Real-Time Ground Vehicle Detection in Aerial Infrared Imagery Based on Convolutional Neural Network


Abstract
:1. Introduction
- We propose a method of detecting ground vehicles in aerial imagery based on convolutional neural network. Firstly, we combine the UAV and infrared sensor to the real-time system. There exist some great challenges like scale, view changes and scene’s complexity in ground vehicle detection. In addition, the aerial imagery is always low-resolution, fuzzy and low-contrast, which adds difficulties to this problem. However, the proposed method adopts a convolutional neural network instead of traditional feature extraction, and uses the more recognized abstract features to search the vehicle, which have the unique ability to detect both the stationary and moving vehicles. It can work in real urban environments at 10 fps, which has a better real-time performance. Compared to the mainstream background model methods, it gets double performances in the and index.
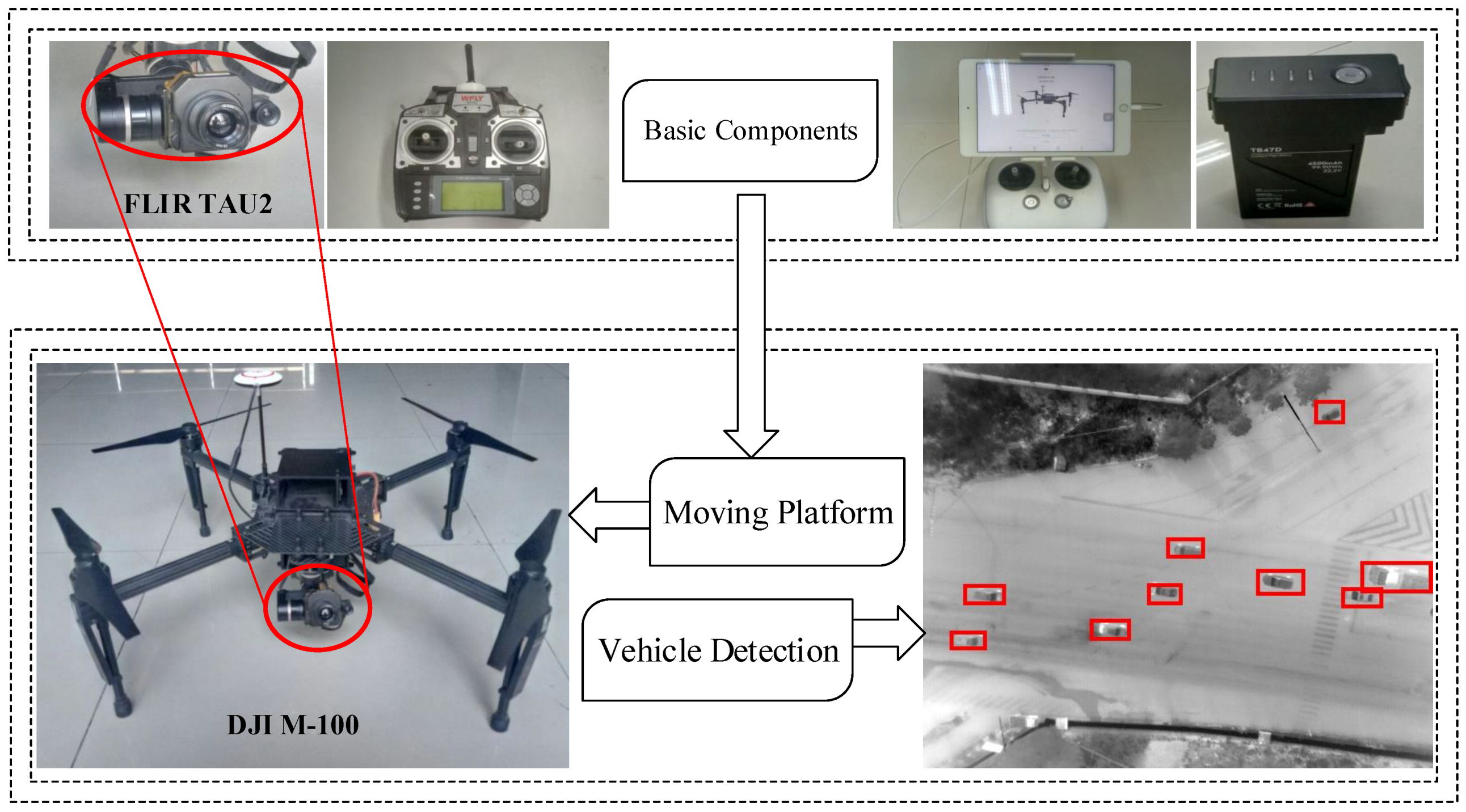
- We construct a real-time ground vehicle detection system in aerial imagery, which includes the DJI M-100 UAV (Shenzhen, China), the FLIR TAU2 infrared camera (Beijing, China.), the remote controls and iPad (Apple, California, US). The system is built to collect large amounts of training samples and test images. These images are captured on different scenes includes road and multi-scenes. Additionally, this dataset is more complex and diversified in vehicle number, shape and surroundings. The aerial infrared vehicle dataset (The dataset (NPU_CS_UAV_IR_DATA) is online at [35],) which is convenient for the future research in this field.
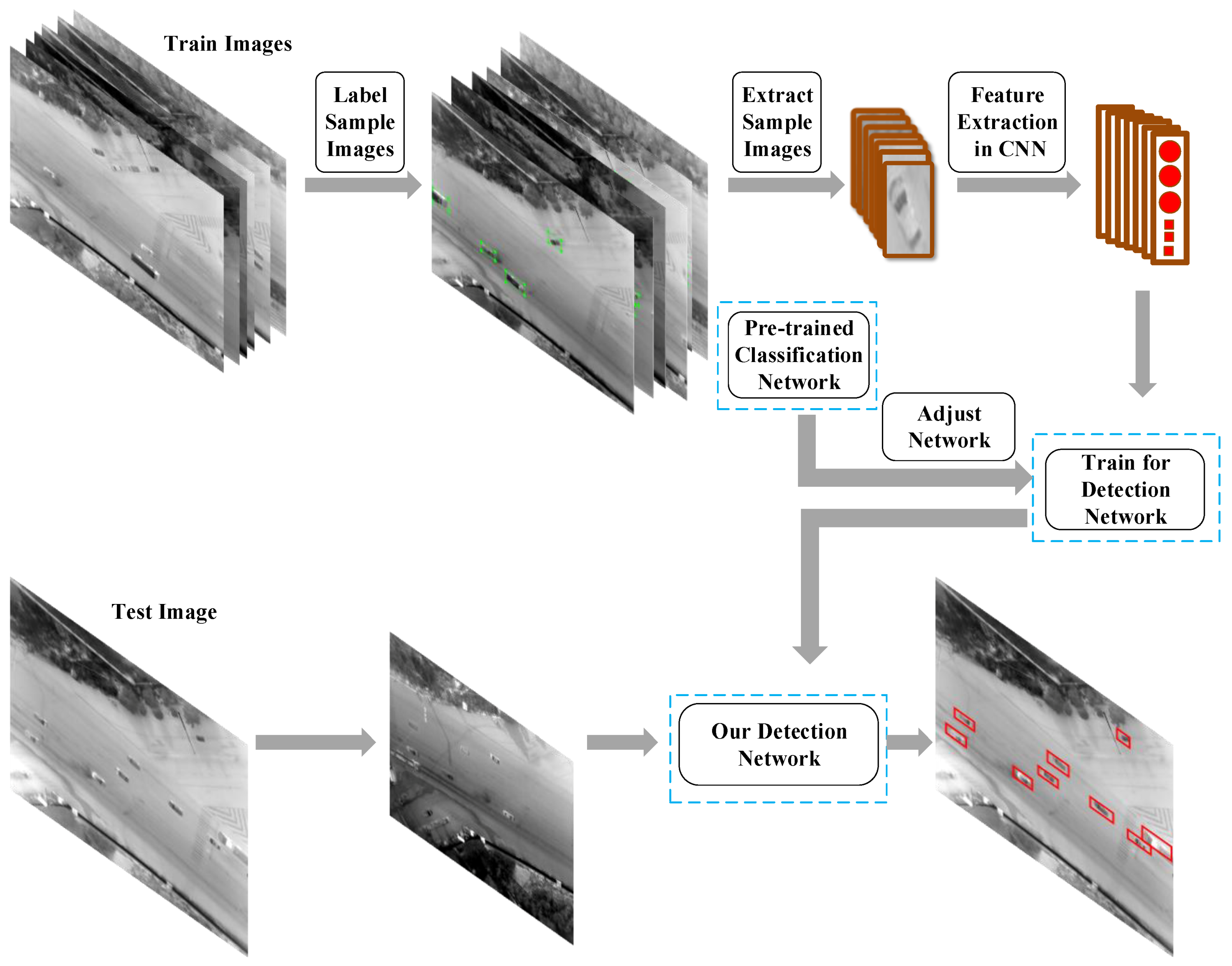
2. Aerial Infrared Ground Vehicle Detection
2.1. Label Train Samples
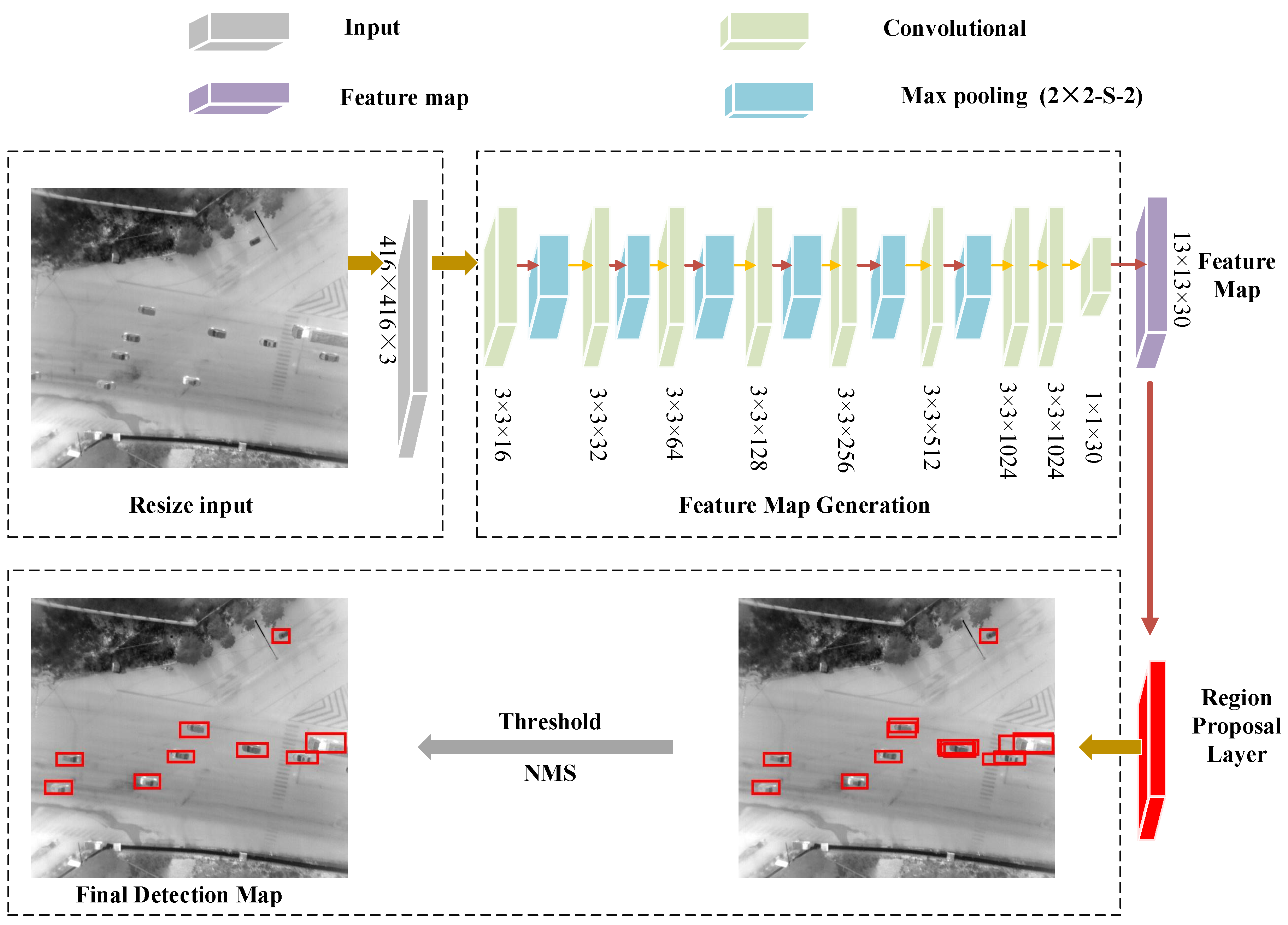
2.2. Convolutional Neural Network
Feature Map Generation
2.3. Bounding Boxes Generation
2.3.1. Vehicle Prediction on Bounding Boxes
2.3.2. Non Maximum Suppression
3. Aerial Infrared System and Dataset
3.1. Aerial Infrared System
3.2. Dataset
3.2.1. Training Samples
3.2.2. Test Images
- NPU_DJM100_1: The sample chosen and their adjacent images from the aerial infrared images captured in the first four times is removed, then the remaining is used as the second test image group.
- NPU_DJM100_2: The images captured at the fifth time are the third test image group. There are few connections with images belonging to the previous four times.
- Scenes Change: The images are captured at earlier times and 80 m flight height. There is not a lot of traffic. This scene is totally different from all of the above. It is used to eliminate scenario training possibilities.
3.3. Training
4. Experimental Results and Discussion
4.1. Achievement Exposition
4.2. Assessment Method
4.3. Statistical Information
4.4. Discussion
Comparison with State-of-the-Art
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| SVM | Support Vector Machines |
| UAV | Unmanned Aerial Vehicle |
| SIFT | Scalar Invariant Feature Transform |
| HOG | Histogram of Oriented Gradient |
| ISM | Implicit Shape Model |
| NMS | Non Maximum Suppression |
| CNN | Convolutional Neural Network |
| MHI | Motion History Image |
| HMM | Hidden Markov Model |
References
- Diamantopoulos, G.; Spann, M. Event detection for intelligent car park video surveillance. Real-Time Imaging 2005, 11, 233–243. [Google Scholar] [CrossRef]
- Cheng, H.; Weng, C.; Chen, Y. Vehicle detection in aerial surveillance using dynamic bayesian networks. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2012, 21, 2152–2159. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhou, Y.; Deng, C. Study and implementation of car video surveillance system. Commun. Technol. 2012, 45, 55–56. [Google Scholar]
- Zhao, G.; Hong-Bing, M.A.; Chen, C. Design of a wireless in-car video surveillance dedicated file system. Electron. Des. Eng. 2016, 24, 10–13. [Google Scholar]
- Bohn, B.; Garcke, J.; Iza-Teran, R.; Paprotny, A.; Peherstorfer, B.; Schepsmeier, U.; Thole, C.A. Analysis of car crash simulation data with nonlinear machine learning methods. Procedia Comput. Sci. 2013, 18, 621–630. [Google Scholar] [CrossRef]
- Saust, F.; Wille, J.M.; Maurer, M. Energy-optimized driving with an autonomous vehicle in urban environments. In Proceedings of the Vehicular Technology Conference, Yokohama, Japan, 6–9 May 2012; pp. 1–5. [Google Scholar]
- Sun, Z.; Bebis, G.; Miller, R. On-road vehicle detection using gabor filters and support vector machines. Int. Conf. Digit. Signal Process. 2002, 2, 1019–1022. [Google Scholar]
- Tsai, L.; Hsieh, J.; Fan, K. Vehicle detection using normalized color and edge map. IEEE Int. Conf. Image Process. 2007, 16, 850–864. [Google Scholar] [CrossRef]
- Zhou, J.; Gao, D.; Zhang, D. Moving vehicle detection for automatic traffic monitoring. IEEE Trans. Veh. Technol. 2007, 56, 51–59. [Google Scholar] [CrossRef]
- Elmikaty, M.; Stathaki, T. Car detection in high-resolution urban scenes using multiple image descriptors. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 4299–4304. [Google Scholar]
- Yang, T.; Wang, X.; Yao, B.; Li, J.; Zhang, Y.; He, Z.; Duan, W. Small moving vehicle detection in a satellite video of an urban area. Sensors 2016, 16, 1528. [Google Scholar] [CrossRef] [PubMed]
- Luo, P.; Liu, F.; Liu, X.; Yang, Y. Stationary Vehicle Detection in Aerial Surveillance With a UAV. In Proceedings of the 8th International Conference on Information Science and Digital Content Technology (ICIDT), Jeju, Korea, 26–28 June 2012; pp. 567–570. [Google Scholar]
- Chen, X.; Meng, Q. Vehicle detection from UAVs by using SIFT with implicit shape model. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics, Manchester, UK, 13–16 October 2013; pp. 3139–3144. [Google Scholar]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A hybrid vehicle detection method based on Viola-Jones and HOG + SVM from UAV images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef] [PubMed]
- Kamal, S.; Jalal, A. A hybrid feature extraction approach for human detection, tracking and activity recognition using depth sensors. Arab. J. Sci. Eng. 2016, 41, 1043–1051. [Google Scholar] [CrossRef]
- Farooq, A.; Jalal, A.; Kamal, S. Dense RGB-D map-based human tracking and activity recognition using skin joints features and self-organizing map. Ksii Trans. Internet Inf. Syst. 2015, 9. [Google Scholar] [CrossRef]
- Kamal, S.; Jalal, A.; Kim, D. Depth images-based human detection, tracking and activity recognition using spatiotemporal features and modified HMM. J. Electr. Eng. Technol. 2016, 11, 1857–1862. [Google Scholar] [CrossRef]
- Yi, K.M.; Yun, K.; Kim, S.W.; Chang, H.J.; Jin, Y.C. Detection of moving objects with non-stationary cameras in 5.8 ms: Bringing motion detection to your mobile device. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 27–34. [Google Scholar]
- Li, L.; Zeng, Q.; Jiang, Y.; Xia, H. Spatio-temporal motion segmentation and tracking under realistic condition. In Proceedings of the International Symposium on Systems and Control in Aerospace and Astronautics, Harbin, China, 19–21 January 2006; pp. 229–232. [Google Scholar]
- Yin, Z.; Collins, R. Moving object localization in thermal imagery by forward-backward MHI. In Proceedings of the Conference on Computer Vision and Pattern Recognition Workshop, New York, NY, USA, 17–22 June 2006; p. 133. [Google Scholar]
- Shao, W.; Yang, W.; Liu, G.; Liu, J. Car detection from high-resolution aerial imagery using multiple features. In Proceedings of the Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4379–4382. [Google Scholar]
- Tuermer, S.; Kurz, F.; Reinartz, P.; Stilla, U. Airborne vehicle detection in dense urban areas using HOG features and disparity maps. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2013, 6, 2327–2337. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, C.; Luo, H.; Wang, H.; Chen, Y.; Wen, C.; Yu, Y.; Cao, L.; Li, J. Vehicle detection in high-resolution aerial images based on fast sparse representation classification and multiorder feature. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2296–2309. [Google Scholar] [CrossRef]
- Yu, S.L.; Westfechtel, T.; Hamada, R.; Ohno, K.; Tadokoro, S. Vehicle detection and localization on bird’s eye view elevation images using convolutional neural network. In Proceedings of the IEEE International Symposium on Safety, Security and Rescue Robotics, Shanghai, China, 11–13 October 2017; pp. 102–109. [Google Scholar]
- Sommer, L.; Schuchert, T.; Beyerer, J. Fast deep vehicle detection in aerial images. In Proceedings of the Applications of Computer Vision, Santa Rosa, CA, USA, 24–31 March 2017; pp. 311–319. [Google Scholar]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Zou, H. Toward fast and accurate vehicle detection in aerial images using coupled region-based convolutional neural networks. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 3652–3664. [Google Scholar] [CrossRef]
- Yang, M.; Liao, W.; Li, X.; Rosenhahn, B. Vehicle detection in aerial images. arXiv, 2018; arXiv:1801.07339. [Google Scholar]
- Konoplich, G.V.; Putin, E.; Filchenkov, A. Application of deep learning to the problem of vehicle detection in UAV images. In Proceedings of the IEEE International Conference on Soft Computing and Measurements, St. Petersburg, Russia, 25–27 May 2016; pp. 4–6. [Google Scholar]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep learning approach for car detection in UAV imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Li, T.; Yang, T.; Lu, Z. Cross-domain co-occurring feature for visible-infrared image matching. IEEE Access 2018, 6, 17681–17698. [Google Scholar] [CrossRef]
- Li, J.; Li, C.; Yang, T.; Lu, Z. A novel visual vocabulary translator based cross-domain image matching. IEEE Access 2017, 5, 23190–23203. [Google Scholar] [CrossRef]
- Test Images and Train Samples. Available online: https://shanxiliuxiaofei.github.io/ (accessed on 2 April 2018 ).
- Pktest01. Available online: http://vision.cse.psu.edu/data/vividEval/datasets/PETS2005/PkTest01/index.html (accessed on 2 April 2018).
- LabelImg Tool. Available online: https://github.com/tzutalin/labelImg (accessed on 2 April 2018).
- Sande, K.E.A.V.D.; Uijlings, J.R.R.; Gevers, T.; Smeulders, A.W.M. Segmentation as selective search for object recognition. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2012; pp. 1879–1886. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Everingham, M.; Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Felzenszwalb, P.F.; Girshick, R.B.; Mcallester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J. Darknet: Open Source Neural Networks in C. 2013–2016. Available online: http://pjreddie.com/darknet/ (accessed on 2 April 2018).
- Pktest02. Available online: http://vision.cse.psu.edu/data/vividEval/datasets/PETS2005/PkTest02/index.html (accessed on 2 April 2018).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Layer | Filters | Size/Stride | Input | Output |
|---|---|---|---|---|---|
| 0 | convolutional | 16 | 3×3/1 | 416 × 416 × 3 | 416 × 416 × 16 |
| 1 | max pooling | 2 × 2/2 | 416 × 416 × 16 | 208 × 208 × 16 | |
| 2 | convolutional | 32 | 3 × 3/1 | 208 × 208 × 16 | 208 × 208 × 32 |
| 3 | max pooling | 2 × 2/2 | 208 × 208 × 32 | 104 × 104 × 32 | |
| 4 | convolutional | 64 | 3 × 3/1 | 104 × 104 × 32 | 104 × 104 × 64 |
| 5 | max pooling | 2 × 2/2 | 104 × 104 × 64 | 52 × 52 × 64 | |
| 6 | convolutional | 128 | 3 × 3/1 | 52 × 52 × 64 | 52 × 52 × 128 |
| 7 | max pooling | 2 × 2/2 | 52 × 52 × 128 | 26 × 26 × 128 | |
| 8 | convolutional | 256 | 3 × 3/1 | 26 × 26 × 128 | 26 × 26 × 256 |
| 9 | max pooling | 2 × 2/2 | 26 × 26 × 256 | 13 × 13 × 256 | |
| 10 | convolutional | 512 | 3 × 3/1 | 13 × 13 × 256 | 13 × 13 × 512 |
| 11 | max pooling | 2 × 2/1 | 13 × 13 × 512 | 13 × 13 × 512 | |
| 12 | convolutional | 1024 | 3 × 3/1 | 13 × 13 × 512 | 13 × 13 × 1024 |
| 13 | convolutional | 1024 | 3 × 3/1 | 13 × 13 × 1024 | 13 × 13 × 1024 |
| 14 | convolutional | 30 | 1 × 1/1 | 13 × 13 × 1024 | 13 × 13 × 30 |
| Camera and UAV | Specification | Parameter |
|---|---|---|
 | aircraft | DJI-MATRICE 100 |
| infrared sensor | FLIR TAU2 | |
| capture solution | ||
| capture frame rate | 10 fps | |
| focal length | 19 mm | |
| head rotation | × |
| Test | Size | Flying Altitude | Scenario | Date/Time | Temperature |
|---|---|---|---|---|---|
| VIVID_pktest1 | 320 × 240 | 80 m | Multi-scene | Unknown | Unknown |
| NPU_DJM100_1 | 640 × 512 | 120 m | Road | 18 May 2017/16:00 pm | 29 C |
| NPU_DJM100_1 | 640 × 512 | 120 m | Road | 18 May 2017/16:30 pm | 29 C |
| Scenes Change | 640 × 512 | 80 m | Road | 14 April 2017/10:30 pm | 18 C |
| Test | Images | Vehicles | TP | FP | FN | Precision | Recall | F1-Score | Time(s) |
|---|---|---|---|---|---|---|---|---|---|
| VIVID_pktest1 | 100 | 446 | 388 | 58 | 7 | 87.00% | 98.23% | 92.27% | 4.50 |
| NPU_DJM100_1 | 189 | 642 | 612 | 30 | 22 | 95.33% | 96.53% | 95.93% | 16.07 |
| NPU_DJM100_2 | 190 | 922 | 903 | 19 | 30 | 97.94% | 96.78% | 97.36% | 17.48 |
| Scenes Change | 100 | 85 | 79 | 6 | 0 | 92.94% | 100% | 96.34% | 9.20 |
| Total | 2095 | 1982 | 113 | 59 | 94.61% | 97.11% | 95.84% |
| Test | Images Number | Vehicles | The Proposed Method | Method in [18] | ||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1-Score | Precision | Recall | F1-Score | |||
| VIVID_pktest1 | 1–100 | 446 | 87.00% | 98.23% | 92.27% | 42.82% | 77.45% | 55.15% |
| NPU_DJM100_1 | 1–60 | 38 | 100% | 100% | 100% | 52.63% | 31.75% | 39.61% |
| NPU_DJM100_2 | 1–100 | 501 | 98.20% | 97.62% | 97.91% | 34.35% | 40.78% | 37.29% |
| Scenes Change | 70–90 | 20 | 100% | 100% | 100% | 100% | 100% | 100% |
| Total | 1005 | 91.34% | 92.08% | 91.71% | 37.98% | 54.44% | 44.74% | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Yang, T.; Li, J. Real-Time Ground Vehicle Detection in Aerial Infrared Imagery Based on Convolutional Neural Network. Electronics 2018, 7, 78. https://doi.org/10.3390/electronics7060078
Liu X, Yang T, Li J. Real-Time Ground Vehicle Detection in Aerial Infrared Imagery Based on Convolutional Neural Network. Electronics. 2018; 7(6):78. https://doi.org/10.3390/electronics7060078
Chicago/Turabian StyleLiu, Xiaofei, Tao Yang, and Jing Li. 2018. "Real-Time Ground Vehicle Detection in Aerial Infrared Imagery Based on Convolutional Neural Network" Electronics 7, no. 6: 78. https://doi.org/10.3390/electronics7060078
APA StyleLiu, X., Yang, T., & Li, J. (2018). Real-Time Ground Vehicle Detection in Aerial Infrared Imagery Based on Convolutional Neural Network. Electronics, 7(6), 78. https://doi.org/10.3390/electronics7060078