Layer Selection in Progressive Transmission of Motion-Compensated JPEG2000 Video

 , and
, and
Abstract
:1. Introduction
2. Background and Related Work
3. MCJ2K
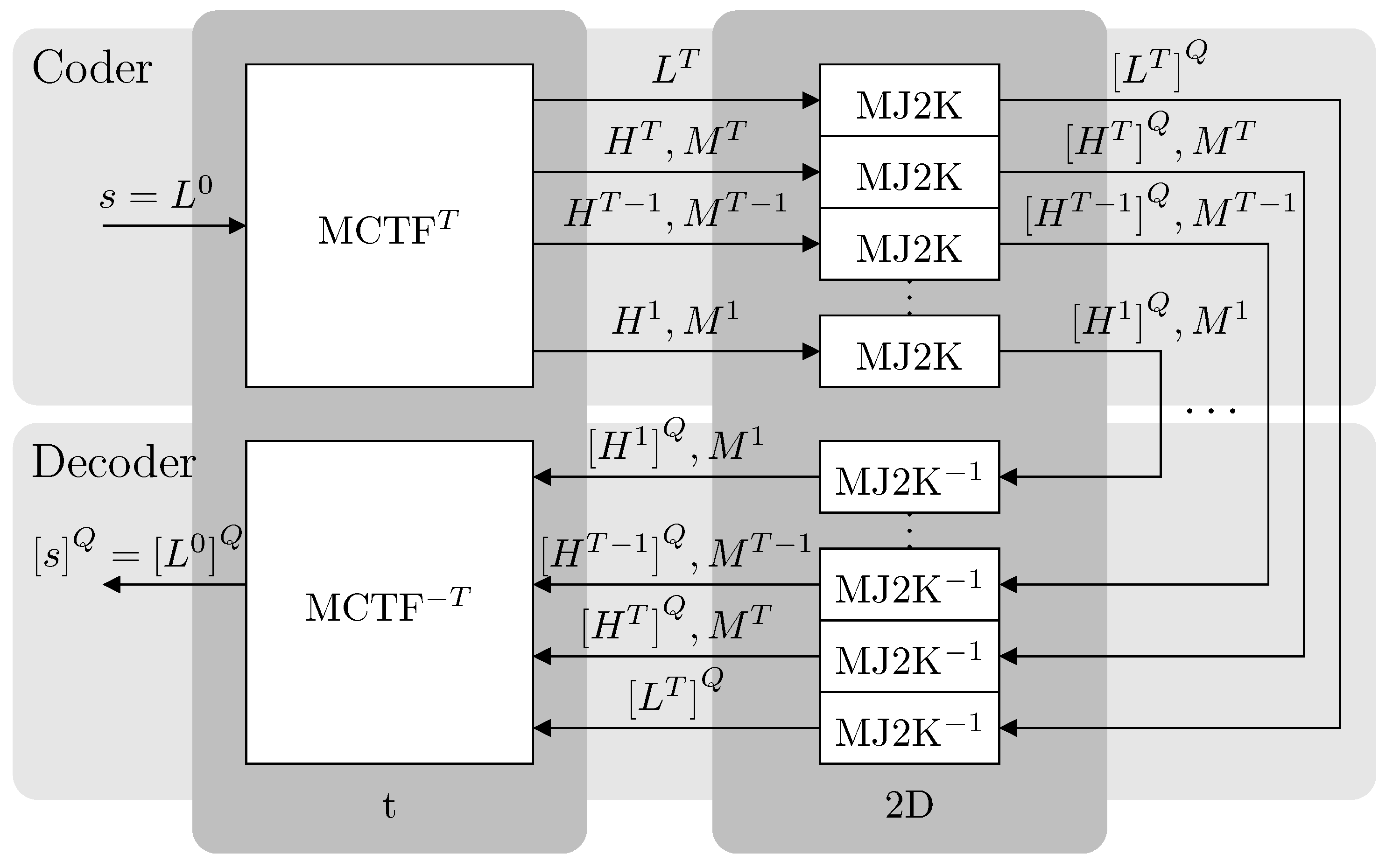
3.1. Codec Overview
3.2. Bitrate Control
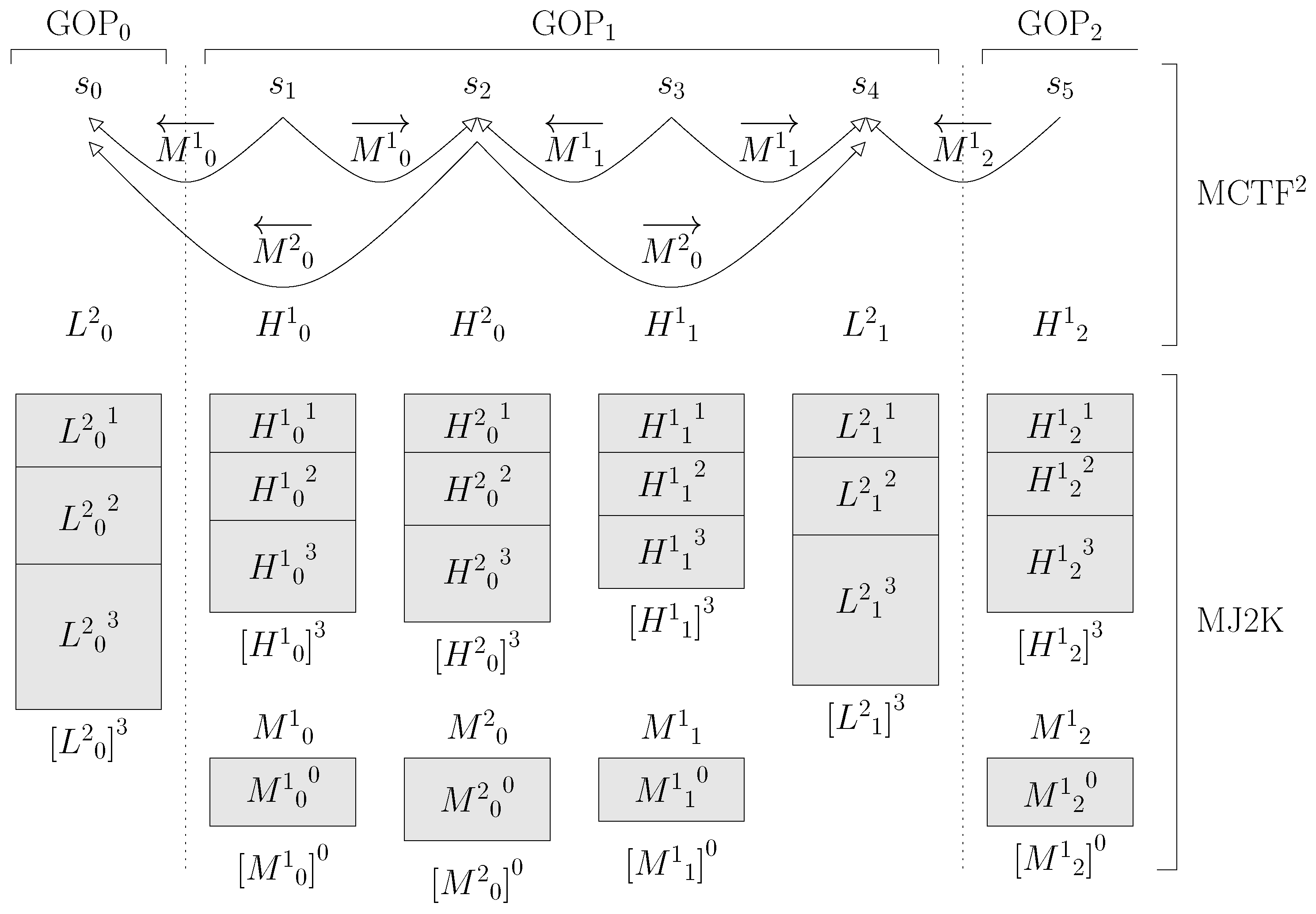
3.3. Post-Compression R/D Allocation
3.3.1. Optimized SL Allocation (OSLA)
| Algorithm 1: OSLA algorithm. | |||
| 1. | for each GOP: | ||
| 2. | ; | ||
| 3. | |||
| 4. | |||
| 5. | while S ≠ ∅: | ||
| 6. | |||
| 7. | |||
| 8. | |||
| 9. | if : | ||
| 10. | |||
| 11. | else if : | ||
| 12. | |||
| 13. | else /* */: | ||
| 14. | |||
| 15. | output Λ | ||
3.3.2. Estimated-slope SLs Allocation (ESLA)
| Algorithm 2: ESLA algorithm. | |
| 1. | for each GOP: |
| 2. | |
| 3. | for each : |
| 4. | |
| 5. | for each : |
| 6. | |
| 7. | |
| 8. | sort_in_descending_order Λ |
| 9. | output Λ |
4. Evaluation
4.1. Materials and Methods
- (1)
- Mobile (http://trace.eas.asu.edu/yuv/mobile/mobile_cif.7z) (YUV 4:2:0, pixels, 30 Hz), a low-resolution video with complex movement.
- (2)
- Container (http://trace.eas.asu.edu/yuv/container/container_cif.7z) (YUV 4:2:0, pixels, 30 Hz), a low-resolution video with simple movement.
- (3)
- Crew (ftp://ftp.tnt.uni-hannover.de/pub/svc/testsequences/CREW704x57660orig01yuv.zip) (YUV 4:2:0 pixels, 60 Hz), a medium-resolution video with complex movement.
- (4)
- CrowdRun (ftp://vqeg.its.bldrdoc.gov/HDTV/SVTMultiFormat/) (YUV 4:2:0, pixels, 50 Hz), a high-resolution video with a high degree of movement.
- (5)
- ReadySetGo (http://ultravideo.cs.tut.fi/video/ReadySetGo3840x2160120fps4208bitYUVRAW.7z) (YUV 4:2:0 pixels, 120 Hz), a high-resolution high degree of movement.
- (6)
- Sun (http://helioviewer.org/jp2/AIA/2015/06/01/131/) (monochromatic, due to represent only one frequency of the spectrum radiated by the Sun, pixels, 1/30 Hz) a sequence of images of the Sun with only small-scale frame-to-frame motion (which is, however, complex to predict due to the random motions of magnetic flux concentrations in the Sun’s photosphere).
4.2. Impact of Motion Compensation
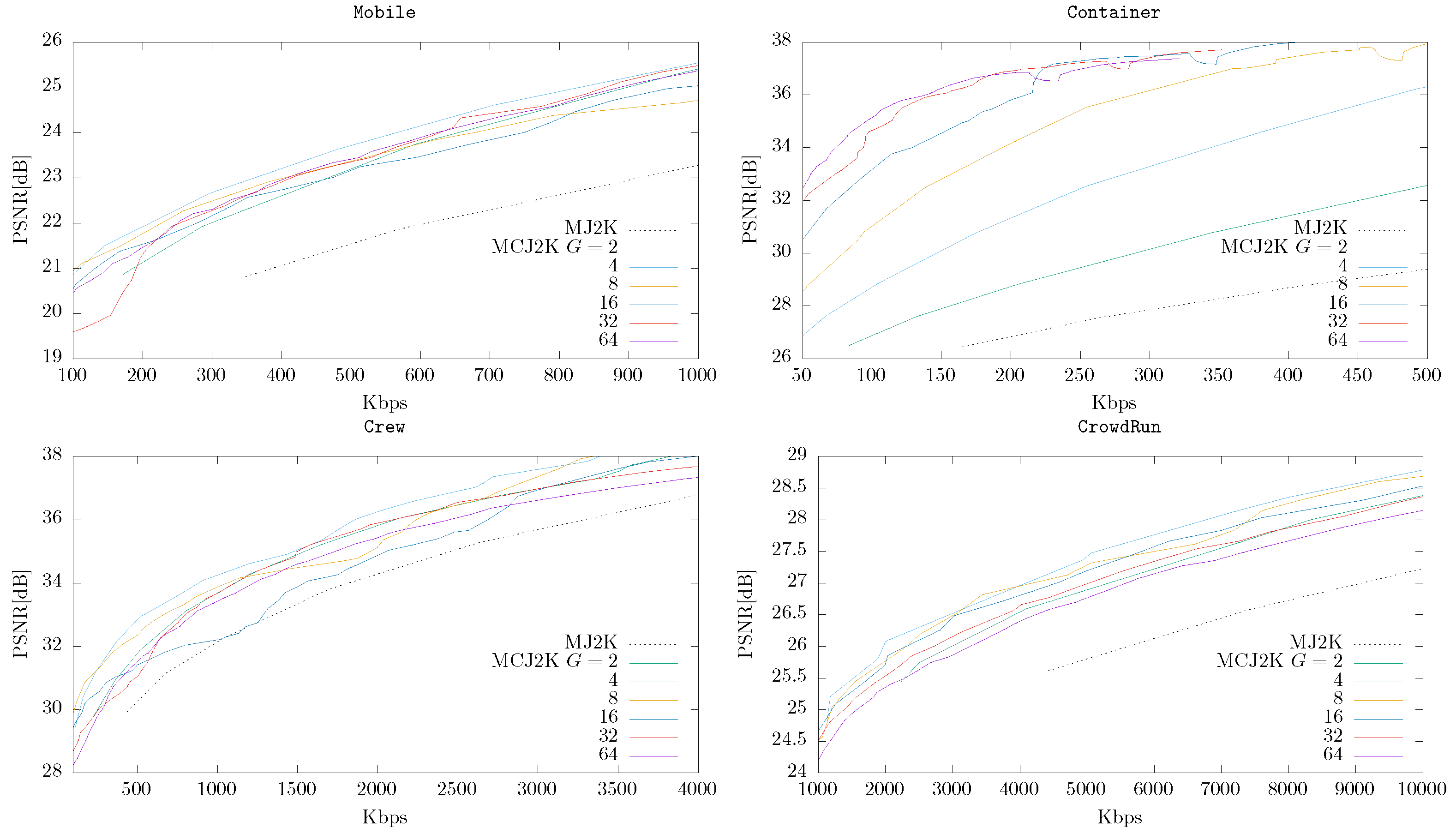
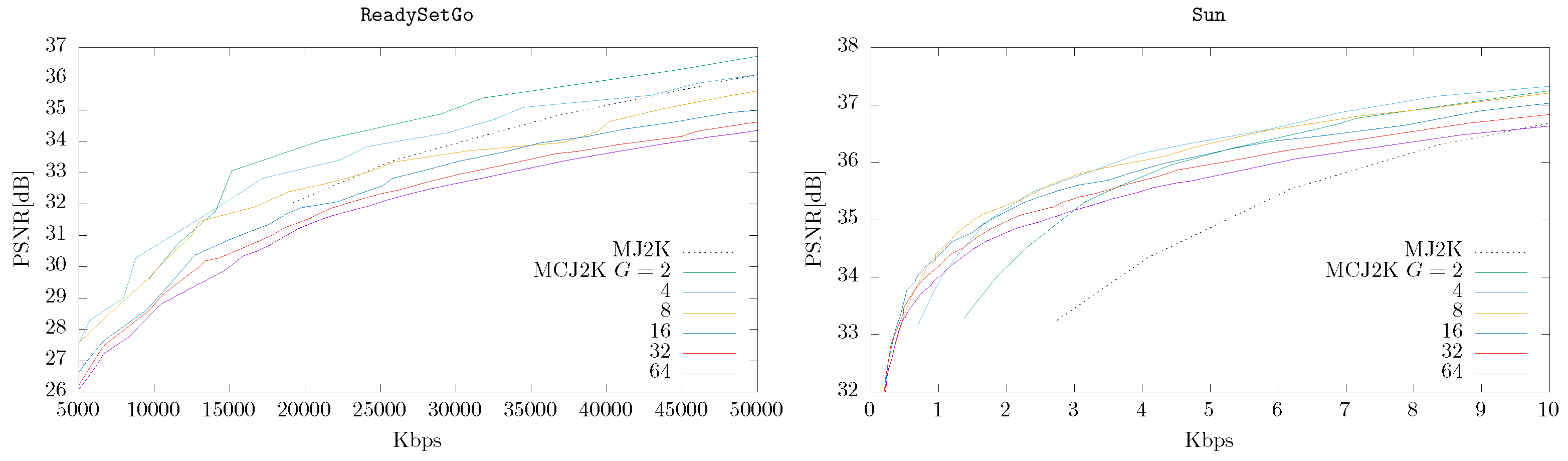
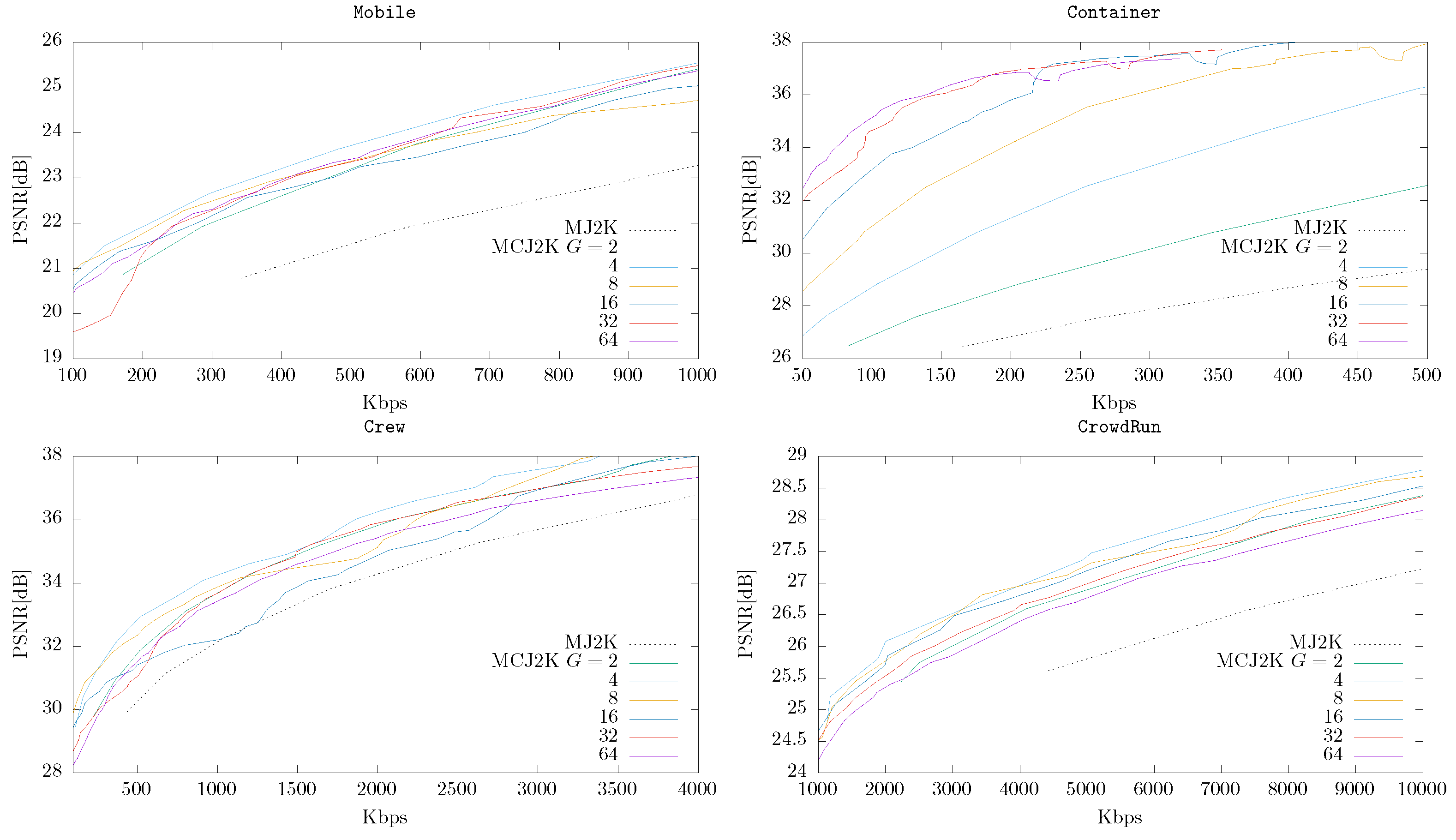
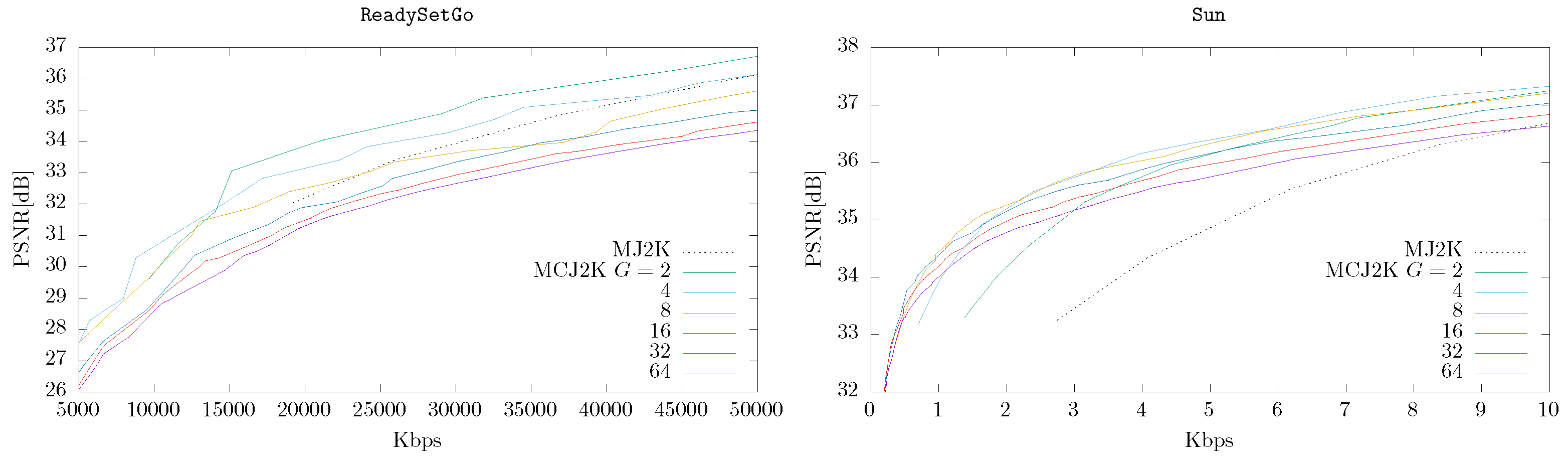
4.3. MCJ2K (Using OSLA or ESLA) vs. MJ2K
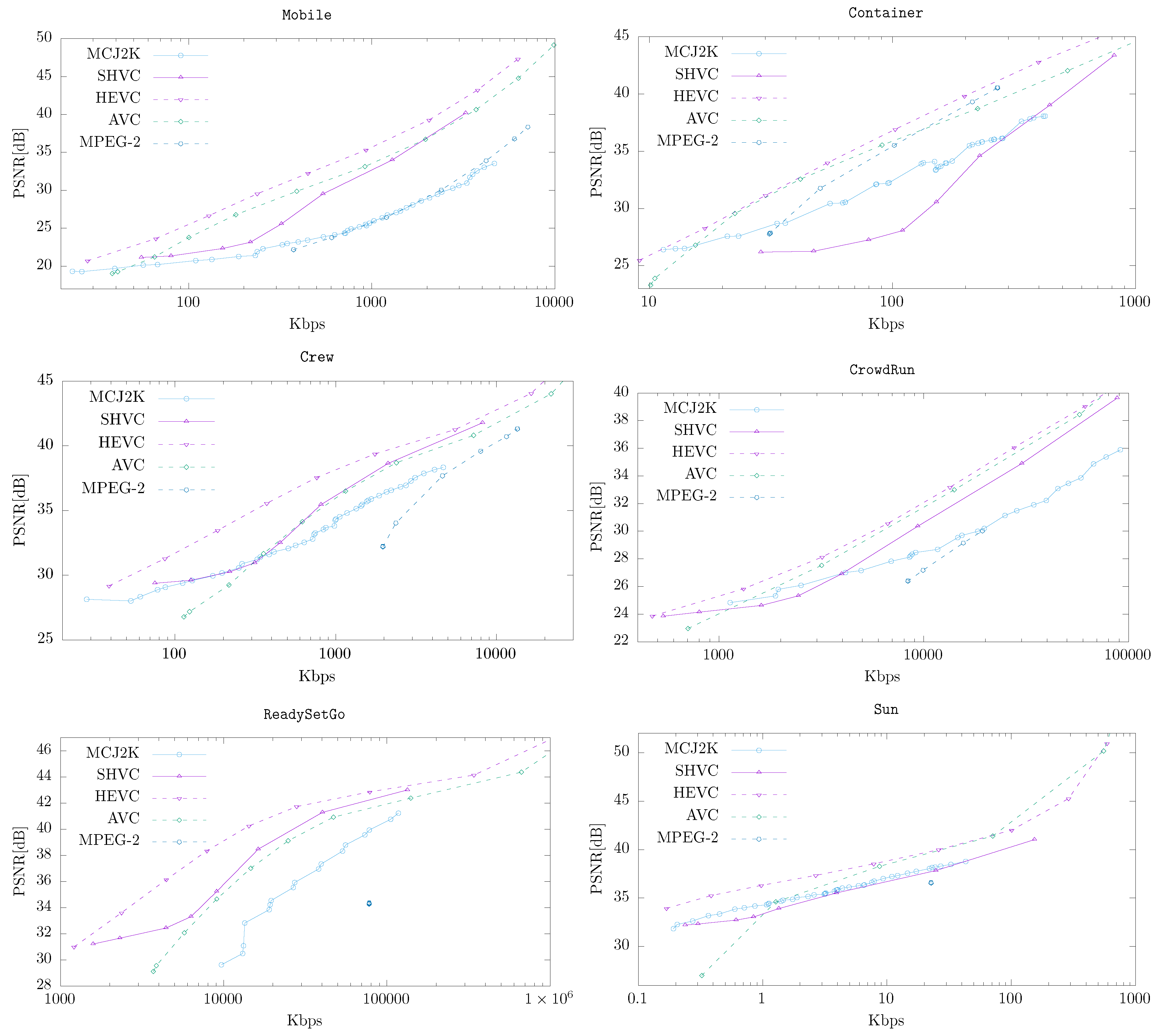
4.4. MCJ2K vs. Other Video Codecs
5. Conclusions
- The compression ratio obtained by MCJ2K is superior to MJ2K if enough time redundancy can be exploited in the MCTF stage. Our experiments show that the quality of the reconstructions can be up to 10 dB in terms of PSNR.
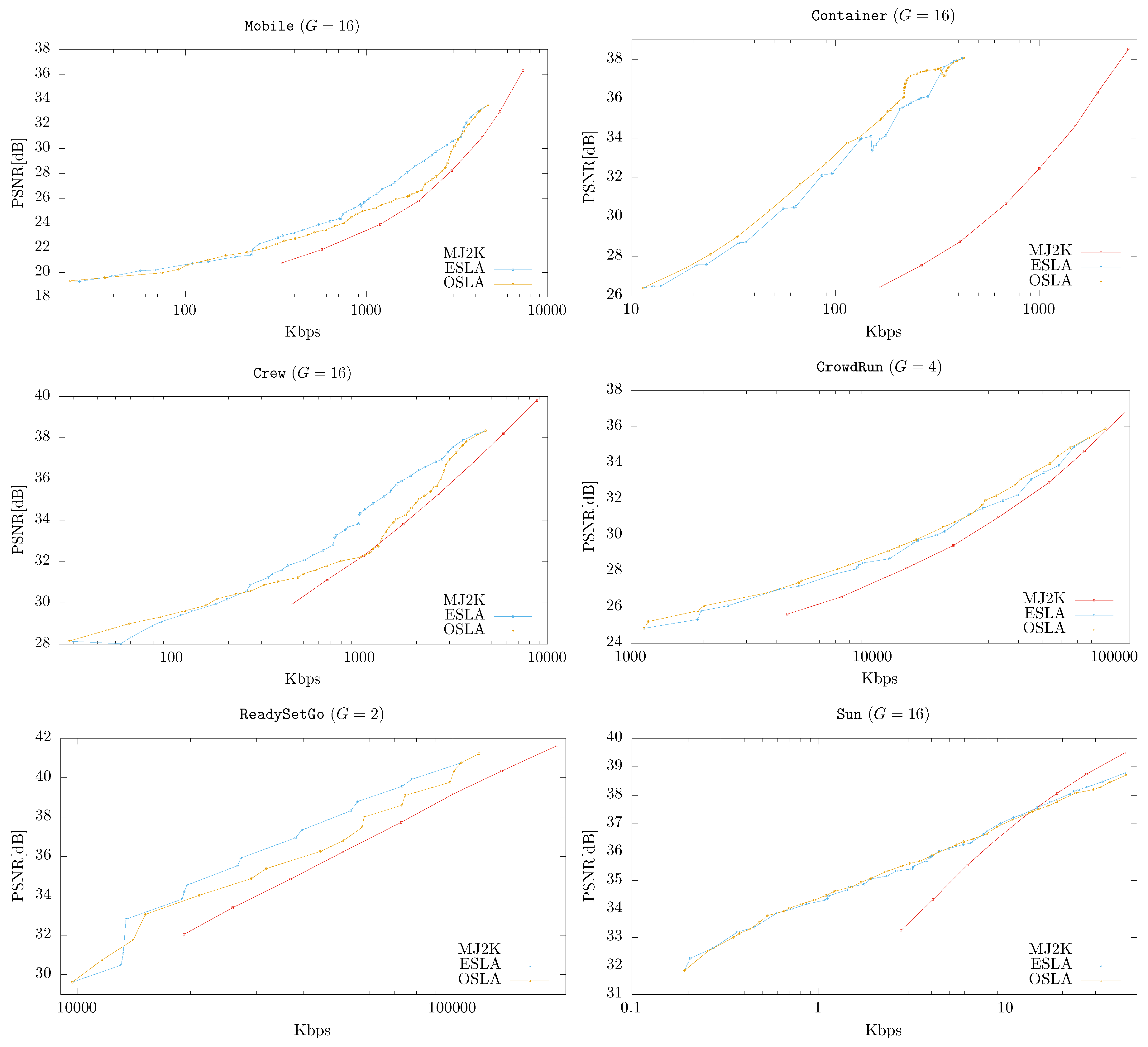
- The increment in the compression ratio provided by OSLA compared to ESLA is small. Considering that the RD performance of OSLA is better than ESLA when the MCTF process is not linear, we conclude (1) that MCDWT is almost linear, and (2) that the position of the motion information in the progression generated by ESLA is near optimal.
- Considering that ESLA requires less computational resources than OSLA, and that ESLA needs to be run only at the receiver, ESLA should be the rate-allocation algorithm used by default in MCJ2K.
- MCJ2K implies recompressing the sequences of images but not modifying the JPIP servers at all. Only the JPIP clients need to implement the logic needed by MCJ2K.
- The compression ratio obtained by MCJ2K is comparable to SHVC, when the movement of the video can be modeled using our ME proposal. However, the quality granularity and the range of decoding bitrates is higher in MCJ2K, which makes MCJ2K more suitable than SHVC for streaming scenarios.
- In MCJ2K the GOP size G significantly affects the RD performance. G should be high if the temporal correlation of the video can be removed by the MCTF stage, and vice versa.
- Compared to the state-of-the-art non-scalable video compressors (such as HEVC), MCJ2K require more bitrate because HEVC use more effective ME schemes than MCJ2K (an aspect out of the scope of this paper). However, at very low bitrates this gap is usually small.
6. Future Research
- Like the rest of video codecs based on MC, MCJ2K has a cost in terms of temporal scalability. A study on the number of bytes required for obtaining the same quality in both codecs, MJ2K and MCJ2K, when only one image of the sequence is decoded could prove worthwhile, especially in interactive browsing systems such as Helioviewer.
- Find a quality scalable representation of the motion data. Such a contribution should reduce the minimal number of bytes required for rendering the image sequence.
- The use of more accurate MCTF schemes should increase the compression ratios.
- The use of encoding schemes where the motion information can be estimated at the decoder (to avoid being sent as a part of the code-stream). This can be carried out in those contexts where the large-scale motion is predictable, such as image sequences of the Sun, whose rotation rate is stable and well known.
- How MCJ2K affects the spatial/WOI scalability provided by the J2K standard.
Author Contributions
Funding
Conflicts of Interest
References
- ISO. Information Technology-JPEG 2000 Image Coding System-Core Coding System; ISO/IEC 15444-1:2004; ISO: Geneva, Switzerland, 2004. [Google Scholar]
- ITU. Information Technology-JPEG 2000 Image Coding System: Interactivity Tools, APIs and Protocols. Available online: http://www.itu.int/rec/T-REC-T.808-200501-I (accessed on 26 August 2019).
- Bilgin, A.; Marcellin, M. JPEG2000 for digital cinema. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Island of Kos, Greece, 21–24 May 2006; pp. 4–3881. [Google Scholar] [CrossRef]
- Müller, D.; Dimitoglou, G.; Caplins, B.; Ortiz, J.P.; Wamsler, B.; Hughitt, K.; Alexanderian, A.; Ireland, J.; Amadigwe, D.; Fleck, B. JHelioviewer: Visualizing large sets of solar images using JPEG 2000. Comput. Sci. Eng. 2009, 11, 38–47. [Google Scholar] [CrossRef]
- Müller, D.; Nicula, B.; Felix, S.; Verstringe, F.; Bourgoignie, B.; Csillaghy, A.; Berghmans, D.; Jiggens, P.; García-Ortiz, J.; Ireland, J.; et al. JHelioviewer-Time-dependent 3D visualisation of solar and heliospheric data. Astron. Astrophys. 2017, 606, A10. [Google Scholar] [CrossRef]
- Cohen, R.; Woods, J. Resolution scalable motion-compensated JPEG 2000. In Proceedings of the 2007 15th International Conference on Digital Signal Processing, Cardiff, UK, 1–4 July 2007; pp. 459–462. [Google Scholar]
- Secker, A.; Taubman, D. Lifting-based Invertible Motion Adaptive Transform (LIMAT) framework for highly scalable video compression. IEEE Trans. Image Process. 2003, 12, 1530–1542. [Google Scholar] [CrossRef] [PubMed]
- Schwarz, H.; Marpe, D.; Wiegand, T. Overview of the scalable video coding extension of the H. 264/AVC standard. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 1103–1120. [Google Scholar] [CrossRef]
- Sullivan, G.; Ohm, J.; Han, W.J.; Wiegand, T. Overview of the High Efficiency Video Coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Andre, T.; Cagnazzo, M.; Antonini, M.; Barlaud, M. JPEG2000-compatible scalable scheme for wavelet-based video coding. EURASIP J. Image Video Process. 2007, 2007, 1–11. [Google Scholar] [CrossRef]
- Cagnazzo, M.; Castaldo, F.; Andre, T.; Antonini, M.; Barlaud, M. Optimal motion estimation for wavelet motion compensated video coding. IEEE Trans. Circuits Syst. Video Technol. 2007, 17, 907–911. [Google Scholar] [CrossRef]
- Ferroukhi, M.; Ouahabi, A.; Attari, M.; Habchi, Y.; Taleb-Ahmed, A. Medical video coding based on 2nd-generation wavelets: Performance evaluation. Electronics 2019, 8, 88. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Wiegand, T. Rate-distortion optimization for video compression. IEEE Signal Process. Mag. 1998, 15, 74–90. [Google Scholar] [CrossRef] [Green Version]
- Barbarien, J.; Munteanu, A.; Verdicchio, F.; Andreopoulos, Y.; Cornelis, J.; Schelkens, P. Motion and texture rate-allocation for prediction-based scalable motion-vector coding. Signal Process. Image Commun. 2005, 20, 315–342. [Google Scholar] [CrossRef]
- Ouahabi, A. Signal and Image Multiresolution Analysis; Wiley Online Library: Hoboken, NJ, USA, 2012. [Google Scholar]
- Aulí-Llinàs, F.; Bilgin, A.; Marcellin, M. FAST Rate Allocation Through Steepest Descent for JPEG2000 video transmission. IEEE Trans. Image Process. 2011, 20, 1166–1173. [Google Scholar] [CrossRef] [PubMed]
- Jiménez-Rodríguez, L.; Aulí-Llinàs, F.; Marcellin, M. FAST rate allocation for JPEG2000 video transmission over time-varying channels. IEEE Trans. Multimed. 2013, 15, 15–26. [Google Scholar] [CrossRef]
- Naman, A.; Taubman, D. JPEG2000-based Scalable Interactive Video (JSIV). IEEE Trans. Image Process. 2011, 20, 1435–1449. [Google Scholar] [CrossRef] [PubMed]
- Naman, A.; Taubman, D. JPEG2000-Based Scalable Interactive Video (JSIV) with motion compensation. IEEE Trans. Image Process. 2011, 20, 2650–2663. [Google Scholar] [CrossRef] [PubMed]
- ISO/IEC 23009-1:2012 Information Technology—Dynamic Adaptive Streaming over HTTP (DASH)—Part 1: Media Presentation Description and Segment Formats. Available online: http://www.iso.org/iso/iso_catalogue/catalogue_tc/catalogue_detail.htm?csnumber=57623 (accessed on 26 August 2019).
- Mehrotra, S.; Zhao, W. Rate-distortion optimized client side rate control for adaptive media streaming. In Proceedings of the IEEE International Workshop on Multimedia Signal Processing (MMSP), Rio de Janeiro, Brazil, 5–7 October 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Secker, A.; Taubman, D. Motion-compensated highly scalable video compression using an adaptive 3D wavelet transform based on lifting. In Proceedings of the IEEE International Conference on Image Processing, Thessaloniki, Greece, 7–10 October 2001; Volume 2, pp. 1029–1032. [Google Scholar]
- Suguri, K.; Minami, T.; Matsuda, H.; Kusaba, R.; Kondo, T.; Kasai, R.; Watanabe, T.; Sato, H.; Shibata, N.; Tashiro, Y.; et al. A real-time motion estimation and compensation LSI with wide search range for MPEG2 video encoding. IEEE J. Solid-State Circuits 1996, 31, 1733–1741. [Google Scholar] [CrossRef]
- Wu, S.; Gersho, A. Joint estimation of forward/backward motion vectors for MPEG interpolative prediction. IEEE Trans. Image Process. 1994, 3, 684–687. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, C.; Liu, Y. Fast Search Algorihtms for Vector Quantization of Images Using Multiple Triangle Inequalities and Wavelet Transform. IEEE Trans. Image Proc. 2000, 9, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Mokry, R.; Anastassiou, D. Minimal error drift in frequency scalability for motion-compensated DCT coding. IEEE Trans. Circuits Syst. Video Technol. 1994, 4, 392–406. [Google Scholar] [CrossRef]
- Andreopoulos, Y.; van der Schaar, M.; Munteanu, A.; Barbarien, J.; Schelkens, P.; Cornelis, J. Fully-scalable wavelet video coding using in-band motion compensated temporal filtering. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, (ICASSP’03), Hong Kong, China, 6–10 April 2003; Volume 3, pp. 417–420. [Google Scholar]
- Dagher, J.; Bilgin, A.; Marcellin, M. Resource-constrained rate control for Motion JPEG2000. IEEE Trans. Image Process. 2003, 12, 1522–1529. [Google Scholar] [CrossRef] [PubMed]
- Sánchez-Hernández, J.; García-Ortiz, J.; González-Ruiz, V.; Müller, D. Interactive streaming of sequences of high resolution JPEG2000 images. IEEE Trans. Multimed. 2015, 17, 1829–1838. [Google Scholar] [CrossRef]
- Xiong, R.; Xu, J.; Wu, F.; Li, S. Adaptive MCTF based on correlation noise model for SNR scalable video coding. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Toronto, ON, Canada, 9–12 July 2006; pp. 1865–1868. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MCTF1 | MCTF2 | MCTF3 | MCTF4 | MCTF5 | MCTF6 | MCTF7 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1.246 | 1.250 | 1.160 | 1.088 | 1.046 | 1.023 | 1.012 | |||||||
| 1.865 | 2.122 | 2.130 | 2.079 | 2.043 | 2.023 | ||||||||
| 3.167 | 3.888 | 4.061 | 4.063 | 4.039 | |||||||||
| 5.802 | 7.431 | 7.936 | 8.031 | ||||||||||
| 11.089 | 14.522 | 15.688 | |||||||||||
| 21.669 | 28.707 | ||||||||||||
| 42.835 | |||||||||||||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maturana-Espinosa, J.C.; García-Ortiz, J.P.; Müller, D.; González-Ruiz, V. Layer Selection in Progressive Transmission of Motion-Compensated JPEG2000 Video. Electronics 2019, 8, 1032. https://doi.org/10.3390/electronics8091032
Maturana-Espinosa JC, García-Ortiz JP, Müller D, González-Ruiz V. Layer Selection in Progressive Transmission of Motion-Compensated JPEG2000 Video. Electronics. 2019; 8(9):1032. https://doi.org/10.3390/electronics8091032
Chicago/Turabian StyleMaturana-Espinosa, José Carmelo, Juan Pablo García-Ortiz, Daniel Müller, and Vicente González-Ruiz. 2019. "Layer Selection in Progressive Transmission of Motion-Compensated JPEG2000 Video" Electronics 8, no. 9: 1032. https://doi.org/10.3390/electronics8091032