1. Introduction
Among the renewable energies promoted worldwide due to the environmental issues, photovoltaic (PV) energy systems are one of the most promising due to its lower environmental impact and abundance [
1]. However, the connection of PV plant to the power utility grid was limited because of voltage mismatch and grid code requirements that could not be met. Thanks to the development of power converters and their control, PV plants can be connected without degrading the energy conversion efficiency thanks to the low switching frequency of cascaded multilevel inverters [
2]. One key aspect in power electronic system is reliability [
3], for those applications that consider availability as a critical parameter, it is important that the application continues to operate even under faulty conditions. For PV grid-connected system, the performance of the inverter is one of the key factors that determine whether the system can continue to operate. Open-circuit and short-circuit faults are the most common faults affecting inverters. Since most modern gate-drivers are equipped with short-circuit protection unit, open-circuit fault attracts more attention [
4].
Figure 1a shows the application of PV grid-connected system and
Figure 1b shows the consequence of photovoltaic inverter fires. Once the fault occurs, the output voltage is distorted and the produced power is degraded. If it cannot be diagnosed and repaired in time, a derivative fault will occur, which may seriously lead to system crash.
The literature on fault diagnosis methods is abundant [
6] but for each system, an appropriate strategy is required. For PV grid-connected systems there are many studies on the closed-loop control. However, for the purpose of health monitoring, most of the studies are conducted considering that the system is in open loop, which is not the usual case [
7,
8,
9]. Moreover, fault diagnosis of PV systems cannot ignore the variability of the irradiance and the temperature induced by the environmental conditions. Indeed, this variability influences the inverter output voltage. Therefore, the results presented in [
10,
11,
12,
13] which only consider one environmental condition for PV inverter fault diagnosis, are limited in scope. Fault diagnosis methods can be decomposed in four steps: modelling, pre-processing, feature extraction and feature analysis for fault detection, fault classification and fault estimation [
14]. In the following, only fault detection and fault classification will be discussed. Fault features can be extracted from different signals obtained from raw measurements in the time domain or transformed into another domain that can be time-frequency, time-scale or frequency. Different techniques can be used to extract and analyze the fault features ranging, e.g., from signal or information processing tools or machine-learning tools.
Here are some examples of signal-processing-based methods. Authors in [
15] have proposed a relative weighting operator of principal component analysis (PCA) to extract the fault information of a cascaded inverter. In Reference [
16], a multilevel signal decomposition and coefficients reconstruction method is used to generate the multiscale features for fault feature extraction. In [
17], authors adopted a second low frequency processing (SLFP) method to obtain the small low-frequency data from the feedback controller. Authors in [
18] have used the average bridge arm pole-to-pole (PTP) voltage and error-adaptive thresholds of the inverter to extract the fault information. In [
19], an adaptive confidence limit (ACL) fault detection method is proposed to process the changing signals. The main drawbacks of these methods are their sensitivity to frequency resolution and environmental nuisances.
Machine-learning methods are becoming more and more attractive in engineering applications. Authors in [
20] have designed a new generator and discriminator of Generative Adversarial Network (GAN) to extract more fault features from Auto Encoder (AE). In Reference [
21], authors have proposed a multiclass Relevance Vector Machine (mRVM) to achieve higher model sparsity and shorter diagnosis time. In Reference [
22], intuitionistic fuzzy logic is integrated to original spiking neural P systems for dealing with the uncertain knowledge of the power system. Authors in [
23] have adopted Genetic Algorithm (GA), Particle Swarm Optimization (PSO) and Cuckoo Search Algorithm (CSA) methods to optimize the neural network in order to have the lowest mean square error.
On one hand, machine learning methods are highly adaptable and do not rely on accurate mathematical models [
24]. On the other hand, they need a large amount of data (representing several operating conditions) for training the network, a significant experience to set a large number of parameters, and the effect of each algorithm is very different for different types of input. The computational cost may also constitute an obstacle to its implementation in real engineering applications.
From the above discussion, we can conclude that time-domain analysis using signal and information processing tools may be more suitable for developing an inverter fault diagnosis method for PV grid-connected inverter system. In addition, the method should be able to cope with the closed-loop behavior and be robust to the variations of the environmental conditions (irradiance and temperature). The fault diagnosis strategy proposed in this paper is based on principle component analysis (PCA) and support vector machine (SVM). It consists of three parts. The first part is devoted to group the similar faults based on Euclidean distance and set the specific labels. The second part is the first classification level based on PCA-SVM. PCA is known as one of the most common multivariate statistical process control (MSPC) methods for dimensionality reduction while retaining the meaningful information [
25]. After the feature extraction, the fault classification is performed with SVM, a classical algorithm for pattern classification. It has better generalization capability than artificial neural networks (ANN), and guarantees that local and global optimal solutions are identical [
26]. The third part is the second classification level. PCA and two-class SVM are used to discriminate the similar faults. The performances of the overall method are evaluated for different environmental conditions.
The fault diagnosis process consists of four steps: modeling, pre-processing, features extraction and features analysis.
The first step is devoted to knowledge building. It can be done through physics-based equations, language-based models or data-driven. In the second step, the input data is pre-processed. The data can be filtered to reduce the nuisances or transformed from time domain to frequency domain or time-frequency domain or projected into another reference frame. The objective of this step is to prepare the information from which the best features will be extracted in the third step. In this third step the fault signatures can be extracted with different techniques ranging from signal processing, information processing and control theory for example. In the last step, the features are analyzed to decide whether a fault has occurred, to classify the different fault types, isolate the faults and eventually estimate the fault severities.
In our study we take benefit of the measured output voltage historical data to model our system. Depending on the applications one can use different signals like vibration, acoustic, phase current or electromagnetic field. Vibration and acoustic signals are most usually used to diagnose mechanical faults. In energy conversion systems the phase currents are very popular. However, in our application the current depends on the load requirement, which varies continuously during daytime. There are many papers [
27,
28,
29] that have already proposed multi-level inverter fault diagnosis using voltage spectral analysis. However, in order to avoid any additional transformation such as Fast Fourier Transform (FFT) or Wavelet Transform, we have decided to exploit the voltage characteristics in the time domain.
Moreover, in multi-level converters [
30], the shape of the output voltage depends on the states of the power switches. Therefore, any fault affecting the power converter will directly modify the shape of the output voltage.
This paper is outlined as follows. In
Section 2, the open-circuit fault features of a cascaded five-level inverter in closed-loop PV grid-connected system are analyzed under different external environments. In
Section 3, the proposed fault diagnosis strategy is presented. In
Section 4, the effectiveness of the proposed strategy is evaluated for several operating time durations and under different environmental conditions through numerical simulations. Finally, the conclusion is provided in
Section 5.
3. Fault Diagnosis Strategy Based on Multilevel Classification
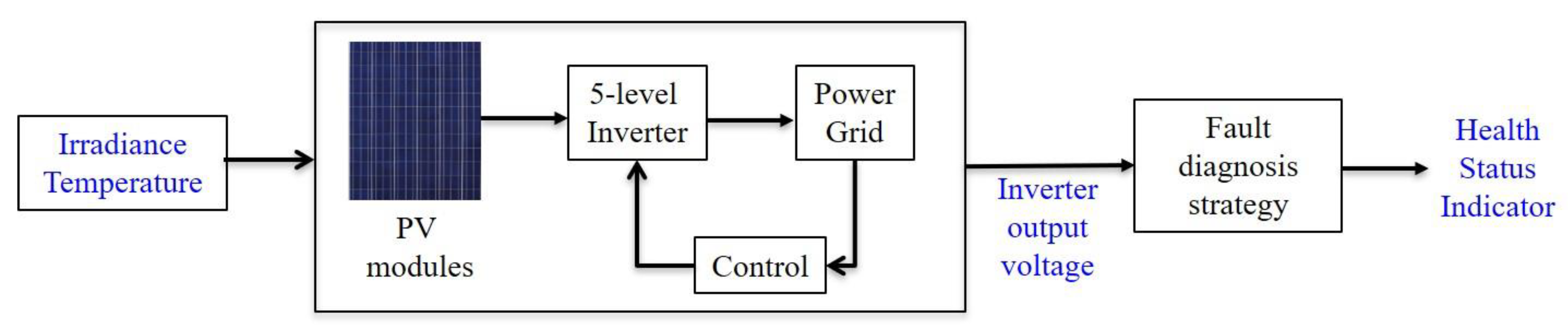
As shown in
Figure 7, a block diagram of grid-connected PV plant fault diagnosis is illustrated. The DC supply of 5-level inverter is from PV modules, which is influenced by solar irradiance and temperature. The output of 5-level inverter is connected to the grid by control strategies. The output voltage of the inverter is collected as the fault diagnosis signals and through the proposed fault diagnosis strategy, the health status of the 5-level inverter is monitored. In this section, the fault diagnosis strategy is focused on described in detail, which is contained three parts: data standardization and faults labeling, the first classification level for all fault types and the second classification level for the faults with similar signatures.
3.1. Data Standardization and Faults Labeling
In order to reduce the influence of the dimension and the wide range of variation of the inverter output voltage on the fault diagnosis, the first step is to standardize the input signals using the Z-score method. Let
X[N×m] be the original data matrix, where
m is the number of variables and
is the number of samples. The matrix is given by:
where
is the
observation. The Z-score formula is expressed as:
where
is the
sample of the
observation,
and
are respectively the mean value and the standard deviation of the
observation.
Hence, the standardized matrix after Z-score is given by:
The second step is to add category labels for the different fault types. In the previous section we have shown that some faults have similar signature. Therefore, in our approach, we will develop a multi-level fault classification. In the first level, faults with similar signatures are merged in the same group and distinguished from other faults. In the second level, they will be discriminated. In this paper we introduce Euclidean distance to group similar faults. Assume that there are
kinds of faults, denoted as
, each kind of fault containing
features. Considering two faults
and
their Euclidean distance
is computed and compared to a threshold. If equation (4) is verified, the two faults
and
are assumed to be similar and classified in the same group.
where
is a similarity threshold adaptively set according to the different systems. Based on the similarity threshold, we will obtain
groups of similar faults.
In the first classification level, the similar faults of each group are regarded as one fault and then all fault types are labeled. In the second classification level, the labels of similar faults in each group are updated. Therefore, in the end each fault has its own and unique label.
3.2. The First Classification Level for all Fault Types
The objective of this first classification level using PCA-SVM is to make a preliminary diagnosis of the faults having distinctive signatures.
PCA [
37] is one of the most widely used data dimensionality reduction methods. It maps the original data to a new coordinate system through linear transformations. It retains the main features and removes noise and outliers to achieve data dimensionality reduction. Starting with the standardized matrix Z given in Equation (3), the covariance matrix s calculated as
where
is the transpose operation. The Cumulative Percentage of Variance for the eigenvalue in descending order is given by:
where
CPV(
k) is
cumulative percentage of variance,
λj(
j = 1, 2, ⋯
m) are the descending eigenvalues of the covariance matrix. The retained number
l of principal components:
where
is a threshold set to minimize the loss information due to the dimension reduction. Finally, the projection of matrix
into the principal subspace is the matrix of principal components denoted as:
where
is the matrix of eigenvectors spanning the principal subspace.
Support vector machine (SVM) will be used for fault classification. SVM [
38,
39] has been originally designed for classifying a dataset in two groups. The main idea consists in finding the linear classifier (hyperplane) in a higher dimensional space that will allow to maximizing the distance between the two classes. Currently, to address multi-classification, the original problem is converted into several two-class problems that can be directly solved by multiple SVMs [
40]. In this paper, the one-versus-one method is used to do the preliminary classification for all fault types.
One-versus-one SVM uses the majority voting mechanism to classify the unknown samples. The classification result is determined by the largest number of votes. In this study, we have used the LIBSVM tool. and labels of the first classification level are used to train the SVM multi-classifier.
3.3. The Second Classification Level for the Faults with Similar Signatures
The goal of this second classification level is to discriminate the faults within the groups of faults with similar signatures. Indeed, after the first classification these faults share the same label. PCA-SVM is also applied in this part and as the methodology is the same, in the following we use group 1 as an example. The classification is organized in three steps:
Step 1. Select the observations that belong to group 1.
Denote
Zg[Ng×m] as the selected data matrix of group 1 with
observations of
m feature variables, the selected data matrix is given by:
Step 2. Feature extraction for the selected data matrix Zg[Ng×m] by using PCA. The matrix of principal components Yg[Ng×lg] is obtained, where lg is the number of principal components of group 1.
Step 3. Fault classification for the selected observations using and the second level classification labels as input data to SVM.
The flowchart of the multi-level classification fault diagnosis strategy based on PCA-SVM is shown in
Figure 8 and the working process can be described as in the following.
The proposed fault diagnosis strategy is divided into two parts, offline process and online process. The offline process includes data standardization, grouping the similar faults based on the similarity threshold, labeling of all faults, then building the proposed classification model, including training the first classification level model for all fault types, and training the second classification level model. For the online process, after the data standardization, the first classification level is performed based on the trained model. Then the similar faults based on the first classification results are processed through the second classification level. Finally, the fault diagnosis results are obtained.
4. Simulation Results and Analysis
In this section, the simulation results of the proposed fault diagnosis strategy are presented along with its performances. The single-phase cascaded five-level photovoltaic grid-connected system is modeled under Matlab-Simulink
®. The output voltage of each PV array is 330 V, the inductance filter is 380 mH, the resistance is 10 Ω, and the voltage frequency of the public grid is 50 Hz. The switching frequency of the inverter is set as 5 kHz, and for data acquisition the sampling frequency is 50 kHz. The corresponding parameters of the fault diagnosis strategy are given in
Table 2. Open-circuit fault is achieved by disconnecting the IGBTs gate drive signals in steady state, and the output voltage of the inverter is used as fault signature.
For the hardware, the system is designed for health monitoring and does not need to be triggered continuously. Considering conventional centralized PV plants, a judicious partitioning could be envisaged between software and hardware. For the electronic hardware, one solution could be to have a dedicated PCB for data acquisition using FPGA (e.g., Altera EP3C16F484C6) at a high sampling rate and another PCB with a microcontroller or a DSP (e.g., TMS320F28335) for data processing. For decentralized PV plants (meaning small DC-DC and DC-AC converters for 2 PV modules) the control and monitoring are embedded within the box attached with the power converters and their sensors. We can take benefit of the rapid development in electronic equipment to include more computational and data acquisition capability for monitoring purposes.
The environmental data for PV panels such as solar irradiation and temperature is acquired from Harnhill and Diddington in United Kingdom [
36]. In order to have variability, we retain the data of every three months in a year (February 18, May 18, August 18 and November 18) and several time ranges in each day at 9:00 a.m., 11:00 a.m., 13:00 p.m. and 15:00 p.m. However, because [
41] have shown that the PV panels output voltage remain fairly constant below 200
, we have removed the data with an irradiance lower than 200
Finally, we have worked with 13 different environmental conditions, denoted as
Ec(
c = 1,2...,13).
Under these conditions, we have collected the output voltage for the healthy state and the eight faulty conditions. Each voltage time-series is composed of 10 fundamental periods after fault occurrence and 1000 samples per period.
For training the proposed fault diagnosis model,
Table 3 shows the fault labels for the different classification levels. In the first level,
and
open-circuit faults of group 1 are labeled as 3,
and
open-circuit faults of group 2 are labeled as 6. The other faults are labeled in order. In the second classification level designed to discriminating faults with similar signatures, the labels of group 1 are changed from 3 to 3 and 4 for
and
open-circuit faults respectively, and for group 2 are changed from 6 to 6 and 9 for
and
open-circuit faults respectively. Therefore, the final output labels have a one-to-one correspondence with all the conditions. The CPV (Cumulative Percentage of Variance) is set to 95% for the first classification level and 99% for the second one. The PCA output will be used as input data for the SVM classifier. In the first classification level, we have used the LIBSVM module that adopts the “one-versus-one” method to do the multi-classification. A Radial Basis Function (RBF) is selected as kernel function and its parameter and the error cost coefficient are both set to 2. In the second classification level, linear kernel function is selected, but for group 1 of similar faults, the parameter and the error cost coefficient are set respectively to 2 and 0.5. For group 2 of similar faults, the parameter and the error cost coefficient are set respectively to 3.1 and 0.4.
Finally, its performance is analyzed with regard to the stability of its results over different periods and its robustness against variations in environmental conditions.
4.1. Stability over Different Periods of The Proposed Strategy
In order to demonstrate that the proposed fault diagnosis strategy is still effectiveness for all types of faults over different periods, we use 10 periods of faulty samples as 10 different test sets for evaluation. Each of the tests set contains samples representing the different environmental conditions. Denote the first period after the fault occurrence as
, the second period is
and so on. The accuracy is introduced as an evaluation index of the performance of the fault diagnosis strategy, and its formula is given by:
Table 4 shows the accuracy of the strategy over the 10 periods and for comparison, three other classical fault diagnosis strategies are chosen, PCA-SVM [
35], PCA-ELM (Extreme Learning Machine) [
33] and PCA-DT (Decision Tree) [
34]. It can be seen from
Table 4 that the accuracy of the proposed strategy is always above 90% and the average accuracy is 95.13%. PCA-SVM is the first part of the proposed strategy but the output labels have a one-to-one correspondence with all types of faults. The accuracy of PCA-SVM is around 90% and the average accuracy is 92.31%, which is lower than the proposed strategy. In the diagnostic strategy of PCA-ELM, the hidden layer nodes are set to 40, and the activation function of the hidden layer neuron is ‘sig’. The accuracy of PCA-ELM is around 80% and the average accuracy is 79.40%, which is much lower than the proposed strategy. PCA-DT is used with the C4.5 algorithm. The accuracy of PCA-DT is around 87%, and the average accuracy is 87.61%.
In order to show the performance of each fault diagnosis strategy more intuitively, we have drawn the results in
Table 4 into a line chart, as shown in
Figure 9. The red line is the accuracy of proposed strategy, and the blue yellow and green lines represent PCA-SVM, PCA-ELM and PCA-DT, respectively. From
Figure 9, we can observe that the accuracy of the proposed strategy is higher than that of the other three strategies over all periods except for
T2 and
where PCA-SVM performs better. Taking period
under the environment
as an example,
Table 5 shows the Euclidean distance for every two faults over period
under
. From
Table 5 we can see that the Euclidean distance between
and
open-circuit faults is smaller than that between
and
open-circuit faults (group 1); meaning that the proposed fault diagnosis strategy with its two classification levels has no advantage over PCA-SVM. The same results are observed over period
.
4.2. Robustness Against Different Environmental Conditions
We have used different kinds of fault samples as test sets to evaluate the robustness of the proposed strategy against the variation of the environmental conditions; irradiance and temperature.
Table 6 shows the accuracy of the different fault diagnosis strategies under 13 environmental conditions. The corresponding line chart is shown in
Figure 10. It can be seen from
Table 6 that the accuracy of the proposed strategy is around 95%, and the average accuracy is 95.81%. Its accuracy is higher than PCA-SVM (85.56%), PCA-ELM (77.10%) and PCA-DT (79.15%). From
Figure 10, we can see that the proposed strategy has a higher accuracy in most cases. The accuracy of PCA-SVM in
is a little bit higher than the proposed strategy, as a whole. The accuracy of PCA-SVM oscillates too much compared to the proposed strategy. That is to say, PCA-SVM has good fault diagnosis performance for constant environmental condition, but the proposed fault diagnosis strategy is more suitable, stable and robust for variable environmental conditions.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}