1. Introduction
Along with the arrival of the era of big data, the third wave of artificial intelligence (AI) has been entered [
1]. AI is being advanced for uniting IoT and robotics, not just as a research craze but through technological advances in hardware.
Commercialized AI is used as a system of prediction or classification that has been confirmed with high precision [
2]. In general, it is difficult and indispensable to classify high quality data from vast amounts of data that contain all the information. However, if the problem is solved using AI, the cost can be greatly reduced. Moreover, the classification problems also exist in fields other than AI [
3,
4,
5]. For example, in the field of gamma ray research in astronomy, cosmic rays can be observed through a telescope [
6]. Due to the complexity of radiation, measurements are currently made using Monte-Carlo simulation. The ability to classify and detect gamma rays based on a limited set of characteristics would contribute to further improvements in telescopy.
The neural network is a symbolic presence that can deal with nonlinear problems in the third wave of AI [
7,
8]. In particular, with the deep learning of the middle layer of the multilayer perceptron (MLP) [
9,
10], which uses nonlinear functions to network, the accuracy is improved with an increase in the amount of data used for learning. However, as the deepening of middle layer and the number of processed data increase, the computing cost becomes huge. As a consequence, with the characteristics of simple structure and cost saving, research into the dendritic neuron model (DNM) [
11,
12,
13,
14,
15,
16] is being developed to achieve high-precision models. Unlike other neural networks, the DNM is a model of one neuron, and much research indicates that the DNM has better performance than the MLP in small-scale classification problems [
17,
18]. Additionally, it is proved that the model, with its excellent metaheuristics, can obtain better classification accuracy by the previous optimization experiment for weight and threshold for small-scale classification problems with the DNM.
In various neuronal models and neural networks, it is necessary to change the weight of bonding strength between neurons in order to reduce the error in the desired output. However, as the neural network with random weights (NNRW) cannot guarantee the convergence of errors to the desired output, it is not considered to be a practical learning algorithm [
19,
20].
Generally, the learning algorithm is used to solve difficult optimization problems since the weighted learning can be considered as an optimization problem. The most famous learning algorithm in local exploration is the back-propagation (BP) [
21,
22,
23], which computes the gradient using the chain rule and has the advantage of low learning cost since the installation is simple. In addition, the method of multi-point exploration, which is used as a model to classify according to natural phenomena and laws, is documented [
24]. For example, the gravitational search algorithm is a basic learning algorithm to simulate physical phenomena [
25,
26,
27,
28,
29], biogeography-based optimization (BBO) [
30] is generally used for simulating ecological concepts since the accuracy and stability are the most outstanding among the models using representative metaheuristics [
31], and some basic learning algorithms can simulate the moving sample population of organisms such as particle swarm optimization (PSO) [
32,
33] and ant colony optimization. Moreover, as a variant of PSO, the competitive swarm optimizer (CSO) [
34,
35] is a simplified metaheuristics set that is suitable for both multi-point and local exploration. Compared to the systems hat only conduct multi-point exploration or local exploration, the trap of the local optimal solution and convergence rate can be balanced using the CSO.
Although the DNM has shown higher accuracy and effectiveness than the MLP in small-scale classification problems, there are no examples that apply it to large-scale classification problems [
36]. In this paper, the most famous learning algorithm using a gradient descent method with low computing cost, BP; the high classification accuracy algorithm for small-scale classification problems, BBO; and the especially low cost CSO algorithm are highlighted. The DNM is applied to large-scale classification problems with the above three learning algorithms, respectively. Consequently, the learning algorithm with BP is named DNM + BP, and DNM + BBO and DNM + CSO are named in a similar way. As a comparison object, the approximate Newton-type method (ANE)-NNRW is selected since it was applied to the same classification problem in the previous study. The ANE-NNRW is an NNRW based on the forward propagation MLP that ensures the convergence of solutions by an approximate Newton-type method [
37].
Therefore, this study verifies the effectiveness of the DNM for large-scale classification problems, very important information for studying the performance of DNM.
3. Experiment
Three classification problems in our experiments are shown in
Table 1 below. The most downloaded open data sets in different fields of the UCI Machine Learning Repository are used [
46], and the value of the characteristic number does not contain the class. F1 classifies whether the cosmic ray received by the Cherenkov telescope is a gamma ray or not, F2 classifies whether the space shuttle radiator is abnormal, and F3 classifies whether the pixel is skin based on the RGB information of the image. Furthermore, the characteristics of any classification problem are expressed by numbers with no data error that contain negative numbers and decimal numbers. According to the input range of the synaptic layer, each characteristic data set is standardized for the experiment.
Each classification problem is tested 30 times independently, and the accuracy of the expected output is calculated according to the classification results. The formula of accuracy is shown in the Equation (18) with TP (true positivity), FP (false positive), TN (true negative), and FN (false negative).
Besides, the mean square error (MSE) is determined as the evaluation function of the solution that is obtained through Equation (5) for DNM + BP, and Equation (19) for DNM + BBO and DNM + CSO:
The termination condition is set to reach the maximum generation number; for DNM + BP, it is 1000; and for DNM+BBO and DNM + CSO, it is 200, according to the ANE-NNRW. The population number of BBO and CSO is 50.
In addition to the partition ratio of F2, which is specified by the data set, the learning data account for 70% and the testing data account for 30%, referring to the previous study of the DNM as shown in
Table 2 [
18], and the proportion in the ANE-NNRW is shown in
Table 3. In order to make the dimensions consistent, the maximum value of m is set based on the maximum value of
m of the interlayer in the previous study.
Moreover, considering the processing load of the DNM, the upper limit of
m is 100.
Table 4 shows a list of
m for the previous study and dimension
D and
m for this study. Due to the experimental load and time, F1, F2, and F3 use different environments as shown in
Table 5.
According to the design of experiment, which is a statistical method for the effective analysis of large combinations using orthogonal arrays based on Latin square, DNM + BP, DNM + BBO, and DNM + CSO are conducted under the above conditions, and the number of experiments can be greatly reduced by the relationship between the factors and levels.
Each factor and level will be applied in the orthogonal array of
L25 (5
6) since this experiment has five factors and five levels.
Table 6 and
Table 7 represent lists of factors and levels used in F1, F2, and F3.
Table 8 applies to the parameters of F1, and
Table 9 applies to those of F2 and F3. Moreover, the numbers in
Table 8 and
Table 9 are the combination numbers of the experimental parameters.
4. Results
By calculating the average accuracy, the optimum parameters used in this experiment are selected as shown in
Table 10,
Table 11 and
Table 12, respectively.
The average accuracy and standard deviation of each problem and learning algorithm are shown in
Table 13. It is clearly that DNM + BP in F1, DNM + CSO in F2, and DNM + BBO in F3 have the highest accuracy.
The results of the ANE-NNRW as the comparison object are shown in
Table 14, and the accuracy of the previous paper is recorded as a percentage [
19]. Obviously, the accuracy of the DNM is higher than that of the ANE-NNRW in all problems. They also prove that the DNM has the advantage of high accuracy even if the data required for learning are not as much as for the ANE-NNRW, which corresponds to
Table 2 and
Table 3.
Table 15 summarizes the average execution time and optimum parameter
m, which is in deep relation to dimension
D. The execution time of the DNM is larger than that of the ANE-NNRW as shown in
Table 15 [
19].
Even in DNM + BP, which has the lowest computational cost in the experimental method, the execution time of the 200th generation is at least four times that of the ANE-NNRW. One of the reasons for this is that the DNM is more time-consuming than the MLP, which is also mentioned in the case of small-scale classification problems. Additionally, the ANE-NNRW is a calculation method based on the pure propagation MLP; it is considered that a similar result should appear for this large-scale classification problem. Secondly, the ANE-NNRW is an efficient way to solve the large-scale problem; the data set segmentation is performed. Besides, the computational cost is less by learning with random weighting to ensure convergence.
According to the average execution time of DNM+BBO and DNM + CSO in F2 and F3, as the optimum parameter m of DNM + BBO is higher than that of DNM + CSO, there is a large difference of more than 3000 seconds between the two methods in F2. Similarly, because the value of m is the same in F3, the difference is about 10 seconds since DNM + BBO has more order of solution updates. In addition, the difference between DNM + BBO and DNM + CSO in F1 can also be considered as the difference between m, but it is not as great as in F2. Therefore, DNM+CSO is better than DNM + BBO in terms of the execution time of the learning algorithm.
On the other hand, for DNM + BP and DNM + CSO, there is a difference of at least 1000 seconds in the execution time between F1 and F2 under the same m, which is caused by the difference in the number of data and features.
As the DNM calculates m and the number of features using Equation (1), it is confirmed that the execution time approximately follows the calculated amount for the model. Consequently, the execution time increases due to the increase in the number of data. In the same problem, it is desirable that a smaller value of m can reduce the time. However, the m of DNM + BP in F2 and F3 obviously shows that the difference in execution time cannot be determined by the number of data alone.
Therefore, for improving the precision, it is necessary to set an upper limit, split data, and process in parallel to reduce the load of a large-scale problem since the DNM varies in precision according to the set parameters.
Furthermore, the upper limit of
m is set as 100 in this experiment, but both of the optimum parameters
m of DNM + BBO and DNM + CSO in F3 are 50, half of the upper limit, with a high accuracy of classification as shown in
Table 13. Therefore, for large-scale classification problems, DNM learning by metaheuristics may not require an extremely large number of
m for problems with a small number of features. As a reference for parameter determination in the application of the DNM to large-scale problems, this will be clarified in the future.
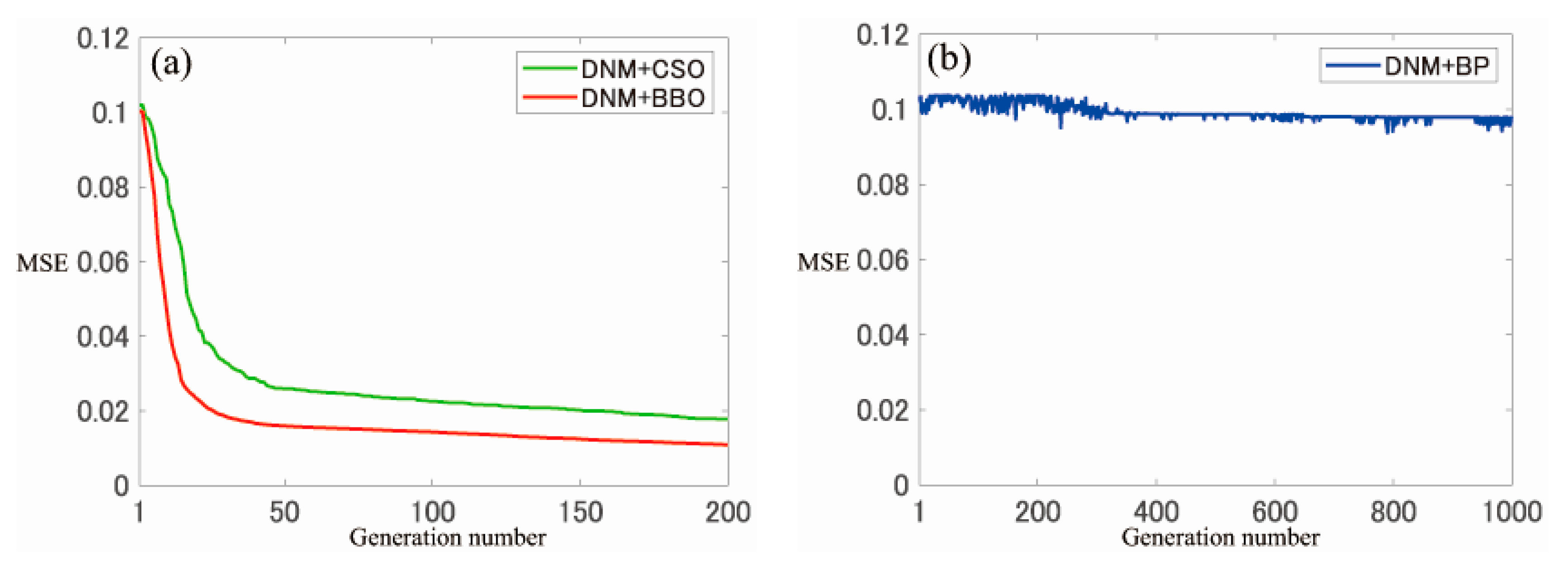
The average convergence graph of each generation of MSE obtained by experiments are shown in
Figure 3,
Figure 4 and
Figure 5.
Figure 3a presents the DNM + BBO and DNM + CSO convergence graphs of F1, and
Figure 3b presents the DNM + BP convergence graph of F1. In a similar way, the convergence graphs of F2 and F3 are shown in
Figure 4 and
Figure 5, respectively.
It is clearly that the values of each learning algorithm converge to the end generation number and that DNM + BBO converged first in all cases. In order to reduce the computation, the CSO only updates the solution of particles equal to half of the population numbers. The BBO of the same multi-point search keeps the elite habitat and changes the solution in each generation, and the number of new candidate optimum solutions produced in one generation is larger than that with the CSO. As a new solution is derived from a candidate optimum solution at a certain point in time, the convergence rate of the higher quality solution will be accelerated. Therefore, it is considered that BBO is more suitable than the CSO to obtain a small MSE with a smaller number of generations.
Furthermore, the MSE does not change greatly due to the local solution of F3 in
Figure 5b, indicating that BP with a feature that tends to trapped in the local solution has the shortcoming of the problem orientation not being significant compared with that with the multi-point search method, with which it is easy to escape from the local solution.
The stability of each method in F1, F2, and F3 is illustrated by the box-plots of
Figure 6,
Figure 7 and
Figure 8, respectively. In the case of the minimum MSE of each problem, F1 is DNM + CSO, and F2 and F3 are DNM + BBO. Besides, for the maximum MSE of each problem, F1 is DNM + BBO, and F2 and F3 are DNM + BP.
However, for the comprehensive consideration, it can be seen that DNM + BP in F1, DNM + CSO in F2, and DNM + BBO in F3 record the best stability. Moreover, the average values of MSE for the end conditions in each problem and method are shown in
Table 16. It shows that the method with excellent stability in each problem is also superior to other methods in terms of the average MSE.
Furthermore, the average of standard deviation of accuracy and the standard deviation of each method for the tests are shown in
Table 17 below. Although DNM + BP has the best stability in F1, both the average value and standard deviation are the highest, which indicates that DNM + BP has a large deviation according to the different problems. To the contrary, DNM + BBO and DNM + CSO have more stability that is not easily affected by these three problems of this experiment.
As a consequence, in terms of the convergence and stability of MSE, it is better to adopt a multi-point search method, especially DNM + BBO with the advantage in terms of the convergence rate.
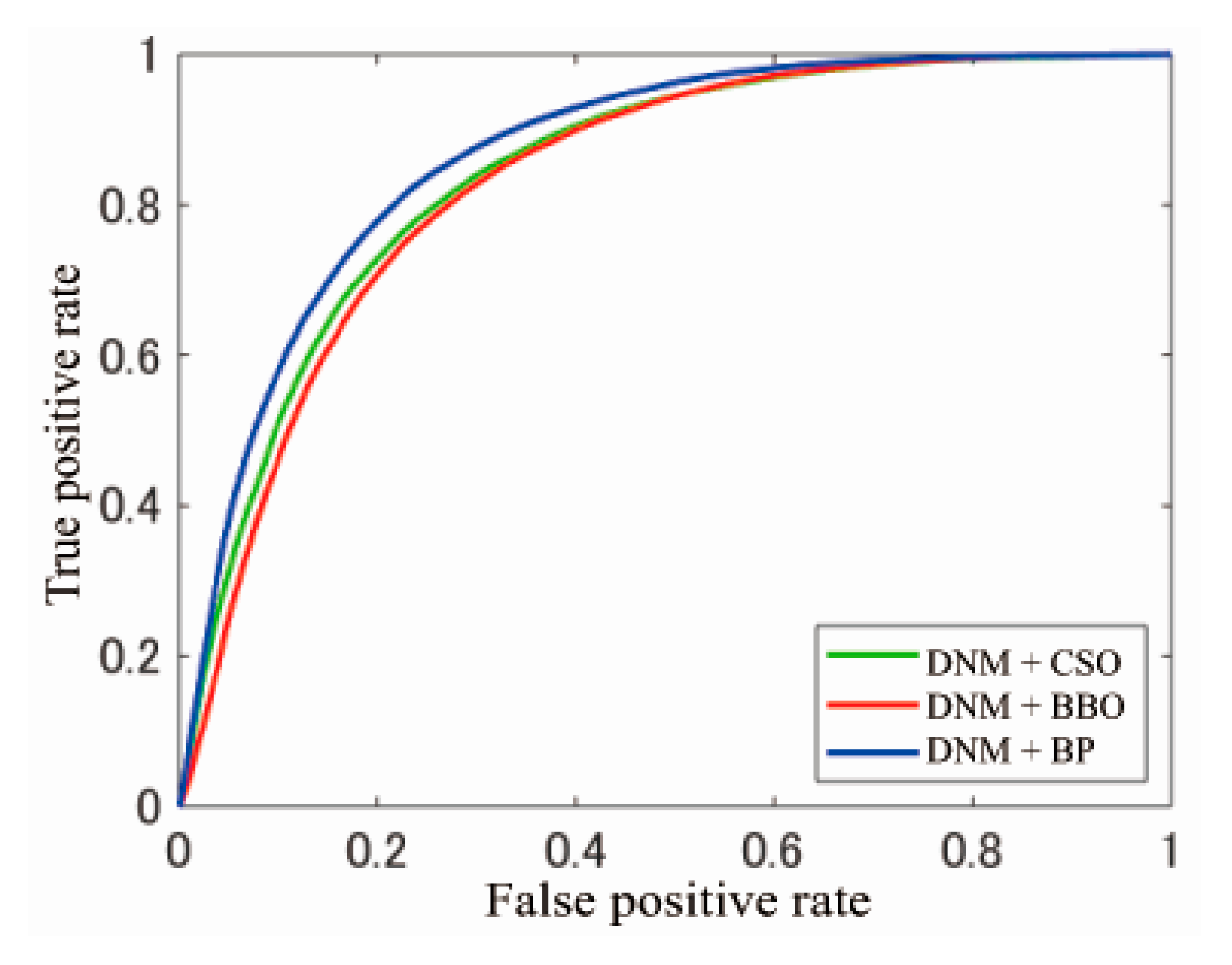
Figure 9,
Figure 10 and
Figure 11 depict the receiver operating characteristic (ROC) of each method in F1, F2 and F3, respectively. Furthermore, the average value of area under curve (AUC) in each problem and method is shown in
Table 18.
According to
Figure 9 and
Figure 11, DNM + BP in F1 and DNM + BBO in F3 obtain the highest classification accuracies. On the other hand, the three methods overlap on the diagonal line in
Figure 10, and the results are similar to those in the case of random classification since the value of AUC is very close to 0.5, as shown in
Table 18.
Although DNM + BBO and DNM + CSO differ to some degree in
Figure 9 and
Figure 11, both of them are convex curves to the upper left. In particular, the AUC of F3 is close to 1, which shows that their classification accuracy is excellent. However, for DNM + BP, the best AUC is a convex curve to the upper left in F1, while F3 is a curve that approximates the diagonal.
On the other hand, in
Table 13 and
Table 18, the difference in accuracy between DNM + BBO and DNM + CSO in F1 and F3 is also reflected in the AUC. To the contrary, even though the difference in accuracy of DNM + BP in F1 and F3 is only about 1%, the AUC is about 0.3. This is because the value of
Op that outputs the error classification result contains many values independent of the set threshold value of DNM + BP in F3. As shown in
Figure 5b, the DNM + BP in F3 is trapped in the local solution since it fails to obtain the output with a higher classification accuracy.
As DNM + BP in F3 above, the value of
Op that outputs the error classification result contains many values independent of the set threshold value as shown in
Figure 10, and the results are almost arranged on the same diagonal by any method in F2. The data set is considered to be the reason for this.
Moreover, because the output range of the DNM is [0, 1], the upper limit of the classifiable class is 2. In this experiment, in order to classify in the DNM, all of the classes representing the abnormality of F2 are unified as a non-anomaly class. It can be seen that the output with a high classification accuracy is not available since the different data trends are aggregated in the class representing each abnormality. Therefore, depending on the network of the DNM, etc., it is possible to expand the output range of the DNM effectively for improvement.
In addition, the average rank of the methods in F1, F2, and F3 obtained by the Friedman test are shown in
Table 19. It is clear that DNM + BP in F1, DNM + CSO in F2, and DNM + BBO in F3 ranked the highest on average, that there is no difference in the average accuracy for each problem, and that the result of this test is proved to be significant.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










