SAPTM: Towards High-Throughput Per-Flow Traffic Measurement with a Systolic Array-Like Architecture on FPGA

Abstract
:1. Introduction
- We propose a systolic array-like multi-stage architecture, named SAPTM, for per-flow traffic measurement purposes. SAPTM enables it to exploit the hardware parallelism of FPGA to pipeline the measurement of flow traffic. Our method also utilizes D-left hashing to improve space utilization, which enables it to trace a large number of flows with only a small storage budget.
- We propose efficient architectural design and working mechanisms for flow insertion and eviction. This approach guarantees that active network flows (flows are extremely large (in total number of packets)) are maintained while mice flows (short flows) with small size are periodically removed from FPGA to the host.
- We prototype SAPTM on the Xilinx VCU118 platform. Evaluations using real-world traces demonstrate that SAPTM can outperform state-of-the-art sketch-based solutions by a factor of 14.1x–70.5x in terms of throughput.
2. Background
2.1. Approaches to Traffic Measurement
2.2. Measurement Data Structures
2.2.1. Sketch
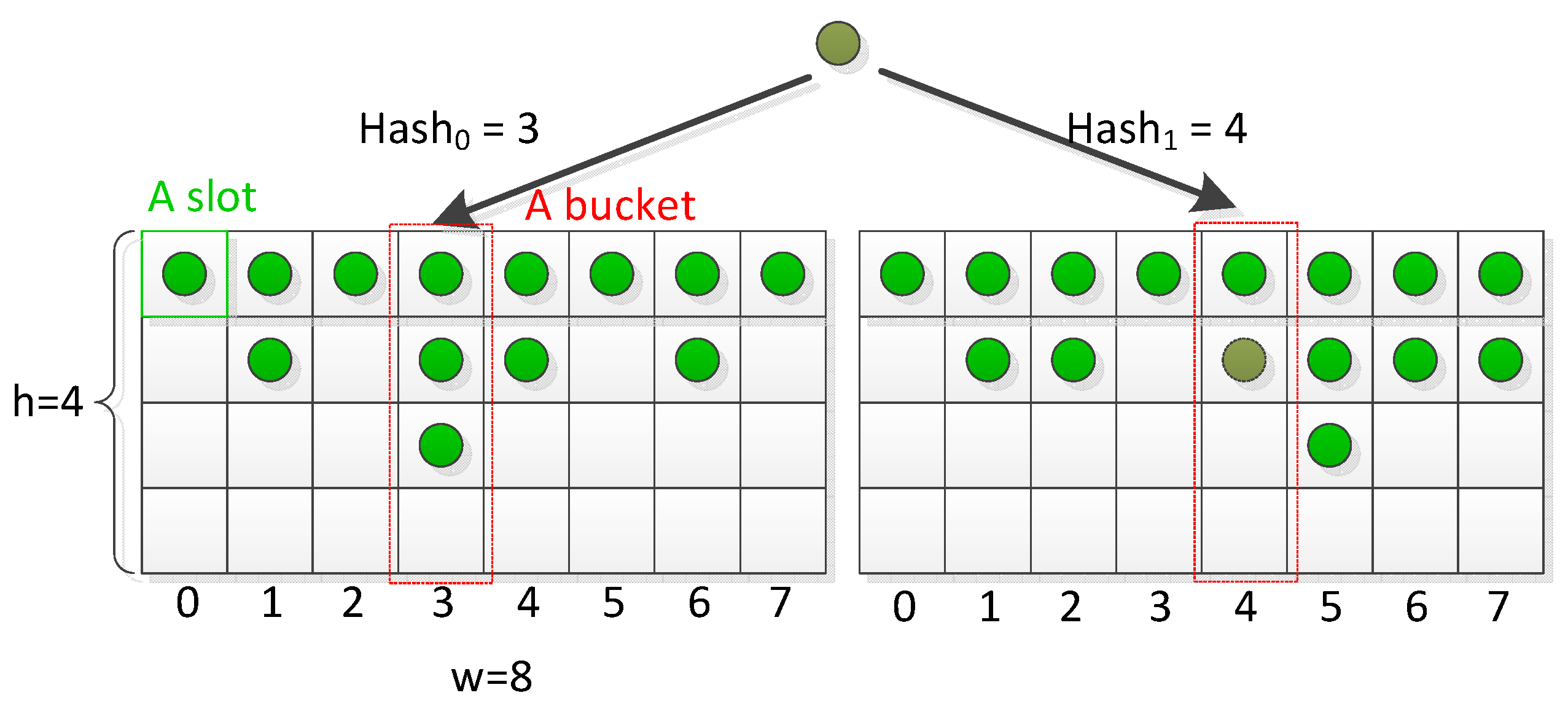
2.2.2. Hash Table
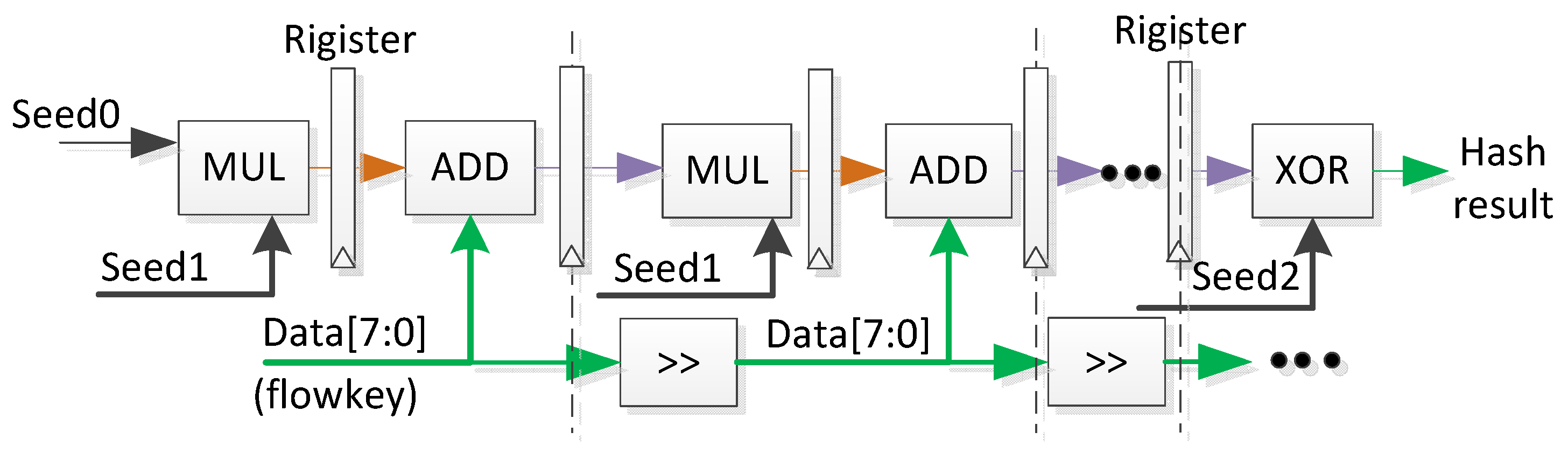
2.3. Memory-Friendly Hash Algorithms
3. Architectural Design and Implementation
- First, SAPTM should be able to exploit the architectural parallelism of FPGA devices. Since FPGA can provide formidable parallel processing capacity, SAPTM should be able to make good use of the characteristics of FPGA, thereby allowing it to efficiently accelerate the procedure of per-flow traffic measurement.
- Second, SAPTM should be able to accurately process all packets at high speed. More specifically, our design goal is to fulfill the line rate requirement of contemporary high speed networks (over 100 Gbps network bandwidth), which puts forward higher requests to the throughput of SAPTM.
3.1. Architecture Overview
Workflow of SAPTM
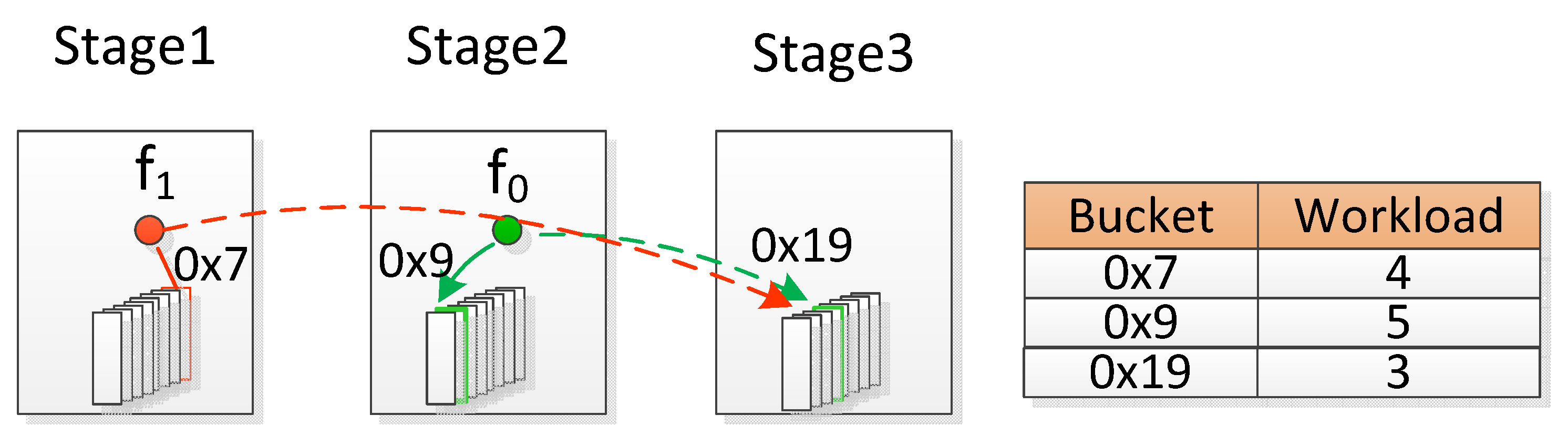
3.2. Hash Table Deployment among Pipelined Stages
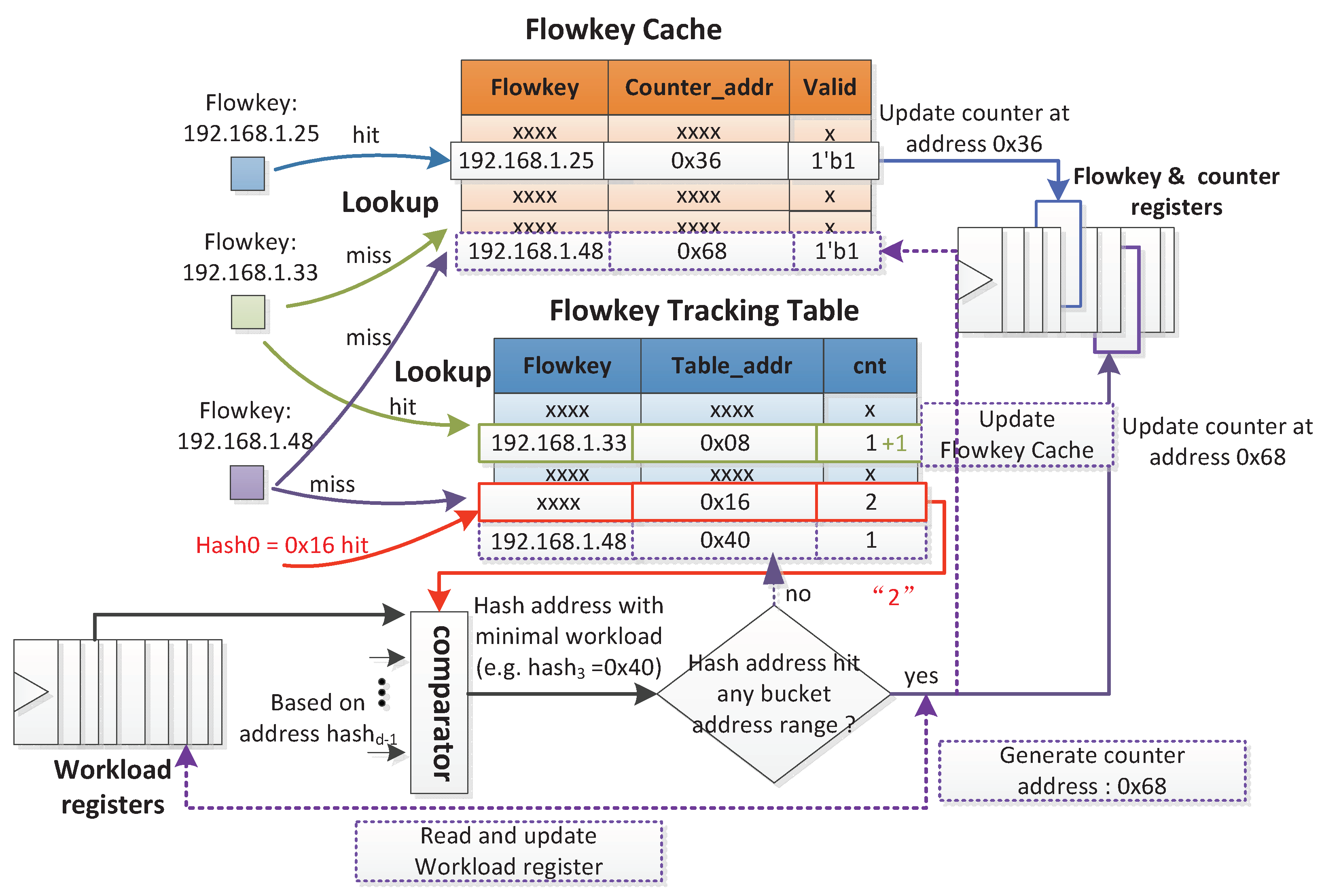
3.3. Flowkey Insertion
3.4. Flowkey Eviction
3.5. Implementation Details
4. Performance Modeling
5. Evaluations
5.1. Experimental Setup
5.2. Experimental Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cisco. Cisco Visual Networking Index: Forecast and Trends, 2017–2022 White Paper. 2019. Available online: https://www.cisco.com/c/en/us/solutions/collateral/service-provider/visual-networking-index-vni/white-paper-c11-741490.html (accessed on 27 February 2019).
- Roy, A.; Zeng, H.; Bagga, J.; Porter, G.; Snoeren, A.C. Inside the social network’s (datacenter) network. In Proceedings of the ACM SIGCOMM Computer Communication Review, London, UK, 17–21 August 2015; Volume 45, pp. 123–137. [Google Scholar]
- Li, Y.; Miao, R.; Kim, C.; Yu, M. Flowradar: A better netflow for data centers. In Proceedings of the 13th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 16), Santa Clara, CA, USA, 16–18 March 2016; pp. 311–324. [Google Scholar]
- Yang, T.; Gao, S.; Sun, Z.; Wang, Y.; Shen, Y.; Li, X. Diamond Sketch: Accurate Per-flow Measurement for Big Streaming Data. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2650–2662. [Google Scholar] [CrossRef]
- Yang, T.; Jiang, J.; Liu, P.; Huang, Q.; Gong, J.; Zhou, Y.; Miao, R.; Li, X.; Uhlig, S. Elastic sketch: Adaptive and fast network-wide measurements. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 561–575. [Google Scholar]
- Huang, Q.; Jin, X.; Lee, P.P.; Li, R.; Tang, L.; Chen, Y.C.; Zhang, G. Sketchvisor: Robust network measurement for software packet processing. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; pp. 113–126. [Google Scholar]
- Claise, B. Cisco Systems Netfow Services Export Version. RFC 3954; Cisco: San Jose, CA, USA, 2005. [Google Scholar]
- Metwally, A.; Agrawal, D.; El Abbadi, A. Efficient computation of frequent and top-k elements in data streams. In Proceedings of the International Conference on Database Theory, Edinburgh, UK, 5–7 January 2005; Springer: Heidelberg, Germnay, 2005; pp. 398–412. [Google Scholar]
- Sivaraman, V.; Narayana, S.; Rottenstreich, O.; Muthukrishnan, S.; Rexford, J. Smoking out the heavy-hitter flows with hashpipe. arXiv 2016, arXiv:1611.04825. [Google Scholar]
- Liu, Z.; Manousis, A.; Vorsanger, G.; Sekar, V.; Braverman, V. One sketch to rule them all: Rethinking network flow monitoring with univmon. In Proceedings of the 2016 ACM SIGCOMM Conference, Florianopolis, Brazil, 22–26 August 2016; pp. 101–114. [Google Scholar]
- Huang, Q.; Lee, P.P.; Bao, Y. Sketchlearn: relieving user burdens in approximate measurement with automated statistical inference. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018; pp. 576–590. [Google Scholar]
- Tang, L.; Huang, Q.; Lee, P.P. MV-Sketch: A Fast and Compact Invertible Sketch for Heavy Flow Detection in Network Data Streams. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 2026–2034. [Google Scholar]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: the count-min sketch and its applications. J. Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef] [Green Version]
- Pagh, R.; Rodler, F.F. Cuckoo hashing. J. Algorithms 2004, 51, 122–144. [Google Scholar] [CrossRef]
- Azar, Y.; Broder, A.Z.; Karlin, A.R.; Upfal, E. Balanced allocations. SIAM J. Comput. 1999, 29, 180–200. [Google Scholar] [CrossRef]
- Vöcking, B. How asymmetry helps load balancing. J. ACM (JACM) 2003, 50, 568–589. [Google Scholar] [CrossRef]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- CAIDA. The CAIDA UCSD Statistical Information for the CAIDA Anonymized Internet Traces. 2018. Available online: http://www.caida.org/data/passive/passive_trace_statistics.xml. (accessed on 27 February 2019).
- Cormode, G.; Muthukrishnan, S. What’s New: Finding Significant Differences in Network Data Streams. IEEE/ACM Trans. Netw. 2004, 13, 1219–1232. [Google Scholar] [CrossRef]
- Schweller, R.; Li, Z.; Chen, Y.; Gao, Y.; Gupta, A.; Zhang, Y.; Dinda, P.A.; Kao, M.; Memik, G. Reversible Sketches: Enabling Monitoring and Analysis Over High-Speed Data Streams. IEEE/ACM Trans. Netw. 2007, 15, 1059–1072. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Definitions | Parameters |
|---|---|
| Number of stages | |
| Latency of hash computation | |
| Latency of Flow Cache lookup | |
| Latency of writing Flow Cache | |
| Latency of writing Flowkey Tracking Table | |
| Latency of updating Flowkey Tracking Table | |
| Latency of Flowkey Tracking Table lookup | |
| Latency of updating flowkey counter | |
| Latency of writing storage for flowkey and counter | |
| Latency of updating Workload Registers | |
| Latency of Comparator | |
| Latency of writing Data queue |
| Resources | BRAMs | DSPs | LUTs | FFs | |
|---|---|---|---|---|---|
| utilization | 4 | 255 (12%) | 68 (1%) | 124K (5.7%) | 110K (4.6%) |
| 8 | 265 (12%) | 68 (1%) | 127K (5.9%) | 138K (5.8%) | |
| 16 | 285 (13%) | 68 (1%) | 135K (6.3%) | 160K (5.5%) | |
| 32 | 325 (15%) | 68 (1%) | 142K (6.6%) | 188K (6.8%) | |
| 64 | 405 (19%) | 68 (1%) | 150K (6.9%) | 202K (8.5%) |
| Parameters | Cycles |
|---|---|
| , , , , , , | 1 |
| , | 1 |
| , | 2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Q.; Zhao, X.; Wen, M.; Shen, J.; Tang, M.; Zhang, C. SAPTM: Towards High-Throughput Per-Flow Traffic Measurement with a Systolic Array-Like Architecture on FPGA. Electronics 2020, 9, 1160. https://doi.org/10.3390/electronics9071160
Cheng Q, Zhao X, Wen M, Shen J, Tang M, Zhang C. SAPTM: Towards High-Throughput Per-Flow Traffic Measurement with a Systolic Array-Like Architecture on FPGA. Electronics. 2020; 9(7):1160. https://doi.org/10.3390/electronics9071160
Chicago/Turabian StyleCheng, Qixuan, Xiaolei Zhao, Mei Wen, Junzhong Shen, Minjin Tang, and Chunyuan Zhang. 2020. "SAPTM: Towards High-Throughput Per-Flow Traffic Measurement with a Systolic Array-Like Architecture on FPGA" Electronics 9, no. 7: 1160. https://doi.org/10.3390/electronics9071160