

Info-CELS: Informative Saliency Map-Guided Counterfactual Explanation for Time Series Classification †



Abstract
1. Introduction
- Avoids unnecessary perturbations: Unlike TimeX, which is restricted to a single continuous subsequence, CELS allows for more flexible, targeted modifications that do not require altering an entire contiguous region of the input.
- Enhances computational efficiency: By directly identifying important time steps, CELS reduces the overhead of shapelet extraction and complex rule mining, making it more suitable for real-time and large-scale applications.
- Improves interpretability and sparsity: The learned saliency map provides an intuitive visualization of the most influential time steps, ensuring that only the most relevant portions of the time series are modified. This leads to more compact, meaningful counterfactual explanations.
2. Preliminaries
2.1. Problem Statement
2.2. Optimal Properties for a Good Counterfactual Explanation
- Validity: The counterfactual instance must yield a different prediction from the original instance when evaluated by the model f. That is, if and , then .
- Proximity: The counterfactual instance should be as close as possible to the original instance , ensuring minimal modifications. This closeness is typically measured using distance metrics, such as L1 distance.
- Sparsity: The counterfactual explanation should involve changes to as few features as possible, making the transformation more feasible. For time series data, sparsity implies that the perturbation applied to to obtain should affect a minimal number of data points.
- Contiguity: The modifications in should occur in a small number of contiguous segments rather than being scattered, ensuring the changes remain semantically meaningful.
- Interpretability (also referred to as plausibility (e.g., [42])): The counterfactual instance should remain within the distribution of real data. Specifically, should be an inlier with respect to both the training dataset and the counterfactual class, ensuring that it represents a realistic and meaningful alternative.
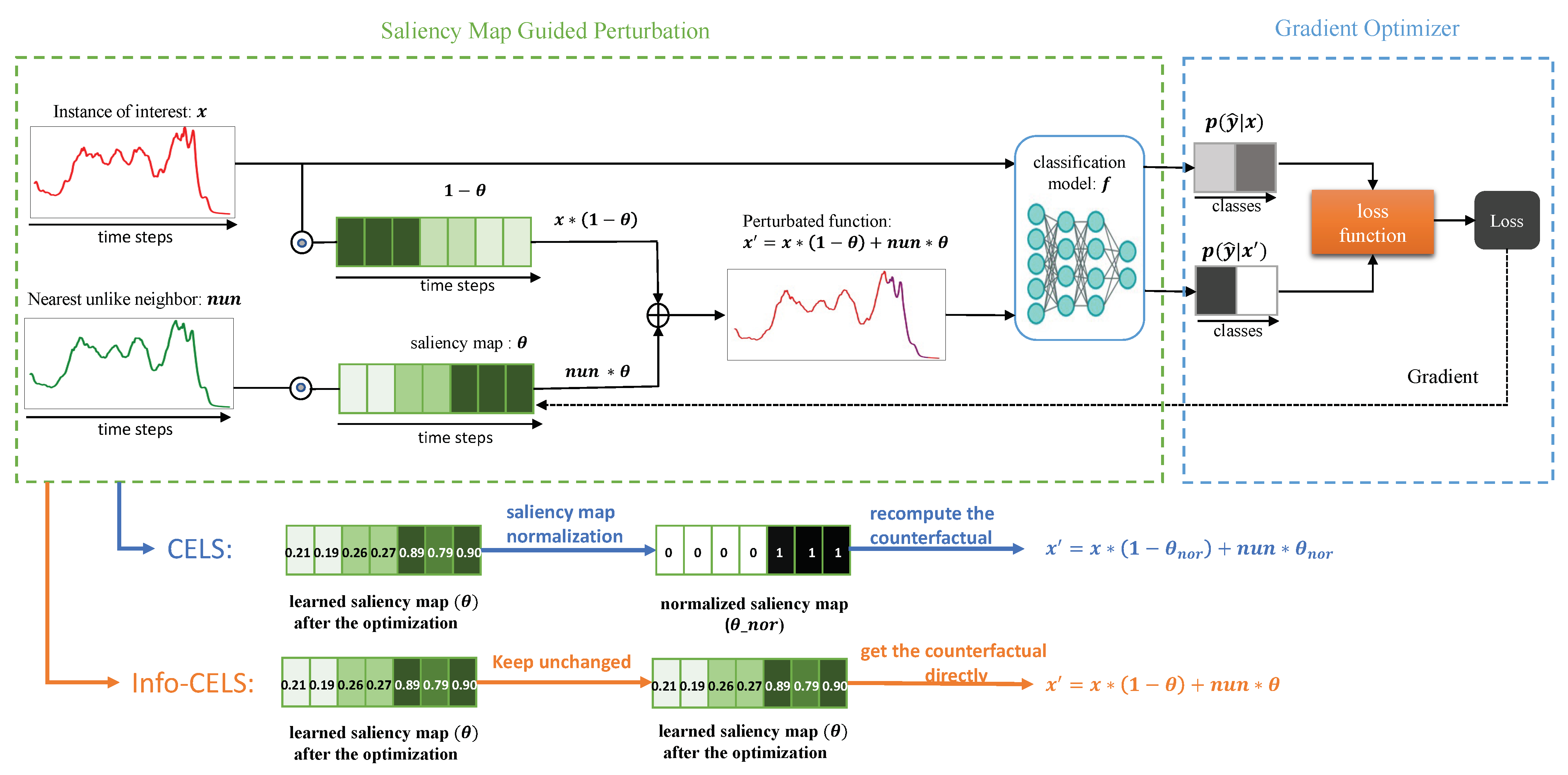
3. Background Works: CELS
3.1. Problem Formulation and Counterfactual Generation Pipeline
| Algorithm 1 CELS Algorithm |
| Inputs: Instance of interest , pretrained time series classification model f, background dataset , the total number of time steps T of the instance, a threshold k to normalize at the end of learning. Output: Saliency map for instance of interest , counterfactual explanation
|
3.2. Replacement Strategy: Nearest Unlike Neighbor (NUN)
3.3. Saliency Map Learning
3.4. Counterfactual Perturbation
4. Informative CELS (Info-CELS)
4.1. Detailed Analysis of Noise and Its Impact
- Binary jumps: When is near k, slight fluctuations during optimization can toggle the corresponding time step from 0 to 1 (or vice versa). This leads to sudden on/off behavior, creating sharp transitions in .
- Loss of Gradient Information: By converting into a binary saliency map, the finer-grained information about how “important” a time step is (e.g., 0.2 vs. 0.8) is lost. The explanation can become less interpretable because partial saliency information is discarded.
- Reduced Smoothness: Counterfactuals often need to maintain temporal coherence—especially in time series—to be interpretable. The normalization step disrupts this coherence by enforcing large, piecewise-constant segments in .
4.2. Info-CELS: Noise Mitigation and Formal Rationale
- Noise Mitigation Strategy:
- Smooth Perturbation: Because Info-CELS does not force into binary values, time steps with moderate importance can be partially perturbed rather than entirely flipped on/off. This yields gradual transitions rather than sudden jumps.
- Preservation of Fine-Grained Importance: The model’s local gradient information is preserved, as each time step’s saliency directly scales the magnitude of perturbation. This more closely aligns the counterfactual instance with the true local decision boundary.
- Formal Explanation of Improved Validity:
- Faithfulness to the Learned Saliency: By using the continuous values of , Info-CELS ensures that the counterfactual generation process remains consistent with the original optimization objective (i.e., finding the minimal perturbation needed to change the classification). This consistency avoids the abrupt, post-hoc distortion caused by thresholding.
- Reduced Over-Correction: Threshold-based normalization can “over-correct” certain time steps, leading to out-of-bound or exaggerated perturbations. Eliminating the threshold reduces these extreme adjustments, increasing the likelihood that will actually shift to the desired class (i.e., higher validity).
- Smoother Decision Boundary Transitions: Many classifiers, especially those based on neural networks, respond more predictably to small, smooth perturbations than to abrupt, binary changes. Thus, Info-CELS produces counterfactuals that are more naturally positioned on the boundary between classes, improving the probability of valid classification.
4.3. Empirical Findings
- Mitigating noise through smooth perturbations;
- Maintaining finer-grained saliency for interpretability;
- Ensuring high validity by avoiding abrupt, post-hoc changes that can distort the explanation’s fidelity.
5. Experiments
5.1. Baseline Methods
- Native guide counterfactual (NG): NG [42] is an instance-based counterfactual method that utilizes feature weight vectors and in-sample counterfactuals to generate counterfactuals. It extracts feature weight vectors using Class Activation Mapping (CAM) [46], which helps NG identify the most distinguishable contiguous subsequences. The nearest unlike neighbor is then used to replace these subsequences. To generate CAM, specific types of networks are typically required, particularly those that include convolutional layers or other feature extraction mechanisms capable of producing feature maps.
- Alibi Counterfactual (ALIBI): ALIBI follows the work of Wachter et al. [31], which generates counterfactual explanations by optimizing an objective function:where encourages the search of counterfactual instance to change the model prediction to the target class, and ensures that is close to original instance . This method generates counterfactuals with only proximity and validity constraints on the perturbation, which could result in modifications across the entire time series to achieve the counterfactuals.
- Shapelet-guied counterfactual (SG): SG [33] is the extension based on wCF, which introduces a new shapelet loss term (see Equation (8)) to enforce the counterfactual instance to be close to the promined shapelet extracted from the training set. This method encourages one segment perturbation based on pre-mined shapelets. Using a brute force approach that compares all possible subsequences of various lengths in the time series could find the most discriminative shapelets, but it is computationally expensive. As a result, SG relies on the availability of high-quality extracted shapelets to guide counterfactual generation effectively. However, obtaining such high-quality shapelets is computationally costly, making the efficiency of SG heavily dependent on the extraction method used.
- Time Series Counterfactual Explanations using Barycenters (TimeX): TimeX [35] builds upon Wachter’s counterfactual generation framework by introducing a new loss term that enhances interpretability and contiguity. It incorporates Dynamic Barycenter Averaging (DBA) [47] to ensure that the generated counterfactual is close to the average time series of the target class, thereby improving representativeness. Additionally, TimeX enforces contiguity by modifying only the most important contiguous segment, identified through saliency maps or perturbation-based evaluation. To ensure a valid counterfactual, the contiguous segment length is gradually increased until the perturbation is sufficient to change the classification, sometimes requiring a long subsequence modification.
- CELS [43]: An optimization-based model that generates counterfactual explanations by learning saliency maps to guide the perturbation. CELS is designed to identify and highlight the key time steps that provide crucial evidence for the model’s prediction. It achieves this by learning a saliency map for each input and using the nearest unlike neighbor as a reference to replace the important time steps identified by the saliency map.
5.2. Implementation Details
5.3. Evaluation Metrics
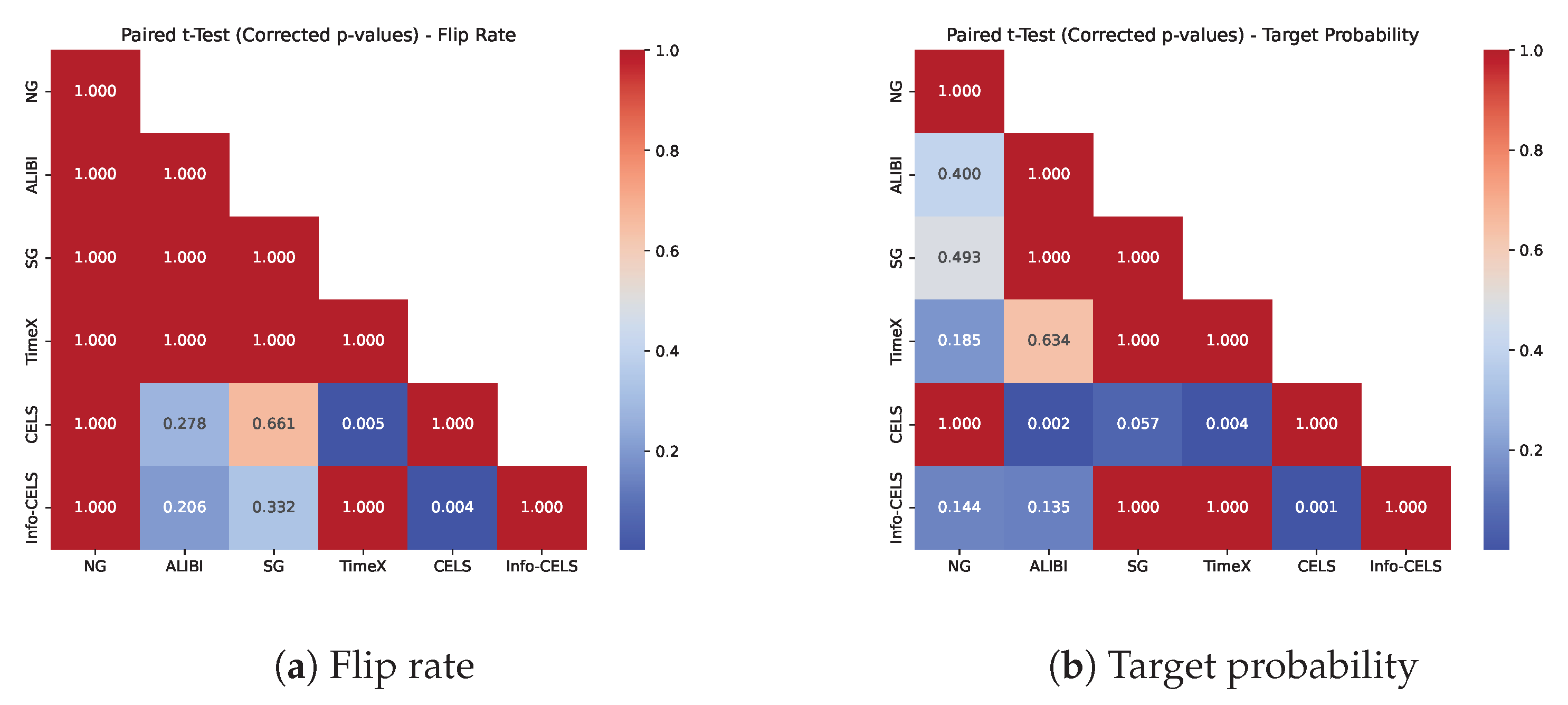
5.4. Evaluation Results
5.4.1. Validity Evaluation:
5.4.2. Sparsity and Proximity Evaluation:
5.5. Exploring Interpretability (Also Referred to as Plausibility (e.g., [42]))
- IF is an algorithm used for anomaly detection, which works on the principle of isolating observations. Unlike many other techniques that rely on a distance or density measure, Isolation Forest is based on the idea that anomalies are ‘few and different.’
- LOF is an algorithm used to identify density-based local outliers in a dataset. It works by comparing a point’s local density with its neighbors’ local densities to determine how isolated the point is.
- OC-SVM is a variant of the Support Vector Machine (SVM) used for anomaly detection. It is an unsupervised learning algorithm designed to identify data points that are significantly different from the majority of the data.
5.6. Parameter Analysis
6. Computational Impact
6.1. Preparation Time
- NG: NG requires extracting feature vectors to locate the most distinguishable subsequences. This is typically achieved by computing Class Activation Maps (CAM) from the intermediate layers of a convolutional neural network. Consequently, a neural network must be trained to obtain these feature maps. If the black-box model is not based on convolutional architectures, alternative methods or modifications are needed to extract analogous features, potentially increasing both the computational cost and the complexity of the counterfactual generation process.
- SG: SG involves an extra step of extracting pre-mined shapelets from the training set, which can be computationally expensive. In this process, the shapelet transform algorithm is applied, as described in [33], where both the number of candidate shapelets and their lengths are defined by a set of window sizes. Specifically, for a time series of length T and k different window sizes, roughly candidate shapelets are generated per series. For each candidate shapelet, the algorithm computes distances to all possible subsequences in the dataset using a sliding window with a step size of 1. This distance computation takes about per candidate for N time series. Consequently, for a single time series, the cost for all candidate shapelets is approximately , and for the entire dataset of N time series, the overall worst-case time complexity becomes . Additionally, the removal of similar shapelets involves sorting and pairwise comparisons of the candidate set, which further increases the computational cost.
- TimeX: TimeX uses dynamic barycenter averaging to ensure that the generated counterfactual is close to the target class average. The dynamic barycenter extraction adds extra overhead, similarly to the cost observed in shapelet extraction, albeit with a different algorithmic complexity. The dynamic barycenter averaging method extracts a representative time series (barycenter) by aligning each time series to the current barycenter using DTW and then updating the barycenter as the weighted average of the aligned points. The main computational cost is derived through computing the DTW paths for each time series, which takes about per series, where T is the time series length and B is the barycenter length. With N time series and a maximum of max_iter iterations, the overall cost is roughly .
- Alibi and CELS: Both methods (Alibi and CELS) do not require additional preparatory steps. In CELS, a saliency map is learned via optimization and is directly integrated into the counterfactual generation process. This eliminates the need for separate feature extraction or subsequence selection procedures, resulting in lower preparation times compared to methods like NG, SG, and TimeX.
6.2. Counterfactual Generation Time
- NG: NG does not involve an optimization process; instead, it extends the subsequence until a valid counterfactual is found; therefore, its generation time is typically very fast if the feature weights vectors are available.
- Alibi, SG, and TimeX: These methods perturb the original time series and optimize a loss function. SG and TimeX incorporate predefined or dynamically determined subsequence positions (via pre-mined shapelets or dynamic barycenter averaging, respectively) to guide the perturbations. Such constraints can accelerate convergence relative to pure optimization, although the overall generation time may still be impacted by the extra preparatory overhead.
- CELS and Info-CELS: Both approaches learn a saliency map from scratch during the optimization process, which generally requires more time to converge compared to methods that use predefined locations to guide the perturbation. However, Info-CELS eliminates the threshold-based normalization step used in CELS. This reduction in processing overhead makes Info-CELS computationally more efficient than CELS, although both are optimization-based.
7. Case Study: Multivariate Time Series Data
7.1. Datasets
7.2. Experimental Results
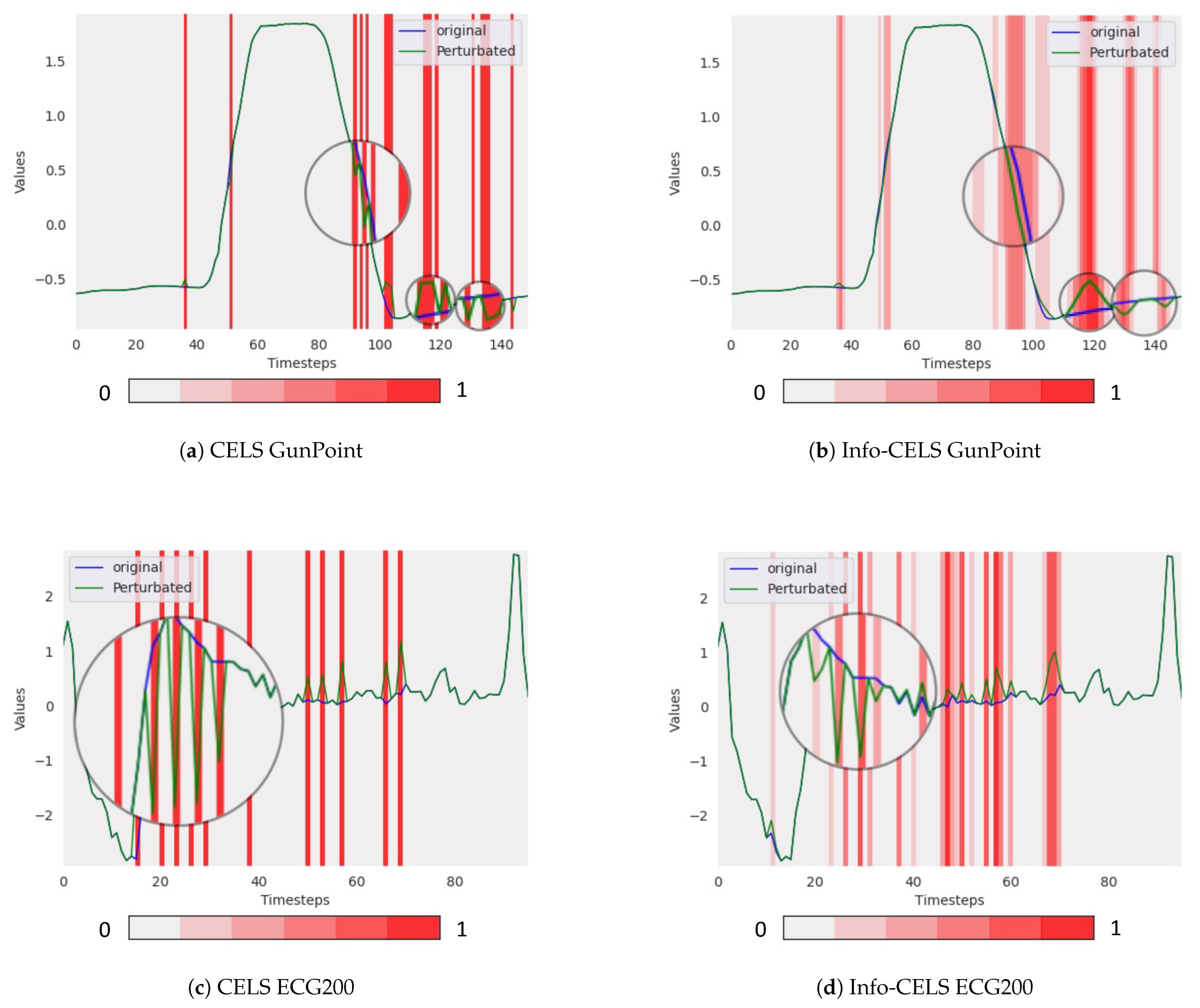
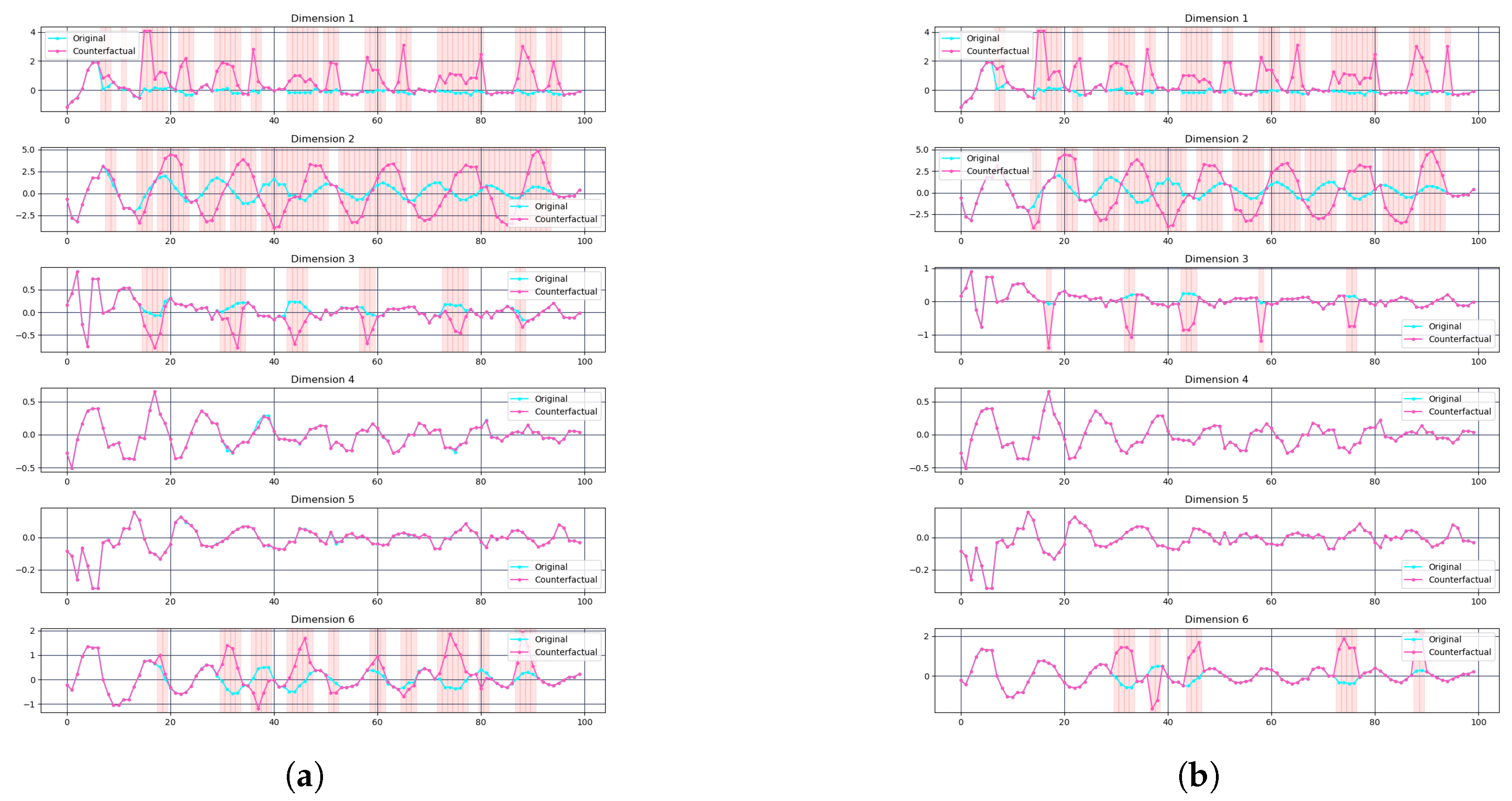
- BasicMotions: Both Info-CELS and CELS achieved a 100% flip rate on the BasicMotions dataset. Info-CELS attained a slightly higher average target probability (0.8935 vs. 0.8807), suggesting marginal gains in confidence. Figure 6a,b display the counterfactual explanations from CELS and Info-CELS on one randomly selected sample from the BasicMotions testing dataset—this sample was chosen at random since all samples successfully flipped the label. Figure 6a,b show that the time series dimensions for BasicMotions are relatively simple, and normalization does not appear to introduce significant noise or abrupt changes. Consequently, eliminating the normalization step offers only a small improvement in performance.
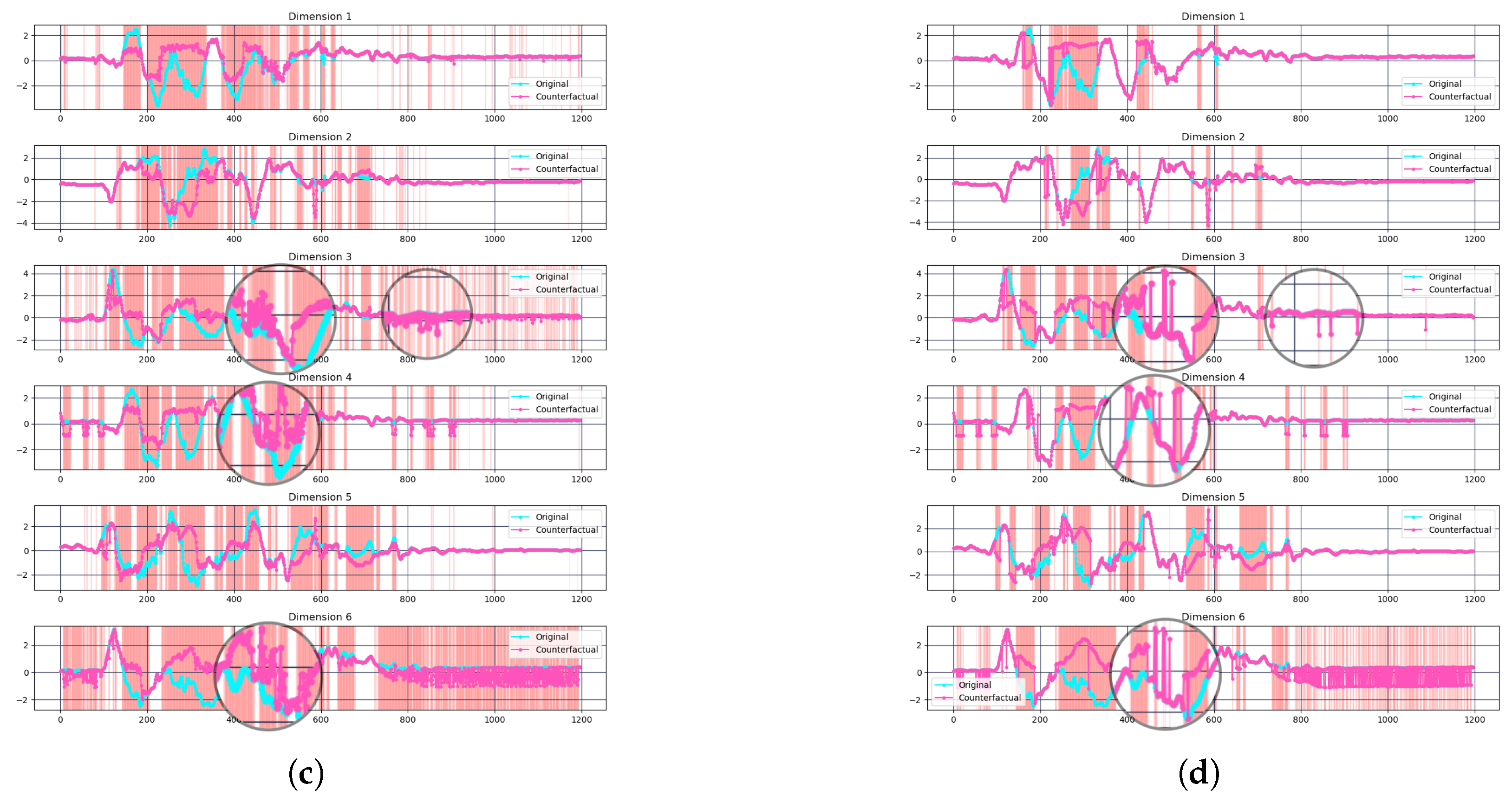
- Cricket: In contrast, Cricket benefits more noticeably from removing normalization. Info-CELS achieves a 100% flip rate, surpassing CELS (94.44%), and also exhibits a higher average target probability (0.8178 vs. 0.7597). Figure 6c,d focus on a Cricket instance that CELS failed to flip. We compared the original CELS explanation with Info-CELS on the same instance. As illustrated in Figure 6c,d, the signals in Cricket were more complex with higher variability across dimensions. Here, threshold-based normalization can cause abrupt, piecewise-constant segments in some channels, potentially undermining their validity. By maintaining continuous saliency values, Info-CELS avoids these artificial jumps, resulting in smoother perturbations and better classification flips.
8. Conclusions
- We propose a novel modification to the CELS framework by eliminating the normalization step, thereby mitigating noise and enhancing the interpretability of counterfactuals.
- We provide a comprehensive empirical evaluation, demonstrating that Info-CELS achieves perfect validity and improved target probabilities across diverse datasets.
- We extend our investigation to multivariate time series data, highlighting their broader applicability in complex real-world scenarios.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kaushik, S.; Choudhury, A.; Sheron, P.K.; Dasgupta, N.; Natarajan, S.; Pickett, L.A.; Dutt, V. AI in healthcare: Time-series forecasting using statistical, neural, and ensemble architectures. Front. Big Data 2020, 3, 4. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.K.; Chen, I.; Hershkovich, L.; Yang, J.; Shetty, A.; Singh, G.; Jiang, Y.; Kotla, A.; Shang, J.Z.; Yerrabelli, R.; et al. A systematic review of time series classification techniques used in biomedical applications. Sensors 2022, 22, 8016. [Google Scholar] [CrossRef]
- Chaovalitwongse, W.A.; Prokopyev, O.A.; Pardalos, P.M. Electroencephalogram (EEG) time series classification: Applications in epilepsy. Ann. Oper. Res. 2006, 148, 227–250. [Google Scholar]
- Mehdiyev, N.; Lahann, J.; Emrich, A.; Enke, D.; Fettke, P.; Loos, P. Time series classification using deep learning for process planning: A case from the process industry. Procedia Comput. Sci. 2017, 114, 242–249. [Google Scholar]
- Susto, G.A.; Cenedese, A.; Terzi, M. Time-series classification methods: Review and applications to power systems data. Big Data Appl. Power Syst. 2018, 179–220. [Google Scholar] [CrossRef]
- Hosseinzadeh, P.; Boubrahimi, S.F.; Hamdi, S.M. An End-to-end Ensemble Machine Learning Approach for Predicting High-impact Solar Energetic Particle Events Using Multimodal Data. Astrophys. J. Suppl. Ser. 2025, 277, 34. [Google Scholar]
- Bahri, O.; Boubrahimi, S.F.; Hamdi, S.M. Shapelet-Based Counterfactual Explanations for Multivariate Time Series. arXiv 2022, arXiv:2208.10462. [Google Scholar]
- Li, P.; Bahri, O.; Boubrahimi, S.F.; Hamdi, S.M. Fast Counterfactual Explanation for Solar Flare Prediction. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 12–14 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1238–1243. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar]
- Liu, C.L.; Hsaio, W.H.; Tu, Y.C. Time series classification with multivariate convolutional neural network. IEEE Trans. Ind. Electron. 2018, 66, 4788–4797. [Google Scholar]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep neural network ensembles for time series classification. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, J.L. Time series classification using multi-channels deep convolutional neural networks. In Proceedings of the International Conference on Web-Age Information Management, Macau, China, 16–18 June 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 298–310. [Google Scholar]
- Gamboa, J.C.B. Deep learning for time-series analysis. arXiv 2017, arXiv:1701.01887. [Google Scholar]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef] [PubMed]
- Dwivedi, R.; Dave, D.; Naik, H.; Singhal, S.; Omer, R.; Patel, P.; Qian, B.; Wen, Z.; Shah, T.; Morgan, G.; et al. Explainable AI (XAI): Core ideas, techniques, and solutions. ACM Comput. Surv. 2023, 55, 1–33. [Google Scholar]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Van der Velden, B.H.; Kuijf, H.J.; Gilhuijs, K.G.; Viergever, M.A. Explainable artificial intelligence (XAI) in deep learning-based medical image analysis. Med Image Anal. 2022, 79, 102470. [Google Scholar] [CrossRef] [PubMed]
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl.-Based Syst. 2023, 263, 110273. [Google Scholar] [CrossRef]
- Nemirovsky, D.; Thiebaut, N.; Xu, Y.; Gupta, A. Countergan: Generating counterfactuals for real-time recourse and interpretability using residual gans. In Proceedings of the Uncertainty in Artificial Intelligence, Eindhoven, The Netherlands, 1–5 August 2022; PMLR: Birmingham, UK, 2022; pp. 1488–1497. [Google Scholar]
- Brughmans, D.; Leyman, P.; Martens, D. Nice: An algorithm for nearest instance counterfactual explanations. Data Min. Knowl. Discov. 2024, 38, 2665–2703. [Google Scholar]
- Dandl, S.; Molnar, C.; Binder, M.; Bischl, B. Multi-objective counterfactual explanations. In Proceedings of the International Conference on Parallel Problem Solving from Nature, Leiden, The Netherlands, 5–9 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 448–469. [Google Scholar]
- Rojat, T.; Puget, R.; Filliat, D.; Del Ser, J.; Gelin, R.; Díaz-Rodríguez, N. Explainable artificial intelligence (xai) on timeseries data: A survey. arXiv 2021, arXiv:2104.00950. [Google Scholar]
- Bodria, F.; Giannotti, F.; Guidotti, R.; Naretto, F.; Pedreschi, D.; Rinzivillo, S. Benchmarking and survey of explanation methods for black box models. Data Min. Knowl. Discov. 2023, 37, 1719–1778. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar]
- Verma, S.; Boonsanong, V.; Hoang, M.; Hines, K.; Dickerson, J.; Shah, C. Counterfactual explanations and algorithmic recourses for machine learning: A review. ACM Comput. Surv. 2024, 56, 1–42. [Google Scholar]
- Lee, M.H.; Chew, C.J. Understanding the effect of counterfactual explanations on trust and reliance on ai for human-ai collaborative clinical decision making. Proc. ACM Human-Comput. Interact. 2023, 7, 1–22. [Google Scholar]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. JL Tech. 2017, 31, 841. [Google Scholar]
- Li, P.; Boubrahimi, S.F.; Hamd, S.M. Motif-guided Time Series Counterfactual Explanations. arXiv 2022, arXiv:2211.04411. [Google Scholar]
- Li, P.; Bahri, O.; Boubrahimi, S.F.; Hamdi, S.M. SG-CF: Shapelet-Guided Counterfactual Explanation for Time Series Classification. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1564–1569. [Google Scholar]
- Bahri, O.; Li, P.; Boubrahimi, S.F.; Hamdi, S.M. Temporal Rule-Based Counterfactual Explanations for Multivariate Time Series. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 12–14 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1244–1249. [Google Scholar]
- Filali Boubrahimi, S.; Hamdi, S.M. On the Mining of Time Series Data Counterfactual Explanations using Barycenters. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3943–3947. [Google Scholar]
- Wang, Z.; Samsten, I.; Miliou, I.; Mochaourab, R.; Papapetrou, P. Glacier: Guided locally constrained counterfactual explanations for time series classification. Mach. Learn. 2024, 113, 4639–4669. [Google Scholar]
- Sivill, T.; Flach, P. Limesegment: Meaningful, realistic time series explanations. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 28–30 March 2022; PMLR: Birmingham, UK, 2022; pp. 3418–3433. [Google Scholar]
- Huang, Q.; Kitharidis, S.; Bäck, T.; van Stein, N. TX-Gen: Multi-Objective Optimization for Sparse Counterfactual Explanations for Time-Series Classification. arXiv 2024, arXiv:2409.09461. [Google Scholar]
- Refoyo, M.; Luengo, D. Sub-SpaCE: Subsequence-Based Sparse Counterfactual Explanations for Time Series Classification Problems. 2023. Available online: https://www.researchsquare.com/article/rs-3706710/v1 (accessed on 23 March 2025).
- Refoyo, M.; Luengo, D. Multi-SpaCE: Multi-Objective Subsequence-based Sparse Counterfactual Explanations for Multivariate Time Series Classification. arXiv 2024, arXiv:2501.04009. [Google Scholar]
- Höllig, J.; Kulbach, C.; Thoma, S. TSEvo: Evolutionary Counterfactual Explanations for Time Series Classification. In Proceedings of the 21st IEEE International Conference on Machine Learning and Applications, ICMLA, Nassau, Bahamas, 12–14 December 2022; pp. 29–36. [Google Scholar] [CrossRef]
- Delaney, E.; Greene, D.; Keane, M.T. Instance-based counterfactual explanations for time series classification. In Proceedings of the International Conference on Case-Based Reasoning, Salamanca, Spain, 13–16 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 32–47. [Google Scholar]
- Li, P.; Bahri, O.; Boubrahimi, S.F.; Hamdi, S.M. CELS: Counterfactual Explanations for Time Series Data via Learned Saliency Maps. In Proceedings of the 2023 IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 718–727. [Google Scholar]
- Mothilal, R.K.; Sharma, A.; Tan, C. Explaining machine learning classifiers through diverse counterfactual explanations. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 607–617. [Google Scholar]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR time series archive. IEEE/CAA J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Petitjean, F.; Ketterlin, A.; Gançarski, P. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognit. 2011, 44, 678–693. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Student. The probable error of a mean. Biometrika 1908, 6, 1–25. [Google Scholar]
- Moore, D.S.; McCabe, G.P.; Craig, B.A. Introduction to the Practice of Statistics; WH Freeman: New York, NY, USA, 2009; Volume 4. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 413–422. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 15–18 May 2000; pp. 93–104. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [PubMed]
- Bagnall, A.; Dau, H.A.; Lines, J.; Flynn, M.; Large, J.; Bostrom, A.; Southam, P.; Keogh, E. The UEA multivariate time series classification archive. arXiv 2018, arXiv:1811.00075. [Google Scholar]
- Ko, M.H.; West, G.; Venkatesh, S.; Kumar, M. Online context recognition in multisensor systems using dynamic time warping. In Proceedings of the 2005 International Conference on Intelligent Sensors, Sensor Networks and Information Processing, Melbourne, Australia, 5–8 December 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 283–288. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Dataset Name | DS Train Size | DS Test Size | Type | ||
|---|---|---|---|---|---|---|
| 0 | Coffee | 2 | 286 | 28 | 28 | SPECTRO |
| 1 | GunPoint | 2 | 150 | 50 | 150 | MOTION |
| 2 | ECG200 | 2 | 96 | 100 | 100 | ECG |
| 3 | TwoLeadECG | 2 | 82 | 23 | 100 | ECG |
| 4 | CBF | 3 | 128 | 30 | 100 | SIMULATED |
| 5 | BirdChicken | 2 | 512 | 20 | 20 | IMAGE |
| 6 | Plane | 7 | 144 | 105 | 105 | SENSOR |
| Flip Rate | Target Probability | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | NG | ALIBI | SG | TimeX | CELS | Info-CELS | NG | ALIBI | SG | TimeX | CELS | Info-CELS |
| Coffee | 1.0 | 0.79 | 0.61 | 1.0 | 0.786 | 1.0 | 0.67 | 0.74 | 0.60 | 0.96 | 0.62 | 0.9 |
| GunPoint | 1.0 | 0.95 | 0.92 | 1.0 | 0.680 | 1.0 | 0.63 | 0.87 | 0.86 | 0.96 | 0.59 | 0.97 |
| ECG200 | 1.0 | 0.88 | 0.93 | 0.98 | 0.820 | 1.0 | 0.79 | 0.82 | 0.93 | 0.97 | 0.68 | 0.86 |
| TwoLeadECG | 1.0 | 0.87 | 1.0 | 1.0 | 0.6 | 1.0 | 0.80 | 0.83 | 0.99 | 0.98 | 0.57 | 0.84 |
| CBF | 0.56 | 0.89 | 0.81 | 0.97 | 0.71 | 1.0 | 0.41 | 0.83 | 0.78 | 0.93 | 0.56 | 0.86 |
| BirdChicken | 1.0 | 1.0 | 0.85 | 0.7 | 0.5 | 1.0 | 0.63 | 0.81 | 0.80 | 0.69 | 0.53 | 0.96 |
| Plane | 0.14 | 0.69 | 0.87 | 1.0 | 0.57 | 1.0 | 0.16 | 0.67 | 0.85 | 0.97 | 0.4 | 0.81 |
| IF | LOF | OC-SVM | ||||
|---|---|---|---|---|---|---|
| Dataset | CELS | Info-CELS | CELS | Info-CELS | CELS | Info-CELS |
| Coffee | 0.34 | 0.318 | 0.036 | 0.036 | 0.143 | 0.107 |
| GunPoint | 0.214 | 0.175 | 0.267 | 0.22 | 0.073 | 0.047 |
| ECG200 | 0.282 | 0.220 | 0.02 | 0.02 | 0.18 | 0.13 |
| TwoLeadECG | 0.381 | 0.362 | 0.02 | 0 | 0.22 | 0.22 |
| CBF | 0.159 | 0.074 | 0 | 0 | 0.75 | 0.38 |
| BirdChicken | 0.5 | 0.5 | 0.05 | 0.05 | 0.5 | 0.3 |
| Plane | 0.33 | 0.17 | 0.4 | 0.31 | 0.35 | 0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Bahri, O.; Hosseinzadeh, P.; Boubrahimi, S.F.; Hamdi, S.M. Info-CELS: Informative Saliency Map-Guided Counterfactual Explanation for Time Series Classification. Electronics 2025, 14, 1311. https://doi.org/10.3390/electronics14071311
Li P, Bahri O, Hosseinzadeh P, Boubrahimi SF, Hamdi SM. Info-CELS: Informative Saliency Map-Guided Counterfactual Explanation for Time Series Classification. Electronics. 2025; 14(7):1311. https://doi.org/10.3390/electronics14071311
Chicago/Turabian StyleLi, Peiyu, Omar Bahri, Pouya Hosseinzadeh, Soukaïna Filali Boubrahimi, and Shah Muhammad Hamdi. 2025. "Info-CELS: Informative Saliency Map-Guided Counterfactual Explanation for Time Series Classification" Electronics 14, no. 7: 1311. https://doi.org/10.3390/electronics14071311
APA StyleLi, P., Bahri, O., Hosseinzadeh, P., Boubrahimi, S. F., & Hamdi, S. M. (2025). Info-CELS: Informative Saliency Map-Guided Counterfactual Explanation for Time Series Classification. Electronics, 14(7), 1311. https://doi.org/10.3390/electronics14071311