Polymorphic Memory: A Hybrid Approach for Utilizing On-Chip Memory in Manycore Systems




Abstract
1. Introduction
2. Related Works
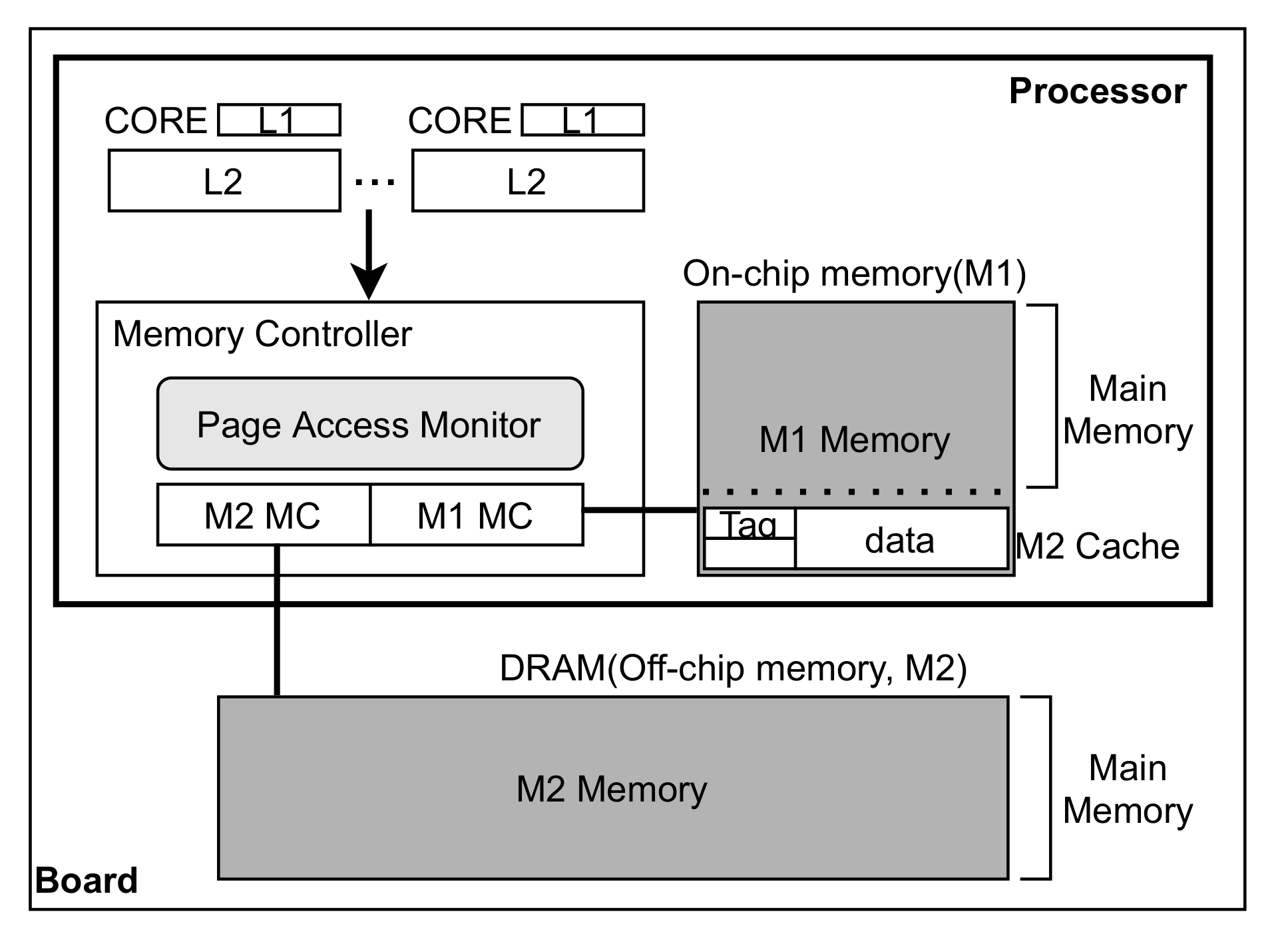
3. Polymorphic Memory System
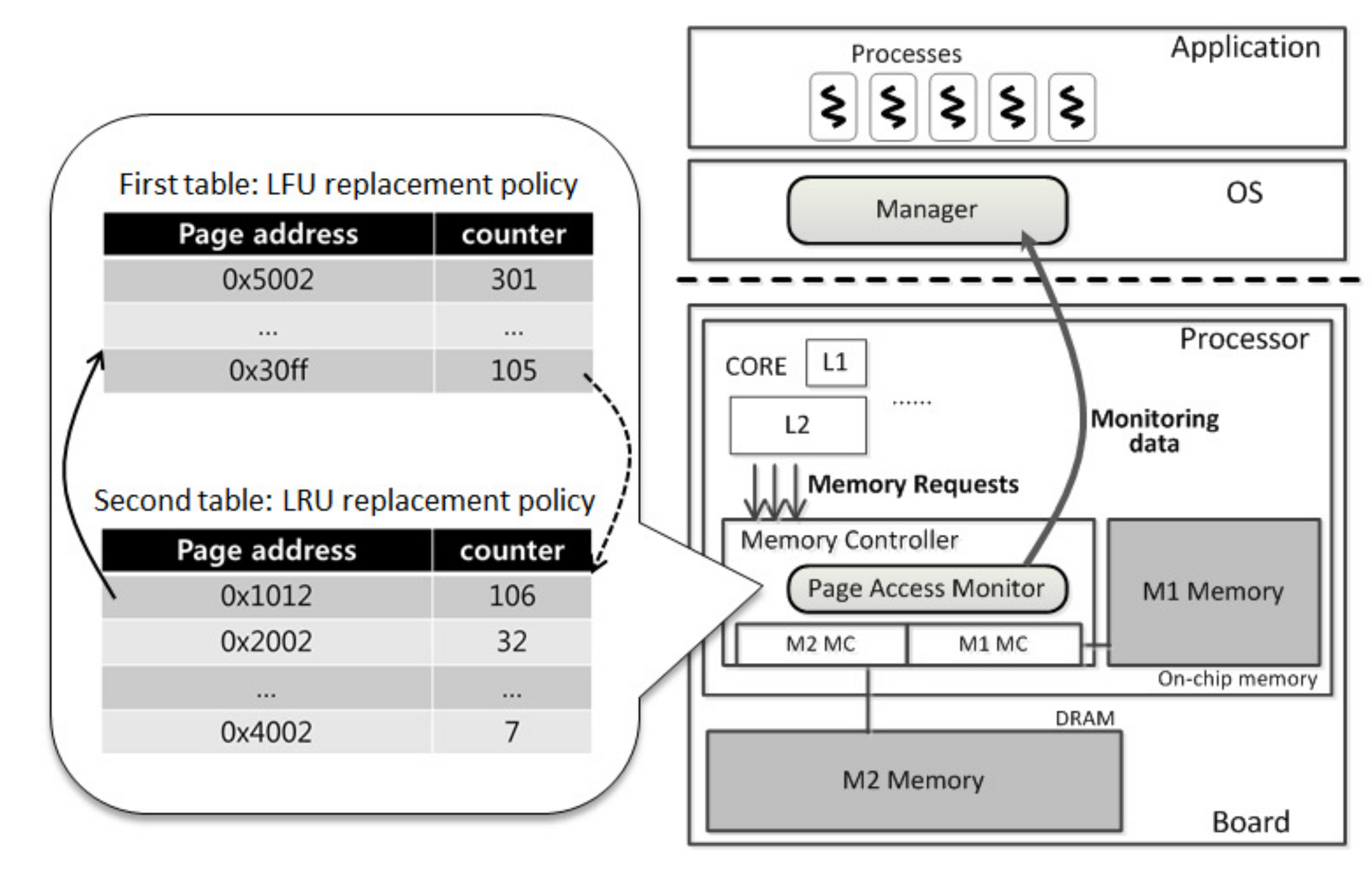
3.1. Memory Management with Monitor
| Algorithm 1 Page access monitoring function. |
| 1: : The first table |
| 2: : The second table |
| 3: : Entry for p page, which includes page address and count value |
| 4: : Count value of |
|
5:
: The smallest count value whose page is q on |
| 6: During a period, p page is accessed |
| 7: if is on then |
| 8: Increase by 1 |
| 9: else |
| 10: if is not full then |
| 11: Insert on with = 1 |
| 12: else |
| 13: if is on then |
| 14: Increase by 1 |
| 15: Move to MRU position |
| 16: else |
| 17: if is full then |
| 18: Remove LRU entry |
| 19: end if |
| 20: Put on MRU of with = 1 |
| 21: end if |
| 22: if ≥ then |
| 23: Move on |
| 24: Move on MRU of |
| 25: end if |
| 26: end if |
|
27:
end if |
| 28: At the end of a period, all pages on are moved to M1 memory. Reset all the count values of and . |
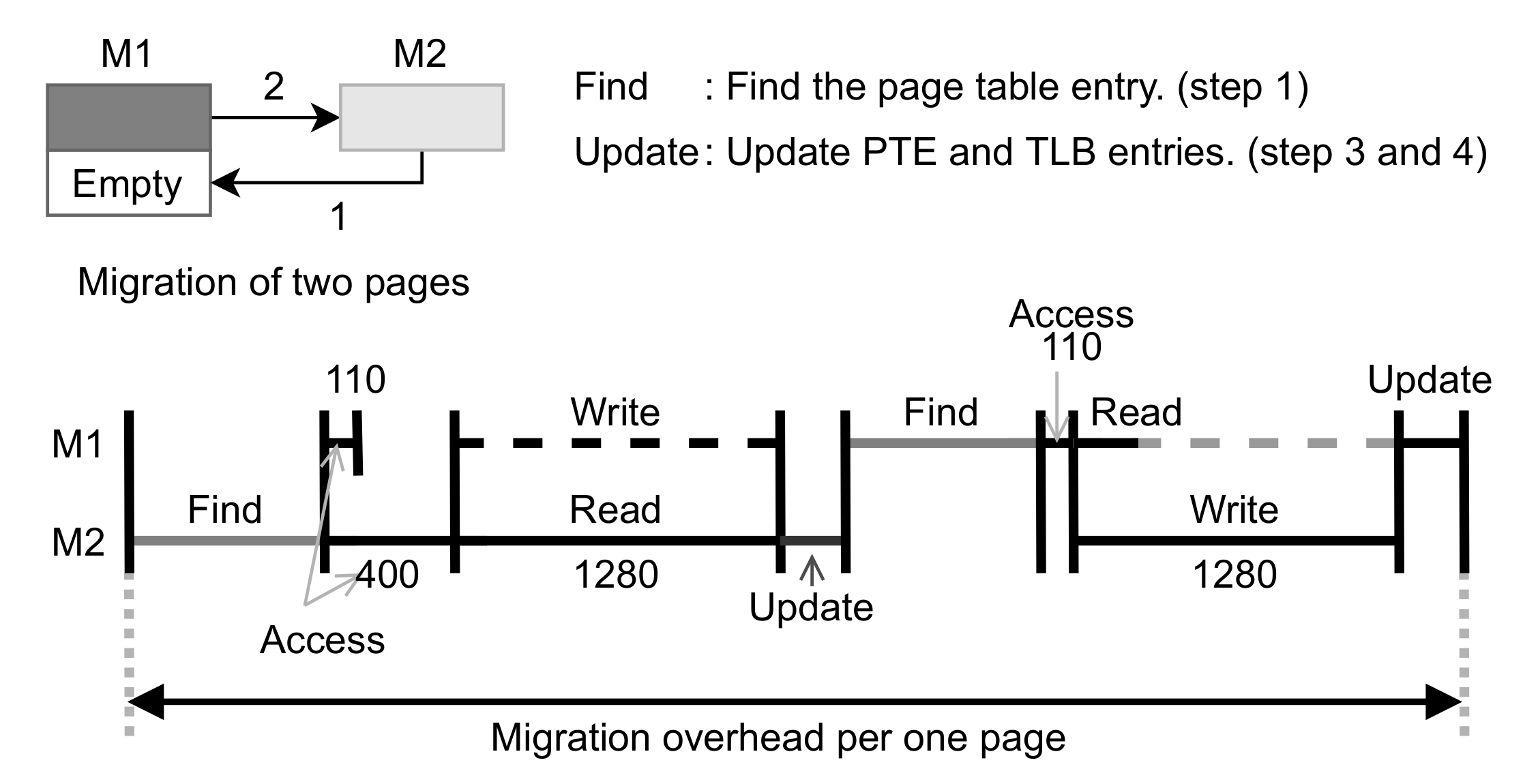
3.2. Page Migration between M1 and M2
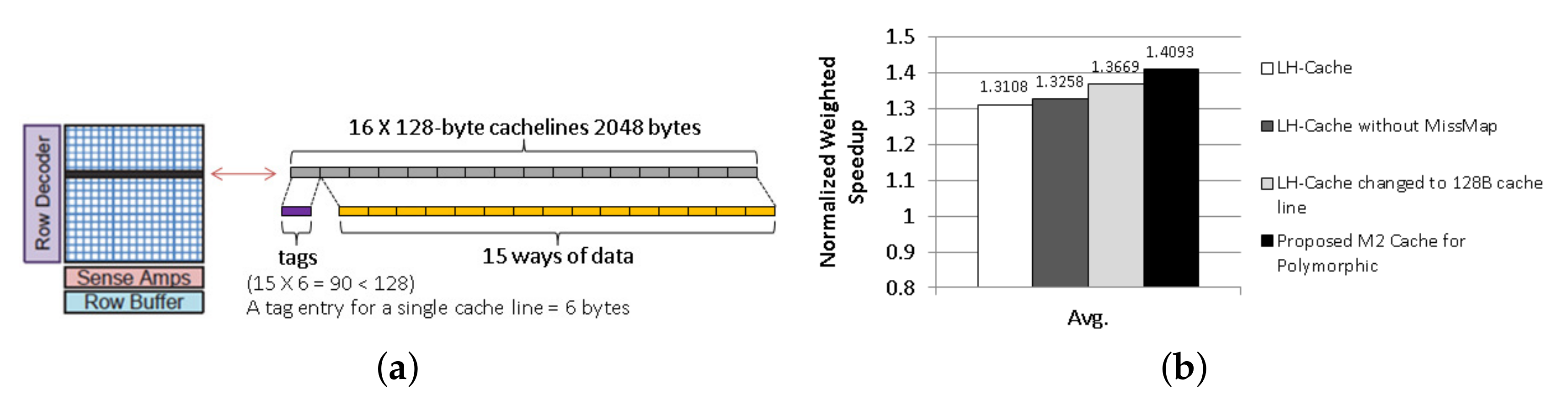
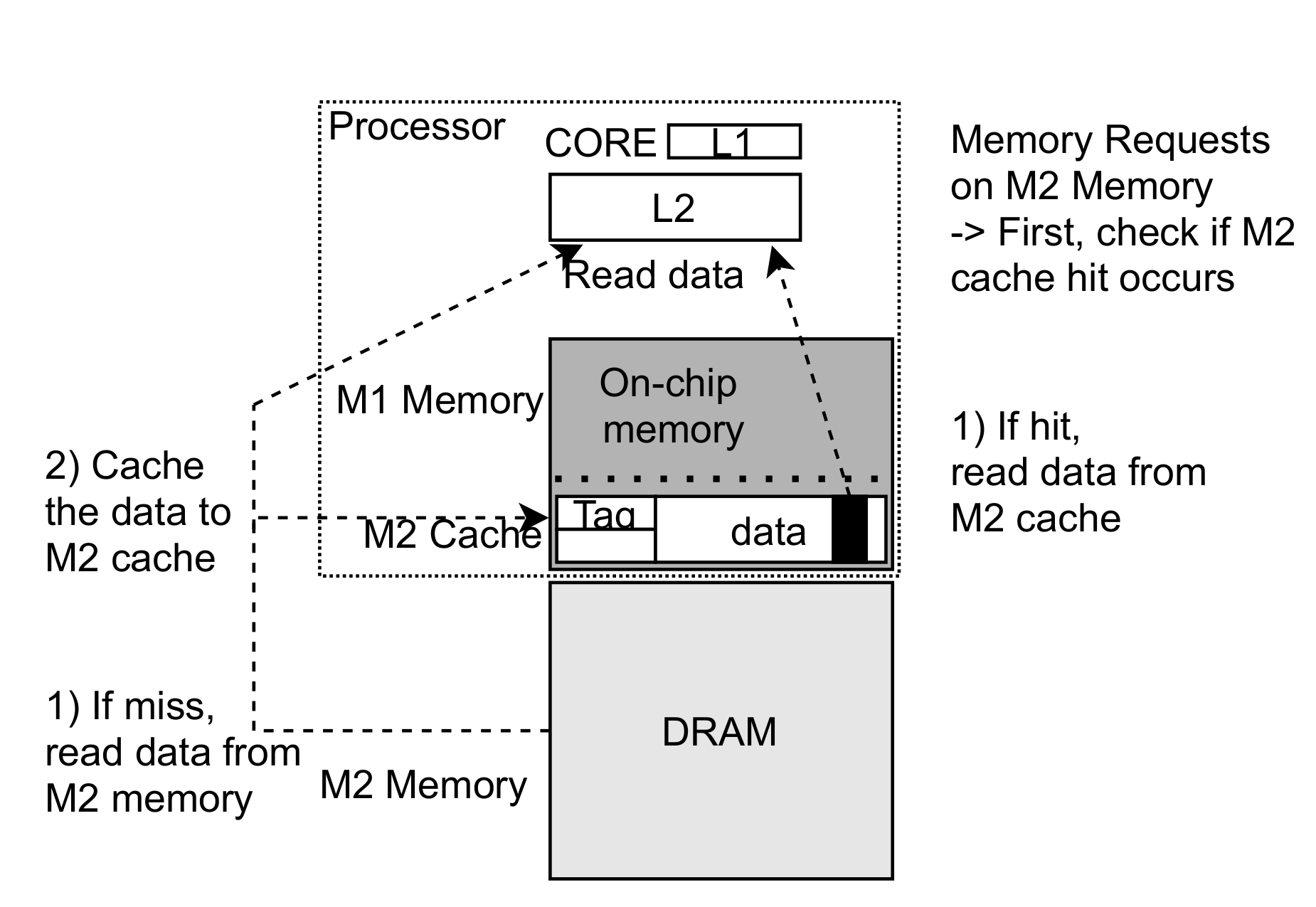
3.3. M2 Cache Management Using Part of M1
3.4. Polymorphic Memory of M1 as Both Part of Memory and M2 Cache
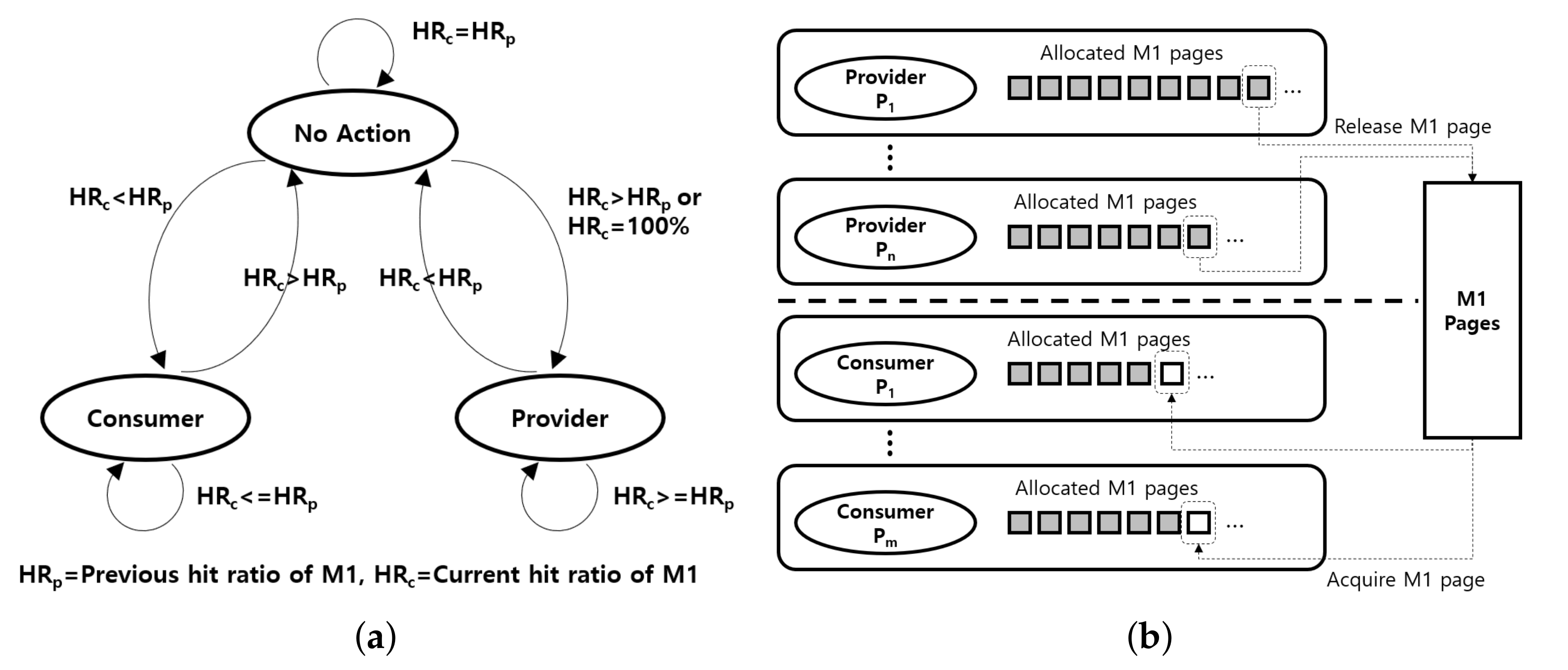
3.5. Multi-Process Support Management
4. Evaluation
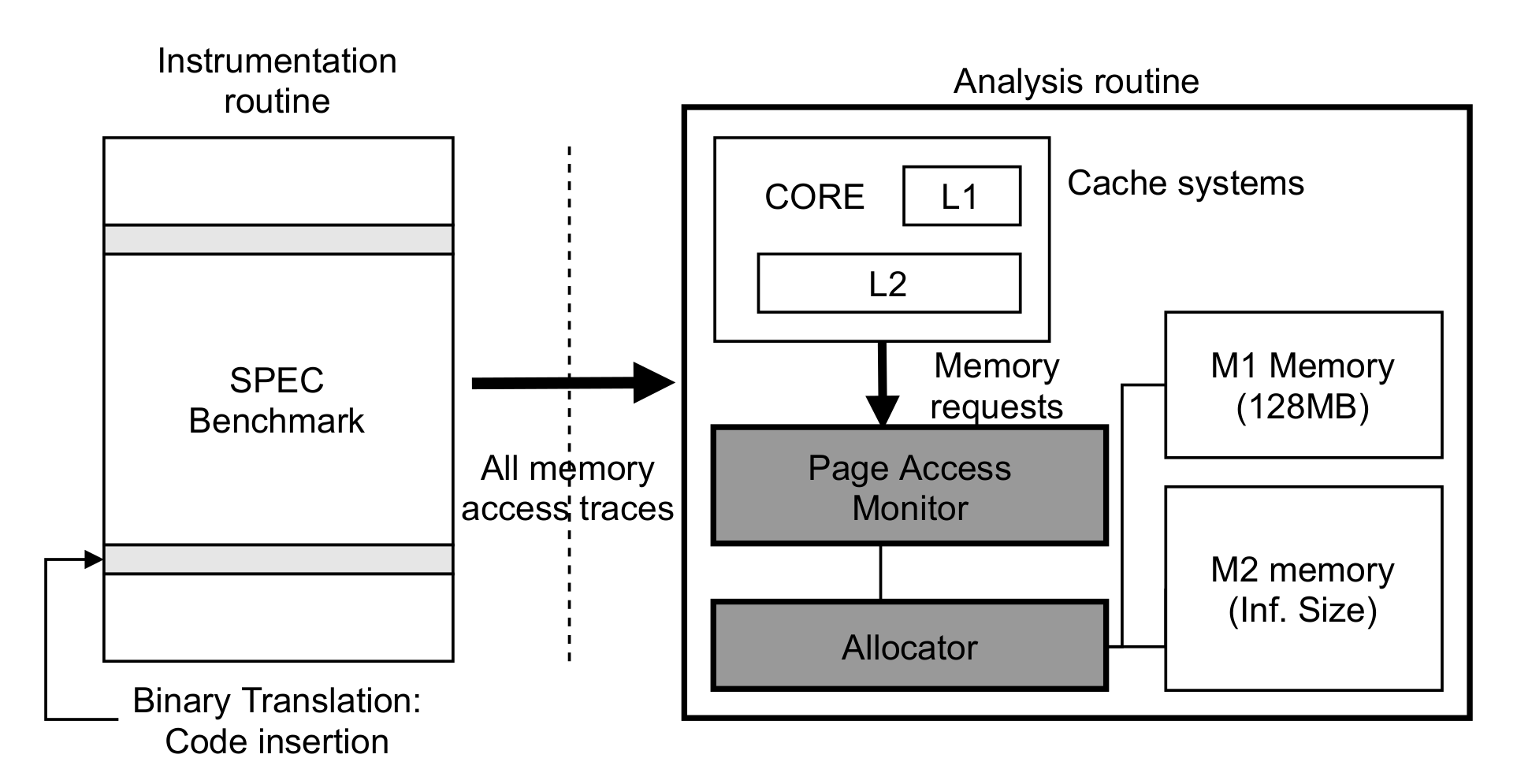
4.1. Simulation Environment
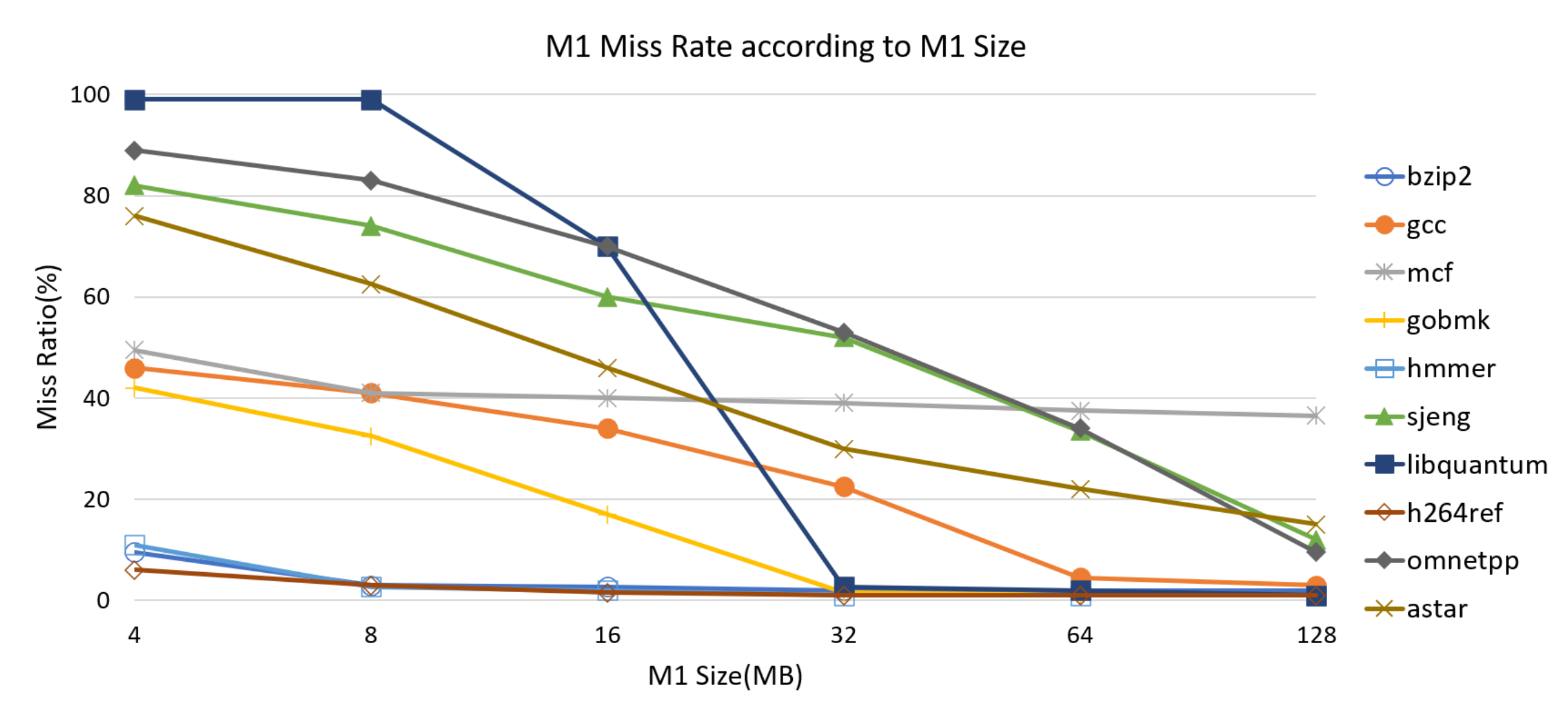
4.2. Evaluation of Memory Management with M1 as Part of Memory
4.2.1. Analysis of Migration Overhead
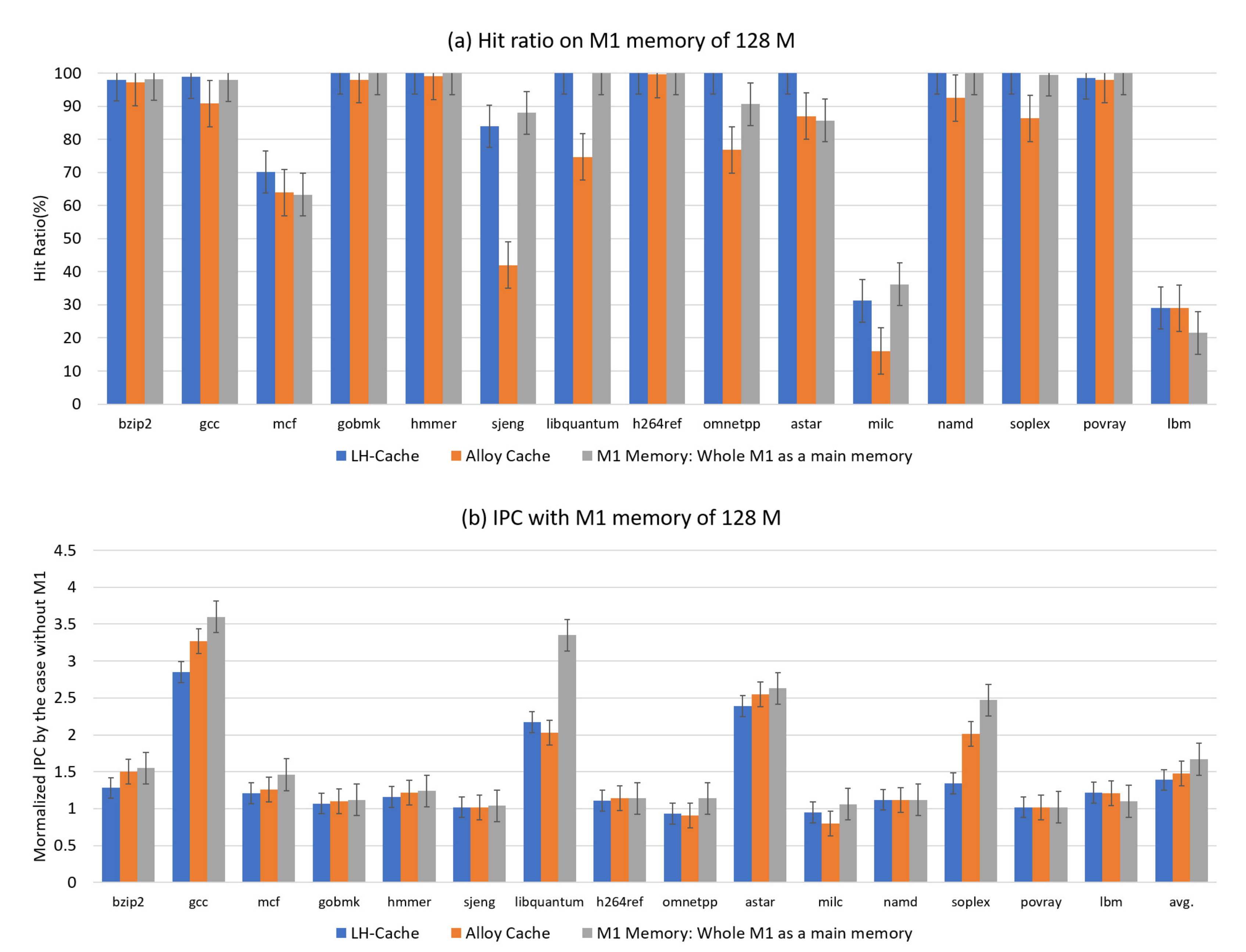
4.2.2. Performance with a Single Workload
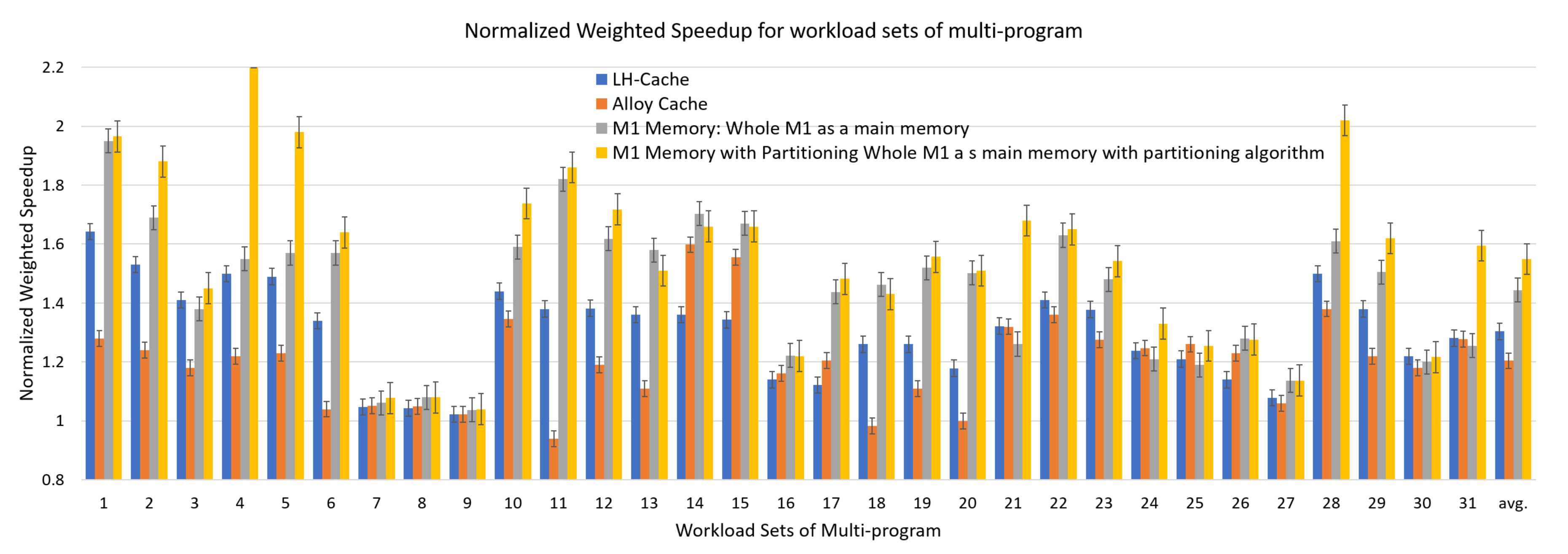
4.2.3. Performance with Multiple Workloads
4.3. Evaluation for Polymorphic Memory System
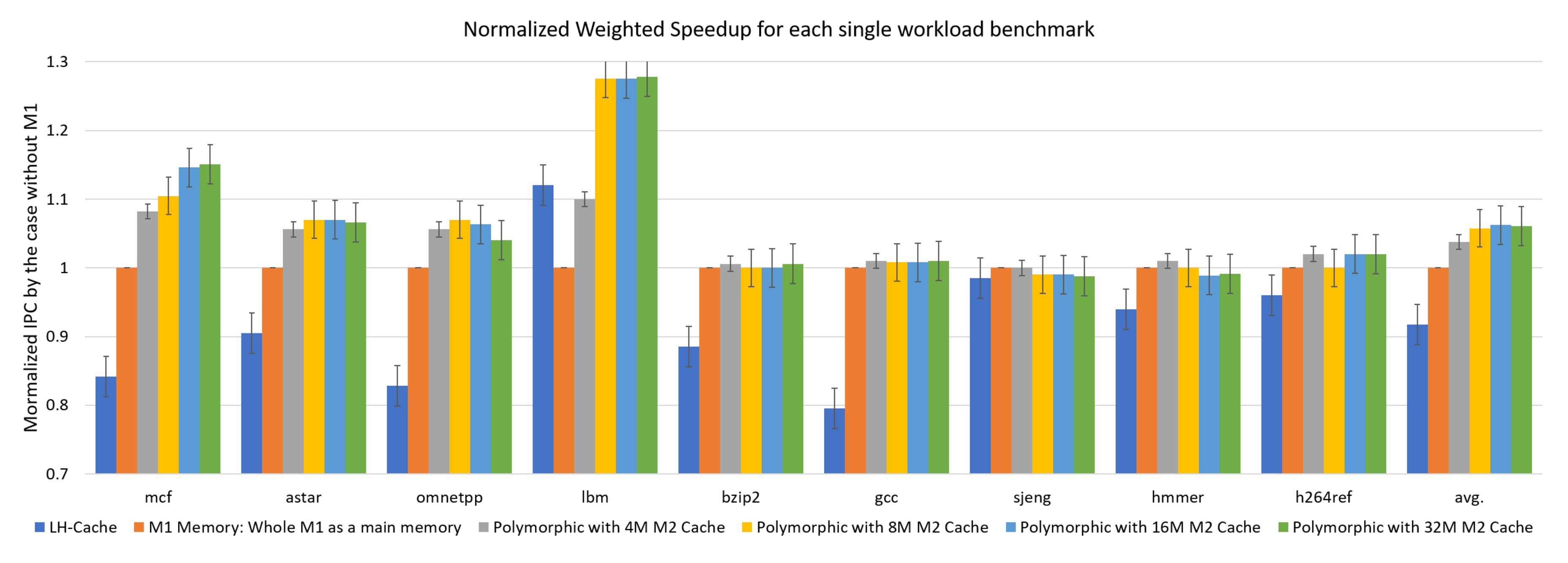
4.3.1. Performance with a Single Workload
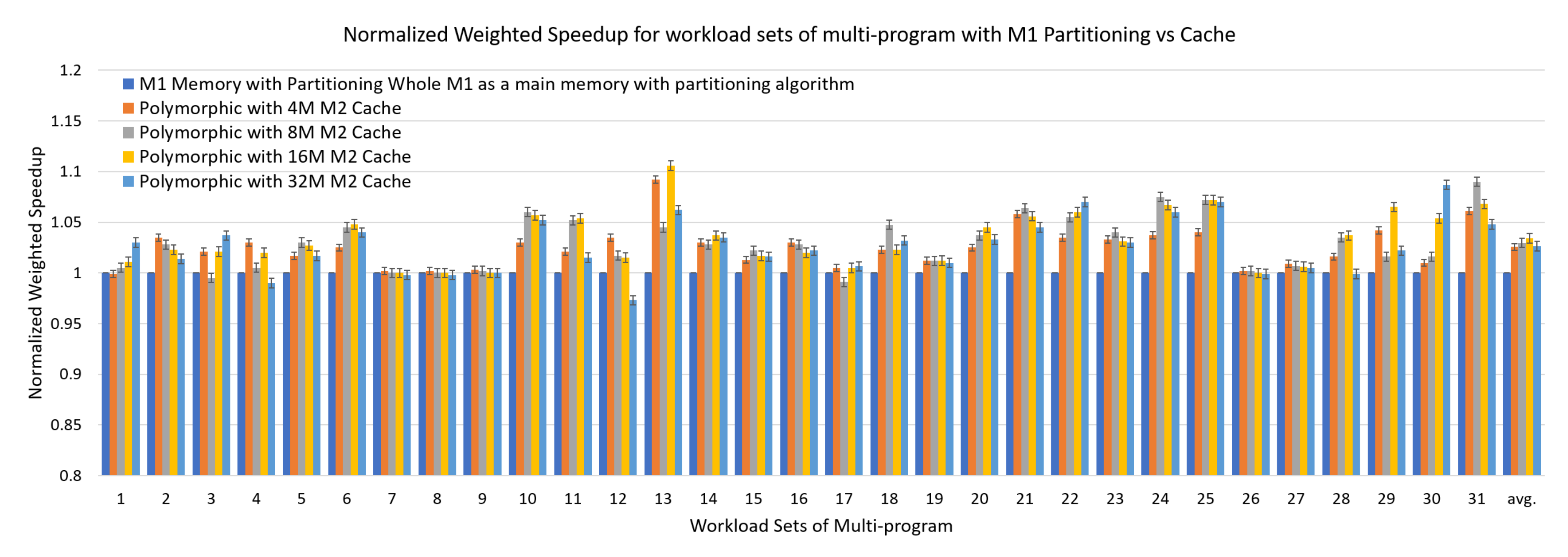
4.3.2. Performance with Multiple Workloads
4.4. Summary and Dicussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ITRS | International Technology Roadmap for Semiconductors |
| CHOP | Caching HOt Pages |
| TAD | Tag and Data |
| PAM | Parallel Access Model |
| RMAP | reverse mapping |
| LLC | Last-Level Cache |
| IPC | instruction per cycle |
| TLB | Translation Lookaside Buffer |
| DRAM | Dynamic Random Access Memory |
| SRAM | Static Random Access Memory |
| DDR | Double Data Rate |
| OS | Operating System |
| LRU | Least Recently Used |
| LFU | Least Frequently Used |
| MRU | Most Recently Used |
| IPC | Instructions Per Cycle |
| GB | Giga Byte |
| SEPC | Standard Performance Evaluation Corporation |
| CPU | Central Processing Unit |
| bzip | Basic Leucine Zipper |
| gcc | GNU Compiler Collection, C Language optimizing compiler |
| mcf | Combinatorial optimization/Single-depot vehicle scheduling |
| sjeng | sjeng chess programming |
| omnetpp | Discrete Event Simulation |
| astar | path-finding algorithms program |
| milc | MIMD Lattice Computation (MILC) collaboration |
| lbm | Lattice Boltzmann Method to simulate incompressible fluids in 3D |
| soplex | a linear program using the Simplex algorithm |
| hmmer | statistical models of multiple sequence alignments |
| h264ref | a reference implementation of H.264/AVC (Advanced Video Coding) |
| libquantum | a library for the simulation of a quantum computer |
| NUMA | NNon-Uniform Memory Access |
References
- Park, K.H.; Park, Y.; Hwang, W.; Park, K.-W. Mn-mate: Resource management of manycores with dram and nonvolatile memories. In Proceedings of the 12th IEEE International Conference on High Performance Computing and Communications (HPCC), Melbourne, Australia, 1–3 September 2010; pp. 24–34. [Google Scholar]
- Borkar, S. Thousand core chips: A technology perspective. In Proceedings of the 44th Annual Design Automation Conference, San Diego, CA, USA, 4–8 June 2007; pp. 746–749. [Google Scholar]
- Liu, R.; Klues, K.; Bird, S.; Hofmeyr, S.; Asanović, K.; Kubiatowicz, J. Tessellation: Space-time partitioning in a manycore client os. In Proceedings of the First USENIX Conference on Hot Topics in Parallelism, Berkeley, CA, USA, 30–31 March 2009; p. 10. [Google Scholar]
- Boyd-Wickizer, S.; Chen, H.; Chen, R.; Mao, Y.; Kaashoek, F.; Morris, R.; Pesterev, A.; Stein, L.; Wu, M.; Dai, Y.; et al. Corey: An operating system for many cores. In Proceedings of the 8th USENIX Conference on Operating Systems Design and Implementation, Carlsbad, CA, USA, 8–10 October 2008; pp. 43–57. [Google Scholar]
- Kozyrakis, C.; Kansal, A.; Sankar, S.; Vaid, K. Server engineering insights for large-scale online services. IEEE Micro 2010, 30, 8–19. [Google Scholar] [CrossRef]
- Ousterhout, J.; Agrawal, P.; Erickson, D.; Kozyrakis, C.; Leverich, J.; Mazières, D.; Mitra, S.; Narayanan, A.; Parulkar, G.; Rosenblum, M.; et al. The case for ramclouds: Scalable high-performance storage entirely in dram. SIGOPS Oper. Syst. Rev. 2010, 43, 92–105. [Google Scholar] [CrossRef]
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A distributed storage system for structured data. ACM Trans. Comput. Syst. 2008, 26, 1–26. [Google Scholar] [CrossRef]
- Choi, J.H.; Park, K.-W.; Park, S.K.; Park, K.H. Multimedia matching as a service: Technical challenges and blueprints. In Proceedings of the 26th International Technical Conference on Circuits/Systems, Computers and Communications, Gyeongju, Korea, 19–22 June 2011. [Google Scholar]
- Memcached: A Distributed Memory Object Caching System. Available online: http://memcached.org/ (accessed on 1 June 2019).
- Wulf, W.A.; Mckee, S.A. Hitting the memory wall: Implications of the obvious. Comput. Archit. News 1995, 23, 20–24. [Google Scholar] [CrossRef]
- Black, B.; Annavaram, M.; Brekelbaum, N.; DeVale, J.; Jiang, L.; Loh, G.H.; McCaule, D.; Morrow, P.; Nelson, D.W.; Pantuso, D.; et al. Die stacking (3d) microarchitecture. In Proceedings of the 39th Annual IEEE/ACM International Symposium on Microarchitecture, Orlando, FL, USA, 9–13 December 2006; pp. 469–479. [Google Scholar]
- Kgil, T.; Saidi, A.; Binkert, N.; Dreslinski, R.; Mudge, T.; Reinhardt, S.; Flautner, K. Picoserver: Using 3d stacking technology to enable a compact energy efficient chip multiprocessor. In Proceedings of the 12th ACM international conference on Architectural support for programming languages and operating systems (ASPLOS XII), New York, NY, USA, 21–25 October 2006; pp. 117–128. [Google Scholar]
- Loh, G.H. 3D-stacked memory architectures for multi-core processors. In Proceedings of the 35th International Symposium on Computer Architecture, Beijing, China, 21–25 June 2008; pp. 453–464. [Google Scholar]
- Liu, C.; Ganusov, I.; Burtscher, M.; Tiwari, S. Bridging the processor-memory performance gap with 3d ic technology. IEEE Des. Test Comput. 2005, 22, 556–564. [Google Scholar] [CrossRef]
- Loi, G.L.; Agrawal, B.; Srivastava, N.; Lin, S.-C.; Sherwood, T.; Banerjee, K. A thermally-aware performance analysis of vertically integrated (3-d) processor-memory hierarchy. In Proceedings of the 43rd Annual Design Automation Conference, San Francisco, CA, USA, 24–28 July 2006; pp. 991–996. [Google Scholar]
- Loh, G.H.; Hill, M.D. Efficiently enabling conventional block sizes for very large die-stacked dram caches. In Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, Porto Alegre, Brazil, 4–7 December 2011; ACM: New York, NY, USA, 2011; pp. 454–464. [Google Scholar]
- Qureshi, M.K.; Loh, G.H. Fundamental latency trade-off in architecting dram caches: Outperforming impractical sram-tags with a simple and practical design. In Proceedings of the 45th Annual IEEE/ACM International Symposium on Microarchitecture, Vancouver, BC, Canada, 1–5 December 2012; pp. 235–246. [Google Scholar]
- Huang, C.; Nagarajan, V. ATCache: Reducing DRAM cache latency via a small sram tag cache. In Proceedings of the 23rd International Conference on Parallel Architectures and Compilation, Edmonton, AB, Canada, 24–27 August 2014; pp. 51–60. [Google Scholar]
- Vasilakis, E.; Papaefstathiou, V.; Trancoso, P.; Sourdis, I. Decoupled fused cache: Fusing a decoupled LLC with a DRAM cache. ACM Trans. Archit. Code Optim. 2019, 15, 1–23. [Google Scholar] [CrossRef]
- Yu, X.; Hughes, C.J.; Satish, N.; Mutlu, O.; Devadas, S. Banshee: Bandwidth-efficient DRAM caching via software/hardware cooperation. In Proceedings of the 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Boston, MA, USA, 14–17 October 2017; pp. 1–14. [Google Scholar]
- Dong, X.; Xie, Y.; Muralimanohar, N.; Jouppi, N.P. Simple but effective heterogeneous main memory with on-chip memory controller support. In Proceedings of the 2010 ACM/IEEE International Conference for High Performance Computing, Networking, Storage and Analysis, New Orleans, LA, USA, 13–19 November 2010; pp. 1–11. [Google Scholar]
- Chou, C.C.; Jaleel, A.; Qureshi, M.K. CAMEO: A twolevel memory organization with capacity of main memory and flexibility of hardware-managed cache. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 1–12. [Google Scholar]
- Sim, J.; Alameldeen, A.R.; Chishti, Z.; Wilkerson, C.; Kim, H. Transparent hardware management of stacked DRAM as part of memory. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; pp. 13–24. [Google Scholar]
- Kotra, J.B.; Zhang, H.; Alameldeen, A.R.; Wilkerson, C.; Kandemir, M.T. CHAMELEON: A dynamically reconfigurable heterogeneous memory system. In Proceedings of the 51st Annual IEEE/ACM International Symposium on Microarchitecture, Fukuoka, Japan, 20–24 October 2018; pp. 533–545. [Google Scholar]
- Prodromou, A.; Meswani, M.; Jayasena, N.; Loh, G.H.; Tullsen, D.M. Mempod: A clustered architecture for efficient and scalable migration in flat address space multi-level memories. In Proceedings of the 2017 IEEE International Symposium on High Performance Computer Architecture, Austin, TX, USA, 4–8 February 2017; pp. 433–444. [Google Scholar]
- Vasilakis, E.; Papaefstathiou, V.; Trancoso, P.; Sourdis, I. LLC-guided data migration in hybrid memory systems. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium, Rio de Janeiro, Brazil, 20–24 May 2019; pp. 932–942. [Google Scholar]
- Vasilakis, E.; Papaefstathiou, V.; Trancoso, P.; Sourdis, I. Hybrid2: Combining Caching and Migration in Hybrid Memory Systems. In Proceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, 22–26 February 2020; pp. 649–662. [Google Scholar]
- Guo, J.; Lai, M.; Pang, Z.; Huang, L.; Chen, F.; Dai, K.; Wang, Z. Memory System Design for a Multi-core Processor. In Proceedings of the 2008 International Conference on Complex, Intelligent and Software Intensive Systems, Barcelona, Spain, 4–7 March 2008; pp. 601–606. [Google Scholar]
- Agrawal, S.R.; Idicula, S.; Raghavan, A.; Vlachos, E.; Govindaraju, V.; Varadarajan, V.; Balkesen, C.; Giannikis, G.; Roth, C.; Agarwal, N.; et al. A Many-core Architecture for In-Memory Data Processing. In Proceedings of the 2017 50th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Boston, MA, USA, 14–17 October 2017; pp. 245–258. [Google Scholar]
- Li, W.; Yang, F.; Zhu, H.; Zeng, X.; Zhou, D. An Efficient Memory Partitioning Approach for Multi-Pattern Data Access via Data Reuse. ACM Trans. Reconfigurable Technol. Syst. 2019, 12, 1. [Google Scholar] [CrossRef]
- Iyer, R. Performance implications of chipset caches in web servers. In Proceedings of the 2003 IEEE International Symposium on Performance Analysis of Systems and Software, Austin, TX, USA, 6–8 March 2003; pp. 176–185. [Google Scholar]
- Zhang, Z.; Zhu, Z.; Zhang, X. Design and optimization of large size and low overhead off-chip caches. IEEE Trans. Comput. 2004, 53, 843–855. [Google Scholar] [CrossRef]
- Zhao, L.; Iyer, R.; Illikkal, R.; Newell, D. Exploring dram cache architectures for cmp server platforms. In Proceedings of the 25th International Conference on Computer Design, Lake Tahoe, CA, USA, 7–10 October 2007; pp. 55–62. [Google Scholar]
- Jiang, X.; Madan, N.; Zhao, L.; Upton, M.; Iyer, R.; Makineni, S.; Newell, D.; Solihin, Y.; Balasubramonian, R. Chop: Adaptive filter-based dram caching for cmp server platforms. In Proceedings of the 2010 IEEE 16th International Symposium on High Performance Computer Architecture (HPCA), Bangalore, India, 9–14 January 2010; pp. 1–12. [Google Scholar]
- Woo, D.H.; Seong, N.H.; Lewis, D.; Lee, H.-H. An optimized 3d-stacked memory architecture by exploiting excessive, high-density tsv bandwidth. In Proceedings of the 2010 IEEE 16th International Symposium on High Performance Computer Architecture (HPCA), Bangalore, India, 9–14 January 2010; pp. 1–12. [Google Scholar]
- Hill, M.D. A case for direct-mapped caches. Computer 1988, 21, 25–40. [Google Scholar] [CrossRef]
- Bovet, D.; Cesati, M. Understanding the Linux Kernel, 3rd ed.; Oram, A., Ed.; O’Reilly & Associates, Inc.: Sebastopol, CA, USA, 2006. [Google Scholar]
- Dhiman, G.; Ayoub, R.; Rosing, T. Pdram: A hybrid pram and dram main memory system. In Proceedings of the Design Automation Conference, San Francisco, CA, USA, 26–31 July 2009; pp. 664–669. [Google Scholar]
- Luk, C.-K.; Cohn, R.; Muth, R.; Patil, H.; Klauser, A.; Lowney, G.; Wallace, S.; Reddi, V.J.; Hazelwood, K. Pin: Building customized program analysis tools with dynamic instrumentation. In Proceedings of the 2005 ACM SIGPLAN Conference on Programming Language Design and Implementation, Chicago, IL, USA, 12–15 June 2005; pp. 190–200. [Google Scholar]
- Spec’s Benchmark. Available online: http://www.spec.org/cpu2006 (accessed on 1 June 2018).
- Liedtke, J. Improving ipc by kernel design. In Proceedings of the 14th ACM Symposium on Operating System Principles (SOSP), Asheville, NC, USA, 5–8 December 1993; pp. 175–188. [Google Scholar]
- Snavely, A.; Tullsen, D.M. Symbiotic jobscheduling for a simultaneous multithreaded processor. In Proceedings of the Ninth International Conference on Architectural Support for Programming Languages and Operating Systems, New York, NY, USA, 12–15 November 2000; pp. 234–244. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Microprocessor | Cache | ||
|---|---|---|---|
| # of cores | 4 | L1 Cache | 32 KB, 64b line, 2-way 5 cycles, private |
| Freq. | 4 GHz | L2 Cache | 512 KB, 64b line, 8-way 18 bybles, private |
| M1 (on-chip memory) | M2 (off-chip memory) | ||
| LLC | 128 MB, 128b line, 16-way hit: 220 cycles, miss: 110 cycles | Infinite size, 400 cycles BW: 12.8 GB/s | |
| Memory | 128 MB, 110 cycles BW:64GB/s | ||
| Class | Benchmark | Epoch Average | |
|---|---|---|---|
| Frequency | Coverage | ||
| Group 1 | mcf | 58,142.79 | 2346.21 |
| milc | 19,081.75 | 1288.17 | |
| soplex | 31,918.00 | 1846.54 | |
| omnetpp | 36,843.53 | 8234.16 | |
| astar | 22,989.37 | 6838.60 | |
| Group 2 | bzip2 | 14,720.05 | 494.11 |
| gcc | 34,717.65 | 1042.55 | |
| libquantum | 54,957.87 | 860.21 | |
| lbm | 25,512.36 | 414.60 | |
| Group 3 | namd | 1536.91 | 34.82 |
| gobmk | 3863.09 | 532.39 | |
| povray | 11.58 | 3.18 | |
| hmmer | 7050.03 | 158.56 | |
| sjeng | 4306.39 | 1050.87 | |
| h264ref | 4403.83 | 245.32 | |
| Workload | % | Workload | % | Workload | % |
|---|---|---|---|---|---|
| bzip2 | 0.16 | sjeng | 0.47 | milc | 3.19 |
| gcc | 0.20 | omnetpp | 0.01 | lbm | 4.33 |
| mcf | 0.61 | astar | 0.04 |
| Workload | 4 Processes | Workload | 4 Processes |
|---|---|---|---|
| 1 | mcf, omnetpp, astar, soplex | 17 | mcf, sjeng, milc, name |
| 2 | mcf, omnetpp, milc, soplex | 18 | sjeng, libquantum, namd, lbm |
| 3 | omnetpp, astar, milc, soplex | 19 | bzip2, sjeng, libquantum, namd |
| 4 | bzip2, gcc, libquantum, lbm | 20 | libquantum, h264ref, namd, lbm |
| 5 | gcc, hmmer, libquantum, lbm | 21 | bzip2, gcc, hmmer, lbm |
| 6 | bzip2, hmmer, libquantum, lbm | 22 | mcf, h264ref, omnetpp, lbm |
| 7 | gobmk, sjeng, h264ref, namd | 23 | bzip2, sjeng, omnetpp, soplex |
| 8 | Gabor, h264ref, namd, povray | 24 | bzip2, gobmk, omnetpp, lbm |
| 9 | sjeng, h264ref, namd, povray | 25 | gobmk, h264ref, omnetpp, lbm |
| 10 | bzip2, mcf, omnetpp, lbm | 26 | h264ref, omnetpp, namd, povray |
| 11 | mcf, libquantum, milc, lbm | 27 | bzip2, sjeng, h264ref, povray |
| 12 | bzip2, libquantum, omnetpp, milc | 28 | gcc, mcf, hmmer, lbm |
| 13 | libquantum, omnetpp, milc, lbm | 29 | mcf, omnetpp, milc, lbm |
| 14 | mcf, sjeng, h264ref, omnetpp | 30 | omnetpp, astar, milc, namd |
| 15 | mcf, sjeng, omnetpp, namd | 31 | bzip2, gcc, namd, lbm |
| 16 | sjeng, omnetpp, milc, namd |
| Evaluation for M1 vs. M1 Used as M2 Cache | Workload Set | Applied Schemes | Avg. Improve | Standard Deviation (Normalized) |
|---|---|---|---|---|
| M1 as Part of Memory only | Single Workload | Dynamic Migration | 13.7% | 0.8 |
| Multiple Workload Sets | Dynamic Migration and M1 Partitioning | 17.6% | 0.3 | |
| M1 as polymorphic Memory (Cache and Part of Memory) | Single Workload | Dynamic Migration and Cache | 15.7% | 0.09 |
| Multiple Workloads Sets | Dynamic Migration and Cache and M1 Partitioning | 21.7% | 0.026 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lim, S.-H.; Seok, H.; Park, K.-W. Polymorphic Memory: A Hybrid Approach for Utilizing On-Chip Memory in Manycore Systems. Electronics 2020, 9, 2061. https://doi.org/10.3390/electronics9122061
Lim S-H, Seok H, Park K-W. Polymorphic Memory: A Hybrid Approach for Utilizing On-Chip Memory in Manycore Systems. Electronics. 2020; 9(12):2061. https://doi.org/10.3390/electronics9122061
Chicago/Turabian StyleLim, Seung-Ho, Hyunchul Seok, and Ki-Woong Park. 2020. "Polymorphic Memory: A Hybrid Approach for Utilizing On-Chip Memory in Manycore Systems" Electronics 9, no. 12: 2061. https://doi.org/10.3390/electronics9122061
APA StyleLim, S.-H., Seok, H., & Park, K.-W. (2020). Polymorphic Memory: A Hybrid Approach for Utilizing On-Chip Memory in Manycore Systems. Electronics, 9(12), 2061. https://doi.org/10.3390/electronics9122061