Facial Expression Recognition of Nonlinear Facial Variations Using Deep Locality De-Expression Residue Learning in the Wild

 ,
,  ,
,
Abstract
:1. Introduction
2. Related Work
2.1. Holistic-Based Approaches
2.2. Part-Based Appoaches
3. Proposed Method
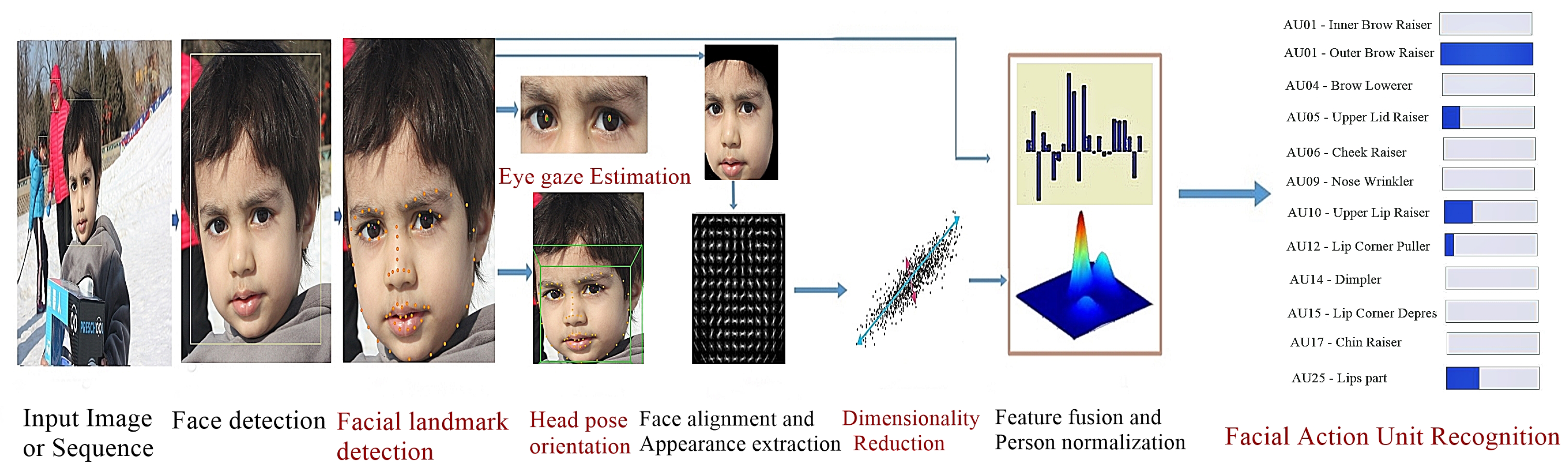
3.1. Preprocessing
3.1.1. Face Detection
3.1.2. Data Augmentation
3.1.3. Illumination Normalization
3.2. Facial Landmark Detection and Tracking
3.3. Head Pose Estimation
3.4. Eye Gaze Estimation
3.5. Deep Preserving Feature Learning
3.5.1. Neutral Face Regeneration
3.5.2. Facial Expressive Component Learning
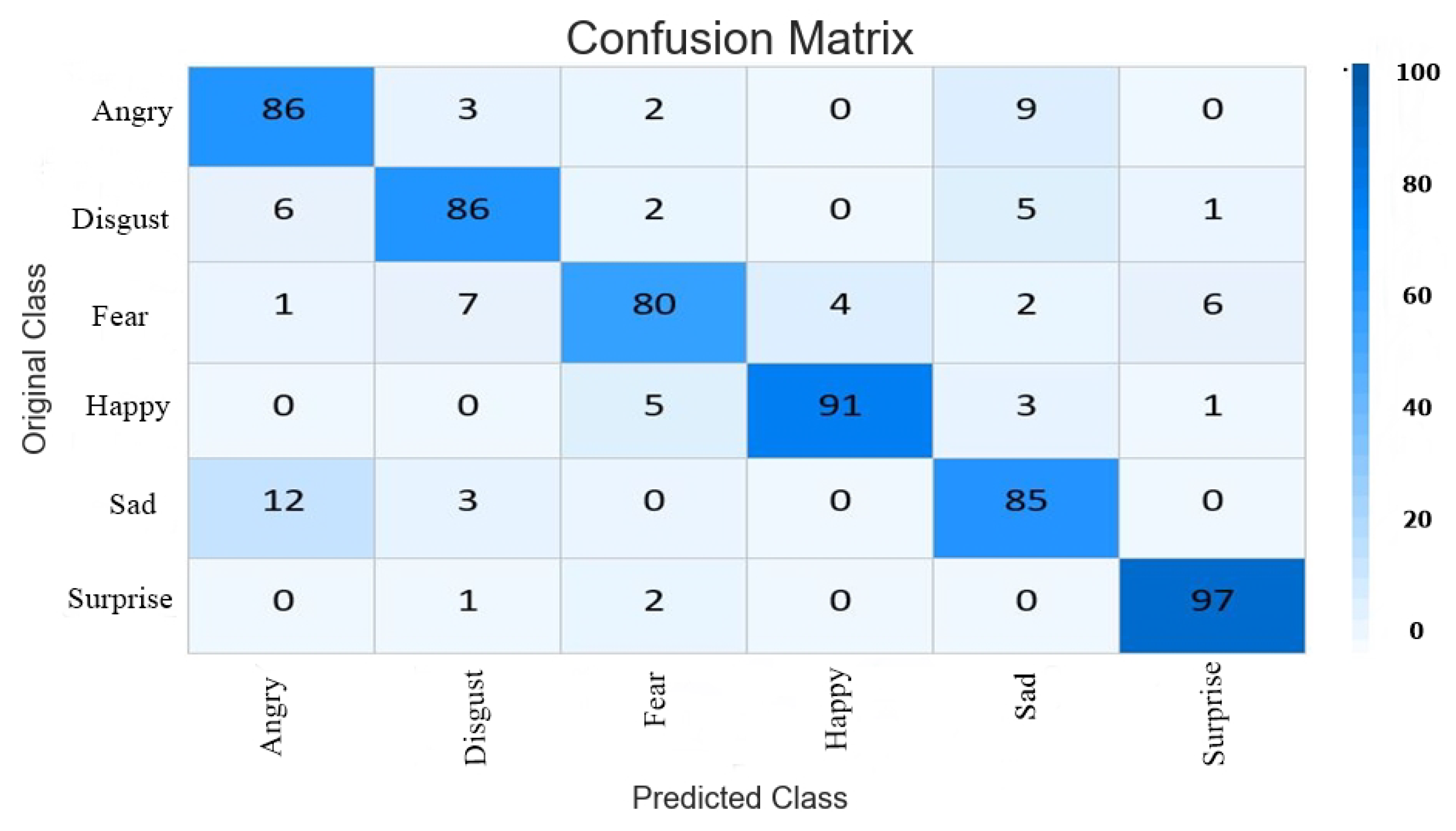
4. Experimental Results
Threats to Validation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Baltrusaitis, T.; Zadeh, A.; Yao, C.L.; Morency, L.P. OpenFace 2.0: Facial Behavior Analysis Toolkit. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Lille, France, 14–18 May 2019; pp. 59–66. [Google Scholar]
- Ullah, A.; Wang, J.; Anwar, M.S.; Ahmad, U.; Wang, J.; Saeed, U. Nonlinear Manifold Feature Extraction Based on Spectral Supervised Canonical Correlation Analysis for Facial Expression Recognition with RRNN. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018; pp. 1–6. [Google Scholar]
- Zhang, L.; Verma, B.; Tjondronegoro, D.; Chandran, V. Facial Expression Analysis under Partial Occlusion: A Survey. ACM Comput. Surv. 2018, 51, 25. [Google Scholar] [CrossRef] [Green Version]
- Polli, E.; Bersani, F.S.; De, R.C.; Liberati, D.; Valeriani, G.; Weisz, F.; Colletti, C.; Anastasia, A.; Bersani, G. Facial Action Coding System (FACS): An instrument for the objective evaluation of facial expression and its potential applications to the study of schizophrenia. Riv. Psichiatr. 2012, 47, 126. [Google Scholar] [PubMed]
- Vail, A.K.; Baltrusaitis, T.; Pennant, L.; Liebson, E.; Baker, J.; Morency, L.P. Visual attention in schizophrenia: Eye contact and gaze aversion during clinical interactions. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, San Antonio, TX, USA, 23–26 October 2017. [Google Scholar]
- Meng, Z.; Liu, P.; Cai, J.; Han, S.; Tong, Y. Identity-Aware Convolutional Neural Network for Facial Expression Recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017), Washington, DC, USA, 1–3 June 2011; pp. 558–565. [Google Scholar]
- Qi, W.; Shen, X.; Fu, X. The Machine Knows What You Are Hiding: An Automatic Micro-expression Recognition System. In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Memphis, TN, USA, 9–12 October 2011. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; Mcallester, D. Cascade object detection with deformable part models. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Yu, Z.; Zhang, C. Image based static facial expression recognition with multiple deep network learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 435–442. [Google Scholar]
- Kotsia, I.; Pitas, I.; Buciu, I. An analysis of facial expression recognition under partial facial image occlusion. Image Vis. Comput. 2008, 26, 1052–1067. [Google Scholar] [CrossRef]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust Face Recognition via Sparse Representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Osherov, E.; Lindenbaum, M. Increasing CNN Robustness to Occlusions by Reducing Filter Support. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Rui, M.; Hadid, A.; Dugelay, J. Improving the recognition of faces occluded by facial accessories. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition and Workshops, Santa Barbara, CA, USA, 21–25 March 2011. [Google Scholar]
- Huang, X.; Zhao, W.; Pietikäinen, G.; Zheng, M. Towards a dynamic expression recognition system under facial occlusion. Pattern Recognit. Lett. 2012, 33, 2181–2191. [Google Scholar] [CrossRef]
- Lin, J.-C.; Wu, C.-H.; Wei, W.-L. Facial action unit prediction under partial occlusion based on Error Weighted Cross-Correlation Model. In Proceedings of the IEEE International Conference on Acoustics, Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Zhang, L.; Tjondronegoro, D.; Chandran, V. Random Gabor based templates for facial expression recognition in images with facial occlusion. Neurocomputing 2014, 145, 451–464. [Google Scholar] [CrossRef] [Green Version]
- Dapogny, A.; Bailly, K.; Dubuisson, S. Confidence-Weighted Local Expression Predictions for Occlusion Handling in Expression Recognition and Action Unit Detection. Int. J. Comput. Vis. 2017, 3, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person Re-identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Afifi, M.; Abdelhamed, A. Deep Gender Classification based on AdaBoost-based Fusion of Isolated Facial Features and Foggy Faces. J. Vis. Commun. Image Represent. 2017, 62, 77–86. [Google Scholar] [CrossRef] [Green Version]
- Sugimoto, A. Facial expression recognition by re-ranking with global and local generic features. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 4118–4123. [Google Scholar]
- Itti, L.; Koch, C. Computational modelling of visual attention. Nat. Rev. Neurosci. 2001, 2, 194–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zheng, H.; Fu, J.; Tao, M.; Luo, J. Learning Multi-attention Convolutional Neural Network for Fine-Grained Image Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017. [Google Scholar]
- Zhao, L.; Xi, L.; Wang, J.; Zhuang, Y. Deeply-Learned Part-Aligned Representations for Person Re-Identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017. [Google Scholar]
- Chen, Z.; Zhao, Y.; Huang, S.; Tu, K.; Yi, M. Structured Attentions for Visual Question Answering. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–27 October 2017. [Google Scholar]
- Juefei-Xu, F.; Verma, E.; Goel, P.; Cherodian, A.; Savvides, M. DeepGender: Occlusion and Low Resolution Robust Facial Gender Classification via Progressively Trained Convolutional Neural Networks with Attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, Nevada, 26 June–1 July 2016. [Google Scholar]
- Norouzi, M.N.; Araabi, E.; Ahmadabadi, B.N. Attention control with reinforcement learning for face recognition under partial occlusion. Mach. Vis. Appl. 2011, 22, 337–348. [Google Scholar] [CrossRef]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion aware facial expression recognition using cnn with attention mechanism. IEEE Trans. Image Process. 2018, 28, 2439–2450. [Google Scholar] [CrossRef]
- Gogić, I.; Manhart, M.; Pandžić, I.S.; Ahlberg, J. Fast facial expression recognition using local binary features and shallow neural networks. Vis. Comput. 2018, 1–16. [Google Scholar] [CrossRef]
- Mahmood, A.; Hussain, S.; Iqbal, K.; Elkilani, W.S. Recognition of Facial Expressions under Varying Conditions Using Dual-Feature Fusion. Math. Probl. Eng. 2019, 2019, 9185481. [Google Scholar] [CrossRef] [Green Version]
- Pan, B.; Wang, S.; Xia, B. Occluded Facial Expression Recognition Enhanced through Privileged Information. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 566–573. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Kauai, HI, USA, USA, 8–14 December 2003. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J. The Extended Cohn-Kanade Dataset (CK+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the Computer Vision and Pattern Recognition Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; Pietikinen, M. Facial expression recognition from near-infrared videos? Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005. [Google Scholar]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D Facial Expression Database For Facial Behavior Research. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Southampton, UK, 10–12 April 2006. [Google Scholar]
- Ullah, A.; Wang, J.; Anwar, M.S.; Ahmad, U.; Saeed, U.; Wang, J. Feature Extraction based on Canonical Correlation Analysis using FMEDA and DPA for Facial Expression Recognition with RNN. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018; pp. 418–423. [Google Scholar]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klaser, A.; Marszałek, M.; Schmid, C. A Spatio-Temporal Descriptor Based on 3D-Gradients. In Proceedings of the BMVC’08, Leeds, UK, 13–15 September 2008. [Google Scholar]
- Liu, M.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply Learning Deformable Facial Action Parts Model for Dynamic Expression Analysis. In Proceedings of the Asian Conference on Computer Vision, Singarpore, 1–5 November 2014. [Google Scholar]
- Liu, M.; Shan, S.; Wang, R.; Chen, X. Learning Expressionlets on Spatio-temporal Manifold for Dynamic Facial Expression Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, Ohio, 24–27 June 2014. [Google Scholar]
- Jung, H.; Lee, S.; Yim, J.; Park, S.; Kim, J. Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Gauthier, J. Conditional generative adversarial nets for convolutional face generation. In Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter Semester; Stanford University: Stanford, CA, USA, 2014; Volume 2014, p. 2. [Google Scholar]
- Yang, H.; Ciftci, U.; Yin, L. Facial Expression Recognition by De-Expression Residue Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, Utah, 19–21 June 2018. [Google Scholar]
- Guo, Y.; Zhao, G.; Pietikäinen, M. Dynamic facial expression recognition using longitudinal facial expression atlases. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 631–644. [Google Scholar]
- Ding, H.; Zhou, S.K.; Chellappa, R. FaceNet2ExpNet: Regularizing a Deep Face Recognition Net for Expression Recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May –3 June 2017. [Google Scholar]
- Zhao, X.; Liang, X.; Liu, L.; Teng, L.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-Piloted Deep Network for Facial Expression Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Wang, J.; Yin, L.; Wei, X.; Yi, S. 3D Facial Expression Recognition Based on Primitive Surface Feature Distribution. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Berretti, S.; Bimbo, A.D.; Pala, P.; Amor, B.B.; Daoudi, M. A Set of Selected SIFT Features for 3D Facial Expression Recognition. In Proceedings of the International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Yang, X.; Di, H.; Wang, Y.; Chen, L. Automatic 3D facial expression recognition using geometric scattering representation. In Proceedings of the IEEE International Conference and Workshops on Automatic Face and Gesture Recognition, Ljubljana, Slovenia, 4–8 May 2015. [Google Scholar]
- Li, H.; Ding, H.; Di, H.; Wang, Y.; Zhao, X.; Morvan, J.M.; Chen, L. An efficient multimodal 2D + 3D feature-based approach to automatic facial expression recognition. Comput. Vis. Image Underst. 2015, 140, 83–92. [Google Scholar] [CrossRef] [Green Version]
- Lopes, A.T.; Aguiar, E.D.; Souza, A.F.D.; Oliveira-Santos, T. Facial Expression Recognition with Convolutional Neural Networks: Coping with Few Data and the Training Sample Order. Pattern Recognit. 2016, 61, 610–628. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Setting | Accuracy |
|---|---|---|
| LBP-TOP [38] | sequence-based | 88.99 |
| HOG 3D [39] | sequence-based | 91.44 |
| 3DCNN [40] | sequence-based | 85.9 |
| STM-Explet [41] | sequence-based | 94.19 |
| DTAGN [42] | sequence-based | 97.27 |
| CNN [43] | image-based | 89.50 |
| IACNN(Baseline) [6] | image-based | 95.37 |
| DLP-DeRL(Ours) | image-based | 97.57 |
| Method | Setting | Accuracy |
|---|---|---|
| LBP-TOP [38] | sequence-based | 68.13 |
| HOG 3D [39] | sequence-based | 70.63 |
| STM-Explet [41] | sequence-based | 74.59 |
| Atlases [45] | sequence-based | 75.52 |
| DTAGN-Joint [44] | sequence-based | 81.46 |
| FN2EN [46] | image-based | 87.71 |
| PPDN [47] | image-based | 84.59 |
| CNN [43] | image-based | 72.92 |
| IACNN(Baseline) [6] | image-based | 82.00 |
| DLP-DeRL(Ours) | image-based | 90.5 |
| Method | Setting | Accuracy |
|---|---|---|
| LBP-TOP [38] | sequence-based | 59.51 |
| HOG 3D [39] | sequence-based | 60.89 |
| STM-Explet [41] | sequence-based | 75.12 |
| DTAGN-Joint [44] | sequence-based | 70.24 |
| CNN [43] | image-based | 57.00 |
| IACNN(Baseline) [6] | image-based | 71.55 |
| DLP-DeRL(Ours) | image-based | 78.33 |
| Method | Setting | Accuracy |
|---|---|---|
| Wang et al. [48] | 3D | 61.79 |
| Berreti et al. [49] | 3D | 77.54 |
| Yang et al. [50] | 3D | 84.80 |
| Lo et al. [51] | 2D Image + 3D | 86.32 |
| Lopes [52] | image-based | 72.89 |
| CNN [43] | image-based | 73.2 |
| IACNN(Baseline) [6] | image-based | 83.15 |
| DLP-DeRL(Ours) | image-based | 87.5 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ullah, A.; Wang, J.; Anwar, M.S.; Ahmad, U.; Saeed, U.; Fei, Z. Facial Expression Recognition of Nonlinear Facial Variations Using Deep Locality De-Expression Residue Learning in the Wild. Electronics 2019, 8, 1487. https://doi.org/10.3390/electronics8121487
Ullah A, Wang J, Anwar MS, Ahmad U, Saeed U, Fei Z. Facial Expression Recognition of Nonlinear Facial Variations Using Deep Locality De-Expression Residue Learning in the Wild. Electronics. 2019; 8(12):1487. https://doi.org/10.3390/electronics8121487
Chicago/Turabian StyleUllah, Asad, Jing Wang, M. Shahid Anwar, Usman Ahmad, Uzair Saeed, and Zesong Fei. 2019. "Facial Expression Recognition of Nonlinear Facial Variations Using Deep Locality De-Expression Residue Learning in the Wild" Electronics 8, no. 12: 1487. https://doi.org/10.3390/electronics8121487