1. Introduction
Elementary functions such as
,
,
,
and
play a key role in a wide variety of applications. These applications include scientific computing, computer graphics, 3D graphics applications and computer aided design (CAD) [
1,
2,
3,
4]. Although software routines can approximate elementary functions accurately, they are often too slow for numerically intensive and real-time applications. Hardware implementations have a significant speed advantage per computation as well as the potential to further increase throughput by using multiple units operating in parallel. Continuously increasing latency and throughput requirements for many scientific applications motivate the development of hardware methods for high-speed function approximation. Furthermore, correct and efficient hardware computation of elementary functions is necessary in platforms such as graphics processing units (GPUs), digital signal processors (DSPs), floating-point units (FPUs) in general-purpose processors, and application-specific integrated circuits (ASICs) [
5,
6,
7].
A number of different algorithms can be used to compute elementary functions in hardware. Published methods include polynomial and rational approximations, shift-and-add methods, table-based and table-driven methods. Each method has trade-offs between lookup-table size, hardware complexity, computational latency and accuracy. Shift-and-add algorithms, such as CORDIC [
8], are less suitable for low-latency applications due to their multi-cycle delays. Direct table lookup, polynomial approximations, rational approximations [
9,
10] and table-based methods [
11,
12,
13,
14,
15,
16], are only suitable for limited-precision operations because their area and delay increase exponentially as the input operand size increases. Table-driven methods combine smaller table sizes with addition or computation of a low-degree polynomial. They use smaller tables than direct table lookup and are faster than polynomial approximations.
Previous table-driven methods have had some success in dealing with the total hardware complexity in terms of the size of the lookup tables and the complexity of the computational units. They can be classified as compute-bound methods, table-bound methods, or in-between methods.
Compute-bound methods use a relatively small lookup table to obtain coefficients which are then used in cubic or higher-degree piecewise-polynomial approximation [
17,
18].
Table-bound methods [
10,
13,
19,
20] use relatively large tables and one or more additions. Examples include partial-product arrays, bipartite-table methods and multipartite-table methods. Bipartite-table methods consist of two tables and one addition [
13,
21]. Multipartite-table methods [
10,
20] are a generalization of bipartite-table methods that use more than two tables and several additions. These methods are fast, but become impractical for computations accurate to more than approximately 20-bits due to excessive table size.
In-between methods [
22,
23,
24] use medium-size tables and a moderate amount of computation. In-between methods can be subdivided into linear approximations [
12,
24] and quadratic interpolation methods [
22,
23,
25,
26,
27] based on the degree of the polynomial approximation employed. The intermediate size of the lookup tables makes them suitable for IEEE single-precision computations (24-bit significand), attaining fast execution with reasonable hardware requirements.
As noted above, in-between methods are the best alternative for higher-precision approximations. For practical implementations, the input interval of an elementary function is divided in subintervals and the elementary function is approximated with a low-degree polynomial within each subinterval. Each subinterval has a different set of coefficients for the polynomial, which are stored in a lookup table, giving a piecewise polynomial approximation of the function. Truncated multiplication and squaring units can be used to reduce the area, delay, and power requirements. However, the error associated with the reduced hardware complicates the error analysis required to ensure accurate evaluation of functions [
26,
27].
This paper presents an optimization method to localize and find a closed-form solution for interpolators that allows for smaller architectures to be realized. Although this paper presents ideas similar to other papers in terms of the implementation, the main contribution is the use of the optimization search algorithm to find a direct solution quickly and efficiently. This paper extends earlier work [
28,
29,
30] by providing the following:
A method to optimize the precision required for polynomial coefficients in order to meet the required output precision
A method to accommodate the errors introduced by utilizing truncated multipliers, squarers and/or cubers so that output precision requirements are met
Synthesis results for linear, quadratic and cubic interpolators for different precisions including area, latency and power, targeting a 65nm CMOS technology
A comparison to other methods to quantify the benefit of utilizing optimization methods to explore a design space with multiple parameters that can be adjusted to meet a given error requirement
The rest of this paper is organized as follows:
Section 2 covers background material related to polynomial function approximation.
Section 3 discusses truncated multipliers, squarers and cubers, and gives equations for reduction error.
Section 4 describes general hardware designs and presents the error analysis used to determine initial coefficient lengths and the number of unformed columns for truncated arithmetic units.
Section 5 describes our method for optimizing the value and precision of the coefficients to minimize the lookup table size while meeting the specifications for output error.
Section 6 presents synthesis results.
Section 7 compares our results with previously proposed methods. Conclusions are given in
Section 8.
2. Polynomial Function Approximation
Polynomial function approximation is one method used to compute elementary functions. This paper presents a technique to compute elementary functions by piecewise polynomial approximation using truncated multipliers, squarers and cubers. Polynomial approximations have the following form
where
is the function to be approximated,
N is the number of terms in the polynomial approximation, and
is the coefficient of the
term. The accuracy of the approximation is dependent upon the number of terms in the approximation, the size of the interval on which the approximation is performed, and the method for selecting the coefficients. In order to reduce the polynomial order while maintaining the desired output accuracy, the interval
is often partitioned into
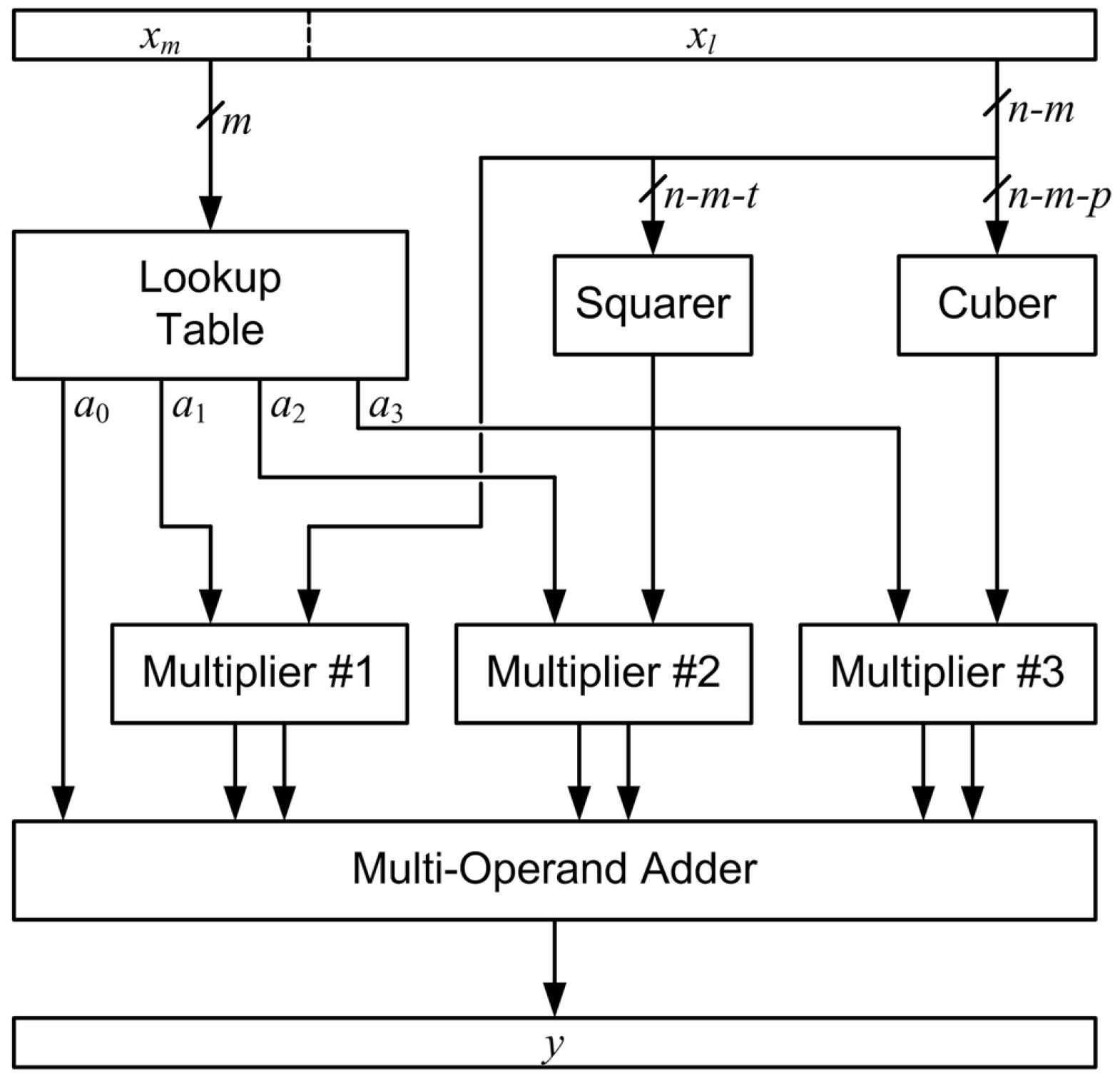
subintervals of equal size, each with a different set of coefficients. To implement this efficiently in hardware, the interpolator input is split into an
m-bit most significant part,
, and an
-bit least significant part,
, where
n is the number of bits input to the interpolator. For normalized IEEE floating point numbers [
31], the input interval for an operand is
. Numbers of this form are specified by the following equation:
The coefficients for each subinterval are stored in a lookup table.
is used to select the coefficients, so Equation (
1) becomes
Some applications require function approximation for large operand sizes, such as IEEE double precision formats. Unfortunately, as operand size grows it becomes increasingly difficult to find coefficient sizes and hardware parameters that meet output error specifications with acceptable total hardware complexity. One solution is to relax the precision requirement, e.g., to allow a maximum absolute error of
of one unit in the last place (ulp) [
32].
Approximation involves the evaluation of a desired function via simpler functions. In this paper, the simpler functions are the polynomials for each interval. Different types of polynomial approximations exist with respect to the error objective, including least-square approximations, which minimize the root-mean-square error, and least-maximum approximations, which minimize the maximum absolute error. For designs with a maximum error constraint, the least-maximum approximations are of interest. The most commonly used least-maximum approximations include the Chebyshev and minimax polynomials. Chebyshev polynomials provide approximations close to the optimal least-maximum approximation and can be constructed analytically. Minimax polynomials provide a better approximation, but must be computed iteratively via the Remez algorithm [
33]. Neither Chebyshev nor minimax polynomials account for the combined non-linear effects of coefficient quantization errors, reduction error due to use of truncated arithmetic units and roundoff error due to rounding intermediate values. Our optimization algorithm adjusts the coefficient values to best account for these errors. Chebyshev polynomials are used as the starting point because they are easier to compute and the optimization algorithm only requires reasonable initial coefficient values. Minimax polynomials can also be utilized for the initial approximation, however, this paper focuses on utilizing Chebyshev polynomials.
It is important to consider that the minimax algorithm provides a better approximation utilizing the Remez algorithm compared to the results obtained in this paper, which is discussed later in
Section 7. Interestingly, recent research in the area of arithmetic generation has produced minimax approximations automatically using the Remez algorithm [
34]. Again, these implementations are complex and designed for Field Programmable Gate Arrays (FPGAs) as denoted on the
website [
34]. This paper utilizes Chebyshev series approximations, because they provide a simple table-driven method for faithfully-rounded approximation to common elementary functions. Some researchers have also stated that Chebyshev interpolating polynomials are just as good as the best polynomials in the context of table-driven methods for elementary function computations and, thus, the common practice of feeding Chebyshev interpolating polynomials into a Remez procedure offers negligible improvement, if any, and thus may be considered unnecessary [
35].
This research targets simple architectures for ASIC implementations. The novel optimization algorithm presented in this paper provides a simple implementation to improve the accuracy of elementary function implementations, especially when using truncated arithmetic units and other approximate arithmetic units [
36]. Another advantage is that the methods presented in this paper utilize truncated units that have been shown to exhibit lower power requirements [
37]. Other similar endeavors, such as the Sollya project, are useful, but are more complex than the algorithm presented in this paper in addition to having different targets [
38]. For example, Sollya is a tool for safe floating-point code development, whereas, the novel direct-search methods in this paper provide another approach that is simple and finds a solution to complex error requirements for elementary functions.
With the approach presented in this paper, Chebyshev series approximations are used to select the initial coefficient values for each subinterval [
26,
27]. First, the number of subintervals,
, is determined. With infinite precision arithmetic, the maximum absolute error of a Chebyshev series approximation is [
18]
where
ξ is the point on the interval being approximated such that the
Nth derivative of
is at its maximum value. The maximum allowable error of the interpolator is
, which is selected as a design parameter. Since there will be error due to finite precision arithmetic in addition to
, we limit
to
, and solve Equation (4) for
m. Since
m must be an integer, this gives
The Chebyshev series approximation polynomial,
of degree
, is computed on the subinterval
by the following method:
The Chebyshev nodes are computed by using
The Chebyshev nodes are transformed from
to
by the following equation:
For subinterval
m on
, this becomes
The Lagrange polynomial,
, is formed, which interpolates the Chebyshev nodes on
as
where
is given in Equation (10)
and
is expressed in the form given in Equation (9) by combining terms in that have equal powers of x.
The coefficients of are rounded to a specified precision using round-to-nearest even.
2.1. Linear Interpolator Coefficients
For a linear interpolator, the coefficients for the interval
are given by
where
2.2. Quadratic Interpolator Coefficients
For a quadratic interpolator, the coefficients for the interval
are given by
where
2.3. Cubic Interpolator Coefficients
For a cubic interpolator, the coefficients for the interval
are given by Equations (24)–(27) where
One method to reduce the hardware needed to accurately approximate elementary functions using polynomials is to use truncated multipliers and squarers within the hardware [
26,
27]. Unfortunately, incorporating truncated arithmetic units into the architecture complicates the error analysis. However, recent advances using optimization methods for minimizing the error of a given function using truncated units have been successful at finding an optimal and efficient table size [
28]. Furthermore, designs that incorporate truncated multipliers, squarers and cubers significantly reduce area and power consumption required for a given elementary function.
Although many optimization methods can be utilized, the designs generated for this paper utilize a modified form of the cyclic direct search [
39]. This optimization method utilizes the optimized most significant bits for each coefficient to significantly reduce the memory requirements. Then, cyclic heuristic direct search is used to optimize the number of truncated columns to decrease the size of the coefficients. Each value is exhaustively tested to ensure that it meets the intended accuracy for a given architecture.
3. Truncated Multipliers, Squarers, and Cubers
Truncated multipliers, squarers, and cubers are units in which several of the least significant columns of partial products are not formed [
40]. Eliminating partial products from the multiplication, squaring and cubing matrix reduces the area of the unit by eliminating the logic needed to generate those terms, as well as reducing the number of adder cells required to reduce the matrix prior to the final addition. Additional area savings are realized because a shorter carry-propagate adder can be used to compute the final results, which may yield reduced delay as well. Eliminating adder cells, and thus their related switching activity, also results in reduced power consumption, particularly dynamic power dissipation.
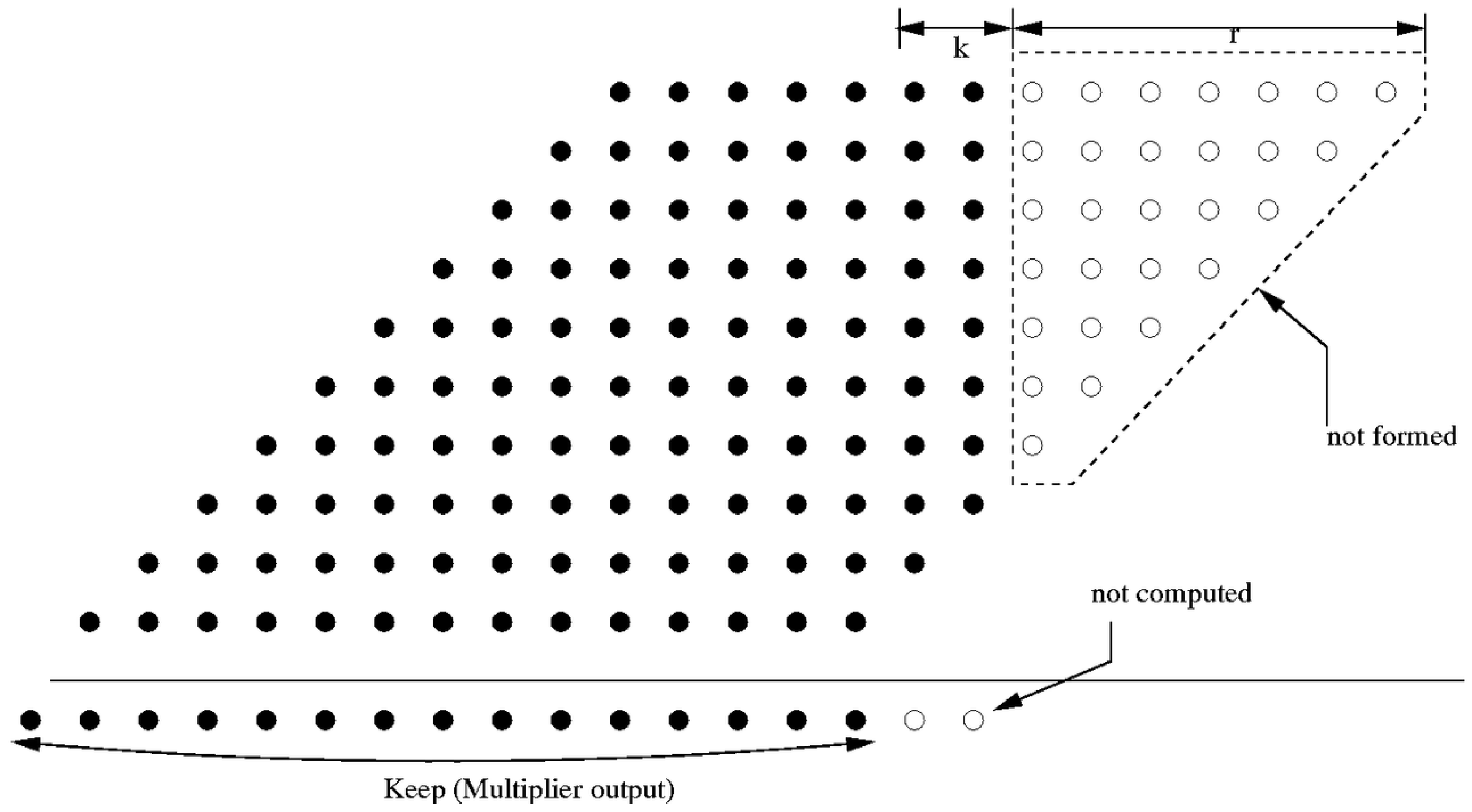
Figure 1 shows a
-bit truncated multiplier, where
r denotes the number of unformed columns and
k denotes the number of columns that are formed but discarded in the final result. In this example,
and
. Eliminating partial products introduces a reduction error,
, into the output. This error ranges from
, which occurs when each of the unformed partial-product bits is a ‘1’, to
, which occurs when each is a ‘0’.
is given by [
41]
where ulps is units in the last place of the full-width true product. The weight of one ulp depends on the location of the radix point. This analysis assumes that the inputs are between
. For the example given in
Figure 1,
is zero and the range of the reduction error is
ulps
ulps. By comparison, the error due to rounding a product using a standard multiplier has a range of
ulps
ulps (round 0.5 toward
mode).
For truncated squarers, as with truncated multipliers,
r denotes the number of unformed columns and
k denotes the number of columns that are formed but discarded in the final result. Unlike truncated multipliers, it is not possible for each of the unformed partial-product bits in a truncated squarer to be ‘1’.
for a truncated squarer depends if
r is even or odd [
42]. If
r is even,
If
r is odd,
The reduction error for truncated cubers is [
37,
43].
5. Coefficient Optimization
After the preliminary design is completed, the coefficients are adjusted based on precision. To minimize the lookup table size based on the term m, the direct search method is selected to find the minimum MSB (most significant bit) of each interpolator. The size of the lookup table is for a linear interpolator, for a quadratic interpolator, and for a cubic interpolator. Finding the minimum value of m where the output precision requirement can be met for all of the values in the reduced input domain reduces the size of the lookup table.
Initially, standard multipliers (full-width, all columns formed) are used. After the optimized value of m is computed, each coefficient is found. Next, the standard multipliers, squarer and cuber are replaced with truncated units. A new optimization method called the cyclic heuristic direct search is used to maximize the number of unformed columns while maintaining design specifications for error. This optimization reduces the area of the computational portion of the interpolator at the same time coefficient sizes are optimized, reducing the size of the lookup table. For example, consider the multiplier that computes in a linear interpolator and note that reducing the size of also reduces the size of the partial-product matrix required. Quadratic interpolators have two terms to optimize, and , and cubic interpolators have three terms to optimize, , and . Cyclic heuristic direct search is used because it is well suited for discrete optimization in multivariable equations.
Discrete optimization means searching for an optimal solution in a finite or countably infinite set of potential solutions. Optimality is defined with respect to some criterion function, which is to be minimized or maximized. In the cyclic heuristic direct search method each iteration involves a “cyclic” cycle in which each dependent variable makes an incremental change in value, one at a time, then repeats the cycle [
39].
5.1. Optimization Method
In the first stage, the number of most-significant bits,
m, of the value input to the interpolator,
x, is optimized such that the function,
, is approximated to the specified accuracy. The decision variable, DV, is
and the objective function, OF, is
. The constraint is
for all
, where
is the exact value of the function,
is the approximated value of the function and
q is the number of bits of precision in the output. The algorithm adjusts the DV to minimize the OF. Direct search methods are known as unconstrained optimization techniques that do not employ a derivative (gradient) [
39].
In the second stage, the coefficients sizes are optimized (minimized) and the number of unformed columns in the arithmetic units are optimized (maximized) at the same time. This further reduces the required size of the lookup tables and reduces the sizes of the partial-product matrices, which reduces the overall area, delay and power of the interpolator.
For the second stage, the cyclic heuristic direct search method is used for several reasons. The algorithm is simple to understand and implement. Direct searches can also satisfy hard constraints well and do not use a derivative, gradient or Hessian, which have difficulty coping with non-analytic surfaces such as ridges, discontinuities in the function or slope, and add computational difficulty and programming complexity. Simplicity, robustness, and accommodation of constraints in this algorithm are significant advantages for use with elementary function error analysis. Each of the coefficients values are adjusted to satisfy the accuracy requirements.
Linear interpolators have 2 DVs, the size of coefficients for
and
. The objective function is
As with the first stage, the algorithm adjusts the DVs to minimize the OF. This paper addresses maximizing the number of unformed columns. Therefore, Equation (66) is chosen because minimizing OF will maximize
. Other optimization algorithms may adjust the DVs to maximize the OF [
39]. If our algorithm maximized the OF then
would be used.
Quadratic interpolators have 3 DVs, the size of coefficients
,
, and
. The objective function is
Finally, cubic interpolator designs have 4 DVs, the size of coefficients
,
,
, and
. The objective function is
The constraint is for faithful rounding, but can be modified for different precision requirements.
The procedure for the cyclic heuristic direct search method is:
Initialize the Decision Variable base (the initial trial solution in a feasible region), , and evaluate the Objective Function, OF.
Start the cycle for one iteration.
Taking each DV, one at a time, set the new trial DV value,
Evaluate the function at the trial value. If worse or “FAIL” keep DV base and set
to a smaller change in the opposite direction, where contract and expand are names arbitrarily chosen as constants used for adjustment in the optimization, such that contract is
and expand is
.
Otherwise, keep the better solution (make it the base point) and accelerate moves in the correct direction
At the end of the cycle check for stopping criteria (excessive iterations, or convergence criteria met).
Stop, or repeat from Step 2.
5.2. Optimization Example and Results
This Section presents a function approximation example to help clarify how the optimization method works and how it improves results. Real numbers equal to the underlying fixed-point binary values, then rounded to 6 fractional digits, are given in the example to improve readability. For the sake of example, an arbitrary chosen input value for the interpolator,
, which has a reciprocal value
. The cyclic heuristic direct search method is employed to find the coefficient values used to compute the approximation of the reciprocal in a similar fashion as the interpolators in this paper.
Table 1 shows the value of the approximation using linear, quadratic and cubic methods described in the paper. The
n-bit range-reduced input to the interpolator,
x, is partitioned into
sub-intervals, each with its own set of coefficients
through
.
is the
m most significant bits of
x and
is the
least significant bits of
x. Although any analytical function can be shown using the results in this paper, reciprocal is utilized as an example as it is one of the more common implementations.
For a linear interpolator, the initial values of the coefficients
and
are found for each sub-interval using Equations (12) and (13), where
and
are given by Equations (14) and (15). The coefficients are then optimized and the number of unformed columns in the truncated arithmetic units are found using the method described in
Section 5.
Table 2 shows the coefficients sizes for each interpolator utilizing traditional multiplication and no optimization compared to using the cyclic heuristic direct search optimization method with truncated multipliers, squarers and cubers. For example, with the 32-bit cubic interpolator the initial size of
is 29 bits, which is then reduced to 16 bits after optimization. This significant reduction in size not only reduces the size of the lookup table, it also significantly reduces the size of the multiplier that computes
, which further reduces area, delay and power in the interpolator. Previous methods of computing the error for each memory or hardware unit relied on trial and error, while the method provided in this paper utilizes an optimal way of finding the coefficients for each table as well as containing the error within all multipliers.
Table 3 shows the hardware requirements comparison between our results and previous research methods.
Table 4 shows the memory requirements comparison between our results with [
18,
26].
Table 5 shows the results for determining the optimal bit-width of the coefficients and their respective lookup table sizes for four elementary functions: reciprocal, square root, reciprocal square root and sine. All values were computed in MATLAB using a script run on a 2.28 GHz Apple MacPro QuadCore Intel Xeon with 4 GB of 800 MHz DDR2 memory. Run times, even for 32-bit cubic interpolators, are under 1 minute for all cases.
The importance of the results is that they seek to find a near-optimal solution of the lowest memory requirements for a given elementary function. The exploration space is based on the input operand space (e.g., 32 bits). Consequently, an exhaustive search for finding the smallest optimal decomposition for a given operand size could take a considerable amount of time. The difficulty in finding these table sub-divisions (e.g.,
and
in
Figure 2) is that each configuration has to run over the total space of the register size. That is, a specific 32-bit operand decomposition would have to exhaustively check all
configurations to find the worst-case error and see if the stopping criterion of being faithfully rounded is met. As a comparison, traditional exhaustive searches (
i.e., checking each configuration for a given operand size one by one) ran several weeks with no tangible result. On the other hand, the algorithms and presented architectures discussed in this research are realizable and complete within a reasonable amount of time for the appropriate sizes presented. Future research might explore looking at larger operand sizes, such as 64 and 128 bits, for more accurate and reliable computations.
6. Implementation Results
The approach described in
Section 5 is implemented using a MATLAB script. The script computes the optimized polynomial coefficients and the maximum number of columns that can be removed from the truncated arithmetic units. Synthesizable Verilog descriptions are then created for linear, quadratic and cubic architectures. Code written in C is used to generate optimized RTL-level Verilog descriptions of the squaring and cubing units used in the interpolators. The Verilog descriptions have been implemented, targeting a 65nm cmos10lpe bulk CMOS technology from IBM
®. Results are obtained using Synopsys
® (formerly Virage Logic) standard-cell libraries and synchronous-based memory compilers. Memories are generated from the compiler to best suit their intended implementation size. Interestingly, most memories do not fit the exact required memory size, so they have empty space that may affect the area and delay estimates. Because of this, the results might be significantly better if the memory compiler could produce sizes that fit the required interpolator size more accurately, such as with some open-source memory compilers [
45]. Designs were synthesized using Synopsys
® Design Compiler
™ and the layout was produced using Synopsys
® IC Compiler (ICC)
™. Power numbers are generated from parasitic extraction of the layout and
random input vectors using Synopsys
® PrimeTime
™.
Both compiler-generated memories and standard-cells are placed and routed together to form the best aspect ratio and area for the smallest delay. The methods employed in this paper are optimized for delay, because the interpolators dominate the total area cost, which is especially true as the operand size increases. Although smaller operand sizes could be produced with random logic, the intended applications for this paper typically use memory-driven layouts (e.g., within multiplicative-division schemes inside general-purpose architecture datapaths). Therefore, to create a consistent comparison all implementations utilize memory generated by a memory compiler.
This paper produces several designs by varying the precision, the architecture, and the approximation order. For this paper, several word sizes are designed for the linear, quadratic and cubic architectures using the function
for
. The area and delay results for 16, 24 and 32-bit interpolators are reported in
Table 6. It can be seen that the piecewise-linear implementation has a unit in the last position (ulp) of
that is more efficient than the quadratic interpolator circuit. For 16-bit accuracy, the linear interpolator has smaller area requirements yet maintains high speed with smaller utilization of standard cells compared to quadratic and cubic interpolators. On the other hand, the 24-bit quadratic interpolator is more efficient than the linear interpolator yet requires approximately
times more area. For 16-bit accuracy, the area requirements are smaller, yet it still maintains its high speed with smaller utilization of standard cells compared to 24 bits. For cubic implementation, the 24-bit cubic interpolator is more efficient than the 16-bit interpolator despite having around
more area than 16-bit architectures. On the other hand, 32-bit architectures have significantly more area than 16 and 24 bits, yet have comparable speed.
For all of the results in
Table 6, the total delay is the post-layout critical path through the circuit including the memory delay. The memory delay is highlighted in
Table 6 to showcase the non-memory delay (
i.e., Non-memory Delay = Total Delay - Memory Delay). Since the memory is synchronous, the memory is read on the clock half-cycle and processed on the subsequent clock half cycle. Therefore, an asynchronous memory design may improve the critical path, since it does not have to wait for the precharge tied to the clock. It is important to also consider that the implementations utilized in this paper use actual extracted memory instantiations as opposed to logic produced from FPGAs. Previous research [
14] has utilized specific FPGAs that have embedded memories, such as Xilinx’s Block RAM (BRAM). Implementations using BRAM usually have integrated columns arranged throughout the FPGA and allocate single columns of memory at a time when needed. When a specific FPGA implementation gets large, it has to route its implementation across multiple columns and, thus, possibly skew the actual propagation times because the place and route of the slices are not efficiently located [
46]. Although previous research could theoretically implement architectures that could use their columns efficiently, it is hard to tell for a given implementation unless otherwise specified.
Some alternative architectures have been proposed to help alleviate some of these problems, such as Xilinx’s UltraScale Architecture [
47]. However, the gap between implementations of silicon and FPGAs can be considerable based on the actual floorplan of its implementation and its routing. Therefore, this paper focuses on implementations utilizing dedicated low-power SRAM implementations and standard-cell logic that have optimized floorplans. An argument could also be made that a full-custom design (for both memory and logic) would produce better results, as well. On the other hand, the implementations in this paper are as close to a full-custom implementation as possible in terms of their implementation. Also, similar to the research presented in [
20], there is a tradeoff between the size of the memory and the amount of logic for these dedicated interpolators, as shown in
Table 6.
The power results for linear, quadratic and cubic with 16, 24 and 32-bit precisions are reported in
Figure 5 and
Figure 6.
Figure 5 shows the dynamic and leakage power for each interpolator based on generating several thousand random input vectors. It can be seen that increasing the complexity of hardware increases the power dissipation.
Figure 6 shows the dynamic power and percentage of memory and logic circuit power usage separately. Interestingly, both quadratic methods incurred a small amount of power for their clock networks (not shown due to the small amount reported), whereas, linear methods do not.
7. Memory Comparison
A comparison of the optimized Chebyshev quadratic and cubic interpolators with existing methods for function approximation is presented in this section. Linear interpolators are not included in the comparison due to the small gains in accuracy compared to their table sizes. All considered interpolators employ similar tables and multipliers. Therefore, the comparison results are technology-independent.
The comparison is presented in two parts. First,
Table 7 compares of our optimized Chebyshev quadratic and cubic interpolators with an optimized bipartite table method (SBTM) [
13], an optimized symmetric table additional method (STAM) [
20], a Chebyshev method without any optimization and standard multipliers [
18], multipartite table methods [
14], a Chebyshev method with constant-correction truncated multipliers [
26], an enhanced quadratic minimax method [
25] and two linear approximation algorithms (DM97 [
12] and Tak98 [
24]). Each of the comparisons are shown for a single operation of reciprocal (
) mainly because most of the papers usually only present reciprocal due to its popularity for floating-point [
31]. Some assumptions have also been made to allow for a fair comparison, such as table sizes corresponding to a final result accurate to less than 1 ulp (
i.e., they produce a faithful result).
It is important to consider that some implementations in
Table 7 only include a carry-propagate adder and not a multiplier (e.g., [
13]). However, the importance of using multipliers in these architectures is that they can realize faithful approximations with larger operand sizes compared to those that are table-driven with adders [
13]. Previous methods [
14] had to overcome larger memory sizes to meet a given accuracy, especially for operands greater than 16 bits. The approach presented in this research allows significantly-reduced memory tables by employing multipliers within the architecture while being faithfully-rounded. That is, the utilization of a multiplier allows the result to converge quicker than those that only utilize adders. More importantly, since traditional rectangular multipliers can consume large quantities of area and power [
48], truncated multipliers along with the algorithms in this paper can be implementated while not dominating area or energy as with conventional approaches.
Second,
Table 8 compares our optimized Chebyshev quadratic and cubic interpolators with other quadratic methods (JWL93 [
49], SS94 [
18], CW97 [
22], CWCh01 [
23], minimax [
25]) when computing several operations (in this case, four operations) with the combinational logic shared for the different computations and a replicated set of lookup tables. In JWL93 [
49], the functions approximated are reciprocal, square root, arctangent, and sine/cosine, CW97 [
22] and CWCh01 [
23] approximate reciprocal, square root, sin/cos and
, and, in both SS94 [
18] and the quadratic minimax interpolators, the functions computed are reciprocal, square root, exponential (
), and logarithm. This paper shows results computed for reciprocal, square root, square root reciprocal and sine. Again, to allow for a fair comparison, table sizes correspond in all cases for faithful results or final answers accurate to less than 1 ulp of error.
The main conclusion to be drawn from this comparison is that SBTM, STAM and multipartite table methods may be excessive for single-precision computations due to the large size of the tables to be employed. It is also noticeable that fast execution times can be obtained with linear approximation methods, but their hardware requirements are two to three times higher per function than those corresponding to the optimized Chebyshev quadratic and cubic interpolator, which, on the other hand, allows for similar execution times. More importantly, fast quadratic and cubic interpolators can significantly reduce the overall constraints for area, delay, and power because they can be tailored for multiple functions. Using bipartite table methods requires significant amounts of area for each function that can grow with the number of functions required for a given architecture.
The analysis of approximations with Chebyshev polynomials of various degrees performed in [
18] shows that Chebyshev polynomials are a good method of approximation compared to multipartite tables that use a Taylor series. Additional savings utilizing truncated multipliers for Chebyshev polynomials demonstrated a significant savings for lookup table sizes [
26]. This paper presents a simple, robust, and constraint-based optimization algorithm that has significant advantages for use in elementary function error analysis. All the coefficients are adjusted based on the minimum most significant bits that allow for compensation of the effects of rounding a coefficient to a finite word length. This property, combined with the intrinsic accuracy of Chebyshev approximations, results in a more accurate polynomial approximation and a reduction in the size of tables (largely determined by
m). The reduction of
m by one results in a reduction by half in the size of the lookup tables to be employed. This is because each table grows exponentially with
m (each table has
entries), and therefore has a strong impact on the hardware requirements of the architecture. Furthermore, a reduction in the wordlength of the coefficients may also help in reducing the size of the accumulation tree to be employed for the polynomial evaluation. Using the optimization method presented demonstrates significant memory savings for 16, 24 and 32 bits of precision that produce faithfully rounded results. More importantly, the optimization method presented in this paper can be theoretically employed for larger operand sizes and in other areas where there are multiple sources of truncation and rounding error for a given architecture. Consequently, the method has a significant return on investment to find a best-fit scenario instead of using a trial-error method for table-based interpolators.
Table 8 displays a comparison for the most common bit sizes employed throughout most papers dealing with interpolators (e.g., 24 bits). Along with our comparison for quadratic and cubic interpolatars, comparisons are shown for the approximation of reciprocal, square root, exponential (
), and logarithm [
18]. Again these results are designed for a target precision of 24 bits with less than 1 ulp of error. The dramatic reduction in memory requirements for the proposed optimization method simplifies the process of creating small memory lookup table sizes. This occurs because most interpolators require several table lookups per function. Therefore, a technique that can optimize the size of the table lookup can benefit the overall memory requirement for all functions. Some results in
Table 8 show smaller table sizes compared to the optimized quadratic interpolator presented in this paper [
25]. This is because they utilize minimax algorithms that are more efficient than Cheybshev polynomials, as mentioned previously. However, the optimization algorithm in this paper could theoretically be equally applied to other algorithms such as minimax, along with reduced precision functional units (e.g., constant-correction truncated multipliers, squarers, and cubers). There are some other entries in
Table 8 that employ hybrid schemes that also perform better than optimized quadratic interpolators. This particular hybrid scheme [
23] utilizes specific table lookups instead of polynomial coefficients. This enables a reduction in the total table size as table-lookup methods can sometimes be more efficient in evaluation of elementary functions [
10]. On the other hand, this technique [
23] achieves this reduction in table size at the expense of computing the coefficients on the fly which adds extra delay to the critical path and, thus, exhibits long latencies.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}