A Multi-Feature Representation of Skeleton Sequences for Human Interaction Recognition


Abstract
1. Introduction
- A multi-feature representation method of interaction skeleton sequence is proposed for extracting various and complementary features. Specifically, three subnets fed with these features are fused into an ensemble network for recognition.
- A framework combining RNN with CNN is designed for skeleton based interaction recognition, which can model the complex spatio-temporal variations in skeleton joints.
2. Related Work
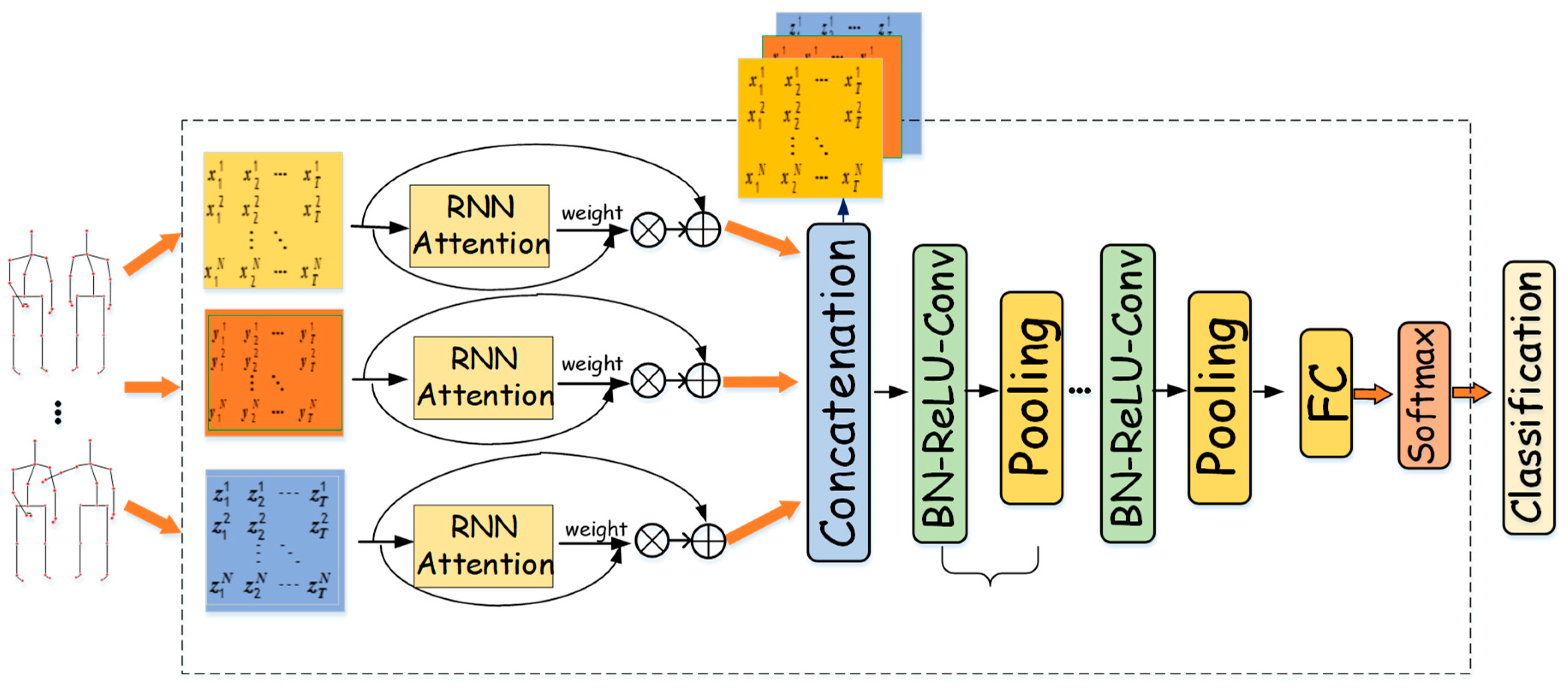
3. Proposed Method
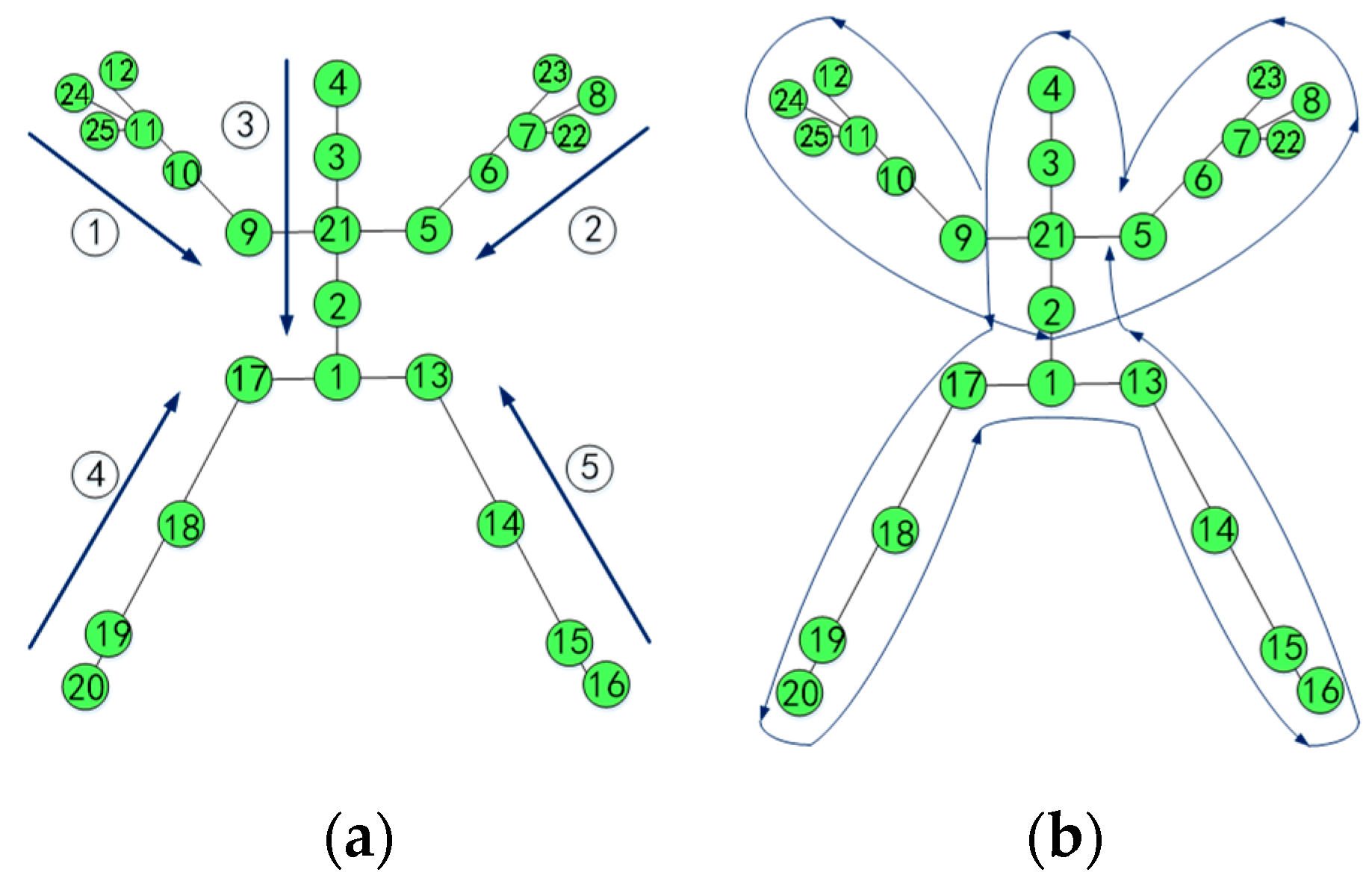
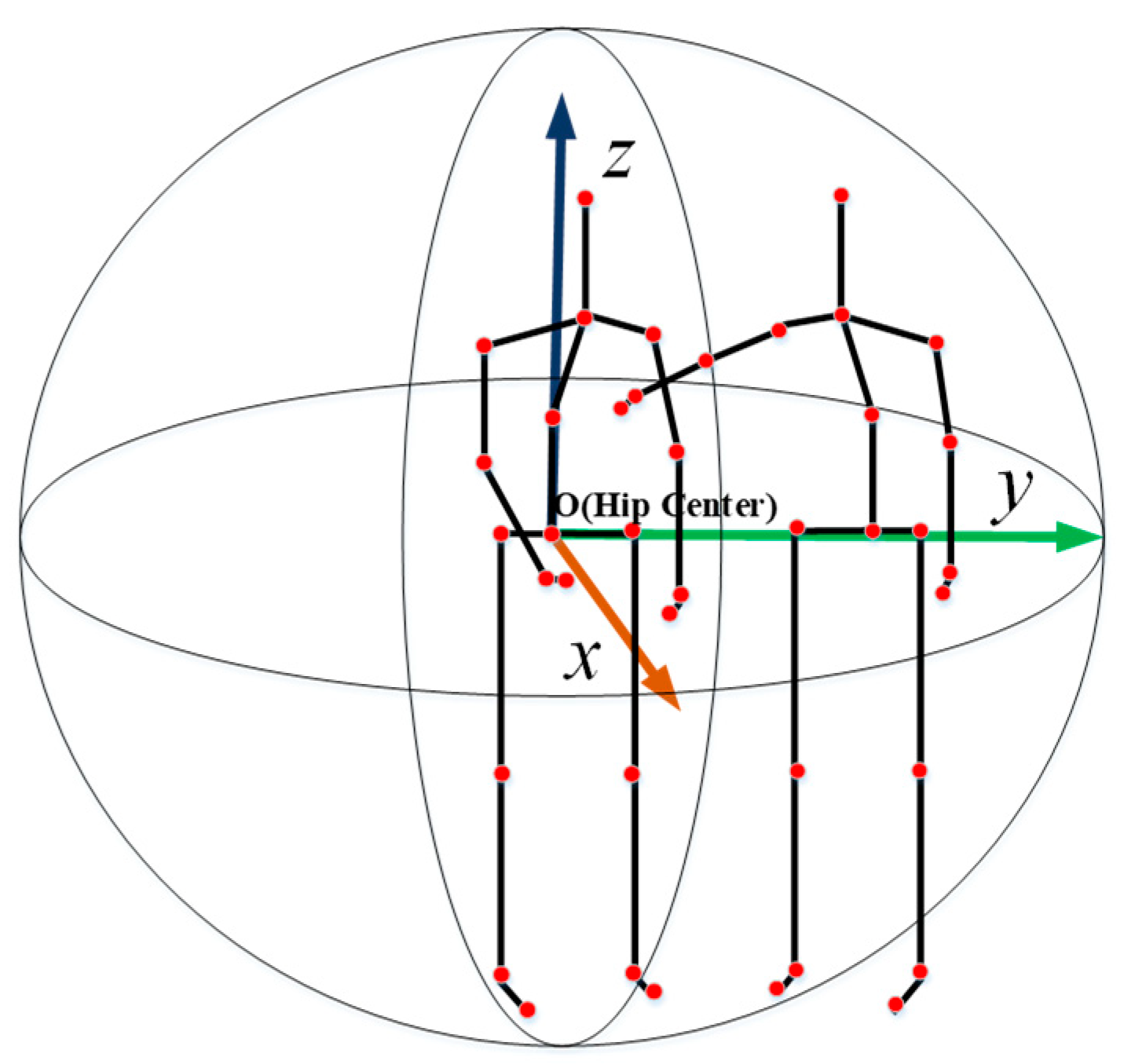
3.1. Multi-Feature Representation from Skeleton Sequences
3.2. Attention Mechanism
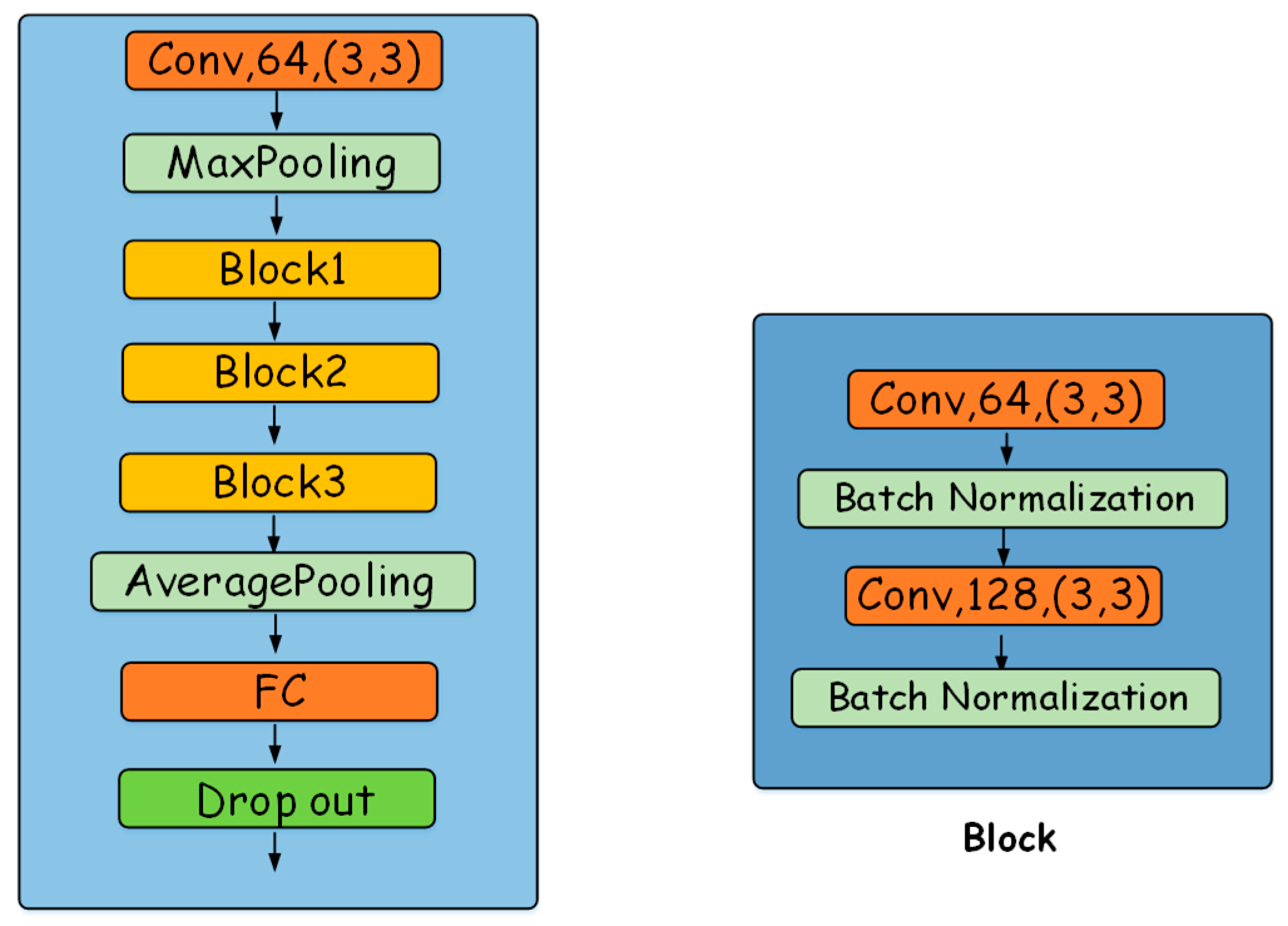
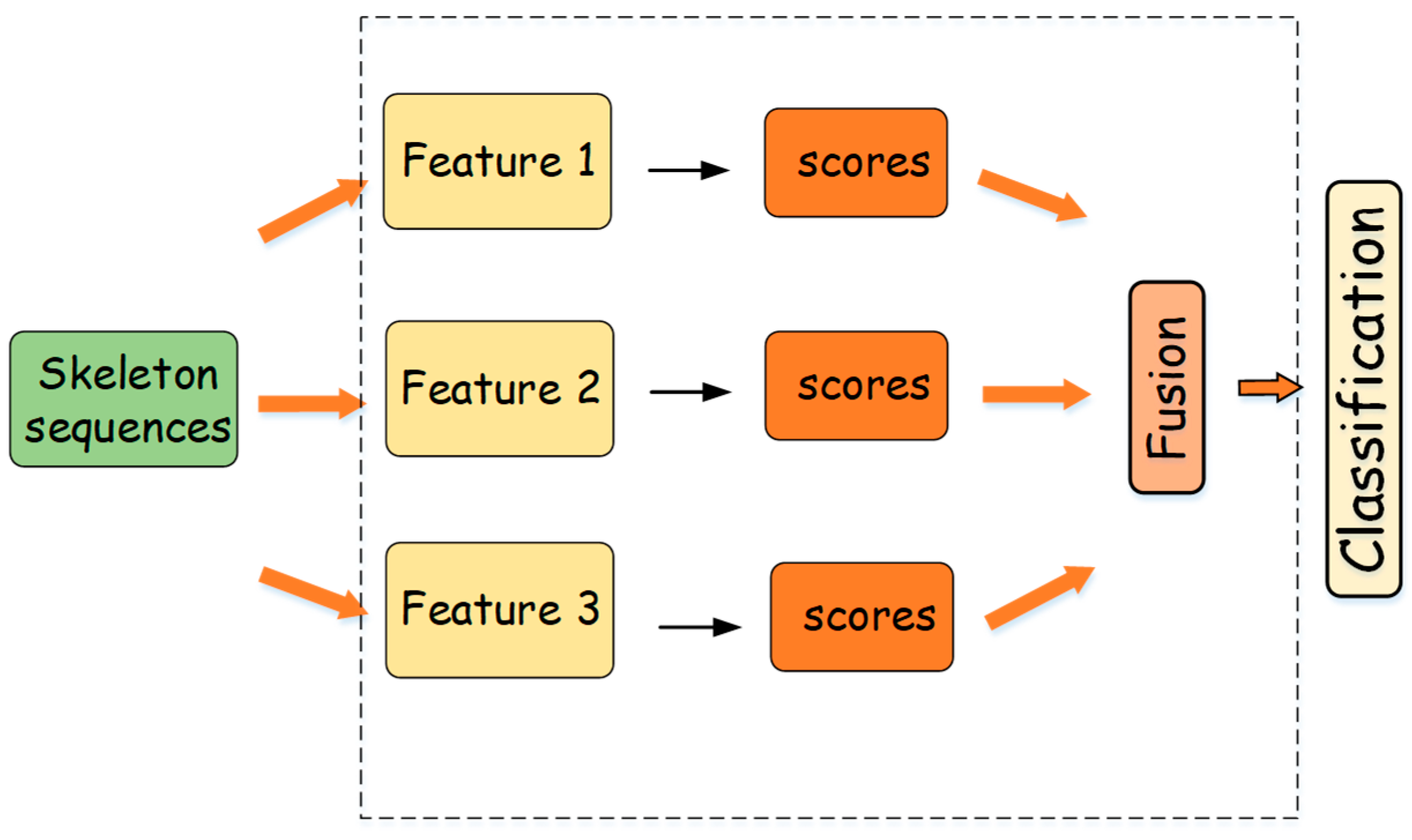
3.3. Ensemble Network
4. Experimental Results
4.1. Dataset
4.2. Implementation Details
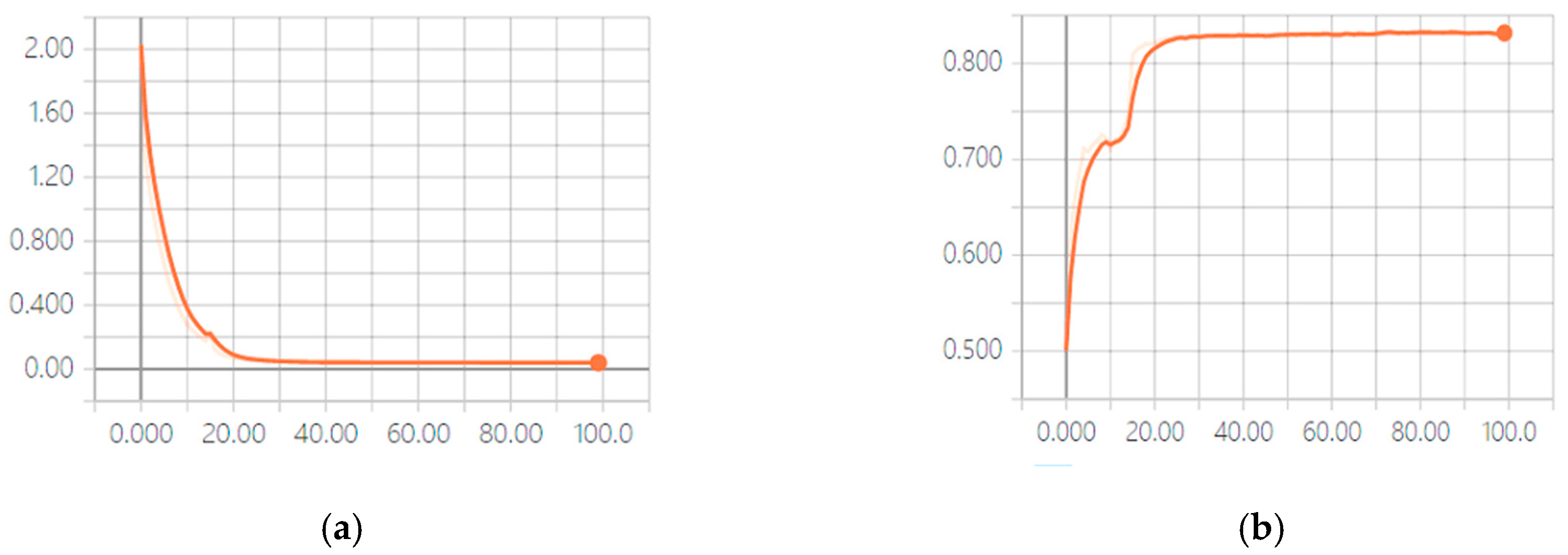
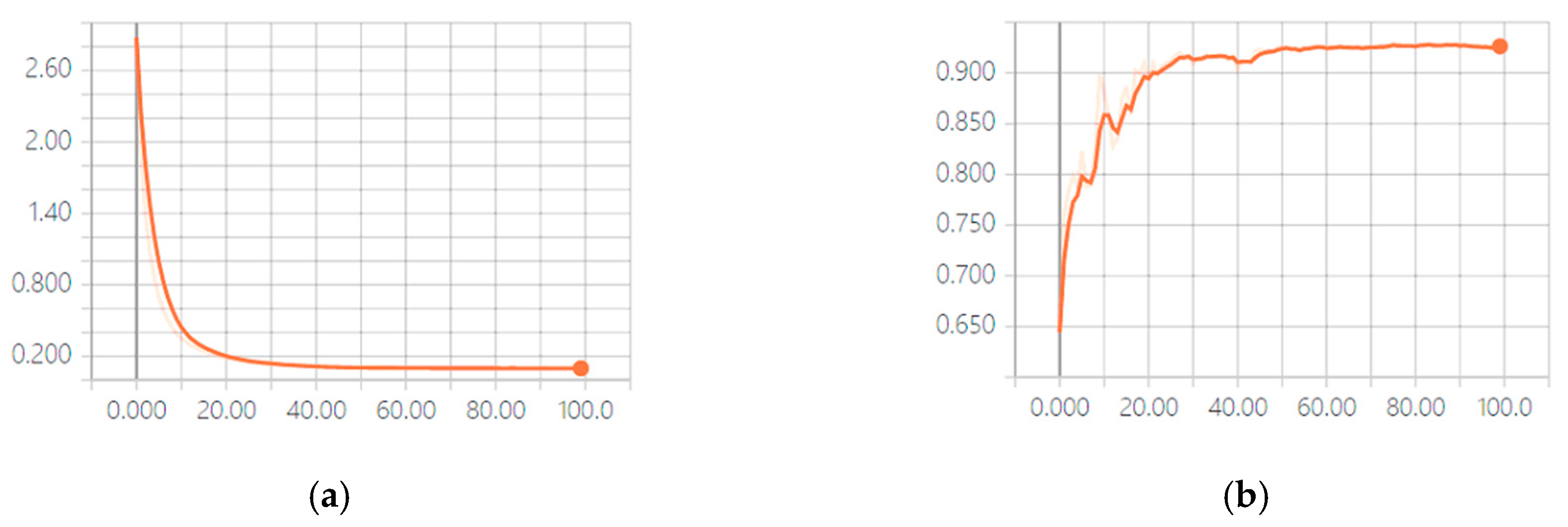
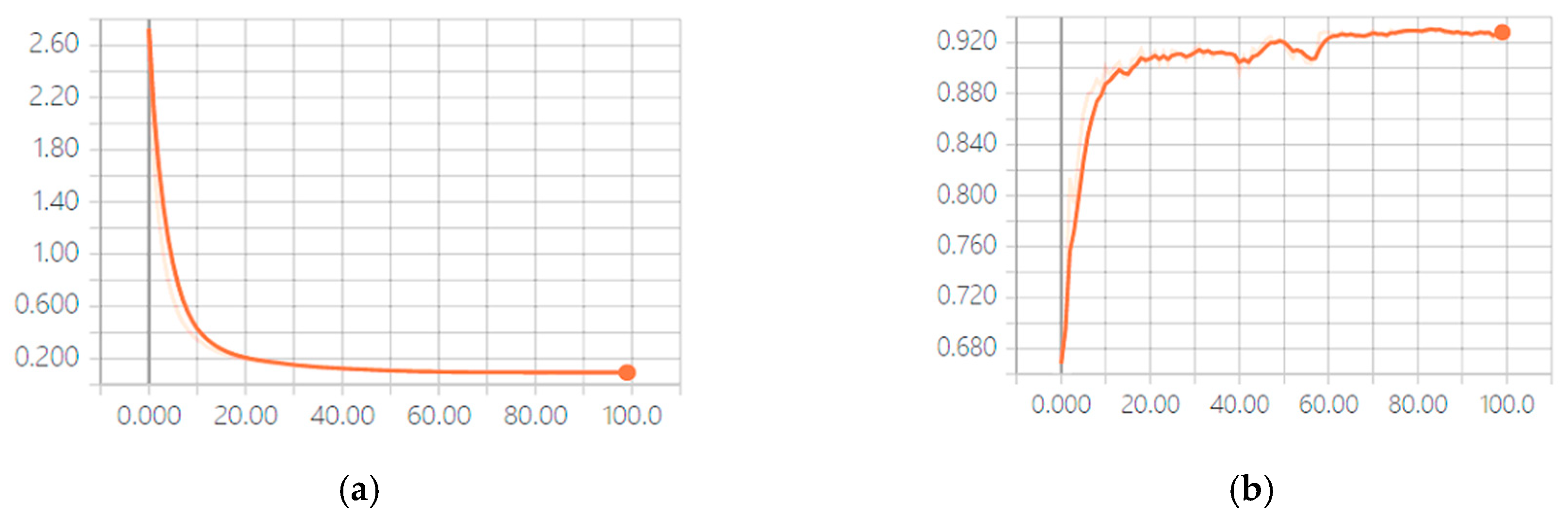
4.3. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Niebles, J.C.; Fei-Fei, L. A hierarchical model of shape and appearance for human action classification. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 19–21 June 2007; pp. 1–8. [Google Scholar]
- Niebles, J.C.; Wang, H.; Fei-Fei, L. Unsupervised learning of human action categories using spatial-temporal words. Int. J. Comput. Vis. 2008, 79, 299–318. [Google Scholar] [CrossRef]
- Rezazadegan, F.; Shirazi, S.; Upcrofit, B.; Milford, M. Action recognition: From static datasets to moving robots. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3185–3191. [Google Scholar]
- Jalal, A.; Kim, Y.H.; Kim, Y.J.; Kamal, S.; Kim, D. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Han, J.G.; Shao, L.; Xu, D.; Shotton, J. Enhanced computer vision with Microsoft Kinect Sensor: A review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [PubMed]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-Time human pose recognition in parts from single depth images. In Proceedings of the IEEE Conference Computer Vision and Pattern Recognition, Providence, RI, USA, 20–25 June 2011; pp. 1297–1304. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Gated feedback recurrent neural networks. In Proceedings of the 32nd International Conference on Machine Learning, Lile, France, 6–11 July 2015. [Google Scholar]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person interaction detection using body-pose features and multiple instance learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 28–35. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A large scale dataset for 3-D human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1010–1019. [Google Scholar]
- Du, Y.; Wang, W.; Wang, H. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Zhu, W.; Lan, C.; Xing, J.; Zeng, W.; Xie, X. Co-occurrence feature learning for skeleton based action recognition using regularized deep lstm networks. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 3697–3704. [Google Scholar]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-Temporal LSTM with trust gates for 3D human action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Volume 9907, pp. 816–833. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatiotemporal attention model for human action recognition from skeleton data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4263–4270. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Joint distance maps based action recognition with convolutional neural network. IEEE Signal Process. Lett. 2017, 24, 624–628. [Google Scholar] [CrossRef]
- Xu, Y.; Cheng, J.; Wang, L.; Xia, H.; Liu, F.; Tao, D. Ensemble one- dimensional convolution neural networks for skeleton-based action recognition. IEEE Signal Process. Lett. 2018, 25, 1044–1048. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4570–4579. [Google Scholar]
- Ke, Q.; An, S.; Bennamoun, M.; Sohel, F.; Boussaid, F. SkeletonNet: Mining deep part features for 3-d action recognition. IEEE Signal Process. Lett. 2017, 24, 731–735. [Google Scholar] [CrossRef]
- Li, C.; Hou, Y.; Wang, P.; Li, W. Multiview-based 3-D action recognition using deep networks. IEEE Trans. Hum. Mach. Syst. 2019, 49, 95–104. [Google Scholar] [CrossRef]
- Kim, T.S.; Reiter, A. InterpreTable 3D Human Action Analysis with Temporal Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1623–1631. [Google Scholar]
- Wang, P.; Li, W.; Ogunbona, P.; Wan, J.; Escalera, S. RGB-D-based human motion recognition with deep learning: A Survey. Comput. Vis. Image Underst. 2018, 171, 118–139. [Google Scholar] [CrossRef]
- Ji, Y.; Cheng, H.; Zheng, Y.; Li, H. Learning contrastive feature distribution model for interaction recognition. J. Vis. Commun. Image Represent. 2015, 33, 340–349. [Google Scholar] [CrossRef]
- Wang, H.; Wang, L. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3633–3642. [Google Scholar]
- Cao, C.; Lan, C.; Zhang, Y.; Zeng, W.; Lu, H.; Zhang, Y. Skeleton- based action recognition with gated convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2018. [Google Scholar] [CrossRef]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. Learning clip representations for skeleton-based 3d action recognition. IEEE Trans. Image Process. 2018, 27, 2842–2855. [Google Scholar] [CrossRef] [PubMed]
- Pei, W.; Baltrusaitis, T.; Tax, D.M.; Morency, L.P. Temporal attention-gated model for robust sequence classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 820–829. [Google Scholar]
- Jain, A.; Nandakumar, K.; Ross, A. Score normalization in multimodal biometric systems. Pattern Recognit. 2005, 38, 2270–2285. [Google Scholar] [CrossRef]
- Liu, B.; Ju, Z.; Liu, H. A structured multi-feature representation for recognizing human action and interaction. Neurocomputing 2018, 318, 287–296. [Google Scholar] [CrossRef]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 786–792. [Google Scholar]
- Ji, Y.; Ye, G.; Cheng, H. Interactive body part contrast mining for human interaction recognition. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Li, W.; Wen, L.; Chuah, M.C.; Lyu, S. Blind human action recognition: A practical recognition system. In Proceedings of the IEEE International Conference on Computer Vision, Columbus, OH, USA, 24–27 June 2014; pp. 4444–4452. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. Joint angles similarities and HOG2 for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 465–470. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Dataset | ||
|---|---|---|---|
| NTU RGB+D | SBU | ||
| Cross Subject | Cross View | ||
| Feature 1 | 77.52% | 86.73% | 89.28% |
| Feature 2 | 77.95% | 86.26% | 89.94% |
| Feature 3 | 79.86% | 87.33% | 92.25% |
| Sum fusion | 81.49% | 90.12% | 93.23% |
| Product fusion | 82.53% | 91.75% | 93.58% |
| Method | Accuracy |
|---|---|
| Raw Skeleton [9] | 49.70% |
| Joint Feature [32] | 86.90% |
| CHARM [33] | 83.90% |
| Hierarchical RNN [11] | 80.35% |
| Deep LSTM [12] | 86.03% |
| Deep LSTM+Co-occurrence [12] | 90.41% |
| ST-LSTM [13] | 88.60% |
| ST-LSTM+Trust Gate [13] | 93.30% |
| RotClips+MTCNN [27] | 94.17% |
| HCN [31] | 98.60% |
| Proposed Method | 93.58% |
| Method | Cross Subject | Cross View |
|---|---|---|
| Hierarchical RNN [11] | 59.10% | 64.00% |
| Dynamic skeletons [34] | 60.23% | 65.22% |
| ST-LSTM+Trust Gate [13] | 69.20% | 77.70% |
| Two-stream RNNs [24] | 71.30% | 79.50% |
| STA-LSTM [30] | 73.40% | 81.20% |
| Res-TCN [22] | 74.30% | 83.10% |
| ST-GCN [35] | 81.50% | 88.30% |
| Multiview IJTM [21] | 82.96% | 90.12% |
| HCN [31] | 86.50% | 91.10% |
| Proposed Method | 82.53% | 91.75% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Deng, H. A Multi-Feature Representation of Skeleton Sequences for Human Interaction Recognition. Electronics 2020, 9, 187. https://doi.org/10.3390/electronics9010187
Wang X, Deng H. A Multi-Feature Representation of Skeleton Sequences for Human Interaction Recognition. Electronics. 2020; 9(1):187. https://doi.org/10.3390/electronics9010187
Chicago/Turabian StyleWang, Xiaohang, and Hongmin Deng. 2020. "A Multi-Feature Representation of Skeleton Sequences for Human Interaction Recognition" Electronics 9, no. 1: 187. https://doi.org/10.3390/electronics9010187
APA StyleWang, X., & Deng, H. (2020). A Multi-Feature Representation of Skeleton Sequences for Human Interaction Recognition. Electronics, 9(1), 187. https://doi.org/10.3390/electronics9010187