Specific Emitter Identification Using IMF-DNA with a Joint Feature Selection Algorithm


Abstract
1. Introduction
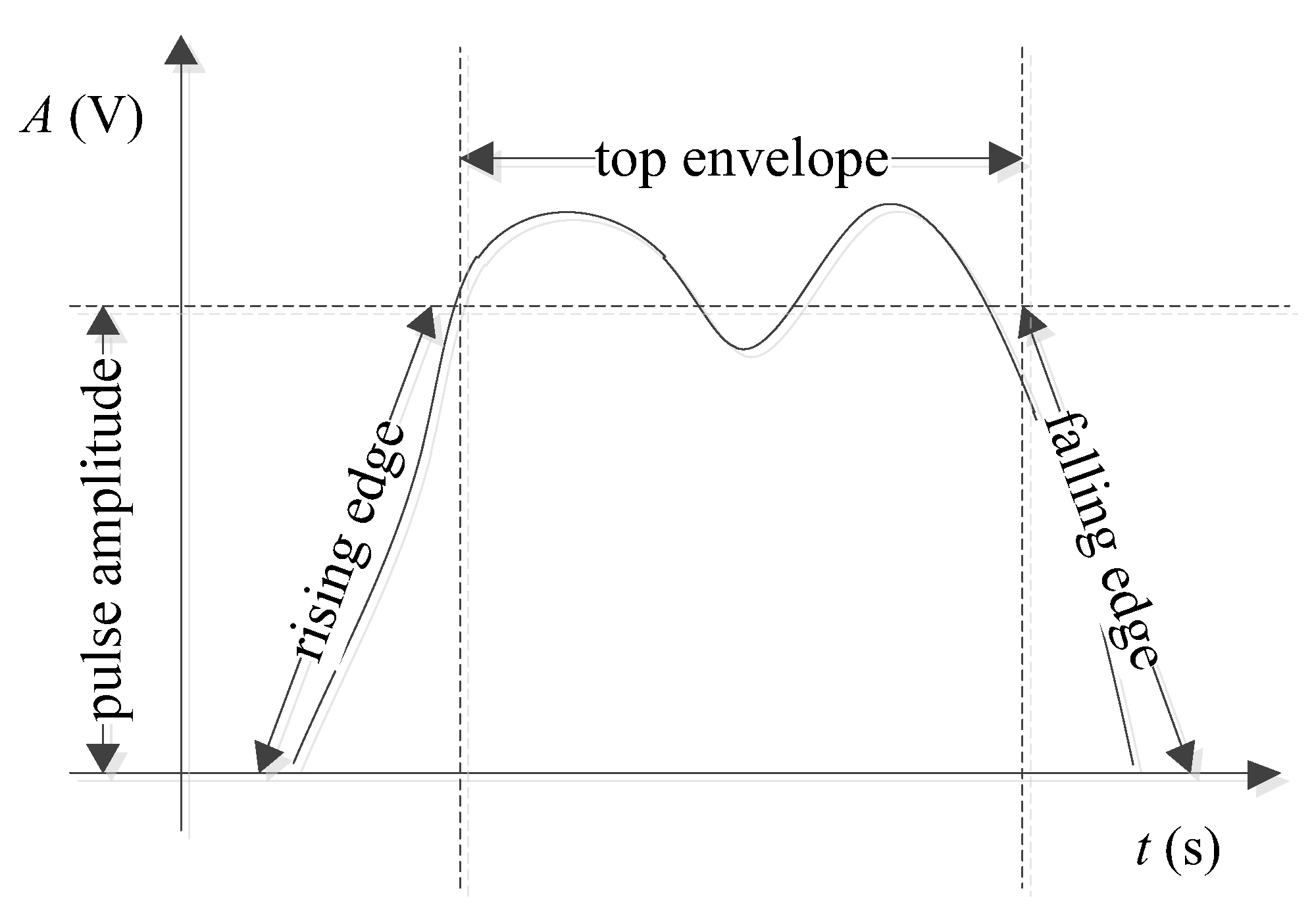
2. Signal Modeling
3. Proposed Algorithm
3.1. Signal Decomposition
3.2. IMF Segmentation
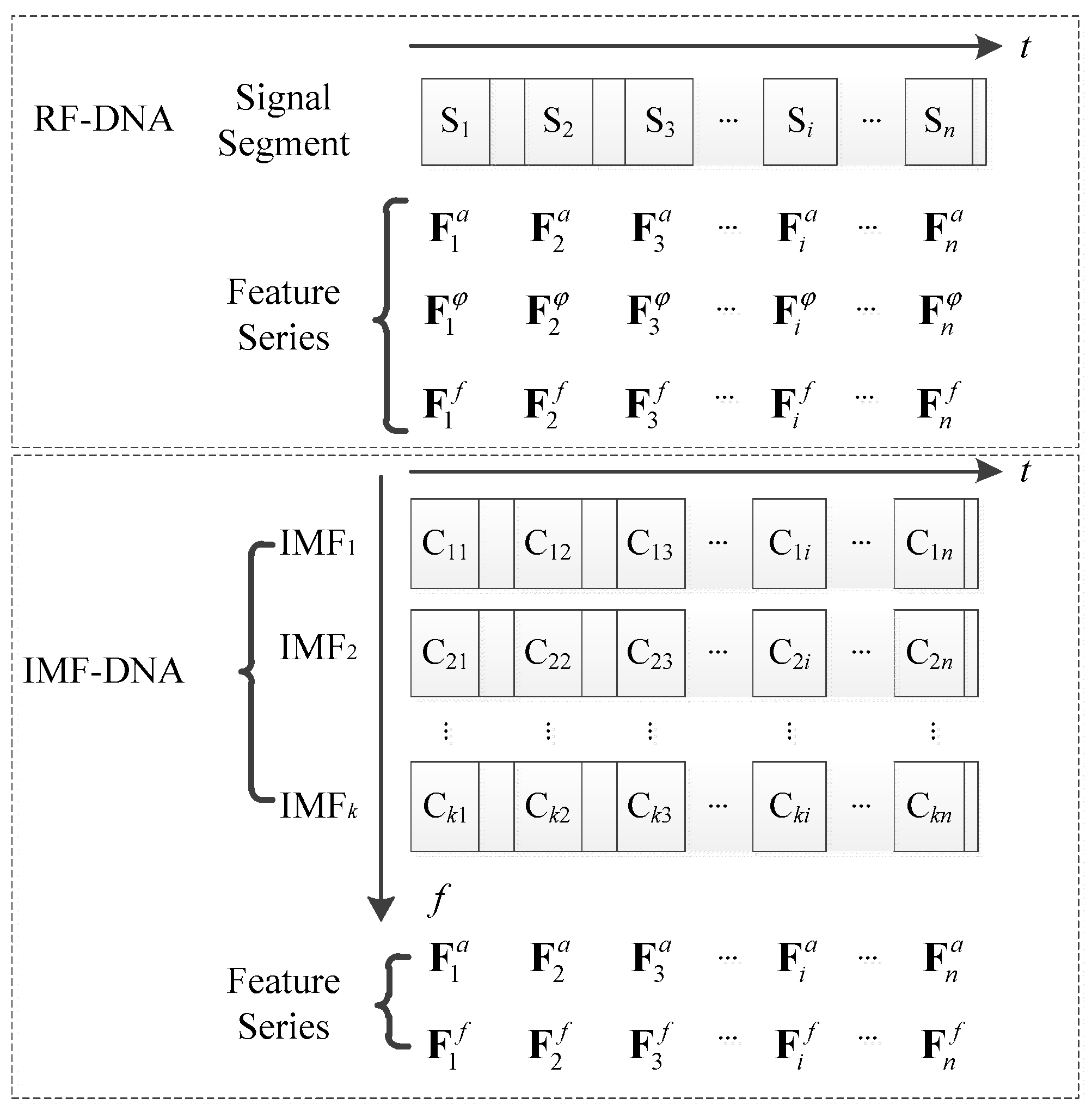
3.3. Feature Extraction from IMFs
3.4. Dimensional Reduction Analysis and the Proposed Joint Feature Selection Algorithm
| Algorithm 1: Joint feature selection (JFS) algorithm |
| Initialize the ranking results obtained using each of the four feature selection algorithms (the Kolmogorov–Smirnov test, the F test, GRLVQI relevance, and Wilks’s lambda ratio) as K1×NF, F1×NF, G1×NF, and W1×NF, which stores the feature index number; i = 0; the vote counting result NVC = 01×NF, any element of which is less than or equal to the number of all voting members (4 in this paper); the index number of a group of features selected FS, index number of a group of features to update FS_update Repeat i = i + 1 Count the votes of each feature from the first i numbers of K1×NF, F1×NF, G1×NF and W1×NF, and update NVC Search the elements of NVC and find the feature index members which obtained votes greater than or equal to Tvoting, and denote the result as FS_temp Check the elements of FS_temp, find the new members which do not appear in FS, and denote these new members as FS_update if FS_update is blank continue else FS ← {FS, FS_update} Clear FS_temp FS_update ← 0 until i = NF |
3.5. Recognition Process Using a Support Vector Machine
4. Numerical Results and Analysis
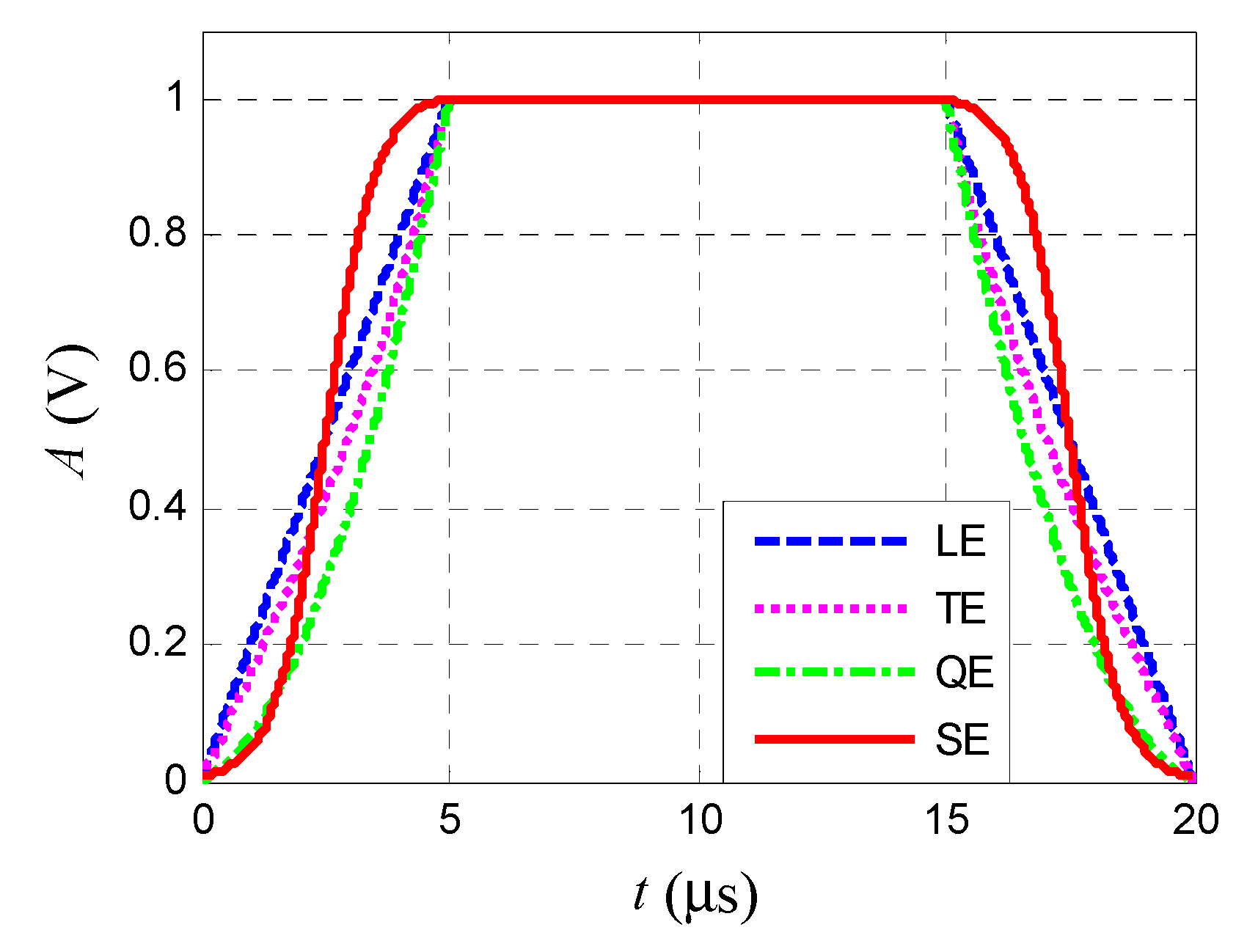
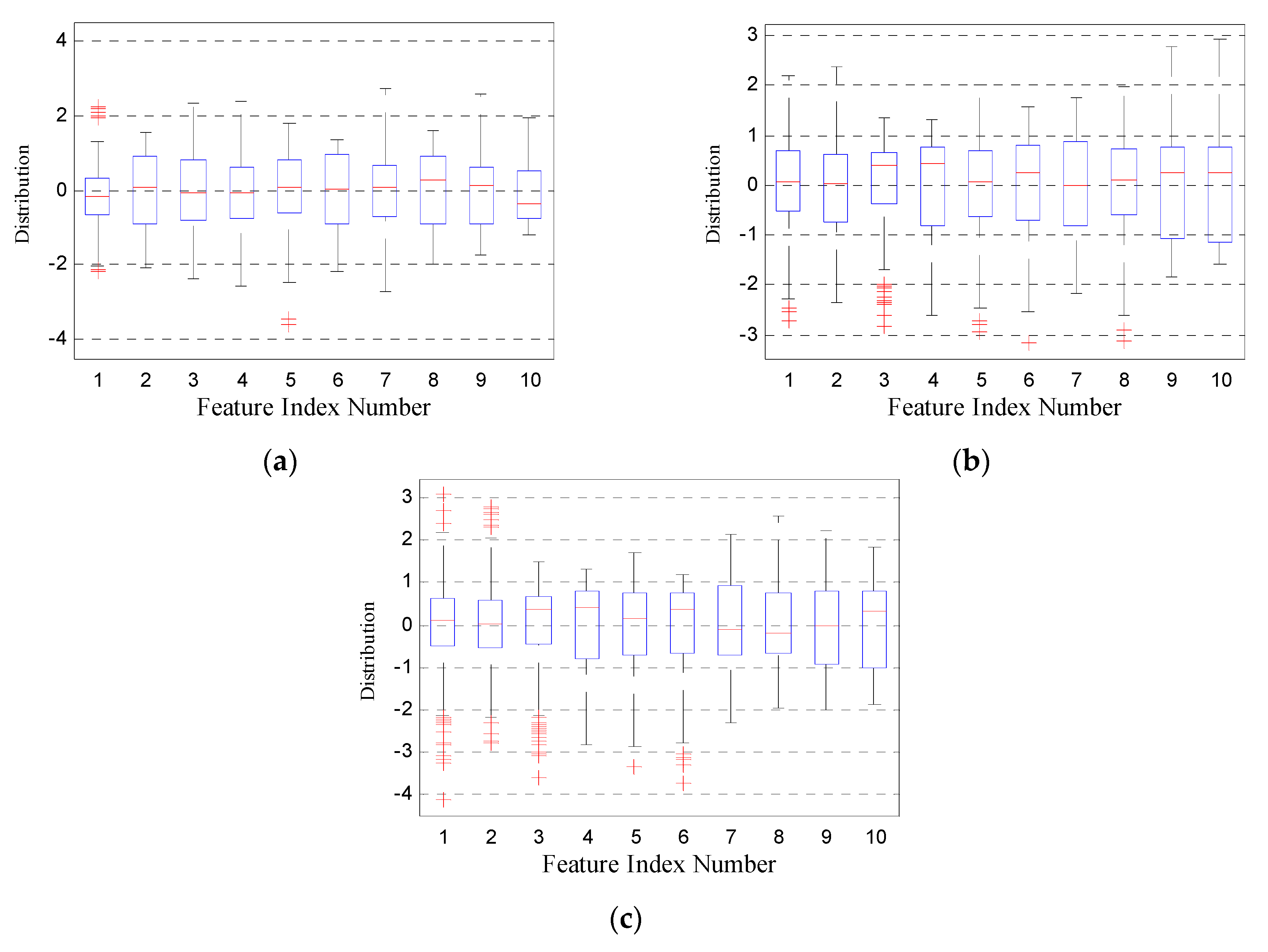
4.1. Signal Simulation and Feature Extraction
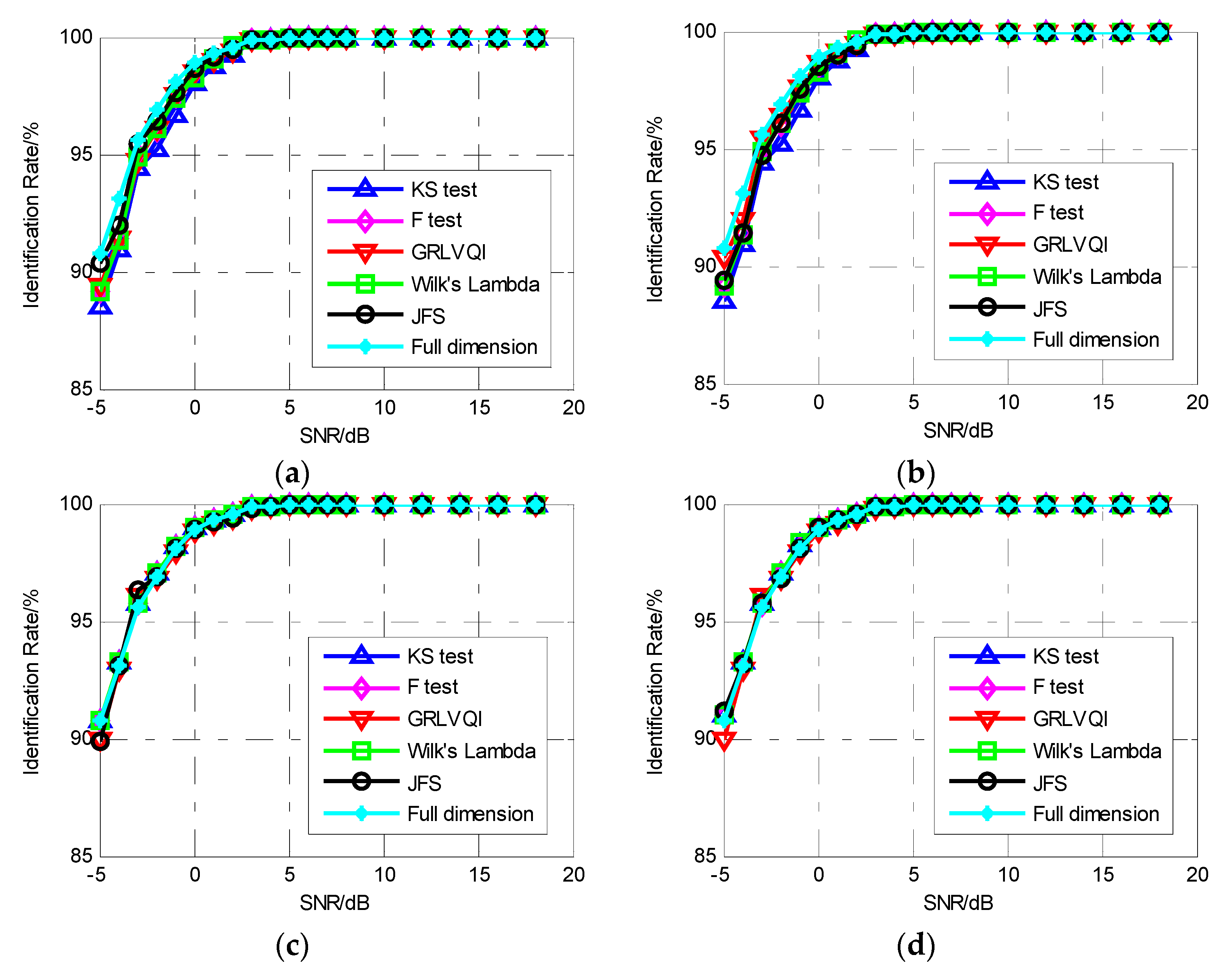
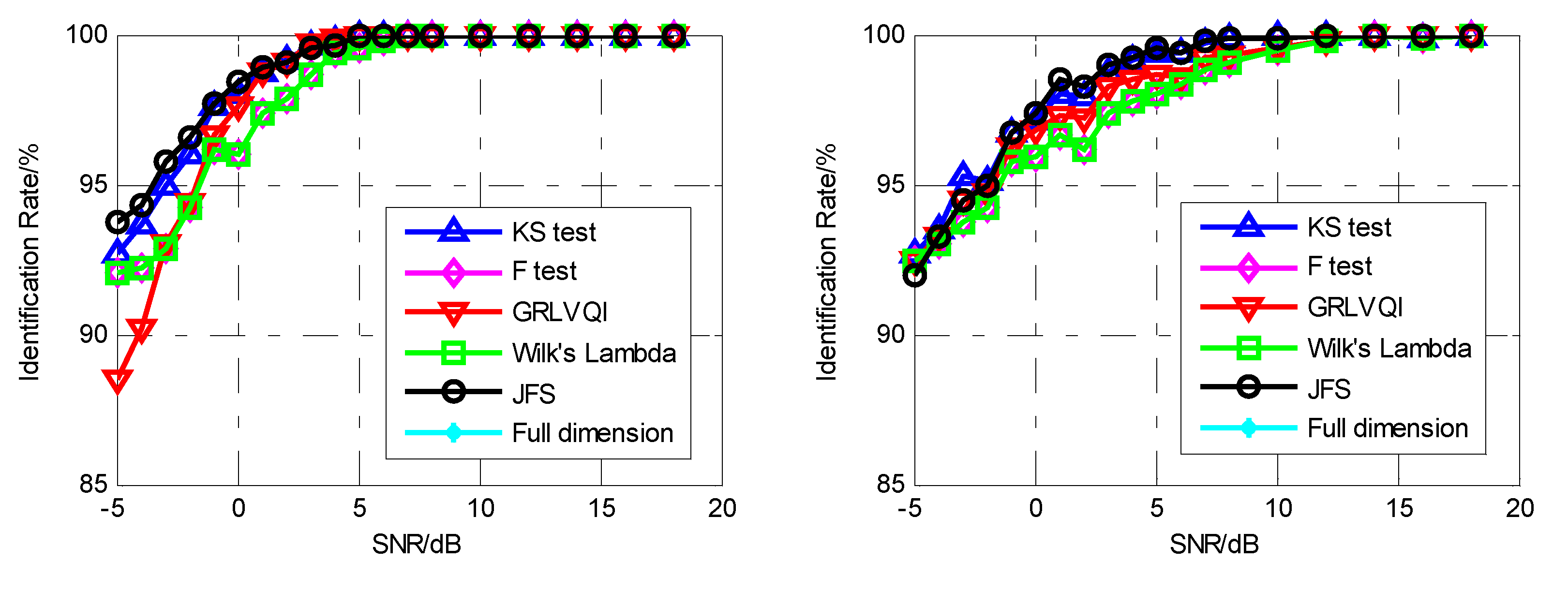
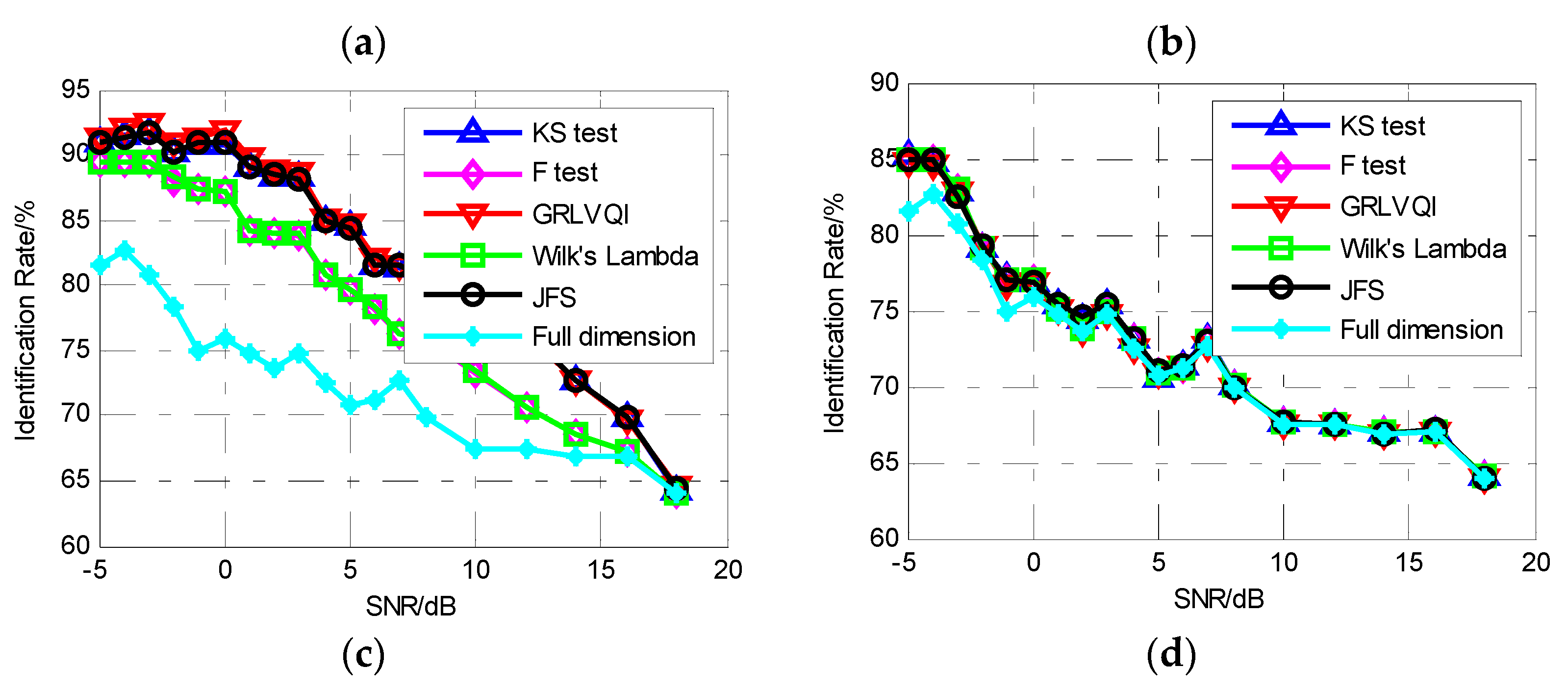
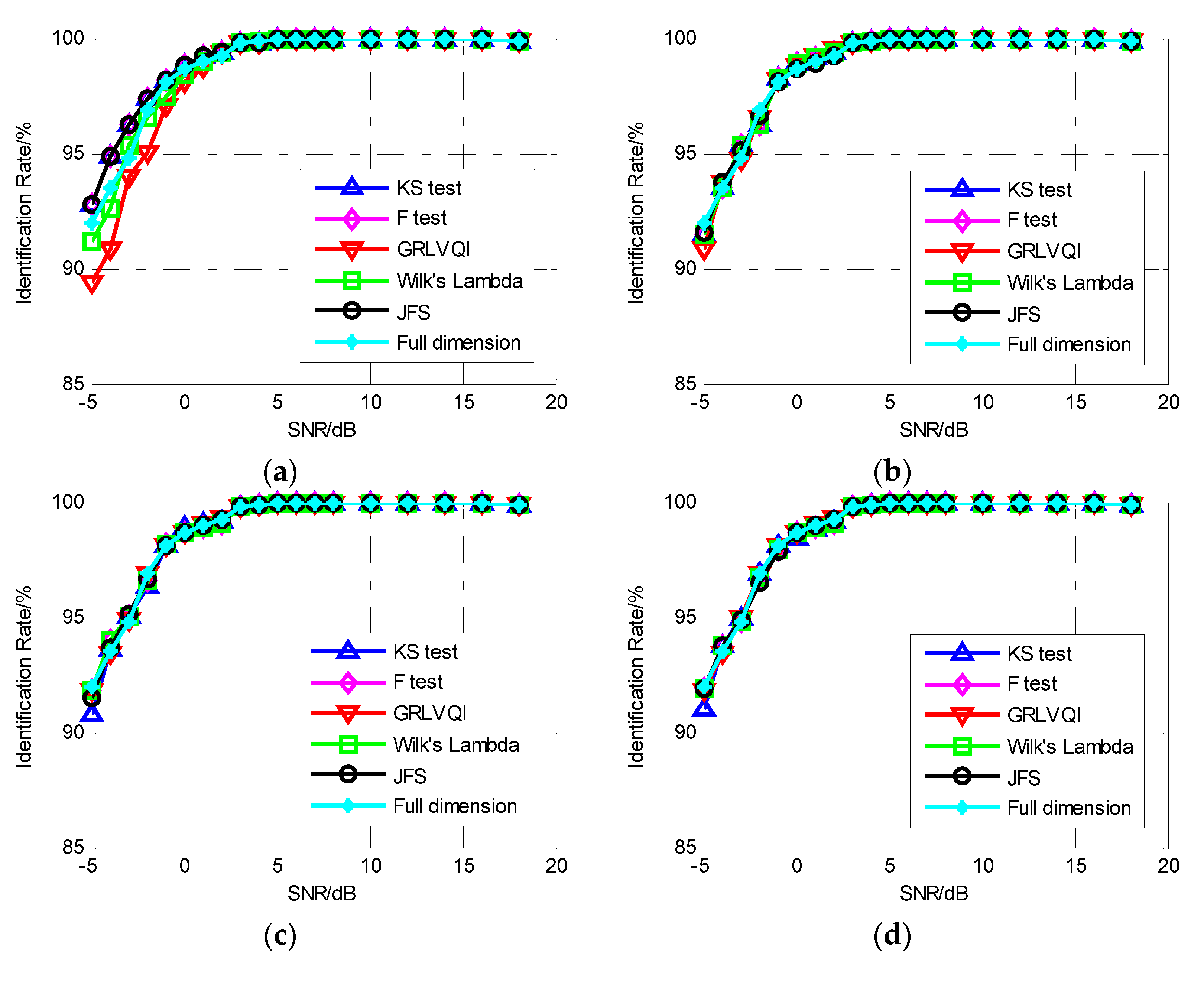
4.2. Recognition of Emitters
- Experiment 1: Classify the six signal sources into six classes, which means the emitters are identified as six emitters. The experiment was designed to prove that the proposed fingerprint algorithm can also be used for modulation classification;
- Experiment 2: Classify s11, s12, s13 as Emitter E1 and s21, s22, s23 as Emitter E2, that is, identify two different emitters. The experiment was designed to determine the influence of the pulse envelope and primary signal on the proposed fingerprint algorithm;
- Experiment 3: Classify s11 as Emitter E1 and s21 as Emitter E2, which removes the influence of the primary signal and can be used to verify the performance of the SEI using pulse envelope characteristics.
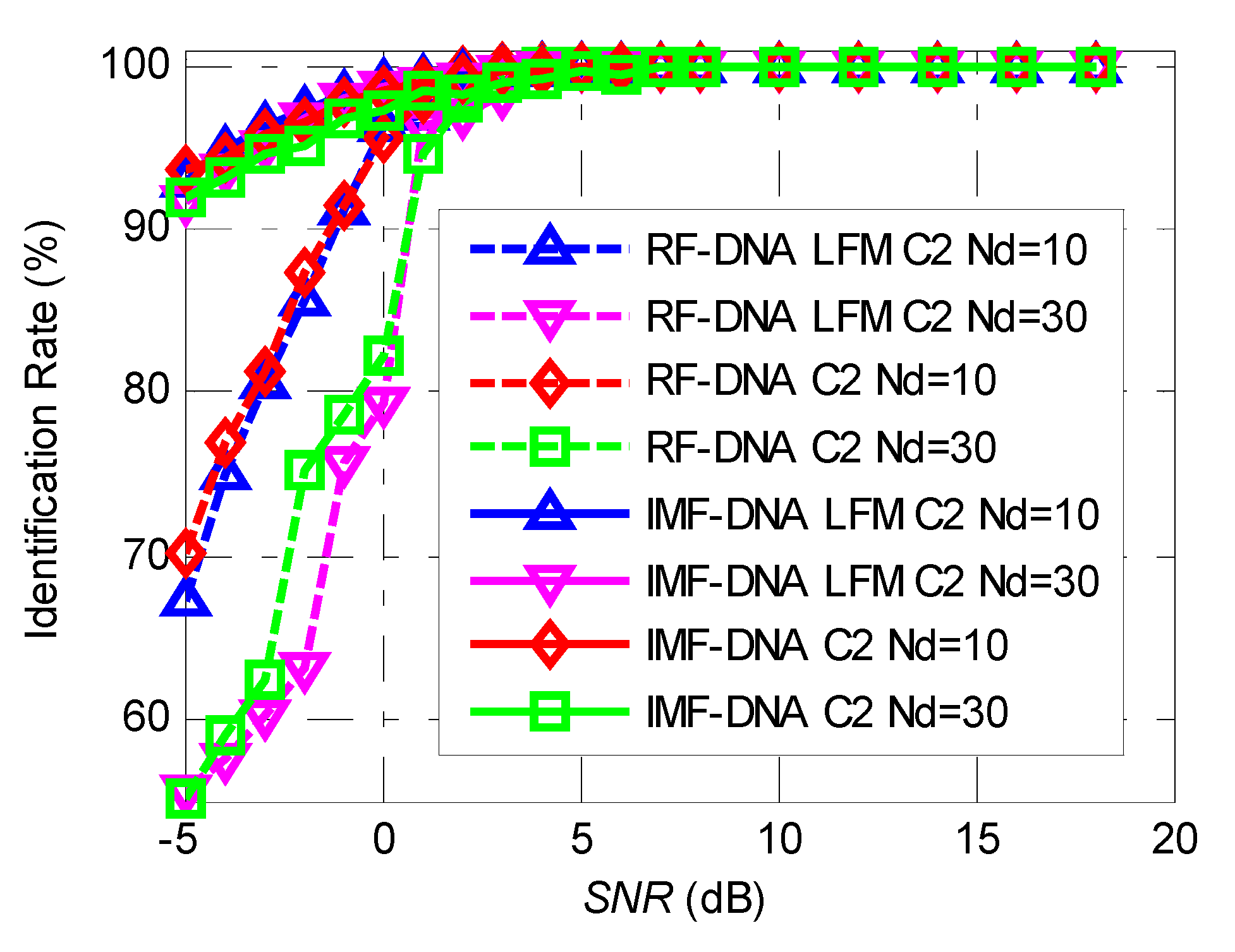
4.3. Comparison between IMF-DNA and RF-DNA
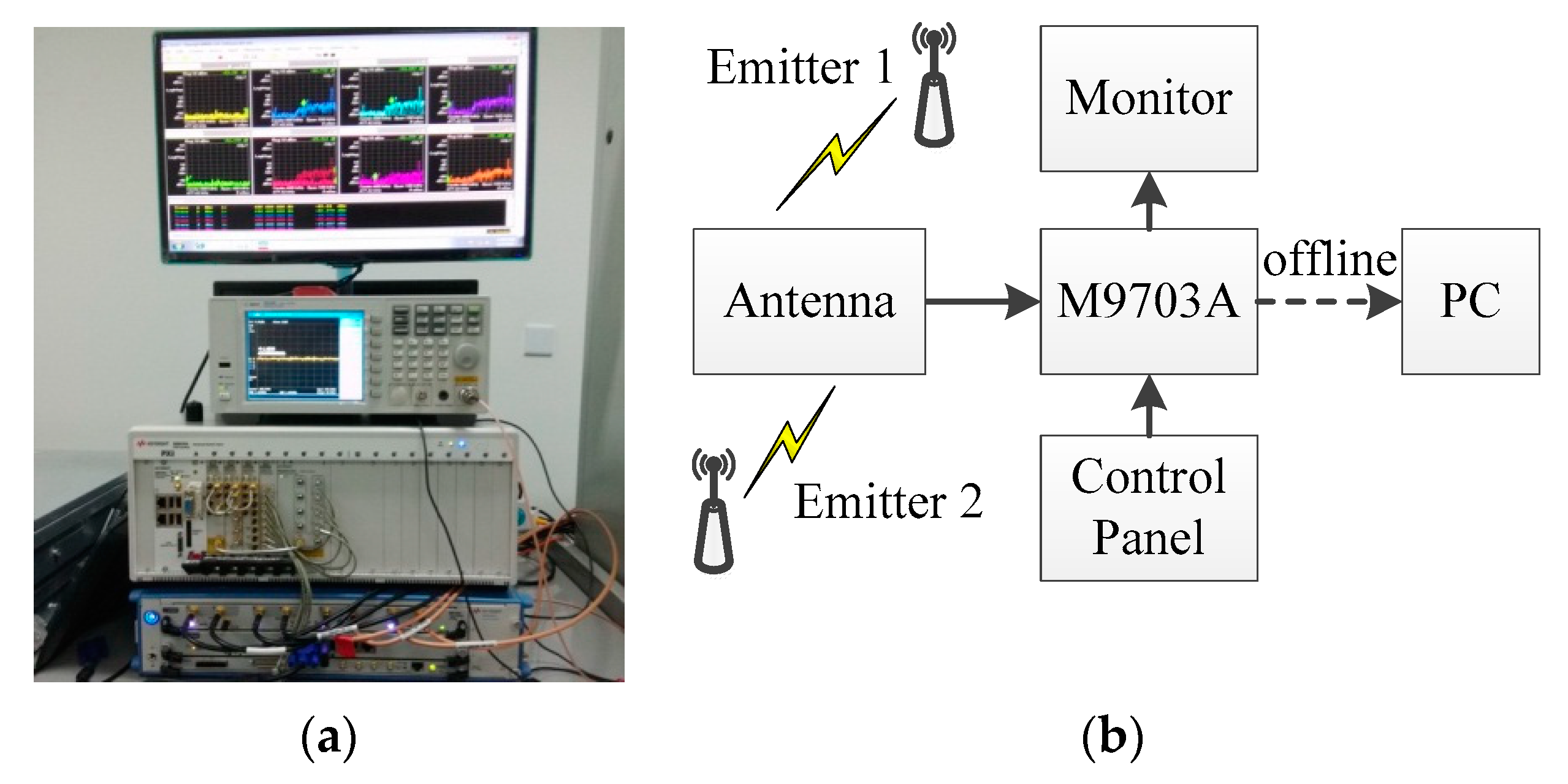
5. Verification Using Real Data
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Langley, L.E. Specific emitter identification (SEI) and classical parameter fusion technology. In Proceedings of the WESCON/’93, San Francisco, CA, USA, 28–30 September 1993; pp. 377–381. [Google Scholar]
- Talbot, K.I.; Duley, P.R.; Hyatt, M.H. Specific emitter identification and verification. Technol. Rev. J. 2003, 113–133. [Google Scholar]
- Stove, A.G.; Hume, A.L.; Baker, C.J. Low probability of intercept radar strategies. IEE Proc. Radar Sonar Navig. 2004, 151, 249. [Google Scholar] [CrossRef]
- Krishnamurthy, V. Emission management for low probability intercept sensors in network centric warfare. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 133–152. [Google Scholar] [CrossRef]
- Lee, K.-W.; Lee, W.-K. The Low Probability of Intercept RADAR Waveform Based on Random Phase and Code Rate Transition for Doppler Tolerance Improvement. J. Korean Inst. Electromagn. Eng. Sci. 2015, 26, 999–1011. [Google Scholar] [CrossRef]
- Rondeau, C.M.; Betances, J.A.; Temple, M.A. Securing ZigBee Commercial Communications Using Constellation Based Distinct Native Attribute Fingerprinting. Secur. Commun. Netw. 2018, 2018. [Google Scholar] [CrossRef]
- Lopez, J.; Liefer, N.C.; Busho, C.R.; Temple, M.A. Enhancing Critical Infrastructure and Key Resources (CIKR) Level-0 Physical Process Security Using Field Device Distinct Native Attribute Features. IEEE Trans. Inf. Forensic Secur. 2018, 13, 1215–1229. [Google Scholar] [CrossRef]
- Zhang, J.W.; Cabric, D.; Wang, F.G.; Zhong, Z.D. Cooperative Modulation Classification for Multipath Fading Channels via Expectation-Maximization. IEEE Trans. Wirel. Commun. 2017, 16, 6698–6711. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, F.; Dobre, O.A.; Zhong, Z. Specific Emitter Identification via Hilbert-Huang Transform in Single-Hop and Relaying Scenarios. IEEE Trans. Inf. Forensic Secur. 2016, 11, 1192–1205. [Google Scholar] [CrossRef]
- Bihl, T.J.; Bauer, K.W.; Temple, M.A. Feature Selection for RF Fingerprinting With Multiple Discriminant Analysis and Using ZigBee Device Emissions. IEEE Trans. Inf. Forensic Secur. 2016, 11, 1862–1874. [Google Scholar] [CrossRef]
- Patel, H.J.; Temple, M.A.; Baldwin, R.O. Improving ZigBee Device Network Authentication Using Ensemble Decision Tree Classifiers With Radio Frequency Distinct Native Attribute Fingerprinting. IEEE Trans. Rel. 2015, 64, 221–233. [Google Scholar] [CrossRef]
- Lukacs, M.; Collins, P.; Temple, M. Classification performance using ’RF-DNA’ fingerprinting of ultra-wideband noise waveforms. Electron. Lett. 2015, 51, 787–788. [Google Scholar] [CrossRef]
- Dubendorfer, C.; Ramsey, B.; Temple, M. ZigBee Device Verification for Securing Industrial Control and Building Automation Systems. In Critical Infrastructure Protection VII: 7th IFIP WG 11.10 International Conference, ICCIP 2013, Washington, DC, USA, March 18–20, 2013, Revised Selected Papers; Butts, J., Shenoi, S., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2013; pp. 47–62. [Google Scholar] [CrossRef]
- Dubendorfer, C.K.; Ramsey, B.W.; Temple, M.A. An RF-DNA verification process for ZigBee networks. In Proceedings of the MILCOM 2012–2012 IEEE Military Communications Conference, Orlando, FL, USA, 29 October–1 November 2012; pp. 1–6. [Google Scholar]
- Cobb, W.E.; Garcia, E.W.; Temple, M.A.; Baldwin, R.O.; Kim, Y.C. Physical Layer Identification of Embedded Devices Using RF-DNA Fingerprinting. In Proceedings of the 2010 - MILCOM 2010 MILITARY COMMUNICATIONS CONFERENCE, San Jose, CA, USA, 31 October–3 November 2010. [Google Scholar] [CrossRef]
- Suski II, W.C.; Temple, M.A.; Mendenhall, M.J.; Mills, R.F. Radio frequency fingerprinting commercial communication devices to enhance electronic security. Int. J. Electron. Secur. Digit. Forensic 2008, 1, 301–322. [Google Scholar] [CrossRef]
- Liu, M.-W.; Doherty, J.F. Nonlinearity Estimation for Specific Emitter Identification in Multipath Environment. In Proceedings of the 2009 IEEE Sarnoff Symposium, Princeton, NJ, USA, 30 March–1 April 2009. [Google Scholar] [CrossRef]
- Dudczyk, J.; Kawalec, A. Identification of emitter sources in the aspect of their fractal features. Bull. Pol. Acad. Sci. Tech. Sci. 2013, 61, 623–628. [Google Scholar] [CrossRef]
- Tang, Z.; Li, S. Steady Signal-Based Fractal Method of Specific Communications Emitter Sources Identification. In Wireless Communications, Networking and Applications, Wcna 2014; Zeng, Q.A., Ed.; Springer: New Delhi, India, 2016; Vol. 348, pp. 809–819. [Google Scholar]
- Huang, G.; Yuan, Y.; Wang, X.; Huang, Z. Specific Emitter Identification Based on Nonlinear Dynamical Characteristics. Canadian J. Electric. Comput. Eng. Rev. Canad. Genie Electriq. Inform. 2016, 39, 34–41. [Google Scholar] [CrossRef]
- Wu, L.; Zhao, Y.; Wang, Z.; Abdalla, F.Y.O.; Ren, G. Specific emitter identification using fractal features based on box-counting dimension and variance dimension. In Proceedings of the 2017 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), 1 Bilbao, Spain, 8–20 December 2017; pp. 226–231. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.L.C.; Shih, H.H.; Zheng, Q.N.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. London, Ser. A 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. Ieee Trans. Sign. Proc. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Gilles, J. Empirical Wavelet Transform. IEEE Trans. Sign. Proc. 2013, 61, 3999–4010. [Google Scholar] [CrossRef]
- Satija, U.; Trivedi, N.; Biswal, G.; Ramkumar, B. Specific Emitter Identification Based on Variational Mode Decomposition and Spectral Features in Single Hop and Relaying Scenarios. IEEE Trans. Inf. Forensic Secur. 2019, 14, 581–591. [Google Scholar] [CrossRef]
- Yuan, Y.; Huang, Z.; Wu, H.; Wang, X. Specific emitter identification based on Hilbert-Huang transform-based time-frequency-energy distribution features. IET Commun. 2014, 8, 2404–2412. [Google Scholar] [CrossRef]
- Gok, G.; Alp, Y.K.; Altiparmak, F. Radar Fingerprint Extraction via Variational Mode Decomposition. In Proceedings of the 2017 25th Signal Processing and Communications Applications Conference (Siu), Antalya, Turkey, 15–18 May 2017. [Google Scholar]
- Li, Y.; Chen, X.; Yu, J.; Yang, X. A Fusion Frequency Feature Extraction Method for Underwater Acoustic Signal Based on Variational Mode Decomposition, Duffing Chaotic Oscillator and a Kind of Permutation Entropy. Electronics 2019, 8. [Google Scholar] [CrossRef]
- Gao, J.; Shen, L.; Gao, L.; Lu, Y. A Rapid Accurate Recognition System for Radar Emitter Signals. Electronics 2019, 8. [Google Scholar] [CrossRef]
- Huang, Y.; Bao, H.; Qi, X. Seismic Random Noise Attenuation Method Based on Variational Mode Decomposition and Correlation Coefficients. Electronics 2018, 7. [Google Scholar] [CrossRef]
- Zhao, Y.; Wu, L.; Zhang, J.; Li, Y. Specific emitter identification using geometric features of frequency drift curve. Bull. Pol. Acad. Sci., Chem. 2018, 66, 99–108. [Google Scholar] [CrossRef]
- Ye, H.; Liu, Z.; Jiang, W. Comparison of unintentional frequency and phase modulation features for specific emitter identification. Electronics Lett. 2012, 48, 875–876. [Google Scholar] [CrossRef]
- Wisell, D.H.; Rudlund, B.; Ronnow, D. Characterization of Memory Effects in Power Amplifiers Using Digital Two-Tone Measurements. IEEE Trans. Instrum. Meas. 2007, 56, 2757–2766. [Google Scholar] [CrossRef]
- Harmer, P.K.; Reising, D.R.; Temple, M.A. Classifier selection for physical layer security augmentation in Cognitive Radio networks. In Proceedings of the 2013 IEEE International Conference on Communications (ICC), Budapest, Hungary, 9–13 June 2013; pp. 2846–2851. [Google Scholar]
- Dudczyk, J.; Kawalec, A. Fast-decision identification algorithm of emission source pattern in database. Bull. Pol. Acad. Sci. Techn. Sci. 2015, 63, 385–389. [Google Scholar] [CrossRef]
- Dudczyk, J.; Kawalec, A. Specific emitter identification based on graphical representation of the distribution of radar signal parameters. Bull. Pol. Acad. Sci. Techn. Sci. 2015, 63, 391–396. [Google Scholar] [CrossRef]
- Kawalec, A.; Owczarek, R.; Dudczyk, J. Data modeling and simulation applied to radar signal recognition. Mol. Quantum Acoust. 2005, 26, 165–173. [Google Scholar]
- Kawalec, A.; Owczarek, R. Specific emitter identification using intrapulse data. In Proceedings of the First European Radar Conference, 2004. EURAD, Amsterdam, The Netherlands, 11–15 October 2004; pp. 249–252. [Google Scholar]
- Jiang, H.; Guan, W.; Ai, L. Specific Radar Emitter Identification Based on a Digital Channelized Receiver. In Proceedings of the 2012 5th International Congress on Image and Signal Processing, Chongqing, China, 16–18 October 2012. [Google Scholar]
- Samborski, R.; Ziolko, M. Speaker Localization in Conferencing Systems Employing Phase Features and Wavelet Transform. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology, Athens, Greece, 12–15 December 2013. [Google Scholar]
- Chen, T.W.; Jin, W.D.; Li, J. Feature Extraction Using Surrounding-Line Integral Bispectrum for Radar Emitter signal. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008. [Google Scholar]
- Shi, Y.; Ji, H. Kernel canonical correlation analysis for specific radar emitter identification. Electronics Lett. 2014, 50, 1318–1319. [Google Scholar] [CrossRef]
- Aubry, A.; Bazzoni, A.; Carotenuto, V.; De Maio, A.; Failla, P. Cumulants-based Radar Specific Emitter Identification. In Proceedings of the 2011 IEEE International Workshop on Information Forensics and Security, Iguacu Falls, Brazil, 29 November–2 December 2011. [Google Scholar]
- Matuszewski, J. Specific emitter identification. In Proceedings of the 2008 International Radar Symposium, Wroclaw, Poland, 21–23 May 2008. [Google Scholar]
- Kawalec, A.; Owczarek, R. Radar emitter recognition using intrapulse data. In Proceedings of the 15th International Conference on Microwaves, Radar and Wireless Communications (IEEE Cat. No.04EX824), Warsaw, Poland, 17–19 May 2004. [Google Scholar]
- Burges, C.J.C. A tutorial on Support Vector Machines for pattern recognition. Data Min. Knowl. Disc. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Gonen, M.; Alpaydin, E. Multiple Kernel Learning Algorithms. J. Mach. Learn. Res. 2011, 12, 2211–2268. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emitter | Envelope Type | Primary Signal Type | ||
|---|---|---|---|---|
| LFM | BPSK | Single Tone | ||
| E1 | LE | s11 | s21 | s31 |
| E2 | TE | s12 | s22 | s32 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, L.; Zhao, Y.; Feng, M.; Abdalla, F.Y.O.; Ullah, H. Specific Emitter Identification Using IMF-DNA with a Joint Feature Selection Algorithm. Electronics 2019, 8, 934. https://doi.org/10.3390/electronics8090934
Wu L, Zhao Y, Feng M, Abdalla FYO, Ullah H. Specific Emitter Identification Using IMF-DNA with a Joint Feature Selection Algorithm. Electronics. 2019; 8(9):934. https://doi.org/10.3390/electronics8090934
Chicago/Turabian StyleWu, Longwen, Yaqin Zhao, Mengfei Feng, Fakheraldin Y. O. Abdalla, and Hikmat Ullah. 2019. "Specific Emitter Identification Using IMF-DNA with a Joint Feature Selection Algorithm" Electronics 8, no. 9: 934. https://doi.org/10.3390/electronics8090934
APA StyleWu, L., Zhao, Y., Feng, M., Abdalla, F. Y. O., & Ullah, H. (2019). Specific Emitter Identification Using IMF-DNA with a Joint Feature Selection Algorithm. Electronics, 8(9), 934. https://doi.org/10.3390/electronics8090934