Exploring Efficient Acceleration Architecture for Winograd-Transformed Transposed Convolution of GANs on FPGAs †


Abstract
1. Introduction
- We present a novel dataflow exploration, so-called Wino-transCONV, which eliminates all the computations involving 0 values and then implements the transposed convolution operation through adding the DECOMPOSITION and REARRANGEMENT stages in a regular Winograd-transformed convolution dataflow. This dataflow optimization allows a significant reduction in computational complexity.
- We propose a custom architecture for implementing transposed convolution layers efficiently by mapping the multiple-stage Wino-transCONV dataflow to FPGA device with pre- and post-processing in place. The design structures include the processing unit and Buffer operating in a combined pipelined and parallel fashion.
- We devise the memory parallelism-aware partition to achieve efficient data access in the paper. Meanwhile, the optimal hardware-based design space is also explored by analyzing the efficiency in resource allocations and the performance in computational executions.
- Several state-of-the-art GANs are verified on Xilinx FPGA devices by employing the proposed approaches in this paper.
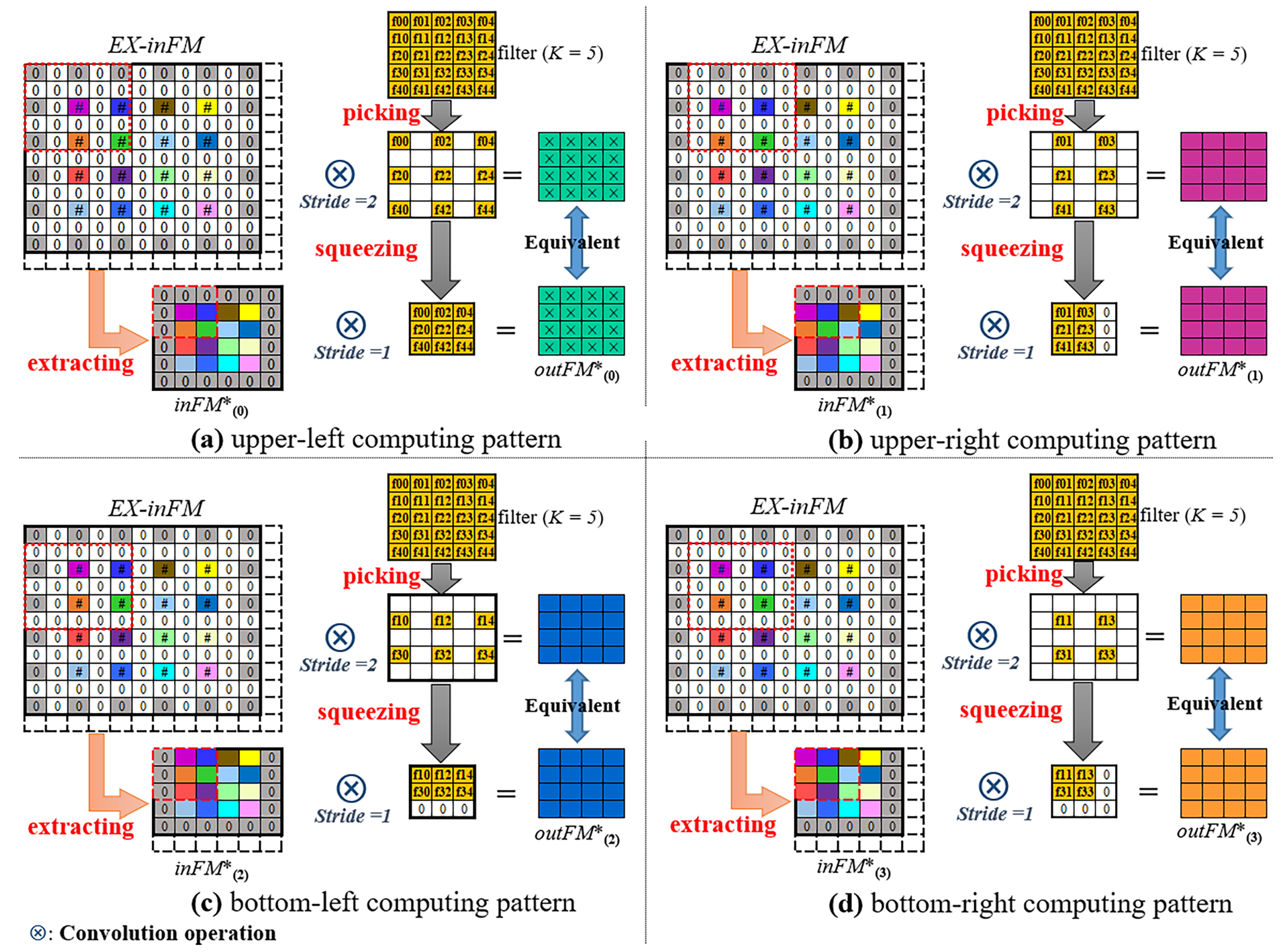
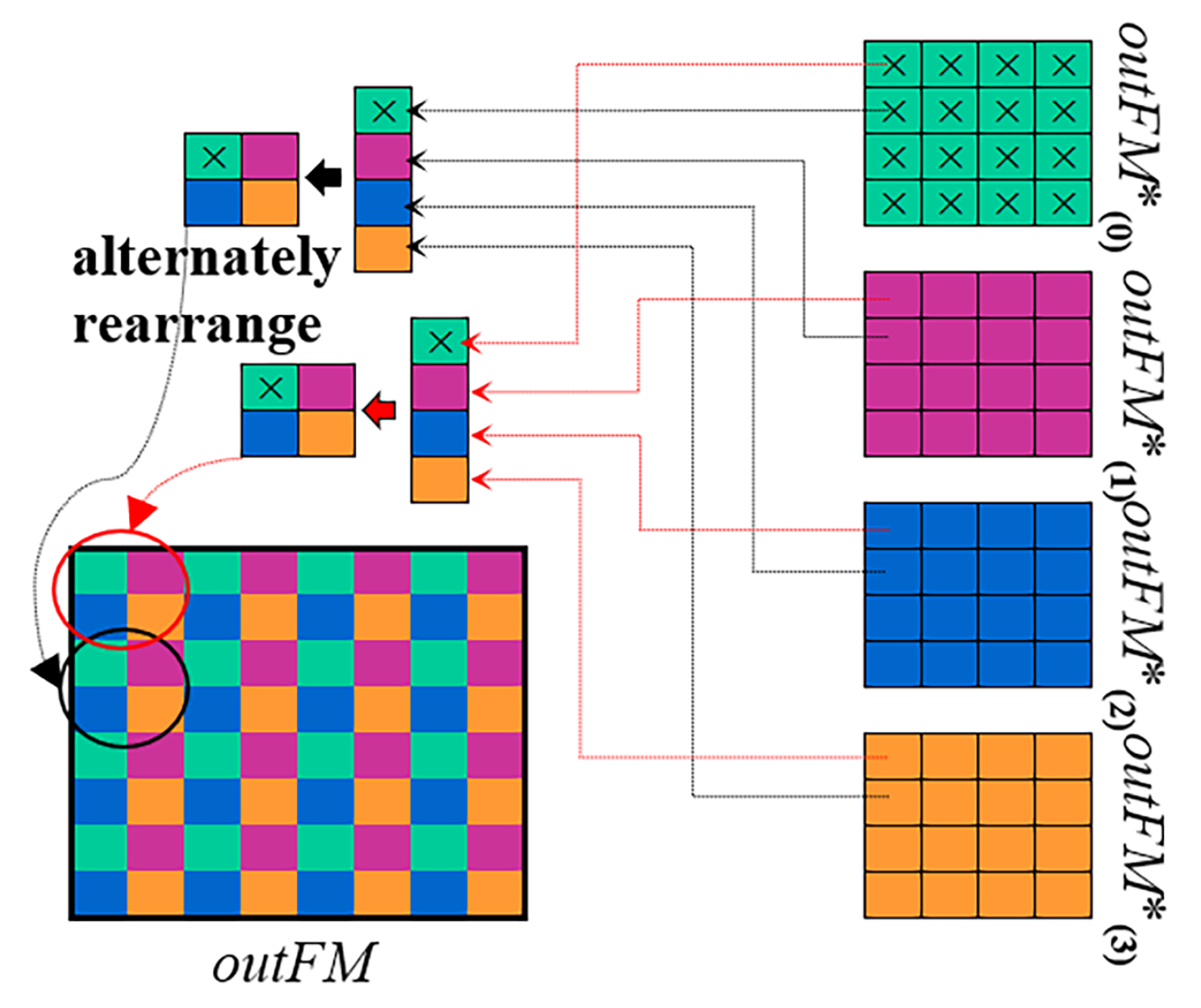
2. Dataflow Exploration
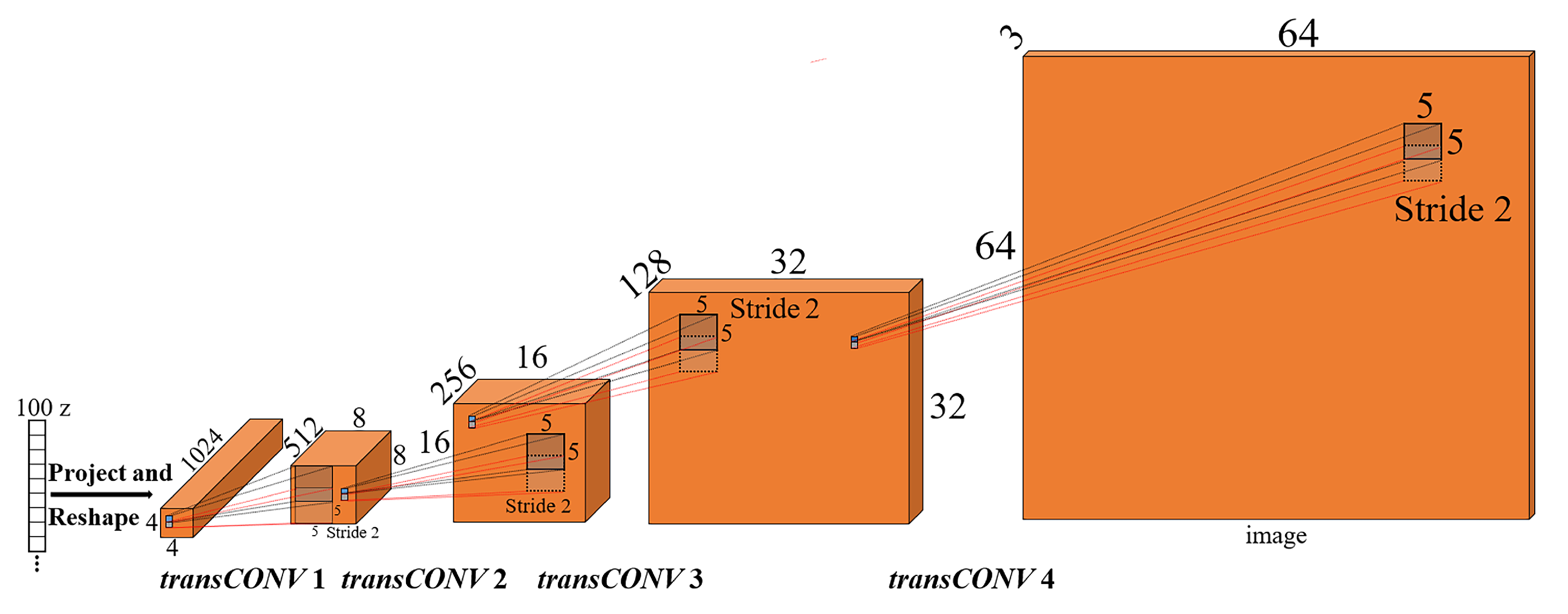
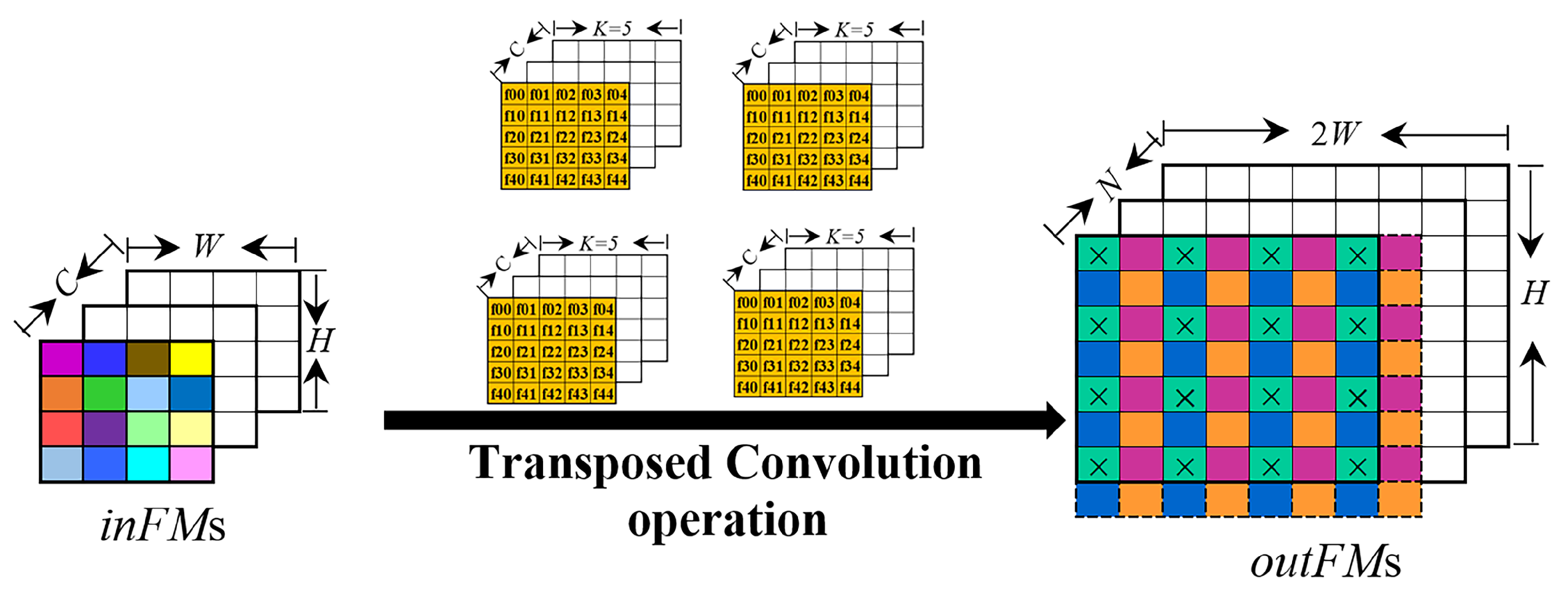
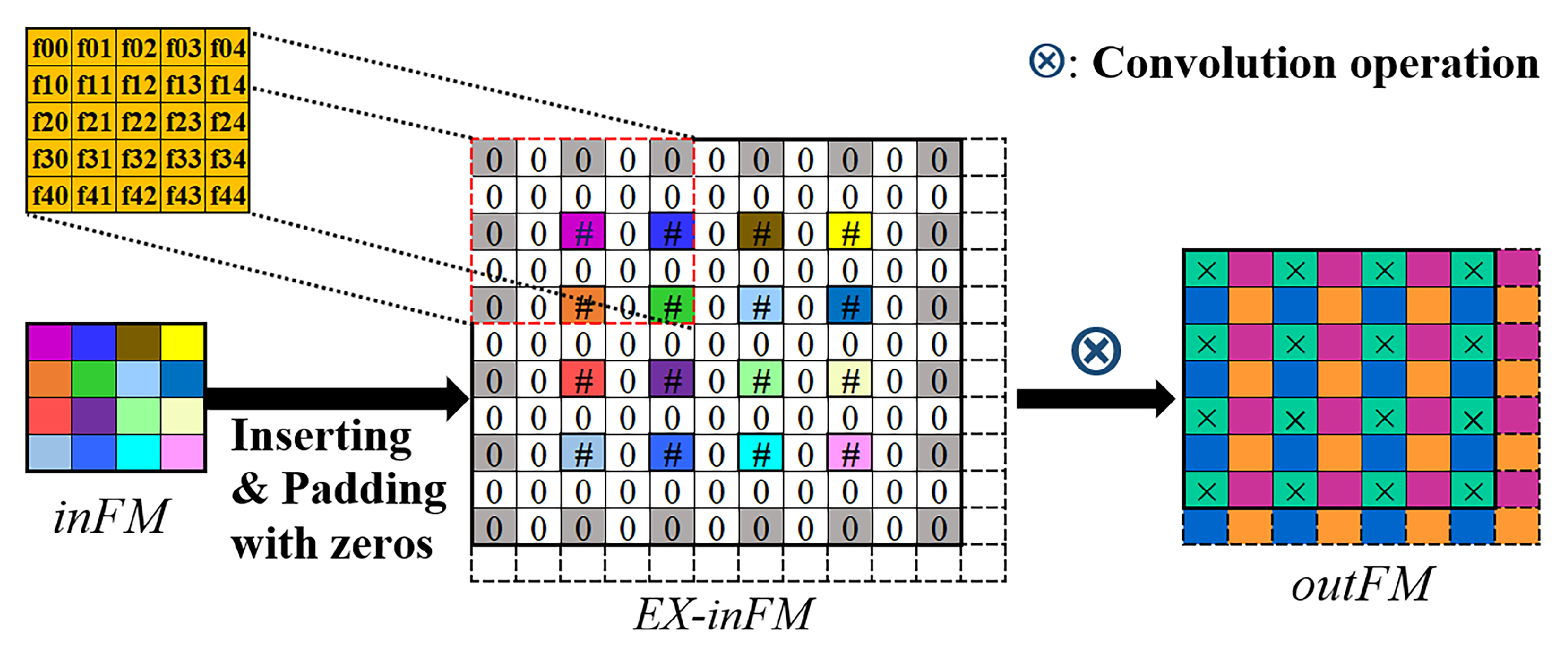
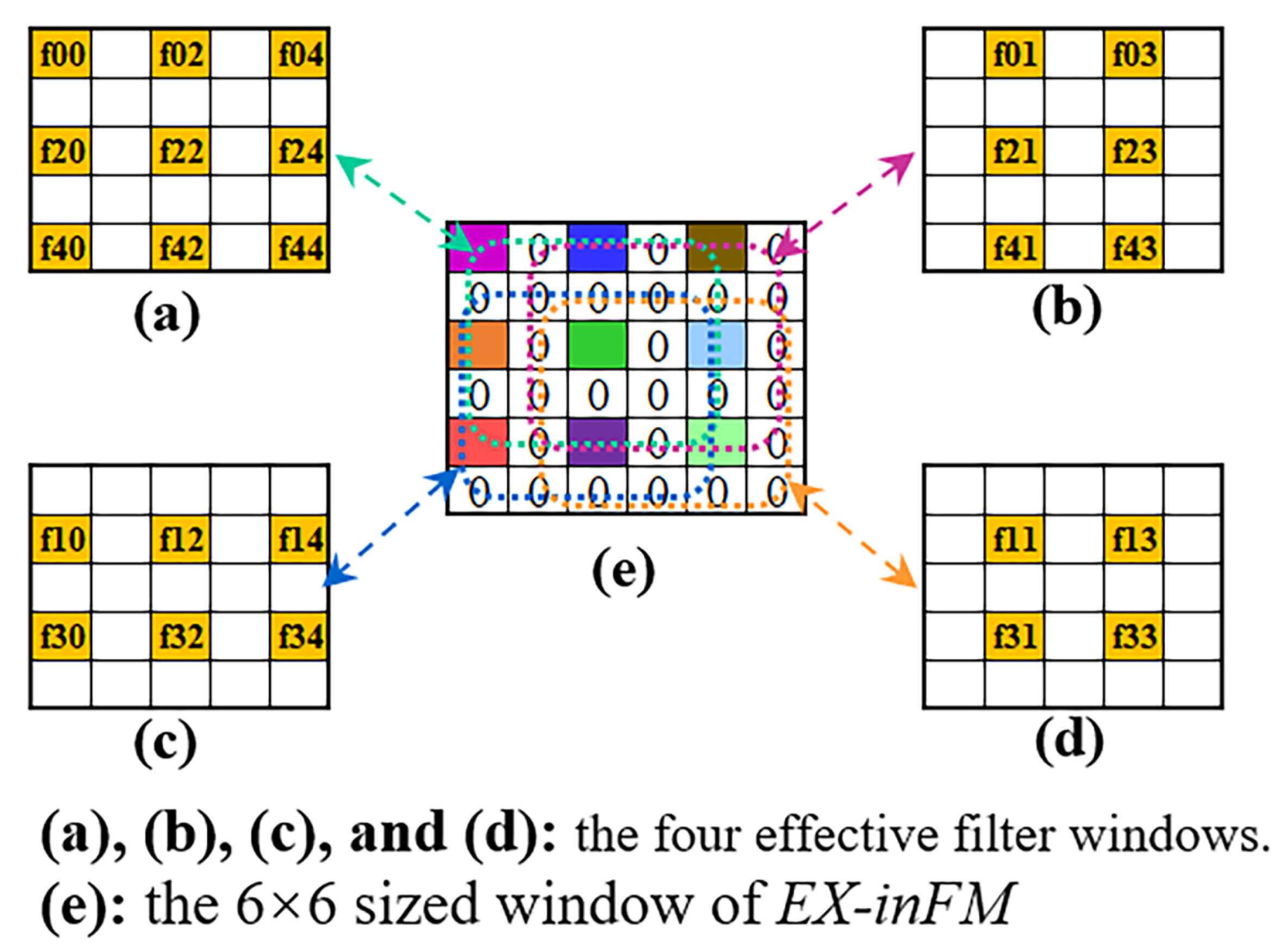
2.1. Transposed Convolution Dataflow Basics
2.2. Winograd Transformation Basics
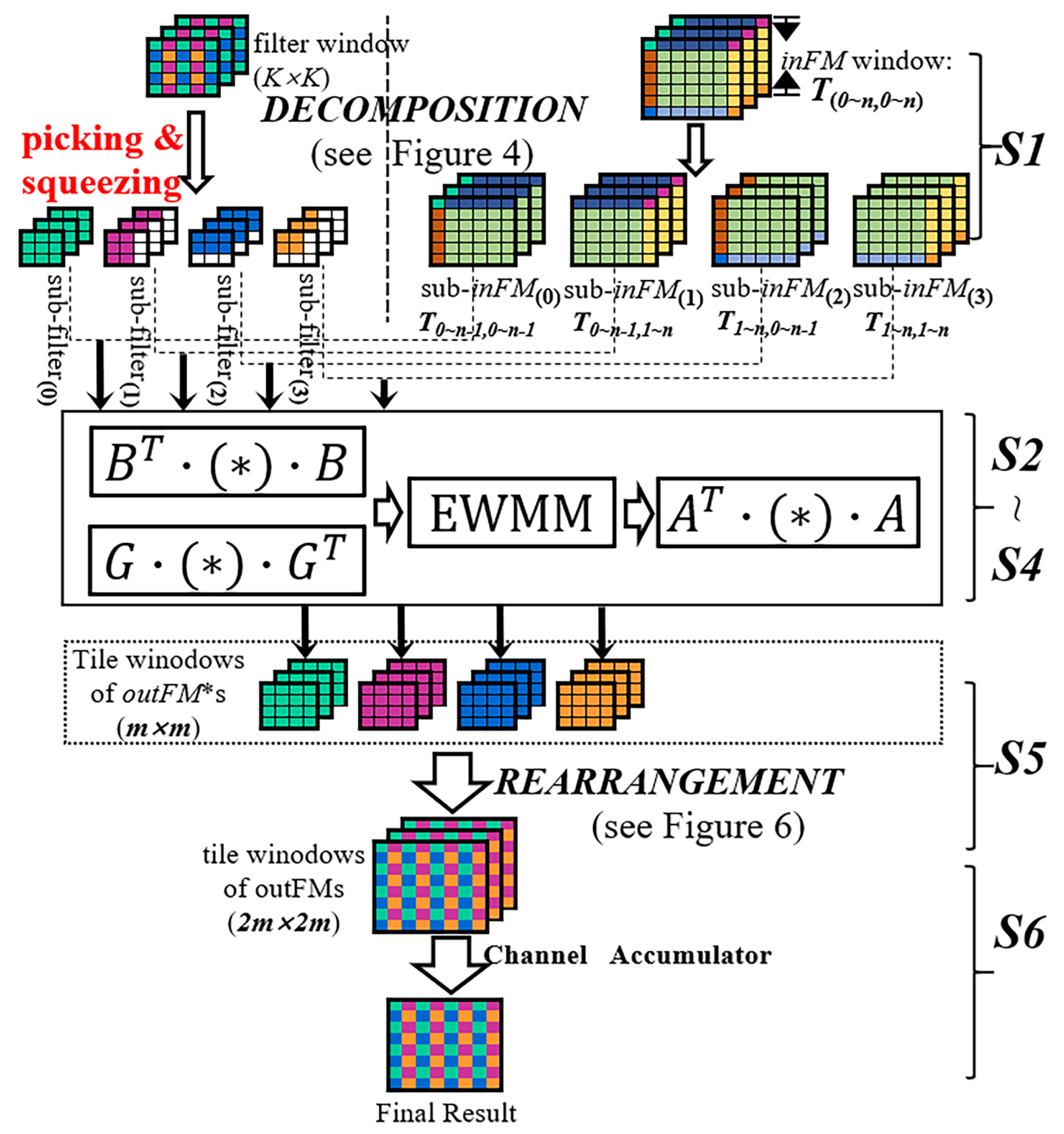
2.3. Wino-transCONV Dataflow Exploration
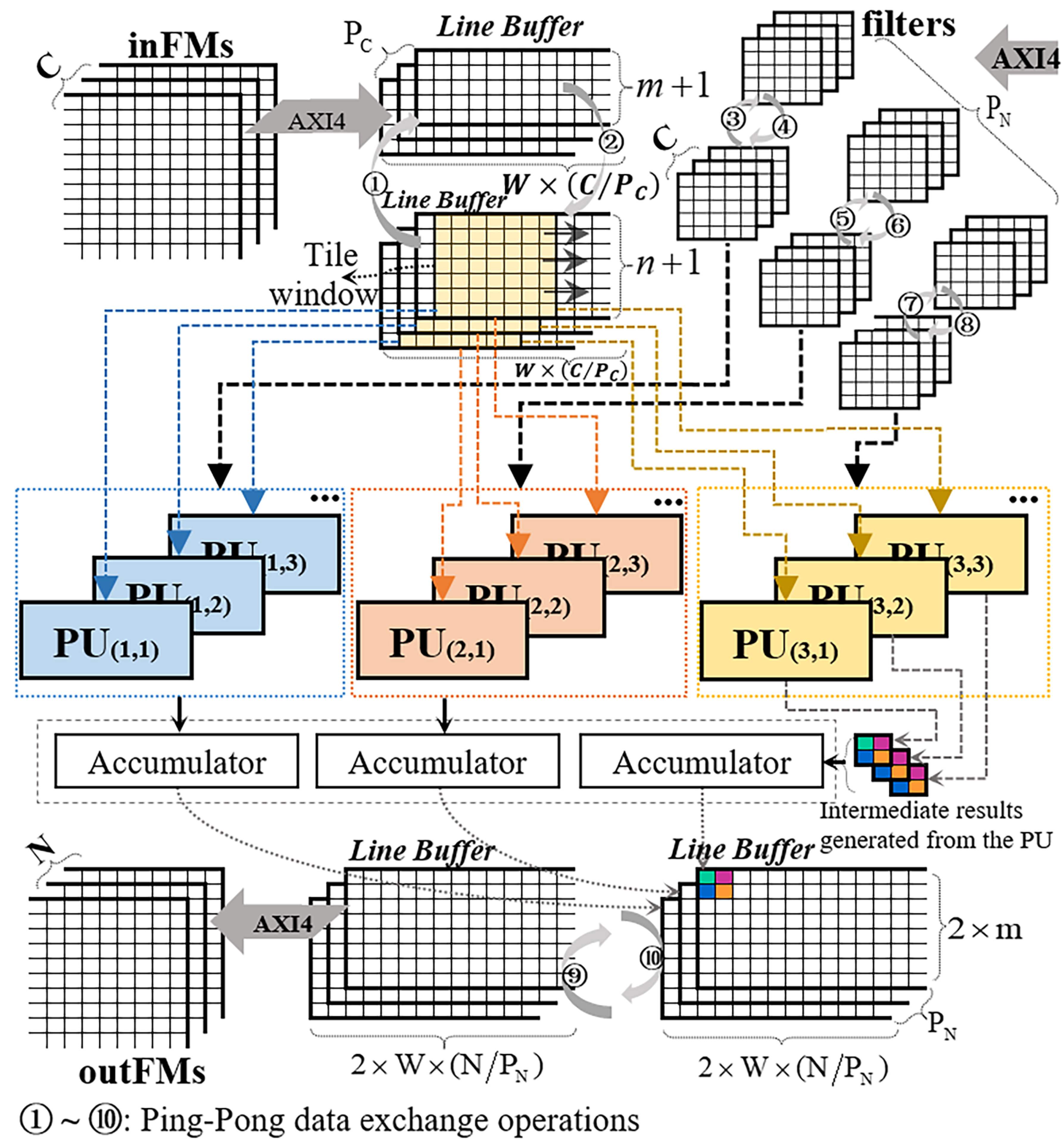
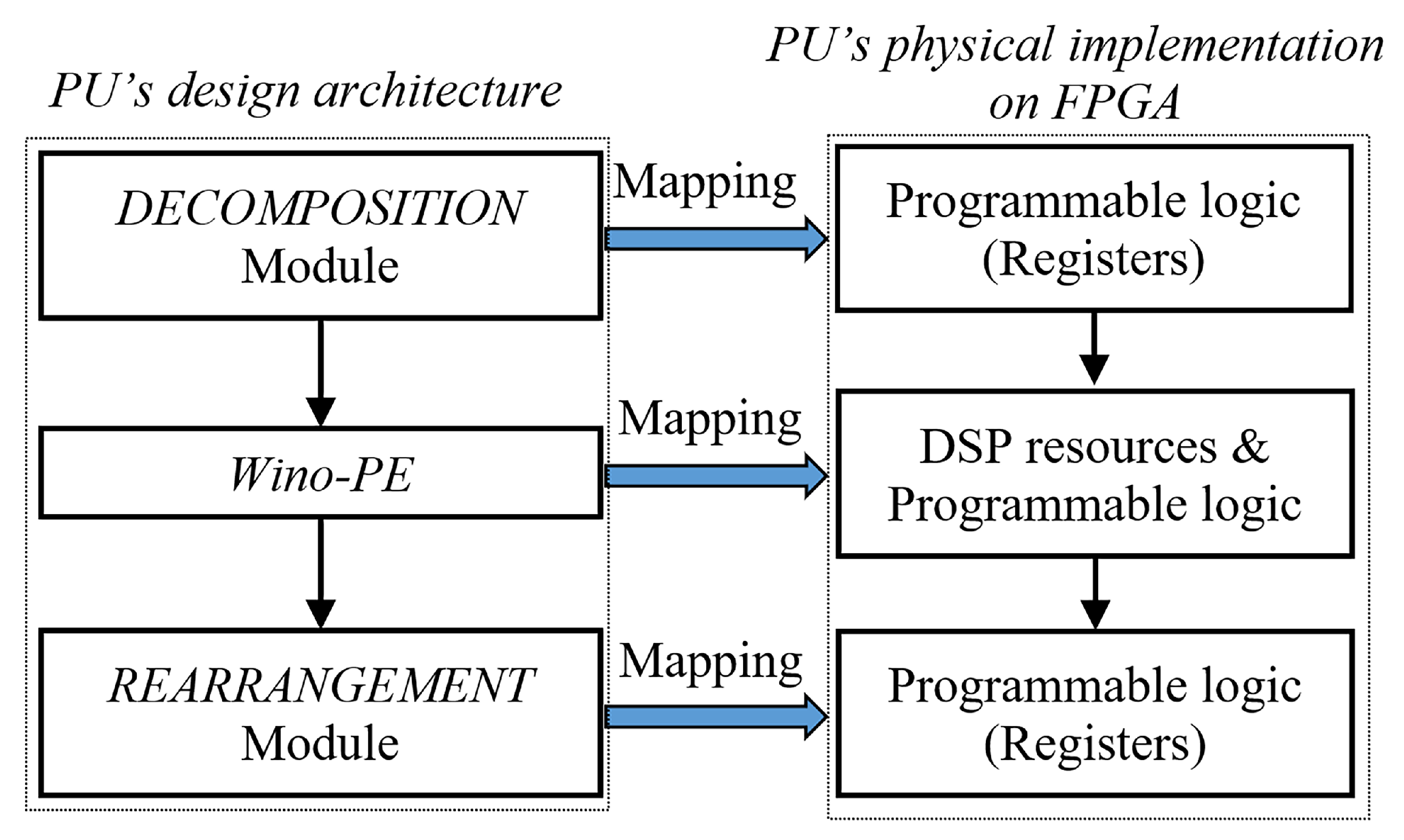
3. Design and Implementation
3.1. Architecture-Wise Optimization
- Inter-PU parallelism: In the design, each PU is accountable for processing the data from one of the C channels of inFMs to one of the N channels of outFMs. Suppose that and denote parallel undertakings of inFMs and outFMs, respectively. Therefore, there are in total (×) PUs to execute their individual operations in parallel.
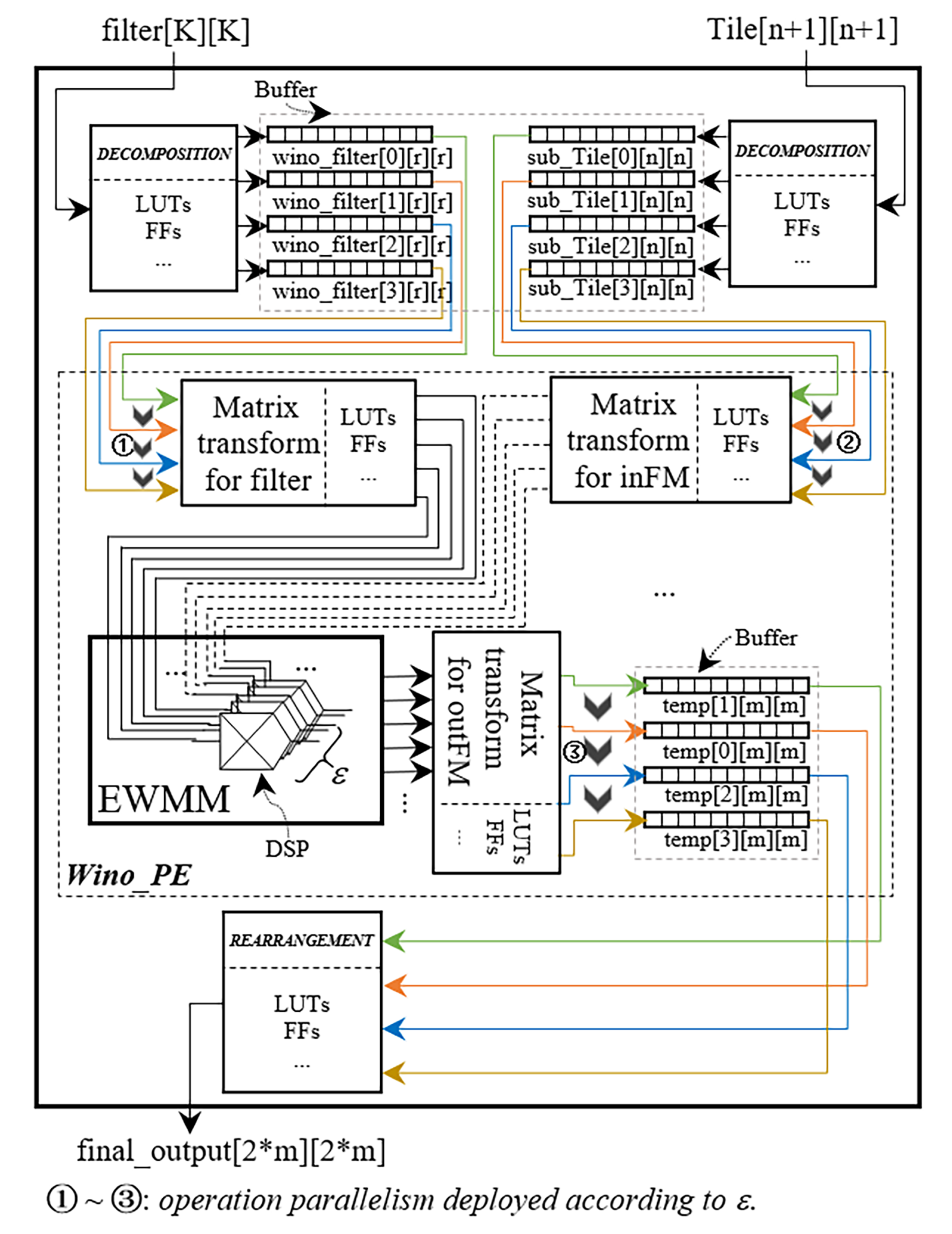
- Intra-PU parallelism: According to Figure 7, the function of Winograd processing inside a single PU is responsible for sequentially processing four pairs of the decomposed data, i.e., (sub-inFMs and sub-filters). Nevertheless, those four pairs can also be individually operated upon in parallel. Thus, the operational speed is improved, although at the expense of additional DSP blocks and programable logic resources being needed. It should be conceded that a single PU having consumed excessive DSP blocks would in practice result in the reduction to the degree of inter-PU parallelism, which must fall towards a smaller measure in terms of the number of (×). This is because the total number of DSP resources available on an FPGA device is always capped.
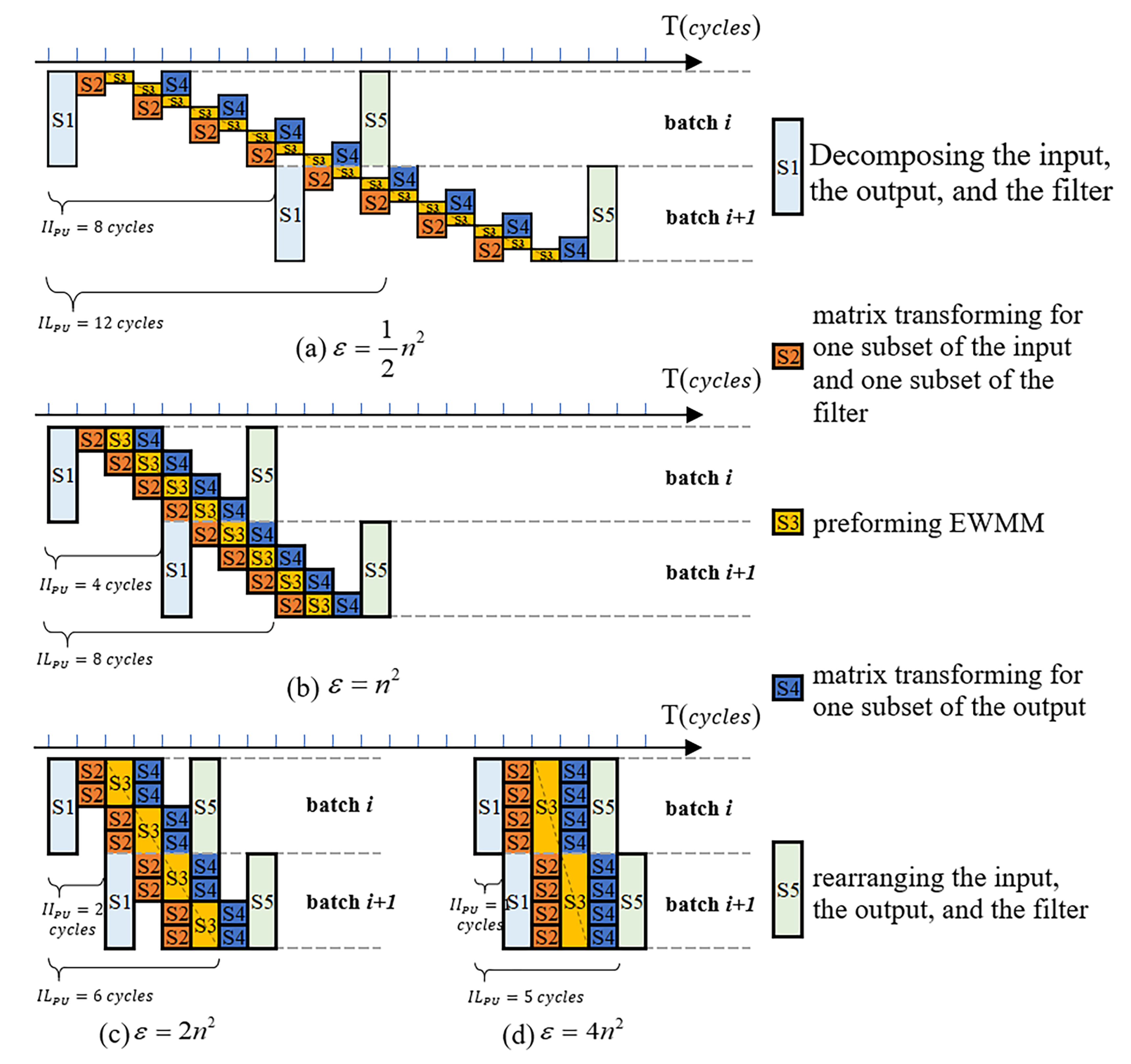
- Intra-PU Pipeline: In a PU structure, Steps S–S4 can be effectively pipelined according to the dataflow of Wino-transCONV given in Figure 7 except for S1 and S5. This is because the DECOMPOSITION (S1) and the REARRANGEMENT (S5) for those four pairs of data (sub-inFMs and sub-filters) cannot share one common set of hardware on a time division multiplexing basis.
3.2. Processing Unit Detail vs. Intra-PU Parallelism & Pipeline
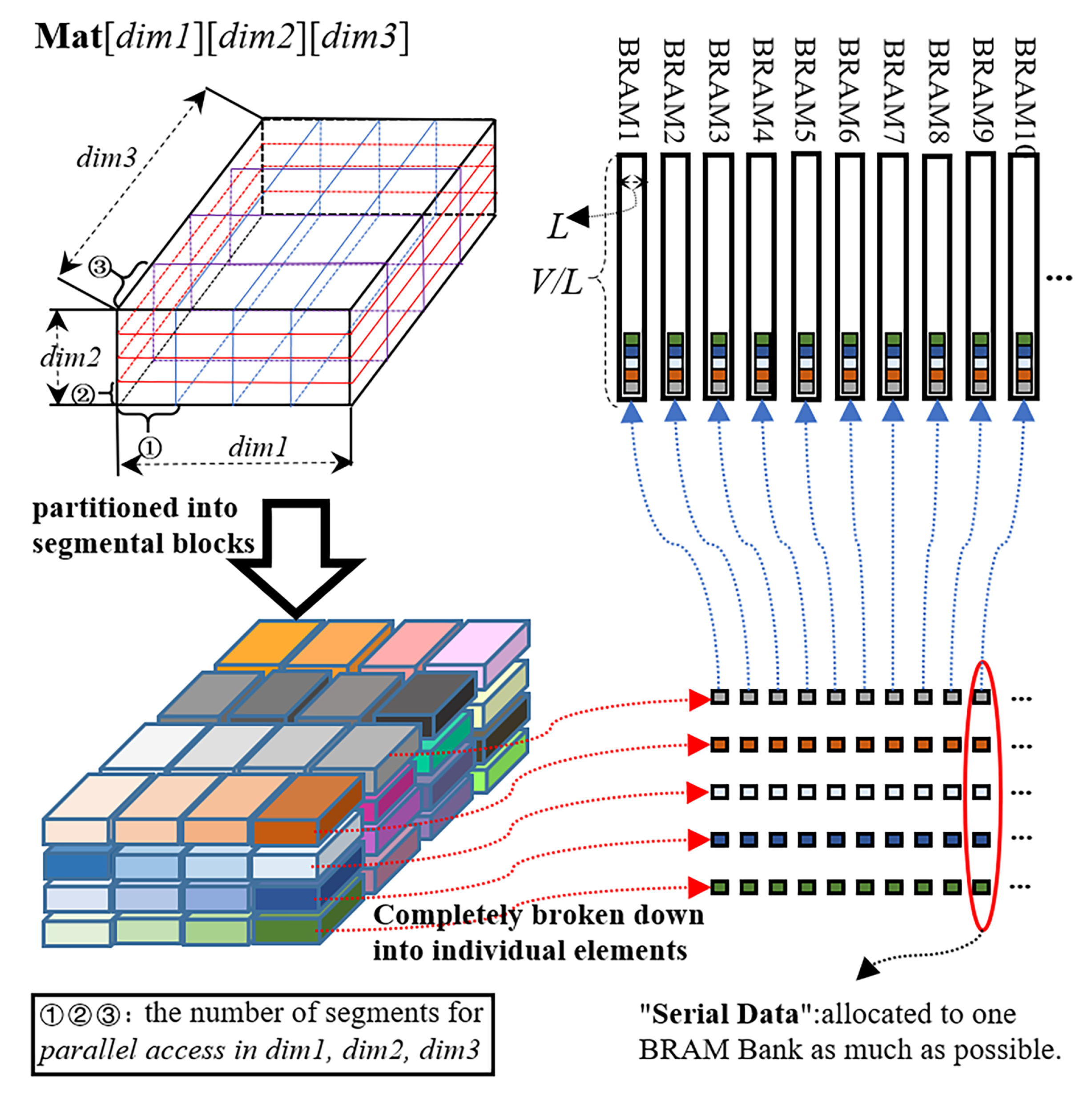
3.3. Memory Sharing—Access and Partition
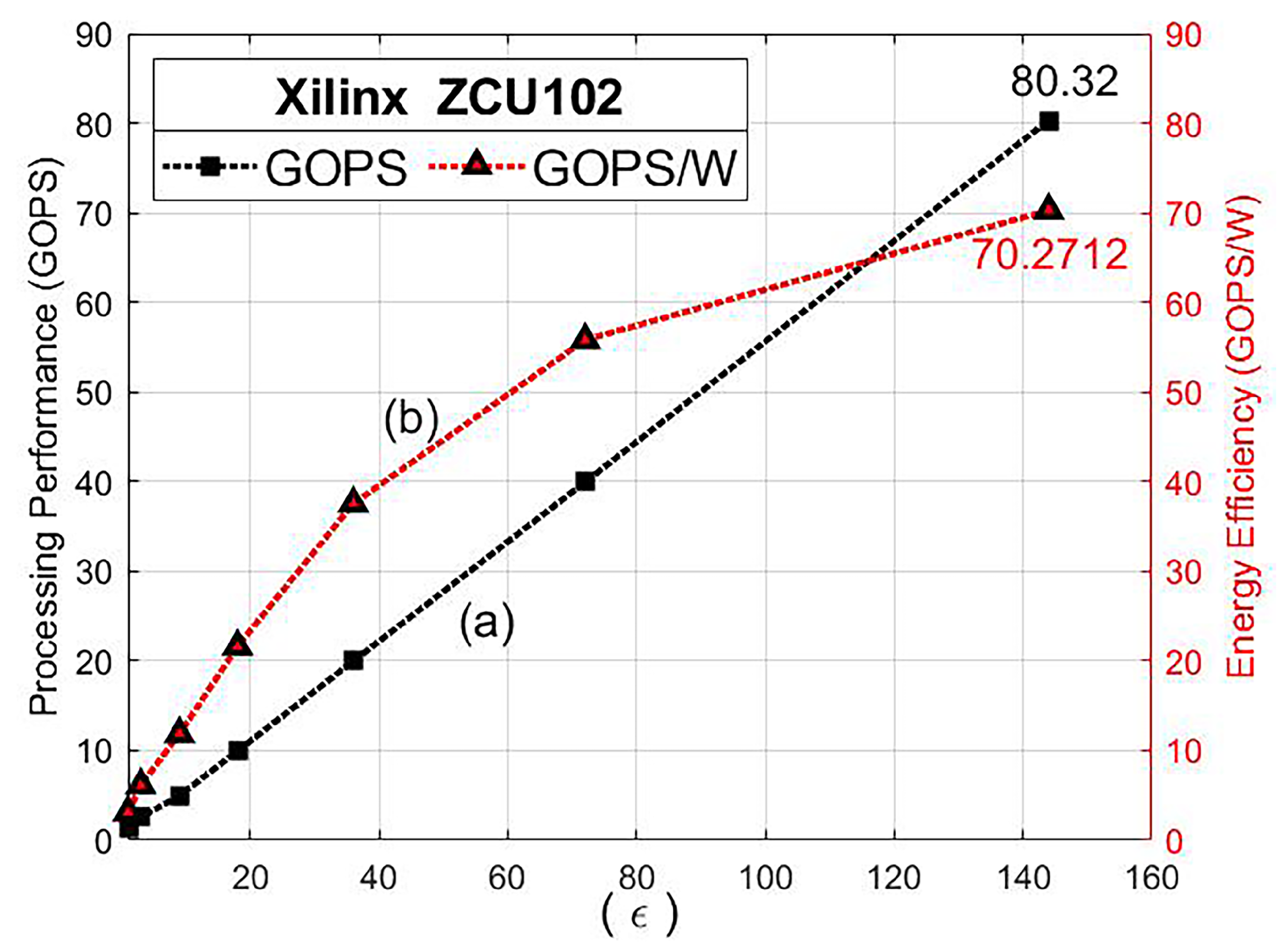
3.4. Design Space Exploration
| Algorithm 1. |
|
4. Experiment Verification
4.1. Experimental Cases for GANs
4.2. Experimental Setup
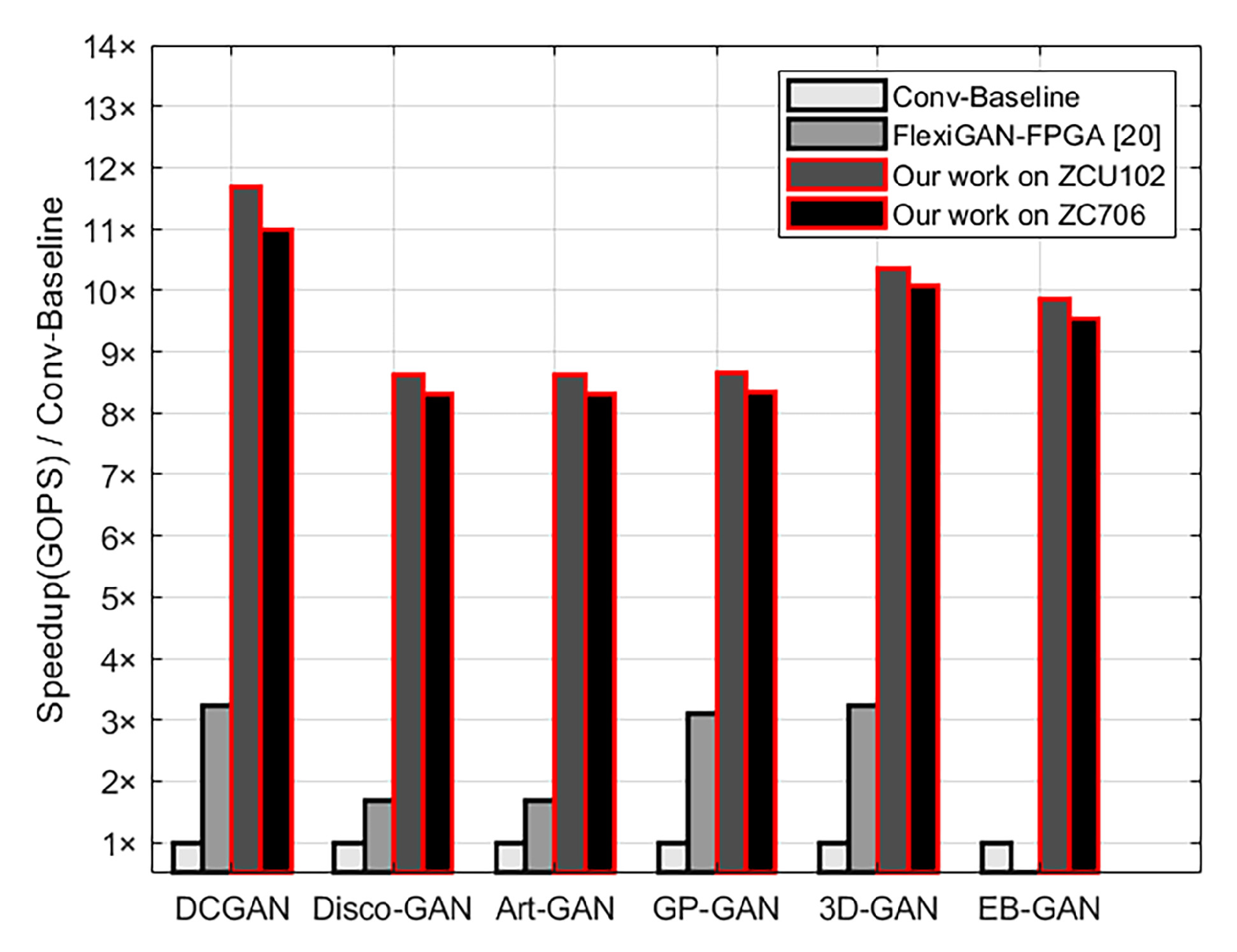
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Laurent, C.; Bengio, Y.; Courville, A. Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks. In Proceedings of the International Symposium on Computer Architecture (ISCA), Seoul, Korea, 8–22 June 2016; pp. 410–414. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Adv. Neural Inf. Process. Syst. 2014, 3, 2672–2680. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Taeksoo, K.; Moonsu, C.; Hyunsoo, K.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1857–1865. [Google Scholar]
- Tan, W.R.; Chan, C.S.; Aguirre, H.E.; Tanaka, K. ArtGAN: Artwork synthesis with conditional categorical GANs. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3760–3764. [Google Scholar]
- Wu, H.; Zheng, S.; Zhang, J.; Huang, K. GP-GAN: Towards Realistic High-Resolution Image Blending. In Proceedings of the 27th ACM International Conference on Multimedia (ACMMM), Nice, France, 21–25 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 2487–2495. [Google Scholar]
- Zhao, J.; Mathieu, M.; Lecun, Y. Energy-based Generative Adversarial Network. In Proceedings of the 5th International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 100–109. [Google Scholar]
- Wang, W.; Huang, Q.; You, S.; Yang, C. Ulrich Neumann. Shape Inpainting Using 3D Generative Adversarial Network and Recurrent Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2317–2325. [Google Scholar]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, B.; Josh, T. Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling. In Proceedings of the Conference and Workshop on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016; pp. 82–90. [Google Scholar]
- Wei, W.; Yu, C.H.; Zhang, P.; Chen, P.; Wang, Y.; Hu, H.; Liang, Y.; Cong, J. Automated Systolic Array Architecture Synthesis for High Throughput CNN Inference on FPGAs. In Proceedings of the 2017 54th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 18–22 June 2017; pp. 1–6. [Google Scholar]
- DiCecco, R.; Lacey, G.; Vasiljevic, J.; Chow, P.; Taylor, G.; Areibi, S. Caffeinated FPGAs: FPGA Framework for Convolutional Neural Networks. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 265–268. [Google Scholar]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing fpga-based accelerator design for deep convolutional neural networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; ACM: New York, NY, USA, 2015; pp. 161–170. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J. Optimizing the Convolution Operation to Accelerate Deep Neural Networks on FPGA. IEEE Trans. Very Large Scale Integr. Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]
- Chen, T.; Du, Z.; Sun, N.; Wang, J.; Wu, C.; Chen, Y.; Temam, O. A High-Throughput Neural Network Accelerator. IEEE Micro 2019, 35, 24–32. [Google Scholar]
- Liu, Z.; Chow, P.; Xu, J.; Jiang, J.; Dou, Y.; Zhou, J. A Uniform Architecture Design for Accelerating 2D and 3D CNNs on FPGAs. Electronics 2019, 8, 65. [Google Scholar] [CrossRef]
- Yan, J.; Yin, S.; Tu, F.; Liu, L.; Wei, S. GNA: Reconfigurable and Efficient Architecture for Generative Network Acceleration. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 2519–2529. [Google Scholar] [CrossRef]
- Zhang, X.; Das, S.; Neopane, O.; Kreutz-Delgado, K. A Design Methodology for Efficient Implementation of Deconvolutional Neural Networks on an FPGA. arXiv 2017, arXiv:1705.02583. [Google Scholar]
- Yazdanbakhsh, A.; Falahati, H.; Wolfe, P.J.; Samadi, K.; Kim, N.S.; Esmaeilzadeh, H. GANAX: A unified MIMD-SIMD acceleration for generative adversarial networks. In Proceedings of the 2018 ACM/IEEE 45th Annual International Symposium on Computer Architecture (ISCA), Los Angeles, CA, USA, 2–6 June 2018; pp. 650–661. [Google Scholar]
- Yazdanbakhsh, A.; Brzozowski, M.; Khaleghi, B.; Ghodrati, S.; Samadi, K.; Kim, N.S.; Esmaeilzadeh, H. FlexiGAN: An End-to-End Solution for FPGA Acceleration of Generative Adversarial Networks. In Proceedings of the 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boulder, CO, USA, 29 April–1 May 2018; pp. 65–72. [Google Scholar]
- Chang, J.W.; Kang, K.W.; Kang, S.J. An Energy-Efficient FPGA-based Deconvolutional Neural Networks Accelerator for Single Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 281–295. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An Energy-Efficient Reconfigurable Accelerator for Deep Convolutional Neural Networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Lu, L.; Liang, Y.; Xiao, Q.; Yan, S. Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017; pp. 101–108. [Google Scholar]
- Aydonat, U.; O’Connell, S.; Capalija, D.; Ling, A.C.; Chiu, G.R. An OpenCL™ Deep Learning Accelerator on Arria 10. In Proceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA), Monterey, CA, USA, 22–24 February 2017; pp. 55–64. [Google Scholar]
- Lavin, A.; Gray, S. Fast Algorithms for Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021. [Google Scholar]
- Guo, K.; Zeng, K.; Yu, J.; Wang, Y.; Yang, H. A Survey of FPGA Based Neural Network Accelerator. arXiv 2017, arXiv:1712.08934. [Google Scholar]
- Xilinx, Inc. UG871-Vivado High Level Synthesis Tutorial; Xilinx: San Jose, CA, USA, 3 April 2013; pp. 120–130. [Google Scholar]
- Xilinx, Inc. UG902 Vivado High Level Synthesis; Xilinx: San Jose, CA, USA, 20 December 2018; pp. 6–8. [Google Scholar]
- Krizhevsky, A.; Sutskever, A.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| inFM | Filter | Methods | Mum_of Operations | Normalized | ||
|---|---|---|---|---|---|---|
| (W×H) | (K×K) | mult (*) | add (+) | total_equiv_add | ||
| 8×8 | 5×5 | Direct-CONV [4] | 5625 | 5400 | 95,400 | 1 |
| Direct-CONV-eff [17,18,19,20,21] | 1600 | 1536 | 27,136 | 0.284 | ||
| Wino-transCONV(m = 4) | 576 | 10,048 | 19,264 | 0.201 | ||
| Wino-transCONV(m = 2) | 1024 | 4928 | 21,312 | 0.223 | ||
| 4×4 | Direct-CONV [4] | 3600 | 3375 | 60,975 | 1 | |
| Direct-CONV-eff [17,18,19,20,21] | 1024 | 960 | 19,394 | 0.318 | ||
| Wino-transCONV(m = 4) | 576 | 10,048 | 19,264 | 0.315 | ||
| Wino-transCONV(m = 2) | 1024 | 4928 | 21,312 | 0.349 | ||
| 16×16 | 5×5 | Direct-CONV [4] | 24,025 | 23,064 | 407,464 | 1 |
| Direct-CONV-eff [17,18,19,20,21] | 6400 | 6144 | 108544 | 0.266 | ||
| Wino-transCONV(m = 4) | 2304 | 40,192 | 77,056 | 0.189 | ||
| Wino-transCONV(m = 2) | 4096 | 19,712 | 85,248 | 0.209 | ||
| 4×4 | Direct-CONV [4] | 15,376 | 14,415 | 260,431 | 1 | |
| Direct-CONV-eff [17,18,19,20,21] | 4096 | 3840 | 77564 | 0.297 | ||
| Wino-transCONV(m = 4) | 2304 | 40,192 | 77,056 | 0.295 | ||
| Wino-transCONV(m = 2) | 4096 | 19,712 | 85,248 | 0.327 | ||
| 64×64 | 5×5 | Direct-CONV [4] | 403,225 | 387,096 | 6,838,696 | 1 |
| Direct-CONV-eff [17,18,19,20,21] | 102,400 | 98,304 | 1,736,704 | 0.253 | ||
| Wino-transCONV(m = 4) | 36,864 | 643,072 | 1,232,896 | 0.18 | ||
| Wino-transCONV(m = 2) | 65,536 | 315,392 | 1,363,968 | 0.199 | ||
| 4×4 | Direct-CONV [4] | 258064 | 241,935 | 4,370,959 | 1 | |
| Direct-CONV-eff [17,18,19,20,21] | 65,536 | 61440 | 1,241,084 | 0.283 | ||
| Wino-transCONV(m = 4) | 36,864 | 643,072 | 1,232,896 | 0.282 | ||
| Wino-transCONV(m = 2) | 65,536 | 315,392 | 1,363,968 | 0.312 | ||
| 128×128 | 5×5 | Direct-CONV [4] | 1,625,625 | 1,560,600 | 27570600 | 1 |
| Direct-CONV-eff [17,18,19,20,21] | 409,600 | 393,216 | 6,946,816 | 0.251 | ||
| Wino-transCONV(m = 4) | 147,456 | 2,572,288 | 4,931,584 | 0.178 | ||
| Wino-transCONV(m = 2) | 262,144 | 1,261,568 | 5,455,872 | 0.197 | ||
| 4×4 | Direct-CONV [4] | 1040400 | 975,375 | 17,621,775 | 1 | |
| Direct-CONV-eff [17,18,19,20,21] | 262,144 | 245,760 | 4,964,352 | 0.281 | ||
| Wino-transCONV(m = 4) | 147,456 | 2,572,288 | 4,931,584 | 0.279 | ||
| Wino-transCONV(m = 2) | 262,144 | 1,261,568 | 5,455,872 | 0.309 | ||
| 144 | 72 | 36 | 18 | 9 | 3 | |
| Cycles required to complete EWMM | 1 | 2 | 4 | 8 | 16 | 48 |
| (Number of segments for parallel access)×(size of the segment) | Total number of the | Data volume defined for one memory block in | |||||
| dim1 | dim2 | dim3 | dim4 | memory blocks required | type (= 16 bits) | ||
| inFM | (m+n+2)×(1) | (n+1)×[W/(n+1)] | (PC)×(C/ PC) | – | (m+n+2)×(n+1)×(PC) | (1)×[W/(n+1)]×(C/ PC) | |
| outFM | (4m)×(1) | (2m)×(2W/2m) | (PN)×(N/ PN) | – | (4m)×(2m)×(PN) | (1)×(2W/2m)×(N/ PN) | |
| filter | (PC)×(C/ PC) | (2PN)×(1) | (K)×(1) | (K)×(1) | (PC)×(2 PN)×(K) ×(K) | (C/ PC)×(1)×(1)×(1) | |
| (a) General model | |||||||
| (Number of segments for parallel access)×(size of the segment) | Total number of the | Data volume defined for one memory block in | |||||
| dim1 | dim2 | dim3 | dim4 | memory blocks required | type (= 16 bits) | ||
| inFM | (12)×(1) | (7)×(1) | (8)×(256) | — | (12)×(7)×(8) = 672 | 1728 | (1)×(1)×(256) |
| outFM | (16)×(1) | (8)×(1) | (2)×(512) | — | (16)×(8)×(2) = 256 | (1)×(1)×(256) | |
| filter | (8)×(256) | (4)×(1) | (5)×(1) | (5)×(1) | (8)×(4)×(5)×(5)=800 | (256)×(1)×(1)×(1) | |
| (b) Instantiation for the second layer of DCGAN | |||||||
| (Number of segments for parallel access)×(size of the segment) | Total number of the | Data volume defined for one memory block in | |||||
| dim1 | dim2 | dim3 | dim4 | memory blocks required | type (= 16 bits) | ||
| inFM | (12)×(1) | (7)×(1) | (8)×(512) | - | (12)×(7)×(8) = 672 | 1440 | (1)×(1)×(512) |
| outFM | (16)×(1) | (8)×(1) | (2)×(512) | - | (16)×(8)×(2) = 256 | (1)×(1)×(512) | |
| filter | (8)×(512) | (4)×(1) | (4)×(1) | (4)×(1) | (8)×(4)×(4)×(4)=512 | (512)×(1)×(1)×(1) | |
| (c) Instantiation for the second layer of EB-GAN | |||||||
| GANs | Transposed Convolution Layers | GANs | Transposed Convolution Layers | ||||
|---|---|---|---|---|---|---|---|
| #num | input | filters | #num | input | filters | ||
| #2 | 4×4×1024 | 5×5×1024×512 | #2 | 4×4×512 | 4×4×512×256 | ||
| DCGAN [4] | #3 | 8×8×512 | 5×5×512×256 | GP-GAN [7] | #3 | 8×8×256 | 4×4×256×128 |
| #4 | 16×16×256 | 5×5×256×128 | #4 | 16×16×128 | 4×4×128×64 | ||
| #5 | 32×32×128 | 5×5×128×3 | #5 | 32×32×64 | 4×4×64×3 | ||
| #2 | 4×4×1024 | 4×4×1024×512 | #2 | 4×4×4×512 | 4×4×4×512×256 | ||
| Disco-GAN [5] | #3 | 8×8×512 | 4×4×512×256 | 3D-GAN [10] | #3 | 8×8×8×256 | 4×4×4×256×128 |
| #4 | 16×16×256 | 4×4×256×128 | 3D-ED-GAN [9] | #4 | 16×16×16×128 | 4×4×4×128×64 | |
| #6 | 32×32×128 | 4×4×128×3 | #5 | 32×32×32×64 | 4×4×4×64×1 | ||
| #2 | 4×4×512 | 4×4×512×256 | #2 | 4×4×2048 | 4×4×2048×1024 | ||
| #3 | 8×8×256 | 4×4×256×128 | #3 | 8×8×1024 | 4×4×1024×512 | ||
| Art-GAN [6] | #4 | 16×16×128 | 4×4×128×128 | EB-GAN [8] | #4 | 16×16×512 | 4×4×512×256 |
| #6 | 16×16×128 | 4×4×128×3 | (256×256 model | #5 | 32×32×256 | 4×4×256×128 | |
| on IMAGENET) | #6 | 64×64×128 | 4×4×128×64 | ||||
| #7 | 128×128×64 | 4×4×64×64 | |||||
| Device | m | × | |
|---|---|---|---|
| XCZU9EG | 144 | 4 | 16 |
| XC7Z045 | 144 | 4 | 4 |
| GAN Models | Layers | Performance (GOPS) | GAN Models | Layers | Performance (GOPS) | ||
|---|---|---|---|---|---|---|---|
| ZCU102 | ZC706 | ZCU102 | ZC706 | ||||
| #2 | 717.2 | 223.7 | #2 | 406.8 | 136.6 | ||
| #3 | 915.9 | 243.4 | 3D-GAN [10] | #3 | 536.4 | 151.3 | |
| DCGAN [4] | #4 | 1058.7 | 254.3 | 3D-ED-GAN [9] | #4 | 627.9 | 159.1 |
| #5 | 320.2 | 133.8 | #5 | 213.7 | 87.5 | ||
| avg | 851.8 | 236.9 | avg | 482.4 | 142.8 | ||
| #2 | 544.9 | 152.1 | #2 | 654.9 | 161.1 | ||
| #3 | 651.8 | 161.2 | #3 | 727.1 | 166.3 | ||
| Disco-GAN [5] | #4 | 719.4 | 165.5 | EB-GAN [8] | #4 | 768.5 | 168.5 |
| #6 | 252.1 | 94.5 | (256×256 model | #5 | 789.1 | 169.6 | |
| avg | 616.1 | 157.6 | on IMAGENET) | #6 | 795.9 | 170.2 | |
| Art-GAN [6] | #2 | 406.8 | 136.6 | #7 | 805 | 170.5 | |
| #3 | 536.4 | 151.3 | avg | 759.9 | 168.2 | ||
| #4 | 627.9 | 159.1 | Freq (MHz) | 200 | 167 | ||
| #6 | 213.7 | 87.5 | LUT Utilization (%) | 97 | 90 | ||
| avg | 486.9 | 145.4 | DSP Utilization (%) | 91.4 | 67 | ||
| GP-GAN [7] | #2 | 406.8 | 136.6 | BRAM Utilization (%) | 90 | 57 | |
| #3 | 536.4 | 151.3 | Performance (GOPS) | 639.2*(avg) | 162.5*(avg) | ||
| #4 | 627.9 | 159.1 | DSP Efficiency (GOPS/DSP) | 0.254(avg) | 0.181(avg) | ||
| #5 | 213.7 | 87.5 | Power (W) | 15.6 | 5.8 | ||
| avg | 486.9 | 145.4 | Energy Efficiency (GOPS/W) | 40.9 | 27.9 | ||
| Models | Works | Device | Precision | DSP | Freq | GOPS | GOPS/DSP |
|---|---|---|---|---|---|---|---|
| AlexNet [21] | [13] | VX485T | float | 2800 | 100 | 61.62 | 0.022 |
| (Convolution) | [23] | ZC706 | 16 fixed | 900 | 167 | 271.8 | 0.224 |
| ASIC | 8 fixed | 409.6 | |||||
| GAN [17] | (TSMC | 16×8 fixed | 200 | 204.8 | |||
| Transposed | 28 nm) | 16 fixed | 102.4 | ||||
| Convolution | [18] | 7Z020 | 12 fixed | 220 | 100 | 2.6 | 0.012 |
| Ours | ZCU102 | 16 fixed | 2520 | 200 | 639.2 * | 0.245 | |
| Ours | ZC706 | 16 fixed | 900 | 167 | 162.5 * | 0.181 | |
| * Our avg GOPS = The total GOP of GANs in Table 4/The total time occupation | |||||||
| Our avg GOP/DSP = The total GOP of GANs in Table 4 /the total time occupation/DSPs | |||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di, X.; Yang, H.-G.; Jia, Y.; Huang, Z.; Mao, N. Exploring Efficient Acceleration Architecture for Winograd-Transformed Transposed Convolution of GANs on FPGAs. Electronics 2020, 9, 286. https://doi.org/10.3390/electronics9020286
Di X, Yang H-G, Jia Y, Huang Z, Mao N. Exploring Efficient Acceleration Architecture for Winograd-Transformed Transposed Convolution of GANs on FPGAs. Electronics. 2020; 9(2):286. https://doi.org/10.3390/electronics9020286
Chicago/Turabian StyleDi, Xinkai, Hai-Gang Yang, Yiping Jia, Zhihong Huang, and Ning Mao. 2020. "Exploring Efficient Acceleration Architecture for Winograd-Transformed Transposed Convolution of GANs on FPGAs" Electronics 9, no. 2: 286. https://doi.org/10.3390/electronics9020286
APA StyleDi, X., Yang, H.-G., Jia, Y., Huang, Z., & Mao, N. (2020). Exploring Efficient Acceleration Architecture for Winograd-Transformed Transposed Convolution of GANs on FPGAs. Electronics, 9(2), 286. https://doi.org/10.3390/electronics9020286