphological information of Chinese characters (such as radicals and strokes), failing to capture the semantic structure embedded within the characters. In this context, subword tokenization methods [24,25], such as BERT’s WordPiece [3], have contributed significantly to addressing vocabulary coverage issues. WordPiece splits words into subword units, alleviating some out-of-vocabulary (OOV) problems [26] and handling morphologically complex language features. However, this method still has limitations, particularly in terms of capturing the fine-grained structural information of Chinese characters, such as radicals, strokes, and pinyin.
To address these limitations, recent research has proposed optimization methods using smaller linguistic units for tokenization, such as SubChar Tokenization [7]. This method decomposes Chinese characters into even finer units, such as strokes or phonetic units, to enhance the model’s ability to understand character-level information and improve fine-grained semantic representation. Such methods improve the model’s accuracy, particularly when dealing with challenges like polysemy and homophony in Chinese. However, SubChar Tokenization requires re-training the model to accommodate this new segmentation approach, which introduces additional computational overhead and training time.
Some studies have proposed incorporating radical information into the tokenization process, aiming to leverage the structural components of Chinese characters to enhance character representations. Zhuang et al. [17] pioneered the integration of sub-character features such as strokes and radicals into Chinese NLP models. They introduced a stroke-based embedding model that analyzes the internal components of Chinese characters for finer-grained information processing. Su et al. [16] introduced a multi-dimensional representation model to capture the morphological characteristics of Chinese characters. Meng et al. [27] designed the Glyce embedding model, which combines the glyph and radical information of Chinese characters to build richer character vector representations. However, these methods typically require re-training the models from scratch, which may increase training time and computational resource requirements.
In this paper, we propose a radical-aware tokenization optimization method that extends the previous work by incorporating radical embeddings into pre-trained language models (PLMs). Unlike Zhuang et al.’s approach, which involves re-training models from scratch with stroke-based representations and multi-dimensional fusion, our method integrates radical embeddings directly into PLMs through a lightweight vocabulary-expansion strategy. This enables us to enhance character-level representations without the need for full re-training, maintaining computational efficiency and adaptability for a range of downstream tasks. The method combines radical and character embeddings using a weighted fusion mechanism, which we believe contributes to a more detailed semantic understanding of Chinese characters while minimizing additional resource requirements.
2.2. Application of Fine-Grained Features in Chinese Deep Learning
Fine-grained features [28] are semantic information extracted from smaller linguistic units, such as characters, radicals, pinyin, and strokes [17]. These features help models to capture subtle differences in text, improving performance in Chinese natural language processing tasks [29]. Given that Chinese characters contain rich structural and phonetic information, incorporating fine-grained features is especially important for a deeper understanding of the language structure and meaning [30,31].
Radicals represent a significant component of Chinese character structure, playing a crucial role in both the writing and retrieval processes. These radicals offer an additional layer of information, facilitating enhanced semantic understanding. In the context of Chinese word segmentation tasks, the incorporation of radical information has been shown to enhance the model’s ability to parse word structures. This is particularly useful when dealing with characters that are morphologically similar but semantically different as radical features provide an effective means of distinction. For example, research has shown that leveraging sub-character information, such as radicals or strokes, can significantly enhance the representation of Chinese characters, improving tasks like neural machine translation [32]. In addition, radical information has also shown significant effects in tasks such as named entity recognition and sentiment analysis.
Similarly, pinyin, as the phonetic representation of Chinese characters, has unique advantages for handling homophones and polyphones. ChineseBERT [33] incorporates pinyin embeddings to address the issue of different pronunciations for the same character, leading to significant improvements in natural language inference and text classification tasks. The introduction of pinyin not only enhances the model’s understanding of pronunciation but also shows superiority in speech recognition and machine translation tasks. In contrast, our approach focuses on radical embeddings, which capture the structural and semantic relationships of characters. While methods like ChineseBERT rely on pinyin to disambiguate meanings, our method emphasizes radical-level information to enhance semantic understanding.
In addition to radicals and pinyin, the stroke order and shape of Chinese characters also contain rich semantic information. In recent years, researchers have proposed various methods to extract these features. For example, the SubChar Tokenization method [7] decomposes Chinese characters into smaller linguistic units (such as strokes or phonetic units), significantly enhancing the model’s understanding of the internal structure of characters. This method not only improves segmentation accuracy but also demonstrates excellent computational efficiency. Some studies have also employed image modeling to learn the visual features of Chinese characters [33], further enriching the model’s understanding of character morphology and enabling it to better handle tasks related to Chinese characters.
In recent years, the fusion of multiple fine-grained features has become a research hotspot. Some studies have explored how to integrate radical, pinyin, and stroke information into pre-trained models to improve overall performance [27,34,35]. For instance, ChineseBERT not only incorporates pinyin information but also integrates the visual features of characters (glyph embedding), achieving new state-of-the-art performance in several downstream tasks. This fusion method captures the diversity and complexity of language at different levels, significantly enhancing the model’s ability to understand complex language phenomena.
In summary, the application of fine-grained features in Chinese NLP has made significant progress. By effectively utilizing information such as radicals, pinyin, and strokes, models can gain a deeper understanding of the structure and meaning of Chinese characters, leading to improved performance in various tasks. Future research can further explore combinations of fine-grained features and investigate how to efficiently integrate these features into large-scale pre-trained models, further advancing Chinese NLP technology.
3. Methodology
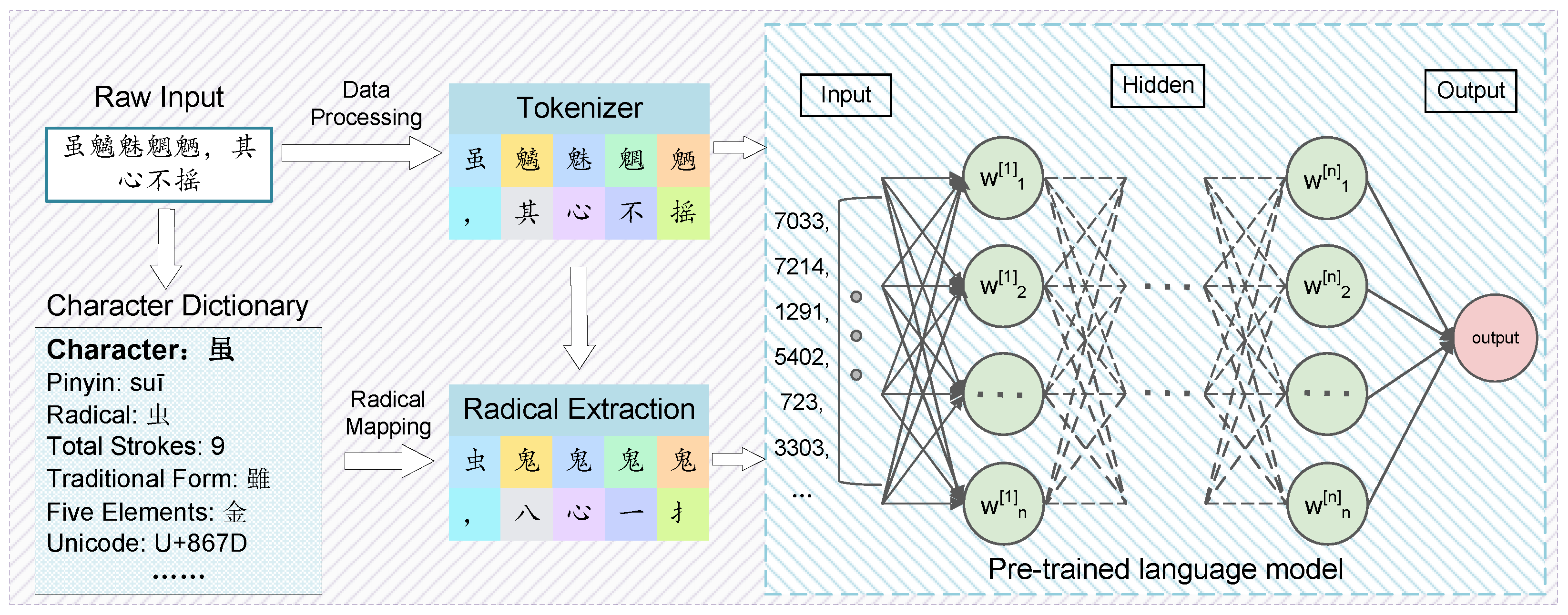
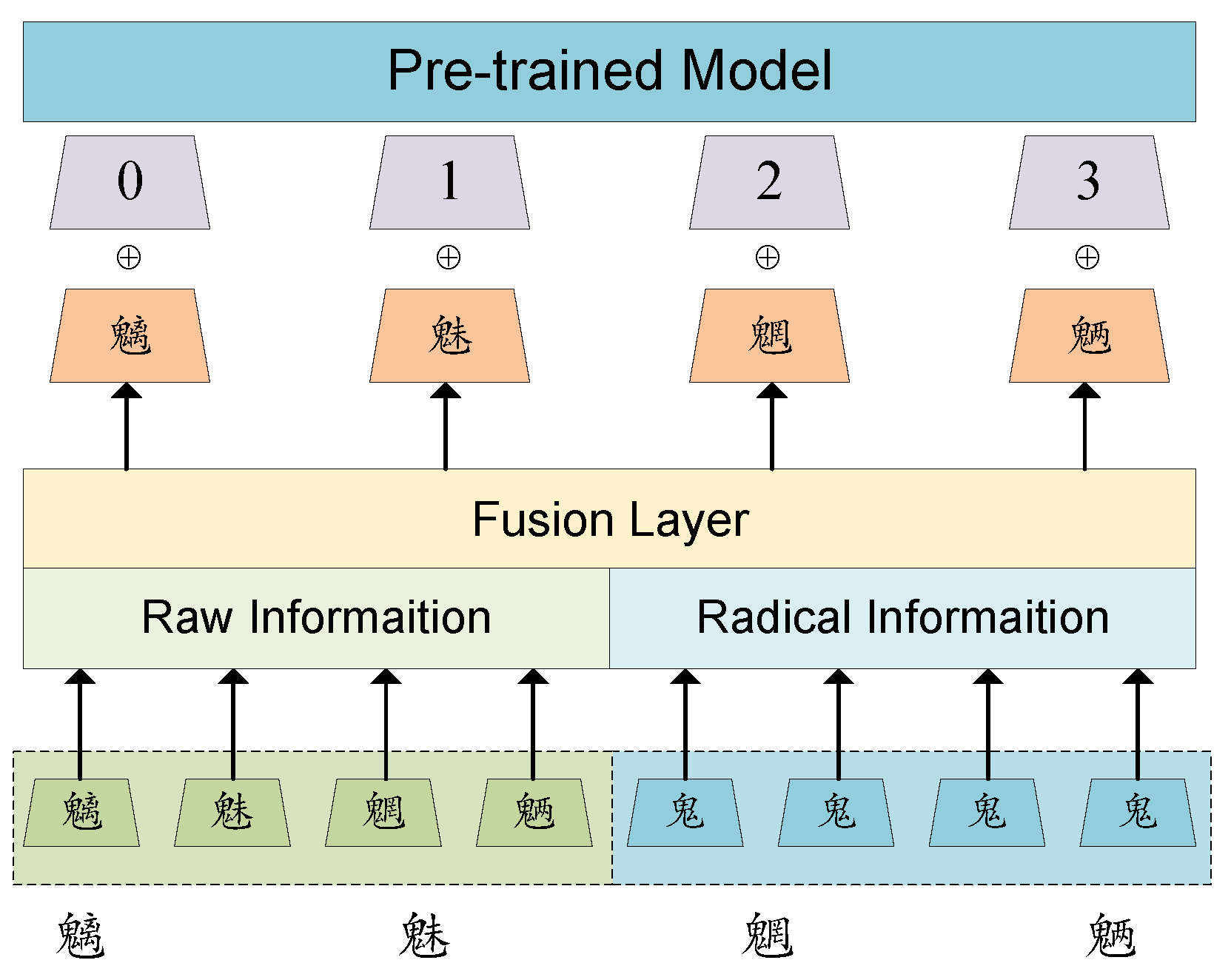
This study seeks to enhance the performance of Chinese pre-trained models through the integration of a radical embedding layer. Radicals play a key role in capturing both the semantic and structural information inherent in Chinese characters, which is critical for improving text processing tasks. Figure 2 illustrates the overall framework of our proposed method, detailing the key components, such as dynamic radical extraction, radical vocabulary construction, and the weighted fusion of radical embeddings with pre-trained embeddings. In this section, we elaborate on the design of our proposed method, including the construction of radical embeddings, their integration into the original pre-trained model, and the experimental framework used to evaluate the approach.
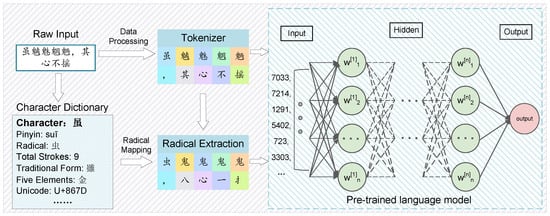
Figure 2.
The overall framework of our proposed method, which integrates radical embeddings into pre-trained models to optimize Chinese word segmentation. The framework includes dynamic radical extraction, radical vocabulary construction, and weighted fusion of radical embeddings with token embeddings. By incorporating fine-grained radical features, this approach enhances the performance of downstream tasks while preserving computational efficiency by avoiding model re-training.
3.1. Radical Mapping Construction
In this method, the vocabulary of the original pre-trained model is first loaded and the token list is obtained. To ensure that radical information is effectively integrated with the model, we have two options: one is to reconstruct an independent radical vocabulary, and the other is to directly merge radical information into the existing model vocabulary. After considering the flexibility and complexity of model training, we decide to use the first approach, which is to reconstruct an independent radical vocabulary.
The construction of the radical vocabulary is based on an independent external resource, specifically a dictionary of Chinese radicals and their corresponding characters, which we retrieved from a GitHub project (cn-radical: https://github.com/wangchuan2008888/cn-radical). This resource is entirely separate from the pre-trained language model’s tokenizer vocabulary. This tool extracts the corresponding radical information for each Chinese character and generates a complete radical vocabulary. For characters that cannot be directly classified (referred to as “hard-to-identify characters” or out-of-vocabulary radicals), we adopt a fallback strategy: when the radical extraction tool cannot recognize a radical, the character itself is treated as a special “radical” and assigned a unique embedding. This ensures that even rare or unseen characters are meaningfully represented in the model rather than being discarded or mapped to an “unknown” token. Since these characters occur infrequently in the dataset, their impact on downstream task performance remains minimal, and the model can still process them effectively.
The construction of an independent radical vocabulary is a method of avoiding conflicts between the IDs of the new radicals and those of the existing vocabulary in the original model. This approach maintains the independence of radical information from the original text information. The radical embedding layer handles only the radical features, while the original model embedding layer continues to process the original text token embeddings. The IDs of the radical vocabulary are reassigned to ensure continuity and prevent exceeding the maximum range of the radical embedding layer.
The introduction of radical embeddings extends the vocabulary size from the original model by an additional 284 tokens. Although this increases the total vocabulary size, the expansion is relatively minor compared to the overall number of tokens in standard Chinese language models, which often contain tens of thousands of entries. This is because many Chinese characters share the same radical, meaning that a relatively small number of additional tokens are needed to represent the rich set of radicals in the vocabulary.
Since our approach constructs a separate radical vocabulary to store the radicals and their mappings, we are not directly creating new tokenized units that combine radicals and characters. Instead, the radical vocabulary is independently integrated with the original character embeddings through a weighted fusion mechanism. This ensures that the additional memory overhead is mainly confined to the radical embedding layer and does not significantly increase the computational complexity.
3.2. Construction and Integration of Radical Embedding Layer
In the model architecture, we introduce a dedicated embedding layer to incorporate radical information. The input to this layer consists of the radical IDs of the Chinese characters, while the output of the radical embedding layer is combined with the output from the original BERT embedding layer using a weighted fusion mechanism. As illustrated in Figure 3, the architecture consists of two parallel embedding layers: the original BERT embedding layer and the radical embedding layer. These embeddings are fused using a weighted mechanism controlled by two coefficients, and , which determine the contributions of the radical embedding and the original BERT embedding, respectively.
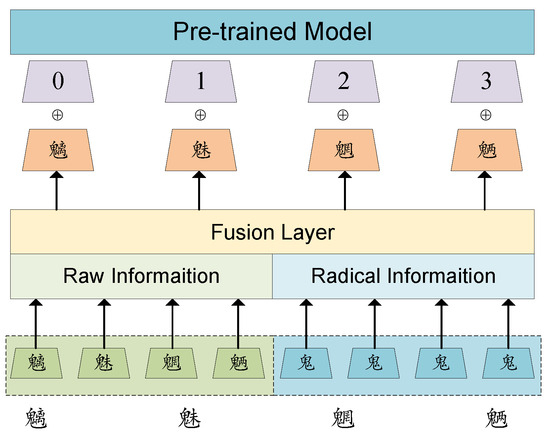
Figure 3.
The model architecture, where token embeddings and radical embeddings are combined via a weighted fusion mechanism to enhance downstream task performance.
- Original Vocabulary Embedding Layer: The original BERT embedding layer is retained to process tokens from the BERT vocabulary, including Chinese characters and common symbols.
- Radical Embedding Layer: An independent embedding layer is designed for radical information, where the input is the radical ID for each character. This layer encodes the radical information for integration into the model.
The fusion of the radical embedding and the original BERT embedding is performed only at the embedding layer, before passing the input through the first layer of the language model. At each subsequent layer of the model, the character representation is not fused with the radical embedding. Instead, after the input is passed through the embedding layer (where the radical and character embeddings are fused), the resulting embeddings are used as input to the following layers of the BERT model. This ensures that the radical information is integrated at the very beginning, providing the model with a rich initial representation that combines both character-level and radical-level features. This combined embedding is then passed to the subsequent layers of the model.
In our approach, the radical embeddings are initialized using an embedding layer, with the dimensionality of the embeddings matching the hidden size of the BERT model (typically 768 dimensions). The initialization follows PyTorch’s default method for embedding layers, which is random but uniformly distributed over the embedding space. The key parameter involved in this initialization is the number of distinct radicals in our vocabulary. During model training, the radical embeddings are fine-tuned along with other model parameters, enabling them to adapt to task-specific data. Additionally, a learnable parameter determines the relative importance of the original word embeddings and the radical embeddings in the final input representation. These contribution weights are normalized using the softmax function to ensure they sum to 1, providing a flexible mechanism for combining the two types of embeddings.
The weighted fusion of the radical and original embeddings is mathematically expressed as
where and represent the original and radical embeddings, respectively. Coefficients and are learnable parameters that determine the relative contribution of the original and radical embeddings to the final embedding . These coefficients are initialized as a tensor [0.5, 0.5] and are treated as learnable parameters during training. They are dynamically adjusted through gradient descent optimization based on the task and dataset, enabling the model to balance the contribution of both embeddings to optimize performance. The final values of and depend on the specific task and data distribution, and their adjustment is expected to improve the model’s ability to capture both semantic and structural information.
3.3. Model Training and Validation
During training, we begin by preprocessing the data to extract radical information for each Chinese character, mapping the radical IDs to a predefined radical vocabulary. The text data are tokenized using the BERT tokenizer, while the radical information serves as an additional input feature. The model is fine-tuned with both BERT and radical embeddings. The training process involves the following steps:
- Input Data: Each input sample consists of two components: the token sequence obtained from the BERT tokenizer and the corresponding sequence of radical IDs.
- Weighted Fusion: The BERT and radical embeddings are combined through a weighted fusion mechanism, and the resulting representation is passed as input to the model.
- Optimization Objective: The model is trained to minimize the loss function, typically cross-entropy loss, for the classification task.
To evaluate model performance, we validate the model on standard datasets (e.g., THUCNews) and perform multi-domain testing to assess the effectiveness of radical embeddings across different types of text, such as news articles and social media posts.
This section presents a model architecture that incorporates radical embeddings. The independent radical embedding layer is fused with the original BERT embeddings through a weighted mechanism. This approach not only enhances the model’s semantic understanding of Chinese characters but also mitigates vocabulary ID conflicts. With a carefully constructed radical vocabulary, a weighted fusion strategy, and a well-defined training procedure, this method demonstrates strong performance in various downstream tasks.
4. Experiment Setup
In this section, we will introduce the baseline methods, the datasets used, and the experimental setup.
4.1. Baseline Methods
The baseline method for this experiment uses the existing WordPiece tokenization method. This approach involves fine-tuning the standard pre-trained model without any modifications. We will compare the baseline model with our method to evaluate the performance improvement of the model enhanced with radical embeddings in Chinese text tasks.
Our method adds radical information mapping for Chinese characters to the embedding layer without changing the vocabulary of the baseline model. This enables the model to better understand the structural features of Chinese characters. We introduce the radical information of each Chinese character into the model’s embedding layer, training it alongside the original word embeddings. Other training parameters remain unchanged, and the same training dataset is used for fine-tuning, ensuring fairness in the comparative experiment.
4.2. Pre-Trained Models
To validate the effectiveness of the radical embedding method, we conducted fine-tuning experiments on multiple pre-trained models. This approach not only tests the generalization ability of our method but also ensures the reliability of the research results. Unlike training models from scratch, our method optimizes existing pre-trained models, saving computational resources and time while fully utilizing the language knowledge embedded in the pre-trained models.
In this study, we selected two widely used Chinese pre-trained models as the foundation: BERT-base-Chinese and Chinese-BERT-wwm. Both models are based on the Transformer architecture and have been pre-trained on large-scale corpora to capture the complex features of the Chinese language.
- BERT-Base-Chinese [10]: The Chinese version of Google’s BERT model, provided by the Hugging Face team, employs WordPiece tokenization during pre-training to segment text into word pieces. In this process, 15% of the word pieces are masked, 80% are replaced by [MASK], 10% are substituted with random tokens, and the remaining 10% remain unchanged.
- Chinese-BERT-wwm [36]: The model proposed by Cui et al. is similar to BERT-Base-Chinese in that both utilize a subword-level tokenizer. However, it introduces a novel approach termed Whole-Word Masking (WWM), which involves leveraging the HIT LTP segmentation tool to identify word boundaries during pre-training. If a character within a word is selected for masking based on the HIT LTP segmentation, all characters in that word are masked collectively. This approach enhances word-level semantic understanding and improves performance on Chinese natural language processing (NLP) tasks.
In this experiment, we used the AdamW optimizer with a learning rate of 2 × . The model was trained for 3 epochs to ensure adequate convergence. To ensure the stability and reliability of the results, we performed 5 independent runs and averaged the results. This approach helps to mitigate the effects of random initialization and other sources of variability, providing more stable and trustworthy performance estimates. We used a validation set during training to monitor the model’s performance and ensure it was not overfitting to the training data, helping to maintain its generalizability.
The choice regarding hyperparameters, such as the learning rate and batch size, was based on prior work and preliminary evaluations. Although we did not conduct explicit hyperparameter optimization during training, these values were selected to ensure stable and reliable model performance within the scope of this study.
4.3. Evaluation Datasets
We fine-tuned and evaluated the different pre-trained models on various downstream task datasets, including single-sentence classification, sentence pair classification, and reading comprehension tasks. While we primarily report performance using accuracy as the evaluation metric, we recognize the importance of additional metrics like F1 score, precision, and recall, especially in tasks involving class imbalance or where both precision and recall play a significant role. Future work will include a more comprehensive evaluation using these metrics to provide a fuller understanding of model performance. Below is a brief introduction to each dataset, and the dataset statistics are provided in Table 1.

Table 1.
Statistics of downstream datasets.
ChnSentiCorp: For the sentiment analysis task, we used the ChnSentiCorp binary sentiment classification dataset. The evaluation metric is accuracy.
THUCNews: For document-level text classification, we selected the THUCNews dataset, released by the Natural Language Processing Laboratory of Tsinghua University. We used one of its subsets, where news articles need to be classified into 1 of 10 categories. The evaluation metric is accuracy.
TNEWS: This is a news headline classification dataset with 15 categories. The evaluation metric is accuracy.
XNLI: For the natural language inference task, we used the XNLI dataset. The task involves classifying the text into one of three categories: entailment, neutral, or contradictory. The evaluation metric is accuracy.
LCQMC: This dataset, released by the Intelligent Computing Research Center of Harbin Institute of Technology (Shenzhen), requires classification of sentence pairs to determine whether the two sentences have the same meaning. The evaluation metric is accuracy.
BQ Corpus: Released by the Intelligent Computing Research Center of Harbin Institute of Technology (Shenzhen), this dataset requires classification of sentence pairs to determine whether the two sentences have the same meaning and is focused on the banking domain. The evaluation metric is accuracy.
OCNLI: This is a natural language inference dataset that involves determining the relationship between a hypothesis and premise as entailment, neutral, or contradiction.
5. Experimental Results
In this section, we evaluate the effectiveness of our proposed method across three representative natural language processing (NLP) tasks: text classification (TC), sentence pair matching (SPM), and natural language inference (NLI). The experiments are conducted using publicly available datasets: ChnSentiCorp, THUCNews, and TNews for TC; LCQMC and BQ Corpus for SPM; and XNLI and OCNLI for NLI. Performance comparisons are conducted against baseline models, including BERT-Base-Chinese and BERT-wwm. In the following experimental results, we will refer to BERT-Base-Chinese simply as “BERT”.
Overall, our method demonstrates consistent improvements across various tasks and datasets. These results confirm the robustness and generalizability of our approach in enhancing pre-trained language models.
5.1. Text Classification (TC)
Table 2 summarizes the performance on the text classification task. Across all the datasets, our method significantly improves the accuracy of the BERT and BERT-wwm baselines.
Table 2.
Performance comparison for text classification across different datasets.
For the ChnSentiCorp dataset, BERT+Ours achieves a test accuracy of 95.28%, surpassing the baseline BERT by 0.95 percentage points. The combination of BERT-wwm with our method further enhances the accuracy to 95.92%, marking the best performance on this dataset.
In the THUCNews dataset, our method achieves test accuracies of 97.64% (BERT+Ours) and 97.42% (BERT-wwm+Ours), outperforming the respective baselines. Notably, the improvements are more pronounced on the TNews dataset, where BERT-wwm+Ours achieves the highest test accuracy of 57.84%, showcasing the strength of our approach in challenging settings.
5.2. Sentence Pair Matching (SPM)
The experimental results for sentence pair matching are presented in Table 3. On the LCQMC dataset, the proposed method demonstrates significant performance enhancements. Notably, BERT-wwm+Ours achieves the highest test set accuracy of 86.97%, outperforming both the BERT and BERT-wwm baselines. This result highlights the efficacy of our approach in enhancing the semantic understanding capabilities of pre-trained models.
Table 3.
Performance comparison for sentence pair matching across different datasets.
For the BQ Corpus dataset, BERT+Ours achieves the highest accuracy on the development set, reaching 86.95%. This improvement underscores the ability of our method to effectively model pairwise semantic relationships. Although the test accuracy for BERT+Ours on LCQMC is slightly lower compared to the standard BERT baseline, this variation may be attributed to dataset-specific characteristics. Overall, the results demonstrate the robustness and generalization ability of our proposed approach across different datasets in the sentence matching task.
5.3. Natural Language Inference (NLI)
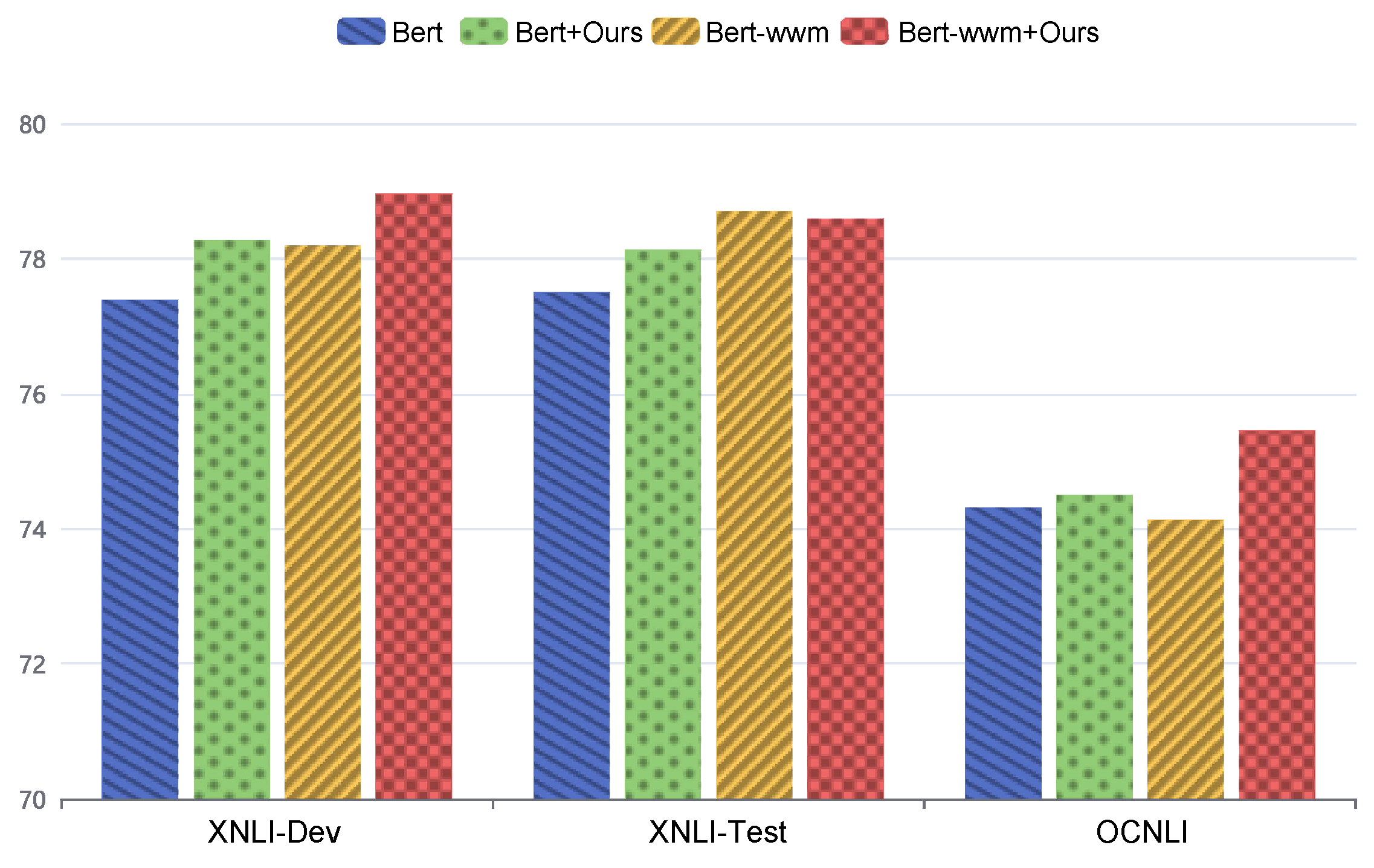
The natural language inference results are summarized in Figure 4. On the XNLI dataset, our method achieves the highest development set accuracy of 78.96% (BERT-wwm+Ours) and 78.59% on the test set, demonstrating improved cross-lingual understanding.
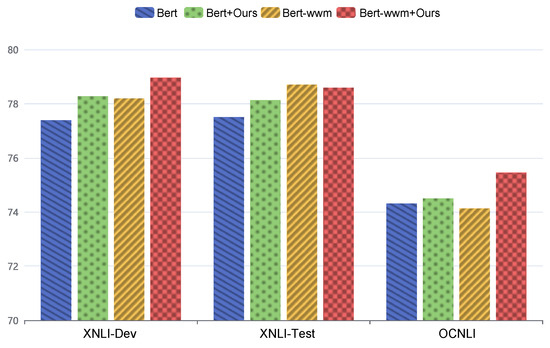
Figure 4.
Performance comparison for natural language inference across different datasets.
For the OCNLI dataset, BERT-wwm+Ours achieves an accuracy of 75.45%, surpassing BERT by 1.94 percentage points. These results validate the generalizability of our method across complex inference tasks, highlighting its ability to enhance pre-trained models consistently.
5.4. Summary of Results
In summary, our method demonstrates consistent improvements across diverse NLP tasks and datasets. The most notable gains are observed on the TNews and OCNLI datasets, where the challenges of semantic understanding and inference are more pronounced. These results confirm the robustness, generalizability, and effectiveness of our approach in enhancing pre-trained language models.
6. Conclusions and Future Work
In this study, we have explored the integration of radical embeddings into pre-trained Chinese language models to address the limitations in capturing fine-grained structural information within Chinese characters. By introducing a novel method for optimizing Chinese word segmentation through radical-aware embeddings, we have expanded the vocabulary of pre-trained models to include radical features, thereby enhancing their linguistic representation and enabling more effective processing of semantic nuances. The proposed architectural adjustments ensure the efficient utilization of additional linguistic information, as demonstrated by the weighted fusion mechanism that combines radical embeddings with existing pre-trained embeddings. Through extensive experimentation on standard datasets, our approach has shown significant improvements in tasks such as text classification and named entity recognition, validating the hypothesis that incorporating radical information can lead to better model performance. The results not only highlight the importance of leveraging character-level structural information in Chinese NLP but also underscore the potential for further advancements in the field by integrating other fine-grained features.
The contributions of this research extend beyond immediate performance gains, offering a new perspective on how to enhance pre-trained models for languages with rich morphological structures. By focusing on the intrinsic components of Chinese characters, this work paves the way for future research exploring the combination of multiple fine-grained features, such as radicals, pinyin, and strokes, to achieve even deeper semantic understanding. Moreover, the methodology presented here is adaptable to other logographic or morphologically complex languages, suggesting broader implications for global NLP efforts. As pre-trained models continue to evolve, the strategies outlined in this paper will be instrumental in advancing the state of the art in multilingual natural language processing, particularly for under-resourced or structurally unique languages.
While the approach presented in this study shows promising results, we sincerely acknowledge that a detailed error analysis is essential for fully understanding the limitations of our method. Unfortunately, due to certain constraints, we have not yet been able to conduct a comprehensive classification of error types. However, we recognize that ambiguities in radical assignments could lead to misclassifications, and this is an area that warrants further attention. In future work, we will prioritize a systematic evaluation of error patterns to identify sources of misclassification. We also plan to explore potential solutions, such as refining radical segmentation rules and introducing adaptive weighting mechanisms based on the contextual significance of radicals. By addressing these issues, we hope to further enhance the model’s ability to handle fine-grained structural features, reduce ambiguity-related errors, and improve overall model performance.
We acknowledge the potential computational implications of radical embeddings. The method expands the original vocabulary by 284 tokens (1.3% of BERT-base’s 21,000 tokens), introducing 218,000 additional parameters (0.2% of the baseline 110M parameters) through 768 dimensional embeddings. This corresponds to a memory increase of 0.83MB under standard 32-bit precision storage. Comprehensive empirical validation of training dynamics and resource utilization will be systematically addressed in future studies.
Additionally, while radical-aware tokenization has shown promising results in general, we acknowledge that the relevance of radicals may vary across different types of text. In certain contexts, such as domain-specific texts (e.g., medical or legal) or informal writing (e.g., social media or slang), the impact of radical-based features may be less significant. Future work will involve evaluating the model’s performance across a broader range of datasets, including those where radicals may be less relevant, to assess when and where radical information is most beneficial. This will help to refine our approach and ensure that radical embeddings are incorporated only when they contribute meaningfully to performance improvements.
Author Contributions
Conceptualization, H.Q., M.L. and J.Z.; Methodology, H.Q. and M.L.; Software, H.Q. and M.L.; Validation, L.W. and Y.G.; Formal analysis, J.Z. and R.Z.; Investigation, H.Q. and M.L.; Resources, J.Z. and R.Z.; Data curation, H.Q., M.L., L.W. and Y.G.; Writing—original draft preparation, H.Q.; Writing—review and editing, H.Q., M.L. and J.Z.; Visualization, H.Q.; Supervision, J.Z. and R.Z.; Project administration, J.Z. and R.Z.; Funding acquisition, L.W. and J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (NSFC) under Grant No. 62172142, and in part by the Postdoctoral Science Foundation of China under Grant No. 2023M730980, and in part by the Key Technologies R & D Program of Henan Province under Grant No. 241111210700, and in part by the the Leading Talents of Science and Technology in the Central Plain of China under Grant No. 234200510018, and in part by the Key Research Project of Higher Education Institutions of Henan Province under Grant No. 25A520017 and Grant No. 25A520032.
Data Availability Statement
The data are contained within the paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hudson, A.; Moore, K.A.; Quinonez-Beltran, J.; Lai, J.; Joshi, R.M. Alphabetic Languages. In Routledge International Handbook of Visual-Motor Skills, Handwriting, and Spelling: Theory, Research, and Practice; Routledge: London, UK, 2023; p. 263. [Google Scholar]
- Ho, C.S.H.; Bryant, P. Learning to read Chinese beyond the logographic phase. Read. Res. Q. 1997, 32, 276–289. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Church, K.W. Emerging trends: Subwords, seriously? Nat. Lang. Eng. 2020, 26, 375–382. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhao, H.; Ling, K.; Li, J.; Li, Z.; He, S.; Fu, G. Effective subword segmentation for text comprehension. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1664–1674. [Google Scholar] [CrossRef]
- Si, C.; Zhang, Z.; Chen, Y.; Qi, F.; Wang, X.; Liu, Z.; Wang, Y.; Liu, Q.; Sun, M. Sub-Character Tokenization for Chinese Pretrained Language Models. Trans. Assoc. Comput. Linguist. 2023, 11, 469–487. [Google Scholar] [CrossRef]
- Hu, H.; Du, X.; Tian, X.; Bai, R. A Preliminary Study on the Semantic Strength of Chinese Radicals. In Proceedings of the Fourth International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2007), Haikou, China, 24–27 August 2007; Volume 2, pp. 658–662. [Google Scholar] [CrossRef]
- Nie, H. Chinese radicals as distinctive marks of language. J. Chin. Writ. Syst. 2019, 3, 115–119. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Wang, H.; Li, J.; Wu, H.; Hovy, E.; Sun, Y. Pre-Trained Language Models and Their Applications. Engineering 2023, 25, 51–65. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Clark, J.H.; Garrette, D.; Turc, I.; Wieting, J. Canine: Pre-training an Efficient Tokenization-Free Encoder for Language Representation. Trans. Assoc. Comput. Linguist. 2022, 10, 73–91. [Google Scholar] [CrossRef]
- Li, J.; Tang, T.; Zhao, W.X.; Nie, J.Y.; Wen, J.R. Pre-trained language models for text generation: A survey. ACM Comput. Surv. 2024, 56, 1–39. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Su, T.R.; Lee, H.Y. Learning Chinese Word Representations From Glyphs Of Characters. arXiv 2017, arXiv:1708.04755. [Google Scholar]
- Zhuang, H.; Wang, C.; Li, C.; Li, Y.; Wang, Q.; Zhou, X. Chinese language processing based on stroke representation and multidimensional representation. IEEE Access 2018, 6, 41928–41941. [Google Scholar] [CrossRef]
- Mielke, S.J.; Alyafeai, Z.; Salesky, E.; Raffel, C.; Dey, M.; Gallé, M.; Raja, A.; Si, C.; Lee, W.Y.; Sagot, B.; et al. Between words and characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP. arXiv 2021, arXiv:2112.10508. [Google Scholar]
- Kaisto, J.; Juutilainen, T.; Kauranen, J. Non-fungible tokens, tokenization, and ownership. Comput. Law Secur. Rev. 2024, 54, 105996. [Google Scholar] [CrossRef]
- Rai, A.; Borah, S. Study of various methods for tokenization. In Proceedings of the 2018 Conference on International Conference on Computer Communication and Internet of Things, Chennai, India, 15–17 February 2018; pp. 193–200. [Google Scholar]
- Xiao, X.; Liu, Y.; Hwang, Y.S.; Liu, Q.; Lin, S. Joint Tokenization and Translation. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 1200–1208. [Google Scholar]
- Cao, L.; Wu, W.; Gu, Y. The research of performance of Lucene’s Chinese tokenizer. In Proceedings of the 2nd International Conference on Artificial Intelligence, Management Science and Electronic Commerce, Zhengzhou, China, 8–10 August 2011; pp. 7398–7401. [Google Scholar] [CrossRef]
- Grefenstette, G. Tokenization. In Syntactic Wordclass Tagging; Springer: Berlin, Germany, 1999; pp. 117–133. [Google Scholar]
- Tay, Y.; Tran, V.Q.; Ruder, S.; Gupta, J.; Chung, H.W.; Bahri, D.; Qin, Z.; Baumgartner, S.; Yu, C.; Metzler, D. Charformer: Fast Character Transformers via Gradient-based Subword Tokenization. arXiv 2021, arXiv:2106.12672. [Google Scholar]
- Ács, J.; Kádár, Á.; Kornai, A. Subword Pooling Makes a Difference. arXiv 2021, arXiv:2102.10864. [Google Scholar]
- Batsuren, K.; Vylomova, E.; Dankers, V.; Delgerbaatar, T.; Uzan, O.; Pinter, Y.; Bella, G. Evaluating Subword Tokenization: Alien Subword Composition and OOV Generalization Challenge. arXiv 2024, arXiv:2404.13292. [Google Scholar]
- Meng, Y.; Wu, W.; Wang, F.; Li, X.; Nie, P.; Yin, F.; Li, M.; Han, Q.; Sun, X.; Li, J. Glyce: Glyph-vectors for chinese character representations. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Ho, C.S.H.; Ng, T.T.; Ng, W.K. A “radical” approach to reading development in Chinese: The role of semantic radicals and phonetic radicals. J. Lit. Res. 2003, 35, 849–878. [Google Scholar] [CrossRef]
- Peng, H.; Cambria, E.; Zou, X. Radical-Based Hierarchical Embeddings for Chinese Sentiment Analysis at Sentence Level. In Proceedings of the the Florida AI Research Society, Marco Island, FL, USA, 22–24 May 2017. [Google Scholar]
- Zhang, L.; Komachi, M. Using sub-character level information for neural machine translation of logographic languages. Trans. Asian Low-Resour. Lang. Inf. Process. 2021, 20, 1–15. [Google Scholar] [CrossRef]
- Taft, M.; Zhu, X.; Ding, G. The relationship between character and radical representation in Chinese. Acta Psychol. Sin. 2000, 32, 3–12. [Google Scholar]
- Wang, Z.; Liu, X.; Zhang, M. Breaking the Representation Bottleneck of Chinese Characters: Neural Machine Translation with Stroke Sequence Modeling. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6473–6484. [Google Scholar] [CrossRef]
- Sun, Z.; Li, X.; Sun, X.; Meng, Y.; Ao, X.; He, Q.; Wu, F.; Li, J. ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information. arXiv 2021, arXiv:2106.16038. [Google Scholar]
- Tao, H.; Tong, S.; Xu, T.; Liu, Q.; Chen, E. Chinese Embedding via Stroke and Glyph Information: A Dual-channel View. arXiv 2019, arXiv:1906.04287. [Google Scholar]
- Chen, H.Y.; Yu, S.H.; Lin, S.D. Glyph2Vec: Learning Chinese Out-of-Vocabulary Word Embedding from Glyphs. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2865–2871. [Google Scholar] [CrossRef]
- Cui, Y.; Che, W.; Liu, T.; Qin, B.; Yang, Z. Pre-training with whole word masking for chinese bert. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3504–3514. [Google Scholar] [CrossRef]
- Tan, S.; Zhang, J. An empirical study of sentiment analysis for chinese documents. Expert Syst. Appl. 2008, 34, 2622–2629. [Google Scholar] [CrossRef]
- Li, J.; Sun, M. Scalable Term Selection for Text Categorization. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech Republic, 28–30 June 2007; pp. 774–782. [Google Scholar]
- Xu, L.; Hu, H.; Zhang, X.; Li, L.; Cao, C.; Li, Y.; Xu, Y.; Sun, K.; Yu, D.; Yu, C.; et al. CLUE: A Chinese Language Understanding Evaluation Benchmark. arXiv 2020, arXiv:2004.05986. [Google Scholar]
- Conneau, A.; Lample, G.; Rinott, R.; Williams, A.; Bowman, S.R.; Schwenk, H.; Stoyanov, V. XNLI: Evaluating Cross-lingual Sentence Representations. arXiv 2018, arXiv:1809.05053. [Google Scholar]
- Liu, X.; Chen, Q.; Deng, C.; Zeng, H.; Chen, J.; Li, D.; Tang, B. Lcqmc: A large-scale chinese question matching corpus. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1952–1962. [Google Scholar]
- Chen, J.; Chen, Q.; Liu, X.; Yang, H.; Lu, D.; Tang, B. The bq corpus: A large-scale domain-specific chinese corpus for sentence semantic equivalence identification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4946–4951. [Google Scholar]
- Hu, H.; Richardson, K.; Xu, L.; Li, L.; Kübler, S.; Moss, L.S. OCNLI: Original Chinese Natural Language Inference. arXiv 2020, arXiv:2010.05444. [Google Scholar]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).