1. Introduction
With the pervasive nature of computing devices that use increasingly complex video processing, there is becoming an ever greater need for faster and more efficient processing of image and video data. One of the key areas in this field is edge detection, particularly in color images, and while it is possible to carry out image processing using software, often it is simply too slow. In order to address this key issue of performance we have designed and implemented a Geometric Algebra Co-Processor that can be applied to image processing, in particular edge detection.
Edge detection is one of the most basic operations in image processing and can be applied to both gray scale and color images. For gray scale images, edges are defined as the discontinuity in the brightness function, whereas in color images they are defined as discontinuities along adjacent regions in the RGB color space. Traditional color edge detection involves applying the uncorrelated monochrome or scalar based technique to three correlated color channels. However, to smooth along a particular color component within the image, component-wise filtering gives incorrect results as described by [
1,
2,
3]. Different techniques exists that treat color as a 3-D vector to avoid such problems [
4,
5]. The techniques of convolution and correlation are quite common to image processing algorithms for scalar fields. Standard techniques used to identify the edges and critical features of an image use the rotational and curvature properties of vector fields, which is increasingly a popular method [
6]. A combination of the scalar and vector field techniques has been extended to vector fields for visualization and signal analysis in [
2]. In [
7], the author developed a hyper-complex Fourier transform of a vector field and has applied this to images.
Geometric Algebra (GA) methods were introduced in [
8] and [
9] for image processing where it was shown that hyper-complex convolution is in fact a subset within GA. Independently, in [
10] the GA or Clifford convolution Fourier transform method was applied to pattern matching on vector fields which are used for the visualization of 3-D vector field flows. This work suggested that the convolution technique based on GA is superior because of the unified notation used to represent scalar and vector fields.
A large body of work exists in the general area of color edge detection which is concerned with the relative merits of different basic approaches and quantifying the ability of algorithms to identify features from images [
11,
12,
13,
14,
15]. For example in [
11] it is suggested that leveraging GA is an effective method of detecting edges and that it can also provide a “metric” for the assessment of the strength of those edges. One of the interesting aspects of the proposed work is taking advantage of the simplification of the terms, which has the potential for much simpler implementation, making this an ideal candidate for hardware implementation. We can contrast our approach and also [
11] with the more general techniques (Euclidean) described in [
12]. In [
12] the author evaluates different approaches for feature detection, however in many cases the relevance comes after the basic transformations, such as those presented in our approach or even in [
11]. Similarly, [
13] discusses the use of visual cues and how the use of an optimally combined set of rules can improve the ability of a vision system to identify edges. However this would be useful in a system environment, again, after the initial transformation had been completed. In a similar manner, [
16] describes derived classes of edge detection techniques and quantifies how effective they are in practice, particularly for natural images. The work described in [
16] also highlights the possibilities for implementing vision systems that target specific operations or transformations such as GA, where significant performance benefits can accrue, and integrating this with a general purpose processor that can then leverage other algorithms taking advantage of the results of the efficient processing completed by the partner GA processor. If we consider the general area of research using GA techniques, in most cases the assumption is made that any algorithm can be implemented in general purpose hardware. Most real world scenarios (such as dynamic object recognition) require real time operation, making a relatively slow software solution based on a general purpose platform impractical.
In our proposed approach, the above ideas have been extended further by introducing color vector transformations and a difference subspace within GA. Based on certain properties of these transformations, a hardware architecture to compute all the different GA products has been proposed. The experimental results show the use of the GA methods and proposed hardware for three different edge detection algorithms.
This paper is organized as follows.
Section 2 establishes some important GA fundamentals and introduces the techniques for implementing rotations in 3-D. This section also demonstrates how the GA and rotation techniques can be applied to the topics of transformation and difference subspace. This introduction therefore establishes the theoretical foundation of the relationship between GA operations and how the transformations in the GA framework can be exploited to identify chromatic or luminance shifts in an image when the color changes.
Section 3 introduces the details of the proposed GA Micro Architecture (GAMA) designed specifically for this application, describes the custom ASIC implementation and reports the experimental results for this hardware implementation, with a focus on the geometric operations per second, and instructions per second, providing a comparison with other hardware and software implementations.
Section 4 demonstrates how the technique can be extended to use rotor convolution for color edge detection, with examples including color “block” images and natural images.
Section 5 and
section 6 extends this to color sensitive edge detection and color smoothing filter, respectively. Finally, concluding remarks are given in
Section 7.
3. Rotor Edge Detection Using Geometric Algebra Co-Processor
The previous section showed that in order to implement color edge detection using rotor transformations the main GA computations required are the geometric product, multi-vector addition and subtraction. From an implementation perspective, these functions can also be decomposed into parallelized tasks, each task involving Multiply and Accumulation (MAC) operations, which can map directly to specific hardware. It is already known that significant speed advantages can be gained when GA is implemented in hardware instead of software [
21,
22,
23]. The hardware architecture is discussed in this section, however, a detailed description is beyond the scope of this paper, and the reader is referred to [
23] for more information. An important advantage of the architecture is that by having dedicated hardware functions to calculate the GA operations directly, significant efficiencies can be achieved over general-purpose hardware. For example, although a general-purpose processor may have dedicated GA software, the underlying transformations will still use standard processing resources, which will be less efficient than a hardware, which directly maps the GA software operations.
3.1. Hardware Architecture Overview
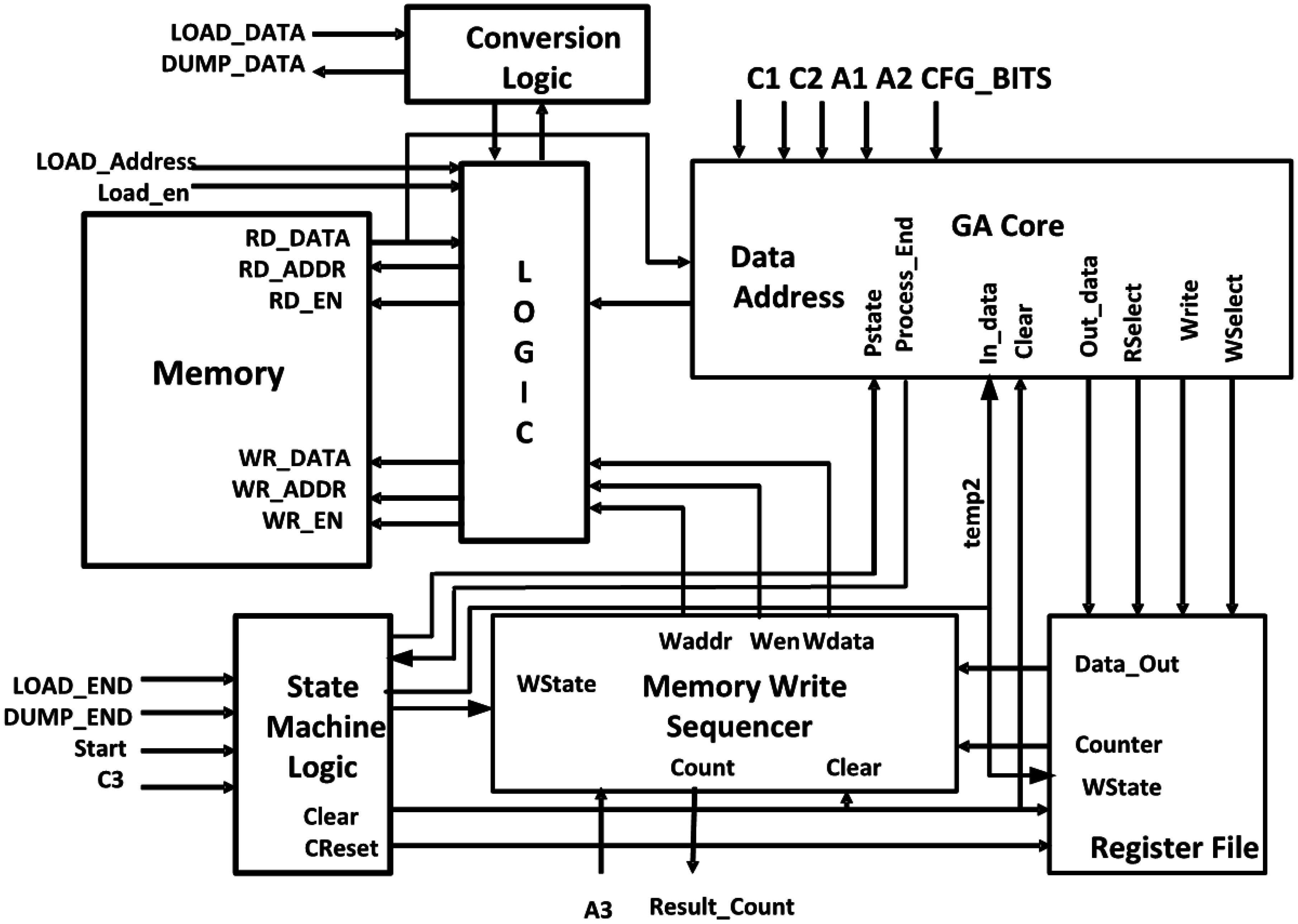
The proposed rotor edge detection hardware architecture consists of an IO interface, control unit, memory unit and a central Geometric Algebra Core [
21,
22,
23] consisting of adder, multiplier, blade logic and a result register (
Figure 2). The architecture supports both single and double precision floating-point numbers, four rounding modes, and exceptions specified by the IEEE 754 standard [
24]. This can be seen as effectively a GA Co-Processor, which operates in conjunction with a conventional general-purpose microprocessor.
Figure 2.
Rotor edge detection geometric algebra co-processor architecture with permission from the authors of ref [
23].
Figure 2.
Rotor edge detection geometric algebra co-processor architecture with permission from the authors of ref [
23].
The floating-point multiplier is a five-stage pipeline that produces a result on every clock cycle. The floating point adder is more complex than the multiplier and involves steps including checking for non-zero operands, subtraction of exponents, aligning the mantissas, adjusting the exponent, normalizing the result, and rounding off the result. The adder is a six-stage pipeline that produces a result on every clock cycle. It is important to state here that the proposed hardware can process other products of Geometric Algebra with ease.
The state machine governing the processing stages of Geometric Algebra has six states, idle, clear, load, process, write, and memory dump. Firstly, the idle state waits for the start signal to be high to trigger the state machine. After that, the state machine will come into the clear state where it clears any registers and then to the load state to export load as “1” to load input data into the registers. Then it processes the result in the required clock cycles based on the control word (cfg_bits). Finally, it outputs the product in the output state. Apart from the transformation of the load state, which is triggered by the start signal, the others just proceed to next state automatically after an expected number of cycles based on the control word.
The long 320-bit word datapath is coordinated by controller (LOGIC) and sequencer unit. The transfer of the data is done in the input and output interface unit (conversion logic). The signals are all defined as input and output registers to the system architecture. Selection of the data input and output is based on the 16-bit control word. The control bits are used for configuring (cfg_bits) the processing core for different operations. These control bits are responsible for defining the data interface and configuring the operators at the correct time and outputting the result. The control block along with the sequencer ensures effective queuing and stalling to balance the inputs in different stages in the datapath.
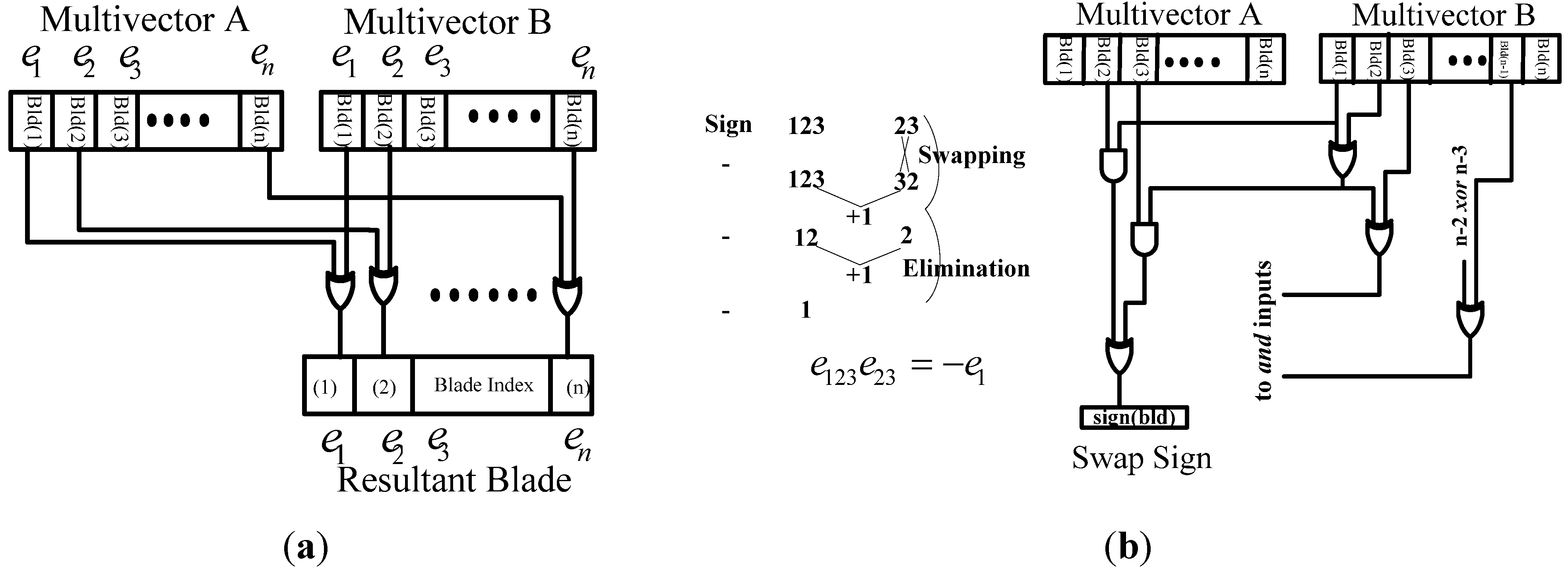
Figure 3.
Computing and swapping of basis blades. (a) Basis vector computation; (b) Swap computation.
Figure 3.
Computing and swapping of basis blades. (a) Basis vector computation; (b) Swap computation.
3.2. Blade Logic
Another important element of this architecture is the blade computation. The “blade” is simply the general definition of vectors, scalar, bivectors and trivectors. The blade index relationship is defined by the elements being computed, in a similar way that matrix operations result in an output matrix dimension that is defined by the input matrix dimensions. For example, to compute
with
, the resultant blade index is
. Similarly if we multiply
with
then the resultant basis blade index is
. This can be implemented by a multiplication table, an approach followed by many software implementations. However, accessing a memory in hardware is a slower operation than a simple EXOR function (
Figure 3a). Determining the sign due to the blade index is not straightforward due to the invertible nature of the geometric operation. For example the blade index multiplication of
with
gives
whereas with
and
results in
. The resulting circuit which is a cascade of EXOR gates takes care of the swapping of the blade vector and the AND gates compute the number of swaps that the blade element undergoes (see
Figure 3b).
Detailed design description of the hardware implementation can be found in [
23].
Table 1.
GA-Coprocessor/Rotor hardware (area, speed).
Table 1.
GA-Coprocessor/Rotor hardware (area, speed).
| Design | No of cells | Area (µm2) | No of gates | Frequency |
|---|
| Rotor Hardware | 35,355 | 813,504 | 133,361 | 130.0 MHz |
3.3. ASIC Implementation
The proposed hardware is described using synthesizable VHDL which means that the architecture can be targeted at any technology, FPGA or ASIC. Standard EDA tools perform all the translation from VHDL to silicon including synthesis and automatic place and route. The architecture was synthesized to a CMOS 130 nm standard cell process. The synthesis was carried out using the Synplify ASIC and the Cadence Silicon Ensemble place and route tools. The synthesis timing and area reports are summarized in
Table 1. The chip area was 1.1 × 1.1 mm
2 (inset in
Figure 4) and the estimated maximum clock frequency of the design was 130 MHz.
The prototype ASIC was packaged in a standard QFP package and this was then placed on a test printed circuit board (PCB), with power supply connections and a link to a FPGA development kit that supported a general purpose processor for programming and data handling (
Figure 4). The test board was then used to evaluate the performance of the GA processor in handling a variety of test data, described in detail in the next section.
3.4. Comparison with Other GA Implementation Hardware and Software
This section describes the experimental verification results. When calculating the GA operations the GOPS (Equation (20)) is particularly important because the designer is then able to determine whether the timing constraint put by the clock cycles and GOPS provided by that particular implementation is relevant.
Table 2 gives a comparison for different dimensions, GA processor performance in MHz, clock cycles, latency and Geometric Operations per Second (GOPS). This also provides a comparison to the GA hardware implementations in [
21,
23,
25,
26,
27,
28,
29,
30]. It was found that the proposed hardware is an order of magnitude faster as shown in
Table 2 (columns 5–6).
In [
27], the normalized GOPS (in
Table 2) is found out by dividing the number of MAC units, in this case it was 74. However, the authors have used the hardware resources available in the FPGA to their advantage and shown a threefold performance improvement as compared to the proposed hardware architecture. The GA products are computed on every clock cycle after a specified latency. The performance of their hardware is further improved by the authors by roughly two to three orders of magnitude in a very recent paper [
28] as compared to the proposed ASIC architecture discussed here.
Table 2.
GA performance figures and comparison with previously published results.
Table 2.
GA performance figures and comparison with previously published results.
| Reference | Frequency (MHz) | HW resources | No of processing cycles | GOPS (in thousands) | GOPS (In thousands, Normalized ‡) |
|---|
| Perwass et al. [25] | 20.0 | 1M, 1A (2) | 176 1, 544 2, 2044 3 | 112.52 1, 36.75 2, 9.79 3 | 56.26, 18.37, 4.89 |
| Mishra-Wilson [21] | 68.0 | 2M, 3A (5) | 84 1, 224 2, 704 3 | 809.6 1, 303.7 2, 96.62 3 | 161.92, 60.74, 19.32 |
| Gentile et al. [26] | 20.0 | 24M, 16A (40) | 56 2 | 357.15 | 8.9 |
| Lange et al. [27] | 170.0 | 74 † | 366 3 | 464.5 | 6.28 |
| Franchini et al. [29] | 50 | 24M | 56 1 | 892.8 | 37.2 |
| Franchini et al. [30] | 100 | 64M | 405 2, 1180 3 | 246.9 2, 84.7 3 | 3.8 2, 1.3 3 |
| Mishra et al. [23] | 65.0 | 1M, 1A (2) | 177 1, 455 2, 1399 3 | 367.2 1, 142.8 2, 46.4 3 | 183.6 1, 71.4 2, 23.2 3 |
| This Work | 125.0 | 2M, 3A (5) | 84 1, 224 2, 704 3 | 1488 1, 558 2, 177.5 3 | 297.6 1, 111.6 2, 35.5 3 |
3.5. FPGA and ASIC Test Results
Subsequently, the ASIC test was performed using a 125 MHz clock (a little less than the maximum clock frequency of 130 MHz). A set of 1 k, 4 k, and 40 k product evaluations was carried out to yield the raw performance (where all multivectors are present) of the hardware. The results for geometric product evaluation at different clock speeds along with the performance measures obtained when the design was targeted to an FPGA family (Xilinx XUPV2P, San Jose, CA, USA) are given in
Table 3 and
Table 4.
The implementation results of the processor core at different dimensions suggest that the performance is comparable to some of the software packages implemented in software (GAIGEN, Amsterdam, The Netherlands) which runs on high speed CPUs. To see how much advantage was gained by this hardware we compared the performance of GABLE [
31], GAIGEN [
32] and the proposed hardware (see
Table 3). To ensure consistency with GABLE, only the three-dimensional GA implementation is considered. For GAIGEN the “e3ga.h” module is used for the performance evaluation.
Table 3.
Comparison of different Software and the proposed hardware.
Table 3.
Comparison of different Software and the proposed hardware.
| Software | FPGA | ASIC |
|---|
| No. | GABLE | GAIGEN | @12.5 MHz | @68 MHz | @125 MHz |
| 1000 | 0.8910 | 9.91 × 10−4 | 6.92 × 10−3 | 1.27 × 10−3 | 6.97 × 10−4 |
| 4000 | 3.5750 | 3.956 × 10−3 | 2.76 × 10−2 | 5.08 × 10−3 | 2.78 × 10−3 |
| 40,000 | 35.210 | 3.978 × 10−2 | 0.276 | 5.08 × 10−2 | 2.78 × 10−2 |
Table 3 and
Table 4 show the performance comparison on the software that ran on 2GHz Intel Pentium processors and the proposed hardware. The software implementation GABLE (in MATLAB) was found to be extremely slow however the GAIGEN software running on a CPU was found to be of comparable performance to our proposed hardware (
Table 3). However, when the number of elements is varied, e.g., (vectors multiplied with a scalar and bivector) (
) it resulted in a performance increase of more than 3× when compared to the software implementation as shown in
Table 4.
Table 4.
Comparison of Software and the hardware for vector and bivector calculations.
Table 4.
Comparison of Software and the hardware for vector and bivector calculations.
| Software | FPGA | ASIC |
|---|
| No. | GABLE | GAIGEN | @12.5MHz | @68MHz | @125MHz |
| 1000 | 0.8920 | 0.001013 | 0.00308 | 0.000567 | 0.000312 |
| 40000 | 35.1910 | 0.040619 | 0.12320 | 0.022638 | 0.012480 |
Furthermore, it was seen from the experiments that the number of cycles can be optimized by hardwiring the operators which are constant over the operation. For example, for a windowing operator typical to an image-processing algorithm, four of the
multivectors which define the window or the filter can be hardwired. This leads to a 25% savings in the processing cycle due to the savings associated with I/O transfers every operation. The overall performance gains using the GA Co-Processor over existing software [
31,
32] approaches are more than 3.2× faster than GAIGEN [
31] and more than 2800× faster than GABLE [
32]. The above comparison shows that the proposed hardware provides speedup and performance improvement over the existing hardware (
Table 2) as well the software implementations on CPU.
In
Section 2, the basic technique of rotor detection has already been discussed. This technique is applied to color difference edge detection on our proposed hardware in the next section.
The proposed hardware architecture supports the general computations involving GA operations. To show the usefulness of the framework, we chose an image processing application in general and edge detection algorithm in particular. In this application, we demonstrate that even if the data is not a full multivector containing all the elements, one could still take advantage of the architecture with very little changes to the way the data is fed into the core. We also demonstrate the performance with two cores. The platform can be used for signal processing, vision and robotics applications.
5. Color Sensitive Edge Detection—Red to Blue—Using the Geometric Algebra Co-Processor
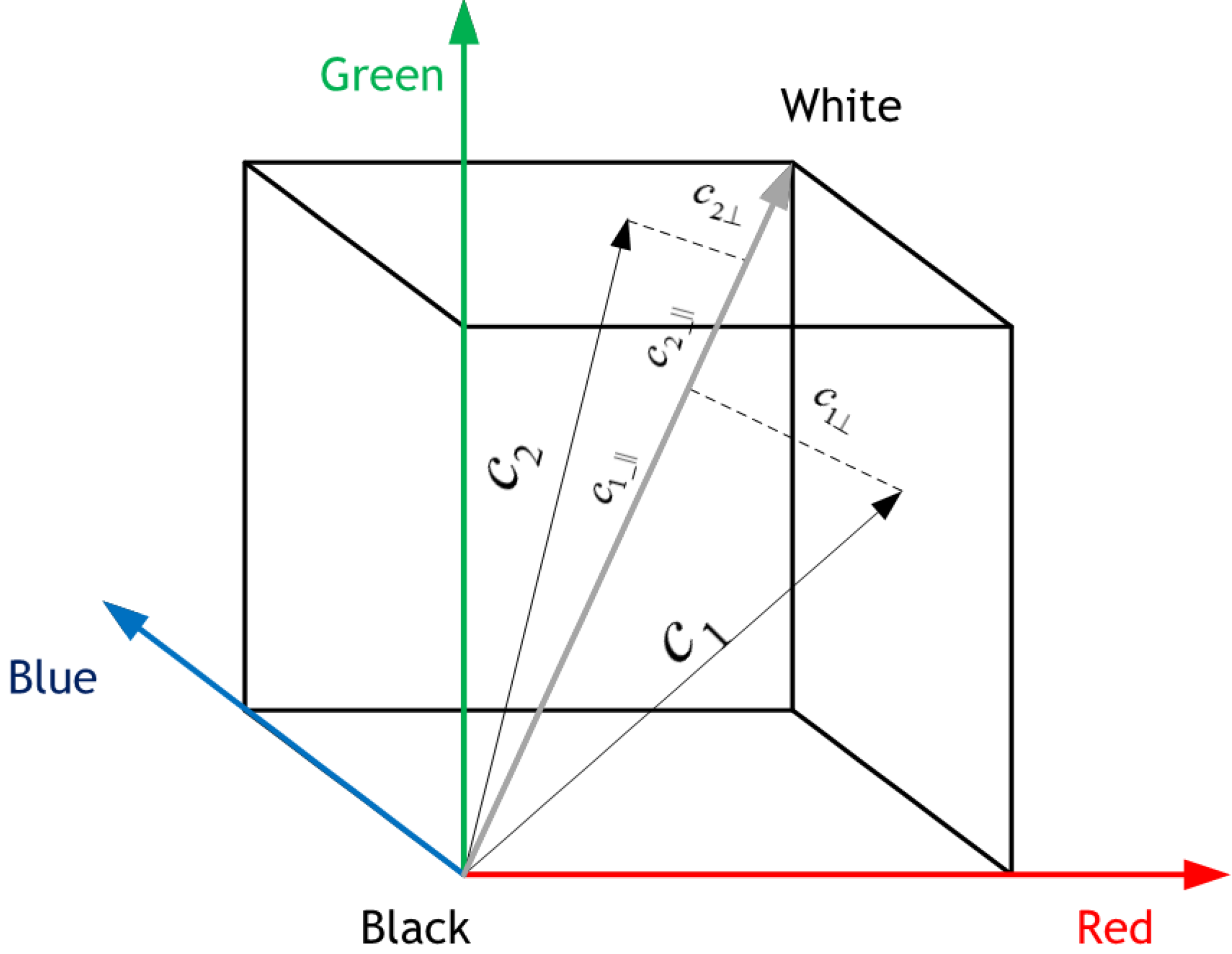
In this section, the detection of homogeneous regions of particular colors
to
(
) are discussed. The edges between these two colors are determined by the GA methods and are an extension of the method discussed in [
34]. To show the feasibility of this approach we have considered only synthetic images with strict thresholding criterion to find the edges are considered because the thresholding criterion for synthetic images is straightforward.
Let
C1 and
C2 be two color bivectors.
is a normalized color bivector of
, where
is given by Equation (27).
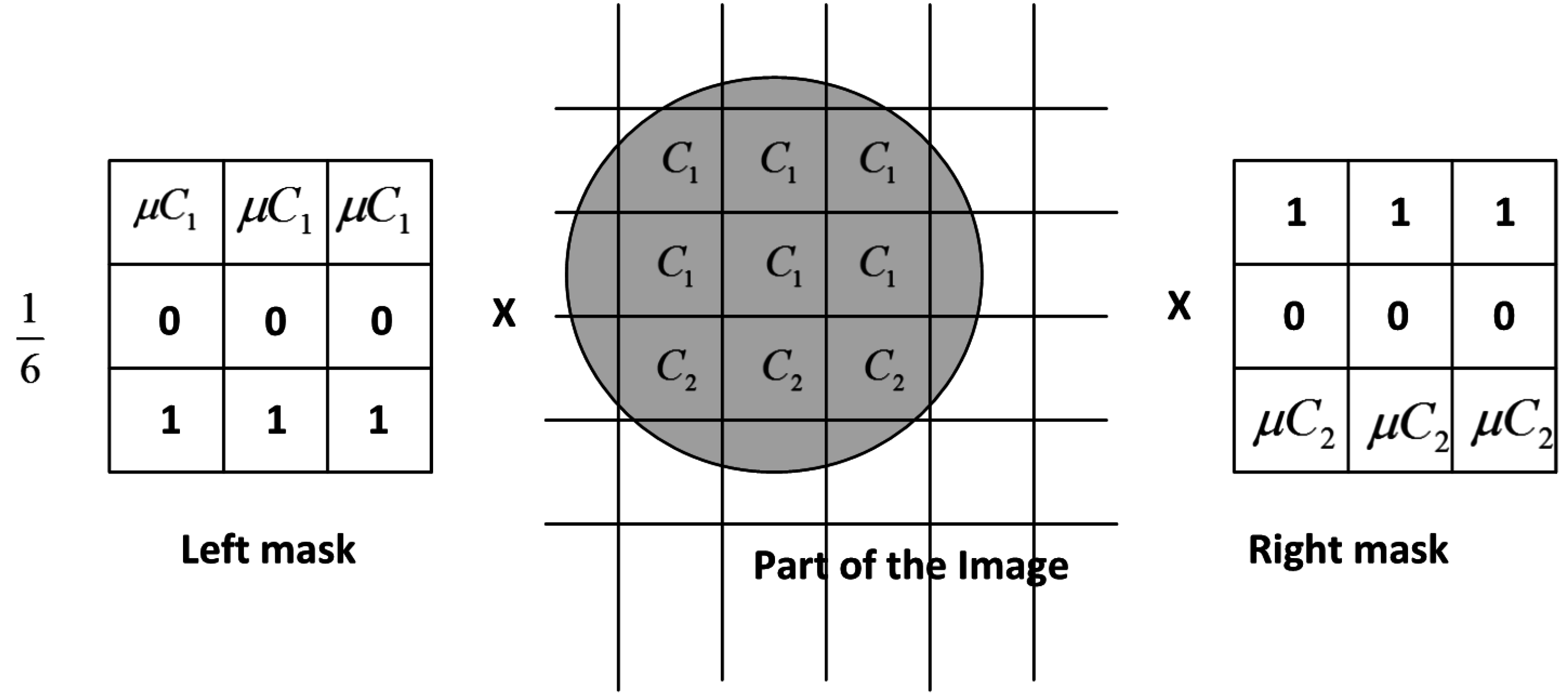
To find the discontinuity between two regions
to
the convolution can be used with the following hypercomplex filter.
Therefore the convolution operation on an image
of size
is given by:
where
,
are horizontal and vertical masks of size 3 × 3 as given in Equations (28) and (29), respectively (see
Figure 9). The above convolution operation results in non-zero scalar part and zero vector part in special cases. For example, to observe the discontinuity from
(red to blue), let
be
(red) and
be
(blue):
Figure 9.
Red to Blue, Convolution by left and right mask.
Figure 9.
Red to Blue, Convolution by left and right mask.
Normalizing both the vectors,
and
, the convolution results in a scalar value
or generally expressed as:
It can be observed that the above convolution results in a non-zero scalar value and zero vector value. As shown in
Figure 10a there is only one block where the red to blue (
) color transition occurs. When convolving with the mask (Equation (30)) the vector part will be zero. In the above example, the non-zero scalar value is the intensity of the pixel shown in the whiter regions in
Figure 10b. In all other places of the image the scalar and vector will have non-zero value. Also, it should be noted that the masks are directional in nature. Therefore, we observe the white line (in the region of interest) when the red to blue occurs and not when the blue to red change occurs.
Figure 10.
(a) Block Image and (b) After Step filtering.
Figure 10.
(a) Block Image and (b) After Step filtering.
Testing of Rotor Convolution in Hardware
Table 7 shows the timing and the clock cycles the hardware takes for the GA geometric product and
Table 8 for the GA addition operations. The results also show varying timing for full multivector and timing with single and two cores for the color bivector. Again in this case only the worst of the two (Geo Product and Geo Addition) is taken into account when showing the convolution operation (marked gray in
Table 8, using only two cores).
Table 7.
Two geometric products for rotor convolution.
Table 7.
Two geometric products for rotor convolution.
| Image Size | Full Multivector | ASIC with single core | ASIC with two Core |
|---|
| Image | Cycles | T (ms) | Cycles | T (ms) | Cycles | T (ms) |
|---|
| 128 × 128 | 2.85 × 106 | 22.8 | 2.49 × 106 | 19.1 | 1.27 × 106 | 9.8 |
| 256 × 256 | 1.19 × 107 | 92.0 | 9.96 × 106 | 76.6 | 5.11 × 106 | 39.3 |
| 512 × 512 | 4.59 × 107 | 367.5 | 3.98 × 107 | 306.5 | 2.04 × 107 | 157.2 |
Table 8.
Four geometric additions for rotor convolution.
Table 8.
Four geometric additions for rotor convolution.
| Image Size | Full Multivector | ASIC with single core | ASIC with two Core |
|---|
| Image | Cycles | T (ms) | Cycles | T (ms) | Cycles | T (ms) |
|---|
| 128 × 128 | 4.71 × 106 | 36.2 | 2.62 × 106 | 20.1 | 2.22 × 106 | 17.1 |
| 256 × 256 | 1.88 × 107 | 145.1 | 1.04 × 107 | 80.6 | 8.91 × 106 | 68.5 |
| 512 × 512 | 7.54 × 107 | 580.7 | 4.19 × 107 | 322.6 | 3.56 × 107 | 274.2 |
6. Color Sensitive Smoothing Filter
Another application of GA in image processing is to apply a low pass filter technique. The smoothing filter can be applied to smooth the color image component in the direction of any color component .
Extending low pass filtering applied to gray scale techniques provides limited color sensitivity as only one color band is convolved with the filter [
2]. If all the color bands are considered, then with traditional filtering all the bands will be smoothed equally which is undesirable. With GA, such affine transformation with low pass filtering is achieved in one step [
35].
The smoothing of red or cyan components is performed by the following mask:
where
is the normalized color vector.
The convolution is used to find the homogeneous regions within the image will result in a non-zero scalar part and a zero vector part for the homogeneous regions where the match is found. In all the other places the masking operation results in a non-zero scalar and vector part. Convolution due to this mask results in smoothing along the C1 direction. The smoothing of red or cyan components, which are parallel to C1, is changed but the other two perpendicular components remain untouched. Furthermore, the left convolution is different to the right convolution. Hence addition due to left and right convolution will result in cancellation of the vector part leaving only the scalar part.
Figure 11.
Outputs of the Cyan block before (a) and after (b) smoothing filter.
Figure 11.
Outputs of the Cyan block before (a) and after (b) smoothing filter.
As shown in the results of
Figure 11b, two sets of masks were chosen for the smoothing operation. The first was set to the color cyan, the color of the block, which is at the lower left corner block of the image (see
Figure 11a). The normalized color filter is set for cyan having RGB values set at (0,127,128). The smoothing operation due to convolution of the mask results in
Figure 11b (the smaller size 128 × 128 is due to a formatting issue). The second mask for smoothing the red component (255,0,0) results in the image shown in
Figure 12.
Table 9.
One geometric product for rotor convolution.
Table 9.
One geometric product for rotor convolution.
| Image Size | Full Multivector | ASIC with single core | ASIC with two Core |
|---|
| Image | Cycles | T (ms) | Cycles | T (ms) | Cycles | T (ms) |
|---|
| 128 × 128 | 1.37 × 106 | 10.5 | 1.24 × 106 | 9.5 | 6.38 × 105 | 4.9 |
| 256 × 256 | 5.50 × 106 | 42.3 | 4.98 × 106 | 38.3 | 2.55 × 106 | 19.6 |
| 512 × 512 | 2.20 × 107 | 169.3 | 1.99 × 107 | 153.2 | 1.02 × 107 | 78.6 |
As shown in the
Table 9 and
Table 10 the step filtering operation could be performed in 1 GP and 8 GA additions.
Table 9 shows the timing and the clock cycles the hardware takes for the GA geometric product and
Table 10 for the GA addition operations. The results also show the variation in timing for full multivector color represented as three bivectors and timing within a single core and two cores.
Table 10.
Eight geometric additions for rotor convolution.
Table 10.
Eight geometric additions for rotor convolution.
| Image Size | Full Multivector | ASIC with single core | ASIC with two Core |
|---|
| Image | Cycles | T (ms) | Cycles | T (ms) | Cycles | T (ms) |
|---|
| 128 × 128 | 9.43 × 106 | 72.5 | 5.24 × 106 | 40.3 | 4.45 × 106 | 34.2 |
| 256 × 256 | 3.77 × 107 | 290.3 | 2.09 × 107 | 161.3 | 1.78 × 107 | 137.1 |
| 512 × 512 | 1.50 × 108 | 1161 | 8.38 × 107 | 645.2 | 7.13 × 107 | 548.4 |
Both the experiments with color sensitive edge detection and smoothing have demonstrated that there is a substantial performance improvement when using the coprocessor. Furthermore, employing simple optimization technique leads to huge benefits. For example, in color sensitive edge detection with an image size 128 × 128, the full multivector expression takes 22.8 ms for 2 GP operations, whereas single core ASIC requires 19.1ms and two cores require 9.8 ms. Similarly for four geometric additions it requires 36.2 ms, 20.1 ms and 17.1 ms, respectively. This leads to 44% (with single core) and 52.7% (with two cores) relative performance improvements. In the case of color smoothing experiment we observe a similar trend with 44% and 52.8% performance improvement with single core and two cores, respectively.
We have shown that with an ASIC implementation it is feasible to achieve data throughput rates, which will provide fast enough operation for video applications, even with this relatively conservative process. For example, taking an image size 128 × 128 we can achieve 46.73 frames per second (fps), 58.48 fps and 29.24 fps for color difference edge detection, color sensitive edge detection and color sensitive smoothing, respectively. The ASIC was implemented as a “proof of concept” and therefore was not optimized for speed, but does demonstrate the advantages of a dedicated co-processor for this type of application, without the compromises inherent in an equivalent FPGA implementation.
Figure 12.
Red only smoothing.
Figure 12.
Red only smoothing.
7. Conclusions
This paper presents an overview of the Geometric Algebra fundamentals and convolution operations involving rotors for image processing applications. The discussion shows that the convolution operation with the rotor masks within GA belongs to a class of linear vector filters and can be applied to image or speech signals. Furthermore, it shows that this kind of edge detection is compact and is performed wholly using bivector color images.
The use of the ASIC GA Co-processor for rotor operations was introduced, including a demonstration of its potential for other applications in Vision and Graphics. This hardware architecture is tailored for image processing applications, providing acceptable application performance requirements. The usefulness of the introduced approach was demonstrated by analyzing and implementing three different edge detection algorithms using this hardware. The qualitative analysis for the edge detection algorithm shows the usefulness of GA based computations within image processing applications in general and the potential of the hardware architectures in signal processing applications.
Details are presented of the custom Geometric Algebra Co-Processor that directly targets GA operations and results in significant performance improvement for color edge detection. The contribution of the proposed approach has been demonstrated by analyzing and implementing three different types of edge detection schemes on the GA Co-Processor and FPGA platforms and overall performance gains is reported. A detailed analysis was undertaken which describes not only the raw timings, but also the trade-offs that can be made in terms of resources, area and timing. In addition, the results were also analyzed in the context of larger numbers of operations, where the potential performance benefits can be seen to scale to larger datasets. Future work will be focused on theoretical understanding of this linear filter and the frequency response, which would be useful in developing further algorithms.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








