Siamese High-Level Feature Refine Network for Visual Object Tracking

 , ,
, , 
Abstract
:1. Introduction
- We introduce an effective feature refine network with an end-to-end learning facility to enhance the target feature representation ability that enables us to capture the salient information location of the target.
- We employ an attention module within a residual feature refine block using identity mapping to augment the overall network discriminative power.
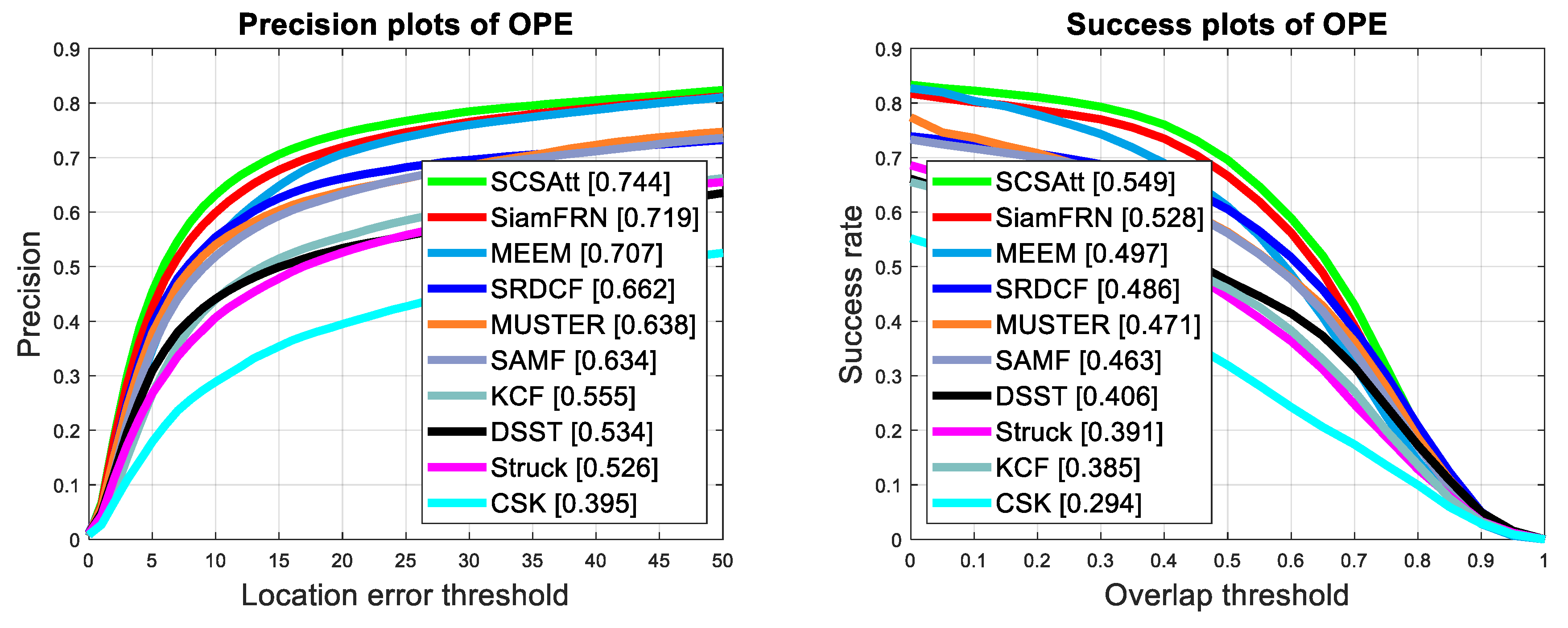
- Extensive experiments has been performed that demonstrates excellent performance over state-of-the-art trackers on several popular benchmarks including (OTB100 [16,17], OTB50 [16,17], UAV123 [18], TC128 [19], VOT2017 [20], and VOT2018 [21]) with 60 frames per second () tracking speed. The codes and results will be available at https://github.com/maklachur/SiamFRN.
2. Related Work
2.1. Tracking with Convolution Neural Network (CNN)
2.2. Tracking with Siamese Network
2.3. Tracking with Visual Attention
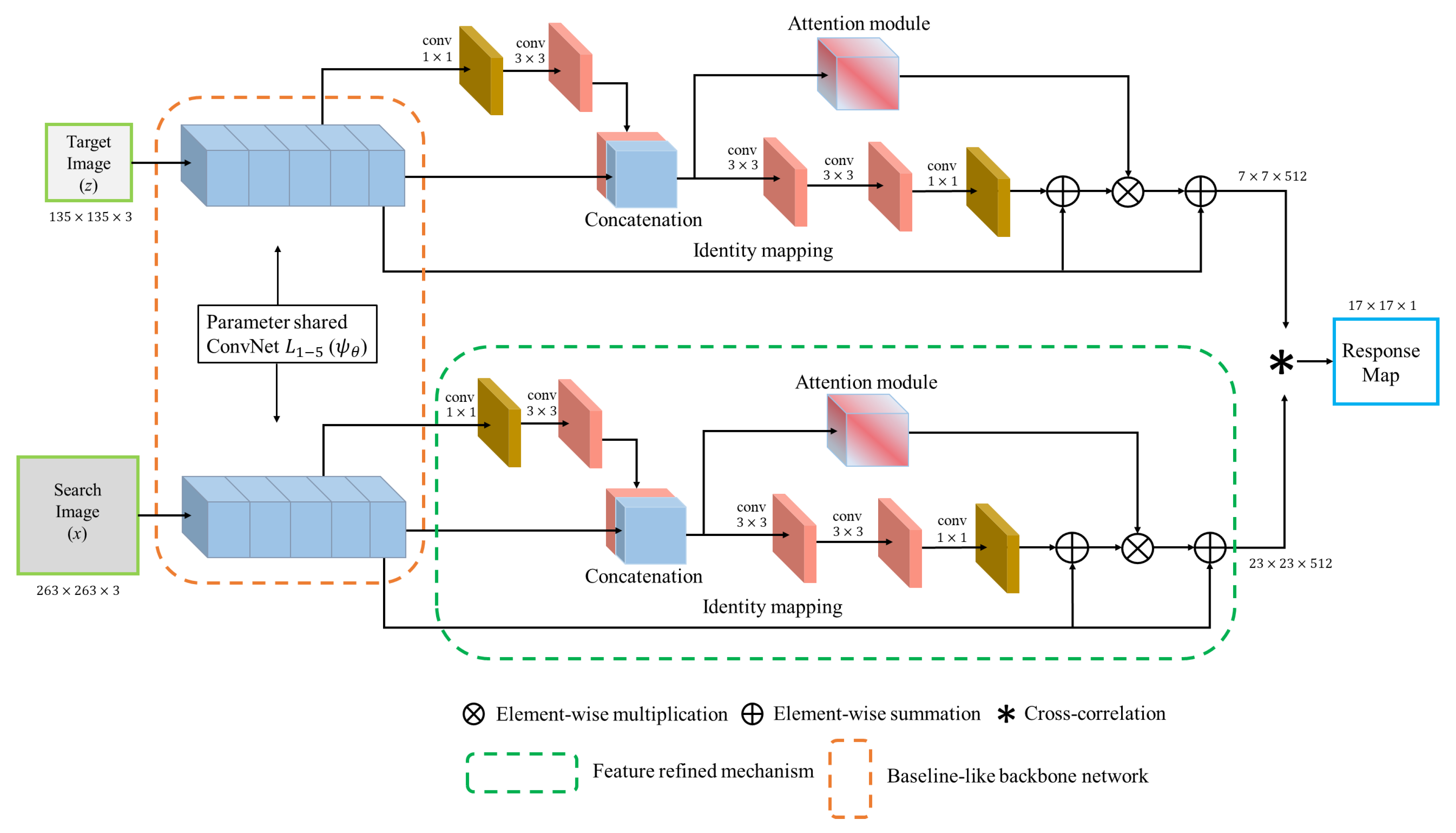
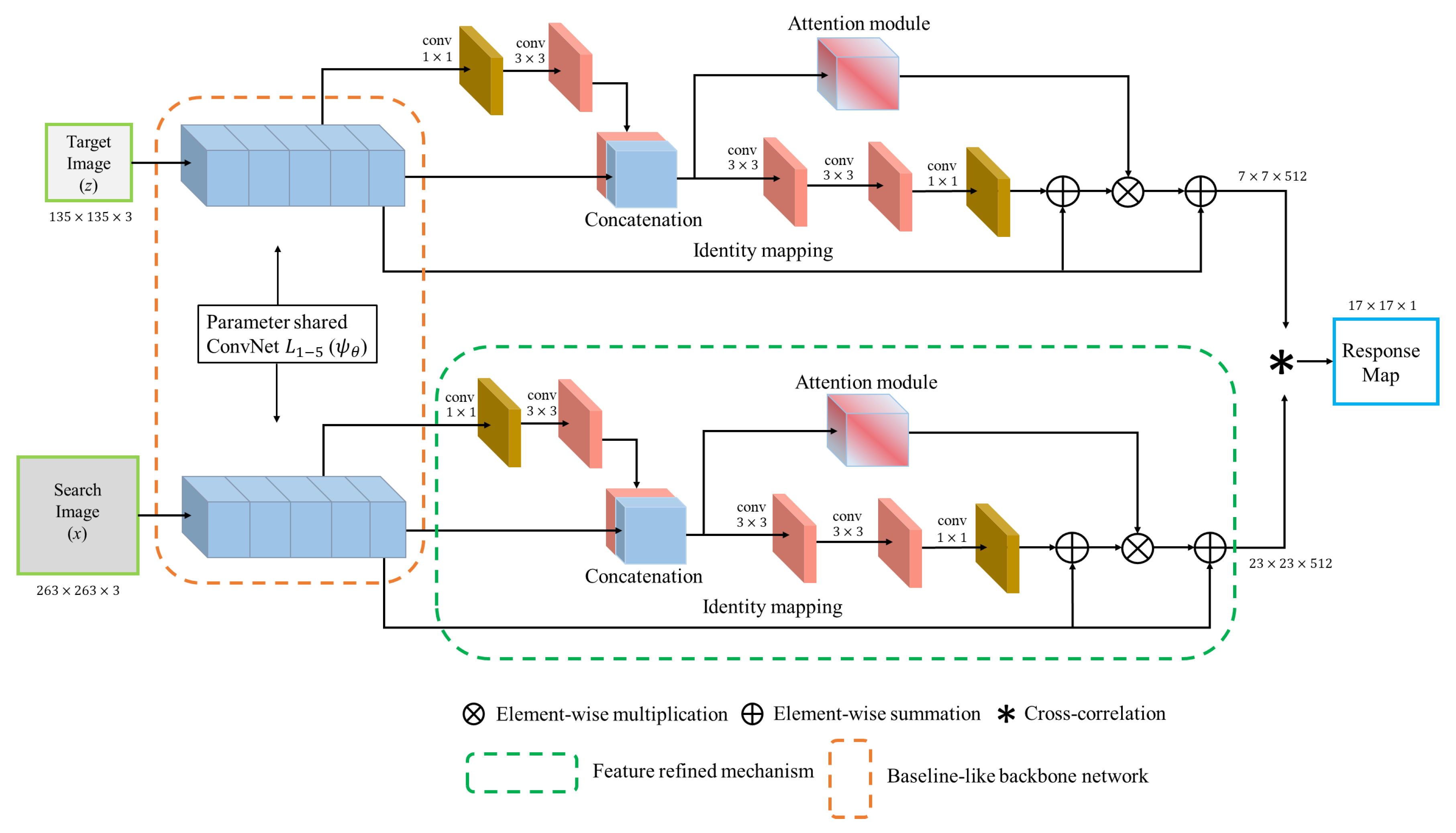
3. Proposed Method
3.1. Siamese Baseline Network
3.2. Feature Refine Network
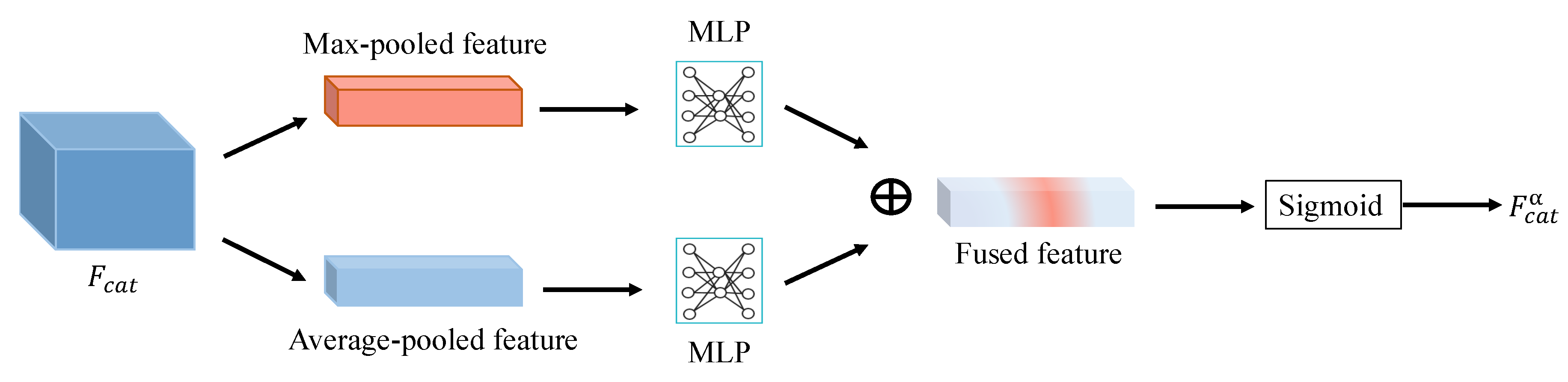
3.3. Feature Attention Network
4. Experiments
4.1. Implementation Details
4.1.1. Network Architecture
4.1.2. Training
4.1.3. Testing
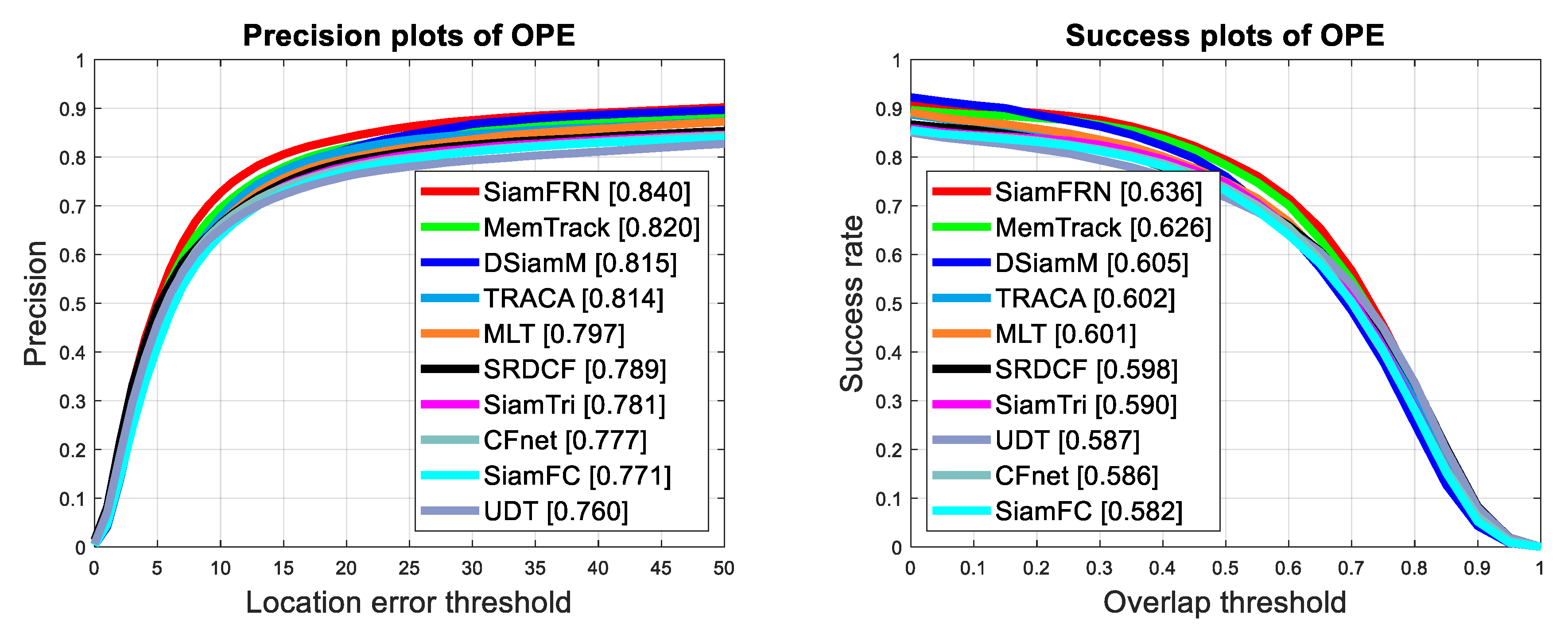
4.2. Comparison with the State-of-the-Art Trackers
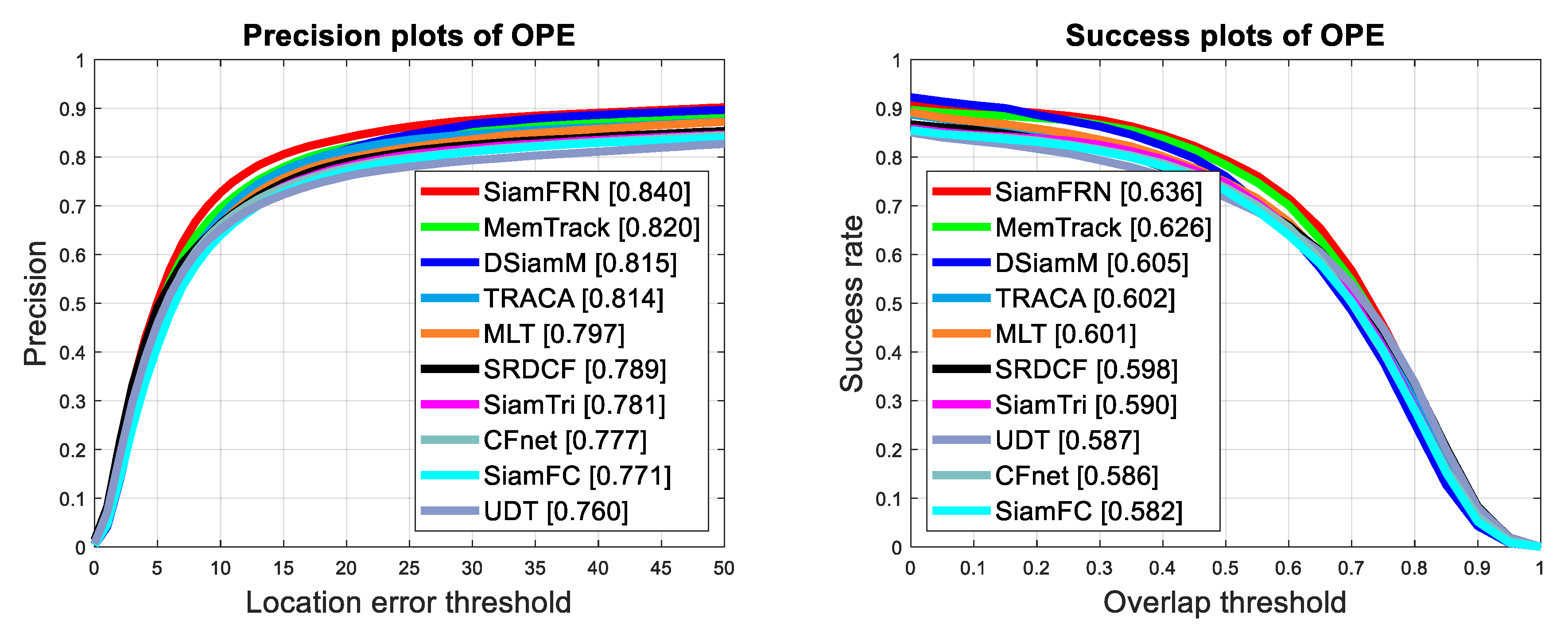
4.2.1. Experiments on OTB100 Benchmark
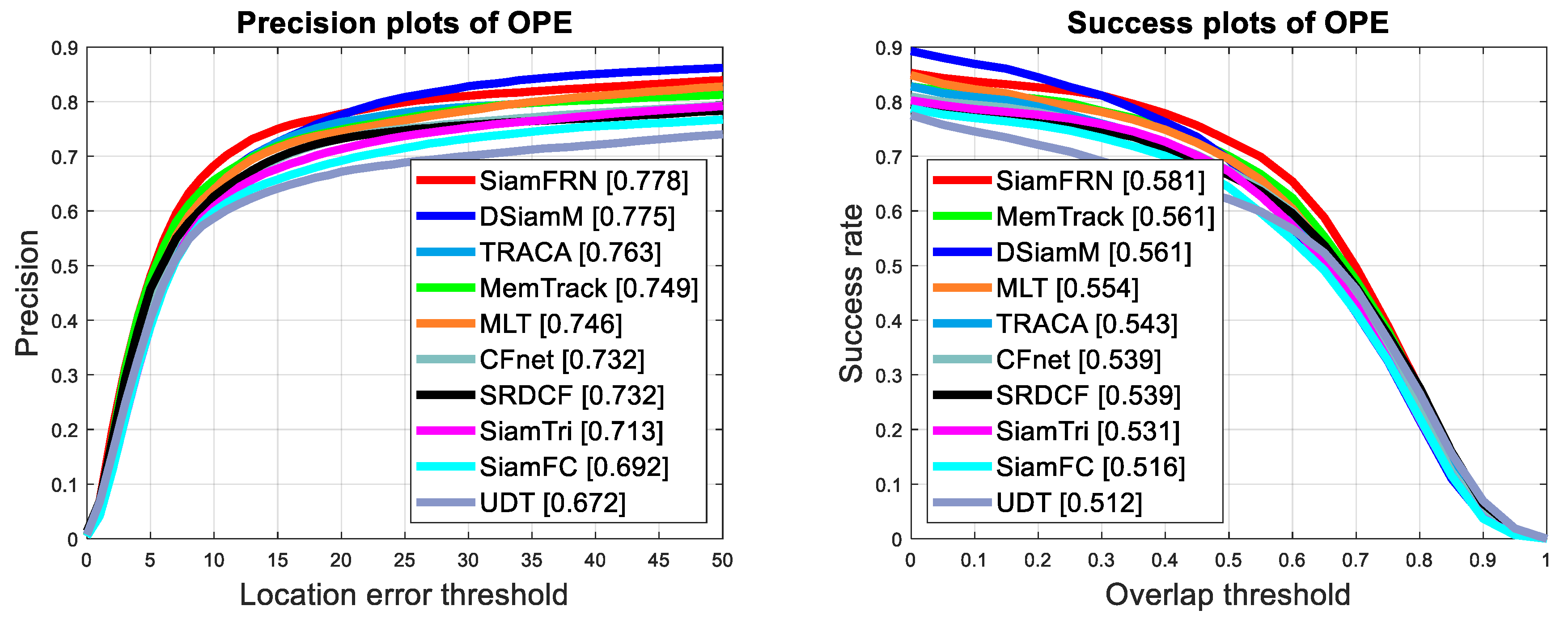
4.2.2. Experiments on OTB50 Benchmark
4.2.3. Experiments on UAV123 Benchmark
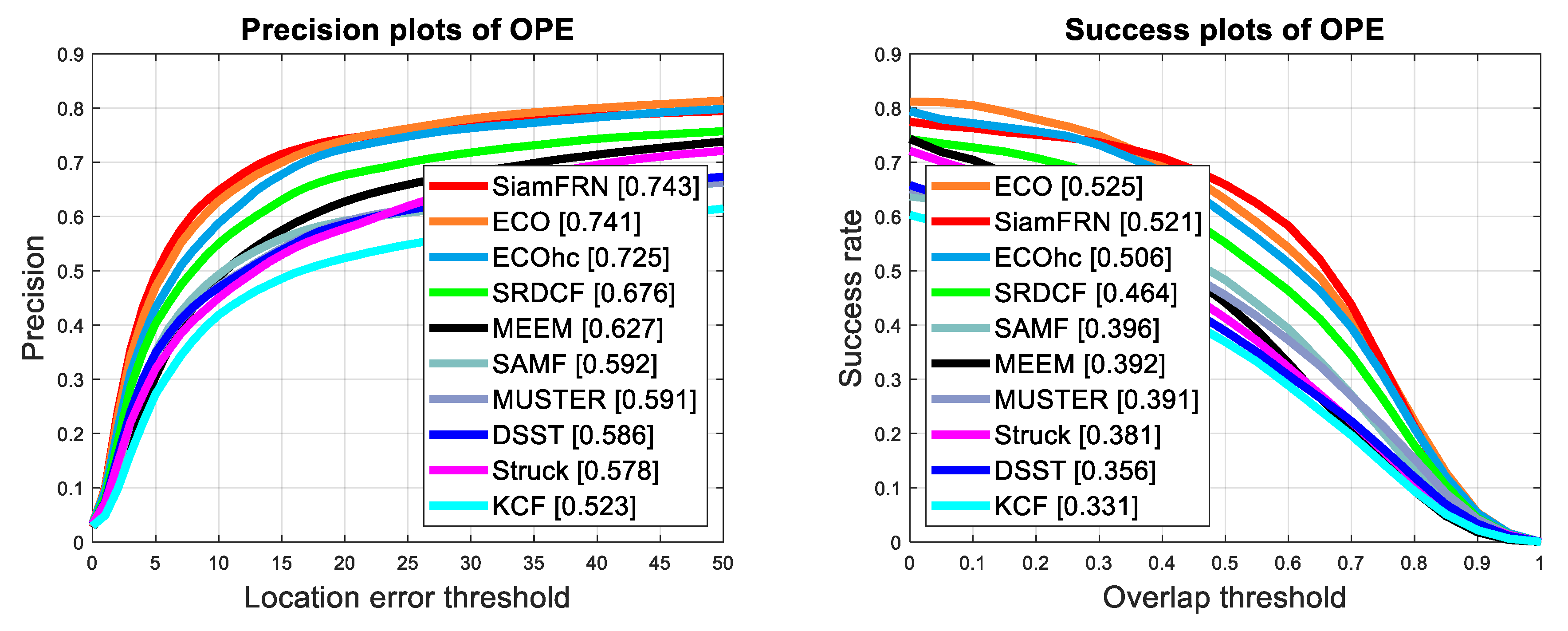
4.2.4. Experiments on TC128 Benchmark
4.2.5. Experiments on VOT2017 and VOT2018 Benchmark
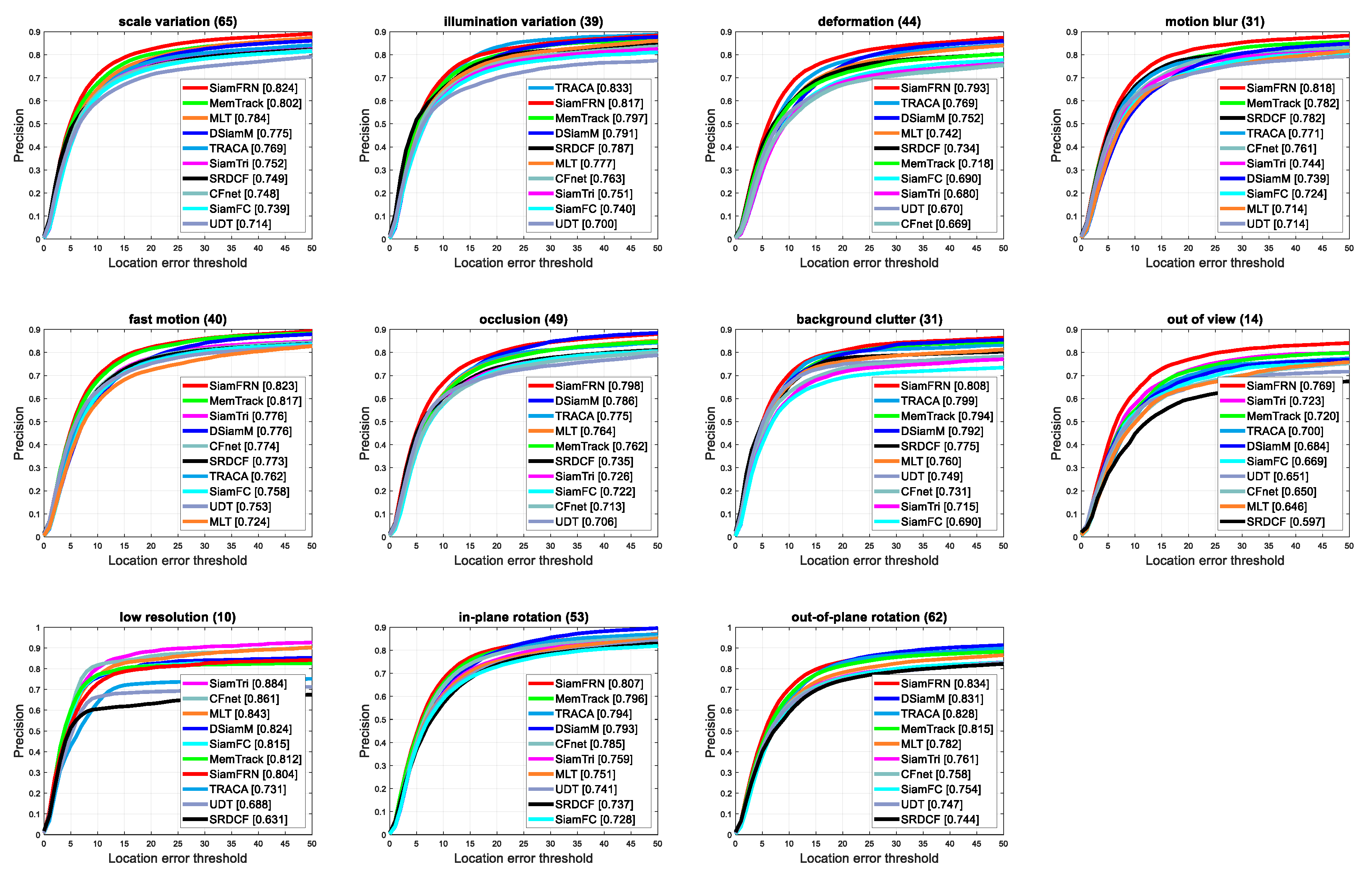
4.3. Ablation Analysis
4.4. Discussion
5. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yao, H.; Cavallaro, A.; Bouwmans, T.; Zhang, Z. Guest Editorial Introduction to the Special Issue on Group and Crowd Behavior Analysis for Intelligent Multicamera Video Surveillance. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 405–408. [Google Scholar] [CrossRef]
- Lu, W.L.; Ting, J.A.; Little, J.J.; Murphy, K.P. Learning to track and identify players from broadcast sports videos. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1704–1716. [Google Scholar] [PubMed]
- Gupta, M.; Kumar, S.; Behera, L.; Subramanian, V.K. A Novel Vision-Based Tracking Algorithm for a Human-Following Mobile Robot. IEEE Trans. Syst. Man, Cybern. Syst. 2017, 47, 1415–1427. [Google Scholar] [CrossRef]
- Menze, M.; Geiger, A. Object scene flow for autonomous vehicles. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3061–3070. [Google Scholar]
- Liang, Z.; Shen, J. Local semantic siamese networks for fast tracking. IEEE Trans. Image Process. 2019, 29, 3351–3364. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Choi, J.; Jin Chang, H.; Fischer, T.; Yun, S.; Lee, K.; Jeong, J.; Demiris, Y.; Young Choi, J. Context-aware deep feature compression for high-speed visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 479–488. [Google Scholar]
- Nam, H.; Han, B. Learning Multi-Domain Convolutional Neural Networks for Visual Tracking. arXiv 2015, arXiv:1510.07945. [Google Scholar]
- Bromley, J.; Guyon, I.; LeCun, Y.; Säckinger, E.; Shah, R. Signature verification using a “siamese” time delay neural network. Adv. Neural Inf. Process. Syst. 1994, 737–744. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 850–865. [Google Scholar]
- Guo, Q.; Feng, W.; Zhou, C.; Huang, R.; Wan, L.; Wang, S. Learning dynamic siamese network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1763–1771. [Google Scholar]
- Dong, X.; Shen, J. Triplet loss in siamese network for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 459–474. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H. End-to-end representation learning for correlation filter based tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2805–2813. [Google Scholar]
- Yang, T.; Chan, A.B. Learning dynamic memory networks for object tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 152–167. [Google Scholar]
- Fiaz, M.; Rahman, M.M.; Mahmood, A.; Farooq, S.S.; Baek, K.Y.; Jung, S.K. Adaptive Feature Selection Siamese Networks for Visual Tracking. In International Workshop on Frontiers of Computer Vision; Springer: Ibusuki, Japan, 2020; pp. 167–179. [Google Scholar]
- Wu, Y.; Lim, J.; Yang, M.H. Object tracking benchmark. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1834–1848. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Lim, J.; Yang, M.H. Online object tracking: A benchmark. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for uav tracking. In European Conference on Computer Vision; Springer: Amsterdam, The Netherlands, 2016; pp. 445–461. [Google Scholar]
- Liang, P.; Blasch, E.; Ling, H. Encoding color information for visual tracking: Algorithms and benchmark. IEEE Trans. Image Process. 2015, 24, 5630–5644. [Google Scholar] [CrossRef]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Cehovin Zajc, L.; Vojir, T.; Hager, G.; Lukezic, A.; Eldesokey, A.; et al. The visual object tracking vot2017 challenge results. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–27 October 2017; pp. 1949–1972. [Google Scholar]
- Kristan, M.; Leonardis, A.; Matas, J.; Felsberg, M.; Pflugfelder, R.; Cehovin Zajc, L.; Vojir, T.; Bhat, G.; Lukezic, A.; Eldesokey, A.; et al. The sixth visual object tracking vot2018 challenge results. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Smeulders, A.W.; Chu, D.M.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, M. Visual tracking: An experimental survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Javed, S.; Jung, S.K. Handcrafted and deep trackers: Recent visual object tracking approaches and trends. ACM Comput. Surv. (CSUR) 2019, 52, 1–44. [Google Scholar] [CrossRef]
- Brendel, W.; Bethge, M. Approximating CNNs with Bag-of-local-Features models works surprisingly well on ImageNet. arXiv 2019, arXiv:1904.00760. [Google Scholar]
- Ahmed, M.R.; Zhang, Y.; Liu, Y.; Liao, H. Single Volume Image Generator and Deep Learning-based ASD Classification. IEEE J. Biomed. Health Inform. 2020, 24, 3044–3054. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Shaban, M.; Mahmood, A.; Al-maadeed, S.; Rajpoot, N. Multi-person Head Segmentation in Low Resolution Crowd Scenes Using Convolutional Encoder-Decoder Framework. In Representations, Analysis and Recognition of Shape and Motion from Imaging Data; Chen, L., Ben Amor, B., Ghorbel, F., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 82–92. [Google Scholar]
- Gao, F.; Wang, C. Hybrid strategy for traffic light detection by combining classical and self-learning detectors. IET Intell. Transp. Syst. 2020, 14, 735–741. [Google Scholar] [CrossRef]
- Shen, J.; Yu, D.; Deng, L.; Dong, X. Fast Online Tracking With Detection Refinement. IEEE Trans. Intell. Transp. Syst. 2018, 19, 162–173. [Google Scholar] [CrossRef]
- Shen, J.; Liang, Z.; Liu, J.; Sun, H.; Shao, L.; Tao, D. Multiobject Tracking by Submodular Optimization. IEEE Trans. Cybern. 2019, 49, 1990–2001. [Google Scholar] [CrossRef]
- Shen, J.; Peng, J.; Dong, X.; Shao, L.; Porikli, F. Higher Order Energies for Image Segmentation. IEEE Trans. Image Process. 2017, 26, 4911–4922. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ross, D.; Lim, J.; Lin, R.S.; Yang, M.H. Incremental Learning for Robust Visual Tracking. Int. J. Comput. Vis. 2008, 77, 125–141. [Google Scholar] [CrossRef]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE computer society conference on computer vision and pattern recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical convolutional features for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar]
- Doulamis, A.; Doulamis, N.; Ntalianis, K.; Kollias, S. An efficient fully unsupervised video object segmentation scheme using an adaptive neural-network classifier architecture. IEEE Trans. Neural Netw. 2003, 14, 616–630. [Google Scholar] [CrossRef]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Visual tracking with fully convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3119–3127. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Luo, W.; Schwing, A.G.; Urtasun, R. Efficient Deep Learning for Stereo Matching. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5695–5703. [Google Scholar]
- Chen, K.; Tao, W. Once for All: A Two-Flow Convolutional Neural Network for Visual Tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3377–3386. [Google Scholar] [CrossRef] [Green Version]
- Tao, R.; Gavves, E.; Smeulders, A.W.M. Siamese Instance Search for Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1420–1429. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Baek, K.Y.; Farooq, S.S.; Jung, S.K. Improving Object Tracking by Added Noise and Channel Attention. Sensors 2020, 20, 3780. [Google Scholar] [CrossRef]
- Rahman, M.M. A DWT, DCT and SVD based watermarking technique to protect the image piracy. arXiv 2013, arXiv:1307.3294. [Google Scholar] [CrossRef]
- Rahman, M.M.; Ahammed, M.S.; Ahmed, M.R.; Izhar, M.N. A semi blind watermarking technique for copyright protection of image based on DCT and SVD domain. Glob. J. Res. Eng. 2017, 16, 9–16. [Google Scholar]
- Xu, K.; Ba, J.L.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Zhao, Y.; Liu, Z.; Yang, L.; Cheng, H. Combing RGB and Depth Map Features for human activity recognition. In Proceedings of the 2012 Asia Pacific Signal and Information Processing Association Annual Summit and Conference, Lanzhou, China, 18–21 November 2012; pp. 1–4. [Google Scholar]
- Cui, Z.; Xiao, S.; Feng, J.; Yan, S. Recurrently Target-Attending Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1449–1458. [Google Scholar]
- Choi, J.; Chang, H.J.; Jeong, J.; Demiris, Y.; Choi, J.Y. Visual Tracking Using Attention-Modulated Disintegration and Integration. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4321–4330. [Google Scholar]
- Choi, J.; Chang, H.J.; Yun, S.; Fischer, T.; Demiris, Y.; Choi, J.Y. Attentional Correlation Filter Network for Adaptive Visual Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4828–4837. [Google Scholar]
- He, A.; Luo, C.; Tian, X.; Zeng, W. A twofold siamese network for real-time object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4834–4843. [Google Scholar]
- Qin, X.; Fan, Z. Initial Matting-Guided Visual Tracking with Siamese Network. IEEE Access 2019, 7, 41669–41677. [Google Scholar] [CrossRef]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P.A. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Wang, Q.; Teng, Z.; Xing, J.; Gao, J.; Hu, W.; Maybank, S. Learning attentions: Residual attentional siamese network for high performance online visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4854–4863. [Google Scholar]
- Li, C.; Yang, B. Adaptive weighted CNN features integration for correlation filter tracking. IEEE Access 2019, 7, 76416–76427. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Zhao, X.; Huang, K. Got-10k: A large high-diversity benchmark for generic object tracking in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.; Kwon, J.; Lee, K.M. Deep meta learning for real-time target-aware visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 911–920. [Google Scholar]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Wang, N.; Song, Y.; Ma, C.; Zhou, W.; Liu, W.; Li, H. Unsupervised deep tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1308–1317. [Google Scholar]
- Zhang, J.; Ma, S.; Sclaroff, S. MEEM: Robust tracking via multiple experts using entropy minimization. In European Conference on Computer Vision; Springer: Zurich, Switzerland, 2014; pp. 188–203. [Google Scholar]
- Kristan, M.; Pflugfelder, R.; Leonardis, A.; Matas, J.; Cehovin, L.; Nebehay, G.; Vojir, T.; Fernandez, G.; Lukezic, A. The visual object tracking vot2014 challenge results. In Proceedings of the Visual Object Tracking Workshop 2014 at ECCV, Zurich, Switzerland, 6–7, 12 September 2014; Volume 1, p. 6. [Google Scholar]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.; Tao, D. Multi-store tracker (muster): A cognitive psychology inspired approach to object tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 749–758. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative scale space tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1561–1575. [Google Scholar] [CrossRef] [Green Version]
- Hare, S.; Golodetz, S.; Saffari, A.; Vineet, V.; Cheng, M.M.; Hicks, S.L.; Torr, P.H. Struck: Structured output tracking with kernels. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2096–2109. [Google Scholar] [CrossRef] [Green Version]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [Green Version]
- Rahman, M.M.; Fiaz, M.; Jung, S.K. Efficient Visual Tracking with Stacked Channel-Spatial Attention Learning. IEEE Access 2020, 8, 100857–100869. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. Exploiting the circulant structure of tracking-by-detection with kernels. In European Conference on Computer Vision; Springer: Firenze, Italy, 2012; pp. 702–715. [Google Scholar]
- Li, P.; Chen, B.; Ouyang, W.; Wang, D.; Yang, X.; Lu, H. Gradnet: Gradient-guided network for visual object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–29 October 2019; pp. 6162–6171. [Google Scholar]
- Fiaz, M.; Mahmood, A.; Jung, S.K. Learning soft mask based feature fusion with channel and spatial attention for robust visual object tracking. Sensors 2020, 20, 4021. [Google Scholar] [CrossRef] [PubMed]
- Gao, P.; Yuan, R.; Wang, F.; Xiao, L.; Fujita, H.; Zhang, Y. Siamese attentional keypoint network for high performance visual tracking. Knowl. Based Syst. 2020, 193, 105448. [Google Scholar] [CrossRef] [Green Version]
- Lukezic, A.; Vojir, T.; Cehovin Zajc, L.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6309–6318. [Google Scholar]
- Wang, Q.; Gao, J.; Xing, J.; Zhang, M.; Hu, W. Dcfnet: Discriminant correlation filters network for visual tracking. arXiv 2017, arXiv:1704.04057. [Google Scholar]
- Abdelpakey, M.H.; Shehata, M.S.; Mohamed, M.M. Denssiam: End-to-end densely-siamese network with self-attention model for object tracking. In International Symposium on Visual Computing; Springer: Las Vegas, NV, USA, 2018; pp. 463–473. [Google Scholar]
- Feng, W.; Han, R.; Guo, Q.; Zhu, J.; Wang, S. Dynamic saliency-aware regularization for correlation filter-based object tracking. IEEE Trans. Image Process. 2019, 28, 3232–3245. [Google Scholar] [CrossRef]
- Yang, T.; Chan, A.B. Visual Tracking via Dynamic Memory Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Target Image | Search Image | Kernel Size | No. of Stride | Feature Map Size |
|---|---|---|---|---|---|
| Input image | - | - | |||
| convol1 | 2 | ||||
| pool1 | 2 | ||||
| convol2 | 1 | ||||
| pool2 | 2 | ||||
| convol3 | 1 | ||||
| convol4 | 1 | ||||
| convol5 | 1 |
| Tracker | Accuracy | Robustness | EAO | Speed () |
|---|---|---|---|---|
| Ours | 0.54 | 0.22 | 0.25 | 60 |
| GradNet [71] | 0.50 | 0.37 | 0.24 | 80 |
| SCS-Siam [72] | 0.52 | 0.29 | 0.24 | 73 |
| MemTrack [14] | 0.49 | 1.77 | 0.24 | 50 |
| ECOhc [6] | 0.49 | 0.44 | 0.24 | 60 |
| SATIN [73] | 0.49 | 1.34 | 0.28 | 24 |
| DSiam [11] | 0.51 | 0.67 | 0.20 | 6 |
| CSRDCF[74] | 0.49 | 0.49 | 0.25 | 13 |
| SiamFC [10] | 0.50 | 0.59 | 0.19 | 86 |
| DCFNet [75] | 0.47 | 0.54 | 0.18 | 60 |
| DensSiam [76] | 0.46 | 0.69 | 0.17 | 60 |
| DSST [66] | 0.39 | 1.45 | 0.08 | 24 |
| SRDCF [61] | 0.49 | 0.97 | 0.12 | 6 |
| Low-Level | High-Level | FRN Mechanism | Performance Results | |||||
|---|---|---|---|---|---|---|---|---|
| L1 | L2 | L3 | L4 | L5 | Residual Refine Module | Attention Module | Success Score | Precision Score |
| ✓ | ✓ | ✓ | ✓ | 58.5 | 78.8 | |||
| ✓ | ✓ | ✓ | ✓ | 57.9 | 77.3 | |||
| ✓ | ✓ | ✓ | ✓ | ✓ | 61.7 | 81.9 | ||
| ✓ | ✓ | ✓ | 62.0 | 82.3 | ||||
| ✓ | ✓ | ✓ | 62.3 | 82.5 | ||||
| ✓ | ✓ | ✓ | ✓ | 63.6 | 84.0 | |||
| ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | 62.9 | 83.2 |
| ✓ | ✓ | ✓ | ✓ | 62.2 | 82.0 | |||
| ✓ | ✓ | ✓ | ✓ | 61.3 | 80.7 | |||
| ✓ | ✓ | ✓ | ✓ | 63.0 | 82.8 | |||
| SiamFC-baseline | ✓ | ✓ | 62.5 | 82.7 | ||||
| SiamFC-baseline | ✓ | 61.2 | 80.9 | |||||
| SiamFC-baseline | ✓ | 61.9 | 81.9 | |||||
| SiamFC-baseline | 59.7 | 79.8 | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, M.M.; Ahmed, M.R.; Laishram, L.; Kim, S.H.; Jung, S.K. Siamese High-Level Feature Refine Network for Visual Object Tracking. Electronics 2020, 9, 1918. https://doi.org/10.3390/electronics9111918
Rahman MM, Ahmed MR, Laishram L, Kim SH, Jung SK. Siamese High-Level Feature Refine Network for Visual Object Tracking. Electronics. 2020; 9(11):1918. https://doi.org/10.3390/electronics9111918
Chicago/Turabian StyleRahman, Md. Maklachur, Md Rishad Ahmed, Lamyanba Laishram, Seock Ho Kim, and Soon Ki Jung. 2020. "Siamese High-Level Feature Refine Network for Visual Object Tracking" Electronics 9, no. 11: 1918. https://doi.org/10.3390/electronics9111918