1. Introduction
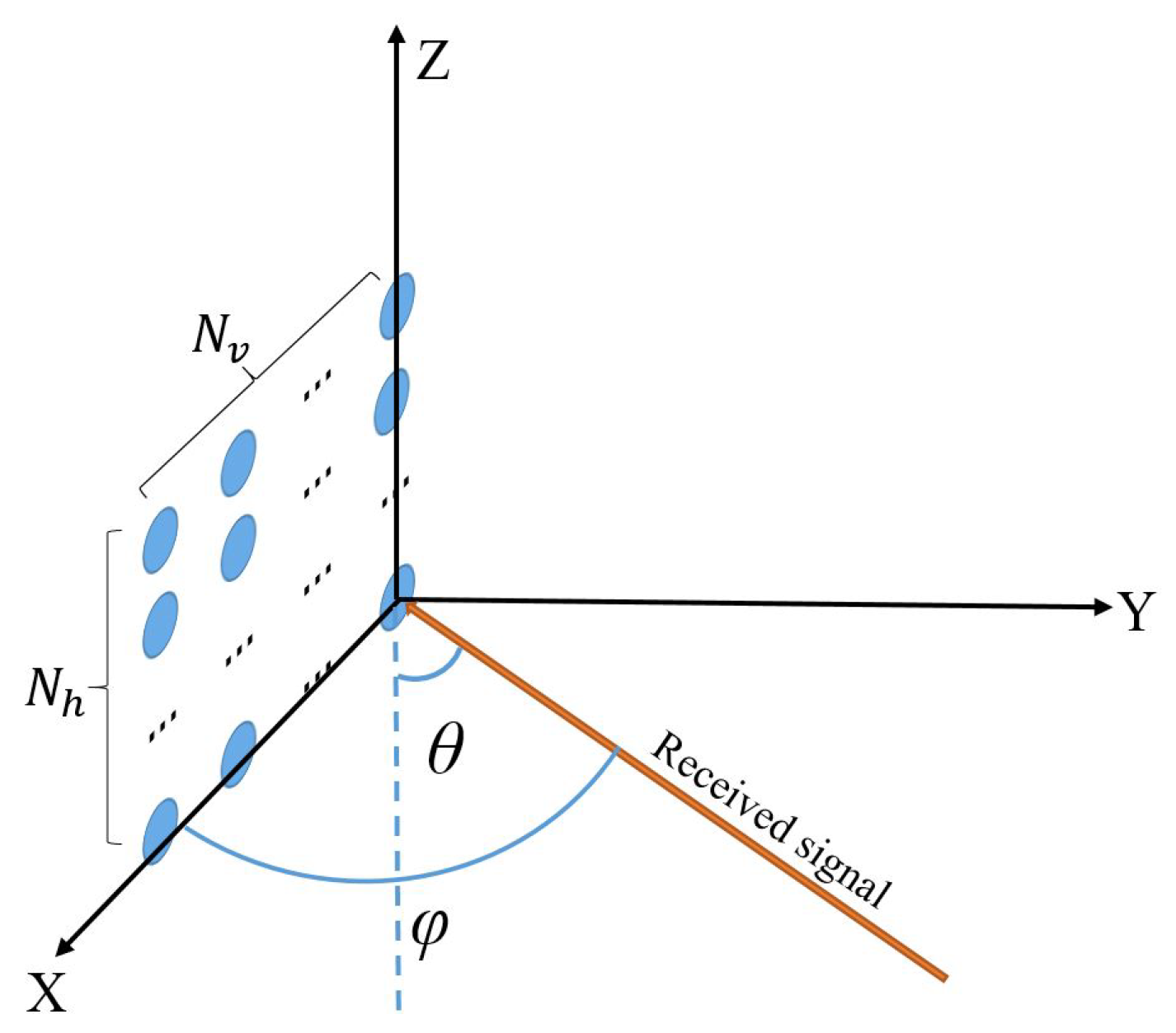
The improvement of data transmission rate in wireless communication is of great meaning. Three-dimensional-multiple-input-multiple-output (3D-MIMO) can improve channel capacity without increasing the transmission power and bandwidth. Therefore, it has been one of the key technologies in the 5th-Generation communication systems. In addition, 3D-MIMO can enhance the spatial available dimension effectively compared with traditional MIMO by which only one horizontal dimension can be provided. Specifically, the traditional MIMO system has fewer ports that can only adjust the beam direction in the horizontal dimension, and cannot concentrate the vertical dimension energy on the receivers, while 3D-MIMO commonly used a two-dimensional antenna array in a large scale such as uniform planar array (UPA) [
1] where hundreds of antennas can be placed in a small area. 3D-MIMO can flexibly adjust the direction of the beam in both the horizontal and vertical directions, forming a more precise and narrower directional beam, so as to enhance the received signal energy and strengthen the cell coverage greatly. Furthermore, 3D-MIMO can achieve the enhancement of spatial multi-user multiplexing capabilities and better interference suppression through the use of advanced signal processing technology. An important issue for 3D-MIMO utilization is to get the channel impulse response (CIR) accurately. However, with the conventional channel estimation method, massive multi-antenna means the sharp increase of pilot number [
2], which is no longer proper for real application. Meanwhile, the MIMO channel is shown to have a specific sparse structure [
3] in which the row and column vectors of the angular domain channel matrix are both sparse. Therefore, sparse estimation technology, such as compressed sensing (CS) based reconstruction algorithms, can be used to do channel estimation.
At the same time, most of the existing communication theory assumes that the noise at the receivers follows a Gaussian distribution [
3,
4,
5]. These theories are mainly based on two reasons: (1) the Gaussian distribution can be expressed in specific mathematical expressions to facilitate analysis and calculation; (2) this assumption conforms to the central limit theorem. However, recent studies have shown that the noise is not always subjected to the Gaussian distribution in a lot of wireless applications [
6,
7,
8]. If the noise is still be treated as a Gaussian distribution, it usually shows poor performance [
9]. The reason for the non-Gaussian noise may be, for example, an atmospheric noise in radio links, lightning, relay contacts, ambient acoustic noise due to ice cracking in the arctic region in underwater sonar [
8] and submarine communications [
10,
11]. Therefore, it is of great importance to address this problem in 3D-MIMO channel estimation.
A structured sparse channel estimation (SSCE) algorithm [
12] has been studied to estimate a 3D-MIMO channel, but the influence of non-Gaussian noise needs to be studied further. The authors in [
13] propose a channel estimation algorithm by refining the selection of dominant entries iteratively until the terminating condition is met but ignores the influence of non-Gaussian noise either. Meanwhile, channel estimation under non-Gaussian noise can be obtained by the method of the Kernel density, but the accuracy of which is seriously affected by the selection of kernel width [
10]. In addition, the expectation maximization (EM) algorithm is regarded as an excellent way to solve the problem by modelling non-Gaussian noise as a Gaussian mixture model (GMM). However, most of the published works assume that the order of GMM is known previously [
10,
14,
15], which is not always the case in real systems. Therefore, the order of GMM should be determined before the establishment of a mixture Gaussian function. This paper tries to address the order selection problem by a pruning approach.
On the other hand, the existence of sparsity of the 3D-MIMO channel matrix in the angular domain has been studied in [
6], in which the channel matrix in the array domain is converted to the angular domain. In fact, as the distance of each antenna on the array are relatively close, the support set of all elements can be considered as the same [
16]. Inspired by these works, this paper uses a CS-based reconstruction algorithm to estimate the common support of the angle domain channel matrix and obtain the sparse position of channel matrix firstly. Meanwhile, an order selection method is implemented in the determination of the order of GMM, which is used to approximate the real probability density function (PDF) of the noise. Finally, an EM algorithm for linear regression is used to estimate the channel support matrix.
The contribution of this paper is that it provides a framework of 3D-MIMO sparse channel estimation under non-Gaussian noise with unknown PDF.
The rest of this paper is organized as follows. In
Section 2, the sparsity of 3D-MIMO channel matrix is presented.
Section 3 gives the channel estimation algorithm under the environment of non-Gaussian noise, and the simulation proves the advantage of this method in
Section 4.
Section 5 provides the conclusions of this paper.
Notion: Let
and
denote transpose and Hermitian transpose, respectively; let ⊗ denote the Kronecker product; let
represent a diagonal matrix with the value of vector
in its diagonal; let
and
represent the absolute value and 2-norm operation respectively; and let
indicate the circularly symmetric complex Gaussian random vector with mean
and covariance matrix
. Its expression for a
d-dimensional vector of
is
3. Channel Estimation under Non-Gaussian Noise
This section proposes a channel estimation algorithm when the noise does not follow Gaussian distribution, and the PDF is unknown either.
In summary, the proposed algorithm estimates the angle domain channel matrix through three steps:
- (1)
Estimate the common support to obtain the sparse position;
- (2)
Approximate the unknown PDF of the noise using mixture Gaussian function;
- (3)
Estimate angle domain channel matrix by linear regression EM algorithms.
3.1. The Estimation of the Common Support
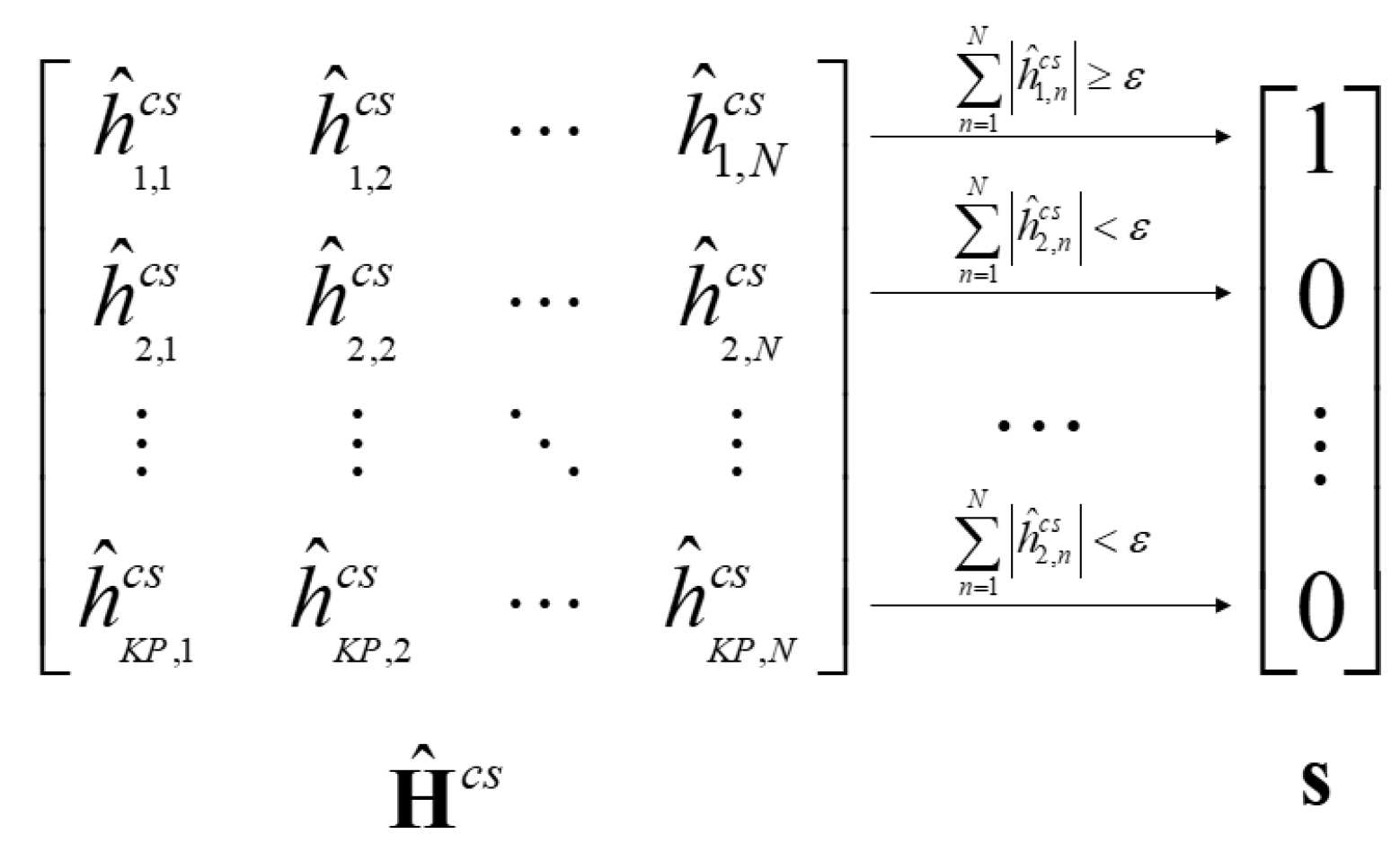
To get the common support, a CS reconstruction algorithm is implemented to coarsely estimate angle domain channel matrix, and then the common support of angle domain channel matrix is obtained directed by a decision rule. After applying Equation (
11) to CS algorithms, we can preliminarily get the estimation of angle domain channel matrix written as
. Then, the common support is denoted as
with
where
is the
i-th element of
, and
is the threshold to judge the value of the common support. In fact,
is related to the signal to noise ratio (SNR) of the receivers. The value should be chosen properly; otherwise, it will lead to an inaccurate estimation of sparse positions and channel estimation. Furthermore, in Equation (
13),
is the sum of the absolute value of the
i-th row in
, and
is the element of
in the
i-th row and the
n-th column. The
i-th element in
is 1 or 0 when the sum of absolute values of the
i-th row in
is larger or smaller than the threshold
, respectively.
Figure 3 gives the detailed conversion relationship between
and
.
Since the column of is sparse, most of its row vectors are the zero vector. The removal of these row vectors can save the computational cost and improve the speed of channel estimation without affecting the value of the received signal. In order to conduct the matrix multiplication operation correctly, the column vectors of at the corresponding positions should also be removed. In other words, the computational cost can be saved by reducing the dimension of and . After dimension reduction operation, the transmission support matrix is a submatrix generated by picking up the column of the transmission matrix , whose column index corresponds to the element 1 in .
3.2. Order Selection
In order to obtain the channel matrix, the PDF of the noise should be cognised firstly. Inspired by [
18], the PDF of the unknown noise can be modeled as GMM with zero mean written as
where the parameter
is the coefficient of component
i, with
for
mixture distribution components,
is the covariance matrix for the
i-th component, and
is the order of GMM. Based on Equation (
14), the noise cognition process can be transformed to the estimation of the key parameters
and
.
It should be noted that the order
in the classical algorithm is assumed to be known, and it is always chosen from 2 to 4. This assumption is reasonable in the case of a specific non-Gaussian noise. Take impulse noise as an example, in the step of establishing its PDF by GMM, the mainstream approach is to select the order as 2 [
19,
20], and the results of this supposition are usually satisfactory. However, for more complicated non-Gaussian noise and interference model in real systems, order 2 to 4 may not be appropriate enough. In fact, when the number of the components is not large enough, the mixture model may underfit the data and may not be flexible enough to approximate the true noise. On the other hand, it may overfit the data and yield poor interpretations with too many components. Therefore, in order to describe the unknown distribution using GMM, the proper order should be studied at this step.
Inspired by the pruning algorithm in [
21], this paper tries to propose an improved approach to determine the order of GMM. The main idea of the algorithm in [
21] is implemented by an iterative manner. After each iteration, a clustering center of the data set is found, and then some data is deleted from the total data set according to this clustering center. Until all of the data has been deleted completely, the iteration is terminated. After the iteration is completed, the number of the clustering center represents the order of GMM. At each iterative step, the clustering centers are determined by the number of data in the neighborhood of a given radius. With the increase of radius, the number of the clustering center will decrease, which leads to different results of cluster numbers. However, the radius of a certain range will lead to the same number and location of the center points. The search procedure is terminated and the order is obtained when one state sustains more than
M times.
However, in the communication systems, the characteristics of the Gaussian components of GMM are not always obvious. Under these circumstances, the method mentioned above needs to be improved. Specifically, when the Gaussian components are similar to each other, this method may take the clustering center center points as a cluster, with each point on the edge as a new one, even if there is only one point left in this cluster. This will lead to a large number of clusters, of which the result is unsatisfactory for the order selection. In order to overcome this problem, this paper proposes an improvement measure. In particular, after finding each clustering center and deleting this cluster of points, the variance of the remaining points is calculated. If the variance is smaller than the threshold
, the next clustering center will be searched sequentially. Otherwise, the remaining points will be abandoned, and then the neighborhood radius is increased in the next step.
Figure 4 illustrates the steps of the proposed method. Therefore, after setting the initial neighborhood radius, the proposed algorithm then gradually increases radius to search for the center cluster point.
The initial radius is set to be
where
r is the initial radius,
and
are arbitrary elements of the data set, and the parameter
R is used to control the search accuracy. The larger the parameter
R is, the more accurate the result is, while the calculation complexity increases. This order reduction process is shown in
Figure 4 and
Figure 5.
3.3. Estimation of Channel Support Matrix
In this section, we will use the received signal
and transmission support matrix
to estimate the channel support matrix
under the influence of non-Gaussian noise
with independent and identically distributed components with PDF approximated by Equation (
1). Without loss of generality, the mean of channel noise is assumed to be
in Equation (
14). In order to estimate the channel support matrix, instead of solving the linear regression problem in vector form in [
19], this paper proposes to make an extension by transforming it into the matrix form. Furthermore, after the order has been obtained at the step of order selection, the channel support matrix can be calculated column by column. For the
i-th column, its elements and the weight value least squares matrix
can be calculated iteratively. Before the start of the algorithm, the
i-th column vector
of channel support matrix, coefficients
and variances
should be given initial values. The calculation process of
is to perform Equations (
16)–(
18) one after another:
In Equation (
16),
is the prior probability of the
k-th component,
,
,
is the element of
in the
n-th row and the
i-th column,
is the element of
in the
n-th row and the
m-th column,
is the
m-th element in
, the superscript
t is the number of iteration, and
and
are coefficients and variances of the
k-th component of GMM.
The
i-th column of channel matrix and its parameters of each component of GMM can be deducted based on
and
as
Repeat Equation (
16)–(
21) for all of the other columns, the whole channel support matrix can be obtained by
The iteration is terminated when the estimation value of channel support matrix is relatively stable or the given number of iterations has been done. This condition can be written in Equation (
23) as
In (23),
m is the total number of the 1 elements in
,
is the threshold, and
is the given number of iteration number. After the iteration is completed, the final angle domain channel matrix can be achieved based on the channel support matrix
and common support
.
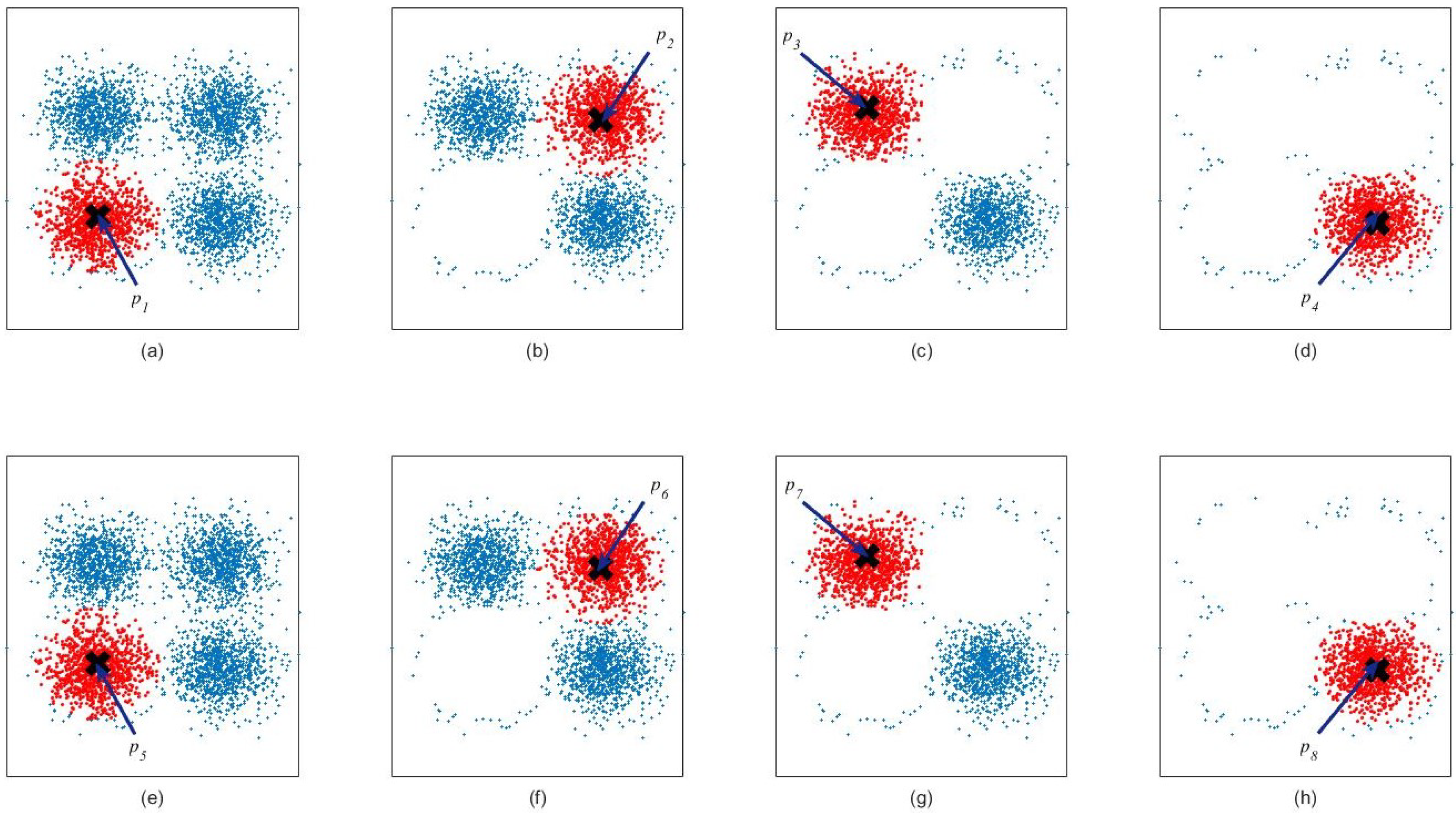
The reason for common support estimation going before order selection is that a large number of vectors which are 0 or close to 0 have a great impact on the accuracy of estimation of the order of GMM. For example,
Figure 6 and
Figure 7 show the result of order selection before and after removing the elements which are close to 0, respectively. In
Figure 6, due to the presence of large number of elements which are close to 0 s, these elements will automatically generate a new class, so its clustering result is bigger than the data of
Figure 7.
The main steps of the above algorithm are summarized in Algorithm 1.
| Algorithm 1 Non-Gaussian Angular Domain Sparse Channel Estimation |
Input: received signal , transmission matrix , iterative counter , threshold: , M, R, , ,
Output: channel matrix - 1:
Estimate channel matrix by CS reconstruction algorithm, then compute the common support via Equation ( 13). - 2:
Order selection for GMM via pruning algorithm. - 3:
Initialize , and . - 4:
Compute the prior probability weight least square matrix via Equations ( 16)–( 18). - 5:
Compute , and based on the result of step 4 via Equations ( 19)–( 21). - 6:
Let i equal to the rest label of the column, repeat the step 3–5. - 7:
Determine whether the condition of Equation ( 23) is set up, if it meets to the condition, the next step is carried out, or return to step 4 and .
|
4. Simulation
This section demonstrates the simulation results. The frequency selective multipath channel consists of 200 independent Rayleigh multipath with maximum delay spread of
s. The total transmission power is 1 W, the number of subcarriers is 2048, and the total transmission bandwidth is 8 MHz. The power delay is assumed to be an exponentially decaying profile. In the simulation process, the channel noise follows a mixture Gaussian distribution. The simulation parameters are shown in
Table 1.
Figure 8 shows the comparison between the proposed algorithm and other three algorithms in aspect of the normalized mean square error (NMSE) over SNR, including an SSCE-based [
12] algorithm, compressive sampling matching pursuit (CoSaMP) [
22] sparse recovery algorithm, and the dual crossing (DC) algorithm [
13]. From
Figure 8, it can be seen that the SSCE algorithm has a comparatively satisfactory performance under Gaussian noise, especially in a relatively low SNR region. However, under the affect of non-Gaussian noise, its performance is not as good as the proposed method, which is reflected in
Figure 8. It should be noted that, when the order of GMM is
= 1, in other words, the noise follows Gaussian distribution, the proposed algorithm is similar to SSCE algorithm. The CoSaMP algorithm which has been used at the step of estimating the support set estimates the channel matrix based on classical CS reconstruction algorithm with the noise distribution being viewed as Gaussian distribution. In fact, the reconstruction performance of CoSaMP outperforms the other CS algorithms. Therefore, it is reasonable to use the CoSaMP algorithm as a reconstruction approach to estimate the support set at step 2 of Algorithm 1. The DC-based algorithm estimates channel by refining the selection of dominant entries iteratively until the terminating condition is met. It can also be seen from
Figure 8 that the NMSE of the proposed algorithm is obviously superior to the traditional CoSaMP-based algorithm, SSCE-based algorithm and DC-bases algorithm. For example, when the SNR is 10 dB, the NMSE of the proposed algorithm is about −21 dB, and the traditional algorithm of SSCE-based, CoSaMP-based and DC-based is about −19 dB, −17 dB and −15 dB, respectively. When the SNR is 15 dB, the NMSE of the proposed algorithm, CoSaMP-based algorithm, SSCE-based algorithm and the DC-based algorithm is about −26 dB, −23 dB, −21 dB and −17 dB, respectively, thus the proposed algorithm has approximately 13.0%, 23.8%, and 52.9% improvement in terms of NMSE compared with traditional SSCE-based, CoSaMP-based, and DC-based, respectively.
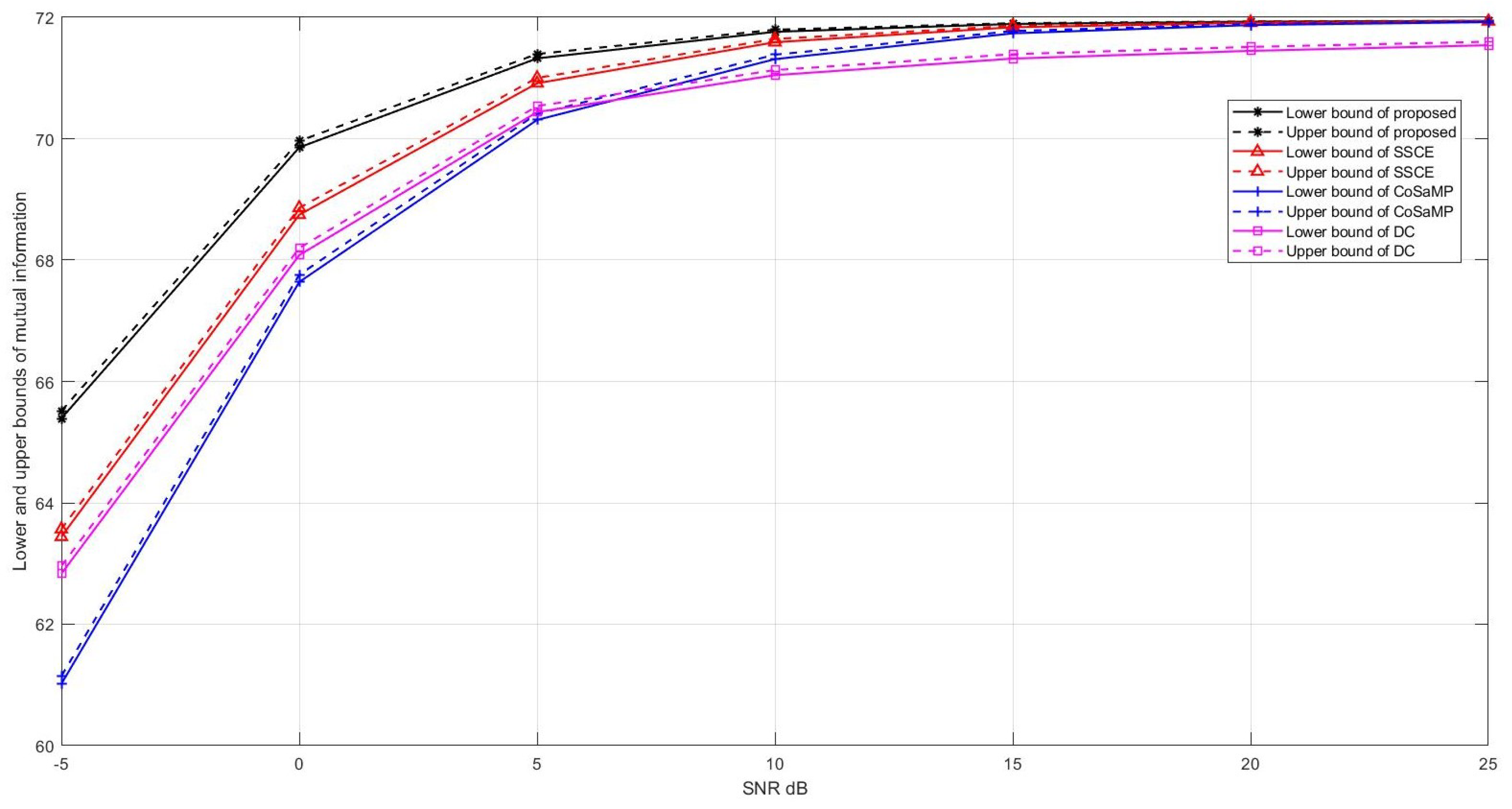
Imperfect channel state information (CSI) can cause the reduction of channel capacity [
23]. Furthermore, if the CSI of the receiver is not perfect, the channel capacity will decrease significantly [
24]. However, to the best of our knowledge, there is no precise mathematical relationship between the estimation error of CSI and the channel capacity for a MIMO system, which is still an open problem in the field of information theory. Fortunately, as mentioned in [
25], the upper and lower bounds of mutual information can be determined according to channel estimation error. Based on [
25],
Figure 9 shows the comparison of the upper and lower bounds of mutual information between the proposed algorithm and other traditional algorithms versus SNR. It can be seen from this figure that the mutual information of the proposed algorithm is bigger than the mutual information of the traditional channel estimation algorithms when the SNR is relatively small. The difference becomes smaller when the SNR is relatively large because the channel estimation of all of the algorithms becomes more accurate and the NMSE of all of the algorithms becomes smaller.
The relationship between the number of antennas and the NMSE is shown in
Figure 10. In the simulation of this figure, the pilot length is set to 512. For a given number of the pilots, the estimated error of the channel matrix increases as the number of antennas. In addition, it can be seen that when the number of antennas increases, the slope of the curves becomes smaller.
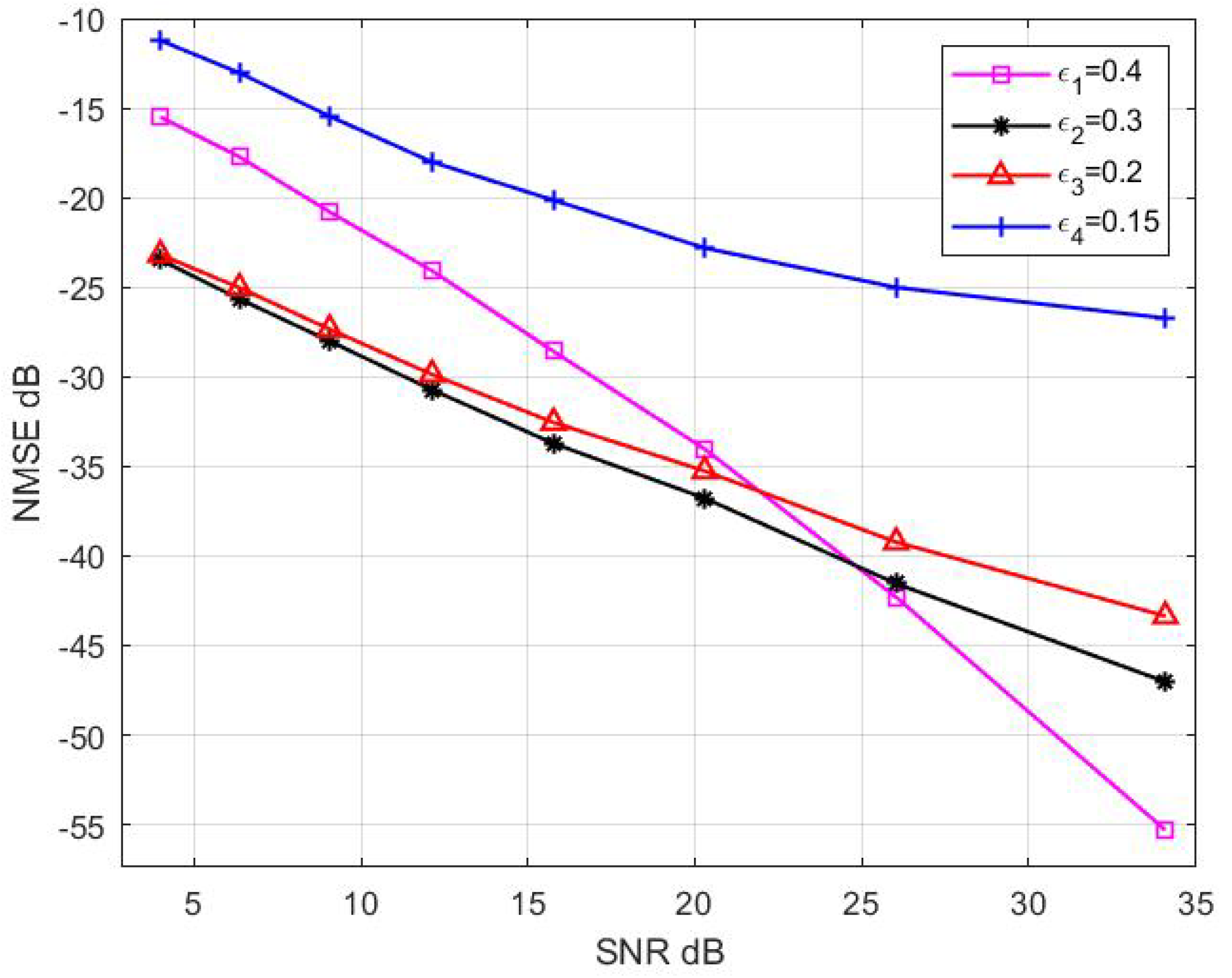
Figure 11 shows the impact of the value of
on the results. According to the theoretical analysis, the value of
is closely related to the received SNR. When the SNR is large, the value of
can be chosen from a relative large range, and vice versa.
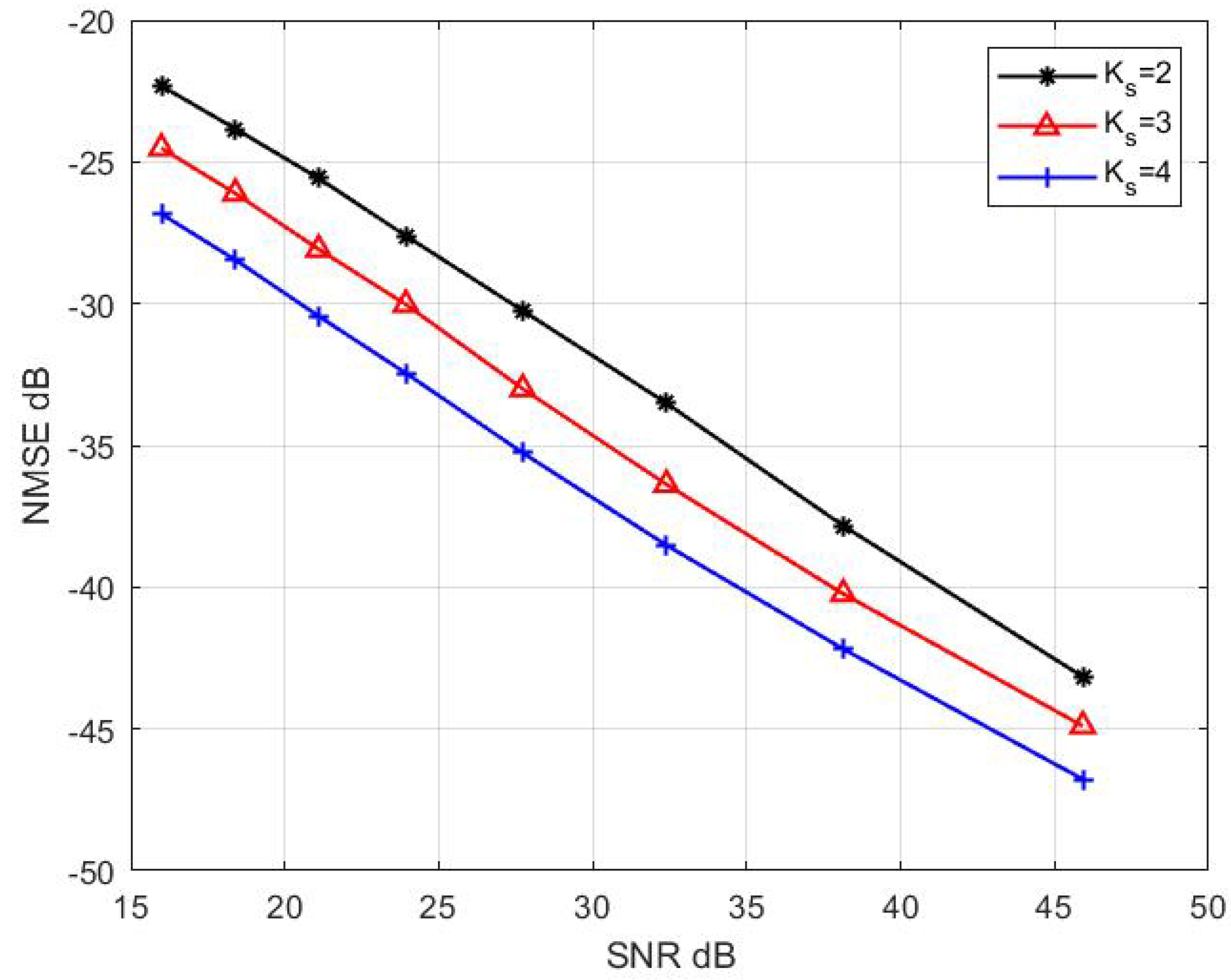
Figure 12 demonstrates the effect of the choice of order of GMM on the performance channel estimation. In the simulation process, the channel noise is set to follow a GMM with order 4. It can been seen that the Gaussian mixture model with order 4 is superior to orders 2 or 3, which is not correctly estimated. For example, when the NMSE is −40 dB, the SNR gap is about 2.75 dB and 6.15 dB over orders 3 and 2, respectively. Therefore, choosing the appropriate GMM order is important for the system performance.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}