Abstract
Gesture recognition has been applied in many fields as it is a natural human–computer communication method. However, recognition of dynamic gesture is still a challenging topic because of complex disturbance information and motion information. In this paper, we propose an effective dynamic gesture recognition method by fusing the prediction results of a two-dimensional (2D) motion representation convolution neural network (CNN) model and three-dimensional (3D) dense convolutional network (DenseNet) model. Firstly, to obtain a compact and discriminative gesture motion representation, the motion history image (MHI) and pseudo-coloring technique were employed to integrate the spatiotemporal motion sequences into a frame image, before being fed into a 2D CNN model for gesture classification. Next, the proposed 3D DenseNet model was used to extract spatiotemporal features directly from Red, Green, Blue (RGB) gesture videos. Finally, the prediction results of the proposed 2D and 3D deep models were blended together to boost recognition performance. The experimental results on two public datasets demonstrate the effectiveness of our proposed method.
1. Introduction
Gesture recognition has attracted great attention from researchers from all over the word due to its applications in many fields such as human–robot interactions, video surveillance, entertainment, and smart houses. Gesture is a natural and comfortable way of communication. However, recognizing meaningful expressions of motion by the human hand is a challenging topic in computer vision because of some gesture-irrelevant factors, for example complex background, illumination artifacts, occlusion, and so on [1].
The issue of hand gesture recognition has been addressed for decades. Over the past decades, many methods were proposed to solve this problem. According to data modalities used to recognize gesture, gesture recognition methods can be broadly grouped into three categories: video-based method, depth information-based method, and skeleton-based method [2]. The video-based gesture methods only rely on Red, Green, Blue (RGB) video information for investigating sophisticated features. In recent years, with the advent of multimodal sensors like Microsoft Kinect, many depth information-based methods have emerged. Due to rich three-dimensional (3D) structural information in depth images, most of the existing methods are mainly based on RGB and Depth (RGB-D) videos. However, there are still some limitations with this kind of method, such as the price of such a camera and the additional computation for depth data. Skeleton-based methods have been intensively studied [3,4] due to their insensitivity to viewpoint, scale, and speed. However, skeletal data have to be estimated by a tracking algorithm, and in some cases, there exist serious noise skeletal data or missing data. As a result, it is less reliable than RGB-D images [5]. Due to the extremely common use of RGB camera in real life, this paper focuses on the video-based method. For video-based gesture recognition methods, the early methods devoted to exploit discriminative and robust features, and then these features were fed into a classifier for gesture recognition. In the studies of Konecny and Hagara [6] and Danafar and Gheissari [7], histogram of oriented gradients (HOG) and histogram of optical flow (HOF) were employed as spatiotemporal features for representing hand gesture motion. Wan, Gui, and Li [8] proposed the mixed features based on sparse key-points for one shot learning of gesture recognition. In a study by Kane and Khanna [9], a shape matrix was devised to describe hand silhouettes; it was a region-based descriptor. Apart from these geometrical features, some statistical models, such as the hidden Markov model (HMM) [10] and conditional random model (CRF) [11] were also used for gesture recognition. For gesture classification, many classifiers like Extreme Learning Machine (ELM) [12], Support Vector Machine (SVM) [7], and Bayes classifier [9], have been used in this field. All of the above discussed methods belong to hand-crafted features. These hand-crafted feature-based methods have the disadvantage of not always extracting the most essential features of gesture motions, which affects the recognition performance.
Recently, with the successful applications of deep learning in various fields [13,14,15], many researchers have addressed deep learning-based methods for gesture recognition. In the study by Chung, Chung, and Tsai [16], two modified deep convolution neural network (CNN) architectures based on AlexNet and VGGNet were developed for gesture recognition. Cheng et al. [17] proposed a joint network based on CNN and Restricted Boltzmann Machine (RBM) for gesture recognition. However, the two above-mentioned studies only focused on static gesture recognition. For dynamic gesture recognition, a 3D CNN model was proposed by Zhang and Wang [18] for encoding spatial and temporal information simultaneously. To better represent motion patterns in video-based gesture, the optical flow images were constructed from the RGB videos in a study by Li et al. [19], and then combined with depth data as inputs of the C3D model for extracting the spatiotemporal features respectively. To further improve the recognition performance, multiple features from different deep models were exploited by Elboushaki et al. [20], and then fused for prediction. The deep model proposed was based on 3D ResNet [20]. Although these 3D CNN-based methods have achieved some promising results, there is still room for improvement. The first is to overcome the influence of interference on recognition performance, such as background, occlusion, lighting, and so on. The other is to design a more effective CNN model to learn spatiotemporal features better.
CNN has the ability of learning high level hierarchical features by increasing the number of layers. However, the input information or gradient tends to vanish when increasing the number of layers. To solve this problem, a more effective deep model, called dense convolutional network (DenseNet), was proposed by Huang et al. [21], which can connect each layer to every other layer in a feed-forward fashion. Inspired by the idea that dense connections can improve the feature utilization, we extended 2D DenseNet to 3D DenseNet for gesture recognition. In this paper, we propose a 3D DenseNet model for better extracting spatiotemporal features. Although 3D DenseNet has been applied in other tasks, there is no previous study to use 3D DenseNet for gesture recognition. To eliminate the influence of irrelevant-gesture factors on recognition performance, the method of motion history image (MHI) [22] is employed to accumulate motion information into a static image, which is an effective de-background process and gives more concerns on the motion of performers. A 2D CNN based on VGG Net [23] is then trained on the MHI images. Finally, the predicted results of 2D CNN and 3D DenseNet are integrated to boost the recognition performance. The advantage of the proposed method is that different deep models can provide more complementary motion patterns, in which the proposed 3D DenseNet model can capture the spatiotemporal information thorough the structure of the 3D deep network, while the spatiotemporal features in the 2D CNN are obtained by training the 2D CNN model on the MHI images. In summary, the contributions of this research are highlighted as follows:
(1) We propose a 3D DenseNet model for gesture recognition, which can directly learn spatiotemporal features from RGB gesture videos. Compared with previous researches based on 3D CNN model, the proposed 3D DenseNet model achieves better recognition performance. To the best of our knowledge, it is the first time a 3D DenseNet model is used for gesture recognition.
(2) We introduce a more compact and robust motion representation process by using MHI and pseudo-coloring technique. The MHI can eliminate the effect of irrelevant-gesture factors and integrate useful motion information into a single image, which can overcome the disadvantage of direct learning on raw data. To further increase the distinctiveness of motion representation, the MHI image is encoded by a pseudo-coloring technique.
(3) To further improve the recognition performance, different fusion strategies at the feature level and decision level are investigated for fusing the outputs of the 3D DenseNet model and 2D CNN model. The experimental results show that the performance based on the fusion mechanism is better than the method based on the individual model.
The rest of this paper is organized as follows. Section 2 gives the details of the proposed method, including the framework of the proposed method, the proposed 3D DenseNet model, the modified 2D CNN model, and the fusion strategy of the predicted results provided by the 3D DenseNet model and the modified 2D CNN model. The experimental results are presented in Section 3. Finally, the conclusion is drawn in Section 4.
2. Methodology
In this section, the framework of the proposed gesture recognition method is given, and then each part of the proposed method is introduced in detail.
2.1. The Framework of the Proposed Method
As shown in Figure 1, the proposed gesture method is composed of two main models: a 3D DenseNet model and a 2D motion representation CNN model based on VGGNet. The proposed 3D DenseNet model includes a 3D convolution layer, three dense blocks, two transition layers, a fully connected layer, and a Softmax classification layer. Compared with the traditional 2D networks, the 3D model can take the temporal information into consideration for simultaneously extracting spatiotemporal features. Thus, it is more beneficial to the video clip inputs. In addition, the 3D DenseNet model requires fewer parameters than a traditional network because of its dense connections. Hence the network is easier to train and can reduce over-fitting. The 2D motion representation CNN model uses MHI and pseudo-coloring technique to get a compact and robust motion representation, which can remove the influence of background and improve the discriminative ability of motion representation. Afterwards, a modified 2D CNN based on VGGNet is employed to extract the features from this motion representation and then a Softmax classifier is used to predict the gesture classes. The proposed 3D DenseNet model and 2D motion representation CNN model can be regarded as two heterogeneous models. To take the advantage of these two models, the scores from both models are later fused to get the final prediction results.
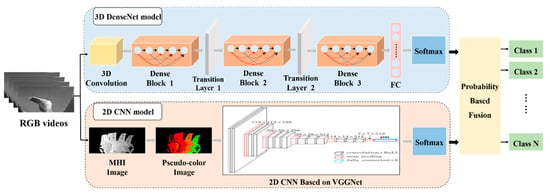
Figure 1.
The framework of the proposed method.
2.2. The Proposed 3D DenseNet Model for Gesture Recognition
Unlike previous well-known CNN networks, such as AlexNet and ResNet, which only connect the output of the (l–1)th layer as input to the lth layer, the DenseNet network uses dense connectivity to alleviate the vanishing-gradient problem and strengthen feature propagation. The dense connectivity means that the feature maps of all preceding layers are concatenated together as inputs of the current layer and the output feature maps of the current layer are used as inputs of all its subsequent layers. Suppose a network consists of L layers and the output of the lth layer is denoted as . For each layer, a non-linear transformation , which includes three consecutive operations of batch normalization (BN), rectified linear unit (ReLU), and convolution, is implemented. Thus, can be represented as follows [21]:
where refers to the concatenation of feature maps generated in layers 0,1,…, l–1.
Based on the idea of dense connectivity, the 2D DenseNet is extended to 3D DenseNet for processing 3D gesture video images. Table 1 presents our designed 3D DenseNet architecture with two versions, the first version named, D20-3D-DenseNet, has 20 layers, while the other version, D40-3D-DenseNet, has 40 layers. In Table 1, each “conv” consists of the sequence of batch normalization (BN), rectified linear unit (ReLU), and convolution. The parameter in Table 1 is the growth rate, which is used to control the number of feature maps produced in each layer. The parameter is usually set as a small value for preventing the number of feature maps growing too fast and causing the number of parameters in the network to be too large. In this paper, is set as 12 based on experience and the experimental test.

Table 1.
The proposed three-dimensional (3D) dense convolutional network (DenseNet) architecture.
As shown in Table 1, the video clips for the input of the network have a size of d × h × w, where d is the number of frames, h and w are the height and width of the frame, respectively. The input gesture videos are firstly convoluted with a 5 × 5 × 5 convolution kernel, where the stride is 1 × 2 × 2. To reduce the size of feature maps, a 3D maximum pooling was then performed. The kernel size of this pooling layer was 2 × 2 × 2 and the stride was 1 × 2 × 2. Afterwards, there were three dense blocks and two transition layers in the proposed 3D DenseNet model. Each dense block was composed by a set of dense units, where a dense unit consisted of a 1 × 1 × 1 conv and a 3 × 3 × 3 conv. The 1 × 1 × 1 convolution was employed as bottleneck layer to reduce the number of input feature-maps. To reduce the size of the feature maps, the transition layer was introduced between two dense blocks. The transition layer was composed of a 1 × 1 × 1 3D conv and a 2 × 2 × 2 3D average pooling layer. At the end of the last dense block, a classification layer, which included a global average pooling layer, a fully connected layer, and a Softmax layer, was attached.
2.3. The 2D Motion Representation CNN Model
As depicted in Figure 1, the 2D motion representation CNN model consists of four parts: MHI, pseudo-coloring, 2D CNN based on VGGNet, and a Softmax classifier.
2.3.1. Motion Representation Based on MHI
Motion history image (MHI) is a simple yet effective motion representation method, which was firstly presented by Bobick and Davis in 2001 [22]. In this paper, MHI is used to encode the motion information of a sequence of gesture videos into a single image. Meanwhile, many gesture-irrelevant factors are eliminated. To make MHI less sensitive to light change and silhouette noise, the RGB image sequence is firstly converted to grayscale images [20]. Let represent a grayscale image sequence, where is the pixel position and is the frame number. The MHI image is denoted by . Then, the MHI of can be computed as Equation (2).
where means the duration time of the movement of a frame, is a decay parameter, and is an updated function which can be computed by frame differences as follows:
where is a threshold parameter. represents the difference between two consecutive frames, which is defined as follows:
For MHI, the parameters , , and have important effects on the motion information contained in the MHI image. Figure 2 gives the experimental results of different parameter values of on four types of gesture motion (swipe-L, swipe-R, close, and open in VIVA gesture dataset [24]). From Figure 2a where is relatively small, we observed that the initial motion information has gotten lost and the gray values in the MHI image are small in whole. On the contrary, in Figure 2c, is relatively large, the gray values on the motion region are too large and do not distinguish the order of movement happening. While is a modest value in Figure 2b, the distribution of gray values is uniform and the contour of the MHI image is clear. Thus, the parameter is selected as 16.

Figure 2.
Motion history image of four gestures (from left to right: swipe-L (left), swipe-R (right), close, and open) with different values. (a) ; (b) ; (c) .
Figure 3 shows the experimental results of parameter , where the value of is fixed as 16. The decay parameter depends on the required time of the value of a pixel decayed to zero. By comparing the third column of Figure 3, we can see the interference region will appear when is small, while the values of the early moving parts are zero and there are hollow regions in the MHI image when is large. Based on the experimental test, is set as 5.

Figure 3.
Motion history image of four gestures (from left to right: swipe-L, swipe-R, close, and open) with different values. (a) ; (b) ; (c) .
For the parameter , three values of 10, 35, and 60 were tested in Figure 4. In Figure 4, there are some undefined moving regions in the MHI image when is small. These undefined moving regions are considered as noise. While is too large, there are some holes in the MHI image, which means much motion information was filtered. From Figure 4, we can see that the value of 35 is appropriate for parameter .
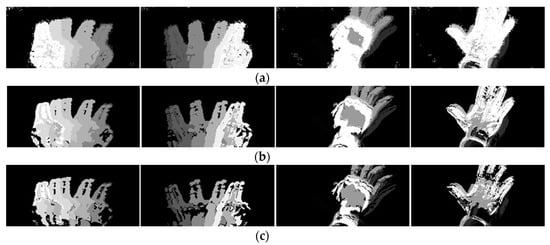
Figure 4.
Motion history image of four gestures (from left to right: swipe-L, swipe-R, close, and open) with different values. (a) ; (b) ; (c) .
2.3.2. Pseudo-Coloring for MHI
Since the human eye only perceives about 100 shades of gray, small differences in gray values are very hard to distinguish. However, the human eye is very sensitive to color. Therefore, the pseudo-coloring technique was investigated in this paper to strengthen the perceptual ability of the human visual system and get more information from gray images. Among the existing pseudo-coloring methods, the rainbow encoding method proposed in [25] is one of the most used methods. To further enhance the spatiotemporal information contained in the MHI gray image, the MHI is transformed into a pseudo-colored image by the rainbow encoding method.
For a given gray image , its corresponding RGB normalized coloring code can be expressed as follows:
where,
Figure 5 shows two MHIs and their corresponding pseudo-colored images. From Figure 5, we can see that there are more discriminative motion patterns in pseudo-colored images compared with their grayscale versions. To further demonstrate the effectiveness of the MHI and pseudo-coloring technique, Figure 6 illustrates four MHIs and their corresponding pseudo-colored images from four types of gesture motions in UTD-MHAD dataset [26].

Figure 5.
Two examples of motion history images (MHIs) and their corresponding pseudo-colored images. (a) Swipe-L; (b) swipe-R.

Figure 6.
Four types of MHIs and their corresponding pseudo-colored images from UTD-MHAD dataset. (a) Swipe-L; (b) swipe-R; (c) draw-circle-CW; (d) draw-circle-CCW.
2.3.3. 2D CNN Based on VGGNet
Once the motion representation is computed from gesture videos, the next stage is to build a 2D CNN model for extracting the features from this motion representation. Due to the powerful ability of VGGNet, it is transferred as our 2D CNN model. In this paper, the VGG19 deep model is used. For our 2D CNN model, the structure and parameters at the first 17 layers of VGG19 are frozen and used as the first part of our 2D CNN model. Next, there are three fully connected layers, which need to be trained using training samples. The first fully connected layer has 4096 nodes followed by a ReLU function, while the second has 1000 nodes also followed by a ReLU function. For the third fully connected layer, the number of its nodes is equal to the number of gesture classes and following it is a Softmax classifier.
2.4. Fusion Scheme
There are three fusion strategies, which are data level, feature level, and decision level. Due to only RGB video inputs, the data level fusion is not considered in this study. For feature level fusion, the outputs of the second fully connected layer with 1000 dimensional features in the 2D CNN are concatenated with the outputs of the 3D DenseNet, and then a Softmax classifier is trained for gesture prediction. As the output of a Softmax classifier is a class-membership probability for each gesture, thus the prediction results of 3D DenseNet and 2D CNN model are fused by a simple probability-based ensemble method at the decision level; the final prediction class is the one whose value is the maximum value. Suppose the prediction result based on 2D CNN is , the prediction result based on 3D DenseNet is . Then the fusion result is defined as follows.
where is the number of gesture classes, and are two weight coefficients which will be determined by the experiment in the next section. The final class label is determined as Equation (8).
3. Experiment
3.1. Dataset
To validate the effectiveness of the proposed method, two challenging public gesture datasets called VIVA [20] and UTD-MHAD [26] were employed to conduct the experiment.
The VIVA challenge is an in-vehicle gesture dataset, where the type of gesture varies from coarse hand motion to fine finger motion, and there are large variations in illumination, occlusion, and performance of the gestures. The dataset includes 19 categories of hand gestures, namely: scroll-right (R), scroll-left (L), scroll-up (U), scroll-down (D), swipe-V, swipe-X, swipe-+, swipe-R, swipe-L, swipe-D, swipe-U, Clike-1, Clike-2, pinch, expand, rotate-CCW, rotate-CW, open, and close. All gestures are performed by eight subjects about five times, which amount to 841 RGB video samples. Due to less samples in the VIVA dataset, the data augmentation technique is used to prevent overfitting. By applying horizontal mirroring, vertical mirroring, and Gaussian blur, the sample size is increased from 841 to 3264.
The UTD-MHAD dataset consists of four temporally synchronized data modalities, including RGB videos, depth videos, skeleton positions, and inertial signals. In this study, we only used the RGB videos. The dataset contains 864 RGB video samples which are labeled into 27 gesture categories, where each gesture action is performed by eight different individuals and each individual repeats each gesture four times. Due to different speeds and different heights of subjects, the dataset has large intra-class variations.
3.2. Experimental Setup
Our experiments are executed on a PC with Intel Core-i7-7700HQ @2.8GHZ, 8GB RAM, and Nvida-GTX1060-6G GPU. The program is implemented by Python under TensorFlow 1.2 on Linux Ubuntu 16.04.
For the training of 2D motion representation CNN model, the stochastic gradient descent (SGD) algorithm was carried out with a cross entropy loss function. The initial learning rate was set to 0.001 and the batch size was set as 45. The training process stopped after 1500 iterations. Figure 7 is the training loss and test accuracy curves. As can be seen in Figure 6, the convergence speed is very fast.
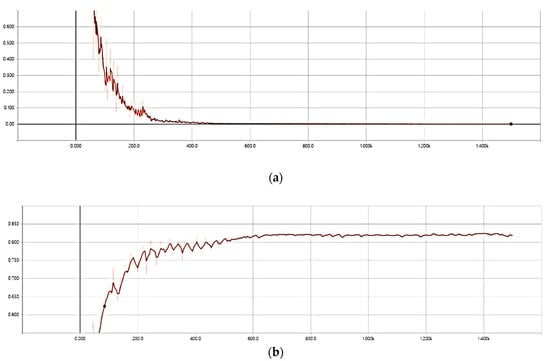
Figure 7.
Training and test curve of two-dimensional (2D) motion representation CNN model on VIVA dataset. (a) training loss curve; (b) test accuracy curve.
With regard to the training of the proposed 3D DenseNet model, we also used the SGD algorithm and the cross entropy loss function. The batch size was set to 10 and the model trained with 70 epochs on the whole training data. The initial learning rate was set to 0.1 and decreased by a factor of 0.1 at the 30th epoch and the 55th epoch. Figure 8 gives the training loss and test accuracy curves of the proposed D40-3D-DenseNet model on VIVA dataset.
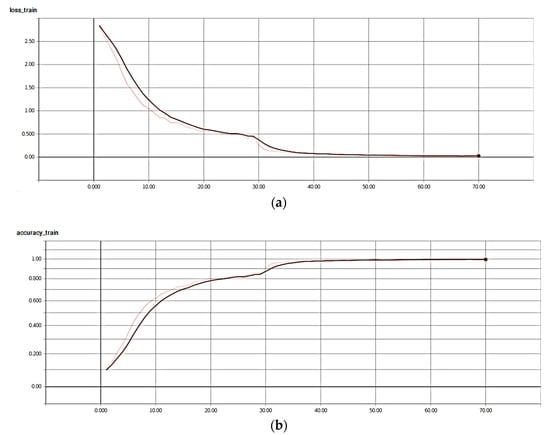
Figure 8.
Training and test curve of the proposed 3D DenseNet model on VIVA dataset. (a) training loss curve; (b) test accuracy curve.
3.3. Performance Evaluation of the Proposed Method
In this subsection, the performance of the proposed 2D motion representation CNN model, 3D DenseNet model, and the fusion scheme are evaluated on the VIVA dataset. The accuracy, which indicates the proportion of correctly classified samples among the whole sample, was used as the evaluation index.
Table 2 gives the results of the proposed 2D motion representation CNN model, where two cases of data augmentation and pseudo coloring are compared. From Table 2, we can conclude that the data augmentation has obvious improvement on model performance. Especially in the case of pseudo-coloring, the performance has been improved greatly, which means the pseudo-coloring has a better ability to enhance the texture and details of the motion patterns compared with the gray MHI.
Table 2.
Performance of the proposed 2D motion representation CNN model.
To analyze the impact of depth on accuracy, the proposed 3D DenseNet model with different depths was used for experiments. As shown in Table 1, the D20-3D-DenseNet model has 20 layers, and the accuracy of this model is 67.13%. Meanwhile, the accuracy of the D40-3D-DenseNet model with 40 layers is 89.82%. The experimental results show that increasing depth properly can improve recognition accuracy.
Based on the above experiment, the prediction results of the D40-3D-DenseNet model is used to fuse with the prediction results of the 2D motion representation CNN model. For fusion at the decision level, different combinations of parameters and in Equation (7) are investigated. By comparing six groups of , that are , ,, , , and , the combination of for and achieves the best performance of 91.96% accuracy. On the contrary, the accuracy of fusion at the feature level is 90.10%. Thus, fusion at the decision level is selected as our fusion scheme.
3.4. Comparison with Other Methods
To make a fair comparison, the 8-fold cross-validation as shown in the compared literature was adopted. Therefore, all the final results of our proposed method are the average of 8-fold cross-validation.
The proposed method is first compared with two existing methods on VIVA dataset. Note that the first compared method in [24] relies on handcrafted feature representations for gesture classification, while the other compared method in [27,28,29,30,31] uses 3D CNN to extract gesture features. Table 3 gives the compared results of these different methods. From Table 3, the following conclusions can be made: (1) In view of the performance comparison of a single deep model, the proposed 3D DenseNet model named D40-3D-DenseNet achieves the best performance compared with other models such as 3D CNN (LRN + HRN) [27], C3D [28], md3D CNN [29], 3D CNN [30], and Faster R-CNN [31], which means the proposed 3D DenseNet model can better represent the spatiotemporal motion patterns than other models. The reason is that it makes the best use of features through dense connections. (2) The proposed 2D motion representation CNN model can provide complementary feature information for gesture recognition. In addition, the fusion at the decision level is superior to fusion at the feature level, and the performance outperforms most of the compared methods. (3) The method in [28] obtained 96.1% accuracy, which outperforms our method because of the effective internal transfer learning (ITL) strategy proposed in [28]. In addition, the performance in [30] is also better than our method since it employs a temporal network like long short-term memory (LSTM). However, the layers in the proposed 3D DenseNet model are very narrow and thus require fewer parameters than these traditional networks. If the ITL or LSTM are incorporated into our proposed 3D DenseNet model, the performance will increase.
Table 3.
Performance comparison of different methods on VIVA dataset.
Table 4 gives another performance comparison results on the UTD-MHAD dataset. As shown in Table 4, the accuracy of our two individual models is low compared to the methods in [26,32]. The reason is that the proposed models only use RGB data, while the methods in [26,32] not only use RGB data but also depth data. However, the fusion result at the decision level outperforms the compared method, which shows the effectiveness of the fusion scheme.
Table 4.
Performance comparison of different methods on UTD-MHAD dataset.
3.5. Performance Evaluation on the Depth Dataset
To further verify the effectiveness of the proposed method for cross-modality dataset, the depth dataset proposed in the reference [33] is conducted for dynamic hand gesture recognition. The dataset includes 14 hand gestures performed by two ways: using one finger and the whole hand, and each gesture is performed by 28 individuals in 2 ways between 1 and 10 times, amounting to 2800 sequences.
Figure 9 gives some MHI images and their corresponding pseudo-colored images from four types of gesture motion in the depth dataset. As shown in Figure 9, the motion patterns in pseudo-colored images can be effectively distinguished from that in the grayscale versions. Due to the limited computing power in our experiment, the image size is zoomed from 640 × 480 to 120 × 90, and the depth data is linearized from 16 bits to 8 bits. In the experiment, the batch size is set as 10, the epoch is 100, and the initial learning rate is set as 0.1. Table 5 shows the experimental results of 14 and 28 gestures obtained by the proposed methods and other methods cited in [33]. As depicted in Table 5, the proposed method has achieved relatively satisfactory results. The accuracy of the proposed method is lower than that of [3,33,34,35] for 14 gestures and lower than that of [3,34,35]. The reason is that the resolution of the original image is reduced, and our method only uses the depth data, while other methods use skeletal data and depth data.

Figure 9.
Illustration of MHIs and their corresponding pseudo-colored images from the depth dataset: (a) swipe-+; (b) swipe-X; (c) swipe-V; (d) rotation CW; (e) rotation CCW.
Table 5.
Accuracy comparison of 14 versus 28 gestures in the depth dataset.
4. Conclusions
In this paper, we propose a novel dynamic gesture recognition method. First, a motion representation 2D CNN model is presented to extract frame-level motion features for gesture classification. For this model, the sequential motion information can be encoded into a single image, and the pseudo-coloring technique can enhance the spatiotemporal information contained in the MHI gray image. Second, the proposed 3D DenseNet model is constructed for capturing the spatiotemporal motion information directly from the RGB videos. Due to the character of dense connection, the proposed 3D DenseNet model has good performance. Finally, the prediction results of the 2D CNN model and the 3D DenseNet model are fused for improving performance, which shows that different deep models can provide more complementary motion patterns. The experimental results verify the effectiveness of our proposed method and demonstrate it is superior to other methods. For the challenging VIVA dataset and UTD-MHAD dataset, our proposed method achieved a classification accuracy rate of 89.1% and 89.5%, respectively. However, the adopted MHI has the limitation that the moving body has to be in a plane perpendicular to the camera. In the future, we will investigate a more robust feature learning method for distinguishing the subtle differences between some gesture classes and study viewpoint free gesture recognition method.
Author Contributions
E.Z. conceived the study and wrote the manuscript. B.X. designed the research and conducted the experiment. F.C. conducted the experiment. J.D. acquired the test images and performed the experiments. G.L. proposed some valuable suggestions and revised the manuscript. Y.L. processed the data and performed some experiments.
Funding
This work was supported by the Key Program of Natural Science Foundation of Shaanxi Province of China under Grant No. 2017JZ020 and the National Natural Science Foundation of China under Grant No. 61771386 and No. 61671374.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mitra, S.; Acharya, T. Gesture recognition: A survey. IEEE Trans. Syst. Man Cybern. Part C. Appl. Rev. 2007, 37, 311–324. [Google Scholar] [CrossRef]
- Han, F.; Reily, B.; Hoff, W.; Zhang, H. Space-time representation of people based on 3D skeletal data: A review. Comput. Vis. Image Underst. 2017, 158, 85–105. [Google Scholar] [CrossRef]
- Maghoumi, M.; LaViola, J.J., Jr. DeepGRU: Deep gesture recognition utility. In Proceedings of the 14th International Symposium on Visual Computing (ISVC 2019), Lake Tahoe, NV, USA, 7–9 October 2019; pp. 16–31. [Google Scholar]
- Paraskevopoulos, G.; Spyrou, E.; Sgouropoulos, D.; Giannakopoulos, T.; Mylonas, P. Real-time arm gesture recognition using 3D skeleton joint data. Algorithm 2019, 12, 108. [Google Scholar] [CrossRef]
- Nguyen, X.; Brun, L.; Lézoray, O.; Bougleux, S. Skeleton-based hand gesture recognition by learning SPD matrices with neural networks. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Konecny, J.; Hagara, M. One-shot-learning gesture recognition using HOG-HOF features. J. Mach. Learn. Res. 2014, 15, 2513–2532. [Google Scholar]
- Danafar, S.; Gheissari, N. Action recognition for surveillance applications using optic flow and SVM. In Proceedings of the 8th Asian Conference on Computer Vision, Tokyo, Japan, 18–22 November 2007; pp. 457–466. [Google Scholar]
- Wan, J.; Guo, G.; Li, S. Explore efficient local features from RGB-D data for one-shot learning gesture recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 1626–1639. [Google Scholar] [CrossRef]
- Kane, L.; Khanna, P. Depth matrix and adaptive Bayes classifier based dynamic hand gesture recognition. Pattern Recognit. Lett. 2019, 120, 24–30. [Google Scholar] [CrossRef]
- Park, H.; Kim, E.; Jang, S.; Park, S.; Park, M.; Kim, H. HMM-based gesture recognition for robot control. In Proceedings of the Second Iberian Conference on Pattern Recognition and Image Analysis, Estoril, Portugal, 7–9 June 2005; pp. 607–614. [Google Scholar]
- Ma, L.; Zhang, J.; Wang, J. Modified CRF algorithm for dynamic hand gesture recognition. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 4763–4767. [Google Scholar]
- Zhang, E.; Zhang, Y.; Duan, J. Color inverse halftoning method with the correlation of multi-color components based on extreme learning machine. Appl. Sci. 2019, 9, 841. [Google Scholar] [CrossRef]
- Song, J.; Kim, W.; Park, K. Finger-vein recognition based on deep DenseNet using composite image. IEEE Access 2019, 7, 66845–66863. [Google Scholar] [CrossRef]
- Kang, X.; Zhang, E. A universal defect detection approach for various types of fabrics based on the Elo-rating algorithm of the integral image. Text. Res. J. 2019, 89, 4766–4793. [Google Scholar] [CrossRef]
- Wang, H.; Shen, Y.; Wang, S.; Xiao, T.; Deng, L.; Wang, X.; Zhao, X. Ensemble of 3D densely connected convolutional network for diagnosis of mild cognitive impairment and alzheimer’s disease. Neurocomputing 2019, 333, 145–156. [Google Scholar] [CrossRef]
- Chung, H.; Chung, Y.; Tsai, W. An efficient hand gesture recognition system based on deep CNN. In Proceedings of the IEEE International Conference on Industrial Technology, Melbourne, VIC, Australia, 13–15 February 2019; pp. 853–858. [Google Scholar]
- Cheng, W.; Sun, Y.; Li, G.; Jiang, G.; Liu, H. Jointly network: A network based on CNN and RBM for gesture recognition. Neural Comput. Appl. 2019, 31, 309–323. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J. Dynamic hand gesture recognition based on 3D convolutional neural network Models. In Proceedings of the 2019 IEEE 16th International Conferences on Networking, Sensing and Control, Banff, AB, Canada, 9–11 May 2019; pp. 224–229. [Google Scholar]
- Li, Y.; Miao, Q.; Tian, K.; Fan, Y.; Xu, X.; Ma, Z.; Song, L. Large-scale gesture recognition with a fusion of RGB-D data based on optical flow and the C3D model. Pattern Recognit. Lett. 2019, 119, 187–194. [Google Scholar] [CrossRef]
- Elboushaki, A.; Hannane, R.; Afdel, K.; Koutti, L. MultiD-CNN: A multi-dimensional feature learning approach based on deep convolutional networks for gesture recognition in RGB-D image sequences. Expert Syst. Appl. 2020, 139, 112829. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition(CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Bobick, A.F.; Davis, J.W. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 2015 International Conference on Learning Representations(ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- Abidi, B.R.; Zheng, Y.; Gribok, A.V.; Abidi, M.A. Improving weapon detection in single energy x-ray images through pseudo coloring. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2006, 36, 784–796. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. UTD-MHAD: A multimodal dataset for human action recognition utilizing a depth camera and a wearable inertial sensor. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP 2015), Quebec City, QC, Canada, 27–30 September 2015; pp. 168–172. [Google Scholar]
- Molchanov, P.; Gupta, S.; Kim, K.; Kautz, J. Hand gesture recognition with 3D convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW 2015), Boston, MA, USA, 7–12 June 2015; pp. 1–7. [Google Scholar]
- Wang, T.; Chen, Y.; Zhang, M.; Chen, J.; Snoussi, H. Internal transfer learning for improving performance in human action recognition for small datasets. IEEE Access 2017, 5, 17627–17633. [Google Scholar] [CrossRef]
- Li, J.; Yang, M.; Liu, Y.; Wang, Y.; Zheng, Q.; Wang, D. Dynamic hand gesture recognition using multi-direction 3D convolutional neural networks. Eng. Lett. 2019, 27, 490–500. [Google Scholar]
- Jiang, S.; Chen, Y. Hand gesture recognition by using 3DCNN and LSTM with adam optimizer. Lect. Notes Comput. Sci. 2018, 10735, 743–753. [Google Scholar]
- Wu, X.; Zhang, J.; Xu, X. Hand gesture recognition algorithm based on faster R-CNN. J. Comput. Aided Des. Comput. Graph. 2018, 30, 468–476. [Google Scholar] [CrossRef]
- Bulbul, M.; Jiang, Y.; Ma, J. DMMs based multiple features fusion for human action recognition. Int. J. Multimed. Data Eng. Manag. 2015, 6, 23–39. [Google Scholar] [CrossRef]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.-P.; Guerry, J.; Le Saux, B.; Filliat, D. SHREC’17 track: 3D hand gesture recognition using a depth and skeletal dataset. In Proceedings of the 10th Eurographics Workshop on 3D Object Retrieval, Lyon, France, 23–24 April 2017; pp. 33–38. [Google Scholar]
- De Smedt, Q.; Wannous, H.; Vandeborre, J.-P. Skeleton-based dynamic hand gesture recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1206–1214. [Google Scholar]
- Ohe-Bar, E.; Trivedi, M. Joint angles similarities and HOG2 for action recognition. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 465–470. [Google Scholar]
- Oreifej, O.; Liu, Z. HON4D: Histogram of oriented 4D normal for activity recognition from depth sequences. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 716–723. [Google Scholar]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3-D human action recognition by shape analysis of motion trajectories on riemannian manifold. IEEE Trans. Cybern. 2015, 45, 1340–1352. [Google Scholar] [CrossRef]









© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).