Abstract
As the frequency of cyberattacks rises, extracting actionable cyber threat intelligence (CTI) from diverse online sources has become critical for proactive threat detection and defense. Named entity recognition (NER) serves as a foundational task in CTI extraction, supporting downstream applications such as cybersecurity knowledge graph construction and attack attribution. However, existing NER methods face significant challenges in the cybersecurity domain, including the need to identify highly specialized entity types and adapt to rapidly evolving threats. These challenges are further exacerbated in few-shot scenarios with limited annotated data. In this work, we focus on few-shot NER for CTI extraction in general cyber environments. Our goal is to develop robust and adaptable methods that are not restricted to specific infrastructures (e.g., traditional IT systems), but instead can generalize across diverse cybersecurity contexts. Specifically, to address these issues, we propose CyberDualNER, a novel dual-stage framework for few-shot NER, which includes span detection and entity classification. In the first stage, we proposed a span detector that can utilize data from large-scale general domains to detect possible entity spans. Based on the detected spans, in the second stage, we propose a prompt-enhanced metric-based classifier. We use category descriptions to build prompt templates, extract category anchor representations, and classify entities based on similarity to span representations. By incorporating prior knowledge, we improve performance while reducing data dependency, which ensures generalizability in the face of emerging entities. Extensive experiments on real-world CTI datasets demonstrate the effectiveness of CyberDualNER, with significant performance improvements over baseline methods. Notably, the framework achieves robust results in scenarios with minimal annotated samples, highlighting its potential for practical applications in cybersecurity intelligence extraction.
1. Introduction
With the exponential expansion of the internet in recent decades, the frequency of cyberattacks has surged, posing serious risks to individuals and organizations alike. According to the annual report “The State of Cyber Security 2025” released by Check Point [1], the number of global cyber attacks has increased sharply by 44% year-on-year. A vast amount of CTI is widely distributed across public media platforms such as technical blogs, community forums, and social media. These information sources are broad in scope and highly timely, offering crucial support for threat warning and defense. By extracting relevant information from CTI data during the early and often stealthy stages of a cyberattack, it becomes possible to predict potential threats earlier [2]. Consequently, security organizations are increasingly focused on extracting CTI from cybersecurity-related texts available online to comprehensively understand current or future cyber threats and enhance defensive capabilities. This demand has spurred intensive research into CTI extraction techniques. Within the realm of cybersecurity, NER [3,4,5] serves as a foundational task for CTI analysis, particularly in constructing cybersecurity knowledge graphs [6,7] or modeling threat [8], which in turn facilitates attack attribution and supports proactive threat hunting, thus paving the way to improve the resilience of the network.
In recent years, numerous studies related to CTI extraction have emerged [9], and existing methods can be broadly categorized into rule-based and model-based approaches. The rule-based approaches [10] employ generic, pre-defined rules and domain-specific dictionaries to extract CTI, which suffer from poor generalization, high maintenance costs, and difficulty in identifying complex entities. On the other hand, the model-based approaches [11,12] leverage pre-trained models such as BERT [13,14] to obtain adaptive word embeddings for CTI extraction, which has demonstrated exceptional performance. However, these methods heavily rely on large-scale, high-quality annotated datasets, resulting in a significant performance degradation due to limited annotated data. Furthermore, their susceptibility to adversarial attacks raises serious concerns regarding their robustness, limiting their reliability in safety-critical or real-world applications [15]. As opposed to conventional NER, few-shot NER [16,17,18,19] aims to perform NER with as few annotated samples as possible and has become a major research focus in general-domain information extraction, which is more helpful for information extraction in specific domains such as cybersecurity.
The NER tasks in the cybersecurity domain also face several significant challenges, such as unique and specialized textual characteristics, for example, special characters and numbers. The emerging entity terms in evolving cybersecurity threats also pose a challenge to NER tasks in the cybersecurity domain.
To address the challenges mentioned above in the cybersecurity domain, we propose a dual-stage NER model called CyberDualNER, which performs well in the data-scarcity setting. To be specific, to use rich annotated examples from the general domain, we divide the NER task into two subtasks: span detection and entity classification. The first stage focuses on detecting all mentioned entities in any text, while the second stage assigns the detected spans to their corresponding cybersecurity entity categories. In the first stage, we focus on span detection, which is more related to linguistic features such as syntax and semantics, independent of the domain. Therefore, we adopt the “BIO” sequence labelling scheme and train a base span detector using rich general-domain corpora. Notably, in order to adapt the model to the unique characteristics of cybersecurity texts, we preprocess the texts while preserving the semantics, including cleaning, filtering, and anonymizing long words. In the second stage, to introduce prior knowledge and improve classification performance in the context of scarce cybersecurity samples, we design a prompt-enhanced metric learning approach. Specifically, we construct templates based on cybersecurity texts and related entity type descriptions to obtain entity type anchor representations that integrate contextual information for domain-specific entity types. We then assign entity types to candidate spans using a similarity-based metric learning strategy. This approach allows entity type representations to be independent of data and improves the detection of temporal dynamics and emergent entities, ensuring generalizability. Experiments on real-world annotated CTI datasets demonstrate that our model achieves significant performance improvements compared to the baseline approaches, highlighting its effectiveness.
To summarize, we make the following contributions:
- We propose an innovative dual-stage framework tailored for few-shot NER in the cybersecurity domain. This framework decouples span detection and entity classification into two separate tasks, leveraging abundant general-domain corpora to build a domain-independent span detector while focusing limited domain-specific resources on high-performance entity classification.
- To ensure the generalization of classification for emerging entities, we design a prompt-enhanced metric-based classifier. This module builds prompt templates to leverage prior knowledge of cybersecurity entity categories, obtains category anchor representations, and compares them with candidate entities based on similarity, achieving data-independent classification, which reduces the impact of few-shot bias.
- Extensive experiments on real-world datasets under various few-shot conditions demonstrate the superiority of our CyberDualNER model. Notably, our method maintains effectiveness even in extremely few-shot scenarios, significantly outperforming baseline models.
2. Problem Definition
2.1. Preliminaries
In this section, we first introduce the notations and definitions used throughout this paper. Then, we formally define the NER and few-shot NER problems. Table 1 lists the notations that will be used in this paper.

Table 1.
Notations and comments.
NER is a fundamental task in information extraction, which aims to identify contiguous spans in a text sequence of length L that refer to entities belonging to a predefined set of categories (e.g., Person, Location, Organization). Formulated as a sequence labeling problem, each token is assigned a label indicating whether it is part of an entity.
Traditional NER methods typically rely on a supervised learning paradigm, requiring a large number of annotated examples per entity type to achieve satisfactory generalization. However, in many real-world domains such as medicine, finance, and law, obtaining high-quality labeled data is costly and time-consuming. This practical constraint motivates the few-shot NER setting, where only m annotated instances are available for each category, with m often being as small as 1, 2, 5, or 10. Formally, let
the objective of few-shot NER is to learn a model using only the limited training set , such that it can accurately detect and classify entity spans in the test set .
In the few-shot regime, two core challenges arise: (1) span detection, since scarce examples hinder accurate boundary identification; and (2) entity type representation, as limited samples make it difficult to learn robust semantic features for each category, especially in domain-specific contexts where specialized terminology appears. To address these issues, recent studies have explored the integration of domain-specific priors (e.g., knowledge graphs) into few-shot learning frameworks, as well as metric-learning and meta-learning approaches such as prototypical networks and contrastive learning, to enhance generalization under few-shot conditions.
2.2. General Domain vs. Cybersecurity Domain
In this section, we introduce the difference between the general domain and the cybersecurity domain in the NER task. Compared to the extensively studied general domain, the cybersecurity domain faces several significant challenges, making it difficult to directly transfer and apply solutions from the general domain.
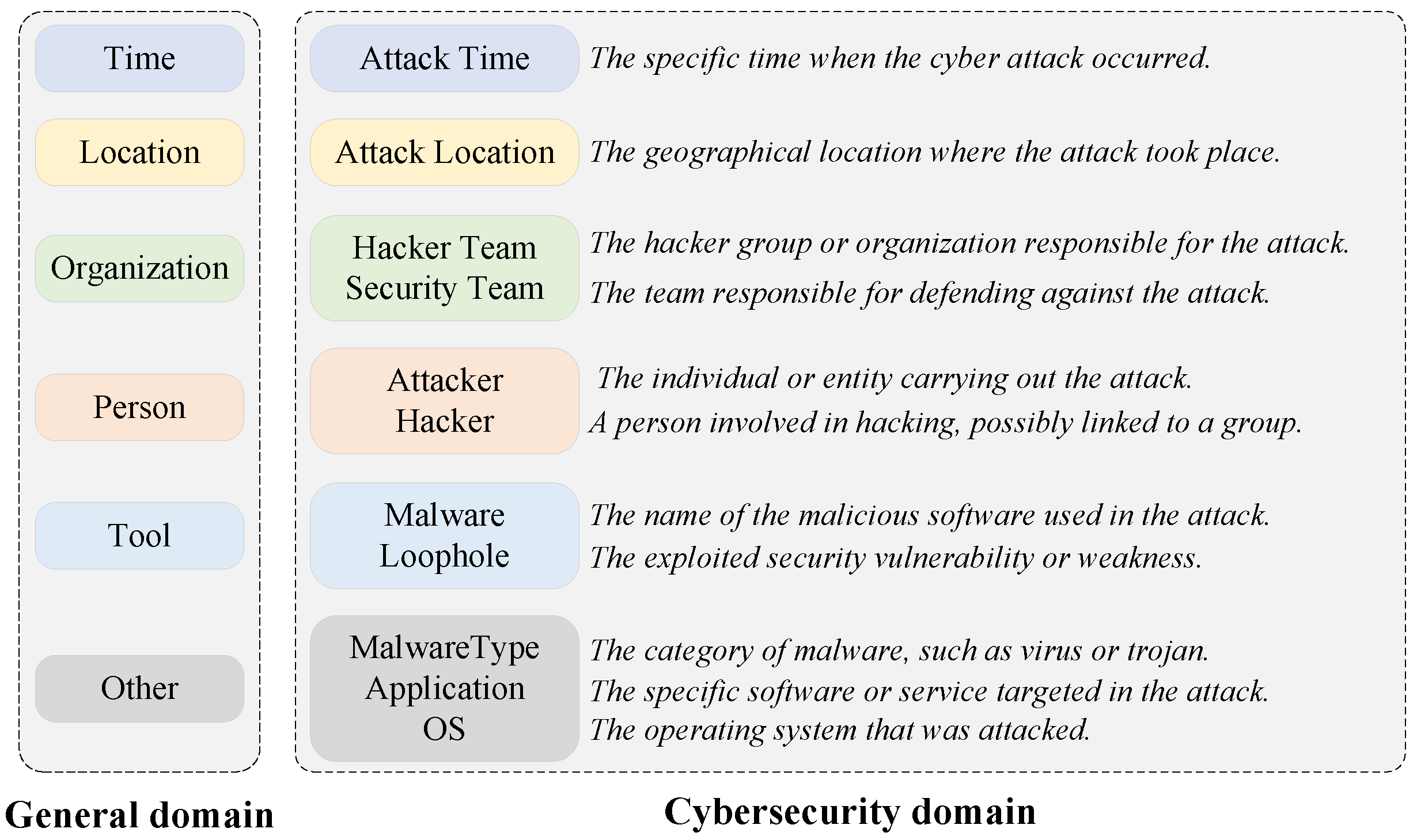
1. Unique textual characteristics: Texts in the cybersecurity domain have distinctive features. In general domains, entities might be ambiguous, but pre-trained language models can leverage contextual dependencies to enhance disambiguation. In contrast, cybersecurity texts often include terms composed of a mix of uppercase and lowercase letters, special characters, and numbers (e.g., malware names such as “AgentTesla2” or lengthy paths, hash values, and URLs). Such characteristics degrade the tokenization quality of default generic tokenizers, leading to subpar token-level representations in pre-trained models, which ultimately impacts performance.
2. Domain-specific entity types: Entity types in the field of cybersecurity exhibit a high degree of specialization. Compared to the general-domain entity types shown in Figure 1, cybersecurity entity types are not only more fine-grained (e.g., “Tool” is refined into “Malware” and “Loophole”) and more specific (e.g., “Time” refers specifically to “Attack Time”), but also include special miscellaneous entity categories such as “MalwareType” and “OS”, which are associated with potential cybersecurity threats. These categories often require domain-specific prior knowledge for accurate differentiation, thus increasing the complexity of extraction.
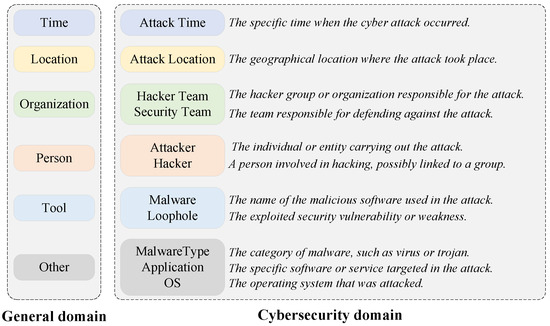
Figure 1.
The comparison of entity categories in the general and cybersecurity domain.
3. Temporal dynamics and emerging entities: Cybersecurity threats evolve rapidly, with attack methods and entities continuously changing. Emerging entity terms often have novel morphological structures that lack direct semantic references or are entirely new coinages. These characteristics hinder extraction models trained on outdated textual data from accurately recognizing specialized terms in new threat intelligence.
Therefore, due to the many challenges mentioned above, we need to design specific pre-processing and external knowledge injection operations for the network security text in order to improve the effectiveness of NER tasks in the cybersecurity domain.
3. Related Work
To provide a comprehensive understanding of the research landscape, we categorize existing studies into three major areas. First, we introduce prior work on CTI extraction, which serves as the primary task of our study. Given the limited availability of annotated CTI data, we further review few-shot NER approaches that aim to alleviate data scarcity. Specifically, we divide these into two categories: metric-based methods, which rely on distance-based learning for entity classification, and prompt-based methods, which utilize the expressive power of pre-trained language models through task-specific prompting. Our approach is designed by integrating ideas from both metric- and prompt-based few-shot learning to improve CTI entity extraction in few-shot scenarios.
3.1. Cyber Threat Intelligence Extraction
Automating the extraction of authoritative CTI plays a pivotal role in identifying, tracking, and mitigating cyberattacks [2]. A fundamental aspect of this process is recognizing cybersecurity entities. Accurate NER not only facilitates the construction of cybersecurity knowledge graphs but also supports informed decision-making in defense strategies and promotes information sharing among organizations.
Early studies predominantly relied on predefined rules [20]. For instance, Liu et al. [21] designed rule-based methods tailored for extracting target entities from XML-formatted data. Burger et al. [10] employed general predefined rules to extract Indicators of Compromise (IoC), such as IP addresses and hashes. While effective, these approaches demanded extensive domain knowledge and imposed stringent requirements on data standardization. In contrast, statistical methods [22,23,24,25] such as those based on support vector machines (SVMs) [24] and conditional random fields (CRFs) [26] bypassed the need for explicit rules, offering greater flexibility. However, these methods struggled with automation in feature extraction and exhibited performance limitations when processing large-scale text data.
With the advent of annotated datasets and advancements in NLP and deep learning, numerous automated approaches for identifying cybersecurity-related entities and relationships have emerged [27]. Dionísio et al. [28] annotated five categories of entities from Twitter data and employed BiLSTM networks for entity recognition. Satyapanich et al. [29] expanded the annotation of 1000 English news articles to include 20 cybersecurity-specific entities (e.g., files, devices, and software). Building on BiLSTM, their work introduced an attention mechanism to highlight salient parts of the text, improving extraction accuracy. Wang et al. [11] developed a dataset annotated by experts with 13 types of cybersecurity entities and provided a benchmark evaluation using deep learning models. Simran et al. [30] combined stacked Bi-GRU and CNN layers to capture high-level token representations. Evangelatos et al. [31] used transformer-based models to perform the NER task in CTI extraction in order to extract actionable information from various online sources. Zhou et al. [32] validated the application of the general-domain BERT-BiLSTM-CRF framework in the cybersecurity domain. Aravind et al. [33] compared five different NER models, such as BiLSTM, BiLSTM-CRF, and BERT-BiLSTM-CRF, and found that the BERT-BiLSTM-CRF model outperforms others. To enhance domain adaptability, Gao et al. [34] leveraged external domain dictionaries and incorporated attention mechanisms to refine specialized representations.
The inherent complexity of cybersecurity entities poses challenges in capturing non-local and non-sequential dependencies in NER. To address this, Fang et al. [35] employed graph neural networks (GNNs) to model both local contexts and global dependencies, thereby enhancing the recognition of professional-domain entities.
Despite their successes, fully supervised approaches heavily rely on the availability of large, high-quality annotated datasets. Constructing such datasets involves extensive data cleaning and relies on expert knowledge. Moreover, the rapid evolution of cyberattack techniques often renders these datasets outdated, making it challenging to adapt to new scenarios. This highlights the necessity of developing few-shot NER frameworks tailored to address the data scarcity challenges in the cybersecurity domain.
3.2. Metric-Based Few-Shot NER
The high cost of annotated data has sparked increasing interest in few-shot learning across the NLP field. In NER, few-shot NER focuses on identifying and classifying entity types with minimal annotated data. Fritzler et al. [17] applied the few-shot prototypical network concept to NER tasks, laying the foundation for subsequent proto-based approaches.
Metric-based learning methods emphasize constructing robust entity representations using limited labeled data and performing entity classification based on similarity calculations. Snell et al. [16] proposed prototypical networks, which learn class anchor representations from a small number of samples, enabling similarity-based classification during the testing phase. Hou et al. [36] adapted CRF for few-shot scenarios by calculating emission scores using token-level similarity and nearest-neighbor strategies, while deriving transition scores from abstract (BIO) matrices. Yang and Katiyar [37] enhanced these abstract matrices into probabilistic distributions in their StructShot framework. Zhang et al. [38] proposed a model-agnostic meta-learning approach that adapts label dependency relationships with few gradient updates and designs adaptive hyperparameters for effective domain-specific learning.
One challenge in learning class anchor representations is that virtual representations derived from limited samples often fail to generalize well, introducing bias. To address this, Tong et al. [39] proposed MUCO, a method that optimizes class-centric representations by training mapping functions. By incorporating clustering principles, they improved inter-class differentiation, enhancing the representation quality for metric-based learning.
Entity boundary or span detection is a critical subtask in NER. Ziyadi et al. [40] fine-tuned BERT to compute similarity for identifying span boundaries and performed span-level classification, extending token-based proto-based methods to span-level implementations. Similarly, Ma et al. [41] fine-tuned BERT to develop a general span detector for recognizing BIO tags and subsequently optimized ProtoNet for span classification. Wang et al. [42] proposed ESD, which emphasized enhancing span representations through interactive learning, thereby improving ProtoNet performance. Yang et al. [43] devised a three-stage approach comprising seed initialization, expansion, and entailment classification for span-based entity recognition. Ji et al. [44] introduced a three-stage framework integrating a distillation learning module to enhance span detection before classification with an adapted ProtoNet. Chen et al. [45] utilized DCONTaiNER [46], hypothesizing Gaussian distribution for representations, and introduced prompts interacting with sequences to produce token representations, with similarity calculated via JS divergence entropy.
3.3. Prompt-Based Few-Shot NER
Pre-trained models excel in semantic and syntactic understanding in general domains. To activate domain-specific knowledge and improve generalization across different scenarios with minimal cost, prompt-based fine-tuning has emerged as a significant research trend. Cui et al. [18] introduced TemplateNER, which employs a BART encoder–decoder framework and designs a prompt template “<xx xx is a type>” to traverse and fine-tune spans, initiating prompt-based few-shot NER research.
A major focus of prompt-based work lies in template design. Lee et al. [47] proposed DemonstrationNER, which appends examples of entities or instances to the original sentence to form input templates, using BERTTagger for recognition. Ma et al. [41] developed EntLM, a template-independent fine-tuning approach that maps entity outputs to synonymous tokens within the same class without altering other positions, eliminating template dependency. Huang et al. [48] fine-tuned BERT using label-only, delimiter-separated label sequences, and soft prompt templates for entity representation learning. To mitigate the reliance on rigid prompt designs, Layegh et al. [49] incorporated contrastive learning with masked soft prompt templates, reducing the encoding distance between entities of the same class.
Span detection also poses challenges in prompt-based approaches. Shen et al. [19] designed a task objective with a reconstructed template “<start><end><type>” that leverages interaction learning to infer spans and entity types without traversal, significantly improving performance. Ye et al. [50] used BMES sequence tagging for span detection, followed by masked span traversal for predictions. Xu et al. [51] proposed a model to determine entity membership and further identify start and end positions, reducing the traversal space for masked prompt prediction while handling complex entities.
In summary, our proposed CyberDualNER addresses the unique challenges of few-shot NER in the cybersecurity domain through a hybrid design that integrates metric-based and prompt-based paradigms. By decomposing the task into span detection and entity classification, we enable better knowledge transfer from general-domain models while improving model interpretability and robustness. This dual-stage, domain-aware design distinguishes our method from existing works and provides a more effective solution for few-shot CTI entity extraction.
4. Model
4.1. Overview of the CyberDualNER Model
To address the challenges of data scarcity and the incompatibility of general knowledge in the cybersecurity domain, we proposed the CyberDualNER model, which operates in a dual-stage framework: (1) Span Detection: This stage focuses on identifying the start and end positions of all entity spans in the input sequence. To tackle the data scarcity challenge in the cybersecurity domain, CyberDualNER leverages a “pre-training + fine-tuning” paradigm. It pre-trains a generic span detector using large-scale annotated datasets from general domains and fine-tunes it on domain-specific data, enabling effective adaptation to cybersecurity contexts. (2) Span Classification: In this stage, CyberDualNER employs prompt-based templates constructed from entity type descriptions to derive data-agnostic type representations. This approach addresses the representation bias caused by limited entity samples while incorporating domain-specific prior knowledge to enhance the quality of entity type representations. A metric-based learning strategy then calculates similarity scores to classify each detected span into its corresponding entity type. The overall structure of CyberDualNER Model is illustrated in Figure 2.
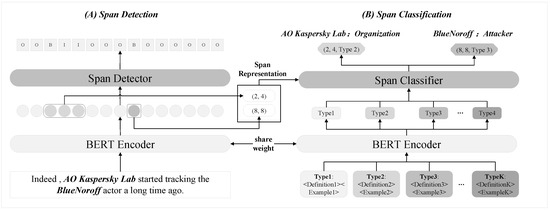
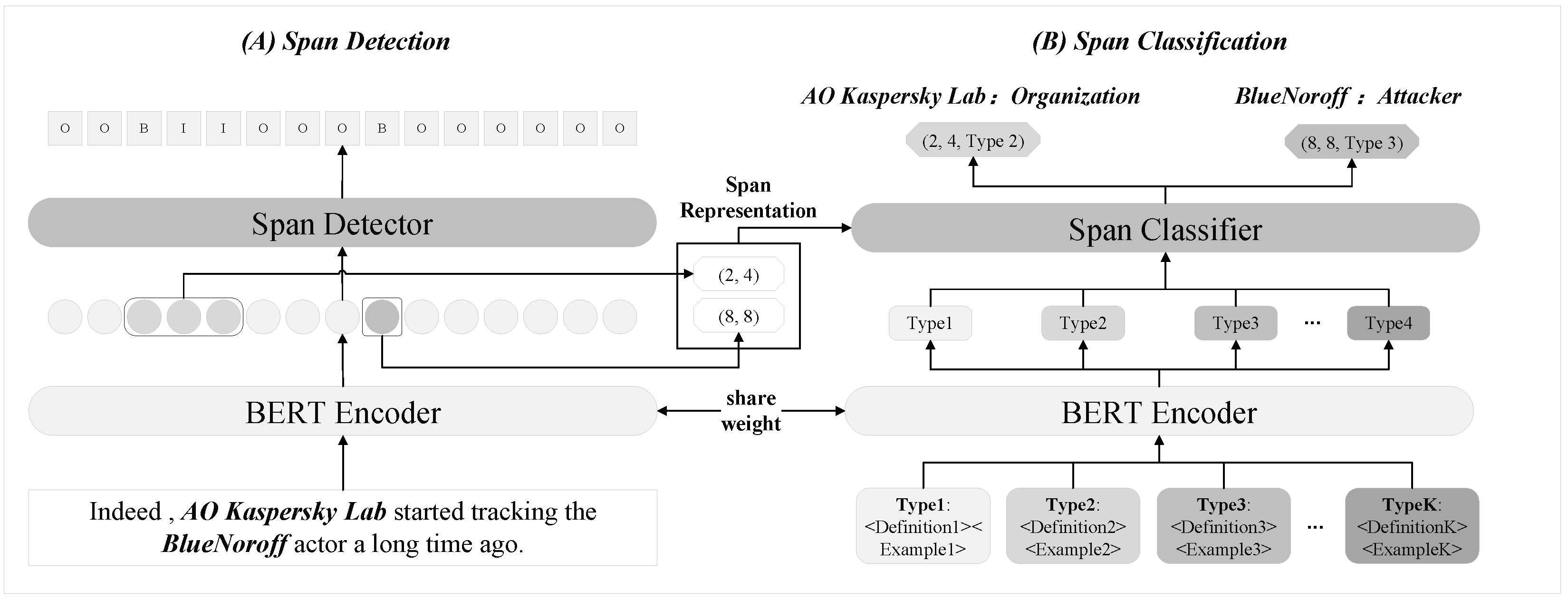
Figure 2.
The overview of CyberDualNER. It consists of two stages: span detection and span classification. First, the model identifies all entity spans through sequence labeling. Then, after extracting representations, it classifies each span by comparing it with entity type embeddings.
For instance, given the input text “Indeed, AO Kaspersky Lab started tracking the BlueNoroff actor a long time ago.”, the first stage identifies entity spans as (2, 4) and (8, 8). In the second stage, prompt-based templates generate robust type representations, allowing the model to classify “AO Kaspersky Lab” as an Organization entity and “BlueNoroff” as an Attacker entity. This dual-stage design reflects CyberDualNER’s targeted focus on separating span detection and classification, ensuring a robust and adaptable solution for cybersecurity NER tasks, particularly in few-shot scenarios.
4.2. Span Detection
NER inherently involves two critical tasks: the accurate detection of entity spans and further classification into predefined categories. Compared to classification, span detection is more syntax- and semantics-driven, often exhibiting greater generalizability across domains. It focuses on training a highly generalized span detector using universal data, with parameters shared across different domains and classes. Specifically, we adopt a “pre-training-finetuning” paradigm within the widely used BERT framework to develop a robust span detection model.
4.2.1. Pre-Training on General Domain
In this work, we implement a span detector through sequence labeling. We employ the standard BIO schema to provide detailed information about entity boundaries. For the encoder, we leverage BERT (https://huggingface.co/google-bert/bert-base-uncased (accessed on 12 December 2024)). Given an input sequence of L tokens, the encoder first generates contextualized representations for all tokens:
For each representation , a linear classification layer combined with the softmax function computes the probability distribution over span labels :
where represents the trainable parameters.
To train the span detector, we employ a cross-entropy loss function over the BIO label space. Given the groundtruth labels , the loss for a single token is computed as
where is the predicted probability of belonging to class c and is an indicator function that equals 1 if the label matches the class c, and 0 otherwise. This ensures that the loss computation focuses only on the probability assigned to the correct class c, while ignoring others.
The total loss for the sequence x is then
This formulation ensures token-wise supervision, enabling the model to accurately learn the boundaries of entity spans.
As general-purpose pre-trained models often lack specific training for entity localization, pre-training on a relevant dataset is essential before domain-specific application. To address this, we utilize the CoNLL03 dataset (https://www.clips.uantwerpen.be/conll2003/ner/ (accessed on 10 January 2025)) for pre-training. This dataset [52], comprising Reuters news articles annotated with entities such as Person, Location, Organization, and Miscellaneous, provides a robust foundation for span detection with broad applicability.
4.2.2. Fine-Tuning on Cybersecurity-Specific Domain
In cybersecurity-specific applications, the distinct style of CTI text poses challenges for direct application of general models. CTI often contains domain-specific artifacts such as URLs and hash values, which differ significantly from general-purpose text and can disrupt downstream performance when processed without adaptation. To address this, we fine-tune the pre-trained span detector using cleaned and domain-adapted data.
Prior to fine-tuning, we perform the following cleaning steps to improve the quality of CTI texts:
- 1.
- Special character separation: Following prior works [7,53], we replace specific characters (e.g., “@” in email addresses or “/” in URLs) with spaces to facilitate tokenization while adjusting corresponding “O” labels.
- Before: text: [“name@email.com”], labels: [O];
- After: text: [“name”, “at”, “email.com”], Labels: [O, O, O].
- 2.
- Handling over-segmented tokens: For tokens excessively segmented by the encoder tokenizer (e.g., tokens with more than 10 subwords, such as hash values), previous methods either delete long tokens entirely [7], losing semantics, or use handcrafted placeholders [54], limiting generalizability. We instead retain the first three sub-tokens as lightweight, schema-free surrogates.
- Before: text: [“5d41402abc4b2a76b9719d911017c592”], Tokens: [‘5’, ‘d’, ‘41402’, ‘ab’, ‘c’, ‘4’, ‘b’, ‘2’, ‘a’, ‘76’, ‘b’, ‘97’, ‘19’, ‘d’, ‘91’, ‘1017’, ‘c’, ‘592’], labels: [O];
- After: text: [“5d41402”], Tokens: [‘5’, ‘d’, ‘41402’], Labels: [O].
Since only non-entity tokens are modified without affecting semantics, these data cleaning steps do not impact model performance. The cleaned small-sample dataset is then used for fine-tuning the pre-trained span detector, thereby improving its adaptability to cybersecurity texts. This step ensures that the span detector effectively captures entity boundaries while maintaining high generalizability and robustness, even in few-shot settings.
4.3. Entity Classification Module
When it comes to span classification, the primary objective is to classify the detected entity spans. This stage necessitates not only the accurate modeling of entity categories but also the effective resolution of category representation bias in few-shot scenarios. Particularly in the cybersecurity domain, the class distribution is highly imbalanced, with certain categories having only a few samples or even no samples, posing significant challenges to the model’s generalization capability.
To tackle these issues, we propose a prompt-based category representation method. By incorporating domain-specific prior knowledge, we construct category description templates in natural language. Coupled with a metric-based learning approach, this method effectively mitigates the impact of class imbalance and limited samples, ultimately improving classification performance.
4.3.1. Prompt-Based Category Representation
To enhance category representation in few-shot scenarios, we introduce category descriptions as prompts, transforming them into data-independent category embeddings. By incorporating domain-specific prior knowledge, high-quality category vectors can be generated even with limited labeled data.
Specifically, each category is defined using domain expertise and described in natural language. These category prompts follow the structure of “<Category> <Definition> <Examples>”. For instance, the prompt for the “Malware” category could be: “Malware: Refers to malicious software designed to harm, exploit, or otherwise compromise computer systems or networks. Examples include viruses, worms, trojans, and ransomware”. Using the detected spans from the input sequence and the same encoder as the span detector, the prompt representation is extracted. Following the initial pre-training paradigm, the “CLS” token embedding is adopted as the category representation . The mathematical formulation is as follows:
where refers to the natural language prompt for category k.
4.3.2. Metric-Based Span Classification
The classification module leverages the spans detected in the first stage, which are extracted based on the “BIO” predictions.The representation of each span s can be obtained using the encoder in the first stage. The specific Algorithm 1 for extracting span representations is as follows:
| Algorithm 1 MaxPool-based span representation extraction |
| Require:, . Ensure:.
|
To assign each span to a category, a metric-based approach calculates the similarity between span embeddings and category embeddings. Cosine similarity is adopted as the similarity function, and the predicted probability of a span belonging to category k is given by
where represents the cosine similarity function.
To focus on true spans while ignoring false spans, a mask () is applied in the classification loss computation. This ensures that only real spans contribute to the loss. The classification loss is defined as
where is a mask that filters out false spans; is an indicator function that equals 1 if the label matches the class k, and 0 otherwise.
This loss function enables precise classification by concentrating on true spans and effectively utilizing the metric-based similarity between span and category representations.
4.4. Overall Loss
During the pre-training stage of the span detector, the model is optimized solely based on the span detection loss . However, in the fine-tuning stage for cybersecurity domain text, we adopt a joint optimization strategy that combines the span detection loss and the span classification loss . The overall loss is defined as follows:
where is a hyperparameter that balances the contributions of the two losses. It is determined through a grid search within a predefined range, as described in Section 5.2.4.
5. Experiment
In this section, we conduct a comprehensive evaluation of the proposed CyberDualNER model against existing baselines under few-shot and even extremely low-resource settings, demonstrating the superiority of our approach. We then present a comparison of different pre-trained backbone models to highlight the critical impact of backbone selection on overall performance. Finally, we perform hyperparameter analysis and ablation studies to further validate the completeness and rationality of our model design.
5.1. Experimental Settings
5.1.1. Dataset Description
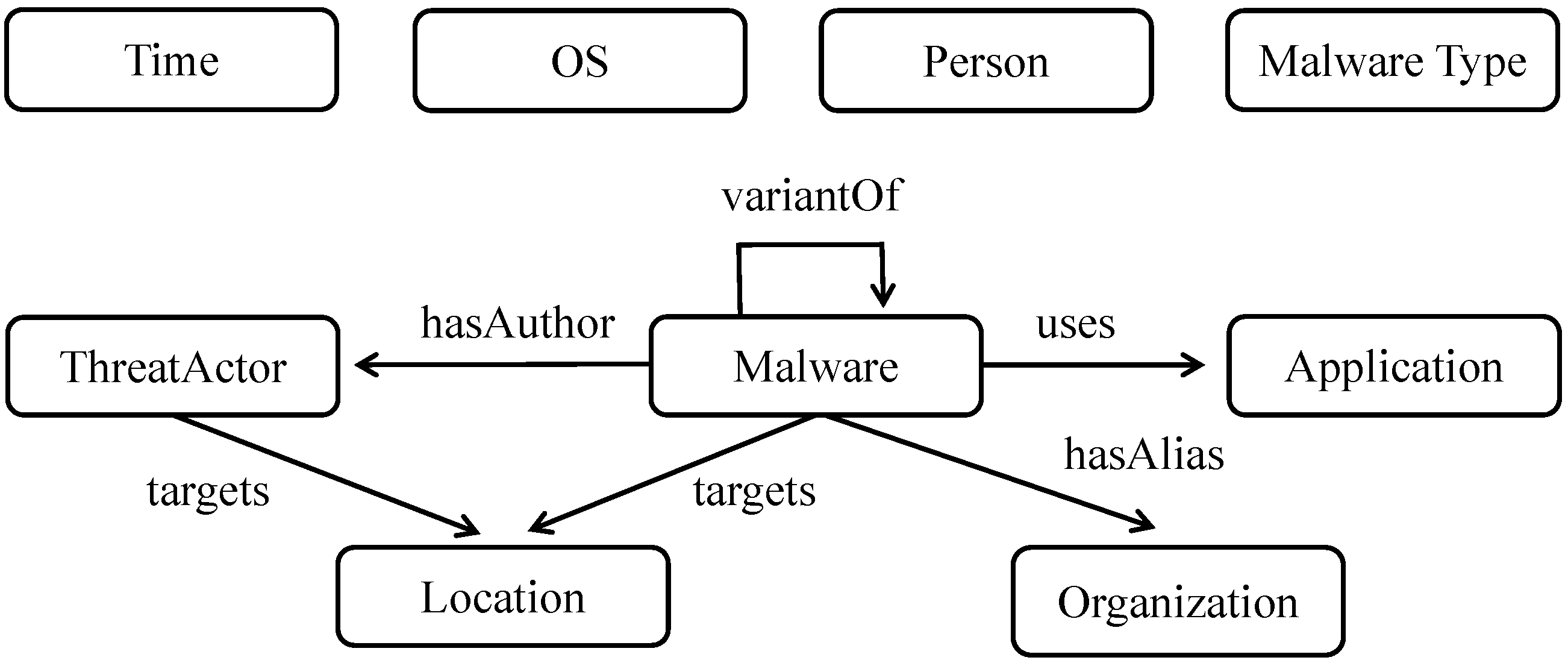
The raw dataset [55] used in this study originates from over 12,000 open-access CTI reports published by several renowned security analysis organizations, including McAfee [56], Symantec [57], and Kaspersky [58]. These reports provide natural language descriptions of the emergence, propagation, attack patterns, and IoC associated with malware. To ensure the quality of the dataset, a data cleaning process was first conducted. Specifically, irrelevant HTML tags, images, and script contents were removed using regular expressions and HTML parsing techniques. Subsequently, manual annotation of the entities and relationships mentioned in the CTI reports was performed using the open-source annotation tool BRAT. Nine types of entities (such as Malware, Application) and seven types of relationships (such as targets, indicates) were identified and labeled. The entities are interconnected through these relationships, providing a comprehensive representation of cyber threats. Part of the ontology on malware is shown in Figure 3. After preprocessing, 5150 annotated sentences remained, which were relevant and complete for the NER task.
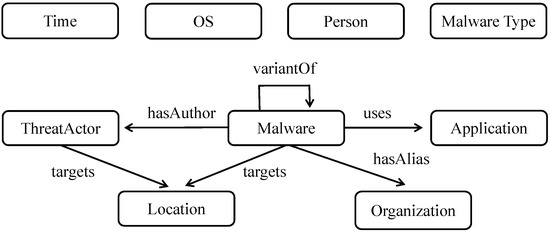
Figure 3.
Part of the ontology on malware.
To perform span-based entity detection and classification, the dataset was further processed to construct the dataset required for the proposed method. Each sentence was tokenized at the word level, and the start and end positions of the spans corresponding to the entities in the text were annotated. Additionally, the BIO annotation scheme was applied for sequence labeling of the sentences. The final processed dataset contains 5150 sentences, involving 9 different entity types. For model training and performance evaluation, the dataset is divided into training set, validation set, and test set, and the data statistics of each subset are shown in Table 2.
Table 2.
Total dataset statistics.
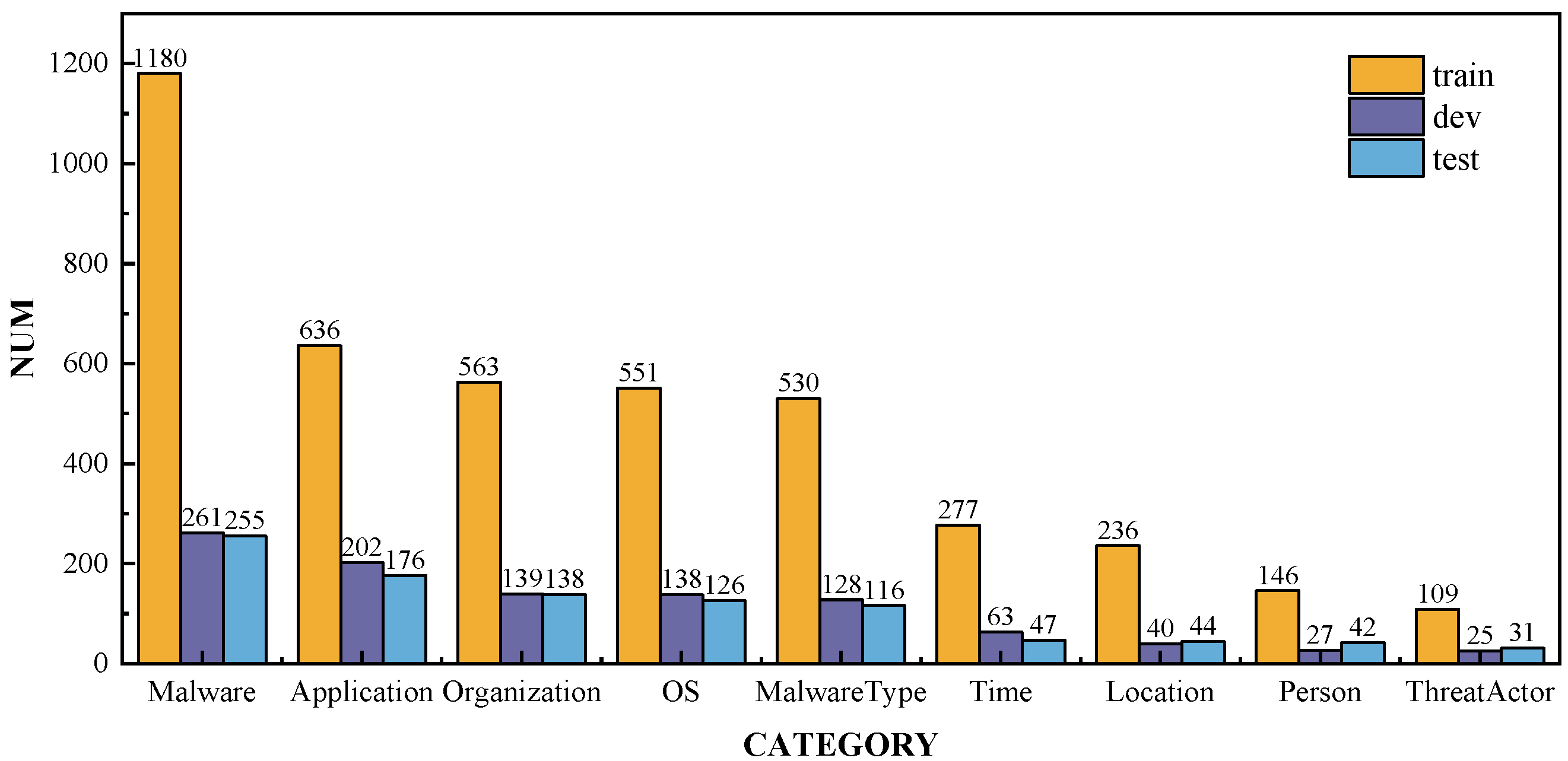
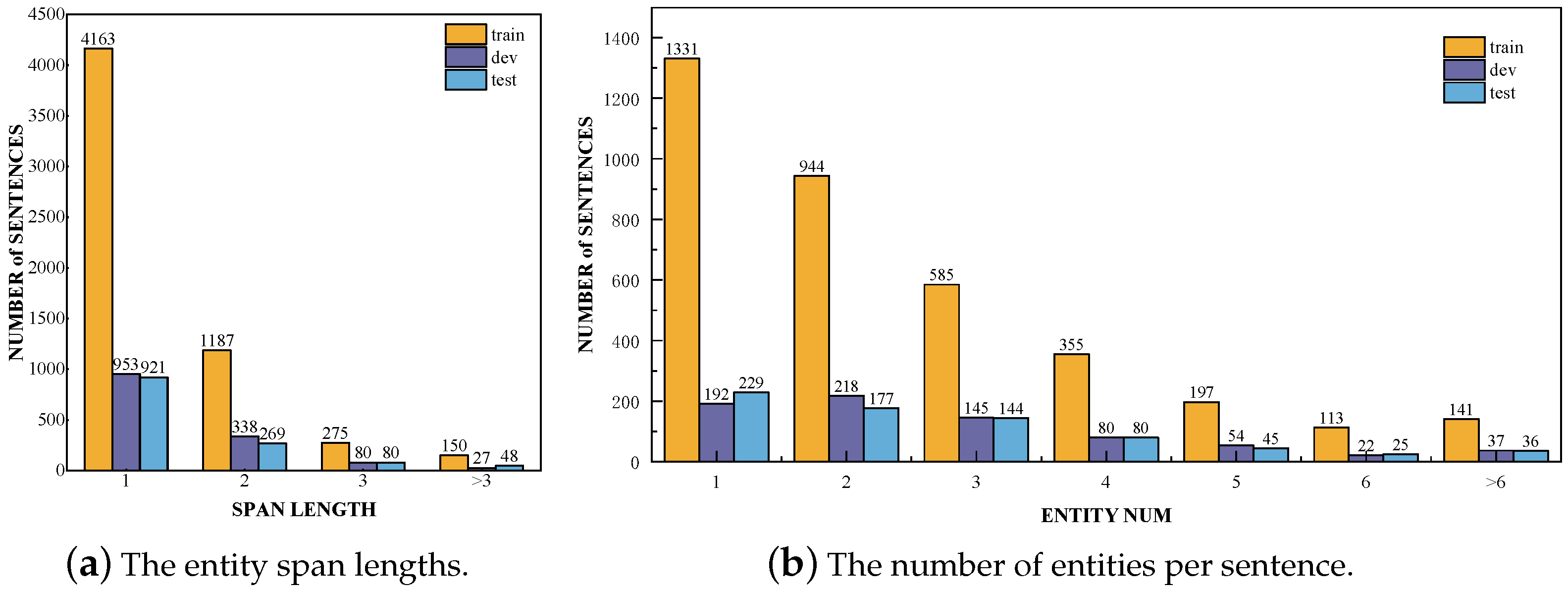
The distribution of entity types in the training, validation, and test sets is shown in Figure 4. Since malware is the primary focus of the dataset, it occupies the largest proportion. Entity types such as Application, Organization, OS, and MalwareType, which are related to the types or attack targets of malware, also have relatively high proportions. In contrast, Time, Location, Person, and Threat Actor have lower proportions, likely because CTI reports focus more on attack targets and methods than on the sources and general attributes of the attacks. Figure 5a illustrates the distribution of entity span lengths in the training, validation, and test sets. The majority of entities in the dataset have a span length of 1, indicating that the entities are represented by specific words. Furthermore, Figure 5b shows the distribution of the number of entities per sentence in the training, validation, and test sets. Most sentences contain fewer than four entities, and some sentences with excessively high entity counts are due to multiple repeated mentions of the same entity.
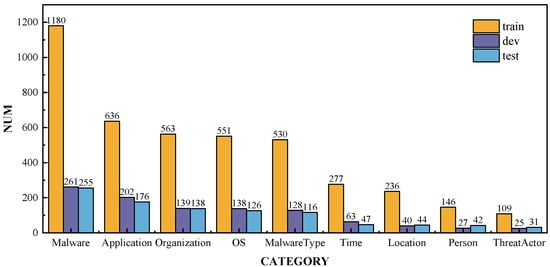
Figure 4.
The distribution of entity types in the constructed cybersecurity dataset; these entity types are closely related to malware attacks.
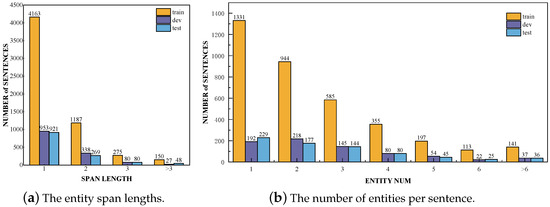
Figure 5.
The distribution statistics of the dataset.
5.1.2. Baseline Method
To evaluate the performance of our proposed method under the few-shot NER setting, we compare it against three widely used fully supervised models (BERT, BERT-CRF, and BERT-BiLSTM-CRF), two classical few-shot approaches (NNShot [37] and StructShot [37]), and a representative prompt-based method (PromptNER [19]). By comparing against these baselines, we aim to demonstrate the effectiveness of our method in addressing the challenges posed by limited training data and domain-specific requirements, particularly in the cybersecurity context. Below, we provide a brief overview of each baseline model.
- BERT: a transformer-based pre-trained language model that encodes contextualized word representations, enabling effective sequence labeling directly for NER tasks.
- BERT-CRF: extends BERT by incorporating a CRF layer on top, improving sequence-level prediction by capturing dependencies between output labels.
- BERT-BiLSTM-CRF: combines BERT’s contextualized embeddings with a BiLSTM layer for sequential modeling, followed by a CRF layer for structured prediction, providing enhanced performance for complex NER tasks.
- NNShot: a classical metric-based few-shot NER method that performs token classification via nearest neighbor search in the embedding space.
- StructShot: extends NNShot by incorporating a CRF-based structure-aware decoder to better model label dependencies.
- PromptNER: a representative prompt-based few-shot NER method that reformulates NER as a masked language modeling task, using manually designed prompts to guide the model in predicting entity types within a few-shot setting.
5.1.3. Parameter Setting and Evaluation Metrics
To simulate few-shot scenarios, we followed the approach proposed by Cui et al. [18], constructing two scenarios based on the dataset. The dataset was downsampled by limiting the number of entity instances per category (m = 1, 2, 5, 10, 20, 50), ensuring the conditions of a few-shot environment. Given that a single sample in NER tasks may contain multiple entity categories, we adopted a two-stage sampling strategy:
1. Initial Sampling: selected samples to ensure the number of entities in each category did not exceed the few-shot threshold.
2. Greedy Sampling: applied a random greedy sampling strategy, including samples as long as at least one entity category had not yet reached the threshold.
This strategy achieved high coverage with minimal sample size, balancing diversity and few-shot constraints effectively. The sampling results are shown in Table 3, which counts the number of sentences, the average number of tokens, and the number of entities under different settings.
Table 3.
Few-shot sampling dataset statistics.
For model configurations, we standardized the embedding and fusion dimensions to . Each experiment was conducted three times, and we reported the average precision, recall, and -score to evaluate performance.
In the multi-class setting, the metrics were computed for each class and averaged across all classes to obtain the macro average:
1. Precision, Recall, and -Score for Class i:
2. Macro-Averaged Metrics:
Here, C is the total number of entity types.
The model was optimized using the AdamW optimizer. During fine-tuning, the learning rate for the BERT encoder was set to , while all other layers in both pre-training and fine-tuning stages used a learning rate of . A cosine annealing warm-up strategy was employed, starting with a small learning rate and gradually adjusting it throughout training to approach a global minimum. To prevent overfitting, early stopping was applied based on validation loss, with a maximum training limit of 10 epochs. Gradient clipping was used to avoid gradient explosion by scaling the L2 norm of the parameter vector if it exceeded a predefined threshold. Considering the inherently small dataset size in the few-shot setting, the batch size was fixed at 1 across all experiments.
5.2. Results and Discussion
5.2.1. Few-Shot NER Performance Comparison
We compared our CyberDualNER model with baseline methods across different few-shot settings (m = 50, 20, 10), with the results presented in Table 4.
Table 4.
Experiment results when m = 50, 20, 10.
BERT-CRF: With more data, the CRF layer begins to demonstrate its ability to model label dependencies effectively. It outperforms standalone BERT, highlighting the CRF’s role in sequence labeling tasks while also emphasizing its dependence on sufficient training data.
BERT-BiLSTM-CRF: As a representative fully supervised baseline, this model exhibits overall performance improvements with larger sample sizes. However, it still lags behind simpler models in few-shot scenarios, reflecting its limitations in adapting to limited data.
NNShot & StructShot: Both are classical metric-based few-shot NER approaches. NNShot exhibits gradually improved performance as the number of support samples increases. In contrast, while StructShot’s precision steadily increases, its recall consistently declines, resulting in a drop in overall F1 score. This can be attributed to two main factors: (1) the varying quality of few-shot samples in the specialized cybersecurity domain, and (2) the limited robustness of CRF-based decoding under significant domain shifts, which undermines its generalizability in few-shot scenarios.
PromptNER: As a representative prompt-based few-shot NER method, PromptNER consistently achieves the second-best performance, slightly below our proposed approach across all settings. Compared to traditional baselines, this demonstrates the overall strength of prompt-based strategies. However, PromptNER’s reliance solely on masked token classification limits its ability to capture the holistic semantic structure of different entity types, which metric-based models can leverage more effectively through representation learning.
CyberDualNER consistently achieves the best performance across all settings. At m = 50, the -score reaches 56.30%. This improvement is largely attributable to the model’s prompt-based approach, which leverages pre-trained embeddings to generate high-quality class representations without introducing additional parameters. The use of domain-specific prior knowledge further alleviates the challenges of learning class representations in few-shot settings.
5.2.2. Performance in Extremely Few-Shot Settings
We compared our CyberDualNER model with baseline methods across different extremely few-shot settings (m = 5, 2, 1), with the results presented in Table 5.
Table 5.
Experiment results when m = 5, 2, 1.
BERT-BiLSTM-CRF: This model fails to achieve meaningful performance due to the small sample size. The large number of parameters in the BiLSTM component makes optimization challenging, driving the need for simpler models with fewer learnable parameters in few-shot settings.
BERT: Compared to BERT-CRF, standalone BERT adapts more quickly to novel data. At m = 2, it achieves an -score of 3.57%, whereas BERT-CRF is still ineffective in this setting.
NNShot & StructShot: These classical metric-based few-shot methods overall outperform both full-supervised and prompt-based baselines, highlighting the effectiveness of metric-based strategies under few-shot scenarios. NNShot consistently ranks among the top performers across all settings, benefiting from its simple yet effective nearest neighbor classification mechanism, which becomes increasingly reliable as support examples grow. StructShot, while showing a strong advantage under extremely limited data (e.g., m = 1), sees diminishing gains as m increases. By m = 5, its performance is surpassed by our method. This suggests that the CRF-based decoder in StructShot may struggle to generalize well under domain shifts and noisy support samples, which are common in the cybersecurity context.
PromptNER: When the sample size is extremely small, it achieves the best performance among prompt-based approaches. This can be attributed to the prior knowledge encoded in pre-trained language models and the use of hand-crafted prompts aligned with the NER task. Its performance improves as m increases, but is ultimately outperformed by our method at m = 5, indicating limitations in relying solely on masked token prediction without structural learning.
CyberDualNER demonstrates superior performance compared to full-supervised baselines across all settings, even when m = 1. This is primarily due to the use of a pre-trained general-purpose span detector, which effectively narrows down entity candidates with minimal supervision. While slightly behind NNShot and PromptNER at extremely low-shot settings, our model steadily improves as m increases, achieving the second-best performance at m = 5. This trend highlights the model’s strong generalization capability and potential under realistic few-shot conditions.
5.2.3. Backbone Selection Comparison
To validate the rationale behind the selection of the pre-trained backbone model, we compared the fully-supervised performance of BERT, RoBERTa (https://huggingface.co/FacebookAI/roberta-base (accessed on 15 April 2025)), ALBERT (https://huggingface.co/albert/albert-base-v2 (accessed on 15 April 2025)), and DeBERTa (https://huggingface.co/microsoft/deberta-v3-base (accessed on 15 April 2025)) at m = 50. RoBERTa is an optimized version of BERT that improves performance by training with larger datasets and longer sequences. ALBERT [59] is a lightweight variant of BERT, designed to reduce model size while maintaining performance through parameter sharing and factorized embeddings. DeBERTa [60,61] enhances BERT’s architecture by introducing disentangled attention mechanisms and an improved position encoding method. The specific experimental results are shown in Table 6. BERT achieves the best performance overall, benefiting from its robust architecture and extensive pre-training, making it well-suited for complex NER tasks. RoBERTa follows closely, with slightly lower results, while DeBERTa shows a solid performance, especially in precision and recall. ALBERT, despite its smaller model size, lags behind the other models, indicating that its reduced parameters may limit its ability to capture complex patterns in the data.
Table 6.
The comparison of backbone performance under full supervision (m = 50).
5.2.4. Parameter Analysis
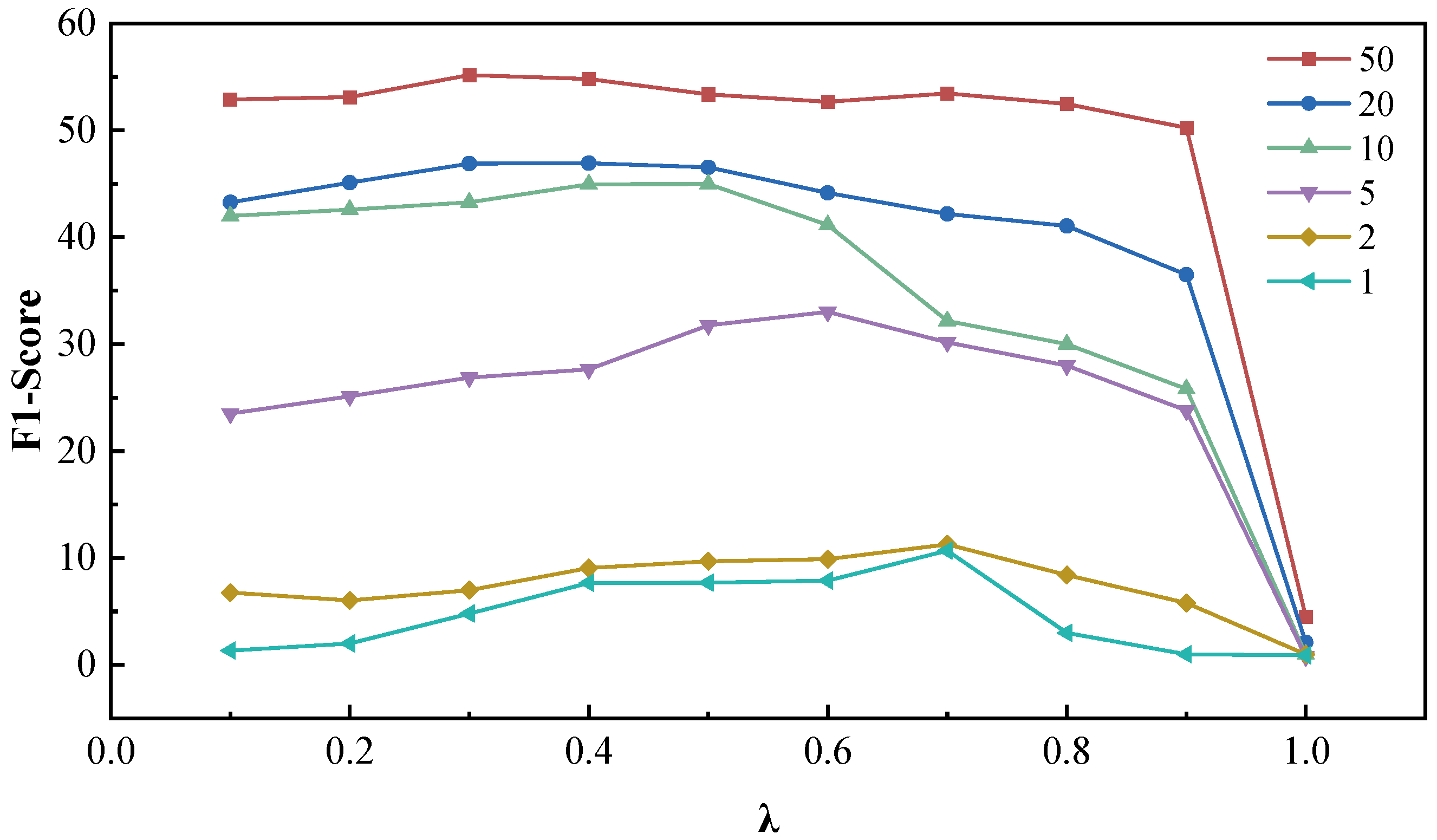
In this section, we conduct a grid search over the hyperparameter , which balances span detection and classification in the loss function, exploring its impact on model performance under different settings. The search range is with a step size of 0.1. The results are illustrated in Figure 6, where the vertical axis represents the -score, and the horizontal axis denotes the values.
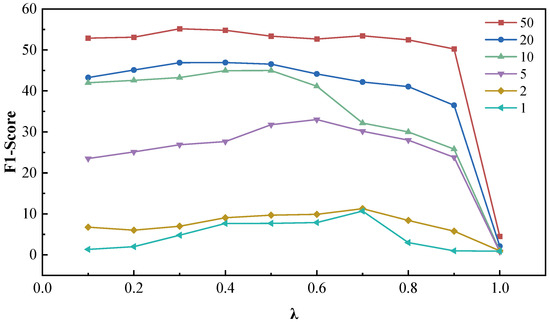
Figure 6.
Impact of hyperparameter on model (optimal highlighted with box markers for fixed ).
Overall, for a fixed value of , the performance improves as the sample size m increases, highlighting that the sample size remains a decisive factor in determining performance. Conversely, with a fixed sample size, the performance initially rises and then declines as increases. Notably, the smaller the sample size, the higher the value at which performance peaks. This trend aligns with the relationship between span detection and classification loss and the sample size: when the sample size is smaller, the model tends to rely more on the pre-trained span detection module for its stability and generalization ability. This minimizes the negative impact of a limited and potentially biased dataset on the overall performance of the classifier.
5.2.5. Ablation Study
To further analyze the contributions of various components in CyberDualNER, we conducted ablation studies under few-shot settings (m = 5 and m = 50). All compared models adopt a dual-stage span-based framework, with variations in classifier types and span detection strategies. Table 7 summarizes the performance comparison. The following observations were made:
Table 7.
Ablation study when m = 50, 5.
1. Classifier choice: Metric-based classifier performs better in extremely few-shot settings (m = 5) by leveraging similarity between entity spans, allowing quick adaptation to limited data. MLP-based classifier outperforms the metric-based classifier when m = 50, as the increased sample size allows the MLP to benefit from data accumulation. However, the metric-based approach struggles to generalize due to biases introduced by sampling or annotation, as evidenced by its lower precision at m = 50.
2. Pre-training strategy: Span detection pre-training consistently improves performance across all settings and classifier choices. For m = 5, the average -score improvement is 17.13%, highlighting the syntactic and semantic commonalities in span detection between general and cybersecurity domains. This emphasizes the benefit of separating span detection and classification, allowing the classification module to focus more on domain-specific knowledge.
3. Overall performance: Our model achieves superior results across all metrics. At m = 50, it surpasses the MLP-based classifier by 6.07%, and at m = 5, it exceeds the metric-based classifier by 5.63%. Unlike other models that initialize class representations randomly, our approach leverages domain knowledge through prompt-based design, incorporating prior knowledge into class representations. This effectively mitigates potential biases from training data discrepancies, leading to significant overall performance gains.
6. Discussion
To address the scarcity of annotated data in cybersecurity-related CTI texts, this paper proposes the CyberDualNER framework by integrating insights from general-domain few-shot NER research. Experimental results confirm the effectiveness of our approach, with key findings summarized as follows:
- Two-stage paradigm adaptation: Decomposing NER into span detection and entity classification proves to be equally effective in the cybersecurity domain. Our approach leverages pre-training in the general domain followed by fine-tuning in the target domain, which alleviates the challenge of limited annotated samples in cybersecurity settings.
- Hybrid classification strategy: Metric-based methods are effective in extremely few-shot scenarios by quickly identifying similar entity types. Prompt-based methods, benefiting from accumulated general-domain knowledge in PLMs, can be activated with just a few samples. By incorporating class descriptions as prompts and using metric-based classification, our method combines the strengths of both strategies and demonstrates superior performance when the sample size exceeds 10.
- Importance of backbone model selection: The choice of pre-trained language model backbone significantly impacts performance. Different models exhibit varying base capabilities, suggesting that selecting an appropriate foundation model for a given domain can yield substantial benefits.
Despite the improvements achieved in mitigating the performance degradation of fully supervised methods under data scarcity, several limitations remain that must be considered in real-world applications:
- Zero-shot challenges: While our framework is tailored to few-shot learning, the cybersecurity domain is highly dynamic, with new threats such as zero-day vulnerabilities and novel malware constantly emerging. This underscores the need for robust zero-shot extraction capabilities.
- Prompt design sensitivity: Although prompt-based approaches enhance performance, they introduce new challenges in template design. Model robustness can be compromised by variations in prompt templates, highlighting the need for more adaptive and stable prompt engineering.
- Handling long CTI documents: CTI texts are often lengthy and sourced from webpages, threat reports, and blogs. Our current framework focuses on extracting entities from short texts, requiring additional preprocessing steps to bridge raw documents and model inputs, which complicates end-to-end deployment.
To further advance this line of research, we plan to focus on the following directions:
- Robust prompt construction and interactive design: We aim to develop adaptive prompt generation paradigms to reduce reliance on manual templates. Future work will explore more guided and context-aware prompting mechanisms to enable effective interaction between input texts and prompt representations, enhancing model robustness.
- Zero-shot entity extraction: Given the unique and evolving nature of cybersecurity threats, zero-shot extraction remains a pressing need. We will investigate how to incorporate sample-independent prior knowledge or design better transfer learning strategies to support zero-shot generalization.
- Generalized entity extraction framework: Sequence labeling approaches often struggle with complex entity structures such as discontinuous or nested entities. Innovating beyond conventional paradigms to support these richer patterns in few-shot settings will be an important research direction.
- End-to-end entity extraction for real-world deployment: With LLMs demonstrating strong capabilities across diverse tasks and the rise of multi-agent frameworks, we envision a fully automated pipeline for CTI processing. This includes data collection, cleaning, extraction, organization, and visualization—culminating in a practical, end-to-end solution for cybersecurity applications.
7. Conclusions
In this study, we proposed CyberDualNER, a dual-stage span framework tailored for cybersecurity NER tasks, addressing the challenges of entity detection and classification in few-shot settings. By decoupling span detection and classification, the model achieves greater flexibility and robustness, especially when combined with a hint-based category representation that incorporates domain-specific prior knowledge. Extensive experiments demonstrate that CyberDualNER consistently outperforms baseline models in different few-shot settings, achieving superior performance even with minimal training data. Notably, pre-training of the span detector on general-domain data proves to be highly effective, significantly enhancing the model’s adaptability to domain-specific text. Overall, CyberDualNER provides a promising solution for cybersecurity NER tasks, especially in data-scarce settings, paving the way for more robust and general models in specialized domains.
In the future, we will further explore the CTI extraction task in few-shot and even zero-shot scenarios, leveraging the prompt learning paradigm to conduct experimental tests on a broader range of data. Meanwhile, LLMs have demonstrated great potential in the CTI extraction task [27]. Therefore, we will also attempt to utilize LLMS for CTI extraction. Additionally, in alignment with practical cybersecurity applications, we will integrate tasks such as relation extraction and knowledge graph construction into our research, refining the extraction framework to support subsequent key downstream tasks such as proactive threat hunting.
Author Contributions
Conceptualization, C.Z. and C.L. (Changqing Li); methodology, C.Z. and C.L. (Changqing Li); software, C.Z.; validation, C.Z.; formal analysis, C.Z. and C.L. (Changqing Li); investigation, C.Z. and C.L. (Changqing Li); resources, C.Z. and C.L. (Cheng Lu); data curation, C.Z.; writing—original draft preparation, C.Z., C.L. (Cheng Lu) and C.L. (Changqing Li); writing—review and editing, C.Z., C.L. (Cheng Lu), C.L. (Changqing Li) and Z.Z.; visualization, C.Z., C.L. (Cheng Lu) and Z.Z.; supervision, C.Z., C.L. (Cheng Lu), C.L. (Changqing Li), Z.Z. and L.P.; project administration, C.Z. and C.L. (Changqing Li); funding acquisition, L.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Key Research and Development Plan in China (No. 2023YFC3306100).
Data Availability Statement
Data are contained within the article.
Acknowledgments
We would like to express our sincere gratitude to Topsec Technologies Inc. for their support throughout this project.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Check Point Software Technologies. Security Report 2025. 2025. Available online: https://www.checkpoint.com/security-report/ (accessed on 14 January 2025).
- Sun, N.; Ding, M.; Jiang, J.; Xu, W.; Mo, X.; Tai, Y.; Zhang, J. Cyber threat intelligence mining for proactive cybersecurity defense: A survey and new perspectives. IEEE Commun. Surv. Tutor. 2023, 25, 1748–1774. [Google Scholar] [CrossRef]
- Dasgupta, S.; Piplai, A.; Kotal, A.; Joshi, A. A comparative study of deep learning based named entity recognition algorithms for cybersecurity. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 2596–2604. [Google Scholar]
- Gao, C.; Zhang, X.; Han, M.; Liu, H. A review on cyber security named entity recognition. Front. Inf. Technol. Electron. Eng. 2021, 22, 1153–1168. [Google Scholar] [CrossRef]
- Wang, X.; Liu, R.; Yang, J.; Chen, R.; Ling, Z.; Yang, P.; Zhang, K. Cyber threat intelligence entity extraction based on deep learning and field knowledge engineering. In Proceedings of the 2022 IEEE 25th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Hangzhou, China, 4–6 May 2022; pp. 406–413. [Google Scholar]
- Hu, Y.; Zou, F.; Han, J.; Sun, X.; Wang, Y. Llm-tikg: Threat intelligence knowledge graph construction utilizing large language model. Comput. Secur. 2024, 145, 103999. [Google Scholar] [CrossRef]
- Mouiche, I.; Saad, S. Entity and relation extractions for threat intelligence knowledge graphs. Comput. Secur. 2025, 148, 104120. [Google Scholar] [CrossRef]
- Liu, M.; Teng, F.; Zhang, Z.; Ge, P.; Sun, M.; Deng, R.; Cheng, P.; Chen, J. Enhancing cyber-resiliency of der-based smart grid: A survey. IEEE Trans. Smart Grid 2024, 15, 4998–5030. [Google Scholar] [CrossRef]
- Liu, P.; Li, H.; Wang, Z.; Liu, J.; Ren, Y.; Zhu, H. Multi-features based semantic augmentation networks for named entity recognition in threat intelligence. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1557–1563. [Google Scholar]
- Burger, E.W.; Goodman, M.D.; Kampanakis, P.; Zhu, K.A. Taxonomy model for cyber threat intelligence information exchange technologies. In Proceedings of the 2014 ACM Workshop on Information Sharing & Collaborative Security, Scottsdale, AZ, USA, 3 November 2014; pp. 51–60. [Google Scholar]
- Wang, X.; Liu, X.; Ao, S.; Li, N.; Jiang, Z.; Xu, Z.; Xiong, Z.; Xiong, M.; Zhang, X. Dnrti: A large-scale dataset for named entity recognition in threat intelligence. In Proceedings of the 2020 IEEE 19th International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Guangzhou, China, 10–13 November 2020; pp. 1842–1848. [Google Scholar]
- Wang, X.; He, S.; Xiong, Z.; Wei, X.; Jiang, Z.; Chen, S.; Jiang, J. Aptner: A specific dataset for ner missions in cyber threat intelligence field. In Proceedings of the 2022 IEEE 25th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Hangzhou, China, 4–6 May 2022; pp. 1233–1238. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Zhang, Z.; Liu, M.; Sun, M.; Deng, R.; Cheng, P.; Niyato, D.; Chow, M.Y.; Chen, J. Vulnerability of machine learning approaches applied in iot-based smart grid: A review. IEEE Internet Things J. 2024, 11, 18951–18975. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Fritzler, A.; Logacheva, V.; Kretov, M. Few-shot classification in named entity recognition task. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 993–1000. [Google Scholar]
- Cui, L.; Wu, Y.; Liu, J.; Yang, S.; Zhang, Y. Template-Based Named Entity Recognition Using BART. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; pp. 1835–1845. [Google Scholar]
- Shen, Y.; Tan, Z.; Wu, S.; Zhang, W.; Zhang, R.; Xi, Y.; Lu, W.; Zhuang, Y. PromptNER: Prompt Locating and Typing for Named Entity Recognition. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 12492–12507. [Google Scholar]
- Bridges, R.A.; Huffer, K.M.; Jones, C.L.; Iannacone, M.D.; Goodall, J.R. Cybersecurity automated information extraction techniques: Drawbacks of current methods, and enhanced extractors. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 437–442. [Google Scholar]
- Liu, X.; Li, J. Key-based method for extracting entities from XML data. J. Comput. Res. Dev. 2014, 51, 64–75. [Google Scholar]
- Morwal, S.; Jahan, N.; Chopra, D. Named entity recognition using hidden Markov model (HMM). Int. J. Nat. Lang. Comput. (IJNLC) Vol 2012, 1, 15–23. [Google Scholar] [CrossRef]
- Mansouri, A.; Affendey, L.S.; Mamat, A. Named entity recognition using a new fuzzy support vector machine. IJCSNS 2008, 8, 320. [Google Scholar]
- Mulwad, V.; Li, W.; Joshi, A.; Finin, T.; Viswanathan, K. Extracting information about security vulnerabilities from web text. In Proceedings of the 2011 IEEE/WIC/ACM International Conferences on Web Intelligence and Intelligent Agent Technology, Lyon, France, 22–27 August 2011; Volome 3; pp. 257–260. [Google Scholar]
- Joshi, A.; Lal, R.; Finin, T.; Joshi, A. Extracting cybersecurity related linked data from text. In Proceedings of the 2013 IEEE Seventh International Conference on Semantic Computing, Irvine, CA, USA, 16–18 September 2013; pp. 252–259. [Google Scholar]
- Lal, R. Information Extraction of Security Related Entities and Concepts from Unstructured Text. Master’s Thesis, University of Maryland Baltimore County, Catonsville, MD, USA, 2013. [Google Scholar]
- Ismayil, H.; Seppo, V.; Antti, H.; Jouni, I. Application of Large Language Models in Cybersecurity: A Systematic Literature Review. IEEE Access 2024, 12, 176751–176778. [Google Scholar]
- Dionísio, N.; Alves, F.; Ferreira, P.M.; Bessani, A. Cyberthreat detection from twitter using deep neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Satyapanich, T.W.; Ferraro, F.; Finin, T. CASIE: Extracting Cybersecurity Event Information from Text. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8749–8757. [Google Scholar]
- Simran, K.; Sriram, S.; Vinayakumar, R.; Soman, K. Deep learning approach for intelligent named entity recognition of cyber security. In Proceedings of the Advances in Signal Processing and Intelligent Recognition Systems: 5th International Symposium, SIRS 2019, Trivandrum, India, 18–21 December 2019; Revised Selected Papers 5. Springer: Berlin/Heidelberg, Germany, 2020; pp. 163–172. [Google Scholar]
- Evangelatos, P.; Iliou, C.; Mavropoulos, T.; Apostolou, K.; Tsikrika, T.; Vrochidis, S.; Kompatsiaris, I. Named entity recognition in cyber threat intelligence using transformer-based models. In Proceedings of the 2021 IEEE International Conference on Cyber Security and Resilience (CSR), Virtual, 26–28 July 2021; pp. 348–353. [Google Scholar]
- Zhou, S.; Liu, J.; Zhong, X.; Zhao, W. Named entity recognition using BERT with whole world masking in cybersecurity domain. In Proceedings of the 2021 IEEE 6th International Conference on Big Data Analytics (ICBDA), Xiamen, China, 5–8 March 2021; pp. 316–320. [Google Scholar]
- Aravind, P.; Arikkat, D.R.; Krishnan, A.S.; Tesneem, B.; Sebastian, A.; Dev, M.J.; Aswathy, K.; Rehiman, K.R.; Vinod, P. CyTIE: Cyber Threat Intelligence Extraction with Named Entity Recognition. In Proceedings of the International Conference on Advancements in Smart Computing and Information Security, Rajkot, India, 7–9 December 2023; pp. 163–178. [Google Scholar]
- Gao, C.; Zhang, X.; Liu, H. Data and knowledge-driven named entity recognition for cyber security. Cybersecurity 2021, 4, 9. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, Y.; Huang, C. CyberEyes: Cybersecurity entity recognition model based on graph convolutional network. Comput. J. 2021, 64, 1215–1225. [Google Scholar] [CrossRef]
- Hou, Y.; Che, W.; Lai, Y.; Zhou, Z.; Liu, Y.; Liu, H.; Liu, T. Few-shot Slot Tagging with Collapsed Dependency Transfer and Label-enhanced Task-adaptive Projection Network. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 1381–1393. [Google Scholar]
- Yang, Y.; Katiyar, A. Simple and Effective Few-Shot Named Entity Recognition with Structured Nearest Neighbor Learning. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6365–6375. [Google Scholar]
- Zhang, S.; Cao, B.; Zhang, T.; Liu, Y.; Fan, J. Task-adaptive label dependency transfer for few-shot named entity recognition. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 3280–3293. [Google Scholar]
- Tong, M.; Wang, S.; Xu, B.; Cao, Y.; Liu, M.; Hou, L.; Li, J. Learning from Miscellaneous Other-Class Words for Few-shot Named Entity Recognition. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 6236–6247. [Google Scholar]
- Ziyadi, M.; Sun, Y.; Goswami, A.; Huang, J.; Chen, W. Example-based named entity recognition. arXiv 2020, arXiv:2008.10570. [Google Scholar]
- Ma, T.; Jiang, H.; Wu, Q.; Zhao, T.; Lin, C.Y. Decomposed Meta-Learning for Few-Shot Named Entity Recognition. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, 22–27 May 2022; pp. 1584–1596. [Google Scholar]
- Wang, P.; Xu, R.; Liu, T.; Zhou, Q.; Cao, Y.; Chang, B.; Sui, Z. An Enhanced Span-based Decomposition Method for Few-Shot Sequence Labeling. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 5012–5024. [Google Scholar]
- Yang, Z.; Zhang, L.; Zhou, D. SEE-Few: Seed, Expand and Entail for Few-shot Named Entity Recognition. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, South Korea, 12–17 October 2022; pp. 2540–2550. [Google Scholar]
- Ji, S.; Kong, F. A Novel Three-stage Framework for Few-shot Named Entity Recognition. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italia, 20–25 May 2024; pp. 1293–1305. [Google Scholar]
- Chen, Y.; Zheng, Y.; Yang, Z. Prompt-Based Metric Learning for Few-Shot NER. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 7199–7212. [Google Scholar]
- Das, S.S.S.; Katiyar, A.; Passonneau, R.J.; Zhang, R. CONTaiNER: Few-Shot Named Entity Recognition via Contrastive Learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 6338–6353. [Google Scholar]
- Lee, D.H.; Kadakia, A.; Tan, K.; Agarwal, M.; Feng, X.; Shibuya, T.; Mitani, R.; Sekiya, T.; Pujara, J.; Ren, X. Good Examples Make A Faster Learner: Simple Demonstration-based Learning for Low-resource NER. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2687–2700. [Google Scholar]
- Huang, Y.; He, K.; Wang, Y.; Zhang, X.; Gong, T.; Mao, R.; Li, C. Copner: Contrastive learning with prompt guiding for few-shot named entity recognition. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 2515–2527. [Google Scholar]
- Layegh, A.; Payberah, A.H.; Soylu, A.; Roman, D.; Matskin, M. ContrastNER: Contrastive-based prompt tuning for few-shot NER. In Proceedings of the 2023 IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC), Torino, Italy, 27–29 June 2023; pp. 241–249. [Google Scholar]
- Ye, F.; Huang, L.; Liang, S.; Chi, K. Decomposed two-stage prompt learning for few-shot named entity recognition. Information 2023, 14, 262. [Google Scholar] [CrossRef]
- Xu, Y.; Yang, Z.; Zhang, L.; Zhou, D.; Wu, T.; Zhou, R. Focusing, bridging and prompting for few-shot nested named entity recognition. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023, Toronto, ON, Canada, 9–14 July 2023; pp. 2621–2637. [Google Scholar]
- Sang, E.T.K.; De Meulder, F. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the Seventh Conference on Natural Language Learning at HLT-NAACL 2003, Edmonton, AB, Canada, 31 May–1 June 2003; pp. 142–147. [Google Scholar]
- Ahmed, K.; Khurshid, S.K.; Hina, S. CyberEntRel: Joint extraction of cyber entities and relations using deep learning. Comput. Secur. 2024, 136, 103579. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Z.; Huang, C.; Wang, N.; Min, H.; Guo, W.; Liu, J. A framework for threat intelligence extraction and fusion. Comput. Secur. 2023, 132, 103371. [Google Scholar] [CrossRef]
- Alam, M.T.; Bhusal, D.; Park, Y.; Rastogi, N. Looking beyond IoCs: Automatically extracting attack patterns from external CTI. In Proceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses, Hong Kong, China, 16–18 October 2023; pp. 92–108. [Google Scholar]
- McAfee. McAfee Blogs. 2022. Available online: https://www.mcafee.com/blogs (accessed on 16 October 2023).
- Symantec. Symantec Enterprise Blogs/Threat Intelligence. 2022. Available online: https://symantec-enterprise-blogs.security.com/blogs/threat-intelligence (accessed on 16 October 2023).
- Kaspersky. Kaspersky Daily. 2022. Available online: https://usa.kaspersky.com/blog/ (accessed on 16 October 2023).
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- He, P.; Gao, J.; Chen, W. Debertav3: Improving deberta using electra-style pre-training with gradient-disentangled embedding sharing. arXiv 2021, arXiv:2111.09543. [Google Scholar]
- He, P.; Liu, X.; Gao, J.; Chen, W. Deberta: Decoding-enhanced bert with disentangled attention. In Proceedings of the International Conference on Learning Representations, Vienna, Austria, 4 May 2021. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).