Abstract
The intense rising of machine learning in the previous years, bolstered by post-COVID-19 digitalization, left some of us pondering upon the transparency practices involving projects sourced from European Union funds. This study focuses on the European Union research clusters and trends in the ecosystem of higher education institutions (HEIs). The manually curated dataset of bibliometric data from 2020 to 2024 was analyzed in steps, from the traditional bibliometric indicators to natural language processing and collaboration networks. Centrality metrics, including degree, betweenness, closeness, and eigenvector centrality, and a three-way-intersection of community detection algorithms were computed to quantify the influence and the connectivity of institutions in different communities in the collaborative research networks. In the EU context, results indicate that institutions such as Universidad Politecnica de Madrid, the University of Cordoba, and Maastricht University frequently occupy central positions, echoing their role as local or regional hubs. At the global level, prominent North American and UK-based universities (e.g., University of Pennsylvania, Columbia University, Imperial College London) also remain influential, standing as a witness to their enduring influence in transcontinental research. Clustering outputs further confirmed that biomedical and engineering-oriented lines of inquiry often dominated these networks. While multiple mid-ranked institutions do appear at the periphery, the data highly implies that large-scale initiatives gravitate toward well-established players. Although the recognized centers provide specialized expertise and resources, smaller universities typically rely on a limited number of niche alliances.
1. Introduction
Over the past couple of years, machine learning (ML) has taken center stage and has grown into a vital area of inquiry for higher education institutions (HEIs) [1], leaving a clear imprint on academic degree programs, research mandates [2,3], and the formation of inter-university cooperation [4,5]. Within the European Union, large-scale efforts have been pursued of late—through Horizon Europe [6], the Digital Europe program, and supplementary national-level schemes—with the aim to bring together university labs, research institutes, and commercial partners for data-centric applications, advanced AI explorations, and specialized postgraduate training. Beyond Europe’s borders, both private and public players across North America [7,8,9], East Asia, and Australia pursue comparable agendas by scaling up research funds and consortium projects, intensifying a worldwide race to lead ML-driven innovation and knowledge production.
Notwithstanding the EU’s ongoing investment in digital transformation, questions remain about whether such resources adequately bolster campus-based research, simulate inter-EU alliances, and encourage major collaborations with extra-EU universities and industries. These funding streams at national and pan-European levels often tie into strategic policy goals, such as protecting personal data, promoting trustworthy AI, and developing advanced infrastructure like supercomputers or quantum-ready systems. Regardless, doubts persist on whether the focus remains too narrow, emphasizing only select hubs—institutions that already rank high in academic reputation or that enjoy robust support from local governments and industries. The existing literature has documented disparities in HPC infrastructure and funding across European institutions, suggesting that Western European universities benefit from preferential access to these resources [10].
These structural differences intensify the demand for a thorough analysis of funding pathways and their outcomes. At the same time, the active participation of non-EU institutions (from Switzerland, the UK, the United States, China, and beyond), which continue to seek collaborative avenues with European institutions, introduces further complexity into the cross-continental flow of scientific expertise and financial backing.
While prior bibliometric studies have explored global machine learning (ML) research trends, limited attention has been given to the specific institutional and funding dynamics shaping ML research in European higher education institutions (HEIs). The existing literature primarily examines AI adoption at a macro level, emphasizing policy frameworks [11], national and EU-level funding trends [12], or regulatory implications such as the AI Act [13]. However, the structural disparities in research networks, particularly between Western and Eastern European universities, remain insufficiently analyzed. Moreover, the role of non-EU institutions—including UK universities post-Brexit—within EU research collaborations has yet to be systematically assessed [14].
This study addresses these gaps by conducting a bibliometric and network analysis of ML-related publications in higher education from 2020 to 2024, focusing on institutional hierarchies, funding-driven research clusters, and the impact of policy-driven initiatives such as Horizon Europe [6]. Through centrality metrics, community detection, and thematic analysis, we provide empirical evidence on how funding mechanisms, access to high-performance computing (HPC) resources [10], and international collaborations influence the structural and thematic evolution of ML research. By systematically mapping institutional roles and research networks, our findings contribute to ongoing discussions about the equitable distribution of resources, research visibility, and the long-term impact of EU-centric funding policies on ML research in academia.
Against this backdrop, this study adopts a bibliometric perspective to explore ML-related publications and research alliances in higher education between 2020 and 2024. Specifically, we aim to test the following research hypotheses:
H1.
institutions from Western Europe dominate ML research networks due to preferential access to high-performance computing (HPC) resources and EU funding;
H2.
transnational collaborations are heavily shaped by European funding mechanisms, leading to the formation of research clusters centered around elite institutions;
H3.
Central and Eastern European universities are underrepresented in ML research networks, reflecting persistent inequalities in access to infrastructure and funding;
H4.
institutions with strong international partnerships exhibit higher academic visibility, measured by publication volume and citation impact;
H5.
biomedical and engineering domains dominate ML collaborations in EU higher education, benefiting from strong synergies between AI, healthcare, and technical sciences;
H6.
non-EU universities, particularly from the US and UK, remain key players in European ML research networks, even post-Brexit.
Specifically, the central objectives of this study are
- To provide a bibliometric summary of publication activities—encompassing citation patterns, top researchers and journals, and the balance between single-country (SCP) and multi-country (MCP) publications—while pinpointing how financial incentives, both public or private, may concentrate resources or reinforce existing inequalities among HEIs.
- To assess, through a thematic analysis, how ML research topics evolve over time within both EU-based and international contexts.
- To map out, via collaboration networks and community structures, the institutional players—both in Europe and around the globe—that consistently occupy “power center” positions, act as bridges linking separate clusters, or lead specialized research communities.
By leveraging a combination of bibliometric indicators and network analysis, this work provides a unique perspective on the structural and thematic evolution of machine learning research within European academia.
2. Literature Review
The recent literature charts a spectrum of applications for machine learning in higher education, complemented by significant policy efforts and funding streams at both national and EU levels. With this in mind, the following sections consider (Section 2.1) how ML tools reshape academic processes, (Section 2.2) how European and national initiatives sustain institutional research, (Section 2.3) the efforts to coordinate policy and align strategic objectives—particularly through advanced digital and HPC (high-performance computing) programs—and how the AI Act and related ethical guidelines fit into this overall picture, and which are the (Section 2.4) gaps in existent literature that necessitate further attention.
2.1. Machine Learning in Higher Education—Core Applications and Evidence
A significant stream of literature chronicles ML’s ability to enhance personalized learning experiences, bolster institutional analytics, and streamline operational activities. Adaptive systems, such as dynamic tutoring platforms and recommendation tools, adjust course materials based on student progress metrics, helping to improve participation and retention [15,16]. Institutions have likewise leveraged predictive models to identify students at heightened risk of dropout, thus optimizing timely interventions [17,18]. In parallel, logistical aspects such as admissions, resource scheduling, and automated advising see incremental productivity gains from ML-driven optimization [19].
While the literature documents such tools, their deployment varies widely across the European Union, with greater adoption rates coming from the universities already accustomed to data-intensive research or which benefit from supportive funding channels [20].
2.2. National and EU-Level Funding—Patterns, Initiatives, and Imbalances
Recent analyses indicate that, from 2020 to 2024, EU allocations to AI-related initiatives rose sharply, with close to 300 AI-focused projects under Horizon Europe already surpassing much of the volume once attributed during the entire seven-year Horizon 2020 program [21]. While near-market “innovation actions” see substantial budget growth, earlier-stage research has remained largely stable. Marie Skłodowska-Curie Actions, for example, have doubled in average size, indicating the EU’s commitment to cultivating a new generation of AI and data science researchers in alignment with the Digital Decade Policy Programme’s objective of developing 20 million ICT specialists by 2030 [22].
Established research institutions, notably Germany’s Fraunhofer and France’s CNRS, secure top positions in AI funding [21]. In parallel, a handful of mid-scale universities, such as the University of Patras in Greece or the University Medical Centers at Utrecht, have seen sudden growth, suggesting that a clear strategic pivot or targeted collaborations can elevate institutional visibility. Nevertheless, geographical imbalances persist. Romania and Poland, for instance, rank lower in AI participation despite marginal gains in “Widening” success rates [21]. Brexit’s disruption is also apparent, as major UK universities once prominent in Horizon 2020 now receive minimal Horizon Europe awards [21]. Swiss entities encounter similar constraints under non-association rules, remaining active collaborators while operating largely outside EU funding pools.
Beyond Horizon Europe, pan-European consortia such as ELLIS and its offshoots—ELISE, ELSA, and ELIAS—prioritize HPC-oriented ML research, interdisciplinary PhD programs, and the ethical deployment of data-centric tools [22]. Countries like Germany and France supplement these efforts with national AI strategies and additional investment, bolstering local HPC capacities and enabling select universities to pioneer advanced ML projects [12]. Nonetheless, for institutions with fewer resources, these overarching frameworks do not guarantee equitable access to major HPC nodes or specialized technical staff.
2.3. Strategic Goals and Policies and the AI Act
The EU’s Digital Europe Programme commits up to 1 billion euros annually for AI technologies, augmented by member states and private sector investments that can approach 20 billion euros [12]. Key initiatives include HPC expansions—exemplified by the EuroHPC Joint Undertaking—and advanced study programs in quantum, big data, and robotics [23]. These measures aim to reinforce Europe’s competitiveness amid global AI frontrunners, especially in view of an estimated 10-billion-euro funding gap relative to the United States and China [12].
On the regulatory front, the adopted EU AI Act shapes how institutions handle data protection, equity, and transparency [11], and it has been noted that these guidelines might direct AI research toward “human-centered” or explainable ML systems [13,24]. For universities, particularly those working at scale with HPC, implementing these rules may introduce added compliance demands, which can be especially challenging for smaller campuses in Eastern Europe or for organizations grappling with limited administrative bandwidth.
While these measures aim to ensure fairness and transparency, they may restrict open data sharing among research institutions, limiting the availability of high-quality datasets for training ML models. Unlike the United States and China, where AI research benefits from extensive access to large-scale datasets with fewer restrictions, EU-based researchers must comply with strict data governance protocols, potentially slowing innovation [25].
In terms of research participation, the AI Act mandates documentation, testing, and risk assessment for AI models, increasing the administrative burden on academic researchers and institutions [26]. These compliance obligations disproportionately affect smaller research groups and universities with fewer legal and financial resources compared to well-funded institutions in Western Europe, which already benefit from superior access to computational resources and research grants [27].
Additionally, the AI Act affects international collaborations by imposing additional regulatory barriers on partnerships between EU-based researchers and non-EU institutions. Some scholars argue that this could lead to a decline in cross-border collaborations, as researchers outside the EU may prefer to work with partners in less regulated environments where AI development is not subject to similar constraints [28]. Furthermore, the classification of some AI techniques as “high-risk” may deter companies and universities from engaging in partnerships that involve sensitive data or ethically complex applications [29].
2.4. Deep Tech Competences
One of the main challenges is the fragmentation of expertise across Europe. While major research hubs like France and Germany have dedicated institutions focused on deep tech, other EU countries lack the specialized infrastructure and funding to develop such competencies. Deep tech development often requires long-term investment, access to advanced computing resources, and collaboration between academia, industry, and government institutions [10].
Another factor is the limited integration between academia and industry. While the EU has made strides in fostering AI research, many ML research networks still operate primarily within academic settings, with fewer direct connections to startups and industrial deep tech players [30]. Unlike in the United States, where AI research is heavily supported by private-sector investment from companies like Google DeepMind and OpenAI, European research networks often struggle to attract venture capital and industry partnerships for deep tech applications [31].
Additionally, the regulatory landscape plays a role in limiting deep tech exploration. The AI Act and GDPR impose strict compliance requirements on AI models, particularly those handling personal data. While these regulations are necessary for ethical AI development, they also increase the complexity and cost of conducting deep tech research, particularly in fields like federated learning and biomedical AI [32].
Finally, talent retention is a major issue. The European Union has faced challenges in retaining top AI and ML researchers as many deep tech experts migrate to the United States or China, where they find more funding opportunities and fewer regulatory constraints [33].
2.5. Methodological Context in Bibliometric Studies
Existing bibliometric analyses of machine learning research typically employ citation-based metrics, co-authorship networks, and thematic clustering to assess publication trends and institutional influence. Prior studies have leveraged centrality measures such as degree, betweenness, and eigenvector centrality to quantify institutional prominence within research networks [34,35]. Community detection techniques, including Louvain and modularity-based clustering, have also been used to reveal structural patterns in collaborative ecosystems [36,37].
While earlier studies have primarily focused on global AI research trends [1,19], fewer have systematically analyzed funding mechanisms, institutional hierarchies, and the impact of EU policies on machine learning research within European higher education. Unlike prior bibliometric research, which often relies solely on citation impact and co-authorship networks, this study integrates funding transparency as a variable, distinguishing between EU-funded research and non-disclosed financial sources. Additionally, by incorporating a three-way intersection of community detection algorithms, this analysis offers a more robust clustering approach, ensuring that institutional collaborations are examined through multiple network segmentation strategies.
By situating this study within established bibliometric methodologies while introducing funding structures and regulatory constraints as key analytical dimensions, this research extends prior work and provides a more policy-relevant perspective on machine learning research in European higher education.
2.6. Gaps in Existing Research
Numerous studies emphasize ML’s transformative promise for higher education, well-supported by policy frameworks and funding. However, persistent gaps remain:
Institutional Heterogeneity. Although a handful of Western European HEIs benefit from HPC investments and large AI grants, many Eastern and smaller universities report scarce resources for ML adoption. Robust longitudinal data is lacking on how these disparities affect learner outcomes and institutional performance.
Post-Brexit Realities. UK institutions face steep declines in Horizon Europe participation, reframing the regional landscape and raising questions about the long-term viability of cross-channel research networks, while Switzerland experiences a parallel limitation in direct EU grants.
Effect of the AI Act. While ethical and regulatory discourse is ongoing, there is limited empirical evidence on how legislative nuances alter HPC-based ML workflows and broader R&D agendas, particularly in terms of data privacy and compliance with equality principles.
Deep Tech Competences. Albeit recent calls for advanced digital skills programs (e.g., Digital-2024-Advanced-Digital-07-KeyCapacity) stress the urgency to update curricula and workforce training, detailed examinations are scarce on how HEIs embed these programs into existing structures or measure subsequent impacts on local industry collaborations.
Regional Focus and Collaboration Dynamics. Most studies adopt a global perspective, with limited attention to the EU’s specific challenges and international collaboration, which are central to ML research in tertiary education. However, their structural and thematic characteristics are insufficiently examined. This paucity of regional specificity hinders the understanding of how EU-centric policies, funding mechanisms, and distribution of expertise through partnerships mold ML adoption withing European Union HEIs.
These theoretical deficiencies expose the necessity for systematic analyses that link funding models, HPC expansions, and policy-based constraints with the on-the-ground realities of how HEIs integrate machine learning.
3. Materials and Methods
3.1. Research Design and Rationale
We designed a multi-stage analytical pipeline to examine how higher education institutions (HEIs) worldwide have engaged in machine learning (ML) research collaborations, aligning with the research hypotheses outlined in the Introduction. To test whether institutional dominance is linked to HPC infrastructure and funding access, we measured network centrality and funding distributions (Hypotheses 1 and 2). To assess disparities in collaboration between Western and Eastern Europe, we compared institutional representation across network metrics (Hypothesis 3). The relationship between international collaboration and research impact is explored through citation analysis and co-authorship metrics (Hypothesis 4). Thematic clustering via NLP-based topic modeling allowed us to investigate domain dominance in ML research (Hypothesis 5). Finally, we mapped the role of non-EU institutions in European ML networks by analyzing cross-regional co-authorship trends (Hypothesis 6). We selected a combination of bibliometric analysis, text mining, and network science to provide multiple lenses for understanding how institutions interact, how funding streams are distributed, and how textual content reveals dominant research themes. This design integrates the following:
- Bibliometric metadata collection: acquiring documents that mention ML applications in HE.
- Data cleaning and integration: consolidating records from multiple sources and removing irrelevant or duplicate items.
- Categorization: classifying funding types, subject domains, and publication locations.
- Textual preprocessing and topic modeling: deriving thematic structures from titles, abstracts, and keywords.
- Network construction and analysis: building collaboration networks, applying community detection algorithms, and computing node-level centrality.
- Validation and cross-validation: testing the robustness of computed metrics under random partitioning of collaboration edges.
We used Kaggle-based Python environments rather than local high-performance computing (HPC) clusters to maintain consistent hardware requirements and ensure reproducibility. Given the nature of the bibliometric and network analyses performed, the computational demands were moderate and well within the capabilities of freely available cloud-based resources. All scripts and configurations are available upon request and were executed with Python 3.9.6 or later. The detailed workflow, from data collection to analysis, is illustrated in the research methodology diagrams (Figure 1 and Figure 2), which summarize the key steps and processes involved in this study.
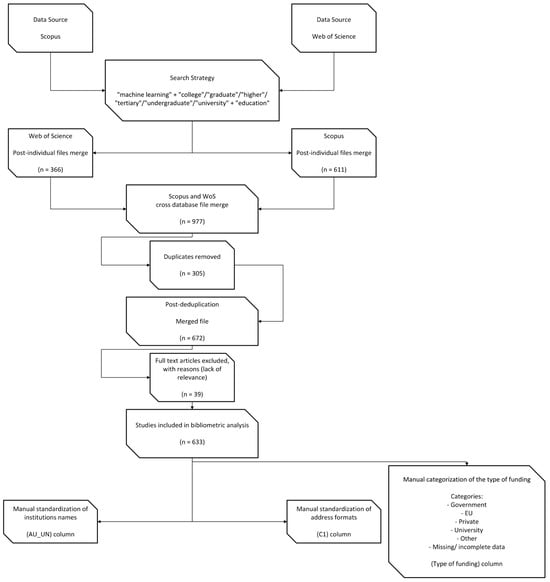
Figure 1.
Workflow of data collection, processing, and cleaning for bibliometric analysis.
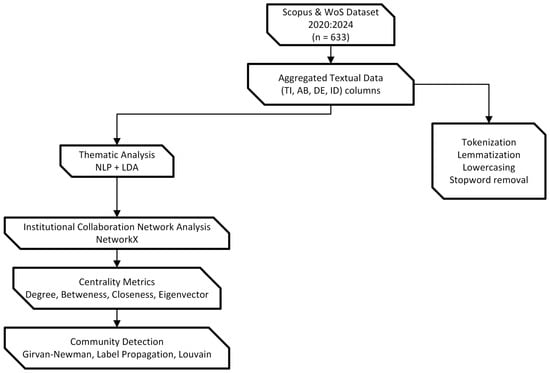
Figure 2.
Thematic and network analysis workflow for institutional collaboration.
3.2. Data Collection and Consolidation
3.2.1. Data Sources and Search Strategy
We extracted primary datasets from two recognized bibliographic platforms, Scopus and Clarivate, covering publications from January 2020 to September 2024. We employed search queries that paired “machine learning” with higher education-related terms (i.e., “college”, “university”, “undergraduate”, “graduate”, “tertiary education”) using logical AND/OR operators. By combining “machine learning” AND (“college” OR “university” OR “undergraduate” OR “graduate” OR “tertiary education”), we obtained an initial corpus of 611 Scopus records and 366 Web of Science records for a total of 977 items.
We selected these databases because they offer (i) extensive coverage across diverse academic fields and (ii) detailed metadata (authors, affiliations, citations, funding sources) essential for bibliometric analysis [38]. We justified the choice of the timespan (2020–2024) on the grounds that recent EU policy efforts, such as Horizon Europe or the Digital Decade, might have significantly reshaped HEI-based ML research.
3.2.2. Deduplication and Relevance Filtering
After importing in Bibliometrix library the bibliographic records in BibTeX format [39], we assigned unique identifiers and merged them on Digital Object Identifiers (DOIs) using Python-based routines (pandas, version 1.4.3). By merging, we found and removed 305 duplicates, leading to a dataset of 672. No specific journals were excluded from the analysis. All retrieved publications in English from Scopus and Web of Science were considered. Subsequently, we identified irrelevant entries that mentioned ML in passing but did not address learning institutions or students in any capacity. We scanned each record’s title, abstract, and keywords for domain-specific language referencing higher education contexts (e.g., references to “teaching”, “university policy”, “student modeling”). We discarded 39 entries that failed to meet these inclusion criteria, culminating in a final corpus of n = 633 relevant publications.
3.2.3. Data Cleaning and Institutional Name Standardization
We converted the remaining records to Excel (.xlsx) to facilitate the manual correction of institutional names. We observed that universities commonly appear under multiple designations—e.g., “Univ. di Bari” and “University of Bari Aldo Moro”—which could fragment analyses. To address this issue, we standardized each unique institution name to a single canonical label (e.g., “University of Bari”). We also corrected typographical inconsistencies, missing characters, and ambiguous geographic references by referencing the pycountry library for validated country codes. This step ensured that further analyses would assign each publication unambiguously to its respective institution(s).
3.3. Funding Categorization and Subject Classification
3.3.1. Funding Sources: Justification and Procedures
We manually validated each record’s “FU” (Funding) column to assess how ML research in higher education is financed. Based on prior bibliometric frameworks [38], we categorized the reported sponsors into five discrete classes:
Government: national ministries, public agencies, and other public administrations;
European Union: central EU programs (e.g., Horizon 2020/Europe) or commission directorates;
University: internal overhead budgets, doctoral grants, or institution-led financing;
Private: corporations, philanthropic organizations, and non-state agencies;
Other: international nonprofits outside the EU, global alliances, or ambiguous sponsors.
We used these categories to examine correlations between collaboration modes (single-country vs. multi-country publications, subsequently referred to as SCP and MCP) and specific funding sources. This classification scheme allowed us to generate cross-tabulations linking sponsor types with co-authorship attributes.
The analysis of institutional collaboration networks in ML research requires an understanding of the financial mechanisms shaping these interactions. A significant challenge in this study arises from the absence of explicit funding information for a large portion of the analyzed publications. To address this limitation, we introduce a comparative framework that examines differences between research articles that explicitly acknowledge EU funding and those that do not disclose funding details. This approach enables a structured evaluation of whether funding transparency influences collaboration structures, research prominence, and institutional centrality within the ML research ecosystem.
To operationalize this comparison, we classified the dataset into two groups: (1) publications with explicit EU funding acknowledgments, identified through funding statements mentioning Horizon Europe, Horizon 2020, or national grants linked to EU-supported programs, and (2) publications where funding details were absent or unreported and belong to authors from European countries. The analysis was conducted by mapping institutional affiliations within these two subsets and computing network metrics, including degree centrality, betweenness centrality, and eigenvector centrality, to assess differences in research influence and connectivity.
The primary objective of this comparison was to determine whether institutions participating in EU-funded projects exhibit higher degrees of multi-country collaboration (MCP), stronger co-authorship ties, and more structured research clusters than those associated with publications without disclosed financial backing. By analyzing patterns of institutional co-authorship, we evaluated the extent to which EU funding acts as a catalyst for international research partnerships or whether non-disclosed funding cases follow different, more localized collaboration trajectories. This distinction is particularly relevant for understanding how funding mechanisms shape the development of ML research across Europe and whether the absence of transparency in financial disclosures introduces potential biases in bibliometric assessments.
Given the methodological constraints associated with missing funding information, we acknowledge the possibility that some non-disclosed funding cases may still involve EU support that was not explicitly recorded. To mitigate this limitation, robustness checks were performed to compare publication venues, citation impact, and institutional affiliations across both subsets, ensuring that observed disparities were not artifacts of dataset composition. This comparative assessment provides a nuanced perspective on the role of funding acknowledgment in shaping institutional collaboration networks, offering insights into both structural advantages conferred by EU funding and the potential implications of limited financial transparency in research reporting.
3.3.2. Subject Category Mapping
We mapped each publication’s subject categories to six macro-level domains—namely, “Computer Science and Engineering”, “Medical and Health Sciences”, “Business and Economics”, “Education and Social Sciences”, and “Environmental and Conservation Sciences”—to facilitate cross-sectional analyses. Because the original dataset spanned 62 granular categories, we consolidated them to reduce complexity while preserving domain specificity. For instance, we grouped “EDUCATION”, “PSYCHOLOGY”, and “SOCIOLOGY” under “Education and Social Sciences” if at least one of these labels were present. We applied this mapping using a custom Python script, ensuring consistency by aligning categories with established frameworks in bibliometrics [39].
3.3.3. Journal Impact Assessment
The h-index was computed as the highest number h for which h articles in a given journal had at least h citations each, providing a measure of consistent influence over time. To complement this, we calculated the g-index, which refines impact assessment by accounting for highly cited papers, defining g as the largest number for which the top g articles collectively received at least g2 citations. Additionally, we introduced the m-index, a time-normalized variant of the h-index, calculated by Formula (1), to account for differences in journal longevity and ensure comparability across publication venues.
These metrics allowed us to contextualize the relative impact of research outlets, distinguishing between consistently high-impact journals, venues with sporadically influential articles, and those with sustained long-term relevance.
3.4. Data Structuring for Collaboration Analysis
3.4.1. Generating Country-Level Metrics
We parsed affiliation lines from each publication to determine the set of unique countries. If the analysis found precisely one country among all author affiliations, the publication was labeled “SCP”, and if multiple countries appeared, we labeled it “MCP.” We subsequently pivoted the dataset by publication year (2020–2024) to create annual country-level publication volumes. We then used quartile-based thresholds (Q1, Q2, Q3) to classify each country into four activity categories (“Very Low”, “Low/Moderate”, “Moderate/High”, and “Very High”). We repeated this process separately for the EU subset and the global corpus to discern whether individual states within the EU diverged from broader global patterns.
3.4.2. Institutional-Level Disaggregation
Next, we exploded each publication’s “AU_UN” field (Author Institutions) into separate rows. This transformation yielded unique article–institution pairs and facilitated the counting of appearances per institution. We relied on this institutional-level data to examine potential co-occurrence patterns, hypothesizing that HPC-equipped or historically prominent universities might appear repeatedly and thus form the backbone of multi-country alliances.
3.5. Textual Preprocessing and Topic Modeling
3.5.1. Preprocessing Pipeline
We merged four metadata fields—“ID” (Keywords Plus), “DE” (Authors’ Keywords), “AB” (Abstract), and “TI” (Title)—into a single text column for each article. To filter out spurious tokens, we implemented a standard NLP pipeline that included lowercasing, regex-based replacements for punctuation, tokenization, and lemmatization [40]. We also removed stopwords (e.g., “the”, “and”, “or”) using the Natural Language Toolkit (NLTK, version 3.5). This pipeline helped us focus on content-bearing terms (e.g., “student”, “neural”, and “curriculum”).
We set frequency thresholds such that words appearing fewer than ten times across the dataset were excluded, mitigating noise from very infrequent tokens. We justified this threshold by balancing coverage of domain-related words against the risk of spurious single-mention terms inflating the dictionary size.
3.5.2. Latent Dirichlet Allocation (LDA)
For thematic exploration, we applied LDA [41] to both the EU-only and global corpora. We built a document-term matrix (DTM) using scikit-learn’s CountVectorizer (version 1.0.2). We tested k = 3 to k = 10 to identify an optimal number of topics, recording perplexity and coherence scores [42]. Each run used a random initialization with ten restarts to stabilize the results. We recorded the top 15 words for each topic to label emergent themes (e.g., “student”, “model”, and “performance” under an academic analytics cluster). We chose LDA because it probabilistically assigns words to topics based on co-occurrence patterns, aligning with our aim to uncover hidden thematic clusters across broad textual sources [43].
3.6. Construction and Analysis of Collaboration Networks
3.6.1. Network Formation
As described in Section 3.4.2, we generated institution-level data from each publication. We aggregated edges by counting the number of multi-country co-publications that each pair of institutions shared. We formed two separate networks in Python 3.9 using the NetworkX library [44]. The first network (“EU Collaboration Network”) included only EU-based institutions and their MCP collaborations. The second (“Global Collaboration Network”) captured links between EU institutions and any extra-EU partners (United States, UK, China, Switzerland, etc.).
We removed self-loops and filtered out nodes that did not co-author with at least one other institution, thus restricting the analysis to actively collaborating entities. We used weighted edges to reflect repeated co-authorship among the same pair of institutions [34]. We adopted these steps to ensure that the resulting graphs accurately represented genuine collaborative ties.
3.6.2. Centrality Metrics
We computed four standard centralities recognized in social network analysis [45,46] to profile institutional roles:
Degree centrality: We measured each node’s total connections, weighing repeated co-publications. High-degree nodes indicate institutions that collaborate frequently.
Betweenness centrality: we identified nodes that lie on many shortest paths [47], highlighting bridging institutions pivotal for connecting distinct subgroups.
Closeness centrality: we calculated the reciprocal of the sum of the shortest path distances from each node to every other node, indicating how quickly an institution can interact with others.
Eigenvector centrality: we captured each node’s influence by weighing connections to other influential nodes [34].
These centrality measures were selected based on their relevance to understanding research collaboration networks. Degree centrality highlights the number of direct institutional partnerships, betweenness centrality identifies key bridging institutions that facilitate collaboration across clusters, closeness centrality assesses how efficiently an institution can interact with others, and eigenvector centrality accounts for influence within the network.
3.6.3. Community Detection
To detect cohesive subgroups, we employed three distinct algorithms:
Girvan–Newman (edge betweenness-based partitioning) identifies communities by progressively removing edges with high betweenness [36].
Louvain (modularity maximization) groups nodes by iteratively optimizing a modularity score, often used to detect hierarchical structures [37].
Label Propagation (consensus-based method) propagates labels within connected components until group membership stabilizes [48].
We intersected the resulting partitions and retained only communities whose membership overlapped in at least two of the three methods, thus mitigating artifacts. We assigned each community a “power” score by summing degree centralities from the intersection subgraph. This additive metric, although simplistic, paralleled synergy-based concepts from prior collaboration literature [35]. The ’Power’ metric is calculated as the sum of the degree centralities of all nodes within a given community. This approach ensures that larger and more connected communities receive higher power scores, effectively capturing their relative importance within the collaboration network. Metrics are particularly useful for identifying dominant research clusters and understanding how institutional collaborations shape the European machine learning research ecosystem.
The selection of centrality measures (degree, betweenness, closeness, and eigenvector centrality) and community detection algorithms (Girvan–Newman, Louvain, and Label Propagation) was motivated by their established relevance in network analysis for identifying key actors, structural influence, and collaboration clusters in research ecosystems [36,48]. These metrics provide a quantitative assessment of institutional prominence and structural positioning in ML research collaborations. However, network analysis alone cannot fully capture the qualitative dimensions of academic partnerships, such as the underlying motivations for collaboration, institutional strategies, or policy constraints influencing funding allocation.
While our approach provides a macro-level perspective on ML research networks, future studies could integrate qualitative methods, such as expert interviews with researchers and institutional policymakers, to contextualize the observed structural patterns. Such complementary insights would refine our understanding of how EU funding policies, institutional priorities, and geopolitical dynamics shape academic collaborations beyond what network analysis can reveal.
3.7. Validation and Cross-Validation
3.7.1. Rationale for Network Cross-Validation
While cross-validation is conventionally applied to supervised learning models, we adapted it here to test the stability of collaboration networks under partial edge removal. We posited that if removing a fraction of co-authorship edges does not substantially change the identity of central nodes or communities, the network structure is likely robust rather than driven by incidental co-authorship patterns.
3.7.2. Implementation of Fold Splits
We randomly shuffled the multi-country edges from each network (EU and global) and split them into five disjoint folds. We designated four folds (80% of edges) as training data and held out the remaining fold (20% of edges) as test data. We then constructed a training network from each subset and recalculated the four centralities (degree, betweenness, closeness, and eigenvector). Institutions that did not appear in a particular fold received zero scores. Subsequently, we standardized the results using min–max normalization, ensuring comparability across folds with varying total edges.
3.7.3. Consistency Measures
We quantified cross-validation consistency via the following:
Correlation Analysis: We computed pairwise Pearson correlations among the centrality metrics across folds, focusing on the upper triangle of each correlation matrix. Higher correlations (e.g., r > 0.75) indicated that node rankings for each metric remained stable when up to 20% of edges were excluded.
Normalized Mutual Information (NMI): We compared community partitions across folds. We created binary membership vectors for each node, indicating whether a node appeared in a given community. We then measured how similarly these vectors overlapped between folds using NMI, where 1.0 indicates perfect agreement [49].
3.7.4. Extended Validation Through Katz Centrality and Clustering Coefficient
We expanded the validation by incorporating Katz Centrality, which weighs paths of increasing length with a damping factor, and the Clustering Coefficient, which measures the extent to which a node’s neighbors also connect to each other. We hypothesized that Katz Centrality might reinforce the patterns observed in eigenvector centrality [50], while local clustering could clarify whether certain nodes remain in tightly knit subgraphs across folds [51].
3.7.5. Citation Data Integration and Field-Specific Assessment
To investigate any relationship between network centralities and citation influence, we aggregated citation counts for each institution from the exploded dataframe, normalizing them by the total number of publications [52]. We then assigned each institution to its primary macro-domain (Section 3.3.2) and plotted log-transformed total citations against degree centrality using a locally weighted scatterplot smoothing (LOWESS) curve. This approach allowed us to visually inspect potential domain-specific patterns (e.g., whether HPC-heavy fields in “Medical and Health Sciences” correlated with higher-degree nodes). We also clustered institutions using k-means (k = 5, random seed = 42) on the min–max standardized centralities to assess whether academic fields and collaboration intensities co-located [53].
3.8. Funding Profiles and Non-EU Countries Involvement
Given the diversity of funding acknowledgments, we systematically defined distinct funding profiles based on explicit mentions of financial support in Section 3.3.1. To thoroughly explore the interplay between funding profiles and the participation of non-EU countries, we established an analytical procedure that involved decomposing each funding profile into subsets, subsequently constructing separate collaboration networks by pairing co-authoring institutions identified through their geographical affiliations. We generated network graphs to serve as a foundation for calculating centrality measures to capture the prominence and influence of individual countries within specific founding contexts.
Emphasis was placed on the evaluation of the roles of two critical non-EU actors—the United Kingdom and the United States—and we examined how their presence and centrality varied across funding profiles relative to leading EU countries. Ratios comparing UK and USA centrality scores to those of top-performing EU countries will be central to seeing how non-EU participation either complements or competes with EU-centric research initiatives. Furthermore, we extended our assessment beyond these prominent actors, considering the involvement of European Free Trade Association (EFTA) countries—primarily Switzerland and Norway—as well as other non-EU nations. Special attention was given to discerning if certain funding profiles fostered greater international collaboration, potentially indicating strategic openness or constraints shaped by funding origin.
4. Results
4.1. Descriptive Publication Metrics and Collaboration Structures
From the merged and cleaned dataset (see Methodology for curation details), we identified 633 publications that met our criteria of explicit ML relevance in tertiary education contexts, authored by 3187 researchers, with a mean collaboration density of 5.14 authors per publication. These team sizes imply that cross-institution synergy is not an outlier but rather a recurring pattern. Only 6.3% (n = 40) of authors published in isolation, contrasting sharply with the 97.3% engaged in multi-institutional consortia.
International co-authorship (MCP) accounted for 46.4% of all items, stressing the robust international engagement—particularly relevant in EU contexts, where multi-lateral funding frameworks encourage cross-border teamwork. About half the articles were classified as journal papers, while nearly one-third were conference papers or proceedings, reinforcing the notion that ML experimentation is frequently presented in conference venues prior to or concurrent with journal publication. The average citation count per document was approximately 7.36, but with notable variance: older papers (2020–2021) demonstrated higher mean citations (often in the 12–15 range) compared to more recent works from 2023 to 2024 (averaging around 3–5 citations). Because the dataset runs to September 2024, the lower figure for 2024’s items is unsurprising, and the natural citation lag also influences aggregated indices such as the h-index or g-index of top sources. The 18,243 references yielded 422 distinct sources (journals, proceedings, or edited collections). One interesting observation is that Sustainability (Switzerland) and IEEE Access share the highest g-index values in this dataset (both at 14), though IEEE Access leads the pack in h-index (8 vs. 6 for Sustainability), reflecting differential uptake in computer science versus interdisciplinary education circles. The difference suggests that IEEE Access has consistently published works that attract references, whereas Sustainability might have a few highly cited publications boosting its g-index.
A key aspect influencing the impact of ML research publications is the prestige of the publication outlets. We analyzed journal impact metrics using h-index, g-index, and m-index, finding that EU-funded research is more frequently published in high-impact journals such as IEEE Access and Sustainability, which display higher h-index values. In contrast, publications with non-disclosed funding exhibit a more dispersed distribution across journals, including venues with lower impact scores.
This discrepancy suggests that structured EU funding not only enhances research collaboration but also facilitates access to prestigious publication outlets, increasing visibility and potential citation impact. While this does not undermine the overall findings, it highlights the need for further examination of how funding acknowledgment interacts with research dissemination and impact metrics in European ML research.
Funding statements, a focal point for transparency considerations, reveal that 435 records (over two-thirds) contained no direct sponsor information. Among those that did, government or university was the most common. Roughly equal percentages of SCP and MCP reported European Union-based grants, as shown in Figure 3. This distribution suggests that large-scale international or trans-European projects, while often associated with Horizon Europe, do not uniquely monopolize public-EU channels since certain national-level programs also encourage cross-border synergy.
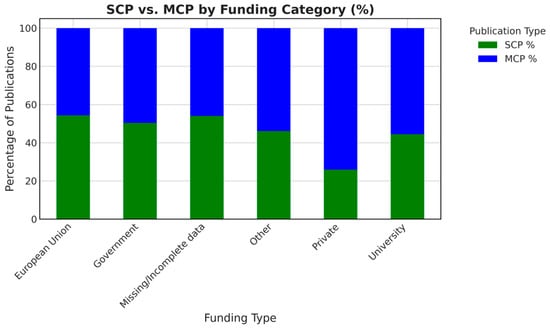
Figure 3.
Single-country publications and multi-country publications distribution by funding category.
4.2. Comparative View: EU vs. Global Activity
Observing the top 15 EU nations in Figure 4, we can clearly notice that Germany tops the charts with 79 publications, of which roughly 85% remain a single country. Spain follows with 61 total documents, and its own SCP ration stands near 79 percent—slightly more reliant on domestic collaboration relative to, say, Austria or the Netherlands, which exhibit a more balanced mix of single-country and multi-country endeavors. Poland’s 21 papers, 90 percent of which are singled out as an SCP, indicate a comparatively lower tradition of cross-border co-publishing, at least within this sample. On the other hand, Italy’s multi-country proportion (25.64%) surpasses the average among the high-output nations, signifying that Italian groups frequently co-author with partners abroad. Interpreted in proportions, Malta, Estonia, Poland, and even Romania maintain high single-country rates, possibly signifying that local teams prefer local alliances. The high rates of MCP from countries such as Slovenia, Luxembourg, and Cyprus align with the notion that their universities often join cross-national consortia to compete for EU framework grants. Extending the lens beyond the EU’s internal collaboration, the global data reveals that Germany and Spain still top the list of total articles, yet the United States makes a strong appearance with 72 papers, all of which (in this dataset) recorded no single-country output because the data specifically targeted publications affiliated with at least one EU-based institution. Interestingly, some smaller EU states (Netherlands, Sweden, etc.) post a high fraction of multi-country collaborations not just with neighboring EU members but also with American, Canadian, or British labs. This observation resonates with the well-funded centers at Dutch and Swedish universities that attract global co-authorship.
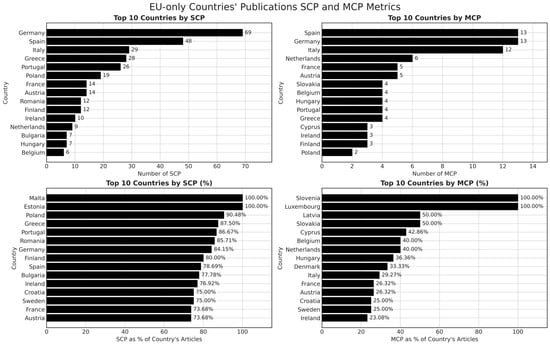
Figure 4.
EU-only countries’ publications: SCP and MCP metrics.
Comparatively, expansions from 2020 to 2024 vary across these states, as traced in the time series in Figure 5. In particular, “Category 4: Very High Activity Countries”, such as Germany or Spain, sustain visible volumes of publications across 2020–2024. Meanwhile, smaller countries like Estonia or Malta, which appear in “Category 1: Very Low Activity”, indicate minimal publication frequencies in this domain, which is reflective of their smaller higher-education system and the fewer local teams that pivot their data science expertise to their educational sphere. The presence of some moderate categories, for instance, Finland or France in “Category 3”, points to a stable output that, while not as large as Germany’s, has expanded more uniformly over these years. Outside of Europe, the pivot-based categorization reveals that several non-EU locations (like Australia or the US) firmly sit in “Category 4: Very High Activity” because they commonly partner with major EU players in multi-year educational analytics ventures. By contrast, many smaller or lower-income countries remain in “Category 1” or “Category 2”, generating either sporadic or minimal publications, accentuating the role of cross-border EU networks that link institutions from advanced economies with those from emerging regions that might have interest but insufficient direct resources to lead projects on their own.
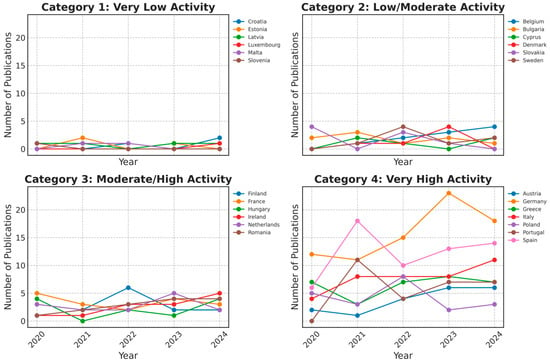
Figure 5.
EU-only publications’ activity over time.
The distribution of ML publications across countries (Figure 4) shows that Germany, Spain, and France lead ML research in the EU, with significantly higher publication volumes compared to Central and Eastern European countries. This trend suggests a strong concentration of scientific output in institutions with extensive access to advanced computing resources and AI-focused funding schemes. These findings support Hypothesis 1, which posits that Western European institutions dominate ML research networks due to their infrastructural and financial advantages.
Figure 4 indicates that Spain ranks among the highest in total publications and international collaborations (MCP), suggesting that key institutions such as Universidad Politécnica de Madrid play a central role in structuring research networks. This is further reinforced by Figure 5, where Spain maintains a strong presence in high-activity categories, aligning with its sustained involvement in EU-funded ML research projects.
The lower presence of Central and Eastern European universities in high-impact collaborations aligns with Hypothesis 3, reinforcing the notion of structural inequalities in research funding and institutional access to ML infrastructure.
4.3. Thematic (NLP) Results: Word Frequencies and Topic Evolution
The textual analysis reveals, for both corpus, prominent tokens such as “student”, “learn”, “data”, “model”, and “AI”. This distribution, consistent across 2020–2024, implies a direct orientation toward how ML is applied to predict or improve learner outcomes, adapt course content, or refine institutional processes (e.g., admissions or scheduling).
Figure 6 displays how each Latent Dirichlet Allocation (LDA)-discovered topic evolves from 2020 to 2024 for the EU-based subset. A typical best configuration based on perplexity and coherence indicated k = 3 or k = 4. In EU-centric machine learning research, LDA with k = 4 revealed distinct thematic clusters:
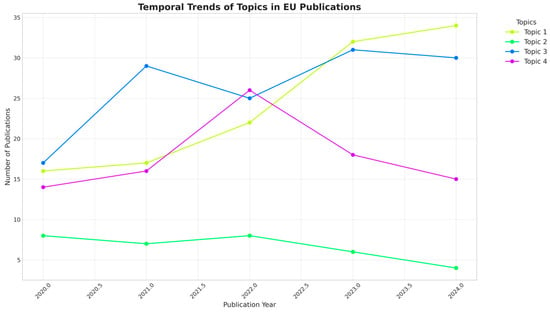
Figure 6.
Temporal trends of topics in EU publications.
- Medical–Educational Synergy (Topic 1): dominated by AI, student, medical, digital, patient, and health, this cluster integrates clinical data with pedagogical tools and grew by 113% from 2020 to 2024.
- Engineering Pedagogy (Topic 2): focused on engineering, technique, image, chatbot, and agriculture, this niche (four publications in 2024) has declined by 50% since 2020.
- Predictive Analytics (Topic 3): centered on prediction, dropout, algorithm, and analytics, this topic surged by 76% (2020–2023), peaking at 31 publications in 2023, correlating with post-pandemic emphasis on student retention.
- Language and Social Learning (Topic 4): highlighting language, teacher, and social, this cluster peaked in 2022 (26 publications) before declining by 42% in 2024, signaling reduced funding for language processing in teacher training.
As temporal shifts, Medical–Educational Synergy (Topic 1) overtook Predictive Analytics (Topic 3) as the dominant theme in 2024 (34 vs. 30 publications), and Engineering Pedagogy (Topic 2) collapsed.
On the global front, LDA with k = 3 uncovered the following topics:
- Educational Predictive Analytics (Topic 1): student, prediction, dropout, algorithm dominated, growing 58% in the dataset period, peaking at 71 publications in 2024, driven by U.S.–EU collaborations on MOOC dropout models.
- AI-Driven Engineering (Topic 2): AI, engineering, technology, and design surged by 88% (2020–2023), reflecting new transatlantic partnerships in industrial AI.
- Clinical Health Analytics (Topic 3): health, clinical, disease, and risk peaked in 2022 (41 publications) before declining by 39% in 2024, paralleling reduced post-pandemic funding for health-tech education.
We can observe that the global Clinical-Health Analytics fell in 2024, despite 2022’s peak, indicating shifting priorities towards foundational AI research, while Predictive Analytics (Topic 1) remained the global focus.
Thematic clusters from Figure 6 reveal strong growth in ML research within the biomedical field, confirming Hypothesis 5 that AI is predominantly applied in healthcare and engineering within European higher education.
4.4. Collaboration Networks and Institutional Hubs
Focusing exclusively on institutions physically located within the EU (or declared as such in the final cleaned dataset), a graph of 375 nodes and 74 edges was created (some nodes with minimal co-authorship were removed in certain visualizations). The top portion of these nodes can be seen in Figure 7, which portrays the EU subgraph after removing isolated nodes (those unconnected to any co-author within the dataset). High-degree nodes (e.g., Universidad Politecnica De Madrid, University of Cordoba) anchor large star-like substructures, consistently bridging smaller universities. Edges with weights >= max_weight/2 appear in green or thicker lines, and many revolve around Spanish–German or Spanish–Italian ties, supporting the notion that Southeastern Europe often collaborates vigorously with Germany’s advanced labs. Labels show synergy among specialized institutions, such as the German Institute of Human Nutrition Potsdam-Rehbruecke with the University of Potsdam, forming a dense local cluster integrated into broader transnational projects by bridging ties to Spanish or Finnish research groups.
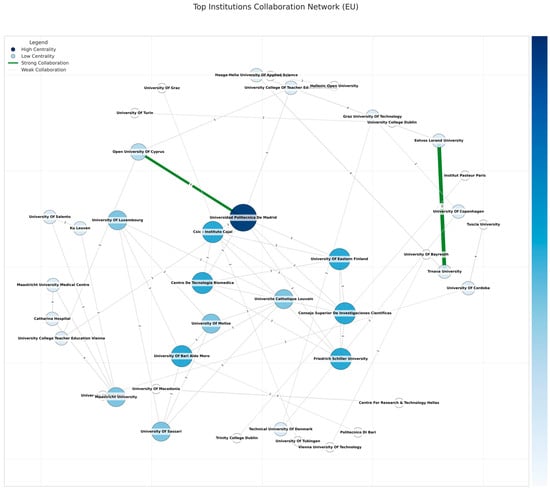
Figure 7.
Top institutions’ collaboration network (EU only). The numbers on the edges represent the collaboration strength between institutions, measured by the weight of their connection (the number of the collaborations).
Figure 8 highlights a more extensive subgraph derived from the top global nodes by publication frequency. Several well-known North American or British universities, absent from purely EU-centered data, now occupy prominent positions. Imperial College London has strong edges to Nanyang Technological University, University of Eastern Finland, Karolinska Institute, and others, consistent with its top betweenness. University Of Pennsylvania co-authors with McGill University, Columbia University, King’s College London, and a handful of Spanish or German institutions, possibly signifying robust HPC-fueled medical or educational data alliances. Columbia University similarly spans transatlantic boundaries, forging repeated pairs with Ludwig Maximilian University in Munich or VU Amsterdam. The net effect is a large, interconnected cluster focusing on advanced ML methods for multiple academic tracks, from health to the humanities.
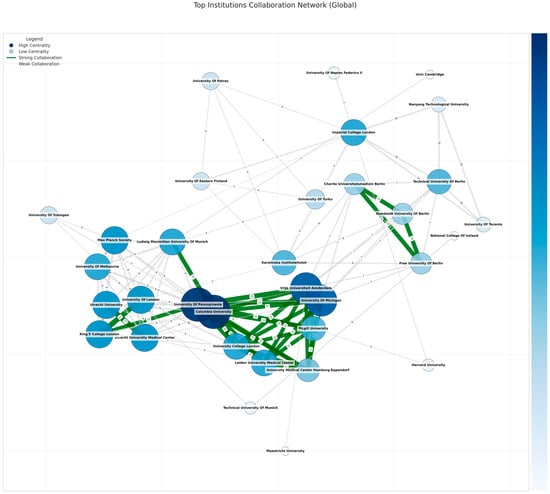
Figure 8.
Top institutions’ collaboration network (global). The numbers on the edges represent the collaboration strength between institutions, measured by the weight of their connection (the number of the collaborations).
The EU collaboration network features several leading institutions with advanced HPC capacities driving multi-country partnerships. Top degree centrality nodes include Universidad Politecnica de Madrid (~0.082) and the University of Cordoba (~0.082), each bridging engineering-based analytics, agricultural applications, and biomedical research. Instituto Maimonides de Investigación Biomédica de Córdoba (~0.072) similarly anchors Andalusian collaborations. High betweenness measures highlight Maastricht University (~0.0045) as a broker linking the Netherlands, Belgium, and Spain, while Politecnica de Madrid again emerges (~0.00397) in large consortia. University of Bari Aldo Moro (~0.00172) connects Italian data science groups with broader EU alliances.
In closeness centrality, Politecnica de Madrid (~0.0835) efficiently reaches many subnodes, the University of Cordoba (~0.0825) facilitates wide biomedical ties, and Instituto de Salud Carlos III (~0.0733) integrates Spanish–German public health studies. Eigenvector scores show the University of Cordoba (~0.359) and the University of Potsdam (~0.352) dominating, alongside the German Institute of Human Nutrition Potsdam-Rehbrücke (~0.352).
Globally, Imperial College London leads degree (~0.078) and betweenness (~0.0937) centrality, collaborating with EU and US hubs, while Karolinska Institutet (~0.0835 betweenness) bridges global medical AI. The University of London remains influential in multiple disciplines, and the University of Pennsylvania (~0.238 eigenvector) heads transatlantic HPC ties, joined by Columbia (~0.234) and King’s College London (~0.163).
The high-degree centrality of universities such as Universidad Politécnica de Madrid and the University of Cordoba supports Hypothesis 1, which suggests that Western European institutions dominate ML research due to funding access and HPC resources.
The strong presence of institutions like Imperial College London and the University of Pennsylvania in European ML networks, despite Brexit, supports Hypothesis 6, indicating that non-EU universities maintain a key role in shaping EU-funded research.
To further investigate the role of funding in shaping collaboration structures, we performed a comparative analysis between EU-funded publications and those without disclosed funding sources. This assessment provides insights into whether funding transparency correlates with network centrality and institutional prominence in ML research.
4.5. Comparing EU-Funded and Non-Disclosed Funding Publications in European Union ML Research
A critical methodological challenge in this study arises from the incomplete reporting of funding sources in a significant proportion of the analyzed publications. Of the 633 articles included, 435 (68.7%) do not explicitly disclose funding details, complicating efforts to assess the role of EU funding in shaping institutional collaboration patterns within ML research. To address this limitation, a comparative analysis was conducted exclusively at the European level, examining differences between studies that explicitly acknowledge EU financial support and those where funding sources remain unspecified. This methodological approach allows for a structured evaluation of whether funding transparency influences institutional collaboration structures, research prominence, and the centrality of key actors within ML research networks across Europe.
The comparative analysis of institutional collaboration structures in European ML research is presented in Figure 9 and Figure 10, which provide a detailed breakdown of publication metrics based on funding transparency. Figure 9 illustrates the distribution of publications explicitly acknowledging EU funding, while Figure 10 presents the corresponding metrics for research articles where funding details remain undisclosed. This comparison enables an assessment of whether institutional prominence, collaboration structures, and research centrality are influenced by financial transparency and access to structured funding programs.
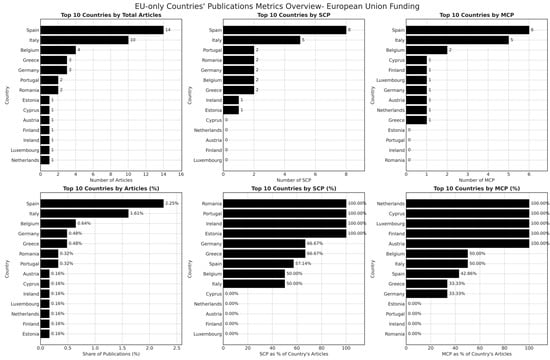
Figure 9.
Publication metrics for EU-Funded machine learning research in European countries.
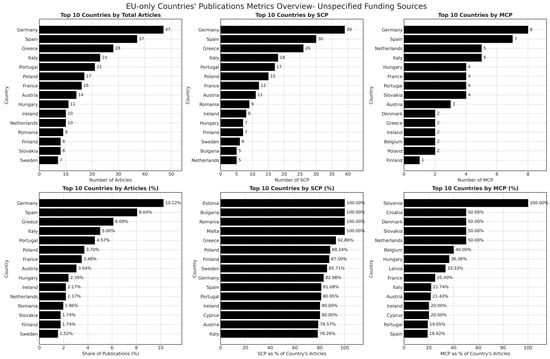
Figure 10.
Publication metrics for machine learning research in European countries with unspecified funding sources.
Figure 9 highlights that Spain and Italy emerge as the most prolific contributors in terms of total publications explicitly linked to EU funding, followed by Belgium, Germany, and Greece. These countries also display a higher number of multi-country collaborations (MCP), reinforcing the role of EU funding mechanisms in fostering international research partnerships. Notably, Belgium exhibits a strong presence in both single-country (SCP) and multi-country collaborations, indicating that EU-backed institutions within the country engage in a diverse range of research initiatives. Conversely, smaller EU member states, such as Cyprus, Estonia, and Austria, demonstrate high reliance on single-country collaboration structures, suggesting a lower degree of international integration despite benefiting from EU funding.
A closer examination of SCP and MCP distribution within EU-funded publications reveals that institutions in countries such as Luxembourg, the Netherlands, and Finland exhibit a 100% MCP rate, signifying that EU-funded research from these nations is exclusively conducted within cross-border partnerships. This pattern suggests that in smaller economies, EU funding serves as a primary enabler for international collaboration. In contrast, larger research-producing countries, such as Spain and Italy, exhibit a mixed pattern, where both national and international collaborations coexist within EU-funded projects. The presence of high-degree centrality institutions in Spain and Italy further reinforces the role of structured EU funding in positioning certain research hubs as key nodes within the broader ML research ecosystem.
Figure 10 presents the same publication metrics for articles without explicit funding disclosures. A key observation is the significant increase in total publication counts across European countries when funding details are absent, with Germany, Spain, and Greece now leading in research output. This shift in publication distribution suggests that a considerable volume of ML research within Europe operates without clearly stated financial backing, raising concerns regarding the transparency of funding acknowledgment practices. Despite the higher publication counts, the structure of collaborations in the absence of funding transparency differs markedly from the EU-funded subset. Single-country publications dominate in several cases, particularly in Germany, Greece, and Spain, where national research clusters appear to drive a substantial portion of the ML research landscape.
The comparative analysis between Figure 9 and Figure 10 underscores the central role of EU funding in shaping research collaboration dynamics within European ML research networks. EU-funded publications demonstrate a higher degree of multi-country collaboration, with structured funding mechanisms facilitating cross-border partnerships and fostering institutional centrality in research networks. In contrast, the dataset comprising publications without disclosed funding exhibits a more fragmented collaboration landscape, where nationally confined research efforts are more prevalent. The lower incidence of MCP in the missing funding dataset further suggests that the absence of acknowledged financial support is associated with reduced institutional integration in transnational research initiatives.
These findings have important implications for the assessment of research collaboration structures within the European ML research ecosystem. The observed discrepancies between EU-funded and non-disclosed funding cases highlight the need for standardized funding acknowledgment practices to ensure accurate bibliometric assessments. The strong correlation between EU funding and institutional prominence further suggests that structured financial support plays a pivotal role in sustaining collaborative research networks. Future research should explore potential biases introduced by incomplete financial disclosures and examine how variations in funding acknowledgment impact the visibility and integration of European research institutions within global scientific collaborations.
The institutional collaboration networks in Figure S1 (EU-funded research) and Figure S2 (research with unspecified funding) highlight stark differences in research connectivity and structural cohesion across European institutions.
The EU-funded network is well-structured, with key institutions such as Universidad Politécnica de Madrid, University of Eastern Finland, and Consejo Superior de Investigaciones Científicas emerging as central hubs. These institutions participate in large-scale, multi-country collaborations, reinforcing the role of structured EU funding in sustaining research cohesion. The presence of strong collaboration links suggests that EU-backed projects are more likely to engage in coordinated, international research efforts.
In contrast, the network in Figure S2 appears more fragmented, with fewer strong connections and a lack of dominant central institutions. Collaborations tend to be weaker and more localized, indicating that the absence of disclosed funding corresponds with less structured research partnerships. The dispersed nature of these institutions suggests that they lack the same level of strategic coordination and cross-border integration seen in EU-funded projects.
These patterns reinforce the notion that EU-funded institutions not only engage in larger-scale projects but also function as critical nodes in European ML research networks. The absence of disclosed funding leads to a weaker transnational research landscape, with fewer structured collaborations and a reduced level of institutional centrality. This highlights the methodological concern that missing funding disclosures can obscure the true impact of financial mechanisms on research networks.
While this does not invalidate the study’s conclusions, it underscores the need for standardized funding acknowledgment practices to improve the accuracy of bibliometric analyses. Future research should advocate for stricter funding disclosure requirements, ensuring a clearer assessment of collaboration dynamics and the role of structured funding in shaping European ML research.
4.6. Community Structures and Leading Clusters
To move beyond individual centralities, we apply a community detection intersection approach (Girvan–Newman, Louvain, Label Propagation) on the EU graph. Out of multiple detected clusters, five robust communities stand out by virtue of repeated membership across methods and meaningful domain synergy. Table 1 outlines them with each group’s approximate “power” rating, an additive measure derived from summing the degree centralities of its members.

Table 1.
Top five EU communities in intersection.
Community 1 unites Spanish–German labs in advanced nutritional or biomedical ML with HPC-based health data modeling. Community 2 links Spanish government labs, a German university, and Finnish or Cypriot teams focusing on HPC-driven neurological or biomedical tasks. Community 3 merges French elite institutes (Pasteur, College de France) and Trinity College Dublin for HPC-based pathogen or life sciences research. Community 4 groups central/northern European labs with southern Italy, targeting advanced dietary or agricultural analytics; Luxembourg often provides large grants. Community 5 unites Germany, Belgium, the Netherlands, and Italy to pursue HPC-based cardiovascular analytics, with Maastricht as a bridging node.
Figure 11 displays these five core communities on the EU network graph, highlighting each cluster’s membership by color. The approximate “Power” values reflect each cluster’s combined connectivity, with Community 1 holding the highest synergy at ~0.598.
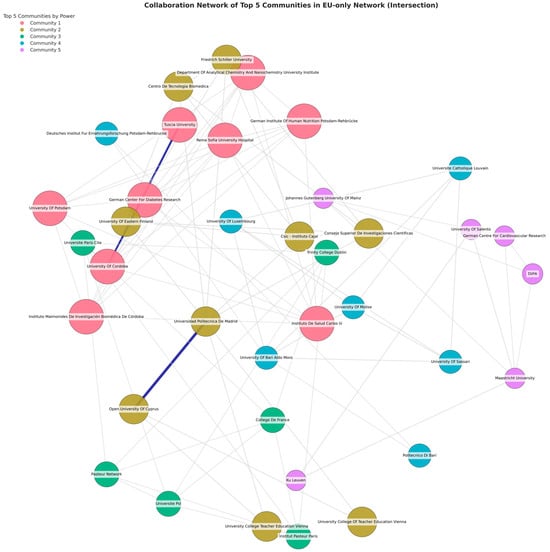
Figure 11.
Collaboration network of top five communities in EU-only network (intersection).
Within the global viewpoint, five clusters emerged in the intersection subgraph that consistently reappeared across algorithmic runs. Table 2 indicates a giant cluster (Power ~7.91) that included major players such as Columbia University, University of Pennsylvania, King’s College London, VU Amsterdam, and Karolinska Institute—it spanned advanced HPC labs and well-funded AI centers with wide disciplinary coverage. Another smaller cluster bridged certain Asia-Pacific institutes with Spanish or Eastern European collaborators, presumably focusing on region-specific educational analytics.
Table 2.
Top five global communities in intersection.
The analysis of research communities (Figure 11) reveals that elite universities, such as Universidad Politécnica de Madrid and the University of Cordoba, serve as central hubs in EU ML networks. Horizon Europe funding appears to facilitate these structures, enabling the formation of strong consortia around institutions with direct access to resources. These findings confirm Hypothesis 2, which suggests that EU funding mechanisms play an important role in shaping international collaborations and reinforcing academic hierarchies.
4.7. Cross-Validation of Network Metrics and Community Stability
Because network metrics and community detections can be sensitive to data perturbations, the methodology included a fivefold edge-based cross-validation. Table 3 summarizes the centrality consistency scores across folds.
Table 3.
Centrality metric consistency scores.
The remarkably high consistency of eigenvector centrality (0.981) suggests that “elite” nodes (for instance, Politecnica de Madrid or University of Cordoba in the EU, or University of Pennsylvania globally) hold stable connections to other well-connected players, even if 20% of edges are randomly removed. Betweenness centrality is inherently more volatile (0.769), as bridging roles can shift drastically if certain edges vanish.
NMI (Normalized Mutual Information) for community detection remains above 0.97 in all fold comparisons, while Variation of Information hovers around 0.095 ± 0.095. The intersection-based approach thus yields near-identical partitions under partial edge removal. Community-level stability (particularly for large power communities) remains high:
- (i).
- Comm 1 in the EU set shows a perfect overlap across folds (1.00 ± 0.00), reflecting the unwavering synergy among Spanish–German labs in nutrition or metabolic HPC research.
- (ii).
- Comm 2 experiences ~0.93 ± 0.13 overlap, reflecting minor membership changes at the edges.
- (iii).
- The smaller communities can show modest dips, but none drop below ~0.87.
Each community’s top institutions reappear among the upper quartile in degree or betweenness across multiple folds. The synergy suggests that HPC-based or well-funded projects drive repeated cross-author ties that do not vanish with random sub-samples of data.
The strong correlation between institutional centrality and citation counts (Figure 12) suggests that universities with extensive international networks benefit from greater academic visibility. This finding supports Hypothesis 4, demonstrating that transnational collaborations are associated with higher scientific impact.
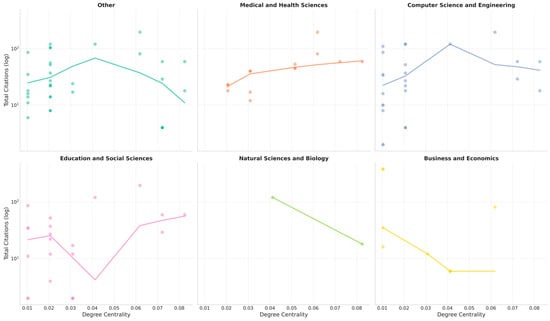
Figure 12.
Field-specific citation patterns: degree centrality relationships (EU network).
4.8. Relationship Between Citation Impact, HPC Capacity, and Network Centralities
An additional dimension of interest concerns whether HPC usage or broad collaborations translate directly into higher citation metrics. The dataset includes partial HPC references and domain-level categories (medical and health sciences, computer science, education, etc.). Figure 10 offers a composite view of log-scale citations vs. node-level degree centrality for institutions mapped to major subject categories (medical/health, computer science/engineering, education/social sciences, etc.), where each panel draws a local regression line (LOWESS) to interpret potential non-linearities, certain patterns emerging:
- A.
- Medical/Health: A positive slope, leveling off past ~0.05 in centrality, indicating that well-connected health institutions typically accumulate moderate to high citations. Extremely high connectivity yields diminishing marginal citation returns.
- B.
- Computer Science/Engineering: A near-linear positive correlation, with certain mid-range nodes hitting 100–200 citations. Possibly, HPC-driven alliances produce consistently high-impact publications, but the densest bridging labs do not necessarily show proportionally higher citations.
- C.
- Education/Social Sciences: An uneven pattern. Some moderate-degree institutions produce a spurt of citations, while others remain small. This irregular distribution may reflect how large consortia in educational research produce a handful of widely cited meta-studies, but numerous smaller collaborative articles remain at lower citation levels.
- D.
- Natural/Biology: A paradoxical region emerges at higher degrees. Some highly connected labs do not see commensurate citations, possibly because biology is subdivided into narrower specializations or because their HPC-based collaboration is too domain-specific to gather general citations.
- E.
- Business/Economics: Sparse data indicates that a few top-tier economic institutions might rank moderately in centrality but yield large citation spikes. This phenomenon suggests business schools can accumulate significant referencing if they tackle popular ML/education topics, even with fewer cross-institution ties.
In our final validation of the EU-centric network, we relied on multiple measures addressing structural cohesion, partition robustness, and cross-fold consistency. As summarized in Table 4 below, the final graph of 98 nodes and 143 edges yielded 26 communities with high modularity (0.877), reflecting strongly cohesive subgroups. Average clustering remained moderate (4.20 for the largest community’s mean degree), while assortativity suggested that well-connected HPC-oriented hubs often co-author with nodes of similarly high connectivity. Cross-validation across five folds confirmed near-perfect Normalized Mutual Information (NMI ~0.972 ± 0.028) and minimal Variation of Information (~0.095 ± 0.095), indicating stable partitions even after randomly excluding 20% of edges. Centrality correlations echoed this pattern: eigenvector centrality retained the highest fold-to-fold consistency (0.981), followed by degree (~0.804), closeness (~0.799), and betweenness (~0.769). Meanwhile, examining the overlap of the top 10 degree-central institutions per fold revealed that larger or HPC-based communities (e.g., Community 1) showed approximately 0.64 overlap with these top nodes, whereas smaller communities displayed lower overlap. Overall, the convergence of these metrics—spanning modularity, average degree, clustering, cross-fold correlation, and stable community boundaries—reinforces that certain well-resourced nodes repeatedly anchor EU-wide collaborations while smaller or more domain-specific enclaves remain intact yet exhibit less overlap with the highest-ranked hubs.
Table 4.
EU network validation summary.
4.9. Non-EU Involvement in Different Funding Profiles
An additional strand of the analysis centers on how non-EU actors—primarily the United Kingdom and the United States—participate in research projects that disclose specific European Union funding combinations alongside other national or private sources. This investigation emerges from a practical curiosity: whether institutions outside the EU gravitate toward particular funding models and whether the presence of EU sponsorship provides any incentives for non-EU countries to associate themselves in this area of research. More than twenty combined “funding profiles” appeared, capturing single-source references (e.g., “Government”, “European Union”, “Private”, “University”) as well as more elaborate mixes that included, for instance, “Government + European Union + Private + University”. Yet, as emphasized in the other sections, over two-thirds of the entire corpus (435 out of 633 publications) did not make any explicit mention of who or what entity had supported the work, relegating these records to a generalized “missing/incomplete data” category. Table 5 condenses the essential findings for all funding profiles, detailing (i) total publication counts, (ii) basic network metrics—namely the number of countries and multi-country links—and (iii) representative centrality ranks for the UK, the US, or other non-EU participants when they appear.
Table 5.
Non-EU country centrality across all funding profiles.
A first glance at Table 5 suggests that the UK and the US occasionally attain substantial centrality levels even within networks ostensibly anchored by national or governmental budgets (e.g., “Government + Private”, “Government + University + Other”), which complicates any assumption that EU-specific funds alone drive non-EU involvement. The United States showcased high centrality in profiles like “Private”, overshadowing European participants, suggesting a scenario where private funding aligns strongly with American institutional participation. Centrality metrics of other non-EU nations, particularly China and Canada, also merit attention. China’s prominence within the “Government” and “Government + University” funding profiles (centrality of 0.43 and 0.26, respectively) indicate targeted collaboration with state-sponsored academic research, possibly a reflection of the strategic EU-China research alliance aligned with broader geopolitical considerations. Canada’s centrality (0.64) in the “Government + University + Other” profile positions it as a significant bridging country, likely propelled by collaborative projects around advanced ML technologies. These discrete examples suggest that certain funding blends, particularly those involving multiple co-sponsors (e.g., governments plus private-sector contributors), coincide with a robust UK or US presence in co-authorship networks.
In contrast, publications explicitly labeled the European Union alone (16 documents) show no direct UK or US centrality in the network portion we examined, and a negligible percentage of those articles involve non-EU participants. A similar observation applies to the Government + European Union (16 documents), which registers no direct centrality for either the UK or the US, although smaller third-country actors (e.g., China or Australia) appear sporadically with moderate centrality scores.
Figure 13 specifically explores the centrality ratio of the UK and USA relative to the leading EU institutions across the diverse funding profiles. It elucidates the distinct trend where the UK significantly surpasses the centrality of the leading EU nations in profiles that blend governmental and private funding sources, particularly notable in the “Government + Private” category. The USA’s centrality, while substantial, remains generally closer to parity with leading EU countries, with notable exceptions such as the “Private “ funding profile.
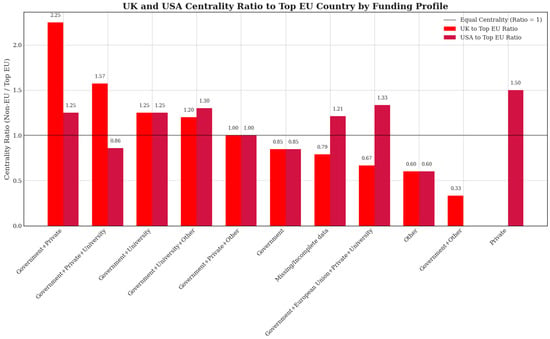
Figure 13.
Ratio of UK and US centrality relative to the leading EU institution across funding profiles.
Figure 14 further contextualizes these centrality patterns by showcasing the marked preference for UK and US institutions in specific hybrid funding models. Notably, the presence of other non-EU countries, especially EFTA members and those from Asia and Latin America, becomes more apparent in mixed or ambiguous funding schemes (e.g., “Government + University + Other” and “Other”), suggesting that such frameworks offer broader international appeal, perhaps due to fewer regulatory constraints or more inclusive eligibility criteria.
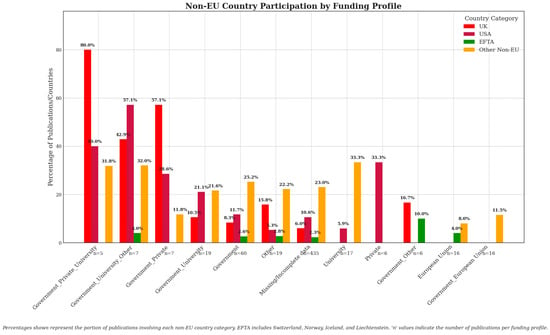
Figure 14.
Percentage of publications involving non-EU countries by funding profiles.
Our findings, summarized visually in Figure 13 (rations of UK and US centrality) and Figure 14 (proportions of non-EU involvement by funding profile), do not conclusively demonstrate that EU-backed initiatives systematically attract non-EU institutions. Indeed, some of the highest non-EU centralities arise in categories that do not explicitly mention EU sponsorship or that incorporate multiple funders, possibly including domestic public grants or private contracts from beyond Europe.
5. Discussion
Our initial assumption—that well-resourced higher education institutions (HEIs) equipped with robust high-performance computing (HPC) infrastructures would anchor multi-country machine learning (ML) collaborations—finds substantial support in this study. Although the dataset under examination extends only to 2024, our mapping of co-authorship networks, the relative prominence of single-country (SCP) vs. multi-country (MCP) research, and the alignment of certain universities with HPC-rich consortia strongly suggest that HPC capacity and prior funding success act as de facto gatekeepers for collaborative ML in academia.
5.1. Dominance of the HPC-Endowed Institutions and Funding Transparency
5.1.1. Institutional Ranking and HPC Capacity
The dataset shows that major nodes—often located in Germany, Spain, or the Netherlands—reappear across multiple communities or bridging positions, indicative of substantial HPC resources or established ties to core funding bodies. Notably, many of these universities align with top positions in widely recognized ranking systems (e.g., Shanghai top 1000), a correlation that emerges because HPC investments often follow or reinforce existing prestige. Prestigious institutions leverage HPC as a tool for advanced deep learning or large-scale analytics, thereby remaining desirable collaborators for smaller or peripheral HEIs keen to publish in competitive venues. By contrast, countries such as Poland, Portugal, and Greece, which do not house as many top-ranked universities or HPC hubs, show higher proportions of single-country research. This pattern may imply, as earlier observers have posited [12], that historically well-funded consortia favor established centers, reducing the impetus to include less-resourced partners.
The prevalence of Western European institutions at the top of ML research networks suggests that access to HPC infrastructure and Horizon Europe funding has a cumulative effect, reinforcing the dominance of already well-established universities. Institutions such as Politecnica de Madrid and the University of Cordoba benefit from substantial resources, whereas institutions in Central and Eastern Europe have more limited access to such facilities. This finding aligns with Hypothesis 1, indicating that institutional hierarchies in ML research are shaped by both infrastructure availability and financial support.
5.1.2. Persistent Disparities in Collaborative Patterns
The notion of “geographical imbalances” [11,12] surfaces repeatedly, with smaller or mid-range universities often overshadowed by HPC-heavy institutes in transnational networks. While some bridging institutions—Maastricht University and Politecnica de Madrid—appear to guide or mentor peripheral HEIs, the data reveals no clear evidence that such mentorship has mitigated structural inequalities in HPC usage or cross-border research volumes. In fact, the synergy among large, historically funded institutes appears self-reinforcing, reminiscent of the repeated calls for “Widening” or “Teaming” instruments that were intended to diffuse HPC competencies into more modestly endowed regions [14]. Although official dashboards [21] do confirm some growth in these smaller locales, the underlying network patterns in our study illustrate how dominant centers still concentrate the lion’s share of multi-author publications and HPC-driven projects.
Universidad Politécnica de Madrid (UPM) emerges as a key hub in European ML research, exhibiting consistently high centrality across collaboration networks. This prominence can be attributed to its strategic involvement in EU-funded research programs, long-standing institutional partnerships, and access to high-performance computing infrastructure.
The distribution of research communities indicates that institutions with direct access to Horizon Europe funds attract the majority of transnational collaborations. This observation strengthens Hypothesis 2, demonstrating that funding schemes directly influence the structure of academic networks, consolidating power centers in ML and limiting opportunities for less connected institutions.
5.1.3. Health and Sensitive Data Handling as a Research Magnet
Consistent with prior discussions [13] on the ethical dimensions of AI in education, one of the most notable domains fueling HPC-based collaborations centers on health: biomedical imaging, nutrition analytics, or advanced patient-oriented modeling. Our data echo the calls to integrate real clinical datasets into postgraduate learning [17,18] while simultaneously amplifying the stakes for data governance. Institutions known for HPC-based medical research—e.g., Potsdam’s nutrition hubs or Spanish biomedical institutes—are well-represented in multi-country clusters, presumably thanks to repeated success securing competitive grants aimed at translational AI in healthcare. Although this synergy can enhance academic training, the limited transparency in some funding statements poses serious concerns: nearly 435 records lack unambiguous sponsor data, making it difficult to ascertain whether HPC expansions benefit only an elite circle or whether a broader educational community reaps these rewards.
5.1.4. Global Collaborations vs. Intra-EU Integration
In addition to identifying HPC-equipped leaders within the EU, our analysis underscores how extra-EU partners—particularly from the United States, China, and, to a lesser extent, Australia—emerge exclusively in multi-country co-authorship. This phenomenon agrees with the broad premise that advanced machine learning, especially for large-scale HPC experiments, transcends regional boundaries. However, the presence of these non-European collaborators also raises the question of how EU public funds (often allocated to strengthen Europe’s digital autonomy, as emphasized by the Digital Decade Policy Programme) might indirectly support non-EU labs that bring specialized expertise or hardware. If those external institutions are also top-ranked, their gravitational pull can overshadow the smaller European HEIs struggling to secure HPC-based partnerships. The mismatch potentially undermines the stated objectives of EU-level policies aimed at fostering AI capacity across all member states [23].
5.1.5. Ties to Multiple Ranking, Cultural Proximity, and Dual Affiliations
A recurring thread underscores that bridging nodes often appear among institutions cited not only in the Shanghai top 1000 but also in other global rankings, such as the QS World University Rankings or the Times Higher Education Index. This observation supports the broader notion that well-established universities with recognized prestige prefer to align with peers of similar stature, a pattern that can sideline institutions lacking comparable visibility in these global listings. Meanwhile, smaller clusters connected by shared language or history—such as Spanish-speaking networks or Germany–Austria academic ties—may operate in relative isolation if they lack HPC capacity, though they can still cultivate synergy on localized research topics.
Beyond these rankings-based preferences, dual affiliations further complicate the landscape. Certain academics hold concurrent appointments, for instance, at a Dutch university and a North American institute or at a Spanish campus and a research lab in Asia. This situation can inflate multi-country publication counts even when day-to-day collaboration remains minimal. Verifying whether these dual-affiliation projects constitute substantial consortia or merely peripheral links hinges on the availability of more transparent metadata, including project documentation and clear sponsor acknowledgments. Without such clarity, it is difficult to determine whether global partnerships genuinely foster deep cross-institutional engagement or simply reflect nominal affiliations that bolster publication metrics while sidestepping the broader goals of equitable resource sharing or meaningful HPC cooperation.
5.2. Accountability and Funding Transparency
5.2.1. Impact of Ambiguous Sponsorship on Trust and Equity
Although HPC-intensive projects frequently require substantial financial backing, the omission of sponsor details in nearly one-third of the records leaves it unclear how or whether public monies are distributed in ways consistent with policy objectives [11]. In principle, thorough funding disclosures, including explicit references to local or EU-level bodies, would help track whether HPC expansions genuinely reduce inequalities or whether they concentrate resources among the same high-ranking centers. The limited presence of sponsor details also complicates discussions around ethical obligations tied to the usage of sensitive student or patient data. Indeed, if major HPC labs secure external private contracts or philanthropic funds under minimal oversight, there is a risk of potential misalignment with guidelines that stress accountable AI in academic settings [13,24].
5.2.2. Broader Reflections on Data Governance
Local IRB frameworks or national data protection standards vary widely across Europe, let alone on a global scale [20]. Our co-authorship findings, highlighting intense HPC usage for health-related or performance-based analytics, suggest that major centers employ specialized compliance teams to meet or exceed the requirements set by the AI Act or GDPR-like rules. In smaller HEIs, compliance efforts are likely more ad hoc, raising the possibility that moral or legal responsibilities for data stewardship become concentrated at the HPC partner’s site, thus perpetuating reliance on external expertise. By extension, policy frameworks could more assertively mandate robust data management protocols for HPC-based educational ML, with strict enforcement of funding transparency as a prerequisite for awarding large AI grants [14].
5.3. The Role of Non-EU Institutions in European ML Research
5.3.1. Structural Centrality and Institutional Dynamics
The institutional collaboration network analysis highlights that several non-EU institutions occupy central positions, even within a dataset primarily focused on European research. This is particularly evident in the network of institutions with missing funding information, where organizations from the United States, the United Kingdom, and Switzerland emerge as major hubs in the ML research landscape. These institutions often co-author with European counterparts, suggesting that their influence extends beyond national boundaries, integrating them into the European research ecosystem.
A possible explanation is that European ML research, even when primarily structured within EU institutions, remains inherently international. Leading non-EU institutions such as the University of Michigan, Case Western Reserve University, and Koc University exhibit strong collaborative ties with EU-based universities. Their centrality may be attributed to their historical research impact, access to advanced computational resources, and established academic partnerships that transcend regional funding structures.
Another key factor could be the institutional positioning of multinational research organizations and industry-academic partnerships. Entities such as the World Health Organization (WHO) and major research hospitals maintain strong European collaborations, often facilitating interdisciplinary ML research in healthcare and biomedical applications. Their presence in the network suggests that certain research domains naturally attract international collaboration, regardless of funding origin.
Given these observations, we hypothesize that the integration of non-EU institutions into European ML research is not solely a product of direct funding mechanisms but rather a reflection of broader academic networks and institutional collaborations. Future research could explore whether non-EU institutions act as structural intermediaries, enhancing Europe’s global research connectivity, or whether their centrality is driven by domain-specific research trends that inherently necessitate international cooperation.
Although the use of centrality measures and community detection provides valuable insights into the structural characteristics of ML research networks, these quantitative methods have inherent limitations. Network metrics indicate relative influence within a collaboration structure but do not reveal the qualitative motivations behind institutional alliances. For example, high betweenness centrality suggests that an institution acts as a bridge between clusters, yet this does not indicate whether the collaboration is policy-driven, opportunistic, or rooted in long-term strategic partnerships.
Moreover, community detection methods identify research clusters based on co-authorship ties, but they do not account for informal academic exchanges, joint grant applications, or unpublished collaborative work. Future research could complement this analysis with qualitative approaches, such as case studies of leading research hubs or interviews with principal investigators, to understand the decision-making processes behind institutional partnerships. This mixed-methods approach would provide a more comprehensive picture of the dynamics shaping ML research in European higher education.
5.3.2. Funding Profiles and Incentives for Non-EU Participation
A broader reading of the numbers suggests that while explicit “EU” labeling in a funding profile does not automatically preclude non-EU implication, the more strongly “European Union”–branded subcategories (e.g., European Union alone, or Government + EU with minimal mention of private or university co-sponsors) tend to show fewer external participants, or none at all. In small subsets labeled purely “EU”, at most, a few Western Balkan neighbors (Serbia, North Macedonia) appear, presumably within educational or cross-border synergy contexts. On the other hand, multi-sponsor hybrids that include government or private agencies—especially from countries with established international ties—consistently bring the US or the UK near the top of the centrality hierarchy, often beyond purely local actors.
One might expect that Horizon Europe or related EU frameworks specifically devoted to “international cooperation” could explain the high presence of external nodes. Yet, there is no definitive indication that “EU-labeled” frameworks systematically encourage or discourage major non-EU collaborators. Rather, these collaborative ties seem propelled by a confluence of factors, as discussed in Section 5.3.1, from local policy aims to prior institutional networks, with some projects simply being large or prestigious enough to attract well-known foreign universities. The single largest cluster of articles remains the missing funding set, where both top-tier EU institutions (Germany, Spain, and the Netherlands) and significant external powerhouses (the US, the UK, and China) appear repeatedly but without a stable link to any declared incentive scheme. This lack of detail makes it impossible to conclude whether external participants directly benefit from or even require the impetus of a formal EU co-funding mechanism.
5.4. Limitations of Our Analysis
Despite assembling an extensive corpus and applying multiple checks on institutional affiliation data, certain constraints dampen the conclusiveness of these findings:
- 1.
- Funding Gaps
Although repeated references to Horizon Europe instruments [21] imply that many HPC-based studies receive partial or full public support, the absence of explicit funder statements in hundreds of papers makes it difficult to correlate HPC usage with exact funding streams. The real distribution of resources may thus be more skewed than our partial records suggest.
- 2.
- Metadata Discrepancies and Affiliation Inconsistencies
The classification of single-country vs. multi-country articles hinges on authors’ formal affiliations. Where authors hold multiple appointments or transition mid-project from one institution to another, the official metadata may inflate cross-border collaboration. Conversely, domestic partnerships might be underrepresented if addresses were not updated or partially missing after institutional restructuring.
- 3.
- Citation Lag and Emerging Research
Publications from late 2023 or early 2024 have had limited time to accumulate references, hindering accurate measurement of their impact or HPC dependence. Rapidly evolving fields such as automated tutoring or real-time analytics might become more prominent in subsequent years, yet our static time window cannot anticipate those shifts.
- 4.
- Overlooked Regional or Niche Topics
Our broad textual analyses emphasize the majority or frequent tokens. Specialized subfields—such as AI-driven student mental health interventions—might remain under-represented if they appear in only a handful of articles. Meanwhile, smaller or region-specific topics could fail to meet minimal token thresholds, leaving them effectively invisible in topic modeling or cluster detection.
- 5.
- Ambiguities in Determining Project Scale
A single multi-country co-authorship might reflect an extensive cross-border HPC collaboration or a single traveling doctoral researcher. Without disaggregated project-level data, one risks conflating minimal involvement with deep synergy. This limitation is relevant in the context of dual or triple affiliations, which can artificially inflate multi-country counts.
- 6.
- Generalization Beyond the EU
While the dataset includes external partners, its principal vantage is EU-based. Global trends (e.g., major expansions in China’s HPC ecosystem) are only indirectly captured. Extrapolations regarding the global AI in the education ecosystem must, therefore, be tempered with caution.
- 7.
- Dual Tenures and Personal Networks
Our co-authorship networks treat each institution as a separate node, but personal ties that traverse multiple affiliations can overstate collaboration levels. If certain senior investigators hold partial appointments in the EU and North America, the dataset may inflate the count of multi-country articles.
- 8.
- Limitations in Assessing the Impact of Brexit
This study is limited by the lack of a direct pre- and post-Brexit comparison, as our dataset (2020–2024) primarily captures post-Brexit collaborations. While UK institutions remain central in ML research networks, the long-term effects of Brexit on EU–UK partnerships are unclear. Future research should conduct longitudinal analyses to assess shifts in collaboration intensity and explore how UK institutions adapt to reduced access to Horizon Europe funding.
- 9.
- Language and Database Selection Bias
The reliance on Scopus and Web of Science may introduce selection bias, as these databases primarily index English-language publications, potentially underrepresenting research from non-Anglophone EU countries. Additionally, their focus on high-impact journals may skew results toward well-established institutions, overlooking contributions from emerging research centers that publish in regional or specialized venues. Future studies could mitigate these limitations by integrating national repositories to ensure broader coverage of European ML research.
6. Conclusions
This study provides a comprehensive network analysis of machine learning research collaborations in European higher education, offering insights into institutional hierarchies, cross-border partnerships, and the role of EU funding. Beyond highlighting funding disparities, our methodological approach—integrating bibliometric indicators, community detection, and centrality metrics—demonstrates the structural dynamics of ML research networks, distinguishing dominant institutions and identifying peripheral actors with emerging influence.
The contemporary epistemological landscape of machine learning within higher education reveals a paradoxical configuration: despite rhetorical narratives of technological democratization, computational research infrastructure remains stratified across a constellation of high-performance computing (HPC) centers. Certain institutional ecosystems wield disproportionate computational and normative power, while peripheral academic domains navigate complex relational networks, strategically negotiating access through interstitial institutional alliances and mediating infrastructural nodes. This asymmetrical topography—emergent from intricate configurations of global academic hierarchies, geopolitical proximities, and institutional affiliations—manifests profound implications for data sovereignty, methodological access, and the ethical distribution of public scholarly investments. The inherent tensions between computational capital and epistemic potential illuminate systemic constraints that transcend mere technological determinism. Notwithstanding these structural impediments, intriguing transformative potentialities reside in emerging collaborative architectures. Particularly compelling are nascent configurations linking mid-tier academic institutions with established HPC infrastructures—a form of intellectual cross-pollination that promises meaningful reconfiguration of existing knowledge production paradigms. The potential for substantive epistemological recalibration hinges critically upon deliberate interventions: funding mechanisms must be strategically reimagined to prioritize inclusive data governance, equitable computational resource allocation, and rigorous ethical stewardship of public intellectual investments. Such structured commitments could precipitate a fundamental restructuring of the machine learning research ecosystem—from a sparse constellation of privileged computational nodes to a more dynamically interconnected, democratically accessible knowledge network. The horizon of possibility emerges not through technological determinism but through intentional, reflexive institutional redesign that recognizes computational infrastructure as a profound site of epistemic potential and social transformation.
Beyond its theoretical implications, these findings have practical applications for research policy and institutional strategy. A more equitable distribution of research resources necessitates policy adjustments that incentivize partnerships between leading research hubs and emerging institutions. Expanding the scope of “Widening Participation” initiatives, creating shared HPC facilities accessible to all EU-based researchers, and integrating structured mentoring programs between high-impact and lower-funded institutions could mitigate existing asymmetries.
Given the increasing regulatory demands imposed by the EU AI Act and GDPR, institutional capacity-building must also be prioritized. Many smaller universities lack the administrative resources to comply effectively, reinforcing the need for centralized support structures that assist in regulatory adherence without disproportionately burdening institutions with limited legal and technical expertise.
Future Directions
While the present analysis maps co-authorship patterns and HPC capacity, the next logical step could investigate whether HPC-driven machine learning truly enhances student learning experiences or institutional educational quality. For instance, do the most HPC-intensive research clusters produce more widely adopted pedagogical tools or a measurable reduction in student dropout rates? Are HPC-based collaborations oriented around real academic improvements, or do they remain at the proof-of-concept stage? Concrete educational outcome metrics—integrated with the bibliometric and network-based approach—might clarify how effectively public funds translate into sustainable improvements in teaching and learning, thus elevating the impact of HPC-based AI beyond academic publications alone.
Moving forward, more systematic linking of project-level data (e.g., from Horizon Europe’s public database) to articles could reveal precisely which consortia lead HPC-based educational research, the breakdown of funds allocated to extraregional labs, and the real scale of data-sharing arrangements. Additional layers of network analysis—disentangling purely HPC-related co-authorship from smaller-scale ML explorations—could show whether resource imbalances persist even when controlling for HPC intensity.
Another important direction involves a deeper analysis of how extraregional partners (e.g., large US or Chinese labs) integrate with EU-funded endeavors. This analysis could clarify whether such relationships spur mutual HPC expansions (e.g., reciprocal hosting of visiting scholars and reciprocal HPC cycles) or simply direct EU project money to external HPC hubs. Similarly, exploring how ethical and regulatory frameworks, including the AI Act or data-protection rules, shape the feasibility of HPC-based educational research would lend a fresh perspective on policy-level transformations that either propel or constrain cross-border synergy.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/electronics14071248/s1, Figure S1: EU-Funded Collaboration Network (EU-only); Figure S2: Unspecified Funding Collaboration Network.
Author Contributions
Conceptualization, L.-E.P.-A. and M.-S.I.; methodology, L.-E.P.-A., M.-S.I. and D.F.; software, L.-E.P.-A.; validation, S.-C.N.; formal analysis, D.F.; investigation, L.-E.P.-A. and M.-S.I.; resources, L.-E.P.-A., D.F. and M.-S.I.; data curation, L.-E.P.-A. and M.-S.I.; writing—original draft preparation, L.-E.P.-A. and M.-S.I.; writing—D.F. and S.-C.N.; visualization, L.-E.P.-A. and M.-S.I.; supervision, D.F. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Dataset available on request from the authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pinto, A.S.; Abreu, A.; Costa, E.; Paiva, J. How machine learning (ML) is transforming higher education: A systematic literature review. J. Inf. Syst. Eng. Manag. 2023, 8, 21168. [Google Scholar] [CrossRef]
- Kuleto, V.; Ilić, M.; Dumangiu, M.; Ranković, M.; Martins, O.M.; Păun, D.; Mihoreanu, L. Exploring opportunities and challenges of artificial intelligence and machine learning in higher education institutions. Sustainability 2021, 13, 10424. [Google Scholar] [CrossRef]
- Liu, B.L.; Morales, D.; Roser-Chinchilla, J.; Sabzalieva, E.; Valentini, A.; Vieira do Nascimento, D.; Yerovi, C. Harnessing the Era of Artificial Intelligence in Higher Education: A Primer for Higher Education Stakeholders; UNESCO International Institute for Higher Education in Latin America and the Caribbean: Caracas, Venezuela, 2023; Available online: https://unesdoc.unesco.org/ark:/48223/pf0000386670 (accessed on 6 February 2025).
- Leifler, K.S. International Collaboration Lays the Foundation for Future AI for Materials. 2024. Available online: https://liu.se/en/news-item/international-collaboration-lays-the-foundation-for-future-ai-for-materials (accessed on 6 February 2025).
- STEM Fellowship. National Inter-University Big Data and AI Challenge. 2023. Available online: https://live.stemfellowship.org/portfolio-items/national-inter-university-big-data-and-ai-challenge-2023/ (accessed on 6 February 2025).
- Guerini, R. And the Winners Are: Horizon Europe Funding for Artificial Intelligence Is Surging, a Science|Business Analysis Finds. 2024. Available online: https://sciencebusiness.net/news/ai/and-winners-are-horizon-europe-funding-artificial-intelligence-surging-sciencebusiness (accessed on 6 February 2025).
- The National Endowment for the Humanities (NEH). NEH Awards $2.72 Million to Create Research Centers Examining the Cultural Implications of Artificial Intelligence. 2024. Available online: https://www.neh.gov/news/neh-awards-272-million-create-ai-research-centers (accessed on 6 February 2025).
- US National Science Foundation. NSF Announces 7 New National Artificial Intelligence Research Institutes. 2023. Available online: https://new.nsf.gov/news/nsf-announces-7-new-national-artificial (accessed on 6 February 2025).
- National Science and Technology Council. National Artificial Intelligence Research and Development Strategic Plan. 2023 Update. Available online: https://www.nitrd.gov/pubs/National-Artificial-Intelligence-Research-and-Development-Strategic-Plan-2023-Update.pdf (accessed on 6 February 2025).
- Bank, E.I. Financing the Future of Supercomputing-How to Increase Investments in High Performance Computing in Europe. 2018. Available online: https://www.eib.org/attachments/pj/financing_the_future_of_supercomputing_en.pdf (accessed on 9 March 2025).
- European Commission Coordinated Plan on Artificial Intelligence: 2021 Review. 2021. Available online: https://digital-strategy.ec.europa.eu/en/library/coordinated-plan-artificial-intelligence-2021-review (accessed on 6 February 2025).
- Fantini, N. Geographical Imbalances Remain in AI Research Funding. 2024. Available online: https://sciencebusiness.net (accessed on 6 February 2025).
- Holmes, W.; Porayska-Pomsta, K.; Holstein, K.; Sutherland, E.; Baker, T.; Shum, S.B.; Santos, O.C.; Rodrigo, M.T.; Cukurova, M.; Bittencourt, I.I.; et al. Ethics of AI in Education: Towards a community-wide framework. Int. J. Artif. Intell. Educ. 2022, 32, 504–526. [Google Scholar] [CrossRef]
- European Commission Digital Decade Policy Programme. 2023. Available online: https://ec.europa.eu/info/strategy/priorities-2019-2024/europe-fit-digital-age/digital-decade_en (accessed on 6 February 2025).
- Khalil, M.; Ebner, M. Clustering patterns of engagement in MOOCs: The use of learning analytics to reveal student categories. J. Comput. High. Educ. 2016, 29, 114–132. [Google Scholar]
- Wollny, S.; Schneider, J.; Di Mitri, D.; Weidlich, J.; Rittberger, M.; Drachsler, H. Are we there yet? A systematic literature review on chatbots in education. Front. Artif. Intell. 2021, 4, 654924. [Google Scholar] [CrossRef]
- Xing, W.; Du, D. Dropout prediction in MOOCs: Using deep learning for personalized intervention. J. Educ. Comput. Res. 2019, 57, 547–570. [Google Scholar] [CrossRef]
- Albreiki, B.; Zaki, N.; Alashwal, H. A systematic literature review of students’ performance prediction using machine learning techniques. Educ. Sci. 2021, 11, 552. [Google Scholar] [CrossRef]
- Baek, C.; Doleck, T. A bibliometric analysis of the papers published in the journal of artificial intelligence in education from 2015–2019. Int. J. Learn. Anal. Artif. Intell. Educ. (IJAI) 2020, 2, 67. [Google Scholar] [CrossRef]
- Valverde-Berrocoso, J.; Fernández-Sánchez, M.R.; Revuelta Dominguez, F.I.; Sosa-Díaz, M.J. The educational integration of digital technologies pre-Covid-19: Lessons for teacher education. PLoS ONE 2021, 16, e0256283. [Google Scholar] [CrossRef]
- European Commission. Horizon Europe: Interactive Dashboard. Funding & Tenders Portal. Available online: https://ec.europa.eu/info/funding-tenders/opportunities/portal/screen/opportunities/horizon-dashboard (accessed on 6 February 2025).
- ELLIS Projects Building on ELLIS. 2023. Available online: https://ellis.eu/projects-building-on-ellis (accessed on 6 February 2025).
- European Commission Advanced Digital Skills (DIGITAL-2024-ADVANCED-DIGITAL-07-KeyCapacity)—Call Documentation. 2024. Available online: https://www.eitdeeptechtalent.eu/calls-and-opportunities/call-for-proposals-on-advanced-digital-skills-7/ (accessed on 6 February 2025).
- Miao, F.; Holmes, W.; Huang, R.; Zhang, H. AI and Education: A Guidance for Policymakers; UNESCO Publishing: Paris, France, 2021. [Google Scholar] [CrossRef]
- Solano, J.L.; Martin, A.; Souza, S.; Taylor, L. Governing Data and Artificial Intelligence for All, STOA|Panel for the Future of Science and Technology. 2022. Available online: https://www.europarl.europa.eu/RegData/etudes/STUD/2022/729533/EPRS_STU(2022)729533_EN.pdf (accessed on 9 March 2025).
- Veale, M.; Zuiderveen Borgesius, F. Demystifying the Draft EU Artificial Intelligence Act—Analysing the good, the bad, and the unclear elements of the proposed approach. Comput. Law Rev. Int. 2021, 22, 97–112. [Google Scholar]
- Floridi, L. The European legislation on AI: A brief analysis of its philosophical approach. Philos. Technol. 2021, 34, 215–222. [Google Scholar] [CrossRef] [PubMed]
- Meltzer, J.; Tielemans, A. The EU AI Act: Its International Implications for AI Policy Development and Cooperation; Encompass: Northbrook, IL, USA, 2022; Available online: https://encompass-europe.com/comment/the-eu-ai-act-its-international-implications-for-ai-policy-development-and-cooperation (accessed on 9 March 2025).
- Hacker, P. AI regulation in Europe: From the AI act to future regulatory challenges. arXiv 2023, arXiv:2310.04072. [Google Scholar]
- Gonçalves, G.; Miranda, J. How deep tech can promote innovation and entrepreneurship in higher education institutions. In INTED2024 Proceedings; IATED: Valencia, Spain, 2024; pp. 3092–3100. [Google Scholar]
- Kask, J.; Linton, G. Navigating the Innovation Process: Challenges Faced by Deep-Tech Startups. In Contemporary Issues in Industry 5.0: Towards an AI Integrated Society; Springer Nature: Cham, Switzerland, 2025; pp. 197–219. [Google Scholar]
- Palmiotto, F. The AI Act Roller Coaster: The Evolution of Fundamental Rights Protection in the Legislative Process and the Future of the Regulation. Eur. J. Risk Regul. 2025, 1–24. [Google Scholar] [CrossRef]
- Vega-Muñoz, A.; González-Gómez-del-Miño, P.; Contreras-Barraza, N. The Determinants of Brain Drain and the Role of Citizenship in Skilled Migration. Soc. Sci. 2025, 14, 132. [Google Scholar] [CrossRef]
- Newman, M.E. Coauthorship networks and patterns of scientific collaboration. Proc. Natl. Acad. Sci. USA 2004, 101, 5200–5205. [Google Scholar] [CrossRef]
- Yan, E.; Ding, Y. Applying centrality measures to impact analysis: A coauthorship network analysis. J. Assoc. Inf. Sci. Technol. 2009, 60, 2107–2118. [Google Scholar] [CrossRef]
- Girvan, M.; Newman, M.E. Community structure in social and biological networks. Proc. Natl. Acad. Sci. USA 2001, 99, 7821–7826. [Google Scholar] [CrossRef]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Gorraiz, J.I. Editorial: Best Practices in Bibliometrics & Bibliometric Services. Front. Res. Metr. Anal. 2021, 6, 771999. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python; O’Reilly Media: Sebastopol, CA, USA, 2009. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2001, 3, 993–1022. [Google Scholar]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the space of topic coherence measures. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015. [Google Scholar] [CrossRef]
- Tong, Z.; Zhang, H. A text mining research based on LDA topic modelling. In Proceedings of the International Conference on Computer Science, Engineering and Information Technology, Sydney, Australia, 23–24 December 2016; pp. 201–210. [Google Scholar] [CrossRef]
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring network structure, dynamics, and function using NetworkX. In Proceedings of the 7th Python in Science Conference (SciPy2008), Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. Available online: https://aric.hagberg.org/papers/hagberg-2008-exploring.pdf (accessed on 6 February 2025).
- Wasserman, S.; Faust, K. Social Network Analysis: Methods and Applications; Cambridge University Press: Cambridge, UK, 1994. [Google Scholar]
- Opsahl, T.; Agneessens, F.; Skvoretz, J. Node centrality in weighted networks: Generalizing degree and shortest paths. Soc. Netw. 2010, 32, 245–251. [Google Scholar] [CrossRef]
- Freeman, L.C. A set of measures of centrality based on betweenness. Sociometry 1977, 40, 35–41. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 532–538. [Google Scholar] [CrossRef]
- Katz, L. A new status index derived from sociometric analysis. Psychometrika 1953, 18, 39–43. [Google Scholar] [CrossRef]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Cohen, J.; Cohen, P.; West, S.G.; Aiken, L.S. Applied Multiple Regression/Correlation Analysis for the Behavioral Sciences; Routledge: London, UK, 2003. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
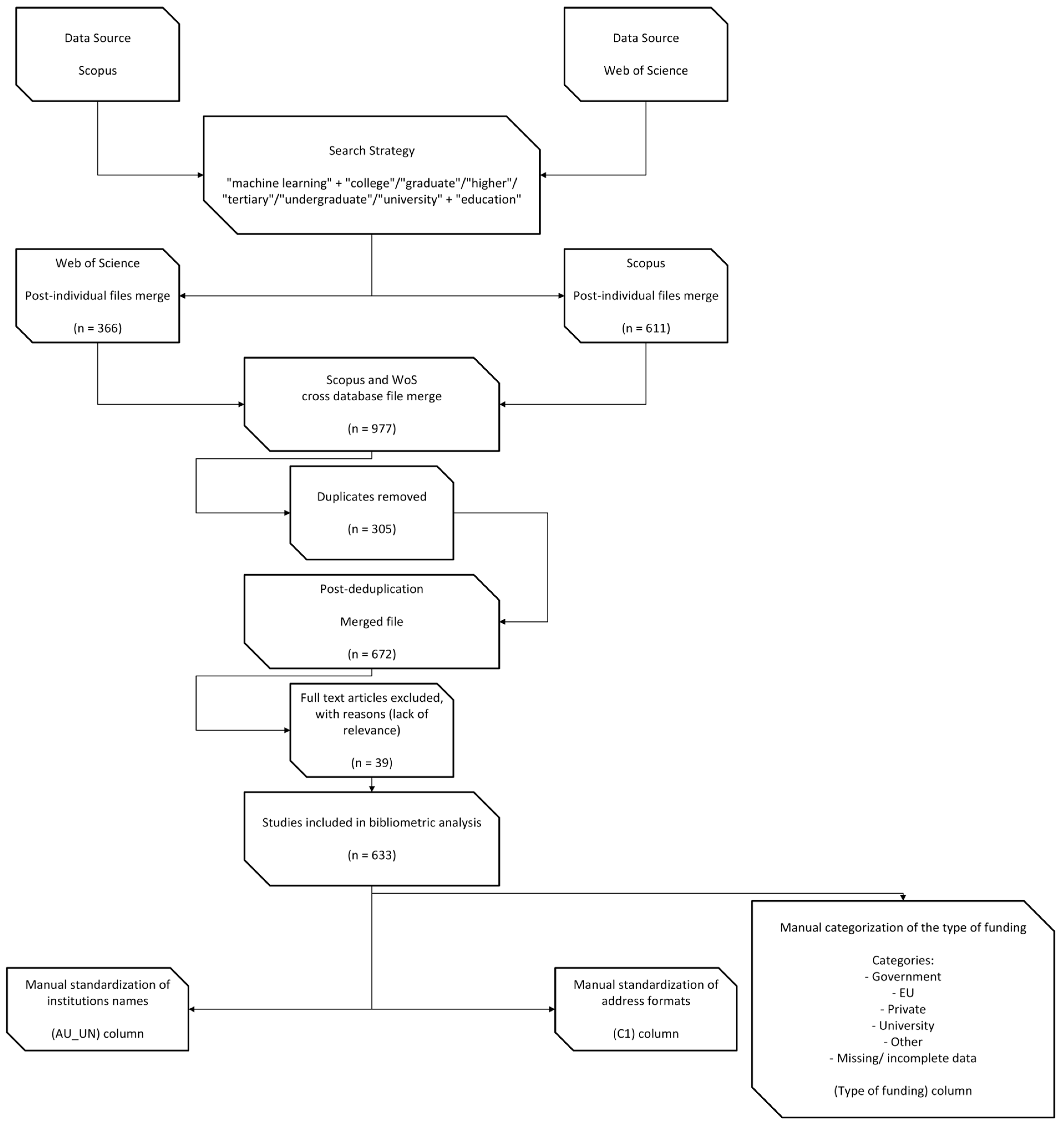
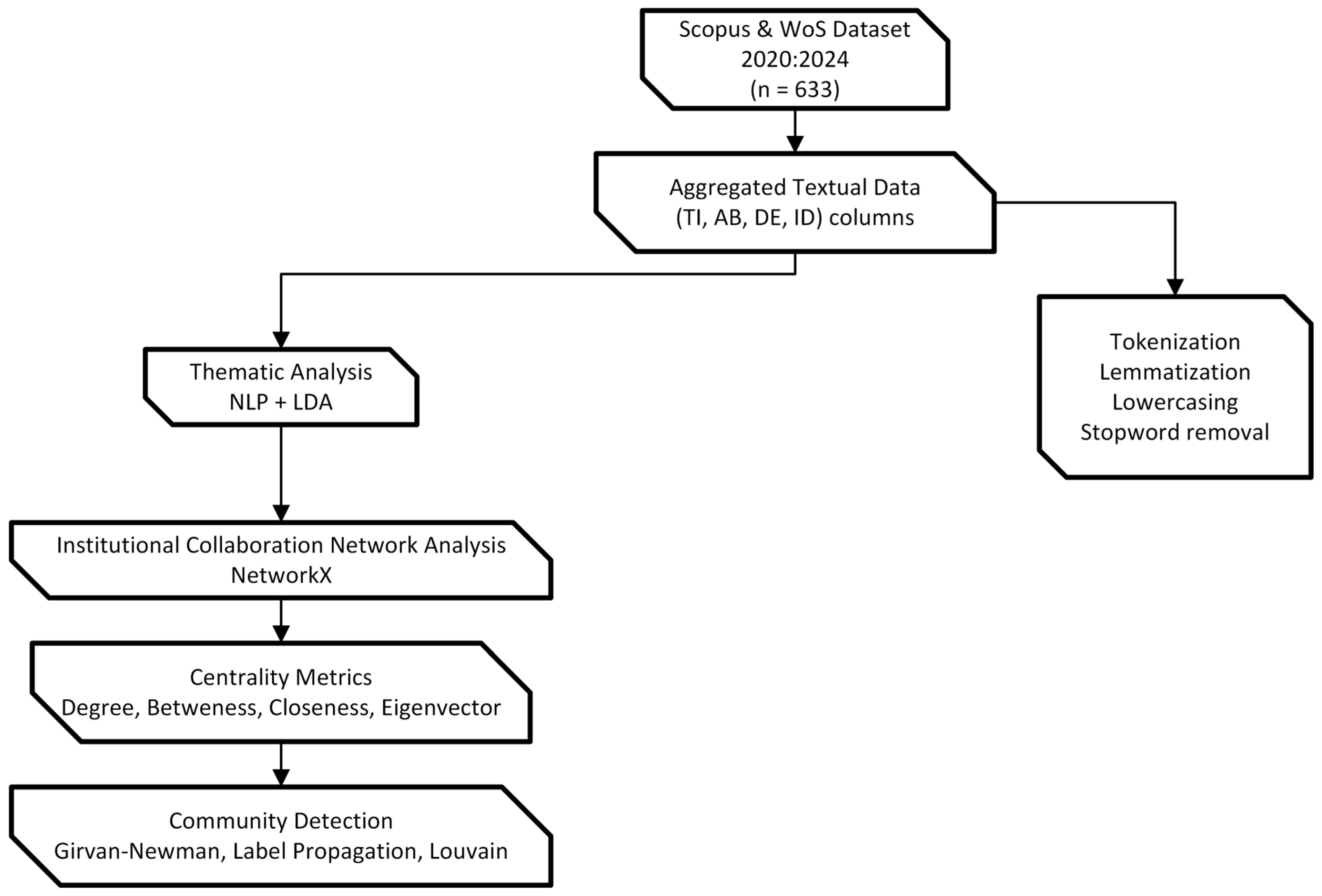
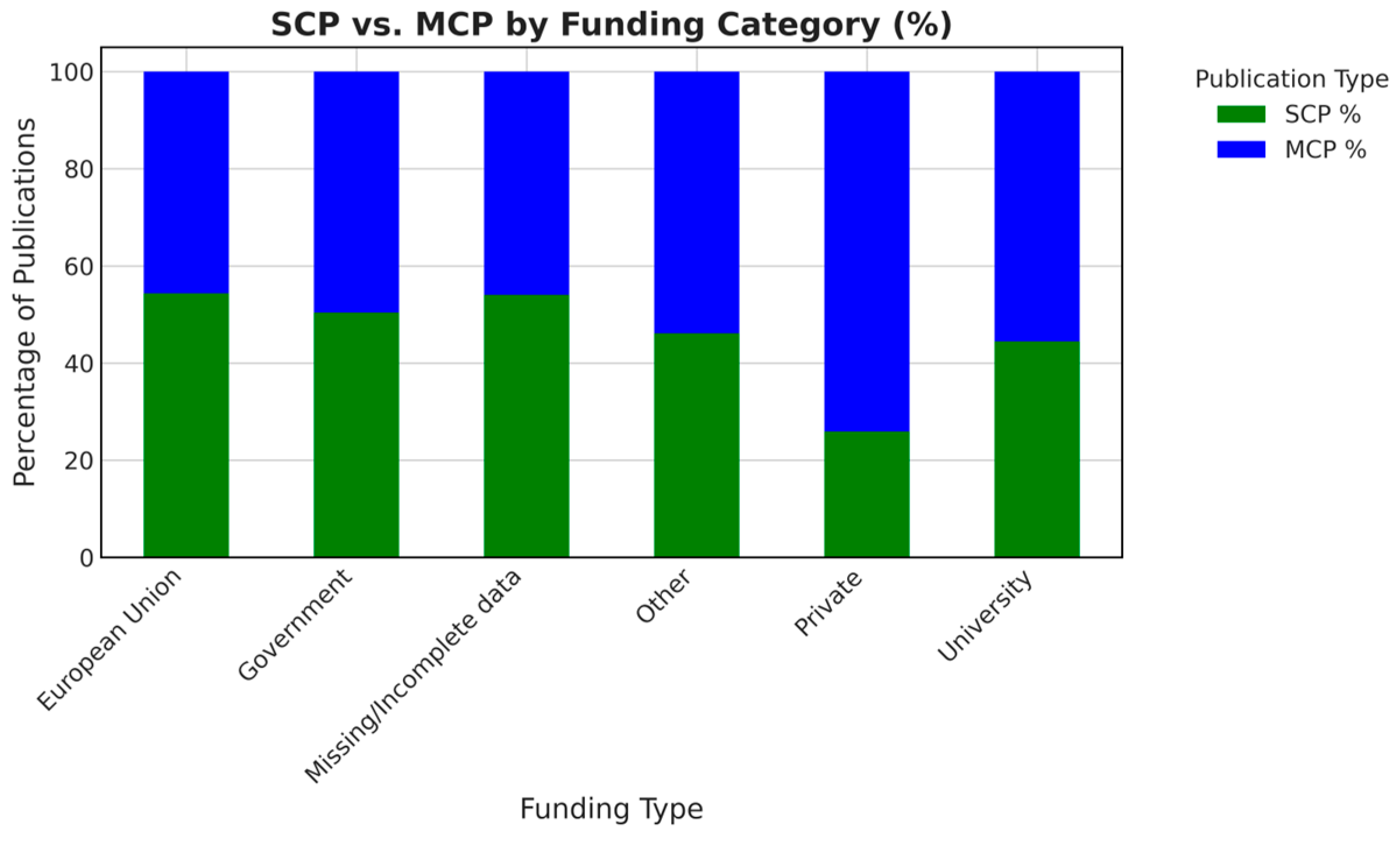
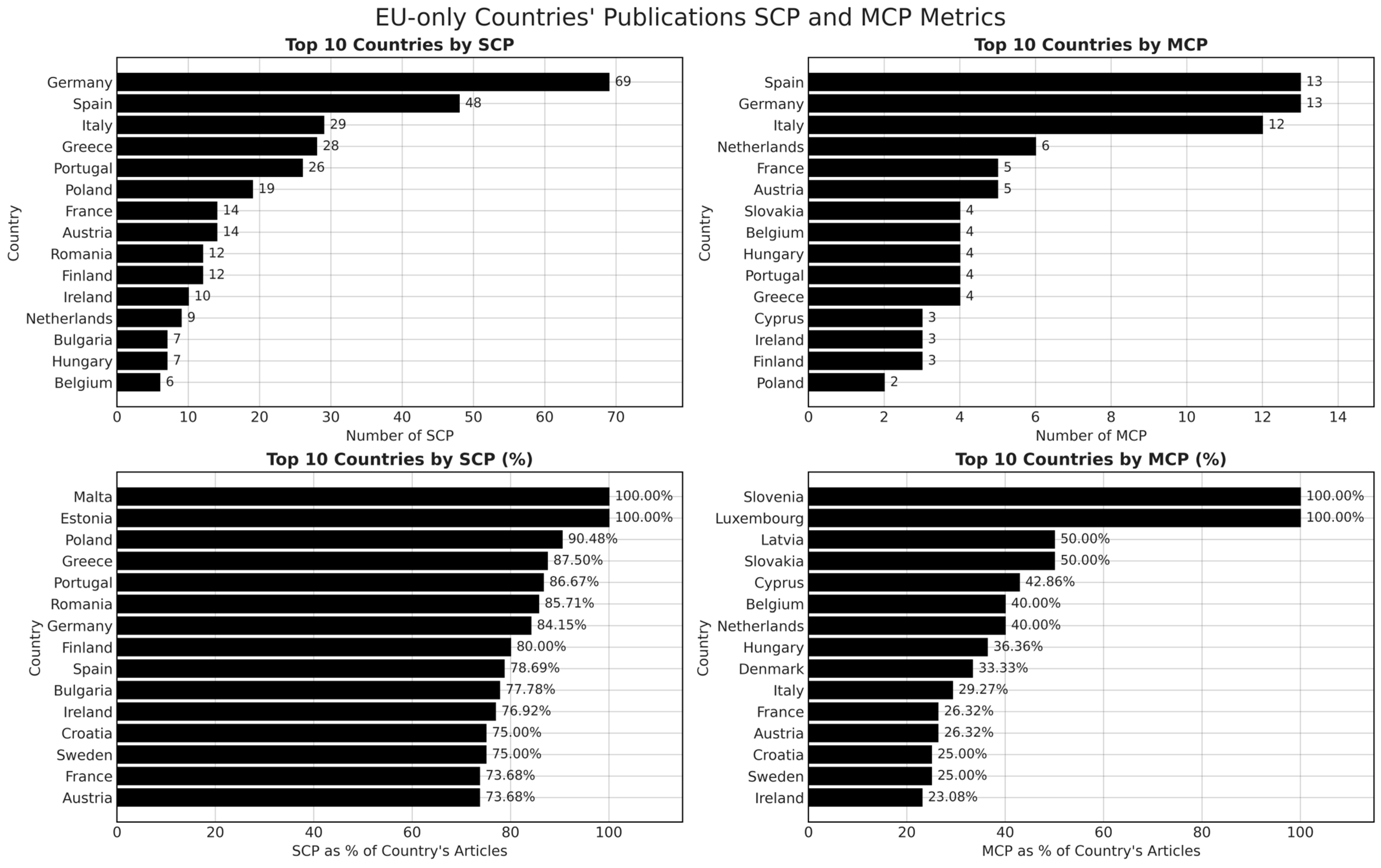
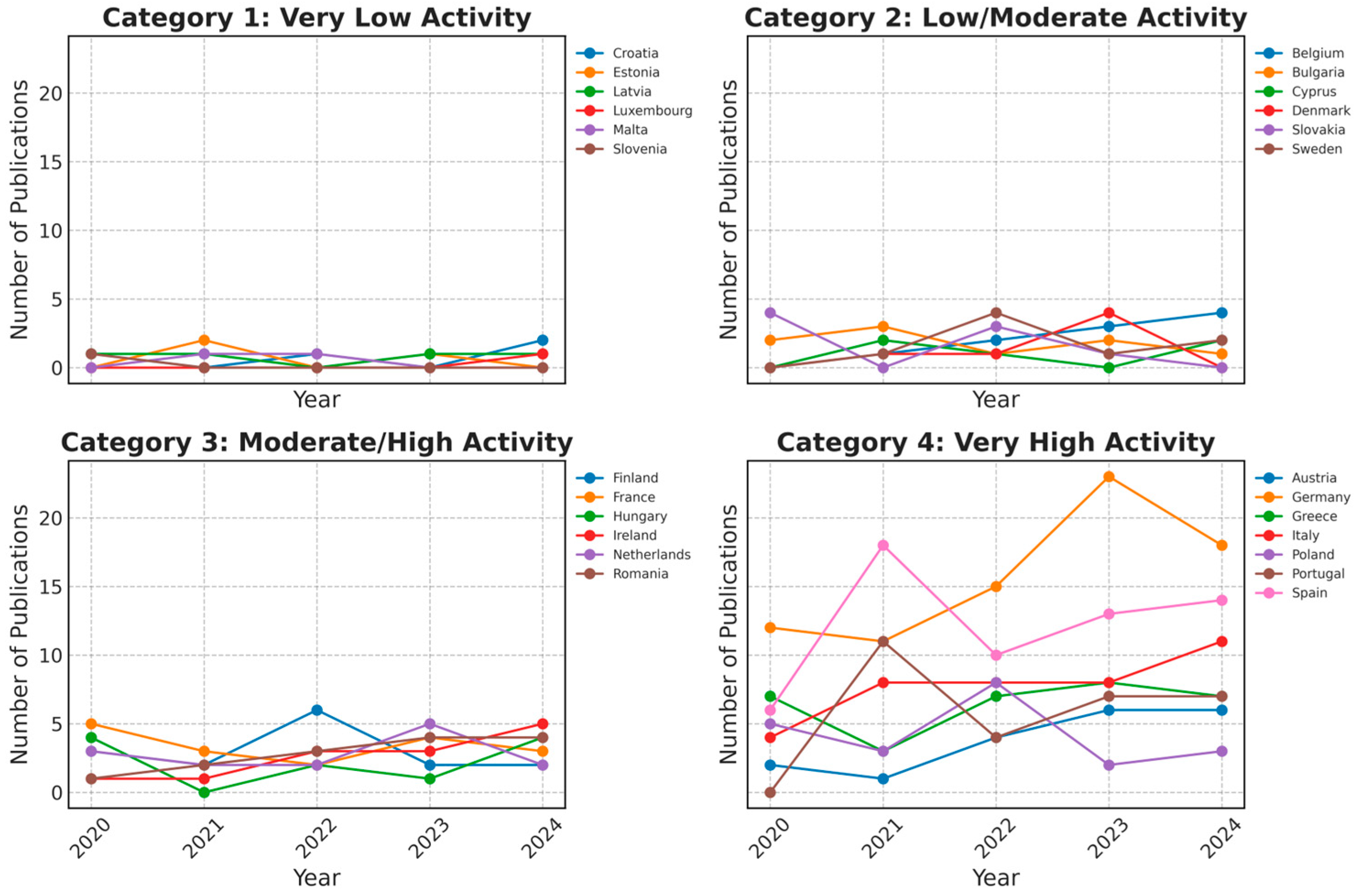
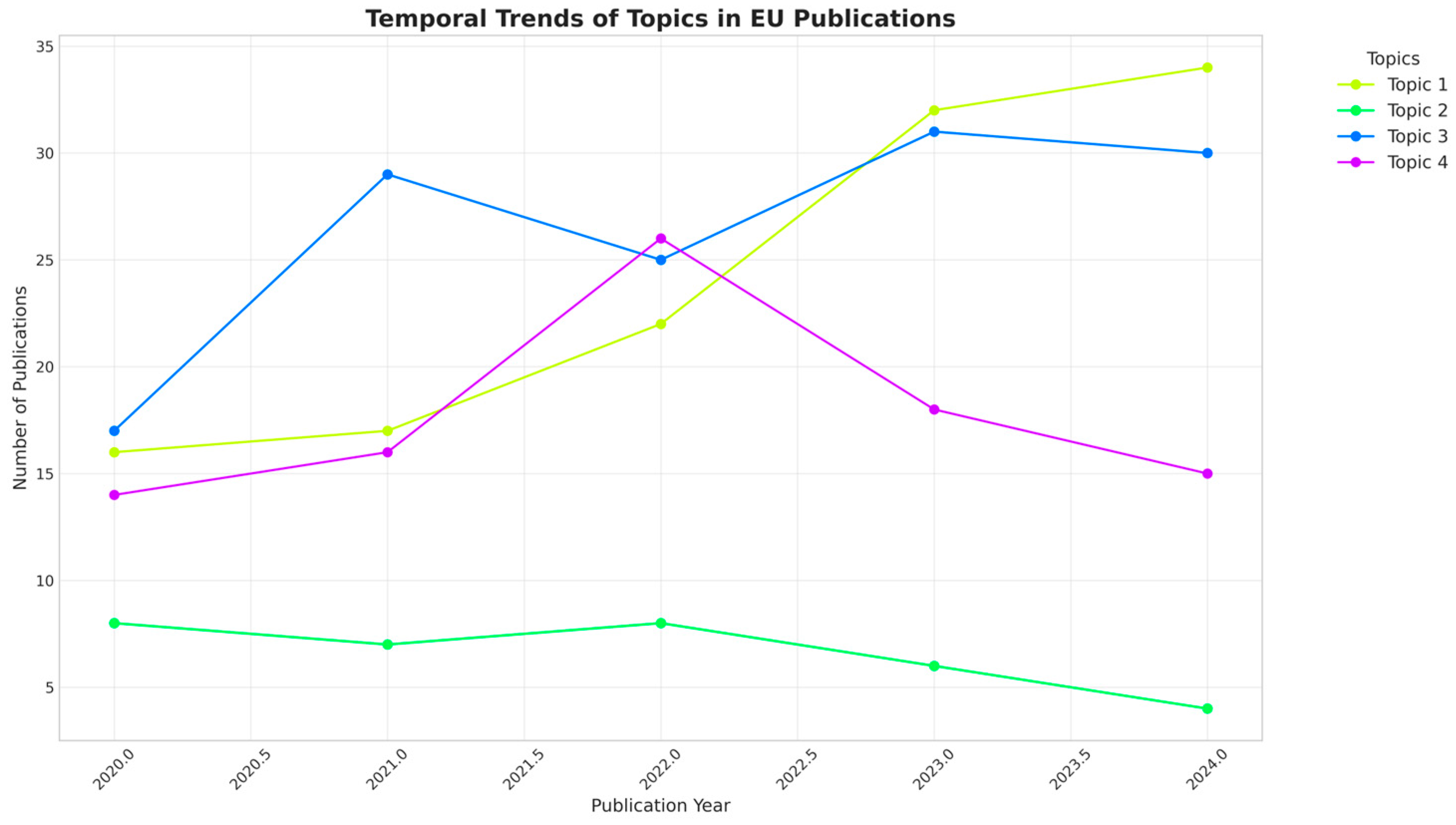
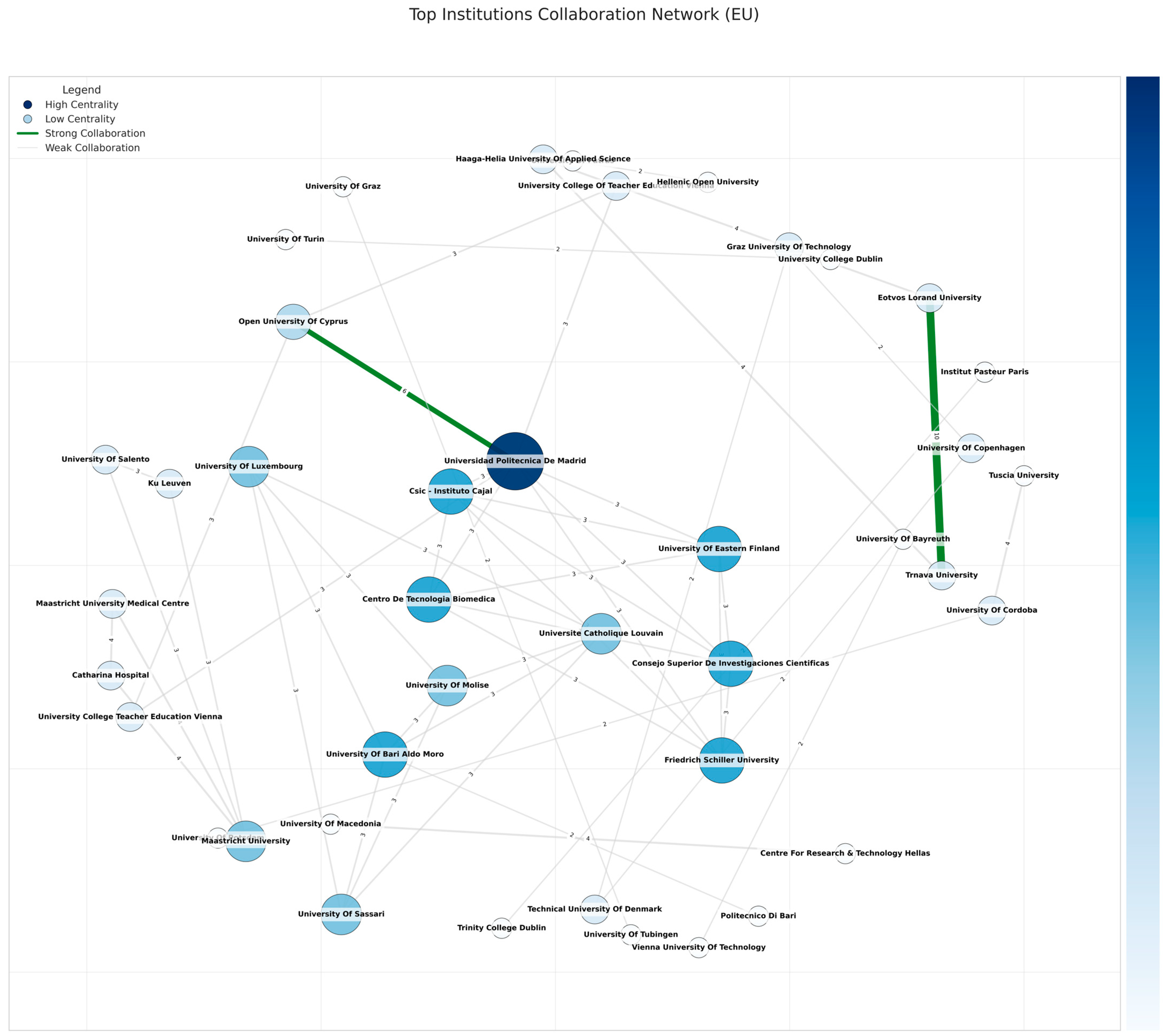
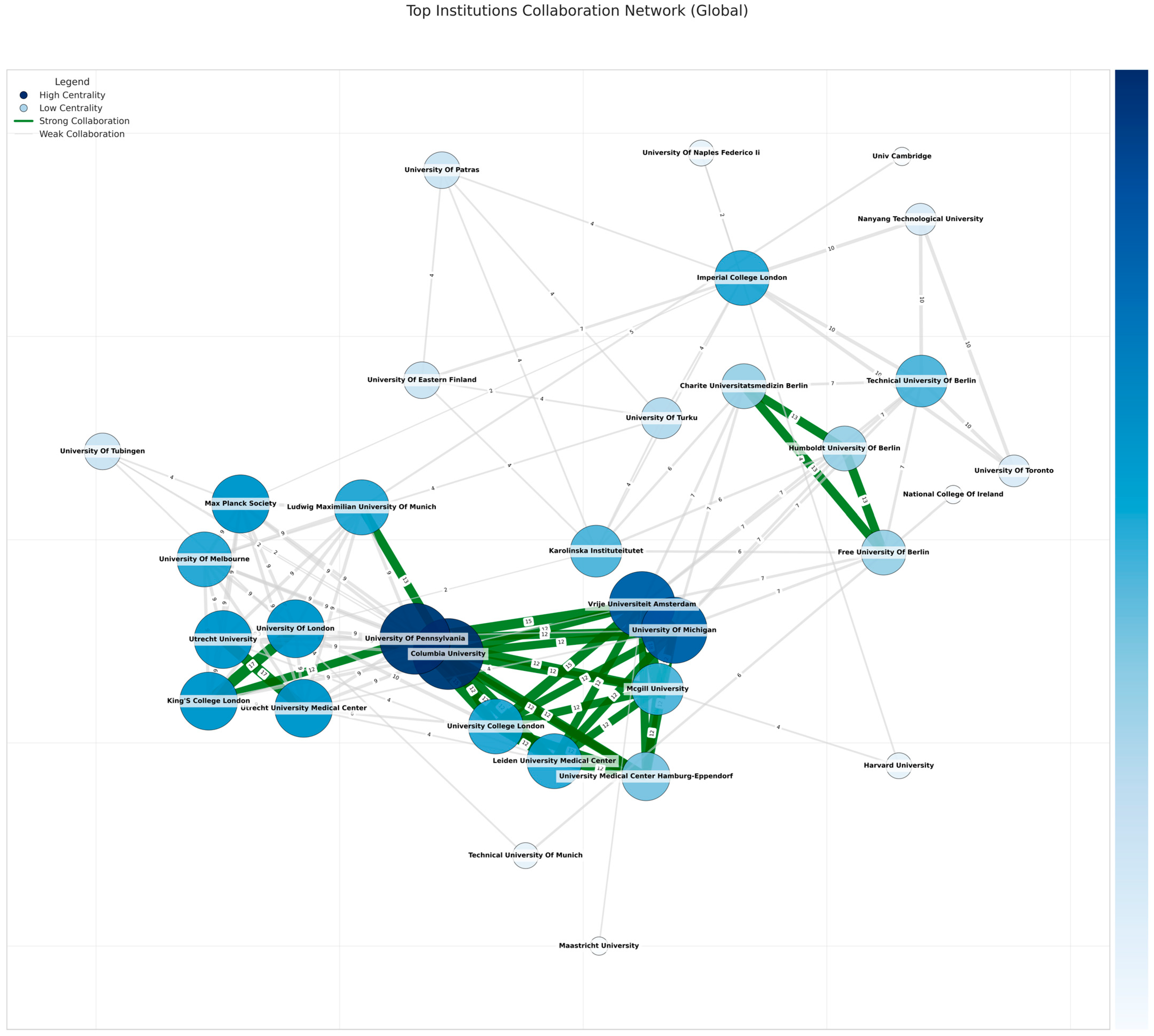
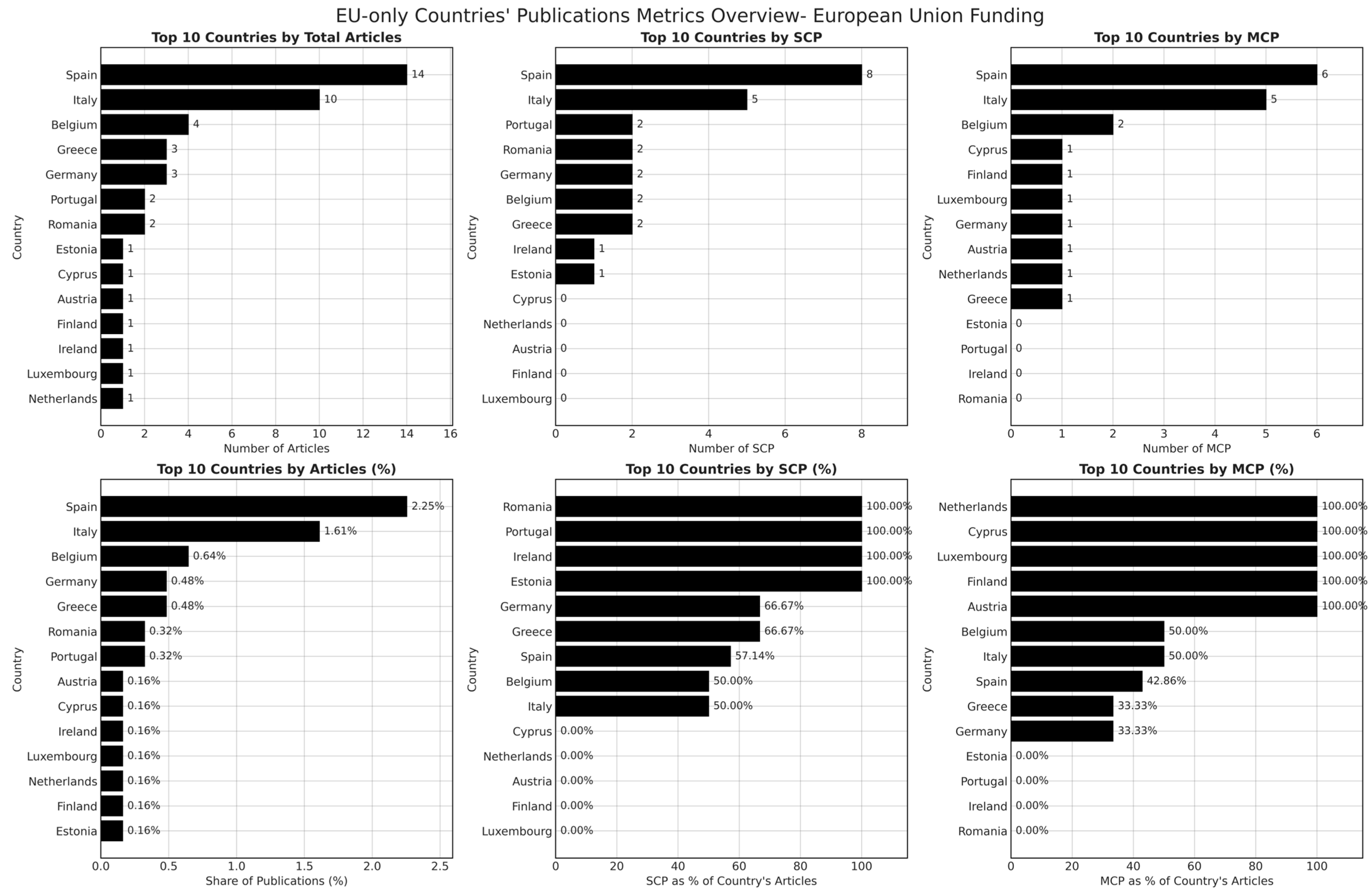
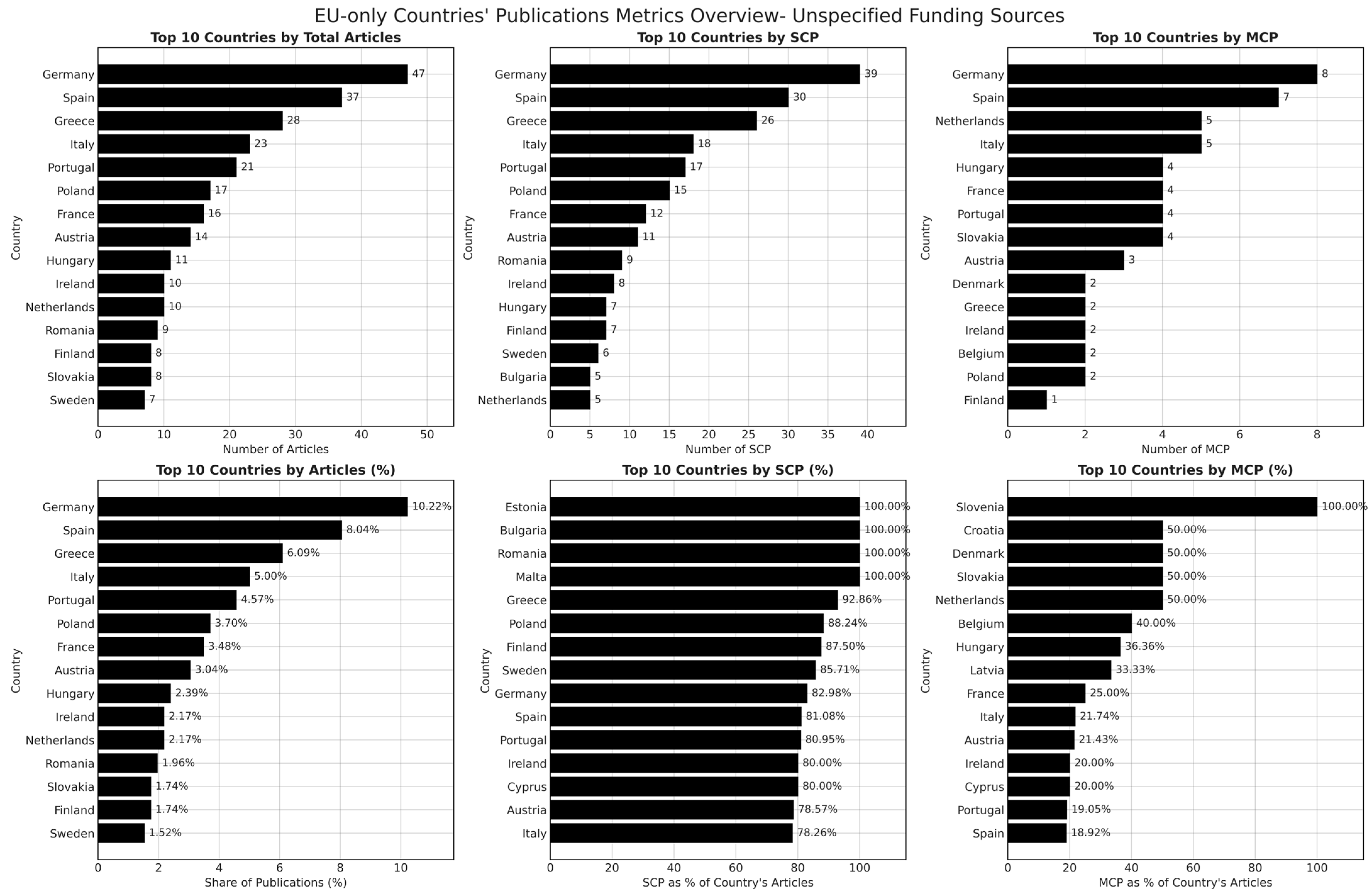
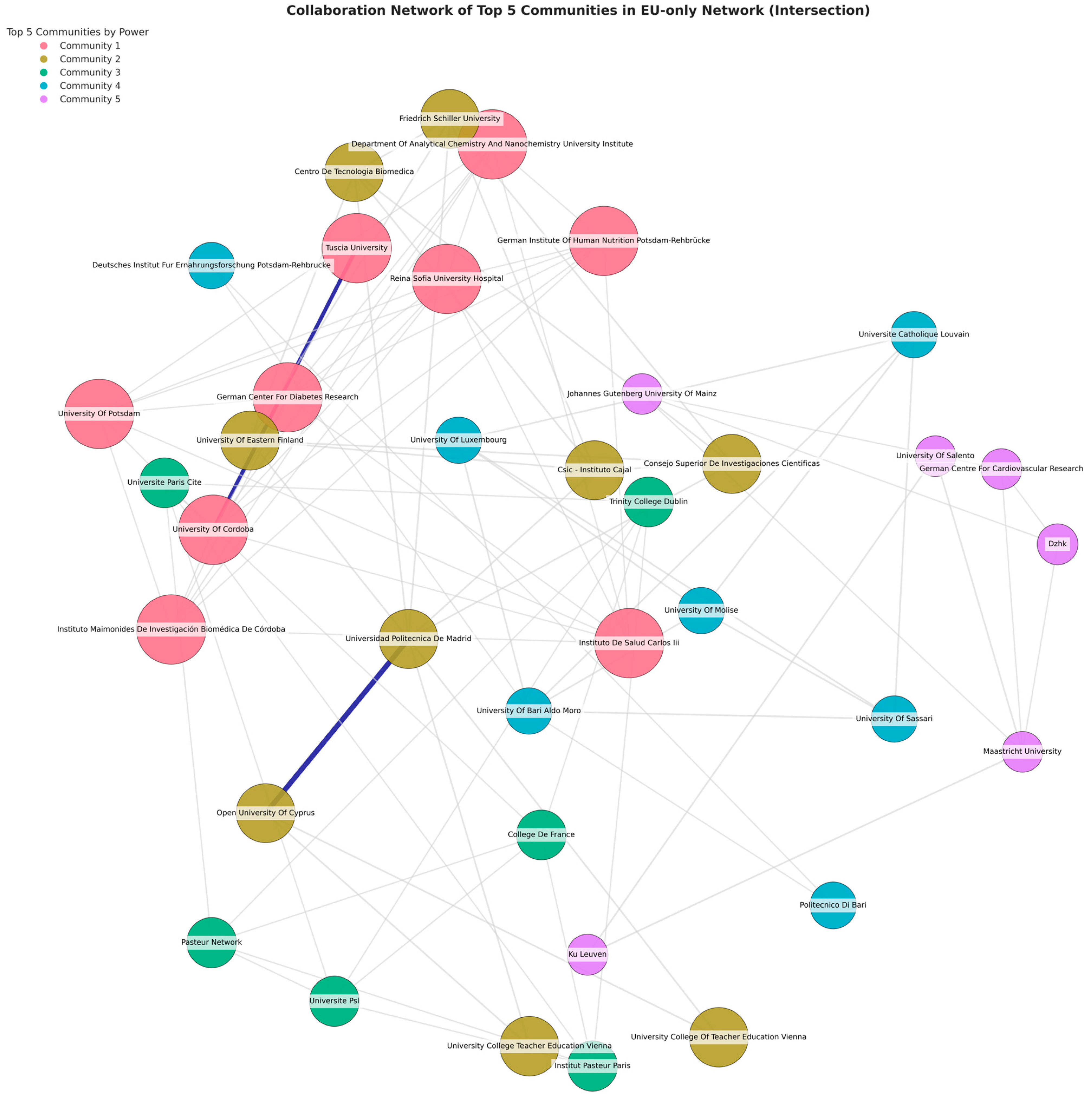
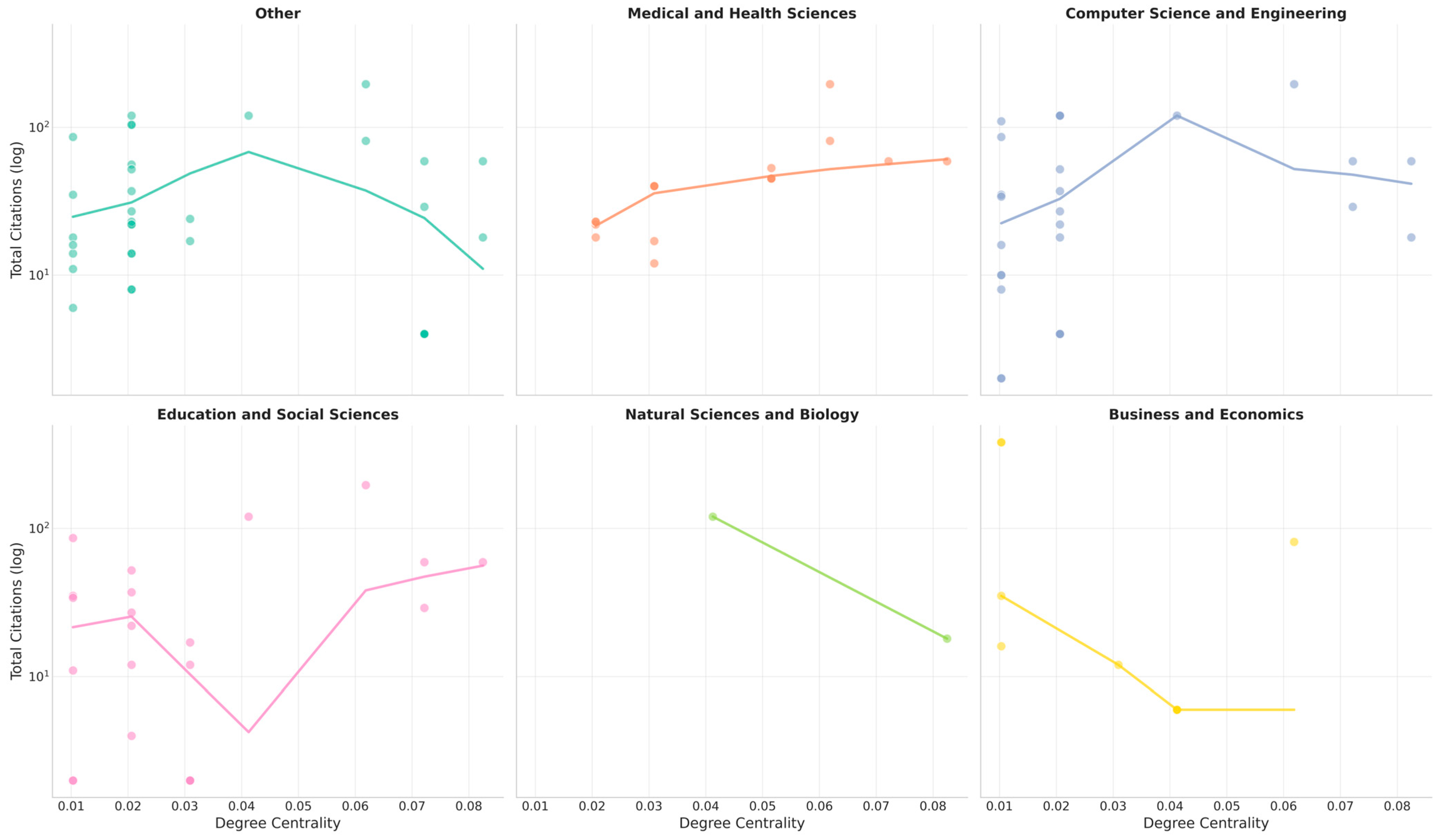
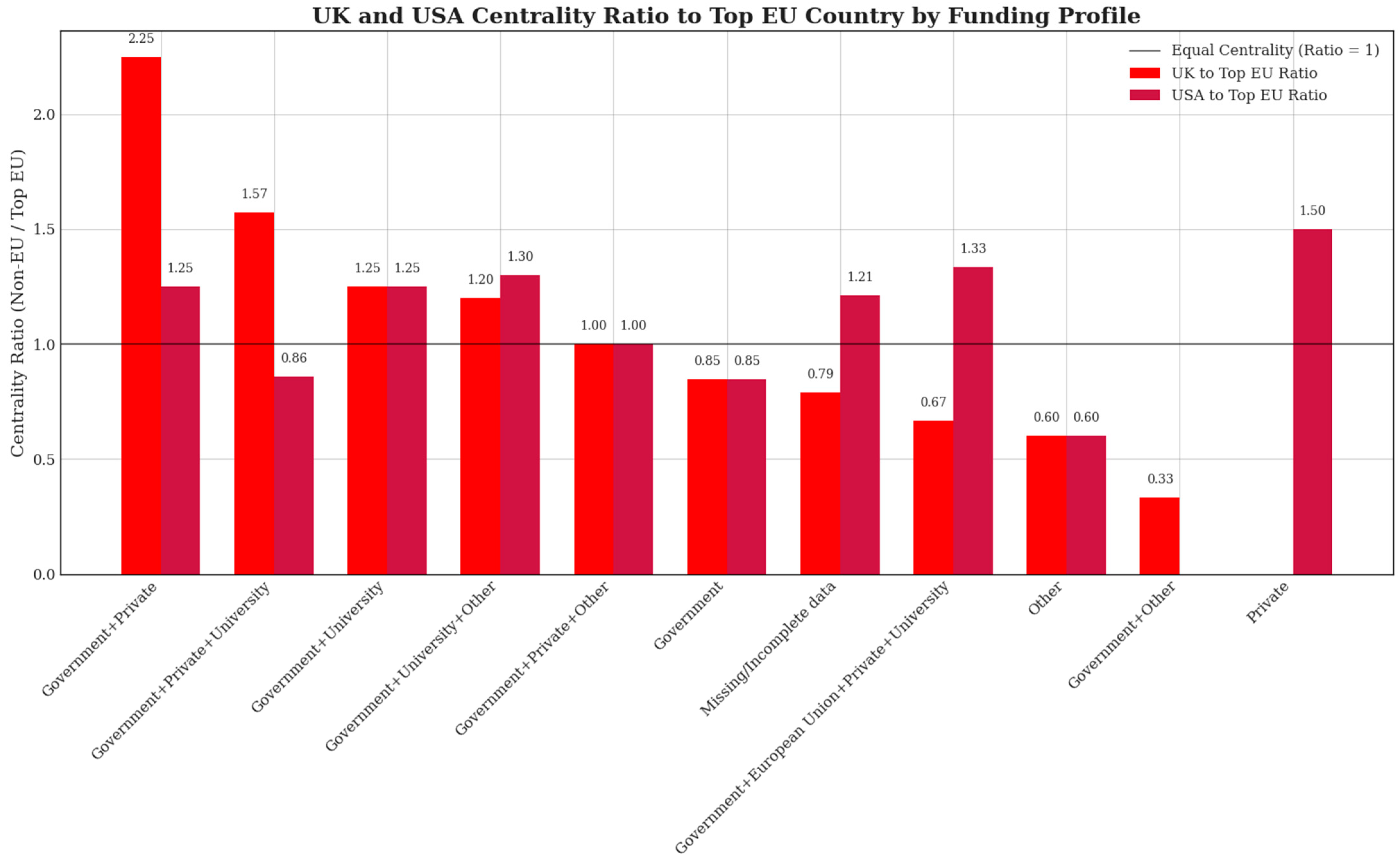
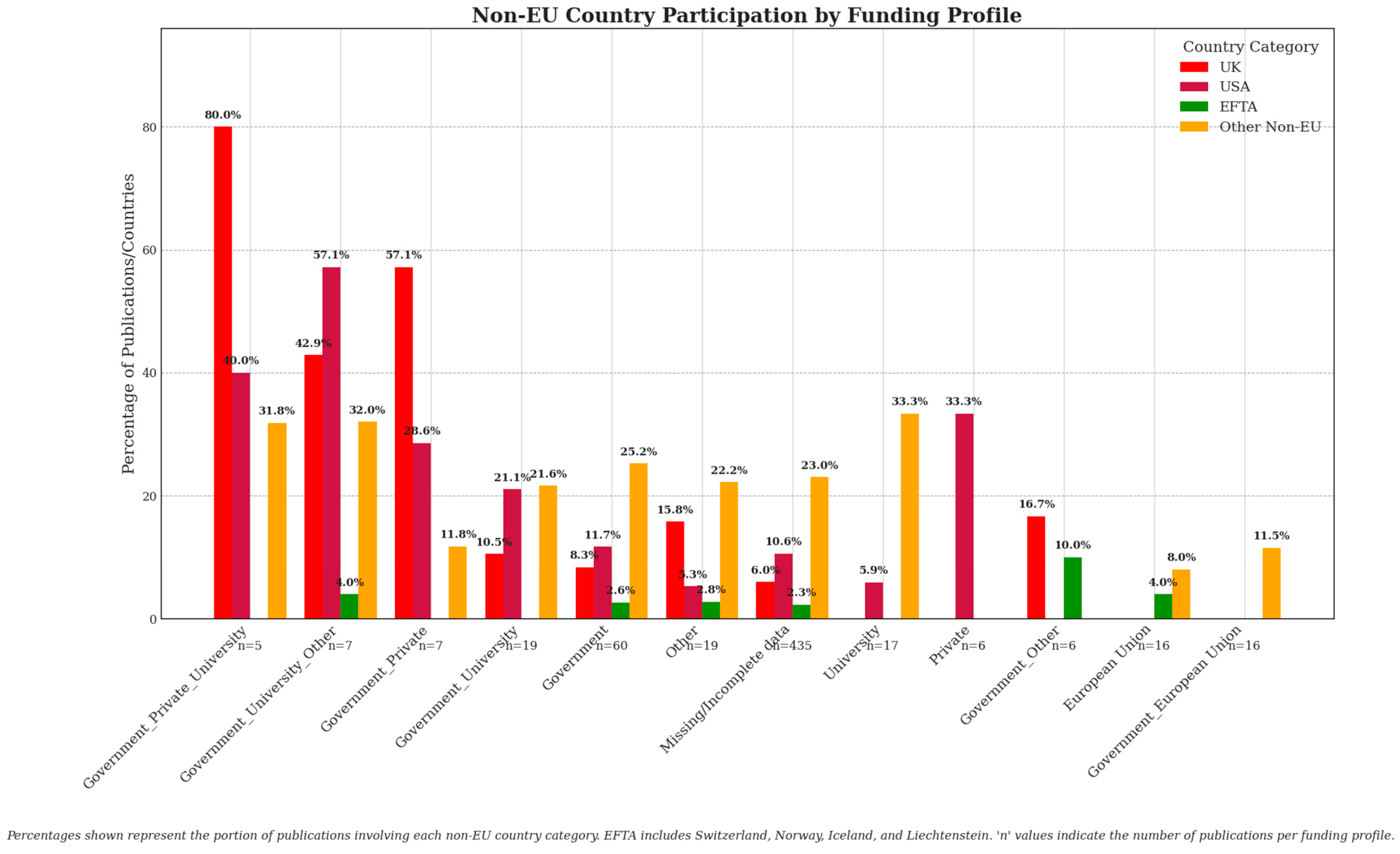
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).