Multi-Scale Dense Attention Network for Stereo Matching

Abstract
:1. Introduction
- A novel network without any post-processing for stereo matching is proposed;
- The DU block is introduced as a more effective upsampling method of fusing multi-scale features;
- The ACPFE block is adopted to extract richer context information.
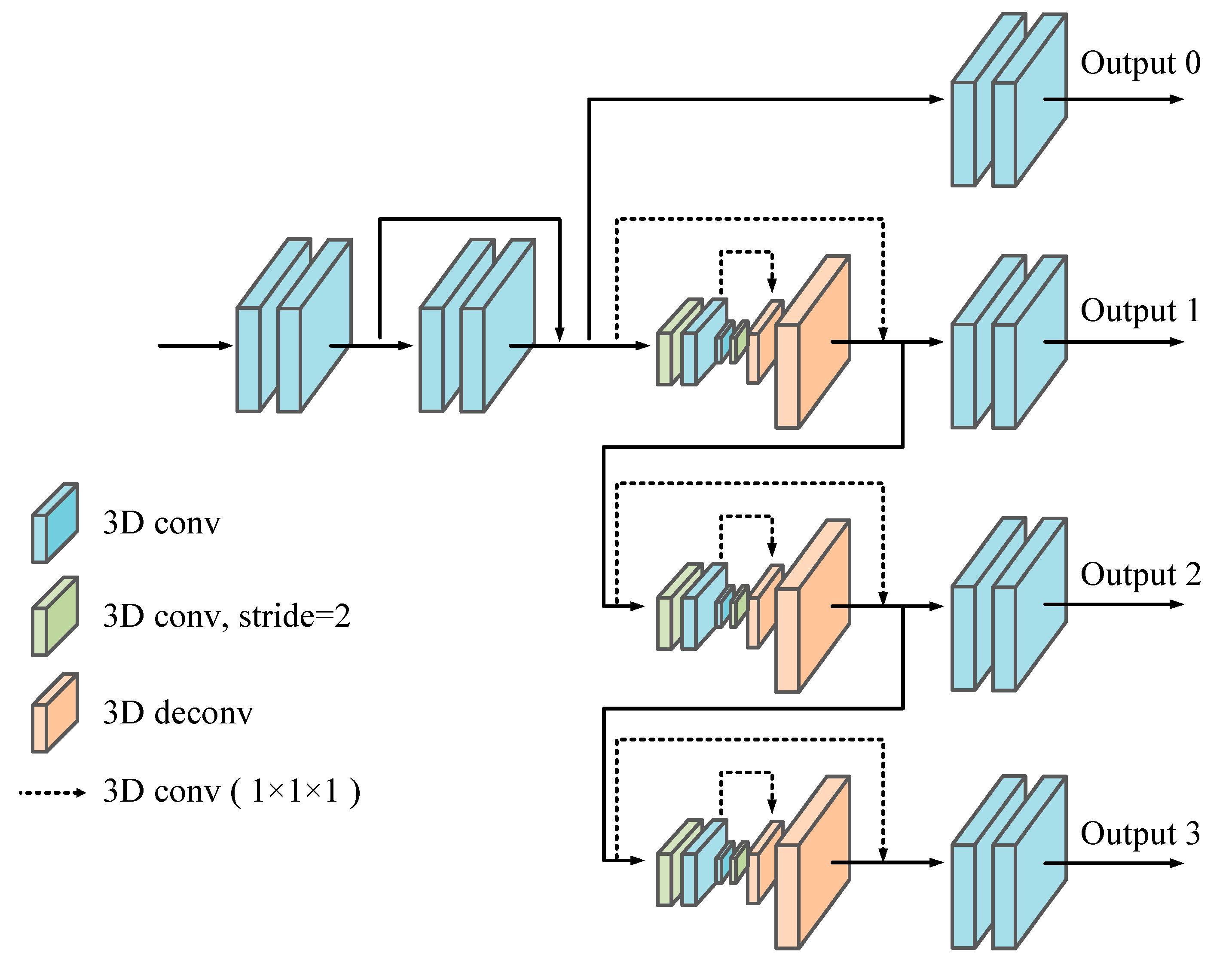
2. Multi-Scale Dense Attention Network
2.1. Siamese Feature Extraction
2.1.1. Shallow Feature Extraction
2.1.2. Stacked Dense Blocks
2.1.3. Dual-Path Upsampling Block
2.1.4. Attention-Guided Context-Aware Pyramid Feature Extraction Block
2.2. 3D Matching Net
2.3. Disparity Regression and Loss Function
3. Experiments
3.1. Datasets
3.2. Experimental Details
3.3. Ablation Study
3.4. Performance Comparison
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, X.; Zhu, Y. 3D Object Proposals for Accurate Object Class Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1259–1272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, C.; Li, Z.; Cheng, Y.; Cai, R.; Chao, H.; Rui, Y. MeshStereo: A Global Stereo Model with Mesh Alignment Regularization for View Interpolation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2057–2065. [Google Scholar]
- Scharstein, D.; Szeliski, R.; Zabih, R. A Taxonomy and Evaluation of Dense Two-Frame Stereo Correspondence Algorithms. In Proceedings of the IEEE Workshop on Stereo and Multi-Baseline Vision (SMBV), Kauai, HI, USA, 9–10 December 2001; pp. 131–140. [Google Scholar]
- Mei, X.; Sun, X.; Dong, W.; Wang, H.; Zhang, X. Segment-Tree Based Cost Aggregation for Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013; pp. 313–320. [Google Scholar]
- Yang, Q. A non-local cost aggregation method for stereo matching. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1402–1409. [Google Scholar]
- Zhang, K.; Lu, J.; Lafruit, G. Cross-Based Local Stereo Matching Using Orthogonal Integral Images. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 1073–1079. [Google Scholar] [CrossRef]
- Zabih, R.; Woodfill, J. Non-parametric local transforms for computing visual correspondence. In Proceedings of the European Conference on Computer Vision (ECCV), Berlin, Germany, 2–6 May 1994; pp. 151–158. [Google Scholar]
- Žbontar, J.; Lecun, Y. Stereo Matching by Training a Convolutional Neural Network to Compare Image Patches. J. Mach. Learn. Res. 2016, 17, 1–32. [Google Scholar]
- Shaked, A.; Wolf, L. Improved Stereo Matching with Constant Highway Networks and Reflective Confidence Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6901–6910. [Google Scholar]
- Guney, F.; Geiger, A. Displets: Resolving stereo ambiguities using object knowledge. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 4165–4175. [Google Scholar]
- Kendall, A.; Martirosyan, H.; Dasgupta, S.; Henry, P.; Kennedy, R.; Bachrach, A.; Bry, A. End-to-End Learning of Geometry and Context for Deep Stereo Regression. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Venice, Italy, 22–29 October 2017; pp. 66–75. [Google Scholar]
- Chang, J.; Chen, Y. Pyramid Stereo Matching Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 5410–5418. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Sun, H.; Li, C.; Liu, B.; Zheng, H.; Feng, D.D.; Wang, S. AUNet: Attention-guided dense-upsampling networks for breast mass segmentation in whole mammograms. Phys. Med. Biol. 2020, 65, 055005. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Zhao, T.; Wu, X. Pyramid Feature Attention Network for Saliency Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3080–3089. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, X.; Yang, K.; Yang, W.; Wang, X.; Li, H. Group-Wise Correlation Stereo Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3268–3277. [Google Scholar]
- Mayer, N.; Ilg, E.; Häusser, P.; Fischer, P.; Cremers, D.; Dosovitskiy, A.; Brox, T. A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4040–4048. [Google Scholar]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Seki, A.; Pollefeys, M. SGM-Nets: Semi-Global Matching with Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6640–6649. [Google Scholar]
- Pang, J.; Sun, W.; Ren, J.S.; Yang, C.; Yan, Q. Cascade Residual Learning: A Two-Stage Convolutional Neural Network for Stereo Matching. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Venice, Italy, 22–29 October 2017; pp. 878–886. [Google Scholar]
- Jie, Z.; Wang, P.; Ling, Y.; Zhao, B.; Wei, Y.; Feng, J.; Liu, W. Left-Right Comparative Recurrent Model for Stereo Matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3838–3846. [Google Scholar]
- Yang, G.; Zhao, H.; Shi, J.; Deng, Z.; Jia, J. SegStereo: Exploiting Semantic Information for Disparity Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 660–676. [Google Scholar]
- Tulyakov, S.; Ivanov, A.; Fleuret, F. Practical Deep Stereo (PDS): Toward applications-friendly deep stereo matching. arXiv 2018, arXiv:1806.01677. [Google Scholar]
- Zhang, F.; Wah, B.W. Fundamental Principles on Learning New Features for Effective Dense Matching. IEEE Trans. Image Process. 2018, 27, 822–836. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | KITTI 2015 (>3 px) | Scene Flow (EPE) |
|---|---|---|
| Dense Block | 1.99% | 0.7043 px |
| Dense Block + DU Block | 1.83% | 0.6905 px |
| Dense Block + DU Block + ACPFE Module | 1.75% | 0.6785 px |
| Methods | Params | FLOPs |
|---|---|---|
| Dense Block | 4.36 M | 128.25 G |
| Dense Block + DU Block | 4.88 M | 130.37 G |
| Dense Block + DU Block + ACPFE Module | 5.13 M | 130.96 G |
| Title 1 | All (%) | Noc (%) | ||||
|---|---|---|---|---|---|---|
| D1-Bg | D1-Fg | D1-All | D1-Bg | D1-Fg | D1-All | |
| GC-Net [11] | 2.21 | 6.16 | 2.87 | 2.02 | 5.58 | 2.61 |
| SGM-Net [25] | 2.66 | 8.64 | 3.66 | 2.23 | 7.44 | 3.09 |
| CRL [26] | 2.48 | 3.59 | 2.67 | 2.32 | 3.12 | 2.45 |
| LRCR [27] | 2.55 | 5.42 | 3.03 | 2.23 | 4.19 | 2.55 |
| PSMNet [12] | 1.86 | 4.62 | 2.32 | 1.71 | 4.31 | 2.14 |
| SegStereo [28] | 1.88 | 4.07 | 2.25 | 1.76 | 3.70 | 2.08 |
| MDA-Net (ours) | 1.76 | 3.77 | 2.10 | 1.61 | 3.38 | 1.90 |
| Title 1 | 2 px | 3 px | 5 px | Mean Error | ||||
|---|---|---|---|---|---|---|---|---|
| Nox | All | Noc | All | Noc | All | Noc | All | |
| GC-Net [11] | 2.71 | 3.46 | 1.77 | 2.30 | 1.12 | 1.46 | 0.6 | 0.7 |
| PDSNet [29] | 3.82 | 4.65 | 1.92 | 2.53 | 1.12 | 1.51 | 0.9 | 1.0 |
| MC-CNN [4] | 3.90 | 5.45 | 2.43 | 3.63 | 1.64 | 2.39 | 0.7 | 0.9 |
| PSMNet [12] | 2.44 | 3.01 | 1.49 | 1.89 | 0.90 | 1.15 | 0.5 | 0.6 |
| SegStereo [28] | 2.66 | 3.19 | 1.68 | 2.03 | 1.00 | 1.21 | 0.5 | 0.6 |
| CNNF + SGM [30] | 3.78 | 5.53 | 2.28 | 3.48 | 1.46 | 2.21 | 0.7 | 0.9 |
| MDA-Net (ours) | 2.27 | 2.83 | 1.40 | 1.78 | 0.83 | 1.08 | 0.5 | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, Y.; Xu, J.; Gao, Z. Multi-Scale Dense Attention Network for Stereo Matching. Electronics 2020, 9, 1881. https://doi.org/10.3390/electronics9111881
Chang Y, Xu J, Gao Z. Multi-Scale Dense Attention Network for Stereo Matching. Electronics. 2020; 9(11):1881. https://doi.org/10.3390/electronics9111881
Chicago/Turabian StyleChang, Yuhui, Jiangtao Xu, and Zhiyuan Gao. 2020. "Multi-Scale Dense Attention Network for Stereo Matching" Electronics 9, no. 11: 1881. https://doi.org/10.3390/electronics9111881