4.1. Management of the Events and Interrupts with Support of Dynamic nHSE Embedded Scheduler
The
crTRi,
crEVi, and
crEPRi control registers (
Table 1) validate, store, and prioritize the events and interrupts expected by each sCPUi. With an independent execution, the scheduler has entries for multiple events prioritized differently by each sCPUi through the
crEPRi (event priority register) control register. In order to store each event treated at the level of a sCPUi,
gr_EV_select_sCPU[3:0] global registers have been used, with values from 0 to 6, depending on the treated event; 7 indicates the fact that there is no active event. The
mrPRIsCPUi[3:0] registers provides the priority of each sCPUi, which can only be modified by the sCPU0.
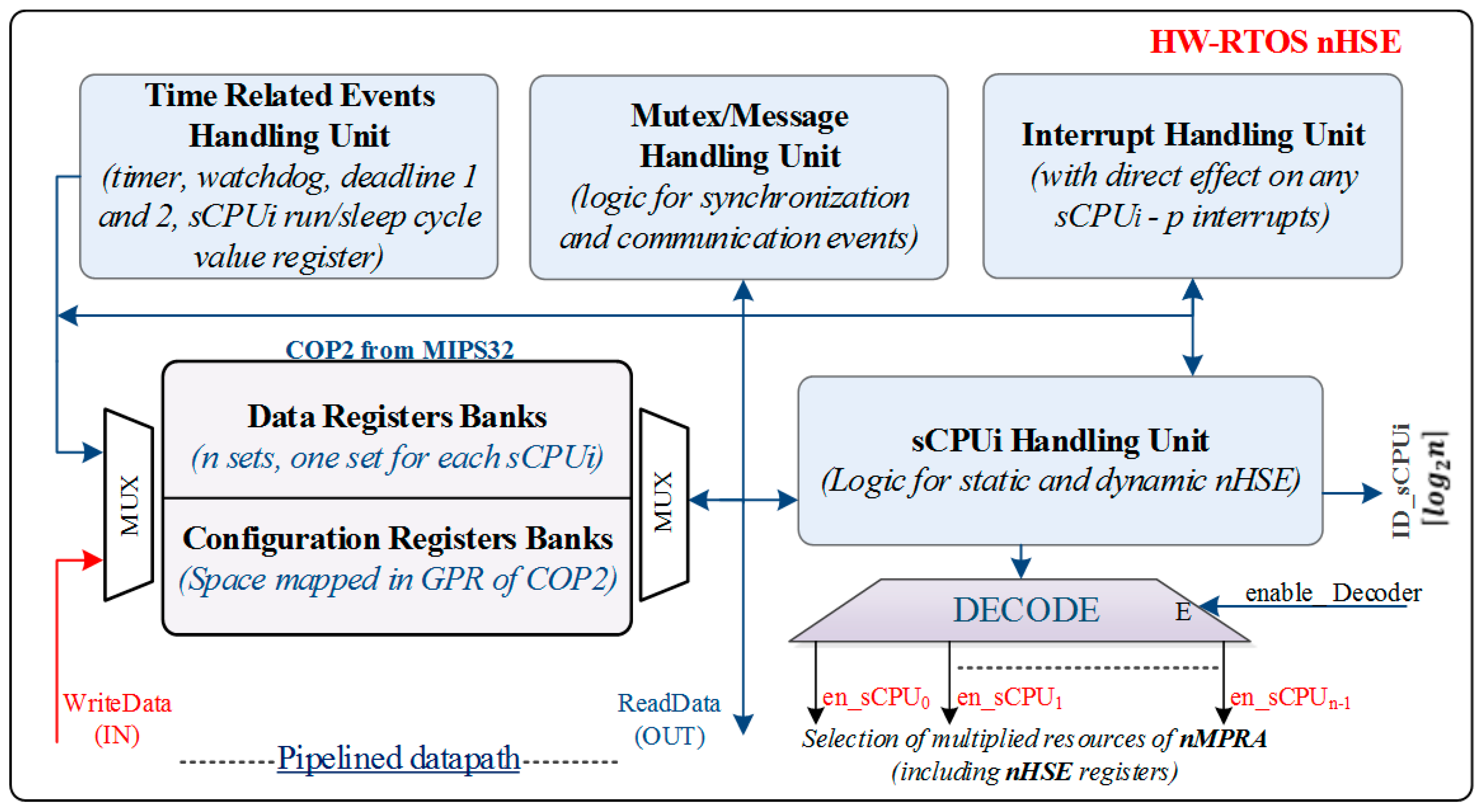
Figure 5 shows the support for the dynamic scheduler. For each sCPUi a local register is provided, enabling the writing of the desired priority at a given moment. An exception to this rule is sCPU0 which always has 0 priority (the highest).
Based on the value stored in the mrPRIsCPUi register, which can be from 1 to n − 1 (without 0), sCPU_Evi and nHSE_EN_sCPUi signals, the pri_1/pri_n − 1 signals are generated; in turn, these signals generate the muxi signal. The sCPU_Ev0, mux1, mux2, …, muxi, …, muxn-1 signals are used to generate the task ID in a similar manner like it was generated for the static scheduler. In fact, the same coder is used for the static ID, the correspondence being sCPU0_ready with sCPU_Ev0, sCPU1_ready with mux1, sCPU2_ready with mux2, sCPUi_ready with muxi, sCPUn-1_ready with muxn-1 respectively.
Figure 6a presents the scheme proposed for the interrupt events. We assume that there are
p interrupts in the system. For each interrupt, there is a global register with
n useful bits and a
INT_IDi_register that stores the ID of the task to which the interrupt is associated. The activation of the
INTi interrupt validates the decoder
Decoder which, in turn, activates one of the
INT_i0 …
INT_in-1 signals.
The gate OR (
Figure 6a) can collect all interrupts from the system. They can be attached to sCPUi if all
p INT_IDi_register (
i = 0…
p-1) registers are written with the
i value. Correspondingly, no interrupt can be attached, if none of the
p INT_IDi_register (
i = 0…
p – 1) registers are written with an
i value. The
D type bistable has the role of synchronizing the random occurrence of the
INTi interrupt event, generating the
IntEvi event. The HW-RTOS scheduler automatically detects that a high priority task (sCPUi) is waiting for this interrupt and thus makes the task ready-to-run.
A deficiency of the priority encoding scheme is that when a task has multiple interrupts attached to it, a loop testing is executed when the prioritization is performed through software, and the response time depends on the position in the loop.
The proposed scheme is very versatile and can implement many interrupt working models in a real-time executive,
Figure 6b presenting a real improvement in this context. If all interrupts were attached to a single task, the interrupt with the highest priority would be
INT0, and the interrupts with the lowest priority would be
INTp-1. From this point of view, the priorities are fixed. In order to take into consideration only the interrupts of a single task, with the highest priority at a given moment, the local registers
crEPIji (one of the local registers for validating the interrupts for their priority encoder) were considered (
j is sCPUj,
i is the register number). These registers contain one bit for each of the
p interrupts. If the bit is 1, the interrupt is attached to the task and the
INT_IDi register must be written with the task ID. This correspondence must be ensured for any interrupt attached to a task. If this correspondence does not occur for an interrupt, the interrupt will never generate an interrupt code because an
evINT_ji signal will always be 0 logic. The
evINT_ji signal will activate only if the sCPUj, to which it was attached, is in execution corresponding to the
sCPUj_ready signal on 1 logic. For example, the
evINTi signal can collect all possible
i interrupts attached to any sCPUi’s, but it is mandatory that an interrupt is attached to a single task (sCPUj). Consequently, since only one sCPUj is active at a given moment on the input of the priority encoder, only the interrupts of that task can be active. Using the
grNrINT register, sCPUj will read the number of the highest priority event.
The response time of the nMPRA processor can be simulated and measured when an asynchronous external event occurs; the time required to switch contexts can also be determined. Simulation waveforms with Vivado illustrate the internal signals of the processor at the working frequency of 33 MHz,
GPIO_SW_N representing the input signal assigned to the
ExtIntEv[0] interrupt event (pushbutton), marked by time moment T1 (
Figure 7). Therefore, to treat this external interrupt attached to sCPU0, about three clock cycles are sufficient (T1–T2 time period). The time moment T2 indicates the response of the nHSE scheduler by modifying the
nHSE_Task_Select internal signals to execute sCPU0. Time moment T3 indicates the change of the
LED[7] signal state (
Figure 7) and the corresponding output of this LED is mapped in the data memory address space. In order to access this led, the processor will run a
sw type MIPS instruction (0xadcc0000). From the occurrence of the external event, until the LED on the Virtex-7 is switched ON, up to eight clock cycles are required (245.062 ns), depending on the moment T1 when
GPIO_SW_N pushbutton is activated.
For treating multiple events with their own trap cells (interrupts, mutexes and message events), the proposed solution integrates the priority encoder for interrupts, on the one hand, and for local events associated to a sCPUi, on the other. This way, the scheduler provides hardware support for an automatic jump to the handler, treating the event with the highest priority assigned to the semiprocessor sCPUi. In software operating systems, the operation of saving and eventually restoring the current task contexts inserts significantly longer delay times (from a few us to tens of us), and it increases the degree of unpredictability generated by various search operations in lists or tables based on the task identifier.
4.2. Inter-Task Synchronization and Communication Mechanisms
Two other fundamental aspects, distinctive to the nMPRA concept are the mechanisms of synchronization and communication. This is an interesting research topic and is related to the sharing of resources by the nMPRA processor tasks. The integration of these mechanisms in hardware conveniently improves the worst-case execution time (WCET), thus providing an optimal solution for communication between tasks and mutual exclusion in the case of shared resources. From an architectural standpoint, these mechanisms must introduce extremely brief critical code sections corresponding to certain atomic operations. In other words, the implementation of mutexes is based on atomic instructions, achieving good performance, and short CPU blocking times.
Table 3 shows the working instructions for mutexes and the communication mechanism through messages implemented at the level of the nHSE module. Mutex and message type events are created through the CTC2 and MTC2 MIPS32 instructions (
Table 1). The
mutexPend,
mutexPost,
mutexAccept, and
msgSent functions are fully or partially implemented in hardware using MIPS32 LWC2 and SWC2 instructions. Therefore, the validation of multiple events, such as mutex or message, can be signaled by the dedicated
wait Rj instruction.
The hardware support for implementing the synchronization mechanism is Mutex Regiter File (MRF) and the associative search of a mutex release is done based on a Content Addressable Memory (CAM) principle. These grMutexi special registers, which compose the MRF, contain the mutex status and the owner task ID. The number of mutexes (we used m as an example) depends on the application. Sharing resources by all sCPUi’s in nMPRA implies that the grMutexi global registers can be accessed by any sCPUi under the direct control of the nHSE scheduler. Regarding the real-time aspect, it is fundamental to avoid suspending execution when a mutex is modified, as the operations with these entities are atomic. As soon as the mutex or the expected message is unlocked or received, the suspended task is reactivated by the nHSE, entered into the Ready state and executed according to its priority. Every grMutexi register contains a bit for storing the state of the mutex and m-1 bits for storing the owner sCPUi ID. When a task i running on the sCPUi semiprocessor receives a message or expects the release of a mutex, it is necessary to identify the source of the event.
Being accessed by all sCPUis, the mutex lock and release operations must be performed indivisibly with the help of
nHSE_inhibit_CC signal. When the
Mutex_i bit is 0, it is considered that the mutex
i is available, a sCPUi being able to lock only one mutex at a certain time. Since these mechanisms are implemented in hardware, the time needed to search the message source or the selection of a sCPUi that is expecting a mutex can be performed in a time period characteristic to real-time systems.
Table 4 describes the MIPS code of a benchmark test to evaluate the synchronization mechanism presented in
Figure 8. In the example illustrated in
Figure 8, the
crEMRi0 = 0x0000000F and
crEERi0 = 0x0000000F registers (
Table 1) indicate the fact that four mutexes and four inter-task communication events are validated. It should be emphasized that these registers have the role of validating the synchronization and communication mechanisms and cannot produce
MutexEvi or
SynEvi events. Next we illustrate the situation where the scheduler waits to deactivate the
nHSE_inhibit_CC signal, delaying the response of the nHSE scheduler. Therefore, it is possible to analyze the contents of the COP2 registers when a context switch is performed concurrently with the occurrence of a mutex event (T1). As we can see, context switching performed at time moment T2 to treats the mutex event requires one clock cycle. When the mutex (
MutexEvi event) is signaled, the HW-RTOS automatically determines whether a sCPUi is waiting for the signal and if so, initiates a context switch to the waiting task based on sCPUi priorities.
In order to implement the inter-task communication mechanism, the nMPRA architecture uses a number of grERFi global registers, each of 2n+k+1 bits. These registers compose the Events Register File (ERF), each register using a bit to store the event status, 2nj bits to store the their tasks ID, source, and destination, and k bits to store the message. Therefore, grERFi is the register that defines an event, and is part of the ERF; after a reset, all bits are 0. The source and destination identifiers have nj bits, where n represents the ID of the sCPUis.
The oscilloscope capture in
Figure 9a illustrates the results of the response time measurement when treating an asynchronous external event attached to sCPU0 semiprocessor. Thus, the presented signals validate the nHSE scheduler by practically checking the waveforms in
Figure 7. There can be a 30.3 ns jitter, depending on the moment when the interrupt occurred and the next rising edge of the clock cycle (nMPRA clock = 33 MHz). The trigger of the input signal generated by the
GPIO_SW_N pushbutton is at the time moment T1 = −2.575 ns, and the reaction of the semiprocessor sCPU0, by switching ON the
LED[7] on the Virtex-7 kit, occurs at time moment T2 = 266.0 ns. The response time, obtained by using the PicoScope 2205MSO oscilloscope by Pico Technology (St Neots, UK), is only of Δt = 268.6 ns (
Figure 9a); this validates the real-time characteristic of the nMPRA architecture and checks the WCET coefficients in Table 8.
Figure 9b presents the jitter of the application running on nMPRA in order to test the communication mechanism. Since the CAM search in the
grERFi registers is performed in hardware, the jump to the trap cell assigned to message events is done in only two clock cycles, sCPU0 having the highest priority in the system. As can be seen in
Figure 10, in order to simulate the standard deviation of the response time, multiple overlapped events attached to sCPU0 and sCPU2 were considered. The
crEPRi[i] registers presented in
Figure 10, represents the priorities attached to each event that can be validated or not at the level of each sCPUi. Thus, at the level of sCPU0 (
mrPRIsCPUi[0] = 0x00000000) the interrupt event has the highest priority (
crEPR0[14:12] = 000), with no other events waiting to be executed for that moment. If a sCPUi has more validated events, the jitter increase according to the priority of the enabled events.
4.3. The Impact of Different Configuration Models on FPGA Resources and Energy Consumption
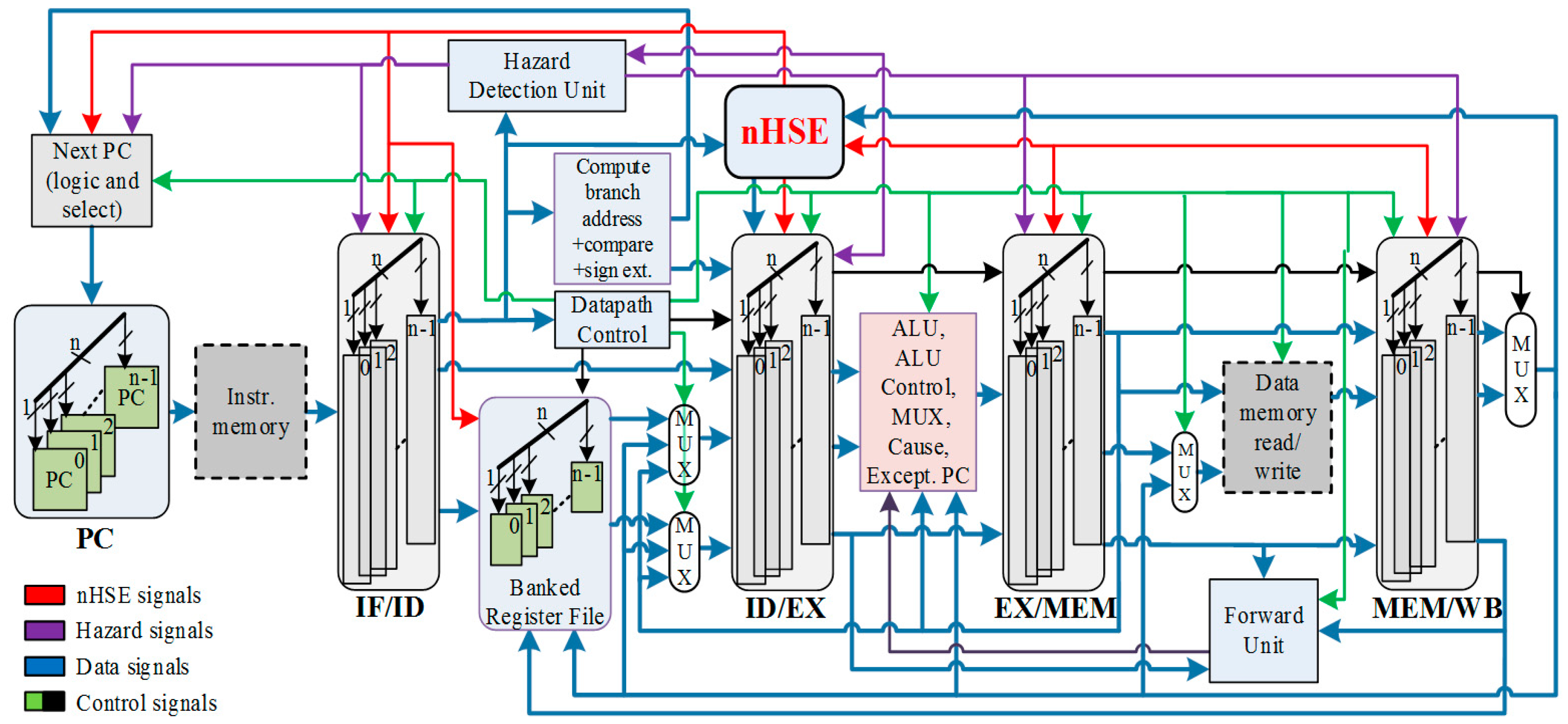
Although nMPRA is a resource multiplexing architecture, its implementation is more cost effective compared to other architectures proposed in the literature. It should be specified that such an implementation has significant advantages over the existing commercial implementations for a number of 16, 32, or even 64 tasks. Implementing this architecture for a large number of tasks would entail too many resources related to the system in which the processor is used, and unwarranted large signal propagation times, significantly reducing the processor’s working frequency. Since the multiplexing resource multiplication operation was performed at the level of each memory element, the cost/performance ratio obtained was more than convenient. Therefore, only the multiplication of the registers contained in the ID/EX pipeline stage was performed, and not the multiplication of the whole ID/EX module, thus gaining a significant advantage over other implementations. The modules containing only combinational elements, such as the Hazard Detection module, have not been multiplied because they provide output signals corresponding to the inputs, these values being already stored in the nMPRA registers.
Table 5 illustrates the logic blocks requirements for implementing the nMPRA architecture with various sCPUi, mutexes (
grMutexi) and message events (
grERFi), where
i = 4, 8, and 16, including the resources needed to implement the nHSE scheduler, the recent version being greatly improved than the one described in [
11,
21]. Therefore, in designing the nHSE module, the number of sCPUis, inter-task synchronization events, and the number of external interrupts are firstly taken into account. The scheduler must contain all the memory elements needed by the above-mentioned entities, as well as the combinational logic necessary to ensure the correct operation of the static and dynamic scheduler, even when exceptions occur. The number of sCPUi that nHSE controls through the generated signals is the key factor in determining the resource requirement for implementing the nMPRA architecture.
Table 6 presents the resource requirements for implementing the entire SoC project that includes the nMPRA processor. It is worth mentioning that these requirements include the resources used for the on-chip implementation of the dual-port memory for instructions and data, the resources needed for implementing the HMI, and the UART communication for writing the program memory and implementing the oversampling mechanism for the input data of the UART module.
Figure 11 shows, in details, the power consumed by the nMPRA implementations, with eight
sCPUi, eight
grMutexi, and eight
grERFi, based on the hardware support for treating interrupts, their dynamic attachment to any sCPUi, and the hardware implementation of the inter-task synchronization and communication mechanisms.
The different values presented in
Figure 11, depending on the nHSE module and xc7vx485tffg1761-2 FPGA used for implementation, were obtained following the practical implementation of the nMPRA processor using the Vivado 2018.2 Design Suite and the Virtex-7 development kit by Xilinx, Inc. (San Jose, CA, USA). However, the overall power consumption is more than acceptable compared to other similar implementations [
22,
23].
The implementation in hardware of the nHSE scheduler and of the synchronization and communication events guarantees the predictability for the task set and the deadline set in the boot and initialization sections. The results have been obtained using an nMPRA processor with working frequency of 33 MHz, which can be increased by the improvement of the instructions and data memory used.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}