
Latency-Aware and Auto-Migrating Page Tables for ARM NUMA Servers


Abstract
1. Introduction
- We design a page table access latency-aware (PTL-aware) mechanism for automatic page table migration (Auto-PTM) to optimize the performance of thin workloads.
- We comprehensively analyze the differences between the ARM architecture and the x86 architecture in terms of page table structure and the implementation of the Linux kernel source code. That makes our design fit to be implemented across both architectures.
- We evaluated our design on real ARM bare-metal NUMA servers. The experimental results show that, compared to the state-of-the-art PTM mechanism, the performance of memory-intensive workloads in this paper increased in different scenarios (GUPS, 3.53x; XSBench, 1.77x; Hashjoin, 1.68x). We have also evaluated that our work has no effect on compute-intensive workloads.
2. Related Work
2.1. Mitigating NUMA Effects via Data Optimization
2.2. Mitigating NUMA Effects via Page Table Optimization
3. Background
3.1. Page Tables
3.2. Page Table-Caused NUMA Effect
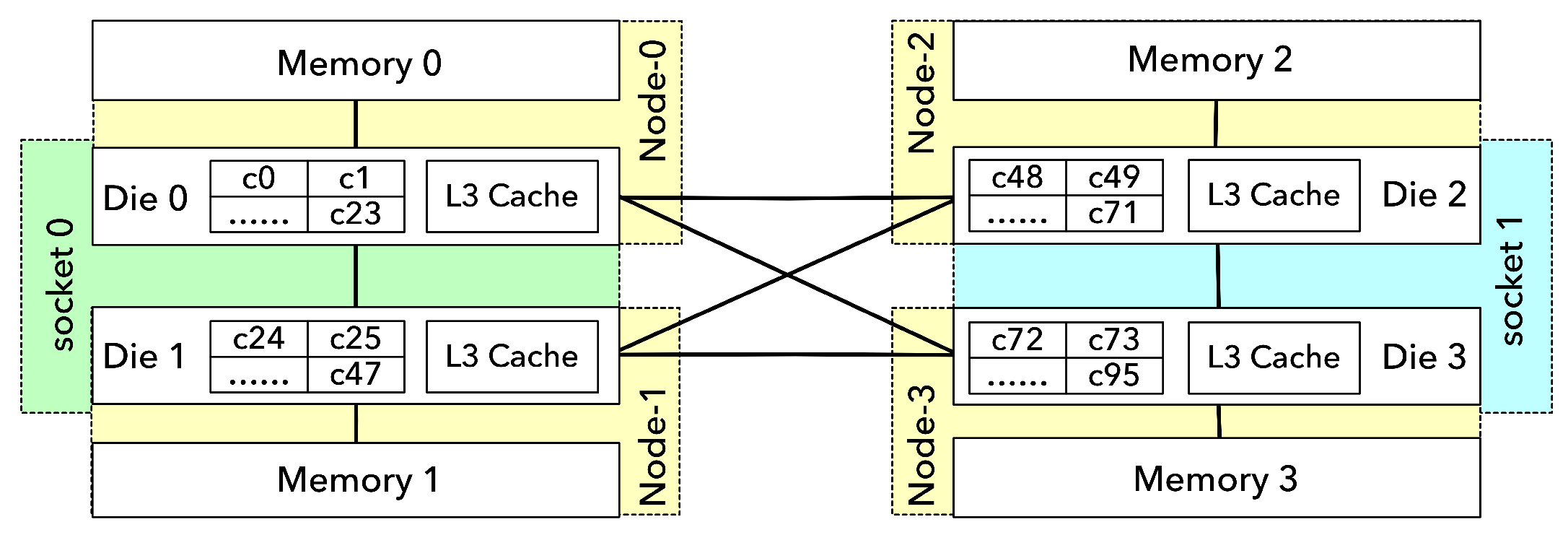
3.2.1. Page Table Distribution and Cross-Node Access
3.2.2. TLB Capacity Limitations
3.3. PTR and PTM
3.4. Motivation
3.4.1. Enhancing Auto-PTM with PTL-Awareness
3.4.2. Cross-Architecture Compatibility
- Page Table Structure—The multi-level page table mechanism in ARMv8-A differs significantly from the x 86 architecture, requiring modifications to the replication and migration logic.
- Para-Virtualization Interface—ARM lacks the para-virtualization interfaces available in x86, necessitating alternative methods for implementing page table self-replication and migration.
- Linux Kernel Implementation—The Linux kernel’s handling of page tables on ARM architectures is fundamentally different from that on x86, presenting additional technical challenges.
4. Design and Implementation
4.1. PTL-Aware Auto-PTM
4.1.1. PTL-Probing
4.1.2. Page Table Scan and Migration Decision
| Algorithm 1 The pseudo-code of the migration algorithm for PTL-aware Auto-PTM. The configuration is a page size of 4KB, and a four-level page table is used |
| Require: : the VMA of the target process to be scanned; Require: : the PTL info array;
|
4.1.3. Workflow
4.1.4. Analysis of Scanning Frequency
4.1.5. Transparent Huge Pages in PTM
4.2. Implementation
4.2.1. Page Table Differences Between ARM64 and x86-64 Processors
4.2.2. Solution
4.2.3. Performance Impact of Page Table Differences
5. Experimental Setup
6. Results and Analysis
6.1. Performance with PTL-Aware Auto-PTM on ARM64 NUMA Server
6.2. Memcached with PTL-Aware Auto-PTM on ARM64
6.3. Evaluation of Compute-Intensive Workloads
6.4. Performance with PTL-Aware Auto-PTM on x86-64 NUMA Server
Why Does the Scanning Frequency Have Little Impact on x86-64 NUMA Server?
6.5. Overhead
6.5.1. Memory Overhead
6.5.2. Runtime Overhead
6.6. Discussion
6.6.1. Scalability
6.6.2. Applicability to Virtualized Systems?
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| NUMA | Non-Uniform Memory Access |
| PTR | Page Table Replication |
| PTM | Page Table Migration |
| PTL | Page Table Access Latency |
| WASP | Workload-Aware Self-Replicating Page Tables |
| VMA | Virtual Memory Areas |
| MMU | Memory Management Unit |
| TLB | Translation Lookaside Buffer |
| TTBR | Translation Table Base Register |
| PGD | Page Global Directory |
| PUD | Page Upper Directory |
| PMD | Page Middle Directory |
| PTE | Page Table Entry |
References
- Demir, Y.; Pan, Y.; Song, S.; Hardavellas, N.; Kim, J.; Memik, G. Galaxy: A High-performance Energy-efficient Multi-chip Architecture Using Photonic Interconnects. In Proceedings of the 28th ACM International Conference on Supercomputing (ICS ’14), Munich, Germany, 10–13 June 2014. [Google Scholar] [CrossRef]
- Iyer, S. Heterogeneous Integration for Performance and Scaling. IEEE Trans. Components Packag. Manuf. Technol. 2016, 6, 973–982. [Google Scholar] [CrossRef]
- Kannan, A.; Jerger, N.E.; Loh, G.H. Enabling interposer-based disintegration of multi-core processors. In Proceedings of the 48th International Symposium on Microarchitecture (MICRO-48), Waikiki, HI, USA, 5–9 December 2015. [Google Scholar] [CrossRef]
- Yin, J.; Lin, Z.; Kayiran, O.; Poremba, M.; Altaf, M.S.B.; Jerger, N.E.; Loh, G.H. Modular Routing Design for Chiplet Based Systems. In Proceedings of the 45th Annual International Symposium on Computer Architecture (ISCA ’18), Los Angeles, CA, USA, 1–6 June 2018. [Google Scholar] [CrossRef]
- Calciu, I.; Sen, S.; Balakrishnan, M.; Aguilera, M.K. Black-box Concurrent Data Structures for NUMA Architectures. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’17), Xi’an, China, 8–12 April 2017. [Google Scholar] [CrossRef]
- Dashti, M.; Fedorova, A.; Funston, J.; Gaud, F.; Lachaize, R.; Lepers, B.; Quema, V.; Roth, M. Traffic Management: A Holistic Approach to Memory Placement on NUMA Systems. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’13), Houston, TX, USA, 16–20 March 2013. [Google Scholar] [CrossRef]
- Kaestle, S.; Achermann, R.; Roscoe, T.; Harris, T. Shoal: Smart Allocation and Replication of Memory for Parallel Programs. In Proceedings of the 2015 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ’15), Santa Clara, CA, USA, 8–10 July 2015. [Google Scholar]
- Kernel, T.L. NUMA Memory Policy. Available online: https://www.kernel.org/doc/html/v5.7/admin-guide/mm/numa_memory_policy.html (accessed on 22 December 2024).
- Corbet, J. AutoNUMA: The Other Approach to NUMA Scheduling. Available online: https://lwn.net/Articles/488709/ (accessed on 22 December 2024).
- Achermann, R.; Panwar, A.; Bhattacharjee, A.; Roscoe, T.; Gandhi, J. Mitosis: Transparently Self-Replicating Page-Tables for Large-Memory Machines. In Proceedings of the Twenty-fifth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’20), Lausanne, Switzerland, 16–20 March 2020. [Google Scholar] [CrossRef]
- Achermann, R.; Panwar, A.; Bhattacharjee, A.; Roscoe, T.; Gandhi, J.; Gopinath, K. Fast Local Page-Tables for Virtualized NUMA Servers with vMitosis. In Proceedings of the Twenty-Sixth International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’21), Virtual, 19–23 April 2021. [Google Scholar] [CrossRef]
- Qu, H.; Yu, Z. WASP: Workload-Aware Self-Replicating Page-Tables for NUMA Servers. In Proceedings of the Twenty-Third International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS ’24), La Jolla, CA, USA, 27 April–1 May 2024. [Google Scholar] [CrossRef]
- linux man page. numactl. Available online: https://linux.die.net/man/8/numactl (accessed on 1 October 2024).
- Lachaize, R.; Lepers, B.; Quéma, V. MemProf: A memory profiler for NUMA multicore systems. In Proceedings of the 2012 USENIX Conference on Annual Technical Conference, Boston, MA, USA, 13–15 June 2012. [Google Scholar]
- Gaud, F.; Fedorova, A.; Funston, J.; Decouchant, J.; Lepers, B.; Quema, V. Large Pages May Be Harmful on NUMA Systems. In Proceedings of the 2014 USENIX Conference on USENIX Annual Technical Conference, Philadelphia, PA, USA, 19–20 June 2014; Available online: https://api.semanticscholar.org/CorpusID:17793052 (accessed on 22 December 2024).
- Denoyelle, N.; Goglin, B.; Jeannot, E.; Ropars, T. Data and Thread Placement in NUMA Architectures: A Statistical Learning Approach. In Proceedings of the 48th International Conference on Parallel Processing (ICPP 2019), Kyoto, Japan, 5–8 August 2019. [Google Scholar] [CrossRef]
- Barrera, I.S.; Black-Schaffer, D.; Casas, M.; Moretó, M.; Stupnikova, A.; Popov, M. Modeling and Optimizing NUMA Effects and Prefetching with Machine Learning. In Proceedings of the 34th ACM International Conference on Supercomputing (ICS ’20), Barcelona, Spain, 29 June–2 July 2020. [Google Scholar] [CrossRef]
- Gao, B.; Kang, Q.; Tee, H.W.; Chu, K.T.N.; Sanaee, A.; Jevdjic, D. Scalable and effective page-table and TLB management on NUMA systems. In Proceedings of the 2024 USENIX Conference on Usenix Annual Technical Conference, Santa Clara, CA, USA, 10–12 July 2025. [Google Scholar]
- Arm Holdings. armv8-a Address Translation. Available online: https://developer.arm.com/documentation/100940/0101/?lang=en (accessed on 22 December 2024).
- Pham, B.; Vaidyanathan, V.; Jaleel, A.; Bhattacharjee, A. CoLT: Coalesced Large-Reach TLBs. In Proceedings of the 2012 45th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO-45), Vancouver, BC, Canada, 1–5 December 2012. [Google Scholar] [CrossRef]
- Basu, A.; Gandhi, J.; Chang, J.; Hill, M.D.; Swift, M.M. Efficient Virtual Memory for Big Memory Servers. In Proceedings of the 40th Annual International Symposium on Computer Architecture (ISCA ’13), Tel-Aviv, Israel, 23–27 June 2013. [Google Scholar] [CrossRef]
- Karakostas, V.; Gandhi, J.; Ayar, F.; Cristal, A.; Hill, M.D.; McKinley, K.S.; Nemirovsky, M.; Swift, M.M.; Ünsal, O. Redundant Memory Mappings for Fast Access to Large Memories. In Proceedings of the 42nd Annual International Symposium on Computer Architecture (ISCA ’15), Portland, OR, USA, 13–17 June 2015. [Google Scholar] [CrossRef]
- Pham, B.; Bhattacharjee, A.; Eckert, Y.; Loh, G.H. Increasing TLB reach by exploiting clustering in page translations. In Proceedings of the 20th IEEE International Symposium on High Performance Computer Architecture (HPCA ’14), Orlando, FL, USA, 15–19 February 2014. [Google Scholar] [CrossRef]
- McCalpin, J.D. The STREAM Benchmark. Available online: https://github.com/jeffhammond/STREAM (accessed on 22 December 2024).
- Kernel.org. Paravirt_ops. Available online: https://www.kernel.org/doc/html/latest/virt/paravirt_ops.html (accessed on 22 December 2024).
- Barham, P.; Dragovic, B.; Fraser, K.; Hand, S.; Harris, T.; Ho, A.; Neugebauer, R.; Pratt, I.; Warfield, A. Xen and the Art of Virtualization. ACM SIGOPS Oper. Syst. Rev. 2003, 37, 164–177. [Google Scholar] [CrossRef]
- HUAWEI. The Taishan-Server. Available online: https://e.huawei.com/cn/products/computing/kunpeng/taishan (accessed on 22 December 2024).
- Gandhi, J.; Hill, M.D.; Swift, M.M. Agile Paging: Exceeding the Best of Nested and Shadow Paging. In Proceedings of the 43rd International Symposium on Computer Architecture, Seoul, Republic of Korea, 18–22 June 2016. [Google Scholar] [CrossRef]
- Kwon, Y.; Yu, H.; Peter, S.; Rossbach, C.J.; Witchel, E. Coordinated and Efficient Huge Page Management with Ingens. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Princeton. PARSEC Benchmark Suite. Available online: https://dl.acm.org/doi/10.1145/3053277.3053279 (accessed on 15 January 2025).
- HPCCALLENGE. RandomAccess: GUPS (Giga Updates Per Second). Available online: https://icl.utk.edu/projectsfiles/hpcc/RandomAccess/ (accessed on 15 January 2025).
- Labs, R. Redis. Available online: https://redis.io (accessed on 15 January 2025).
- Tramm, J.R.; Siegel, A.R.; Islam, T.; Schulz, M. XSBench-The Development and Verification of a Performance Abstraction for Monte Carlo Reactor Analysis. In Proceedings of the In PHYSOR 2014-The Role of Reactor Physics toward a Sustainable Future, Kyoto, Japan, 28 September–3 October 2014. [Google Scholar]
- Ang, J.; Barrett, K.W.B.; Murphy, R. Introducing the Graph500. Available online: https://graph500.org/ (accessed on 15 January 2025).
- Bailey, D. NAS Parallel Benchmarks. Available online: https://www.nas.nasa.gov/software/npb.html (accessed on 15 January 2025).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Difference | x86 | ARM64 |
|---|---|---|
| Page table related para-virtualization support | Yes | No |
| Page table base address register | CR3 | TTBR0, TTBR1 |
| Page table levels support | 5 | 4 |
| Workload | Description | Memory |
|---|---|---|
| Canneal | using simulated annealing to minimize the routing cost [30]. | 10 GB |
| GUPS | measuring the random memory access performance [31]. | 16 GB |
| Hashjoin | hash-table probing in databases. | 10 GB |
| Redis | an in-memory data store [32]. | 13 GB |
| XSBench | Monte Carlo neutronics [33]. | 20 GB |
| BTree | index lookups used in database. | 22 GB |
| Memcached | an event-based key/value store. | 14 GB |
| cg | Conjugate Gradient [35]. | 1 GB |
| mg | Multi-Grid on meshes [35]. | 3 GB |
| Configuration | Workload | Data | Page Table | I | m | w | f |
|---|---|---|---|---|---|---|---|
| RPLDLI | A | A | B | A | - | - | - |
| RPLDLI-m | A | A | B | A | enable | - | - |
| RPLDLI-w | A | A | B | A | enable | enable | - |
| LPLDLI | A | A | A | A | - | - | - |
| LPLDLI-m | A | A | A | A | enable | - | - |
| LPLDLI-w | A | A | A | A | enable | enable | - |
| RPLDRI | A | A | B | B | - | - | - |
| RPLDRI-m | A | A | B | B | enable | - | - |
| RPLDRI-w | A | A | B | B | enable | enable | - |
| RPLDRI-f | A | A | B | B | - | - | enable |
| RPLDRILI | A | A | B | A,B | - | - | - |
| RPLDRILI-m | A | A | B | A,B | enable | - | - |
| RPLDRILI-w | A | A | B | A,B | enable | enable | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, H.; Wang, P. Latency-Aware and Auto-Migrating Page Tables for ARM NUMA Servers. Electronics 2025, 14, 1685. https://doi.org/10.3390/electronics14081685
Qu H, Wang P. Latency-Aware and Auto-Migrating Page Tables for ARM NUMA Servers. Electronics. 2025; 14(8):1685. https://doi.org/10.3390/electronics14081685
Chicago/Turabian StyleQu, Hongliang, and Peng Wang. 2025. "Latency-Aware and Auto-Migrating Page Tables for ARM NUMA Servers" Electronics 14, no. 8: 1685. https://doi.org/10.3390/electronics14081685
APA StyleQu, H., & Wang, P. (2025). Latency-Aware and Auto-Migrating Page Tables for ARM NUMA Servers. Electronics, 14(8), 1685. https://doi.org/10.3390/electronics14081685