
AI4PD—Towards a Standardized Interconnection of Artificial Intelligence Methods with Product Development Processes

Abstract
:Featured Application
Abstract
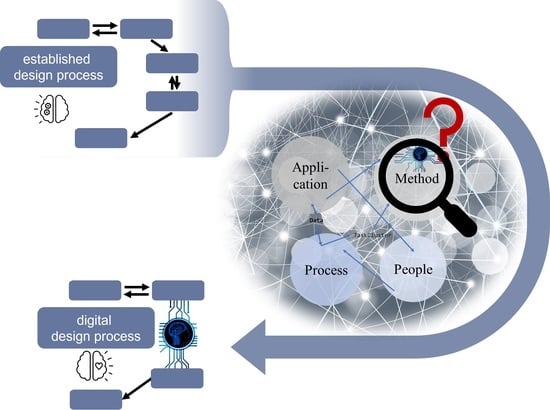
1. Introduction
How can the domains of artificial intelligence and product development be linked to simplify the introduction of Digital Engineering in small and medium-sized enterprises by improving method knowledge availability?
2. Materials and Methods
2.1. Use Case: Integrating Data-Driven Methods into Product Development Processes
2.2. Philosophy of AI4PD
2.3. Purpose and Scope
- Use case coverage: Avoid re-implementing since the ontology should answer queries about already implemented solutions for different problems and use cases. CQ: Is there a solution for predicting manufacturing possibilities based on test data and CAD files?
- Identification of suitable methods: Available data-driven tools need different databases and IT infrastructure. Furthermore, they are only suitable for some tasks. The ontology should be able to answer queries about which method would fit the given prerequisites. CQ: Which method and tool can support simulation engineers in estimating FEM results based on a CAD parameter configuration?
2.4. Concepts and Terminology
3. Results
3.1. Task Cluster Examples
3.2. Use Case 1: Use Case Coverage
- A description of the product development process;
- Used tools and toolboxes as well as the applied data-driven method;
- Required input and corresponding output data.
3.3. Use Case 2: Identification of Suitable Methods
| Listing 1. SPARQL Select query. |
|
4. Discussion
4.1. Linking the Domains of AI and Product Development Processes
4.2. Simplify the Introduction of Digital Engineering in SMEs
4.3. Improve Method Knowledge Availability
5. Conclusions and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| CRISP-DM | Cross-industry standard process for Data Mining |
| CAD | Computer-Aided Design |
| CSV | Comma-separated values |
| CWA | Closed world assumption |
| DM | Data Mining |
| FEM | Finite Element Method |
| GPU | Graphics Processing Unit |
| IRI | Internationalised Resource Identifier |
| JSON | JavaScript object notation |
| KDD | Knowledge discovery in databases |
| ML | Machine Learning |
| OWA | Open world assumption |
| PD | Product development |
| PDM | Product data management |
| PDP | Product development process |
| SDM | Simulation data management |
| SME | Small and medium-sized enterprise |
References
- Lunnemann, P.; Stark, R.; Wang, W.M.; Stark, R.; Manteca, P.I. Engineering Activities — Considering Value Creation from a Holistic Perspective. In Proceedings of the 2017 International Conference on Engineering, Technology and Innovation (ICE/ITMC), Madeira, Portugal, 27–29 June 2017; pp. 315–323. [Google Scholar] [CrossRef]
- Gerschütz, B.; Spießl, B.V.M.; Schleich, B.; Wartzack, S. An Adapted Method for Design Process Capturing to Meet the Challenges of Digital Product Development. In Proceedings of the International Conference on Engineering Design (ICED21), Gothenburg, Sweden, 16–19 August 2021; Volume 1, pp. 365–374. [Google Scholar] [CrossRef]
- Stark, R.; Brandenburg, E.; Lindow, K. Characterization and Application of Assistance Systems in Digital Engineering. CIRP Ann. 2021, 70, 131–134. [Google Scholar] [CrossRef]
- Gerschütz, B.; Bickel, S.; Schleich, B.; Wartzack, S. Enabling Initial Design-Checks of Parametric Designs Using Digital Engineering Methods. Proc. Des. Soc. 2022, 2, 405–414. [Google Scholar] [CrossRef]
- El Sayed, M.A.; Farahat, F.A.; Elsisy, M.A. A novel interactive approach for solving uncertain bi-level multi-objective supply chain model. Comput. Ind. Eng. 2022, 169, 108225. [Google Scholar] [CrossRef]
- Montáns, F.J.; Chinesta, F.; Gomez-Bombarelli, R.; Kutz, J.N. Data-Driven Modeling and Learning in Science and Engineering. Comptes Rendus MÉcanique 2019, 347, 845–855. [Google Scholar] [CrossRef]
- Samuel, A.L. Some Studies in Machine Learning Using the Game of Checkers. IBM J. Res. Dev. 2000, 44, 206–226. [Google Scholar] [CrossRef]
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. From Data Mining to Knowledge Discovery in Databases. AI Mag. 1996, 17, 37. [Google Scholar] [CrossRef]
- StackExchange. Distinction between AI, ML, Neural Networks, Deep Learning and Data Mining. Available online: https://softwareengineering.stackexchange.com/q/366996 (accessed on 24 January 2023).
- Kulin, M.; Kazaz, T.; De Poorter, E.; Moerman, I. A Survey on Machine Learning-Based Performance Improvement of Wireless Networks: PHY, MAC and Network Layer. Electronics 2021, 10, 318. [Google Scholar] [CrossRef]
- Cambridge University Press. Artificial Intelligence|Meaning in the Cambridge English Dictionary. Available online: https://dictionary.cambridge.org/de/worterbuch/englisch/artificial-intelligence (accessed on 24 January 2023).
- Monostori, L. Artificial Intelligence. In CIRP Encyclopedia of Production Engineering; Laperrière, L., Reinhart, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2014; pp. 47–50. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 25 January 2023).
- Chapman, P.; Clinton, J.; Kerber, R.; Khabaza, T.; Reinartz, T.; Shearer, C.; Wirth, R. CRISP-DM 1.0 Step-by-Step Data Mining Guide; The CRISP-DM Consortium: Chicago, IL, USA, 2000. [Google Scholar]
- Azevedo, A.; Santos, M.F. KDD, SEMMA and CRISP-DM: A Parallel Overview. In Proceedings of the IADIS European Conference on Data Mining 2008, Amsterdam, The Netherlands, 24–26 July 2008; Abraham, A., Ed.; IADIS: Jambi, Indonesia, 2008; pp. 182–185. [Google Scholar]
- Erlhoff, M.; Marshall, T.; Bruce, L.M.J.; Lindberg, S. Design Dictionary: Perspectives on Design Terminology; Birkhäuser: Berlin, Germany; Boston, UK, 2007. [Google Scholar] [CrossRef]
- Krensky, P.; Idoine, C.; Brethenoux, E.; den Hamer, P.; Choudhary, F.; Jaffri, A.; Vashisth, S. Magic Quadrant for Data Science and Machine Learning Platforms; 2022. Available online: https://www.gartner.com/en/documents/3998753 (accessed on 30 May 2022).
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine Learning in Manufacturing: Advantages, Challenges, and Applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef] [Green Version]
- Gerschütz, B.; Schleich, B.; Wartzack, S. A Semantic Web Approach for Structuring Data-Driven Methods in the Product Development Process. In Proceedings of the DS 111: 32nd Symposium Design for X, The Design Society, Tutzing, Germany, 27–28 September 2021. [Google Scholar] [CrossRef]
- Mikut, R.; Reischl, M. Data Mining Tools. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2011, 1, 431–443. [Google Scholar] [CrossRef]
- Pahl, G.; Wallace, K.; Blessing, L.; Pahl, G. (Eds.) Engineering Design: A Systematic Approach, 3rd ed.; Springer: London, UK, 2007. [Google Scholar]
- VDI 2221 Blatt 1 Design of Technical Products and Systems—Model of Product Design; Beuth: Berlin, Germany, 2019.
- VDI/VDE 2206:2021-11—Development of Mechatronic and Cyber-Physical Systems; Beuth: Berlin, Germany, 2021.
- Nattermann, R.; Anderl, R. The W-model – Using Systems Engineering for Adaptronics. Procedia Comput. Sci. 2013, 16, 937–946. [Google Scholar] [CrossRef] [Green Version]
- Avnet, M.S.; Weigel, A.L. The Structural Approach to Shared Knowledge: An Application to Engineering Design Teams. Hum. Factors: J. Hum. Factors Ergon. 2013, 55, 581–594. [Google Scholar] [CrossRef]
- Gruber, T.R. A Translation Approach to Portable Ontology Specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Kügler, P.; Marian, M.; Schleich, B.; Tremmel, S.; Wartzack, S. tribAIn—towards an Explicit Specification of Shared Tribological Understanding. Appl. Sci. 2020, 10, 4421. [Google Scholar] [CrossRef]
- Gene Ontology Consortium. The Gene Ontology (GO) Database and Informatics Resource. Nucleic Acids Res. 2004, 32, 258–261. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Chen, C.H.; Leong, K.F.; Jiang, X. An Ontology Learning System for Customer Needs Representation in Product Development. Int. J. Adv. Manuf. Technol. 2013, 67, 441–453. [Google Scholar] [CrossRef]
- Kim, K.Y.; Manley, D.G.; Yang, H. Ontology-Based Assembly Design and Information Sharing for Collaborative Product Development. Comput.-Aided Des. 2006, 38, 1233–1250. [Google Scholar] [CrossRef]
- Kestel, P.; Kügler, P.; Zirngibl, C.; Schleich, B.; Wartzack, S. Ontology-Based Approach for the Provision of Simulation Knowledge Acquired by Data and Text Mining Processes. Adv. Eng. Inform. 2019, 39, 292–305. [Google Scholar] [CrossRef]
- Kügler, P.; Kestel, P.; Schon, C.; Marian, M.; Schleich, B.; Staab, S.; Wartzack, S. Ontology-based approach for the use of intentional forgetting in product development. In Proceedings of the 15th International Design Conference, Dubrovnik, Croatia, 21–24 May 2018; pp. 1595–1606. [Google Scholar] [CrossRef]
- Yang, Q.; Miao, C.; Zhang, Y.; Gay, R. Ontology Modelling and Engineering for Product Development Process Description and Integration. In Proceedings of the 2006 IEEE International Conference on Industrial Informatics, Singapore, 16–18 August 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 85–90. [Google Scholar] [CrossRef]
- Lebo, T.; Sahoo, S.; McGuinnes, D. PROV-O The PROV Ontology. Available online: https://www.w3.org/TR/prov-o/ (accessed on 24 January 2023).
- Brickley, D.; Miller, L. FOAF Vocabulary Specification. Available online: http://xmlns.com/foaf/0.1/ (accessed on 24 January 2023).
- Uschold, M.; Gruninger, M. Ontologies: Principles, Methods and Applications. Knowl. Eng. Rev. 1996, 11, 93–136. [Google Scholar] [CrossRef] [Green Version]
- Hitzler, P.; Krötzsch, M.; Parsia, B.; Patel-Schneider, P.F.; Rudolph, S. OWL 2 Web Ontology Language Primer (Second Edition). Available online: https://www.w3.org/TR/owl2-primer/ (accessed on 24 January 2023).
- Musen, M.A. The Protégé Project: A Look Back and a Look Forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef] [Green Version]
- Sauer, C.; Breitsprecher, T.; Küstner, C.; Schleich, B.; Wartzack, S. SLASSY—An Assistance System for Performing Design for Manufacturing in Sheet-Bulk Metal Forming: Architecture and Self-Learning Aspects. AI 2021, 2, 307–329. [Google Scholar] [CrossRef]
- Alchourrón, C.E.; Gärdenfors, P.; Makinson, D. On the Logic of Theory Change: Partial Meet Contraction and Revision Functions. J. Symb. Log. 1985, 50, 510–530. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Goal | Knowledge Work | Data Type Change | Input | Output |
|---|---|---|---|---|---|
| Creation of Reports | documentation | no | yes | engineering data | report |
| Approval | release of defined statuses | yes | yes | report | decision |
| Relationships | transform inputs to defined outputs | yes | yes | engineering data | different but engineering data |
| Data as basis | use old data for new product generation | yes | no | engineering data | same as input |
| Result evaluation | evaluation of measurements or simulations | yes | yes | engineering data | plausibility assessment |
| Knowledge management | maintenance of knowledge management systems | no | yes | knowledge | formalised knowledge |
| Assignment of other departments | transfer information to subcontractors | no | yes/no | task-dependent | task-dependent |
| Data procurement | obtain missing data or information | no | no | task-dependent | task-dependent |
| Concept | Value |
|---|---|
| Team | Simulation Department |
| SubProcess | Simulation |
| DataIn.Format | CAD-Data ∩ Numerical parameters |
| DataIn.Storage | PDM System |
| DataOut.Format | FEM Result ∩ Numerical value |
| DataOut.Storage | SDM System |
| TrainingHardware | GPU-based |
| UsageHardware | low computing ∪ command line |
| DataDrivenTask | DataDrivenMethod | DataDrivenTool |
|---|---|---|
| Regression | Regression-Tree (M5P) | RapidMinerM5PModell |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gerschütz, B.; Goetz, S.; Wartzack, S. AI4PD—Towards a Standardized Interconnection of Artificial Intelligence Methods with Product Development Processes. Appl. Sci. 2023, 13, 3002. https://doi.org/10.3390/app13053002
Gerschütz B, Goetz S, Wartzack S. AI4PD—Towards a Standardized Interconnection of Artificial Intelligence Methods with Product Development Processes. Applied Sciences. 2023; 13(5):3002. https://doi.org/10.3390/app13053002
Chicago/Turabian StyleGerschütz, Benjamin, Stefan Goetz, and Sandro Wartzack. 2023. "AI4PD—Towards a Standardized Interconnection of Artificial Intelligence Methods with Product Development Processes" Applied Sciences 13, no. 5: 3002. https://doi.org/10.3390/app13053002