Support Vector Regression (SVR) belongs to a classic application in Support Vector Machine (SVM) [
1]. It has been widely used in the fields of sample regression [
2], data prediction [
3], fault diagnosis [
4] and so on. The existing libraries for implementation of SVR, such as SVM Light and LibSVM, need to be run based on personal computers. These methods focus on the application of SVR and do not consider the underlying design of the software. With the increasing use of embedded artificial intelligence in various fields, there is an urgent need for a platform with small size, high performance, and low power consumption. Commonly used embedded artificial intelligence platforms include Advanced RISC Machine (ARM) and Field-Programmable Gate Array (FPGA). ARM-based SVR depends on the performance of hardware kernel. The development of SVR based on bare metal is difficult and time-consuming. High performance kernels usually support embedded systems with complex peripheral circuits, high power consumption and costs. All of these restrict the application of SVR in ARM. Compared with ARM, FPGA has obvious advantages, such as high flexibility, simple hardware circuit, and low power consumption. The implementation of SVR using FPGA has attracted a large number of researchers. Noronha et al. proposes a parallel FPGA implementation of the Sequential Minimal Optimization (SMO) of SVM [
5]. After the parallel implementation, SVM is validated by bit-accurate simulation. Meanwhile, Lopes et al. realize parallel implementation of SVM using Stochastic Gradient Descent (SGD) algorithm on FPGA [
6]. In order to model the implied volatility surface, Yaxiong Zeng et al. implement most computationally intensive parts in a FPGA, where a 132× speedup is achieved during online prediction [
7]. Matrix product is the key step in SVM, and a novel matrix-vector product approach is proposed in [
8].
The training method of SVR is similar to that of SVM, thus the research on SVM is also applicable to SVR. The implementation of SVM is divided into two parts: forward inference and training. For the research of forward inference on FPGA, a high performance, low resource consuming hardware design for Support Vector Classification (SVC), and SVR is proposed in [
9]. This system is implemented on a low cost FPGA and exploits the advantages of parallel processing to compute the feed forward in SVM. The method of cascade SVM in [
10] is used to implement face recognition on FPGA. In [
11] the authors propose a parallel hardware architecture for target detection, which applies SVM to real-time detection of targets such as faces, pedestrians, and vehicles. A low-complexity pedestrian detection framework is proposed in [
12] for intelligent video surveillance systems. Jian Hua Luo et al. [
13] combined SVM and Histogram of Oriented Gradient (HOG) to realize real-time pedestrian detection system design on FPGA with a small amount of resources. Early research emphasized the processing of kernel functions and the implementation of parallel computation of multiple input data and achieved significant acceleration effects. The detection object in the above applications is a fixed model. Usually the training of model is achieved through a computer, and then the model should be imported into FPGA. Therefore, if the model changes, the new model needs to be retrained on the computer to get new training parameters. In order to adapt to changes in the model, the accelerated training method based on FPGA has caused widespread concern. Papadonikolakis et al. focus on the acceleration of training phase and a geometric approach to SVM training based on Gilbert’s Algorithm is targeted, due to the high parallelization potential of the heavy computational tasks [
14]. Cao Kui Kang et al. proposed a parallel scalable digital architecture of SMO, which realized online training of SVM based on FPGA [
15]. The test is performed using sonar data with a maximum classification error of 8.65%. This method provides guidance for online training of SVM. For the key steps of SMO to satisfy Karush–Kuhn–Tucher (KKT) conditions during training, Jhing-Fa Wang et al. studied the implementation of SMO, which includes Intellectual Property (IP) core implementation of SMO [
16], an efficient configurable chip design based on SMO acceleration training method [
17], and implementation of a low cost trainable SMO mode classifier [
18]. The above research adopts a development method close to the underlying layer. It still requires a lot of manpower and time. In order to reduce the FPGA-based development cycle, Afifi et al. implemented the SVM classifier for online detection of skin cancer based on Zynq platform, and the system power consumption is less than 1.5 W [
19,
20]. Hongda Wang et al. proposed a real-time seizure detection hardware design based on STFT for nonlinear SVM [
21]. The experiment achieves a 1.7× improvement, and the total power is less than 380 mW. Tsoutsouras V uses Vivado High-Level Synthesis (HLS) to implement hardware acceleration of SVM for electrocardiogram arrhythmia detection, achieving 78× acceleration compared to software execution [
22]. Based on the Zynq platform, Benkuan Wang et al. used the Least Squares Support Vector Machine (LSSVM) for online fault diagnosis of an Unmanned Aerial Vehicle (UAV) [
23,
24]. The Vivado HLS accelerated kernel matrix and inversion processing of LSSVM to realize data prediction and state judgment. The above research provide new ideas for hardware implementation of SVM/SVR. To our best knowledge, the existing literature does not have a systematic research and implementation of ε-SVR training method based on FPGA. Therefore, this paper studies the implementation of ε-SVR training method based on FPGA. The main contributions of this paper are as follows:
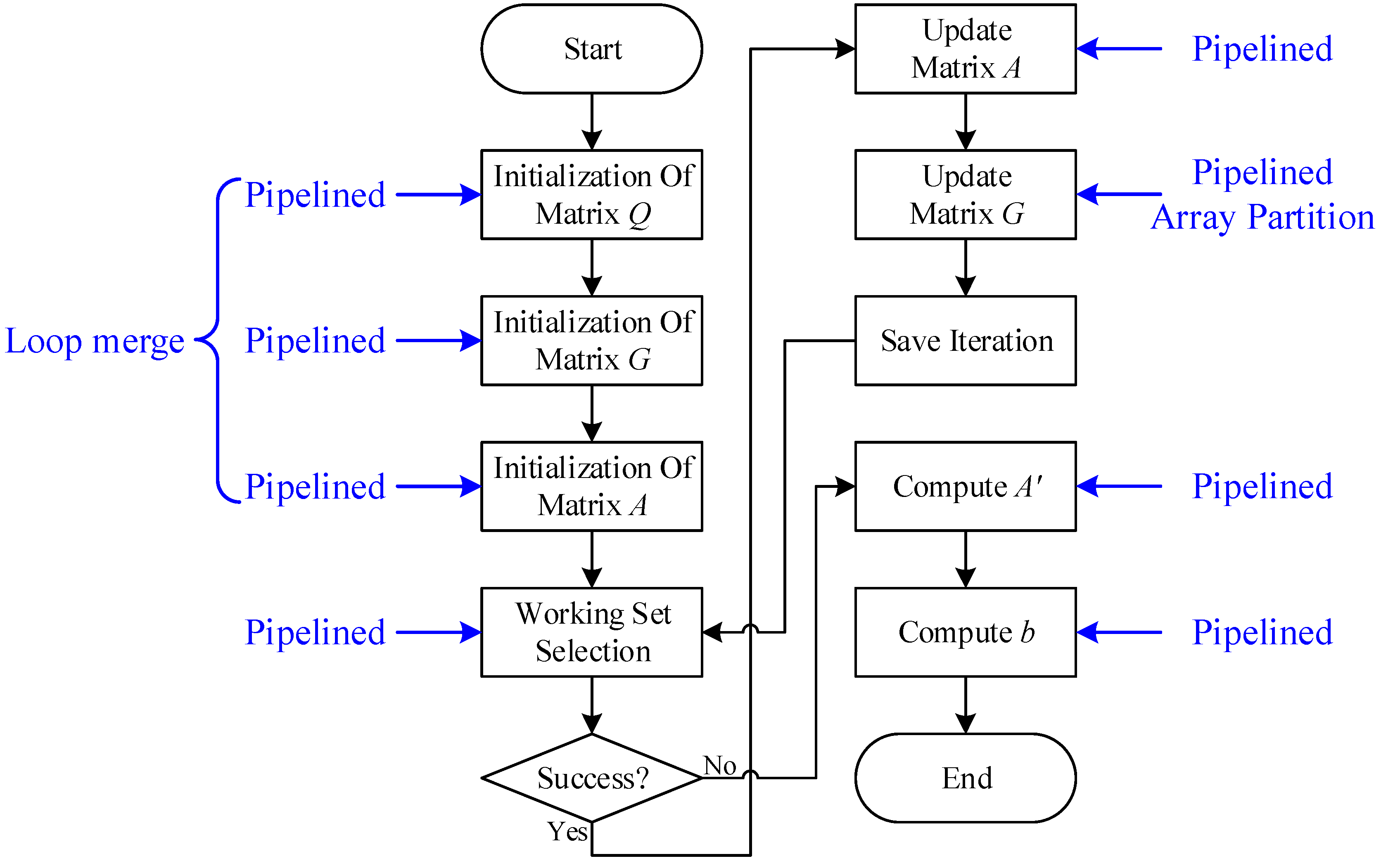
(1) In view of the complexity of the existing training method, this paper reconstructs the training framework and implementation without precision loss to reduce the total latency required for matrix update.
(2) Based on the parallel characteristics of FPGA, this paper uses the techniques of pipeline and array partition to optimize the execution of ε-SVR. A small amount of resource consumption in exchange for a significant increase in performance.
(3) A general ε-SVR training system with low latency is implemented on Zynq platform, software and hardware co-design makes this system suitable for different regression scenarios with low power consumption and high performance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}