Figure 1 shows the proposed PM-DAN for a single image SR. Similar to DIP [
11], we take the output
of a parametric generator
G to represent the unknown HR image
, in which the random noise tensor
is the network input and
is the network parameters.
z has the same spatial resolution as the network output
.
C is the channel number of
, and it is set as 3 for the color image. In the case of supervised learning, the network parameters are usually learned from the training set under the objective function that minimizes the mean reconstruction error. Unlike previous work, we optimize the network parameters according to the image resolution degradation model to ensure that the output of the generator
can match with the given LR image
, and the objective function of network learning is formulated as,
where
D is the down-sampling operator for image resolution degeneration,
is the perceptual metric consisting of the mean absolute error metric
and multi-scale structural similarity metric
[
13], and
is the regularization weight. The weights
are learned to minimize the perceptual metric given a specific LR image
, thereby boosting visual quality of the reconstructed image.
3.1. Network Architecture
As shown in the bottom half of
Figure 1, our generator network
G has an attention-based encoder-decoder architecture consisting of three types of modules, namely a down-scale module, a skip connection module, and an up-scale module. The detailed configurations of our generator network
G are shown in
Table 1. The down-scale module in encoder is used to extract multi-scale features, the skip connection module delivers feature maps from encoder to decoder via convolution and concatenation operation, and the up-scale module in decoder is responsible for conducting reconstruction at different scales. Each convolution layer in these modules is coupled with batch normalization (BN) and nonlinear LeakyReLU (0.2) activation, and the kernel size of convolutional layers is set as
. Different from Reference [
11], we enhance the up-scale module by inserting two residual spatial attention (RSA) units. Under the guidance of the perceptual metric, it is expected that the predicted spatial attention maps will highlight areas with rich visually sensitive structures. Therefore, the up-scale module can pay more attention to informative features at different scales for reconstruction.
The inner diagram of RSA unit is shown in
Figure 2. Motivated by Reference [
26,
27], RSA adopts residual learning mechanism, and the output of RSA is computed as the sum of input and input masked by the predicted attention map. The mathematical formulation of RSA is
where
represents the convolution operation,
is the input of RSA,
is an intermediate result computed from
through the operation flow of convolution
, ReLU activation function
[
28] and convolution
,
predicts the spatial attention map from
, ⊙ is the point-wise multiplication, and
is the final output of RSA. The spatial attention map
is computed as,
where
is a
dilated convolution [
29] with the dilation rate of 3, and
is the obtained single-channel attention map. By enlarging the receptive field through dilated convolution, a larger range of information can be used to predict response in the attention map. By using a residual link, cascading two RSA units does not cause attenuation of the response values in the feature map. In contrast, RSA units not only increase the depth of the network but also enable the network to focus on important features, thereby improving the quality of the reconstructed image.
3.2. Loss Function
According to the study of Reference [
13], we take the perceptual metric defined in Equation (
1) as the loss layer to drive our attention-based network learning, thereby preserving the visually sensitive structures in the HR image. The first loss term
in
is
norm, which sums the absolute error at each pixel
p. The mathematical formulation is defined as:
where
is the pixel value of
at the position
p,
N is the total number of pixels in
, and
is the downsampled image from
and denotes as
y. The second loss term in
exploits MSSSIM metric [
12] to measure the reconstruction error between
and
y. MSSSIM is a multi-scale generalization of SSIM metric. Before introducing the mathematical formula of MSSSIM, we first give the definition of SSIM metric as,
By iteratively filtering and downsampling of the input image by
times, we can obtain
M scales of the input image, and, accordingly, MSSSIM calculates structural similarity by combining the measurement of
M scales,
Therefore, the loss
is set to 1 minus the negative MSSSIM metric,
In Equations (
5) and (
6),
is the divergence in brightness,
is the compound divergence in contrast and structure at scale
,
and
represent the mean and standard deviations of the patch
P centered at a pixel
p of
, respectively,
and
correspond to the mean and standard deviations of
y at the pixel
p, respectively,
denotes the covariance of
and
y, and
are small positive constants which can avoid the case of dividing by zero. The mean and standard variance associated with the patch
P are calculated by a convolution with Gaussian kernel
with the standard variance
. The subscript
p is omitted in MSSSIM metric for simplicity.
N is the total number of patches produced by sliding the patch along the whole image
y.
In order to propagate the reconstruction error from the loss layer to the previous layers, we need to first define the derivative of
loss. Specifically, the derivative of
for back-propagation can be calculated as,
where
is the transpose of the downsampling matrix
D. The calculation of MSSSIM for each patch
P involves neighborhood pixels of the pixel
p. According to the chain rule, we need to calculate the derivative of
at the pixel
p with respect to all the other pixels
in the patch
P, and the derivation formula is
where
and
are corresponding to the brightness divergence and compound divergence of contrast and structure at the pixel
p, namely the first and second term of Equation (
5). Their derivation details can be referred to the additional material in Reference [
13].
The derivatives of the perceptual metric
can hence simply calculated as the weighed sum of the derivatives of
and
according to Equations (
8) and (
9). Adam algorithm is then used to minimize
and the optimal network parameters can be found for reconstruction. Different from supervised learning over a given training set in Reference [
13], our network is optimized for SR reconstruction from only a given LR observation.




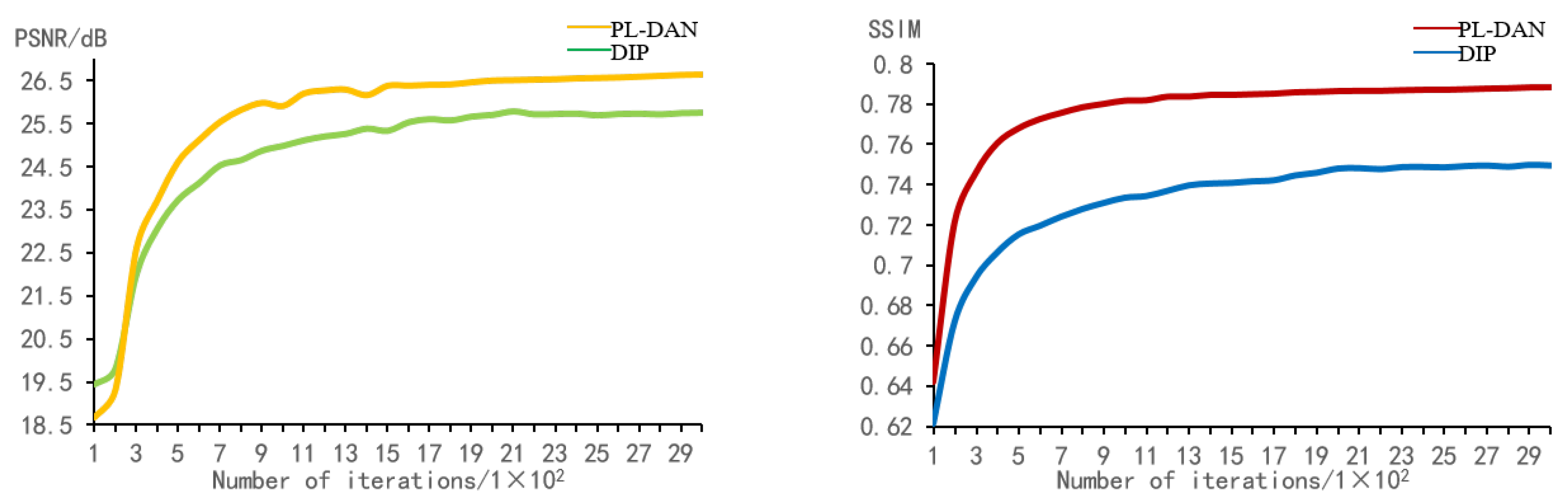






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}