Investigating Semi-Automated Cadastral Boundaries Extraction from Airborne Laser Scanned Data





Abstract
:1. Introduction
1.1. Background
1.2. Literature Review
1.2.1. Advances in Cadastral Concepts
1.2.2. Developments in Feature Extraction
2. Methods and Materials
2.1. Overarching Methodology
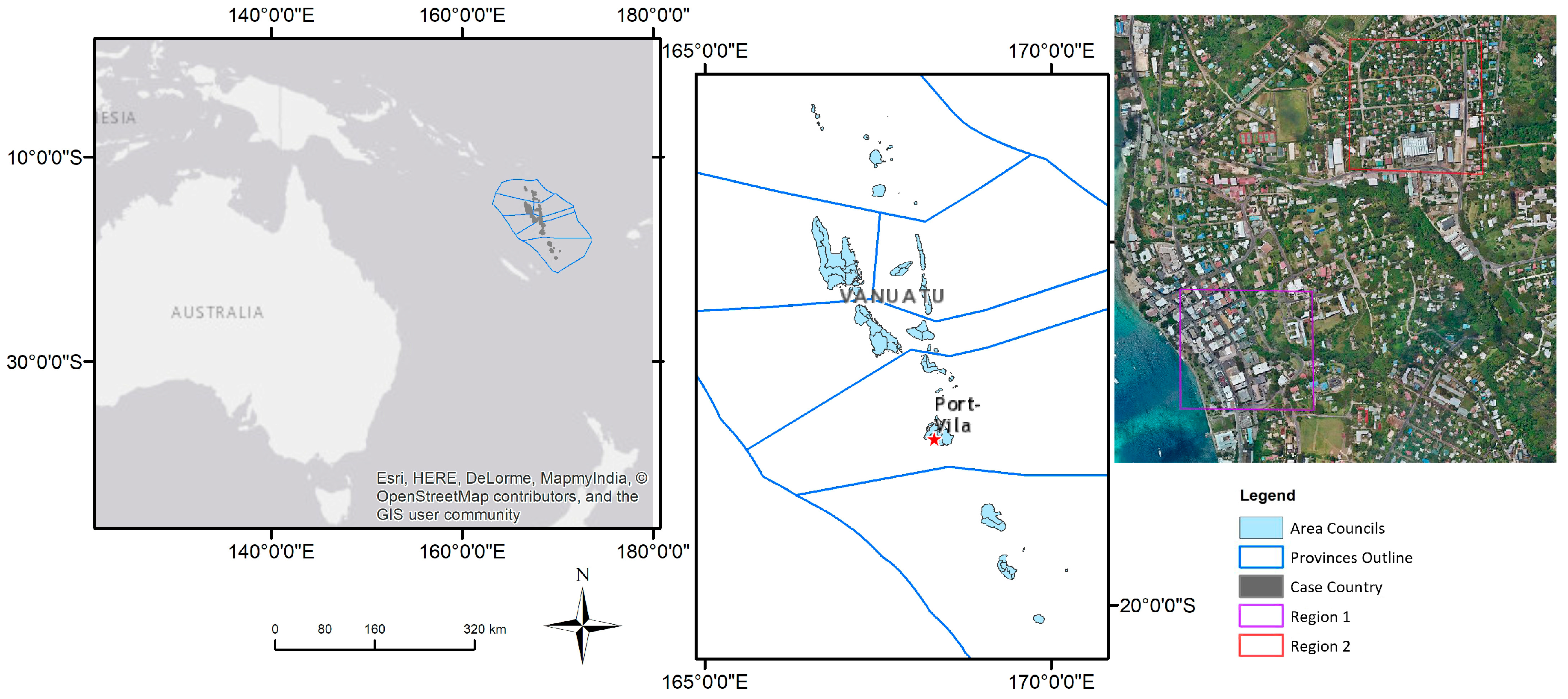
2.2. Study Area and Research Data
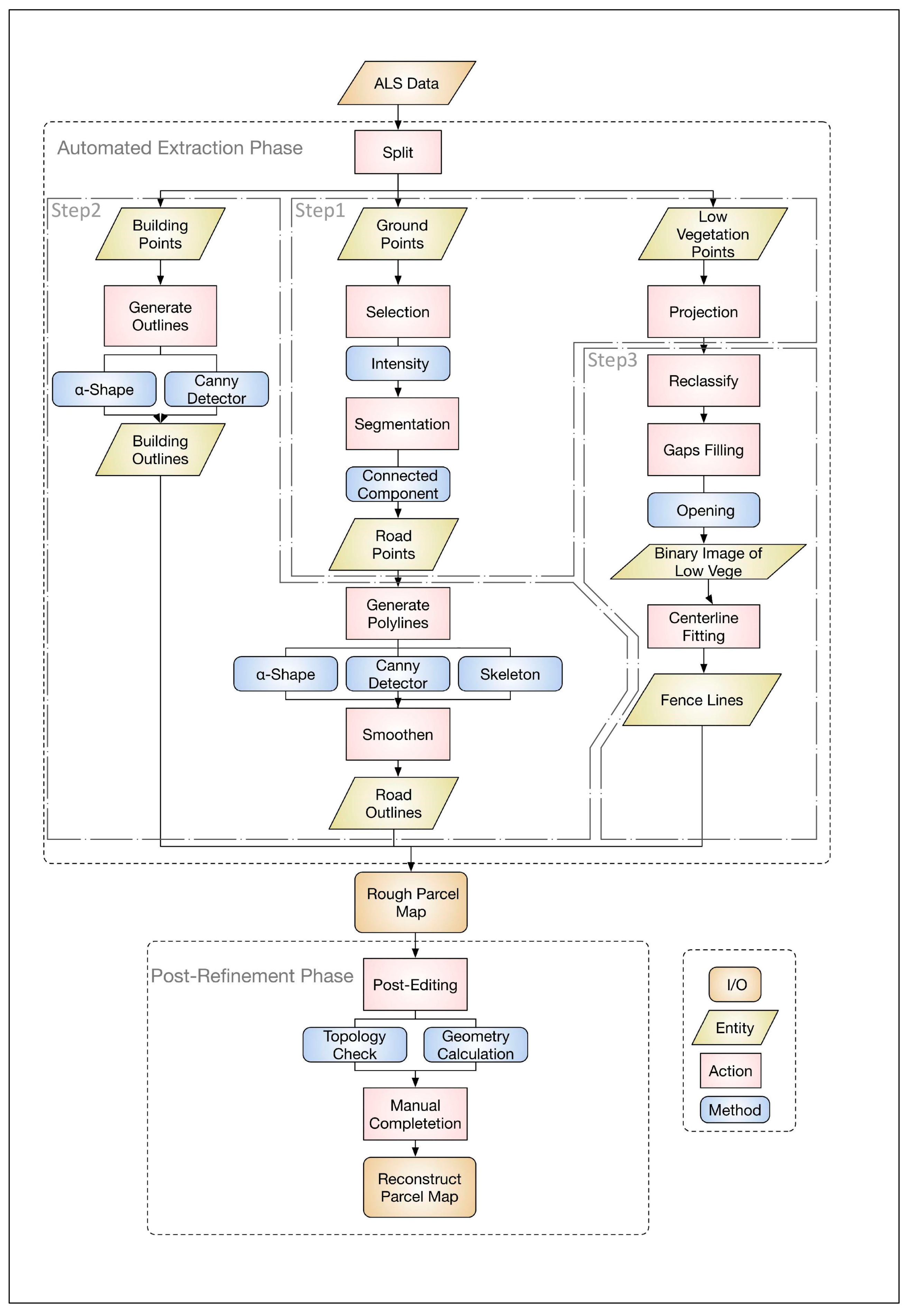
3. The Semi-Automated Workflow of Cadastral Boundaries Extraction
3.1. Overview of the Semi-Automated Workflow
3.2. Further Classification for Expected Objects
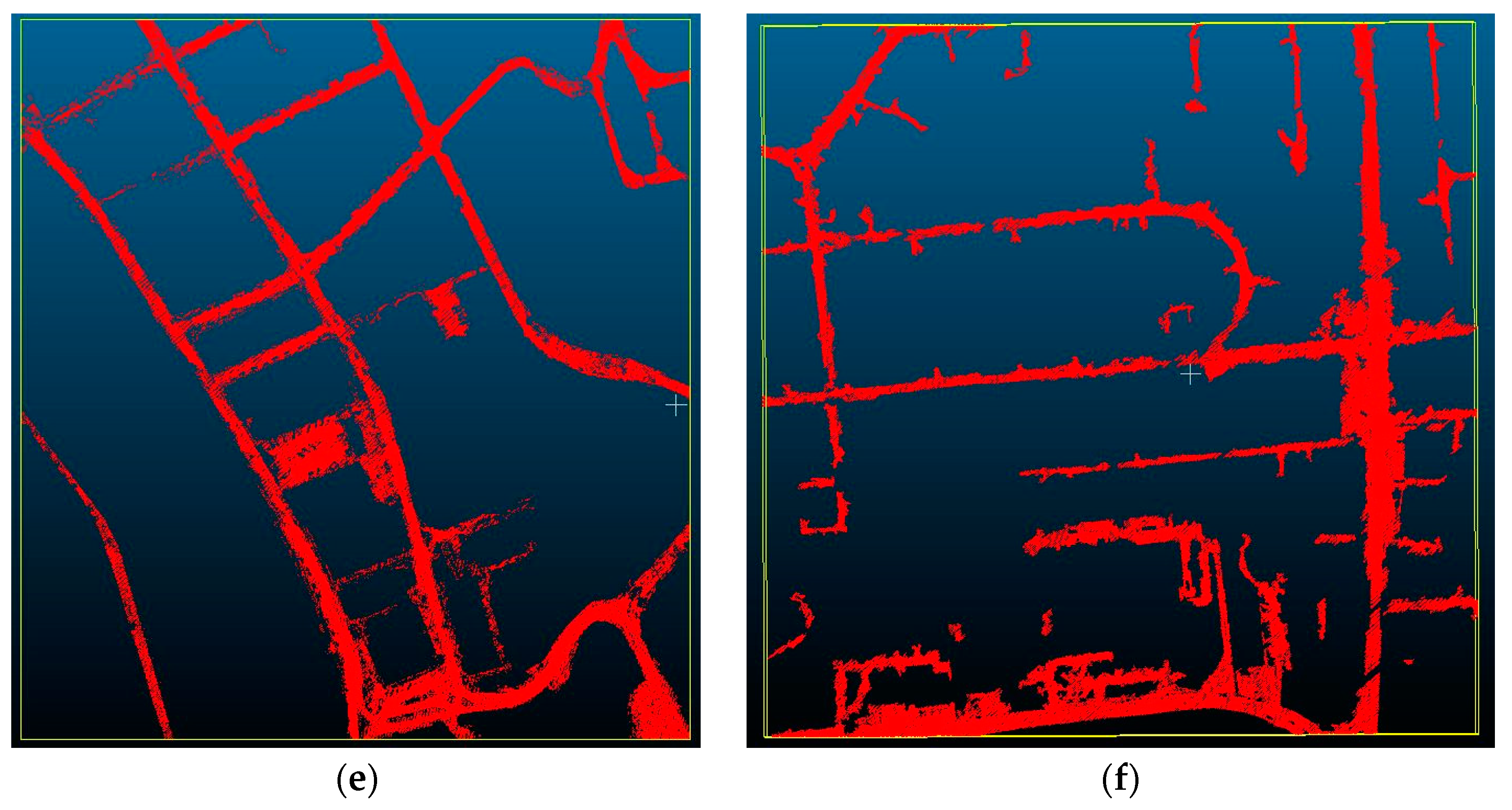
3.2.1. Road Detection from Ground Points
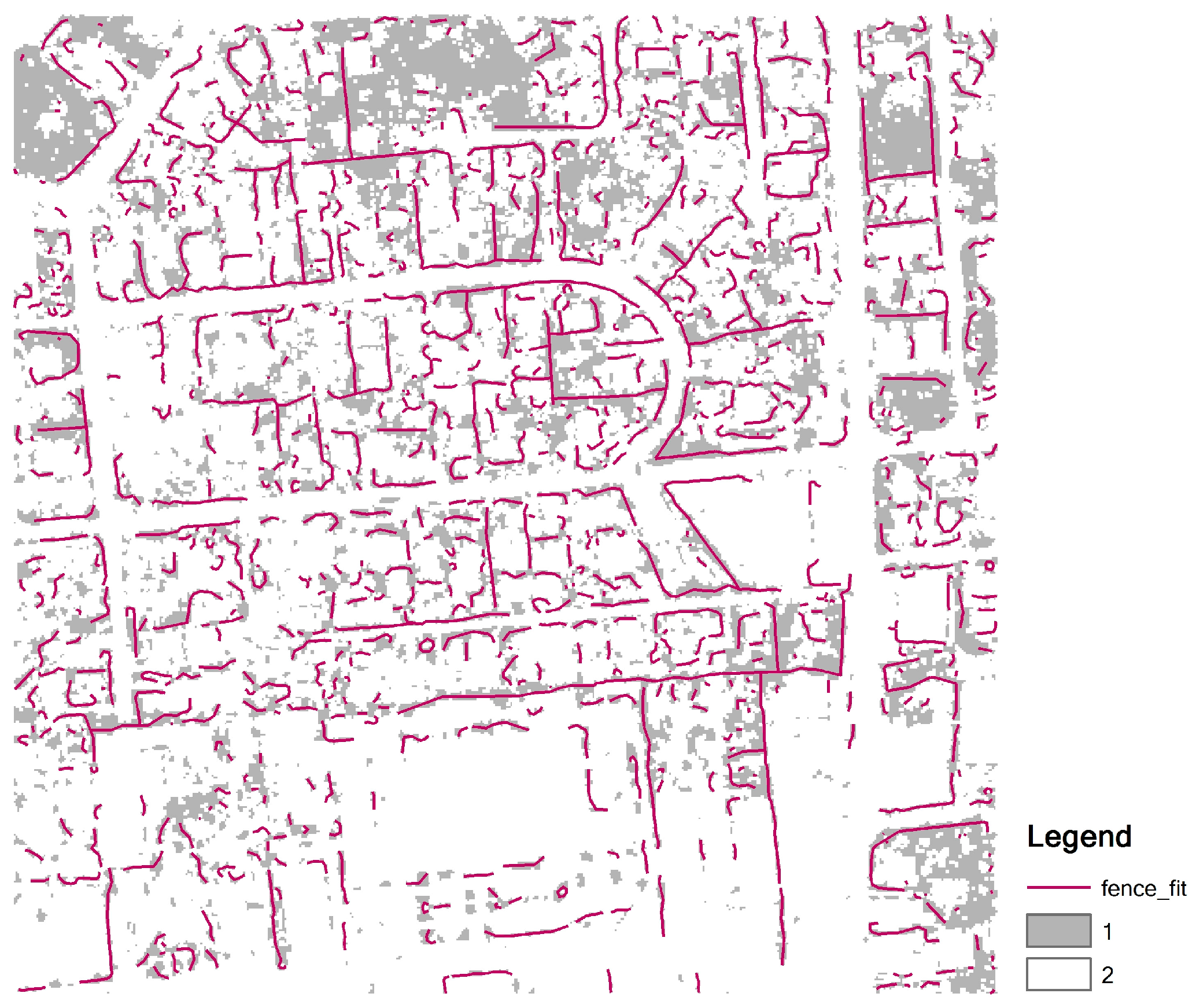
3.2.2. Fence Detection for Low Vegetation
3.3. Complemented Knowledge from Height Jumps
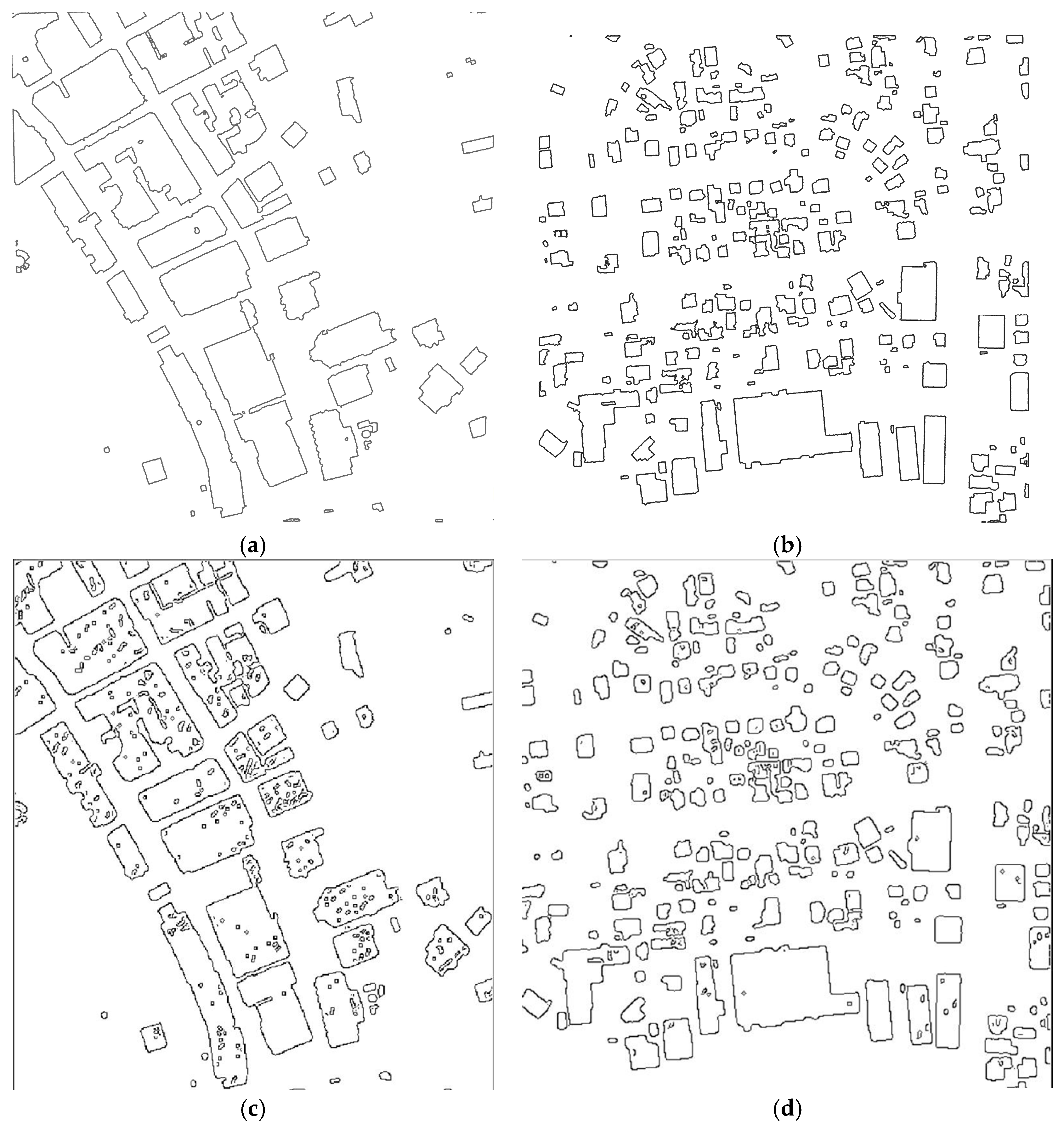
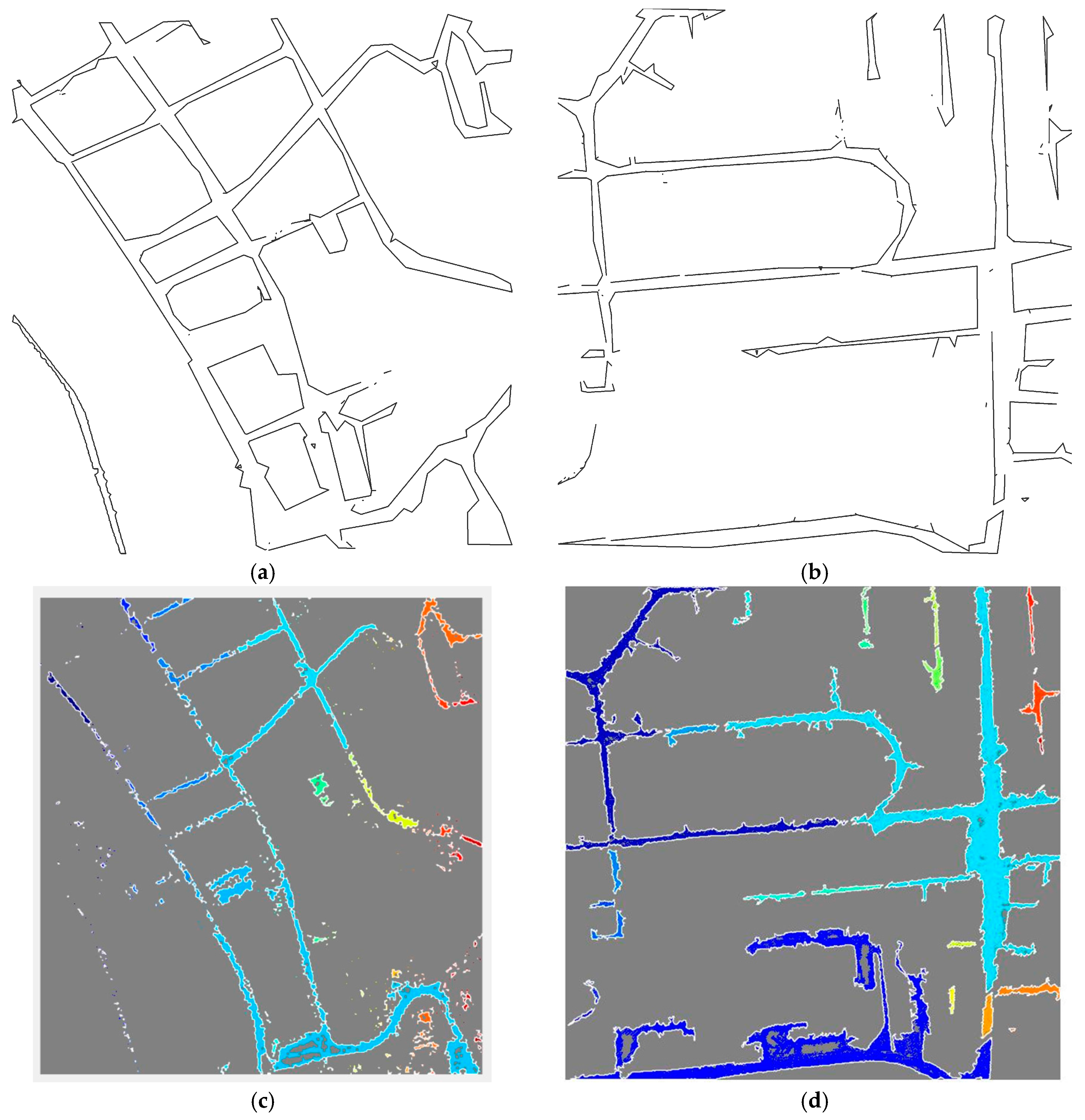
3.4. Outline Generation of Detected Planar Objects
3.4.1. Building Outlines Extraction
3.4.2. Road Outlines Extraction
3.5. Line Fitting From Linear Fences
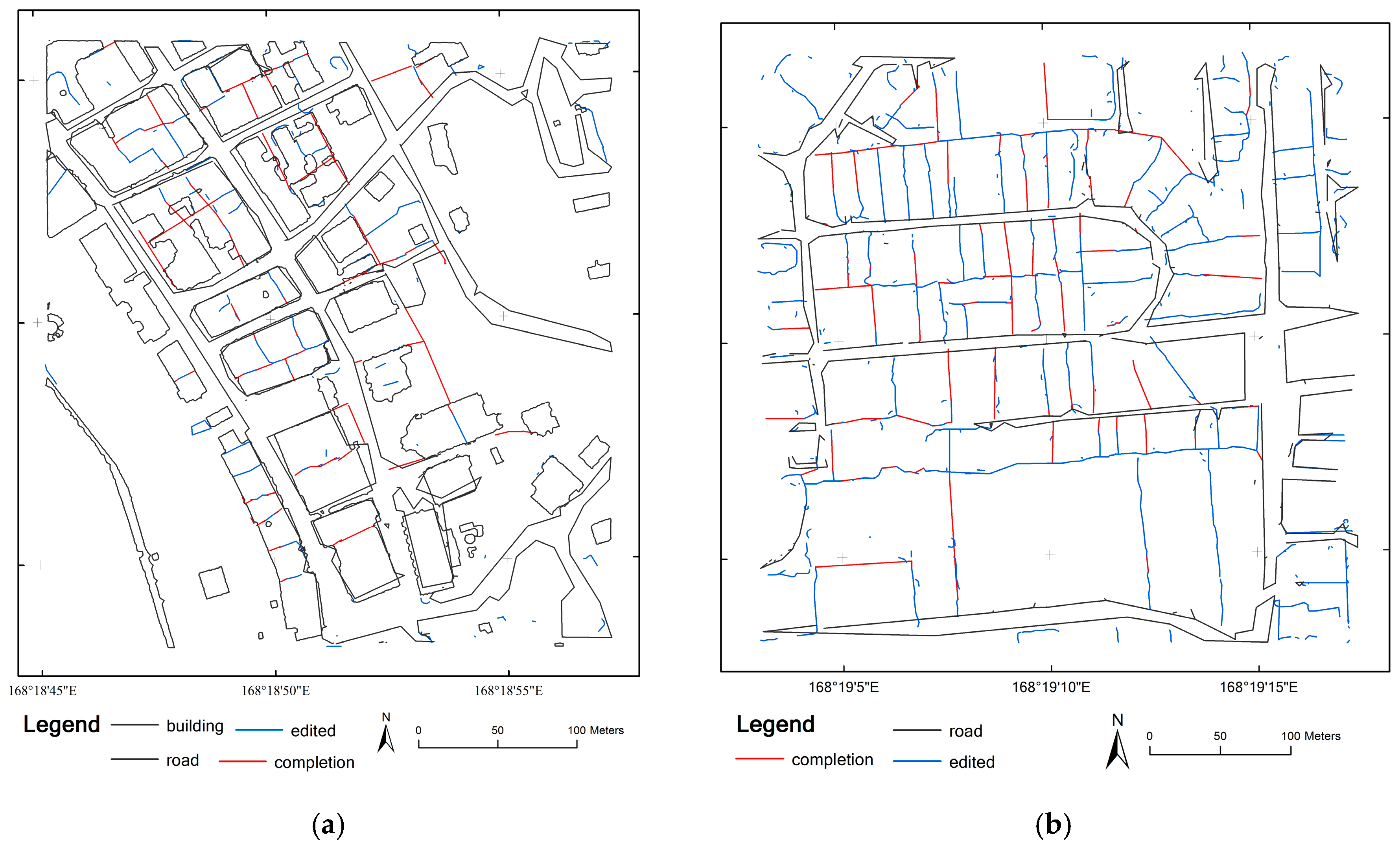
3.6. Reconstructing the Parcel Map by Post-Refinement
4. Workflow Performance Evaluation
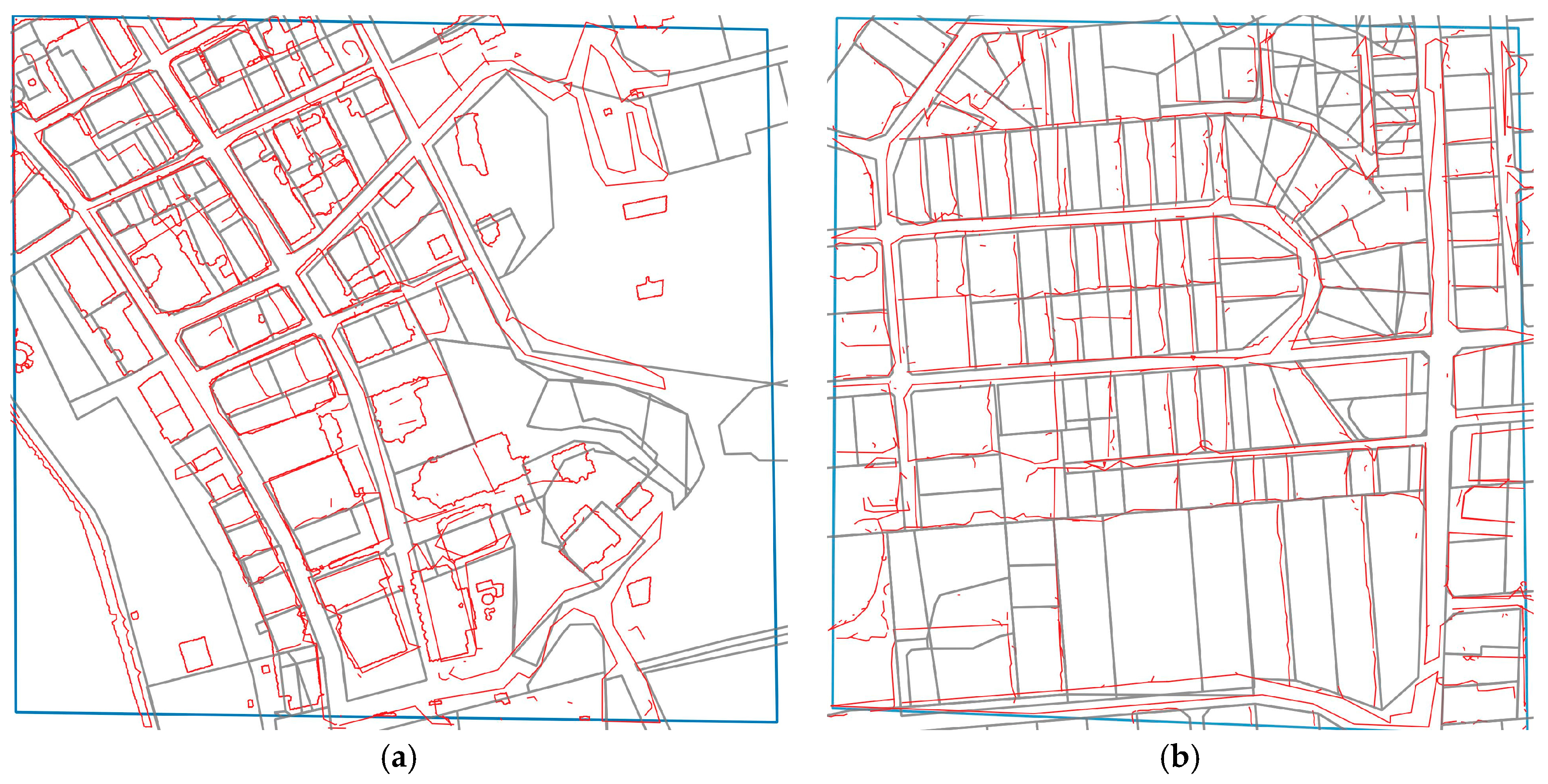
4.1. Comparison with Exiting Cadastral Map
4.2. Error and Tolerance
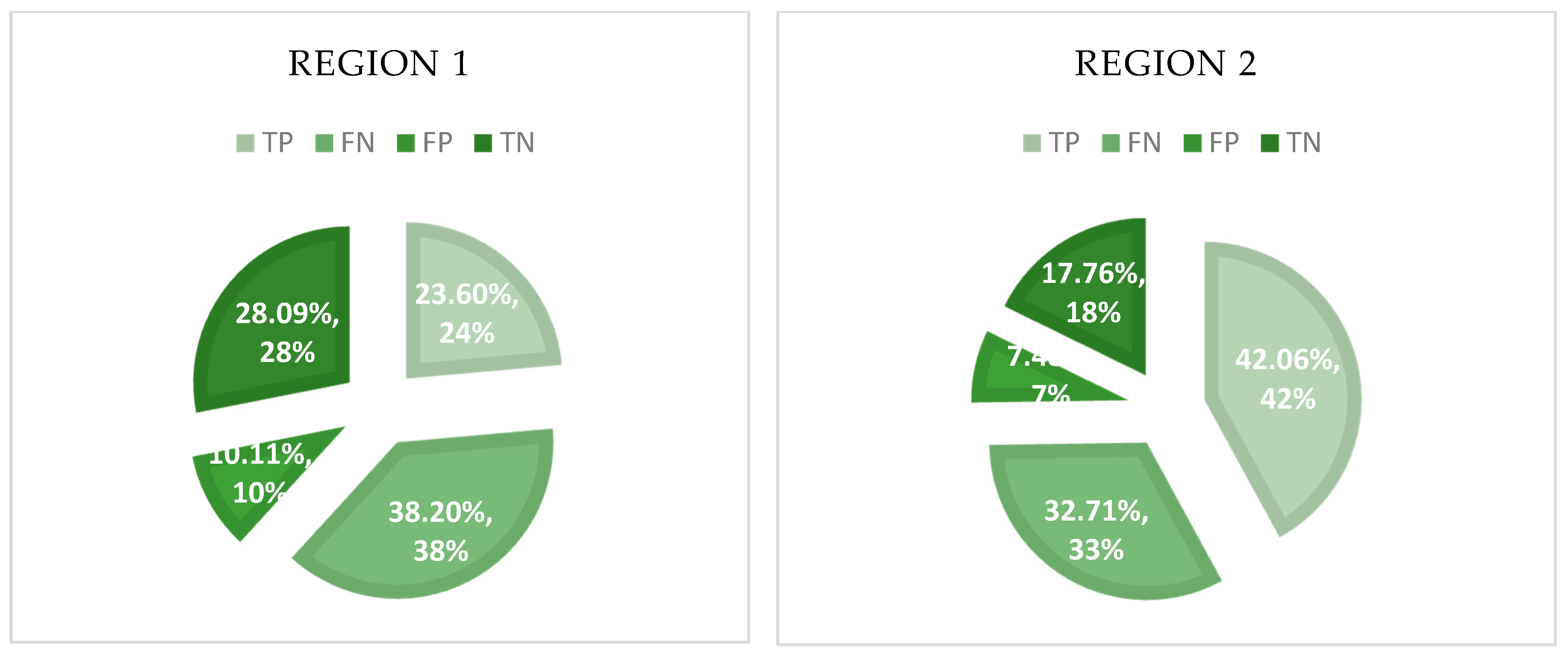
4.3. Workflow Correctness and Completeness
4.3.1. Proportion of Detected Lines from Each Kind of Feature
4.3.2. Performance of Full Parcel Identification
4.4. Degree of Automation
4.5. Suitable Point Density for Target Objects
5. Discussion
5.1. Observations from the Workflow Development
5.2. Strenghts and Limitation
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Enemark, S.; Bell, K.; Lemmen, C.; McLaren, R. Fit-for-Purpose Land Administration; No. 60; Joint FIG/World Bank Publication: Copenhagen, Denmark, 2014. [Google Scholar]
- Roger, J.; Kain, P.; Elizabeth, B. The Cadastral Map in the Service of the State: A History of Property Mapping; The University of Chicago Press: Chicago, IL, USA, 1992. [Google Scholar]
- Zevenbergen, J.; Augustinus, C. Designing a pro poor land recordation system. In Proceedings of the FIG Working Week, Marrakech, Morocco, 18–22 May 2011; pp. 18–22. [Google Scholar]
- Simbizi, M.C.D.; Bennett, R.M.; Zevenbergen, J. Land tenure security: Revisiting and refining the concept for Sub-Saharan Africa’s rural poor. Land Use Policy 2014, 36, 231–238. [Google Scholar] [CrossRef]
- Jochem, A.; Höfle, B.; Wichmann, V.; Rutzinger, M.; Zipf, A. Area-wide roof plane segmentation in airborne LiDAR point clouds. Comput. Environ. Urban. Syst. 2012, 36, 54–64. [Google Scholar] [CrossRef]
- Vosselman, G.; Dijkman, S. 3D Building Model reconstruction from point clouds and ground plans. Int. Arch. Photogramm. Remote Sens. 2001, XXXIV, 22–24. [Google Scholar]
- Yu, Y.; Li, J.; Member, S.; Guan, H.; Jia, F.; Wang, C. Learning hierarchical features for automated extraction of road markings from 3-D Mobile LiDAR point clouds. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 709–726. [Google Scholar] [CrossRef]
- Monnier, F.; Vallet, B.; Soheilian, B. Trees detection from laser point clouds acquired in dense urban areas by a mobile mapping system. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, I-3, 245–250. [Google Scholar] [CrossRef]
- Van Beek, N. Using Airborne Laser Scanning for Deriving Topographic Features for the Purpose of General Boundary Based Cadastral Mapping. Master’s Thesis, University of Delft, Delft, The Netherlands, 2015. [Google Scholar]
- Crommelinck, S.; Bennett, R.; Gerke, M.; Nex, F.; Yang, M.Y.; Vosselman, G. Review of automatic feature extraction from high-resolution optical sensor data for UAV-based cadastral mapping. Remote Sens. 2016, 8, 689–717. [Google Scholar] [CrossRef]
- Luo, X. Cadastral boundaries from point clouds?: Towards semi-automated cadastral boundary extraction from ALS data. GIM Int. 2016, 30, 16–17. [Google Scholar]
- Dale, P.; McLaughlin, J. Land Administration; Oxford University Press: Oxford, UK, 2000. [Google Scholar]
- Zevenbergen, J. Systems of Land Registration, Aspects and Effects; NCC: Amersfoort, The Netherlands, 2002. [Google Scholar]
- Williamson, I.P. Land administration ‘best practice’ providing the infrastructure for land policy implementation. Land Use Policy 2001, 18, 297–307. [Google Scholar] [CrossRef]
- Abdulai, R.T.; Obeng-Odoom, F.; Ochieng, E.; Maliene, V. (Eds.) Real Estate, Construction and Economic Development in Emerging Market Economies; Routledge: Abingdon, Oxfordshire, UK, 2015. [Google Scholar]
- Bennett, R.; Alemie, B. Fit-for-purpose land administration: Lessons from urban and rural Ethiopia. Surv. Rev. 2016, 48, 11–20. [Google Scholar] [CrossRef]
- GLTN—Global Land Tool Network. 2016. Available online: http://www.gltn.net/index.php?option=com_content&view=article&id=437 (accessed on 4 February 2016).
- Robillard, W.; Brown, C.; Wilson, D. Brown’s Boundary Control and Legal Principles; Wiley: Hoboken, NJ, USA, 2003. [Google Scholar]
- Bruce, J.W. Review of tenure terminology. Tenure Br. 1998, 1, 1–8. [Google Scholar]
- Dale, P.; McLaughlin, J.D. Land Information Management an Introduction with Special Reference to Cadastral Problems in Developing Countries; Clarendon Press: Gloucestershire, UK, 1988. [Google Scholar]
- Tuladhar, A. Spatial cadastral boundary concepts and uncertainty in parcel-based information systems. Int. Arch. Photogramm. Remote Sens. 1996, 16, 890–893. [Google Scholar]
- Kern, P. Automated feature extration: A history. In Proceedings of the MAPPS/ASPRS 2006 Fall Conference, San Antonio, TX, USA, 6–10 November 2006. [Google Scholar]
- Overly, J.; Bodum, L.; Kjems, E. Automatic 3D building reconstruction from airborne laser scanning and cadastral data using Hough transform. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Syst. 2004, 34, 296–301. [Google Scholar]
- Dorninger, P.; Pfeifer, N. A comprehensive automated 3D approach for building extraction, reconstruction, and regularization from airborne laser scanning point clouds. Sensors 2008, 8, 7323–7343. [Google Scholar] [CrossRef] [PubMed]
- Elberink, O.; J, S.; Vosselman, G. 3D information extraction from laser point clouds covering complex road junctions. Photogramm. Rec. 2009, 24, 23–36. [Google Scholar] [CrossRef]
- Sohn, G.; Jwa, Y.; Kim, H.B. Automatic powerline scene classification and reconstruction using airborne lidar data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, I, 167–172. [Google Scholar] [CrossRef]
- Vosselman, G. Point cloud segmentation for urban scene classification. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2013, XL-7/W2, 257–262. [Google Scholar] [CrossRef]
- Xu, S.; Vosselman, G.; Elberink, S.O. Multiple-entity based classification of airborne laser scanning data in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 88, 1–15. [Google Scholar] [CrossRef]
- Hopcroft, J.; Tarjan, R. Algorithm 447: Efficient algorithms for graph manipulation. Commun. ACM 1973, 16, 372–378. [Google Scholar] [CrossRef]
- Rubio, D.O.; Lenskiy, A.; Ryu, J.H. Connected components for a fast and robust 2D Lidar data segmentation. In Proceedings of the 7th Asia Modelling Symposium (AMS), Hong Kong, China, 23–25 July 2013; pp. 160–165. [Google Scholar]
- Bai, X.; Latecki, L.J.; Liu, W.Y. Skeleton pruning by contour partitioning with discrete curve evolution. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 449–462. [Google Scholar] [CrossRef] [PubMed]
- Hough, P.V.C. Method and Means for Recognizing Complex Patterns. U.S. Patent 3069654 A, 1962. [Google Scholar]
- Ballard, D.H. Generalizing the Hough transform to detect arbitrary shapes. Pattern Recognit. 1981, 13, 111–122. [Google Scholar] [CrossRef]
- Edelsbrunner, H.; Kirkpatrick, D.; Seidel, R. On the shape of a set of points in the plane. IEEE Trans. Inf. Theory 1983, 29, 551–559. [Google Scholar] [CrossRef]
- Lindeberg, T. Edge Detection and ridge detection with automatic scale selection. Int. J. Comput. Vis. 1998, 30, 117–156. [Google Scholar] [CrossRef]
- Deriche, R. Using Canny’s criteria to derive a recursively implemented optimal edge detector. Int. J. Comput. Vis. 1987, 1, 179. [Google Scholar] [CrossRef]
- Reuter, T. Sharing the Earth, Dividing the Land: Land and Territory in the Austronesian World; ANU Press: Canberra, Australia, 2006; p. 385. [Google Scholar]
- Quadros, N.; Keysers, J. LiDAR Acquisition in the Vanuatu–Efate, Malekula and Espiritu Santo, Australia; CRC for Spatial Information: Victoria, Australia, 2014; unpublished. [Google Scholar]
- LAS Specification-Version 1.3–R10; The American Society for Photogrammetry and Remote Sensing (ASPRS): Bethesda, MD, USA, 2009.
- Clode, S.; Rottensteiner, F.; Kootsookos, P.J. The automatic extraction of roads from LIDAR data. In Proceedings of the International Society for Photogrammetry and Remote Sensing’s Twentieth Annual Congress, Istanbul, Turkey, 12–23 July 2004; pp. 231–236. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | Feature | Extracted | True | False | Lost |
|---|---|---|---|---|---|
| Region 1 | Road | 111 | 90 | 21 | 13 |
| Building | 97 | 23 | 74 | 62 | |
| Region 2 | Road | 177 | 148 | 29 | 49 |
| Fence_fit | 106 | 91 | 15 | 11 |
| Region | Feature | Correctness | Completeness | Overall | Expected | Completeness |
|---|---|---|---|---|---|---|
| Region 1 | Road | 81.08% | 87.38% | 43.13% | 71.76% | 60.11% |
| Building | 23.71% | 27.06% | ||||
| Region 2 | Road | 83.62% | 75.13% | 59.60% | 74.56% | 79.93% |
| Fence_fit | 85.85% | 89.22% |
| Region | Tested | True | False | Shifted | Lost | Total | Correctness |
|---|---|---|---|---|---|---|---|
| Region 1 | 55 | 21 | 9 | 25 | 34 | 89 | 38.18% |
| Region 2 | 72 | 45 | 8 | 19 | 35 | 107 | 62.50% |
| Region | Feature | Length | True | Correctness |
|---|---|---|---|---|
| Region 1 | Manual | 982.05 | 667 | 67.93% |
| Edited | 1111.54 | 727 | 65.46% | |
| Road | 5354.7 | 3945 | 73.69% | |
| Building | 12,133 | 9214 | 75.94% | |
| Region 2 | Edited | 4787.57 | 4376 | 91.41% |
| Manual | 1651.8 | 1374 | 83.22% | |
| Road | 5428.36 | 5011 | 92.33% | |
| Building | 11,392.59 | 11,252 | 98.80% | |
| Fence_fit | 10,099.8 | -- | -- |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Bennett, R.M.; Koeva, M.; Lemmen, C. Investigating Semi-Automated Cadastral Boundaries Extraction from Airborne Laser Scanned Data. Land 2017, 6, 60. https://doi.org/10.3390/land6030060
Luo X, Bennett RM, Koeva M, Lemmen C. Investigating Semi-Automated Cadastral Boundaries Extraction from Airborne Laser Scanned Data. Land. 2017; 6(3):60. https://doi.org/10.3390/land6030060
Chicago/Turabian StyleLuo, Xianghuan, Rohan Mark Bennett, Mila Koeva, and Christiaan Lemmen. 2017. "Investigating Semi-Automated Cadastral Boundaries Extraction from Airborne Laser Scanned Data" Land 6, no. 3: 60. https://doi.org/10.3390/land6030060
APA StyleLuo, X., Bennett, R. M., Koeva, M., & Lemmen, C. (2017). Investigating Semi-Automated Cadastral Boundaries Extraction from Airborne Laser Scanned Data. Land, 6(3), 60. https://doi.org/10.3390/land6030060